Impact of Calibrating Filtering Algorithms on the Quality of LiDAR-Derived DTM and on Forest Attribute Estimation through Area-Based Approach

 ,
,  ,
,  ,
,  , and
, and 
Abstract
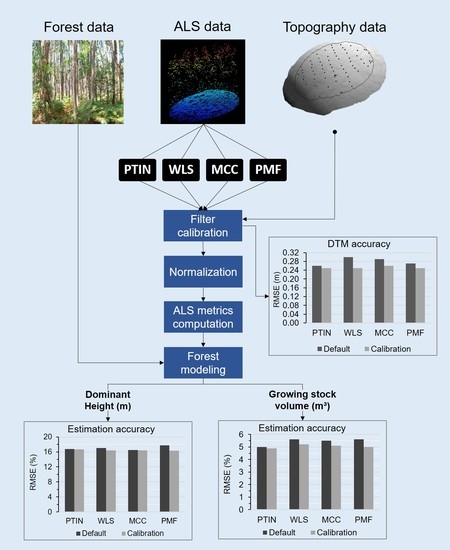
1. Introduction
2. Material and Methods
2.1. Study Area
2.2. Field Data Collection
2.3. ALS Data Collection and Pre-Processing
2.4. Filtering Calibration
2.4.1. Progressive Triangulated Irregular Network (PTIN)
2.4.2. Weighted Linear Least-Squares Interpolation (WLS)
2.4.3. Multiscale Curvature Classification (MCC)
2.4.4. The Progressive Morphological Filter (PMF)
2.5. Filtering Accuracy Assessment
2.6. Forest Modeling Assessment
3. Results
3.1. Filtering Parameters Calibration
3.2. Estimation of Forest Attributes
4. Discussion
5. Conclusions
- -
- The calibration of the ground filter parameters improved the quality of the DTM.
- -
- The calibrated parameter values for WLS, MCC, and PMF allowed deriving more accurate estimated forest attributes than those obtained when filtering using their default counterparts, with a more highlighted impact on the estimation of dominant height than of growing stock.
- -
- The results derived when using the PTIN filter varied the least with the calibration of the parameters.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wehr, A.; Lohr, U. Airborne laser scanning—An introduction and overview. ISPRS J. Photogramm. Remote Sens. 1999, 54, 68–82. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Maltamo, M.; Mcroberts, R.E.; Næsset, E. Forestry Applications of Airborne Laser Scanning; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Managing Forest Ecosystems; Springer: Dordrecht, The Netherlands, 2014; Volume 27. [Google Scholar]
- Eitel, J.U.H.; Höfle, B.; Vierling, L.A.; Abellán, A.; Asner, G.P.; Deems, J.S.; Glennie, C.L.; Joerg, P.C.; LeWinter, A.L.; Magney, T.S.; et al. Beyond 3-D: The new spectrum of lidar applications for earth and ecological sciences. Remote Sens. Environ. 2016, 186, 372–392. [Google Scholar] [CrossRef]
- Nelson, R. How did we get here? An early history of forestry lidar. Can. J. Remote Sens. 2013, 39, S6–S17. [Google Scholar] [CrossRef]
- Hyyppä, J.; Hyyppä, H.; Leckie, D.; Gougeon, F.; Yu, X.; Maltamo, M. Review of methods of small-footprint airborne laser scanning for extracting forest inventory data in boreal forests. Int. J. Remote Sens. 2008, 29, 1339–1366. [Google Scholar] [CrossRef]
- Nilsson, M.; Nordkvist, K.; Jonzén, J.; Lindgren, N.; Axensten, P.; Wallerman, J.; Egberth, M.; Larsson, S.; Nilsson, L.; Eriksson, J.; et al. A nationwide forest attribute map of Sweden predicted using airborne laser scanning data and field data from the National Forest Inventory. Remote Sens. Environ. 2017, 194, 447–454. [Google Scholar] [CrossRef]
- Næsset, E. Area-based inventory in Norway—From innovation to an operational reality. In Forestry Applications of Airborne Laser Scanning; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 215–240. [Google Scholar]
- Kotivuori, E.; Korhonen, L.; Packalen, P. Nationwide airborne laser scanning based models for volume, biomass and dominant height in Finland. Silva Fenn 2016, 50, 1–28. [Google Scholar] [CrossRef]
- Liu, X. Airborne LiDAR for DEM generation: Some critical issues. Prog. Phys. Geogr. Earth Environ. 2008, 32, 31–49. [Google Scholar]
- Chen, Z.; Gao, B.; Devereux, B. State-of-the-art: DTM generation using airborne LIDAR data. Sensors 2017, 17, 150. [Google Scholar] [CrossRef]
- Næsset, E. Practical large-scale forest stand inventory using a small-footprint airborne scanning laser. Scand. J. For. Res. 2004, 19, 164–179. [Google Scholar] [CrossRef]
- Meng, X.; Currit, N.; Zhao, K. Ground filtering algorithms for airborne LiDAR data: A review of critical issues. Remote Sens. 2010, 2, 833–860. [Google Scholar] [CrossRef]
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. In Proceedings of the International Archives of Photogrammetry and Remote Sensing. XIXth ISPRS Congress, Amsterdam, The Netherlands, 16–23 July 2000; Schenk, T., Vosselman, G., Eds.; International Society for Photogrammetry and Remote Sensing: Amsterdam, The Netherlands, 2000; Volume XXXIII, pp. 110–117. [Google Scholar]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 1998, 53, 193–203. [Google Scholar] [CrossRef]
- Evans, J.S.; Hudak, A.T. A multiscale curvature algorithm for classifying discrete return LiDAR in forested environments. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1029–1038. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, S.C.; Whitman, D.; Shyu, M.L.; Yan, J.; Zhang, C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef]
- Tinkham, W.T.; Huang, H.; Smith, A.M.S.; Shrestha, R.; Falkowski, M.J.; Hudak, A.T.; Link, T.E.; Glenn, N.F.; Marks, D.G. A Comparison of two open source LiDAR surface classification algorithms. Remote Sens. 2011, 3, 638–649. [Google Scholar] [CrossRef]
- Silva, C.A.; Klauberg, C.; Hentz, Â.M.K.; Corte, A.P.D.; Ribeiro, U.; Liesenberg, V. Comparing the performance of ground filtering algorithms for terrain modeling in a forest environment using airborne LiDAR data. Floresta E Ambiente 2018, 25, 1–10. [Google Scholar] [CrossRef]
- Stereńczak, K.; Ciesielski, M.; Balazy, R.; Zawiła-Niedźwiecki, T. Comparison of various algorithms for DTM interpolation from LIDAR data in dense mountain forests. Eur. J. Remote Sens. 2016, 49, 599–621. [Google Scholar] [CrossRef]
- Sithole, G.; Vosselman, G. Experimental comparison of filter algorithms for bare-Earth extraction from airborne laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2004, 59, 85–101. [Google Scholar] [CrossRef]
- Korzeniowska, K.; Pfeifer, N.; Mandlburger, G.; Lugmayr, A. Experimental evaluation of ALS point cloud ground extraction tools over different terrain slope and land-cover types. Int. J. Remote Sens. 2014, 35, 4673–4697. [Google Scholar] [CrossRef]
- Polat, N.; Uysal, M. Investigating performance of Airborne LiDAR data filtering algorithms for DTM generation. Measurement 2015, 63, 61–68. [Google Scholar] [CrossRef]
- White, J.C.; Arnett, J.T.T.R.; Wulder, M.A.; Tompalski, P.; Coops, N.C. Evaluating the impact of leaf-on and leaf-off airborne laser scanning data on the estimation of forest inventory attributes with the area-based approach. Can. J. For. Res. 2015, 45, 1498–1513. [Google Scholar] [CrossRef]
- Hu, H.; Ding, Y.; Zhu, Q.; Wu, B.; Lin, H.; Du, Z.; Zhang, Y.; Zhang, Y. An adaptive surface filter for airborne laser scanning point clouds by means of regularization and bending energy. ISPRS J. Photogramm. Remote Sens. 2014, 92, 98–111. [Google Scholar] [CrossRef]
- Zhang, K.; Whitman, D. Comparison of three algorithms for filtering airborne LiDAR data. Photogramm. Eng. Remote Sens. 2005, 71, 313–324. [Google Scholar] [CrossRef]
- Montealegre, A.L.; Lamelas, M.T.; de la Riva, J. A comparison of open-source LiDAR filtering algorithms in a Mediterranean forest environment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4072–4085. [Google Scholar] [CrossRef]
- Prodan, M. Holzmesslehre; Sauerländer’s Verlag: Frankfurt, Germany, 1965. [Google Scholar]
- Tomé, M.; Tomé, J.; Ribeiro, F.; Faias, S. Equações de volume total, volume percentual e de perfil do tronco para Eucalyptus globulus Labill. em Portugal. Silva Lusitana 2007, 15, 25–39. [Google Scholar]
- Gobakken, T.; Næsset, E. Assessing effects of positioning errors and sample plot size on biophysical stand properties derived from airborne laser scanner data. Can. J. For. Res. 2009, 39, 1036–1052. [Google Scholar] [CrossRef]
- Aderson, J.; Mikhail, E. Surveying: Theory and Practice, 7th ed.; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Gonçalves, G.R.; Gomes Pereira, L. A thorough accuracy estimation of DTM produced from airborne full-waveform laser scanning data of unmanaged eucalypt plantations. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3256–3266. [Google Scholar] [CrossRef]
- Hug, C.; Ullrich, A.; Grimm, A. Litemapper-5600—A waveform-digitizing LIDAR terrain and vegetation mapping system. In Proceedings of the ISPRS Working Grounp VIII/2, Freiburg, Germany, 3–6 October 2004; International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. volume 36–8/W2, pp. 24–29. [Google Scholar]
- Ferraz, A.; Bretar, F.; Jacquemoud, S.; Gonçalves, G.; Pereira, L.; Tomé, M.; Soares, P. 3-D mapping of a multi-layered Mediterranean forest using ALS data. Remote Sens. Environ. 2012, 121, 210–223. [Google Scholar] [CrossRef]
- McGaughey, R. FUSION/LDV: Software for LIDAR data analysis and visualization, v3.60+; Pacific Northwest Research Station, United States Department of Agriculture Forest Service: Corvallis, OR, USA, 2016. [Google Scholar]
- R Core Team R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org/ (accessed on 10 January 2020).
- Maltamo, M.; Bollandsås, O.M.; Næsset, E.; Gobakken, T.; Packalén, P. Different plot selection strategies for field training data in ALS-assisted forest inventory. Forestry 2011, 84, 23–31. [Google Scholar] [CrossRef]
- Lauri, K.; Jussi, P.; Jukka, M.; Aki, S.; Matti, M.; Petteri, P.; Jyrki, K. The use of airborne laser scanning to estimate sawlog volumes. Forestry 2008, 81, 499–510. [Google Scholar] [CrossRef]
- Jakubowski, M.K.; Guo, Q.; Kelly, M. Tradeoffs between lidar pulse density and forest measurement accuracy. Remote Sens. Environ. 2013, 130, 245–253. [Google Scholar] [CrossRef]
- Guerra-Hernández, J.; Görgens, E.B.; García-Gutiérrez, J.; Rodriguez, L.C.E.; Tomé, M.; González-Ferreiro, E. Comparison of ALS based models for estimating aboveground biomass in three types of Mediterranean forest. Eur. J. Remote Sens. 2016, 49, 185–204. [Google Scholar] [CrossRef]
- Arias-Rodil, M.; Diéguez-Aranda, U.; Álvarez-González, J.G.; Pérez-Cruzado, C.; Castedo-Dorado, F.; González-Ferreiro, E. Modeling diameter distributions in radiata pine plantations in Spain with existing countrywide LiDAR data. Ann. For. Sci. 2018, 75, 36. [Google Scholar] [CrossRef]
- Cosenza, D.N.; Soares, P.; Guerra-Hernández, J.; Pereira, L.; González-Ferreiro, E.; Castedo-Dorado, F.; Tomé, M. Comparing Johnson’s SB and Weibull functions to model the diameter distribution of forest plantations through ALS data. Remote Sens. 2019, 11, 2792. [Google Scholar] [CrossRef]
- Silva, A.G.P.; Görgens, E.B.; Campoe, O.C.; Alvares, C.A.; Stape, J.L.; Rodriguez, L.C.E. Assessing biomass based on canopy height profiles using airborne laser scanning data in eucalypt plantations. Sci. Agric. 2015, 72, 504–512. [Google Scholar] [CrossRef]
- Falkowski, M.J.; Evans, J.S.; Martinuzzi, S.; Gessler, P.E.; Hudak, A.T. Characterizing forest succession with lidar data: An evaluation for the Inland Northwest, USA. Remote Sens. Environ. 2009, 113, 946–956. [Google Scholar] [CrossRef]
- Montealegre, A.L.; Lamelas, M.T.; de la Riva, J.; García-Martín, A.; Escribano, F. Use of low point density ALS data to estimate stand-level structural variables in Mediterranean Aleppo pine forest. Forestry 2016, 89, 373–382. [Google Scholar] [CrossRef]
- Roussel, J.-R.; Auty, D.; De Boissieu, F.; Meador, A.S. lidR: Airborne LiDAR Data Manipulation and Visualization for Forestry Applications. Available online: https://cran.r-project.org/package=lidR (accessed on 12 September 2019).
- Fawcett, D.; Azlan, B.; Hill, T.C.; Kho, L.K.; Bennie, J.; Anderson, K. Unmanned aerial vehicle (UAV) derived structure-from-motion photogrammetry point clouds for oil palm (Elaeis guineensis) canopy segmentation and height estimation. Int. J. Remote Sens. 2019, 40, 7538–7560. [Google Scholar] [CrossRef]
- Montealegre, A.L.; Lamelas, M.T.; de la Riva, J. Interpolation routines assessment in ALS-derived digital elevation models for forestry applications. Remote Sens. 2015, 7, 8631–8654. [Google Scholar] [CrossRef]
- García-Gutiérrez, J.; Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C. A comparison of machine learning regression techniques for LiDAR-derived estimation of forest variables. Neurocomputing 2015, 167, 24–31. [Google Scholar] [CrossRef]
- Gonçalves-Seco, L.; González-Ferreiro, E.; Diéguez-Aranda, U.; Fraga-Bugallo, B.; Crecente, R.; Miranda, D. Assessing the attributes of high-density Eucalyptus globulus stands using airborne laser scanner data. Int. J. Remote Sens. 2011, 32, 9821–9841. [Google Scholar] [CrossRef]
- Görgens, E.B.; Packalen, P.; da Silva, A.G.P.; Alvares, C.A.; Campoe, O.C.; Stape, J.L.; Rodriguez, L.C.E. Stand volume models based on stable metrics as from multiple ALS acquisitions in Eucalyptus plantations. Ann. For. Sci. 2015, 72, 489–498. [Google Scholar] [CrossRef]
- Pascual, A.; Bravo, F.; Ordoñez, C. Assessing the robustness of variable selection methods when accounting for co-registration errors in the estimation of forest biophysical and ecological attributes. Ecol. Modell. 2019, 403, 11–19. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Hartig, F.; Latifi, H.; Berger, C.; Hernández, J.; Corvalán, P.; Koch, B. Importance of sample size, data type and prediction method for remote sensing-based estimations of aboveground forest biomass. Remote Sens. Environ. 2014, 154, 102–114. [Google Scholar] [CrossRef]
- Gregoire, T.G.; Lin, Q.F.; Boudreau, J.; Nelson, R. Regression estimation following the square-root transformation of the response. For. Sci. 2008, 54, 597–606. [Google Scholar]
- Myers, R.H. Classical and Modern Regression with Applications; Duxbury Press: Boston, MA, USA, 1989. [Google Scholar]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression. Available online: https://socialsciences.mcmaster.ca/jfox/Books/Companion/ (accessed on 12 September 2019).
- Cosenza, D.N.; Lauri, K.; Matti, M.; Petteri, P.; Strunk, J.L.; Næsset, E.; Gobakken, T.; Soares, P.; Tomé, M. Comparison of linear regression, k-nearest neighbor, and random forest methods in airborne laser scanning based prediction of growing stock. Forestry. under review.
- Wilcoxon, F. Individual comparisons by ranking methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Riis-Nielsen, T. Developing an airborne laser scanning dominant height model from a countrywide scanning survey and national forest inventory data. Scand. J. For. Res. 2010, 25, 262–272. [Google Scholar] [CrossRef]
- Tompalski, P.; White, J.C.; Coops, N.C.; Wulder, M.A. Demonstrating the transferability of forest inventory attribute models derived using airborne laser scanning data. Remote Sens. Environ. 2019, 227, 110–124. [Google Scholar] [CrossRef]
- Lim, K.; Hopkinson, C.; Treitz, P. Examining the effects of sampling point densities. For. Chron. 2008, 84, 876–885. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Chen, Q.; Domke, G.M.; Næsset, E.; Gobakken, T.; Chirici, G.; Mura, M. Optimizing nearest neighbour configurations for airborne laser scanning-assisted estimation of forest volume and biomass. Forestry 2017, 90, 99–111. [Google Scholar] [CrossRef]
- Görgens, E.B.; Montaghi, A.; Rodriguez, L.C.E. A performance comparison of machine learning methods to estimate the fast-growing forest plantation yield based on laser scanning metrics. Comput. Electron. Agric. 2015, 116, 221–227. [Google Scholar] [CrossRef]
- Colomina, I.; Molina, P. Unmanned aerial systems for photogrammetry and remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef]
- Goodbody, T.R.H.; Coops, N.C.; Marshall, P.L.; Tompalski, P.; Crawford, P. Unmanned aerial systems for precision forest inventory purposes: A review and case study. For. Chron. 2017, 93, 71–81. [Google Scholar] [CrossRef]
- Graham, A.; Coops, N.; Wilcox, M.; Plowright, A. Evaluation of ground surface models derived from unmanned aerial systems with digital aerial photogrammetry in a disturbed conifer forest. Remote Sens. 2019, 11, 84. [Google Scholar] [CrossRef]
- Pingel, T.J.; Clarke, K.C.; Mcbride, W.A. An improved simple morphological filter for the terrain classification of airborne LIDAR data. ISPRS J. Photogramm. Remote Sens. 2013, 77, 21–30. [Google Scholar] [CrossRef]
- Wallace, L.; Bellman, C.; Hally, B.; Hernandez, J.; Jones, S.; Hillman, S. Assessing the ability of image based point clouds captured from a UAV to measure the terrain in the presence of canopy cover. Forests 2019, 10, 284. [Google Scholar] [CrossRef]
- Hollaus, M.; Wagner, W.; Eberhöfer, C.; Karel, W. Accuracy of large-scale canopy heights derived from LiDAR data under operational constraints in a complex alpine environment. ISPRS J. Photogramm. Remote Sens. 2006, 60, 323–338. [Google Scholar] [CrossRef]
- Hollaus, M.; Wagner, W.; Maier, B.; Schadauer, K. Airborne laser scanning of forest stem volume in a mountainous environment. Sensors 2007, 7, 1559–1577. [Google Scholar] [CrossRef]
- Lee, H.S.; Younan, N.H. DTM extraction of Lidar returns via adaptive processing. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2063–2069. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An sasy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Tompalski, P.; Coops, N.C.; White, J.C.; Wulder, M.A. Augmenting site index estimation with airborne laser scanning data. For. Sci. 2015, 61, 861–873. [Google Scholar] [CrossRef]
- Gregoire, T.G.; Næsset, E.; McRoberts, R.E.; Ståhl, G.; Andersen, H.E.; Gobakken, T.; Ene, L.; Nelson, R. Statistical rigor in LiDAR-assisted estimation of aboveground forest biomass. Remote Sens. Environ. 2016, 173, 98–108. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T. Inference for lidar-assisted estimation of forest growing stock volume. Remote Sens. Environ. 2013, 128, 268–275. [Google Scholar] [CrossRef]
- Graham, A.N.V.; Coops, N.C.; Tompalski, P.; Plowright, A.; Wilcox, M. Effect of ground surface interpolation methods on the accuracy of forest attribute modelling using unmanned aerial systems-based digital aerial photogrammetry. Int. J. Remote Sens. 2020, 41, 3287–3306. [Google Scholar] [CrossRef]
- Simpson, J.E.; Smith, T.E.L.; Wooster, M.J. Assessment of errors caused by forest vegetation structure in airborne LiDAR-derived DTMs. Remote Sens. 2017, 9, 1101. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Assessment | Plots | * Attribute | Unit | Minimum | Mean | Maximum | σ |
|---|---|---|---|---|---|---|---|
| Calibration | 41 | dg | cm | 3.0 | 11.7 | 19.3 | 4.4 |
| hd | m | 3.67 | 15.54 | 26.50 | 5.79 | ||
| V | m³ | 0.011 | 2.937 | 11.726 | 2.605 | ||
| N | trees ha−1 | 875 | 1528 | 3613 | 534 | ||
| Forest modeling | 25 | dg | cm | 5.6 | 12.3 | 18.2 | 3.6 |
| hd | m | 6.55 | 16.74 | 23.10 | 4.48 | ||
| V | m³ | 0.088 | 3.134 | 7.891 | 2.232 | ||
| N | trees ha−1 | 875 | 1470 | 2343 | 361 |
| Filter | Software | Parameters | Default | Set of Values for Calibration |
|---|---|---|---|---|
| PTIN | LASground | Spike | 0.5 | 0.0, 0.5, 1.0, 1.5, 2.0 |
| Step size | 5 | 1,3,5,7 | ||
| Granularity | Fine | None, coarse, fine, extra fine | ||
| WLS | FUSION | g | −2.5 | −3.0, −2.5, −2.0, …, 0.0 |
| w | 2.5 | 0.0, 0.5, 1.0, …, 3.0 | ||
| Iterations | 5 | 3, 5, 7 | ||
| Window size | 5 * | 1, 3, 5 | ||
| MCC | MCC-LIDAR | Scale (λ) | 1.5 | 0.5, 1.0, 1.5, …, 5.0 |
| Tolerance (t) | 0.3 | 0.1, 0.2, 0.3, …, 1.0 | ||
| PMF | lidR | Threshold | 0.3 | 0.1, 0.2, 0.3…, 1.5 |
| Window size | 5, 9, 13, 17 | 1, 3, 5, …, 19 |
| Metric Type | Metric | Description |
|---|---|---|
| Position | Zmin, Zmean, Zmax | Minimum (Zmin), mean (Zmean) and maximum (Zmax) return height |
| Z5, Z10, Z15, Z20, Z25, Z30, Z35, Z40, Z45, Z50, Z55, Z60, Z65, Z70, Z75, Z80, Z85, Z90, Z95 | Zx-th percentile (quantile) of height distribution | |
| MQ, MC | Quadratic (MQ) and cubic (MC) mean height | |
| Height variability | Zcv, Zsd | Height coefficient of variation (Zcv) and standard deviation (Zsd) |
| Zsqew, Zkurt | Height skewness (Zsqew) and kurtosis (Zkurt) | |
| Density | PFRZmean, PARZmean | Percentage of first (PFRZmean) and all returns (PARZmean) above Zmean |
| PFR2m, PAR2m | Percentage of first (PFR2m) and all returns (PAR2m) above 2 m | |
| C1, C2, C3, C4, C5, C6, C7, C8, C9 | Cumulative percentage of returns in the C-th layer, i.e., C10 = 100% | |
| Others | CR | Canopy relief ratio: (Zmean – Zmin)/(Zmax – Hmin) |
| Filter | RMSE (m) | Difference * | Calibrated Parameters Values | |
|---|---|---|---|---|
| Default | Calibration | |||
| PTIN | 0.26 | 0.25 | −0.01 (−4%) | Spike: 0 |
| Step size: 5 | ||||
| Granularity: Fine, extra fine | ||||
| WLS | 0.30 | 0.25 | −0.05 (−16%) | |g| = w = 0.0, 0.5, 1.0, …, 3.0 |
| Iterations: 3 | ||||
| Window size: 1 | ||||
| MCC | 0.29 | 0.26 | −0.03 (−10%) | Scale: 1, 1.5, 2, …, 4.5 |
| Tolerance: 0.1 | ||||
| PMF | 0.27 | 0.25 | −0.02 (−7%) | Threshold: 0.1 |
| Window size: 5 | ||||
| Filter | Setting | * Equation | σ² (m) | ** RMSEmed (m) | p-value |
|---|---|---|---|---|---|
| PTIN | Calibrated | 0.009 | 0.829 (4.9%) | 0.011 | |
| Default | 0.009 | 0.844 (5.0%) | |||
| WLS | Calibrated | 0.010 | 0.86 (5.2%) | <0.001 | |
| Default | 0.009 | 0.94 (5.6%) | |||
| MCC | Calibrated | 0.009 | 0.86 (5.1%) | <0.001 | |
| Default | 0.009 | 0.92 (5.5%) | |||
| PMF | Calibrated | 0.009 | 0.84 (5.0%) | <0.001 | |
| Default | 0.009 | 0.94 (5.6%) |
| Filter | Setting | * Equation | σ² (m³) | ** RMSEmed (m³) | p-value |
|---|---|---|---|---|---|
| PTIN | Calibrated | 0.021 | 0.522 (16.7%) | 0.554 | |
| Default | 0.020 | 0.528 (16.8%) | |||
| WLS | Calibrated | 0.019 | 0.514 (16.4%) | 0.007 | |
| Default | 0.019 | 0.532 (17.0%) | |||
| MCC | Calibrated | 0.019 | 0.515 (16.4%) | 0.267 | |
| Default | 0.018 | 0.517 (16.5%) | |||
| PMF | Calibrated | 0.020 | 0.510 (16.3%) | <0.001 | |
| Default | 0.020 | 0.554 (17.7%) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cosenza, D.N.; Gomes Pereira, L.; Guerra-Hernández, J.; Pascual, A.; Soares, P.; Tomé, M. Impact of Calibrating Filtering Algorithms on the Quality of LiDAR-Derived DTM and on Forest Attribute Estimation through Area-Based Approach. Remote Sens. 2020, 12, 918. https://doi.org/10.3390/rs12060918
Cosenza DN, Gomes Pereira L, Guerra-Hernández J, Pascual A, Soares P, Tomé M. Impact of Calibrating Filtering Algorithms on the Quality of LiDAR-Derived DTM and on Forest Attribute Estimation through Area-Based Approach. Remote Sensing. 2020; 12(6):918. https://doi.org/10.3390/rs12060918
Chicago/Turabian StyleCosenza, Diogo N., Luísa Gomes Pereira, Juan Guerra-Hernández, Adrián Pascual, Paula Soares, and Margarida Tomé. 2020. "Impact of Calibrating Filtering Algorithms on the Quality of LiDAR-Derived DTM and on Forest Attribute Estimation through Area-Based Approach" Remote Sensing 12, no. 6: 918. https://doi.org/10.3390/rs12060918
APA StyleCosenza, D. N., Gomes Pereira, L., Guerra-Hernández, J., Pascual, A., Soares, P., & Tomé, M. (2020). Impact of Calibrating Filtering Algorithms on the Quality of LiDAR-Derived DTM and on Forest Attribute Estimation through Area-Based Approach. Remote Sensing, 12(6), 918. https://doi.org/10.3390/rs12060918