An End-To-End Bayesian Segmentation Network Based on a Generative Adversarial Network for Remote Sensing Images




Abstract
1. Introduction
1.1. Background
1.2. Problems and Motivations
1.3. Contribution and Structure
- (1)
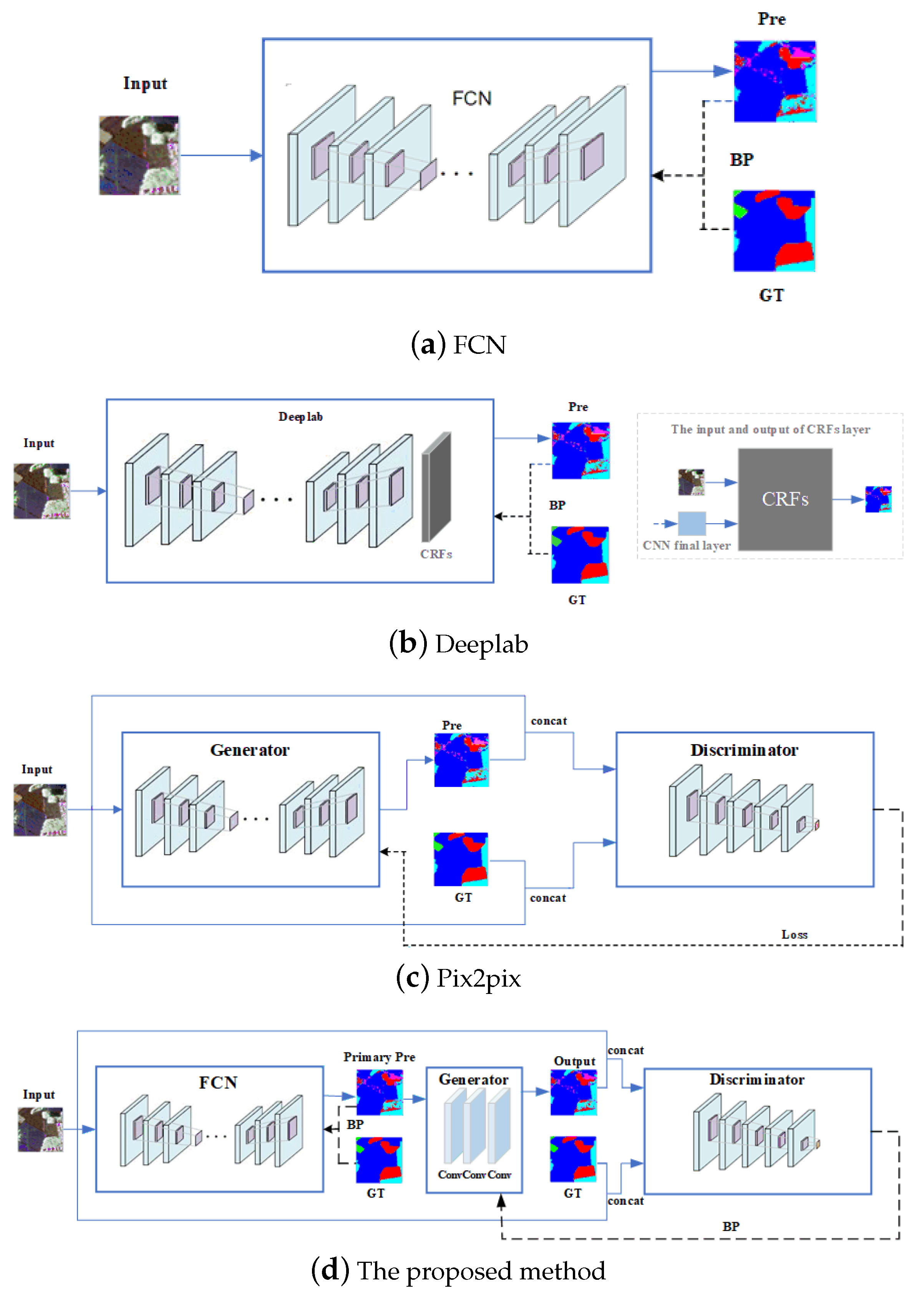
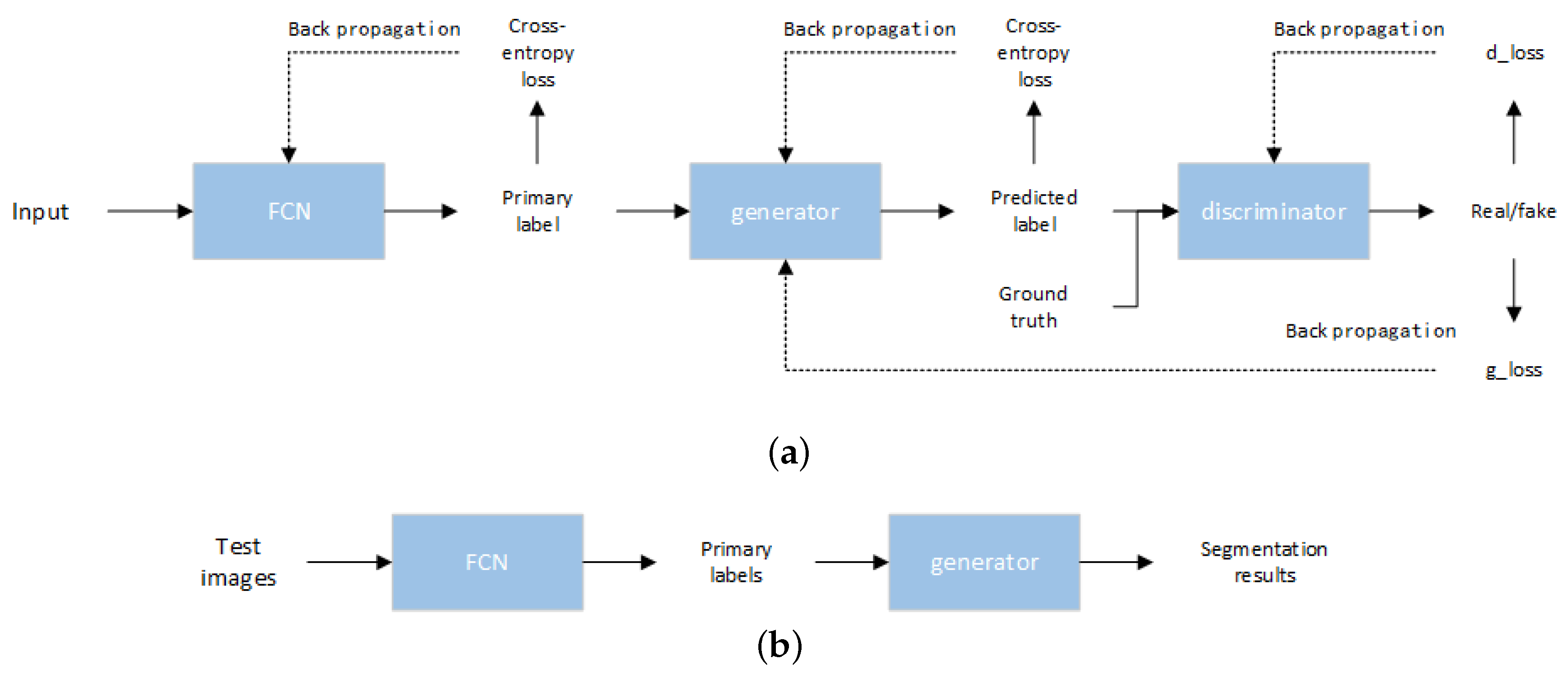
- An end-to-end Bayesian segmentation network was designed, which uses FCN and GAN to achieve the derivation of the prior probability and likelihood function to the posterior probability. In the entire network architecture, FCN is used as the prior network, while GAN can be used as the likelihood network. The cross-entropy loss in the FCN is directly associated with the prior probability, and the loss of the GAN is correlated with the likelihood probability. Thus, a complete Bayesian framework has been constructed.
- (2)
- The cross-entropy loss in the FCN and the loss in the GAN are separately trained, rather than just using cross-entropy loss as part of the loss of a GAN generator. In the absence of effective guidance, GAN may often be plagued by the problem of model crashes. Therefore, we use the cross-entropy loss of FCN as an a priori guide for the training of GAN to make the network converge to global optimality. We verified that the proposed approach can not only improve the segmentation performance, but also enhance the stability of training.
- (3)
- The generator of GAN acts as a spatial filter which is integrated into the semantic segmentation framework to explore the spatial relationship between each label and optimize the results of the prior network. Unlike other GAN-based segmentation methods, the input of the generator is the output of the FCN instead of the image that needs to be predicted. It can be seen that the function of GAN is to further optimize the results obtained by FCN. Therefore, we provide a viable architecture for semantic segmentation.
2. Methodology
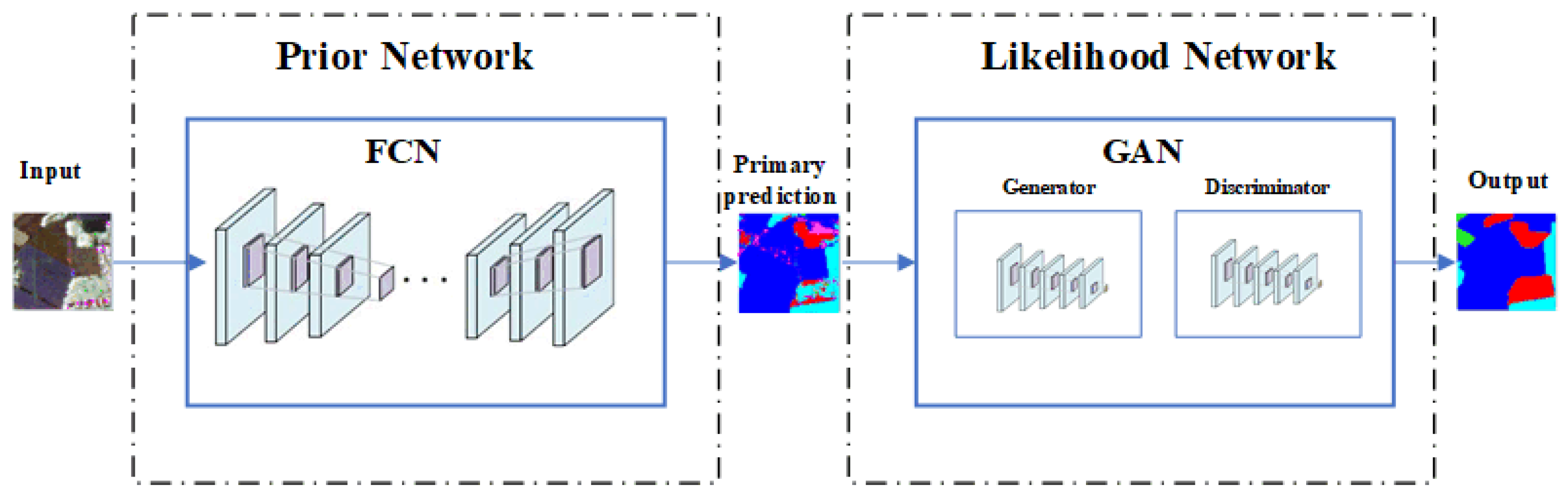
2.1. Bayesian Segmentation Network
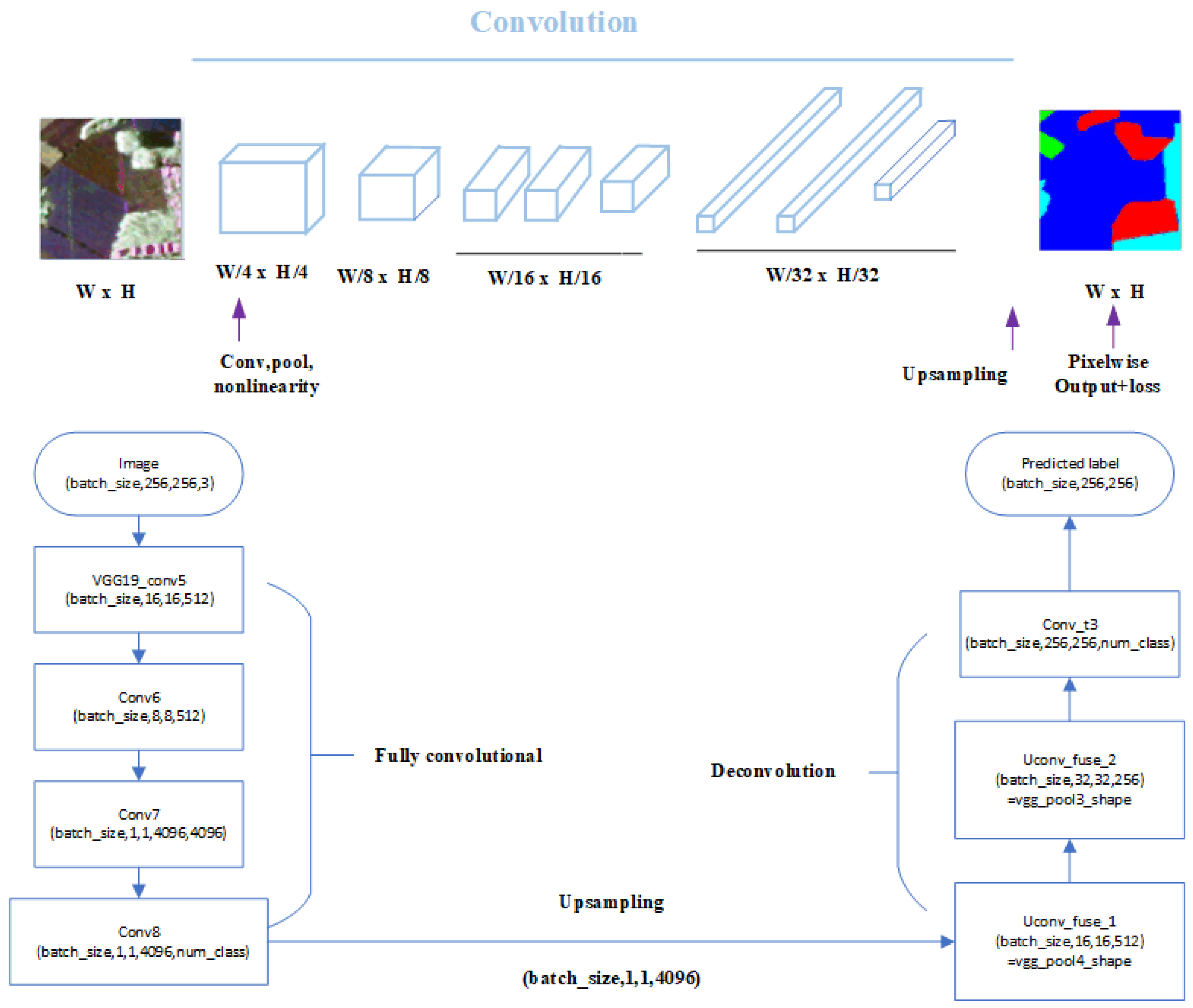
2.2. Prior Network
2.3. Likelihood Network
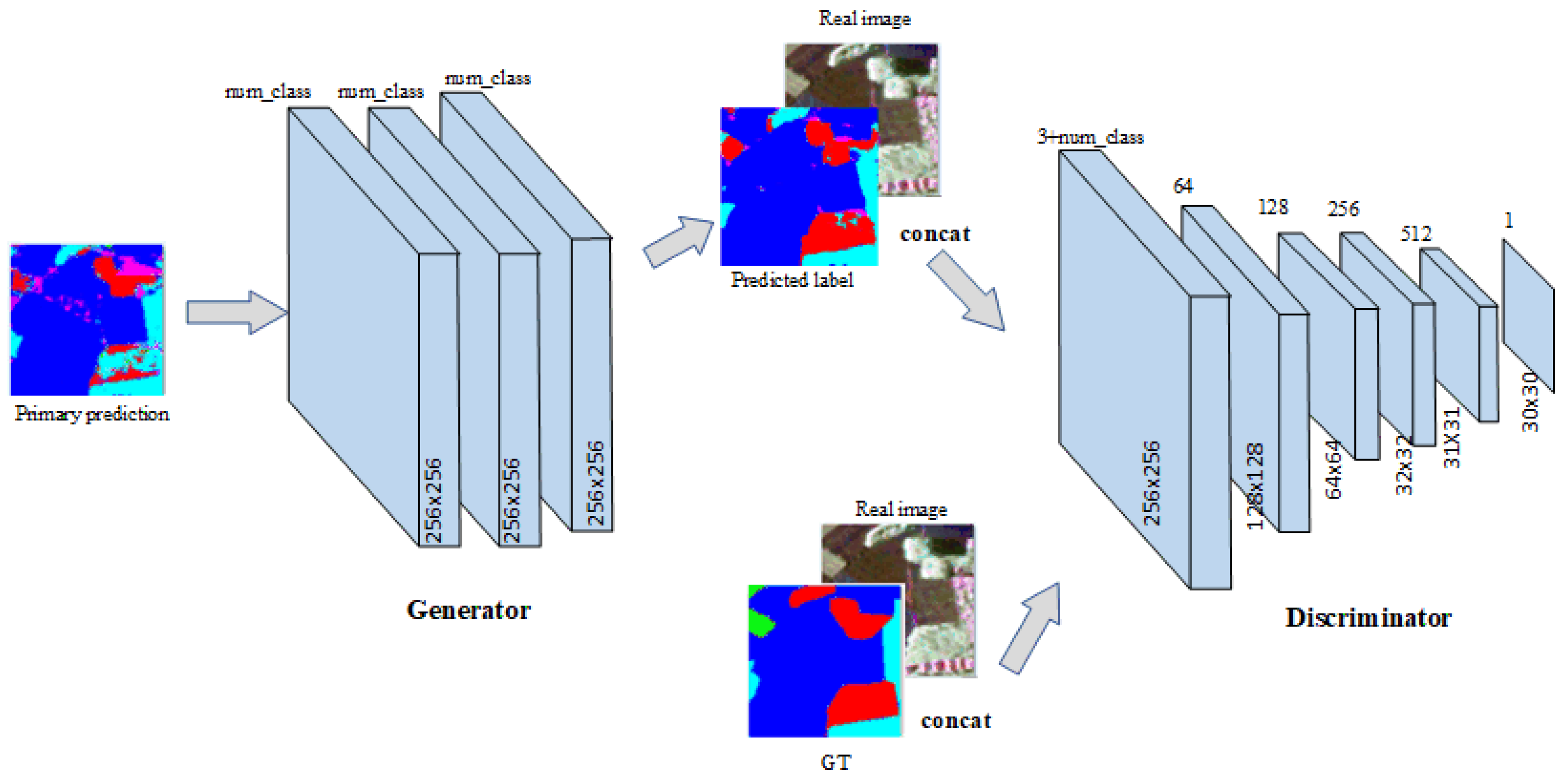
2.3.1. Generative Model
2.3.2. Discriminative Model
2.4. Loss Function
3. Flowchart and Setting
4. Experiment
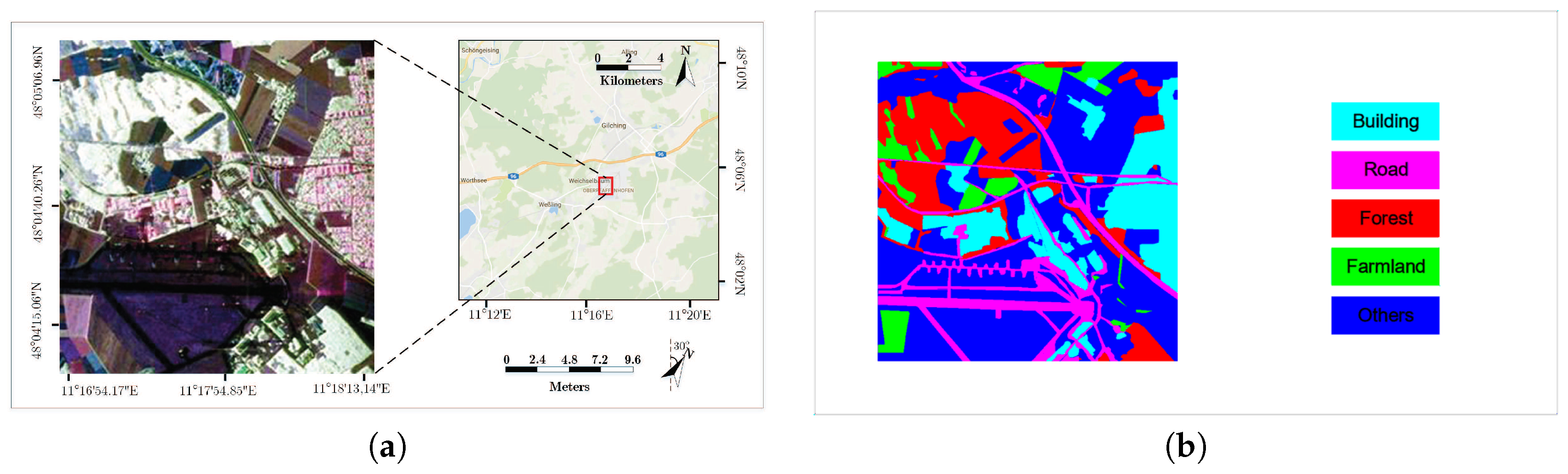
4.1. Experiment Data
4.2. Experiment Results
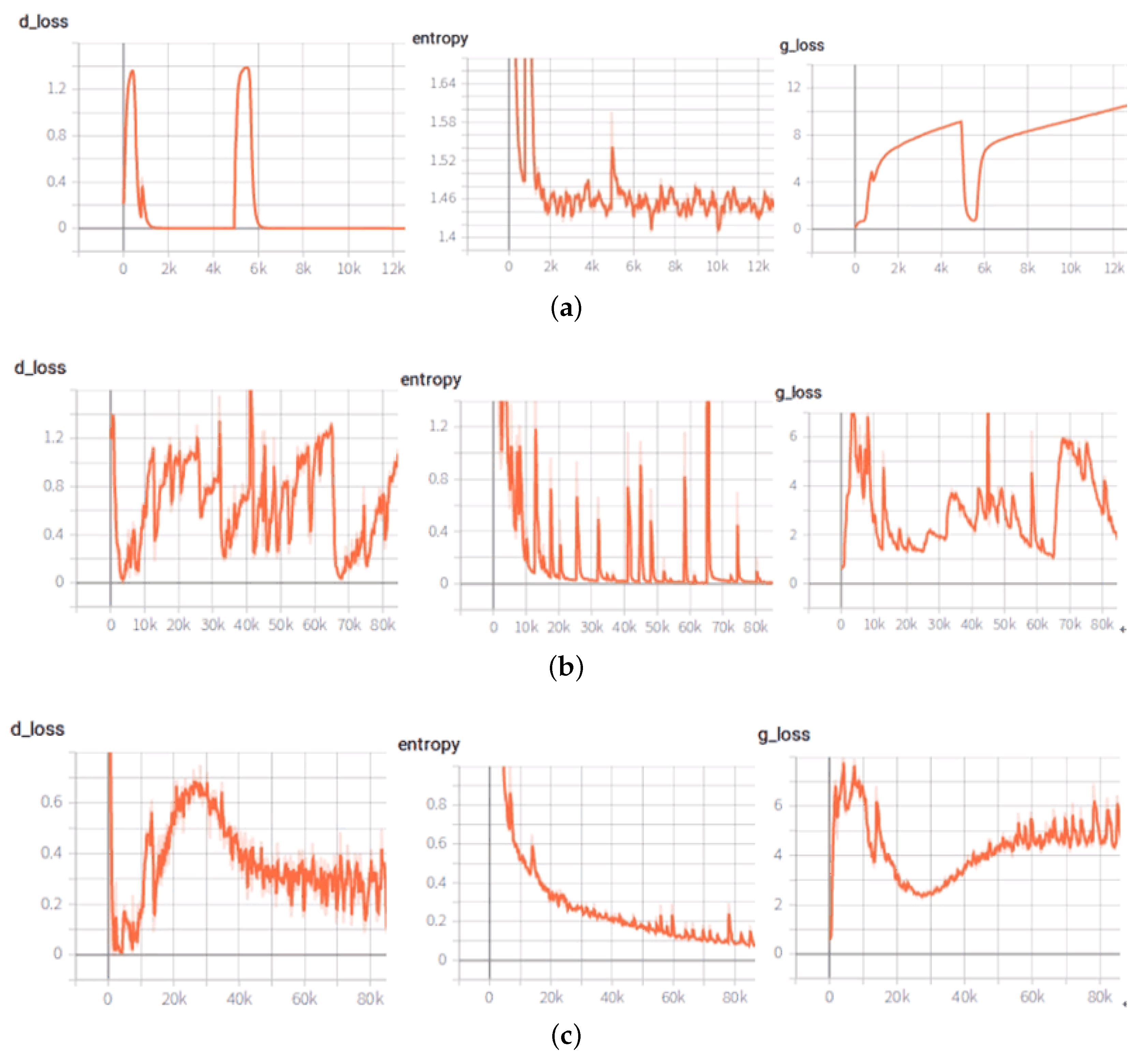
4.2.1. Training Stability Comparison
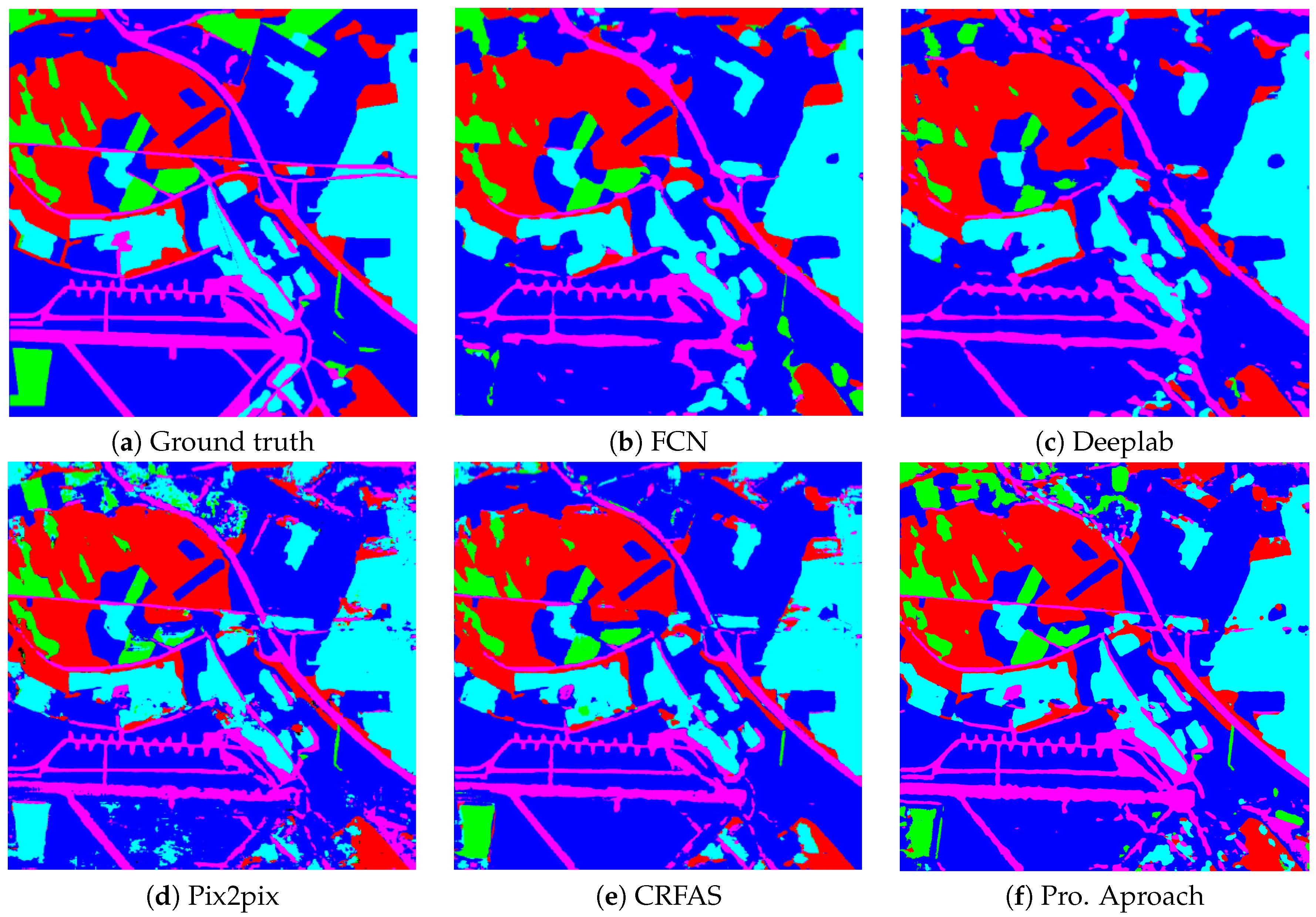
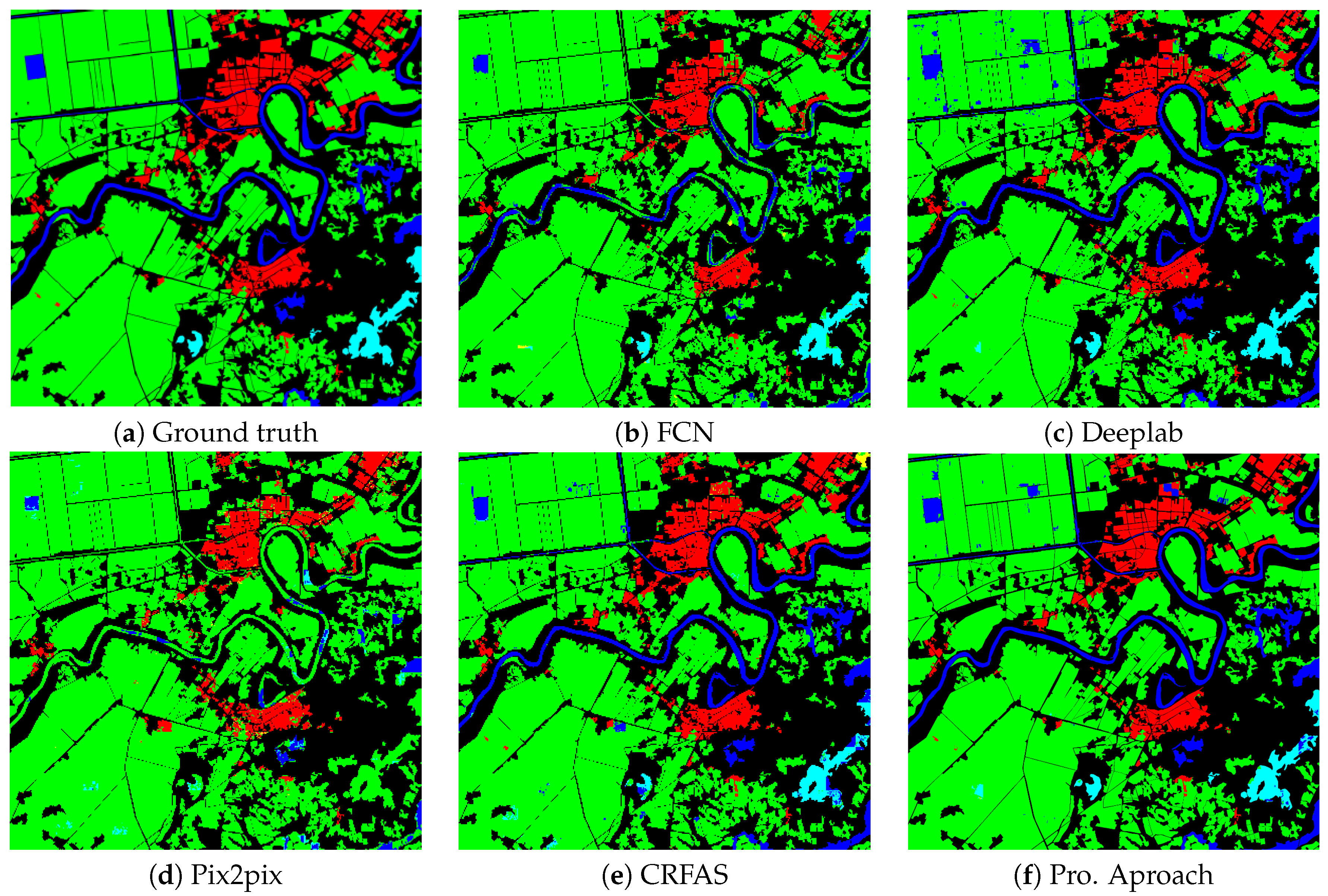
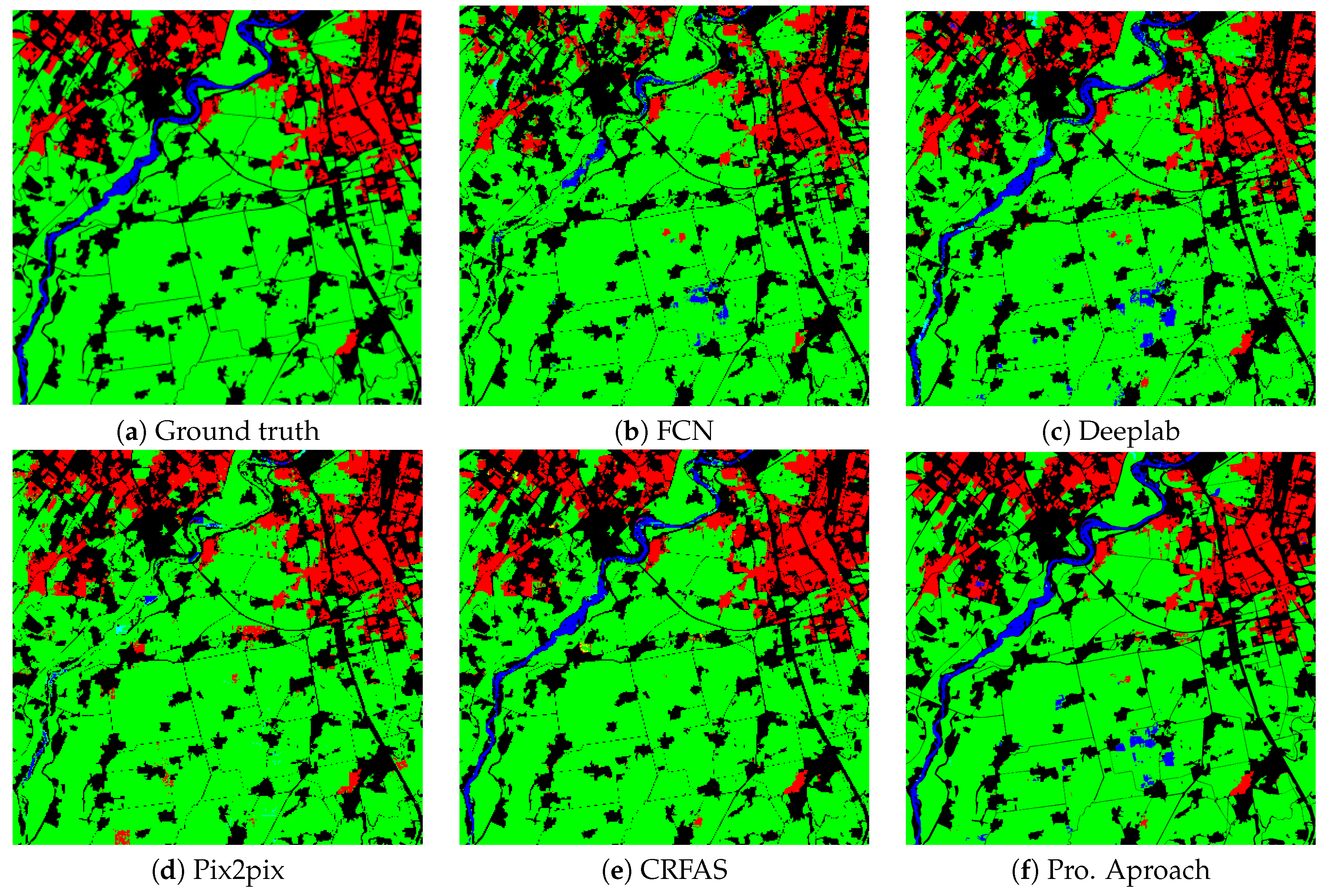
4.2.2. Segmentation Results
4.3. Time Consumption
5. Discussion
- (1)
- The proposed approach utilizes the generative adversarial network to explore the potential spatial relationships between labels. The structure of GAN has a great impact on the results of the segmentation. Therefore, building a more reasonable generator and discriminator is the key to further improving the performance of semantic segmentation.
- (2)
- In the proposed method, FCN plays a crucial role as the prior network. Adequate prior knowledge is the foundation of the Bayesian network. To further improve the segmentation accuracy, FCN can be replaced by other better networks, which can be studied in the subsequent work.
- (3)
- On the GID dataset, compared to other methods in the experiments, although the proposed approach has obvious advantages on MIoU and achieves the highest average accuracy, the F1 scores for each category are not always the highest. Table 7 shows that CRFAS had higher F1 scores for “Farmland”, “Water”, “Building”, and “Meadow” categories than the proposed method. The confusion matrix of GID shown in Table 5 indicates other categories are most often misclassified as ”Farmland”, and that “Meadow” is not effectively segmented. The reasons for this may be related to the inherent properties of the category. This is a question worthy of further study.
- (4)
- GAN has a problem of mode collapse during the training process. The proposed method uses the cross-entropy loss to guide the training of GAN to avoid this problem. However, this problem has not been completely resolved. Therefore, it is necessary to conduct more in-depth research from the basic principles of GAN.
- (5)
- In future work, the proposed method will be extended to the segmentation of PolSAR data by using the covariance matrix or coherency matrix .
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands Deep in Deep Learning for Hand Pose Estimation. arXiv 2015, arXiv:1502.06807. [Google Scholar]
- Barth, A.; Siegemund, J.; Meißner, A.; Franke, U.; Förstner, W. Probabilistic Multi-class Scene Flow Segmentation for Traffic Scenes. In Proceedings of the Dagm Conference on Pattern Recognition, Darmstadt, Germany, 22–24 September 2010. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. arXiv 2016, arXiv:1604.01685. [Google Scholar]
- Deren, L.; Guifeng, Z.; Zhaocong, W.; Lina, Y. An edge embedded marker-based watershed algorithm for high spatial resolution remote sensing image segmentation. IEEE Trans. Image Process. 2010, 19, 2781–2787. [Google Scholar] [CrossRef]
- Zhang, X.; Xiao, P.; Feng, X.; Wang, J.; Zuo, W. Hybrid region merging method for segmentation of high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2014, 98, 19–28. [Google Scholar] [CrossRef]
- Nogueira, K.; Miranda, W.O.; Dos Santos, J.A. Improving spatial feature representation from aerial scenes by using convolutional networks. In Proceedings of the 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; pp. 289–296. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, lSantiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters–Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Dan, C.C.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. Adv. Neural Inf. Process. Syst. 2012, 25, 2852–2860. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, lBoston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, lBoston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, lVegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Mortensen, E.N.; Jia, J. Real-time semi-automatic segmentation using a Bayesian network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 1007–1014. [Google Scholar]
- Pelizzari, S.; Bioucas-Dias, J.M. Bayesian Segmentation of Oceanic SAR Images: Application to Oil Spill Detection. arXiv 2010, arXiv:1007.4969. [Google Scholar]
- Zhang, L.; Ji, Q. A Bayesian network model for automatic and interactive image segmentation. IEEE Trans. Image Process. 2011, 20, 2582–2593. [Google Scholar] [CrossRef] [PubMed]
- Vezhnevets, A.; Ferrari, V.; Buhmann, J.M. Weakly supervised structured output learning for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 845–852. [Google Scholar]
- Ge, W.; Liu, G. Semantic segmentation based on neural network and Bayesian network. Proc. SPIE 2013, 8917, 89170Z. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- Coombes, M.; Eaton, W.; Chen, W.H. Unmanned ground operations using semantic image segmentation through a Bayesian network. In Proceedings of the International Conference on Unmanned Aircraft Systems, Arlington, VA, USA, 7–10 June 2016. [Google Scholar]
- Wu, F.Y. The potts model. Rev. Mod. Phys. 1982, 54, 235. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2 December 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Zhu, W.; Xiang, X.; Tran, T.D.; Xie, X. Adversarial deep structural networks for mammographic mass segmentation. arXiv 2016, arXiv:1612.05970. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Souly, N.; Spampinato, C.; Shah, M. Semi supervised semantic segmentation using generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5688–5696. [Google Scholar]
- Fu, C.; Lee, S.; Joon Ho, D.; Han, S.; Salama, P.; Dunn, K.W.; Delp, E.J. Three dimensional fluorescence microscopy image synthesis and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2221–2229. [Google Scholar]
- Huo, Y.; Xu, Z.; Bao, S.; Bermudez, C.; Plassard, A.J.; Liu, J.; Yao, Y.; Assad, A.; Abramson, R.G.; Landman, B.A. Splenomegaly segmentation using global convolutional kernels and conditional generative adversarial networks. Int. Soc. Opt. Photonics 2018, 10574, 1057409. [Google Scholar]
- Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Weakly Supervised Segmentation of SAR Imagery Using Superpixel and Hierarchically Adversarial CRF. Remote Sens. 2019, 11, 512. [Google Scholar] [CrossRef]
- He, C.; Fang, P.; Zhang, Z.; Xiong, D.; Liao, M. An End-to-End Conditional Random Fields and Skip-Connected Generative Adversarial Segmentation Network for Remote Sensing Images. Remote Sens. 2019, 11, 1604. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. Remote Sens. Environ. 2019, 237, 111322. [Google Scholar] [CrossRef]
- Wei, X.; Guo, Y.; Gao, X.; Yan, M.; Sun, X. A new semantic segmentation model for remote sensing images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1776–1779. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef]
- Cheng, W.; Yang, W.; Wang, M.; Wang, G.; Chen, J. Context Aggregation Network for Semantic Labeling in Aerial Images. Remote Sens. 2019, 11, 1158. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | Farmland | Forest | Others | Road | Building | Average |
|---|---|---|---|---|---|---|---|
| FCN | Farmland | 0.4617 | 0.0897 | 0.3863 | 0.0216 | 0.0407 | 0.8183 |
| Forest | 0.0167 | 0.8756 | 0.0390 | 0.0125 | 0.0562 | ||
| Others | 0.0433 | 0.0135 | 0.8751 | 0.0387 | 0.0295 | ||
| Road | 0.490 | 0.0208 | 0.2858 | 0.5934 | 0.0509 | ||
| Building | 0.0004 | 0.0228 | 0.0461 | 0.0108 | 0.9199 | ||
| Deeplab | Farmland | 0.4503 | 0.2191 | 0.3143 | 0.0039 | 0.0124 | 0.8387 |
| Forest | 0.0074 | 0.8901 | 0.0514 | 0.0161 | 0.0350 | ||
| Others | 0.0164 | 0.0116 | 0.9226 | 0.0327 | 0.0166 | ||
| Road | 0.0087 | 0.0419 | 0.3430 | 0.5509 | 0.0509 | ||
| Building | 0.0004 | 0.0228 | 0.0461 | 0.0108 | 0.9448 | ||
| Pix2pix | Farmland | 0.3588 | 0.0623 | 0.2377 | 0.0255 | 0.3156 | 0.8243 |
| Forest | 0.0206 | 0.8430 | 0.0505 | 0.0221 | 0.0638 | ||
| Others | 0.0218 | 0.0061 | 0.8802 | 0.0479 | 0.0440 | ||
| Road | 0.0028 | 0.0087 | 0.2002 | 0.7500 | 0.0383 | ||
| Building | 0.0042 | 0.0275 | 0.0541 | 0.0181 | 0.8962 | ||
| CRFAS | Farmland | 0.4781 | 0.0970 | 0.2306 | 0.0277 | 0.1515 | 0.8474 |
| Forest | 0.0127 | 0.8351 | 0.0506 | 0.0229 | 0.0786 | ||
| Others | 0.0222 | 0.0093 | 0.9373 | 0.0312 | 0.0001 | ||
| Road | 0.0067 | 0.0245 | 0.2342 | 0.6879 | 0.0467 | ||
| Building | 0.0047 | 0.0371 | 0.0489 | 0.0222 | 0.8870 | ||
| Pro. Aproach | Farmland | 0.5861 | 0.2346 | 0.1487 | 0.0203 | 0.0103 | 0.8648 |
| Forest | 0.0442 | 0.8864 | 0.0123 | 0.0409 | 0.0162 | ||
| Others | 0.0086 | 0.0278 | 0.9123 | 0.0089 | 0.0424 | ||
| Road | 0.0064 | 0.1592 | 0.0204 | 0.7715 | 0.0425 | ||
| Building | 0.0007 | 0.0312 | 0.0175 | 0.0109 | 0.9397 |
| Method | Category | Farmland | Water | Building | Meadow | Forest | Average |
|---|---|---|---|---|---|---|---|
| FCN | Farmland | 0.9839 | 0.0008 | 0.0001 | 0.0127 | 0.0025 | 0.7631 |
| Water | 0.2499 | 0.7501 | 0.0000 | 0.0000 | 0.0000 | ||
| Building | 0.0640 | 0.0011 | 0.9349 | 0.0000 | 0.0000 | ||
| Meadow | 0.9871 | 0.0006 | 0.0000 | 0.0064 | 0.0059 | ||
| Forest | 0.3137 | 0.0224 | 0.0000 | 0.0349 | 0.6290 | ||
| Deeplab | Farmland | 0.9310 | 0.0502 | 0.000 | 0.0077 | 0.0111 | 0.7799 |
| Water | 0.0048 | 0.9947 | 0.0000 | 0.0000 | 0.0004 | ||
| Building | 0.0213 | 0.0000 | 0.9787 | 0.0000 | 0.0000 | ||
| Meadow | 0.6742 | 0.0034 | 0.0000 | 0.0329 | 0.2895 | ||
| Forest | 0.0042 | 0.0000 | 0.0000 | 0.0000 | 0.9958 | ||
| Pix2pix | Farmland | 0.9153 | 0.0000 | 0.0000 | 0.0000 | 0.847 | 0.7178 |
| Water | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Building | 0.1352 | 0.0000 | 0.8546 | 0.0101 | 0.0000 | ||
| Meadow | 0.9831 | 0.0000 | 0.0000 | 0.0000 | 0.0169 | ||
| Forest | 0.3265 | 0.0000 | 0.0000 | 0.0000 | 0.6735 | ||
| CRFAS | Farmland | 0.9569 | 0.0071 | 0.0000 | 0.0261 | 0.0099 | 0.7827 |
| Water | 0.0082 | 0.2857 | 0.0000 | 0.0000 | 0.7061 | ||
| Building | 0.0165 | 0.0000 | 0.9710 | 0.0125 | 0.0000 | ||
| Meadow | 0.8544 | 0.0004 | 0.0000 | 0.1121 | 0.0332 | ||
| Forest | 0.2200 | 0.0081 | 0.0000 | 0.0006 | 0.7713 | ||
| Pro. Aproach | Farmland | 0.9211 | 0.0169 | 0.0000 | 0.0590 | 0.0030 | 0.8160 |
| Water | 0.0034 | 0.9966 | 0.0000 | 0.0000 | 0.0000 | ||
| Building | 0.0184 | 0.0000 | 0.9816 | 0.0000 | 0.0000 | ||
| Meadow | 0.4844 | 0.0029 | 0.0000 | 0.2917 | 0.2210 | ||
| Forest | 0.0132 | 0.0000 | 0.0000 | 0.0001 | 0.9867 |
| Method | Category | Farmland | Water | Building | Meadow | Forest | Average |
|---|---|---|---|---|---|---|---|
| FCN | Farmland | 0.9969 | 0.0006 | 0.0009 | 0.0120 | 0.0004 | 0.9245 |
| Water | 0.5007 | 0.4922 | 0.0069 | 0.0002 | 0.0002 | ||
| Building | 0.3320 | 0.0010 | 0.6667 | 0.0000 | 0.0003 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.1373 | 0.0006 | 0.0015 | 0.0071 | 0.8535 | ||
| Deeplab | Farmland | 0.9891 | 0.0101 | 0.002 | 0.0000 | 0.0006 | 0.9803 |
| Water | 0.0138 | 0.9857 | 0.0004 | 0.0000 | 0.0000 | ||
| Building | 0.0918 | 0.0062 | 0.9020 | 0.0000 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0014 | 0.0008 | 0.0000 | 0.0000 | 0.9978 | ||
| Pix2pix | Farmland | 0.9899 | 0.0003 | 0.0070 | 0.0004 | 0.0025 | 0.8827 |
| Water | 0.7370 | 0.2045 | 0.0062 | 0.0003 | 0.0519 | ||
| Building | 0.2900 | 0.0000 | 0.6996 | 0.0204 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.9656 | 0.0000 | 0.0000 | 0.0000 | 0.0344 | ||
| CRFAS | Farmland | 0.9926 | 0.0033 | 0.0008 | 0.0014 | 0.0019 | 0.9817 |
| Water | 0.0336 | 0.9616 | 0.0004 | 0.0000 | 0.0044 | ||
| Building | 0.0383 | 0.0000 | 0.9596 | 0.0021 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0727 | 0.1828 | 0.0000 | 0.0006 | 0.7445 | ||
| Pro. Aproach | Farmland | 0.9956 | 0.0033 | 0.0003 | 0.0000 | 0.0008 | 0.9887 |
| Water | 0.0058 | 0.9942 | 0.0000 | 0.0000 | 0.0000 | ||
| Building | 0.0533 | 0.0038 | 0.9429 | 0.0000 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0238 | 0.0609 | 0.0000 | 0.0000 | 0.9153 |
| Method | Category | Farmland | Water | Building | Meadow | Forest | Average |
|---|---|---|---|---|---|---|---|
| FCN | Farmland | 0.9890 | 0.0050 | 0.0056 | 0.0000 | 0.0004 | 0.9316 |
| Water | 0.6899 | 0.3099 | 0.0000 | 0.0000 | 0.0001 | ||
| Building | 0.2941 | 0.0040 | 0.7019 | 0.0000 | 0.0001 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Deeplab | Farmland | 0.9808 | 0.0114 | 0.063 | 0.0000 | 0.0015 | 0.9754 |
| Water | 0.0798 | 0.8835 | 0.0000 | 0.0000 | 0.0366 | ||
| Building | 0.0349 | 0.0053 | 0.9598 | 0.0000 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Pix2pix | Farmland | 0.9783 | 0.0114 | 0.0063 | 0.0000 | 0.0015 | 0.9559 |
| Water | 0.7815 | 0.1436 | 0.0047 | 0.0000 | 0.0701 | ||
| Building | 0.0386 | 0.0000 | 0.9609 | 0.0005 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| CRFAS | Farmland | 0.9932 | 0.0000 | 0.0058 | 0.0008 | 0.0001 | 0.9881 |
| Water | 0.0095 | 0.8785 | 0.0009 | 0.0000 | 0.0256 | ||
| Building | 0.0214 | 0.0003 | 0.9765 | 0.0018 | 0.0000 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Pro. Aproach | Farmland | 0.9864 | 0.0065 | 0.0071 | 0.0000 | 0.0000 | 0.9851 |
| Water | 0.0102 | 0.9897 | 0.0000 | 0.0000 | 0.0000 | ||
| Building | 0.00217 | 0.0019 | 0.9764 | 0.00000 | 0.0001 | ||
| Meadow | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Forest | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Method | Category | Farmland | Water | Building | Meadow | Forest | Average |
|---|---|---|---|---|---|---|---|
| FCN | Farmland | 0.9399 | 0.0042 | 0.0493 | 0.0022 | 0.0044 | 0.8711 |
| Water | 0.2568 | 0.7238 | 0.0116 | 0.0007 | 0.0071 | ||
| Building | 0.1905 | 0.0065 | 0.7995 | 0.0002 | 0.0033 | ||
| Meadow | 0.9871 | 0.0006 | 0.0000 | 0.0064 | 0.0059 | ||
| Forest | 0.5022 | 0.0088 | 0.0011 | 0.0434 | 0.4445 | ||
| Deeplab | Farmland | 0.9534 | 0.0180 | 0.0232 | 0.0004 | 0.0049 | 0.9238 |
| Water | 0.1198 | 0.8774 | 0.0013 | 0 | 0.0015 | ||
| Building | 0.0465 | 0.0026 | 0.9502 | 0 | 0.0007 | ||
| Meadow | 0.6741 | 0.0034 | 0 | 0.0330 | 0.2894 | ||
| Forest | 0.3131 | 0.0629 | 0.0008 | 0.0370 | 0.5862 | ||
| Pix2pix | Farmland | 0.9443 | 0.0017 | 0.0318 | 0.0034 | 0.0187 | 0.8704 |
| Water | 0.2189 | 0.7440 | 0.0039 | 0.0001 | 0.0331 | ||
| Building | 0.1851 | 0.0013 | 0.8044 | 0.0091 | 0.0001 | ||
| Meadow | 0.9831 | 0 | 0 | 0 | 0.0169 | ||
| Forest | 0.8250 | 0.0004 | 0 | 0 | 0.1750 | ||
| CRFAS | Farmland | 0.9773 | 0.0030 | 0.0103 | 0.0043 | 0.0050 | 0.9414 |
| Water | 0.0630 | 0.9275 | 0.0021 | 0.0004 | 0.0070 | ||
| Building | 0.0443 | 0.0007 | 0.9522 | 0.0027 | 0 | ||
| Meadow | 0.8543 | 0.0004 | 0 | 0.1121 | 0.0332 | ||
| Forest | 0.6464 | 0.0131 | 0.0012 | 0.0011 | 0.3383 | ||
| Pro. Aproach | Farmland | 0.9690 | 0.0065 | 0.0195 | 0.0020 | 0.0030 | 0.9483 |
| Water | 0.1288 | 0.8691 | 0.0007 | 0.0002 | 0.0012 | ||
| Building | 0.0255 | 0.0023 | 0.9720 | 0.00000 | 0.0002 | ||
| Meadow | 0.7478 | 0.0082 | 0.0000 | 0.0651 | 0.1789 | ||
| Forest | 0.1486 | 0.0064 | 0.0007 | 0.0008 | 0.8435 |
| Data | Method | F1 Score | MIoU | ||||
|---|---|---|---|---|---|---|---|
| Farmland | Forest | Others | Road | Building | |||
| ESAR | FCN | 0.4871 | 0.8840 | 0.8558 | 0.6698 | 0.8697 | 0.6270 |
| Deeplab | 0.5634 | 0.8732 | 0.8781 | 0.6489 | 0.9105 | 0.6529 | |
| Pix2pix | 0.4550 | 0.8807 | 0.8707 | 0.7555 | 0.8001 | 0.6266 | |
| CRFAS | 0.5717 | 0.8570 | 0.9032 | 0.7349 | 0.8580 | 0.6612 | |
| Pro. Aproach | 0.6094 | 0.8915 | 0.8981 | 0.7908 | 0.9097 | 0.7091 | |
| Data | Method | F1 Score | MIoU | ||||
|---|---|---|---|---|---|---|---|
| Farmland | Water | Building | Meadow | Forest | |||
| GID-image1 | FCN | 0.8484 | 0.3413 | 0.9656 | 0.0118 | 0.7617 | 0.4994 |
| Deeplab | 0.8785 | 0.0713 | 0.9892 | 0.0621 | 0.7998 | 0.4995 | |
| Pix2pix | 0.8104 | 0 | 0.9216 | 0 | 0.6239 | 0.3978 | |
| CRFAS | 0.8565 | 0.1003 | 0.9849 | 0.1852 | 0.8195 | 0.5137 | |
| Pro. Aproach | 0.8923 | 0.1881 | 0.9906 | 0.3898 | 0.8429 | 0.5723 | |
| GID-image2 | FCN | 0.9556 | 0.6560 | 0.7940 | 0 | 0.9130 | 0.5803 |
| Deeplab | 0.9882 | 0.9355 | 0.9472 | 0 | 0.9882 | 0.7464 | |
| Pix2pix | 0.9349 | 0.3385 | 0.7880 | 0 | 0.0530 | 0.3518 | |
| CRFAS | 0.9915 | 0.9364 | 0.9760 | 0 | 0.8132 | 0.7004 | |
| Pro. Aproach | 0.9940 | 0.9670 | 0.9696 | 0 | 0.9390 | 0.7500 | |
| GID-image3 | FCN | 0.9604 | 0.4106 | 0.8094 | 0 | 0 | 0.3724 |
| Deeplab | 0.9864 | 0.7635 | 0.9615 | 0 | 0 | 0.5032 | |
| Pix2pix | 0.9747 | 0.2496 | 0.9240 | 0 | 0 | 0.3904 | |
| CRFAS | 0.9934 | 0.9338 | 0.9715 | 0 | 0 | 0.5615 | |
| Pro. Aproach | 0.9912 | 0.9912 | 0.8901 | 0 | 0 | 0.5442 | |
| GID | FCN | 0.9148 | 0.8247 | 0.7681 | 0.0099 | 0.5521 | 0.5109 |
| Deeplab | 0.9508 | 0.8803 | 0.9141 | 0.0569 | 0.6398 | 0.6068 | |
| Pix2pix | 0.9156 | 0.8479 | 0.8111 | 0 | 0.1925 | 0.4738 | |
| CRFAS | 0.9609 | 0.9523 | 0.9471 | 0.1543 | 0.4468 | 0.6209 | |
| Pro. Aproach | 0.9578 | 0.8936 | 0.9307 | 0.1077 | 0.8480 | 0.6817 | |
| Method | FCN | Deeplab | pix2pix | CRFAS | Pro. Approach |
|---|---|---|---|---|---|
| time(h) | 16.9 | 25.3 | 26.7 | 81.2 | 26.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, D.; He, C.; Liu, X.; Liao, M. An End-To-End Bayesian Segmentation Network Based on a Generative Adversarial Network for Remote Sensing Images. Remote Sens. 2020, 12, 216. https://doi.org/10.3390/rs12020216
Xiong D, He C, Liu X, Liao M. An End-To-End Bayesian Segmentation Network Based on a Generative Adversarial Network for Remote Sensing Images. Remote Sensing. 2020; 12(2):216. https://doi.org/10.3390/rs12020216
Chicago/Turabian StyleXiong, Dehui, Chu He, Xinlong Liu, and Mingsheng Liao. 2020. "An End-To-End Bayesian Segmentation Network Based on a Generative Adversarial Network for Remote Sensing Images" Remote Sensing 12, no. 2: 216. https://doi.org/10.3390/rs12020216
APA StyleXiong, D., He, C., Liu, X., & Liao, M. (2020). An End-To-End Bayesian Segmentation Network Based on a Generative Adversarial Network for Remote Sensing Images. Remote Sensing, 12(2), 216. https://doi.org/10.3390/rs12020216