1. Introduction
Earthquakes, landslides, debris flows, and other natural disasters have occurred more frequently in recent years and have caused greater damage than before. When natural disasters occur, rapid emergency response and rescue are critical. However, it is often difficult for rescuers to access disaster areas because routes leading to them may be damaged or hindered. Unmanned aerial vehicles (UAVs) have been widely used in earthquake relief and other rescue efforts because of their flexibility, low cost, and small constraints related to the terrain. With their rapid response capability, UAVs have played a significant role in emergency rescue work [
1,
2,
3]. Moreover, to obtain three-dimensional (3D) topographic information of disaster areas, UAVs can be used in dangerous areas in place of surveyors and mapping personnel. They can cruise below clouds and obtain high-resolution images that can be used for 3D model reconstruction through some processing, e.g., the computation of stereo vision [
4]. Based on the acquired 3D model, the degree of damage caused in the disaster areas can be estimated, and decision-makers can use the spatial information to quickly formulate rescue plans and routes.
With the development of computing technologies, 3D model reconstruction has emerged as a popular subject of research. Microsoft has developed Kinect Fusion based on Kinect, which scans the environment by letting users move with the device in hand and reconstructs a 3D model of the scanned environment based on the scanned data (
https://www.microsoft.com/en-us/research/projects/surfacecon). However, Kinect is sensitive to distance and its effective range is limited. As a result, it can reconstruct the environment only over a small range of 3D “maps” (in this paper, a “map” means the visual scene of the 3D point cloud obtained by 3D dense reconstruction, and is equivalent to a 3D model). Structure from motion (SfM) is a method of 3D reconstruction in computer vision that is not constrained by many assumptions in photogrammetry theory and has good versatility. Notable achievements have been made using this method, such as the bundler-based incremental 3D reconstruction of SfM methods by Agarwal et al. [
5]. Schonberger et al. proposed an improved SfM algorithm that can overcome challenges associated with the robustness, accuracy, completeness, and scalability of incremental reconstruction systems. This was a big step up toward a general purpose SfM system, COLMAP (
https://colmap.github.io/index.html) [
6,
7]. Moreover, some researchers have reconstructed a few ancient buildings based on UAV images and analyzed the damage to them over time [
8,
9]. Others have studied 3D reconstruction based on the SfM algorithm [
10,
11,
12,
13].
Traditional methods of 3D model construction are based on image data at different viewing angles for 3D geometric reconstruction. However, the cycle of production is long, the cost is high, and the process is cumbersome. In specific application scenarios, such as natural disasters, people are in urgent need of help, the environment is unknown, and rescue operations need to be as fast as possible. Thus, 3D maps need to be generated quickly or even in real time. Traditional methods cannot solve this problem due to three shortcomings.
(1) Many preparatory steps are needed before data acquisition that require highly accurate data.
(2) In most of the process of 3D reconstruction, the UAV is used only as a tool for data acquisition. The data can be processed only once they have been acquired, and the 3D information cannot be fed back in real time. Thus, the convenience of the UAV platform cannot be fully exploited for 3D model reconstruction in a timely manner.
(3) In processing UAV images, traditional methods take a long time for calculations due to the complexity of the algorithm. It is thus difficult to quickly complete the process from image sequencing to 3D model generation.
Vision-based SLAM (simultaneous localization and mapping) is a 3D “map-building” technology that estimates the trajectory of motion and then constructs the 3D information of the environment during the motion of the sensor [
14,
15,
16,
17]. Early implementation of SLAM for monocular vision was achieved using filters [
18,
19]. Chekhlov et al. [
20] and Martinez-Cantin et al. [
21] introduced the unscented Kalman filter (UKF) to improve the robustness of the Kalman filter algorithm but increased its computational complexity. In recent years, SLAM has been adapted rapidly to underwater robots, land robots, and UAVs [
22,
23,
24,
25,
26], and significant advances have been made in algorithm structure and data association problems [
27,
28,
29,
30]. Visual SLAM uses cameras as data acquisition sensors. It significantly enhances the capability of embedded systems to process a large amount of information due to its flexibility, low cost, efficiency, and ease of use. Classical SLAM algorithms include the extended Kalman filter (EKF) [
31], extended information filter (EIF) [
32], and particle filter (PF) [
33]. However, these methods cannot solve the problem in the reconstruction of large-scale 3D “maps” [
34,
35,
36].
With significant improvements in hardware performance, the development of parallel computing technology, and the emergence of efficient solutions, keyframe-based monocular vision SLAM [
37,
38,
39,
40] has advanced, and graph-based optimization has become popular in SLAM research [
41,
42,
43,
44,
45,
46,
47,
48,
49,
50]. In dense SLAM reconstruction, Engel et al. constructed a semi-dense “map” in which the camera pose was calculated by dense image matching, and the depth of pixels with prominent gradient changes in the image is estimated [
51]. Stühmer et al. estimated the camera pose using every pixel of a given image and constructed a dense 3D model based on it [
52]. Progress has also been made [
53,
54] in improving the robustness of SLAM by predicting the depths of pixels and extracting image blocks. The large-scale direct monocular SLAM (LSD-SLAM) algorithm proposed by Engel et al. [
55] improved the accuracy of camera pose estimation and creates semi-dense, large-scale environmental “maps”. Based on visual SLAM, Liu et al. proposed a 3D modeling technology using UAV monocular video that relies only on the visual mode and does not need additional hardware equipment to assist in the construction of the 3D “map” of the shooting area in the video [
56]. The experimental evaluation of the algorithm’s construction results verified its feasibility. Elena et al. proposed a 3D reconstruction method based on LSD-SLAM [
57]. By analyzing video data and extracting keyframes, they generated 3D point cloud data and panoramic images. Finally, the 3D “map” was reconstructed by the fusion of the 3D point cloud and the panoramic image.
Despite the technical advancements mentioned above, SLAM is computationally intensive and takes too long for it to be used in applications. With progress in parallel computing technology and improvement in hardware performance, SLAM can now be quickly executed. For example, based on the FastSLAM algorithm, Zhang examined the resampling process and landmark estimation process [
58]. Based on the parallel computing framework of the compute unified device architecture (CUDA), he made full use of resources of the CPU and graphics processing unit (GPU) to accelerate SLAM. Zhu et al. proposed a parallel optimization method for the GPU based on a particle filter and the SLAM algorithm [
59]. The GPU has many processing cores and powerful floating-point computing capability. It is mainly used in data-intensive computing and is particularly suitable for the processing of 3D mapping algorithms based on visual SLAM, which requires a large amount of computation, independent calculation, and fast real-time performance. Therefore, combining the GPU with SLAM on a UAV platform for certain application scenarios has important research value. Such applications include emergency management in case of natural disasters, e.g., earthquakes, debris flows, or complex battlefield environments, in which the state of the environment is unknown and terrain-related information needs to be obtained quickly. To the best of our knowledge, ours is the first team to investigate this application.
The main contributions of this paper are as follows.
(1) The characteristics of the distributed robot operating system (ROS) computing architecture and multi-node distributed computing were used. The strategies of communication were designed in combination with the visual SLAM algorithm.
(2) An ROS network was built for the real-time monitoring of the operational status of the ROS nodes, images, and 3D information based on visualization tools.
(3) The CUDA parallel programming model was used to analyze the proposed algorithms for 3D model reconstruction. A parallel algorithm was designed and implemented on an embedded GPU platform to improve performance.
(4) Based on the distributed ROS computing framework, we designed and implemented a prototype for a multi-process reconstruction system for processing 3D point clouds of visual SLAM.
The remainder of this paper is organized as follows:
Section 2 briefly introduces the proposed methodology and key technologies used in this study.
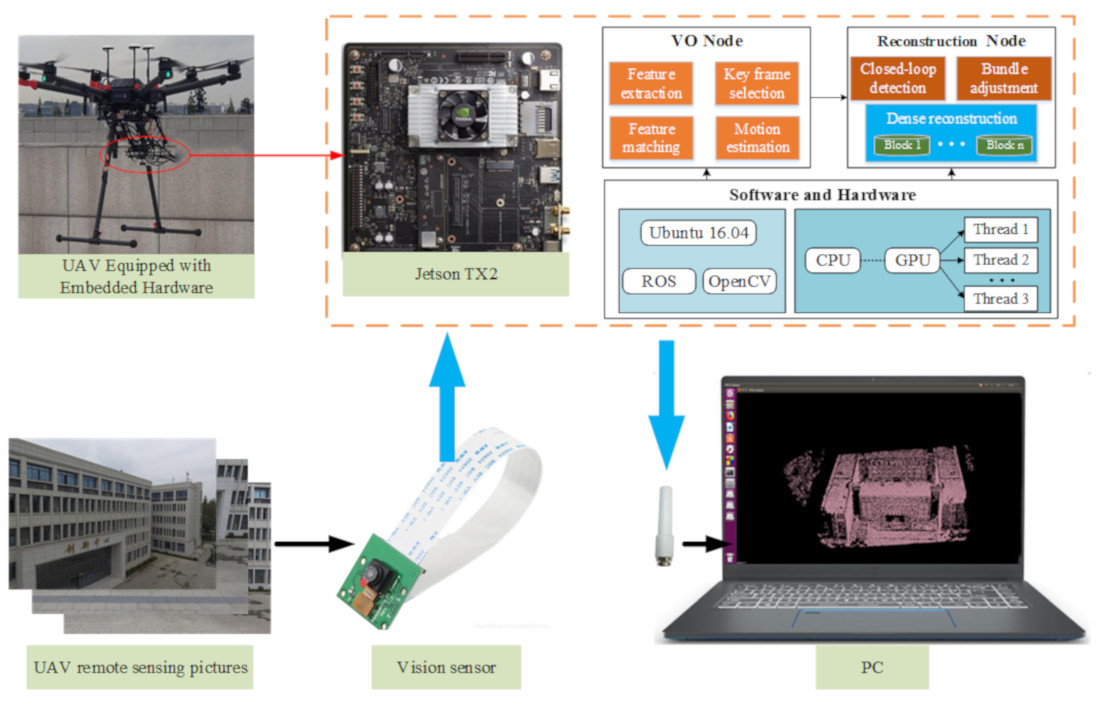
Section 3 describes the design and implementation of the software and hardware systems for the fast reconstruction of the 3D model based on UAV images with visual SLAM from the aspects of system structure, algorithm flow, and parallel computing.
Section 4 describes the experimental aims, design, and data.
Section 5 introduces the results mainly from the perspectives of the visual effect of the reconstruction of the 3D point cloud and a preliminary quantitative analysis of the dense point cloud obtained using this method.
Section 6 offers the conclusions of this study and suggests future directions of research.
6. Conclusions and Future Work
In this paper, using a distributed ROS computing framework and parallel computing through a GPU, the authors proposed a fast method for 3D “map” reconstruction based on visual SLAM for the UAV platform. Based on key technologies, e.g., real-time data acquisition and fast processing in embedded environments, a prototype of the fast 3D reconstruction system based on a UAV was implemented. However, we conducted only preliminary research in this direction, and the prototype system was not sophisticated enough in some respects. There is room for improvement in the proposed method. Specifically, the following issues are worth further investigation:
(1) A systematic test, evaluation, and comparisons of the prototype system should be carried out. This is also the most important task in future work in the area.
(2) Although the proposed method achieved good results in terms of performance, it did not consider the scale-to-scale relationship between the constructed 3D “map” and real objects, and lacked a precise geospatial reference system for such a comparison and reference. In follow-up work, GPS and other technical means like the ground control point (GCP) should be added to the proposed method to assist in this respect. The corresponding relationship between the 3D “map” and real 3D objects as well as the controllable accuracy of the ground sample distance (GSD) should also be strengthened.
(3) Because of the distributed ROS computing framework, the reconstruction method designed in this paper communicated only with different functional nodes of the same device through message transmission, where the transmission of messages containing large amounts of data, such as images, consumed a large amount of system resources and thus required processors or data transmission parts. The proposed system was equipped with hardware equipment at the UAV’s onboard terminal that ensured high level performance to solve this problem, but this increased costs. Follow-up research can be carried out on real-time data transmission of the UAV at low cost.
(4) The 3D UAV model used in this research was a dense point cloud “map” that can provide only visually intuitive 3D information but did not study the implementation of its processing and reprocessing functions. In follow-up work, based on this study, the triangulation and texture mapping of 3D point cloud “maps” can be studied to better use them.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}