A Feature-Enhanced Anchor-Free Network for UAV Vehicle Detection




Abstract
1. Introduction
- (1)
- We propose a feature-enhanced anchor-free network (FEAF) for UAV vehicle detection, reducing excessive complex calculations related to anchor boxes and relieving the imbalance between positive and negative samples.
- (2)
- We adopt an effective 49-layer backbone that can offer appropriate receptive fields and keep precise localization information to match exactly small-sized vehicles. Besides, a multi-scale semantic enhancement block (MSEB) is proposed to strengthen discriminative feature representation for vehicles at various scales, without changing the spatial resolution of prediction layers.
- (3)
- Our method achieves the state-of-the-art performance on the two datasets, which are the UAVDT dataset [44] and the XDUAV dataset [45]. On the first dataset, 81.4% AP is achieved, which is 2.4%, 1.7%, 0.8%, and 2.2% higher than FPN [28], Mask R-CNN [15], FCOS [30], and RetinaNet [32] respectively. On the second one, 73.5% AP is achieved, which is 1.6%, 1.7%, 1.9%, and 2.5% higher than FPN, Mask R-CNN, FCOS, and RetinaNet respectively. Particularly, the main part of UAV datasets is much smaller vehicles, and its accuracy is about 2% higher than other existing methods. While, the proposed detector can run at 22 frames per second on a single NVIDIA TITAN Xp GPU.
2. Related Work
2.1. Anchor-Based UAV Vehicle Detection
2.2. Anchor-Free UAV Vehicle Detection
2.3. Feature-Enhanced UAV Vehicle Detection
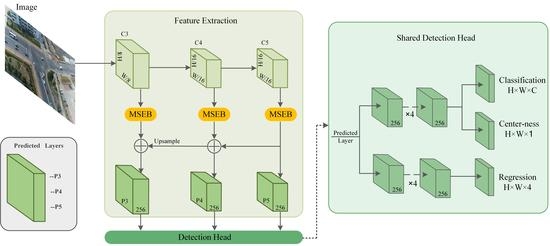
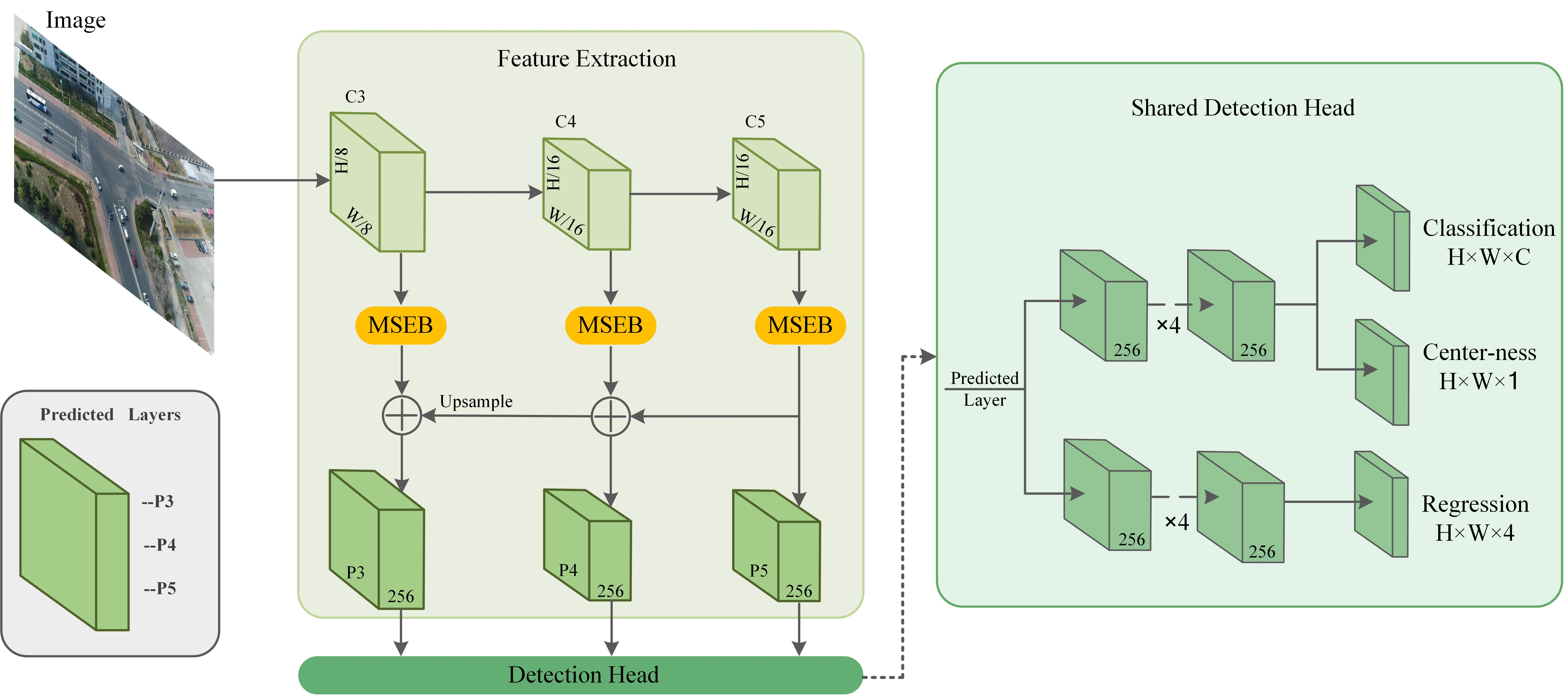
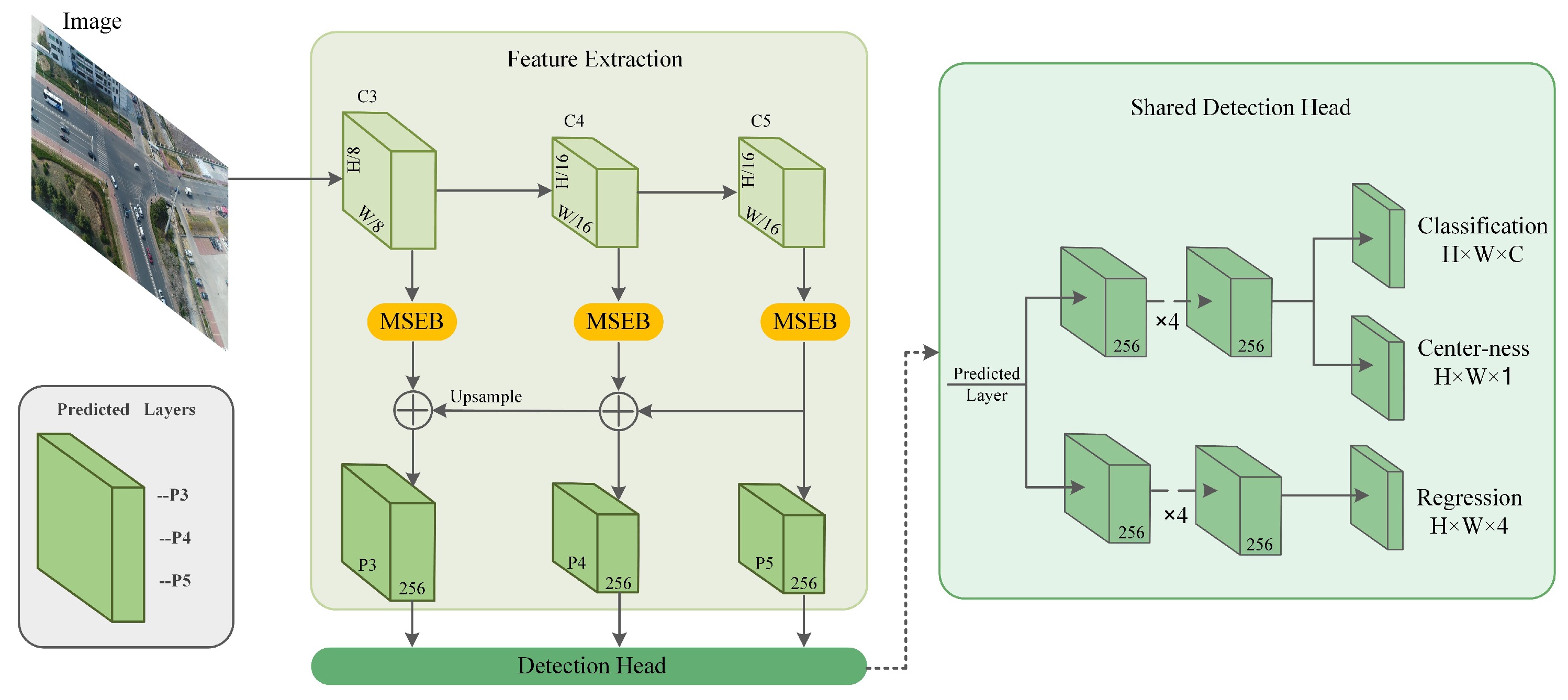
3. Proposed Method
3.1. Architecture
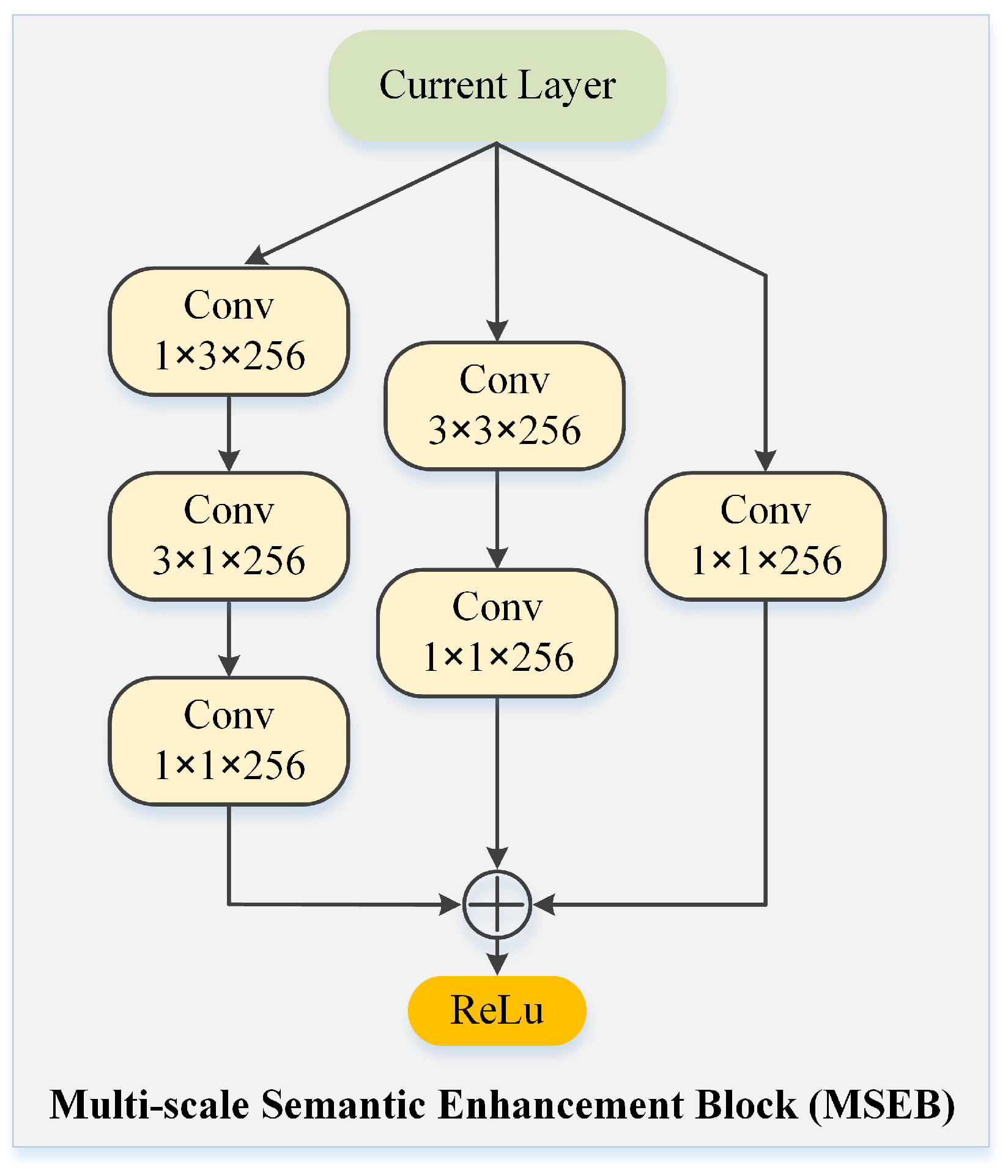
3.2. Multi-Scale Semantic Enhancement Block
3.3. Anchor-Free Mechanism
4. Experimental Results and Analysis
4.1. Dataset Preparation and Training Implementation Details
4.2. Ablation Study
4.2.1. Backbone Network Analysis
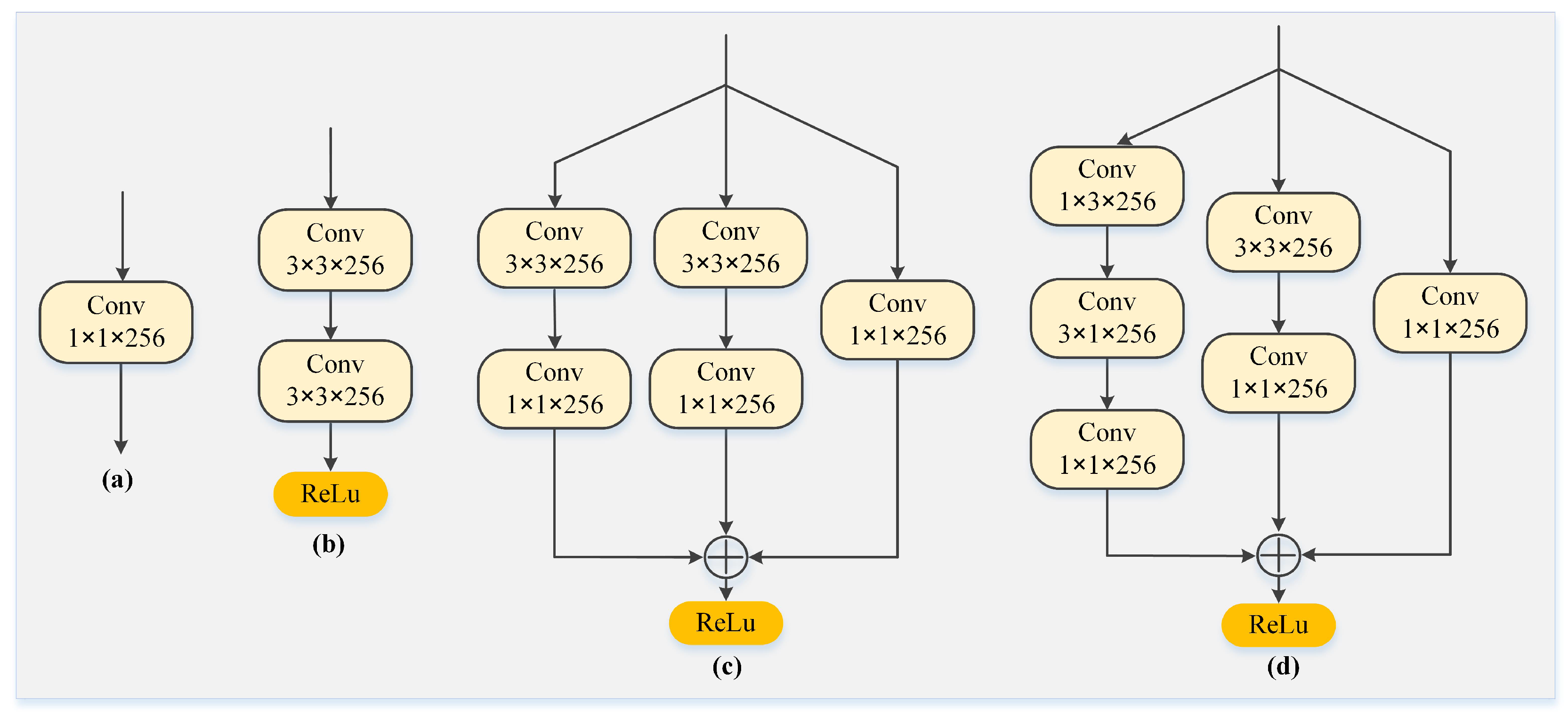
4.2.2. Multi-Scale Semantic Enhancement Block (MSEB) Analysis
4.2.3. Anchor-Free vs. Anchor-Based Vehicle Detectors
4.3. Overall Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| UAV | unmanned aerial vehicle |
| CNN | convolutional neural networks |
| FCN | fully convolutional neural network |
| FEAF | feature-enhanced anchor-free network |
| MSEB | multi-scale semantic enhancement block |
| FPN | feature pyramid network |
| AP | mean average precision |
References
- Alotaibi, E.T.; Alqefari, S.S.; Koubaa, A. LSAR: Multi-UAV Collaboration for Search and Rescue Missions. IEEE Access 2019, 7, 55817–55832. [Google Scholar] [CrossRef]
- Koubaa, A.; Qureshi, B. DroneTrack: Cloud-Based Real-Time Object Tracking Using Unmanned Aerial Vehicles Over the Internet. IEEE Access 2018, 6, 13810–13824. [Google Scholar] [CrossRef]
- Leitloff, J.; Rosenbaum, D.; Kurz, F.; Meynberg, O.; Reinartz, P. An operational system for estimating road traffic information from aerial images. Remote Sens. 2014, 6, 11315–11341. [Google Scholar] [CrossRef]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car Detection using Unmanned Aerial Vehicles: Comparison between Faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar]
- Li, X.; Chuah, M.C.; Bhattacharya, S. UAV assisted smart parking solution. In Proceedings of the 2017 International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL USA, 13–16 June 2017; pp. 1006–1013. [Google Scholar]
- Liu, K.; Mattyus, G. Fast multiclass vehicle detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Moranduzzo, T.; Melgani, F. Automatic car counting method for unmanned aerial vehicle images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1635–1647. [Google Scholar] [CrossRef]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne vehicle detection in dense urban areas using HoG features and disparity maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Detecting cars in UAV images with a catalog-based approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Teutsch, M.; Kruger, W. Robust and fast detection of moving vehicles in aerial videos using sliding windows. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 26–34. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. Car detection from low-altitude UAV imagery with the faster R-CNN. J. Adv. Transp. 2017, 2017. [Google Scholar] [CrossRef]
- Sommer, L.W.; Schuchert, T.; Beyerer, J. Fast deep vehicle detection in aerial images. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 311–319. [Google Scholar]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A CNN-Based Method of Vehicle Detection from Aerial Images Using Hard Example Mining. Remote Sens. 2018, 10, 124. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Radovic, M.; Adarkwa, O.; Wang, Q. Object Recognition in Aerial Images Using Convolutional Neural Networks. J. Imaging 2017, 3, 21. [Google Scholar] [CrossRef]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast vehicle detection in UAV images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 19–21 May 2017; pp. 1–5. [Google Scholar]
- Ringwald, T.; Sommer, L.; Schumann, A.; Beyerer, J.; Stiefelhagen, R. UAV-Net: A Fast Aerial Vehicle Detector for Mobile Platforms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 544–552. [Google Scholar]
- Yang, J.; Xie, X.; Yang, W. Effective Contexts for UAV Vehicle Detection. IEEE Access 2019, 7, 85042–85054. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Shrivastava, A.; Sukthankar, R.; Malik, J.; Gupta, A. Beyond skip connections: Top-down modulation for object detection. arXiv 2016, arXiv:1612.06851. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October2017; pp. 2980–2988. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Xu, L.; Chen, Q. Remote-Sensing Image Usability Assessment Based on ResNet by Combining Edge and Texture Maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1825–1834. [Google Scholar] [CrossRef]
- Yang, L.; Song, Q.; Wu, Y.; Hu, M. Attention Inspiring Receptive-Fields Network for Learning Invariant Representations. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1744–1755. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Zhang, X.; Sun, J. Object Detection Networks on Convolutional Feature Maps. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1476–1481. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A backbone network for object detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. DetNet: Design Backbone for Object Detection. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 339–354. [Google Scholar]
- Samuel, N.; Diskin, T.; Wiesel, A. Learning to Detect. IEEE Trans. Signal Process. 2019, 67, 2554–2564. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, W.; Zhan, R.; He, Z.; Zhang, J.; Zhuang, Z. Cascaded Detection Framework Based on a Novel Backbone Network and Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3480–3491. [Google Scholar] [CrossRef]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 October 2018; pp. 370–386. [Google Scholar]
- Xie, X.; Yang, W.; Cao, G.; Yang, J.; Shi, G. The Collected XDUAV Dataset. Available online: https://share.weiyun.com/8rAu3kqr (accessed on 10 September 2018).
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Sommer, L.W.; Schuchert, T.; Beyerer, J. Deep learning based multi-category object detection in aerial images. In Proceedings of the Automatic Target Recognition XXVII, Anaheim, CA, USA, 10–11 April 2017; Volume 10202, p. 1020209. [Google Scholar]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and Small Object Detection in UAV Vision Based on Cascade Network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27–28 October 2019; pp. 118–126. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Majid Azimi, S. ShuffleDet: Real-Time Vehicle Detection Network in On-board Embedded UAV Imagery. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 88–99. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. Densebox: Unifying landmark localization with end to end object detection. arXiv 2015, arXiv:1509.04874. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Vancouver, BC, Canada, 19–24 October 2016; pp. 516–520. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Chen, S.; Li, J.; Yao, C.; Hou, W.; Qin, S.; Jin, W.; Tang, X. DuBox: No-Prior Box Objection Detection via Residual Dual Scale Detectors. arXiv 2019, arXiv:1904.06883. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5187–5196. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. arXiv 2017, arXiv:1611.05424. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. FoveaBox: Beyond Anchor-based Object Detector. arXiv 2019, arXiv:1904.03797. [Google Scholar]
- Chen, C.; Zhang, Y.; Lv, Q.; Wei, S.; Wang, X.; Sun, X.; Dong, J. RRNet: A Hybrid Detector for Object Detection in Drone-Captured Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27–28 October 2019; pp. 100–108. [Google Scholar]
- Cai, Y.; Du, D.; Zhang, L.; Wen, L.; Wang, W.; Wu, Y.; Lyu, S. Guided Attention Network for Object Detection and Counting on Drones. arXiv 2019, arXiv:1909.11307. [Google Scholar]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1522–1530. [Google Scholar]
- Woo, S.; Hwang, S.; Kweon, I.S. StairNet: Top-Down Semantic Aggregation for Accurate One Shot Detection. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1093–1102. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5936–5944. [Google Scholar]
- Kong, T.; Sun, F.; Tan, C.; Liu, H.; Huang, W. Deep feature pyramid reconfiguration for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 169–185. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 845–853. [Google Scholar]
- Wang, H.; Wang, Z.; Jia, M.; Li, A.; Feng, T.; Zhang, W.; Jiao, L. Spatial Attention for Multi-Scale Feature Refinement for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27–28 October 2019; pp. 64–72. [Google Scholar]
- Li, J.; Wang, R.; Ding, J. Tiny Vehicle Detection from UAV Imagery. In Image and Graphics Technologies and Applications; Springer: Berlin, Germany, 2019. [Google Scholar]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27–28 October 2019; pp. 37–45. [Google Scholar]
- Ammar, A.; Koubaa, A.; Ahmed, M.; Saad, A. Aerial Images Processing for Car Detection using Convolutional Neural Networks: Comparison between Faster R-CNN and YoloV3. arXiv 2019, arXiv:1910.07234. [Google Scholar]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small Object Detection in Unmanned Aerial Vehicle Images Using Feature Fusion and Scaling-Based Single Shot Detector with Spatial Context Analysis. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1758–1770. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009; pp. 248–255. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| XDUAV Dataset | Category | Car | Bus | Truck | Motor | Bicycle | Tanker |
| Number | 33,841 | 2690 | 2848 | 6656 | 2024 | 173 | |
| UAVDT Dataset | Category | Car | Truck | Bus | - | - | - |
| Number | 755,197 | 25,086 | 17,450 | - | - | - |
| Methods | Backbone | Additional Layers | AP | |||||
|---|---|---|---|---|---|---|---|---|
| FCOS [30] | ResNet-50 | w | 71.2 | 95.4 | 82.3 | 33.2 | 68.1 | 80.9 |
| ResNet-50 | w/o | 70.2 | 95.4 | 80.9 | 34.1 | 65.3 | 79.3 | |
| ResNet-101 | w | 71.6 | 96.1 | 82.6 | 34.1 | 67.1 | 81.3 | |
| ResNet-101 | w/o | 71.3 | 96.1 | 82.4 | 34.3 | 68.3 | 80.2 | |
| Ours * | DetNet-59 | - | 71.6 | 96.0 | 83.1 | 35.1 | 67.9 | 81.0 |
| DetNet-49 | - | 71.9 | 95.7 | 83.5 | 35.4 | 69.4 | 80.1 |
| Different Blocks | Backbone | AP | |||||
|---|---|---|---|---|---|---|---|
| M_1 block | DetNet-49 | 71.9 | 95.7 | 83.5 | 35.4 | 69.4 | 80.1 |
| M_2 block | DetNet-49 | 72.4 | 96.0 | 83.7 | 34.3 | 69.5 | 81.2 |
| M_3 block | DetNet-49 | 72.6 | 95.7 | 83.7 | 34.8 | 69.1 | 81.3 |
| Proposed MSEB block | DetNet-49 | 73.5 | 97.5 | 84.2 | 35.7 | 71.9 | 81.4 |
| Methods | Backbone | Input Size | AP | |||||
|---|---|---|---|---|---|---|---|---|
| two-stage | ||||||||
| Faster R-CNN+++ [37] | ResNet-101 | ∼1333800 | 69.9 | 95.0 | 79.7 | 34.2 | 66.7 | 79.3 |
| Faster R-CNN w FPN [28] | ResNet-101 | ∼1333800 | 71.9 | 96.8 | 83.7 | 35.0 | 67.4 | 80.5 |
| Mask R-CNN [15] | ResNet-101 | ∼1333800 | 71.8 | 96.3 | 82.8 | 35.2 | 67.2 | 81.3 |
| single-stage | ||||||||
| RetinaNet [32] | ResNet-101 | ∼1333800 | 71.0 | 95.1 | 81.5 | 31.8 | 67.1 | 81.4 |
| FCOS [30] | ResNet-50 | ∼1333800 | 71.2 | 95.4 | 82.3 | 33.2 | 68.1 | 80.9 |
| FCOS [30] | ResNet-101 | ∼1333800 | 71.6 | 96.1 | 82.6 | 34.1 | 67.1 | 81.3 |
| Our Method | DetNet-49 | ∼1333800 | 73.5 | 97.5 | 84.2 | 35.7 | 71.9 | 81.4 |
| Methods | Backbone | Input Size | AP | |||||
|---|---|---|---|---|---|---|---|---|
| two-stage | ||||||||
| Faster R-CNN+++ [37] | ResNet-101 | ∼1333800 | 74.1 | 98.1 | 88.7 | 67.4 | 82.3 | 89.8 |
| Faster R-CNN w FPN [28] | ResNet-101 | ∼1333800 | 79.0 | 97.9 | 93.3 | 73.1 | 85.5 | 90.7 |
| Mask R-CNN [15] | ResNet-101 | ∼1333800 | 79.7 | 98.3 | 94.2 | 74.1 | 86.0 | 90.7 |
| single-stage | ||||||||
| RetinaNet [32] | ResNet-101 | ∼1333800 | 79.2 | 97.6 | 90.4 | 71.0 | 86.8 | 93.7 |
| FCOS [30] | ResNet-50 | ∼1333800 | 79.4 | 98.7 | 93.2 | 73.1 | 85.9 | 93.5 |
| FCOS [30] | ResNet-101 | ∼1333800 | 80.6 | 98.7 | 93.2 | 73.3 | 87.1 | 93.7 |
| Our Method | DetNet-49 | ∼1333800 | 81.4 | 98.7 | 94.5 | 75.3 | 87.4 | 93.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Xie, X.; Shi, G.; Yang, W. A Feature-Enhanced Anchor-Free Network for UAV Vehicle Detection. Remote Sens. 2020, 12, 2729. https://doi.org/10.3390/rs12172729
Yang J, Xie X, Shi G, Yang W. A Feature-Enhanced Anchor-Free Network for UAV Vehicle Detection. Remote Sensing. 2020; 12(17):2729. https://doi.org/10.3390/rs12172729
Chicago/Turabian StyleYang, Jianxiu, Xuemei Xie, Guangming Shi, and Wenzhe Yang. 2020. "A Feature-Enhanced Anchor-Free Network for UAV Vehicle Detection" Remote Sensing 12, no. 17: 2729. https://doi.org/10.3390/rs12172729
APA StyleYang, J., Xie, X., Shi, G., & Yang, W. (2020). A Feature-Enhanced Anchor-Free Network for UAV Vehicle Detection. Remote Sensing, 12(17), 2729. https://doi.org/10.3390/rs12172729