Deep Learning-Based Drivers Emotion Classification System in Time Series Data for Remote Applications

 ,
, 
 ,
,  ,
, 
Abstract

1. Introduction
2. Related Works
- -
- First CNN-based research to classify aggressive and normal driving by facial emotion and gaze change features as input while using single NIR camera.
- -
- From the NIR camera, facial images are collected to calculate change in gaze and change in facial emotions while aggressive and normal driving.
- -
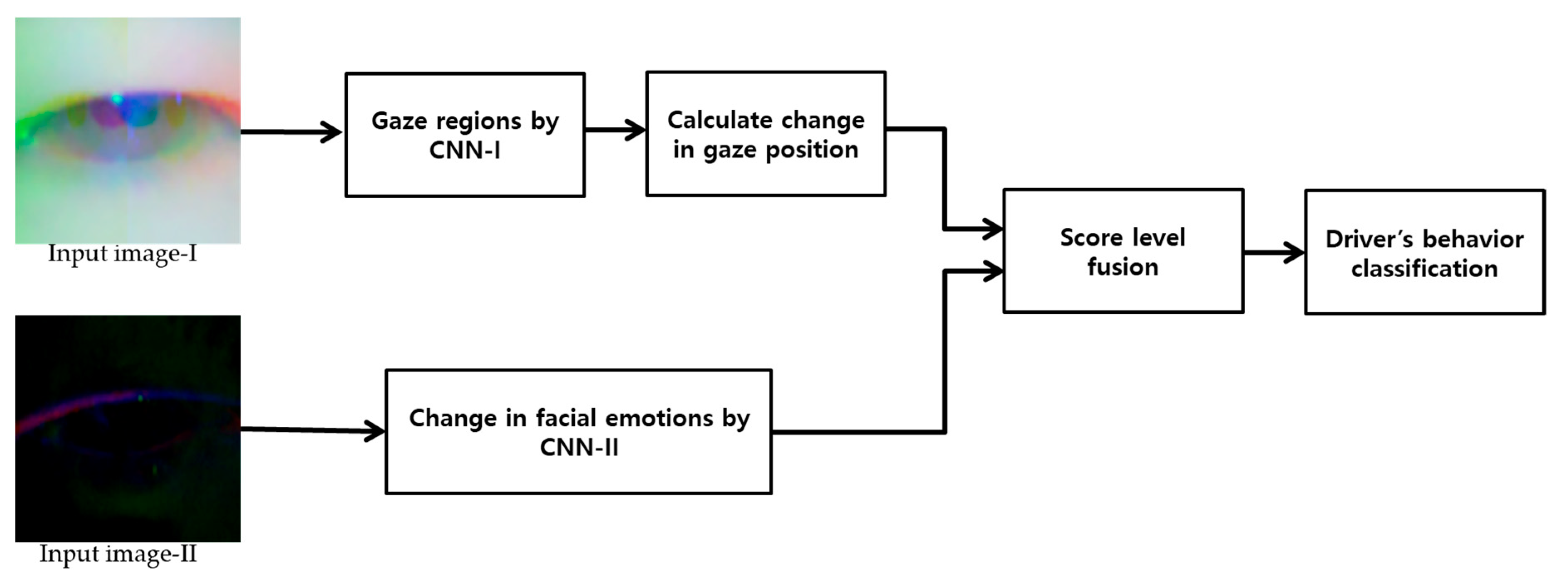
- Change in gaze is calculated from left eye, right eye and combined left and right eyes extracted from facial images and converted into three-channel images and used as input to the first CNN. Similarly, a change of facial emotion is calculated from left eye, right eye and mouth, and they are combined to convert them into three-channel images to use as input to the second CNN. The outputs of these two CNN are then combined by score-level fusion to enhance the classification accuracy for aggressive and normal driving emotions.
- -
- A database of driver facial images is collected in this research for calculating driver’s change in gaze and facial emotions while using NIR camera. Two separate CNN models are intensively trained for change in gaze and facial emotions.
3. Classification of Aggressive and Normal Driving Behavior Using CNN
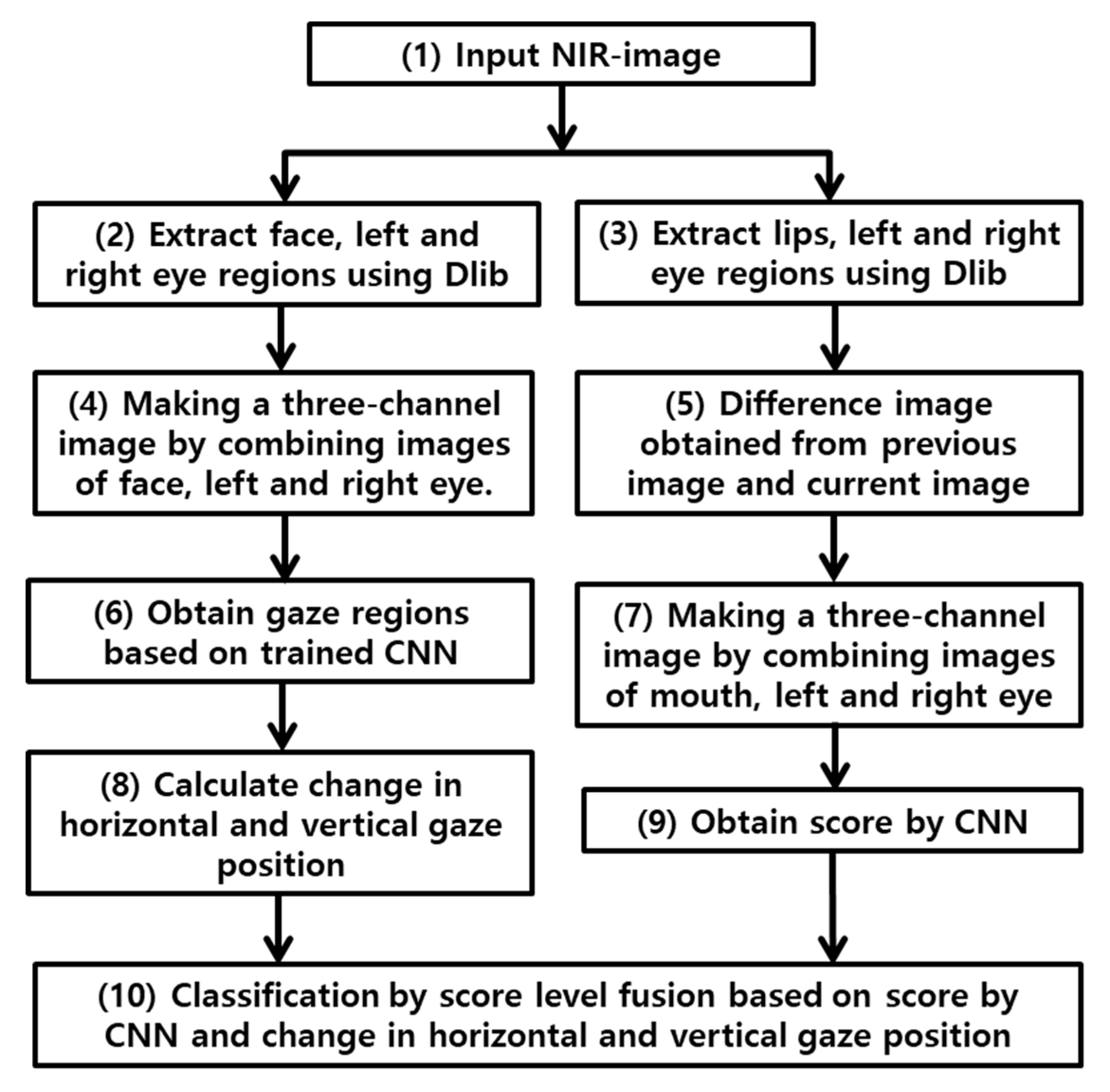
3.1. Overview of Proposed Method
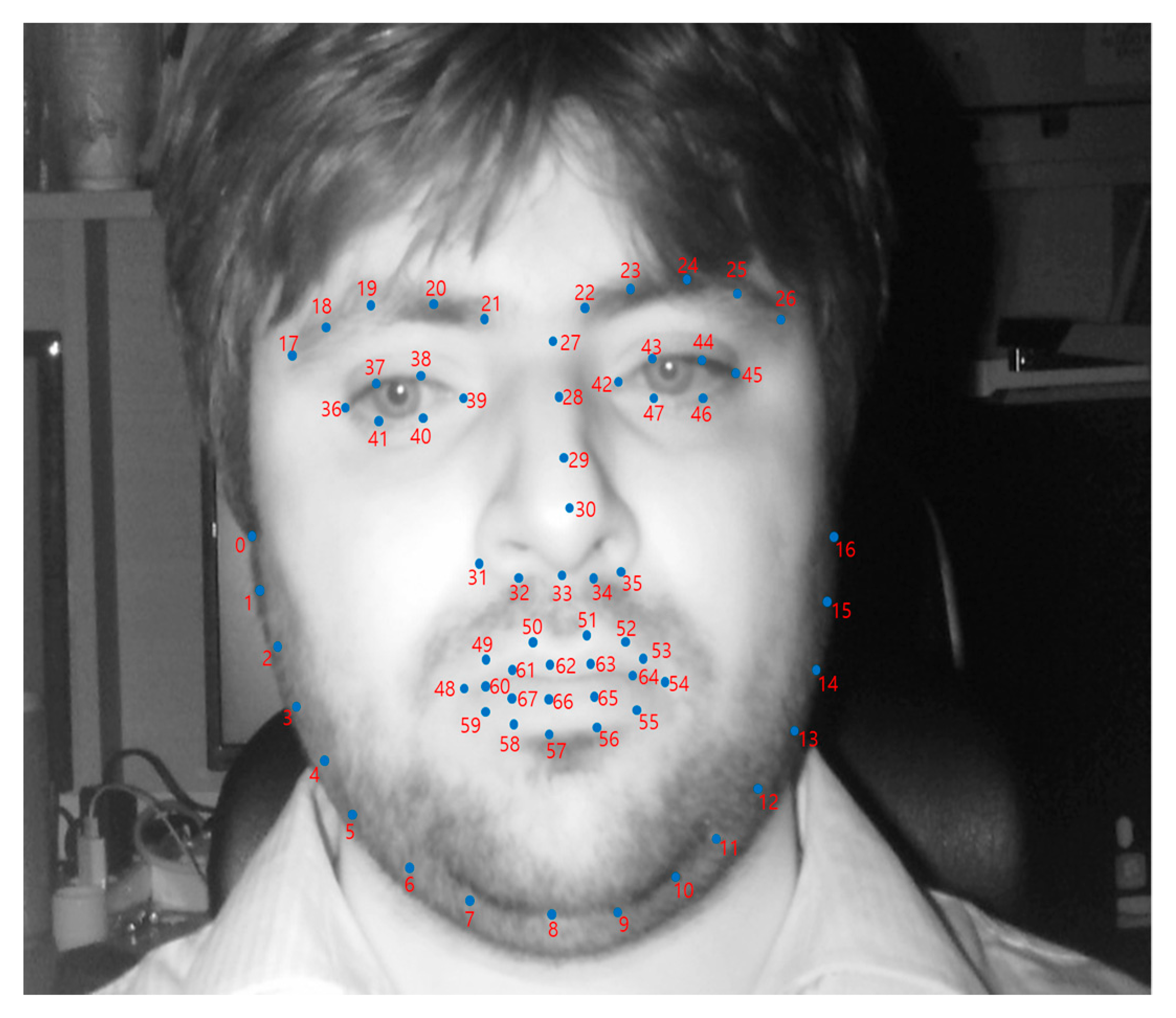
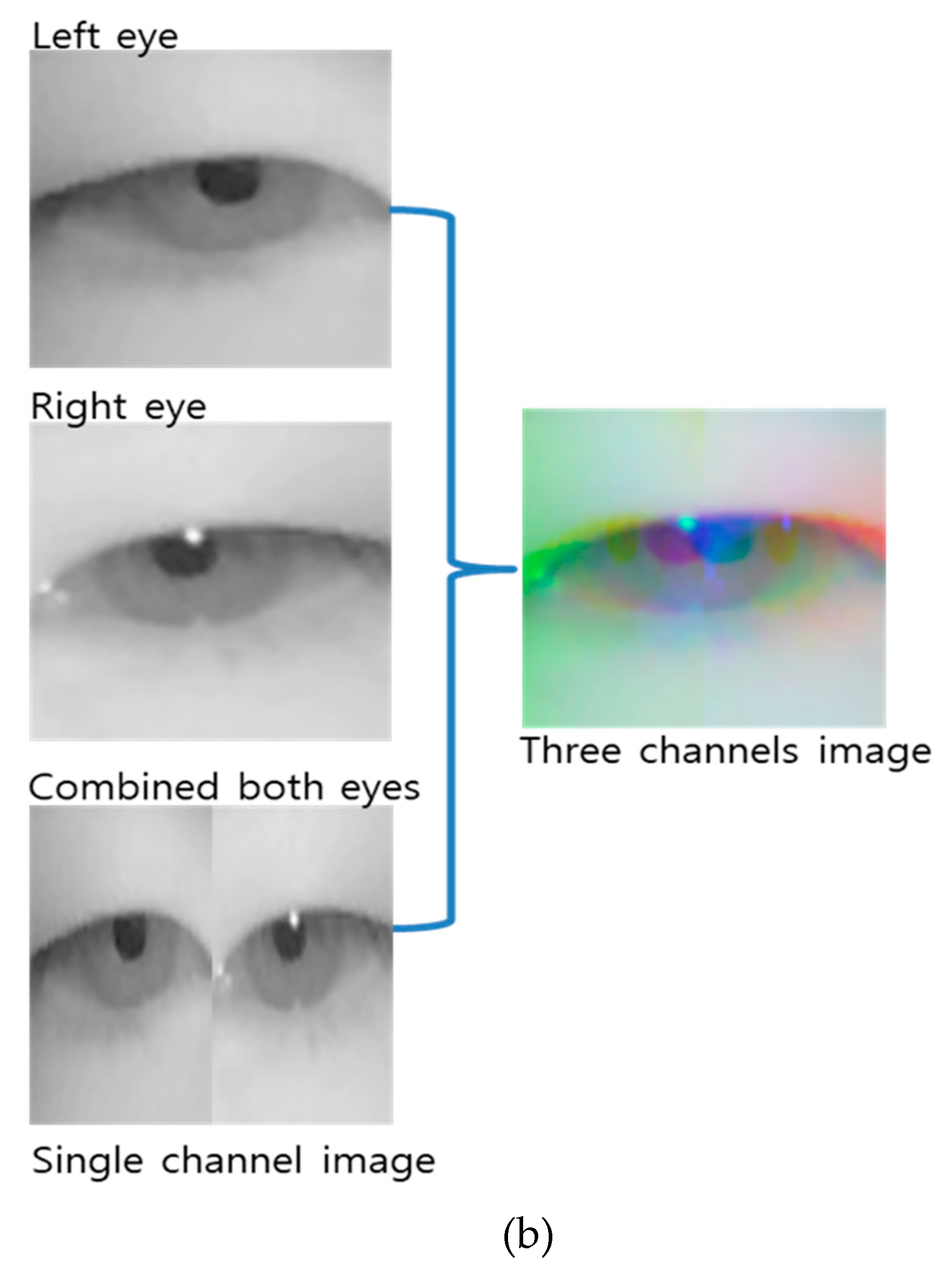
3.2. Change in Horizontal and Vertical Gaze Positions
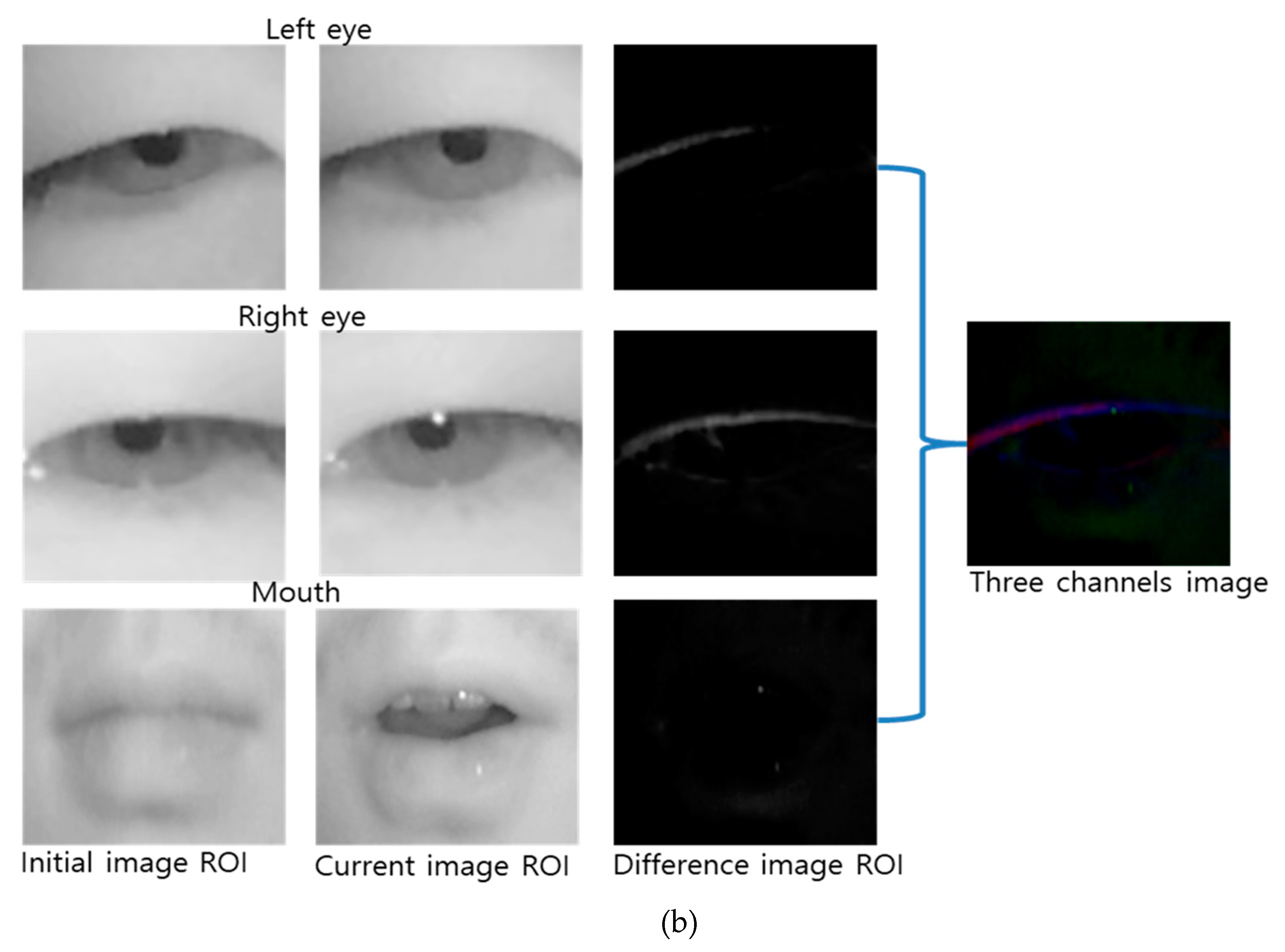
3.3. Change in Facial Emotions
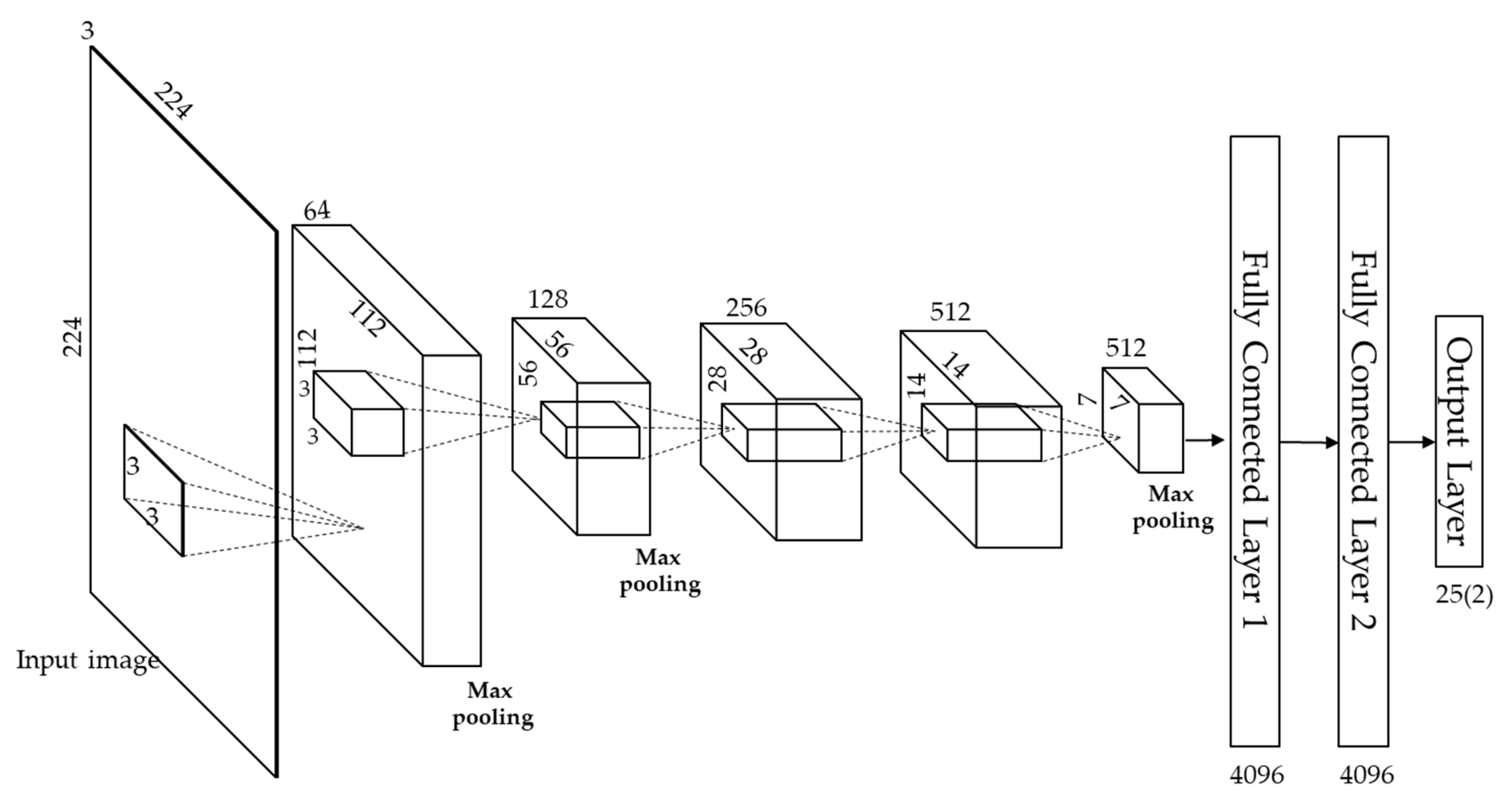
3.4. CNN Structure
3.5. Score-level Fusion
4. Experimental Results
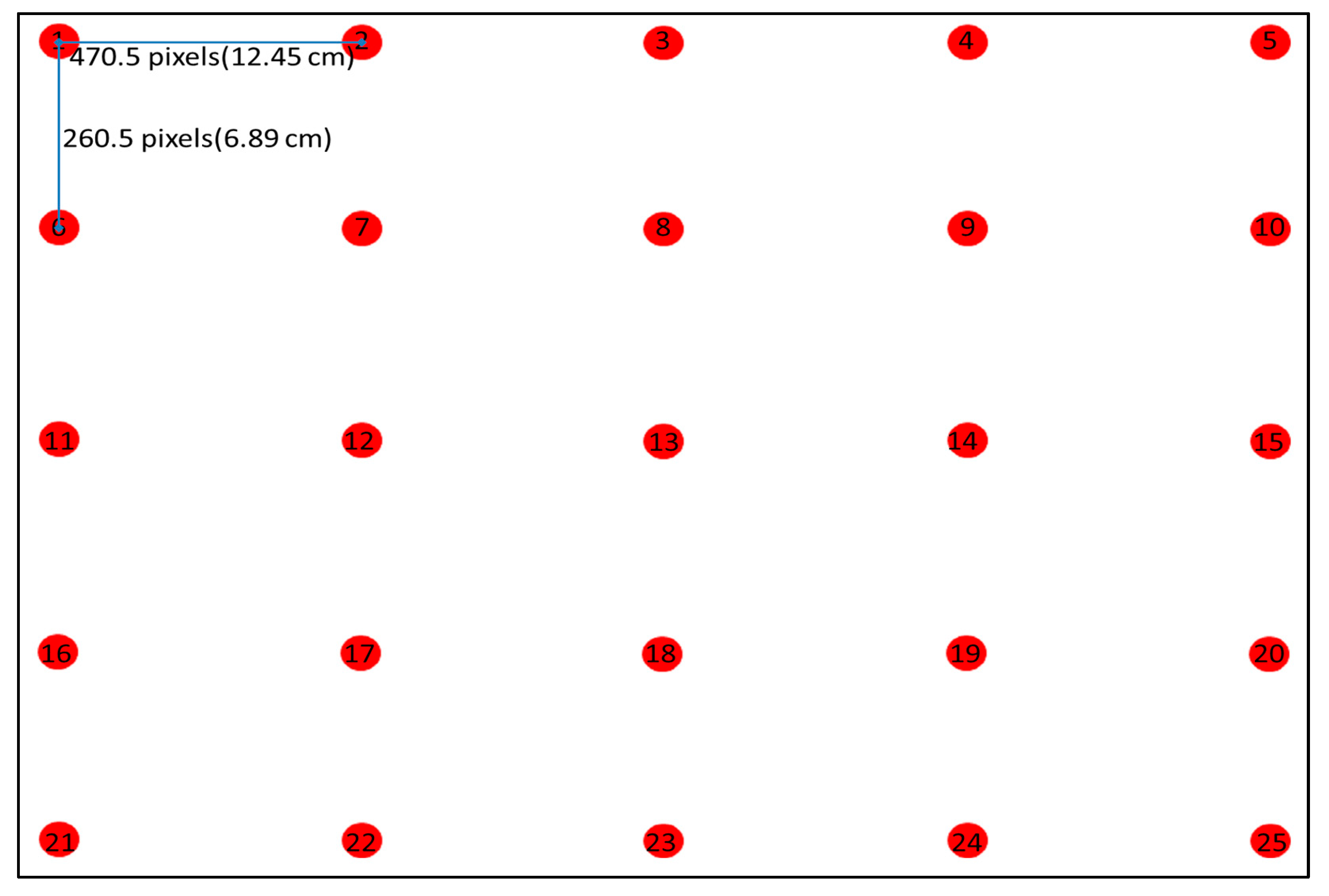
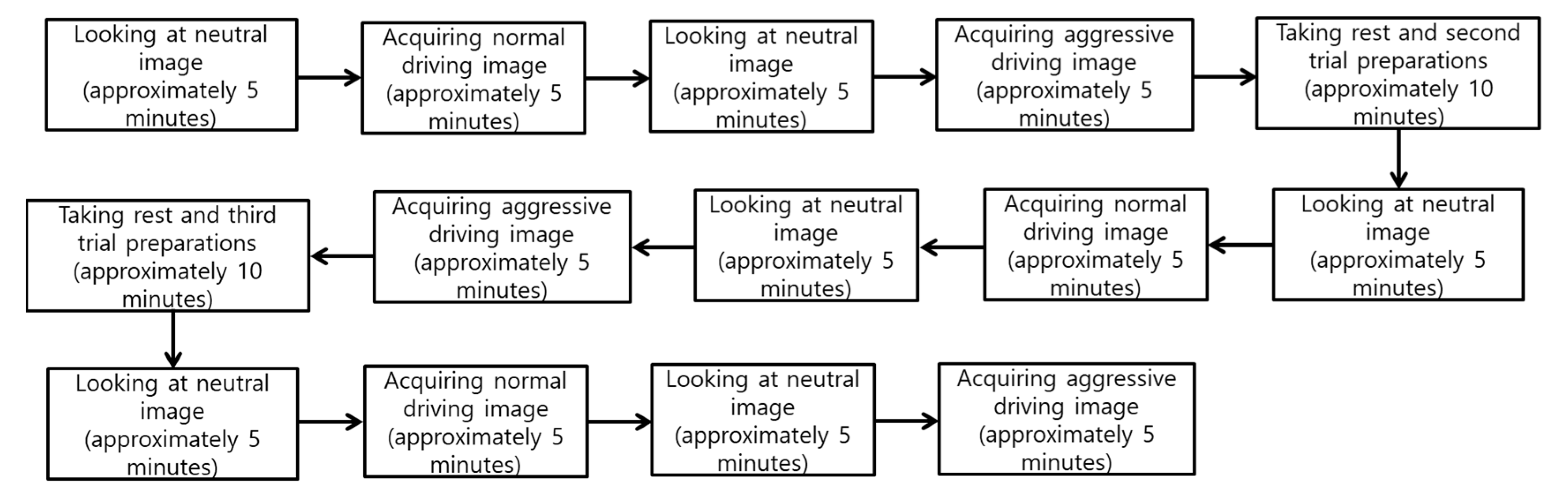
4.1. Experimental Data and Environment
4.2. Extracted Features and the Comparison of Performance
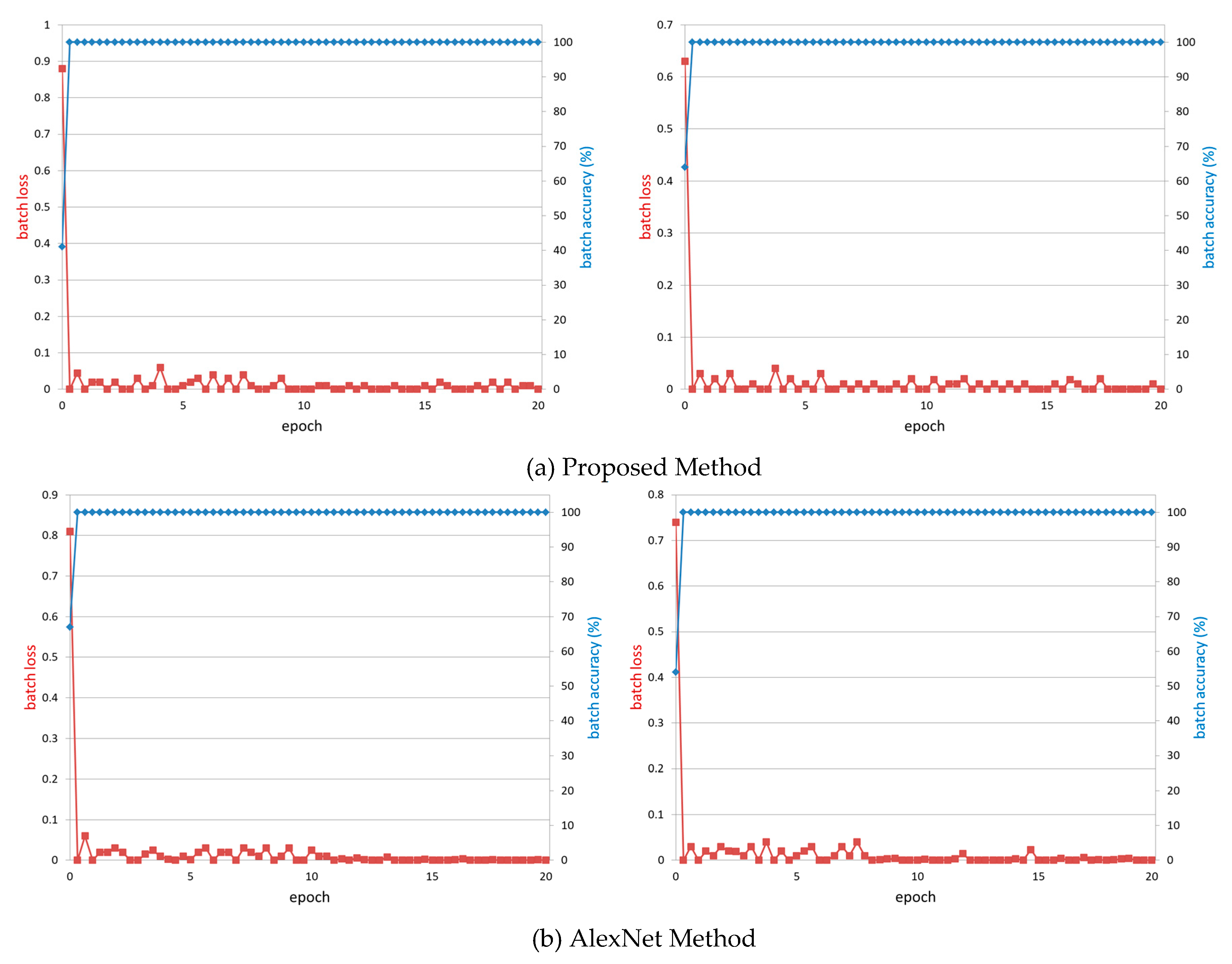
4.3. Training of CNN Model
4.4. Testing of CNN Model
4.4.1. Comparison with Previous Methods
4.4.2. Comparison with Open Database
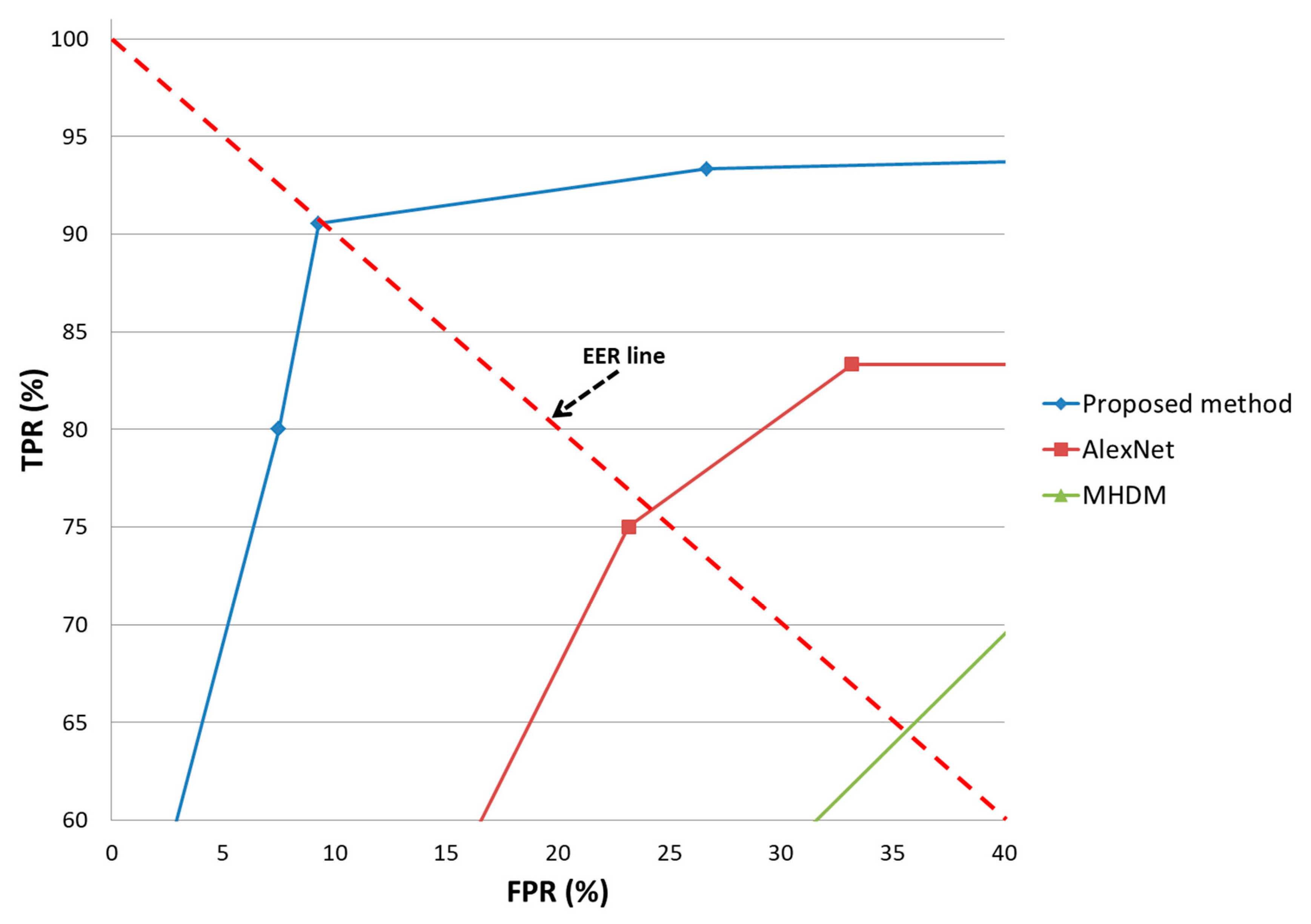
4.4.3. Comparison with Receiver Pperation Characteristic (ROC) Curves
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Global Status Report on Road Safety. 2015. Available online: http://apps.who.int/iris/bitstream/10665/189242/1/9789241565066_eng.pdf?ua=1 (accessed on 26 February 2018).
- Aggressive Driving: Research Update. Available online: http://www.adtsea.org/Resources%20PDF’s/AAA%202009%20Aggressive%20Driving%20Research%20Update.pdf (accessed on 26 February 2018).
- Chen, Z.; Yu, J.; Zhu, Y.; Chen, Y.; Li, M. D3: Abnormal Driving Behaviors Detection and Identification Using Smartphone Sensors. In Proceedings of the 12th Annual IEEE International Conference on Sensing, Communication, and Networking, Seattle, WA, USA, 22–25 June 2015; pp. 524–532. [Google Scholar]
- Bhoyar, V.; Lata, P.; Katkar, J.; Patil, A.; Javale, D. Symbian Based Rash Driving Detection System. Int. J. Emerg. Trends Technol. Comput. Sci. 2013, 2, 124–126. [Google Scholar]
- Coughlin, J.F.; Reimer, B.; Mehler, B. Monitoring, Managing, and Motivating Driver Safety and Well-Being. IEEE Pervasive Comput. 2011, 10, 14–21. [Google Scholar] [CrossRef]
- Lin, C.-T.; Liang, S.-F.; Chao, W.-H.; Ko, L.-W.; Chao, C.-F.; Chen, Y.-C.; Huang, T.-Y. Driving Style Classification by Analyzing EEG Responses to Unexpected Obstacle Dodging Tasks. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Taipei, Taiwan, 8–11 October 2006; pp. 4916–4919. [Google Scholar]
- Zheng, W.-L.; Dong, B.-N.; Lu, B.-L. Multimodal Emotion Recognition Using EEG and Eye Tracking Data. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 5040–5043. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.-S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Kodagoda, S.; Lal, S.; Dissanayake, G. Driver Drowsiness Classification Using Fuzzy Wavelet-Packet-Based Feature-Extraction Algorithm. IEEE Trans. Biomed. Eng. 2011, 58, 121–131. [Google Scholar] [CrossRef] [PubMed]
- Kamaruddin, N.; Wahab, A. Driver Behavior Analysis through Speech Emotion Understanding. In Proceedings of the IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 238–243. [Google Scholar]
- Nass, C.; Jonsson, I.-M.; Harris, H.; Reaves, B.; Endo, J.; Brave, S.; Takayama, L. Improving Automotive Safety by Pairing Driver Emotion and Car Voice Emotion. In Proceedings of the Conference on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 1973–1976. [Google Scholar]
- Jones, C.M.; Jonsson, I.-M. Automatic Recognition of Affective Cues in the Speech of Car Drivers to Allow Appropriate Responses. In Proceedings of the 17th Australia Conference on Computer-Human Interaction, Canberra, Australia, 21–25 November 2005; pp. 1–10. [Google Scholar]
- Tawari, A.; Trivedi, M. Speech Based Emotion Classification Framework for Driver Assistance System. In Proceedings of the IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 174–178. [Google Scholar]
- Eren, H.; Makinist, S.; Akin, E.; Yilmaz, A. Estimating Driving Behavior by a Smartphone. In Proceedings of the Intelligent Vehicles Symposium, Alcalá de Henares, Spain, 3–7 June 2012; pp. 234–239. [Google Scholar]
- Boonmee, S.; Tangamchit, P. Portable Reckless Driving Detection System. In Proceedings of the 6th IEEE International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Pattaya, Thailand, 6–9 May 2009; pp. 412–415. [Google Scholar]
- Koh, D.-W.; Kang, H.-B. Smartphone-Based Modeling and Detection of Aggressiveness Reactions in Senior Drivers. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June–1 July 2015; pp. 12–17. [Google Scholar]
- Imkamon, T.; Saensom, P.; Tangamchit, P.; Pongpaibool, P. Detection of Hazardous Driving Behavior Using Fuzzy Logic. In Proceedings of the 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Krabi, Thailand, 14–17 May 2008; pp. 657–660. [Google Scholar]
- Fazeen, M.; Gozick, B.; Dantu, R.; Bhukhiya, M.; González, M.C. Safe Driving Using Mobile Phones. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1462–1468. [Google Scholar] [CrossRef]
- Dai, J.; Teng, J.; Bai, X.; Shen, Z.; Xuan, D. Mobile Phone Based Drunk Driving Detection. In Proceedings of the 4th International Conference on Pervasive Computing Technologies for Healthcare, Munich, Germany, 22–25 March 2010; pp. 1–8. [Google Scholar]
- Wang, Q.; Yang, J.; Ren, M.; Zheng, Y. Driver Fatigue Detection: A Survey. In Proceedings of the 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006; pp. 8587–8591. [Google Scholar]
- Grace, R.; Byrne, V.E.; Bierman, D.M.; Legrand, J.-M.; Gricourt, D.; Davis, R.K.; Staszewski, J.J.; Carnahan, B. A Drowsy Driver Detection System for Heavy Vehicles. In Proceedings of the 17th AIAA/IEEE/SAE Digital Avionics Systems Conference, Bellevue, WA, USA, 31 October–7 November 1998; pp. I36-1–I36-8. [Google Scholar]
- Ji, Q.; Zhu, Z.; Lan, P. Real-Time Nonintrusive Monitoring and Prediction of Driver Fatigue. IEEE Trans. Veh. Technol. 2004, 53, 1052–1068. [Google Scholar] [CrossRef]
- Tawari, A.; Chen, K.H.; Trivedi, M.M. Where is the Driver Looking: Analysis of Head, Eye and Iris for Robust Gaze Zone Estimation. In Proceedings of the 17th International Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; pp. 988–994. [Google Scholar]
- Ahlstrom, C.; Kircher, K.; Kircher, A. A Gaze-Based Driver Distraction Warning System and Its Effect on Visual Behavior. IEEE Trans. Intell. Transp. Syst. 2013, 14, 965–973. [Google Scholar] [CrossRef]
- Lee, K.W.; Yoon, H.S.; Song, J.M.; Park, K.R. Convolutional Neural Network-Based Classification of Driver’s Emotion during Aggressive and Smooth Driving Using Multi-Modal Camera Sensors. Sensors 2018, 18, 957. [Google Scholar] [CrossRef]
- You, C.-W.; Montes-de-Oca, M.; Bao, T.J.; Lane, N.D.; Lu, H.; Cardone, G.; Torresani, L.; Campbell, A.T. CarSafe: A Driver Safety App that Detects Dangerous Driving Behavior Using Dual-Cameras on Smartphones. In Proceedings of the ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 671–672. [Google Scholar]
- Hariri, B.; Abtahi, S.; Shirmohammadi, S.; Martel, L. Demo: Vision Based Smart In-Car Camera System for Driver Yawning Detection. In Proceedings of the 5th ACM/IEEE International Conference on Distributed Smart Cameras, Ghent, Belgium, 22–25 August 2011; pp. 1–2. [Google Scholar]
- Smith, P.; Shah, M.; da Vitoria Lobo, N. Determining Driver Visual Attention with One Camera. IEEE Trans. Intell. Transp. Syst. 2003, 4, 205–218. [Google Scholar] [CrossRef]
- Ishikawa, T.; Baker, S.; Matthews, I.; Kanade, T. Passive Driver Gaze Tracking with Active Appearance Models. In Proceedings of the 11th World Congress on Intelligent Transportation Systems, Nagoya, Japan, 18–24 October 2004; pp. 1–12. [Google Scholar]
- Serrano-Cuerda, J.; Fernández-Caballero, A.; López, M.T. Selection of a Visible-Light vs. Thermal Infrared Sensor in Dynamic Environments Based on Confidence Measures. Appl. Sci. 2014, 4, 331–350. [Google Scholar] [CrossRef]
- Bergasa, L.M.; Nuevo, J.; Sotelo, M.A.; Barea, R.; Lopez, M.E. Real-Time System for Monitoring Driver Vigilance. IEEE Trans. Intell. Transp. Syst. 2006, 7, 63–77. [Google Scholar] [CrossRef]
- Cheng, S.Y.; Park, S.; Trivedi, M.M. Multi-spectral and Multi-perspective Video Arrays for Driver Body Tracking and Activity Analysis. Comput. Vis. Image Underst. 2007, 106, 245–257. [Google Scholar] [CrossRef]
- Kolli, A.; Fasih, A.; Machot, F.A.; Kyamakya, K. Non-intrusive Car Driver’s Emotion Recognition Using Thermal Camera. In Proceedings of the IEEE Joint International Workshop on Nonlinear Dynamics and Synchronization & the 16th International Symposium on Theoretical Electrical Engineering, Klagenfurt, Austria, 25–27 July 2011; pp. 1–5. [Google Scholar]
- Liang, Y.; Reyes, M.L.; Lee, J.D. Real-Time Detection of Driver Cognitive Distraction Using Support Vector Machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 340–350. [Google Scholar] [CrossRef]
- USB2.0 5MP Usb Camera Module OV5640 Color CMOS Sensor. Available online: http://www.elpcctv.com/usb20-5mp-usb-camera-module-ov5640-color-cmos-sensor-36mm-lens-p-216.html (accessed on 24 December 2017).
- 850nm CWL, 12.5mm Dia. Hard Coated OD 4 50nm Bandpass Filter. Available online: https://www.edmundoptics.co.kr/optics/optical-filters/bandpass-filters/850nm-cwl-12.5mm-dia.-hard-coated-od-4-50nm-bandpass-filter/ (accessed on 24 December 2017).
- OSLON® Black, SFH 4713A. Available online: https://www.osram.com/os/ecat/OSLON%C2%AE%20Black%20SFH%204713A/com/en/class_pim_web_catalog_103489/global/prd_pim_device_2219797/ (accessed on 28 March 2018).
- Facial Action Coding System. Available online: https://en.wikipedia.org/wiki/Facial_Action_Coding_System (accessed on 28 March 2018).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861v1, 1–9. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Convolutional Neural Network. Available online: https://en.wikipedia.org/wiki/Convolutional_neural_network (accessed on 28 March 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Heaton, J. Artificial Intelligence for Humans. In Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015. [Google Scholar]
- Softmax Regression. Available online: http://ufldl.stanford.edu/wiki/index.php/Softmax_Regression (accessed on 28 March 2018).
- Need for Speed (Deluxe Edition). Available online: https://en.wikipedia.org/wiki/Need_for_Speed (accessed on 28 March 2018).
- Euro Truck Simulator 2. Available online: https://en.wikipedia.org/wiki/Euro_Truck_Simulator_2 (accessed on 28 March 2018).
- Lang, P.J.; Bradley, M.M.; Cuthbert, B.N. International Affective Picture System (IAPS): Affective Ratings of Pictures and Instruction Manual; Technical Report A-8; University of Florida: Gainesville, FL, USA, 2008. [Google Scholar]
- Samsung LS24D300HL/ZA Monitor. Available online: http://www.samsung.com/us/computer/monitors/LS24D300HL/ZA-specs (accessed on 28 March 2018).
- Caffe. Deep Learning Framework. Available online: http://caffe.berkeleyvision.org (accessed on 28 March 2018).
- NVIDIA Geforce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1070-ti/ (accessed on 28 March 2018).
- OpenCV Library. Available online: https://opencv.org/ (accessed on 28 March 2018).
- Student’s t-Test. Available online: https://en.wikipedia.org/wiki/Student%27s_t-test (accessed on 28 March 2018).
- Nakagawa, S.; Cuthill, I.C. Effect Size, Confidence Interval and Statistical Significance: A Practical Guide for Biologists. Biol. Rev. 2007, 82, 591–605. [Google Scholar] [CrossRef]
- Stochastic Gradient Descent. Available online: https://en.wikipedia.org/wiki/Stochastic_gradient_descent (accessed on 28 March 2018).
- TrainingOptions. Available online: http://kr.mathworks.com/help/nnet/ref/trainingoptions.html (accessed on 28 March 2018).
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Precision and Recall. Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 28 March 2018).
- Naqvi, R.A.; Arsalan, M.; Batchuluun, G.; Yoon, H.S.; Park, K.R. Deep Learning-Based Gaze Detection System for Automobile Drivers Using a NIR Camera Sensor. Sensors 2018, 18, 456. [Google Scholar] [CrossRef]
- Pires-de-Lima, R.; Marfurt, K. Convolutional Neural Network for Remote-Sensing Scene Classification: Transfer Learning Analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef]
- Sedona, R.; Cavallaro, G.; Jitsev, J.; Strube, A.; Riedel, M.; Benediktsson, J.A. Remote Sensing Big Data Classification with High Performance Distributed Deep Learning. Remote Sens. 2019, 11, 3056. [Google Scholar] [CrossRef]
- Gwon, S.Y.; Jung, D.; Pan, W.; Park, K.R. Estimation of Gaze Detection Accuracy Using the Calibration Information-Based Fuzzy System. Sensors 2016, 16, 60. [Google Scholar] [CrossRef] [PubMed]
- Pan, W.; Jung, D.; Yoon, H.S.; Lee, D.E.; Naqvi, R.A.; Lee, K.W.; Park, K.R. Empirical Study on Designing of Gaze Tracking Camera Based on the Information of User’s Head Movement. Sensors 2016, 16, 1396. [Google Scholar] [CrossRef] [PubMed]
- Dzedzickis, A.; Kaklauskas, A.; Bucinskas, V. Human Emotion Recognition: Review of Sensors and Methods. Sensors 2020, 20, 592. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Lee, T.; Yang, T.; Yoon, C.; Kim, S.-P. Detection of Drivers’ Anxiety Invoked by Driving Situations Using Multimodal Biosignals. Processes 2020, 8, 155. [Google Scholar] [CrossRef]
- Rahman, H.; Ahmed, M.U.; Barua, S.; Begum, S. Non-contact-based Driver’s Cognitive Load Classification Using Physiological and Vehicular Parameters. Biomed. Signal Process. Control 2020, 55, 1–13. [Google Scholar]
- Badshah, A.M.; Rahim, N.; Ullah, N.; Ahmad, J.; Muhammad, K.; Lee, M.Y.; Kwon, S.; Baik, S.W. Deep Features-based Speech Emotion Recognition for Smart Affective Services. Biomed. Tools Appl. 2019, 78, 5571–5589. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantage | Disadvantage | ||
|---|---|---|---|---|---|
| Non-visual behavior based methods | Bio-signal-based method [10,11,12,13] | Driver’s emotions or exhaustion is measured using different bio-electric signals such as ECG, EEG | - Useful to detect physiological changes in the form of bio-signals - Bio-signals can be used as an input data for detecting emotions - Bio-electric signals are high-speed signals that cannot be detected by naked eyes | - Bio-signal sensors are expensive and not feasible for commercial use - Possibility of detachment from driver’s body - Psychological discomfort for the user | |
| Voice-based method [14,15,16,17] | Driver’s voice or car-voice interaction was examined to analyze driver’s emotion | - Sensors used for this method are very cheap | - Performance of system is badly affected by surrounding noise | ||
| Gyro-sensor and accelerometer-based method [3,4,18,19,20,21,22,23] | Driver’s driving behavior is detected | - Highly portable as accelerometer and gyro-sensor in a smart phone can be used for this method - No extra device needs to be purchased or installed - Close correlation with aggressive driving as vehicles motion can be observed easily | - Method is inapplicable in areas out of coverage of GPS systems - Performance is highly dependent on the efficiency of GPS receiver - Driving on mountainous roads can be misclassified as aggressive driving | ||
| Visual-behavior based methods | Multi cameras-based system [25,26,27,28,29] | Fuse different information from eyes and head pose from more than one camera sensor for analyzing drivers | - Higher reliability due to less possibility of invisible face regions by wide range of multiple cameras - Reliability is higher due to multiple sources of information | - Computational complexity is higher as compared to single camera-based methods - Only applicable for the characteristics visible by naked eye | |
| Single camera-based systems | Visible light camera-based systems [30,31,32,33] | Driver’s behavior detection using visible light camera | - Normal common purpose camera is used | - In efficient in dark environment especially during night or passing through a tunnel - Higher possibility of invisible face regions that can reversely affect the efficiency of system | |
| Thermal camera-based systems [36,37] | Driver’s facial emotion recognition using thermal camera | - Precise physical signals for particular emotion can be detected that is not possible with visible light or NIR camera - No special illuminator is required to operate at night | - Efficiency for detecting facial emotions is lower as compared to visible light and NIR camera - Thermal cameras are expensive as compared to others | ||
| NIR camera-based systems | Driver’s vigilance monitoring using NIR camera [35] | - Fuzzy system is used for PERCLOS to detect vigilance level - No intensive training is required | - Work with the fatigue level of the driver only - System does not work well at day time and with driver’s wearing glasses | ||
| Single NIR camera based driver’s driving behavior classification using change in gaze and facial emotions purely based on CNN (Proposed Method) | - NIR camera can efficiently detect facial features as well as gaze information - An intensively trained CNN is robust to various environmental and driver conditions - Cheaper system with multiple features | - Only work with the physical characteristics that can be observed with naked eye - Intensive CNN training is required | |||
| Layer Type | Number of Filter | Size of Feature Map | Size of Kernel | Number of Stride | Number of Padding | |
|---|---|---|---|---|---|---|
| Image input layer | 224 × 224 × 3 | |||||
| Group 1 | Conv1_1 (1st CL) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu1_1 | 224 × 224 × 64 | |||||
| Conv1_2 (2nd CL) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu1_2 | 224 × 224 × 64 | |||||
| Pool1 | 1 | 112 × 112 × 64 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 2 | Conv2_1 (3rd CL) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu2_1 | 112 × 112 × 128 | |||||
| Conv2_2 (4th CL) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu2_2 | 112 × 112 × 128 | |||||
| Pool2 | 1 | 56 × 56 × 128 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 3 | Conv3_1 (5th CL) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu3_1 | 56 × 56 × 256 | |||||
| Conv3_2 (6th CL) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu3_2 | 56 × 56 × 256 | |||||
| Conv3_3 (7th CL) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu3_3 | 56 × 56 × 256 | |||||
| Pool3 | 1 | 28 × 28 × 256 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 4 | Conv4_1 (8th CL) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu4_1 | 28 × 28 × 512 | |||||
| Conv4_2 (9th CL) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu4_2 | 28 × 28 × 512 | |||||
| Conv4_3 (10th CL) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu4_3 | 28 × 28 × 512 | |||||
| Pool4 | 1 | 14 × 14 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 5 | Conv5_1 (11th CL) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu5_1 | 14 × 14 × 512 | |||||
| Conv5_2 (12th CL) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu5_2 | 14 × 14 × 512 | |||||
| Conv5_3 (13th CL) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu5_3 | 14 × 14 × 512 | |||||
| Pool5 | 1 | 7 × 7 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Fc6 (1st FCL) | 4096 × 1 | |||||
| Relu6 | 4096 × 1 | |||||
| Dropout6 | 4096 × 1 | |||||
| Fc7 (2nd FCL) | 4096 × 1 | |||||
| Relu7 | 4096 × 1 | |||||
| Dropout7 | 4096 × 1 | |||||
| Fc8 (3rd FCL) | 25 × 1(2 × 1) | |||||
| Softma × layer | 25 × 1(2 × 1) | |||||
| Output layer | 25 × 1(2 × 1) | |||||
| Training | Testing | |||
|---|---|---|---|---|
| Normal Driving | Aggressive Driving | Normal Driving | Aggressive Driving | |
| 1st fold cross validation | 19,642 | 19,642 | 19,642 | 19,642 |
| 2nd fold cross validation | 19,642 | 19,642 | 19,642 | 19,642 |
| Change in Horizontal Gaze | Change in Vertical Gaze | Change in Facial Emotions | ||||
|---|---|---|---|---|---|---|
| Normal | Aggressive | Normal | Aggressive | Normal | Aggressive | |
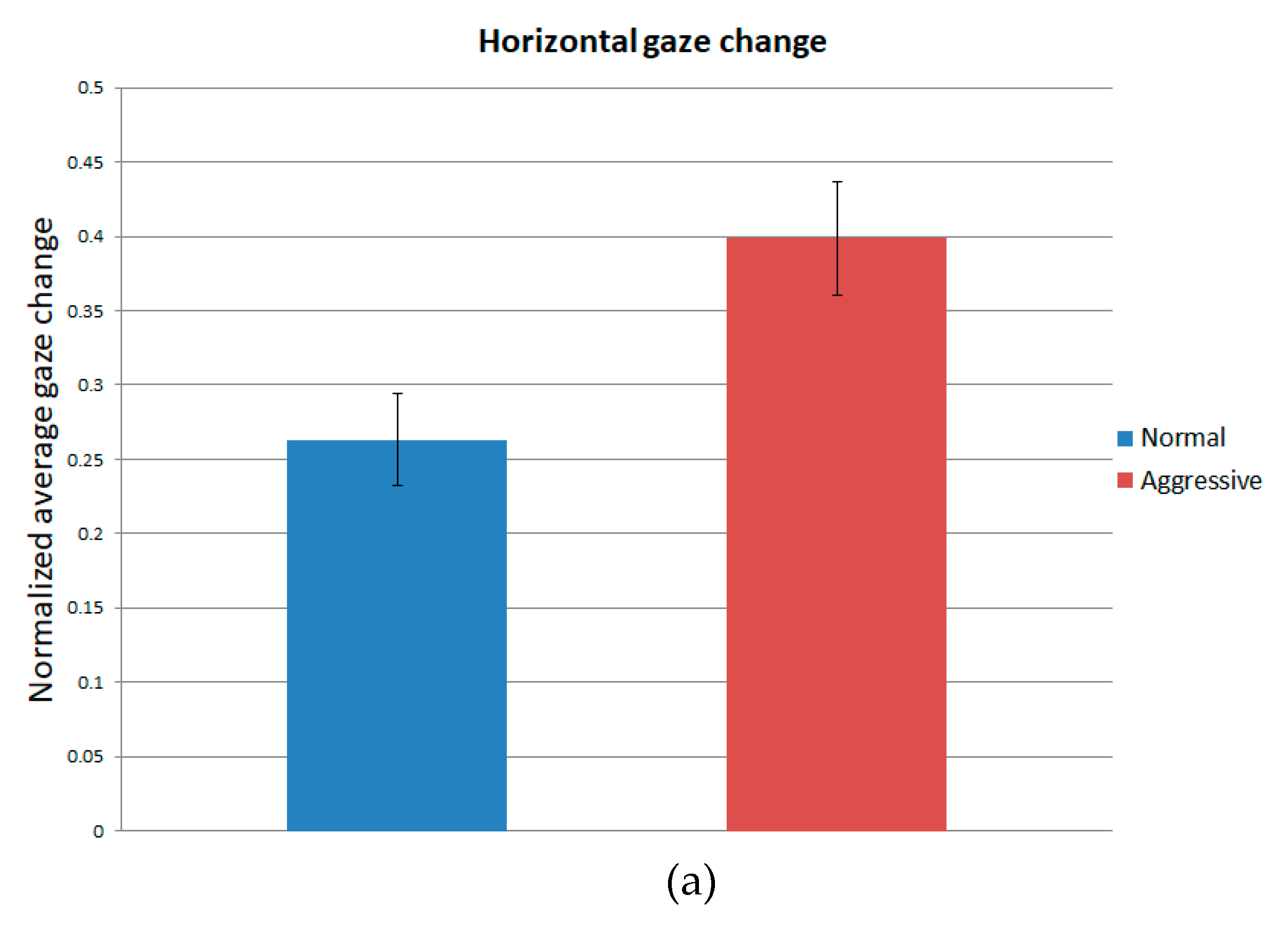
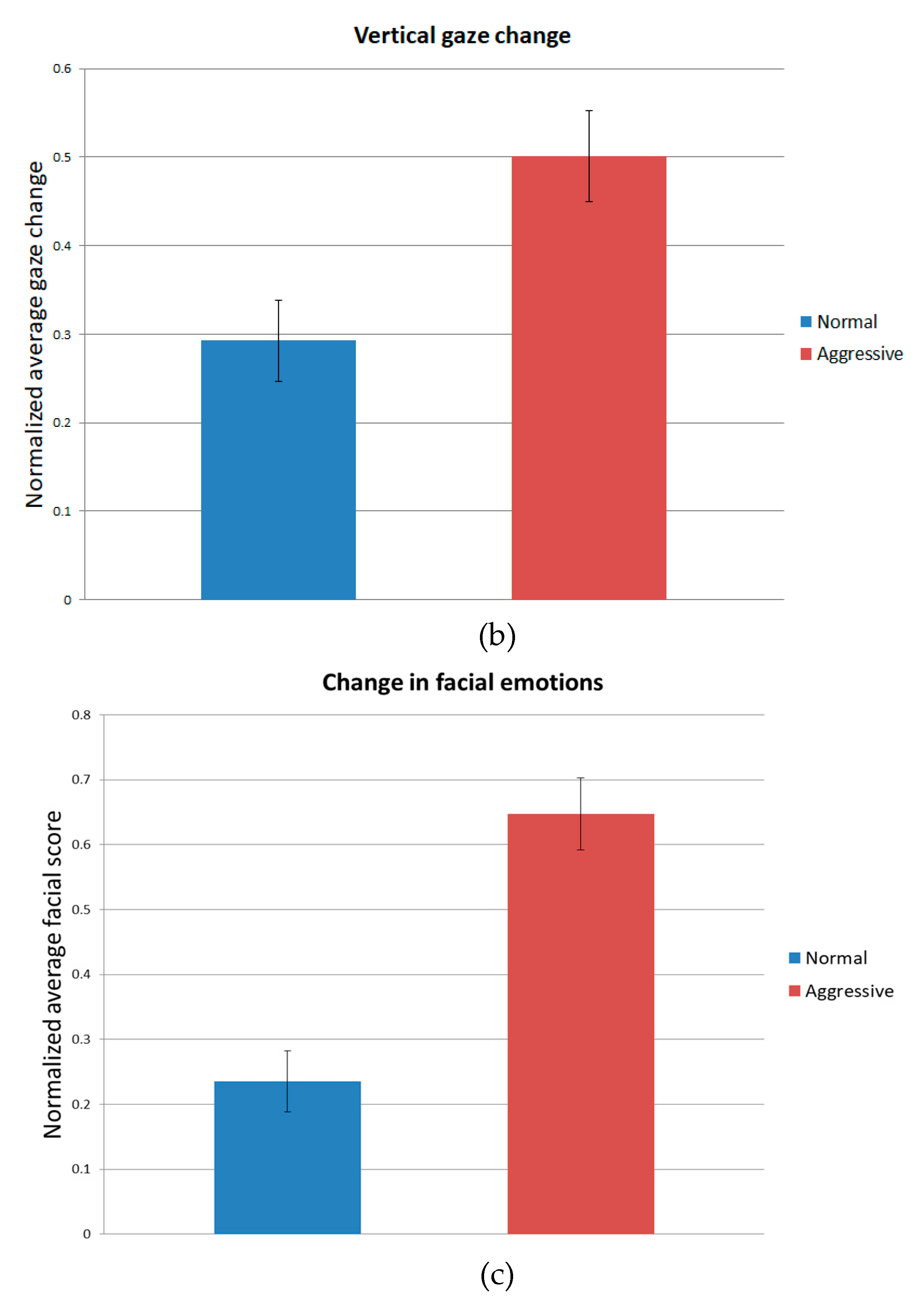
| Average | 0.263 | 0.399 | 0.293 | 0.501 | 0.236 | 0.647 |
| Standard deviation | 0.031 | 0.038 | 0.045 | 0.052 | 0.047 | 0.055 |
| p-value | 2.66 × 10−4 | 1.44 × 10−4 | 3.56 × 10−5 | |||
| Cohen’s d value | 3.94 | 4.29 | 8.06 | |||
| Strength | Large | Large | Large | |||
| Learning Rate Drop Period (Epochs) | Learning Rate | Learning Rate Drop Factor | L2 Regularization | Momentum | Mini-batch Size |
|---|---|---|---|---|---|
| 20 | 0.001 | 0.1 | 0.0001 | 0.9 | 20 |
| VGG-16 model (CHG) | ||||||
| Actual | Predicted | |||||
| 1st fold | 2nd fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 71.67 | 28.33 | 73.31 | 26.69 | 72.49 | 27.51 |
| Normal | 27.78 | 72.22 | 26.34 | 73.66 | 27.06 | 72.94 |
| VGG-16 (CVG) | ||||||
| Actual | Predicted | |||||
| 1st fold | 2nd fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 75.88 | 24.12 | 76.97 | 23.03 | 76.425 | 23.575 |
| Normal | 24.02 | 75.98 | 77.07 | 22.93 | 50.545 | 49.455 |
| VGG-16 (CFE) | ||||||
| Actual | Predicted | |||||
| 1st fold | 2nd fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 85.43 | 14.57 | 83.91 | 16.09 | 84.67 | 15.33 |
| Normal | 15.11 | 84.89 | 16.14 | 83.86 | 15.625 | 84.375 |
| Change in Horizontal Gaze Position | Change in Vertical Gaze Position | Change in Facial Emotions | Equal Error Rate (%) |
|---|---|---|---|
| 0.5 | 0 | 0.5 | 9.4% |
| 0 | 0.5 | 0.5 | 8.6% |
| 0.5 | 0.5 | 0 | 26.6% |
| 0.33 | 0.33 | 0.33 | 11.0% |
| 0.3 | 0.2 | 0.5 | 5.8% |
| 0.2 | 0.3 | 0.5 | 3.7% |
| 0.2 | 0.2 | 0.6 | 1.9% |
| 0.21 | 0.19 | 0.6 | 2.3% |
| 0.19 | 0.21 | 0.6 | 1.1% |
| 0.18 | 0.22 | 0.6 | 1.6% |
| 0.15 | 0.15 | 0.7 | 4.7% |
| Change in Horizontal Gaze Position | Change in Vertical Gaze Position | Change in Facial Emotions | Equal Error Rate (%) |
|---|---|---|---|
| 0.5 | 0 | 0.5 | 10.9% |
| 0 | 0.5 | 0.5 | 9.6% |
| 0.5 | 0.5 | 0 | 27.2% |
| 0.33 | 0.33 | 0.33 | 11.2% |
| 0.3 | 0.2 | 0.5 | 7.1% |
| 0.2 | 0.3 | 0.5 | 4.5% |
| 0.2 | 0.2 | 0.6 | 3.3% |
| 0.21 | 0.19 | 0.6 | 3.9% |
| 0.19 | 0.21 | 0.6 | 2.6% |
| 0.18 | 0.22 | 0.6 | 3.1% |
| 0.15 | 0.15 | 0.7 | 6.2% |
| Actual | Predicted | |||||
|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 99.03 | 0.97 | 98.83 | 1.17 | 98.93 | 1.07 |
| Normal | 0.98 | 99.02 | 1.15 | 98.85 | 1.065 | 98.935 |
| AlexNet model (CHG) | ||||||
| Actual | Predicted | |||||
| 1st fold | 2nd fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 61.78 | 38.22 | 62.53 | 37.47 | 62.155 | 37.845 |
| Normal | 39.66 | 60.34 | 38.77 | 61.23 | 39.215 | 60.785 |
| AlexNet model (CVG) | ||||||
| Actual | Predicted | |||||
| 1st fold | 2nd fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 64.9 | 35.1 | 65.31 | 34.69 | 65.105 | 34.895 |
| Normal | 35.16 | 64.84 | 34.53 | 65.47 | 34.845 | 65.155 |
| AlexNet model (CFE) | ||||||
| Actual | Predicted | |||||
| 1st fold | 2nd fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 71.32 | 28.68 | 72.1 | 27.9 | 71.71 | 28.29 |
| Normal | 28.63 | 71.37 | 28.15 | 71.85 | 28.39 | 71.61 |
| Actual | Predicted | |||||
|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 87.60 | 12.40 | 87.20 | 12.80 | 87.40 | 12.60 |
| Normal | 12.25 | 87.75 | 12.93 | 87.07 | 12.59 | 87.41 |
| Actual | Predicted | |||||
|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 91.36 | 8.64 | 89.92 | 10.08 | 90.64 | 9.36 |
| Normal | 8.77 | 91.23 | 10.17 | 89.83 | 9.47 | 90.53 |
| Actual | Predicted | |||||
|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | ||||
| Aggressive | Normal | Aggressive | Normal | Aggressive | Normal | |
| Aggressive | 75.58 | 24.42 | 76.15 | 23.85 | 75.865 | 24.135 |
| Normal | 24.29 | 75.71 | 23.16 | 76.84 | 23.725 | 76.275 |
| PPV | TPR | ACC | F_Score | |
|---|---|---|---|---|
| Proposed method | 98.93 | 98.935 | 98.933 | 98.933 |
| Proposed method (open database [69]) | 90.64 | 90.54 | 90.585 | 90.59 |
| AlexNet [53] | 87.40 | 87.409 | 87.405 | 87.404 |
| AlexNet [53] (open database [69]) | 75.865 | 76.177 | 76.07 | 76.02 |
| MHDM [37] | 74.58 | 74.647 | 74.625 | 74.614 |
| MHDM [37] (open database [69]) | 64.51 | 63.821 | 63.97 | 64.164 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naqvi, R.A.; Arsalan, M.; Rehman, A.; Rehman, A.U.; Loh, W.-K.; Paul, A. Deep Learning-Based Drivers Emotion Classification System in Time Series Data for Remote Applications. Remote Sens. 2020, 12, 587. https://doi.org/10.3390/rs12030587
Naqvi RA, Arsalan M, Rehman A, Rehman AU, Loh W-K, Paul A. Deep Learning-Based Drivers Emotion Classification System in Time Series Data for Remote Applications. Remote Sensing. 2020; 12(3):587. https://doi.org/10.3390/rs12030587
Chicago/Turabian StyleNaqvi, Rizwan Ali, Muhammad Arsalan, Abdul Rehman, Ateeq Ur Rehman, Woong-Kee Loh, and Anand Paul. 2020. "Deep Learning-Based Drivers Emotion Classification System in Time Series Data for Remote Applications" Remote Sensing 12, no. 3: 587. https://doi.org/10.3390/rs12030587
APA StyleNaqvi, R. A., Arsalan, M., Rehman, A., Rehman, A. U., Loh, W.-K., & Paul, A. (2020). Deep Learning-Based Drivers Emotion Classification System in Time Series Data for Remote Applications. Remote Sensing, 12(3), 587. https://doi.org/10.3390/rs12030587