3D Point Cloud to BIM: Semi-Automated Framework to Define IFC Alignment Entities from MLS-Acquired LiDAR Data of Highway Roads





Abstract
:1. Introduction
- (1)
- A point cloud-processing method that extracts the road main alignment and offset alignment of a highway road. In order to do so, a method for detection and classification of solid and dashed road markings is also presented. Note that this road marking processing method does not aim to be a contribution by itself, but it is essential for the whole workflow and will be validated to prove that it has state-of-the-art performance.
- (2)
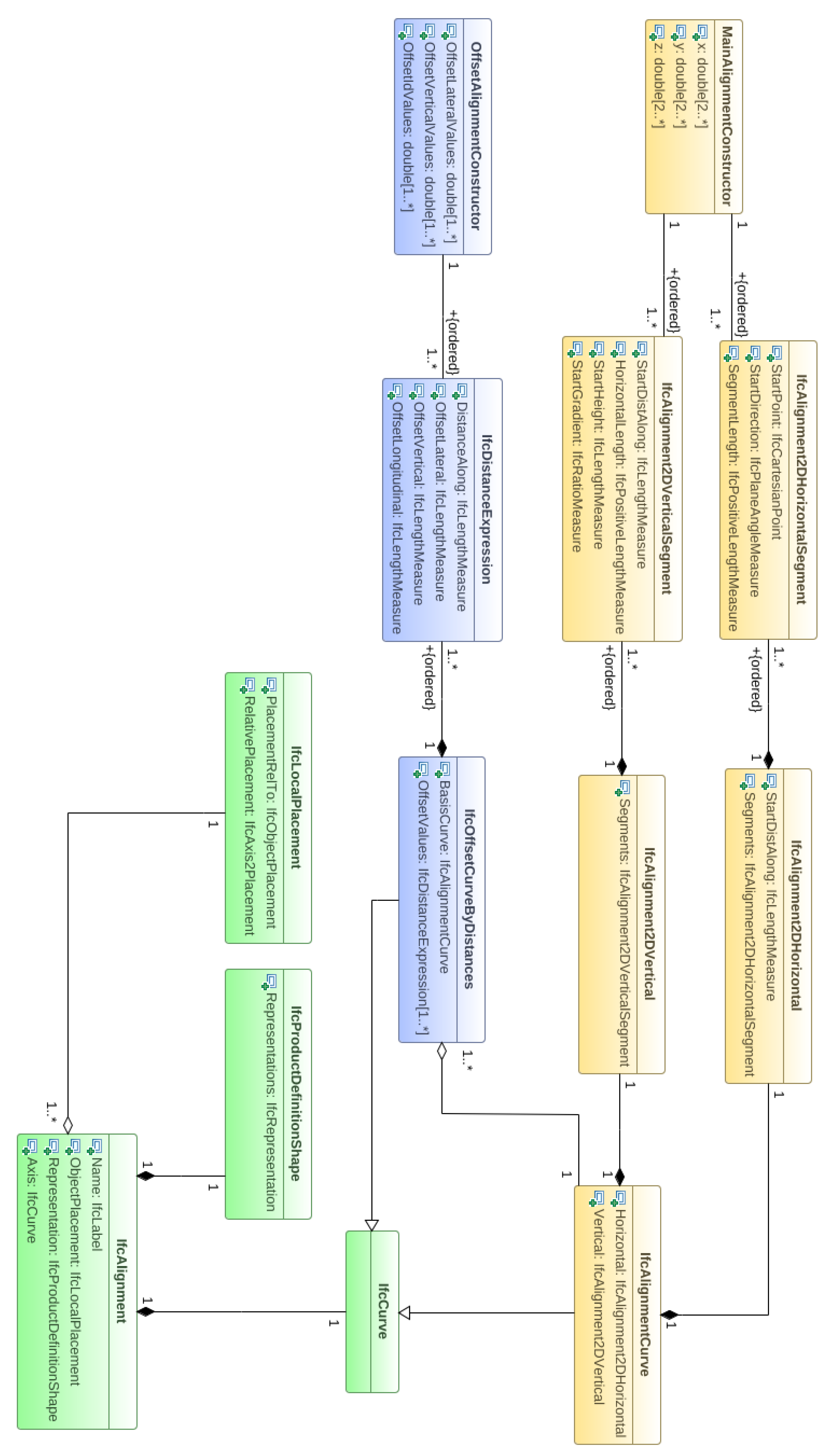
- A conversion of the main alignment and offset alignment as exported from the point cloud processing method, to an IFC Alignment model, which is part of IFC 4.1 standard. The model is supported with UML diagrams.
2. Materials and Methods
2.1. Case Study Data
2.2. Methodology
2.2.1. Ground Segmentation
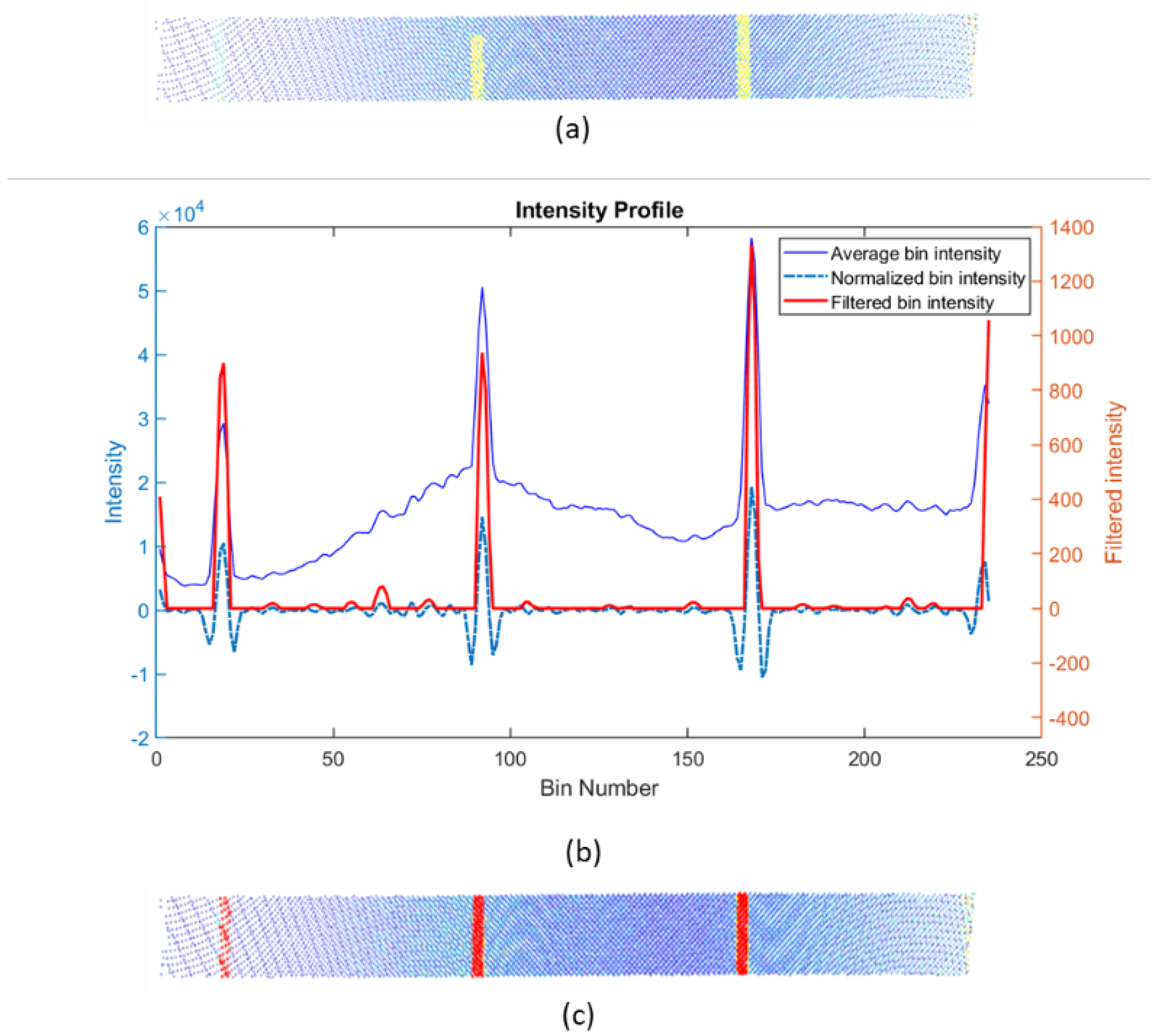
2.2.2. Road Markings Detection
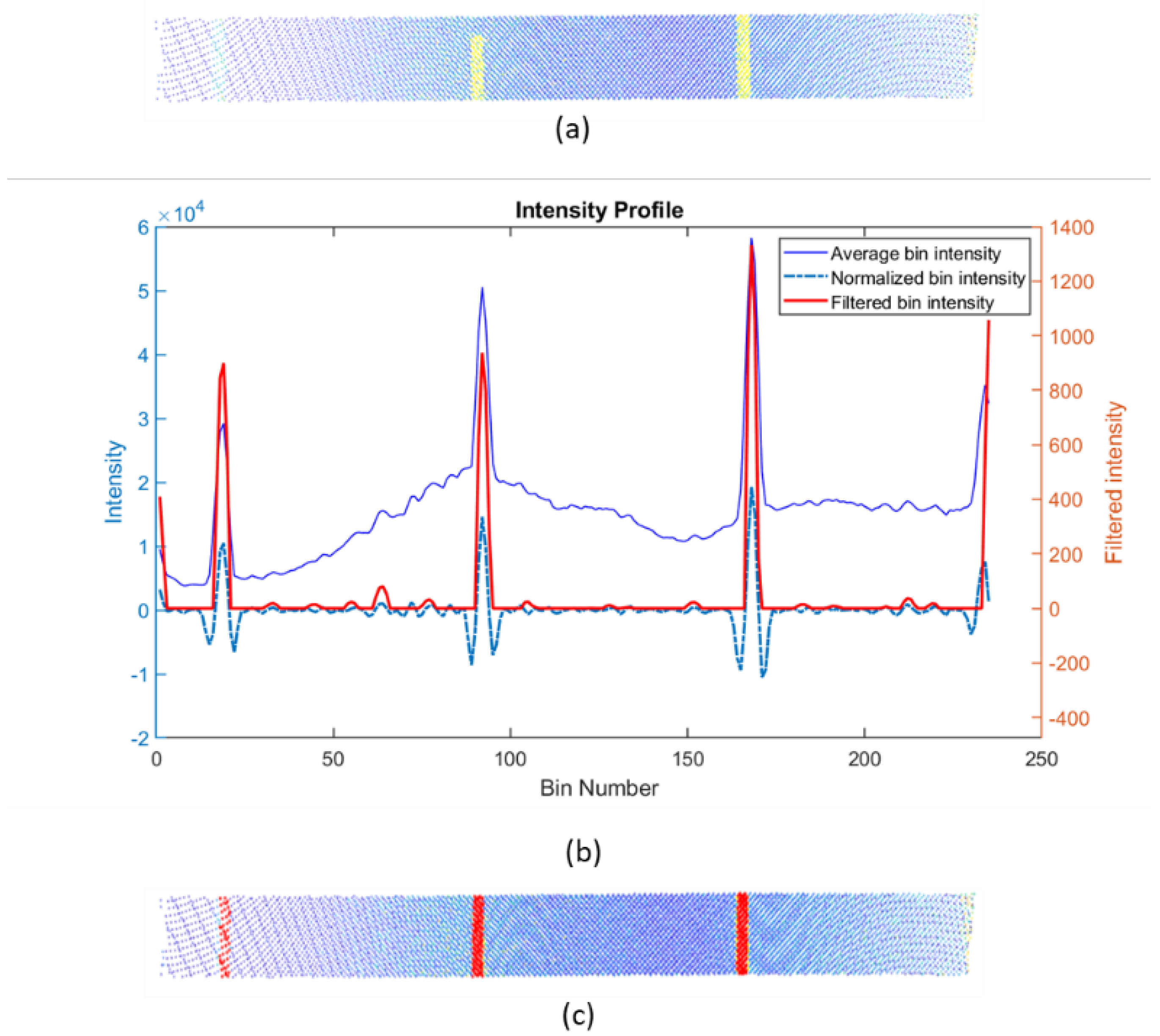
- The intensity of a point is an attribute that depends on the distance between the sensor and the point itself. Therefore, usage of global intensity thresholds is not feasible. Instead, the intensity attribute should be analyzed locally, among points with similar distance with respect to the sensor.
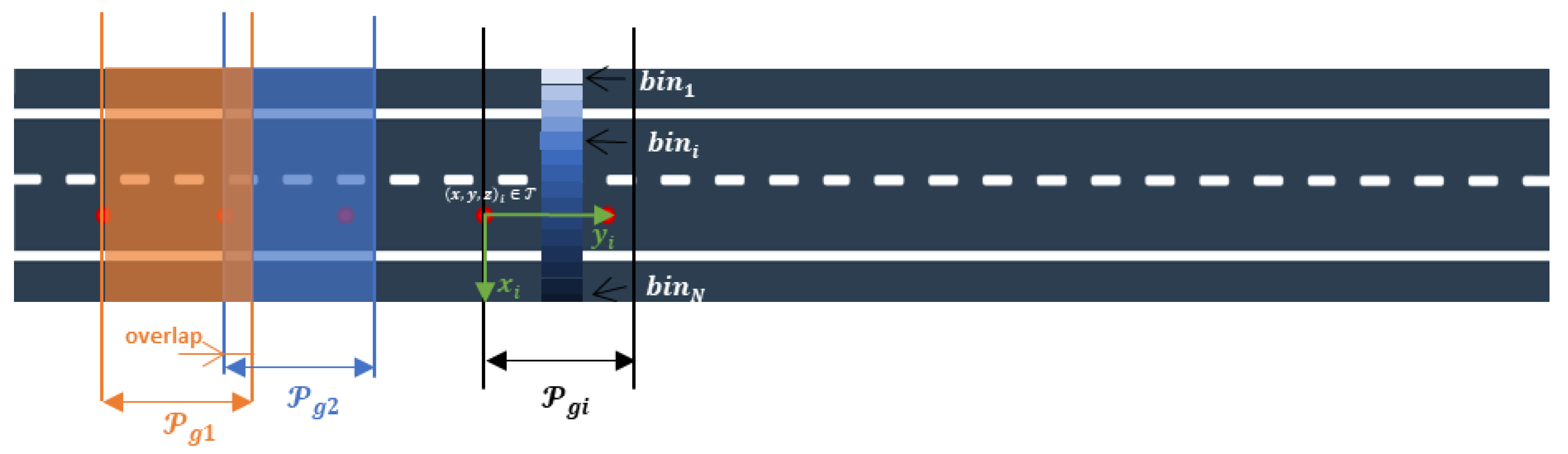
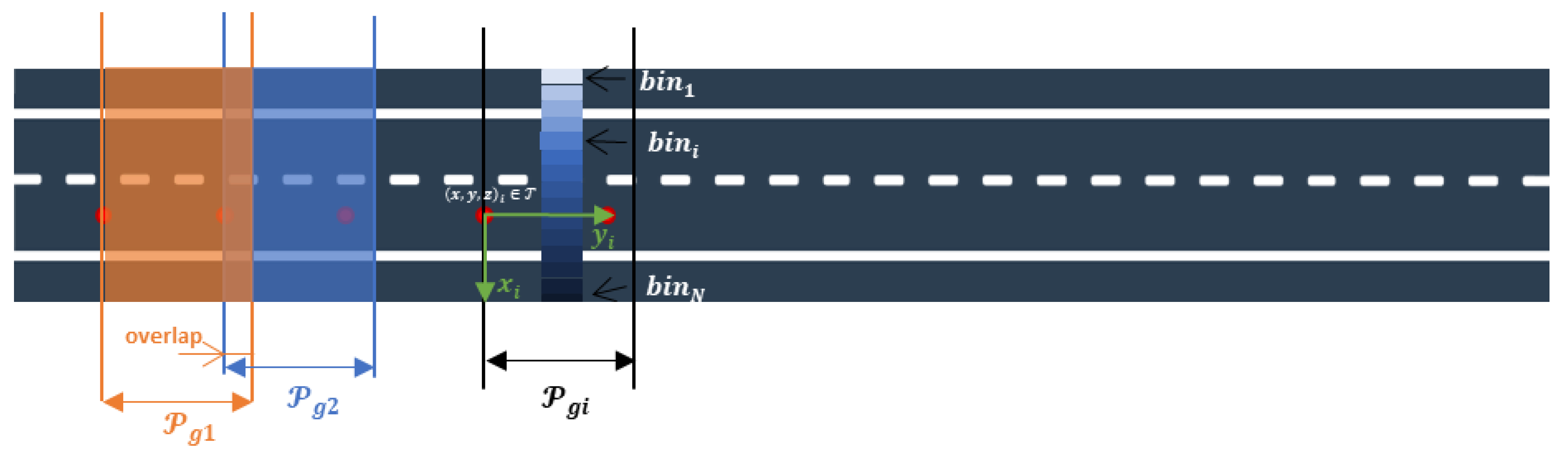
- Most of the markings are linear elements that follow the direction of the vehicle trajectory (solid and dashed lines). Therefore, it seems convenient to locally search for road markings in a set of slices parallel to the trajectory.
- The generation of those slices needs to have into account the curvature of the road. The longer the slice in the direction of the trajectory at a point, the larger the effect of the curvature of the road. Hence, it is preferable to define short slices and process them iteratively.
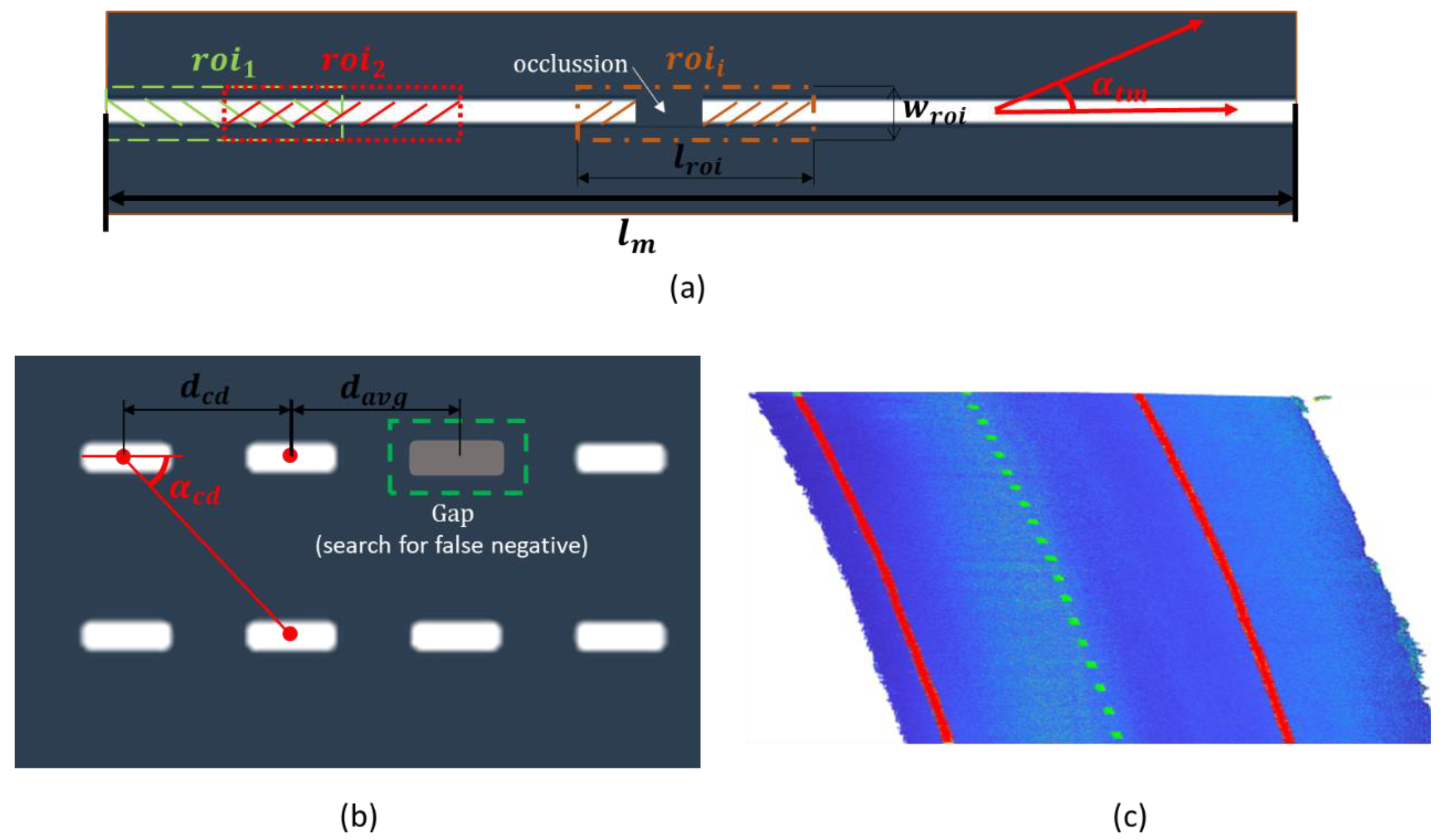
2.2.3. Road Markings Processing
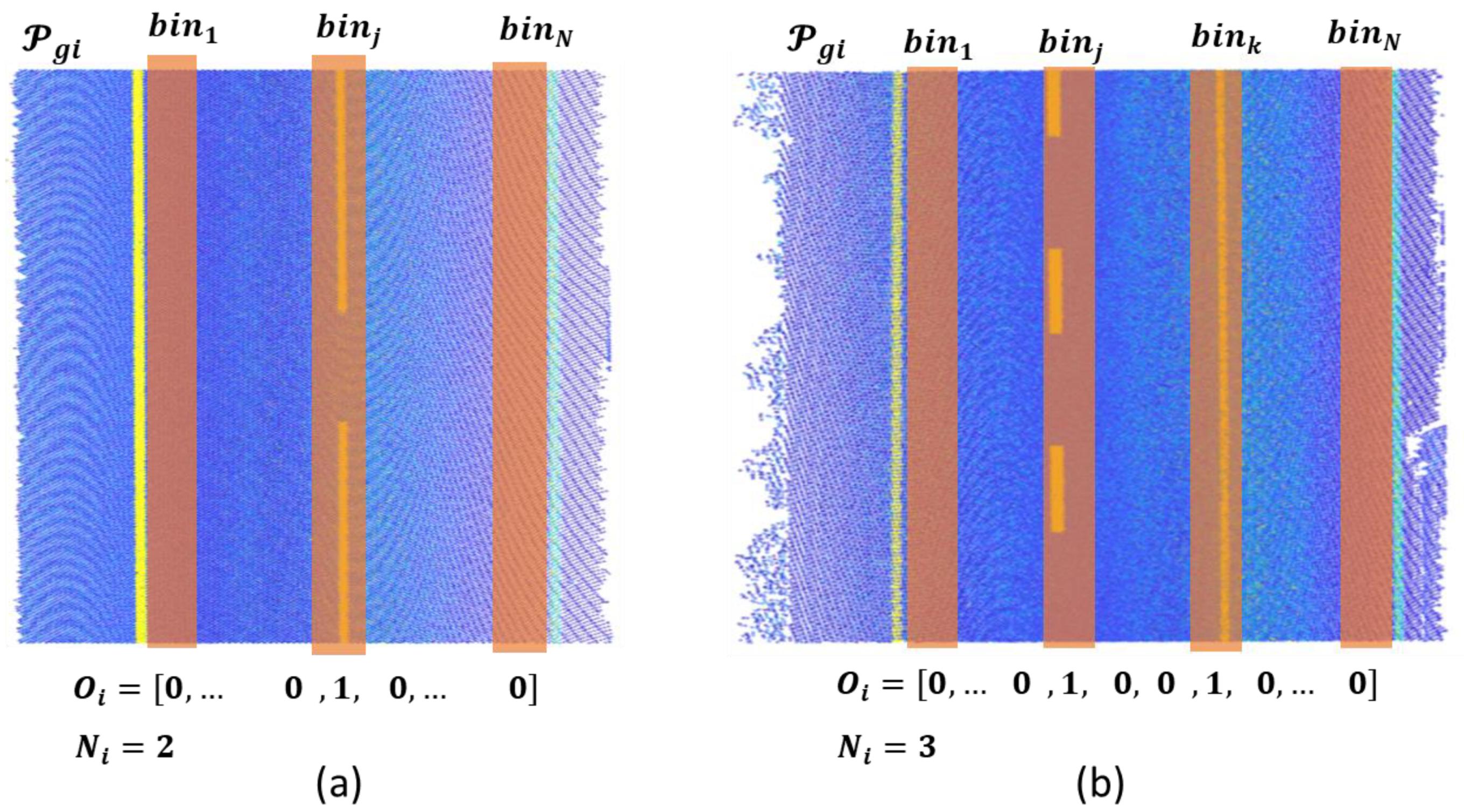
- The main objective of the whole process is to extract the center of the road and each lane using the information given by the road markings. Therefore, the relevant markings to be classified are solid and dashed lines.
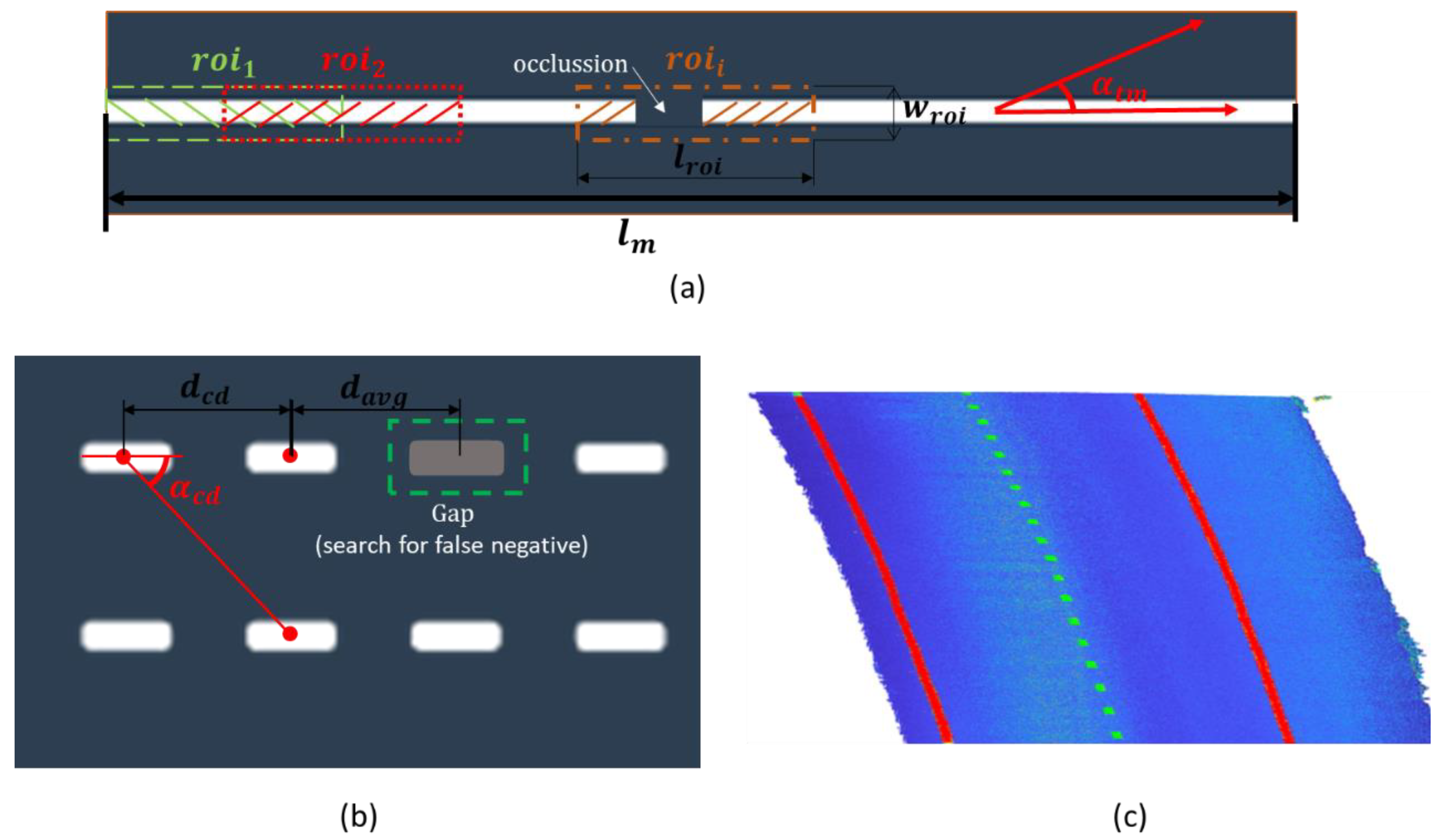
- The knowledge about the semantics of the road markings will allow to analyze the presence of false positives as well as occlusions and other false negatives on the point cloud of detected road markings, .
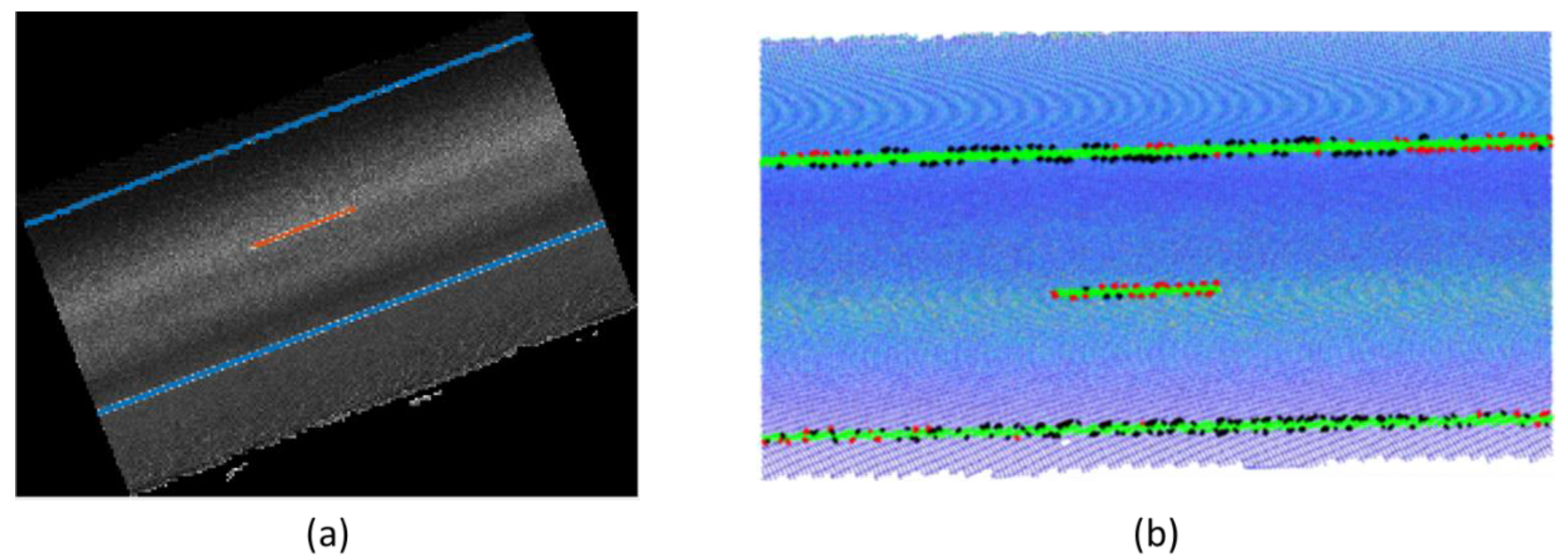
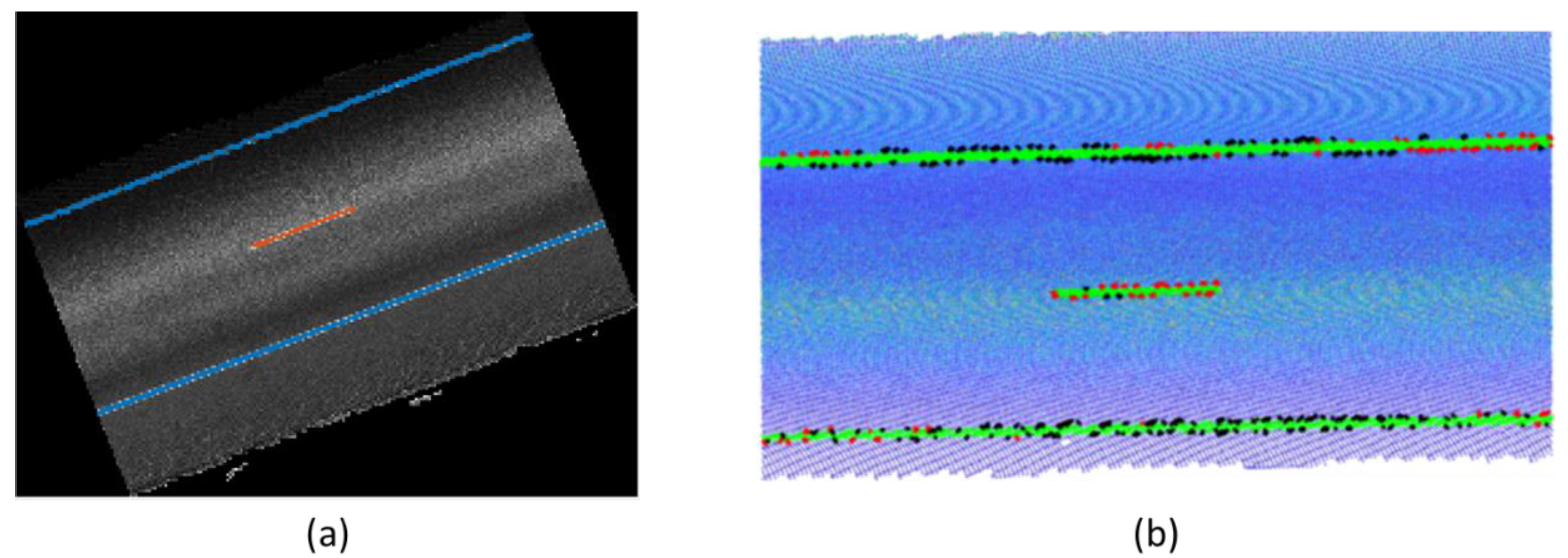
2.2.4. Road Edge Detection
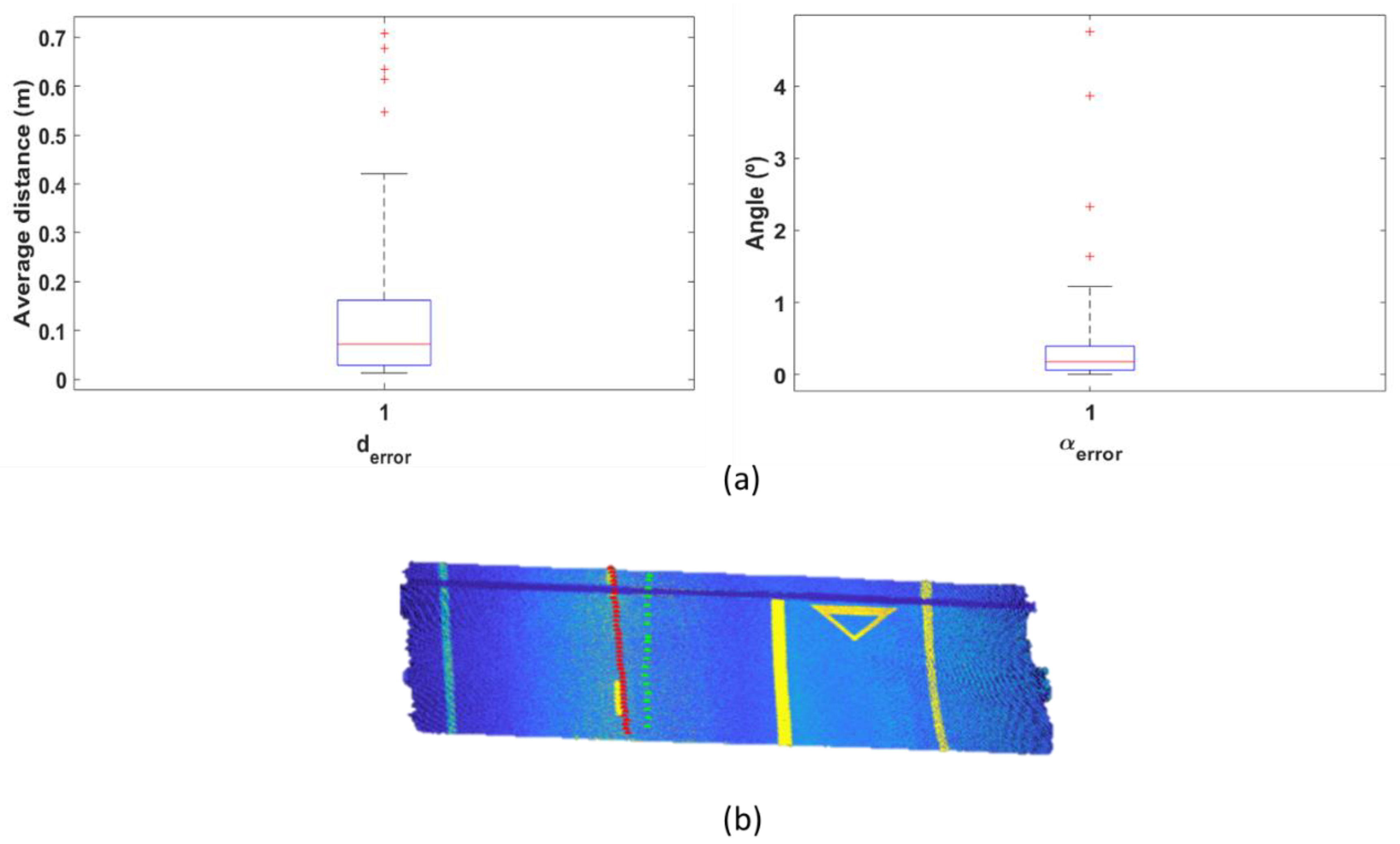
- The geometric data that are exported to build the IFC alignment model must not contain any error, so the model can be created correctly. This will be ensured if road edges are detected with no errors.
- A fully automated approach is not desirable for this module. Even if complex heuristics are defined, it is not possible to ensure that road edges are correctly detected in all cases. Therefore, an efficient approach would include an automated process with manual verification, and only in those cases when errors are detected, a manual delineation of road edges would be enabled.
- Manual verification of the results allows the definition of simple heuristics that are able to efficiently detect road edges in most cases, even if they are not robust enough to perform correctly in all cases.
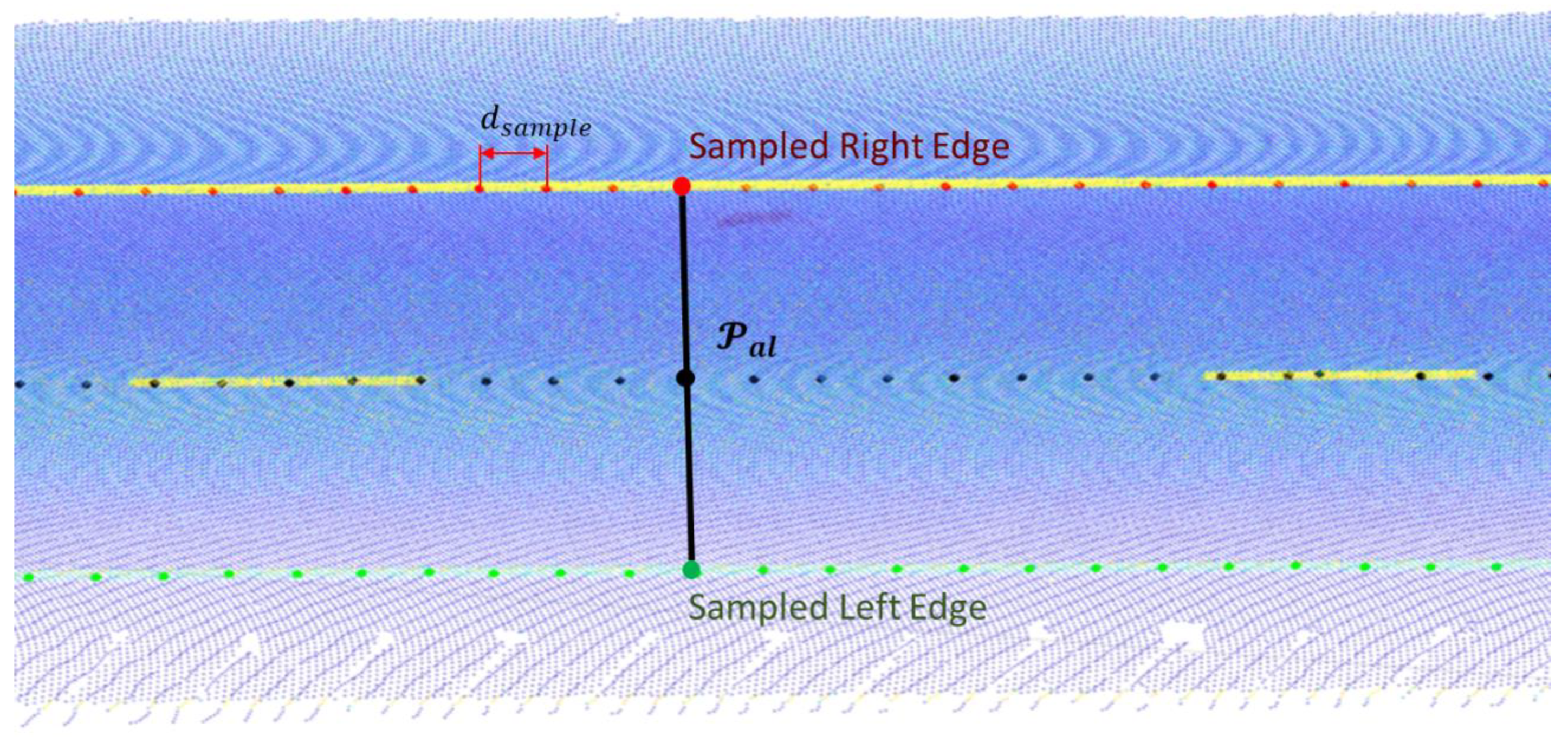
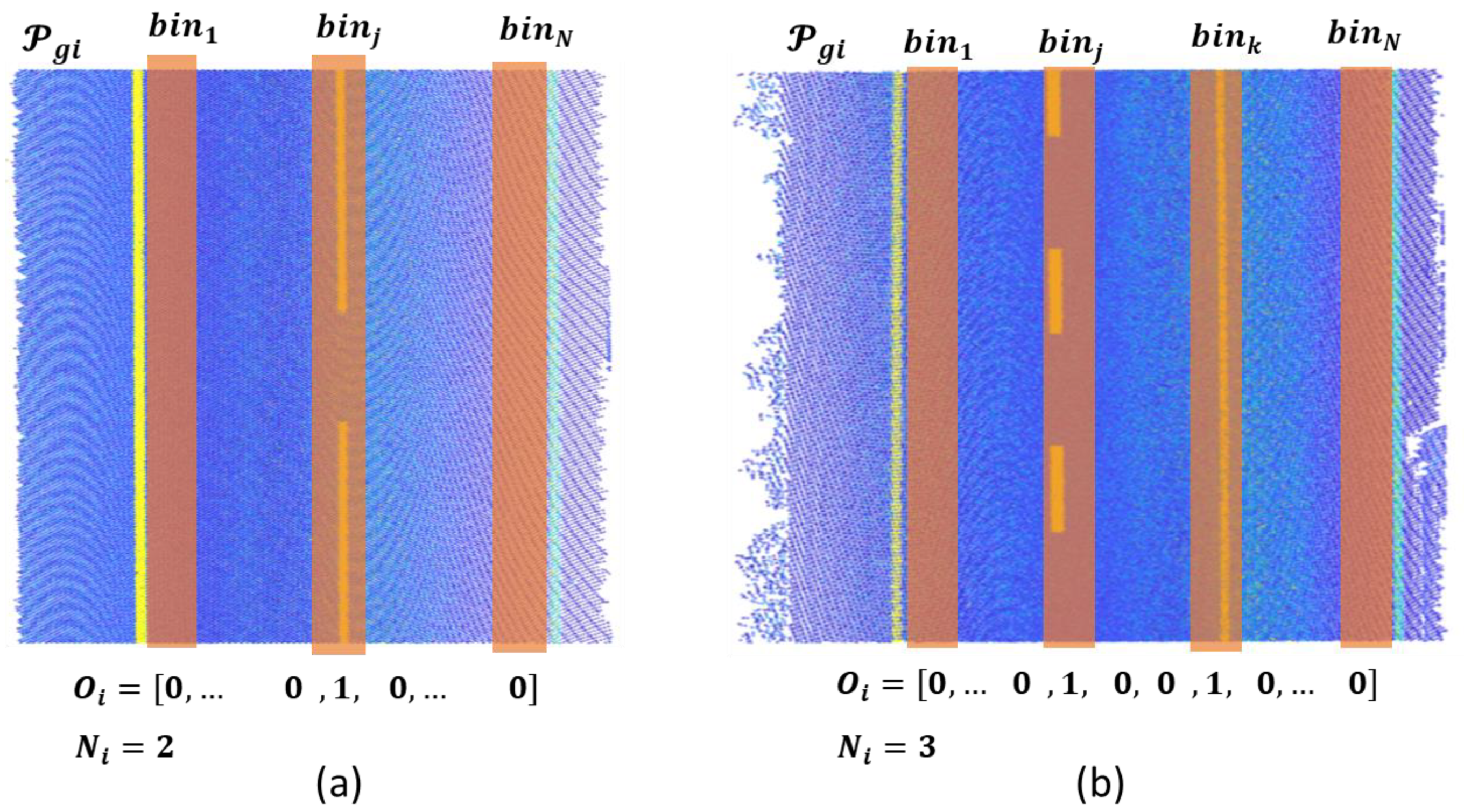
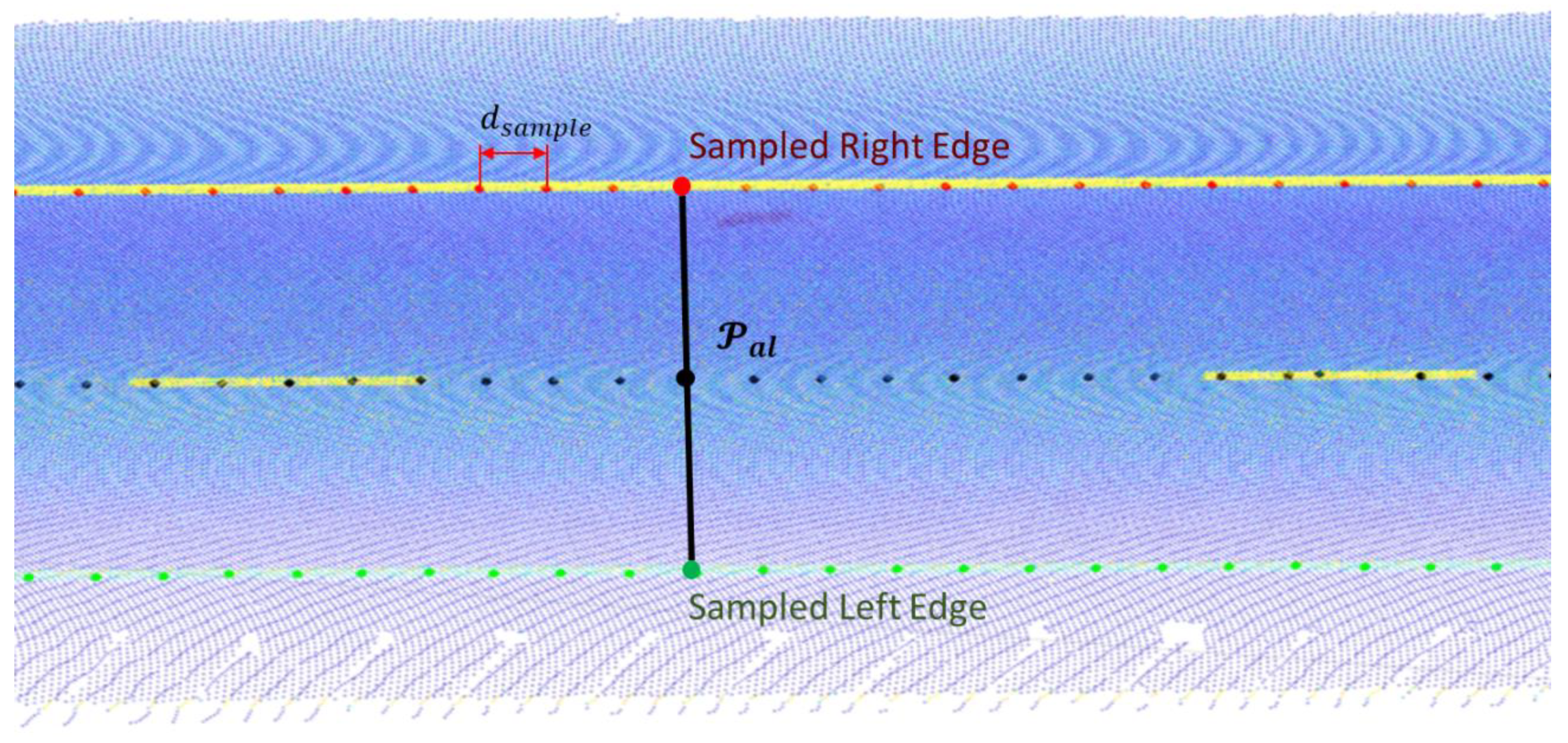
2.2.5. Alignment and Road Lane Processing
- The first necessary step is to detect the number of road lanes. This number is not constant along the study area, and a single point cloud may have different numbers of lanes when, for instance, there is a highway entrance or exit.
- Both solid and dashed markings can separate two lanes. However, the separation between the same lines can change along the road (for instance, a dashed line can be replaced by a solid line for a road section with prohibition of overtaking).
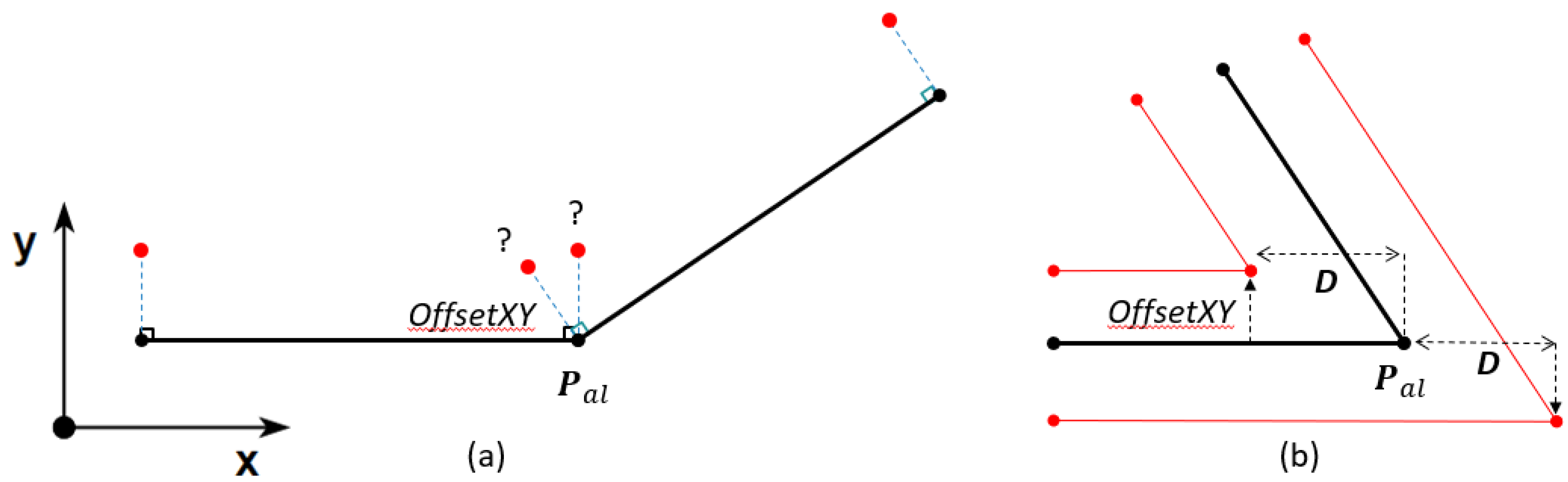
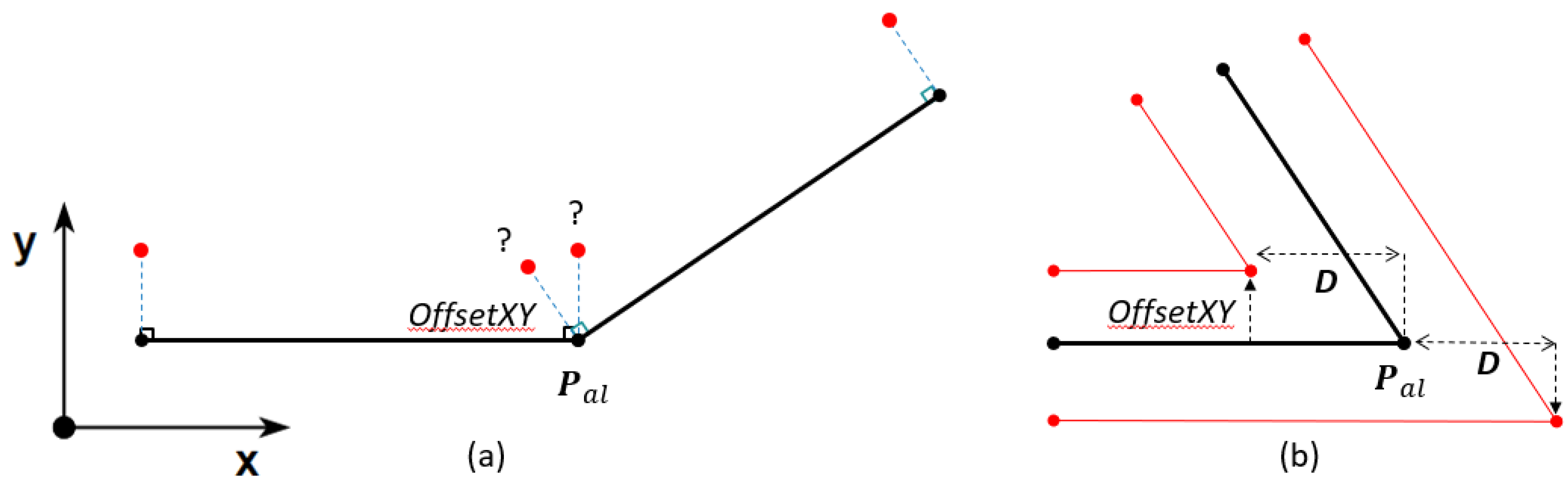
- OffsetXY: The perpendicular distance between each point in and each middle point of each road line.
- OffsetZ: The vertical distance between each point in and each middle point of each road line.
- Offset_id: Since there may be more than one lane per point in , an index is stored for each pair of (OffsetXY, OffsetZ) that points to the coordinate in from which the offsets were obtained, allowing the offset alignment generation as explained in Section 2.2.6.
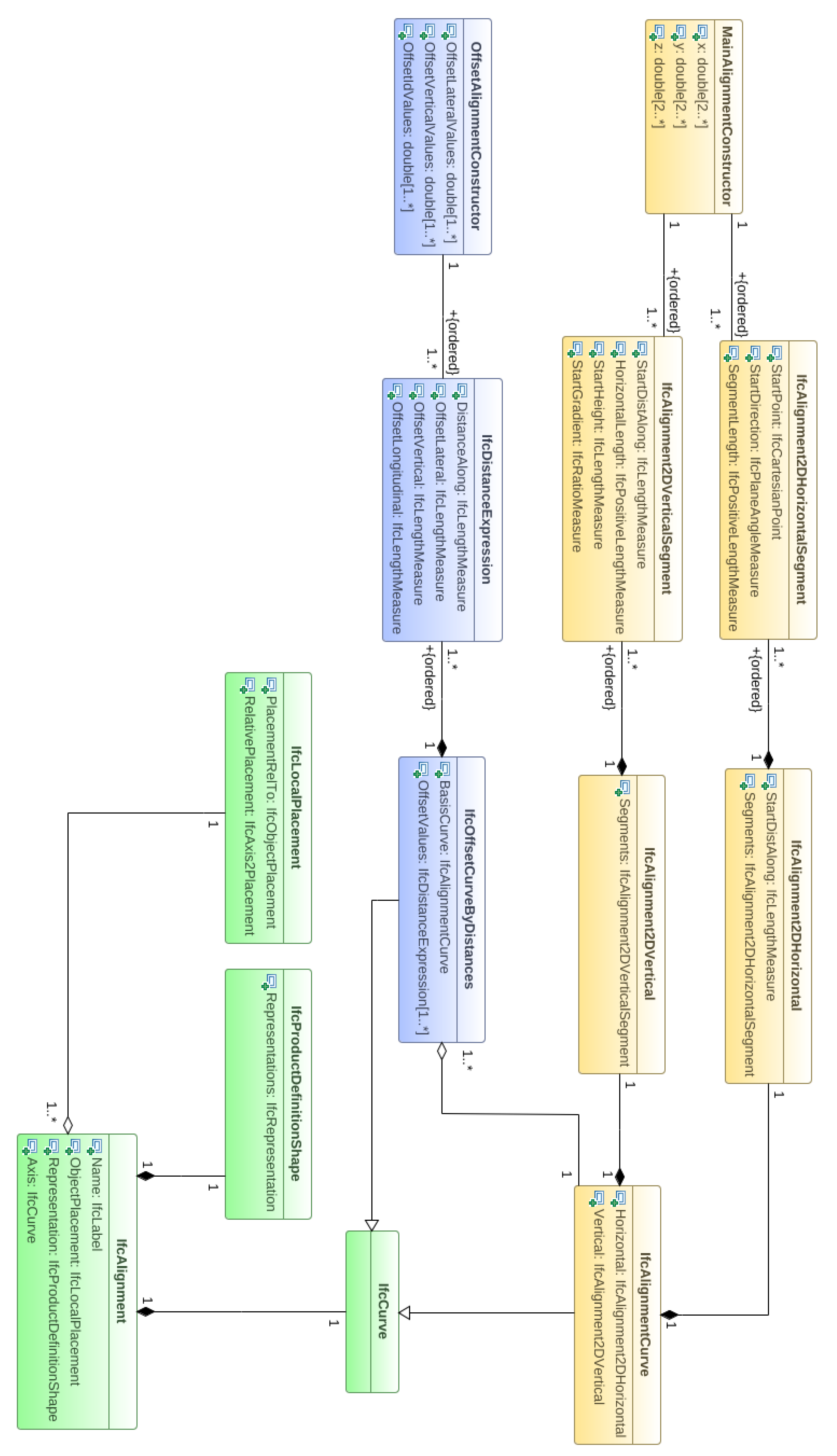
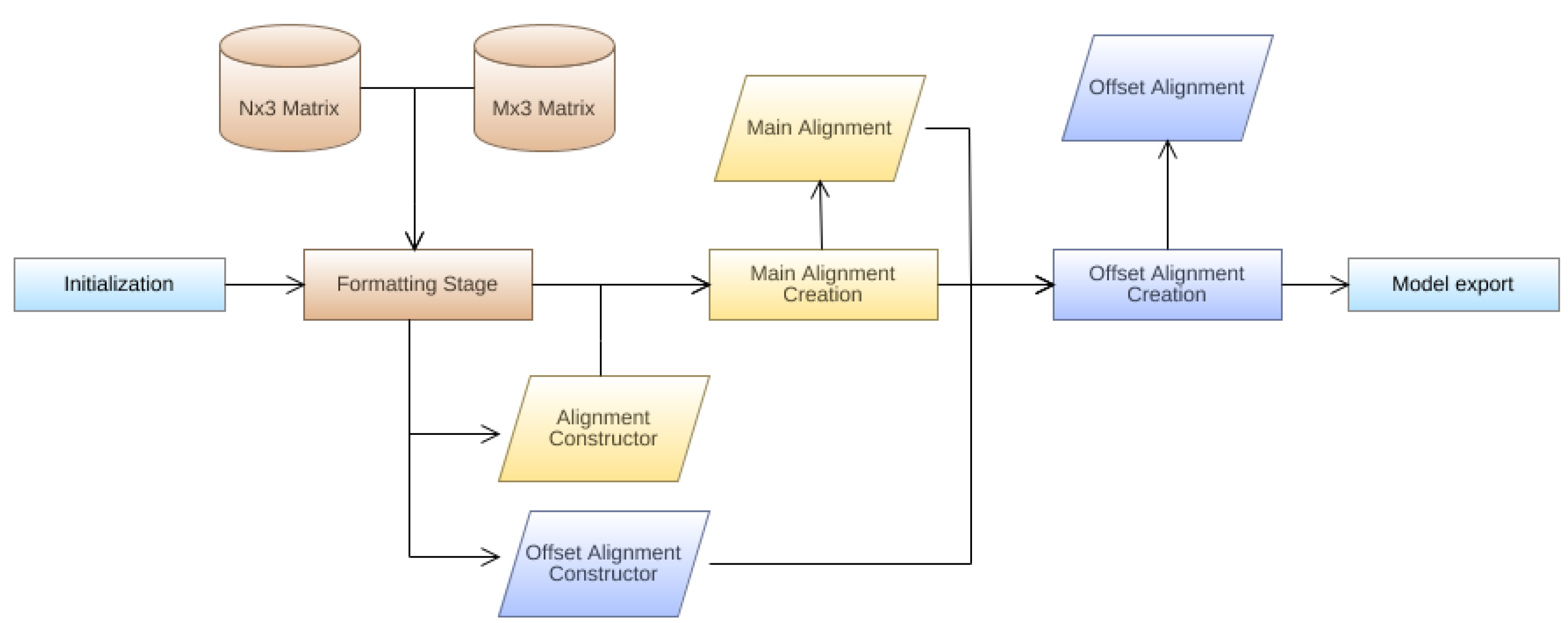
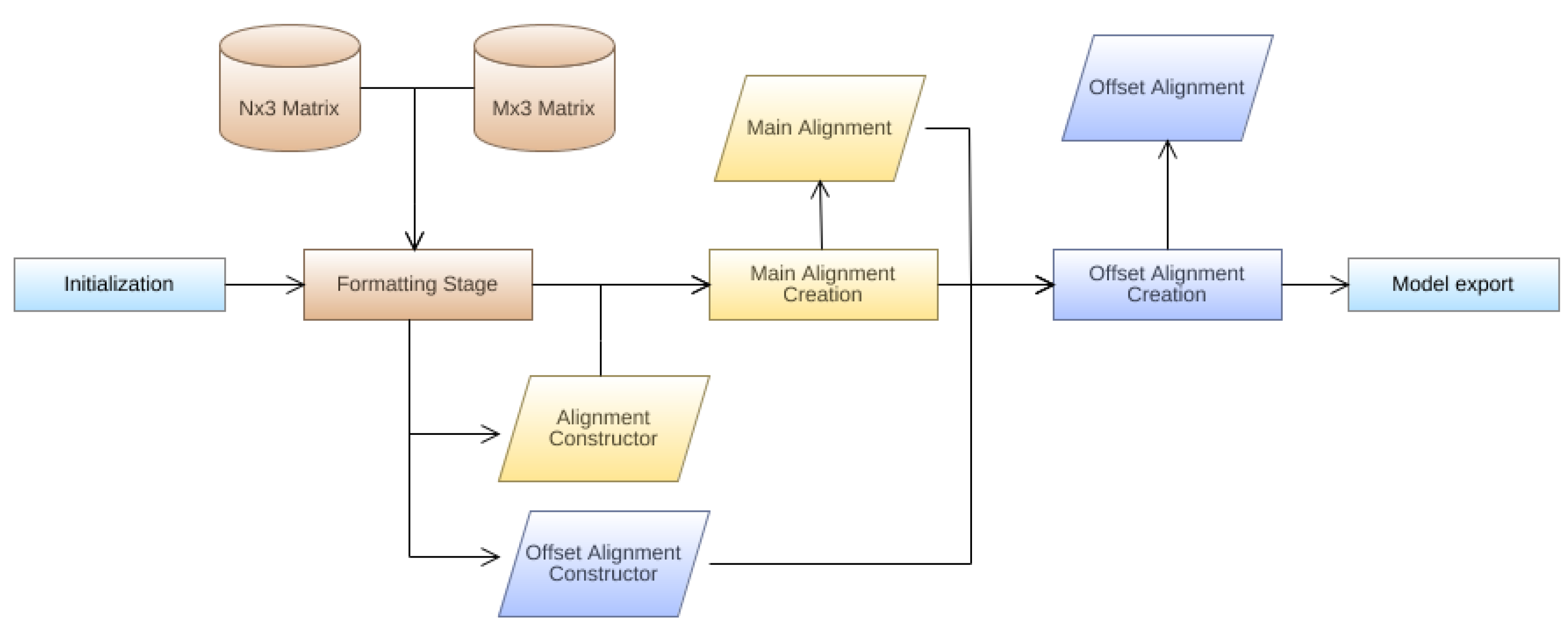
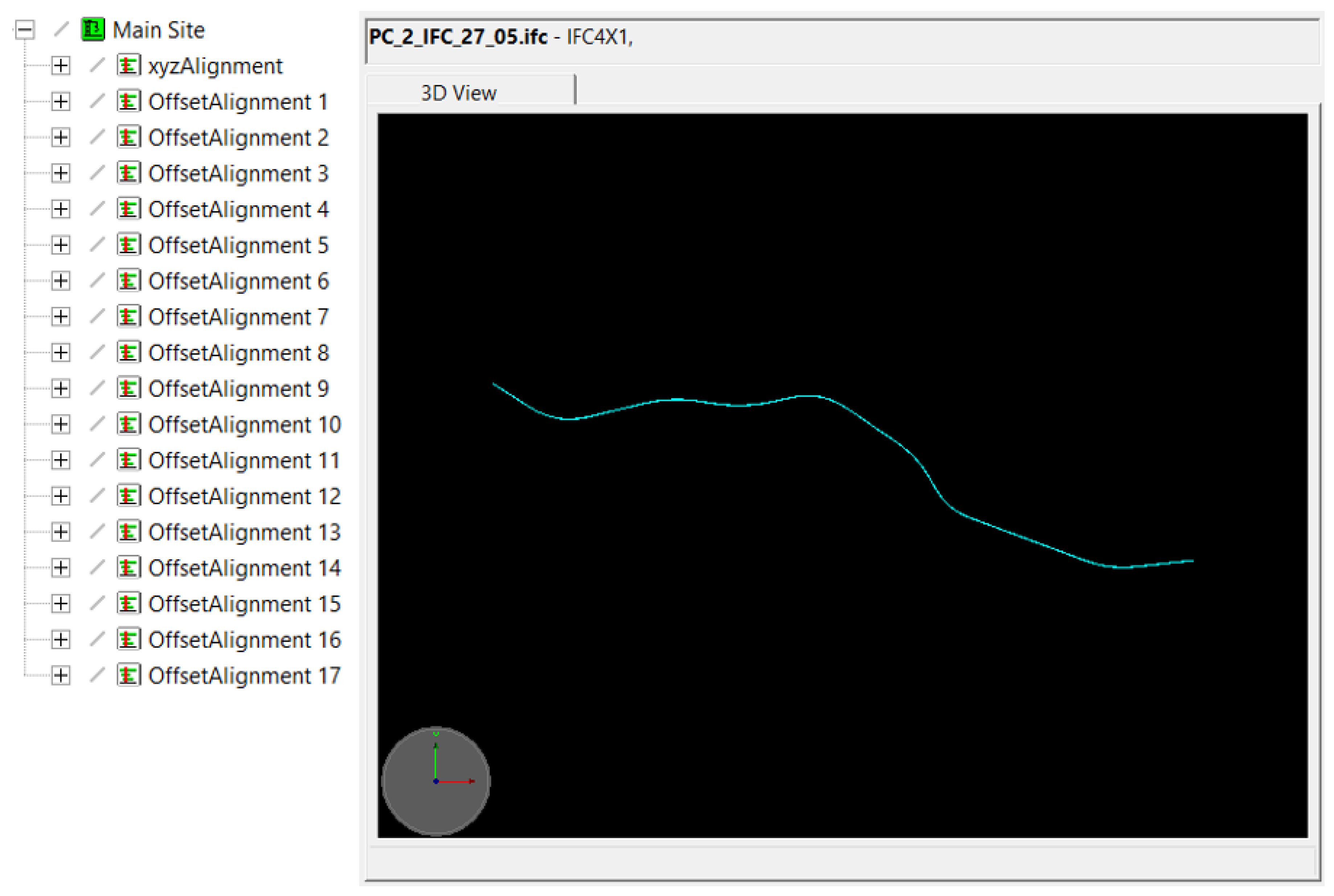
2.2.6. IFC Alignment Model Generation
3. Results
3.1. Parameters
3.2. Road Marking Detection and Processing
3.3. Alignment and Road Lane Processing
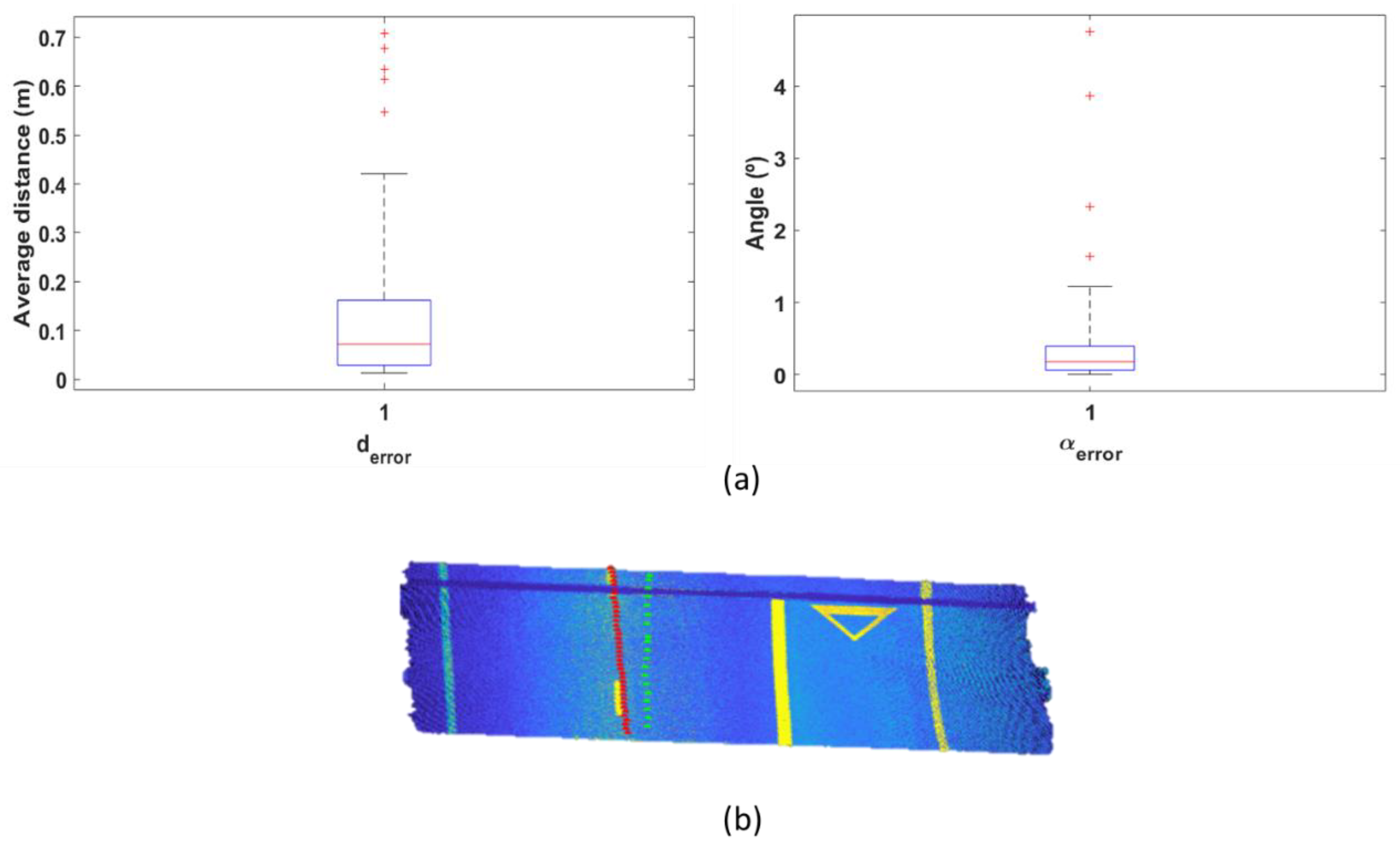
3.4. IFC Alignment Model Generation
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Borrmann, A.; König, M.; Koch, C.; Beetz, J. Building Information Modeling: Technology Foundations and Industry Practice; Springer: Berlin, Germany, 2018; ISBN 9783319928623. [Google Scholar]
- Costin, A.; Adibfar, A.; Hu, H.; Chen, S.S. Building Information Modeling (BIM) for transportation infrastructure–Literature review, applications, challenges, and recommendations. Autom. Constr. 2018, 94, 257–281. [Google Scholar] [CrossRef]
- Chong, H.Y.; Lopez, R.; Wang, J.; Wang, X.; Zhao, Z. Comparative analysis on the adoption and use of BIM in Road infrastructure projects. J. Manag. Eng. 2016, 32, 05016021. [Google Scholar] [CrossRef]
- Bradley, A.; Li, H.; Lark, R.; Dunn, S. BIM for infrastructure: An overall review and constructor perspective. Autom. Constr. 2016, 71, 139–152. [Google Scholar] [CrossRef]
- IFC Release Notes–building SMART Technical. Available online: https://technical.buildingsmart.org/standards/ifc/ifc-schema-specifications/ifc-release-notes/ (accessed on 17 July 2020).
- Pătrăucean, V.; Armeni, I.; Nahangi, M.; Yeung, J.; Brilakis, I.; Haas, C. State of research in automatic as-built modelling. Adv. Eng. Inform. 2015, 29, 162–171. [Google Scholar] [CrossRef] [Green Version]
- Sacks, R.; Kedar, A.; Borrmann, A.; Ma, L.; Brilakis, I.; Hüthwohl, P.; Daum, S.; Kattel, U.; Yosef, R.; Liebich, T.; et al. SeeBridge as next generation bridge inspection: Overview, information delivery manual and model view definition. Autom. Constr. 2018, 90, 134–145. [Google Scholar] [CrossRef] [Green Version]
- Guan, H.; Li, J.; Cao, S.; Yu, Y. Use of mobile LiDAR in road information inventory: A review. Int. J. Image Data Fusion 2016, 7, 219–242. [Google Scholar] [CrossRef]
- Gargoum, S.A.; El-Basyouny, K. Automated extraction of road features using LiDAR data: A review of LiDAR applications in transportation. In Proceedings of the 2017 4th International Conference on Transportation Information and Safety (ICTIS), Baniff, AB, Canada, 8–10 August 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 563–574. [Google Scholar]
- Ma, L.; Li, Y.; Li, J.; Wang, C.; Wang, R.; Chapman, M.A. Mobile laser scanned point-clouds for road object detection and extraction: A review. Remote Sens. 2018, 10, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Soilán, M.; Sánchez-Rodríguez, A.; Del Río-Barral, P.; Perez-Collazo, C.; Arias, P.; Riveiro, B.; Rodríguez, S.; Barral, R.; Collazo, P. Review of laser scanning technologies and their applications for road and railway infrastructure monitoring. Infrastructures 2019, 4, 58. [Google Scholar] [CrossRef] [Green Version]
- Arcos-García, Á.; Soilán, M.; Álvarez-García, J.A.; Riveiro, B. Exploiting synergies of mobile mapping sensors and deep learning for traffic sign recognition systems. Expert Syst. Appl. 2017, 89, 286–295. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Wen, C.; Guan, H.; Luo, H.; Wang, C. Bag-of-visual-phrases and hierarchical deep models for traffic sign detection and recognition in mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2016, 113, 106–123. [Google Scholar] [CrossRef]
- Ai, C.; Tsai, Y.C. An automated sign retroreflectivity condition evaluation methodology using mobile LIDAR and computer vision. Transp. Res. Part C Emerg. Technol. 2016, 63, 96–113. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, C.; Lin, L.; Wen, C.; Yang, C.; Zhang, Z.; Li, J. Automated visual recognizability evaluation of traffic sign based on 3D LiDAR point clouds. Remote Sens. 2019, 11, 1453. [Google Scholar] [CrossRef] [Green Version]
- Novo, A.; González-Jorge, H.; Martínez-Sánchez, J.; González-De Santos, L.M.; Lorenzo, H. Automatic detection of forest-road distances to improve clearing operations in road management. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences. ISPRS Geospatial Week, Enschede, The Netherlands, 10–14 June 2019; pp. 1083–1088. [Google Scholar]
- Novo, A.; González-Jorge, H.; Martínez-Sánchez, J.; Lorenzo, H. Canopy detection over roads using mobile lidar data. Int. J. Remote Sens. 2019, 41, 1927–1942. [Google Scholar] [CrossRef]
- Zou, X.; Cheng, M.; Wang, C.; Xia, Y.; Li, J. Tree classification in complex forest point clouds based on deep learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2360–2364. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Wen, C. Bag of contextual-visual words for road scene object detection from mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3391–3406. [Google Scholar] [CrossRef]
- Luo, H.; Wang, C.; Wen, C.; Cai, Z.; Chen, Z.; Wang, H.; Yu, Y.; Li, J. Patch-based semantic labeling of road scene using colorized mobile LiDAR point clouds. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1286–1297. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Jia, F.; Wang, C. Learning hierarchical features for automated extraction of road markings from 3-D mobile LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 709–726. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Yu, Y.; Ji, Z.; Wang, C. Using mobile LiDAR data for rapidly updating road markings. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2457–2466. [Google Scholar] [CrossRef]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Segmentation and classification of road markings using MLS data. ISPRS J. Photogramm. Remote Sens. 2017, 123, 94–103. [Google Scholar] [CrossRef]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- Zhao, H. Recognizing Features in Mobile Laser Scanning Point Clouds Towards 3D High-definition Road Maps for Autonomous Vehicles. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2017. [Google Scholar]
- Ye, C.; Li, J.; Jiang, H.; Zhao, H.; Ma, L.; Chapman, M. Semi-automated generation of road transition lines using mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1877–1890. [Google Scholar] [CrossRef]
- Puente, I.; González-Jorge, H.; Riveiro, B.; Arias, P. Accuracy verification of the Lynx Mobile Mapper system. Opt. Laser Technol. 2013, 45, 578–586. [Google Scholar] [CrossRef]
- Douillard, B.; Underwood, J.; Kuntz, N.; Vlaskine, V.; Quadros, A.; Morton, P.; Frenkel, A. On the segmentation of 3D LIDAR point clouds. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2798–2805. [Google Scholar] [CrossRef]
- Otsu, N. Threshold selection method from grey-level histograms. IEEE Trans. Syst. Man. Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Traffic sign detection in MLS acquired point clouds for geometric and image-based semantic inventory. ISPRS J. Photogramm. Remote Sens. 2016, 114, 92–101. [Google Scholar] [CrossRef]
- Barazzetti, L.; Previtali, M.; Scaioni, M. Roads detection and parametrization in integrated BIM-GIS using LiDAR. Infrastructures 2020, 5, 55. [Google Scholar] [CrossRef]
- Liu, X.; Wang, X.; Wright, G.; Cheng, J.C.; Li, X.; Liu, R. A state-of-the-art review on the integration of building information modeling (BIM) and geographic information system (GIS). ISPRS Int. J. Geo-Inf. 2017, 6, 53. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Description |
|---|---|
| path | Path of the point cloud |
| indices | Indices of the marking in |
| points | Nx3 array with the coordinates of the marking |
| class | Class of the marking (solid, dashed, or others) |
| geometry | Geometric properties of the marking |
| line | Polynomic parametrization of the marking |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 0.05 m | 3.5 m | ||
| 0.05 | 10º | ||
| 1 m | 20 m | ||
| 0.15 m | 0.75 m | ||
| 15 | 0.75 m | ||
| 5 | 𝛼𝑡ℎ | 15º | |
| 0.5 | 50 m | ||
| 0.2 m | 0.999 | ||
| 0.98 | 1 m | ||
| 0.5 m | 0.5 m | ||
| 7.5 m | 100 m |
| Precision | Recall | F-score | ||
|---|---|---|---|---|
| 0.919 | 0.964 | 0.932 | 0.184 | 0.333 |
| GT/Prediction | Solid Line | Dashed Line |
|---|---|---|
| Solid Line | 99826 | 163 |
| Dashed Line | 466 | 13805 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soilán, M.; Justo, A.; Sánchez-Rodríguez, A.; Riveiro, B. 3D Point Cloud to BIM: Semi-Automated Framework to Define IFC Alignment Entities from MLS-Acquired LiDAR Data of Highway Roads. Remote Sens. 2020, 12, 2301. https://doi.org/10.3390/rs12142301
Soilán M, Justo A, Sánchez-Rodríguez A, Riveiro B. 3D Point Cloud to BIM: Semi-Automated Framework to Define IFC Alignment Entities from MLS-Acquired LiDAR Data of Highway Roads. Remote Sensing. 2020; 12(14):2301. https://doi.org/10.3390/rs12142301
Chicago/Turabian StyleSoilán, Mario, Andrés Justo, Ana Sánchez-Rodríguez, and Belén Riveiro. 2020. "3D Point Cloud to BIM: Semi-Automated Framework to Define IFC Alignment Entities from MLS-Acquired LiDAR Data of Highway Roads" Remote Sensing 12, no. 14: 2301. https://doi.org/10.3390/rs12142301
APA StyleSoilán, M., Justo, A., Sánchez-Rodríguez, A., & Riveiro, B. (2020). 3D Point Cloud to BIM: Semi-Automated Framework to Define IFC Alignment Entities from MLS-Acquired LiDAR Data of Highway Roads. Remote Sensing, 12(14), 2301. https://doi.org/10.3390/rs12142301