A Deep Learning Model for Automatic Plastic Mapping Using Unmanned Aerial Vehicle (UAV) Data



Abstract
1. Introduction
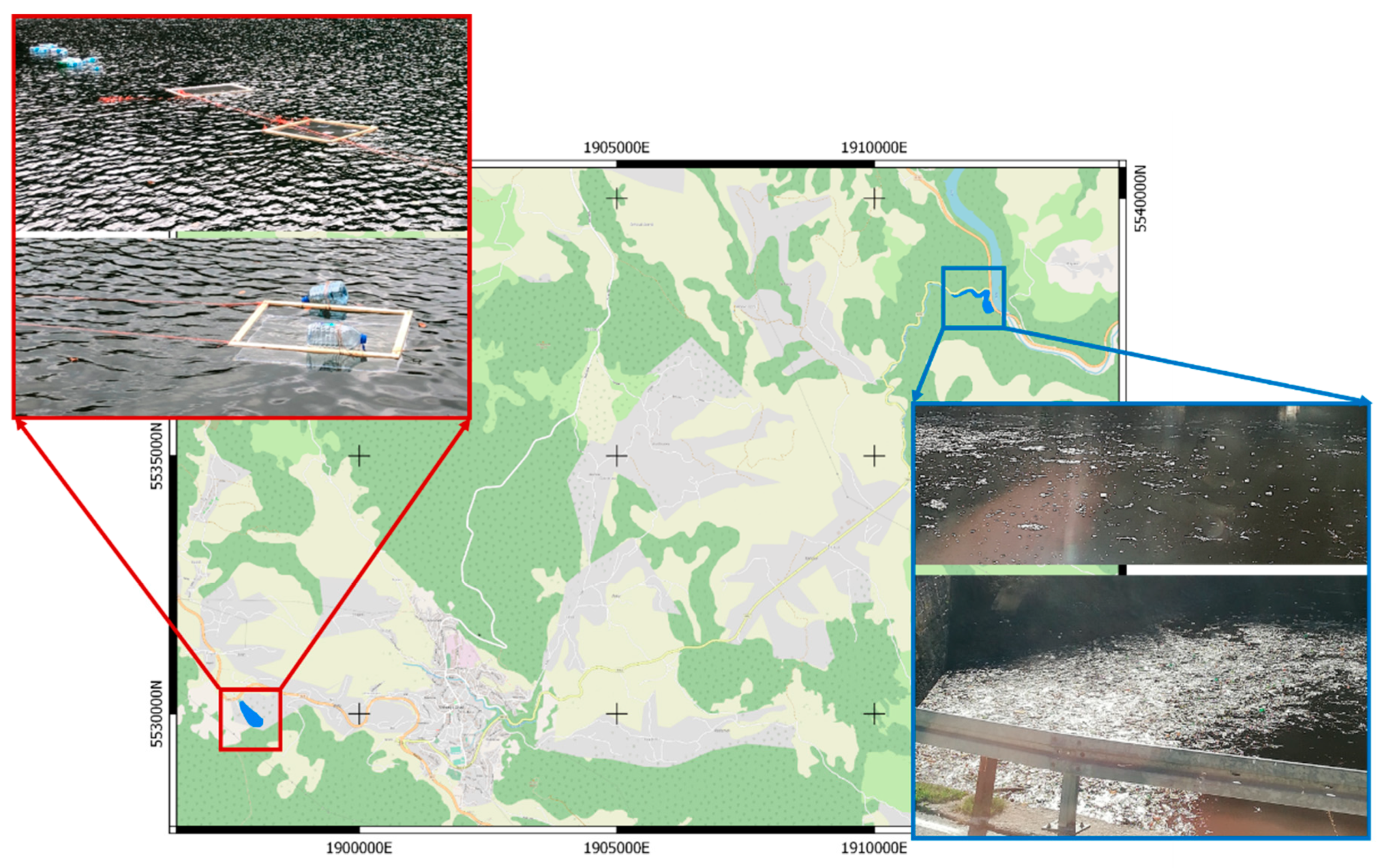
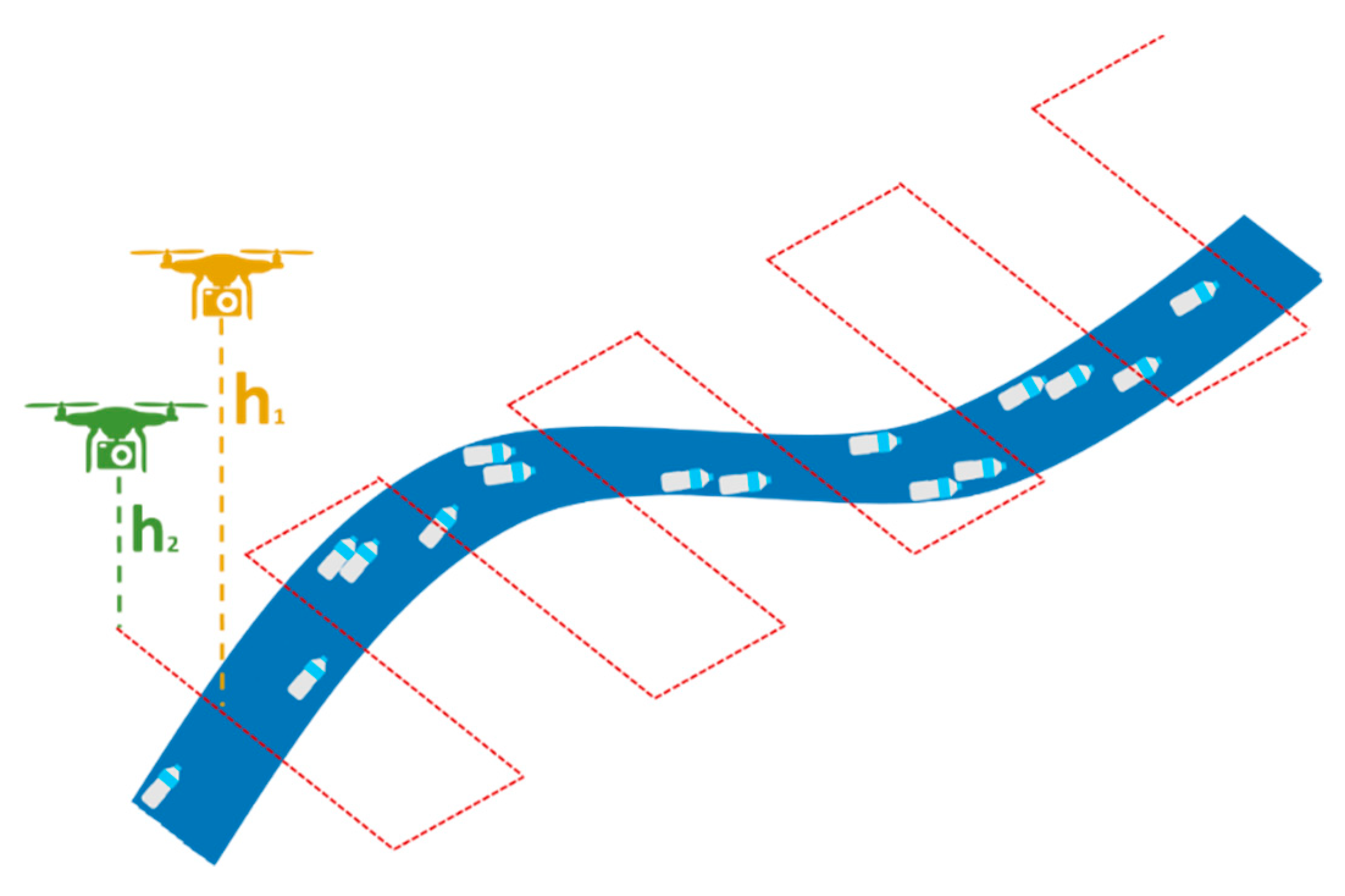
2. Study Area
3. Materials
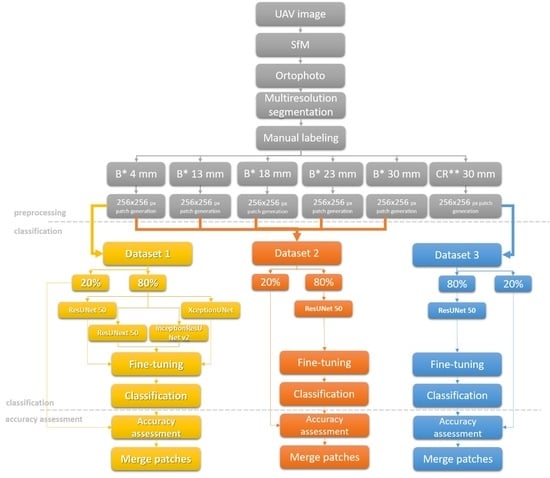
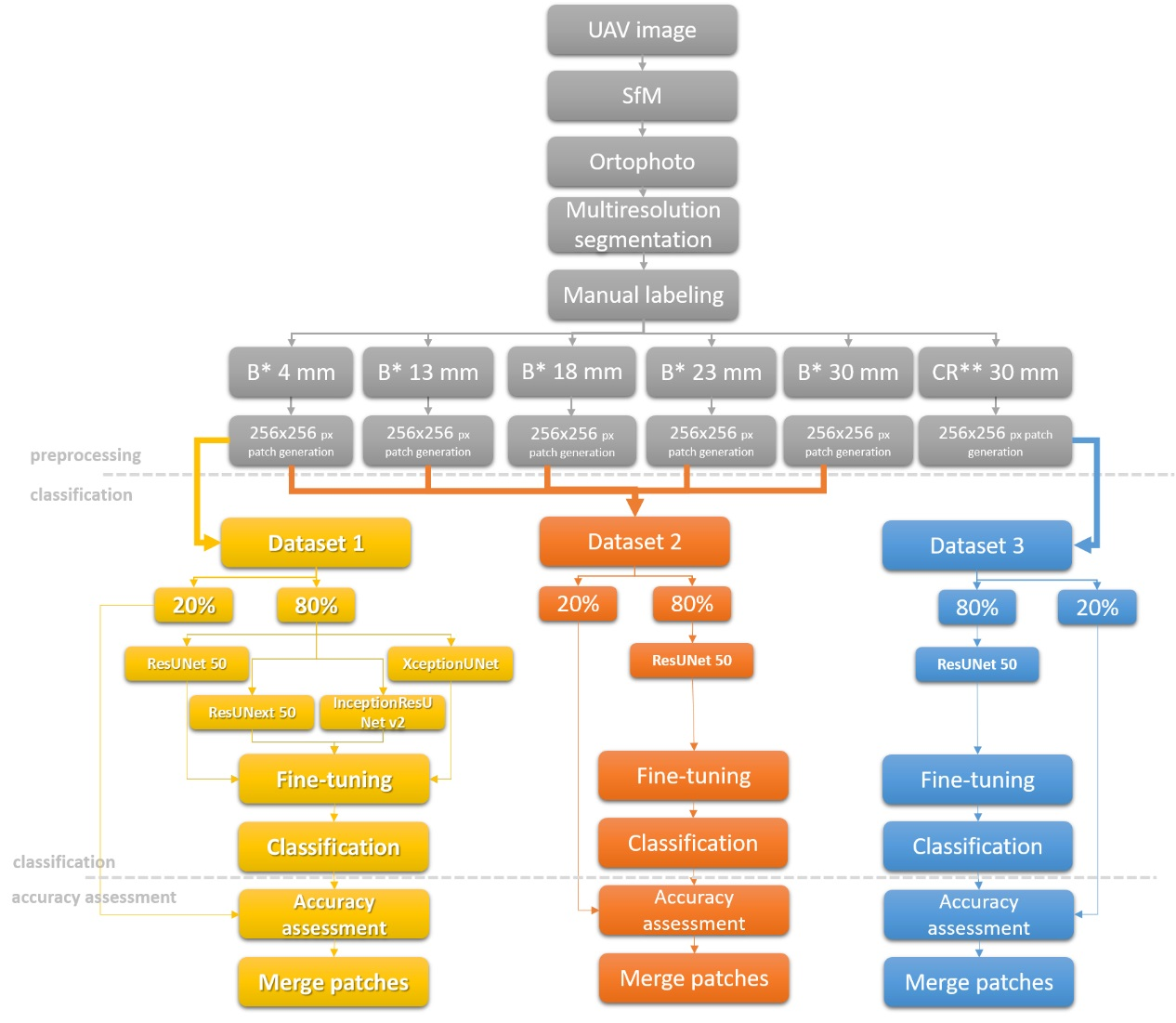
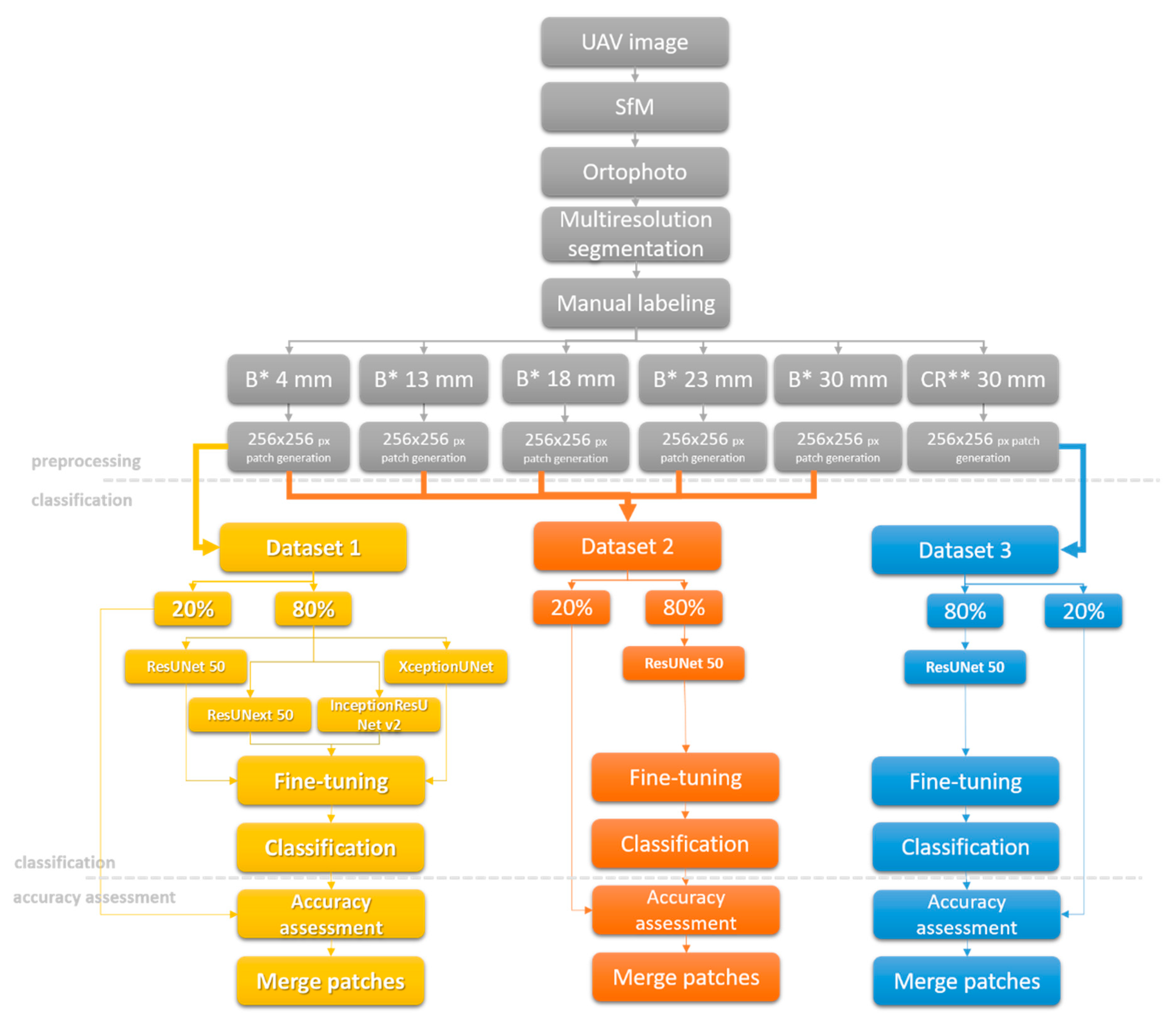
4. Methods
4.1. Preprocessing
4.2. Classification
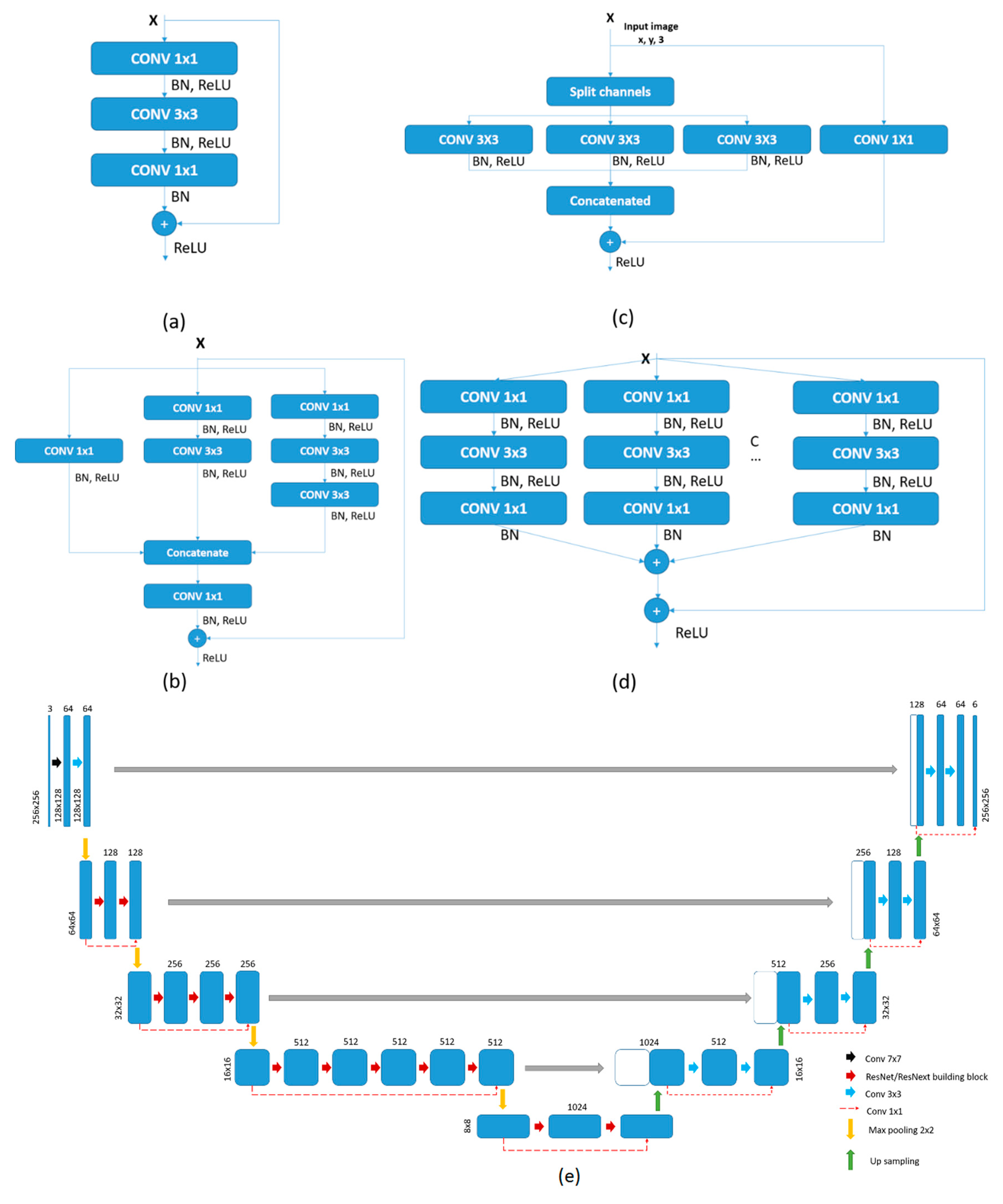
4.2.1. Encoder
4.2.2. Decoder
4.2.3. Data Augmentation and Transfer Learning
4.3. Accuracy Assessment
4.4. Implementation
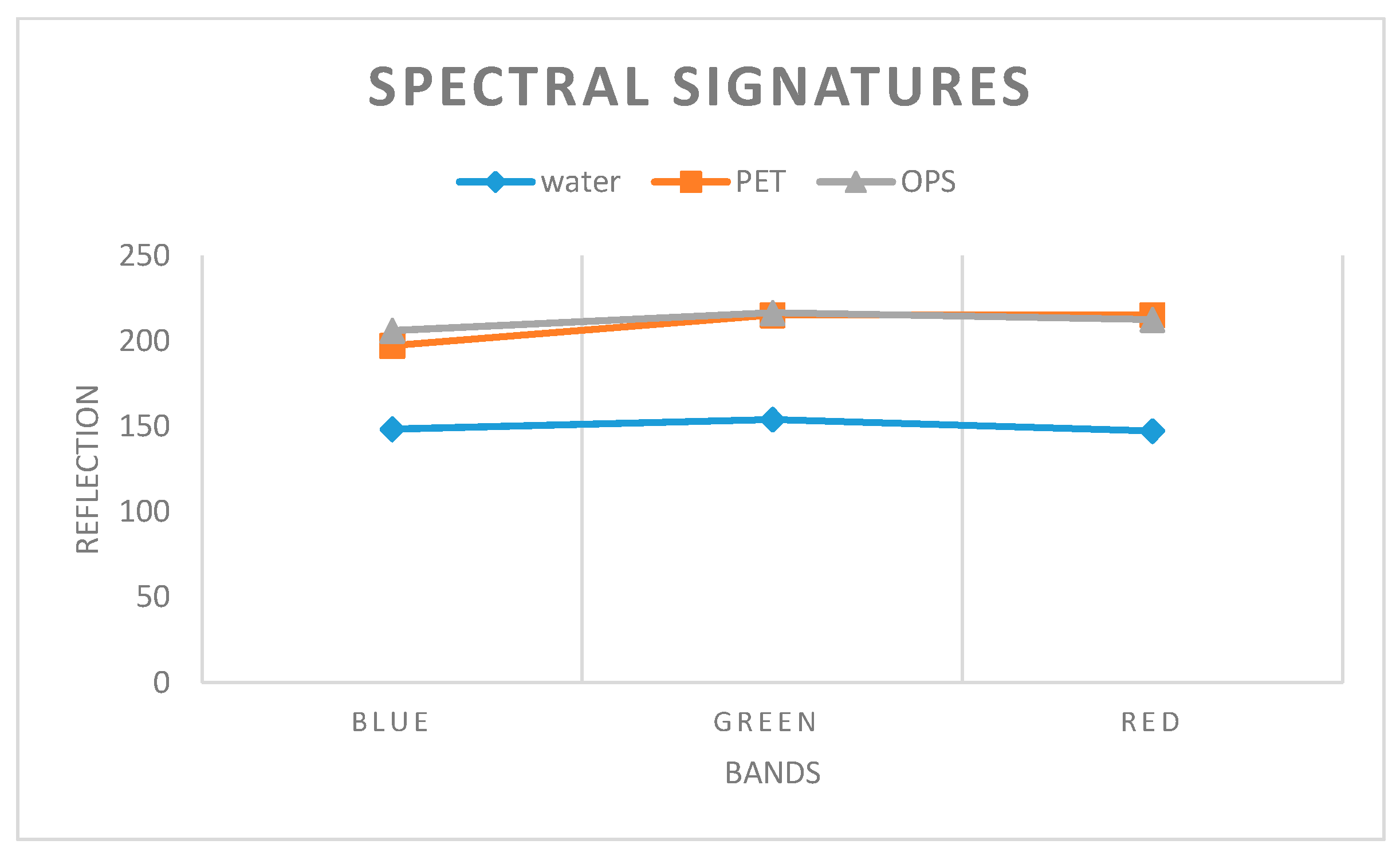
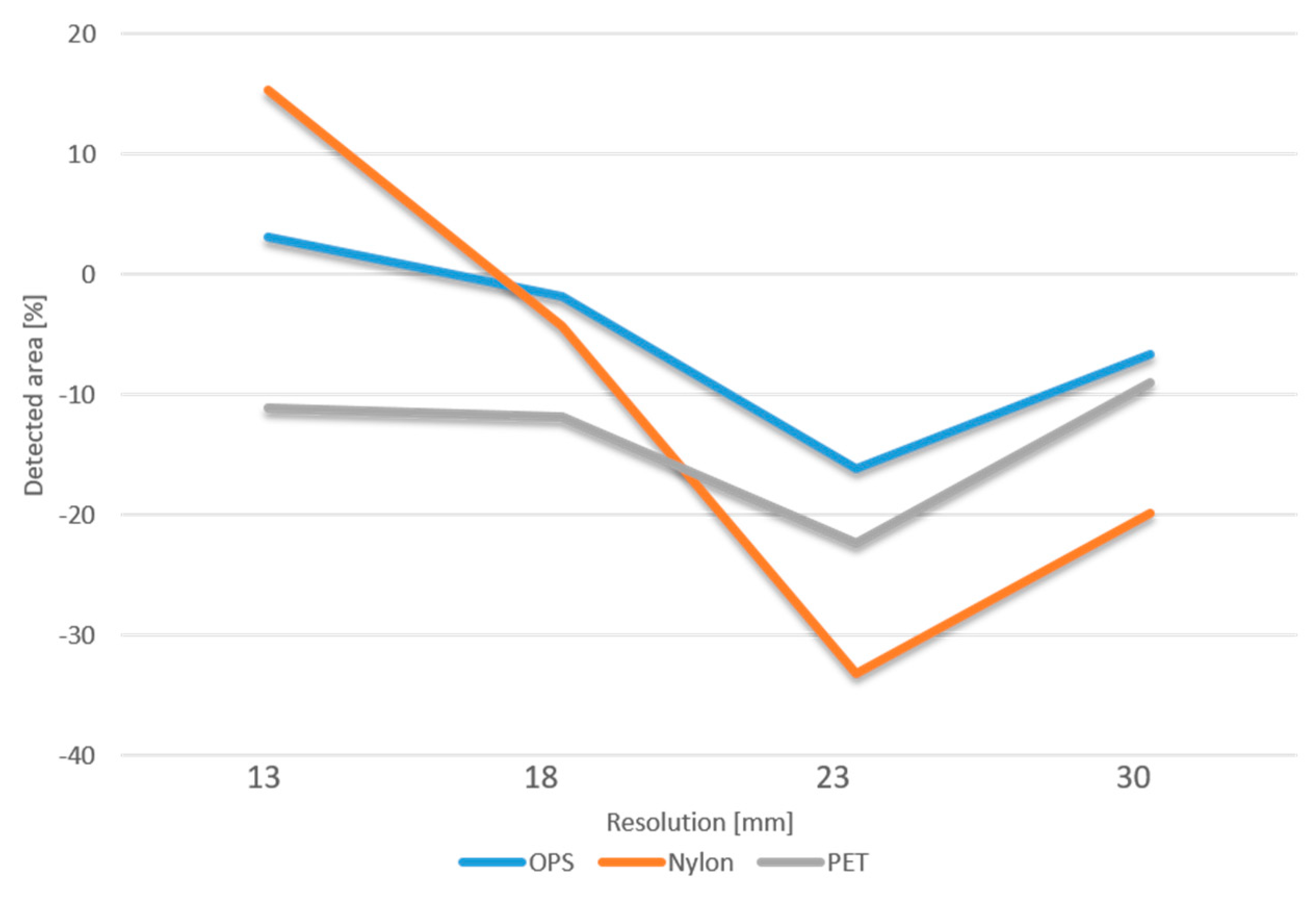
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Plastics Europe. Available online: https://www.plasticseurope.org/application/files/9715/7129/9584/FINAL_web_version_Plastics_the_facts2019_14102019.pdf (accessed on 27 April 2020).
- United Nations Environment Program. Available online: https://www.unenvironment.org/news-and-stories/press-release/un-declares-war-ocean-plastic-0 (accessed on 27 April 2020).
- United Nations Environment Program. The state of plastic. Available online: https://wedocs.unep.org/bitstream/handle/20.500.11822/25513/state_plastics_WED.pdf?isAllowed=y&sequence=1 (accessed on 27 April 2020).
- Lebreton, L.; van der Zwet, J.; Damsteeg, J.W.; Slat, B.; Andrady, A.; Reisser, J. River plastic emissions to the world’s oceans. Nat. Commun. 2017, 8, 15611. [Google Scholar] [CrossRef] [PubMed]
- Jambeck, J.R.; Hardesty, B.D.; Brooks, A.L.; Friend, T.; Teleki, K.; Fabres, J.; Beaudoin, Y.; Bamba, A.; Francis, J.; Ribbink, A.J.; et al. Challenges and emerging solutions to the land-based plastic waste issue in Africa. Mar. Policy 2018, 96, 256–263. [Google Scholar] [CrossRef]
- The guardian. Available online: https://www.theguardian.com/science/2017/nov/05/terrawatch-the-rivers-taking-plastic-to-the-oceans (accessed on 27 April 2020.).
- Eriksen, M.; Lebreton, L.C.M.; Carson, H.S.; Thiel, M.; Moore, C.J.; Borerro, J.C.; Galgani, F.; Ryan, P.G.; Reisser, J. Plastic pollution in the world’s oceans: More than 5 trillion plastic pieces weighing over 250,000 tons afloat at sea. PLoS ONE 2014, 9, e111913. [Google Scholar] [CrossRef] [PubMed]
- Jambeck, J.R.; Geyer, R.; Wilcox, C.; Siegler, T.R.; Perryman, M.; Andrady, A.; Narayan, R.; Law, K.L. Plastic waste inputs from land into the ocean. Science 2015, 347, 768–771. [Google Scholar] [CrossRef]
- OSPAR commission. Guideline for Monitoring Marine Litter on the Beaches in the OSPAR Monitoring Area. Available online: https://www.ospar.org/documents?v=7260 (accessed on 22 April 2020).
- Hardesty, B.D.; Lawson, T.J.; van der Velde, T.; Lansdell, M.; Wilcox, C. Estimating quantities and sources of marine debris at a continental scale. Front. Ecol. Environ. 2016, 15, 18–25. [Google Scholar] [CrossRef]
- Opfer, S.; Arthur, C.; Lippiatt, S. NOAA Marine Debris Shoreline Survey Field Guide, 2012. Available online: https://marinedebris.noaa.gov/sites/default/files/ShorelineFieldGuide2012.pdf (accessed on 25 April 2020).
- Cheshire, A.C.; Adler, E.; Barbière, J.; Cohen, Y.; Evans, S.; Jarayabhand, S.; Jeftic, L.; Jung, R.T.; Kinsey, S.; Kusui, E.T.; et al. UNEP/IOC Guidelines on Survey and Monitoring of Marine Litter. UNEP Regional Seas Reports and Studies 2009, No. 186; IOC Technical Series No. 83: xii + 120 pp. Available online: https://www.nrc.govt.nz/media/10448/unepioclittermonitoringguidelines.pdf (accessed on 25 April 2020).
- Ribic, C.A.; Dixon, T.R.; Vining, I. Marine Debris Survey Manual. Noaa Tech. Rep. Nmfs 1992, 108, 92. [Google Scholar]
- Kooi, M.; Reisser, J.; Slat, B.; Ferrari, F.F.; Schmid, M.S.; Cunsolo, S.; Brambini, R.; Noble, K.; Sirks, L.-A.; Linders, T.E.W.; et al. The effect of particle properties on the depth profile of buoyant plastics in the ocean. Sci. Rep. 2016, 6, 33882. [Google Scholar] [CrossRef]
- Jakovljevic, G.; Govedarica, M.; Alvarez Taboada, F. Remote Sensing Data in Mapping Plastic at Surface Water Bodies. In Proceedings of the FIG Working Week 2019 Geospatial Information for A Smarter Life and Environmental Resilience, Hanoi, Vietnam, 22–26 April 2019. [Google Scholar]
- Aoyama, T. Extraction of marine debris in the Sea of Japan using high-spatial resolution satellite images. In SPIE Remote Sensing of the Oceans and Inland Waters: Techniques, Applications, and Challenges; SPIE—International Society for Optics and Photonics: New Delhi, India, 2016. [Google Scholar] [CrossRef]
- Gray, P.C.; Fleishman, A.B.; Klein, D.J.; McKown, M.W.; Bezy, V.S.; Lohmann, K.J.; Jhonston, D.W. A Convolutional Neural Network for Detecting Sea Turtles in Drone Imagery. Methods Ecol. Evol. 2018, 10, 345–355. [Google Scholar] [CrossRef]
- Hong, S.-J.; Han, Y.; Kim, S.-Y.; Lee, A.-Y.; Kim, G. Application of Deep-Learning Methods to Bird Detection Using Unmanned Aerial Vehicle Imagery. Sensors 2019, 19, 1651. [Google Scholar] [CrossRef]
- Martin, C.; Parkes, S.; Zhang, Q.; Zhang, X.; McCabe, M.F. Use of unnamed aerial vehicle for efficient beach litter monitoring. Mar. Pollut. Bull. 2018, 131, 662–673. [Google Scholar] [CrossRef]
- Topouzelis, K.; Papakonstantinou, A.; Garaba, S.P. Detection of floating plastics from satellite and unmanned aerial systems (Plastic Litter Project 2018). Int. J. Appl. Earth Obs. Geoinf. 2019, 79, 175–183. [Google Scholar] [CrossRef]
- Geraeds, M.; van Emmeric, T.; de Vries, R.; bin Ab Razak, M.S. Riverine Plastic Litter Monitoring Using Unmanned Aerial Vehicles (UAVs). Remote Sens. 2019, 11, 2045. [Google Scholar] [CrossRef]
- Moy, K.; Neilson, B.; Chung, A.; Meadows, A.; Castrence, M.; Ambagis, S.; Davidson, K. Mapping coastal marine debris using aerial imagery and spatial analysis. Mar. Pollut. Bull. 2018, 132, 52–59. [Google Scholar] [CrossRef] [PubMed]
- Boonpook, W.; Tan, Y.; Ye, Y.; Torteeka, P.; Torsri, K.; Dong, S. A Deep Learning Approach on Building Detection from Unmanned Aerial Vehicle-Based Images in Riverbank Monitoring. Sensors 2018, 18, 3921. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597v1. Available online: https://arxiv.org/abs/1505.04597 (accessed on 25 April 2020.).
- Schmidt, C.; Krauth, T.; Wagner, S. Export of Plastic Debris by Rivers into the Sea. Environ. Sci. Technol. 2017, 51, 12246–12253. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, ND, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. 2016, arXiv:1608.06993. Available online: https://arxiv.org/abs/1608.06993 (accessed on 25 April 2020).
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-4, Inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- Song, H.S.; Kim, Y.H.; Kim, Y.I. A Patch-Based Light Convolutional Neural Network for Land-Cover Mapping Using Landsat-8 Images. Remote Sens. 2019, 11, 114. [Google Scholar] [CrossRef]
- Lagkvist, M.; Kiselev, A.; Alirezaie, M.; Loutfi, A. Classification and Segmentation of Satellite Orthoimagery Using Convolutional Neural Networks. Remote Sens. 2016, 8, 329. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolution. arXiv 2016, arXiv:1511.07122. Available online: https://arxiv.org/abs/1511.07122 (accessed on 25 April 2020).
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Yuan, Y.; Song, M.; Ding, Y.; Lin, F.; Liang, D.; Zhang, D. Use of Unmanned Aerial Vehicle Imagery and Deep Learning UNet to Extract Rice Lodging. Sensors 2019, 19, 3859. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Guo, H.; He, G.; Jiang, W.; Yin, R.; Yan, L.; Leng, W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. Isprs Int. J. Geo Inf. 2020, 9, 189. [Google Scholar] [CrossRef]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-Spatial Imagery: A Case Study Over a Wetland. Remote Sens. 2020, 12, 959. [Google Scholar] [CrossRef]
- Ekocentar Bočac. Available online: https://ekocentar-bocacjezero.com/zastitna_mreza/zaustavljanje-plutajuceg-otpada-na-mrezi/ (accessed on 29 February 2020).
- Govedarica, M.; Jakovljević, G.; Taboada, F.A. Flood risk assessment based on LiDAR and UAV points clouds and DEM. In Proceedings of the SPIE 10783, Remote Sensing for Agriculture, Ecosystems, and Hydrology XX, 107830B, Berlin, Germany, 10 October 2018. [Google Scholar] [CrossRef]
- Trimble. Available online: http://www.ecognition.com/ (accessed on 12 January 2020).
- Zhou, Z.; Siddiquee, M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging. 2020. Available online: https://arxiv.org/pdf/1912.05074.pdf (accessed on 27 April 2020). [CrossRef]
- Wang, Y.; Liang, B.; Ding, M.; Li, J. Dense Semantic Labeling with Atrous Spatial Pyramid Pooling and Decoder for High-Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 20. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications Co.: Greenwich, CT, USA, 2017. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning. The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Available online: https://arxiv.org/abs/1611.05431 (accessed on 25 April 2020).
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Hasini, R.; Shokri, M.; Dehghan, M. Augmentation Scheme for Dealing with Imbalanced Network Traffic Classification Using Deep Learning. arXiv 2019, arXiv:1901.00204. Available online: https://arxiv.org/pdf/1901.00204.pdf (accessed on 25 April 2020).
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Advances in Neural Information Processing Systems 27 (NIPS ’14); NIPS Foundation: Montreal, QC, Canada, 2014. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Bekkar, M.; Kheliouane Djemaa, H.; Akrouf Alitouche, T. Evaluation Measure for Models Assessment over Imbalanced Data Sets. J. Inf. Eng. Appl. 2013, 3, 27–38. [Google Scholar]
- Innamorati, C.; Ritschel, T.; Weyrich, T.; Mitra, N.J. Learning on the Edge: Explicit Boundary Handling in CNNs. arXiv 2018, arXiv:180503106.2018. Available online: https://arxiv.org/pdf/1805.03106.pdf (accessed on 25 April 2020).
- Cui, Y.; Zhang, G.; Liu, Z.; Xiong, Z.; Hu, J. A Deep Learning Algorithm for One-step Contour Aware Nuclei Segmentation of Histopathological Images. Med. Biol. Eng. Comput. 2019, 57, 2027–2043. [Google Scholar] [CrossRef]
- Goddijn-Murphy, L.; Peters, S.; van Sebille, E.; James, N.; Gibb, S. Concept for a hyperspectral remote sensing algorithm for floating marine macro plastics. Mar. Pollut. Bull. 2018, 126, 255–262. [Google Scholar] [CrossRef] [PubMed]
- Kannoji, S.P.; Jaiswal, G. Effects of Varying Resolution on Performance of CNN based Image Classification: An Experimental Study. Int. J. Comput. Sci. Eng. 2018, 6, 451–456. [Google Scholar] [CrossRef]
- Kay, S.; Hedley, J.; Lavender, S. Sun Glint Correction of High and Low Spatial Resolution Images of Aquatic Scenes: A Review of Methods for Visible and Near-Infrared Wavelengths. Remote Sens. 2009, 1, 697–730. [Google Scholar] [CrossRef]
- Ji, L.; Gong, P.; Geng, X.; Zhao, Y. Improving the Accuracy of the Water Surface Cover Type in the 30 m FROM-GLC Product. Remote Sens. 2015, 7, 13507–13527. [Google Scholar] [CrossRef]
- Anggoro, A.; Siregar, V.; Agus, S. The effect of sunglint on benthic habitats mapping in Pari Island using worldview-2 imagery. Procedia Environ. Sci. 2016, 33, 487–495. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flight Height (m) | Spatial Resolution (mm) | |
|---|---|---|
| Balkana | Crna Rijeka | |
| 12 | 4 | - |
| 40 | 13 | - |
| 55 | 18 | - |
| 70 | 23 | - |
| 90 | 30 | 30 |
| Study Area | Dataset | Architecture | Batch Size | Learning Rate | Training Time |
|---|---|---|---|---|---|
| Balkana | Dataset 1 | ResUNet50 | 8 | 8 × 10−5 | 31 min |
| Balkana | Dataset 1 | ResUNext50 | 8 | 1 × 10−6 | 44 min |
| Balkana | Dataset 1 | XceptionUNet | 8 | 2 × 10−5 | 21 min |
| Balkana | Dataset 1 | InceptionUResNet v2 | 8 | 1 × 10−5 | 33 min |
| Balkana | Dataset 2 | ResUNet50 | 8 | 3 × 10−5 | 40 min |
| Crna Rijeka | Dataset 3 | ResUNet50 | 8 | 4 × 10−6 | 3 h |
| ResUNet50 | ResUNext50 | XceptionUNet | InceptionResUNet v2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| OPS | 0.86 | 0.86 | 0.86 | 0.99 | 0.19 | 0.31 | 0.81 | 0.39 | 0.53 | 0.01 | 0.00 | 0.00 |
| Nylon | 0.92 | 0.85 | 0.88 | 0.77 | 0.96 | 0.85 | 0.76 | 0.87 | 0.81 | 0.76 | 0.74 | 0.75 |
| PET | 0.92 | 0.92 | 0.92 | 0.82 | 0.96 | 0.88 | 0.78 | 0.75 | 0.77 | 0.60 | 0.72 | 0.65 |
| 13 mm | 18 mm | 23 mm | 30 mm | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| OPS | 0.88 | 0.77 | 0.82 | 0.69 | 0.71 | 0.70 | 0.79 | 0.31 | 0.44 | 0.75 | 0.45 | 0.56 |
| Nylon | 0.89 | 0.75 | 0.82 | 0.91 | 0.52 | 0.66 | 0.76 | 0.26 | 0.39 | 0.87 | 0.20 | 0.33 |
| PET | 0.92 | 0.83 | 0.87 | 0.78 | 0.84 | 0.81 | 0.83 | 0.68 | 0.75 | 0.77 | 0.70 | 0.73 |
| Precision | Recall | F1 | |
|---|---|---|---|
| Plastic | 0.82 | 0.75 | 0.78 |
| Maybe Plastic | 0.62 | 0.34 | 0.43 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jakovljevic, G.; Govedarica, M.; Alvarez-Taboada, F. A Deep Learning Model for Automatic Plastic Mapping Using Unmanned Aerial Vehicle (UAV) Data. Remote Sens. 2020, 12, 1515. https://doi.org/10.3390/rs12091515
Jakovljevic G, Govedarica M, Alvarez-Taboada F. A Deep Learning Model for Automatic Plastic Mapping Using Unmanned Aerial Vehicle (UAV) Data. Remote Sensing. 2020; 12(9):1515. https://doi.org/10.3390/rs12091515
Chicago/Turabian StyleJakovljevic, Gordana, Miro Govedarica, and Flor Alvarez-Taboada. 2020. "A Deep Learning Model for Automatic Plastic Mapping Using Unmanned Aerial Vehicle (UAV) Data" Remote Sensing 12, no. 9: 1515. https://doi.org/10.3390/rs12091515
APA StyleJakovljevic, G., Govedarica, M., & Alvarez-Taboada, F. (2020). A Deep Learning Model for Automatic Plastic Mapping Using Unmanned Aerial Vehicle (UAV) Data. Remote Sensing, 12(9), 1515. https://doi.org/10.3390/rs12091515