SAFDet: A Semi-Anchor-Free Detector for Effective Detection of Oriented Objects in Aerial Images

 ,
,  , ,
, , 
Abstract
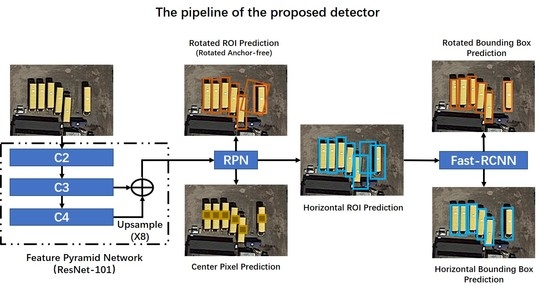
1. Introduction
- A semi-anchor-free detector (SAFDet) is proposed for effective detection of oriented objects in aerial images;
- A rotation-anchor-free branch (RAFB) is proposed to tackle the misalignment problem when using horizontal anchors, which can predict the OBB directly without any predefined anchor setting;
- A center prediction module (CPM) is implemented to enhance the capability of feature extraction during the training of RPN, hence avoiding increased computational cost of inference;
2. Related Works
2.1. Anchor-Based Oriented Aerial Object Detection
2.2. Anchor-Free Object Detection
2.3. Multi-Task Loss of Oriented Aerial Object Detection
3. The Proposed Method
3.1. Overall Architecture
3.2. Rotational Anchor-Free Branch
Regression Scheme of the Rotation Branch
3.3. Center Prediction Module
3.4. Loss Function
4. Experiments and Analysis
4.1. Datasets and Implementation Details
4.1.1. DOTA
4.1.2. HRSC2016
4.1.3. Implementation Details and Evaluation Metrics
4.2. Ablation Study
4.2.1. Baseline Setup
4.2.2. Effect of Rotation on the Anchor-Free Branch
4.2.3. The Effect of the Center Prediction Module
4.3. Comparison with the State-of-the-Art Detectors
4.3.1. DOTA
4.3.2. HRSC2016
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards multi-class object detection in unconstrained remote sensing imagery. In Proceedings of the 2018 Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 150–165. [Google Scholar]
- Wang, J.; Yuan, Y.; Yu, G. Face attention network: An effective face detector for the occluded faces. arXiv 2017, arXiv:1711.07246. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Mathias, M.; Benenson, R.; Pedersoli, M.; Van Gool, L. Face detection without bells and whistles. In Proceedings of the 2014 European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 720–735. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the 2019 IEEE ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the 2019 IEEE Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5187–5196. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bradski, G.; Kaehler, A. The OpenCV library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine feature pyramid network and multi-layer attention network for arbitrary-oriented object detection of remote sensing images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the 2017 International Conference on Pattern Recognition Applications and Methods (ICPRAM), Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Tian, T.; Pan, Z.; Tan, X.; Chu, Z. Arbitrary-Oriented Inshore Ship Detection based on Multi-Scale Feature Fusion and Contextual Pooling on Rotation Region Proposals. Remote Sens. 2020, 12, 339. [Google Scholar] [CrossRef]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Yan, Y.; Ren, J.; Sun, G.; Zhao, H.; Han, J.; Li, X.; Marshall, S.; Zhan, J. Unsupervised image saliency detection with Gestalt-laws guided optimization and visual attention based refinement. Pattern Recognit. 2018, 79, 65–78. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Yang, M.; Zhang, Y.; Wang, J.; Marshall, S.; Han, J. Novel folded-PCA for improved feature extraction and data reduction with hyperspectral imaging and SAR in remote sensing. ISPRS J. Photogramm. Remote Sens. 2014, 93, 112–122. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Zheng, J.; Han, J.; Zhao, H.; Li, S.; Marshall, S. Novel two-dimensional singular spectrum analysis for effective feature extraction and data classification in hyperspectral imaging. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4418–4433. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Strides | mAP | Time (ms) | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 56.22 | 65 | 86.09 | 65.02 | 22.73 | 49.46 | 38.26 | 49.84 | 52.26 | 90.44 | 53.60 | 74.03 | 61.95 | 61.70 | 55.14 | 47.92 | 34.88 |
| 8 | 61.53 | 72 | 88.17 | 68.54 | 30.64 | 53.10 | 49.41 | 59.43 | 63.76 | 90.73 | 52.34 | 83.29 | 63.80 | 62.09 | 63.24 | 52.71 | 41.83 |
| 4 | 65.08 | 238 | 88.99 | 71.13 | 40.54 | 61.83 | 51.60 | 66.99 | 68.33 | 90.73 | 59.81 | 83.65 | 63.65 | 62.72 | 64.60 | 52.92 | 48.72 |
| Methods | mAP | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2CNN-8 (Baseline) | 61.53 | 88.17 | 68.54 | 30.64 | 53.10 | 49.41 | 59.43 | 63.76 | 90.73 | 52.34 | 83.29 | 63.80 | 62.09 | 63.24 | 52.71 | 41.83 |
| +RAFB | 63.12 | 88.59 | 68.57 | 36.92 | 61.68 | 48.65 | 61.57 | 57.86 | 90.53 | 60.44 | 79.30 | 71.95 | 63.75 | 58.47 | 50.88 | 47.67 |
| +RAFB+ATT | 63.33 | 88.81 | 72.28 | 38.04 | 64.10 | 47.33 | 60.37 | 58.67 | 90.65 | 57.89 | 79.01 | 72.01 | 64.29 | 57.48 | 51.54 | 47.53 |
| +RAFB+ATT (loss only) | 62.46 | 88.86 | 69.86 | 35.01 | 62.87 | 48.59 | 60.49 | 58.91 | 90.32 | 55.10 | 79.27 | 69.34 | 60.56 | 57.96 | 51.80 | 47.35 |
| +RAFB+CPM | 64.17 | 88.63 | 71.34 | 37.43 | 63.51 | 47.11 | 62.04 | 58.62 | 90.71 | 64.20 | 79.23 | 74.91 | 63.46 | 58.06 | 52.86 | 50.44 |
| Methods | FR-O [18] | R2CNN [4] | RRPN [12] | ICN [15] | RADet [32] | RoI-Trans. [5] | FFA [33] | SCRDet [14] | R3Det [17] | SAFDet (Proposed) |
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | 52.93 | 60.67 | 61.01 | 68.20 | 69.09 | 69.56 | 71.80 | 72.61 | 71.69 | 71.33 |
| PL | 79.09 | 80.94 | 88.52 | 81.40 | 79.45 | 88.64 | 89.60 | 89.98 | 89.54 | 89.78 |
| BD | 69.12 | 65.67 | 71.20 | 74.30 | 76.99 | 78.52 | 76.40 | 80.65 | 81.99 | 80.77 |
| BR | 17.17 | 35.34 | 31.66 | 47.70 | 48.05 | 43.44 | 48.20 | 52.09 | 48.46 | 46.61 |
| GTF | 63.49 | 67.44 | 59.30 | 70.30 | 65.83 | 75.92 | 58.90 | 68.36 | 62.52 | 75.31 |
| SV | 34.20 | 59.92 | 51.85 | 64.90 | 65.46 | 68.81 | 67.20 | 68.36 | 70.48 | 66.47 |
| LV | 37.16 | 50.91 | 56.19 | 67.80 | 74.40 | 73.68 | 76.50 | 60.32 | 74.29 | 60.41 |
| SH | 36.20 | 55.81 | 57.25 | 70.00 | 68.86 | 83.59 | 81.40 | 72.41 | 77.54 | 66.43 |
| TC | 89.19 | 90.67 | 90.81 | 90.80 | 89.70 | 90.74 | 90.10 | 90.85 | 90.80 | 90.27 |
| BC | 69.60 | 66.92 | 72.84 | 79.10 | 78.14 | 77.27 | 83.30 | 87.94 | 81.39 | 82.94 |
| ST | 58.96 | 72.39 | 67.38 | 78.20 | 74.97 | 81.46 | 83.40 | 86.86 | 83.54 | 85.88 |
| SBF | 49.4 | 55.06 | 56.69 | 53.60 | 49.92 | 58.39 | 55.70 | 65.02 | 61.97 | 63.19 |
| RA | 52.52 | 52.23 | 52.84 | 62.90 | 64.63 | 53.54 | 60.20 | 66.68 | 59.82 | 62.33 |
| HA | 46.69 | 55.14 | 53.08 | 67.00 | 66.14 | 62.83 | 73.20 | 66.25 | 65.44 | 65.06 |
| SP | 44.80 | 53.35 | 51.94 | 64.20 | 71.58 | 58.93 | 66.70 | 68.24 | 67.46 | 70.27 |
| HC | 46.30 | 48.22 | 53.58 | 50.20 | 62.16 | 47.67 | 64.90 | 65.21 | 60.05 | 64.29 |
| Methods | mAP (%) | Inference Speed (FPS) |
|---|---|---|
| R2CNN [4] | 73.07 | 3 |
| RC1 & RC2 [34] | 75.70 | 1 |
| RRPN [12] | 79.08 | 4.8 |
| R2PN [13] | 79.60 | 1.3 |
| Tian et al. [35] | 80.80 | 4 |
| RetinaNet [17] | 82.89 | 16 |
| RoI-Trans. [5] | 86.20 | 9 |
| R3Det [17] | 89.14 | 6 |
| SCRDet [14] | 89.27 | 0.8 |
| SAFDet (proposed) | 89.38 | 11 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Z.; Ren, J.; Sun, H.; Marshall, S.; Han, J.; Zhao, H. SAFDet: A Semi-Anchor-Free Detector for Effective Detection of Oriented Objects in Aerial Images. Remote Sens. 2020, 12, 3225. https://doi.org/10.3390/rs12193225
Fang Z, Ren J, Sun H, Marshall S, Han J, Zhao H. SAFDet: A Semi-Anchor-Free Detector for Effective Detection of Oriented Objects in Aerial Images. Remote Sensing. 2020; 12(19):3225. https://doi.org/10.3390/rs12193225
Chicago/Turabian StyleFang, Zhenyu, Jinchang Ren, He Sun, Stephen Marshall, Junwei Han, and Huimin Zhao. 2020. "SAFDet: A Semi-Anchor-Free Detector for Effective Detection of Oriented Objects in Aerial Images" Remote Sensing 12, no. 19: 3225. https://doi.org/10.3390/rs12193225
APA StyleFang, Z., Ren, J., Sun, H., Marshall, S., Han, J., & Zhao, H. (2020). SAFDet: A Semi-Anchor-Free Detector for Effective Detection of Oriented Objects in Aerial Images. Remote Sensing, 12(19), 3225. https://doi.org/10.3390/rs12193225