Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery

 ,
,  , , and
, , and
Abstract
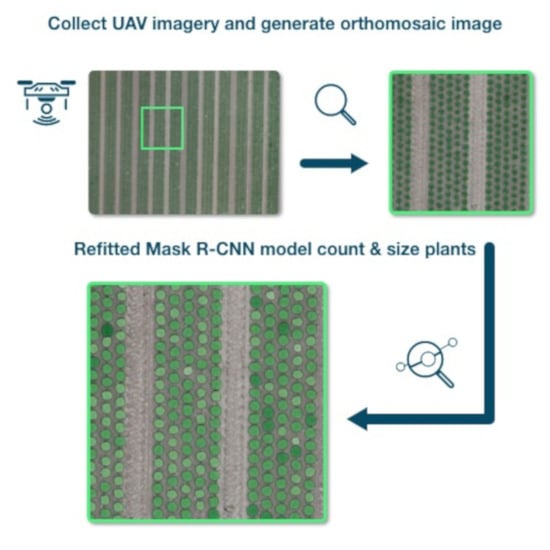
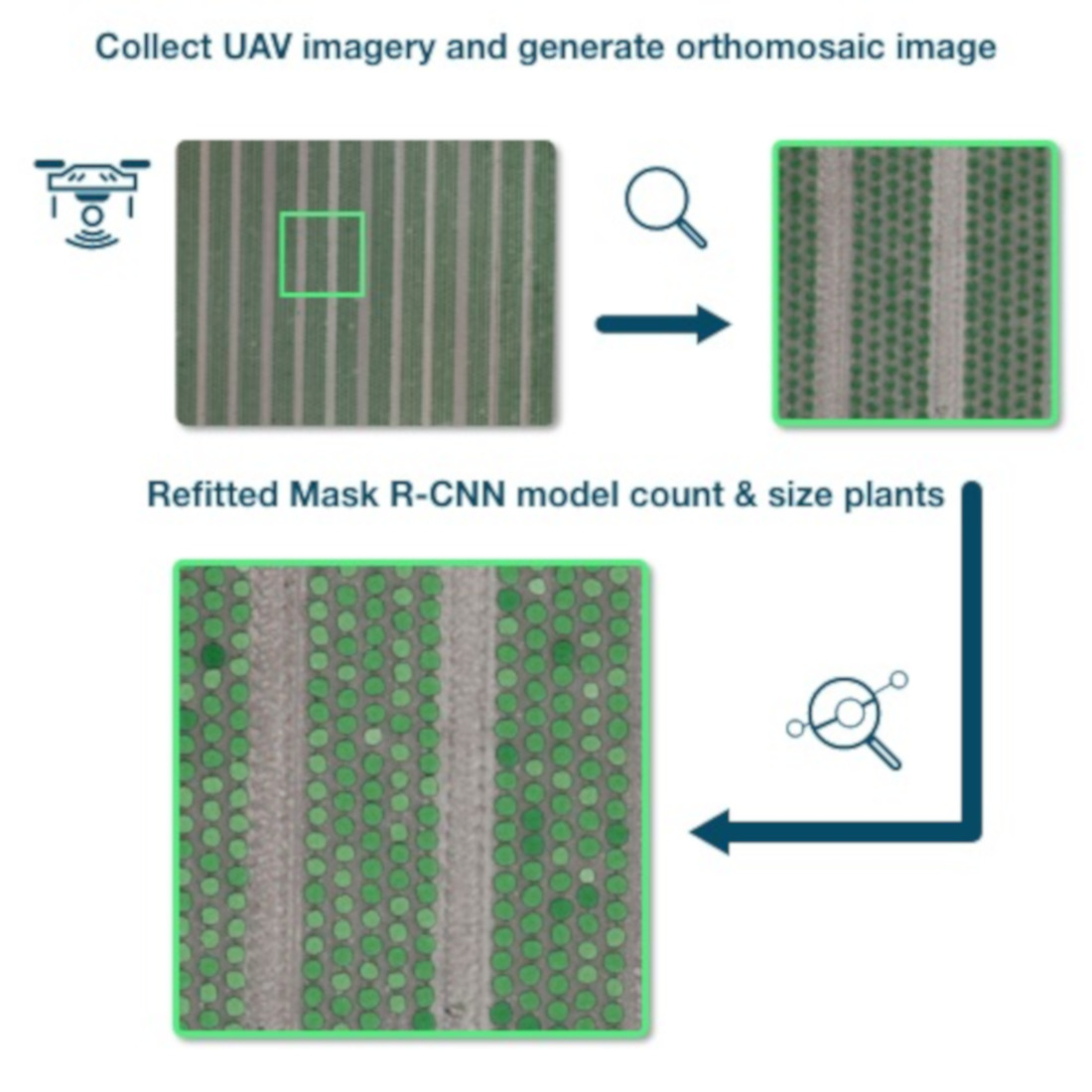
1. Introduction
1.1. Recent Progress on Instance Segmentation and Instantiation
1.2. Plant Counting, Detection and Sizing
1.3. Aim of the Study
2. Materials and Methods
2.1. Datasets
2.1.1. Study Area
2.1.2. Datasets’ Specifications
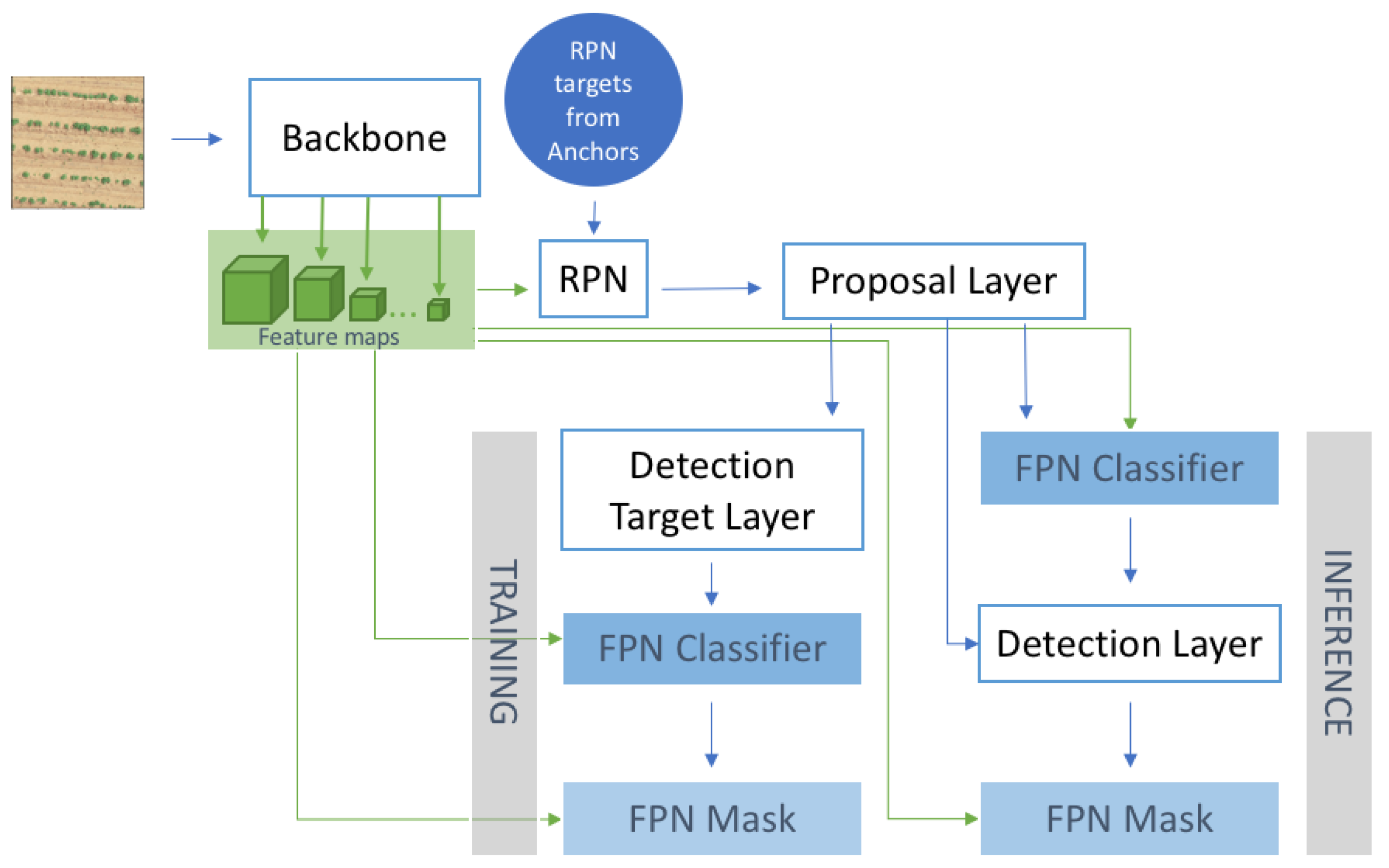
2.2. Mask R-CNN Refitting Strategy
2.2.1. Architectural Design and Parameters
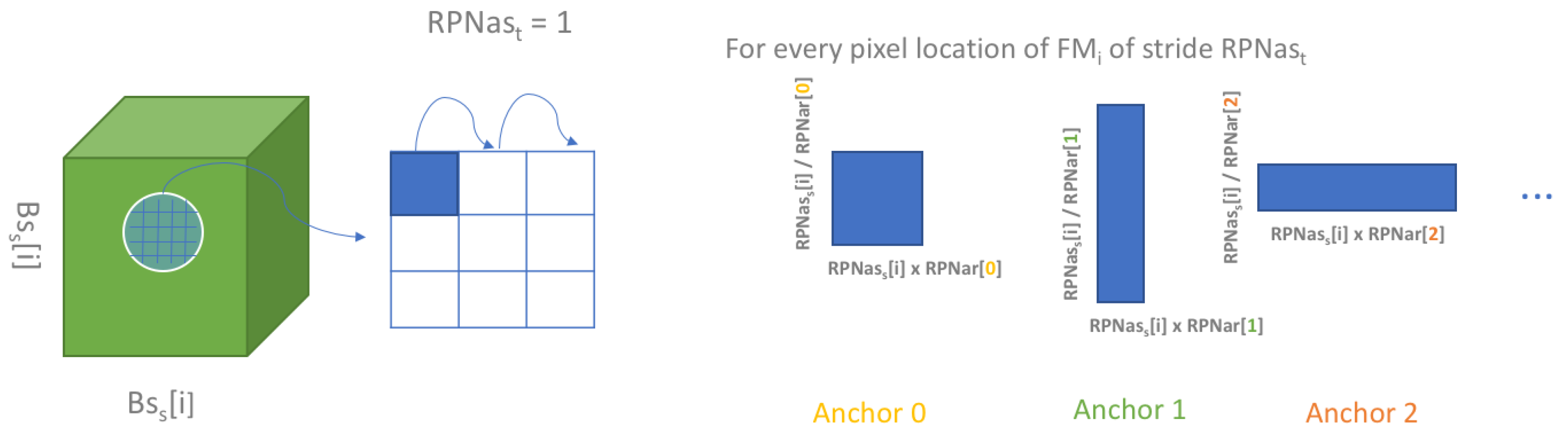
2.2.2. Backbone and RPN Frameworks
2.2.3. Proposal Layer
2.2.4. Detection Target Layer
2.2.5. Feature Pyramid Network
2.2.6. Detection Layer
2.2.7. Transfer Learning Strategy
2.2.8. Hyper Parameters Selection
2.3. Computer Vision Baseline
2.4. Evaluation Metrics
3. Results
3.1. Individual Plant Segmentation with Transfer Learning
3.2. A Comparison of Computer Vision Baseline and Mask R-CNN Model for Plant Detection
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Variable Name in Matterport Implementation [48] | Description |
|---|---|---|
| List of strides in pixels of each convolution layer which generates the feature maps used from the Backbone. | ||
| List of width in pixels of each squared feature map used to feed the RPN obtained from | ||
| List of base width in pixels of each anchor used for each feature map. | ||
| Stride in pixels of the locations of the anchors generated for each feature map. | ||
| List of ratio to apply on each element of aiming at generating non squared anchors (see Figure 4). | ||
| Number of anchors per image selected to train the RPN. | ||
| Number of kept proposals outputted by the RPN based on their RPN scores. | ||
| IoU threshold for stating overlapping RPN predicted boxes. | ||
| Number of ROIs to keep after NMS in the Proposal Layer for the training phase. | ||
| Number of ROIs to keep after NMS in the Proposal Layer for the inference phase. | ||
| Number of groundtruth instances per image kept to train the network. | ||
| Number of ROIs to keep after the Detection Target Layer. | ||
| Ratio of positive ROIs among the . | ||
| Maximal number of instances that the Mask R-CNN is allowed to output per image in the prediction mode. It also corresponds to the number of AOIs outputted by the Detection Layer. | ||
| Minimum FPN Classifier probability for an AOI to be considered as containing an object of interest. | ||
| NMS threshold used in the Detection Layer. |
References
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Han, S.; Hendrickson, L.; Ni, B. A variable rate application system for sprayers. In Proceedings of the 5th International Conference on Precision Agriculture, Bloomington, MN, USA, 16–19 July 2000; pp. 1–9. [Google Scholar]
- Wu, J.; Yang, G.; Yang, X.; Xu, B.; Han, L.; Zhu, Y. Automatic counting of in situ rice seedlings from UAV images based on a deep fully convolutional neural network. Remote Sens. 2019, 11, 691. [Google Scholar] [CrossRef]
- Melland, A.R.; Silburn, D.M.; McHugh, A.D.; Fillols, E.; Rojas-Ponce, S.; Baillie, C.; Lewis, S. Spot spraying reduces herbicide concentrations in runoff. J. Agric. Food Chem. 2015, 64, 4009–4020. [Google Scholar] [CrossRef]
- Rees, S.; McCarthy, C.; Baillie, C.; Burgos-Artizzu, X.; Dunn, M. Development and evaluation of a prototype precision spot spray system using image analysis to target Guinea Grass in sugarcane. Aust. J. Multi-Discip. Eng. 2011, 8, 97–106. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77, J.ISPRSJPRS.2018.04.014. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, inception-resNet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Learn. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-dcale context sggregation by filated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; IEEE: New York, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Ribera, J.; Chen, Y.; Boomsma, C.; Delp, E.J. Counting plants using deep learning. In Proceedings of the IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 1344–1348. [Google Scholar]
- Aich, S.; Ahmed, I.; Ovsyannikov, I.; Stavness, I.; Josuttes, A.; Strueby, K.; Duddu, H.S.; Pozniak, C.; Shirtliffe, S. DeepWheat: Estimating phenotypic traits from images of crops using deep learning. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 323–332. [Google Scholar]
- Li, B.; Xu, X.; Han, J.; Zhang, L.; Bian, C.; Jin, L.; Liu, J. The estimation of crop emergence in potatoes by UAV RGB imagery. Plant Methods 2019, 15, 15. [Google Scholar] [CrossRef]
- Guo, W.; Zheng, B.; Potgieter, A.B.; Diot, J.; Watanabe, K.; Noshita, K.; Jordan, D.R.; Wang, X.; Watson, J.; Ninomiya, S.; et al. Aerial imagery analysis—Quantifying appearance and number of sorghum heads for applications in breeding and agronomy. Front. Plant Sci. 2018, 9, 1544. [Google Scholar] [CrossRef]
- Lu, H.; Cao, Z.; Xiao, Y.; Zhuang, B.; Shen, C. TasselNet: Counting maize tassels in the wild via local counts regression network. Plant Methods 2017, 13, 79. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Sheppard, C. Deep count: Fruit counting based on deep simulated learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef]
- Xiong, H.; Cao, Z.; Lu, H.; Madec, S.; Liu, L.; Shen, C. TasselNetv2: In-field counting of wheat spikes with context-augmented local regression networks. Plant Methods 2019, 15, 150. [Google Scholar] [CrossRef]
- Pidhirniak, O. Automatic Plant Counting Using Deep Neural Networks. Master’s Thesis, Department of Computer Sciences, Ukrainian Catholic University, Lviv, Ukraine, 2019. [Google Scholar]
- Fan, Z.; Lu, J.; Gong, M.; Xie, H.; Goodman, E.D. Automatic tobacco plant detection in UAV images via deep neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 876–887, JSTARS.2018.2793849. [Google Scholar] [CrossRef]
- Kitano, B.T.; Mendes, C.C.T.; Geus, A.R.; Oliveira, H.C.; Souza, J.R. Corn Plant Counting Using Deep Learning and UAV Images. IEEE Geosci. Remote Sens. Lett. 2019. [Google Scholar] [CrossRef]
- García-Martínez, H.; Flores-Magdaleno, H.; Khalil-Gardezi, A.; Ascencio-Hernández, R.; Tijerina-Chávez, L.; Vázquez-Peña, M.A.; Mancilla-Villa, O.R. Digital count of corn plants using images taken by unmanned aerial vehicles and cross correlation of templates. Agronomy 2020, 10, 469. [Google Scholar]
- Malambo, L.; Popescu, S.; Rooney, W.; Zhou, T. A deep learning semantic segmentation-based approach for field-level sorghum panicle counting. Remote Sens. 2019, 11, 939. [Google Scholar] [CrossRef]
- Xia, L.; Zhang, R.; Chen, L.; Huang, Y.; Xu, G.; Wen, Y.; Yi, T. Monitor cotton budding using SVM and UAV images. Appl. Sci. 2019, 9, 4312. [Google Scholar] [CrossRef]
- Epperson, M.; Rotenberg, J.; Lo, E.; Afshari, S.; Kim, B. Deep Learning for Accurate Population Counting in Aerial Imagery; Technical Report; Kastner Research Group: La Jolla, CA, USA, 2014. [Google Scholar]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S.; et al. A weakly supervised deep learning framework for sorghum head detection and counting. Plant Phenomics 2019, 2019, 1525874. [Google Scholar] [CrossRef]
- Dijkstra, K.; van de Loosdrecht, J.; Schomaker, L.R.B.; Wiering, M.A. CentroidNet: A Deep Neural Network for Joint Object Localization and Counting; Springer: Cham, Switzerland, 2019; pp. 585–601. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Oh, M.H.; Olsen, P.A.; Ramamurthy, K.N. Counting and segmenting sorghum heads. arXiv 2019, arXiv:1905.13291. [Google Scholar]
- Neupane, B.; Horanont, T.; Hung, N.D. Deep learning based banana plant detection and counting using high-resolution red-green-blue (RGB) images collected from unmanned aerial vehicle (UAV). PLoS ONE 2019, 14, e0223906. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Cen, C.; Ke, Y.C.R.; Ma, Y. Detection of maize tassels from UAV RGB imagery with faster R-CNN. Remote Sens. 2020, 12, 338. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Paterson, A.H.; Robertson, J.S. DeepSeedling: Deep convolutional network and Kalman filter for plant seedling detection and counting in the field. Plant Methods 2019, 15, 141. [Google Scholar] [CrossRef]
- Song, Z.; Fu, L.; Wu, J.; Liu, Z.; Li, R.; Cui, Y. Kiwifruit detection in field images using Faster R-CNN with VGG16. IFAC Pap. 2019, 52, 76–81. [Google Scholar] [CrossRef]
- Ganesh, P.; Volle, K.; Burks, T.; Mehta, S. Deep orange: Mask R-CNN based orange detection and segmentation. IFAC Pap. 2019, 52, 70–75. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 19 September 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, X.; Gupta, A. An Implementation of Faster RCNN with Study for Region Sampling. arXiv 2017, arXiv:1702.02138. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; p. 526. Available online: http://www.deeplearningbook.org (accessed on 19 September 2019).
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? NIPS: Montréal, QC, Canada, 2014. [Google Scholar]
- Zlateski, A.; Jaroensri, R.; Sharma, P.; Durand, F. On the importance of label quality for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1479–1487. [Google Scholar] [CrossRef]
- Hamuda, E.; Glavin, M.; Jones, E. A survey of image processing techniques for plant extraction and segmentation in the field. Comput. Electron. Agric. 2016, 125, 184–199. [Google Scholar] [CrossRef]
- Kataoka, T.; Kaneko, T.; Okamoto, H.; Hata, S. Crop growth estimation system using machine vision. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Kobe, Japan, 20–24 July 2003; pp. 1079–1083. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]







| Field Name | Region | Crop | Date | UAV | Camera RGB Sensor | Relative Flight Height |
|---|---|---|---|---|---|---|
| P1 | Fife, Scotland, UK | potato | 13 June 2018 | DJI S900 | Panasonic GH4 | 50 |
| P1 | Fife, Scotland, UK | potato | 22 June 2018 | DJI S900 | Panasonic GH4 | 50 |
| P1 | Fife, Scotland, UK | potato | 28 June 2018 | DJI S900 | Panasonic GH4 | 50 |
| P1 | Fife, Scotland, UK | potato | 6 July 2018 | DJI S900 | Panasonic GH4 | 50 |
| P2 | Fife, Scotland, UK | potato | 22 June 2018 | DJI S900 | Panasonic GH4 | 50 |
| P2 | Fife, Scotland, UK | potato | 28 June 2018 | DJI S900 | Panasonic GH4 | 50 |
| P3 | Cambridgeshire, England, UK | potato | 4 June 2018 | DJI S900 | Panasonic GH4 | 50 |
| P4 | South Australia, Australia | potato | 13 November 2018 | DJI Inspire 2 | DJI Zenmuse X4S | 50 |
| L1 | Cambridgeshire, England, UK | lettuce | 29 July 2018 | DJI S900 | Panasonic GH4 | 50 |
| L2 | West Sussex, England, UK | lettuce | 31 May 2018 | DJI S900 | Panasonic GH4 | 50 |
| Name | Type of Set | Number of Images | Type of Labeling | Fields | Objects |
|---|---|---|---|---|---|
| COCO | Train | 200 K | Coarse | Natural Scene | |
| POT_CTr | Train | 347 | Coarse | P1, P2 | Potato |
| POT_RTr | Train | 124 | Refined | P1, P2, P3, P4 | Potato |
| POT_RTe | Test | 31 | Refined | P1, P2, P3, P4 | Potato |
| LET_RTr | Train | 153 | Refined | L1, L2 | Lettuce |
| LET_RTe | Test | 39 | Refined | L1, L2 | Lettuce |
| Parameter | COCO | Model M1_POT | Models M2_POT and M3_POT | Models M1_LET and M2_LET and for M3_POT in Inference on LET_RTe Dataset |
|---|---|---|---|---|
| [4, 8, 16, 32, 64] | [4, 8, 16, 32, 64] | [4, 8, 16, 32, 64] | [4, 8, 16, 32, 64] | |
| (32, 64, 128, 256, 512) | (8, 16, 24, 32, 48) | (8, 16, 24, 32, 48) | (8, 16, 24, 32, 48) | |
| 2 | 2 | 2 | 2 | |
| [0.5, 1, 2] | [0.5, 1, 2] | [0.5, 1, 2] | [0.5, 1, 2] | |
| 256 | 128 | 128 | 300 | |
| 6000 | 6000 | 6000 | 6000 | |
| 0.7 | 0.7 | 0.7 | 0.7 | |
| 2000 | 1500 | 1500 | 1800 | |
| 1000 | 800 | 800 | 1100 | |
| 100 | 128 | 128 | 300 | |
| 128 | 128 | 128 | 300 | |
| 0.33 | 0.33 | 0.33 | 0.33 | |
| 100 | 80 | 120 | 300 | |
| 0.5 | 0.9 | 0.7 | 0.7 | |
| 0.3 | 0.3 | 0.5 | 0.5 |
| CV | M3_POT | |
|---|---|---|
| MOTA | 0.766886 | 0.781426 |
| Precision | 0.983295 | 0.997166 |
| Recall | 0.800657 | 0.825047 |
| CV | M2_LET | |
|---|---|---|
| MOTA | 0.857887 | 0.918403 |
| Precision | 0.997476 | 1.0 |
| Recall | 0.882192 | 0.954365 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Machefer, M.; Lemarchand, F.; Bonnefond, V.; Hitchins, A.; Sidiropoulos, P. Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery. Remote Sens. 2020, 12, 3015. https://doi.org/10.3390/rs12183015
Machefer M, Lemarchand F, Bonnefond V, Hitchins A, Sidiropoulos P. Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery. Remote Sensing. 2020; 12(18):3015. https://doi.org/10.3390/rs12183015
Chicago/Turabian StyleMachefer, Mélissande, François Lemarchand, Virginie Bonnefond, Alasdair Hitchins, and Panagiotis Sidiropoulos. 2020. "Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery" Remote Sensing 12, no. 18: 3015. https://doi.org/10.3390/rs12183015
APA StyleMachefer, M., Lemarchand, F., Bonnefond, V., Hitchins, A., & Sidiropoulos, P. (2020). Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery. Remote Sensing, 12(18), 3015. https://doi.org/10.3390/rs12183015