Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles

 ,
, 
 ,
,  ,
,
Abstract
:1. Introduction
2. EMSER-Guided MPs
2.1. MSER
2.2. EMSER-MPs
3. XGBoost
3.1. Conventional XGBoost
3.2. Meta-XGBoost
4. Data Sets and Setup
4.1. Datasets
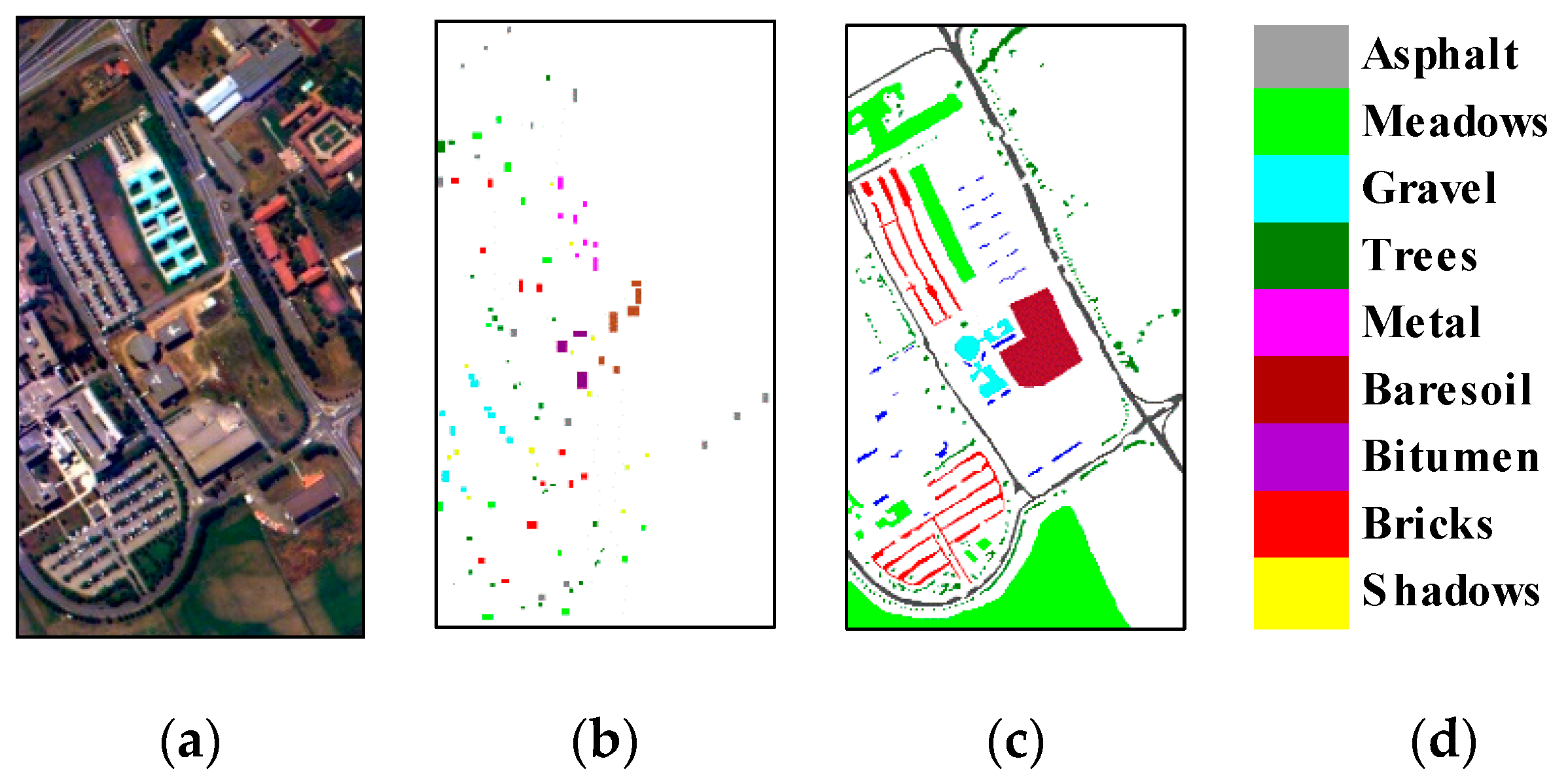
4.1.1. ROSIS Pavia University Data Set
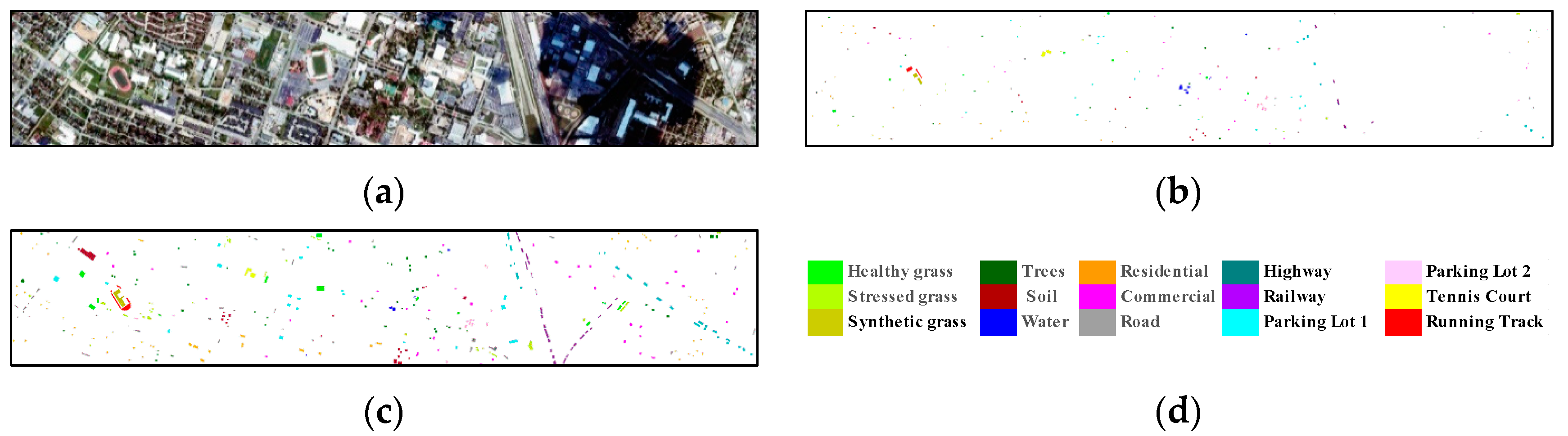
4.1.2. GRSS-DFC2013 Data Set
4.2. Experimental Setup
5. Analysis of Results and Discussion
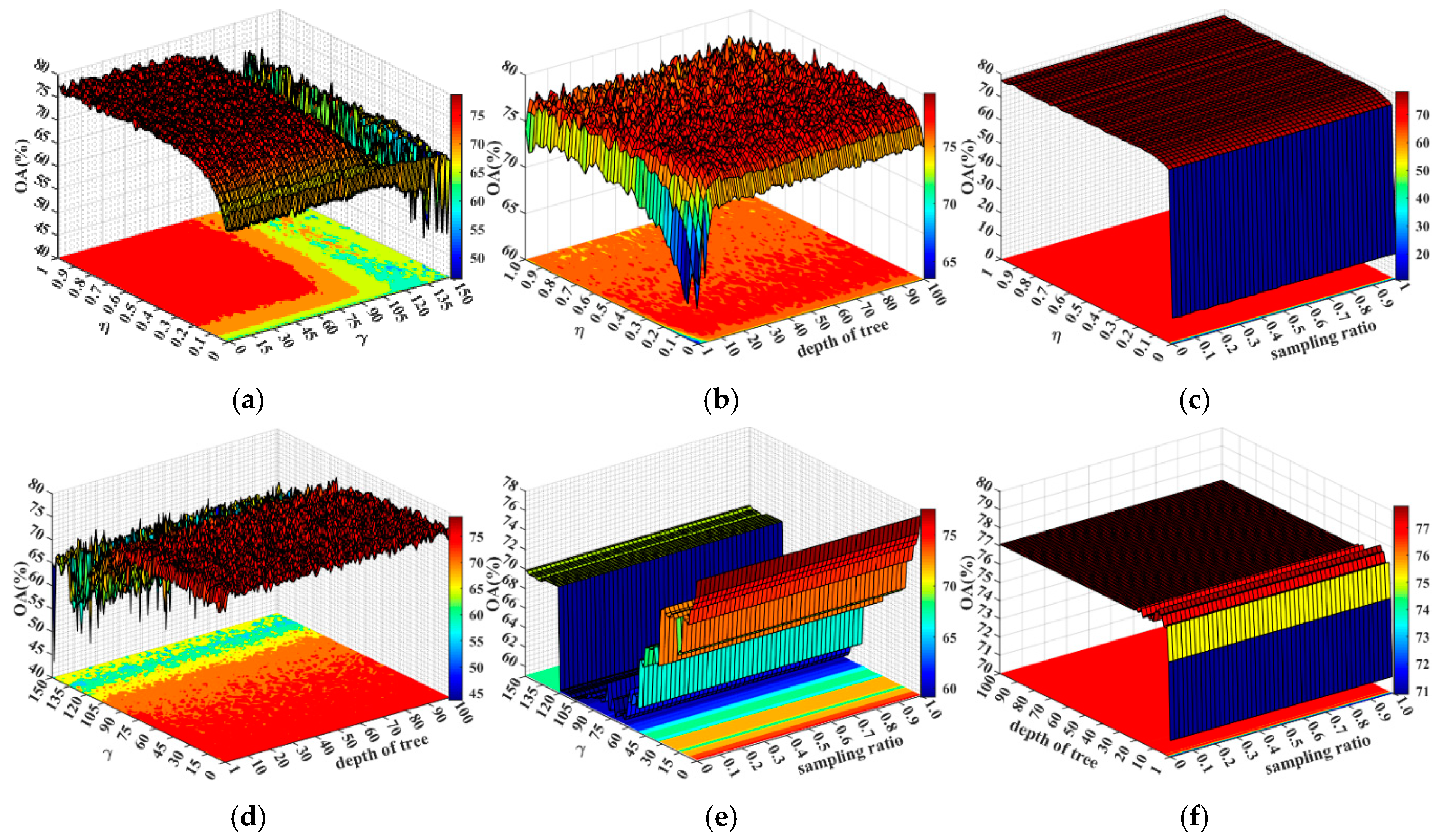
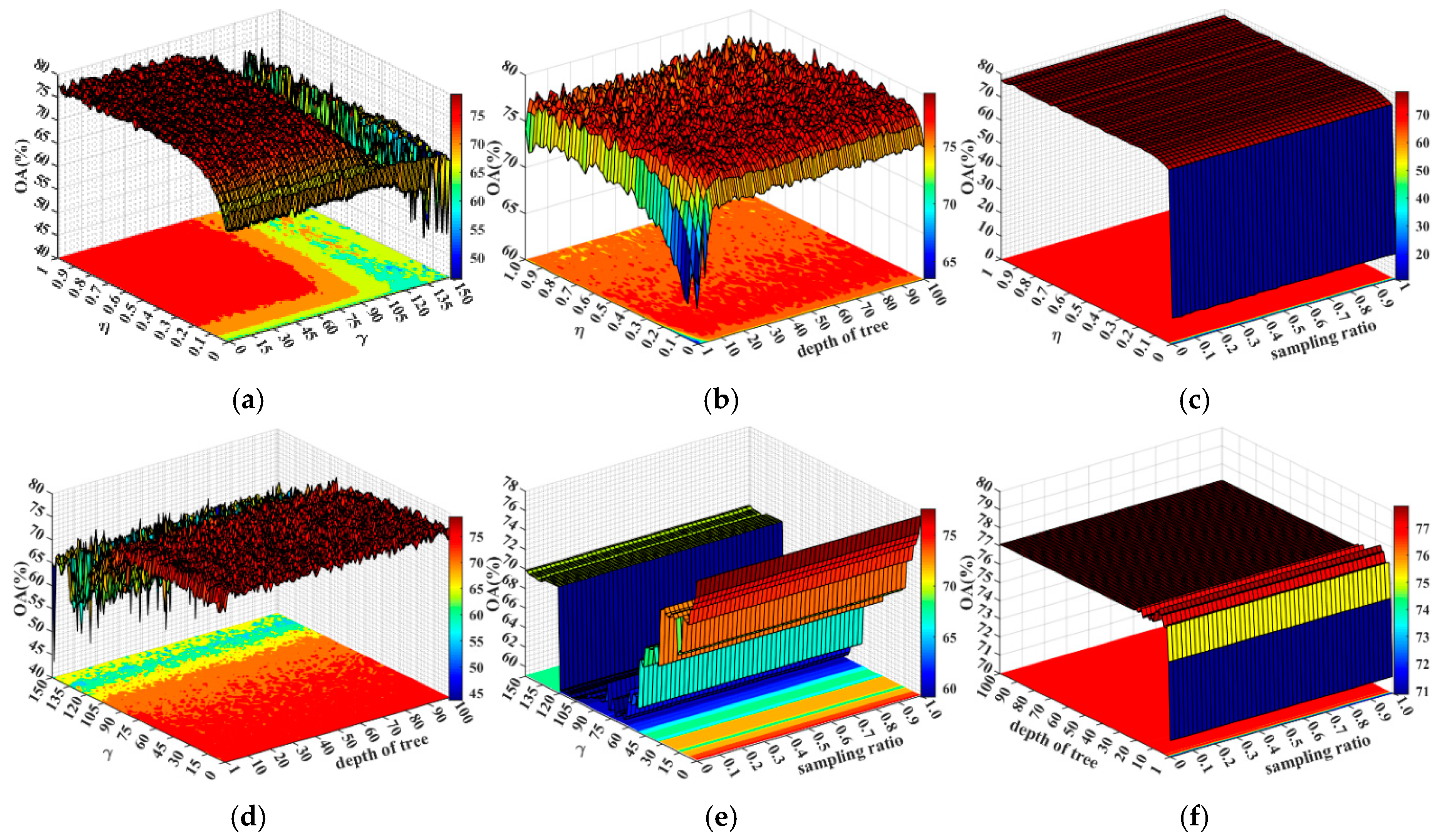
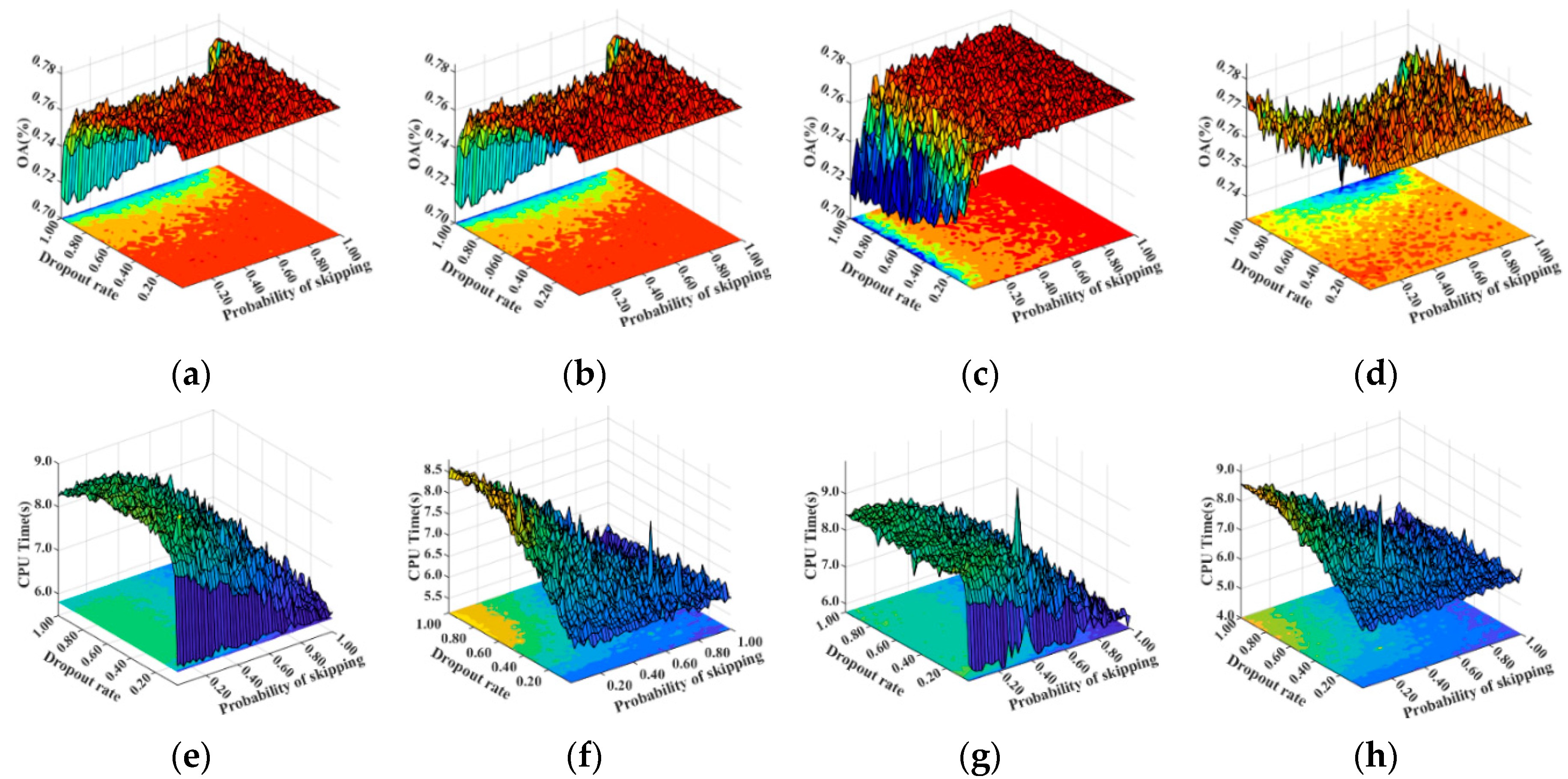
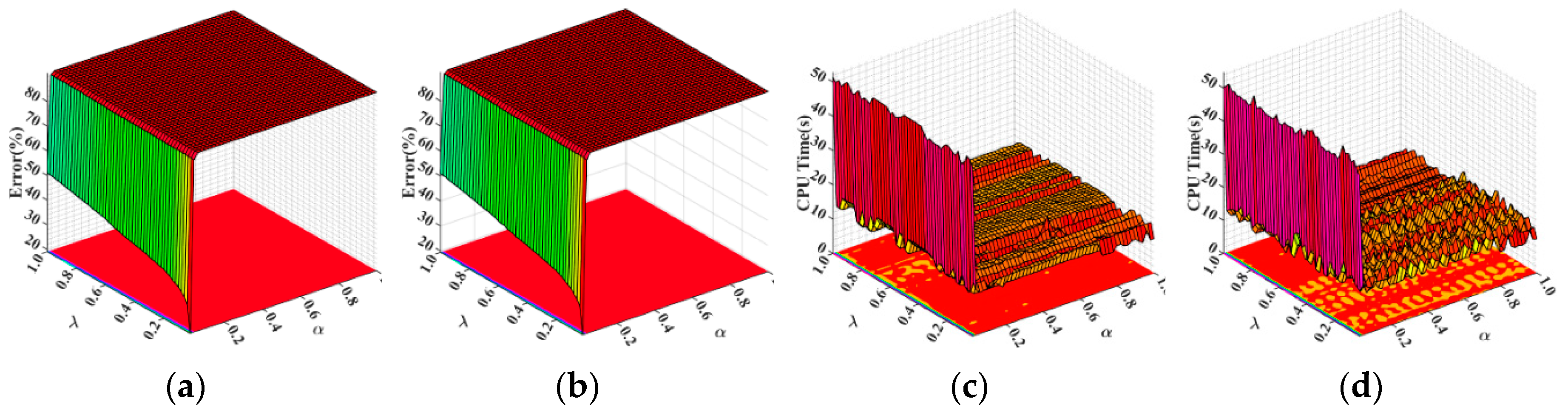
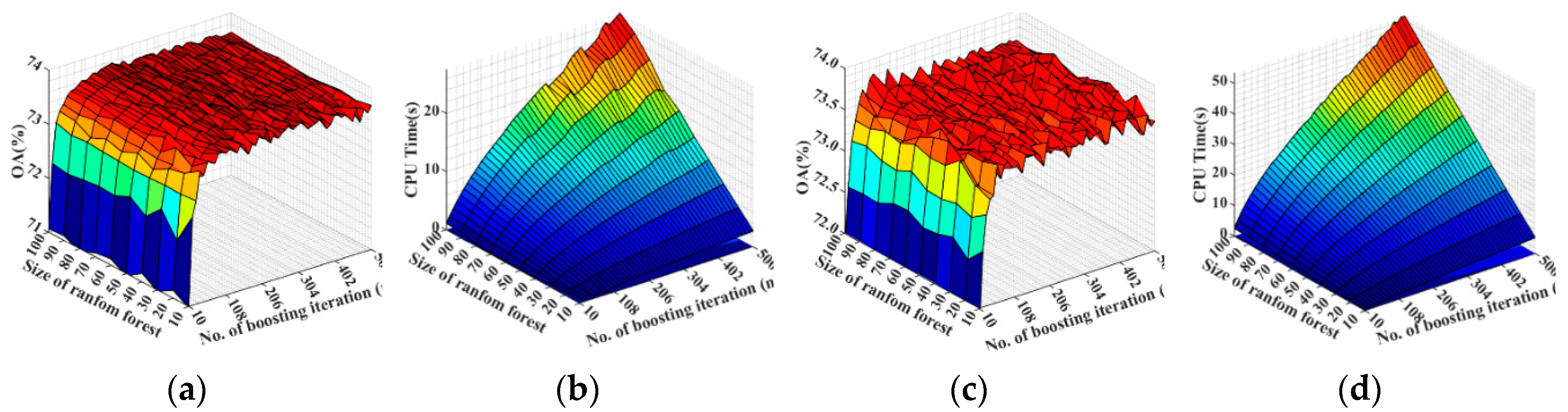
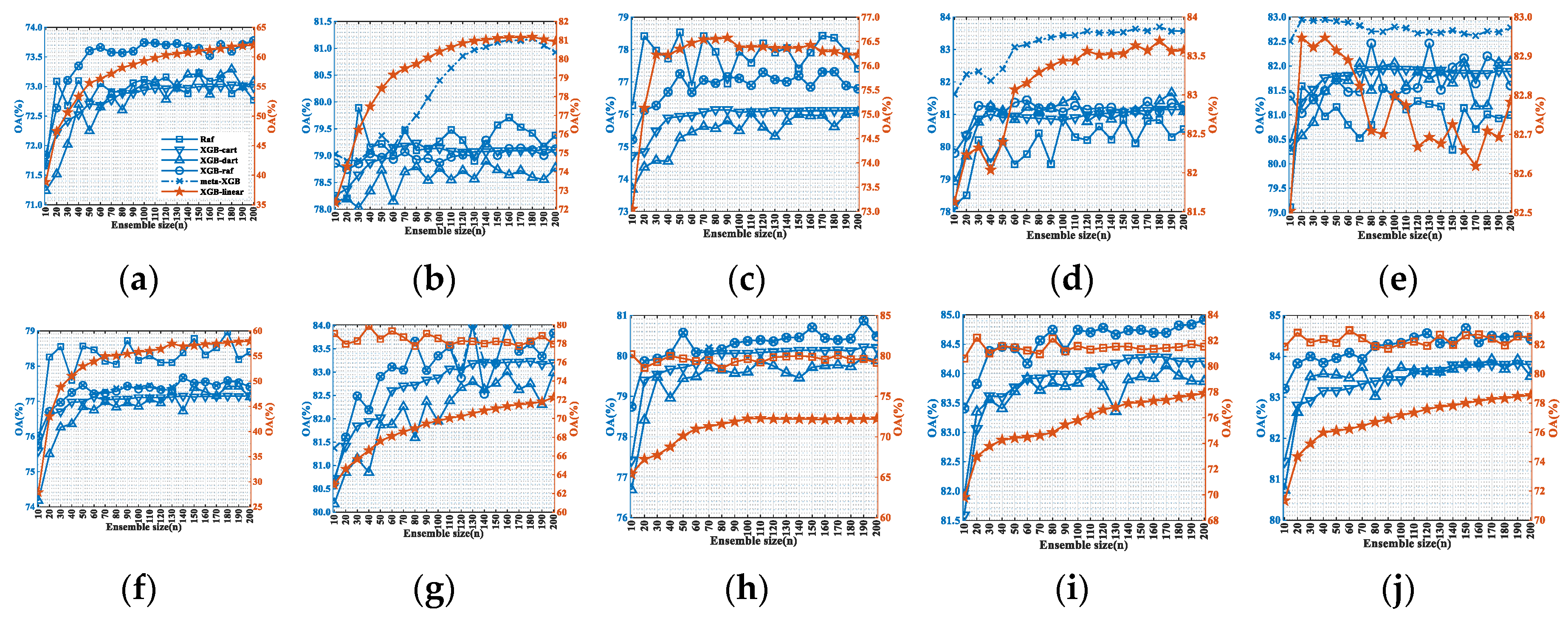
5.1. Parameter Configuration in XGBoost
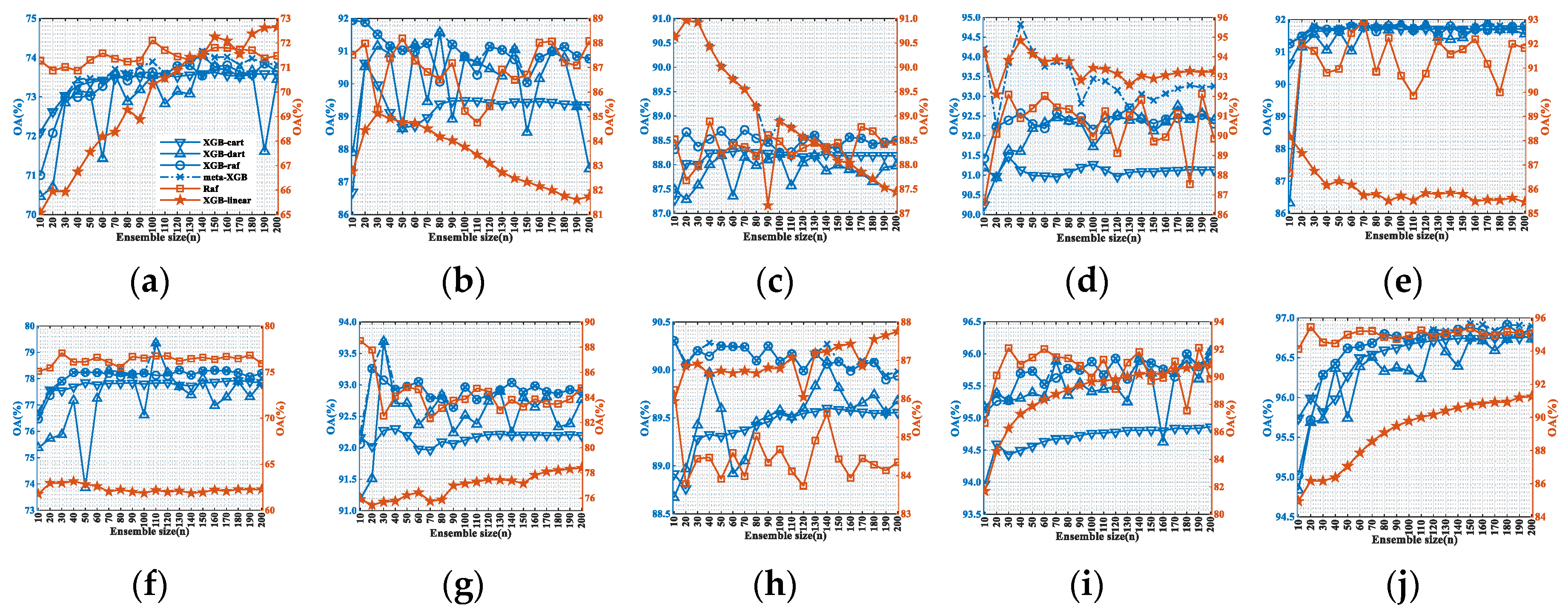
5.2. Classification Performance of Meta-XGBoost
5.2.1. Classification Accuracy
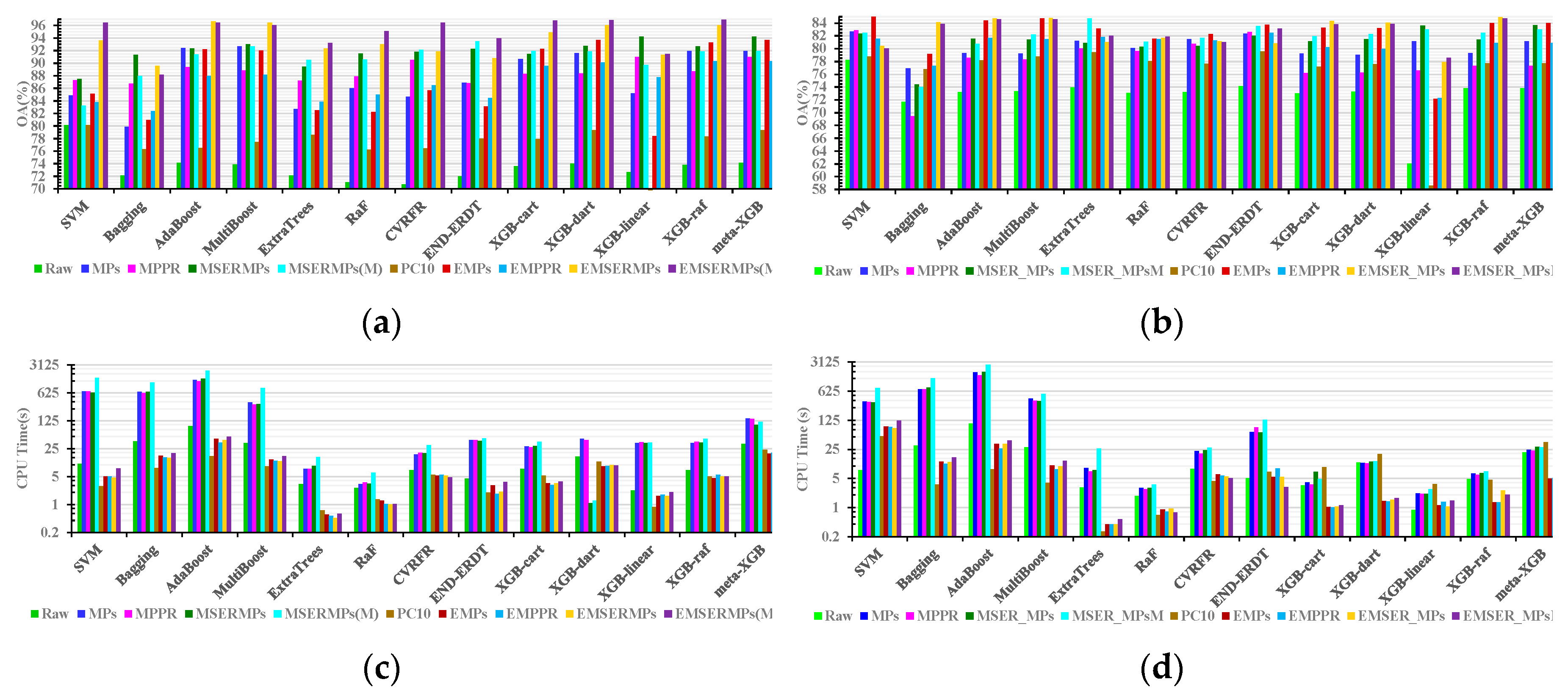
5.2.2. Computational Efficiency
5.3. Performance of EMSER_MPs
5.4. Classification Maps
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data and Software Availability
References
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Gamba, P.; Dell’Acqua, F.; Stasolla, M.; Trianni, G.; Lisini, G. Limits and challenges of optical high-resolution satellite remote sensing for urban applications. In Urban Remote Sensing—Monitoring, Synthesis and Modelling in the Urban Environment; Yang, X., Ed.; Wiley: New York, NY, USA, 2011; pp. 35–48. [Google Scholar]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef] [Green Version]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Samat, A.; Du, P.; Liu, S.; Li, J.; Cheng, L. E2LMs: Ensemble Extreme Learning Machines for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1060–1069. [Google Scholar] [CrossRef]
- Samat, A.; Persello, C.; Liu, S.; Li, E.; Miao, Z.; Abuduwaili, J. Classification of VHR multispectral images using extratrees and maximally stable extremal region-guided morphological profile. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3179–3195. [Google Scholar] [CrossRef]
- Samat, A.; Gamba, P.; Liu, S.; Miao, Z.; Li, E.; Abuduwaili, J. Quad-PolSAR data classification using modified random forest algorithms to map halophytic plants in arid areas. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 503–521. [Google Scholar] [CrossRef]
- Samat, A.; Yokoya, N.; Du, P.; Liu, S.; Ma, L.; Ge, Y.; Lin, C. Direct, ECOC, ND and END Frameworks—Which One Is the Best? An Empirical Study of Sentinel-2A MSIL1C Image Classification for Arid-Land Vegetation Mapping in the Ili River Delta, Kazakhstan. Remote Sens. 2019, 11, 1953. [Google Scholar] [CrossRef] [Green Version]
- Samat, A.; Li, J.; Liu, S.; Du, P.; Miao, Z.; Luo, J. Improved hyperspectral image classification by active learning using pre-designed mixed pixels. Pattern Recognit. 2016, 51, 43–58. [Google Scholar] [CrossRef]
- Du, P.; Bai, X.; Tan, K.; Xue, Z.; Samat, A.; Xia Ju Li, E.; Su, H.; Liu, W. Advances of Four Machine Learning Methods for Spatial Data Handling: A Review. J. Geovisualization Spat. Anal. 2020, 4, 13. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Learning nonlinear functions using regularized greedy forest. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 942–954. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ye, J.; Chow, J.H.; Chen, J.; Zheng, Z. Stochastic gradient boosted distributed decision trees. In Proceedings of the 18th ACM Conference on INFORMATION and Knowledge management, Hongkong, China, 2–6 November 2009; pp. 2061–2064. [Google Scholar]
- Ma, X.; Ding, C.; Luan, S.; Wang, Y.; Wang, Y. Prioritizing influential factors for freeway incident clearance time prediction using the gradient boosting decision trees method. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2303–2310. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Zha, H.; Zhang, T.; Chapelle, O.; Chen, K.; Sun, G. A general boosting method and its application to learning ranking functions for web search. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 12 December 2008; pp. 1697–1704. [Google Scholar]
- Lombardo, L.; Cama, M.; Conoscenti, C.; Märker, M.; Rotigliano, E. Binary logistic regression versus stochastic gradient boosted decision trees in assessing landslide susceptibility for multiple-occurring landslide events: Application to the 2009 storm event in Messina (Sicily, southern Italy). Nat. Hazards 2015, 79, 1621–1648. [Google Scholar] [CrossRef]
- Lin, L.; Yue, W.; Mao, Y. Multi-class image classification based on fast stochastic gradient boosting. Informatica 2014, 38, 145–153. [Google Scholar]
- Guelman, L. Gradient boosting trees for auto insurance loss cost modeling and prediction. Expert Syst. Appl. 2012, 39, 3659–3667. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Lawrence, R.; Bunn, A.; Powell, S.; Zambon, M. Classification of remotely sensed imagery using stochastic gradient boosting as a refinement of classification tree analysis. Remote Sens. Environ. 2004, 90, 331–336. [Google Scholar] [CrossRef]
- Moisen, G.G.; Freeman, E.A.; Blackard, J.A.; Frescino, T.S.; Zimmermann, N.E.; Edwards, T.C. Predicting tree species presence and basal area in Utah: A comparison of stochastic gradient boosting, generalized additive models, and tree-based methods. Ecol. Model. 2006, 199, 176–187. [Google Scholar] [CrossRef]
- Chirici, G.; Scotti, R.; Montaghi, A.; Barbati, A.; Cartisano, R.; Lopez, G.; Marchetti, M.; McRoberts, R.E.; Olsson, H.; Corona, P. Stochastic gradient boosting classification trees for forest fuel types mapping through airborne laser scanning and IRS LISS-III imagery. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 87–97. [Google Scholar] [CrossRef] [Green Version]
- Freeman, E.A.; Moisen, G.G.; Coulston, J.W.; Wilson, B.T. Random forests and stochastic gradient boosting for predicting tree canopy cover: Comparing tuning processes and model performance. Can. J. For. Res. 2015, 46, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Panda, B.; Herbach, J.S.; Basu, S.; Bayardo, R.J. Planet: Massively parallel learning of tree ensembles with mapreduce. Proc. Vldb Endow. 2009, 2, 1426–1437. [Google Scholar] [CrossRef]
- Meng, Q.; Ke, G.; Wang, T.; Chen, W.; Ye, Q.; Ma, Z.M.; Liu, T. A communication-efficient parallel algorithm for decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1279–1287. [Google Scholar]
- Chen, J.; Li, K.; Tang, Z.; Bilal, K.; Yu, S.; Weng, C.; Li, K. A parallel random forest algorithm for big data in a spark cloud computing environment. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 919–933. [Google Scholar] [CrossRef] [Green Version]
- Abuzaid, F.; Bradley, J.K.; Liang, F.T.; Feng, A.; Yang, L.; Zaharia, M.; Talwalkar, A.S. Yggdrasil: An Optimized System for Training Deep Decision Trees at Scale. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3817–3825. [Google Scholar]
- Zhang, H.; Si, S.; Hsieh, C.J. GPU-acceleration for Large-scale Tree Boosting. arXiv 2017, arXiv:1706.08359. [Google Scholar]
- Dong, H.; Xu, X.; Wang, L.; Pu, F. Gaofen-3 PolSAR image classification via XGBoost and polarimetric spatial information. Sensors 2018, 18, 611. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Chen, Z.; Yu, B.; Wang, L.; Wu, B.; Wu, J.; Zhao, F. Exploring the relationship between 2D/3D landscape pattern and land surface temperature based on explainable eXtreme Gradient Boosting tree: A case study of Shanghai, China. Sci. Total Environ. 2020, 725, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Eziz, A.; Xiao, J.; Tao, S.; Wang, S.; Tang, Z.; Fang, J. High-Resolution Vegetation Mapping Using eXtreme Gradient Boosting Based on Extensive Features. Remote Sens. 2019, 11, 1505. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhang, T.; Zhang, R.; Zhu, Z.; Yang, J.; Chen, P.; Ou, C.; Guo, Y. Extreme gradient boosting model to estimate PM2.5 concentrations with missing filled satellite data in China. Atmos. Environ. 2019, 202, 180–189. [Google Scholar] [CrossRef]
- Freund, Y. An adaptive version of the boost by majority algorithm. Mach. Learn. 2001, 43, 293–318. [Google Scholar] [CrossRef]
- Rashmi, K.V.; Gilad-Bachrach, R. DART: Dropouts meet Multiple Additive Regression Trees. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), San Diego, CA, USA, 9–12 May 2015; pp. 489–497. [Google Scholar]
- Bradley, J.K.; Kyrola, A.; Bickson, D.; Guestrin, C. Parallel coordinate descent for l1-regularized loss minimization. arXiv 2011, arXiv:1105.5379. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; He, T.; Benesty, M. xgboost: Extreme Gradient Boosting; R Package Version 0.3-0; Technical Report; R Foundation for Statistical Computing: Vienna, Austria.
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Donoser, M.; Bischof, H. Efficient maximally stable extremal region (MSER) tracking. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 553–560. [Google Scholar]
- Forssén, P.E. Maximally stable colour regions for recognition and matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Mitchell, R.; Frank, E. Accelerating the XGBoost algorithm using GPU computing. Peerj Comput. Sci. 2017, 3, e127. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; van Kasteren, T.; Philips, W. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Bauer, E.; Kohavi, R. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- Benbouzid, D.; Busa-Fekete, R.; Casagrande, N.; Collin, F.D.; Kégl, B. MultiBoost: A multi-purpose boosting package. J. Mach. Learn. Res. 2012, 13, 549–553. [Google Scholar]
- Liao, W.; Dalla Mura, M.; Chanussot, J.; Bellens, R.; Philips, W. Morphological attribute profiles with partial reconstruction. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1738–1756. [Google Scholar] [CrossRef]
- Liao, W.; Chanussot, J.; Dalla Mura, M.; Huang, X.; Bellens, R.; Gautama, S.; Philips, W. Taking Optimal Advantage of Fine Spatial Resolution: Promoting partial image reconstruction for the morphological analysis of very-high-resolution images. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–28. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AdaBoost | Adaptive boosting | MSER_MPs | Maximally stable extreme-region-guided morphological profiles |
| CART | Classification and regression tree | MSER_MPsM | MSER_MPs with mean pixel values within region |
| CBR | Closing by partial reconstruction | MultiBoost | Multiclass Adaboost |
| CVRFR | Classification via random forest regression | MV | Majority voting |
| DART | Dropout-introduced multiple additive regression tree | NCALM | NSF-funded Center for Airborne Laser Mapping |
| DFTC | Data Fusion Technical Committee | OA | Overall accuracy |
| DL | Deep learning | OBR | Opening by partial reconstruction |
| DTs | Decision trees | PCA | Principal component analysis |
| EMSER_MPs | Extended maximally stable extreme-region-guided morphological profiles | PM2.5 | Particle matters less than 2.5 micrometers in diameter |
| EMSER_MPsM | EMSER_MPs with mean pixel values within region | PV-Tree | Parallel voting DT |
| END-ERDT | Ensemble of nested dichotomies with extremely randomized decision tree | PolSAR | Polarimetric SAR |
| ERM | Empirical risk minimization | PRF | Parallel random forest |
| ExtraTrees | Extremely randomized decision trees | RaF | Random forest |
| GBDT | Gradient-boosting decision trees | RBF | Radial basis function |
| GRSS | Geoscience and Remote Sensing Society | RGF | Regularized greedy forest |
| HR | High resolution | ROSIS | Reflective Optics System Imaging Spectrometer |
| LightGBM | Light gradient boosting machine | SAR | Synthetic aperture radar |
| EL | Ensemble learning | SE | Structural element |
| EMPs | Extended MPs | SVM | Support vector machine |
| EMPPR | Extended MPPR | SGBDT | Stochastic GBDT |
| MARTs | Multiple additive regression trees | XGBoost | Extreme gradient boosting |
| MPs | Morphological profiles | VHR | Very high resolution |
| MPPR | Morphological profile with partial reconstruction | IRS | Indian remote sensing satelllite |
| MSER | Maximally stable extreme region | LISS-III | Linear image self scanning system III |
| Class No. | Class | Test | Training |
|---|---|---|---|
| 1 | Asphalt | 6631 | 548 |
| 2 | Meadows | 18,649 | 540 |
| 3 | Gravel | 2099 | 392 |
| 4 | Trees | 3064 | 524 |
| 5 | Metal | 1345 | 265 |
| 6 | Bare soil | 5029 | 532 |
| 7 | Bitumen | 1330 | 375 |
| 8 | Bricks | 3682 | 514 |
| 9 | Shadows | 947 | 231 |
| Class No. | Class | Training | Test | Class No. | Class | Training | Test |
|---|---|---|---|---|---|---|---|
| 1 | Healthy grass | 198 | 1053 | 9 | Road | 193 | 1053 |
| 2 | Stressed grass | 190 | 1064 | 10 | Highway | 191 | 1036 |
| 3 | Synthetic grass | 192 | 505 | 11 | Railway | 181 | 1050 |
| 4 | Trees | 188 | 1056 | 12 | Parking Lot 1 | 192 | 1041 |
| 5 | Soil | 186 | 1056 | 13 | Parking Lot 2 | 184 | 285 |
| 6 | Water | 182 | 143 | 14 | Tennis Court | 181 | 247 |
| 7 | Residential | 196 | 1072 | 15 | Running Track | 187 | 473 |
| 8 | Commercial | 191 | 1046 |
| Features | Raw | MPs | MPPR | MSERMPs | MSERMPs(M) | PC10 | EMPs | EMPPR | EMSERMPs | EMSERMPs(M) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k |
| SVM | 80.18 | 0.75 | 84.86 | 0.81 | 87.25 | 0.83 | 87.50 | 0.84 | 83.29 | 0.79 | 80.16 | 0.75 | 85.15 | 0.81 | 83.79 | 0.79 | 93.62 | 0.92 | 86.72 | 0.83 |
| Bagging | 72.18 | 0.66 | 79.90 | 0.74 | 86.74 | 0.82 | 91.32 | 0.88 | 87.96 | 0.84 | 76.36 | 0.70 | 80.97 | 0.76 | 82.42 | 0.77 | 89.59 | 0.87 | 88.15 | 0.85 |
| AdaBoost | 74.18 | 0.68 | 92.44 | 0.90 | 89.38 | 0.86 | 92.34 | 0.90 | 91.41 | 0.89 | 76.51 | 0.71 | 92.21 | 0.89 | 87.93 | 0.84 | 96.63 | 0.96 | 96.46 | 0.95 |
| MultiBoost | 73.91 | 0.68 | 92.66 | 0.90 | 88.80 | 0.85 | 93.03 | 0.91 | 92.71 | 0.90 | 77.49 | 0.72 | 92.01 | 0.89 | 88.18 | 0.84 | 96.44 | 0.95 | 96.04 | 0.95 |
| ExtraTrees | 72.18 | 0.66 | 82.69 | 0.78 | 87.22 | 0.83 | 89.41 | 0.86 | 90.53 | 0.88 | 78.63 | 0.73 | 82.53 | 0.78 | 83.84 | 0.79 | 92.33 | 0.90 | 93.22 | 0.91 |
| RaF | 71.08 | 0.64 | 85.99 | 0.82 | 87.85 | 0.84 | 91.54 | 0.89 | 90.56 | 0.88 | 76.29 | 0.70 | 82.29 | 0.77 | 84.99 | 0.80 | 93.02 | 0.91 | 95.06 | 0.94 |
| CVRFR | 70.73 | 0.64 | 84.70 | 0.80 | 90.50 | 0.87 | 91.78 | 0.89 | 92.16 | 0.89 | 76.48 | 0.71 | 85.71 | 0.82 | 86.49 | 0.82 | 91.88 | 0.90 | 96.43 | 0.95 |
| END-ERDT | 72.01 | 0.66 | 86.88 | 0.83 | 86.77 | 0.84 | 92.29 | 0.90 | 93.46 | 0.91 | 78.03 | 0.73 | 83.15 | 0.79 | 84.46 | 0.80 | 90.78 | 0.88 | 93.91 | 0.92 |
| XGB-CART | 73.63 | 0.68 | 90.63 | 0.87 | 88.30 | 0.84 | 91.47 | 0.89 | 91.89 | 0.89 | 77.93 | 0.72 | 92.28 | 0.90 | 89.60 | 0.86 | 94.86 | 0.93 | 96.77 | 0.96 |
| XGB-DART | 74.06 | 0.68 | 91.57 | 0.89 | 88.39 | 0.84 | 92.75 | 0.90 | 91.85 | 0.89 | 79.34 | 0.74 | 93.69 | 0.92 | 90.08 | 0.86 | 96.04 | 0.95 | 96.85 | 0.96 |
| XGB-linear | 72.65 | 0.66 | 85.19 | 0.81 | 90.96 | 0.88 | 94.21 | 0.92 | 89.70 | 0.86 | 63.16 | 0.55 | 78.39 | 0.73 | 87.75 | 0.84 | 91.35 | 0.89 | 91.49 | 0.89 |
| XGB-RaF | 73.85 | 0.68 | 91.95 | 0.90 | 88.71 | 0.85 | 92.70 | 0.90 | 91.84 | 0.89 | 78.33 | 0.73 | 93.26 | 0.91 | 90.31 | 0.87 | 96.00 | 0.95 | 96.91 | 0.97 |
| meta-XGB | 74.17 | 0.68 | 91.95 | 0.90 | 90.96 | 0.88 | 94.21 | 0.92 | 91.94 | 0.89 | 79.34 | 0.74 | 93.69 | 0.92 | 90.31 | 0.87 | 96.04 | 0.95 | 96.93 | 0.97 |
| Features | Raw | MPs | MPPR | MSER_MPs | MSER_MPsM | PC10 | EMPs | EMPPR | EMSER_MPs | EMSER_MPsM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k | OA | k |
| SVM | 78.27 | 0.77 | 82.70 | 0.81 | 82.85 | 0.81 | 82.32 | 0.81 | 82.49 | 0.81 | 78.78 | 0.77 | 85.07 | 0.84 | 81.53 | 0.80 | 80.44 | 0.79 | 80.01 | 0.78 |
| Bagging | 71.72 | 0.71 | 76.95 | 0.75 | 69.49 | 0.67 | 74.43 | 0.72 | 73.97 | 0.72 | 76.79 | 0.75 | 79.18 | 0.78 | 77.31 | 0.75 | 84.14 | 0.83 | 83.89 | 0.83 |
| AdaBoost | 73.23 | 0.71 | 79.33 | 0.78 | 78.58 | 0.77 | 81.56 | 0.80 | 80.75 | 0.79 | 78.20 | 0.76 | 84.38 | 0.83 | 81.71 | 0.80 | 84.72 | 0.83 | 84.55 | 0.83 |
| MultiBoost | 73.35 | 0.71 | 79.21 | 0.78 | 78.34 | 0.77 | 81.44 | 0.80 | 82.21 | 0.81 | 78.76 | 0.77 | 84.72 | 0.83 | 81.49 | 0.80 | 84.78 | 0.83 | 84.55 | 0.83 |
| ExtraTrees | 73.89 | 0.72 | 81.22 | 0.80 | 80.02 | 0.78 | 80.84 | 0.79 | 84.74 | 0.83 | 79.45 | 0.78 | 83.14 | 0.82 | 81.81 | 0.80 | 80.98 | 0.79 | 82.02 | 0.81 |
| RaF | 73.12 | 0.71 | 80.09 | 0.78 | 79.59 | 0.78 | 80.26 | 0.79 | 81.07 | 0.80 | 78.07 | 0.76 | 81.56 | 0.80 | 81.50 | 0.80 | 81.66 | 0.80 | 81.84 | 0.80 |
| CVRFR | 73.24 | 0.71 | 81.46 | 0.80 | 80.72 | 0.79 | 80.40 | 0.79 | 81.67 | 0.80 | 77.65 | 0.76 | 82.27 | 0.81 | 81.26 | 0.80 | 81.12 | 0.80 | 80.99 | 0.80 |
| END-ERDT | 74.10 | 0.72 | 82.32 | 0.81 | 82.59 | 0.81 | 81.98 | 0.81 | 83.51 | 0.82 | 79.52 | 0.78 | 83.72 | 0.82 | 82.46 | 0.81 | 80.77 | 0.79 | 83.10 | 0.82 |
| XGB-CART | 73.03 | 0.71 | 79.24 | 0.78 | 76.14 | 0.74 | 81.16 | 0.80 | 81.93 | 0.80 | 77.16 | 0.75 | 83.23 | 0.82 | 80.22 | 0.79 | 84.28 | 0.83 | 83.81 | 0.83 |
| XGB-DART | 73.29 | 0.71 | 79.01 | 0.77 | 76.27 | 0.74 | 81.49 | 0.80 | 82.30 | 0.81 | 77.59 | 0.76 | 83.17 | 0.82 | 79.97 | 0.78 | 84.05 | 0.83 | 83.88 | 0.83 |
| XGB-linear | 62.10 | 0.59 | 81.17 | 0.80 | 76.57 | 0.75 | 83.58 | 0.82 | 82.97 | 0.82 | 58.63 | 0.55 | 72.17 | 0.70 | 72.32 | 0.70 | 77.90 | 0.76 | 78.56 | 0.77 |
| XGB-RaF | 73.78 | 0.72 | 79.29 | 0.77 | 77.32 | 0.75 | 81.44 | 0.80 | 82.46 | 0.81 | 77.67 | 0.76 | 84.01 | 0.82 | 80.89 | 0.79 | 84.92 | 0.84 | 84.69 | 0.84 |
| meta-XGB | 73.78 | 0.72 | 81.19 | 0.80 | 77.67 | 0.75 | 83.69 | 0.82 | 82.95 | 0.81 | 77.67 | 0.76 | 84.01 | 0.82 | 80.89 | 0.79 | 84.92 | 0.84 | 84.69 | 0.84 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samat, A.; Li, E.; Wang, W.; Liu, S.; Lin, C.; Abuduwaili, J. Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sens. 2020, 12, 1973. https://doi.org/10.3390/rs12121973
Samat A, Li E, Wang W, Liu S, Lin C, Abuduwaili J. Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sensing. 2020; 12(12):1973. https://doi.org/10.3390/rs12121973
Chicago/Turabian StyleSamat, Alim, Erzhu Li, Wei Wang, Sicong Liu, Cong Lin, and Jilili Abuduwaili. 2020. "Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles" Remote Sensing 12, no. 12: 1973. https://doi.org/10.3390/rs12121973
APA StyleSamat, A., Li, E., Wang, W., Liu, S., Lin, C., & Abuduwaili, J. (2020). Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sensing, 12(12), 1973. https://doi.org/10.3390/rs12121973