Spectral-Spatial Attention Networks for Hyperspectral Image Classification

 ,
,  ,
, 
Abstract
:
1. Introduction
1.1. Motivation
1.2. Contribution
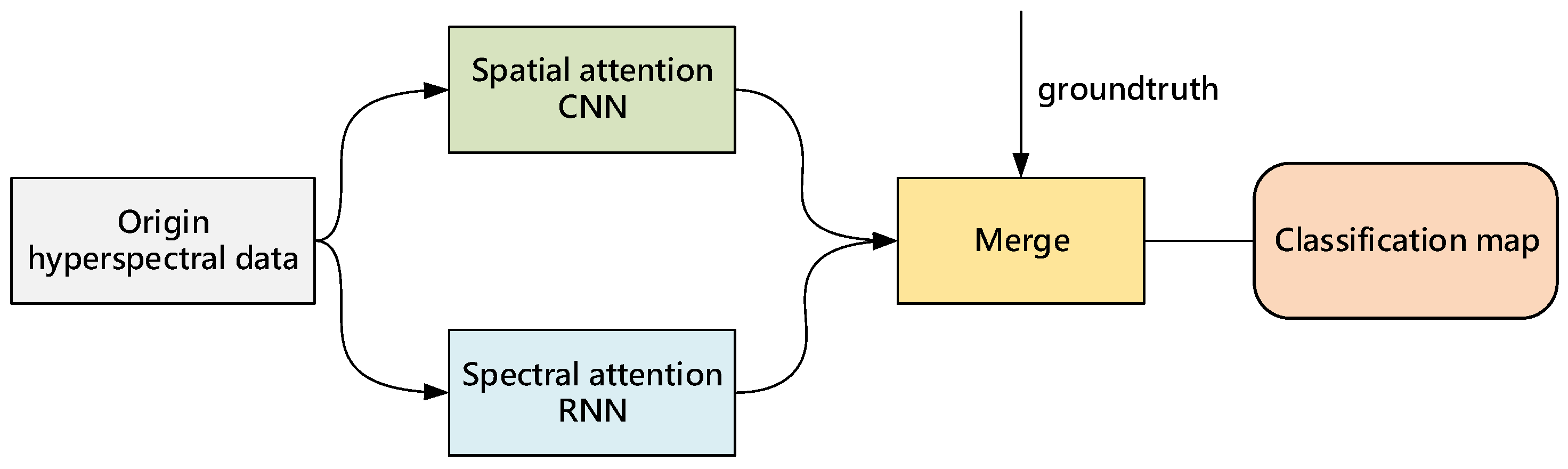
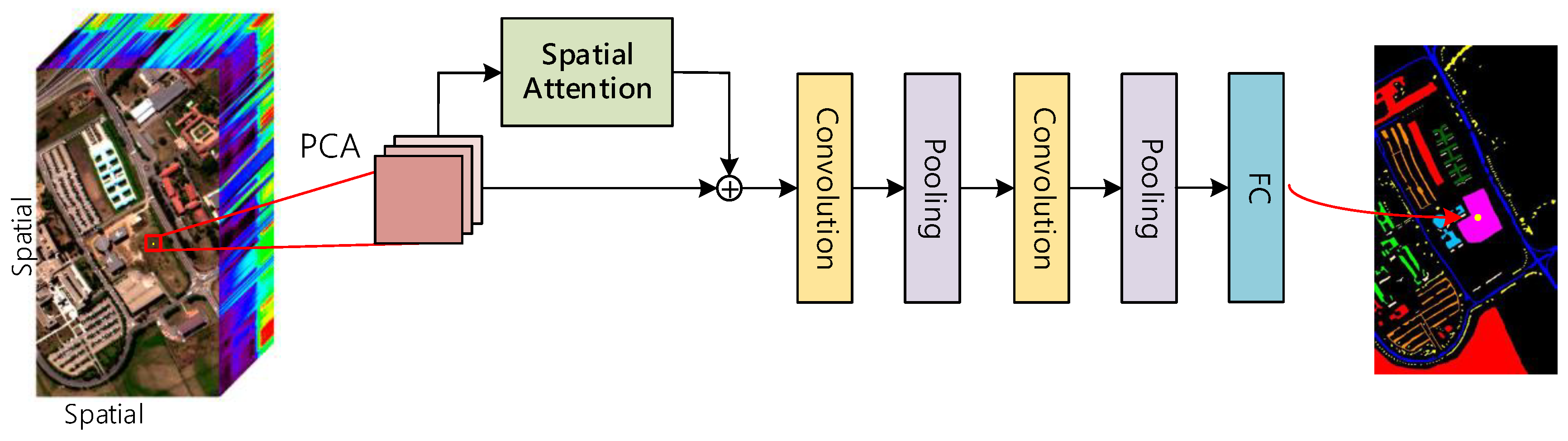
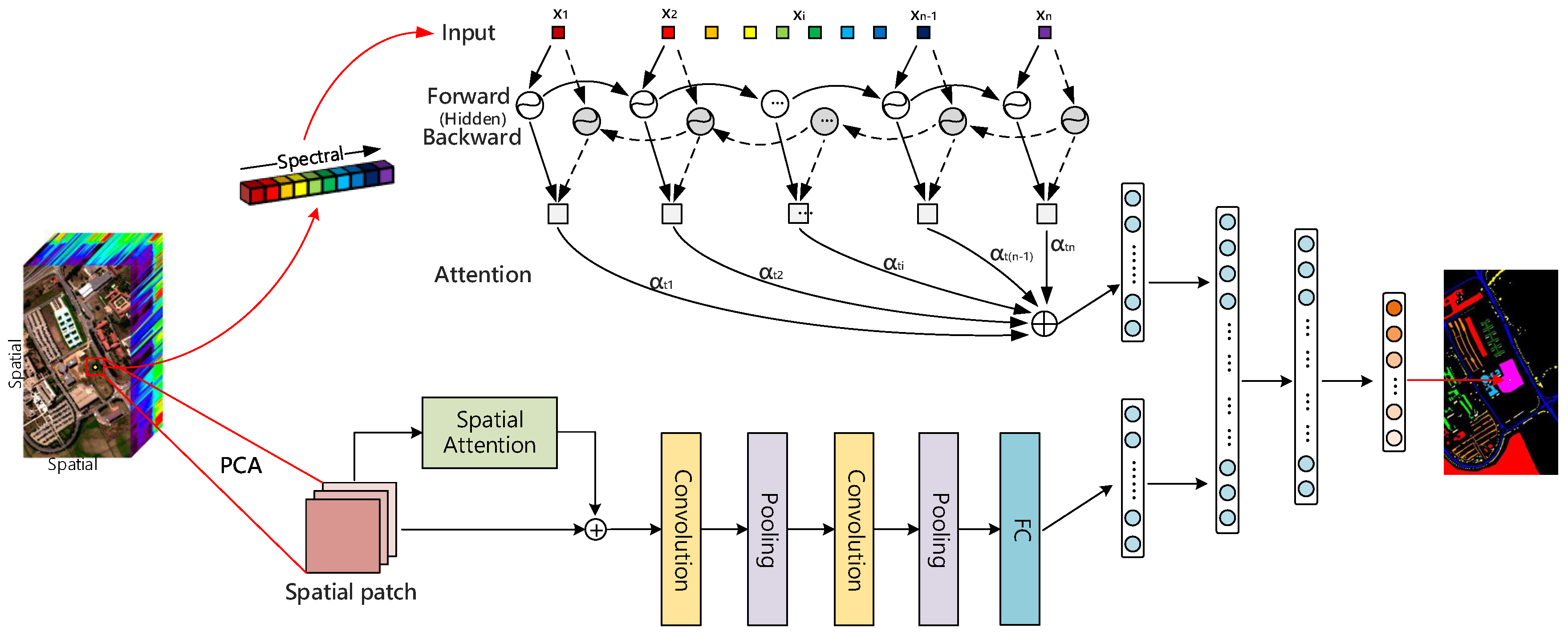
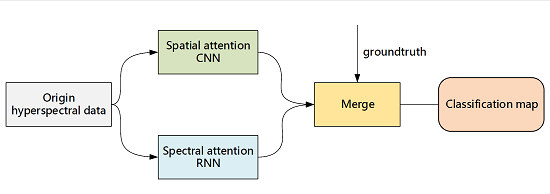
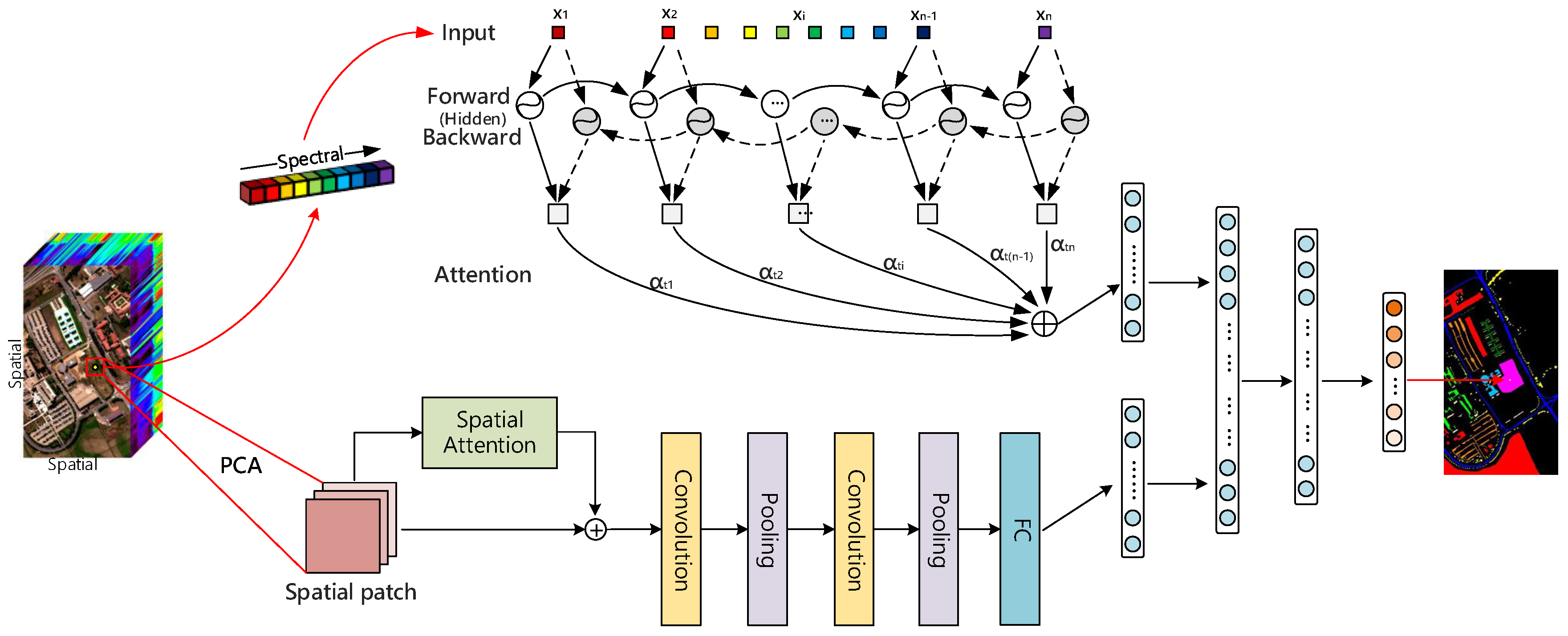
- We design a joint network with a spectral attention bi-directional RNN branch and a spatial attention CNN branch to extract spectral-spatial features for HSI classification. An attention mechanism is used to emphasize meaningful features along the two branches, as shown in Figure 1. Our goal is to improve representation ability by using the attention mechanism, namely, to focus on the correlations between adjacent spectral dimensions and the spatial dependency in spatial domain, as well as to suppress unnecessary features.
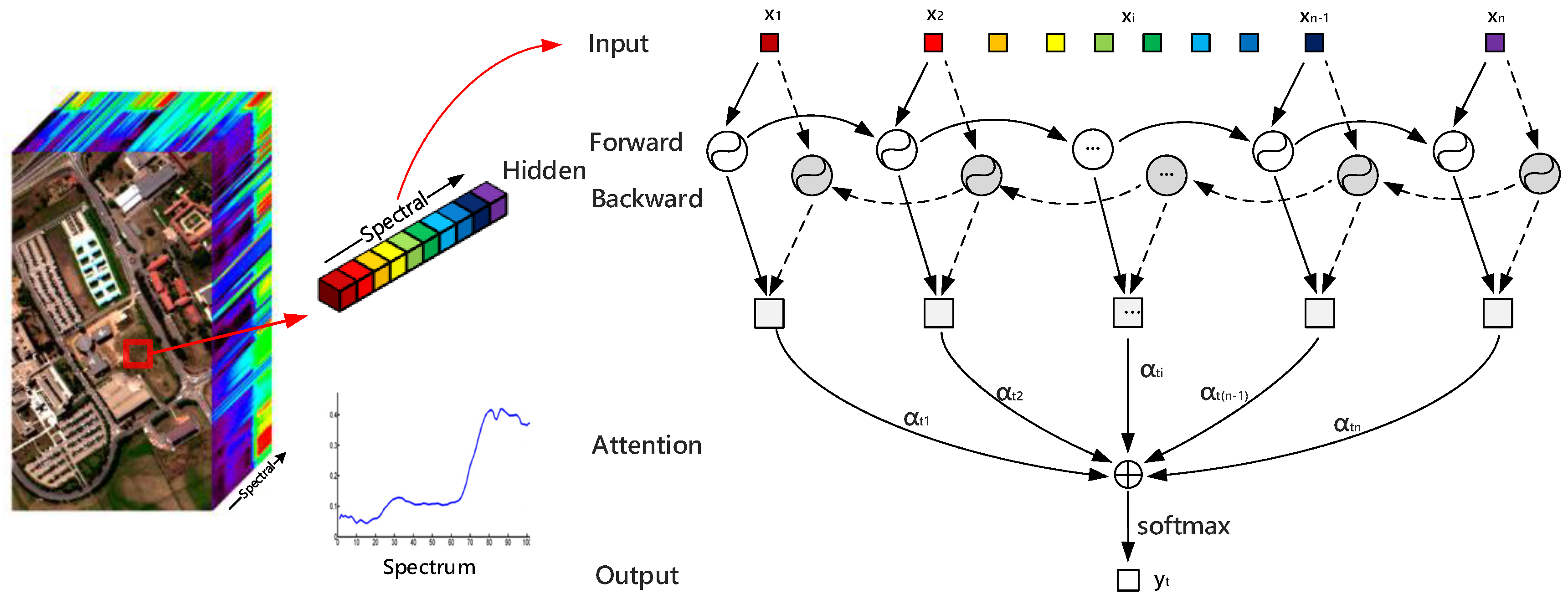
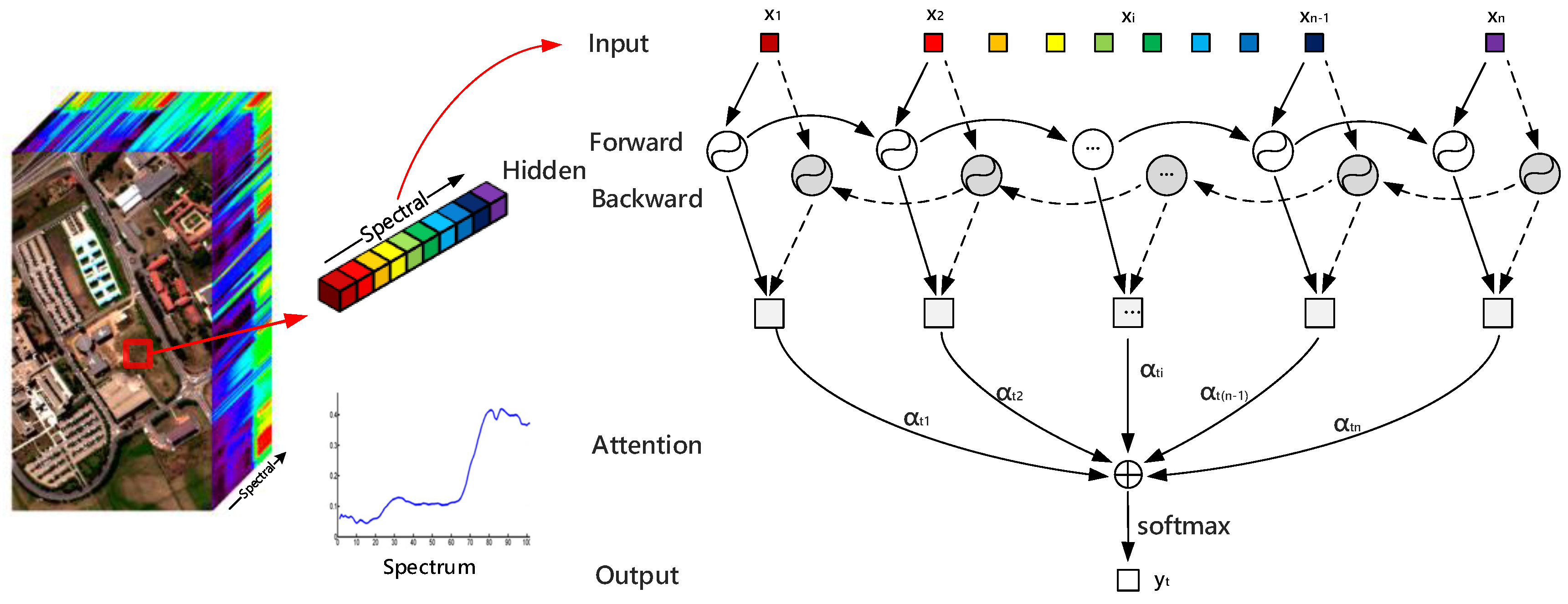
- A bi-directional RNN with an attention mechanism is designed for spectral information in both backward and forward directions. For each pixel, a spectral vector is decomposed into a set of ordered single data and fed into GRU units one by one. Additional attention weights strengthen the spectral correlation between spectrum channels. We compare the attention RNN to the ordinary bi-directional RNN, and the experimental results in Tables 7–9 have proven its effectiveness for the classification with spectral information.
- For spatial axes, we add attention to 2D CNN and train this model on the image patch around the pixel. Compared with the average consideration of each image region, the attention parameter assigns a greater weight to the key parts to make the model focus on the primary features. The classification results of attention CNN and CNN in Tables 7–9 show that the central pixel is classified better by adding attention weight.
2. Related Works
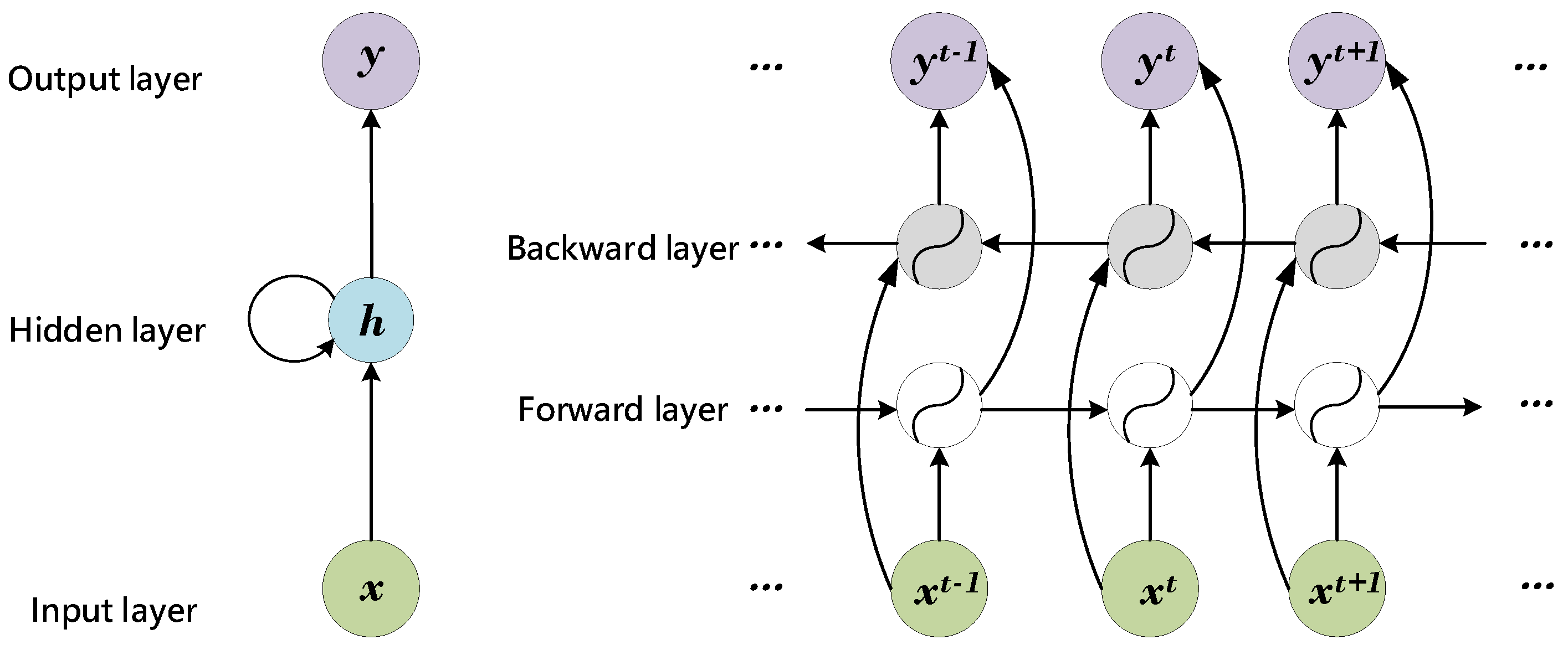
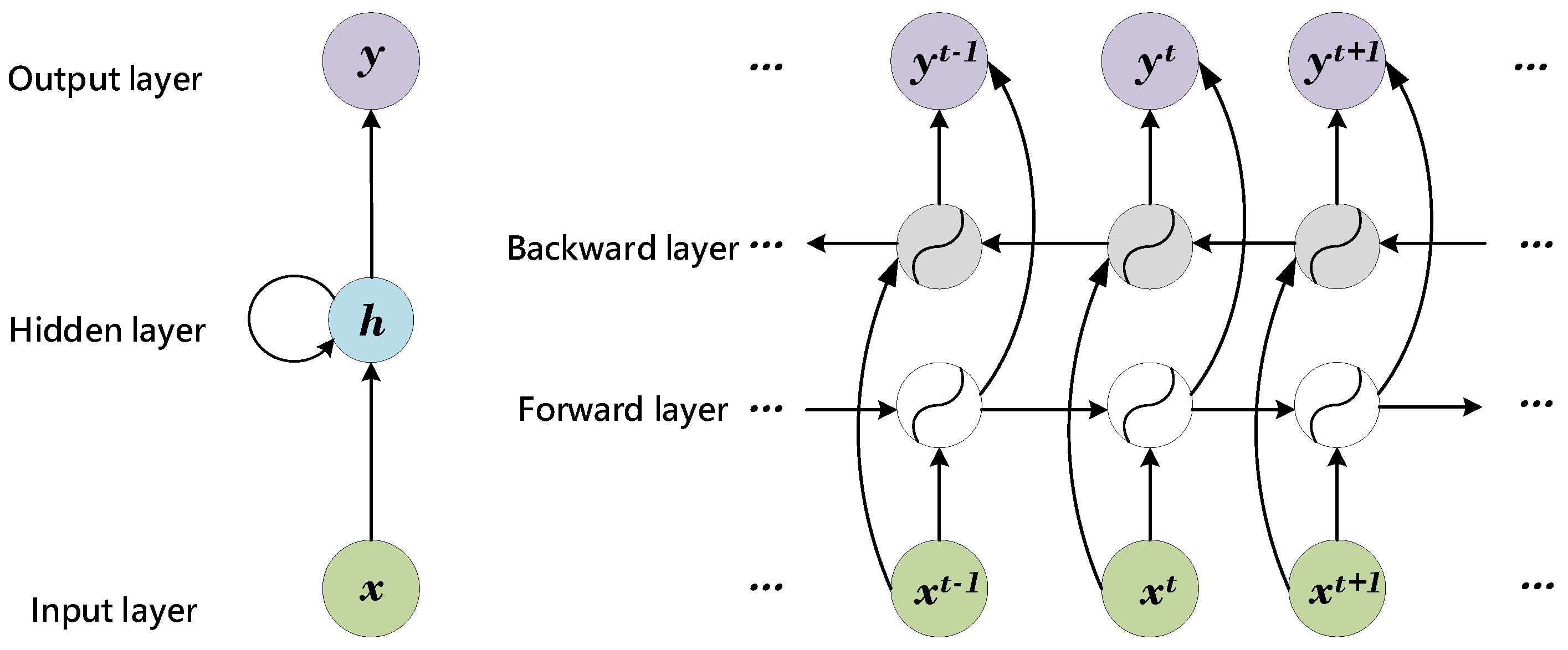
2.1. Bi-Directional Recurrent Network
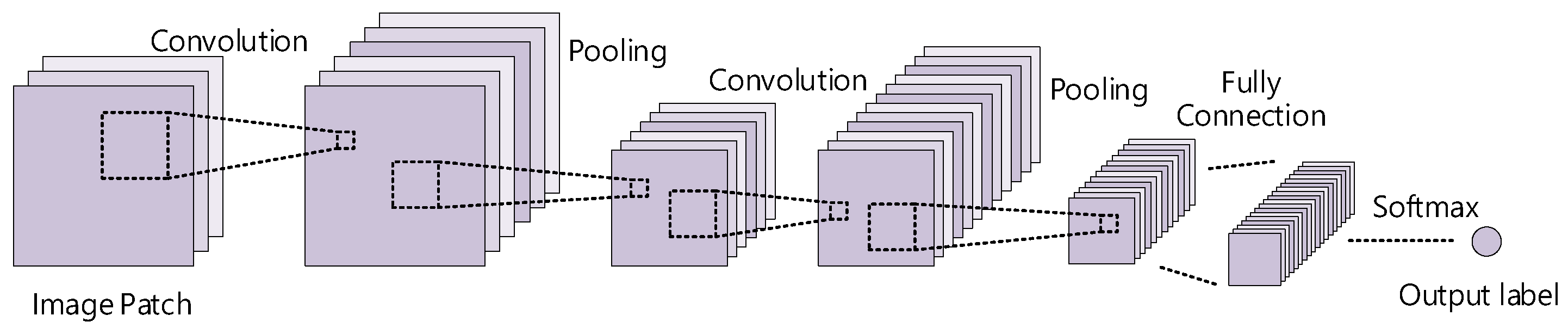
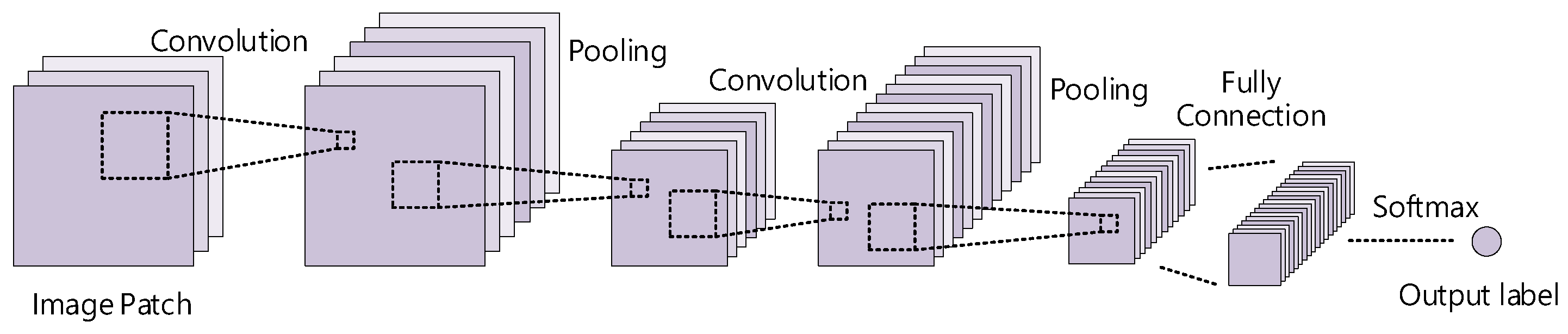
2.2. CNN
2.3. Attention Mechanism
3. Methods
3.1. Attention with RNN for Spectral Classification
3.2. Attention with CNN for Spatial Classification
3.3. Merge
4. Experiment Results
4.1. Data Description
- Pavia Center: The first dataset is gained by ROSIS. We utilize 102 spectral bands after removing 13 noisy channels. The image is of pixels covering the center of Pavia. The available training samples contain nine urban land-cover classes.
- Pavia University: The second dataset is obtained by the ROSIS sensor during a flight campaign over Pavia. The ROSIS-03 sensor recorded the orginal image in 115 spectral channels ranging from 430 to 860nm. Removing 12 noisy bands, the left 103 bands are adopted. The spatial size of the image is pixels. The ground truth map contains nine different urban land-cover types with more than 1000 labeled pixels for each class.
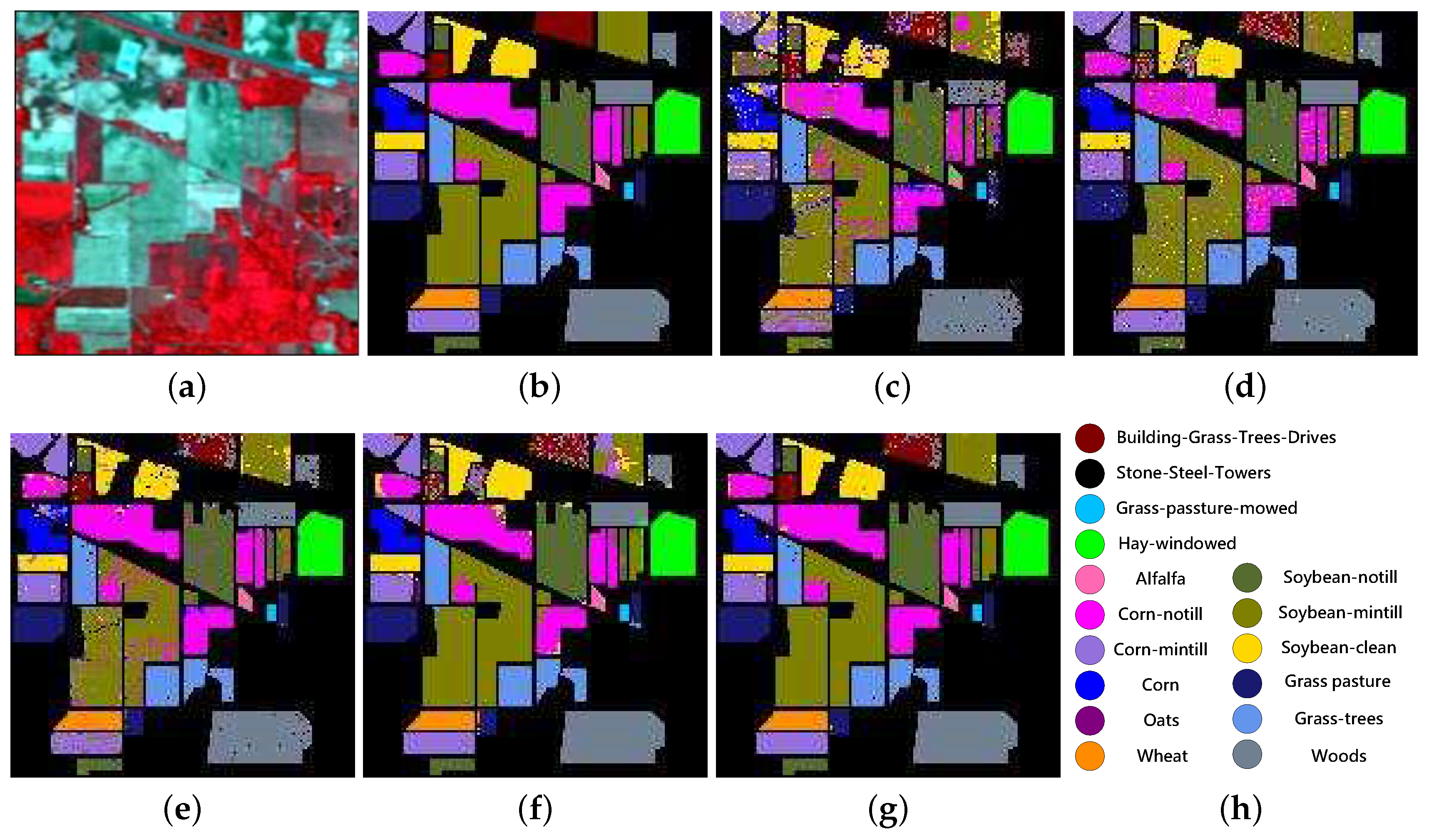
- Indian Pines: The third dataset is gathered by AVIRIS sensor over the Indian Pines test site in Northwestern Indiana. Removing bands that cover water absorption features, the remaining 200 bands with pixels are used in this paper. The original data consists of observations from 16 identified classes representing the land cover types.
4.2. Parameter Setting
4.3. Classification Results
- (1)
- KNN: k nearest neighbors, the parameter k is set to for the Pavia Center dateset, the Pavia University dataset and the Indian Pines dataset, respectively.
- (2)
- SVM: Support vector machine with radial basis function kernel.
- (3)
- RNN: GRU-based bi-directional RNN, which is the base RNN model in our proposed SSAN. Learning rate and the training step have been optimized to fulfill a great classification accuracy.
- (4)
- CNN: Two-dimensional CNN, which has the same structure with CNN branch in SSAN. Learning rate and the spatial input size are optimized on validation samples.
- (5)
- ARNN: Our attention Bi-RNN branch in SSAN.
- (6)
- ACNN: Our attention CNN branch in SSAN.
- (7)
- SSAN: The proposed spectral-spatial attention network.
4.4. Results on the Pavia Center Dataset
4.5. Results on the Pavia University Dataset
4.6. Results on the Indian Pine Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Zhu, L.; Liu, Y. Centroid and Covariance Alignment-Based Domain Adaptation for Unsupervised Classification of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2305–2323. [Google Scholar] [CrossRef]
- Tao, C.; Wang, Y.; Cui, W.; Zou, B.; Zou, Z.; Tu, Y. A transferable spectroscopic diagnosis model for predicting arsenic contamination in soil. Sci. Total. Environ. 2019, 669, 964–972. [Google Scholar] [CrossRef]
- Fan, F.; Ma, Y.; Li, C.; Mei, X.; Huang, J.; Ma, J. Hyperspectral image denoising with superpixel segmentation and low-rank representation. Inf. Sci. 2017, 397, 48–68. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Chen, C.; Wang, Z.; Cai, Z.; Wang, L. SuperPCA: A Superpixelwise PCA Approach for Unsupervised Feature Extraction of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef]
- Roscher, R.; Waske, B.; Forstner, W. Incremental import vector machines for classifying hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3463–3473. [Google Scholar] [CrossRef]
- Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Generalized composite kernel framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4816–4829. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Wang, Z.; Chen, C.; Liu, X. Hyperspectral Image Classification in the Presence of Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 851–865. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Convolutional recurrent neural networks forhyperspectral data classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.Q.; Chan, J.C.W. Learning and transferring deep joint spectral–spatial features for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4729–4742. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, L.; Du, B.; Zhang, F. Spectral-Spatial Unified Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5893–5909. [Google Scholar] [CrossRef]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Xu, R.; Tao, Y.; Lu, Z.; Zhong, Y. Attention-Mechanism-Containing Neural Networks for High-Resolution Remote Sensing Image Classification. Remote Sens. 2018, 10, 1602. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6298–6306. [Google Scholar]
- Nam, H.; Ha, J.W.; Kim, J. Dual attention networks for multimodal reasoning and matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 299–307. [Google Scholar]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality preserving matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Yan, J.; Li, C.; Li, Y.; Cao, G. Adaptive discrete hypergraph matching. IEEE Trans. Cybern. 2018, 48, 765–779. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, J.; Zhou, H.; Zhao, J.; Guo, X. Guided locality preserving feature matching for remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4435–4447. [Google Scholar] [CrossRef]
- Kuen, J.; Wang, Z.; Gang, W. Recurrent Attentional Networks for Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 3668–3677. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.d.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Pei, W.; Dibeklioğlu, H.; Baltrušaitis, T.; Tax, D.M. Attended End-to-end Architecture for Age Estimation from Facial Expression Videos. arXiv 2017, arXiv:1711.08690. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, DC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Sundermeyer, M.; Ney, H.; Schluter, R. From Feedforward to Recurrent LSTM Neural Networks for Language Modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 517–529. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Wang, Z.; Yi, P.; Jiang, K.; Jiang, J.; Han, Z.; Lu, T.; Ma, J. Multi-memory convolutional neural network for video super-resolution. IEEE Trans. Image Process. 2019, 28, 2530–2544. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Tian, T.; Li, C.; Xu, J.; Ma, J. Urban area detection in very high resolution remote sensing images using deep convolutional neural networks. Sensors 2018, 18, 904. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning source-invariant deep hashing convolutional neural networks for cross-source remote sensing image retrieval. IEEE Trans. Geosci. Remote. Sens. 2018, 1–16. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J. Robust topological navigation via convolutional neural network feature and sharpness measure. IEEE Access 2017, 5, 20707–20715. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Kim, J.H.; Lee, S.W.; Kwak, D.H.; Heo, M.O.; Kim, J.; Ha, J.W.; Zhang, B.T. Multimodal Residual Learning for Visual QA. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; pp. 361–369. [Google Scholar]
- Yang, Y.; Zhong, Z.; Shen, T.; Lin, Z. Convolutional Neural Networks with Alternately Updated Clique. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2413–2422. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Size | Activation | Strides |
|---|---|---|---|
| conv1 | ReLU | 1 | |
| max pooling | / | 2 | |
| conv2 | ReLU | 1 | |
| max pooling | / | 2 | |
| FC | 1024 | / | / |
| Label | Class Name | Training | Testing | |
|---|---|---|---|---|
| Labeled | Validation | |||
| 1 | Waters | 100 | 100 | 65,771 |
| 2 | Trees | 100 | 100 | 7398 |
| 3 | Asphalt | 100 | 100 | 2890 |
| 4 | Self-Blocking Bricks | 100 | 100 | 2485 |
| 5 | Bitumen | 100 | 100 | 6384 |
| 6 | Tiles | 100 | 100 | 9048 |
| 7 | Shadows | 100 | 100 | 7087 |
| 8 | Meadows | 100 | 100 | 42,626 |
| 9 | Bare soil | 100 | 100 | 2663 |
| Total | 900 | 900 | 146,352 | |
| Label | Class Name | Training | Testing | |
|---|---|---|---|---|
| Labeled | Validation | |||
| 1 | Asphalt | 100 | 100 | 6431 |
| 2 | Meadows | 100 | 100 | 18,449 |
| 3 | Gravel | 100 | 100 | 1899 |
| 4 | Trees | 100 | 100 | 2864 |
| 5 | Painted mental sheets | 100 | 100 | 1145 |
| 6 | Bare Soil | 100 | 100 | 4829 |
| 7 | Bitumen | 100 | 100 | 1130 |
| 8 | Self-Blocking Bricks | 100 | 100 | 3482 |
| 9 | Shadows | 100 | 100 | 747 |
| Total | 900 | 900 | 40,976 | |
| Label | Class Name | Training | Testing | |
|---|---|---|---|---|
| Labeled | Validation | |||
| 1 | Alfalfa | 8 | 4 | 34 |
| 2 | Corn-notill | 100 | 100 | 1228 |
| 3 | Corn-mintill | 100 | 100 | 630 |
| 4 | Corn | 50 | 50 | 137 |
| 5 | Grass-pasture | 50 | 50 | 383 |
| 6 | Grass-trees | 100 | 100 | 530 |
| 7 | Grass-pasture-mowed | 8 | 4 | 16 |
| 8 | Hay-windowed | 50 | 50 | 378 |
| 9 | Oats | 8 | 4 | 8 |
| 10 | Soybean-notill | 100 | 100 | 772 |
| 11 | Soybean-mintill | 100 | 100 | 2255 |
| 12 | Soybean-clean | 100 | 100 | 393 |
| 13 | Wheat | 50 | 50 | 105 |
| 14 | Woods | 100 | 100 | 1065 |
| 15 | Buildings-Grass-Trees-Drives | 100 | 100 | 186 |
| 16 | Stone-Steel-Towers | 20 | 10 | 63 |
| Total | 1044 | 922 | 8283 | |
| Spatial Size | Overall Accuracy | ||
|---|---|---|---|
| Pavia Center | Pavia University | Indian Pines | |
| 97.71 | 94.18 | 92.69 | |
| 98.24 | 96.57 | 94.70 | |
| 98.66 | 98.21 | 96.55 | |
| 99.25 | 98.87 | 97.23 | |
| 98.51 | 96.33 | 97.01 | |
| Dropout | Overall Accuracy | ||
|---|---|---|---|
| Pavia Center | Pavia University | Indian Pines | |
| 0.2 | 94.78 | 90.32 | 92.55 |
| 0.3 | 95.33 | 95.49 | 91.74 |
| 0.4 | 98.11 | 97.12 | 95.26 |
| 0.5 | 97.32 | 98.66 | 97.14 |
| 0.6 | 99.13 | 96.45 | 96.32 |
| Label | Class Name | KNN | SVM | RNN | CNN | ARNN | ACNN | SSAN |
|---|---|---|---|---|---|---|---|---|
| 1 | Waters | 99.15 | 99.17 | 99.63 | 98.22 | 98.87 | 99.63 | 99.97 |
| 2 | Trees | 88.76 | 80.54 | 86.34 | 89.37 | 91.32 | 92.15 | 98.37 |
| 3 | Asphalt | 76.34 | 94.22 | 85.46 | 77.92 | 86.28 | 84.63 | 93.04 |
| 4 | Self-Blocking Bricks | 81.92 | 83.27 | 50.46 | 86.39 | 76.69 | 87.35 | 94.22 |
| 5 | Bitumen | 86.39 | 51.33 | 94.29 | 89.77 | 94.05 | 98.07 | 98.40 |
| 6 | Tiles | 91.44 | 93.24 | 91.75 | 79.89 | 95.88 | 87.36 | 97.11 |
| 7 | Shadows | 81.31 | 75.47 | 81.63 | 87.28 | 84.21 | 96.42 | 97.03 |
| 8 | Meadows | 93.67 | 94.55 | 97.18 | 98.27 | 98.75 | 97.91 | 98.22 |
| 9 | Bare soil | 97.18 | 98.16 | 99.31 | 93.87 | 99.13 | 89.22 | 99.63 |
| OA | 92.66 | 93.11 | 99.04 | 99.13 | 99.24 | 99.39 | 99.69 | |
| AA | 88.22 | 85.74 | 89.21 | 90.26 | 92.56 | 93.72 | 98.31 | |
| Kappa | 90.13 | 90.03 | 97.34 | 97.37 | 97.48 | 98.33 | 99.18 | |
| Label | Class Name | KNN | SVM | RNN | CNN | ARNN | ACNN | SSAN |
|---|---|---|---|---|---|---|---|---|
| 1 | Asphalt | 76.00 | 78.90 | 80.86 | 92.13 | 88.94 | 98.46 | 98.73 |
| 2 | Meadows | 69.33 | 82.31 | 68.69 | 94.23 | 83.56 | 98.59 | 95.72 |
| 3 | Gravel | 84.00 | 81.41 | 80.23 | 76.83 | 82.99 | 77.36 | 95.27 |
| 4 | Trees | 95.44 | 93.99 | 95.23 | 74.67 | 94.22 | 94.66 | 96.34 |
| 5 | Painted mental sheets | 96.88 | 99.21 | 99.21 | 91.95 | 99.46 | 99.23 | 99.66 |
| 6 | Bare Soil | 71.34 | 83.67 | 82.35 | 86.34 | 86.25 | 87.07 | 98.78 |
| 7 | Bitumen | 95.26 | 92.20 | 86.98 | 72.84 | 90.45 | 97.08 | 96.34 |
| 8 | Self-Blocking Bricks | 73.00 | 86.56 | 78.22 | 88.86 | 82.29 | 90.39 | 95.26 |
| 9 | Shadows | 97.42 | 99.74 | 99.84 | 87.40 | 99.63 | 99.79 | 99.89 |
| OA | 84.89 | 84.03 | 95.42 | 97.36 | 97.37 | 98.98 | 99.24 | |
| AA | 84.89 | 88.59 | 87.66 | 86.34 | 90.71 | 94.07 | 98.07 | |
| Kappa | 83.57 | 79.94 | 87.21 | 93.77 | 92.22 | 97.17 | 98.17 | |
| Label | Class Name | KNN | SVM | RNN | CNN | ARNN | ACNN | SSAN |
|---|---|---|---|---|---|---|---|---|
| 1 | Alfalfa | 35.91 | 84.89 | 83.43 | 76.52 | 79.32 | 95.44 | 97.76 |
| 2 | Corn-notill | 47.32 | 71.78 | 77.87 | 87.19 | 85.27 | 92.76 | 98.83 |
| 3 | Corn-mintill | 51.68 | 63.07 | 76.21 | 82.91 | 84.23 | 87.83 | 99.25 |
| 4 | Corn | 68.77 | 89.57 | 55.39 | 88.32 | 67.65 | 87.29 | 99.67 |
| 5 | Grass-pasture | 87.32 | 93.86 | 87.98 | 91.68 | 92.14 | 96.82 | 99.24 |
| 6 | Grass-trees | 90.24 | 94.62 | 94.57 | 94.35 | 95.57 | 96.37 | 98.36 |
| 7 | Grass-pasture-mowed | 82.49 | 92.77 | 89.42 | 81.67 | 98.04 | 99.73 | 100 |
| 8 | Hay-windowed | 96.75 | 98.79 | 94.65 | 87.02 | 99.26 | 91.42 | 99.32 |
| 9 | Oats | 63.26 | 92.36 | 42.47 | 83.14 | 84.41 | 90.87 | 99.76 |
| 10 | Soybean-notill | 61.89 | 76.22 | 68.49 | 85.29 | 83.85 | 89.64 | 98.79 |
| 11 | Soybean-mintill | 54.71 | 62.33 | 86.52 | 94.31 | 94.62 | 95.39 | 99.47 |
| 12 | Soybean-clean | 49.37 | 77.56 | 78.61 | 85.14 | 86.33 | 97.66 | 98.65 |
| 13 | Wheat | 96.84 | 98.39 | 93.58 | 94.32 | 95.79 | 99.13 | 100 |
| 14 | Woods | 84.39 | 93.64 | 94.91 | 96.42 | 96.03 | 98.81 | 99.46 |
| 15 | Buildings-Grass-Trees-Drives | 47.85 | 69.48 | 74.82 | 76.59 | 89.28 | 92.27 | 99.32 |
| 16 | Stone-Steel-Towers | 81.09 | 86.78 | 82.68 | 62.33 | 96.82 | 83.15 | 97.53 |
| OA | 64.52 | 78.03 | 91.31 | 95.24 | 94.87 | 97.27 | 99.67 | |
| AA | 69.03 | 83.92 | 82.05 | 86.78 | 89.92 | 94.32 | 99.08 | |
| Kappa | 62.39 | 75.26 | 87.67 | 93.05 | 92.71 | 95.86 | 98.37 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sens. 2019, 11, 963. https://doi.org/10.3390/rs11080963
Mei X, Pan E, Ma Y, Dai X, Huang J, Fan F, Du Q, Zheng H, Ma J. Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sensing. 2019; 11(8):963. https://doi.org/10.3390/rs11080963
Chicago/Turabian StyleMei, Xiaoguang, Erting Pan, Yong Ma, Xiaobing Dai, Jun Huang, Fan Fan, Qinglei Du, Hong Zheng, and Jiayi Ma. 2019. "Spectral-Spatial Attention Networks for Hyperspectral Image Classification" Remote Sensing 11, no. 8: 963. https://doi.org/10.3390/rs11080963
APA StyleMei, X., Pan, E., Ma, Y., Dai, X., Huang, J., Fan, F., Du, Q., Zheng, H., & Ma, J. (2019). Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sensing, 11(8), 963. https://doi.org/10.3390/rs11080963