Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh

 , , ,
, , ,  , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
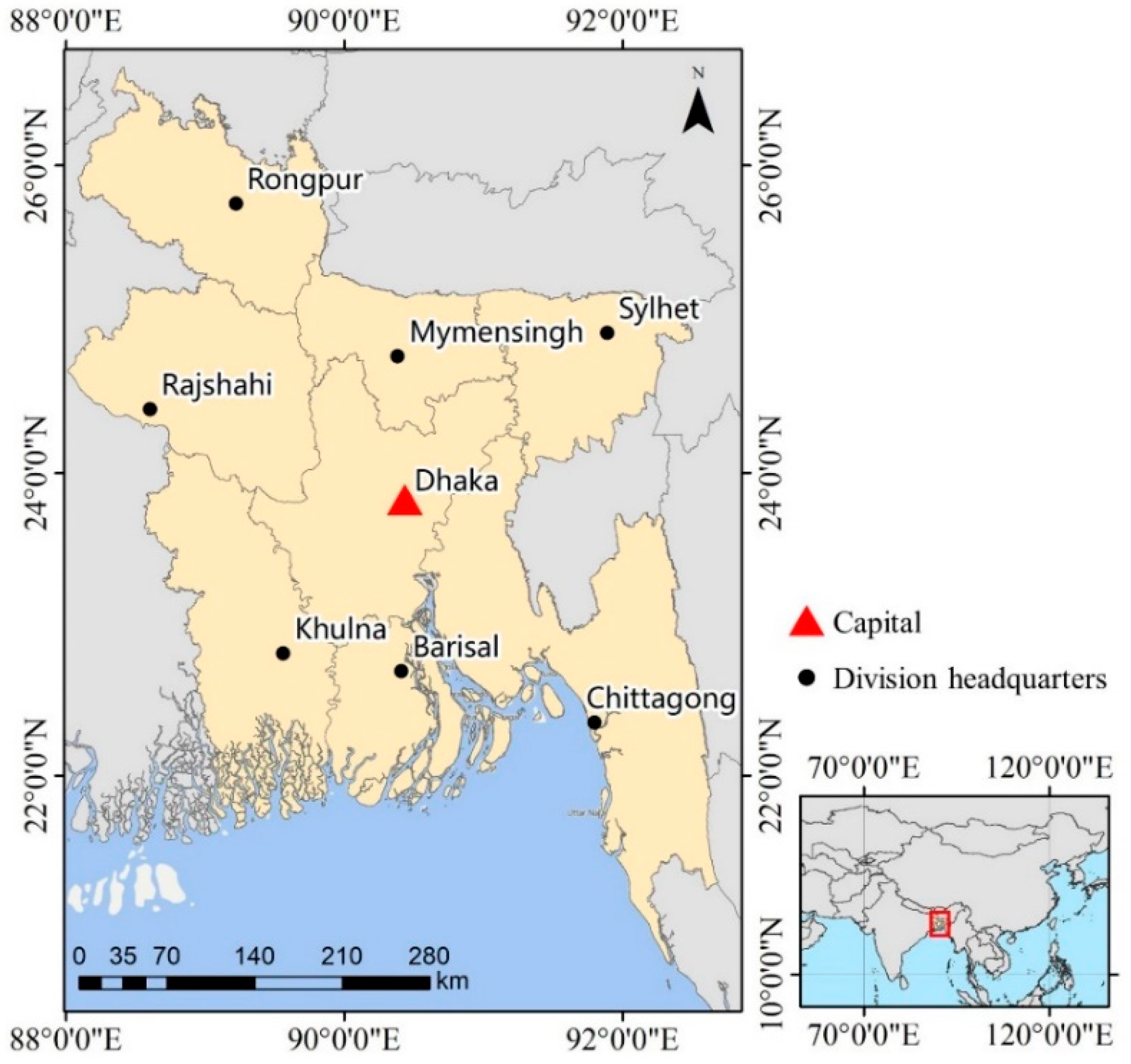
2.1. Study Area
2.2. Data
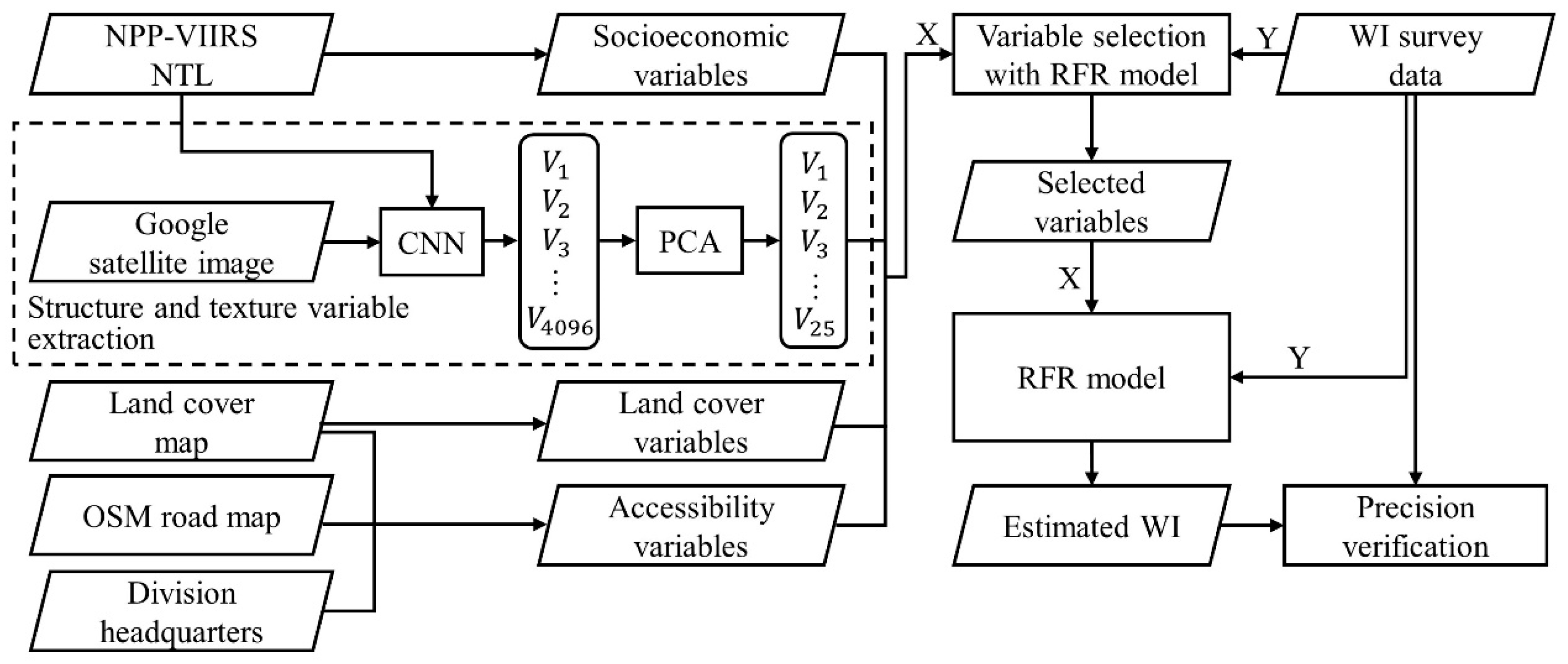
2.3. Methods
2.3.1. Feature Extraction
2.3.2. The RFR Model
2.3.3. Collinearity Analysis of Variables
3. Results
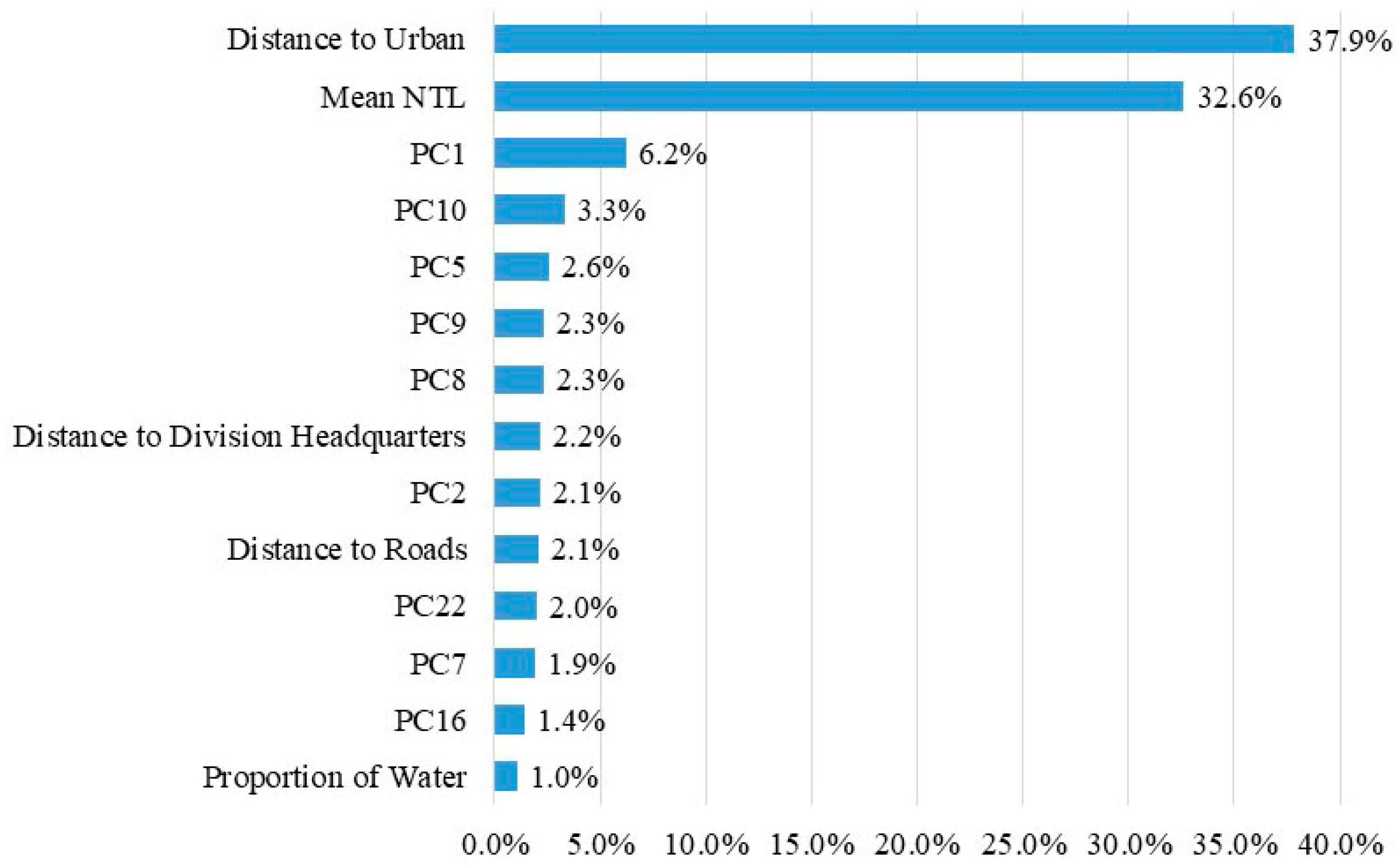
3.1. Variables Selection Results
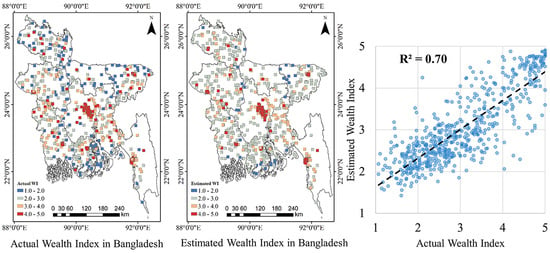
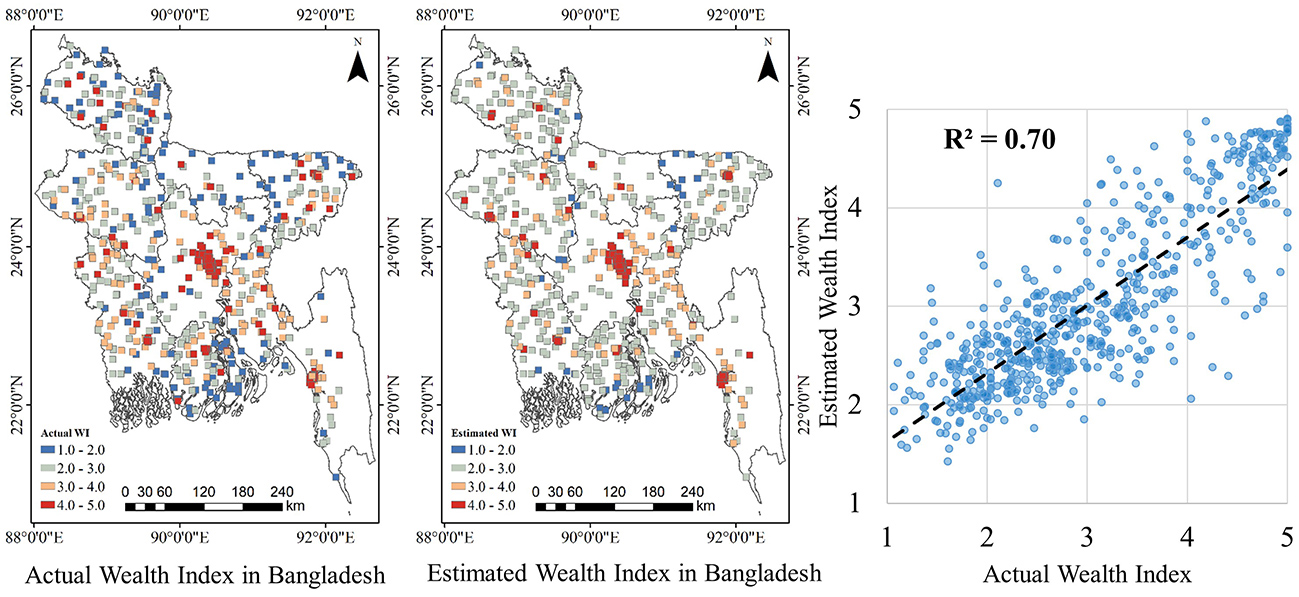
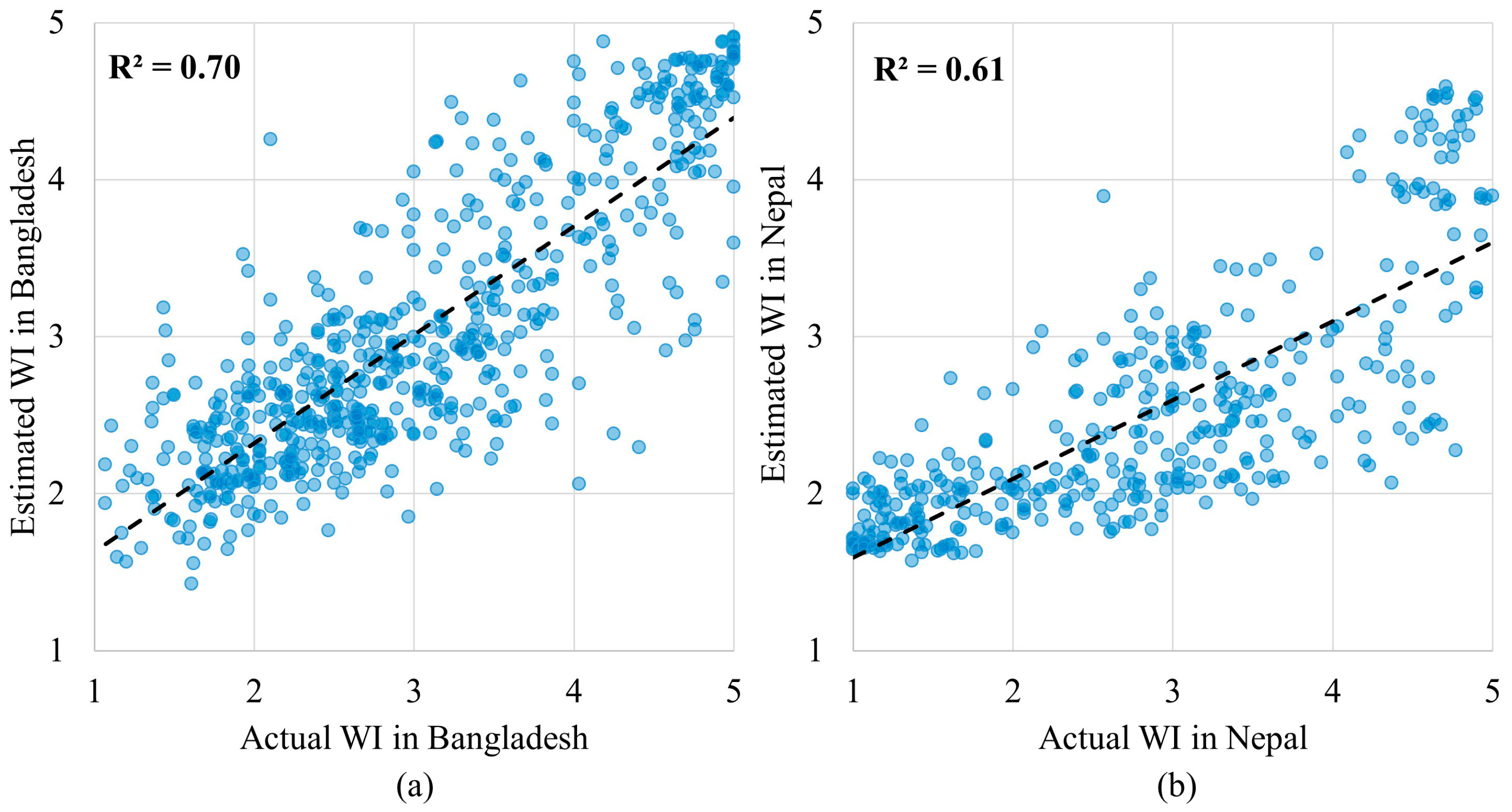
3.2. Accuracy Evaluation of the RFR Model
3.3. Accuracy Evaluation by A Comparison with District-Level Census Data
3.4. Collinearity of Variables
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- United Nations. About the Sustainable Development Goals. Available online: https://www.un.org/sustainabledevelopment/sustainable-development-goals/ (accessed on 31 January 2019).
- Decline of Global Extreme Poverty Continues but Has Slowed: World Bank. Available online: http://www.worldbank.org/en/news/press-release/2018/09/19/decline-of-global-extreme-poverty-continues-but-has-slowed-world-bank (accessed on 15 December 2018).
- Coudouel, A.; Hentschel, J.S.; Wodon, Q.T. Poverty measurement and analysis. In A Sourcebook for Poverty Reduction Strategies; Klugman, J., Ed.; World Bank: Washington, DC, USA, 2002; Volume 1, pp. 27–74. [Google Scholar]
- Carvalho, S.; White, H. Combining the Quantitative and Qualitative Approaches to Poverty Measurement and Analysis: The Practice and the Potential; World Bank technical paper; no. WTP 366; The World Bank: Washington, DC, USA, 1997. [Google Scholar]
- Shi, K.; Yu, B.; Huang, Y.; Hu, Y.; Yin, B.; Chen, Z.; Chen, L.; Wu, J. Evaluating the Ability of NPP-VIIRS Nighttime Light Data to Estimate the Gross Domestic Product and the Electric Power Consumption of China at Multiple Scales: A Comparison with DMSP-OLS Data. Remote Sens. 2014, 6, 1705–1724. [Google Scholar] [CrossRef]
- Zhao, N.; Liu, Y.; Cao, G.; Samson, E.L.; Zhang, J. Forecasting China’s GDP at the pixel level using nighttime lights time series and population images. GISci. Remote Sens. 2017, 54, 407–425. [Google Scholar] [CrossRef]
- Sutton, P.; Roberts, D.; Elvidge, C.; Baugh, K. Census from Heaven: An estimate of the global human population using night-time satellite imagery. Int. J. Remote Sens. 2001, 22, 3061–3076. [Google Scholar] [CrossRef]
- Sutton, P.; Roberts, C.; Elvidge, C.; Meij, H. A comparison of nighttime satellite imagery and population density for the continental united states. Photogramm. Eng. Remote Sens. 1997, 63, 1303–1313. [Google Scholar]
- Chand, T.K.; Badarinath, K.; Elvidge, C.; Tuttle, B. Spatial characterization of electrical power consumption patterns over India using temporal DMSP-OLS night-time satellite data. Int. J. Remote Sens. 2009, 30, 647–661. [Google Scholar] [CrossRef]
- Shi, K.; Yu, B.; Huang, C.; Wu, J.; Sun, X. Exploring spatiotemporal patterns of electric power consumption in countries along the Belt and Road. Energy 2018, 150, 847–859. [Google Scholar] [CrossRef]
- Shi, K.; Chen, Y.; Yu, B.; Xu, T.; Yang, C.; Li, L.; Huang, C.; Chen, Z.; Liu, R.; Wu, J. Detecting spatiotemporal dynamics of global electric power consumption using DMSP-OLS nighttime stable light data. Appl. Energy 2016, 184, 450–463. [Google Scholar] [CrossRef]
- Shi, K.; Yang, Q.; Fang, G.; Yu, B.; Chen, Z.; Yang, C.; Wu, J. Evaluating spatiotemporal patterns of urban electricity consumption within different spatial boundaries: A case study of Chongqing, China. Energy 2019, 167, 641–653. [Google Scholar] [CrossRef]
- Shi, K.; Chen, Y.; Yu, B.; Xu, T.; Chen, Z.; Liu, R.; Li, L.; Wu, J. Modeling spatiotemporal CO2 (carbon dioxide) emission dynamics in China from DMSP-OLS nighttime stable light data using panel data analysis. Appl. Energy 2016, 168, 523–533. [Google Scholar] [CrossRef]
- Ghosh, T.; Elvidge, C.D.; Sutton, P.C.; Baugh, K.E.; Ziskin, D.; Tuttle, B.T. Creating a global grid of distributed fossil fuel CO2 emissions from nighttime satellite imagery. Energies 2010, 3, 1895–1913. [Google Scholar] [CrossRef]
- Chen, Z.Q.; Yu, B.L.; Hu, Y.J.; Huang, C.; Shi, K.F.; Wu, J.P. Estimating House Vacancy Rate in Metropolitan Areas Using NPP-VIIRS Nighttime Light Composite Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2188–2197. [Google Scholar] [CrossRef]
- Shi, K.; Yu, B.; Hu, Y.; Huang, C.; Chen, Y.; Huang, Y.; Chen, Z.; Wu, J. Modeling and mapping total freight traffic in China using NPP-VIIRS nighttime light composite data. GISci. Remote Sens. 2015, 52, 274–289. [Google Scholar] [CrossRef]
- Yu, B.; Shu, S.; Liu, H.; Song, W.; Wu, J.; Wang, L.; Chen, Z. Object-based spatial cluster analysis of urban landscape pattern using nighttime light satellite images: a case study of China. Int. J. Geogr. Inf. Sci. 2014, 28, 2328–2355. [Google Scholar] [CrossRef]
- Shi, K.; Huang, C.; Yu, B.; Yin, B.; Huang, Y.; Wu, J. Evaluation of NPP-VIIRS nighttime light composite data for extracting built-up urban areas. Remote Sens. Lett. 2014, 5, 358–366. [Google Scholar] [CrossRef]
- Chen, Z.; Yu, B.; Song, W.; Liu, H.; Wu, Q.; Shi, K.; Wu, J. A New Approach for Detecting Urban Centers and Their Spatial Structure With Nighttime Light Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6305–6319. [Google Scholar] [CrossRef]
- Yu, B.; Tang, M.; Wu, Q.; Yang, C.; Deng, S.; Shi, K.; Peng, C.; Wu, J.; Chen, Z. Urban Built-Up Area Extraction From Log-Transformed NPP-VIIRS Nighttime Light Composite Data. IEEE Geosci. Remote Sens. Lett. 2018. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Cinzano, P.; Pettit, D.; Arvesen, J.; Sutton, P.; Small, C.; Nemani, R.; Longcore, T.; Rich, C.; Safran, J. The Nightsat mission concept. Int. J. Remote Sens. 2007, 28, 2645–2670. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.; Zhizhin, M.; Hsu, F.C.; Ghosh, T. VIIRS night-time lights. Int. J. Remote Sens. 2017, 38, 5860–5879. [Google Scholar] [CrossRef]
- Noor, A.M.; Alegana, V.A.; Gething, P.W.; Tatem, A.J.; Snow, R.W. Using remotely sensed night-time light as a proxy for poverty in Africa. Popul. Health Metr. 2008, 6, 5. [Google Scholar] [CrossRef] [PubMed]
- Elvidge, C.D.; Sutton, P.C.; Ghosh, T.; Tuttle, B.T.; Baugh, K.E.; Bhaduri, B.; Bright, E. A global poverty map derived from satellite data. Comput. Geosci. 2009, 35, 1652–1660. [Google Scholar] [CrossRef]
- Yu, B.; Shi, K.; Hu, Y.; Huang, C.; Chen, Z.; Wu, J. Poverty Evaluation Using NPP-VIIRS Nighttime Light Composite Data at the County Level in China. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, PP, 1–13. [Google Scholar] [CrossRef]
- Varshney, K.R.; Chen, G.H.; Abelson, B.; Nowocin, K.; Sakhrani, V.; Xu, L.; Spatocco, B.L. Targeting Villages for Rural Development Using Satellite Image Analysis. Big Data 2015, 3, 41–53. [Google Scholar] [CrossRef] [PubMed]
- Duque, J.C.; Patino, J.E.; Ruiz, L.A.; Pardo-Pascual, J.E. Measuring intra-urban poverty using land cover and texture metrics derived from remote sensing data. Landsc. Urban Plann. 2015, 135, 11–21. [Google Scholar] [CrossRef]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining satellite imagery and machine learning to predict poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [PubMed]
- Watmough, G.R.; Atkinson, P.M.; Hutton, C.W. Predicting socioeconomic conditions from satellite sensor data in rural developing countries: A case study using female literacy in Assam, India. Appl. Geogr. 2013, 44, 192–200. [Google Scholar] [CrossRef]
- Weiss, D.; Nelson, A.; Gibson, H.; Temperley, W.; Peedell, S.; Lieber, A.; Hancher, M.; Poyart, E.; Belchior, S.; Fullman, N. A global map of travel time to cities to assess inequalities in accessibility in 2015. Nature 2018, 553, 333. [Google Scholar] [CrossRef] [PubMed]
- Sen, B. Drivers of escape and descent: Changing household fortunes in rural Bangladesh. World Develop. 2003, 31, 513–534. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. In Machine learning; Schapire, R.E., Ed.; Kluwer Academic Publishers: Boston, MA, USA, 2001; Volume 45, pp. 5–32. [Google Scholar]
- Abdel-Rahman, E.M.; Ahmed, F.B.; Ismail, R. Random forest regression and spectral band selection for estimating sugarcane leaf nitrogen concentration using EO-1 Hyperion hyperspectral data. Int. J. Remote Sens. 2012, 34, 712–728. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree Species Classification with Random Forest Using Very High Spatial Resolution 8-Band WorldView-2 Satellite Data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef]
- Wang, L.a.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. The Crop Journal 2016, 4, 212–219. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, X.; Li, X.; Zhang, J.; Liang, Z.; Mai, K.; Zhang, Y. Mapping fine-scale population distributions at the building level by integrating multisource geospatial big data. Int. J. Geogr. Inf. Sci. 2017. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Van Beijma, S.; Comber, A.; Lamb, A. Random forest classification of salt marsh vegetation habitats using quad-polarimetric airborne SAR, elevation and optical RS data. Remote Sens. Environ. 2014, 149, 118–129. [Google Scholar] [CrossRef]
- The World Bank Data—Bangladesh. Available online: https://data.worldbank.org/country/bangladesh (accessed on 31 October 2018).
- ADB. ADB Annual Report 2005; Asian Development Bank: Mandaluyong, Metro Manila, Philippines, 2005. [Google Scholar]
- Ahmed, S.A.; Diffenbaugh, N.S.; Hertel, T.W. Climate volatility deepens poverty vulnerability in developing countries. Environ. Res. Lett. 2009, 4, 8. [Google Scholar] [CrossRef]
- ICF. The DHS Program. Available online: https://dhsprogram.com/data/ (accessed on 31 October 2018).
- Rutstein, S.O. The DHS Wealth Index: Approaches for Rural and Urban Areas; Macro International: Calverton, MD, USA, 2008. [Google Scholar]
- ICF. Demographic and Health Surveys; Funded by USAID; ICF: Rockville, MD, USA, 2018. [Google Scholar]
- Smith, B.; Wills, S. Left in the dark? oil and rural poverty. J. Assoc. Environ. Resour. Econ. 2016, 5, 865–904. [Google Scholar] [CrossRef]
- Version 1 VIIRS Day/Night Band Nighttime Lights. Available online: https://ngdc.noaa.gov/eog/viirs/download_dnb_composites.html (accessed on 5 November 2018).
- Google Maps Platform-Maps Static API. Available online: https://developers.google.com/maps/documentation/maps-static/intro (accessed on 11 January 2018).
- Open Street Map. Available online: https://www.openstreetmap.org (accessed on 9 March 2018).
- European Space Agency Climate Change Initiatiue Land Cover. Available online: http://maps.elie.ucl.ac.be/CCI/viewer/ (accessed on 6 October 2018).
- GeoDASH. Available online: https://geodash.gov.bd/ (accessed on 11 March 2018).
- Ma, T.; Zhou, C.H.; Pei, T.; Haynie, S.; Fan, J.F. Responses of Suomi- NPP VIIRS- derived nighttime lights to socioeconomic activity in China’s cities. Remote Sens. Lett. 2014, 5, 165–174. [Google Scholar] [CrossRef]
- Zhou, Y.K.; Ma, T.; Zhou, C.H.; Xu, T. Nighttime Light Derived Assessment of Regional Inequality of Socioeconomic Development in China. Remote Sens. 2015, 7, 1242–1262. [Google Scholar] [CrossRef]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Tree-based methods. In Modern Applied Statistics with S; Springer: New York, NY, USA, 2002; pp. 251–269. [Google Scholar]
- Dasgupta, A.; Sun, Y.V.; König, I.R.; Bailey-Wilson, J.E.; Malley, J.D. Brief review of regression-based and machine learning methods in genetic epidemiology: the Genetic Analysis Workshop 17 experience. Genetic Epidemiology 2011, 35, S5–S11. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees; Routledge: New York, NY, USA, 1984. [Google Scholar] [CrossRef]
- Scikit-Learn. Available online: https://scikit-learn.org/stable/index.html (accessed on 10 December 2018).
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar] [CrossRef]
- Lerman, P. Fitting segmented regression models by grid search. Appl. Stat. 1980, 77–84. [Google Scholar] [CrossRef]
- O’brien, R.M. A Caution Regarding Rules of Thumb for Variance Inflation Factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Bangladesh Bureau of Statistics. Preliminary Report on Household Income and Expenditure Survey 2016; Bangladesh Bureau of Statistics: Dhaka, Bangladesh, October 2017.
- Brewer, C.A.; Pickle, L. Evaluation of methods for classifying epidemiological data on choropleth maps in series. Ann. Assoc. Am. Geogr. 2002, 92, 662–681. [Google Scholar] [CrossRef]
- Kühnlein, M.; Appelhans, T.; Thies, B.; Nauss, T. Improving the accuracy of rainfall rates from optical satellite sensors with machine learning—A random forests-based approach applied to MSG SEVIRI. Remote Sens. Environ. 2014, 141, 129–143. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
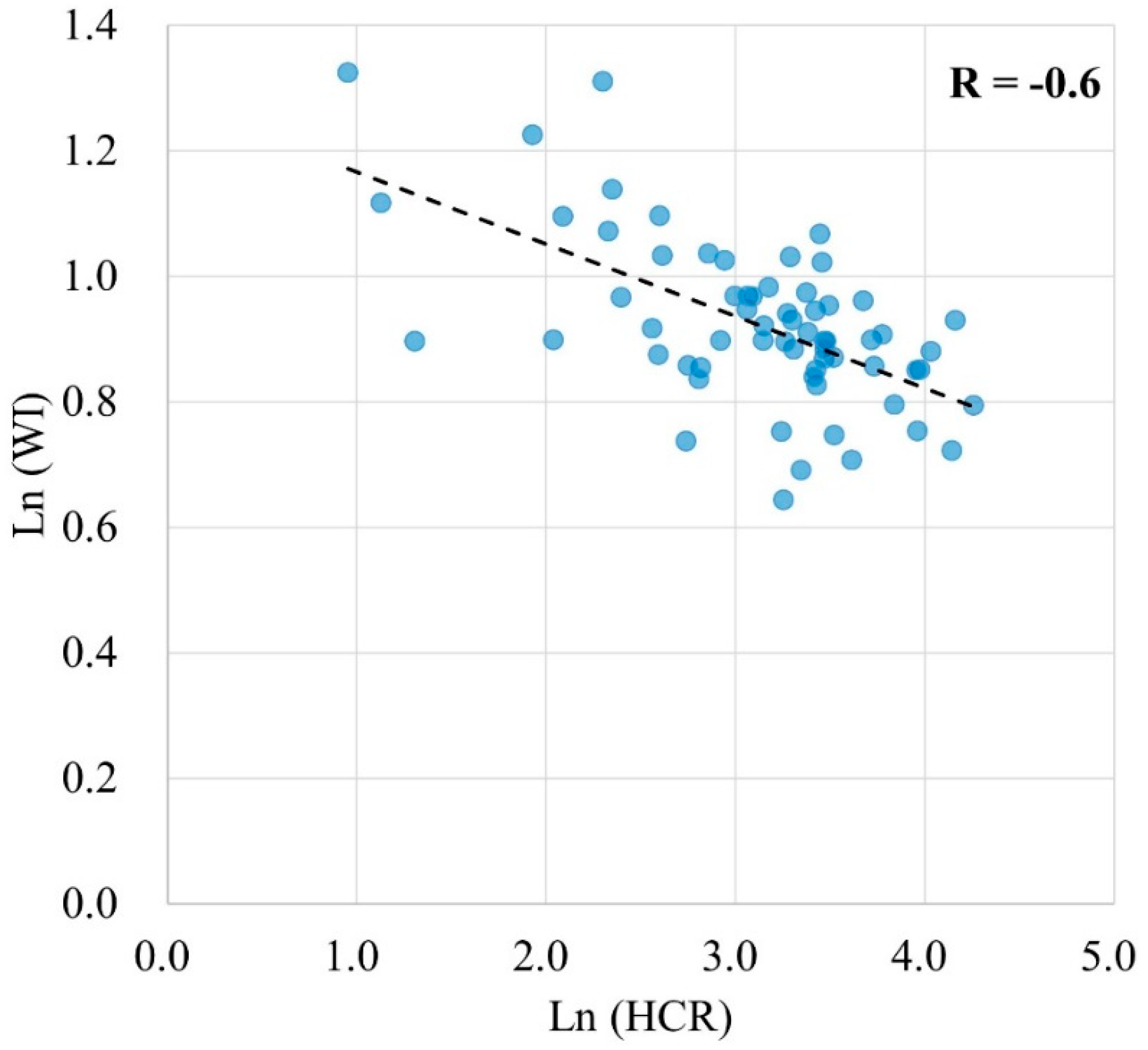{kind=link}
| Variable Type | Variable Name | Description | Data Source |
|---|---|---|---|
| Socioeconomic | Mean NTL | The mean radiance value of NTL in each grid. | NPP-VIIRS NTL |
| Min NTL | The minimum radiance value of NTL in each grid. | ||
| Max NTL | The maximum radiance value of NTL in each grid. | ||
| Structure and texture | PC1~PC25 | 25 principal components extracted from Google Satellite Map. | Google satellite image |
| Land cover | Proportion of Urban | Proportion of urban area in each grid. | Land cover map |
| Proportion of Cropland | Proportion of cropland in each grid. | ||
| Proportion of Tree | Proportion of tree cover in each grid. | ||
| Proportion of Water | Proportion of water cover in each grid. | ||
| Accessibility | Road Density | The total length of primary and secondary roads in each grid. | OSM road map |
| Distance to Roads | The distance from the grid center to the nearest primary or secondary roads. | OSM road map | |
| Distance to Urban | The distance from the grid center to the nearest urban area. | Land cover map | |
| Distance to Division Headquarters | The distance from the grid center to the nearest headquarter of divisions. | Division headquarter map |
| Parameter Name | Description | Value |
|---|---|---|
| n_estimators | The number of trees in RFR. | 280 |
| max_depth | The maximum depth of the tree. | 56 |
| min_samples_split | The minimum number of samples required to split an internal node. | 2 |
| min_samples_leaf | The minimum number of samples required to be at a leaf node. | 3 |
| Distance to Urban | Mean NTL | Distance to Division Headquarters | Distance to Roads | Proportion of Water | |
|---|---|---|---|---|---|
| Distance to Urban | 1.00 | ||||
| Mean NTL | −0.40 ** | 1.00 | |||
| Distance to Division Headquarters | 0.25 ** | −0.46 ** | 1.00 | ||
| Distance to Roads | 0.34 ** | −0.28 ** | 0.17 ** | 1.00 | |
| Proportion of Water | −0.16 ** | 0.37 ** | −0.21 ** | −0.06 | 1.00 |
| PC1 | −0.49 ** | 0.90 ** | −0.44 ** | −0.30 ** | 0.42 ** |
| PC2 | 0.13 ** | 0.11 ** | 0.07 | −0.03 | 0.01 |
| PC5 | 0.11 ** | 0.11 ** | −0.20 ** | 0.14 ** | 0.10 * |
| PC7 | 0.12 ** | −0.04 | 0.05 | 0.10 * | −0.05 |
| PC8 | −0.02 | 0.03 | −0.03 | −0.02 | 0.09 * |
| PC9 | 0.04 | −0.03 | −0.14 ** | 0.02 | 0.07 |
| PC10 | 0.11 ** | 0.10 * | −0.10 * | 0.07 | 0.03 |
| PC16 | 0.04 | -0.10 * | 0.16 ** | 0.14 ** | −0.01 |
| PC22 | 0.00 | 0.02 | 0.01 | 0.02 | 0.11 ** |
| Variables | Tolerance | VIF |
|---|---|---|
| Distance to Urban | 0.66 | 1.51 |
| Mean NTL | 0.15 | 6.84 |
| Distance to Division Headquarters | 0.69 | 1.44 |
| Distance to Roads | 0.81 | 1.23 |
| Proportion of Water | 0.78 | 1.29 |
| PC1 | 0.13 | 7.58 |
| PC2 | 0.90 | 1.11 |
| PC5 | 0.84 | 1.19 |
| PC7 | 0.96 | 1.05 |
| PC8 | 0.98 | 1.02 |
| PC9 | 0.96 | 1.04 |
| PC10 | 0.91 | 1.10 |
| PC16 | 0.89 | 1.12 |
| PC22 | 0.98 | 1.02 |
| Method | R2 | |
|---|---|---|
| 1 | The proposed RFR model | 0.70 |
| 2 | Linear Regression model (with NTL) | 0.58 |
| 3 | Transfer learning model (with Google satellite imagery and NTL) | 0.63 |
| 4 | RFR model (without the use of Google satellite images) | 0.66 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Yu, B.; Liu, Y.; Chen, Z.; Li, Q.; Wang, C.; Wu, J. Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh. Remote Sens. 2019, 11, 375. https://doi.org/10.3390/rs11040375
Zhao X, Yu B, Liu Y, Chen Z, Li Q, Wang C, Wu J. Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh. Remote Sensing. 2019; 11(4):375. https://doi.org/10.3390/rs11040375
Chicago/Turabian StyleZhao, Xizhi, Bailang Yu, Yan Liu, Zuoqi Chen, Qiaoxuan Li, Congxiao Wang, and Jianping Wu. 2019. "Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh" Remote Sensing 11, no. 4: 375. https://doi.org/10.3390/rs11040375
APA StyleZhao, X., Yu, B., Liu, Y., Chen, Z., Li, Q., Wang, C., & Wu, J. (2019). Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh. Remote Sensing, 11(4), 375. https://doi.org/10.3390/rs11040375