Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends


Abstract
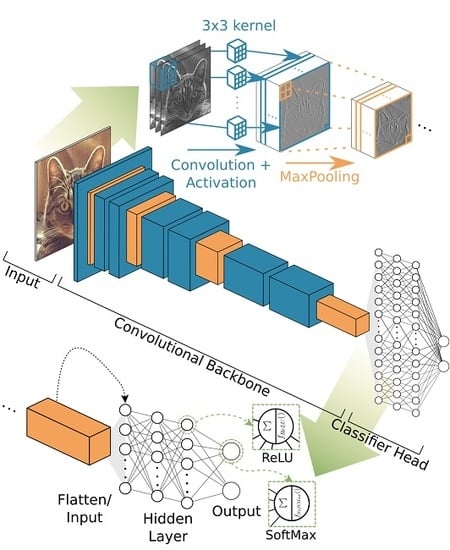
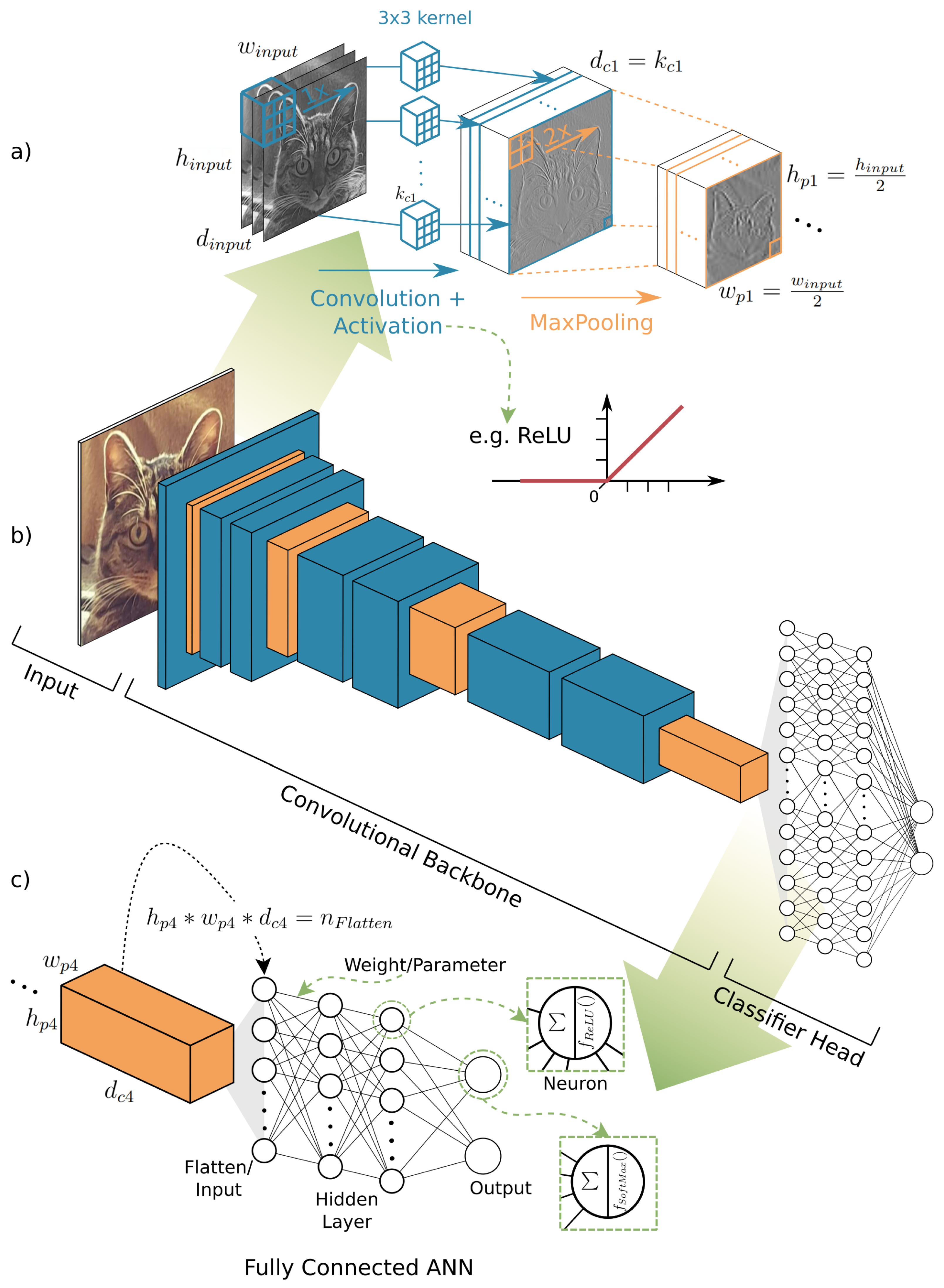
1. Introduction
2. Terminology and Basic Concepts of Deep Learning with CNNs
- The convolutional backbone is a strong feature extractor for a natural signal, while it maintains the fundamental structure of that signal and is sensitive for local connectivity.
- Instead of pairwise connections of neurons, kernel functions are used to connect layers, in order to learn features from training data.
- By sequentially repeating convolution, activation and pooling, the idea of how natural signals are composed, of low combined to high level features, the artificial architectures of CNNs for extracting features follows the hierarchical structure of a natural signal and mimic the behaviour of the visual cortex of living mammals [96,97,98,99].
- The modular composition of both the convolutional backbone itself and the overall architecture makes the CNN approach highly adaptable for a variety of tasks and optimisations.
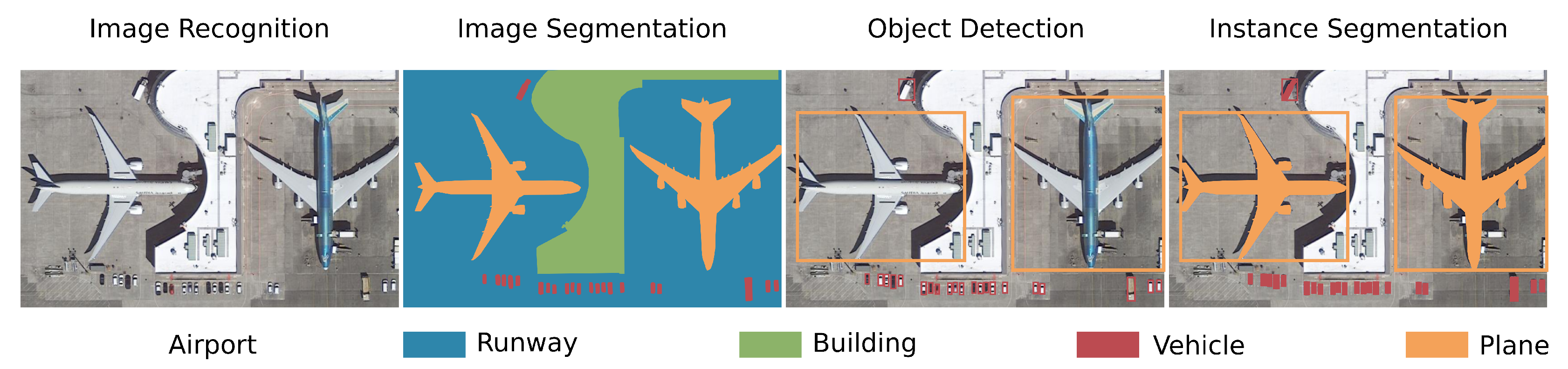
- Image recognition is understood as the prediction of a class label for a whole image.
- Image segmentation, semantic segmentation or pixel wise classification segments the whole image into semantic meaningful classes, where the smallest segment can be a single pixel.
- Object detection predicts locations of objects as bounding boxes and a class label.
- Instance segmentation is an object detection task on which an image segmentation task for the specific bounding box and class is applied additionally. This results in a segmentation mask of the specific object predictions. In this review, instance segmentation is discussed together with object detection, due to their evolutionary closeness.
3. Evolution of CNN Architectures in Computer Vision
3.1. Image Recognition and Convolutional Backbones
3.1.1. Vintage Architectures
- The convolutional backbone consists of repeated convolutions to increase the feature depth and some kind of resizing method such as pooling with stride 2 to decrease resolution.
- In VGG-19, the repeated building blocks with stacked convolutions of constant size enlarge the receptive field and deepen the network.
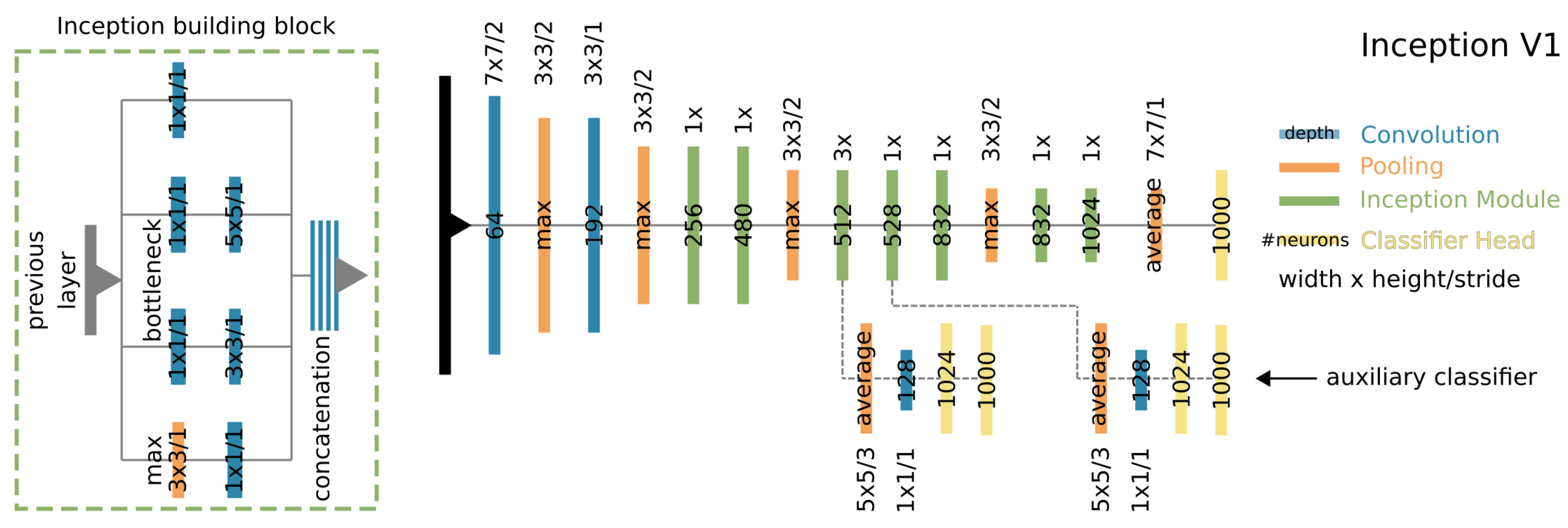
3.1.2. Inception Family
- Bottleneck designs and complex building block structures
- Batch normalisation to make deep networks trainable faster via stochastic gradient descent
- Factorisation of convolutions in space and depth
3.1.3. ResNet Family
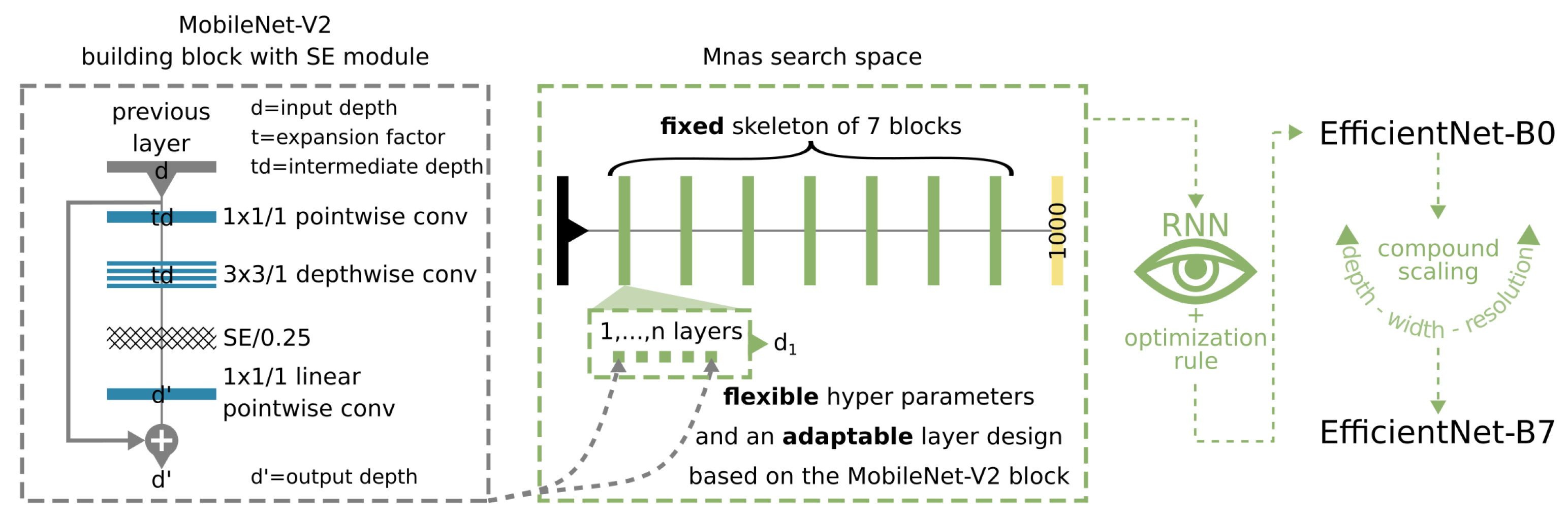
3.1.4. Efficient Designs
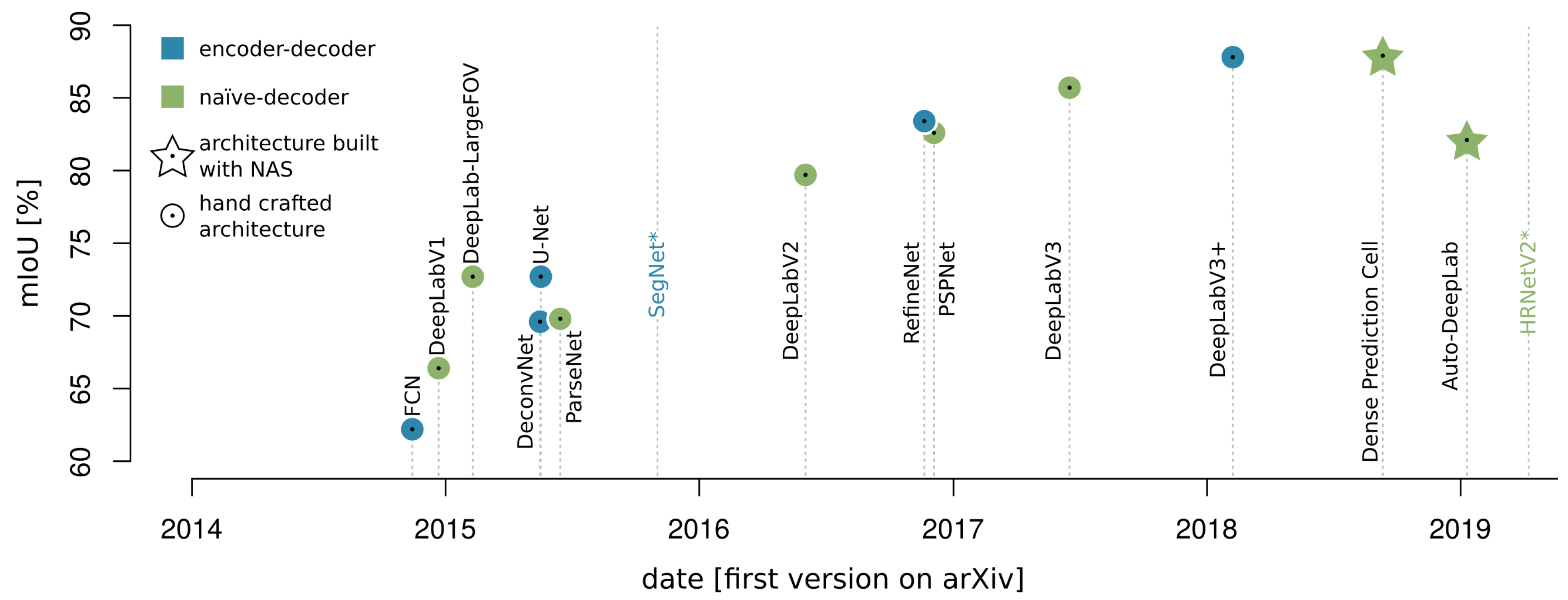
3.2. Image Segmentation
3.2.1. Naïve Decoder
3.2.2. Encoder–Decoder Models
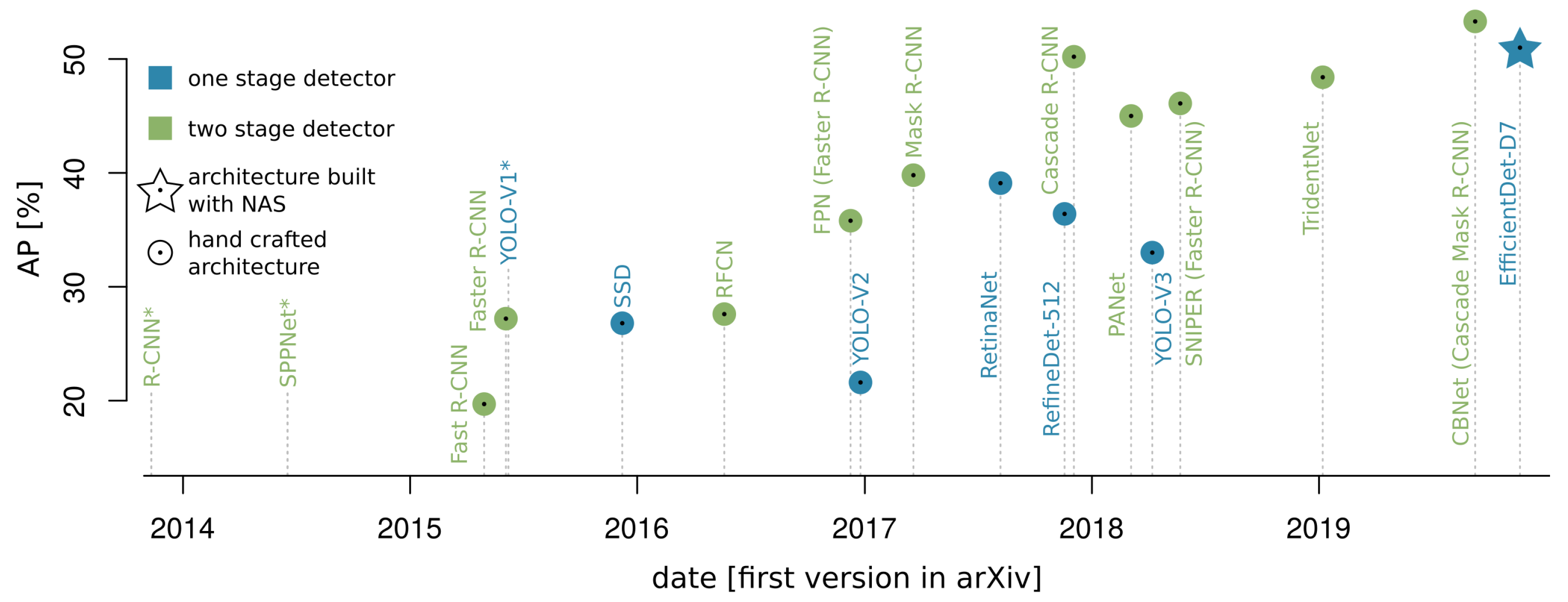
3.3. Object Detection
3.3.1. Two-Stage Detectors
3.3.2. One-Stage Detectors
4. Popular Deep Learning Frameworks and Earth Observation Datasets
4.1. Deep Learning Frameworks
4.2. Earth Observation Datasets
- The position of the sensor in Earth observation data has mostly an overhead perspective relative to the scene, whereas a natural image is captured from a side looking perspective, hence the same object classes appear differently.
- Data intensively used in computer vision are often three channel RGB images, whereas Earth observation data often consist of a multichannel image stack with more than three channels, which has to be considered, especially when transferring models from computer vision to Earth observation applications.
- Computer vision model input data are often from the same sensor and platform, whereas in Earth observation both can change and data fusion has to be incorporated into the model.
- Objects which appear in overhead images do not have a general orientation. That means that objects of the same class commonly appear at 360° rotation, which has to be considered in training data, architecture or both. Whereas in natural images bottom and top of the image and therewith also of the pictured objects are often defined more specifically which results in a general orientation of objects which can be expected for natural images.
- In natural images, objects of interest tend to be in the centre of the image and in high resolution, whereas in Earth observation data the objects can lie off nadir or at boarders with coarse resolution.
5. Future Research
6. Conclusions
- A stack of fully connected artificial neurons uses the extracted features to predict the probability of the class.
- Such deep models need specific normalisation schemes such as batch normalisation to make supervised training of deep networks possible and faster [41].
- Residual connections further alleviates the training of increasingly deep architectures [43].
- The recent findings in neural architecture search (NAS) bring together complex network structures and efficient usage of parameters. With NAS, architectures are searched for by an artificial controller. This controller tries to maximise specific metrics of the networks it creates iteratively and therewith finds highly efficient architectures [48,52].
- So-called atrous convolutions [58], which maintain resolution while extracting features, are widely used to cope with the high resolution-feature depth trade-off.
- The combination of feature maps of different scales with context information from image level was found to contribute effectively to pixel wise classification [59].
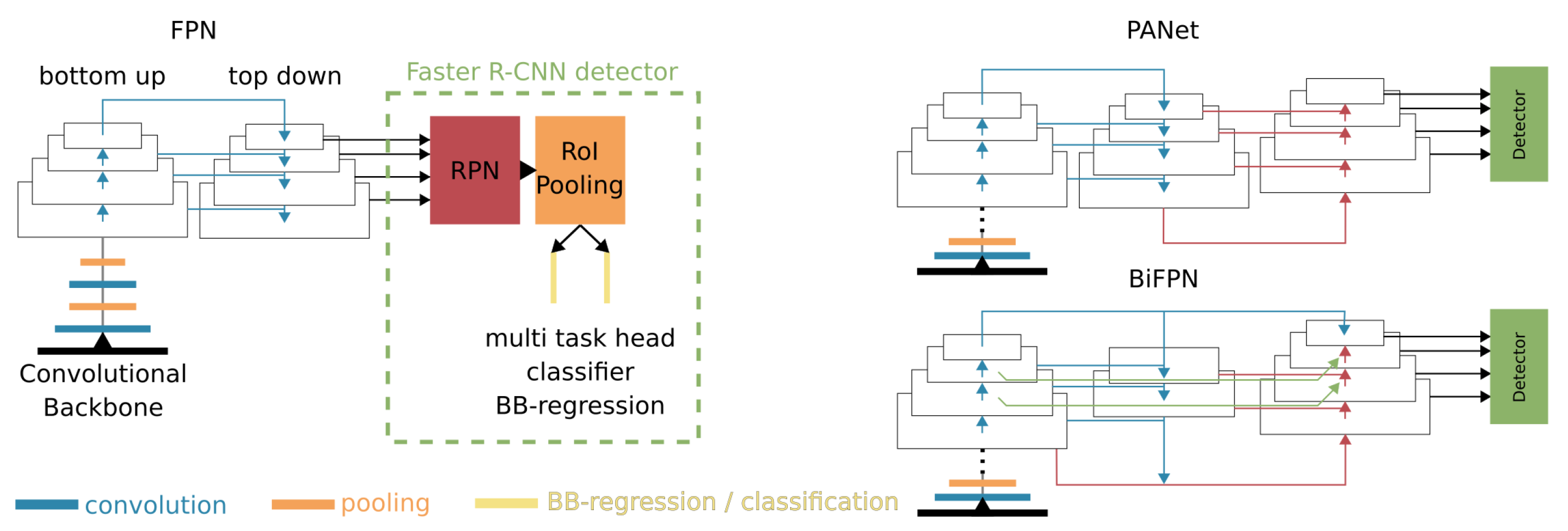
- Two stage object detectors show both good performance and adaptability. The most popular detectors are the Faster R-CNN [76] design and its successors. In the first stage, they propose class agnostic regions of interest (RoIs) for objects. During the second stage those RoIs are classified and the bounding box is regressed to tight object boundaries.
- For multiscale processing, the feature pyramid network (FPN) [77] enhances the convolutional backbone by merging high semantic features with precise localisation information.
- Cascading classifiers and bounding box regression suppress noisy detections by iteratively refining RoIs [79].
- Building models with NAS might lead to overly optimised architectures for specific tasks and datasets. Therefore, it is questionable if such models which are recently successful in computer vision tasks perform equally well in Earth observation, as was the case with hand crafted designs. However, NAS can also be used to find Earth observation specific designs.
- The number of DL datasets for Earth observation applications is still small in relation to possible applications and sensor diversity. Since datasets are highly important to push the understanding of the interaction between DL models and specific types of data, an increase in datasets has huge potential for further advances for DL in Earth observation.
- Beside more datasets, weakly supervised learning provides encouraging results as an alternative to expensive dataset creation. It is especially important for proof of concepts studies and experimental research.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bengio, Y. Deep Learning of Representations: Looking Forward. In Statistical Language and Speech Processing; Dediu, A.H., Martin-Vide, C., Mitkov, R., Truthe, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–37. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S., Sr. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 1–54. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Google Scholar. Top Publication. Available online: https://scholar.google.com/citations?view_op=top_venues&hl=en (accessed on 1 April 2020).
- Acemap. NeurIPS Affiliation Statistics. Available online: https://archive.acemap.info/conference-statistics/affiliation-rank?name=NIPS&year=2018&type=affiliation#table-1 (accessed on 1 April 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online: https://www.tensorflow.org/ (accessed on 1 April 2020).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32, pp. 8024–8035. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Dahl, G.E.; Ranzato, M.; Mohamed, A.R.; Hinton, G. Phone Recognition with the Mean-Covariance Restricted Boltzmann Machine. In Proceedings of the 23rd International Conference on Neural Information Processing Systems—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2010; pp. 469–477. [Google Scholar]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. Trans. Audio Speech and Lang. Proc. 2012, 20, 30–42. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; Schölkopf, B., Platt, J., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2007; Volume 19, pp. 153–160. [Google Scholar]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Cho, K.; Raiko, T.; Ilin, A. Enhanced Gradient for Training Restricted Boltzmann Machines. Neural Comput. 2013, 25, 805–831. [Google Scholar] [CrossRef]
- Cho, K. Foundations and Advances in Deep Learning. Ph.D. Thesis, Aalto University, Espoo, Finland, 2014. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In ICML; Fürnkranz, J., Joachims, T., Eds.; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations; Rumelhart, D.E., Mcclelland, J.L., Eds.; MIT Press: Cambridge, MA, USA, 1986; pp. 318–362. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27, pp. 2672–2680. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Proc. Mach. Learn. Res. 2015, 37, 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2815–2823. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Proc. Mach. Learn. Res. 2019, 97, 6105–6114. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vision 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vision 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Papandreou, G.; Chen, L.C.; Murphy, K.; Yuille, A.L. Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation. arXiv 2015, arXiv:1502.02734. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Advances in Neural Information Processing Systems; Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24, pp. 109–117. [Google Scholar]
- Chen, L.C.; Collins, M.; Zhu, Y.; Papandreou, G.; Zoph, B.; Schroff, F.; Adam, H.; Shlens, J. Searching for Efficient Multi-Scale Architectures for Dense Image Prediction. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 8699–8710. [Google Scholar]
- Liu, C.; Chen, L.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 82–92. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar] [CrossRef]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vázquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I.D. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venicnisee, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, Y.; Wang, Y.; Wang, S.; Liang, T.; Zhao, Q.; Tang, Z.; Ling, H. CBNet: A Novel Composite Backbone Network Architecture for Object Detection. arXiv 2019, arXiv:1909.03625. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection—SNIP. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient multi-scale training. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 9310–9320. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6053–6062. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision – ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Ghiasi, G.; Lin, T.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7029–7038. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Howard, R.E.; Habbard, W.; Jackel, L.D.; Henderson, D. Handwritten Digit Recognition with a Back-Propagation Network. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; Volume 2, pp. 396–404. [Google Scholar]
- Ranzato, M.; Huang, F.J.; Boureau, Y.; LeCun, Y. Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Cadieu, C.F.; Hong, H.; Yamins, D.L.K.; Pinto, N.; Ardila, D.; Solomon, E.A.; Majaj, N.J.; DiCarlo, J.J. Deep Neural Networks Rival the Representation of Primate IT Cortex for Core Visual Object Recognition. PLOS Comput. Biol. 2014, 10, 1–18. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognit. 1982, 15, 455–469. [Google Scholar] [CrossRef]
- Felleman, D.J.; Van Essen, D.C. Distributed Hierarchical Processing in the Primate Cerebral Cortex. Cerebral Cortex 1991, 1, 1–47. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- LeCun, Y.; Bottou, L.; Orr, G.; Müller, K. Efficient BackProp. In Neural Networks: Tricks of the Trade; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; Chapter 2; p. 546. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the Importance of Initialization and Momentum in Deep Learning. In Proceedings of the 30th International Conference on International Conference on Machine Learning—Volume 28; Microtome Publishing: Brookline, MA, USA, 2013; pp. III-1139–III-1147. [Google Scholar]
- Saxe, A.M.; McClelland, J.L.; Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv 2013, arXiv:1312.6120. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Sandler, M. MobileNet V2 ImageNet Checkpoints. Available online: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/README.md (accessed on 1 April 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Available online: https://www.cs.toronto.edu/kriz/learning-features-2009-TR.pdf (accessed on 1 April 2020).
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 18–14 September 2018; pp. 19–35. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honululu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Zhang, X.; Li, Z.; Loy, C.C.; Lin, D. PolyNet: A Pursuit of Structural Diversity in Very Deep Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3900–3908. [Google Scholar] [CrossRef]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. BigEarthNet: A Large-Scale Benchmark Archive For Remote Sensing Image Understanding. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5901–5904. [Google Scholar] [CrossRef]
- Sumbul, G.; Kang, J.; Kreuziger, T.; Marcelino, F.; Costa, H.; Benevides, P.; Caetano, M.; Demir, B. BigEarthNet Dataset with A New Class-Nomenclature for Remote Sensing Image Understanding. arXiv 2020, arXiv:2001.06372. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Scharwächter, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset. In Proceedings of the CVPR Workshop on the Future of Datasets in Vision, Boston, MA, USA, 7–12 June 2015; Volume 2. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Holschneider, M.; Kronland-Martinet, R.; Morlet, J.; Tchamitchian, P. A Real-Time Algorithm for Signal Analysis with the Help of the Wavelet Transform. In Wavelets; Combes, J.M., Grossmann, A., Tchamitchian, P., Eds.; Springer: Berlin/Heidelberg, Germany, 1990; pp. 286–297. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 18–14 September 2018; pp. 269–284. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support—4th International Workshop, DLMIA 2018 and 8th International Workshop, ML-CDS 2018 Held in Conjunction with MICCAI 2018; Maier-Hein, L., Syeda-Mahmood, T., Taylor, Z., Lu, Z., Stoyanov, D., Madabhushi, A., Tavares, J., Nascimento, J., Moradi, M., Martel, A., et al., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar] [CrossRef]
- ISPRS. 2D Semantic Labeling Challenge. Available online: http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html (accessed on 1 April 2020).
- Wang, Y.; Liang, B.; Ding, M.; Li, J. Dense Semantic Labeling with Atrous Spatial Pyramid Pooling and Decoder for High-Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 20. [Google Scholar] [CrossRef]
- Common Objects in COntext. Detection Evaluation. Available online: http://cocodataset.org/#detection-eval (accessed on 1 April 2020).
- Common Objects in COntext. MS-COCO Github Repository: Cocoapi. Available online: https://github.com/cocodataset/cocoapi (accessed on 1 April 2020).
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.W.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2018, 128, 261–318. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Balan, A.K.; Fathi, A.; Fischer, I.C.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Uijlings, J.; van de Sande, K.; Gevers, T.; Smeulders, A. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R.; Radosavovic, I.; Gkioxari, G.; Dollár, P.; He, K. Detectron. Available online: https://github.com/facebookresearch/detectron (accessed on 1 April 2020).
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 113–123. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2844–2853. [Google Scholar]
- Theano Development Team. Theano: A Python framework for fast computation of mathematical expressions. arXiv 2016, arXiv:1605.02688.
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; López García, A.; Heredia, I.; Malík, P.; Hluch, L. Machine Learning and Deep Learning Frameworks and Libraries for Large-Scale Data Mining: A Survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef]
- Theano Development Team. Theano: News. Available online: http://deeplearning.net/software/theano/ (accessed on 1 April 2020).
- Chollet, F. Keras. Available online: https://keras.io (accessed on 1 April 2020).
- TensorFlow Development Team. TensorFlow Github Repository. Available online: https://github.com/tensorflow/tensorflow (accessed on 1 April 2020).
- TensorFlow Development Team. TensorFlow Keras API. Available online: https://www.tensorflow.org/guide/keras (accessed on 1 April 2020).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Caffe2 Development Team. Caffe2: News. Available online: https://caffe2.ai/blog/2018/05/02/Caffe2_PyTorch_1_0.html (accessed on 1 April 2020).
- ESRI. Image Analyst—Deep Learning in ArcGIS Pro. Available online: https://pro.arcgis.com/de/pro-app/help/analysis/image-analyst/deep-learning-in-arcgis-pro.htm (accessed on 15 May 2020).
- OTB Development Team. Orfeo ToolBox—Documentation. Available online: https://www.orfeo-toolbox.org/CookBook/ (accessed on 15 May 2020).
- Cresson, R. A framework for remote sensing images processing using deep learning technique. arXiv 2018, arXiv:1807.06535. [Google Scholar] [CrossRef]
- azavea. Rastervision Documentation. Available online: https://docs.rastervision.io/en/0.10/index.html (accessed on 15 May 2020).
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting Large-Scale Urban Land Cover Changes from Very High Resolution Remote Sensing Images Using CNN-Based Classification. ISPRS Int. J. Geo-Inf. 2019, 8, 189. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bengio, Y. Deep Learning of Representations for Unsupervised and Transfer Learning. In Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning Workshop—Volume 27; Microtome Publishing: Brookline, MA, USA, 2011; pp. 17–37. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Introducing Eurosat: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 June 2018; pp. 204–207. [Google Scholar]
- Zhu, X.; Hu, J.; Qiu, C.; Shi, Y.; Kang, J.; Mou, L.; Bagheri, H.; Haberle, M.; Hua, Y.; Huang, R.; et al. So2Sat LCZ42: A Benchmark Dataset for Global Local Climate Zones Classification. arXiv 2019, arXiv:1912.12171. [Google Scholar] [CrossRef]
- SpaceNet. SpaceNet 1: Building Detection v1. Available online: https://github.com/SpaceNetChallenge/BuildingDetectors (accessed on 1 April 2020).
- Dai, J.; He, K.; Sun, J. Instance-Aware Semantic Segmentation via Multi-task Network Cascades. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- SpaceNet. SpaceNet 2: Building Detection v2. Available online: https://github.com/SpaceNetChallenge/BuildingDetectors_Round2 (accessed on 1 April 2020).
- SpaceNet. SpaceNet 3: Road Network Detection. Available online: https://github.com/SpaceNetChallenge/RoadDetector (accessed on 1 April 2020).
- SpaceNet. SpaceNet 4: Off-Nadir Buildings. Available online: https://github.com/SpaceNetChallenge/SpaceNet_Optimized_Routing_Solutions (accessed on 1 April 2020).
- Etten, A.V. City-Scale Road Extraction from Satellite Imagery v2: Road Speeds and Travel Times. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1786–1795. [Google Scholar]
- Etten, A.V. City-scale Road Extraction from Satellite Imagery. arXiv 2019, arXiv:1904.09901. [Google Scholar]
- SpaceNet. SpaceNet6: Multi Sensor—All Weather. Available online: https://spacenet.ai/sn6-challenge/ (accessed on 1 April 2020).
- Shermeyer, J.; Hogan, D.; Brown, J.; Etten, A.V.; Weir, N.; Pacifici, F.; Haensch, R.; Bastidas, A.; Soenen, S.; Bacastow, T.; et al. SpaceNet 6: Multi-Sensor All Weather Mapping Dataset. arXiv 2020, arXiv:2004.06500. [Google Scholar]
- Ding, L.; Tang, H.; Bruzzone, L. Improving Semantic Segmentation of Aerial Images Using Patch-based Attention. arXiv 2019, arXiv:1911.08877. [Google Scholar]
- Zhang, G.; Lei, T.; Cui, Y.; Jiang, P. A Dual-Path and Lightweight Convolutional Neural Network for High-Resolution Aerial Image Segmentation. ISPRS Int. J. Geo-Inf. 2019, 8, 582. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth Through Satellite Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 172–17209. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 192–1924. [Google Scholar]
- Buslaev, A.; Seferbekov, S.S.; Iglovikov, V.; Shvets, A. Fully Convolutional Network for Automatic Road Extraction From Satellite Imagery. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 207–210. [Google Scholar]
- Hamaguchi, R.; Hikosaka, S. Building Detection from Satellite Imagery using Ensemble of Size-Specific Detectors. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 223–2234. [Google Scholar]
- Iglovikov, V.; Seferbekov, S.; Buslaev, A.; Shvets, A. TernausNetV2: Fully Convolutional Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 228–2284. [Google Scholar]
- Tian, C.; Li, C.; Shi, J. Dense Fusion Classmate Network for Land Cover Classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 262–2624. [Google Scholar]
- Kuo, T.; Tseng, K.; Yan, J.; Liu, Y.; Wang, Y.F. Deep Aggregation Net for Land Cover Classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 247–2474. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Audebert, N.; Boulch, A.; Le Saux, B.; Lefèvre, S. Distance transform regression for spatially-aware deep semantic segmentation. Comput. Vision Image Underst. 2019, 189, 102809. [Google Scholar] [CrossRef]
- Duke Applied Machine Learning Lab. DukeAMLL Repository of Winning INRIA Building Labeling. Available online: https://github.com/dukeamll/inria_building_labeling_2017 (accessed on 1 April 2020).
- Azimi, S.M.; Henry, C.; Sommer, L.; Schumann, A.; Vig, E. SkyScapes Fine-Grained Semantic Understanding of Aerial Scenes. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7393–7403. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, J.; Liu, Y.; Yu, J. VaryBlock: A Novel Approach for Object Detection in Remote Sensed Images. Sensors 2019, 19, 5284. [Google Scholar] [CrossRef]
- Tayara, H.; Chong, K.T. Object Detection in Very High-Resolution Aerial Images Using One-Stage Densely Connected Feature Pyramid Network. Sensors 2018, 18, 3341. [Google Scholar] [CrossRef]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 785–800. [Google Scholar]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A Method for Vehicle Detection in High-Resolution Satellite Images that Uses a Region-Based Object Detector and Unsupervised Domain Adaptation. Remote Sens. 2020, 12, 575. [Google Scholar] [CrossRef]
- Hsieh, M.; Lin, Y.; Hsu, W.H. Drone-Based Object Counting by Spatially Regularized Regional Proposal Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4165–4173. [Google Scholar]
- Liu, K.; Mattyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Azimi, S.M. ShuffleDet: Real-Time Vehicle Detection Network in On-Board Embedded UAV Imagery. In Computer Vision–ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 88–99. [Google Scholar]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2017, 5, 44–53. [Google Scholar] [CrossRef]
- Shi, Z.; Yang, Y.; Hospedales, T.M.; Xiang, T. Weakly-Supervised Image Annotation and Segmentation with Objects and Attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2525–2538. [Google Scholar] [CrossRef]
- Diba, A.; Sharma, V.; Pazandeh, A.; Pirsiavash, H.; Van Gool, L. Weakly Supervised Cascaded Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5131–5139. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Reference | Explanation |
|---|---|---|
| DL | [2,25] | Deep Learning |
| ANN | [25] | Artificial Neural Network |
| SGD | [26,27,28,29] | Stochastic Gradient Descent |
| BP | [25,26,30] | Backpropagation |
| ReLU | [31,32,33] | Rectified Linear Unit |
| CNN | [2] | Convolutional Neural Network |
| RNN | [34] | Recurrent Neural Network |
| LSTM | [35] | Long Short Term Memory |
| GAN | [36] | Generative Adversarial Network |
| IR | Image Recognition | |
| ImageNet | [37] | DL dataset |
| ILSVRC | [3] | ImageNet Large Scale Vision Recognition Challenge |
| AlexNet | [3] | CNN by Alex Krizhevsky et al. [3] |
| ZFNet | [38] | CNN by Zeiler and Fergus [38] |
| VGG-16/19 | [39] | CNN by members of the Visual Geometry Group |
| LRN | [3,38] | Local Response Normalisation |
| Inception V1-3 | [40,41,42] | CNN architectures with Inception modules |
| BN | [41] | Batch Normalisation |
| ResNet | [43] | CNN architecture with residual connections |
| ResNeXt | [44] | Advanced CNN architecture with residual connections |
| Xception | [45] | ResNet-Inception combined CNN architecture |
| DenseNet | [46] | Very deep, ResNet based CNN |
| SENet | [47] | Squeeze and Excitation Network |
| NAS | [48] | Neural Architecture Search |
| NASNet | [49] | CNN architecture drafted with NAS |
| MobileNet | [50] | Efficient CNN architecture |
| MnasNet | [51] | Efficient CNN architecture drafted with NAS |
| EfficientNet | [52] | Efficient CNN architecture drafted with NAS |
| IS | Image Segmentation | |
| PASCAL-VOC | [53,54] | Pattern Analysis, Statistical modeling and Computational Learning— Visual Object Classes dataset |
| FCN | [55] | Fully Convolutional Network |
| DeepLabV1-V3+ | [56,57,58,59,60] | CNN architectures for IS |
| CRF | [61] | Conditional Random Field |
| ASPP | [58,59] | Atrous Spatial Pyramid Pooling |
| DPC | [62] | Dense Prediction Cell, CNN module drafted with NAS |
| AutoDeepLab | [63] | CNN architecture drafted with NAS |
| DeconvNet | [64] | Deconvolutional Network CNN |
| ParseNet | [65] | Parsing image context CNN |
| PSPNet | [66] | Pyramid Scene Parsing Network |
| U-Net | [67] | U-shaped encoder–decoder CNN |
| Tiramisu | [68] | U-Net-DenseNet combined CNN |
| RefineNet | [69] | Encoder–decoder CNN |
| HRNetV1-2 | [70,71] | High Resolution Networks CNNs for IS |
| OD | Object Detection | |
| MS-COCO | [72] | Microsoft-Common Object in Context dataset |
| R-CNN | [73] | Region based CNN |
| SPPNet | [74] | Spatial Pyramid Pooling Network |
| RoI pooling | [75] | Discretised pooling of Regions of Interest |
| Fast R-CNN | [75] | R-CNN + RoI pooling based CNN |
| RPN | [76] | Region (RoI) Proposal Network |
| Faster R-CNN | [76] | R-CNN + RPN + RoI pooling based CNN |
| FPN | [77] | Feature Pyramid Network |
| IoU | [53,78] | Intersection over Union (metric) |
| Cascade R-CNN | [79] | Faster R-CNN based cascading detector for less noisy detections |
| RoI align | [80] | Floating point variant of RoI pooling for higher accuracy |
| Mask R-CNN | [80] | Faster R-CNN + FCN based instance segmentation |
| CBNet | [81] | Composite Backbone Network for R-CNN based networks |
| PANet | [82] | Path Aggregation Network |
| SNIP(ER) | [83,84] | Scale Normalisation for Image Pyramids (with Efficient Resampling) |
| TridentNet | [85] | CNN using atrous convolution |
| fps | frames per second (metric) | |
| YOLO-V1-3 | [86,87,88] | You Only Look Once |
| NMS | Non-Maximum Suppression | |
| DarkNet | [87,88] | CNN backbone for YOLO-V2+3 |
| SSD | [89] | Single Shot MultiBox Detector |
| RetinaNet | [90] | CNN using an adaptive loss function for OD |
| RefineDet | [91] | CNN performing anchor refinement before detection |
| NAS-FPN | [92] | FPN variant drafted with NAS |
| EfficientDet | [93] | Efficient CNN for OD based on EfficientNet |
| BiFPN | [93] | Bi-directional FPN |
| Architecture | Year | Bottleneck | Factorisation | Residual | NAS | M Parameters | [%] |
|---|---|---|---|---|---|---|---|
| AlexNet [3] | 2012 | 62 | 81.8 | ||||
| ZFNet [38] | 2013 | 62 | 83.5 | ||||
| VGG-19 [39] | 2014 | 144 | 91.9 | ||||
| Inception-V1 + BN [41] | 2015 | ✓ | 11 | 92.2 | |||
| ResNet-152 [43] | 2015 | ✓ | ✓ | 60 | 95.5 | ||
| Inception-V3 [42] | 2015 | ✓ | ✓ | 24 | 94.4 | ||
| DenseNet-264 [46] | 2016 | ✓ | ✓ | 34 | 93.9 | ||
| Xception [45] | 2016 | ✓ | ✓ | ✓ | 23 | 94.5 | |
| ResNeXt-101 [44] | 2016 | ✓ | ✓ | 84 | 95.6 | ||
| MobileNet-224 [50] | 2017 | ✓ | ✓ | ✓ | 4.2 | 89.9 | |
| NasNet [49] | 2017 | ✓ | ✓ | ✓ | ✓ | 89 | 96.2 |
| MobileNet V2 [108] | 2018 | ✓ | ✓ | ✓ | 6.1 | 92.5 | |
| MnasNet [51] | 2018 | ✓ | ✓ | ✓ | ✓ | 5.2 | 93.3 |
| EfficientNet-B7 [52] | 2019 | ✓ | ✓ | ✓ | ✓ | 66 | 97.1 |
| Architecture | Year | Backbone | Type | CRF | Atrous | Multiscale | NAS | mIoU [%] |
|---|---|---|---|---|---|---|---|---|
| FCN-8s [55] | 2014 | VGG-16 | encoder–decoder | 62.2 | ||||
| DeepLabV1 [56] | 2014 | VGG-16 | naïve decoder | ✓ | ✓ | 66.4 | ||
| DeconvNet [64] | 2015 | VGG-16 | encoder–decoder | 69.6 | ||||
| U-Net [67] | 2015 | Own | encoder–decoder | 72.7 | ||||
| ParseNet [65] | 2015 | VGG-16 | naïve decoder | ✓ | 69.8 | |||
| DeepLabV2 [58] | 2016 | ResNet-101 | naïve decoder | ✓ | ✓ | ✓ | 79.7 | |
| RefineNet [69] | 2016 | ResNet-152 | encoder–decoder | 83.4 | ||||
| PSPNet [66] | 2016 | ResNet-101 | naïve decoder | ✓ | 82.6 | |||
| DeepLabV3 [59] | 2017 | ResNet-101 | naïve decoder | ✓ | ✓ | 85.7 | ||
| DeepLabV3+ [60] | 2018 | Xception | encoder–decoder | ✓ | ✓ | 87.8 | ||
| DensePredictionCell [62] | 2018 | Xception | naïve decoder | ✓ | ✓ | ✓ | 87.9 | |
| Auto-DeepLab [63] | 2019 | Own | naïve decoder | ✓ | ✓ | ✓ | 82.1 |
| Two-Stage Detector | ||||||
| Architecture | Year | Backbone | RPN | RoI | Multiscale Feature | AP [%] |
| R-CNN [73] | 2013 | AlexNet | - | |||
| Fast R-CNN [75] | 2015 | VGG-16 | pooling | 19.7 | ||
| Faster R-CNN [76] | 2015 | VGG-16 | ✓ | pooling | 27.2 | |
| Faster R-CNN + FPN [77] | 2016 | ResNet-101 | ✓ | pooling | FPN | 35.8 |
| Mask R-CNN [80] | 2017 | ResNeXt-101 | ✓ | align | FPN | 39.8 |
| Cascade R-CNN [79] | 2017 | ResNet-101 | ✓ | align | FPN | 50.2 |
| PANet [82] | 2018 | ResNeXt-101 | ✓ | align | FPN | 45 |
| TridentNet [85] | 2019 | ResNet-101-Deformable | ✓ | pooling | 3xAtrous | 48.4 |
| Cascade Mask R-RCNN [81] | 2019 | CBNet (3xResNeXt-152) | ✓ | align | FPN | 53.3 |
| One-Stage Detector | ||||||
| Architecture | Year | Backbone | Anchors | NAS | Multiscale Feature | AP [%] |
| YOLO-V1 [86] | 2015 | custom | - | |||
| SSD [89] | 2015 | VGG-16 | ✓ | ✓ | 26.8 | |
| YOLO-V2 [87] | 2016 | DarkNet-19 | ✓ | 21.6 | ||
| RetinaNet [90] | 2017 | ResNet-101 | ✓ | FPN | 39.1 | |
| YOLO-V3 [88] | 2018 | DarkNet-53 | ✓ | FPN-like | 33 | |
| EfficientDet-D7 [93] | 2019 | EfficientNet-B6 | ✓ | ✓ | BiFPN | 52.2 |
| Dataset | Task | Topic | Platform | Sensor | Resolution | Example Application by Architectures |
|---|---|---|---|---|---|---|
| NWPU RESISC45 [155] | IR | LULC | multiple platforms | optical | high | VGG-16 [155] |
| EuroSAT [156] | IR | LULC | Sentinel 2 | multispectral | medium | Inception-V1 and ResNet-50 [156] |
| BigEarthNet [116,117] | IR | LULC | Sentinel 2 | multispectral | medium | ResNet-50 [117] |
| So2Sat LCZ42 [157] | IR | local climate zones | Sentinel 1+2 | mltspectr+SAR | medium | ResNeXt-29 + CBAM [157] |
| SpaceNet1 [158] | IS | building footprints | - | multispectral | low | VGG-16 + MNC [158,159] |
| SpaceNet2 [160] | IS | building footprints | WorldView3 | multispectral | high | U-Net (modified: inputdepth = 13) [160] |
| SpaceNet3 [161] | IS | road network | WorldView3 | multispectral | high | ResNet-34 + U-Net [161] |
| SpaceNet4 [162] | IS | building footprints | WorldView2 | multispectral | high | SE-ResNeXt-50/101 + U-Net [162] |
| SpaceNet5 [163] | IS | road network | WorldView3 | multispectral | high | ResNet-50 + U-Net [164], SE-ResNeXt-50 + U-Net [163] |
| SpaceNet6 [165,166] | IS | building footprints | WordView2 + Capella36 | mltspectr + SAR | high | VGG-16 + U-Net [166] |
| ISPRS 2D Sem. Lab. [126] | IS | multiple classes | plane | multispectral | very high | U-Net, DeepLabV3+, PSPNet, LANet (patch attention module) [167], MobileNetV2(with atrous conv) + Dual path encoder + SE modules [168] |
| DeepGlobe-Road [169] | IS | road network | WorldView3 | multispectral | high | D-LinkNet (ResNet-34 + U-Net with atrous decoder) [170], ResNet-34 + U-Net [171] |
| DeepGlobe-Building [169] | IS | building footprints | WorldView3 | multispectral | high | ResNet-18 + Multitask U-Net [172], WideResNet-38 + U-Net [173] |
| DeepGlobe-LCC [169] | IS | LULC | WorldView3 | multispectral | high | Dense Fusion Classmate Network (DenseNet + FCN varaint) [174], Deep Aggregation Net (ResNet + DeepLabV3 + variant) [175] |
| WHU Building [176] | IS | building footprints | multiple platforms | optical | high | VGG-16 + ASPP + FCN [177] |
| INRIA [178] | IS | building footprints | multiple platforms | multispectral | very high | ResNet-50 + SegNet variant [179], U-Net variant [180] |
| DLR-SkyScapes [181] | IS | multiple classes | helicopter | optical | very high | SkyScapesNet (custom design [181]) |
| NWPU VHR-10 [182] | OD | multiple classes | airborne platforms | optical | very high | DarkNet + YOLO (modified: VaryBlock) [183], ResNet-101 + FPN (modified: Densely connected top-down path) + fully convolutional detector head [184] |
| COWC [185] | OD | vehicle detection | airborne platforms | optical | very high | VGG16 + SSD + correlation alignment domain adaptation [186] |
| CARPK [187] | OD | vehicle detection | drone | optical | very high | VGG16 + LPN (Layout Proposal Net) [187] |
| DLR 3K Munich [188] | OD | vehicle detection | airborne platform | optical | very high | ShuffleDet (ShuffleNet + modified SSD) [189] |
| DOTA [100] | OD | multiple classes | airborne platforms | optical | very high to high | ResNet-50+improved Cascade R2CNN see leader board of [100], ResNet-101/FPN + Fater R-CNN OBB + RoI transformer [138] |
| DIOR [24] | OD | multiple classes | multiple platforms | optical | heigh to medium | ResNet-101 + PAnet and ResNet-101 + RetinaNet [24] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. https://doi.org/10.3390/rs12101667
Hoeser T, Kuenzer C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sensing. 2020; 12(10):1667. https://doi.org/10.3390/rs12101667
Chicago/Turabian StyleHoeser, Thorsten, and Claudia Kuenzer. 2020. "Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends" Remote Sensing 12, no. 10: 1667. https://doi.org/10.3390/rs12101667
APA StyleHoeser, T., & Kuenzer, C. (2020). Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sensing, 12(10), 1667. https://doi.org/10.3390/rs12101667