1. Introduction
Ship classification in optical remote sensing imagery is important for enhancing maritime safety and security [
1,
2]. However, the appearance of ships is easily affected by natural factors such as cloud, sunlight, etc., and wide variations within class in some types of ships and viewing geometry, which make the improvement of the efficiency of ship classification more challenging and complicated [
3,
4].
Over the last decade, different kinds of feature extraction algorithms have been proposed to solve the problem of ship classification using remote sensing images. For example, principal components analysis (PCA) [
5], as the one of most popular tools in feature extraction and dimensionality reduction, was employed to ship classification. Then, linear discriminant analysis (LDA) was also used in vessel recognition [
6], which can make better use of class information to maximize inter-class dispersion and minimize intra-class dispersion compared with PCA. In [
7], hierarchical multi-scale local binary pattern (HMLBP) was applied to extract local features. In [
8], histogram of oriented gradients (HOG) was adopted to extract features because it is a better image descriptor, able to capture the local object appearance and shape in the image. In [
9], the bag of visual words (BOVW) was employed in vessel classification, which is inspired by the bag of words representation used in text classification tasks. In [
10], Rainey et al. proposed several object recognition algorithms to classify the category of vessel, which obtained good results. In [
11], the local binary patterns (LBP) operator was developed for vessel classification. In [
12], the completed local binary patterns (CLBP) was proposed to overcome the shortcoming of LBP. Furthermore, the multiple features learning (MFL) framework [
13], including Gabor-based multi-scale completed local binary pattern (MS-CLBP), patch-based MS-CLBP and Fisher vector (FV) [
14], and BOVW-based spatial pyramid matching (SPM), were all presented for ship classification. Gabor filtering has been employed in some object recognition tasks, such as facial expression recognition [
15] and image classification [
16].
Compared with the Gabor filter, fractional Fourier transform (FrFT) has lower computational complexity and time-frequency focusing characteristics. As a generalization of conventional Fourier transform, the FrFT is a powerful and effective tool for time-frequency analysis, including time-frequency characteristics of the signal [
17]. FrFT executes a rotation of signal to any angle, while the conventional Fourier transform is just a
rotation in the frequency plane. Therefore, it is regarded as an appropriate representation of the chirp signal and has been widely used in the field of signal processing [
18,
19]. In 2001, two-dimensional discrete FrFT (2D-DFrFT) was presented to accomplish optical image encryption [
20]. 2D-DFrFT can capture more characters of a face image in different angles, and the lower-frequency bands contain most facial discriminating features, while high bands contain the noise. Thus, it has been employed in face recognition [
21], human emotional state recognition [
22] and facial expression recognition [
23], and obtained good results.
Recently, convolutional neural network (CNN) has shown great potential in the field of vision recognition tasks by learning high-level features from raw data via convolution operation automatically [
24,
25,
26]. CNN is an application of deep learning algorithms in the field of image processing [
27]. A powerful part of deep learning is that the output of one layer in the middle can be regarded as another expression of data. Compared with the above hand-crafted features, it has the following advantages: first, the process of feature extraction and classification is dependent, which means the results can be fed back for learning better features; second, the features extracted by CNN have a lower complexity image. CNN has been employed successfully in the field of computer vision, including image classification [
28,
29,
30], which demonstrates excellent performance. Although CNN has performed promisingly, it also carries some limitations: firstly, the CNN learning feature is based on low-level features obtained in the first convolution layer, which may cause some important information to be lost, such as edge, contour, and so on. Secondly, it cannot learn global rotation-invariant features of ship images [
31,
32], which is of importance for classifying vessel category. Thirdly, because the bottom of CNN acquires information such as image edge, when the edge of the image is not clear, it cannot achieve good results.
Therefore, to overcome these shortcomings, a multifeature ensemble based on convolutional neural network (ME-CNN) framework, which combines multi-diversity in hand-crafted features with the advantage of high-level features in CNN, is presented to classify the category of ship types. The proposed method employs 2D-DFrFT in the preprocessing stage to produce amplitude and phase information of different orders. Signal-order features are not enough to classify the image type and 2D-DFrFT features of various orders extracted from the same image usually reflect different characteristic of the original image. Therefore, it is important to combine various multi-order features, which not only obtains more discriminative descriptions of multi-order features, but also eliminates redundant information about certain angles. Gabor filtering has an excellent ability to represent the spatial structures of different scales and orientations, which is employed when extracting global rotation-invariant features. Since CLBP can extract detailed local structure and texture information in images, it is used to obtain local texture information about the ship image. In this paper, multi-order features, including amplitude and phase information, and Gabor feature and CLBP images, are viewed as inputs of the CNN to obtain excellent performance. Furthermore, decision-level fusion strategy is adopted for better results based on multi-pipeline CNN models, which operates on probability outputs of each individual classification pipeline, and combines the distinct decisions into a final one.
There are two primary contributions in this work. First, multiple features are employed for multi-pipeline CNN models that apply low-level representations of the original images as inputs of the hierarchical architecture to extract abstract high-level features, which enhances some important information of the ship, such as edge, profile, local texture, and global rotation-invariant information; furthermore, because these feature images make up the multi-channel image as the input of CNN, the amount of data is increased to avoid the over-fitting problem. Second, it is worth mentioning that 2D-DFrFT can enhance the edges, corners, and knots information of a ship image, which is useful for CNN to learn high-level features; therefore, various orders of 2D-DFrFT feature contain different characteristics, which is the motivation of combining them with a Gabor filter and CLBP for classification improvement; in addition, because each feature does not possess all the advantages required for ship identification, a fusion strategy is adopted to synthesize the advantages of all branches that can detect complementary features on the basis of a multifeature ensemble, which could provide an effective and rich representation of the ship image.
The remainder of this paper is organized as follows.
Section 2 provides a detailed description of the proposed classification framework.
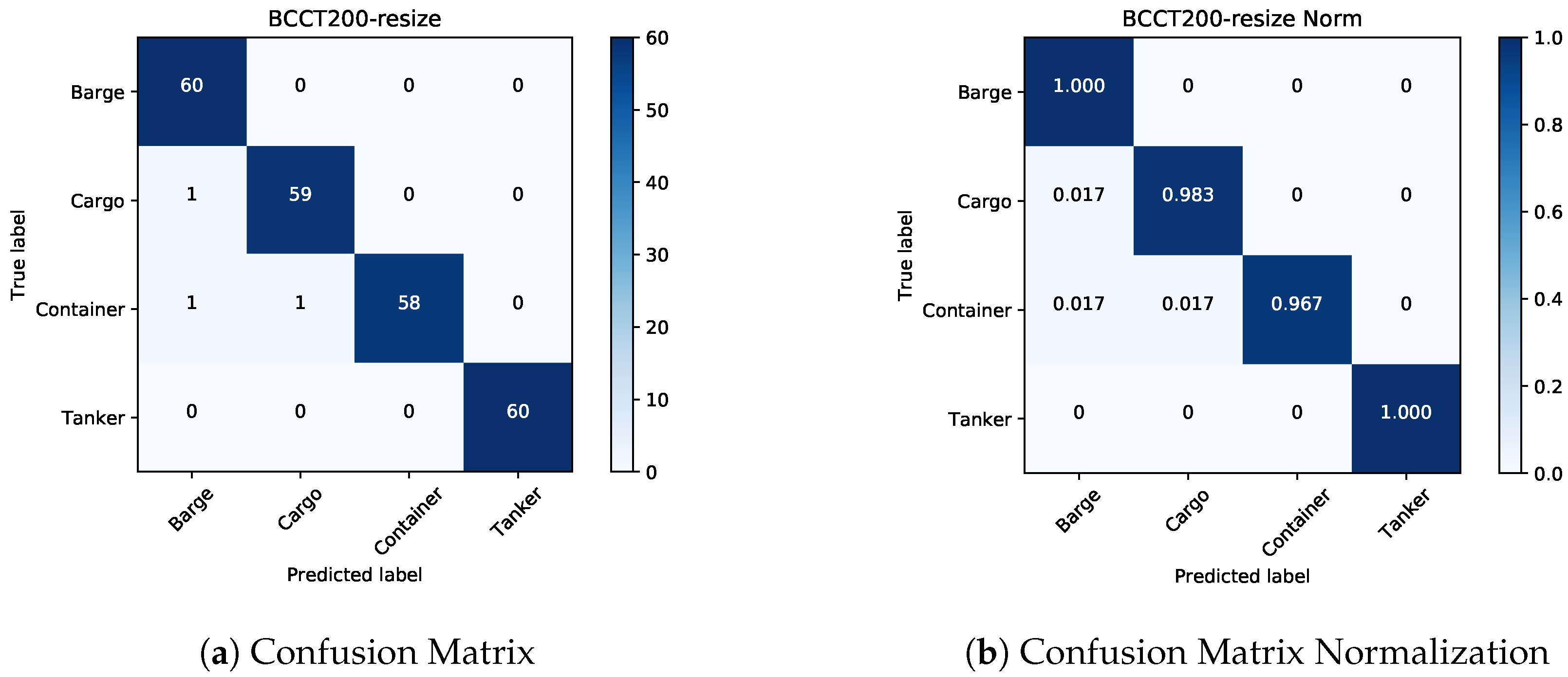
Section 3 reports the experimental results and analyses on the experimental datasets (i.e., BCCT200-resize [
33] and VAIS [
34]).
Section 4 makes concluding remarks.
2. Proposed Ship Classification Method
The task of the current work is to design a framework consisting of CNN and multifeatures for ship classification using optical remote sensing images. The flowchart of the proposed method is shown in
Figure 1, which consists of four parts. In the first part, we extract the multifeatures that are viewed as the input of CNN. In the second part, CNN is used to learn the high-level features based on the image information mentioned above. To reduce network complexity, the network structure of each branch is the same. The probability of each branch can be obtained from the SoftMax layer of CNN in the third part. In the last part, the proposed method merges the outputs of each individual classification pipeline using decision-level soft fusion (i.e., logarithmic opinion pools (LOGP)) to gain the final classification result.
2.1. 2D Discrete Fractional Fourier Transformation
For the FrFT, the normalization of the data can reduce computational complexity, which makes the research process more convenient and effective. In this paper, we first normalize the image before the FrFT. Let
be the ship image with the size of
. The formula is as follows:
where
is maximum value of the sample image. Regarding deep learning, normalization can accelerate the speed of finding the optimal solution when the gradient descends, and improve classification accuracy. Thus, we take absolute values of amplitude and phase after inverse transformation, normalize them, and then put them into CNN for training.
To deal with the two-dimensional imagery and increase the speed of calculation, two-dimensional fractional Fourier transform (2D-FrFT) [
20,
35] is adopted. Compared with convolutional 2D discrete Fourier transform (DFT), 2D-DFrFT is more suitable and flexible with various orders. With the changing of rotation angle, the time-frequency domain characteristics of a transformed image are varied. For normalized images
with the size of
, the 2D-DFrFT is calculated by the following equations:
with the kernel:
the
is defined as:
where
is the order,
is the rotation angle. Moreover,
and
have a similar form. Both are set as the same value,
, where
p is the order of 2D-DFrFT, which is a significant parameter for vessel classification. Based on the above equation, it is obvious that the period of the transform kernel
p is 4. Thus, any real value in range
can be selected for
p. Specifically, FrFT is equivalent to the conventional FT when
. Because fractional transformation itself has periodicity and the symmetry property, we only need to study the transformation order value in the range
.
Given the aforementioned brief description of the 2D-DFrFT, there are some difficulties in analyzing the amplitude and phase information of the fractional domain directly, because the amplitude and phase information of the fractional domain contain time-frequency domain information. Therefore, the next step of analysis is based on the amplitude and phase information after the fractional Fourier inverse transform is done. As shown in
Figure 2 and
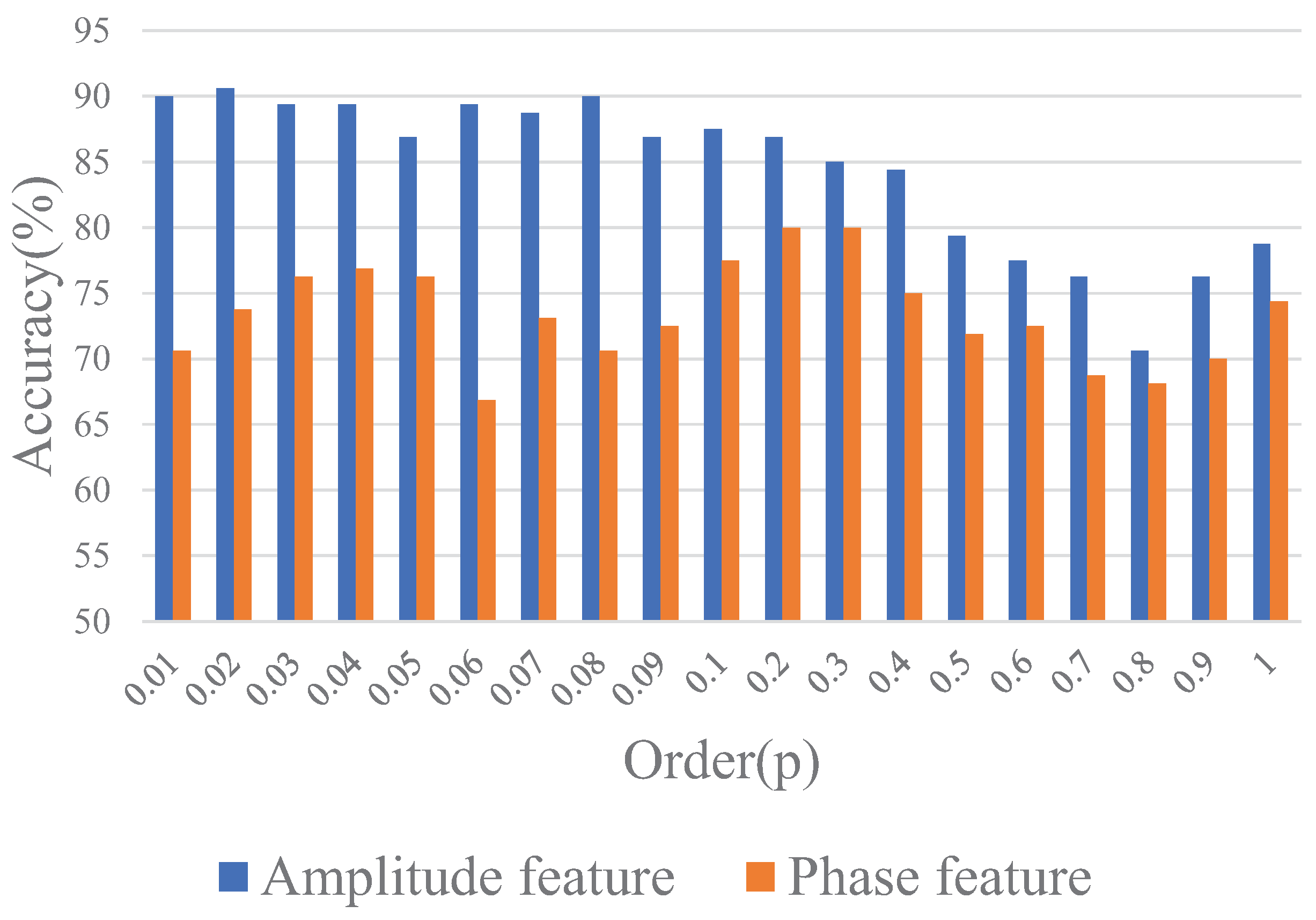
Figure 3, it can be noticed that both amplitude and phase information contain some useful characteristics for contributing the improvement of the classification approach. Furthermore, it is easily found that amplitude information extracted from the inverse 2D-DFrFT mainly contains useful information such as profile, texture, etc., especially small details; in addition, with the gradual increase of order, the energy of the image becomes more concentrated. The phase information obtained from the inverse 2D-DFrFT mainly consists of edges, profile information. In addition, various 2D-DFrFT order amplitude features can reflect different characteristics of the original ship image. Therefore, combining multi-order 2D-DFrFT features can achieve better classification performance compared with using only single 2D-DFrFT features.
2.2. Reverse 2D-DFrFT on Amplitude Image
For each ship image, it is first handled by 2D-DFrFT, according to the above-mentioned details, to get amplitude and phase information. As shown in
Figure 1, the amplitude of the inverse 2D-DFrFT is calculated according to amplitude value in the fractional domain. For the ship image
,
represents 2D-DFrFT operator, and the amplitude information
is obtained as follows:
The inverse 2D-DFrFT of amplitude is the 2D-DFrFT with order
. Specifically, assuming
represents the amplitude information of the ship image in fractional domain transformed by inverse 2D-DFrFT,
is the inverse 2D-DFrFT operator:
The amplitude information of Equation (
7) is one of the multifeature inputs of the third CNN pipeline.
2.3. Reverse 2D-DFrFT on Phase Image
The phase of the inverse 2D-DFrFT is calculated based on phase information in the fractional domain. The calculation process is very similar to the amplitude, that is, the phase information
of 2D-DFrFT is defined,
Assuming
represent the phase information of inverse 2D-DFrFT,
The phase information of Equation (
9) is the feature used in the last branch. However, compared with the original data, the phase image of the inverse 2D-DFrFT tends to contain a lot of noise. To obtain better classification results, a simple low-pass Gaussian filter is employed to remove noise, and then it is fed into CNN.
2D-DFrFT, as above-mentioned in detail, is employed to acquire amplitude and phase information. Then both, after inverse 2D-DFrFT, are fed into CNN to obtain more abstract feature representation. As described in Algorithm 1, the training set is first prepared well; then, the phase and amplitude information are obtained by 2D-DFrFT. To reduce the complexity of research, we use the inverse transform information, which is calculated by inverse 2D-DFrFT. Since the inverse transform information is still a complex value, we only take its absolute value to study, and because the phase information contains noise, the filtering operation is performed.
| Algorithm 1 Amplitude and phase information extraction |
Require: Prepared training set and testing set
- 1:
Each ship image is normalized and transformed by using 2D-DFrFT filter to obtain amplitude pictures (AP) and phase pictures (PP) in fractional domain. - 2:
AP and PP are handled using inverse 2D-DFrFT. - 3:
The absolute value of AP and PP after inverting is obtained. - 4:
This information after inversion is normalized. - 5:
For PP, because it contains noise, Gaussian filter is adopted to obtain better features.
Ensure: AP and PP in time domain |
2.4. Gabor Filter and CLBP
A Gabor filter has good characteristics to extract directional features and enhance the global rotation invariance, which has been applied in face recognition [
36] and scene classification [
37].
It is defined as follows:
where
c and
d are the location of the pixels in the space,
is the aspect ratio that determines the ellipticity of the Gabor function (its value is 0.5),
is the wavelength (note that its value is usually greater than or equal to 2 but less than
of the input image),
is the bandwidth,
is the phase offset (its value range is from −180 to 180 degrees), and
is the direction that regulates the direction of the parallel stripes when the Gabor function processes the image, taking values between 0 and 360 degrees.
A LBP descriptor has been applied in vessel recognition. However, it is not perfect and still needs to be improved. Based on this, CLBP was proposed to overcome the shortcoming of LBP, which mainly includes sign and magnitude information and has the advantages of lower computational complexity and high distinctiveness. It mainly contains two kinds of descriptive operators, such as CLBP_Sign (CLBP_S), CLBP_Magnitude (CLBP_M). Both are complementary to one another. The definition is expressed as follows:
where
R is the distance from the center point, and
m is the number of nearest neighbors,
represents the gray value of the neighbors,
, and
L is the number of sub-windows for image partition. Here, CLBP_S is the same as the traditional LBP definition. CLBP_M compares the difference between the grayscale amplitude of two pixels and the global grayscale and describes the gradient difference information of the local window, which reflects the contrast.
2.5. Convolutional Neural Network
Based on the multifeatures ensemble, CNN is further employed for feature extraction. A normal CNN consists of several layers: convolutional layers to learn hierarchy local features; pooling layers to reduce the dimension of the feature maps; activation layers to produce non-linearity; dropout layers to avoid the problem of over-fitting; fully connected layers to use the global feature and SoftMax layers to predict the category probability. Here, the cross-entropy loss formula is defined as:
where
is the
th feature,
is the target class,
is the batch size,
is the number of the category, and
W is the weight matrix of the fully connected layer and
b is the bias.
In the proposed framework, based on AlextNet, we have made some changes to the network structure. Firstly, because each feature image is composed of multiple channels as the input of CNN, which increases the number of datasets in a sense, we choose to start the training network from scratch instead of using the fine-tuning strategy. Considering the performance and computational complexity, we reduce the number of convolution layers from five to three. Secondly, Batchnorm layer [
38] is added to the network, which can reduce the absolute difference between images, highlight relative differences, and accelerate training speed. Furthermore, a strategy, i.e., local response normalization, LRN, is adopted to improve the performance of the framework and accelerate the training speed of the network. The dropout layer is employed in the last two fully connected layers to avoid the problem of over-fitting and improve the generalization ability of the network. Here, the drop parameter is set 0.75. The further parameters of the designed CNN are listed in
Table 1 and the detailed structure is shown in
Figure 4.
Finally, since multifeatures can reflect different information about the original image, and to obtain better classification accuracy, integration strategies, i.e., decision-level fusion, are adopted. Soft LOGP [
16,
39] is employed to combine the posterior probability estimations provided from each individual classification pipeline. The process further improves the performance of a single classifier that uses a certain type of feature.
2.6. Decision-Level Fusion
Decision-level fusion merges results from different classification pipelines and combines distinct classification results into a final decision, which can show better performance than a single classifier using an individual feature. As a special case of decision-level fusion, score-level fusion is equivalent to soft fusion. The aim is to combine the posterior probability estimations provided from each single classifier by using score-level fusion. In this work, the soft LOGP is employed to obtain the result.
The LOGP [
16,
39] takes advantage of conditional class probability from the individual classification pipeline to estimate a global membership function
. Assume
r is a final class label, which can be given according to:
where
Q is the number of classes, and
indicates the
qth class belong to which one in a sample
t. The global membership function is as follows:
or
where
represents the conditional class probability of the
z classifier,
is the classifier weights uniformly distributed over all of classifiers, and
Z is number classifiers.
2.7. Motivation of Proposed Method
The motivation of developing a ME-CNN to learn image characteristics for ship classification is as follows: firstly, for Gabor filter, which is rotation-invariant and orientation-sensitive; i.e., it can extract the global features in different directions for images. In terms of ship recognition, this characteristic is very important, because different orientations of the bow lead to greater intra-class differences, which may affect the classification results. For CNN, it can only obtain local rotation invariance features by pooling operations, but it is more important for ship recognition with global rotation invariance. Therefore, it is meaningful to combine Gabor filter with CNN for ship recognition.
Secondly, because the categories of ship are various, this may cause the structure features to be more complex and changeable; thus, the local texture, edge, and profile information are expected; however, CNN cannot extract all low-level features based on the raw data. CLBP descriptor, as a local texture feature descriptor, captures the spatial information of the original image and extracts the local texture features, and has two descriptor operators CLBP_S and CLBP_M. CLBP_M extracts more contour information of the ship image, while CLBP_S extracts more detailed features of local texture of ship image. Therefore, the obtained features have stronger robustness. The Gabor filter and CLBP images are shown in
Figure 5.
Thirdly, 2D-DFrFT, as a generalized form of Fourier transform, has the advantages of Fourier transform and has its own unique characteristics. As shown in
Figure 2 and
Figure 3, 2D-DFrFT features of various orders extracted from the same image usually reflect different characteristics of the original image. Therefore, the combination of multi-order various features is important, which makes the feature representation more discriminative. Furthermore, it has been viewed as a vital tool for handling chirp signals, which can capture the profile and detailed formation. The ship image can be regarded as a gradually changing signal and has some similarity to a face image. Thus, inspired by this advantage of 2D-DFrFT, we use it to extract amplitude and phase information. Although the features mentioned above have their own advantages, they do not have all the characteristics of ship identification, and they are complementary. Therefore, it is necessary to form multifeatures, which combine their respective advantages, making the features richer and more separable.
Finally, the reason that CNN is chosen to continue to learn high-level features based on the features mentioned above is that the network has the capacity to capture structure information automatically by layer-to-layer propagation. Compared with low-level features, these are more abstract, robust, and discriminative for dealing with within-class differences and inter-class similarity.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}