An Improved GrabCut Method Based on a Visual Attention Model for Rare-Earth Ore Mining Area Recognition with High-Resolution Remote Sensing Images



Abstract
1. Introduction
2. Materials and Methods
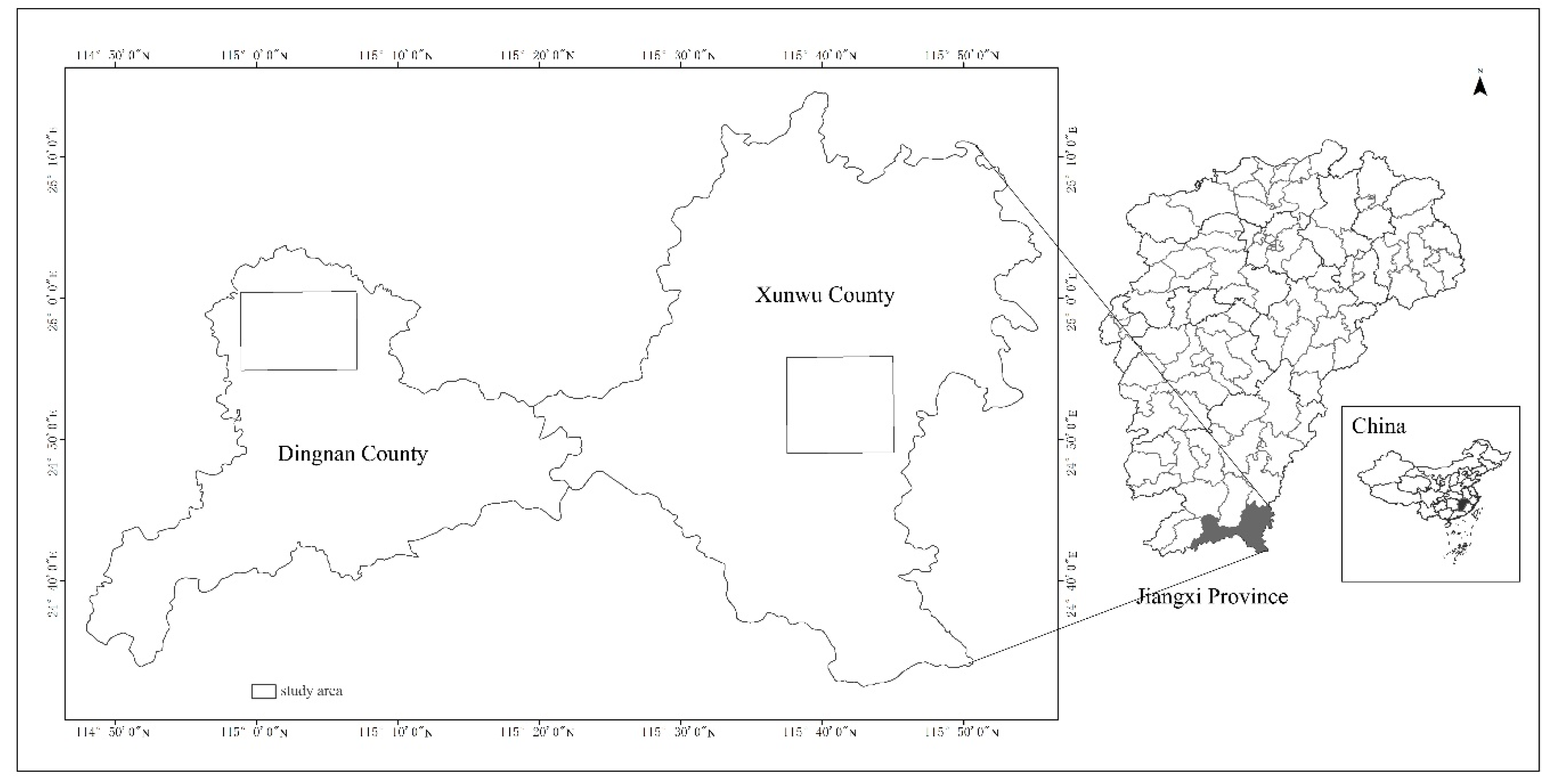
2.1. Research Area, Data, and Preprocessing
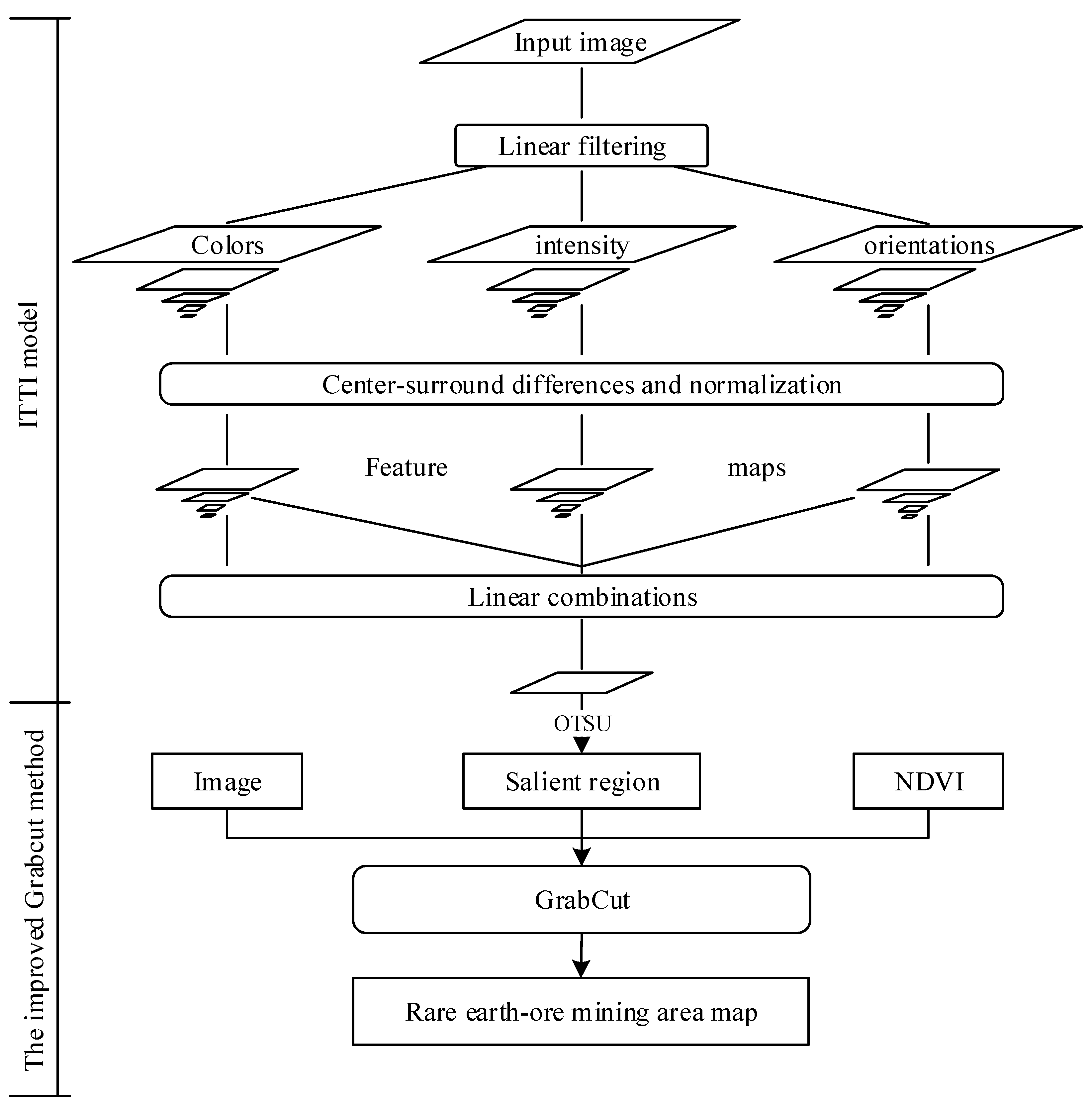
2.2. Methods
2.2.1. ITTI Visual Attention Model
- Center-surround difference.The center-surround difference means the differences between “center” fine scale yield and “surround” coarser scale yield of the feature maps [11]. Both types of sensitivities are simultaneously computed in a set of six maps [11]. Setting as the pyramid image, the center-surround difference of a feature can be obtained by Equation (1), and the feature map can be calculated by Equation (2).where is the difference between two different level images, which are resampled to the same resolution, means absolute value, is across-scale addition consist of reduction of each map to scale four and point-by-point addition, , .
- Normalization Operator.The normalization operator is a key process in the ITTI model, and it mainly includes three steps. The first step is to unify the dimension among these feature maps, i.e., these maps are normalized to a fixed value range . Secondly, the location of the maximum feature value is calculated and the mean of the maximum values for all other local regions () is also calculated. Finally, the feature maps are multiplied by pixel by pixel.
- Saliency Map Generation.In order to widen the gap among different center-surround differences of the same feature map in the saliency, and to ensure that effects of different features on the overall saliency map are independent, it is necessary to independently generate a conspicuity map for each channel’s features before generating the overall saliency map, and the detailed process is expressed as Equations (3)–(5) [11]. The feature conspicuity maps include intensity, color, and orientation conspicuity maps. Then, the three conspicuity maps are normalized and weighted into the final saliency map, expressed as Equation (6).where , , indicate intensity, color, and orientation, respectively; has been defined previously. For orientation, four (0°, 45°, 90°, 135°) values were given.where is the normalization, and is the final saliency map.
2.2.2. Rare-earth Ore Mining Area Extraction Based on GrabCut
- Energy Function.NDVI, a commonly used vegetation index in the quantitative remote sensing community, was added to the original energy function as a bound term, therefore, the improved energy function is expressed as Equation (10):where is a bound term of NDVI to assist in extracting the REO mining area. It signifies the weight of a pixel belonging to the corresponding category identified by the NDVI data, and can be expressed as Equation (11):where is the weight of the added bound term, and it can be adjusted according to the actual situation. represent the category tag of pixel .
- Initial setting.For the original GrabCut method, user interaction is generally needed to fulfil satisfactory segmentation work. The initial and incomplete user-labeling, which is drawn as a rectangle by users, may finish the entire segmentation, but further user editing is required sometimes. Moreover, a remote sensing image is usually larger, more fragmented, and more complex than natural pictures; user interaction with labeled seed points will result in an inefficient segmentation process when GrabCut is applied for remote sensing image segmentation. Therefore, in this study the binarized map generated from the saliency map with the ITTI model was employed as an initial of the improved GrabCut method in order to accomplish the entire segmentation process efficiently and automatically.
2.2.3. Accuracy Evaluation Metrics
3. Results
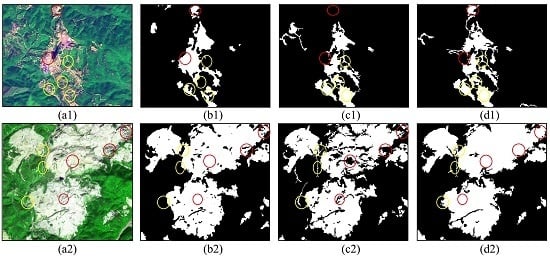
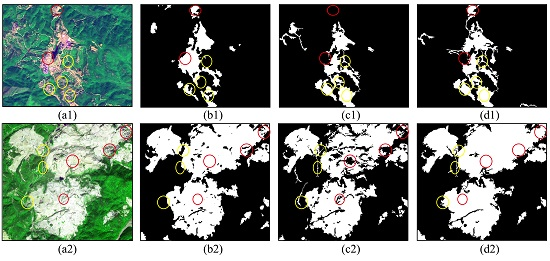
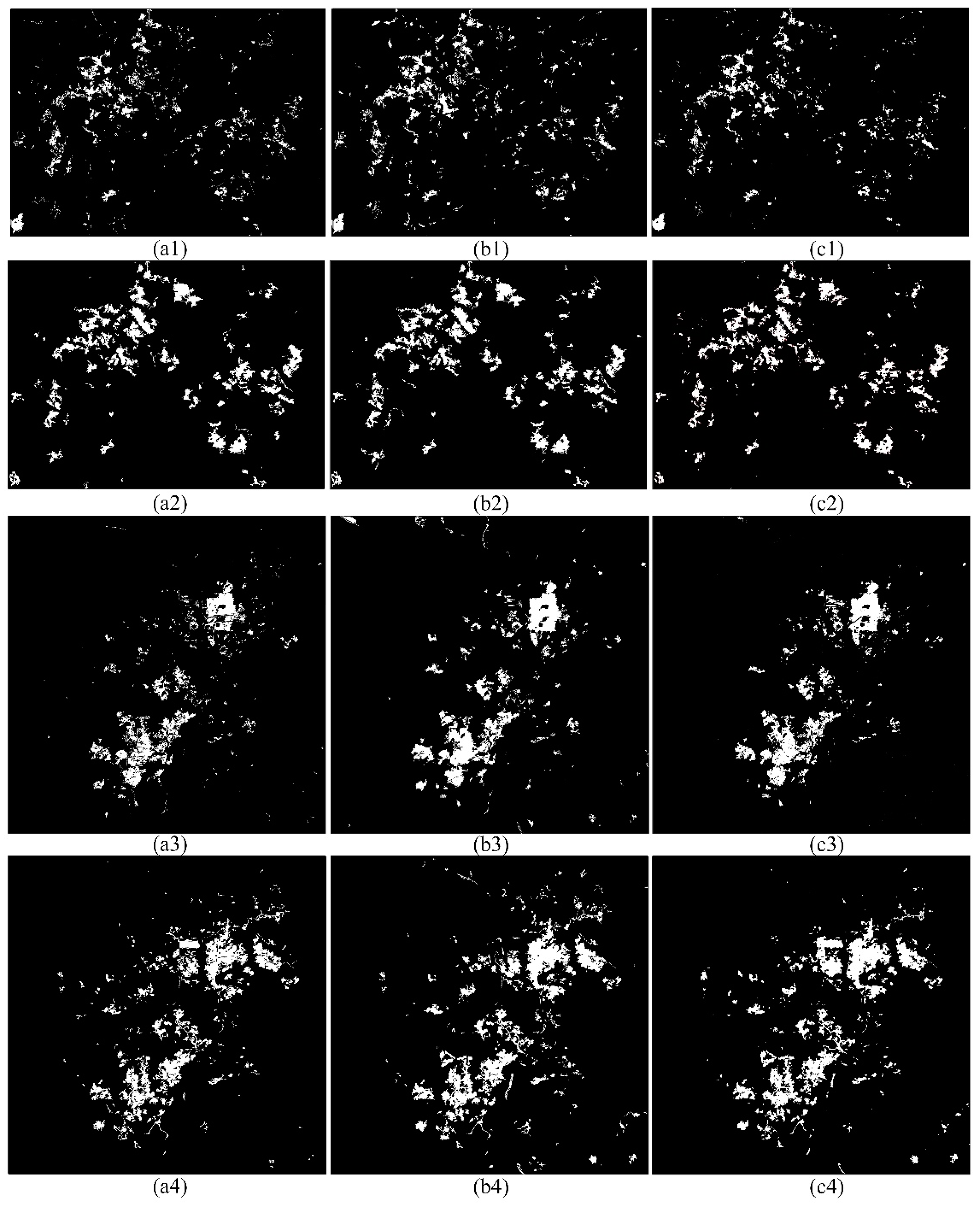
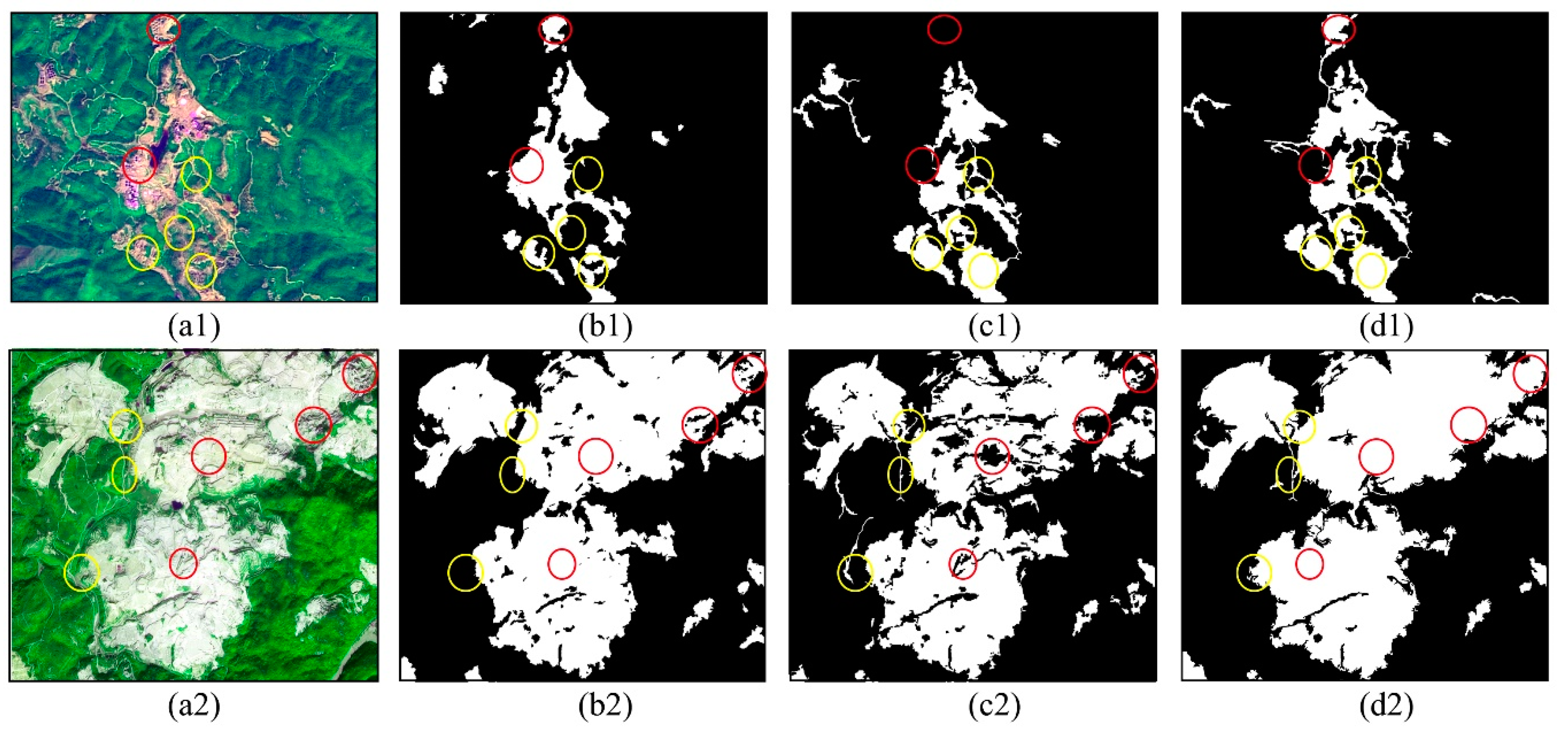
3.1. REO Mining Information Extraction Result from High-Resolution Remote Sensing Images
3.2. Precision Verification
3.2.1. Effectiveness Evaluation
3.2.2. Comparison with Traditional Methods
4. Discussion
5. Conclusions
- Introducing the visual attention model to generate the salient region as the initial input of the GrabCut model made the extraction process fully automatic and improved extraction accuracy.
- Adding NDVI information as the bound term of energy function achieved a higher precision than the original GrabCut model.
- The proposed method outperformed the traditional CART and SVM methods.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Demirel, N.; Kemal Emil, M.; Sebnem Duzgun, H. Surface Coal Mine Area Monitoring Using Multi-temporal High-resolution Satellite Imagery. Int. J. Coal Geol. 2011, 86, 3–11. [Google Scholar] [CrossRef]
- Zhang, Z.; He, G.; Wang, M.; Wang, Z.; Long, T.; Peng, Y. Detecting decadal land cover changes in mining regions based on satellite remotely sensed imagery: A case study of the stone mining area in Luoyuan county, SE China. Photogramm. Eng. Remote Sens. 2015, 81, 745–751. [Google Scholar] [CrossRef]
- Song, X.; He, G.; Zhang, Z.; Long, T.; Peng, Y.; Wang, Z. Visual attention model based mining area recognition on massive high-resolution remote sensing images. Clust. Comput. 2015. [Google Scholar] [CrossRef]
- Karan, S.K.; Samadder, S.R.; Maiti, S.K. Assessment of the capability of remote sensing and GIS techniques for monitoring reclamation success in coal mine degraded lands. J. Environ. Manag. 2016, 182, 272–283. [Google Scholar] [CrossRef]
- Yu, L.; Xu, Y.; Xue, Y.; Li, X.; Cheng, Y.; Liu, X.; Porwal, A.; Holden, E.; Yang, J.; Gong, P. Monitoring surface mining belts using multiple remote sensing datasets: A global perspective. Ore Geol. Rev. 2018, 101, 675–687. [Google Scholar] [CrossRef]
- Prakash, A.; Gupta, R.P. Land-use mapping and change detection in a coal mining area—A case study in the Jharia coalfield, India. Int. J. Remote Sens. 1998, 19, 391–410. [Google Scholar] [CrossRef]
- Kassouk, Z.; Thouret, J.; Gupta, A.; Solikhin, A.; Liew, S.C. Object-oriented classification of a high-spatial resolution SPOT5 image for mapping geology and landforms of active volcanoes: Semeru case study, Indonesia. Geomorphology 2014, 221, 18–33. [Google Scholar] [CrossRef]
- Zeng, X.; Liu, Z.; He, C.; Ma, Q.; Wu, J. Detecting surface coal mining areas from remote sensing imagery: An approach based on object-oriented decision trees. J. Appl. Remote Sens. 2017, 11, 015025. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, H.; Jin, Z. A visual attention based ROI detection method for facial expression recognition. Neurocomputing 2018, 296, 12–22. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. Hum. Neurobiol. 1985, 4, 219–227. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef]
- Tosun, A.B.; Kandemir, M.; Sokmensuer, C.; Gunduz-Demir, C. Object-oriented texture analysis for the unsupervised segmentation of biopsy images for cancer detection. Pattern Recognit. 2009, 42, 1104–1112. [Google Scholar] [CrossRef]
- Ning, J.; Zhang, L.; Zhang, D.; Wu, C. Interactive image segmentation by maximal similarity based region merging. Pattern Recognit. 2010, 43, 445–456. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, Y.; Bai, P. Object Localization improved GrabCut for Lung Parenchyma Segmentation. Procedia Comput. Sci. 2018, 131, 1311–1317. [Google Scholar] [CrossRef]
- Liu, L.; Yu, X.; Ding, B. A Fast Segmentation Algorithm of PET Images Based on Visual Saliency Model. In Proceedings of the 2nd International Conference on Intelligent Computing, Communication & Convergence (ICCC-2016), Bhubaneswar, Odisha, India, 24–25 January 2016. [Google Scholar]
- Khattab, D.; Theobalt, C.; Hussein, A.S.; Tolba, M.F. Modified GrabCut for human face segmentation. Ain Shams Eng. J. 2014, 5, 1083–1091. [Google Scholar] [CrossRef]
- Salau, A.O.; Yesufu, T.K.; Ogundare, B.S. Vehicle plate number localization using a modified GrabCut algorithm. J. King Saud Univ.-Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, Y.; Cui, W. Semiautomatic right-angle building extraction from very graph cuts with star shape constraint and regularization. J. Appl. Remote Sens. 2018, 12, 026005. [Google Scholar] [CrossRef]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef]
- Alberto, G.G.; Sergio, O.E.; Sergiu, O.; Victor, V.M.; Jose, G.R. A Review on Deep Learning Techniques Applied to Semantic Segmentation. Comput. Vis. Pattern Recognit. 2017, arXiv:1704.06857. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Sys. Man. Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–165. [Google Scholar] [CrossRef]
- Zhang, Z.; He, G.; Wang, X.; Jiang, H. Leaf area index estimation of bamboo forest in Fujian province based on IRS P6 LISS 3 imagery. Int. J. Remote Sens. 2011, 32, 5365–5379. [Google Scholar] [CrossRef]
- Meroni, M.; Fasbender, D.; Rembold, F.; Atzberger, C.; Klisch, A. Near real-time vegetation anomaly detection with MODIS NDVI: Timeliness vs. accuracy and effect of anomaly computation options. Remote Sens. Environ. 2019, 221, 508–521. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Sensor | Resolution | Acquired Time | Study Area |
|---|---|---|---|---|
| 1 | GF-1 MSS2 1 | 8 m | 2015-10-16 | Lingbei |
| GF-1 PMS2 2 | 2 m | 2015-10-16 | ||
| 2 | ALOS AVNIR-2 3 | 10 m | 2010-11-01 | |
| ALOS PRISM 4 | 2.5 m | 2010-11-01 | ||
| 3 | GF-1 MSS1 5 | 8 m | 2014-12-12 | Shipai |
| GF-1 PMS1 6 | 2 m | 2014-12-12 | ||
| 4 | ALOS AVNIR-2 | 10 m | 2008-11-24 | |
| ALOS PRISM | 2.5 m | 2008-11-24 |
| Areas | Methods | FPR | FNR | PA | MPA | MIoU | FWIoU |
|---|---|---|---|---|---|---|---|
| Lingbei GF-1 | Normal GrabCut | 93.4 | 4.0 | 54.3 | 74.4 | 29.7 | 51.2 |
| Salient region as initial | 69.1 | 1.6 | 92.6 | 95.3 | 61.5 | 90.2 | |
| The improved GrabCut | 9.1 | 4.9 | 99.5 | 97.4 | 93.2 | 99.1 | |
| Lingbei ALOS | Normal GrabCut | 91.6 | 1.3 | 31.8 | 63.0 | 17.9 | 26.2 |
| Salient region as initial | 36.0 | 1.2 | 96.4 | 97.5 | 79.9 | 94.1 | |
| The improved GrabCut | 4.6 | 6.5 | 99.3 | 96.6 | 94.4 | 98.6 | |
| Shipai GF-1 | Normal GrabCut | 88.5 | 0.1 | 68.6 | 83.6 | 39.4 | 65.0 |
| Salient region as initial | 61.9 | 0.1 | 93.4 | 96.5 | 65.6 | 90.9 | |
| The improved GrabCut | 9.9 | 5.7 | 99.3 | 96.9 | 92.4 | 98.8 | |
| Shipai ALOS | Normal GrabCut | 85.9 | 2.0 | 64.7 | 80.3 | 38.3 | 59.7 |
| Salient region as initial | 50.2 | 1.1 | 94.1 | 96.3 | 71.6 | 91.1 | |
| The improved GrabCut | 12.5 | 5.1 | 98.9 | 97.0 | 91.2 | 97.9 |
| SVM | CART | ||
|---|---|---|---|
| kernel type | linear | depth | 0 |
| c | 2 | max categories | 16 |
| gamma | 0 | cross validation folds | 3 |
| features | NDVI and (NDWI); Mean Blue, Mean Red, Mean NIR, Brightness, Max. diff; GLDV Entropy (all directions). | features | NDVI and (NDWI); Mean Blue, Mean Red, Mean NIR, Brightness, Max.diff. |
| Study Areas | SVM | CART | ||
|---|---|---|---|---|
| REO | Non-REO | REO | Non-REO | |
| Lingbei GF-1 | 76 | 138 | 76 | 138 |
| Lingbei ALOS | 76 | 132 | 76 | 132 |
| Shipai GF-1 | 23 | 48 | 77 | 131 |
| Shipai ALOS | 40 | 109 | 40 | 109 |
| Areas | Methods | FPR | FNR | PA | MPA | MIoU | FWIoU |
|---|---|---|---|---|---|---|---|
| Lingbei GF-1 | SVM | 39.3 | 15.3 | 97.6 | 91.4 | 76.2 | 96.1 |
| CART | 28.2 | 15.4 | 98.4 | 91.7 | 80.9 | 97.2 | |
| the improved GrabCut | 9.1 | 4.9 | 99.5 | 97.4 | 93.2 | 99.1 | |
| Lingbei ALOS | SVM | 21.8 | 13.6 | 97.6 | 92.4 | 83.5 | 95.7 |
| CART | 21.1 | 13.9 | 97.7 | 92.3 | 83.8 | 95.8 | |
| the improved GrabCut | 4.6 | 6.5 | 99.3 | 96.6 | 94.4 | 98.6 | |
| Shipai GF-1 | SVM | 26.8 | 11.2 | 98.2 | 93.7 | 82.6 | 96.9 |
| CART | 17.4 | 22.9 | 98.4 | 88.2 | 82.4 | 97.1 | |
| the improved GrabCut | 9.9 | 5.7 | 99.3 | 96.9 | 92.4 | 98.8 | |
| Shipai ALOS | SVM | 20.5 | 11.3 | 97.9 | 93.6 | 85.0 | 96.4 |
| CART | 15.9 | 20.8 | 97.9 | 89.1 | 83.3 | 96.1 | |
| the improved GrabCut | 12.5 | 5.1 | 98.9 | 97.0 | 91.2 | 97.9 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Zhang, Z.; He, G.; Wei, M. An Improved GrabCut Method Based on a Visual Attention Model for Rare-Earth Ore Mining Area Recognition with High-Resolution Remote Sensing Images. Remote Sens. 2019, 11, 987. https://doi.org/10.3390/rs11080987
Peng Y, Zhang Z, He G, Wei M. An Improved GrabCut Method Based on a Visual Attention Model for Rare-Earth Ore Mining Area Recognition with High-Resolution Remote Sensing Images. Remote Sensing. 2019; 11(8):987. https://doi.org/10.3390/rs11080987
Chicago/Turabian StylePeng, Yan, Zhaoming Zhang, Guojin He, and Mingyue Wei. 2019. "An Improved GrabCut Method Based on a Visual Attention Model for Rare-Earth Ore Mining Area Recognition with High-Resolution Remote Sensing Images" Remote Sensing 11, no. 8: 987. https://doi.org/10.3390/rs11080987
APA StylePeng, Y., Zhang, Z., He, G., & Wei, M. (2019). An Improved GrabCut Method Based on a Visual Attention Model for Rare-Earth Ore Mining Area Recognition with High-Resolution Remote Sensing Images. Remote Sensing, 11(8), 987. https://doi.org/10.3390/rs11080987