Remote Sensing Image Scene Classification Using CNN-CapsNet



Abstract
1. Introduction
- To further improve classification accuracy, especially classes that have high homogeneity in the image content, a new novel architecture named CNN-CapsNet is proposed to deal with the remote sensing image scene classification problem, which can discriminate scene classes effectively.
- By combining the CNN and the CapsNet, the proposed method can obtain a superior result compared with the state-of-the-art methods on three challenging datasets without any data-augmentation operation.
- This paper also analyzes the influence of different factors in the proposed architecture on the classification result, including the routing number in the training phase, the dimension of capsules in the CapsNet and different pretrained CNN models, which can provide valuable guidance for subsequent research on the remote sensing image scene classification using CapsNet.
2. Materials
2.1. UC Merced Land-Use Dataset
2.2. AID Dataset
2.3. NWPU-RESISC45 Dataset
3. Method
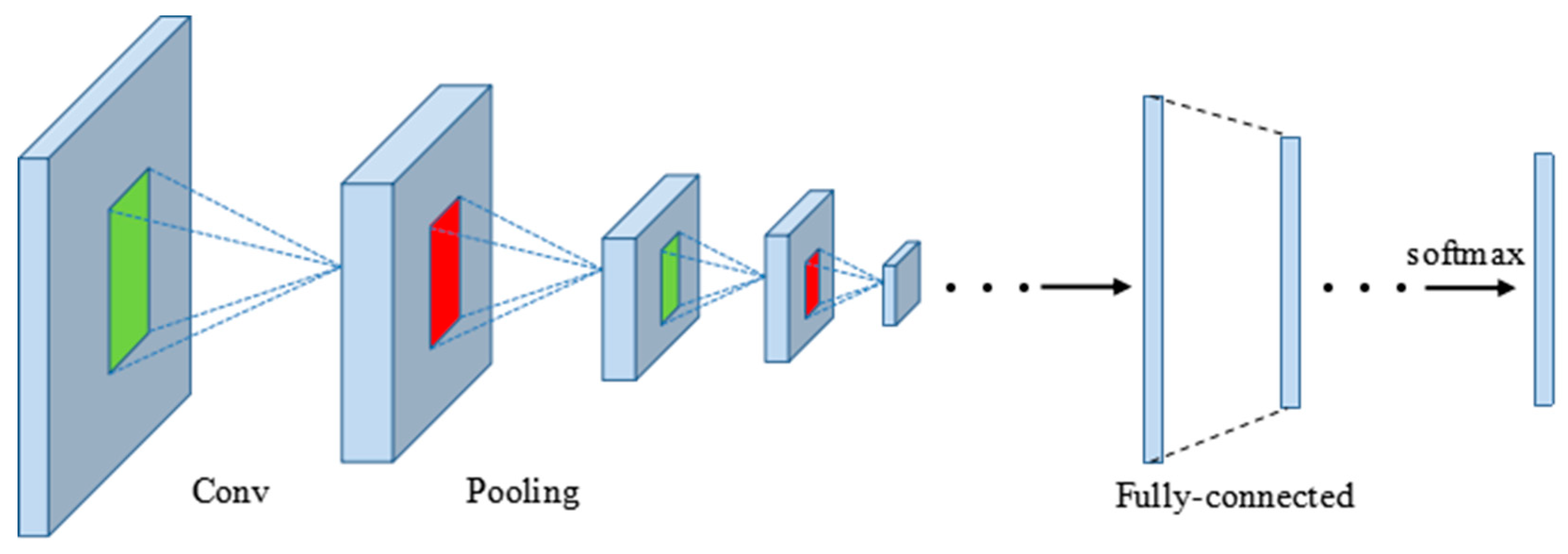
3.1. CNN
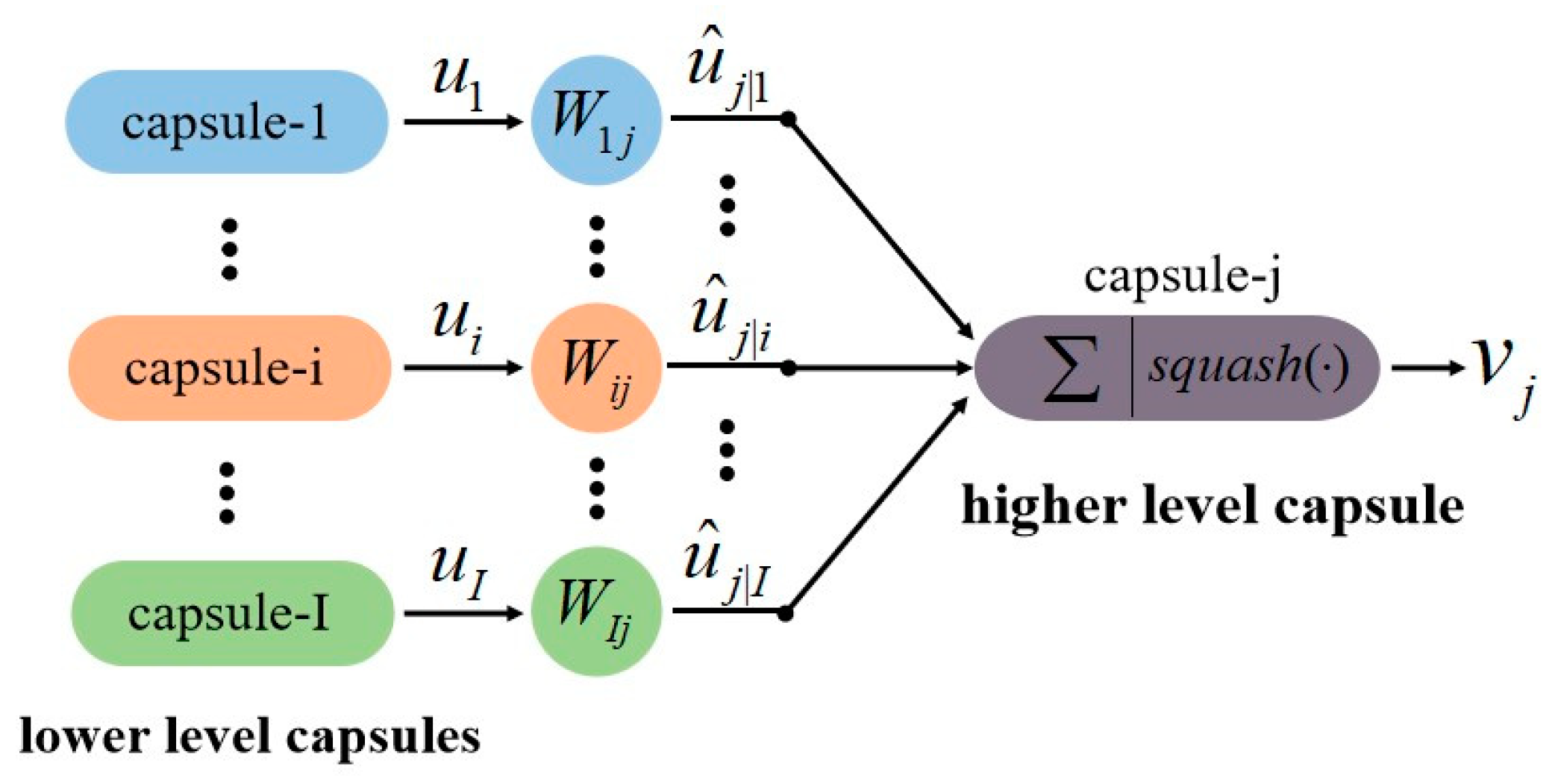
3.2. CapsNet
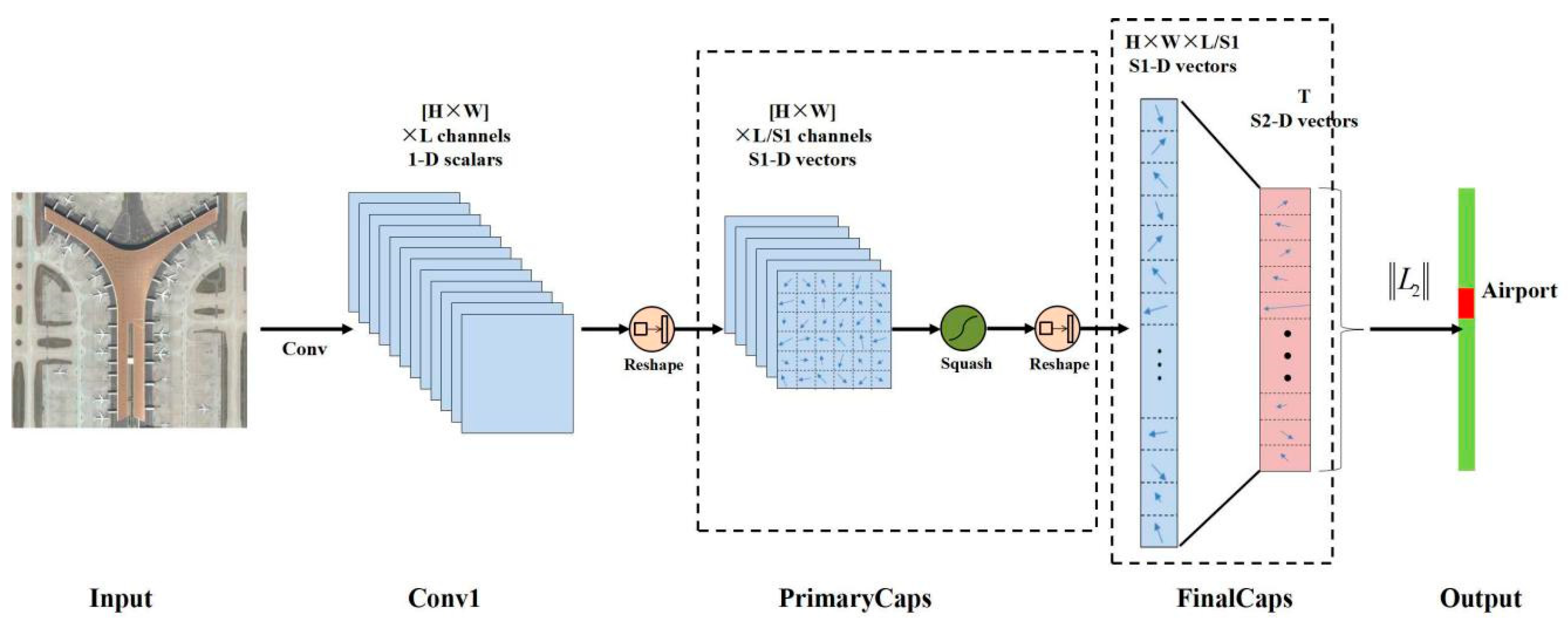
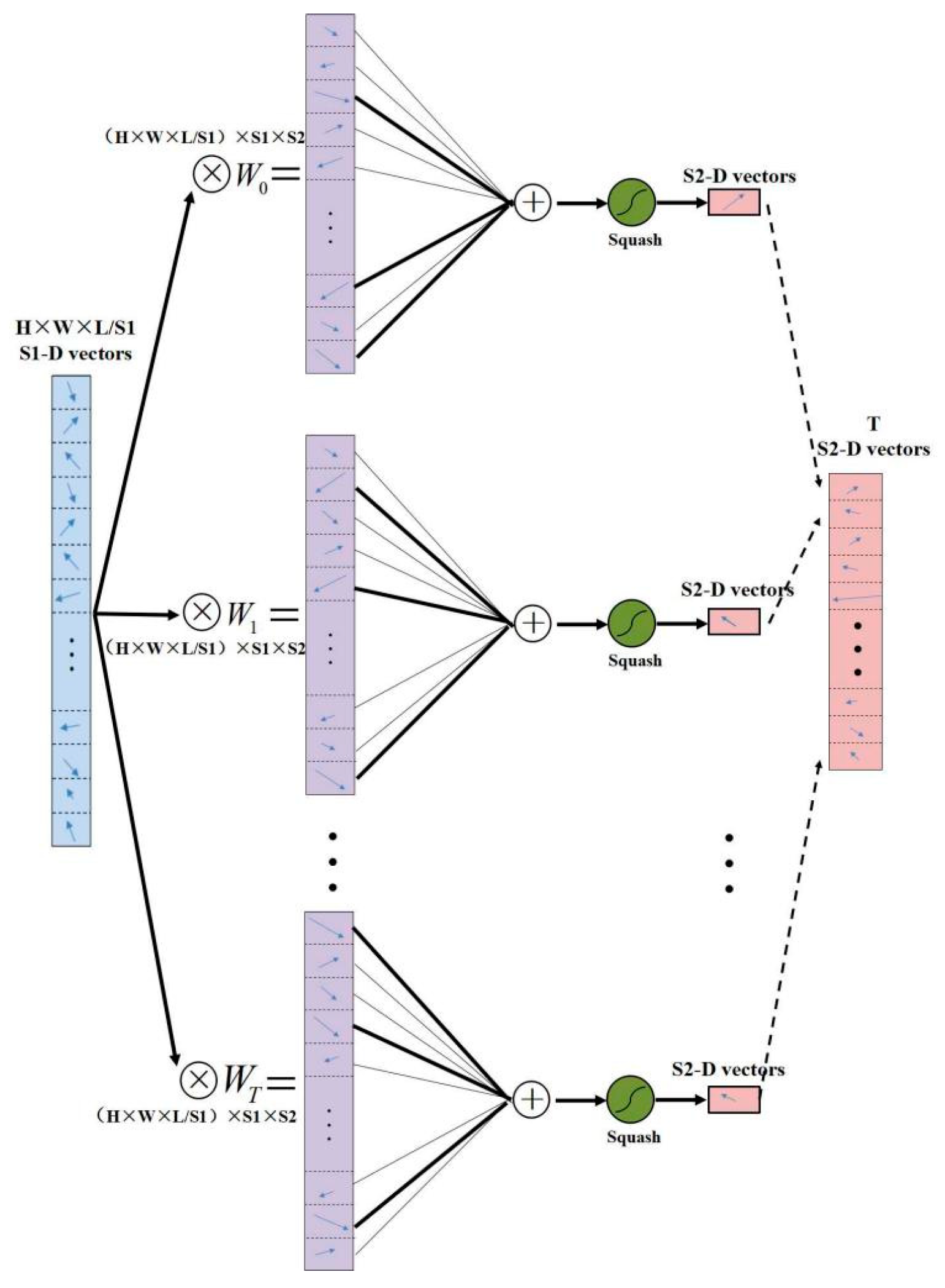
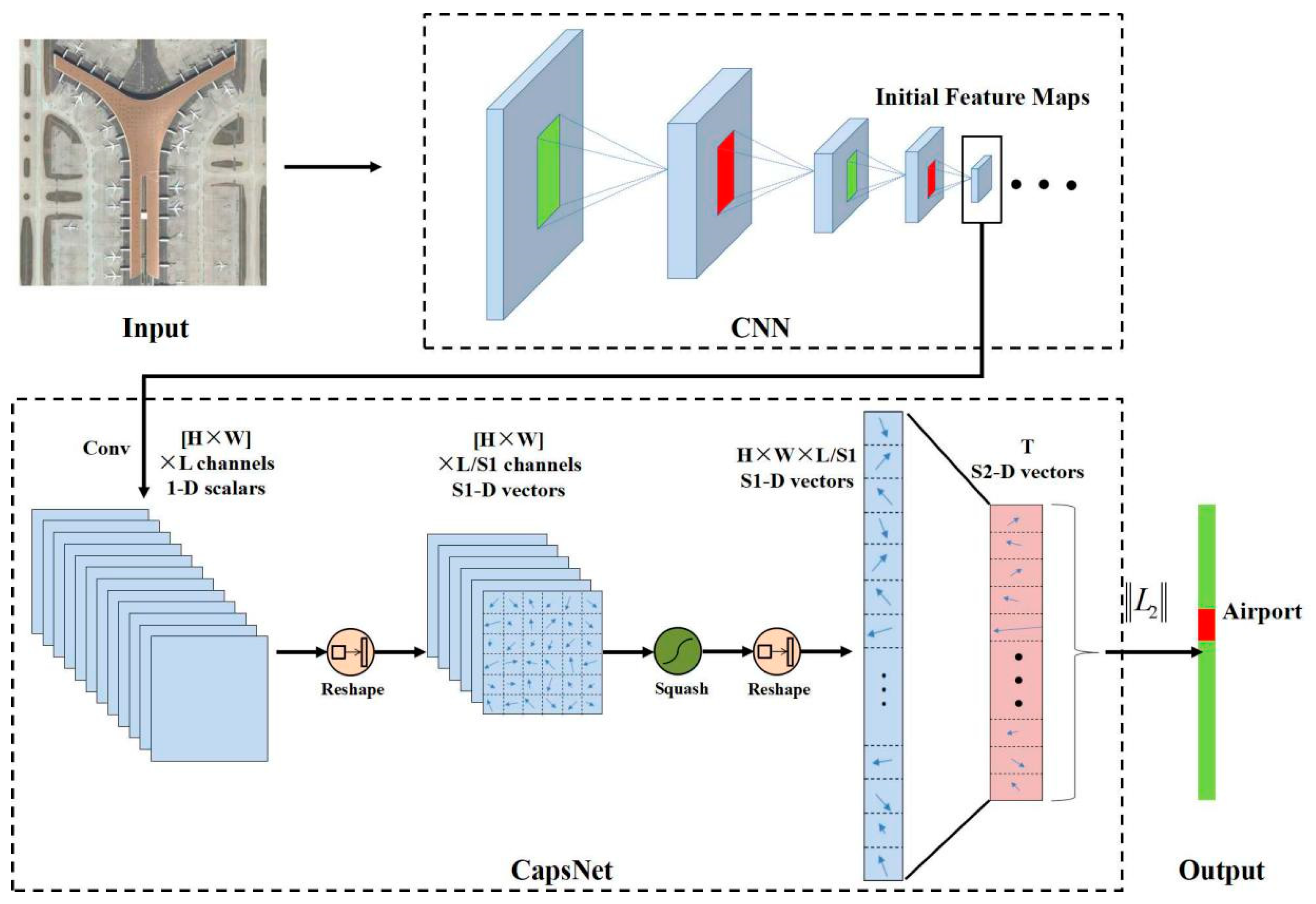
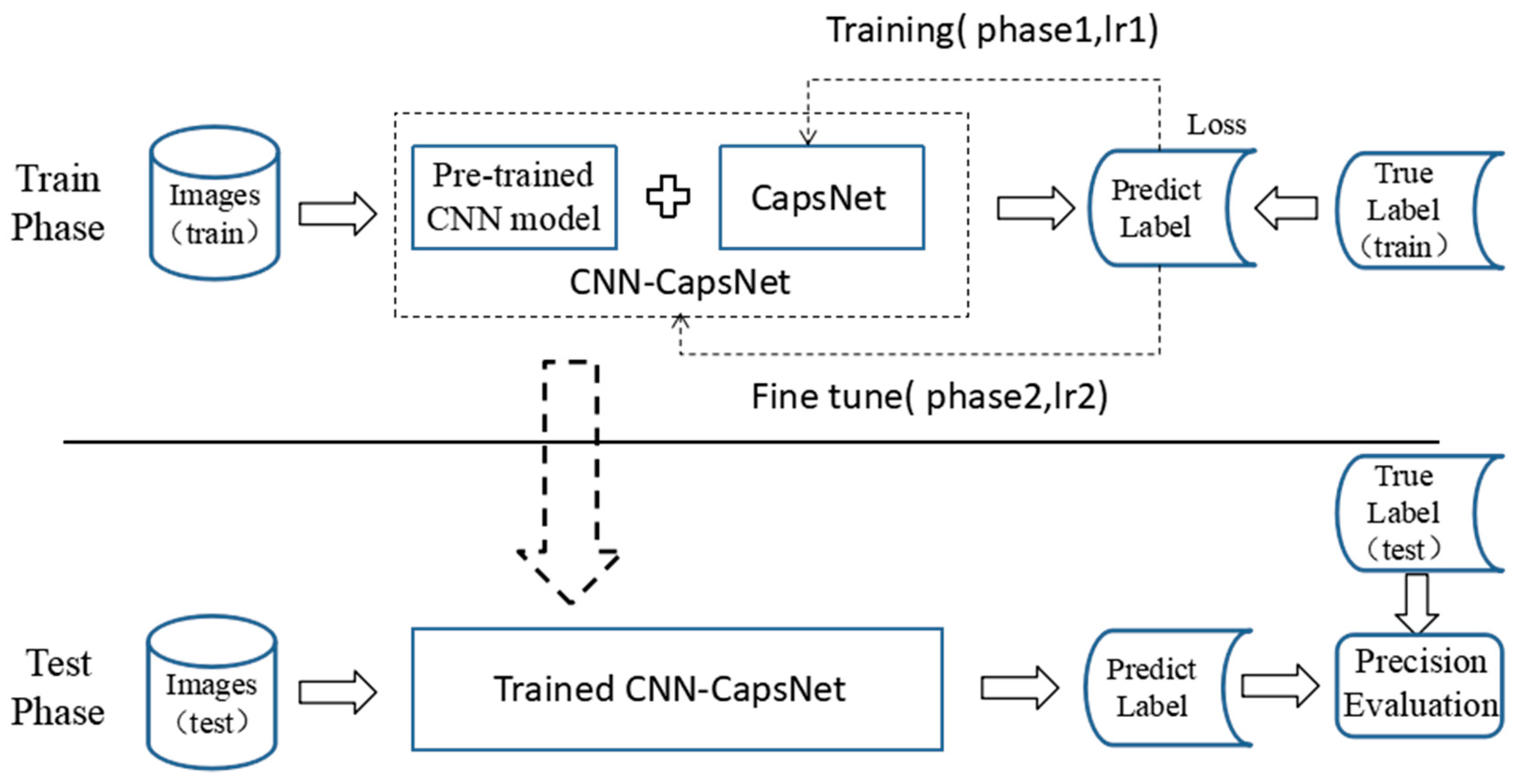
3.3. Proposed Method
- VGG-16: Simonyan et al. [51] presented the very deep CNN models that secured the first and the second places in the localization and classification tracks, respectively, on ILSVRC2014. The two best-performing deep models, named VGG-16 (containing 13 convolutional layers and 3 fully connected layers) and VGG-19 (containing 16 convolutional layers and 3 fully connected layers) are the basis of their team’s submission, which demonstrates the important aspect of the model’s depth. Rather than using relatively large receptive fields in the convolutional layers, such as 11 × 11 with stride 4 in the first convolutional layer of AlexNet [60], VGGNet uses very small 3 × 3 receptive fields through the whole network. VGG-16 is the most representative sequence-like CNN architecture as shown in Figure 5 (consisting of a simple chain of blocks such as the convolution layer and pooling layer), which has achieved great success in the field of remote sensing image scene classification.
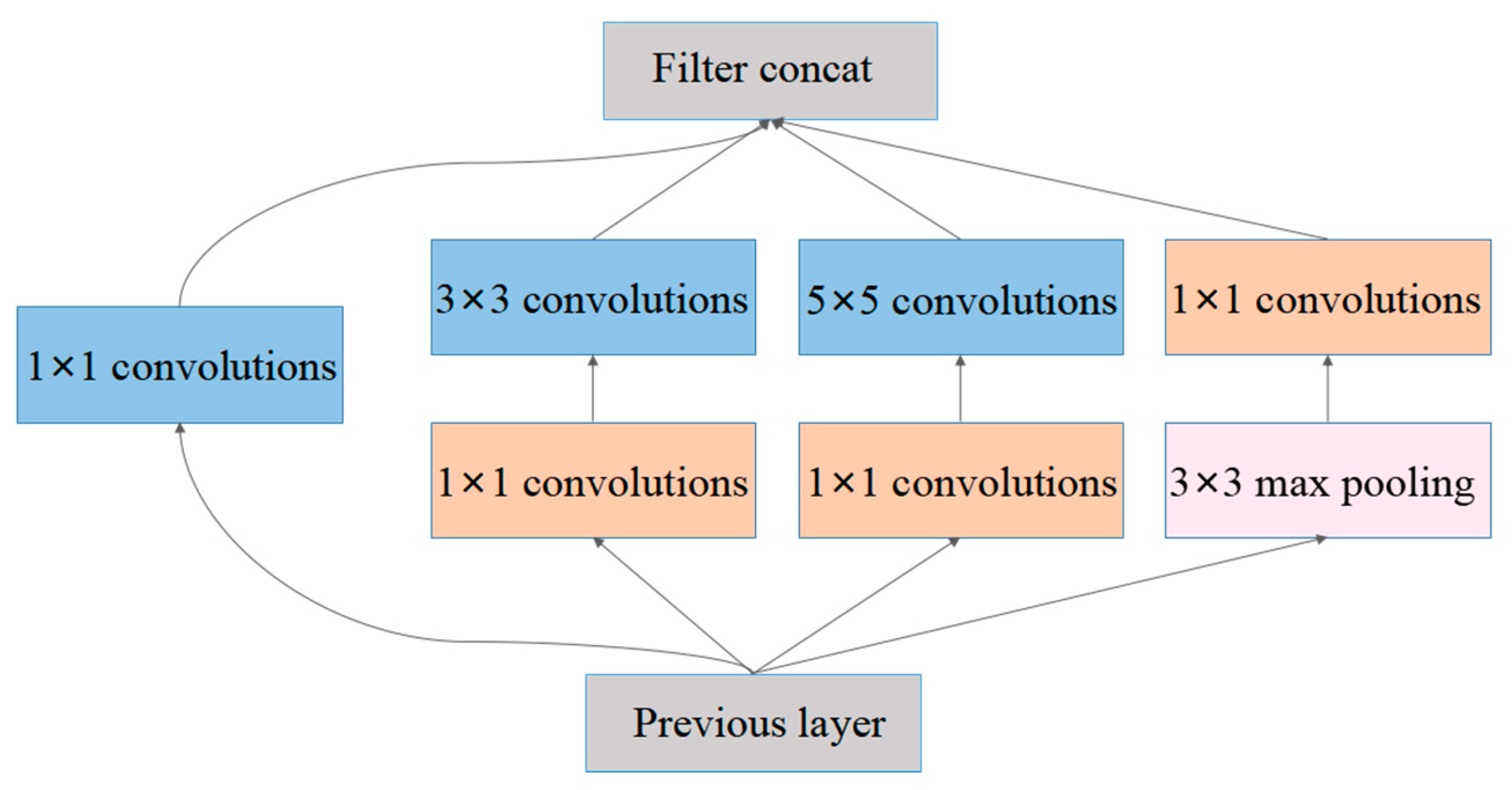
- Inception-v3: Unlike the sequence-like CNN architecture such as VGG-16, which only increases the depth of the convolution layers, the Inception-like CNN architecture attempts to increase the width of a single convolution layer, which means different sizes of kernels are used on the single convolution layer and can extract different scales of features. As shown in Figure 10, it is the core component of GoogLeNet [61] named Inception-v1. Inception-v3 [62] is an improved version of Inception-v1 and is designed on the following four principles: to avoid representation bottlenecks, especially early in the network; higher dimensional representations are easier to process locally within a network; spatial aggregation can be done over lower dimensional embedding without much or any loss in representation; to balance the width and depth of the network. The Inception-v3 reached 21.2% top-1 and 5.6% top-5 error on the ILSVR 2012 classification.
4. Results and Analysis
4.1. Experimental Setup
4.1.1. Implementation Details
4.1.2. Evaluation Protocol
4.2. Experimental Results and Analysis
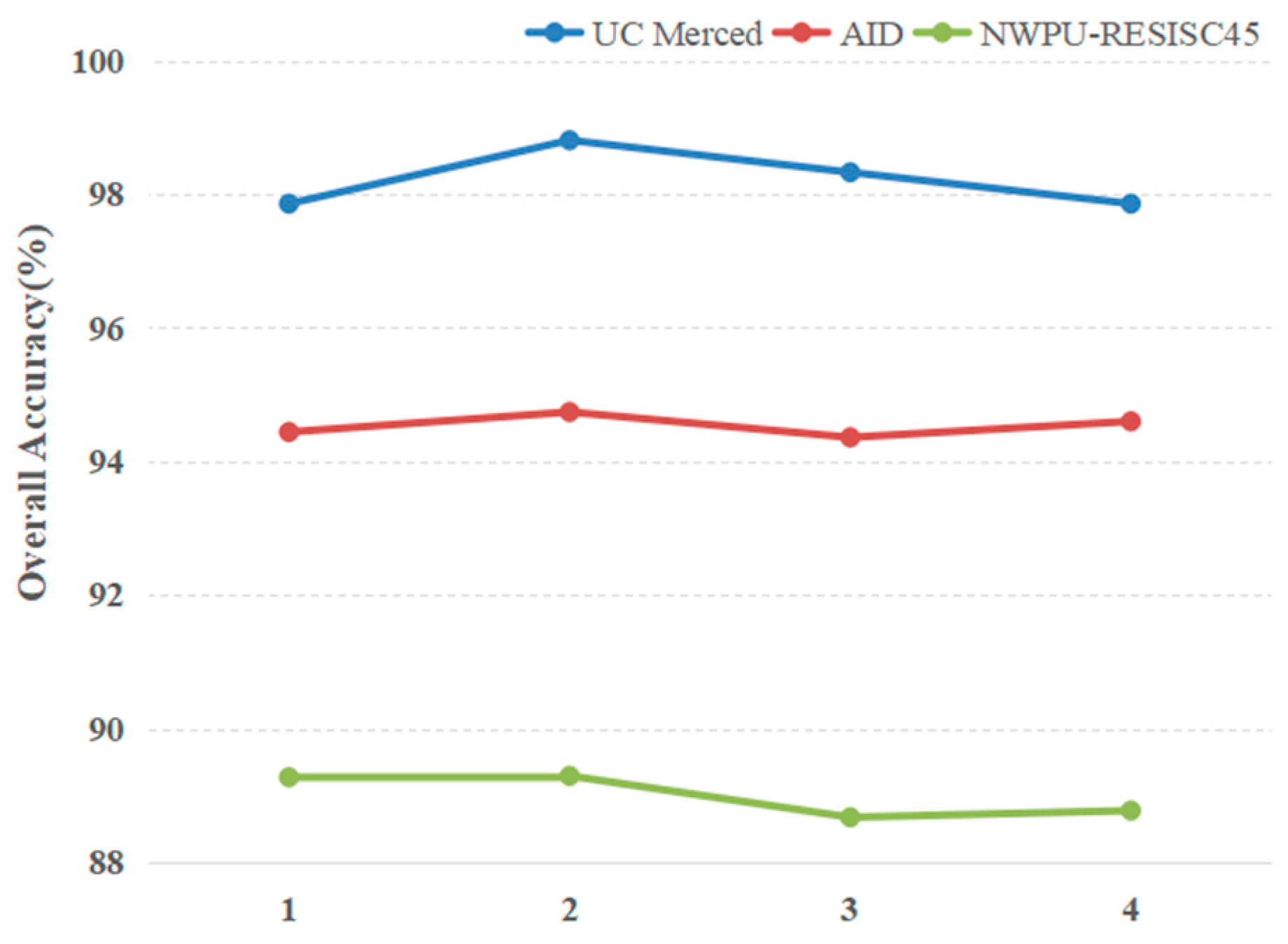
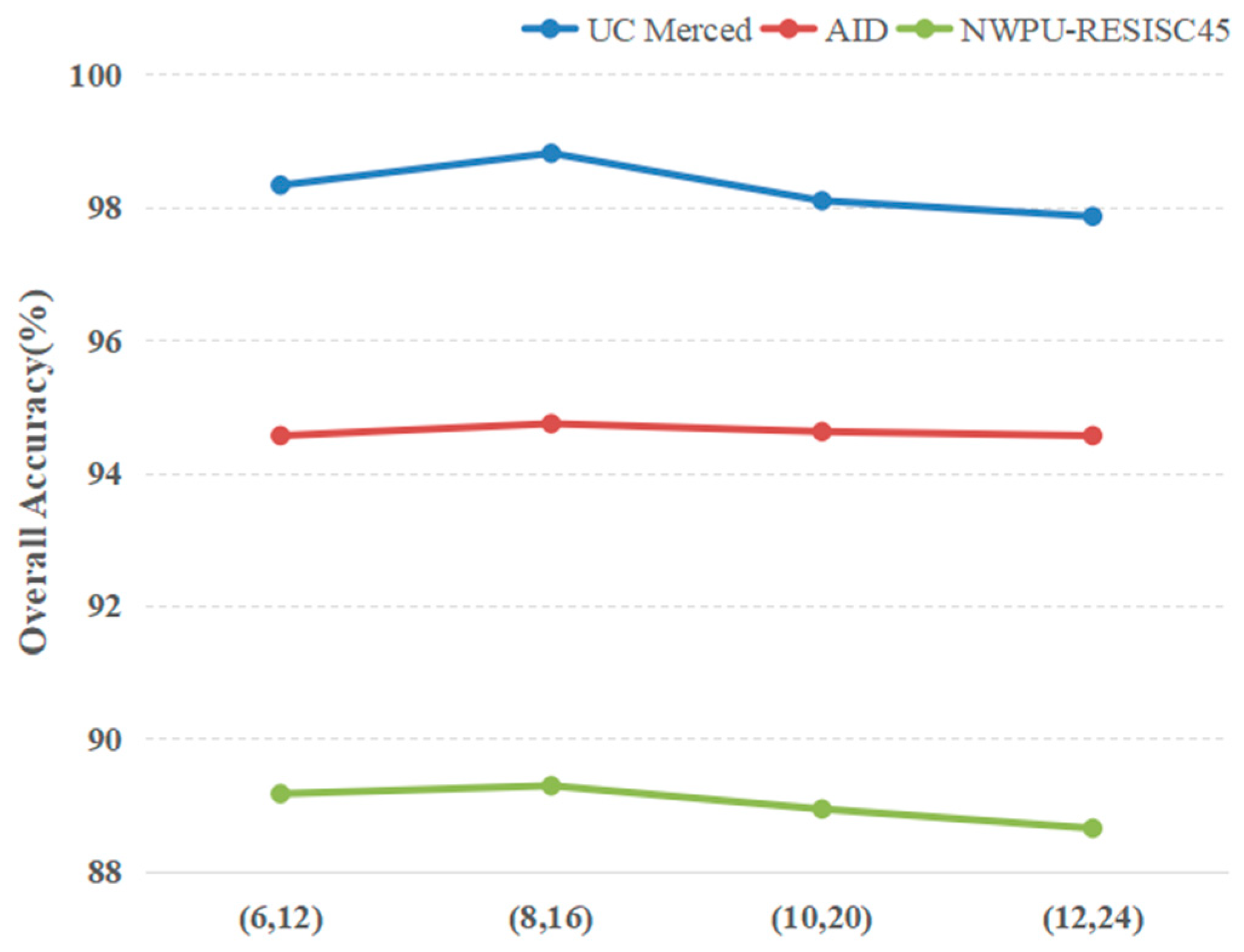
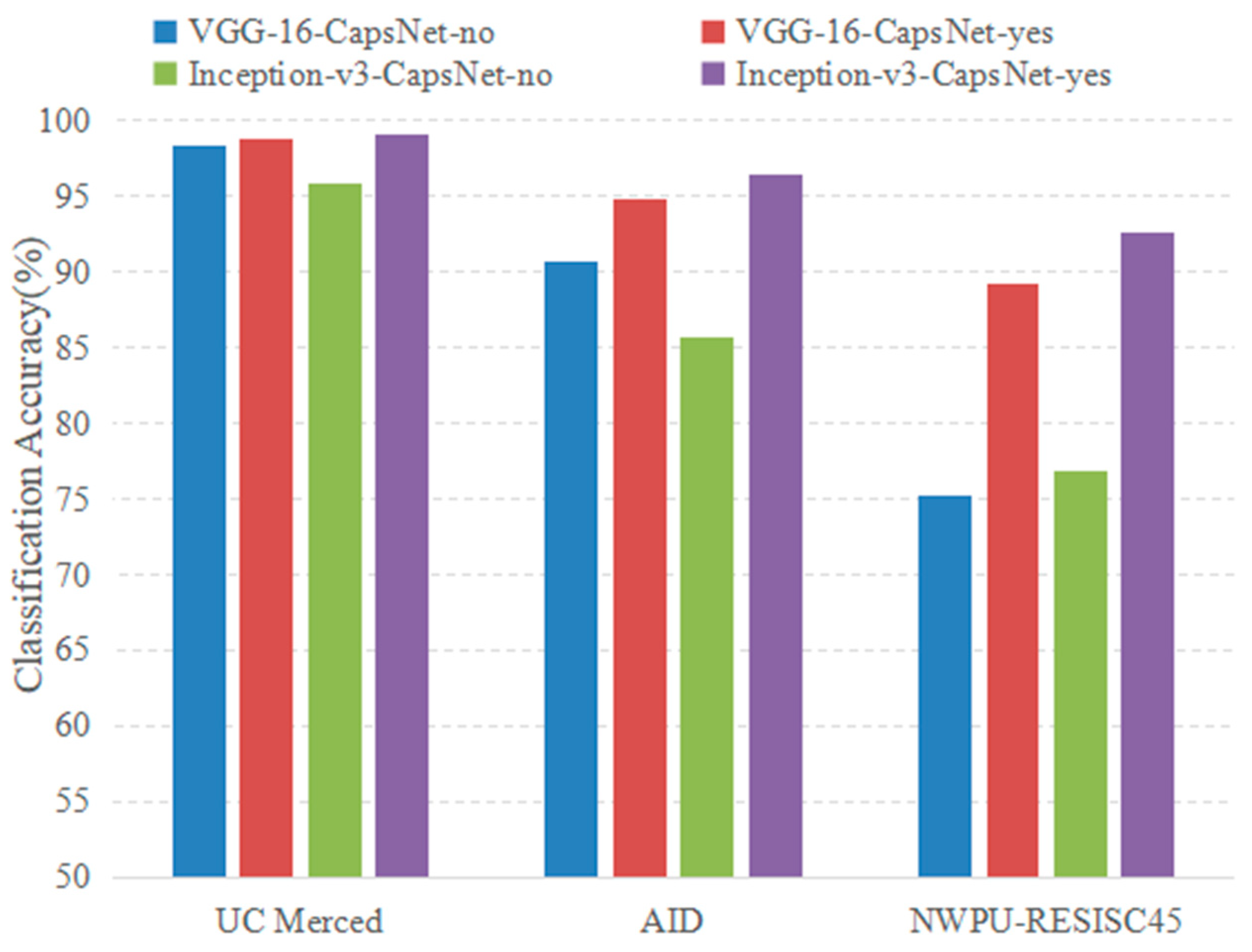
4.2.1. Analysis of Experimental Parameters
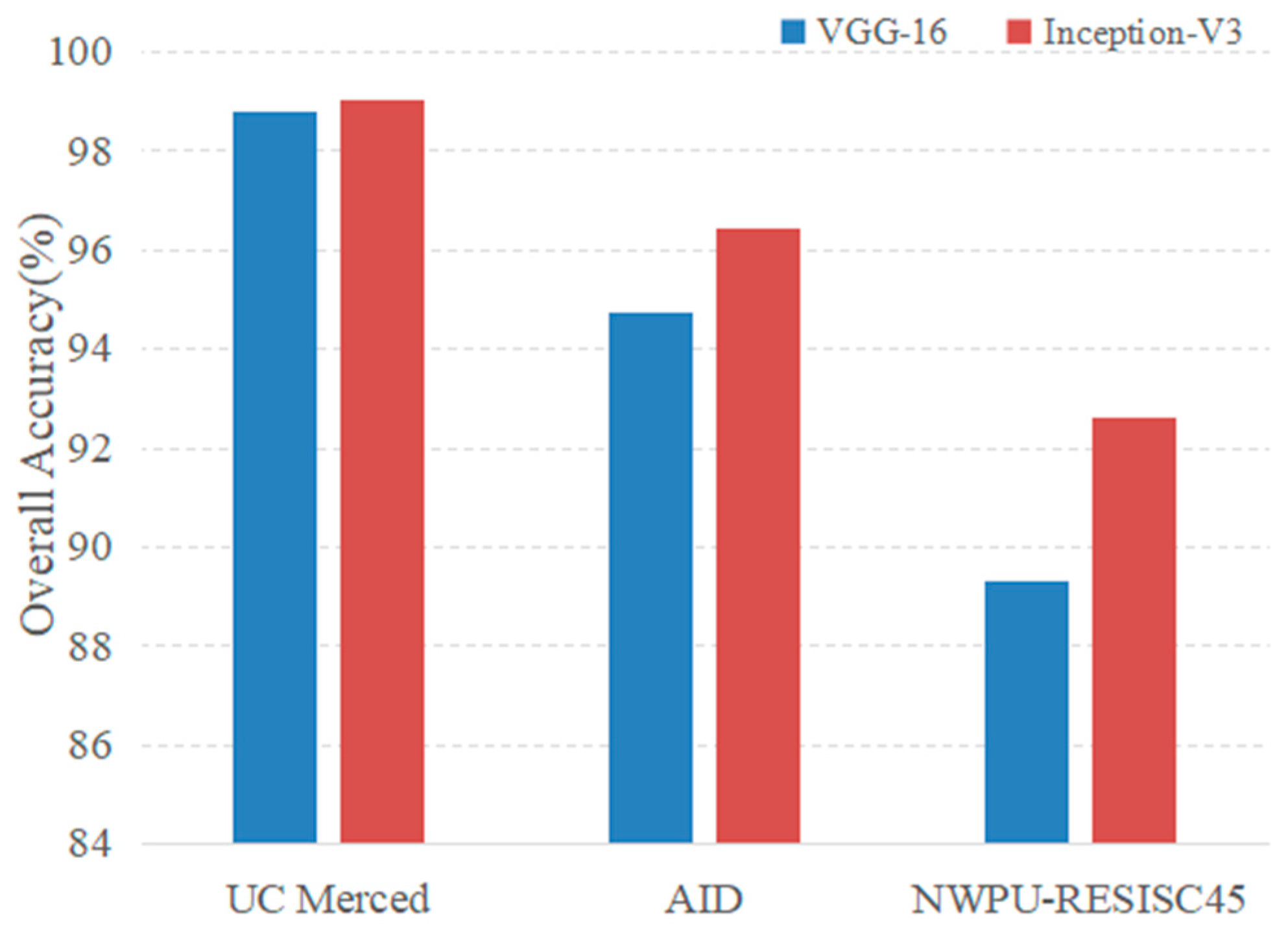
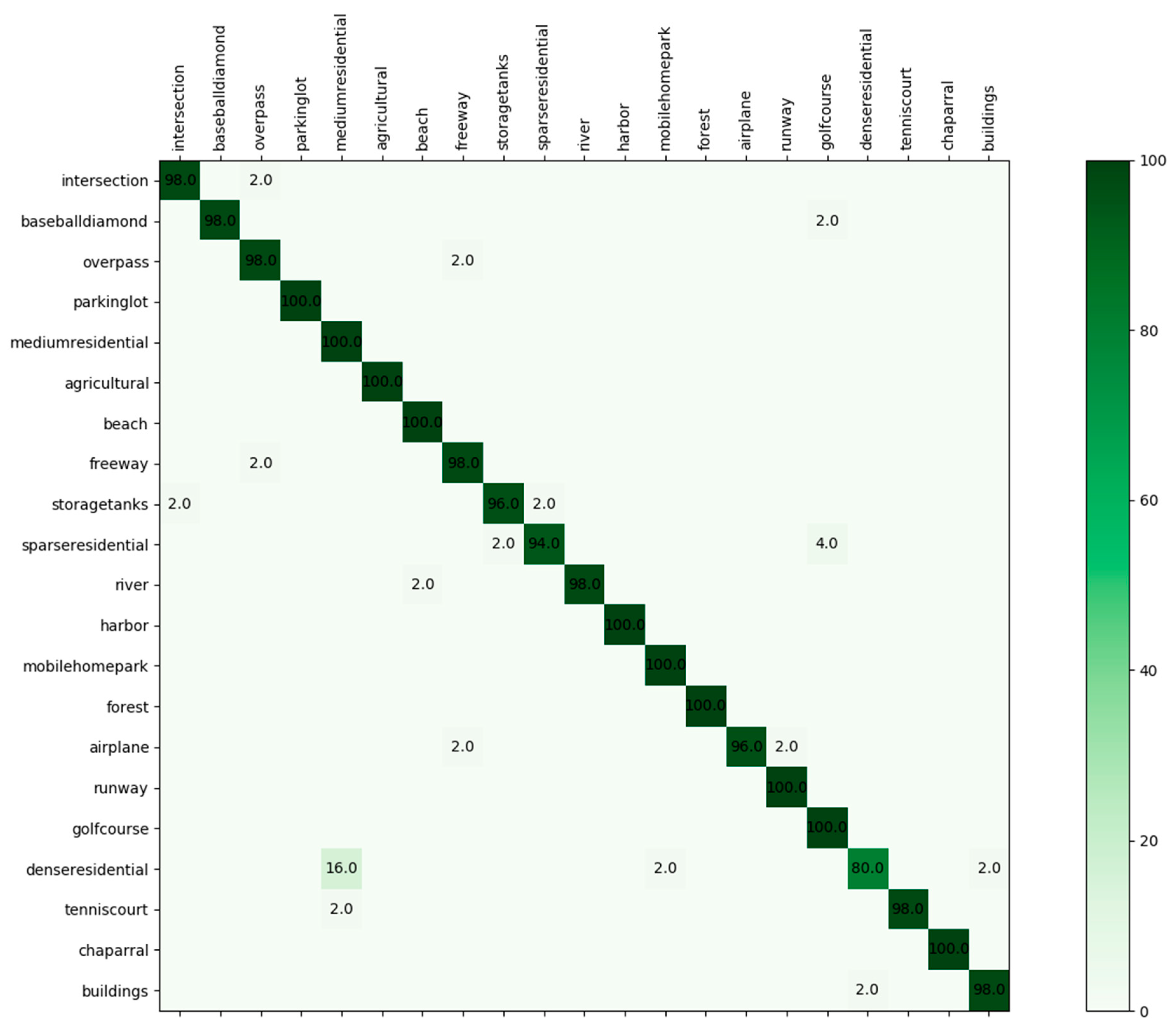
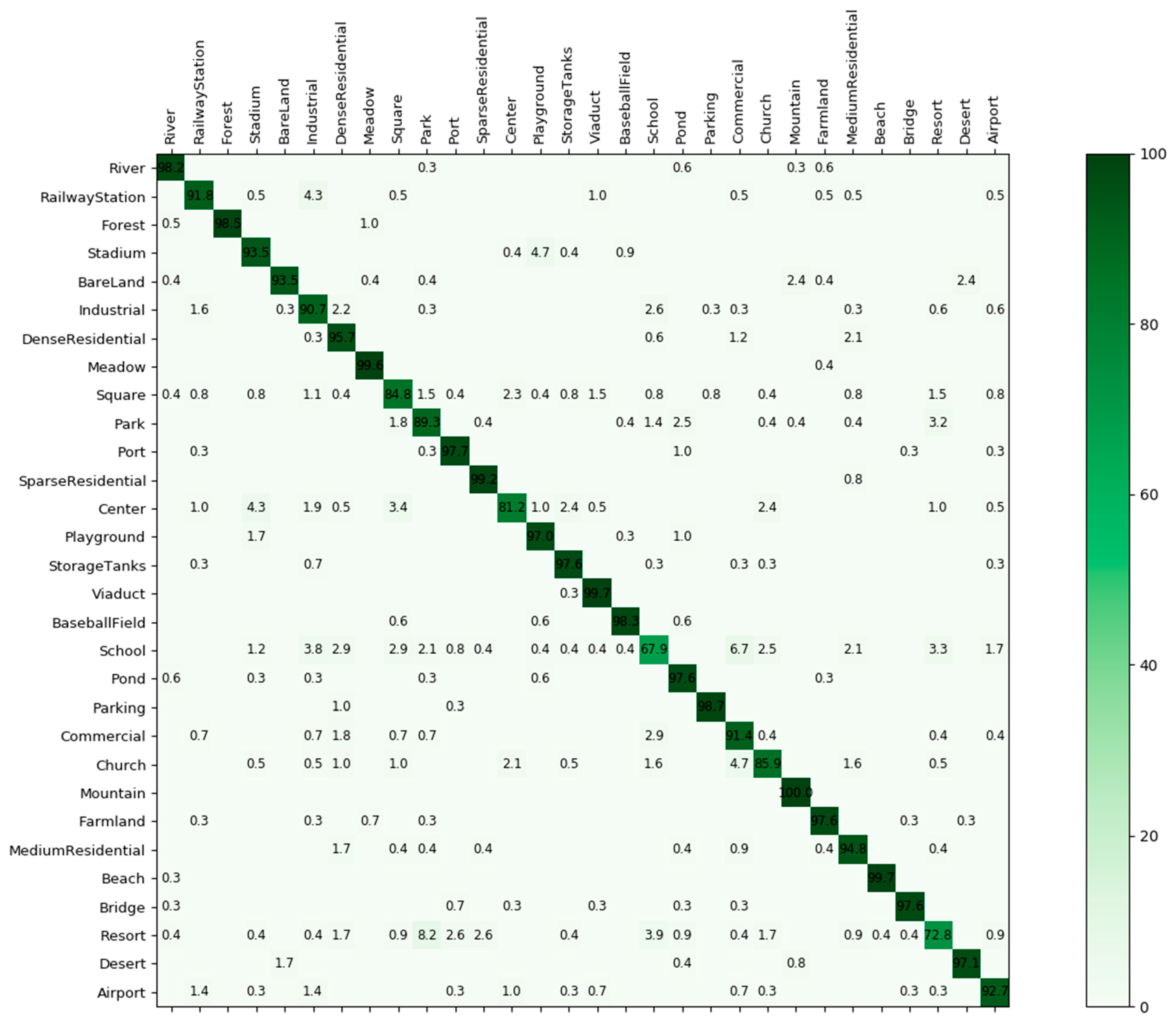
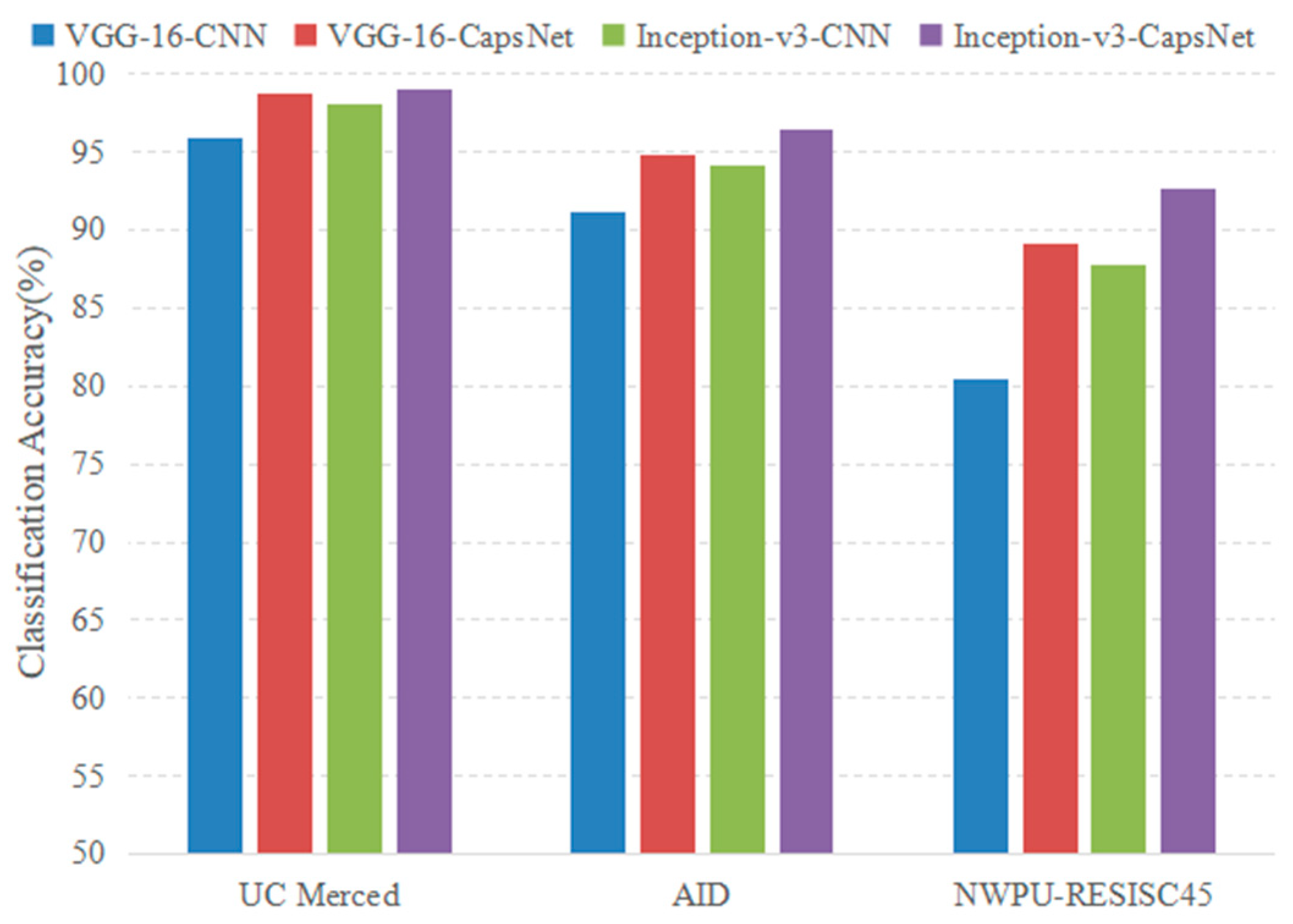
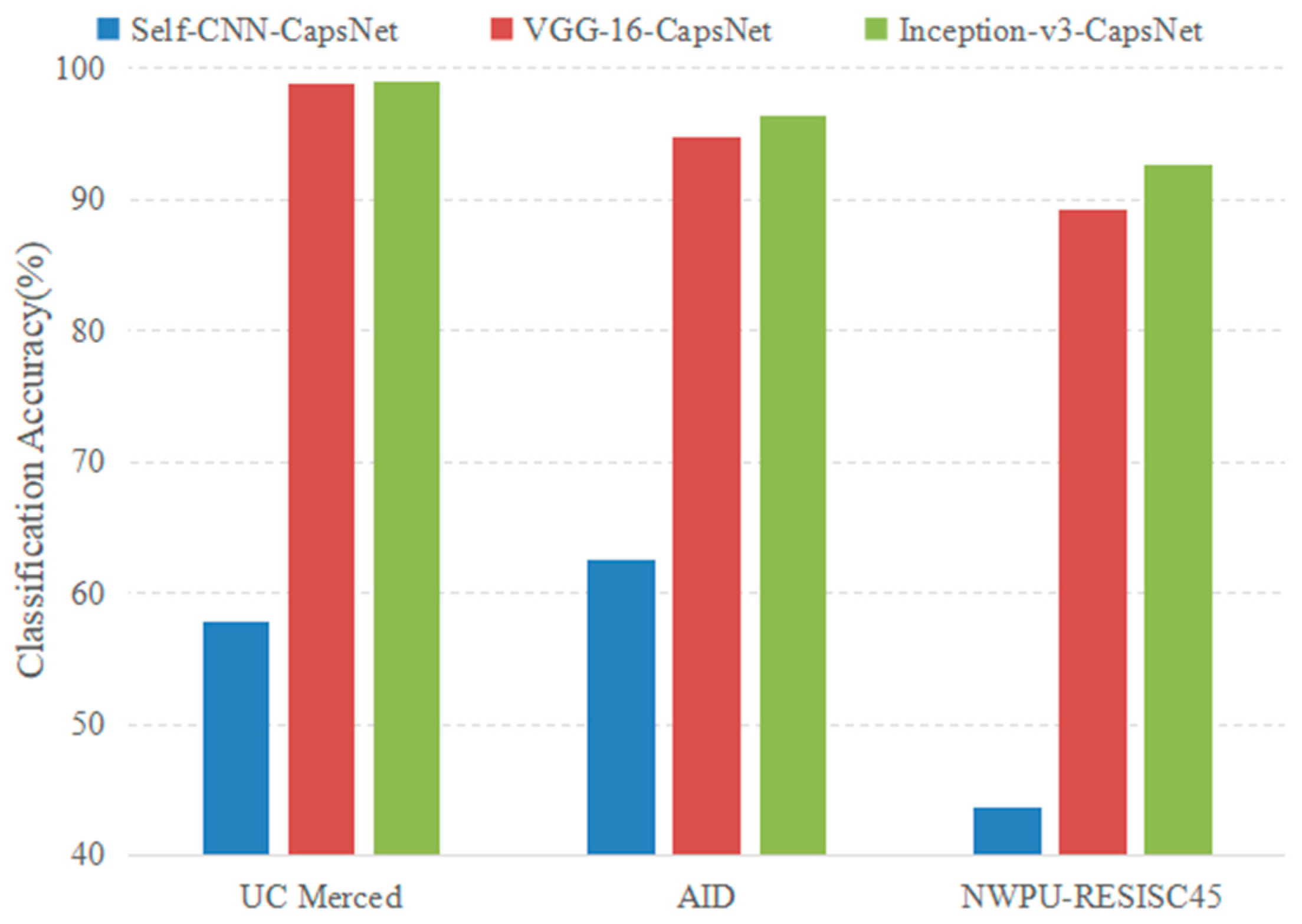
4.2.2. Experimental Results
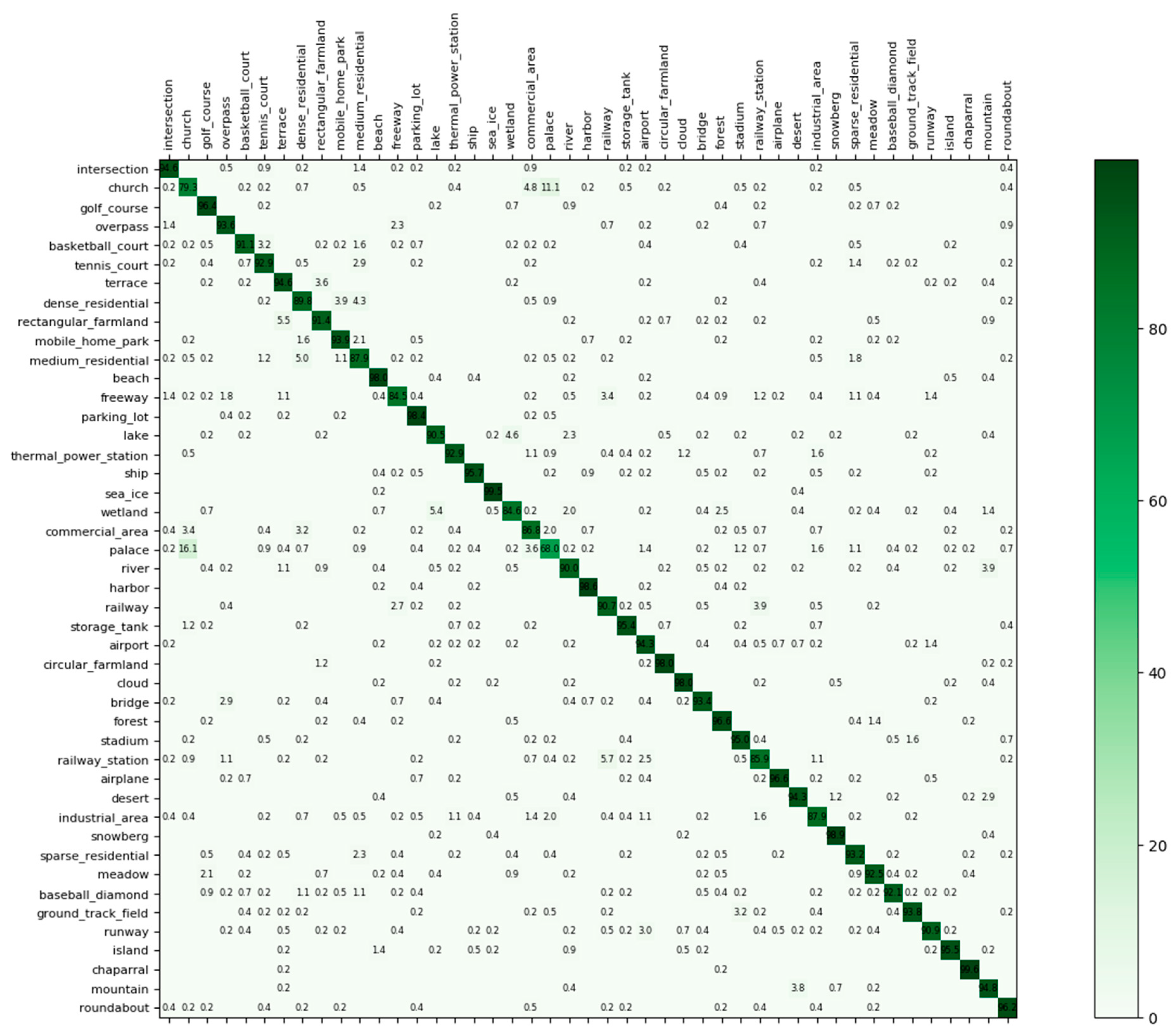
4.2.3. Further Explanation
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Plaza, A.; Plaza, J.; Paz, A.; Sanchez, S. Parallel hyperspectral image and signal processing. IEEE Signal Process. Mag. 2011, 28, 119–126. [Google Scholar] [CrossRef]
- Hubert, M.J.; Carole, E. Airborne SAR-efficient signal processing for very high resolution. Proc. IEEE 2013, 101, 784–797. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S. Extreme value theory-based calibration for the fusion of multiple features in high-resolution satellite scene classification. Int. J. Remote Sens. 2013, 34, 8588–8602. [Google Scholar] [CrossRef]
- Estoque, R.C.; Murayama, Y.; Akiyama, C.M. Pixel-based and object-based classifications using high- and medium-spatial-resolution imageries in the urban and suburban landscapes. Geocarto Int. 2015, 30, 1113–1129. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Q.; Chen, G.; Dai, F.; Zhu, K.; Gong, Y.; Xie, Y. An object-based supervised classification framework for very-high-resolution remote sensing images using convolutional neural networks. Remote Sens. Lett. 2018, 9, 373–382. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and Gabor texture features for classification of remote sensed imagery. In Proceedings of the 15th IEEE International Conference on Image Processing (ICIP), San Diego, CA, USA, 12–15 October 2008; pp. 1852–1855. [Google Scholar]
- Dos Santos, J.A.; Penatti, O.A.B.; da Silva Torres, R. Evaluating the Potential of Texture and Color Descriptors for Remote Sensing Image Retrieval and Classification. In Proceedings of the VISAPP, Angers, France, 17–21 May 2010; pp. 203–208. [Google Scholar]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Li, H.T.; Gu, H.Y.; Han, Y.S.; Yang, J.H. Object oriented classification of high-resolution remote sensing imagery based on an improved colour structure code and a support vector machine. Int. J. Remote Sens. 2010, 31, 1453–1470. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Luo, B.; Jiang, S.J.; Zhang, L.P. Indexing of remote sensing images with different resolutions by multiple features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1899–1912. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using a multi-resolution bag-of-features model. Pattern Recognit. 2013, 46, 424–433. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Sridharan, H.; Cheriyadat, A. Bag of lines (bol) for improved aerial scene representation. IEEE Geosci. Remote Sens. Lett. 2015, 12, 676–680. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Ohio, CO, USA, 24–27 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Zhong, Y.; Fei, F.; Zhang, L. Large patch convolutional neural networks for the scene classification of high spatial resolution imagery. J. Appl. Remote Sens. 2016, 10, 025006. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network ramework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhu, Q.; Qin, Q. Scene Classification Based on a Deep Random-Scale Stretched Convolutional Neural Network. Remote Sens. 2018, 10, 444. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef] [PubMed]
- Othman, E.; Bazi, Y.; Alajlan, N.; Alhichri, H.; Melgani, H. Using convolutional features and a sparse autoencoder for land-use scene classification. Int. J. Remote Sens. 2016, 37, 2149–2167. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Cheng, G.; Ma, C.; Zhou, P.; Yao, X.; Han, J. Scene classification of high resolution remote sensing images using convolutional neural networks. In Proceedings of the IEEE International Geoscience Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 767–770. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, W.; Tang, P. Analysis of the inter-dataset representation ability of deep features for high spatial resolution remote sensing image scene classification. Multimed. Tools Appl. 2018. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 3859–3869. [Google Scholar]
- Andersen, P.A. Deep Reinforcement learning using capsules in advanced game environments. arXiv, 2018; arXiv:1801.09597. [Google Scholar]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N. Brain Tumor Type Classification via Capsule Networks. arXiv, 2018; arXiv:1802.10200. [Google Scholar]
- Iqbal, T.; Xu, Y.; Kong, Q.; Wang, W. Capsule routing for sound event detection. arXiv, 2018; arXiv:1806.04699. [Google Scholar]
- LaLonde, R.; Bagci, U. Capsules for object segmentation. arXiv, 2018; arXiv:1804.04241. [Google Scholar]
- Deng, F.; Pu, S.; Chen, X.; Shi, Y.; Yuan, T.; Pu, S. Hyperspectral Image Classification with Capsule Network Using Limited Training Samples. Sensors 2018, 18, 3153. [Google Scholar] [CrossRef] [PubMed]
- Xi, E.; Bing, S.; Jin, Y. Capsule Network Performance on Complex Data. arXiv, 2017; arXiv:1712.03480. [Google Scholar]
- Jaiswal, A.; AbdAlmageed, W.; Natarajan, P. CapsuleGAN: Generative adversarial capsule network. arXiv, 2018; arXiv:1802.06167. [Google Scholar]
- Neill, J.O. Siamese capsule networks. arXiv, 2018; arXiv:1805.07242. [Google Scholar]
- Mobiny, A.; Nguyen, H.V. Fast CapsNet for lung cancer screening. arXiv, 2018; arXiv:1806.07416. [Google Scholar]
- Kumar, A.D. Novel Deep learning model for traffic sign detection using capsule networks. arXiv, 2018; arXiv:1805.04424. [Google Scholar]
- Li, Y.; Qian, M.; Liu, P.; Cai, Q.; Li, X.; Guo, J.; Yan, H.; Yu, F.; Yuan, K.; Yu, J.; et al. The recognition of rice images by UAV based on capsule network. Clust. Comput. 2018. [Google Scholar] [CrossRef]
- Qiao, K.; Zhang, C.; Wang, L.; Yan, B.; Chen, J.; Zeng, L.; Tong, L. Accurate reconstruction of image stimuli from human fMRI based on the decoding model with capsule network architecture. arXiv, 2018; arXiv:1801.00602. [Google Scholar]
- Zhao, W.; Ye, J.; Yang, M.; Lei, Z.; Zhang, S.; Zhao, Z. Investigating capsule networks with dynamic routing for text classification. arXiv, 2018; arXiv:1804.00538. [Google Scholar]
- Xiang, C.; Zhang, L.; Tang, Y.; Zou, W.; Xu, C. MS-CapsNet: A novel multi-scale capsule network. IEEE Signal Process. Lett. 2018, 25, 1850–1854. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Russakovsky, A.; Deng, J.; Su, H. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Gong, X.; Xie, Z.; Liu, Y.; Shi, X.; Zheng, Z. Deep salient feature based anti-noise transfer network for scene classification of remote sensing imagery. Remote Sens. 2018, 10, 410. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, X.; Tan, X.; Cheng, Y.F.; Dai, F.; Zhu, K.; Gong, Y.; Wang, Q. Training small networks for scene classification of remote sensing images via knowledge distillation. Remote Sens. 2018, 10, 719. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving remote sensing scene classification by integrating global-context and local-object features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; Ma, Z.; Chen, J.; He, D.; Ackland, S. Remote sensing scene classification based on convolutional neural networks pre-trained using attention-guided sparse filters. Remote Sens. 2018, 10, 290. [Google Scholar] [CrossRef]
- Zou, J.; Li, W.; Chen, C.; Du, Q. Scene classification using local and global features with collaborative representation fusion. Inf. Sci. 2018, 348, 209–226. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very Deep Convolutional Neural Networks for Complex Land Cover Mapping Using Multispectral Remote Sensing Imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, CA, USA, 3–8 December 2012; NIPS Foundation: La Jolla, CA, USA, 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J. Rethinking the inception architecture for computer vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; van deWeijer, J.; Monlinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. arXiv, 2017; arXiv:1706.01171. [Google Scholar] [CrossRef]
- Weng, Q.; Mao, Z.; Lin, J.; Guo, W. Land-Use Classification via Extreme Learning Classifier Based on Deep Convolutional Features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 704–708. [Google Scholar] [CrossRef]
- Qi, K.; Guan, Q.; Yang, C.; Peng, F.; Shen, S.; Wu, H. Concentric Circle Pooling in Deep Convolutional Networks for Remote Sensing Scene Classification. Remote Sens. 2018, 10, 934. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Li, K.; Wei, Z. Remote Sensing Image Scene Classification Using Bag of Convolutional Features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, C. Scene classification via triplet networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 220–237. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 80% Training Ratio | 50% Training Ratio |
|---|---|---|
| CaffeNet [35] | 95.02 ± 0.81 | 93.98 ± 0.67 |
| GoogLeNet [35] | 94.31 ± 0.89 | 92.70 ± 0.60 |
| VGG-16 [35] | 95.21 ± 1.20 | 94.14 ± 0.69 |
| SRSCNN [24] | 95.57 | / |
| CNN-ELM [65] | 95.62 | / |
| salM3LBP-CLM [63] | 95.75 ± 0.80 | 94.21 ± 0.75 |
| TEX-Net-LF [64] | 96.62 ± 0.49 | 95.89 ± 0.37 |
| LGFBOVW [18] | 96.88 ± 1.32 | / |
| Fine-tuned GoogLeNet [25] | 97.10 | / |
| Fusion by addition [28] | 97.42 ± 1.79 | / |
| CCP-net [66] | 97.52 ± 0.97 | / |
| Two-Stream Fusion [30] | 98.02 ± 1.03 | 96.97 ± 0.75 |
| DSFATN [54] | 98.25 | / |
| Deep CNN Transfer [27] | 98.49 | / |
| GCFs+LOFs [56] | 99 ± 0.35 | 97.37 ± 0.44 |
| VGG-16-CapsNet (ours) | 98.81 ± 0.22 | 95.33 ± 0.18 |
| Inception-v3-CapsNet (ours) | 99.05 ± 0.24 | 97.59 ± 0.16 |
| Method | 50% Training Ratio | 20% Training Ratio |
|---|---|---|
| CaffeNet [35] | 89.53 ± 0.31 | 86.86 ± 0.47 |
| GoogLeNet [35] | 86.39 ± 0.55 | 83.44 ± 0.40 |
| VGG-16 [35] | 89.64 ± 0.36 | 86.59 ± 0.29 |
| salM3LBP-CLM [63] | 89.76 ± 0.45 | 86.92 ± 0.35 |
| TEX-Net-LF [64] | 92.96 ± 0.18 | 90.87 ± 0.11 |
| Fusion by addition [28] | 91.87 ± 0.36 | / |
| Two-Stream Fusion [30] | 94.58 ± 0.25 | 92.32 ± 0.41 |
| GCFs+LOFs [56] | 96.85 ± 0.23 | 92.48 ± 0.38 |
| VGG-16-CapsNet (ours) | 94.74 ± 0.17 | 91.63 ± 0.19 |
| Inception-v3-CapsNet (ours) | 96.32 ± 0.12 | 93.79 ± 0.13 |
| Method | 20% Training Ratio | 10% Training Ratio |
|---|---|---|
| GoogLeNet [53] | 78.48 ± 0.26 | 76.19 ± 0.38 |
| VGG-16 [53] | 79.79 ± 0.15 | 76.47 ± 0.18 |
| AlexNet [53] | 79.85 ± 0.13 | 76.69 ± 0.21 |
| Two-Stream Fusion [30] | 83.16 ± 0.18 | 80.22 ± 0.22 |
| BoCF [67] | 84.32 ± 0.17 | 82.65 ± 0.31 |
| Fine-tuned AlexNet [53] | 85.16 ± 0.18 | 81.22 ± 0.19 |
| Fine-tuned GoogLeNet [53] | 86.02 ± 0.18 | 82.57 ± 0.12 |
| Fine-tuned VGG-16 [53] | 90.36 ± 0.18 | 87.15 ± 0.45 |
| Triple networks [68] | 92.33 ± 0.20 | / |
| VGG-16-CapsNet (ours) | 89.18 ± 0.14 | 85.08 ± 0.13 |
| Inception-v3-CapsNet (ours) | 92.6 ± 0.11 | 89.03 ± 0.21 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. https://doi.org/10.3390/rs11050494
Zhang W, Tang P, Zhao L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sensing. 2019; 11(5):494. https://doi.org/10.3390/rs11050494
Chicago/Turabian StyleZhang, Wei, Ping Tang, and Lijun Zhao. 2019. "Remote Sensing Image Scene Classification Using CNN-CapsNet" Remote Sensing 11, no. 5: 494. https://doi.org/10.3390/rs11050494
APA StyleZhang, W., Tang, P., & Zhao, L. (2019). Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sensing, 11(5), 494. https://doi.org/10.3390/rs11050494