DGCB-Net: Dynamic Graph Convolutional Broad Network for 3D Object Recognition in Point Cloud



Abstract
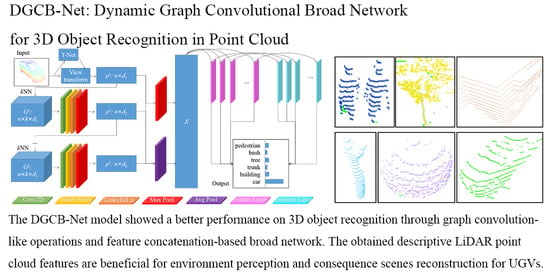
1. Introduction
- A DGCB-Net architecture adopts a broad method to improve the recognition performance of deep learning structures. This way, the model capabilities of both feature extraction and object recognition are strengthened.
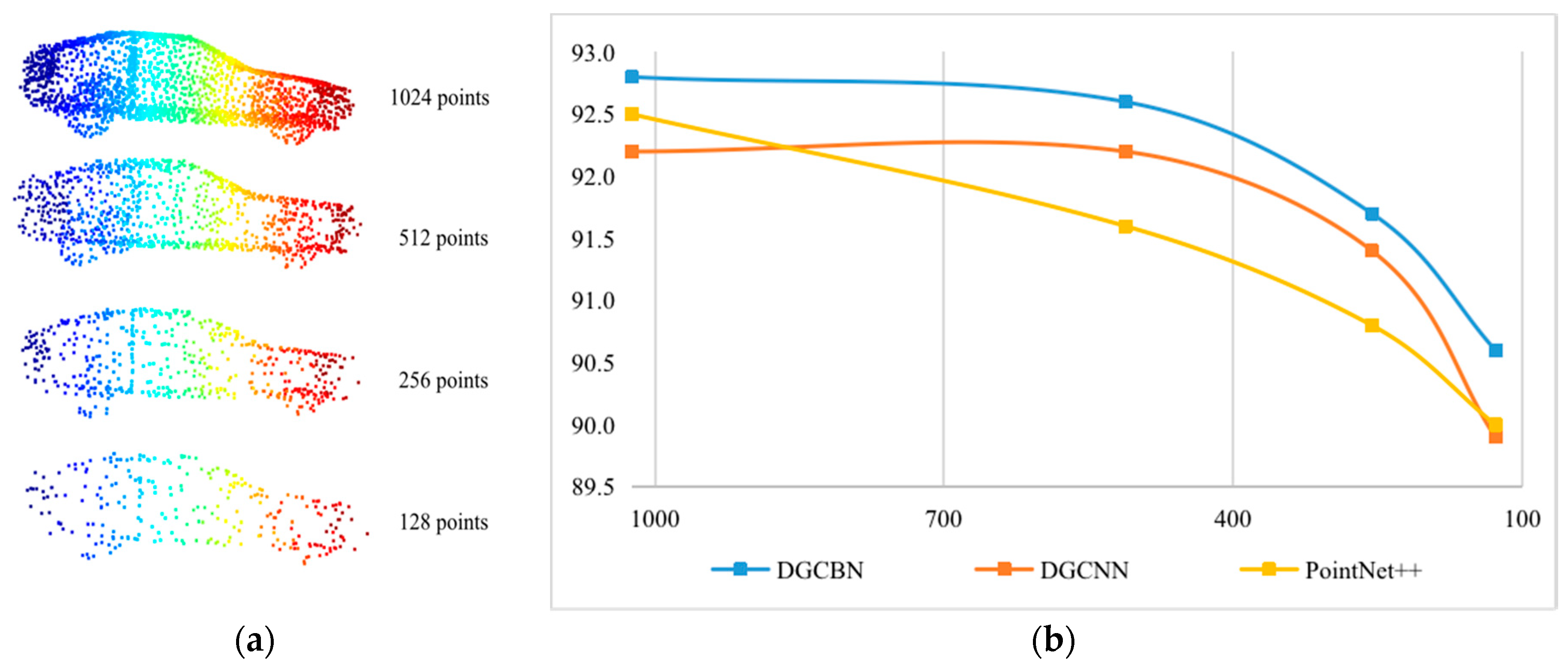
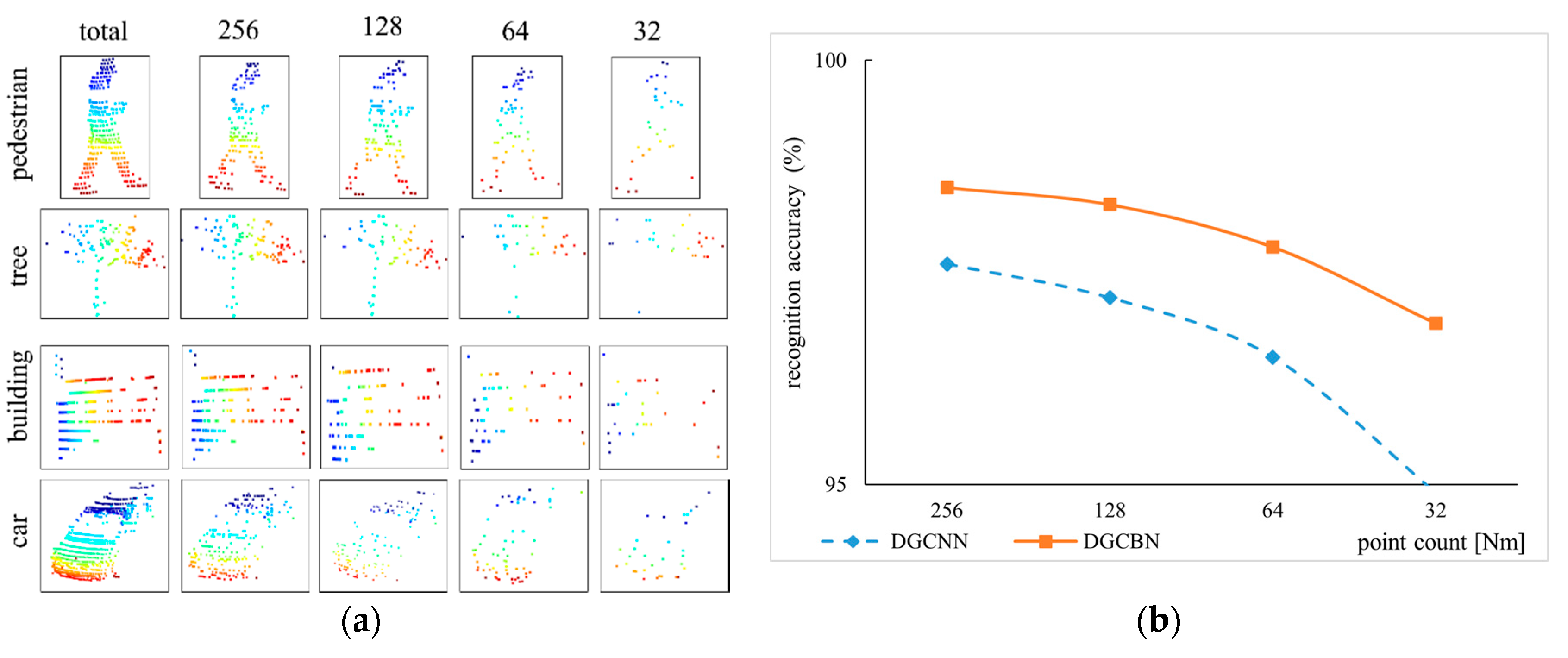
- The object recognition performance of the proposed DGCB-Net consists of improvement in both open point cloud dataset ModelNet10/40 and our collected outdoor common objects. When the inputting point counts are uniformly downsampled, the recognition results are especially better than the other popular methods, which means our proposed DGCB-Net shows robust performance for sparse point clouds.
- Pioneeringly, we bring the broad structure into the point cloud processing domain to enhance the convolutional features of point clouds. Besides, the proposed broad structure is lightweight with fast training speed, which means it only requires a few additional time and calculation consumptions to produce an efficient improvement for the deep learning model.
2. Related Works
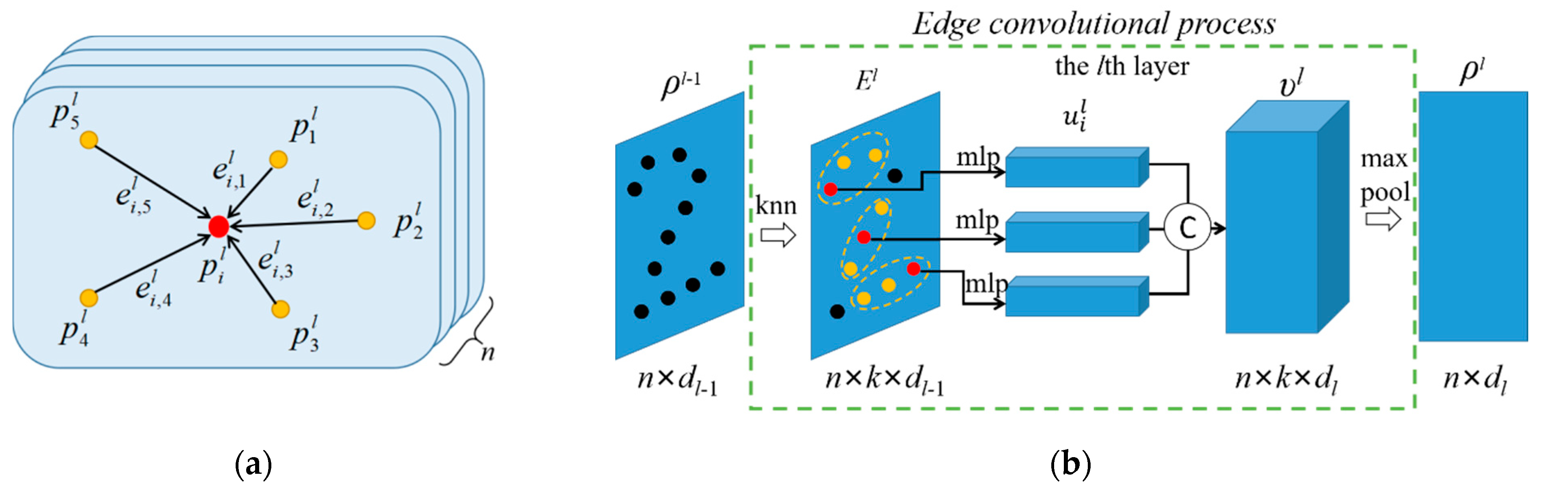
3. Object Recognition Method from 3D Point Clouds
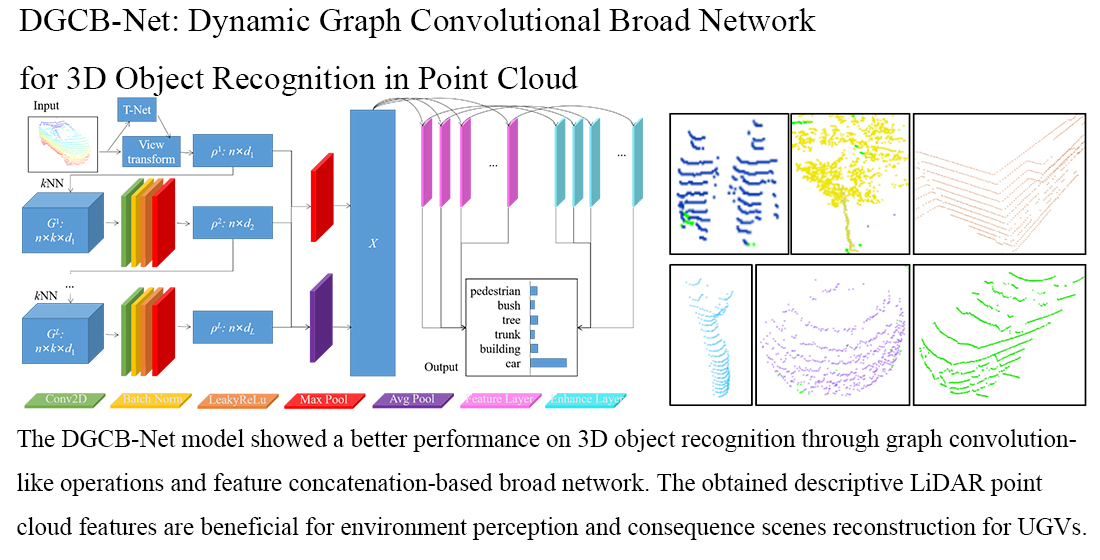
3.1. Graph Feature Generalization and Aggregation
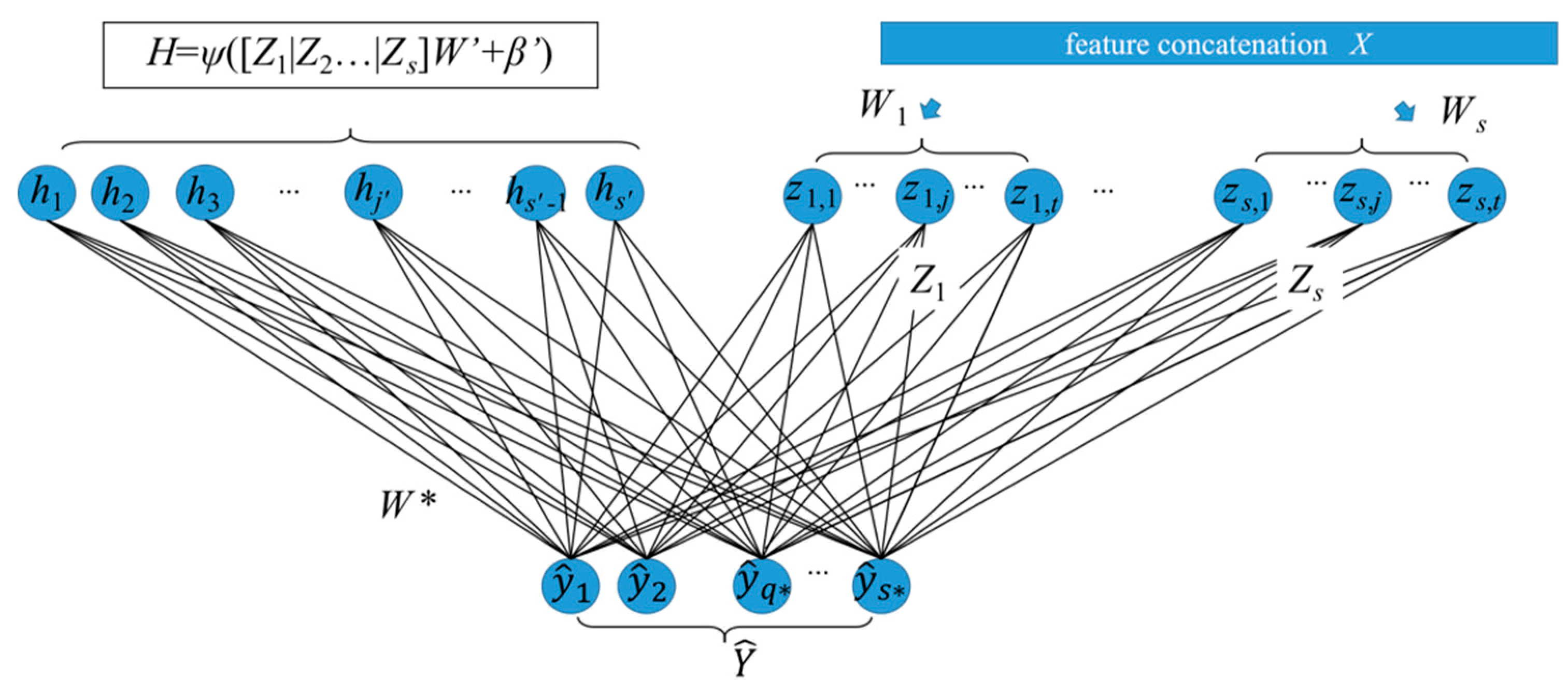
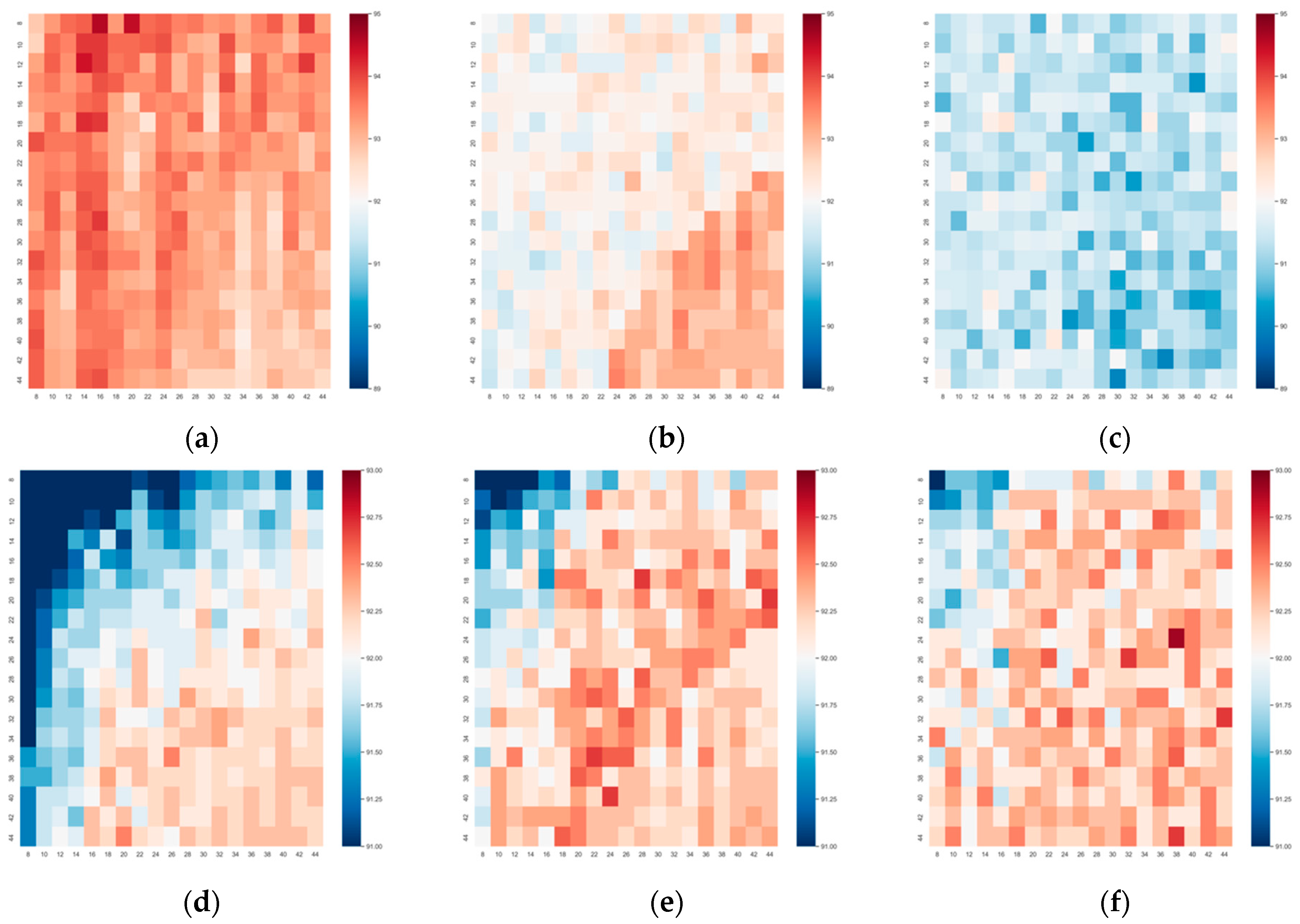
3.2. Broad Network Construction
4. Experiments and Analysis
4.1. Modelnet10 and Modelnet40
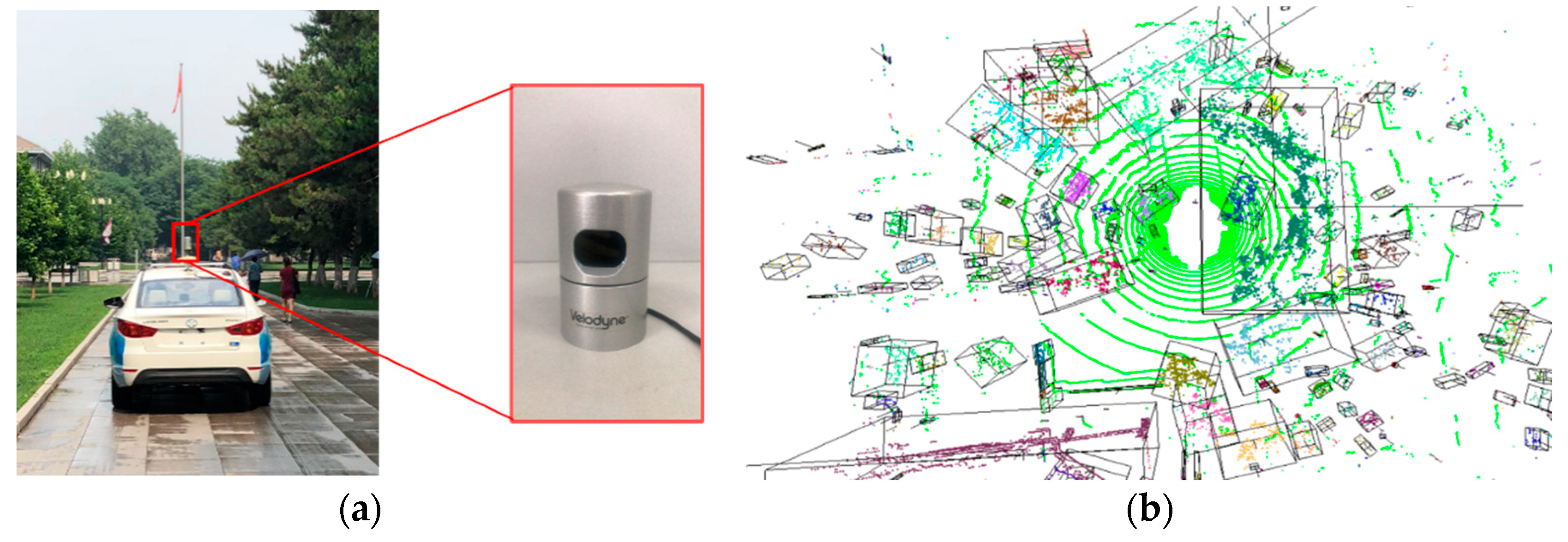
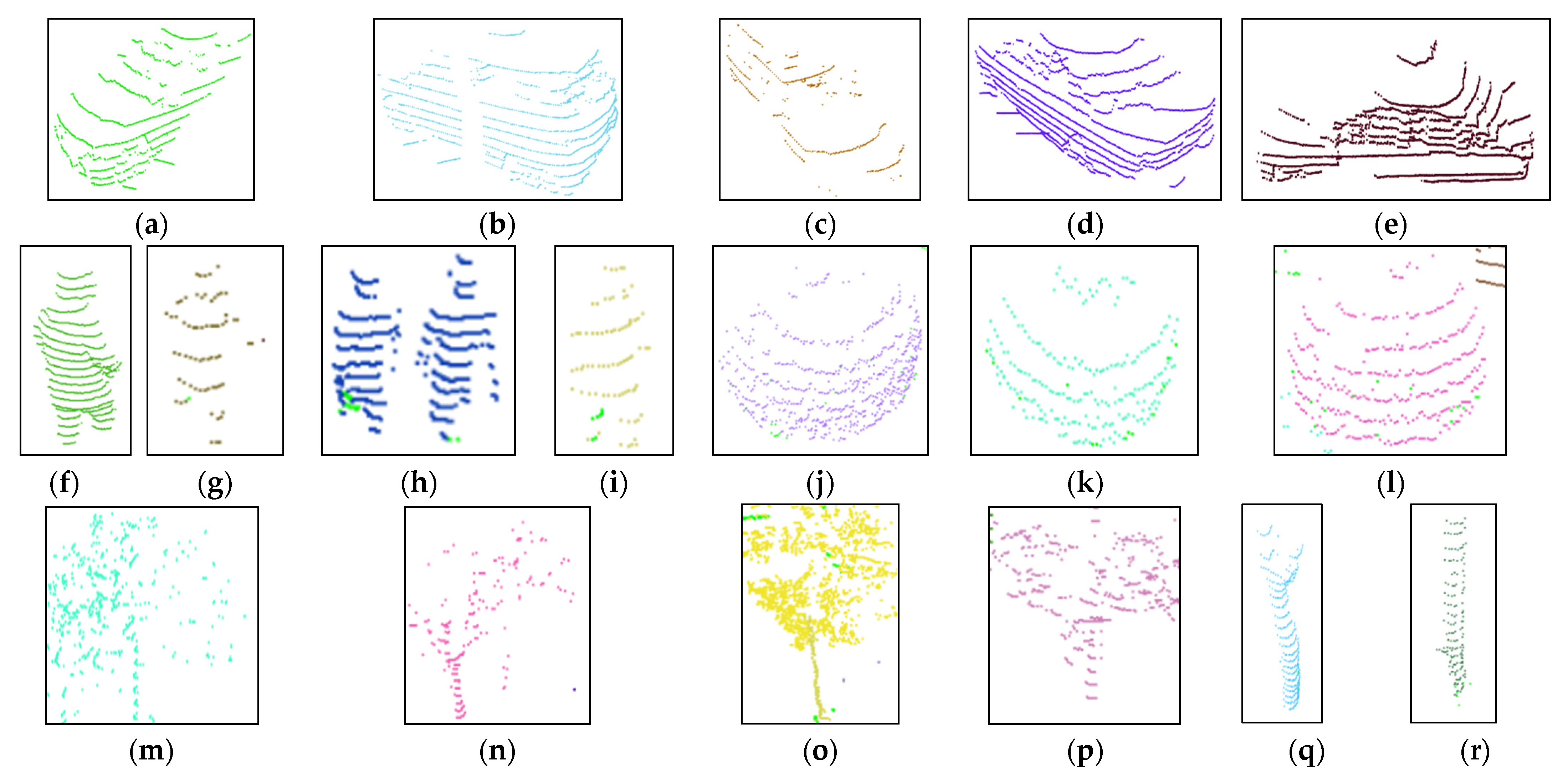
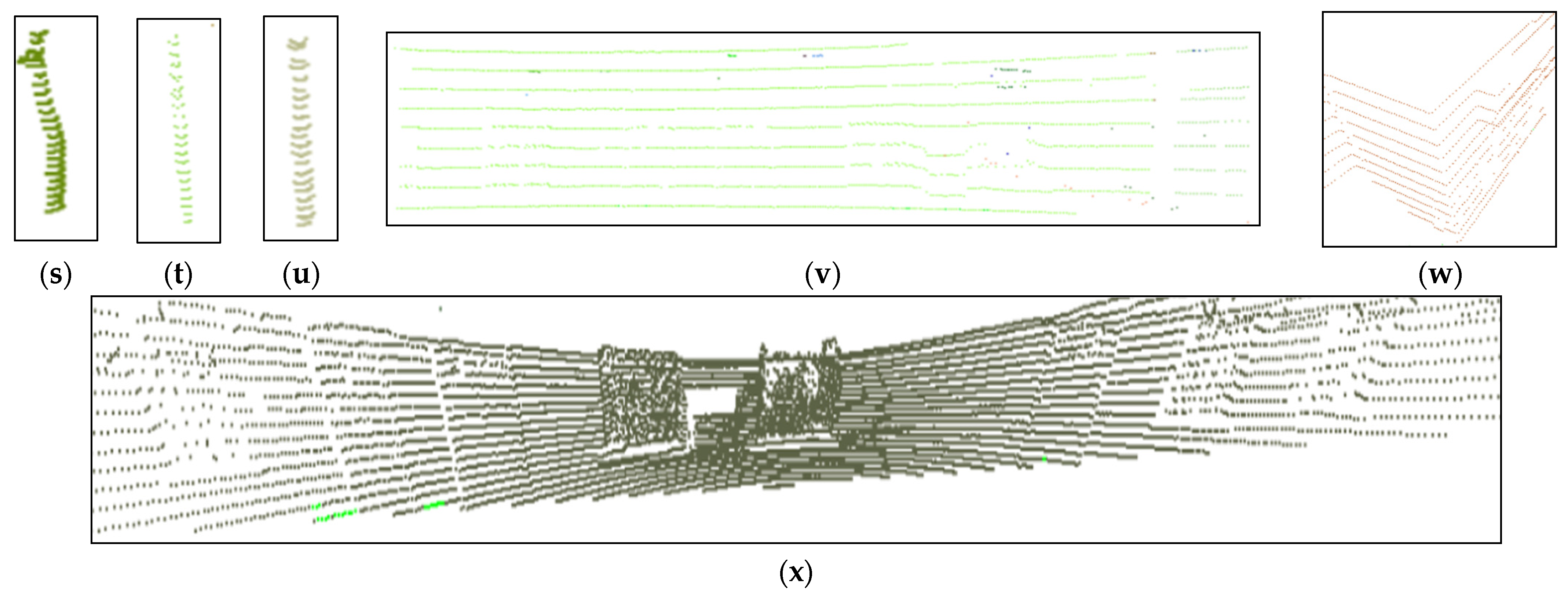
4.2. Outdoor Object Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rozsa, Z.; Sziranyi, T. Obstacle Prediction for Automated Guided Vehicles Based on Point Clouds Measured by a Tilted LIDAR Sensor. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2708–2720. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D Object Recognition in Cluttered Scenes with Local Surface Features: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar] [CrossRef] [PubMed]
- Lei, H.; Jiang, G.; Quan, L. Fast Descriptors and Correspondence Propagation for Robust Global Point Cloud Registration. IEEE Trans. Image Process 2017, 26, 1. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep Learning on Point Clouds and Its Application: A Survey. Sensors 2019, 19, 4188. [Google Scholar] [CrossRef] [PubMed]
- Chang, W.-C.; Pham, V.-T. 3-D Point Cloud Registration Using Convolutional Neural Networks. Appl. Sci. 2019, 9, 3273. [Google Scholar] [CrossRef]
- Li, M. A Voxel Graph-Based Resampling Approach for the Aerial Laser Scanning of Urban Buildings. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1899–1903. [Google Scholar] [CrossRef]
- Qin, N.; Hu, X.; Dai, H. Deep fusion of multi-view and multimodal representation of ALS point cloud for 3D terrain scene recognition. ISPRS J. Photogramm. Remote. Sens. 2018, 143, 205–212. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Tran. Graphics 2019, 38, 5. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Joint classification and contour extraction of large 3D point clouds. ISPRS J. Photogramm. Remote. Sens. 2017, 130, 231–245. [Google Scholar] [CrossRef]
- Yang, B.; Liu, Y.; Dong, Z.; Liang, F.; Li, B.; Peng, X. 3D local feature BKD to extract road information from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote. Sens. 2017, 130, 329–343. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J.; Kwok, N.M. A Comprehensive Performance Evaluation of 3D Local Feature Descriptors. Int. J. Comput. Vis. 2016, 116, 66–89. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Q.; Xiao, Y.; Cao, Z. TOLDI: An effective and robust approach for 3D local shape description. Pattern Recognit. 2017, 65, 175–187. [Google Scholar] [CrossRef]
- Quan, S.; Ma, J.; Hu, F.; Fang, B.; Ma, T. Local voxelized structure for 3D binary feature representation and robust registration of point clouds from low-cost sensors. Inf. Sci. 2018, 444, 153–171. [Google Scholar] [CrossRef]
- Yang, J.; Cao, Z.; Zhang, Q. A fast and robust local descriptor for 3D point cloud registration. Inf. Sci. 2016, 163–179. [Google Scholar] [CrossRef]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional ShapeContextNet for Point Cloud Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Han, Z.; Liu, Z.; Han, J.; Vong, C.M.; Bu, S.; Chen, C.L.P. Unsupervised Learning of 3-D Local Features From Raw Voxels Based on a Novel Permutation Voxelization Strategy. IEEE Trans. Cybern. 2017, 49, 481–494. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Putman, E.B.; Popescu, S.C. Automated Estimation of Standing Dead Tree Volume Using Voxelized Terrestrial Lidar Data. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 6484–6503. [Google Scholar] [CrossRef]
- Rao, Y.; Lu, J.; Zhou, J. Spherical Fractal Convolutional Neural Networks for Point Cloud Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Groh, F.; Wieschollek, P.; Lensch, H.P.A. Flex-Convolution (Million-Scale Point-Cloud Learning Beyond Grid-Worlds). In Proceedings of the Asian Conference on Computer Vision ACCV 2018: Computer Vision—ACCV 2018, Perth, Australia, 2–6 December 2018; pp. 105–122. [Google Scholar]
- Huang, J.; You, S. Point Cloud Labeling using 3D Convolutional Neural Network. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016. [Google Scholar]
- Liu, Y.; Fan, B.; Meng, G.; Lu, J.; Xiang, S.; Pan, C. DensePoint: Learning Densely Contextual Representation for Efficient Point Cloud Processing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Esteves, C.; Allen-Blanchette, C.; Makadia, A.; Daniilidis, K. Learning SO(3) Equivariant Representations with Spherical CNNs. Int. J. Comput. Vis. 2019, 128, 588–600. [Google Scholar] [CrossRef]
- Simonovsky, M.; Komodakis, N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, C.; Li, G.; Xu, R.; Chen, T.; Wang, M.; Lin, L. ClusterNet: Deep Hierarchical Cluster Network with Rigorously Rotation-Invariant Representation for Point Cloud Analysis. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4994–5002. [Google Scholar]
- Liu, Y.; Li, X.; Guo, Y. LightNet: A lightweight 3D convolutional neural network for real-time 3D object recognition. In Eurographics Workshop on 3D Object Retrieval; Eurographics Association: Geneva, Swtzerland, 2017. [Google Scholar]
- Hua, B.S.; Tran, M.K.; Yeung, S.K. Pointwise Convolutional Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, C.L.P.; Liu, Z. Broad Learning System: An Effective and Efficient Incremental Learning System Without the Need for Deep Architecture. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 10–24. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, X.; Xu, X.; Chen, C.L.P. GCB-Net: Graph Convolutional Broad Network and Its Application in Emotion Recognition. IEEE Trans. Affect. Comput. 2019, 1. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems 30 Confernce(NIPS 2017), Long Beach, CA, USA, 4–6 December 2017. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Tang, X.; Xiao, J. 3D ShapeNets for 2.5D object recognition and next-best-view prediction. arXiv 2014, arXiv:1406.5670. [Google Scholar]
- BV-CNNs: Binary volumetric convolutional neural networks for 3D object recognition. In Proceedings of the BMVC2017, Verona, Italy, 5–8 September 2017.
- Orientation-boosted Voxel Nets for 3D Object Recognition. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017.
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E.G. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Shi, B.; Bai, S.; Zhou, Z.; Bai, X. DeepPano: Deep Panoramic Representation for 3-D Shape Recognition. IEEE Signal Process. Lett. 2015, 22, 2339–2343. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modelnet10 | Modelnet40 | Outdoor Object | |
|---|---|---|---|
| Training Samples | 3991 | 9840 | 1010 |
| Testing Samples | 908 | 2468 | 463 |
| Avg. Point Number | 1024 | 1024 | 415 |
| Classes | 10 | 40 | 6 |
| Method | Input | Modelnet40 (Accuracy %) | Modelnet10 (Accuracy %) | |
|---|---|---|---|---|
| Pointwise-based Networks | PointNet [8] | point | 89.2 | - |
| PointNet++ [33] | point | 90.7 | - | |
| Pointwise-CNN [30] | point | 86.1 | - | |
| Voxel-based Networks | VoxNet [34] | voxel | 83 | 92 |
| 3DShapeNets [35] | voxel | 77.3 | 83.5 | |
| BV-CNNs [36] | voxel | 85.4 | 92.3 | |
| ORION [37] | voxel | - | 93.8 | |
| Image-based Networks | MVCNN [38] | image | 90.1 | - |
| DeepPano [39] | image | 82.5 | 88.7 | |
| Graph-based Networks | ECC [26] | graph | 87.4 | 90.8 |
| DGCNN [9] | graph | 92.2 | - | |
| DGCB-Net (Our) | graph | 92.9 | 94.6 | |
| Network | Performance | Airplane | Bathtub | Bed | Bench | Bookshelf | Bottle | Bowl | Car | Chair | Cone |
| DGCNN | PR | 1.0 | 0.98 | 0.97 | 0.79 | 0.90 | 0.95 | 0.83 | 0.99 | 0.98 | 1.00 |
| RC | 1.0 | 0.90 | 0.99 | 0.75 | 0.99 | 0.98 | 0.95 | 1.00 | 0.98 | 0.95 | |
| F1 | 1.0 | 0.94 | 0.98 | 0.77 | 0.94 | 0.97 | 0.88 | 0.99 | 0.98 | 0.97 | |
| Ours | PR | 1.0 | 0.99 | 0.99 | 0.70 | 0.99 | 0.97 | 0.90 | 1.0 | 0.98 | 1.00 |
| RC | 1.0 | 0.98 | 0.97 | 0.82 | 0.93 | 0.97 | 0.82 | 0.99 | 0.96 | 1.00 | |
| F1 | 1.0 | 0.96 | 0.98 | 0.76 | 0.96 | 0.97 | 0.86 | 1.00 | 0.97 | 1.00 | |
| Network | Performance | Cup | Curtain | Desk | Door | Dresser | Flower Pot | Glass Box | Guitar | Keyboard | Lamp |
| DGCNN | PR | 0.61 | 0.95 | 0.79 | 0.95 | 0.80 | 0.20 | 0.97 | 0.99 | 0.95 | 1.00 |
| RC | 0.70 | 0.95 | 0.88 | 0.95 | 0.86 | 0.30 | 0.95 | 1.00 | 0.95 | 0.90 | |
| F1 | 0.65 | 0.95 | 0.84 | 0.95 | 0.83 | 0.24 | 0.96 | 1.00 | 0.95 | 0.95 | |
| Ours | PR | 0.70 | 0.90 | 0.90 | 0.85 | 0.92 | 0.10 | 0.96 | 1.00 | 0.95 | 0.85 |
| RC | 0.67 | 0.82 | 0.84 | 0.94 | 0.72 | 0.18 | 0.97 | 0.98 | 0.95 | 1.00 | |
| F1 | 0.68 | 0.86 | 0.87 | 0.89 | 0.81 | 0.13 | 0.96 | 0.99 | 0.95 | 0.92 | |
| Network | Performance | Laptop | Mantel | Monitor | Night Stand | Person | Piano | Plant | Radio | Range Hood | Sink |
| DGCNN | PR | 0.95 | 0.99 | 0.97 | 0.81 | 1.00 | 1.00 | 0.88 | 0.80 | 0.98 | 0.94 |
| RC | 1.00 | 0.98 | 1.00 | 0.81 | 0.95 | 0.95 | 0.80 | 0.80 | 0.97 | 0.85 | |
| F1 | 0.98 | 0.98 | 0.99 | 0.81 | 0.97 | 0.97 | 0.84 | 0.80 | 0.97 | 0.89 | |
| Ours | PR | 1.0 | 0.95 | 1.0 | 0.74 | 0.95 | 0.94 | 0.88 | 0.75 | 0.97 | 0.95 |
| RC | 1.0 | 0.97 | 0.95 | 0.91 | 1.0 | 1.00 | 0.87 | 0.94 | 1.00 | 1.00 | |
| F1 | 1.0 | 0.96 | 0.98 | 0.82 | 0.97 | 0.97 | 0.88 | 0.83 | 0.98 | 0.97 | |
| Network | Performance | Sofa | Stairs | Stool | Table | Tent | Toilet | Tv Stand | Vase | Wardrobe | Xbox |
| DGCNN | PR | 0.98 | 1.00 | 0.84 | 0.86 | 0.95 | 1.00 | 0.92 | 0.87 | 0.76 | 0.94 |
| RC | 1.00 | 0.95 | 0.80 | 0.79 | 0.95 | 0.99 | 0.86 | 0.80 | 0.80 | 0.85 | |
| F1 | 0.99 | 0.97 | 0.82 | 0.82 | 0.95 | 0.99 | 0.89 | 0.83 | 0.78 | 0.89 | |
| Ours | PR | 1.0 | 0.95 | 0.75 | 0.86 | 0.95 | 1.00 | 0.87 | 0.90 | 0.75 | 0.80 |
| RC | 0.97 | 0.95 | 0.88 | 0.83 | 0.90 | 0.99 | 0.95 | 0.84 | 0.88 | 0.89 | |
| F1 | 0.99 | 0.95 | 0.81 | 0.85 | 0.93 | 1.00 | 0.91 | 0.87 | 0.81 | 0.84 |
| Object Type | Pedestrian | Bush | Tree | Trunk | Building | Car | Total |
|---|---|---|---|---|---|---|---|
| Train | 100 | 100 | 300 | 150 | 300 | 60 | 1010 |
| Test | 52 | 100 | 115 | 86 | 82 | 28 | 463 |
| Number | 152 | 200 | 415 | 236 | 382 | 88 | 1473 |
| No. | DGCBN | DGCNN | PointNet | PointNet++ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| 0 | Pedestrian | 0.93 | 0.96 | 0.95 | 0.93 | 1.00 | 0.96 | 0.43 | 0.92 | 0.59 | 0.96 | 0.87 | 0.92 |
| 1 | Bush | 0.98 | 0.96 | 0.97 | 1.00 | 0.95 | 0.97 | 0.98 | 0.76 | 0.86 | 0.92 | 0.98 | 0.95 |
| 2 | Tree | 1.00 | 1.00 | 1.00 | 1.00 | 0.97 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 1.00 | 0.99 |
| 3 | Trunk | 0.95 | 1.00 | 0.98 | 0.97 | 0.99 | 0.98 | 0.99 | 0.99 | 0.99 | 0.92 | 1.00 | 0.96 |
| 4 | Building | 1.00 | 0.98 | 0.99 | 1.00 | 0.93 | 0.96 | 0.99 | 0.99 | 0.99 | 1.00 | 0.97 | 0.99 |
| 5 | Car | 0.99 | 0.96 | 0.98 | 0.84 | 0.97 | 0.90 | 0.98 | 0.98 | 0.98 | 0.99 | 0.92 | 0.95 |
| avg | 0.98 | 0.98 | 0.98 | 0.97 | 0.96 | 0.96 | 0.97 | 0.95 | 0.95 | 0.97 | 0.97 | 0.97 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Chen, L.; Song, W.; Sung, Y.; Woo, S. DGCB-Net: Dynamic Graph Convolutional Broad Network for 3D Object Recognition in Point Cloud. Remote Sens. 2021, 13, 66. https://doi.org/10.3390/rs13010066
Tian Y, Chen L, Song W, Sung Y, Woo S. DGCB-Net: Dynamic Graph Convolutional Broad Network for 3D Object Recognition in Point Cloud. Remote Sensing. 2021; 13(1):66. https://doi.org/10.3390/rs13010066
Chicago/Turabian StyleTian, Yifei, Long Chen, Wei Song, Yunsick Sung, and Sangchul Woo. 2021. "DGCB-Net: Dynamic Graph Convolutional Broad Network for 3D Object Recognition in Point Cloud" Remote Sensing 13, no. 1: 66. https://doi.org/10.3390/rs13010066
APA StyleTian, Y., Chen, L., Song, W., Sung, Y., & Woo, S. (2021). DGCB-Net: Dynamic Graph Convolutional Broad Network for 3D Object Recognition in Point Cloud. Remote Sensing, 13(1), 66. https://doi.org/10.3390/rs13010066