FGATR-Net: Automatic Network Architecture Design for Fine-Grained Aircraft Type Recognition in Remote Sensing Images

Abstract
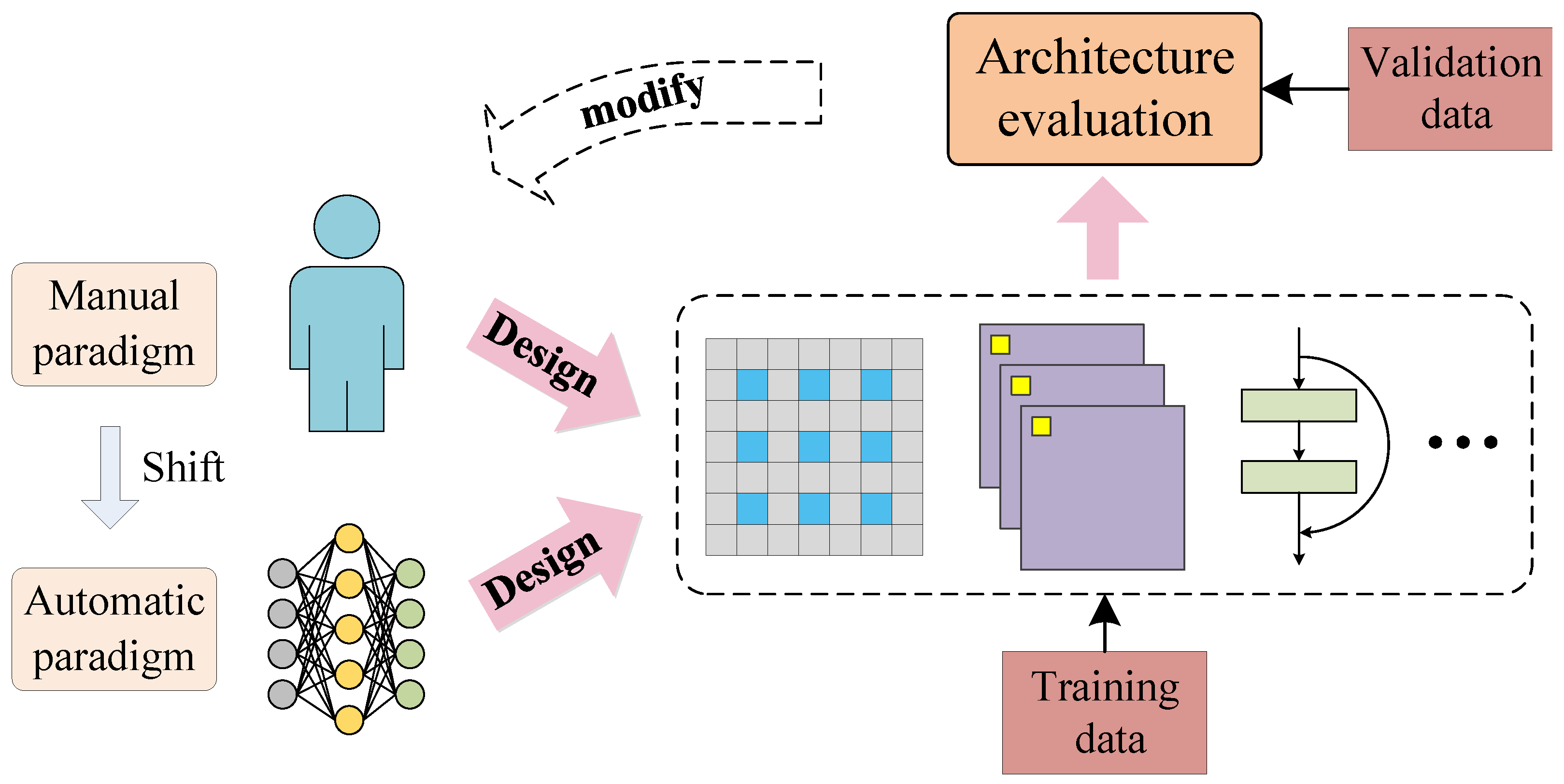
1. Introduction
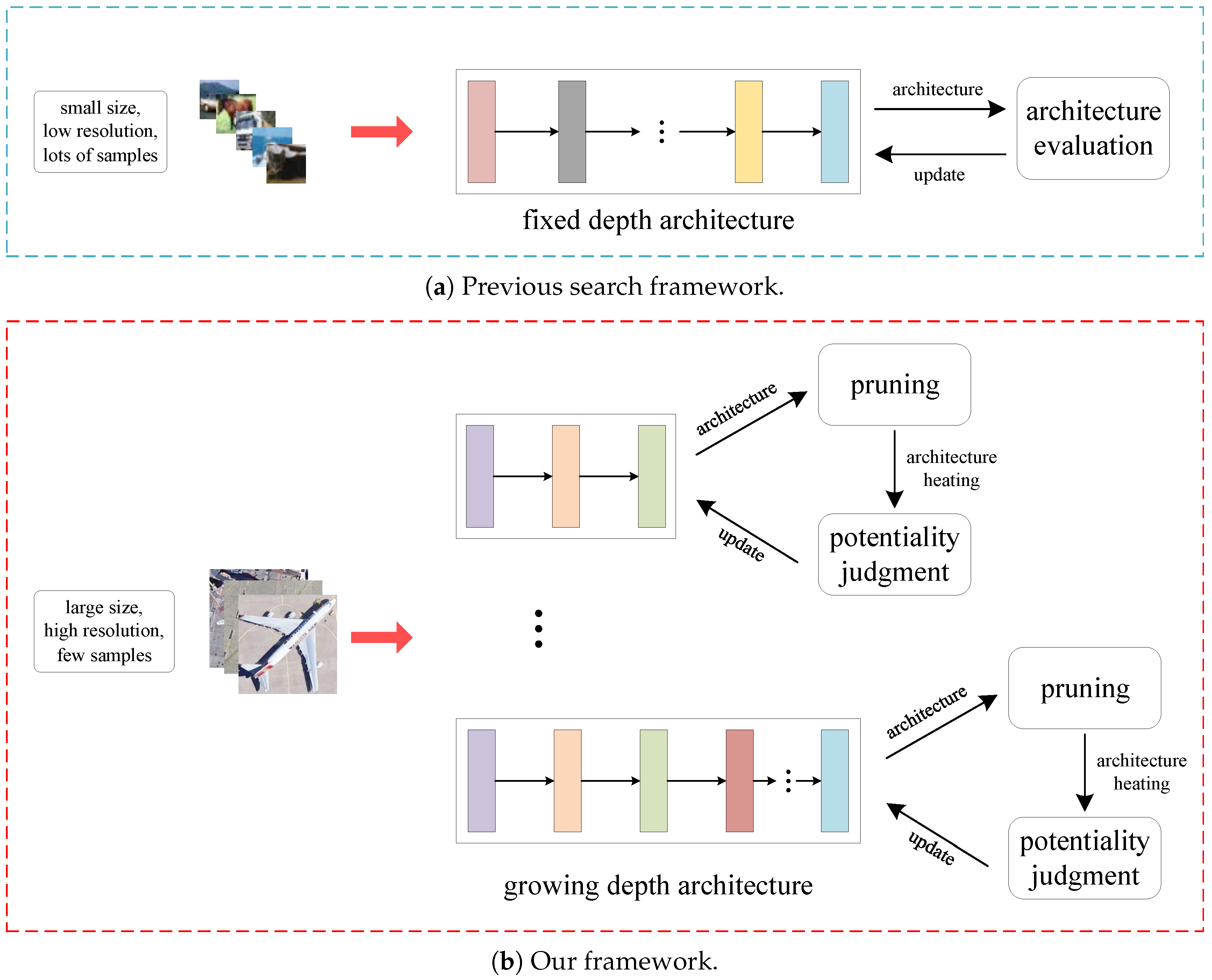
- A differentiable automatic network architecture design paradigm for fine-grained recognition in remote sensing images is explored for the first attempt to the best of our knowledge.
- Considering the relatively large size of remote sensing images, network architecture deepens gradually in the search process. In the meanwhile, some unimportant edges are removed through different pruning strategies with the increase of network layers, making the network more compact.
- In order to discriminate which architecture has more potential, we adopt potentiality judgment to determine the network architecture after an architecture heating process.
- Experimental results on two challenging fine-grained aircraft type recognition datasets show that FGATR-Net is able to achieve the highest accuracy with just much fewer parameters. This strongly confirms the feasibility and effectiveness of the proposed method.
2. Methodology
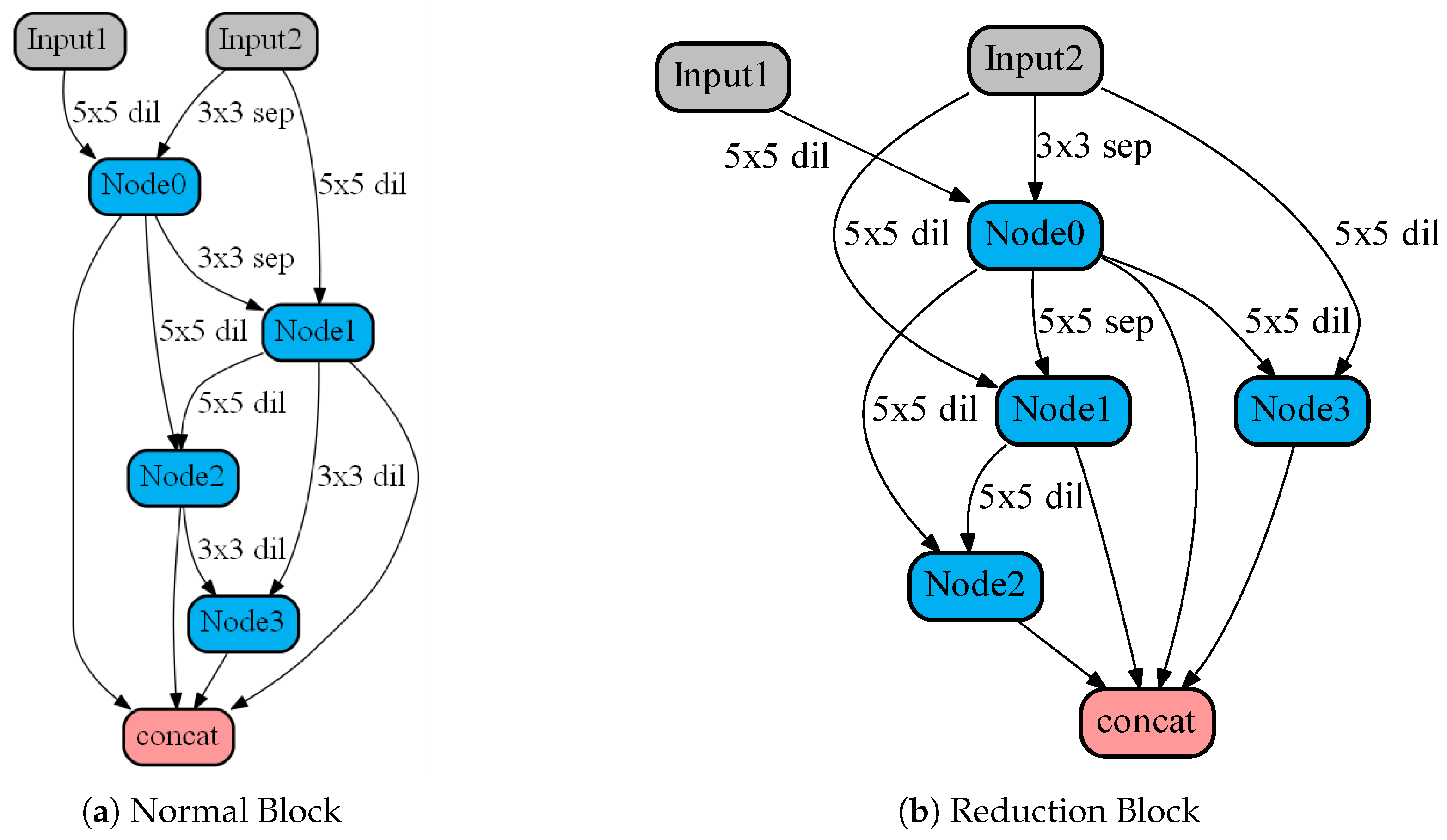
2.1. Differentiable Automatic Network Architecture Design
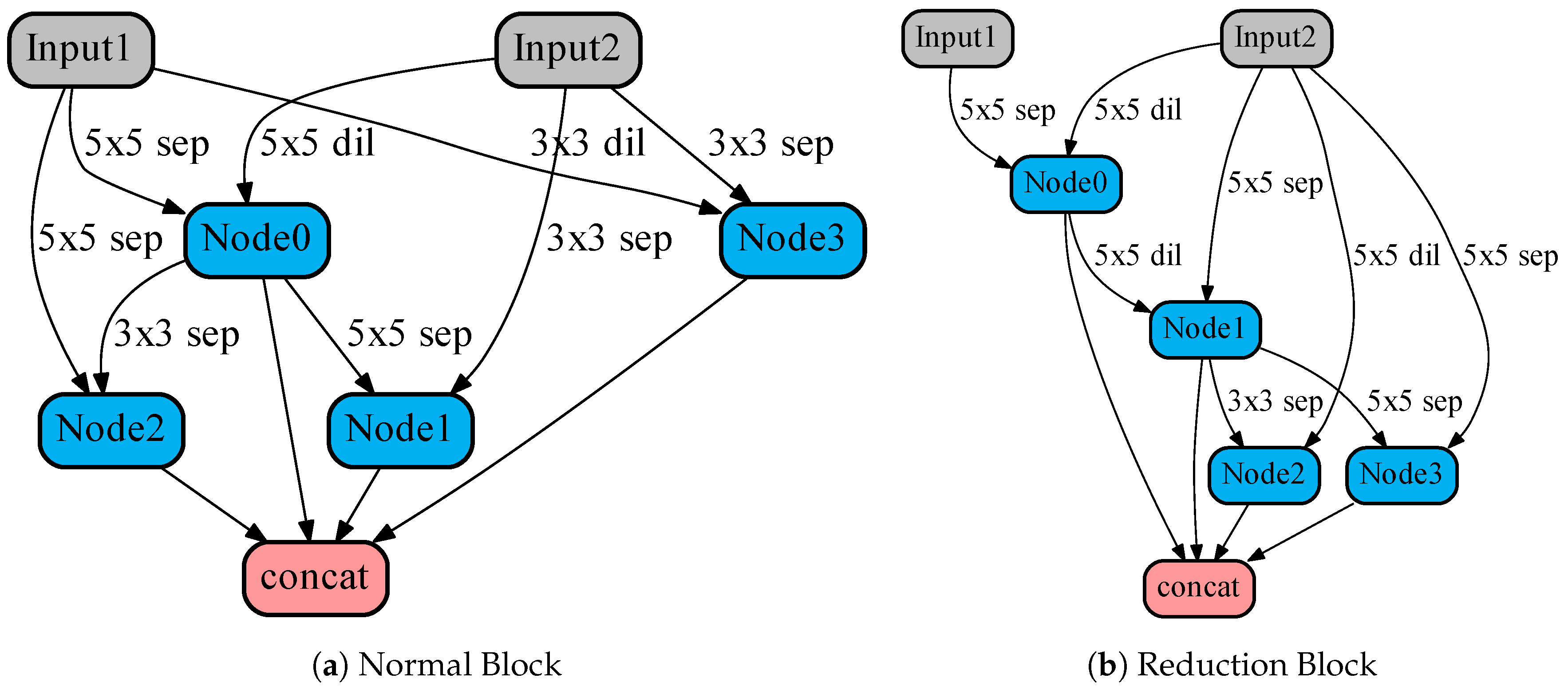
2.1.1. Block Representation as a DAG
2.1.2. Architecture Parameters Relaxation
2.1.3. Optimization Policy
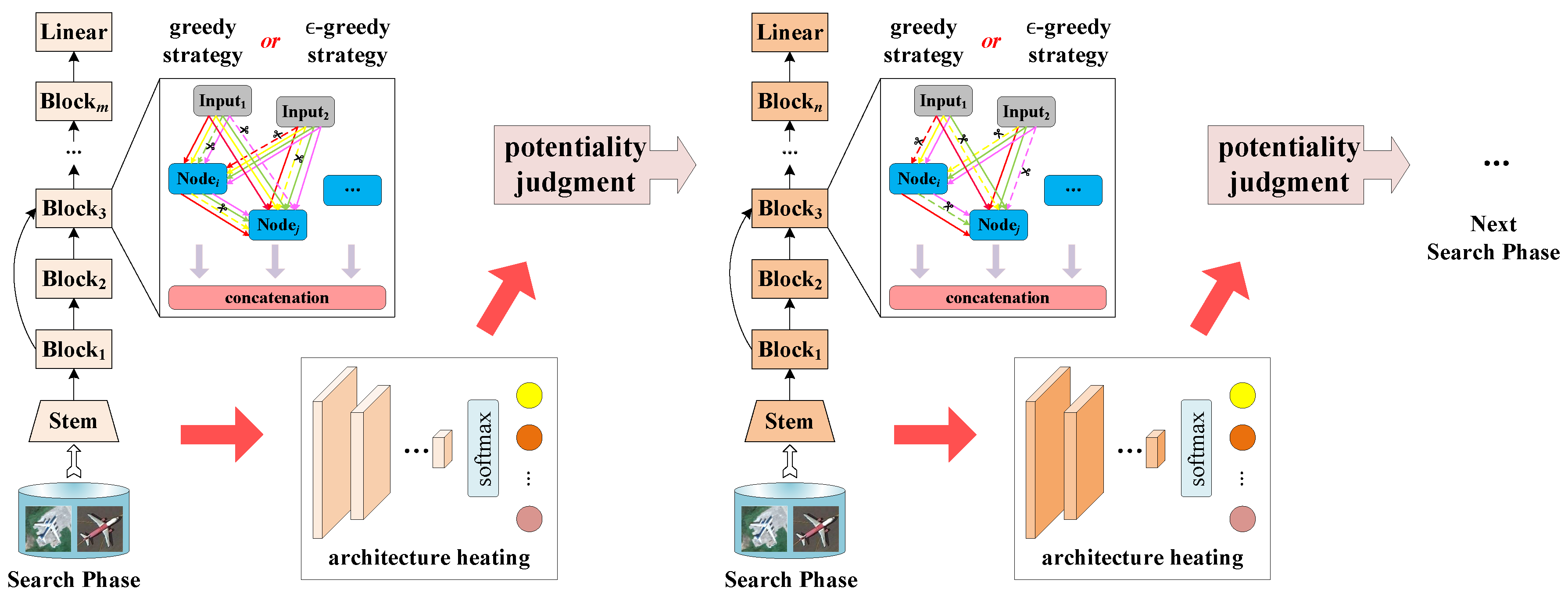
2.2. Model Pruning Strategy
2.2.1. Network Layers Growth
2.2.2. Greedy Strategy and -Greedy Strategy
2.2.3. Potentiality Judgment
| Algorithm 1 Search framework for FGATR-Net. |
|
3. Experiment Settings
3.1. Dataset
3.1.1. MTARSI
3.1.2. Aircraft17
3.2. Evaluation Metrics
3.3. Implementation Details
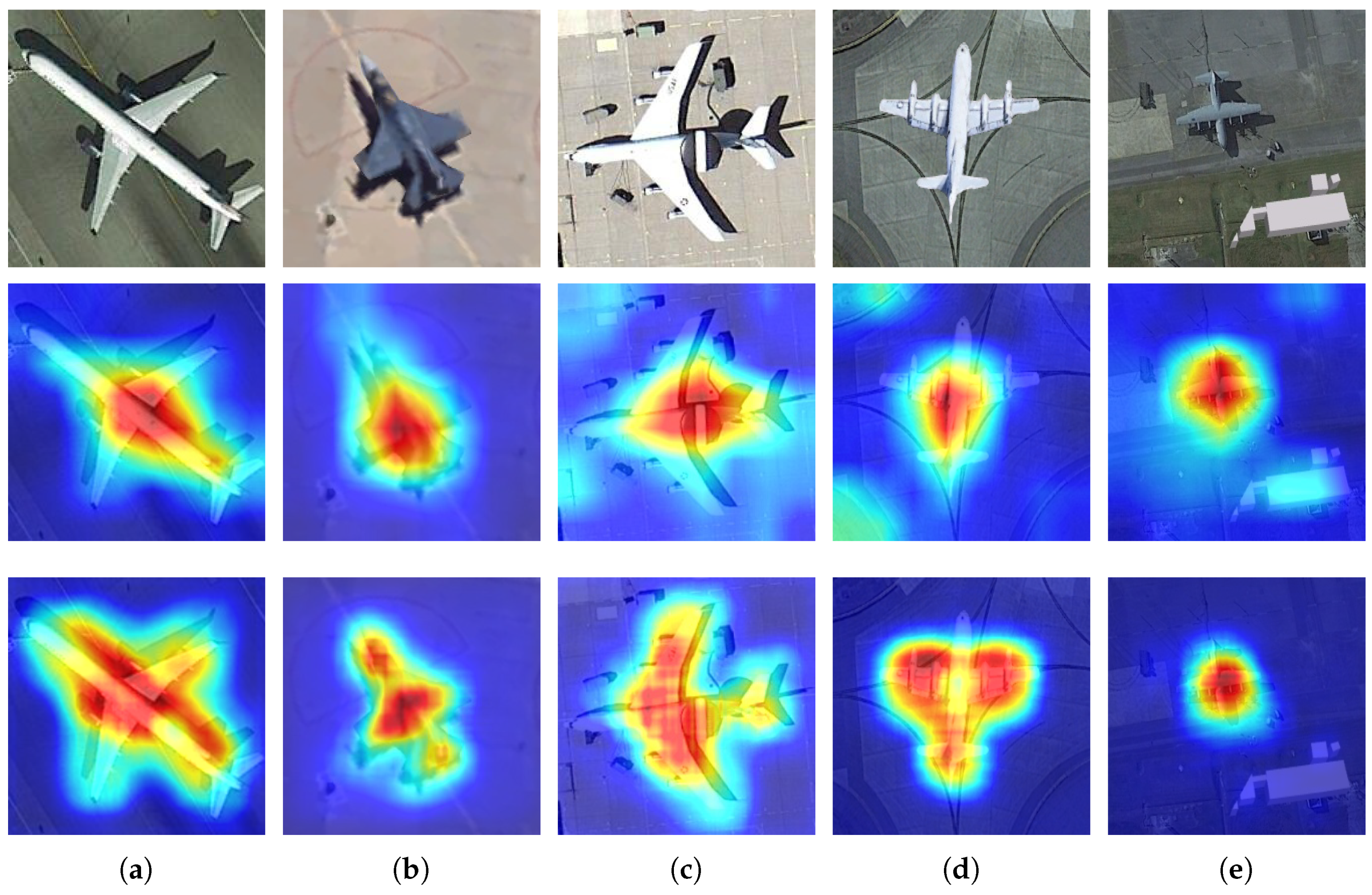
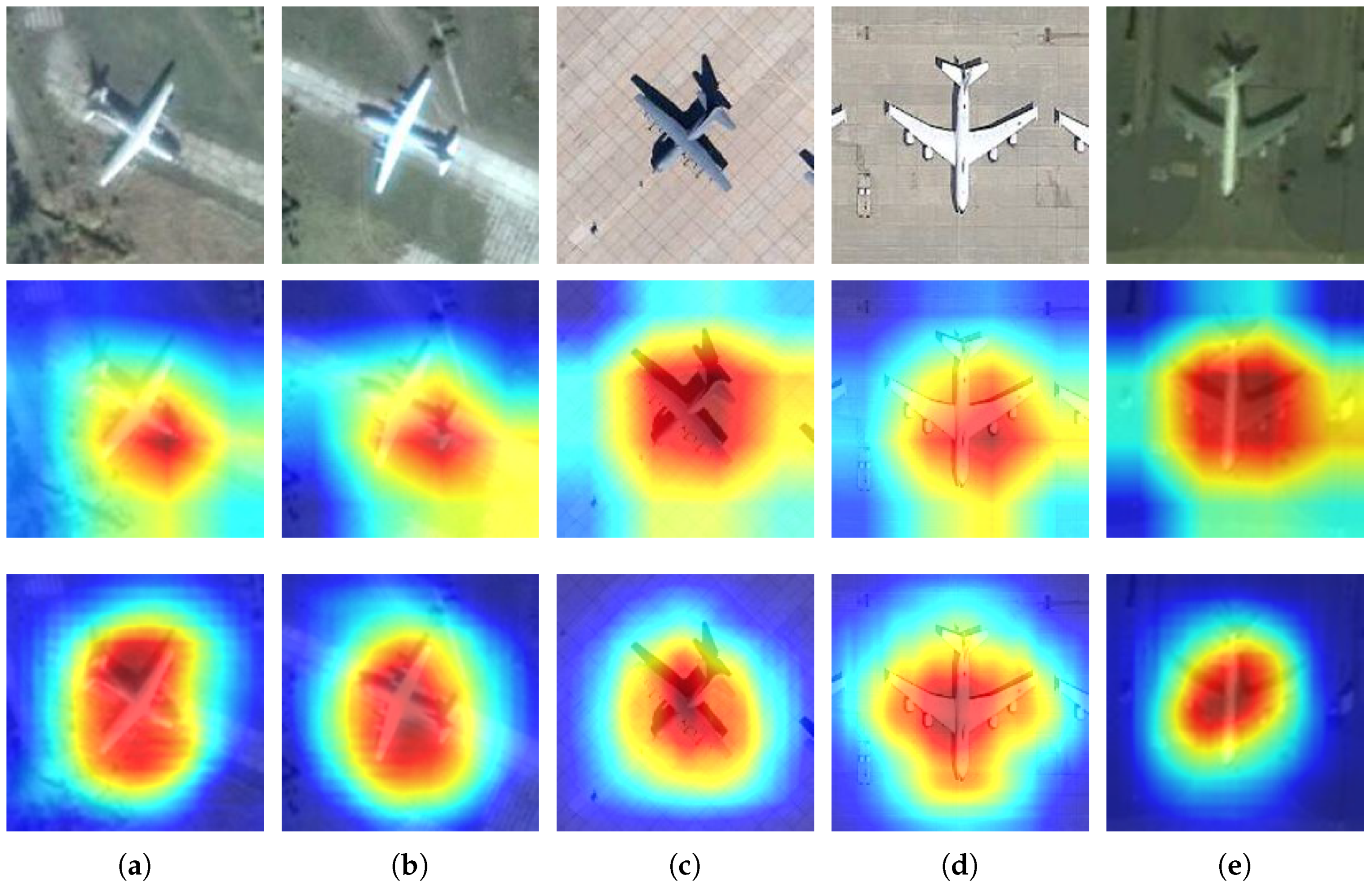
4. Experimental Results
4.1. Results on MTARSI
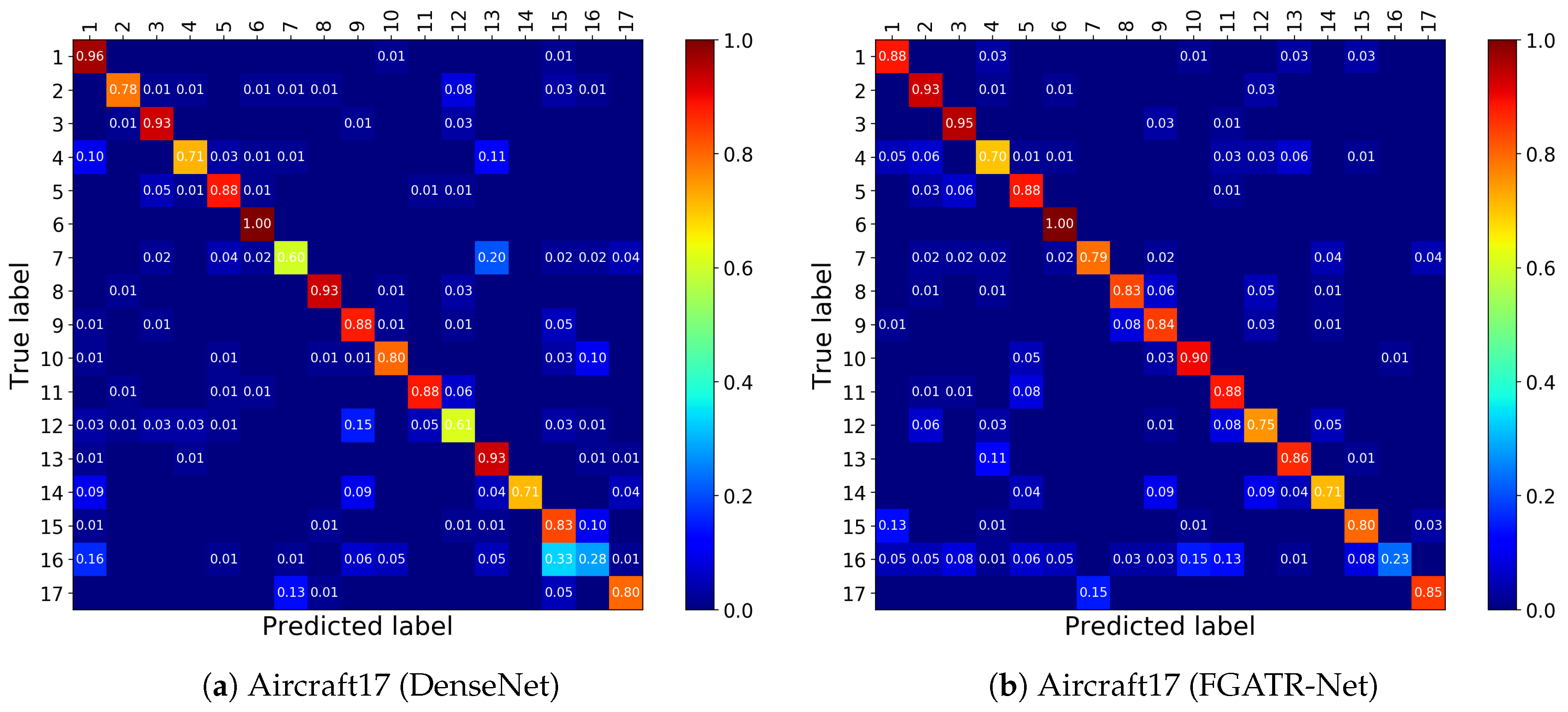
4.2. Results on Aircraft17
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Zhang, B.; Wang, C. Backscattering feature analysis and recognition of civilian aircraft in TerraSAR-X images. IEEE Geosci. Remote Sens. Lett. 2014, 12, 796–800. [Google Scholar] [CrossRef]
- Zhong, Y.; Ma, A.; soon Ong, Y.; Zhu, Z.; Zhang, L. Computational intelligence in optical remote sensing image processing. Appl. Soft Comput. 2018, 64, 75–93. [Google Scholar] [CrossRef]
- Hsieh, J.W.; Chen, J.M.; Chuang, C.H.; Fan, K.C. Aircraft type recognition in satellite images. IEE Proc. Vis. Image Signal Process. 2005, 152, 307–315. [Google Scholar] [CrossRef]
- Xu, C.; Duan, H. Artificial bee colony (ABC) optimized edge potential function (EPF) approach to target recognition for low-altitude aircraft. Pattern Recognit. Lett. 2010, 31, 1759–1772. [Google Scholar] [CrossRef]
- Liu, G.; Sun, X.; Fu, K.; Wang, H. Aircraft recognition in high-resolution satellite images using coarse-to-fine shape prior. IEEE Geosci. Remote Sens. Lett. 2012, 10, 573–577. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 4700–4708. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Diao, W.; Sun, X.; Dou, F.; Yan, M.; Wang, H.; Fu, K. Object recognition in remote sensing images using sparse deep belief networks. Remote Sens. Lett. 2015, 6, 745–754. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Fu, K.; Dai, W.; Zhang, Y.; Wang, Z.; Yan, M.; Sun, X. Multicam: Multiple class activation mapping for aircraft recognition in remote sensing images. Remote Sens. 2019, 11, 544. [Google Scholar] [CrossRef]
- Zhao, A.; Fu, K.; Wang, S.; Zuo, J.; Zhang, Y.; Hu, Y.; Wang, H. Aircraft recognition based on landmark detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1413–1417. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, H.; Zuo, J.; Wang, H.; Xu, G.; Sun, X. Aircraft type recognition in remote sensing images based on feature learning with conditional generative adversarial networks. Remote Sens. 2018, 10, 1123. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical representations for efficient architecture search. arXiv 2017, arXiv:1711.00436. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Chen, X.; Xie, L.; Wu, J.; Tian, Q. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1294–1303. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Zhu, K.; Zhu, L.; He, X.; Ghamisi, P.; Benediktsson, J.A. Automatic design of convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7048–7066. [Google Scholar] [CrossRef]
- Zhang, M.; Jing, W.; Lin, J.; Fang, N.; Wei, W.; Woźniak, M.; Damaševičius, R. NAS-HRIS: Automatic design and architecture search of neural network for semantic segmentation in remote sensing images. Sensors 2020, 20, 5292. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Wu, Z.Z.; Wan, S.H.; Wang, X.F.; Tan, M.; Zou, L.; Li, X.L.; Chen, Y. A benchmark data set for aircraft type recognition from remote sensing images. Appl. Soft Comput. 2020, 89, 106132. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Anandalingam, G.; Friesz, T.L. Hierarchical optimization: An introduction. Ann. Oper. Res. 1992, 34, 1–11. [Google Scholar] [CrossRef]
- Colson, B.; Marcotte, P.; Savard, G. An overview of bilevel optimization. Ann. Oper. Res. 2007, 153, 235–256. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Method | OA (%) | Param (MB) |
|---|---|---|---|
| AlexNet [28] | Manual | 85.61 | 57.09 |
| VGGNet [28] | Manual | 87.56 | 134.34 |
| GoogLeNet [28] | Manual | 86.53 | 5.62 |
| ResNet [28] | Manual | 89.61 | 23.55 |
| DenseNet [28] | Manual | 89.15 | 6.97 |
| EfficientNet [28] | Automatic | 89.79 | 4.03 |
| FGATR-Net | Automatic | 93.76 | 2.33 |
| Network | Method | OA (%) | Param (MB) |
|---|---|---|---|
| AlexNet [6] | Manual | 70.30 | 57.07 |
| VGGNet [7] | Manual | NC | 134.33 |
| GoogLeNet [8] | Manual | 71.13 | 5.62 |
| ResNet [9] | Manual | 77.88 | 23.54 |
| DenseNet [10] | Manual | 80.48 | 6.97 |
| ShuffleNetV2 [11] | Manual | 73.94 | 2.50 |
| FGATR-Net | Automatic | 81.72 | 1.86 |
| Search Phase | Aircraft17 | MTARSI | ||
|---|---|---|---|---|
| Phase I | Phase II | Phase I | Phase II | |
| greedy strategy | ✓ | |||
| -greedy strategy | ✓ | ✓ | ✓ | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, W.; Li, J.; Diao, W.; Sun, X.; Fu, K.; Wu, Y. FGATR-Net: Automatic Network Architecture Design for Fine-Grained Aircraft Type Recognition in Remote Sensing Images. Remote Sens. 2020, 12, 4187. https://doi.org/10.3390/rs12244187
Liang W, Li J, Diao W, Sun X, Fu K, Wu Y. FGATR-Net: Automatic Network Architecture Design for Fine-Grained Aircraft Type Recognition in Remote Sensing Images. Remote Sensing. 2020; 12(24):4187. https://doi.org/10.3390/rs12244187
Chicago/Turabian StyleLiang, Wei, Jihao Li, Wenhui Diao, Xian Sun, Kun Fu, and Yirong Wu. 2020. "FGATR-Net: Automatic Network Architecture Design for Fine-Grained Aircraft Type Recognition in Remote Sensing Images" Remote Sensing 12, no. 24: 4187. https://doi.org/10.3390/rs12244187
APA StyleLiang, W., Li, J., Diao, W., Sun, X., Fu, K., & Wu, Y. (2020). FGATR-Net: Automatic Network Architecture Design for Fine-Grained Aircraft Type Recognition in Remote Sensing Images. Remote Sensing, 12(24), 4187. https://doi.org/10.3390/rs12244187