Nonlocal CNN SAR Image Despeckling





Abstract
1. Introduction
- suppress most of the speckle in homogeneous regions;
- preserve textures;
- preserve region boundaries and other linear structures;
- avoid altering natural or man-made permanent scatterers; and
- avoid introducing filtering artifacts.
2. Related Work
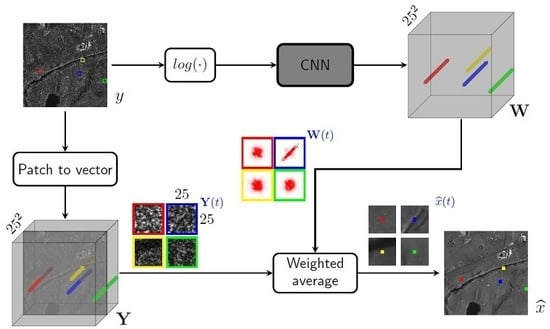
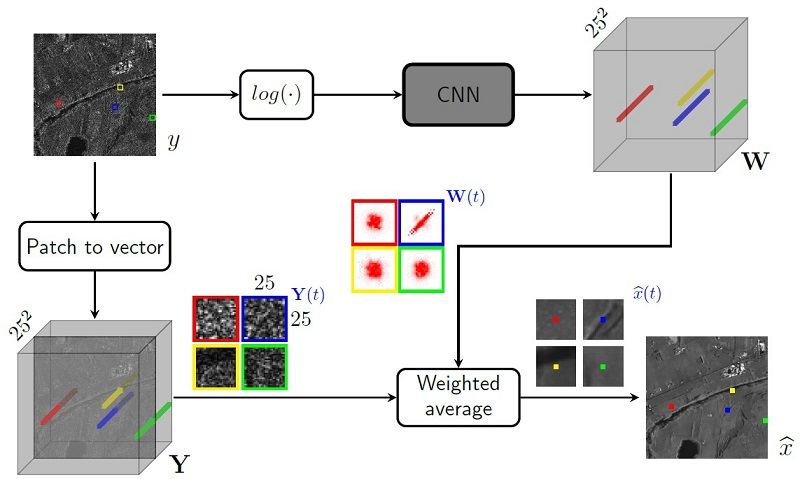
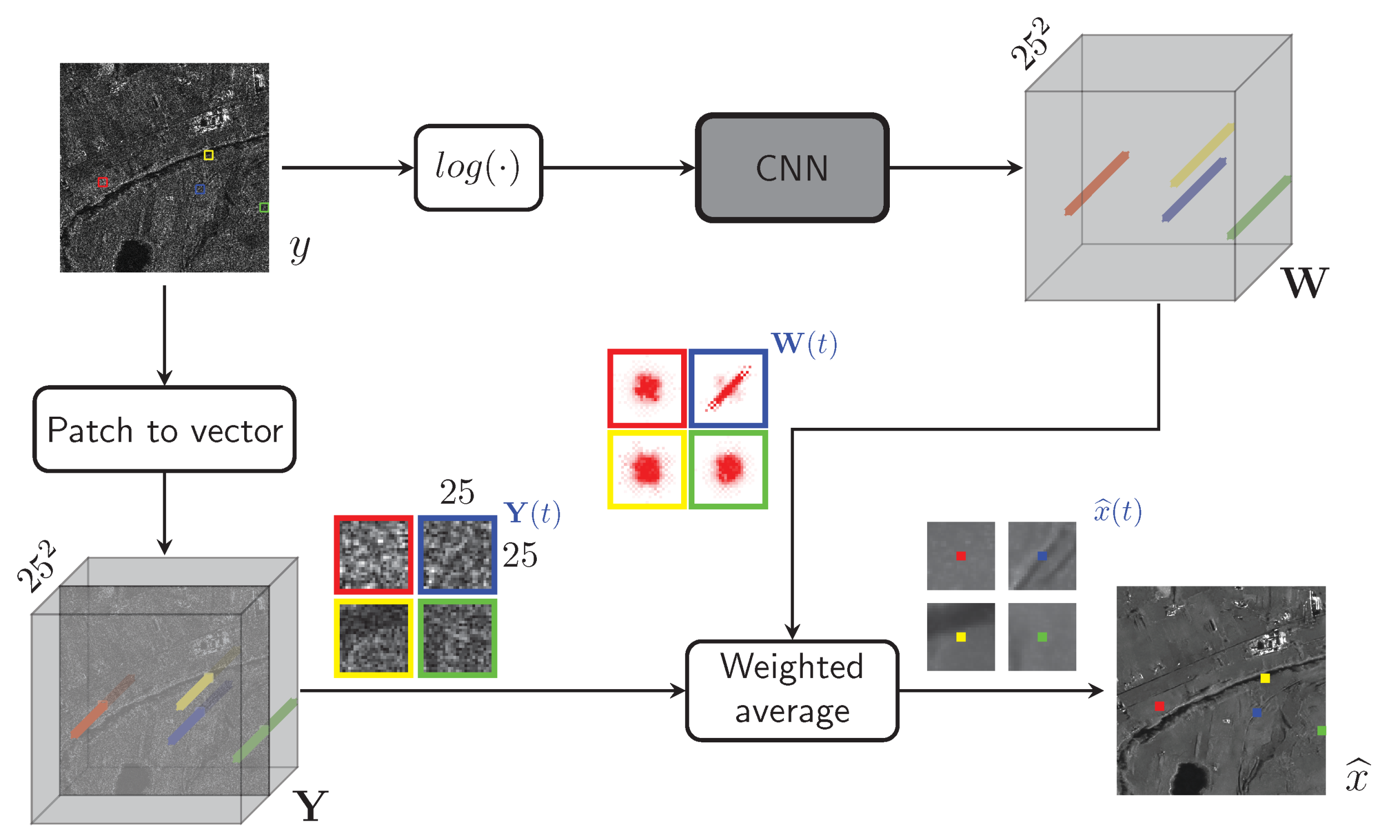
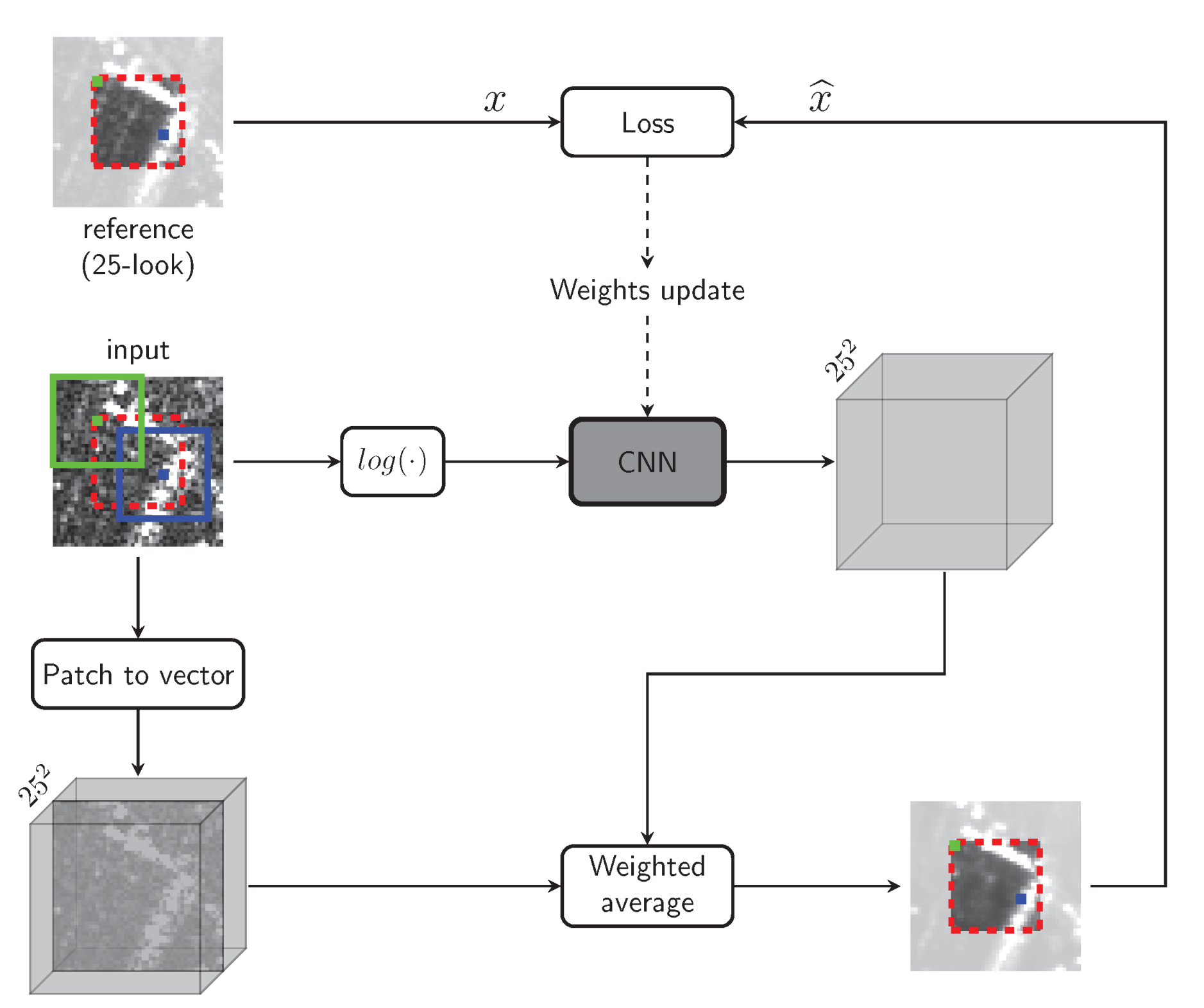
3. Proposed Method
3.1. CNN-Powered Nonlocal Means
3.2. Estimating Weights with a Conventional CNN
3.3. Estimating Weights with a “Nonlocal” CNN
4. Experimental Validation
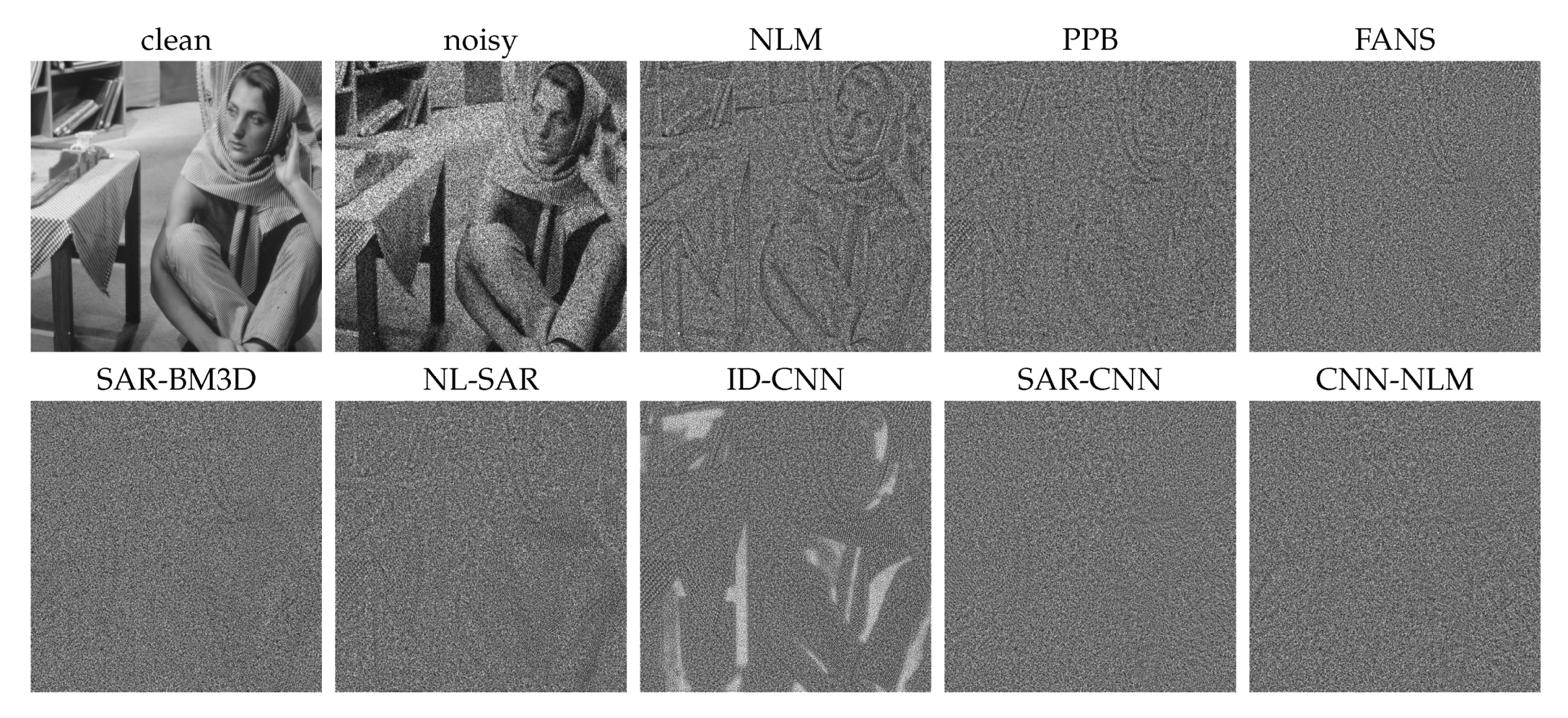
4.1. Experiments on Simulated Images
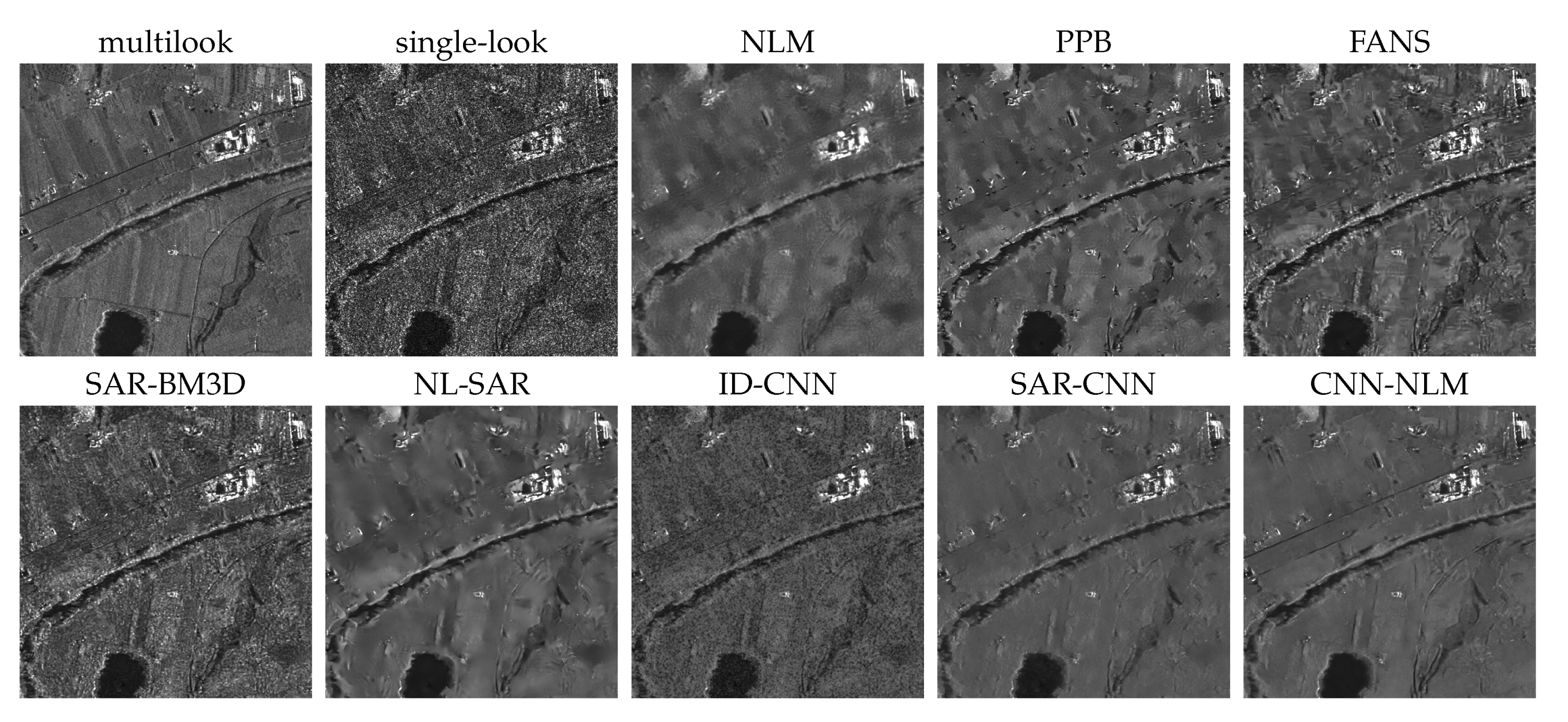
4.2. Experiments on Real-World SAR Images
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Lin, H.; Li, Y. Impacts of Feature Normalization on Optical and SAR Data Fusion for Land Use/Land Cover Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1061–1065. [Google Scholar] [CrossRef]
- Baghdadi, N.; Hajj, M.; Zribi, M.; Fayad, I. Coupling SAR C-Band and Optical Data for Soil Moisture and Leaf Area Index Retrieval Over Irrigated Grasslands. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1229–1243. [Google Scholar] [CrossRef]
- Scarpa, G.; Gargiulo, M.; Mazza, A.; Gaetano, R. A CNN-Based Fusion Method for Feature Extraction from Sentinel Data. Remote Sens. 2018, 10, 236. [Google Scholar] [CrossRef]
- Vitale, S.; Cozzolino, D.; Scarpa, G.; Verdoliva, L.; Poggi, G. Guided Patchwise Nonlocal SAR Despeckling. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6484–6498. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Poggi, G.; Scarpa, G.; Verdoliva, L. SAR despeckling by soft classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2118–2130. [Google Scholar] [CrossRef]
- Argenti, F.; Lapini, A.; Bianchi, T.; Alparone, L. A tutorial on speckle reduction in synthetic aperture radar images. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–35. [Google Scholar] [CrossRef]
- Lee, J. Speckle Analysis and Smoothing of Synthetic Aperture Radar Images. Comput. Graph. Image Process. 1981, 17, 27–32. [Google Scholar] [CrossRef]
- Kuan, D.; Sawchuk, A.; Strand, T.; Chavel, P. Adaptive Noise Smoothing Filter for Images with Signal-Dependent Noise. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 7, 165–177. [Google Scholar] [CrossRef]
- Xie, H.; Pierce, L.; Ulaby, F. SAR speckle reduction using wavelet denoising and Markov random field modeling. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2196–2212. [Google Scholar] [CrossRef]
- Solbo, S.; Eltoft, T. Homomorphic wavelet-based statistical despeckling of SAR images. IEEE Trans. Geosci. Remote Sens. 2004, 42, 711–721. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.M. A review of image denoising algorithms, with a new one. Multiscale Model. Simul. 2005, 4, 490–530. [Google Scholar] [CrossRef]
- Dabov, K.; A. Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Deledalle, C.A.; Denis, L.; Tupin, F. Iterative weighted maximum likelihood denoising with probabilistic patch-based weights. IEEE Trans. Image Process. 2009, 18, 2661–2672. [Google Scholar] [CrossRef] [PubMed]
- Parrilli, S.; Poderico, M.; Angelino, C.; Verdoliva, L. A nonlocal SAR image denoising algorithm based on LLMMSE wavelet shrinkage. IEEE Trans. Geosci. Remote Sens. 2012, 50, 606–616. [Google Scholar] [CrossRef]
- Cozzolino, D.; Parrilli, S.; Scarpa, G.; Poggi, G.; Verdoliva, L. Fast adaptive nonlocal SAR despeckling. IEEE Geosci. Remote Sens. Lett. 2014, 11, 524–528. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Denis, L.; Tupin, F.; Reigber, A.; Jäger, M. NL-SAR: A unified nonlocal framework for resolution-preserving (Pol)(In)SAR denoising. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2021–2038. [Google Scholar] [CrossRef]
- Penna, P.A.; Mascarenhas, N.D. (Non-) homomorphic approaches to denoise intensity SAR images with non-local means and stochastic distances. Comput. Geosci. 2018, 111, 127–138. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Marmanis, D.; Wegner, J.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNNs. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, S.; Lu, X. Hyperspectral image superresolution by transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR image despeckling through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5438–5441. [Google Scholar]
- Wang, P.; Zhang, H.; Patel, V. SAR Image Despeckling Using a Convolutional Neural Network. IEEE Signal Process. Lett. 2017, 24, 1763–1767. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Patel, V. Generative adversarial network-based restoration of speckled SAR images. In Proceedings of the IEEE 7th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Curacao, The Netherlands, 10–13 December 2017; pp. 1–5. [Google Scholar]
- Liu, S.; Liu, T.; Gao, L.; Li, H.; Hu, Q.; Zhao, J.; Wang, C. Convolutional Neural Network and Guided Filtering for SAR Image Denoising. Remote Sens. 2019, 11, 702. [Google Scholar] [CrossRef]
- Gu, F.; Zhang, H.; Wang, C. A Two-Component Deep Learning Network for SAR Image Denoising. IEEE Access 2020, 8, 17792–17803. [Google Scholar] [CrossRef]
- Lefkimmiatis, S. Non-local color image denoising with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 5882–5891. [Google Scholar]
- Yang, D.; Sun, J. BM3D-net: A convolutional neural network for transform-domain collaborative filtering. IEEE Signal Process. Lett. 2018, 25, 55–59. [Google Scholar] [CrossRef]
- Cruz, C.; Foi, A.; Katkovnik, V.; Egiazarian, K. Nonlocality-reinforced convolutional neural networks for image denoising. arXiv 2018, arXiv:1803.02112. [Google Scholar] [CrossRef]
- Plotz, T.; Roth, S. Neural nearest neighbors networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 1087–1098. [Google Scholar]
- Cozzolino, D.; Verdoliva, L.; Scarpa, G.; Poggi, G. Nonlocal SAR image despeckling by convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokahama, Japan, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Denis, L.; Deledalle, C.; Tupin, F. From Patches to Deep Learning: Combining Self-Similarity and Neural Networks for Sar Image Despeckling. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokahama, Japan, 28 July–2 August 2019; pp. 5113–5116. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Deledalle, C.; Denis, L.; Tupin, F. How to compare noisy patches? Patch similarity beyond Gaussian noise. Int. J. Comput. Vis. 2012, 99, 86–102. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, Q.; Yuan, Q.; Li, J.; Yang, Z.; Ma, X. Learning a Dilated Residual Network for SAR Image Despeckling. Remote Sens. 2018, 10, 196. [Google Scholar] [CrossRef]
- Gui, Y.; Xue, L.; Li, X. SAR image despeckling using a dilated densely connected network. Remote Sens. Lett. 2018, 9, 857–866. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Xiao, Y.; Bai, Y. HDRANet: Hybrid Dilated Residual Attention Network for SAR Image Despeckling. Remote Sens. 2019, 11, 2921. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-Of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, J.; Li, W.; Li, Y. SAR Image Despeckling Using Multiconnection Network Incorporating Wavelet Features. IEEE Geosci. Remote Sens. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Lattari, F.; Leon, B.G.; Asaro, F.; Rucci, A.; Prati, C.; Matteucci, M. Deep Learning for SAR Image Despeckling. Remote Sens. 2019, 11, 1532. [Google Scholar] [CrossRef]
- Vitale, S.; Ferraioli, G.; Pascazio, V. A New Ratio Image Based CNN Algorithm for SAR Despeckling. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokahama, Japan, 28 July–2 August 2019; pp. 9494–9497. [Google Scholar] [CrossRef]
- Yang, X.; Denis, L.; Tupin, F.; Yang, W. SAR Image Despeckling Using Pre-trained Convolutional Neural Network Models. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Deledalle, C.; Denis, L.; Tabti, S.; Tupin, F. MuLoG, or How to Apply Gaussian Denoisers to Multi-Channel SAR Speckle Reduction? IEEE Trans. Image Process. 2017, 26, 4389–4403. [Google Scholar] [CrossRef] [PubMed]
- Pan, T.; Peng, D.; Yang, W.; Li, H.C. A Filter for SAR Image Despeckling Using Pre-Trained Convolutional Neural Network Model. Remote Sens. 2019, 11, 2379. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2808–2817. [Google Scholar] [CrossRef]
- Lehtinen, J.; Munkberg, J.; Hasselgren, J.; Laine, S.; Karras, T.; Aittala, M.; Aila, T. Noise2noise: Learning image restoration without clean data. arXiv 2018, arXiv:1803.04189. [Google Scholar]
- Ravani, K.; Saboo, S.; Bhatt, J.S. A Practical Approach for SAR Image Despeckling Using Deep Learning. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokahama, Japan, 28 July–2 August 2019; pp. 2957–2960. [Google Scholar] [CrossRef]
- Yuan, Y.; Guan, J.; Sun, J. Blind SAR Image Despeckling Using Self-Supervised Dense Dilated Convolutional Neural Network. arXiv 2019, arXiv:1908.01608. [Google Scholar]
- Yuan, Y.; Sun, J.; Guan, J.; Feng, P.; Wu, Y. A Practical Solution for SAR Despeckling with Only Single Speckled Images. arXiv 2019, arXiv:1912.06295. [Google Scholar]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. Towards deep unsupervised SAR despeckling with blind-spot convolutional neural networks. arXiv 2020, arXiv:2001.05264v1. [Google Scholar]
- Selvaraju, R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the ICCV 2017—IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Doshi-Velez, F.; Kortz, M.; Budish, R.; Bavitz, C.; Gershman, S.; O’Brien, D.; Scott, K.; Schieber, S.; Waldo, J.; Weinberger, D.; et al. Accountability of AI Under the Law: The Role of Explanation. arXiv 2017, arXiv:1711.01134v2. [Google Scholar] [CrossRef]
- Gomez, L.; Ospina, R.; Frery, A.C. Unassisted Quantitative Evaluation of Despeckling Filters. Remote Sens. 2017, 9, 389. [Google Scholar] [CrossRef]
- Gomez, L.; Ospina, R.; Frery, A.C. Statistical Properties of an Unassisted Image Quality Index for SAR Imagery. Remote Sens. 2019, 11, 385. [Google Scholar] [CrossRef]
- Lopes, A.; Touzi, R.; Nezry, E. Adaptive speckle filters and scene heterogeneity. IEEE Trans. Geosci. Remote Sens. 1990, 28, 992–1000. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Spatial Support | Out. Features | Nonlin. | Batchnorm |
|---|---|---|---|---|---|
| 1 | conv | 5 × 5 | 13 | leaky ReLU | n |
| 2 | conv | 3 × 3 | 15 | leaky ReLU | y |
| 3 | conv | 3 × 3 | 17 | leaky ReLU | y |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 11 | conv | 3 × 3 | 33 | leaky ReLU | y |
| 12 | conv | 1 × 1 | 25 | none | n |
| 13 | softmax | 25 × 25 | 25 | softmax | n |
| Layer | Type | Spatial Support | Out. Features | Nonlin. | Batchnorm |
|---|---|---|---|---|---|
| 1÷5 | conv | 3 × 3 | 64 | ReLU | y |
| 6 | conv + skip | 3 × 3 | 8 | ReLU | n |
| 7 | 80 × 80 | 64 | none | n | |
| 8÷12 | conv | 3 × 3 | 64 | ReLU | y |
| 13 | conv + skip | 3 × 3 | 8 | ReLU | n |
| 14 | 80 × 80 | 64 | none | n | |
| 15÷19 | conv | 3 × 3 | 64 | ReLU | y |
| 20 | conv | 3 × 3 | 25 | softmax | n |
| Method | PSNR | SSIM | TIME (s) |
|---|---|---|---|
| noisy | 11.69 | 0.183 | 0.000 |
| enhanced-Lee | 20.95 | 0.474 | 0.012 |
| Kuan | 21.94 | 0.541 | 0.017 |
| NLM | 22.75 | 0.599 | 15.355 |
| PPB | 23.43 | 0.639 | 32.637 |
| NL-SAR | 24.01 | 0.678 | 5.944 |
| SAR-BM3D | 24.98 | 0.728 | 48.085 |
| FANS | 24.89 | 0.736 | 4.415 |
| ID-CNN | 24.22 | 0.687 | 0.014 |
| SAR-CNN | 25.95 | 0.762 | 0.029 |
| CNN-NLM (w/o layers) | 25.96 | 0.758 | 0.036 |
| CNN-NLM (with layers) | 26.45 | 0.786 | 0.360 |
| Method | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| enhanced-Lee | 50.70 | 20.89 | 49.80 | 21.80 | 34.40 | 28.15 | 84.86 | 14.71 | 15.68 | 20.57 | 34.16 |
| Kuan | 89.14 | 20.04 | 39.24 | 16.26 | 52.95 | 31.32 | 107.86 | 12.10 | 11.27 | 20.51 | 40.07 |
| NLM | 21.85 | 17.26 | 15.99 | 12.78 | 27.59 | 31.52 | 44.40 | 12.19 | 7.57 | 16.87 | 20.80 |
| PPB | 10.10 | 13.57 | 11.29 | 11.45 | 15.06 | 13.93 | 24.23 | 7.00 | 7.51 | 8.22 | 12.24 |
| NL-SAR | 15.84 | 15.47 | 26.24 | 12.52 | 19.25 | 14.54 | 33.40 | 6.55 | 9.49 | 7.81 | 16.11 |
| SAR-BM3D | 15.92 | 12.55 | 10.37 | 15.25 | 15.67 | 13.33 | 42.46 | 6.15 | 7.62 | 8.12 | 14.74 |
| FANS | 10.41 | 9.41 | 9.04 | 8.87 | 12.86 | 7.41 | 19.91 | 2.96 | 6.46 | 5.21 | 9.25 |
| ID-CNN | 50.08 | 33.37 | 3.69 | 10.08 | 178.12 | 3.76 | 55.74 | 26.82 | 3.82 | 11.01 | 37.65 |
| SAR-CNN | 15.57 | 11.75 | 11.84 | 14.06 | 14.81 | 10.64 | 20.14 | 4.94 | 7.03 | 6.52 | 11.73 |
| CNN-NLM | 11.55 | 9.62 | 9.89 | 11.75 | 11.73 | 9.11 | 19.24 | 4.03 | 6.72 | 4.90 | 9.85 |
| Method | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | Average |
|---|---|---|---|---|---|---|---|---|---|
| noisy | 0.98 | 1.00 | 1.01 | 1.01 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 |
| enhanced-Lee | 7.69 | 8.43 | 6.72 | 8.63 | 8.12 | 7.99 | 9.14 | 7.07 | 7.97 |
| Kuan | 14.37 | 16.74 | 12.17 | 16.69 | 15.14 | 15.32 | 15.85 | 14.35 | 15.08 |
| NLM | 41.54 | 84.96 | 33.57 | 58.15 | 51.15 | 49.25 | 41.31 | 62.79 | 52.84 |
| PPB | 43.34 | 101.19 | 24.70 | 42.84 | 45.94 | 49.43 | 38.98 | 27.29 | 46.71 |
| NL-SAR | 59.95 | 97.17 | 150.31 | 131.86 | 97.72 | 43.73 | 102.26 | 134.14 | 102.14 |
| SAR-BM3D | 5.58 | 7.85 | 4.78 | 6.90 | 5.01 | 6.92 | 6.19 | 5.90 | 6.14 |
| FANS | 24.35 | 81.14 | 16.16 | 27.34 | 29.35 | 30.38 | 29.88 | 19.49 | 32.26 |
| ID-CNN | 5.76 | 9.52 | 8.10 | 8.99 | 6.37 | 2.82 | 8.40 | 6.77 | 7.09 |
| SAR-CNN | 24.97 | 237.09 | 177.40 | 317.63 | 64.92 | 117.69 | 175.53 | 73.54 | 148.60 |
| CNN-NLM | 316.84 | 464.88 | 235.08 | 271.52 | 94.18 | 171.39 | 346.70 | 100.19 | 250.10 |
| Method | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | Average |
|---|---|---|---|---|---|---|---|---|---|
| enhanced-Lee | 18.54 | 14.12 | 21.39 | 23.92 | 16.01 | 14.88 | 30.48 | 17.81 | 19.64 |
| Kuan | 15.18 | 9.09 | 31.21 | 14.78 | 17.14 | 14.43 | 63.89 | 13.60 | 22.41 |
| NLM | 11.80 | 9.74 | 16.54 | 9.78 | 9.75 | 8.59 | 19.80 | 10.19 | 12.02 |
| PPB | 10.44 | 12.44 | 14.36 | 11.93 | 7.89 | 8.74 | 27.75 | 10.10 | 12.96 |
| NL-SAR | 8.64 | 11.34 | 6.66 | 6.04 | 4.00 | 5.95 | 17.20 | 3.69 | 7.94 |
| SAR-BM3D | 28.13 | 27.27 | 26.52 | 30.14 | 30.26 | 27.88 | 33.17 | 29.28 | 29.08 |
| FANS | 7.60 | 12.33 | 15.12 | 10.46 | 9.04 | 10.09 | 25.63 | 8.68 | 12.37 |
| ID-CNN | 12.06 | 9.16 | 11.86 | 11.27 | 9.43 | 10.32 | 9.69 | 9.71 | 10.44 |
| SAR-CNN | 13.12 | 12.83 | 37.99 | 40.64 | 44.42 | 16.16 | 67.93 | 16.06 | 31.14 |
| CNN-NLM | 32.60 | 20.47 | 33.33 | 43.38 | 60.31 | 13.11 | 71.82 | 21.65 | 37.09 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cozzolino, D.; Verdoliva, L.; Scarpa, G.; Poggi, G. Nonlocal CNN SAR Image Despeckling. Remote Sens. 2020, 12, 1006. https://doi.org/10.3390/rs12061006
Cozzolino D, Verdoliva L, Scarpa G, Poggi G. Nonlocal CNN SAR Image Despeckling. Remote Sensing. 2020; 12(6):1006. https://doi.org/10.3390/rs12061006
Chicago/Turabian StyleCozzolino, Davide, Luisa Verdoliva, Giuseppe Scarpa, and Giovanni Poggi. 2020. "Nonlocal CNN SAR Image Despeckling" Remote Sensing 12, no. 6: 1006. https://doi.org/10.3390/rs12061006
APA StyleCozzolino, D., Verdoliva, L., Scarpa, G., & Poggi, G. (2020). Nonlocal CNN SAR Image Despeckling. Remote Sensing, 12(6), 1006. https://doi.org/10.3390/rs12061006