Uncertainty Analysis for Object-Based Change Detection in Very High-Resolution Satellite Images Using Deep Learning Network



Abstract
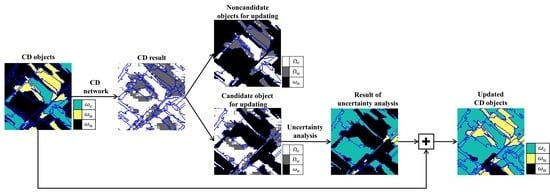
1. Introduction
2. Methods
2.1. Generating CD Objects
2.1.1. Initial CD Map Generated from Unsupervised CD Methods
2.1.2. Segmentation of Temporal Images
2.1.3. Reflection of the Uncertainty in an Object Unit
2.2. Updating CD Object
2.3. Performance Evaluation
3. Dataset
4. Results
4.1. Generation of CD Objects
4.2. CD Result of Traditional Approaches Using the CD Network
- Case 1: The original multitemporal images were used as the input data, and the initial pixel-level CD map was used as the label data in the case of the CD network. After training, the network produced a pixel-level CD map. In this case, object information could not be obtained.
- Case 2: The original multitemporal images were used as the input data, and the CD objects generated in Section 4.1 were used as the label data to train the CD network. In other words, the object information was reflected in the preprocessing phase, and the network produced a pixel-level CD map.
- Case 3: The segmentation image, in which each image has a unique value, was added to the original images. Thus, a band containing object information was stacked onto the existing bands. The new images adding one more band were used as the input data, and the initial pixel-level CD map was used as the label data for the CD network.
- Case 4: The result of Case 1 was subjected to postprocessing. In this case, the object was reclassified as the most dominant class of pixels within the object.
4.3. CD Result of the Proposed Method
5. Discussion
5.1. Comparison with Traditional CD Approaches
5.2. The Effect of Uncertainty Level
5.3. The Effect of Segmentation Scale
5.4. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic Object-based Image Analysis (GEOBIA): Emerging trends and future opportunities. GISci. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Lang, S. Object-based image analysis for remote sensing applications: Modeling reality-dealing with complexity. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 3–27. [Google Scholar]
- Laliberte, A.S.; Rango, A. Texture and scale in object-based analysis of subdecimeter resolution unmanned aerial vehicle (UAV) imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 761–770. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Pu, R.; Landry, S.; Yu, Q. Object-based urban detailed land cover classification with high spatial resolution ikonos imagery. Int. J. Remote Sens. 2011, 32, 3285–3308. [Google Scholar] [CrossRef]
- Ye, S.; Pontius, R.G.; Rakshit, R. A review of accuracy assessment for object-based image analysis: From per-pixel to per-polygon approaches. ISPRS J. Photogramm. 2018, 141, 137–147. [Google Scholar] [CrossRef]
- Liu, D.; Xia, F. Assessing object-based classification: Advantages and limitations. Remote Sens. Lett. 2010, 1, 187–194. [Google Scholar] [CrossRef]
- Gao, Y.; Mas, J.F. A comparison of the performance of pixel-based and object-based classifications over images with various spatial resolutions. J. Earth Sci. 2008, 2, 27–35. [Google Scholar]
- Definients Image. eCognition User’s Guide 4; Definients Image: Bernhard, Germany, 2004. [Google Scholar]
- Hexagon Geospatial. ERDAS Imagine; Erdas Inc.: Madison, AL, USA, 2016. [Google Scholar]
- Feature Extraction Module Version 4.6. In ENVI Feature Extraction Module User’s Guide; ITT Corporation: Boulder, CO, USA, 2008.
- Chen, G.; Hay, G.J.; Carvalho, L.M.T.; Wulder, M.A. Object-based change detection. Int. J. Remote Sens. 2012, 33, 4434–4457. [Google Scholar] [CrossRef]
- Stow, D. Geographic object-based image change analysis. In Handbook of Applied Spatial Statistics; Fischer, M.M., Getis, A., Eds.; Springer: Berlin, Germany, 2010; Volume 4, pp. 565–582. [Google Scholar]
- Walter, V. Object-based classification of remote sensing data for change detection. ISPRS J. Photogramm. Remote Sens. 2004, 58, 225–238. [Google Scholar] [CrossRef]
- Im, J.; Jensen, J.; Tullis, J. Object-based CD using correlation image analysis and image segmentation. Int. J. Remote Sens. 2008, 29, 399–423. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Blaschke, T.; Ma, X.; Tiede, D.; Cheng, L.; Chen, Z.; Chen, D. Object-based CD in urban areas: The effects of segmentation strategy, scale, and feature space on unsupervised methods. Remote Sens. 2016, 8, 761. [Google Scholar] [CrossRef]
- Desclée, B.; Bogaert, P.; Defourny, P. Forest CD by statistical object-based method. Remote Sens. Environ. 2006, 102, 1–11. [Google Scholar] [CrossRef]
- Chehata, N.; Orny, C.; Boukir, S.; Guyon, D.; Wigneron, J.P. Object-based CD in wind storm-damaged forest using high-resolution multispectral images. Int. J. Remote Sens. 2014, 35, 4758–4777. [Google Scholar] [CrossRef]
- Al-Khudhairy, D.; Caravaggi, I.; Giada, S. Structural damage assessments from Ikonos data using change detection, object-oriented segmentation, and classification techniques. Photogramm. Eng. Remote Sens. 2005, 71, 825–837. [Google Scholar] [CrossRef]
- Niemeyer, I.; Marpu, P.; Nussbaum, S. CD using object features. In Object-Based Image Analysis; Blaschke, T., Lang, S., Hay, G., Eds.; Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2008; pp. 185–201. [Google Scholar]
- Han, Y.; Javed, A.; Jung, S.; Liu, S. Object-Based CD of Very High Resolution Images by Fusing Pixel-Based CD Results Using Weighted Dempster–Shafer Theory. Remote Sens. 2020, 12, 983. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A novel object-based deep learning framework for semantic segmentation of very high-resolution remote sensing data: Comparison with convolutional and fully convolutional networks. Remote Sens. 2019, 11, 684. [Google Scholar] [CrossRef]
- Jin, B.; Ye, P.; Zhang, X.; Song, W.; Li, S. Object-Oriented Method Combined with Deep Convolutional Neural Networks for Land-Use-Type Classification of Remote Sensing Images. J. Indian Soc. Remote Sens. 2019, 47, 951–965. [Google Scholar] [CrossRef]
- Liu, S.; Qi, Z.; Li, X.; Yeh, G.A. Integration of convolutional neural networks and object-based post-classification refinement for land use and land cover mapping with optical and sar data. Remote Sens. 2019, 11, 690. [Google Scholar] [CrossRef]
- Song, A.; Kim, Y. Transfer Change Rules from Recurrent Fully Convolutional Networks for Hyperspectral Unmanned Aerial Vehicle Images without Ground Truth Data. Remote Sens. 2020, 12, 1099. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.M.; Cheng, A.; Wei, H.; Stanley, D. CD from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogram Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Benediktsson, J.A.; Bovolo, F.; Bruzzone, L. An unsupervised technique based on morphological filters for CD in very high resolution images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 433–437. [Google Scholar] [CrossRef]
- Bruzzone, L.; Bovolo, F. A novel framework for the design of change-detection systems for very-high-resolution remote sensing images. Proc. IEEE 2013, 101, 609–630. [Google Scholar] [CrossRef]
- Singh, A. Review Article Digital CD techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. CD techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Malila, W.A. Change vector analysis: An approach for detecting forest changes with Landsat. In LARS Symposia; Laboratory for Applications of Remote Sensing: West Lafayette, IN, USA, 1980. [Google Scholar]
- Ilsever, M.; Unsalan, C. Two-Dimensional Change Detection Methods; Springer: London, UK, 2012. [Google Scholar]
- Deng, J.; Wang, K.; Deng, Y.; Qi, G. Pca-based land-use CD and analysis using multitemporal and multisensor satellite data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Nielsen, A.A. The regularized iteratively reweighted MAD method for change detection in multi-and hyperspectral data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef]
- Nielsen, A.A. Multi-channel remote sensing data and orthogonal transformations for change detection. In Machine Vision and Advanced Image Processing in Remote Sensing; Springer: Berlin/Heidelberg, Germany, 1999; pp. 37–48. [Google Scholar]
- Zhang, G.; Jia, X.; Kwok, N.M. Super pixel based remote sensing image classification with histogram descriptors on spectral and spatial data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4335–4338. [Google Scholar]
- Felzenszwalb, P.; Huttenlocher, D. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Schallner, L.; Rabold, J.; Scholz, O.; Schmid, U. Effect of Superpixel Aggregation on Explanations in LIME--A Case Study with Biological Data. arXiv 2019, arXiv:1910.07856. Available online: https://link.springer.com/chapter/10.1007/978-3-030-43823-4_13 (accessed on 22 July 2020).
- Song, A.; Choi, J.; Han, Y.; Kim, Y. Change detection in hyperspectral images using recurrent 3D fully convolutional networks. Remote Sens. 2018, 10, 1827. [Google Scholar] [CrossRef]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 1, 802–810. [Google Scholar]
- Acquarelli, J.; Marchiori, E.; Buydens, L.M.C.; Tran, T.; van Laarhoven, T. Spectral-spatial classification of hyperspectral images: Three tricks and a new learning setting. Remote Sens. 2018, 10, 1156. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral-spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Aguilar, M.A.; del Mar Saldana, M.; Aguilar, F.J. Assessing geometric accuracy of the orthorectification process from GeoEye-1 and WorldView-2 panchromatic images. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 427–435. [Google Scholar] [CrossRef]
- Gašparović, M.; Dobrinić, D.; Medak, D. Geometric accuracy improvement of WorldView-2 imagery using freely available DEM data. Photogramm. Rec. 2019, 34, 266–281. [Google Scholar] [CrossRef]
- Han, Y.; Choi, J.; Jung, J.; Chang, A.; Oh, S.; Yeom, J. Automated co-registration of multi-sensor orthophotos generated from unmanned aerial vehicle platforms. J. Sens. 2019, 2019. [Google Scholar] [CrossRef]
- Han, Y.; Kim, T.; Yeom, J. Improved piecewise linear transformation for precise warping of very-high-resolution remote sensing images. Remote Sens. 2019, 11, 2235. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Site | Methods | OA | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Site 1 | 0.8316 | 0.6147 | 0.7760 | 0.6860 | |
| 0.7778 | 0.5107 | 0.6685 | 0.5790 | ||
| CVA | 0.8298 | 0.6189 | 0.7676 | 0.6853 | |
| IR-MAD | 0.8200 | 0.5946 | 0.7520 | 0.6641 | |
| PCA | 0.8471 | 0.8177 | 0.7135 | 0.7620 | |
| Site 2 | 0.8649 | 0.7797 | 0.6676 | 0.7193 | |
| 0.7705 | 0.5417 | 0.4848 | 0.5117 | ||
| CVA | 0.8716 | 0.7762 | 0.6863 | 0.7285 | |
| IR-MAD | 0.8033 | 0.7496 | 0.5410 | 0.6285 | |
| PCA | 0.8108 | 0.6693 | 0.5622 | 0.6110 |
| Study Site | Uncertainty Level | The Number of Pixels in | ||
|---|---|---|---|---|
| Site 1 | Level 1 | 185,626 | 938,376 | 315,998 |
| Level 2 | 215,381 | 997,600 | 227,019 | |
| Level 3 | 263,464 | 1,043,117 | 133,419 | |
| Site 2 | Level 1 | 19,215 | 96,322 | 44,463 |
| Level 2 | 22,066 | 108,230 | 29,704 | |
| Level 3 | 24,280 | 117,225 | 18,495 | |
| Study Site | Uncertainty Level | Precision | NPV |
|---|---|---|---|
| Site 1 | Level 1 | 0.9420 | 0.9432 |
| Level 2 | 0.9224 | 0.9331 | |
| Level 3 | 0.9183 | 0.9077 | |
| Site 2 | Level 1 | 0.9420 | 0.9432 |
| Level 2 | 0.9153 | 0.9399 | |
| Level 3 | 0.8912 | 0.9339 |
| Study Site | Methods | OA | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Site 1 | Case 1 | 0.8623 | 0.6535 | 0.8726 | 0.7473 |
| Case 2 | 0.8727 | 0.6335 | 0.9378 | 0.7562 | |
| Case 3 | 0.8436 | 0.5618 | 0.8982 | 0.6913 | |
| Case 4 | 0.8874 | 0.6878 | 0.9336 | 0.7921 | |
| Site 2 | Case 1 | 0.8787 | 0.5127 | 0.8883 | 0.6501 |
| Case 2 | 0.8821 | 0.4933 | 0.9438 | 0.6479 | |
| Case 3 | 0.8772 | 0.5114 | 0.8801 | 0.6469 | |
| Case 4 | 0.8831 | 0.5068 | 0.9296 | 0.6560 |
| Study Site | Uncertainty Level | OA | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Site 1 | Level 1 | 0.8180 | 0.9446 | 0.4262 | 0.5874 |
| Level 2 | 0.9174 | 0.9373 | 0.7847 | 0.8542 | |
| Level 3 | 0.8769 | 0.6444 | 0.9206 | 0.7581 | |
| Level 3 to Level 1 | 0.8735 | 0.6330 | 0.9193 | 0.7498 | |
| Level 2 to Level 1 | 0.9185 | 0.9411 | 0.7846 | 0.8558 | |
| Level 1 to Level 3 | 0.8611 | 0.9608 | 0.5780 | 0.7218 | |
| Level 2 to Level 3 | 0.9299 | 0.8158 | 0.9422 | 0.8745 | |
| Site 2 | Level 1 | 0.8998 | 0.6252 | 0.8908 | 0.7348 |
| Level 2 | 0.9006 | 0.6220 | 0.8991 | 0.7353 | |
| Level 3 | 0.8802 | 0.9359 | 0.5159 | 0.6651 | |
| Level 3 to Level 1 | 0.8987 | 0.8908 | 0.6252 | 0.7348 | |
| Level 2 to Level 1 | 0.8957 | 0.9146 | 0.6766 | 0.7778 | |
| Level 1 to Level 3 | 0.8859 | 0.5223 | 0.9341 | 0.6700 | |
| Level 2 to Level 3 | 0.9012 | 0.6164 | 0.9092 | 0.7347 |
| Study Site | Scale Factors | OA | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Site 1 | 30 | 0.8795 | 0.6495 | 0.9256 | 0.7634 |
| 50 | 0.8969 | 0.7194 | 0.9185 | 0.8068 | |
| 100 | 0.8965 | 0.7102 | 0.9267 | 0.8041 | |
| 200 | 0.9299 | 0.8158 | 0.9422 | 0.8745 | |
| 300 | 0.9097 | 0.7621 | 0.9228 | 0.8348 | |
| Site 2 | 30 | 0.8920 | 0.5627 | 0.9197 | 0.6982 |
| 50 | 0.9012 | 0.6164 | 0.9092 | 0.7347 | |
| 100 | 0.8915 | 0.6063 | 0.8644 | 0.7127 | |
| 200 | 0.8935 | 0.5621 | 0.9306 | 0.7009 | |
| 300 | 0.8931 | 0.5632 | 0.9261 | 0.7004 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, A.; Kim, Y.; Han, Y. Uncertainty Analysis for Object-Based Change Detection in Very High-Resolution Satellite Images Using Deep Learning Network. Remote Sens. 2020, 12, 2345. https://doi.org/10.3390/rs12152345
Song A, Kim Y, Han Y. Uncertainty Analysis for Object-Based Change Detection in Very High-Resolution Satellite Images Using Deep Learning Network. Remote Sensing. 2020; 12(15):2345. https://doi.org/10.3390/rs12152345
Chicago/Turabian StyleSong, Ahram, Yongil Kim, and Youkyung Han. 2020. "Uncertainty Analysis for Object-Based Change Detection in Very High-Resolution Satellite Images Using Deep Learning Network" Remote Sensing 12, no. 15: 2345. https://doi.org/10.3390/rs12152345
APA StyleSong, A., Kim, Y., & Han, Y. (2020). Uncertainty Analysis for Object-Based Change Detection in Very High-Resolution Satellite Images Using Deep Learning Network. Remote Sensing, 12(15), 2345. https://doi.org/10.3390/rs12152345