Using Multi-Temporal MODIS NDVI Data to Monitor Tea Status and Forecast Yield: A Case Study at Tanuyen, Laichau, Vietnam


Abstract

1. Introduction
2. Materials and Methods
2.1. Materials
2.1.1. Sentinel-2
2.1.2. Moderate Resolution Imaging Spectroradiometer Vegetation Index Data
2.1.3. The Other Data
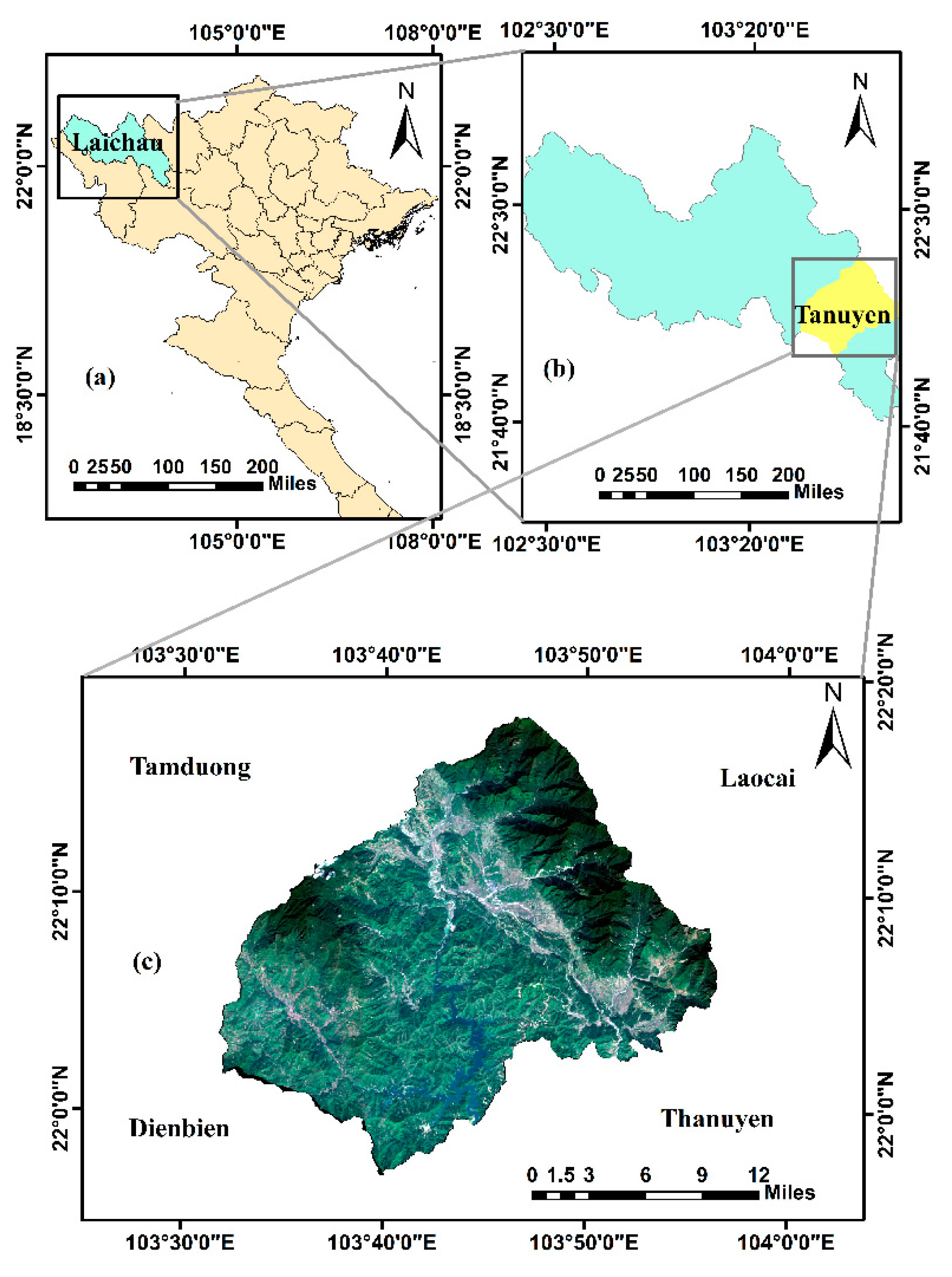
2.1.4. Study Area
2.2. Methods
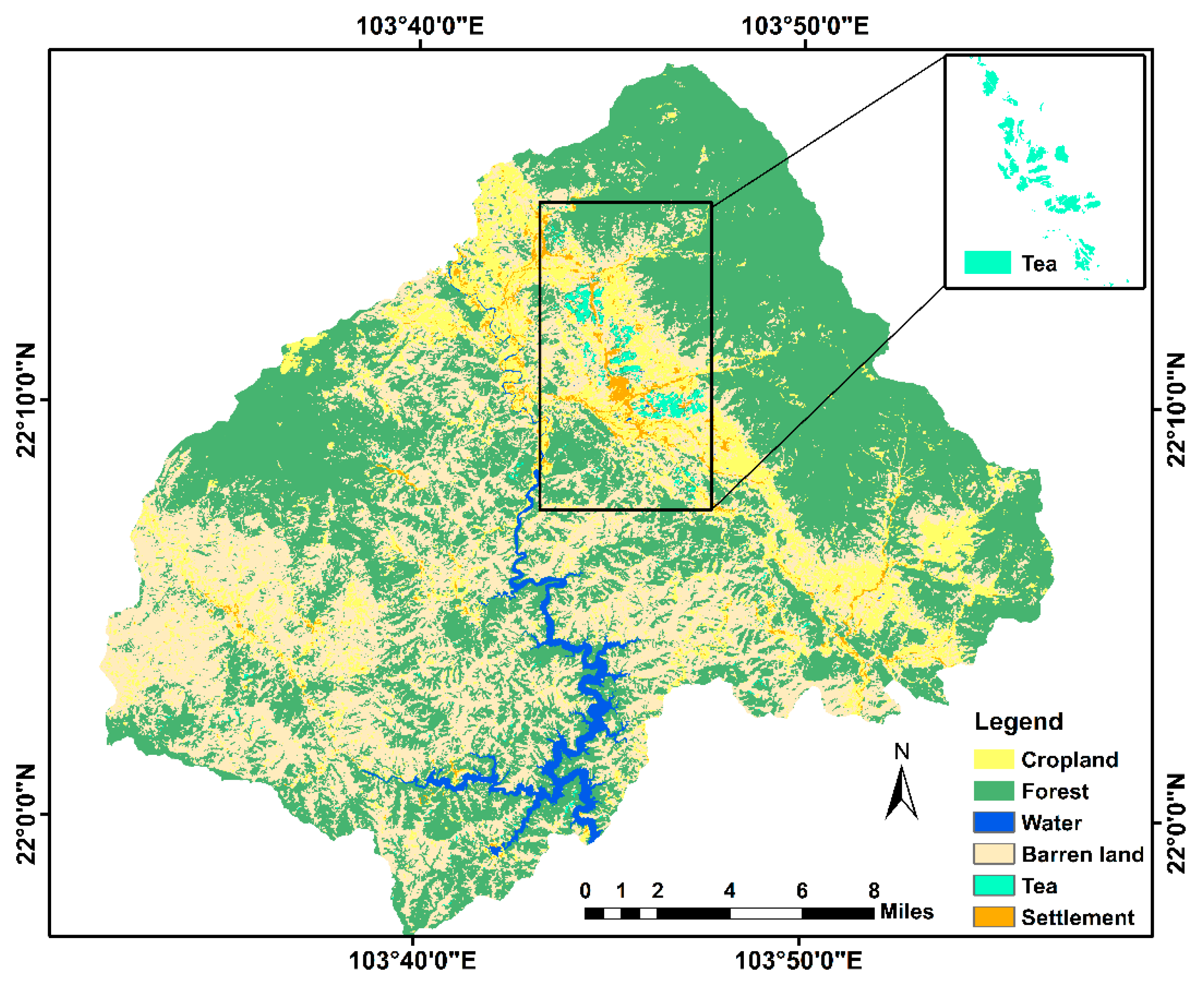
2.2.1. Land-Use/Land-Cover Map
2.2.2. Calculating the Mean Normalized Difference Vegetation Index (NDVI) Value of Tea
2.2.3. Predicting Tea Yield Methods
3. Results
3.1. Landuse–Landcover Classification and Normalized Difference Vegetation Index (NDVI) Analysis
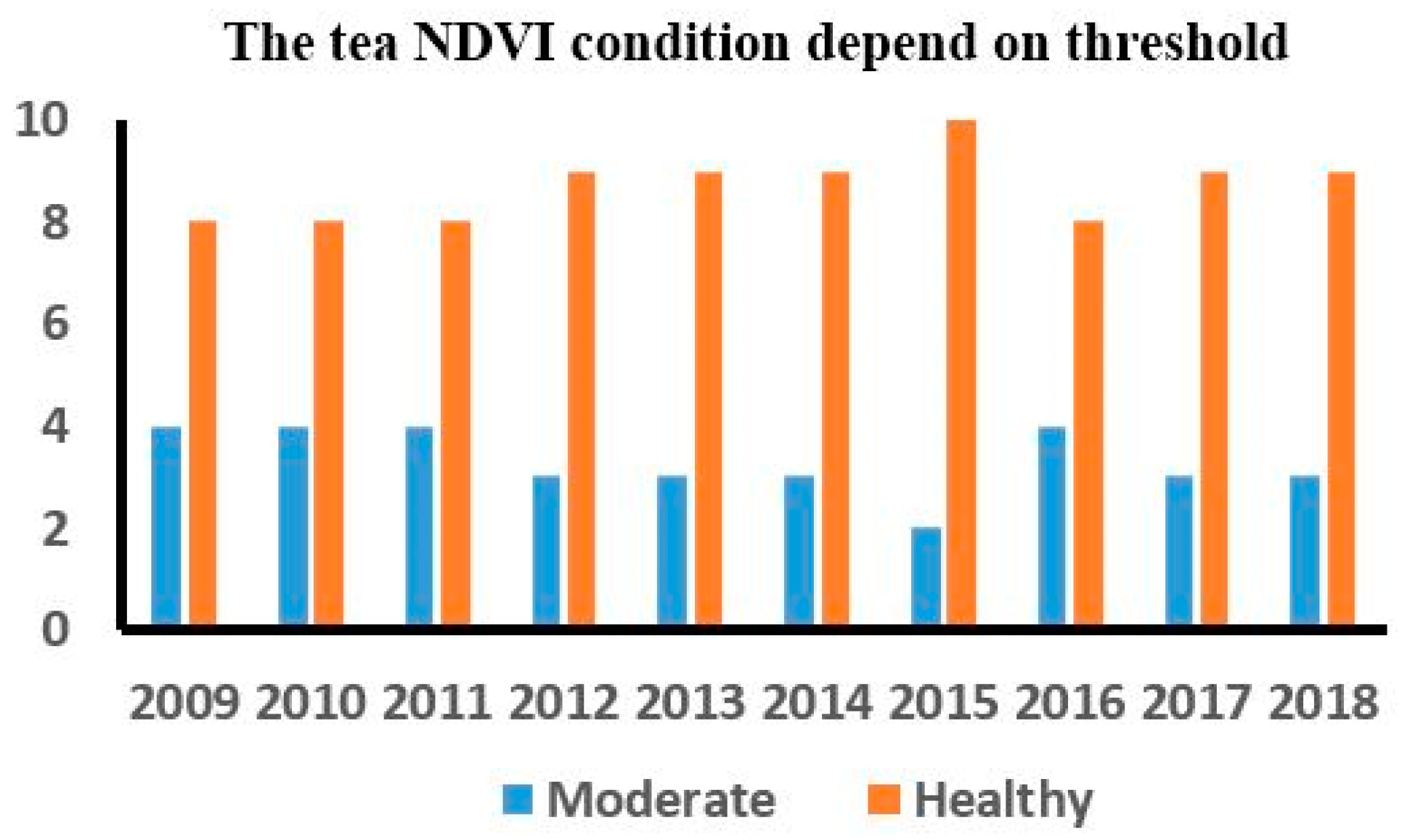
3.1.1. Land-Use/Land-Cover Map and the Change of Tea NDVI
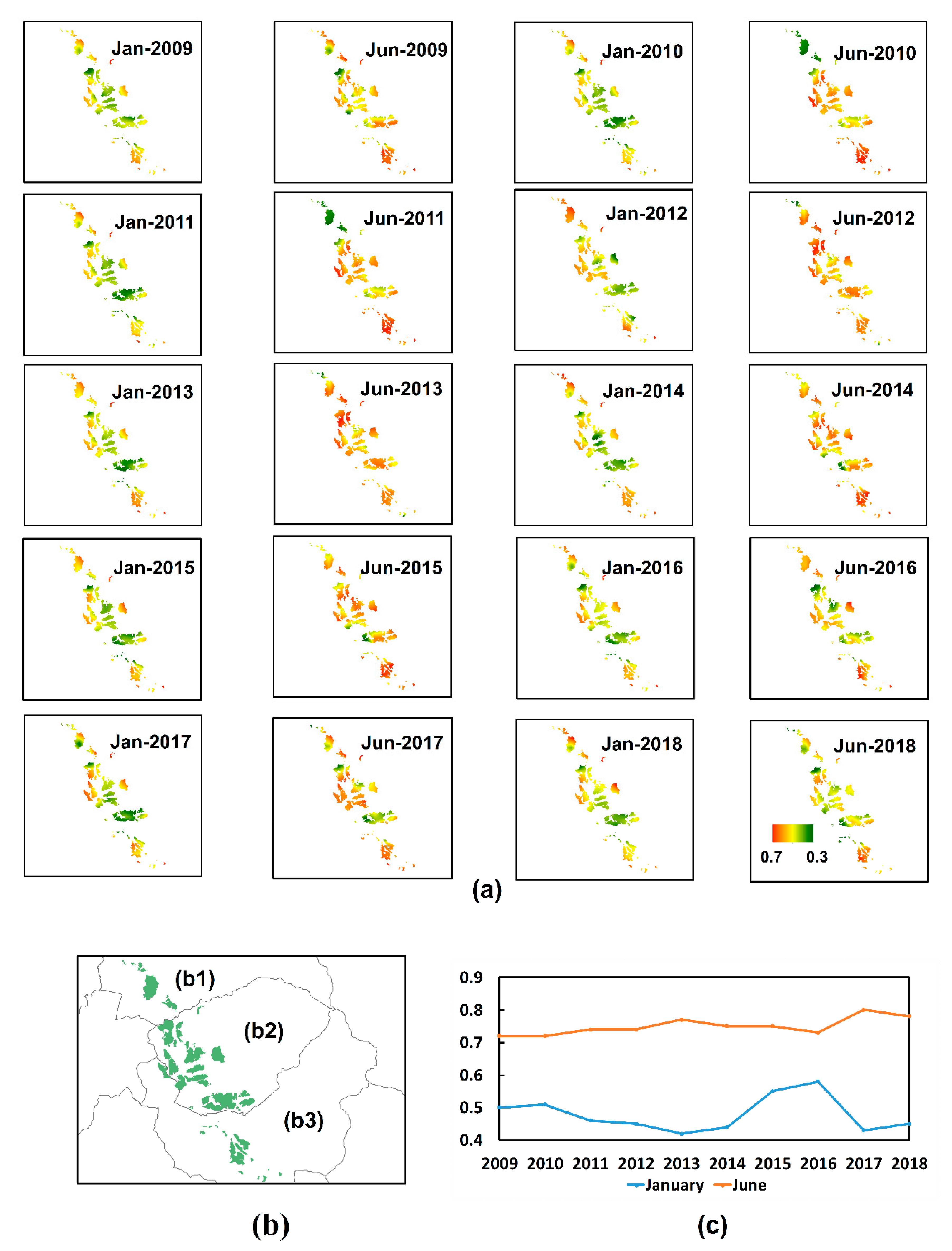
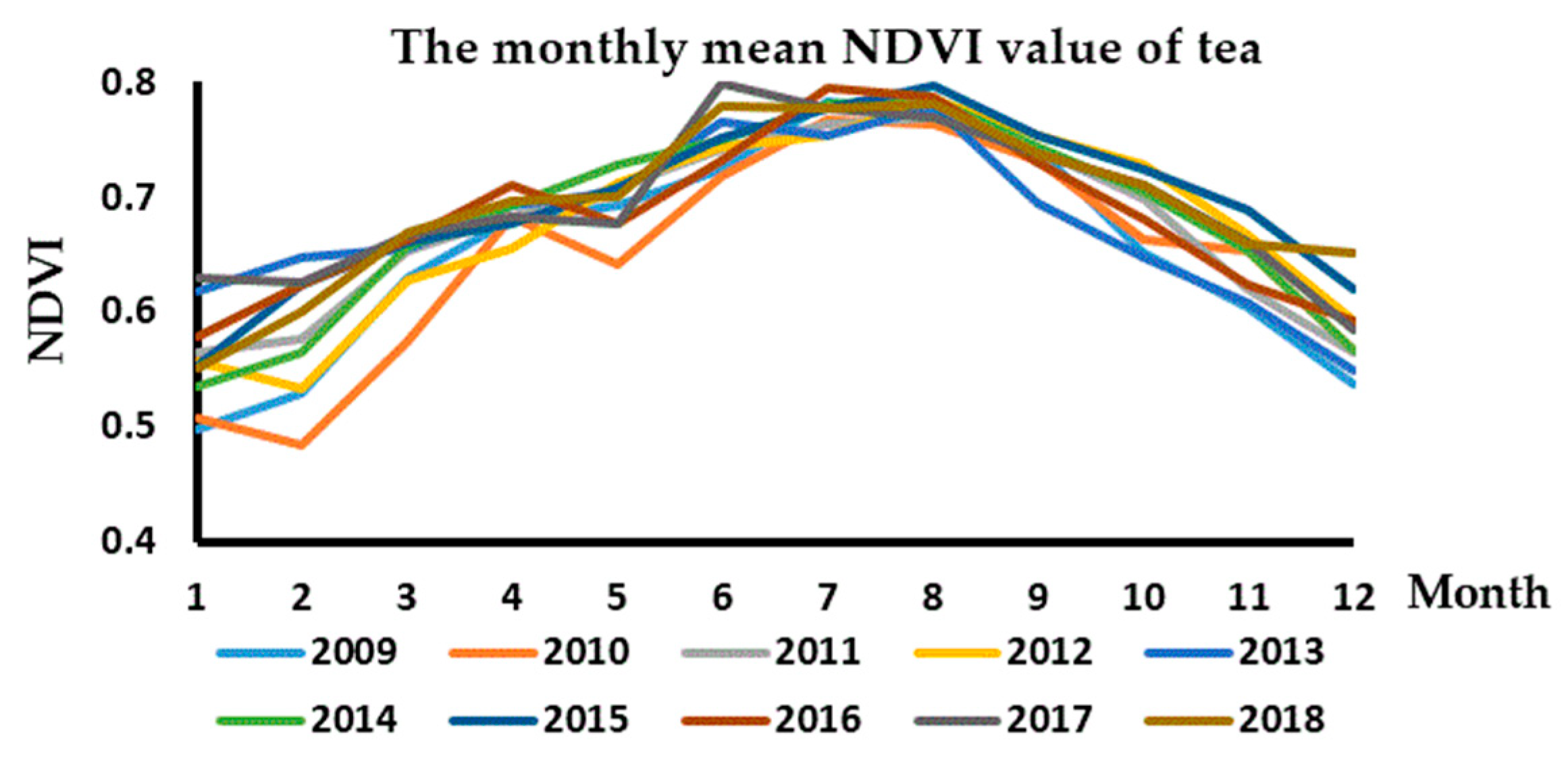
3.1.2. The Change of Tea NDVI on Temporal and Spatial
3.2. The Prediction of Tea Yield
3.2.1. The Correlation between Climatic Variables, NDVI, and Tea Yield
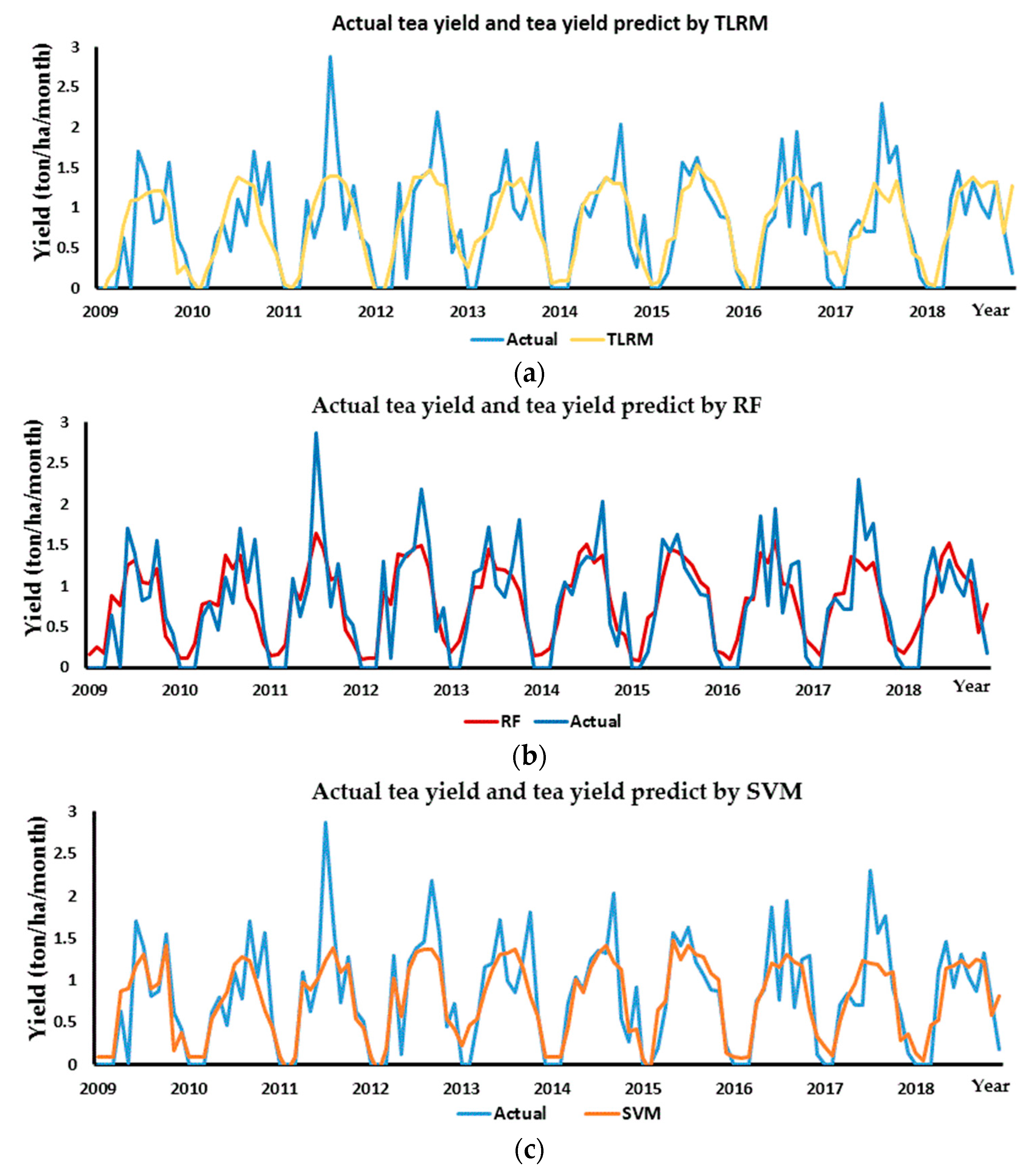
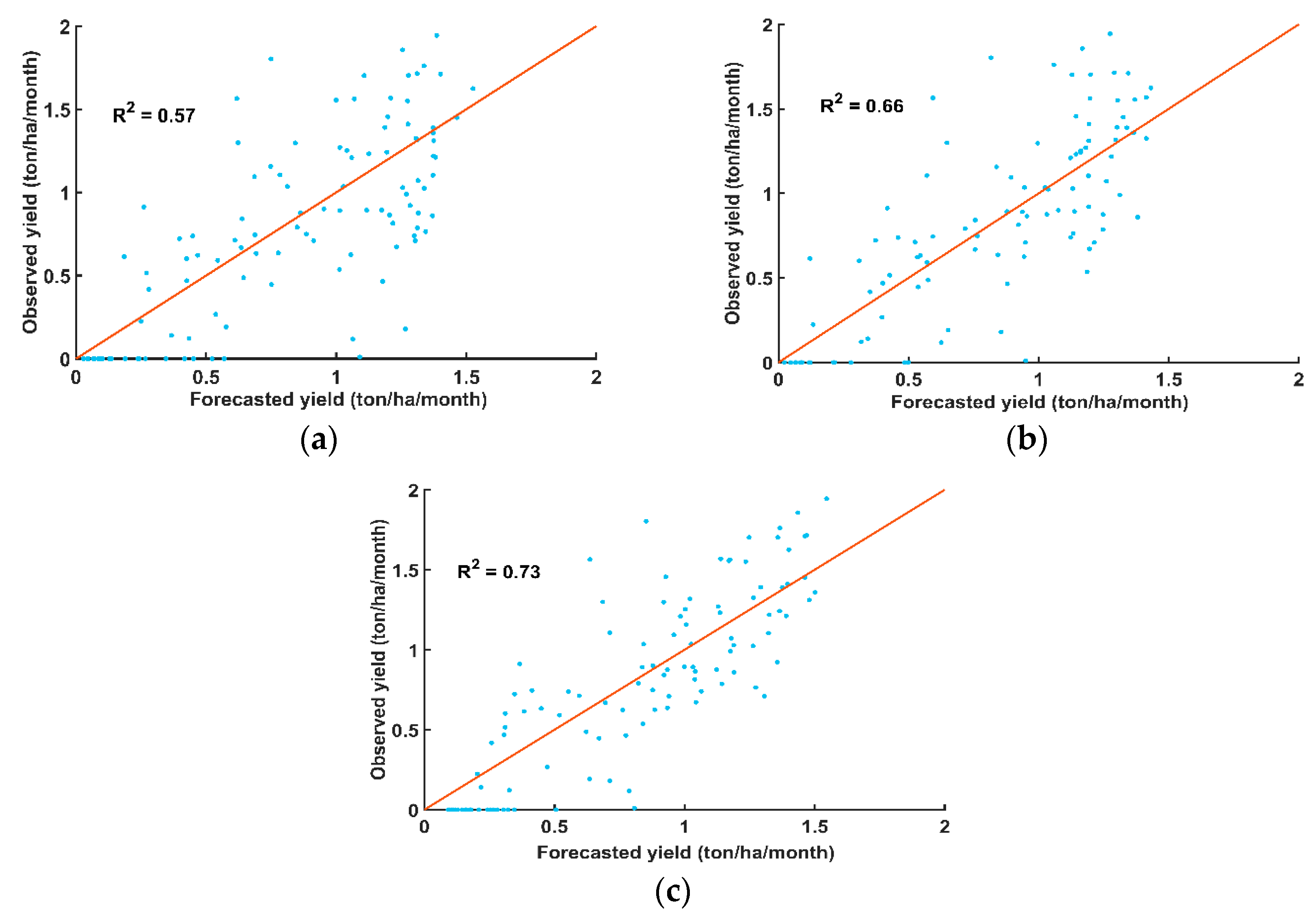
3.2.2. Predicting Tea Yield Base on Support Vector Machines (SVM) and Random Forest (RF)
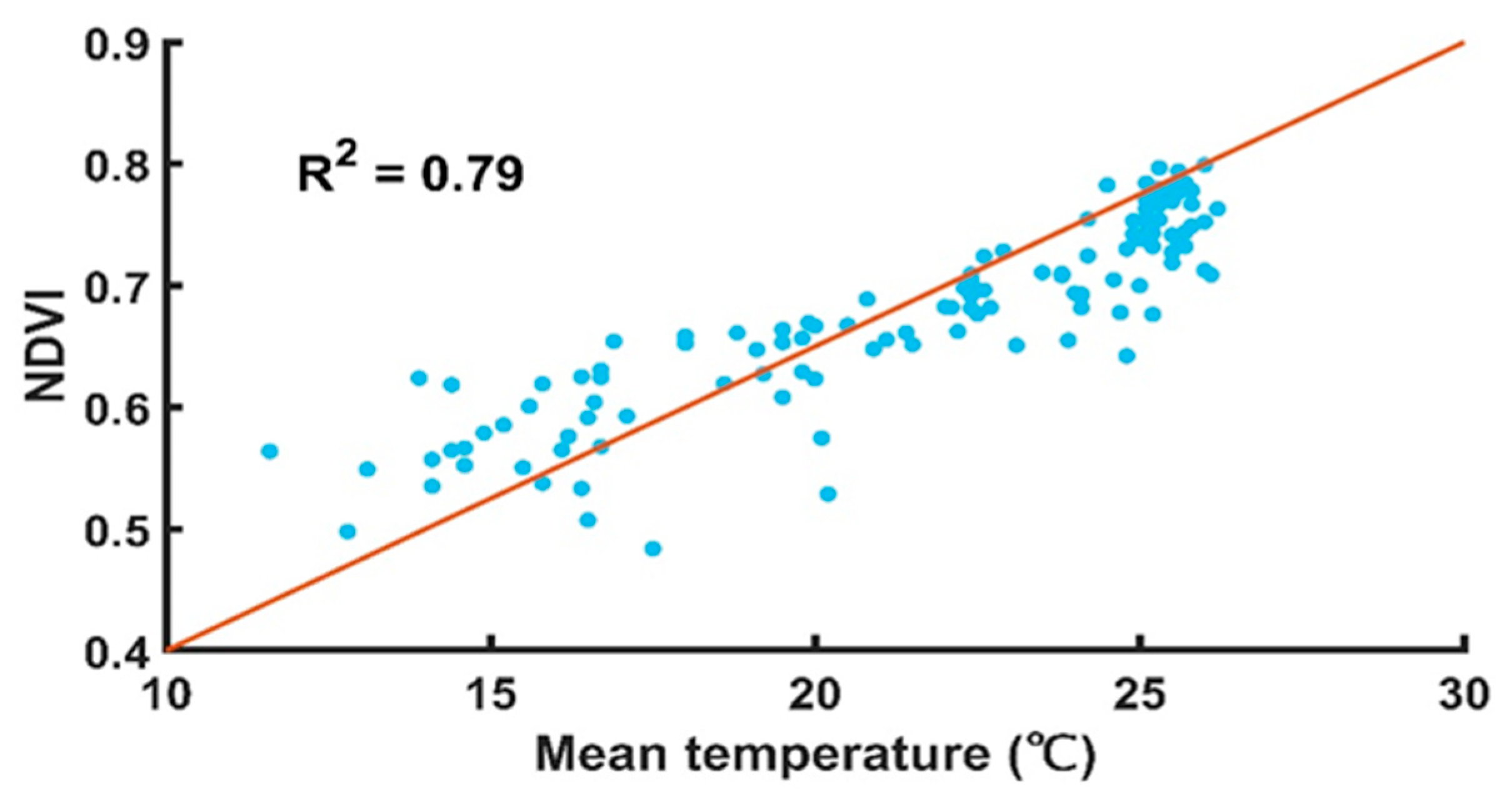
3.2.3. Correlations Analysis between Tea NDVI and Temperature
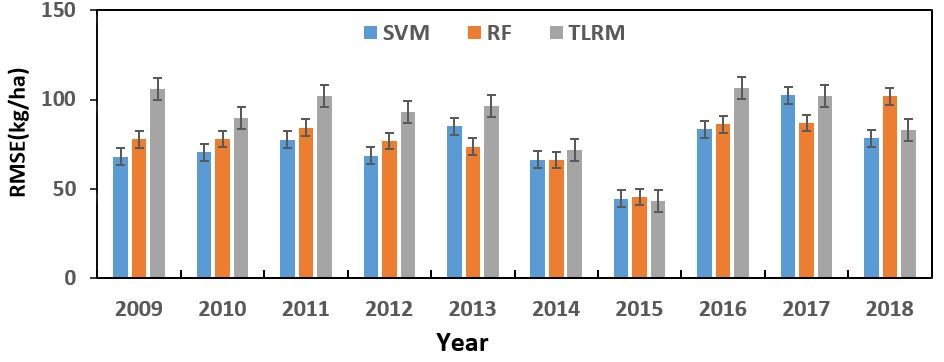
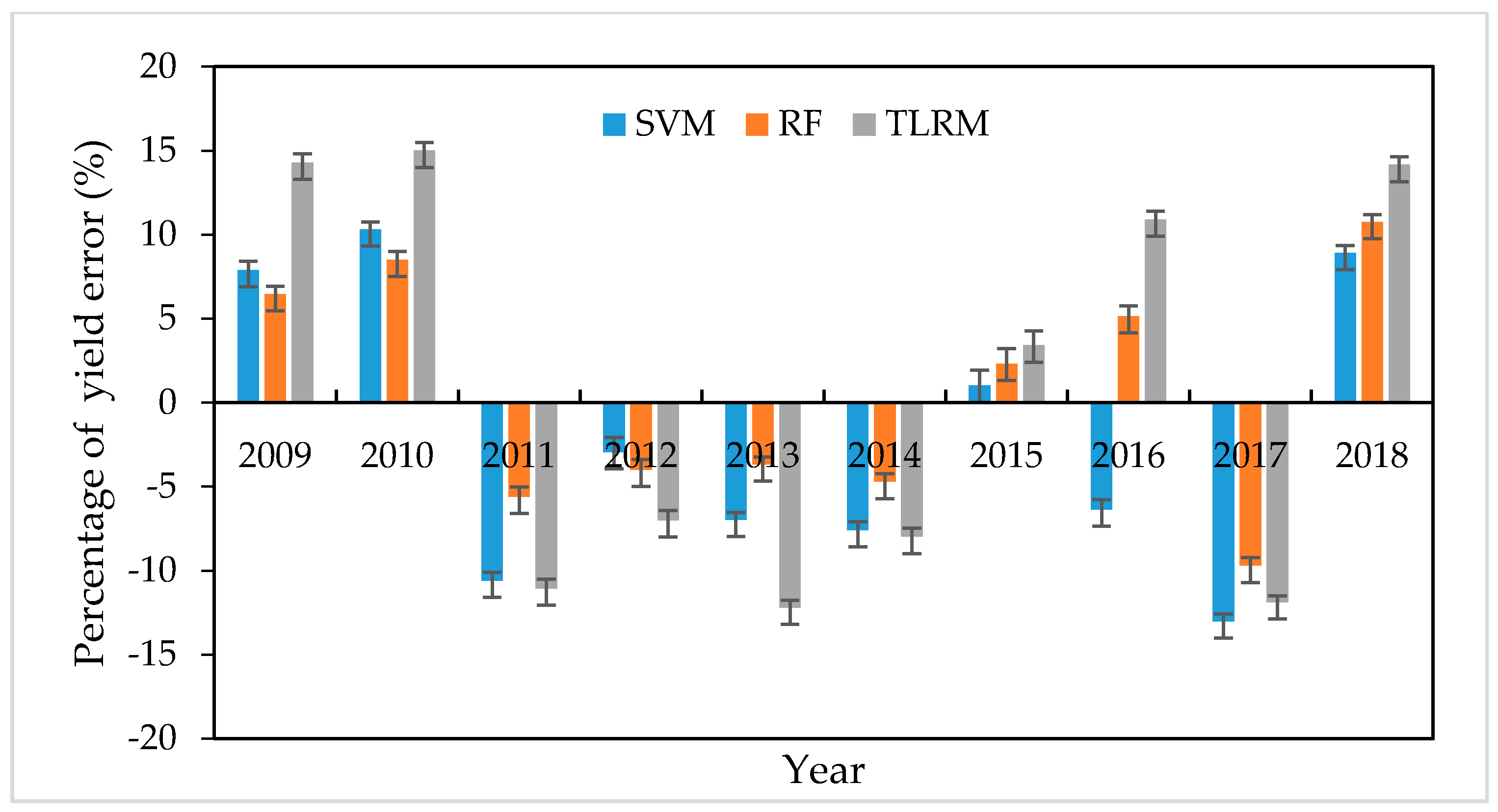
3.2.4. Comparison of Accuracy of Prediction Models and Forecast Errors
4. Discussion
4.1. The Status Monitoring of Tea by NDVI
4.2. The Forecast Tea Yield
4.3. Limitation and Future Perspectives
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Laichau Provincial People’s Committee. Final Report of Laichau Tea Project from 2009 to 2018; Laichau Provincial people’s Committee: Lai Chau, Vietnam, 2018. [Google Scholar]
- Doraiswamy, P.C.; Moulin, S.; Cook, P.W.; Stern, A. Crop Yield Assessment from Remote Sensing. Photogramm. Eng. Remote Sens. 2003, 69, 665–674. [Google Scholar] [CrossRef]
- Huang, J.; Dai, Q.; Wang, H. Empirical Regression Model Using Ndvi, Meteorological Factors For Estimation Of Wheat Yield In Yunnan, China. In Proceedings of the 11th Academic Works International Conference On Hydroinformatics, New York, NY, USA, 17–21 August 2014. [Google Scholar]
- Henik, J.J. Utilizing NDVI and Remote Sensing Data to Identify Spatial Variability in Plant Stress as Influenced by Management; Iowa State University: Ames, IA, USA, 2012. [Google Scholar]
- Recanatesi, F.; Giuliani, C.; Ripa, M.N. Monitoring Mediterranean Oak Decline In A Peri-Urban Protected Area Using The Ndvi And Sentinel-2 Images: The Case Study Of Castelporziano State Natural Reserve. Sustainability 2018, 10, 3308. [Google Scholar] [CrossRef]
- Barman, T. Tea Bush Health Demetermination and Yield Estimation. Master’s Thesis, San Jose State University, San Jose, CA, USA, 2008. [Google Scholar]
- Huang, J.; Han, D.; Wang, H. Analysis of Ndvi Data For Crop Identification And Yield Estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4374–4384. [Google Scholar] [CrossRef]
- Kumar, A.; Denis, D.; Mishra, H.; Indwar, S. Application Of Ndvi In Vegetation Monitoring And Drought Detection Using Remote Sensing For Lower Rajghat Canal Command Area. Int. Res. J. Eng. Technol. (IRJET) 2019, 6, 210–215. [Google Scholar]
- Rajapakse, R.M.S.S.; Tripathi, N.K.; Honda, K. Spectral Characterization And Lai Modelling For The Tea (Camellia Sinensis (L.) O. Kuntze) Canopy. Int. J. Remote Sens. 2010, 23, 3569–3577. [Google Scholar] [CrossRef]
- Dutta, R. Assessment Of Tea Bush Health And Yield Using Geospatial Techniques. Master’s Thesis, ITC, Enschede, The Netherlands, 2006. [Google Scholar]
- Akar, O.; Gungor, O. Integrating Multiple Texture Methods And Ndvi To The Random Forest Classification Algorithm To Detect Tea And Hazelnut Plantation Areas In Northeast Turkey. Int. J. Remote Sens. 2015, 36, 442–464. [Google Scholar] [CrossRef]
- Ghosh, J.K.; Godbole, P.N.; Ghosh, S.K. Mapping Of Tea Gardens From Satellite Images-A Fuzzy Knowledge-Base Image Interpetation System. Int. Arch. Photogramm. Remote Sens. 2000, 33, 460–468. [Google Scholar]
- Zhu, J.; Pan, Z.; Wang, H.; Huang, P.; Sun, J.; Qin, F.; Liu, Z. An Improved Multi-Temporal And Multi-Feature Tea Plantation Identification Method Using Sentinel-2 Imagery. Sensors 2019, 19, 2089. [Google Scholar] [CrossRef]
- Dihkan, M.; Guneroglu, N.; Karsli, F.; Guneroglu, A. Remote Sensing Of Tea Plantations Using An Svm Classifier And Pattern-Based Accuracy Assessment Technique. Int. J. Remote Sens. 2013, 34, 8549–8565. [Google Scholar] [CrossRef]
- Zhang, H. The Model Of Wheat Yield Forecast Based On Modis-Ndvi—A Case Study Of Xinxang. In Proceedings of the ISPRS Annals of The Photogrammetry, Remote Sensing And Spatial Information Sciences, Melbourne, Australia, 25 August–1 September 2012. [Google Scholar]
- Bala, S.K.; Islam, A.S. Correlation Between Potato Yield And Modis-Derived Vegetation Indices. Int. J. Remote Sens. 2009, 30, 2491–2507. [Google Scholar] [CrossRef]
- Balaghi, R.; Tychon, B.; Eerens, H.; Jlibene, M. Empirical Regression Models Using Ndvi, Rainfall And Temperature Data For The Early Prediction Of Wheat Grain Yields In Morocco. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 438–452. [Google Scholar] [CrossRef]
- Tucker, C.J.; Sellers, P.J. Satellite Remote Sensing Of Primary Production. Int. J. Remote Sens. 1986, 7, 1395–1416. [Google Scholar] [CrossRef]
- Pandey, C. Crop Yield Estimation Based on Landsat-NDVI A Case Study of Sitapur District, Uttar Pradesh, India. Int. J. Appl. Remote Sens. Gis 2018, 4, 23–29. [Google Scholar]
- Dong, J. Study On The Interaction Between Ndvi Profile And The Growing Status Of Crops. Chin. Geogr. Sci. 2003, 13, 62–65. [Google Scholar]
- Foster, A.J.; Kakani, V.G.; Ge, J.; Mosali, J. Predicting biomass yield in bioenergy crop production systems using canopy NDVI. In Proceedings of the Sun Grant National Conference: Science for Biomass Feedstock Production and Utilization, New Orleans, LA, USA, 21 February 2017. [Google Scholar]
- Dutta, R. Impact of age and management factors on tea yield and modelling the influence of leaf area index on yield variations. Sci. J. Sci. Soc. Thail. 2011, 37, 83–87. [Google Scholar]
- Fauziana, F.; Danoedoro, P.; Murti, A.S.H. Linear Spectral Mixture Analysis Of Spot-7 For Tea Yield Estimation In Pagilaran Estate, Batang Central Java. In Proceedings of the 2nd International Conference of Indonesian Society of Remote Sensing, Yogyakarta, Indonesia, 17–19 October 2016. [Google Scholar]
- Sitienei, B.J.; Juma, S.G.; Opere, I.A.E. On The Use Of Regression Models To Predict Tea Crop Yield Responses To Climate Change: A Case Of Nandi East, Sub-County Of Nandi County, Kenya. Climate 2017, 5, 54. [Google Scholar] [CrossRef]
- Raj, E.E.; Ramesh, K.V.; Rajkumar, R.; Moral, M.T. Modelling The Impact Of Agrometeorological Variables On Regional Tea Yield Variability In South Indian Tea-Growing Regions: 1981–2015. Cogent Food Agric. 2019, 5, 1581457. [Google Scholar] [CrossRef]
- Wijeratne, M.A.; Anandacoomaraswamy, A.; Amarathunga, M.K.S.L.D. Assessment Of Impact Of Climate Change On Productivity Of Tea (Camellia Sinensis L.) Plantations In Sri Lanka. Nat. Sci. Found. Sri Lanka 2007, 35, 119–126. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, Z.; Zhang, S.; Zhu, Z.; Shi, W. Response Of Crop Yields To Climate Trends Since 1980in China. Clim. Res. 2012, 54, 233–247. [Google Scholar] [CrossRef]
- Rao, N.R.; Kapoor, M.; Sharma, N.; Venkateswarlu, A. Yield Prediction And Waterlogging Assessment For Tea Plantation Land Using Satellite Image-Based Techniques. Int. J. Remote Sens. 2007, 28, 1561–1576. [Google Scholar]
- Jaikla, R.; Jintrawet, A.; Auephanwiriyakul, S. Rice Yield Prediction Using A Support Vector Regression Method. In Proceedings of the Electrical Engineering/Electronics, Computer, Telecommunications And Information Technology, Krabi, Thailand, 14–17 May 2008. [Google Scholar]
- Kim, N.; Lee, Y.-W. Machine Learning Approaches To Corn Yield Estimation Using Satellite Images And Climate Data: A Case Of Iowa State. J. Korean Soc. Surv. Geod. Photogramm. Cart. 2016, 34, 383–390. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Muthukumarasamy, G. Crop Prodiction-Ensemble Machine Learning Model For Prediction. Int. J. Comput. Sci. Softw. Eng. 2016, 5, 148. [Google Scholar]
- Priya, P.; Muthaiah, U.; Balamurugan, M. Predicting Yield Of The Crop Using Machine Learning Algorithm. Int. J. Eng. Sci. Res. Technol. 2018, 7, 1–7. [Google Scholar]
- Kumar, A.; Kumar, N.; Vats, V. Efficent Crop Yield Prediction Using Machine Learning Algorithms. Int. Res. J. Eng. Technol. (Irjet) 2018, 5, 3151–3159. [Google Scholar]
- Caia, Y.; Guanb, K.; David Lobelld, E.; Potgieterf, A.B.; Shaowen Wanga, C.; Pengg, J.; Xuh, T.; Assengi, S.; Zhangj, Y.; Liangzhi Youl, B.P. Integrating Satellite And Climate Data To Predict Wheat Yield In Australia Using Machine Learning Approaches. Agric. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- National Centre for Hydro—Meteorological Forecasting. Available online: http://kttvtaybac.org/index.php/vi/gioi-thieu/Don-vi-truc-thuoc/Dai-KTTV-tinh-Lai-Chau-10/ (accessed on 1 May 2019).
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.E.A. Sentinel-2: Esa’s Optical High-Resolution Mission For Gmes Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience With Sentinel-2 Data For Crop And Tree Species Classifications In Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- ESA Website. Available online: https://sentinel.esa.int/documents/247904/685211/Sentinel-2-Data-Quality-Report (accessed on 1 April 2018).
- Gómez, V.P.; Medina, V.D.; Bengoa, J.L.; García, D.A.N. Accuracy Assessment Of A 122 Classes Land Cover Map Based On Sentinel-2, Landsat 8 And Deimos-1 Images And Ancillary Data. In Proceedings of the IGARSS 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review Of Developments And Applications. Sensors 2017, 2017, 1353691. [Google Scholar] [CrossRef]
- Usgs.Gov. Ndvi, The Foundation For Remote Sensing Phenology. Available online: https://www.usgs.gov/land-resources/eros/phenology/science/ndvi-foundation-remote-sensing-phenology?qt-science_center_objects=0#qt-science_center_objects (accessed on 1 November 2019).
- Vapnik, V. The Nature Of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Ghosh, S. SVM-PGSL coupled approach for statistical downscaling to predict rainfall from GCM output. J. Geophys. Res. Atmos. 2010, 115. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests, Machine Learning; Kluwer Academic: Dordrecht, The Netherlands, 2001. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification And Regression Trees; CRC Press: Wadsworth, OH, USA, 1984. [Google Scholar]
- Mao, D.; Wang, Z.; Luo, L.; Ren, C. Integrating Avhrr And Modis Data To Monitor Ndvi Changes And Their Relationships With Climatic Parameters In Northeast China. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 528–536. [Google Scholar] [CrossRef]
- Piao, S.; Fang, J.; Zhou, L.; Guo, Q.; Henderson, M.; Ji, W.; Li, Y.; Tao, S. Interannual Variations Of Monthly And Seasonal Normalized Difference Vegetation Index (Ndvi) In China From 1982 To 1999. Geophys 2003, 108. [Google Scholar] [CrossRef]
- Kawabata, A.; Ichii, K.; Yamaguchi, Y. Global Monitoring Of Interannual Changes In Vegetation Activities Using Ndvi And Its Relationships To Temperature And Precipitation. Int. J. Remote Sens. 2010, 22, 1377–1382. [Google Scholar] [CrossRef]
- Chuai, X.W.; Huang, A.X.J.; Wanga, W.J.; Baoc, G. Ndvi, Temperature And Precipitation Changes And Their Relationships With Different Vegetation Types During 1998–2007 In Inner Mongolia, China. Int. J. Climatol. 2013, 33, 1696–1706. [Google Scholar] [CrossRef]
- Zhang, Y.D.; Zhang, X.H.; Liu, S.R. Correlation analysis on normalized difference vegetation index (NDVI) of different vegetations and climatic factors in Southwest China. Chin. J. Appl. Ecol. 2011, 22, 323–330. [Google Scholar]
- Nemec-Boehm, R.L.; Cash, S.B.; Ahmed, S. Climate change, the monsoon, and tea yields in China. In Proceedings of the Agricultural and Applied Economics Association’s Annual Meeting, Minneapolis, MN, USA, 27–29 July 2014. [Google Scholar]
- Van Leeuwen, W.J.; Orr, B.J.; Marsh, S.E.; Herrmann, S.M. Multi-sensor NDVI data continuity: Uncertainties and implications for vegetation monitoring applications. Remote Sens. Environ. 2006, 100, 67–81. [Google Scholar] [CrossRef]
- Curci, S.; Lavecchia, C.; Frustaci, G.; Paolini, R. Assessing measurement uncertainty in meteorology in urban environments. Meas. Sci. Technol. 2017, 28, 104002. [Google Scholar] [CrossRef]
- Merker, C.; Geppert, G.; Clemens, M.; Ament, F. Estimating the uncertainty of areal precipitation using data assimilation. Tellus A Dyn. Meteorol. Oceanogr. 2019, 71, 1–16. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Source | Characteristics/Features | Date |
|---|---|---|---|
| Sentinel-2 | https://earthexplorer.usgs.gov | 13 spectral bands: four bands at 10 m, six bands at 20 m and three bands at 60 m spatial resolution (images) | 3 November 2018 |
| MODIS NDVI | MODIS13A3H27V06 (Laichau) | MODIS/Terra vegetation Indices Monthly L3 Global 1 km (images) | January 2005 to December 2018 |
| Climate data | Hydro-meteorological station of Laichau Province [35] (Thanuyen station: 21°57′N and 103°53′E) | Mean temperature, minimum temperature (Tmin), maximum temperature (Tmax), precipitation, solar radiation | January 2005 to December 2018 |
| Tea yield data | Department of Natural Resources and Environment, Tanuyen District, Laichau Province, Vietnam [1] | Yield monitor data (productivity/area), unit (ton/ha) | January 2009 to December 2018 |
| Base map data | Department of Natural Resources and Environment, Tanuyen District, Laichau Province, Vietnam | Vector | 2009 |
| Field survey data | GPS (GTField) | Longitude, latitude | November 2018 |
| Class Name | Sentinel-2 | |
|---|---|---|
| Producer Accuracy | User Accuracy | |
| Tea | 99% | 100% |
| Cropland | 100% | 98% |
| Forest | 97.03% | 97.03% |
| Settlement | 85% | 100% |
| Water | 100% | 98% |
| Barren land | 100% | 81% |
| Year | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2009 | 0.50 | 0.53 | 0.43 | 0.68 | 0.69 | 0.72 | 0.78 | 0.77 | 0.74 | 0.65 | 0.60 | 0.54 |
| 2010 | 0.51 | 0.48 | 0.47 | 0.68 | 0.64 | 0.72 | 0.77 | 0.76 | 0.73 | 0.66 | 0.65 | 0.57 |
| 2011 | 0.46 | 0.48 | 0.45 | 0.68 | 0.71 | 0.74 | 0.76 | 0.77 | 0.74 | 0.70 | 0.62 | 0.56 |
| 2012 | 0.45 | 0.53 | 0.48 | 0.65 | 0.71 | 0.74 | 0.75 | 0.78 | 0.75 | 0.73 | 0.67 | 0.59 |
| 2013 | 0.42 | 0.45 | 0.66 | 0.69 | 0.70 | 0.77 | 0.75 | 0.78 | 0.69 | 0.65 | 0.61 | 0.45 |
| 2014 | 0.44 | 0.46 | 0.66 | 0.69 | 0.73 | 0.75 | 0.78 | 0.78 | 0.74 | 0.70 | 0.65 | 0.57 |
| 2015 | 0.55 | 0.42 | 0.66 | 0.68 | 0.71 | 0.75 | 0.78 | 0.80 | 0.75 | 0.72 | 0.69 | 0.62 |
| 2016 | 0.58 | 0.42 | 0.46 | 0.71 | 0.68 | 0.73 | 0.79 | 0.79 | 0.73 | 0.68 | 0.62 | 0.49 |
| 2017 | 0.43 | 0.46 | 0.67 | 0.68 | 0.68 | 0.80 | 0.78 | 0.77 | 0.74 | 0.71 | 0.66 | 0.59 |
| 2018 | 0.45 | 0.50 | 0.47 | 0.70 | 0.70 | 0.78 | 0.78 | 0.78 | 0.74 | 0.71 | 0.66 | 0.65 |
| Year | |||
|---|---|---|---|
| SVM-Actual | RF-Actual | TLRM-Actual | |
| 2009 | 0.69 | 0.71 | 0.4 |
| 2010 | 0.58 | 0.6 | 0.45 |
| 2011 | 0.66 | 0.8 | 0.59 |
| 2012 | 0.86 | 0.79 | 0.62 |
| 2013 | 0.57 | 0.74 | 0.49 |
| 2014 | 0.66 | 0.74 | 0.64 |
| 2015 | 0.9 | 0.87 | 0.89 |
| 2016 | 0.68 | 0.75 | 0.59 |
| 2017 | 0.61 | 0.67 | 0.61 |
| 2018 | 0.52 | 0.52 | 0.54 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phan, P.; Chen, N.; Xu, L.; Chen, Z. Using Multi-Temporal MODIS NDVI Data to Monitor Tea Status and Forecast Yield: A Case Study at Tanuyen, Laichau, Vietnam. Remote Sens. 2020, 12, 1814. https://doi.org/10.3390/rs12111814
Phan P, Chen N, Xu L, Chen Z. Using Multi-Temporal MODIS NDVI Data to Monitor Tea Status and Forecast Yield: A Case Study at Tanuyen, Laichau, Vietnam. Remote Sensing. 2020; 12(11):1814. https://doi.org/10.3390/rs12111814
Chicago/Turabian StylePhan, Phamchimai, Nengcheng Chen, Lei Xu, and Zeqiang Chen. 2020. "Using Multi-Temporal MODIS NDVI Data to Monitor Tea Status and Forecast Yield: A Case Study at Tanuyen, Laichau, Vietnam" Remote Sensing 12, no. 11: 1814. https://doi.org/10.3390/rs12111814
APA StylePhan, P., Chen, N., Xu, L., & Chen, Z. (2020). Using Multi-Temporal MODIS NDVI Data to Monitor Tea Status and Forecast Yield: A Case Study at Tanuyen, Laichau, Vietnam. Remote Sensing, 12(11), 1814. https://doi.org/10.3390/rs12111814