Fine-Grained Classification of Hyperspectral Imagery Based on Deep Learning




Abstract
1. Introduction
2. Densely Connected CNN for HSI Supervised Fine-grained Classification
2.1. Deep Learning and Convolutional Neural Network
2.2. Densely Connected CNN for HSI Supervised Fine-grained Classification
2.3. Dimensionality Reduction with DenseNet for HSI Fine-Grained Classification
2.4. CRF with DenseNet for HSI Fine-grained Classification
3. Generative Adversarial Networks for HSI Semi-Supervised Fine-grained Classification
3.1. Generative Adversarial Network (GAN)
3.2. Generative Adversarial Networks for HSI Semi-Supervised Fine-grained Classification
4. Experimental Results
4.1. Data Description and Environmental Setup
4.2. HSI Supervised Fine-Grained Classification
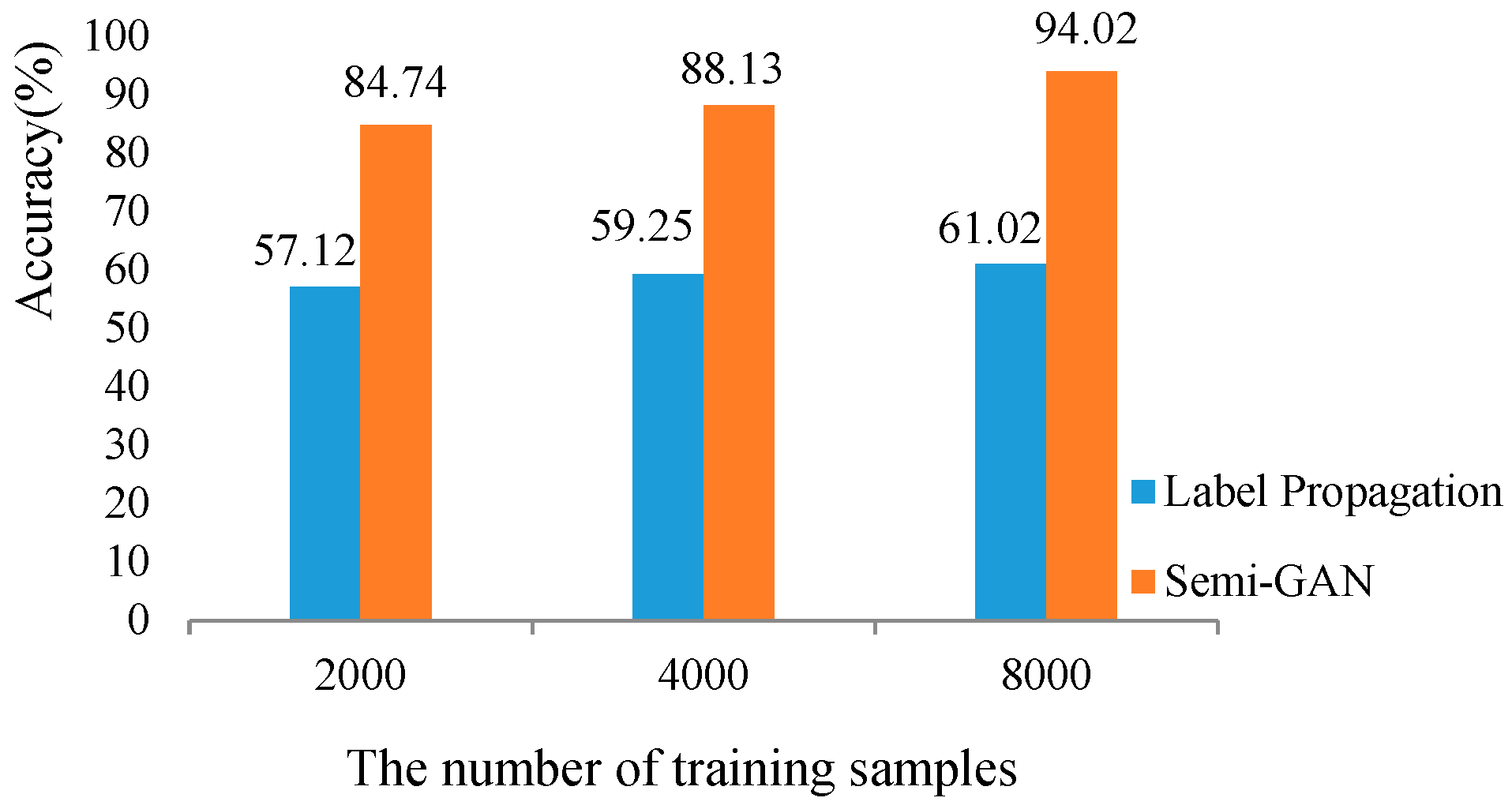
4.3. HSI Semi-Supervised Fine-grained Classification
4.4. Limited Training Samples and Classification Maps
4.5. Consuming Time
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in Spectral-Spatial Classification of Hyperspectral Images. Proc. IEEE 2012, 101, 652–675. [Google Scholar] [CrossRef]
- Chang, C.-I. Hyperspectral Imaging: Techniques for Spectral Detection and Classification; Kluwer Academic Publishers: New York, NY, USA, 2003; pp. 15–35. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2011, 50, 809–823. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef]
- Yang, H. A back-propagation neural network for mineralogical mapping from AVIRIS data. Int. J. Remote Sens. 1999, 20, 97–110. [Google Scholar] [CrossRef]
- Gualtieri, J.A.; Cromp, R.F. Support vector machines for hyperspectral remote sensing classification. In Proceedings of the 27th AIPR Workshop: Advances in Computer-Assisted Recognition, Washington, DC, USA, 14–16 October 1998; pp. 221–232. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Ghamisi, P.; Plaza, J.; Chen, Y.; Li, J.; Plaza, A.J. Advanced spectral classifiers for hyperspectral images: A review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–32. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 56, 937–949. [Google Scholar] [CrossRef]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Palmason, J.A.; Benediktsson, J.A.; Sveinsson, J.R.; Chanussot, J. Classification of hyperspectral data from urban areas using morphological preprocessing and independent component analysis. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Korea, 25–29 July 2005; pp. 176–179. [Google Scholar]
- Pesaresi, M.; Benediktsson, J.A. A new approach for the morphological segmentation of high-resolution satellite imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 309–320. [Google Scholar] [CrossRef]
- Gu, Y.; Chanussot, J.; Jia, X.; Benediktsson, J.A. Multiple kernel learning for hyperspectral image classification: A review. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6547–6565. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Song, B.; Li, J.; Dalla Mura, M.; Li, P.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A.; Chanussot, J. Remotely sensed image classification using sparse representations of morphological attribute profiles. IEEE Trans. Geosci. Remote Sens. 2013, 52, 5122–5136. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Muñoz-Marí, J.; Vila-Francés, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Baraldi, A.; Bruzzone, L.; Blonda, P. Quality assessment of classification and cluster maps without ground truth knowledge. IEEE Trans. Geosci. Remote Sens. 2005, 43, 857–873. [Google Scholar] [CrossRef]
- Chi, M.; Bruzzone, L. A semilabeled-sample-driven bagging technique for ill-posed classification problems. IEEE Geosci. Remote Sens. Lett. 2005, 2, 69–73. [Google Scholar] [CrossRef]
- Shahshahani, B.M.; Landgrebe, D.A. The effect of unlabeled samples in reducing the small sample size problem and mitigating the Hughes phenomenon. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1087–1095. [Google Scholar] [CrossRef]
- Bruzzone, L.; Chi, M.; Marconcini, M. A novel transductive SVM for semisupervised classification of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3363–3373. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Marsheva, T.V.B.; Zhou, D. Semi-supervised graph-based hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.-r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Kingsbury, B. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Gao, J.; He, X.; Yih, W.-T.; Deng, L. Learning semantic representations for the phrase translation model. arXiv 2013, arXiv:1312.0482. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Geng, J. Spectral–spatial classification of hyperspectral image based on deep auto-encoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Zhong, P.; Gong, Z.; Li, S.; Schönlieb, C.-B. Learning to diversify deep belief networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3516–3530. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 1–12. [Google Scholar] [CrossRef]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1349–1362. [Google Scholar] [CrossRef]
- Tao, Y.; Xu, M.; Lu, Z.; Zhong, Y. DenseNet-based depth-width double reinforced deep learning neural network for high-resolution remote sensing image per-pixel classification. Remote Sens. 2018, 10, 779. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral image classification using deep pixel-pair features. IEEE Trans. Geosci. Remote Sens. 2016, 55, 844–853. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, M.; Farah, I.R.; Solaiman, B. Hyperspectral imagery classification based on semi-supervised 3-D deep neural network and adaptive band selection. Expert Syst. Appl. 2019, 129, 246–259. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Zhan, Y.; Hu, D.; Wang, Y.; Yu, X. Semisupervised hyperspectral image classification based on generative adversarial networks. IEEE Geosci. Remote Sens. Lett. 2017, 15, 212–216. [Google Scholar] [CrossRef]
- Cavallaro, G.; Riedel, M.; Richerzhagen, M.; Benediktsson, J.A.; Plaza, A. On understanding big data impacts in remotely sensed image classification using support vector machine methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4634–4646. [Google Scholar] [CrossRef]
- Richards, J.A.; Richards, J. Remote Sensing Digital Image Analysis; Springer: Berlin, Germany, 1999; pp. 161–201. [Google Scholar]
- Mughees, A.; Tao, L. Efficient deep auto-encoder learning for the classification of hyperspectral images. In Proceedings of the 2016 International Conference on Virtual Reality and Visualization (ICVRV), Hangzhou, China, 23–25 September 2016; pp. 44–51. [Google Scholar]
- Chu, X.; Ouyang, W.; Wang, X. Crf-cnn: Modeling structured information in human pose estimation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 316–324. [Google Scholar]
- Kirillov, A.; Schlesinger, D.; Zheng, S.; Savchynskyy, B.; Torr, P.H.; Rother, C. Joint training of generic CNN-CRF models with stochastic optimization. In Proceedings of the Asian Conference on Computer Vision, Taipei, China, 20–24 November 2016; pp. 221–236. [Google Scholar]
- Liu, F.; Lin, G.; Shen, C. CRF learning with CNN features for image segmentation. Pattern Recognit. 2015, 48, 2983–2992. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1529–1537. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; pp. 2483–2493. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. Grabcut: Interactive foreground extraction using iterated graph cuts. ACM Trans. Gr. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. Int. J. Comput. Vision 2009, 81, 2–23. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; pp. 109–117. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 4681–4690. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep multi-scale video prediction beyond mean square error. arXiv 2015, arXiv:1511.05440. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 702–716. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Breiman, L. RF/tools: A class of two-eyed algorithms. In Proceedings of the SIAM Workshop, San Francisco, CA, USA, 1–3 May 2003; pp. 1–56. [Google Scholar]
- Dalla Mura, M.; Atli Benediktsson, J.; Waske, B.; Bruzzone, L. Extended profiles with morphological attribute filters for the analysis of hyperspectral data. Int. J. Remote Sens. 2010, 31, 5975–5991. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Benediktsson, J.A.; Waske, B.; Bruzzone, L. Morphological attribute profiles for the analysis of very high resolution images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3747–3762. [Google Scholar] [CrossRef]
- Ghamisi, P.; Benediktsson, J.A.; Cavallaro, G.; Plaza, A. Automatic framework for spectral–spatial classification based on supervised feature extraction and morphological attribute profiles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2147–2160. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Color | Number of Samples | Number of Training Samples (I) | Number of Training Samples (II) | Number of Test Samples (I) | Number of Test Samples (II) |
|---|---|---|---|---|---|---|
| 1 |  | 17,195 | 423 | 436 | 1080 | 1042 |
| 2 |  | 17,783 | 428 | 437 | 1043 | 1088 |
| 3 |  | 158 | 3 | 4 | 6 | 11 |
| 4 |  | 514 | 10 | 9 | 41 | 32 |
| 5 |  | 2356 | 53 | 68 | 130 | 139 |
| 6 |  | 12,404 | 319 | 300 | 677 | 732 |
| 7 |  | 26,486 | 638 | 612 | 1600 | 1556 |
| 8 |  | 39,678 | 985 | 947 | 2471 | 2400 |
| 9 |  | 800 | 12 | 16 | 47 | 47 |
| 10 |  | 1728 | 36 | 40 | 105 | 127 |
| 11 |  | 1049 | 29 | 31 | 54 | 63 |
| 12 |  | 5629 | 144 | 149 | 318 | 311 |
| 13 |  | 8862 | 204 | 205 | 550 | 541 |
| 14 |  | 4381 | 114 | 109 | 240 | 249 |
| 15 |  | 1206 | 36 | 43 | 77 | 80 |
| 16 |  | 5685 | 131 | 125 | 358 | 367 |
| 17 |  | 114 | 6 | 2 | 10 | 4 |
| 18 |  | 1147 | 29 | 27 | 56 | 78 |
| 19 |  | 2331 | 51 | 71 | 132 | 148 |
| 20 |  | 1128 | 30 | 25 | 53 | 61 |
| 21 |  | 2185 | 49 | 53 | 124 | 138 |
| 22 |  | 2258 | 52 | 51 | 144 | 140 |
| 23 |  | 224 | 5 | 7 | 8 | 13 |
| 24 |  | 1940 | 50 | 38 | 116 | 124 |
| 25 |  | 1742 | 42 | 53 | 103 | 106 |
| 26 |  | 335 | 7 | 10 | 14 | 18 |
| 27 |  | 10,386 | 273 | 210 | 634 | 657 |
| 28 |  | 102 | 4 | 2 | 6 | 8 |
| 29 |  | 9391 | 220 | 223 | 553 | 597 |
| 30 |  | 894 | 23 | 22 | 51 | 45 |
| 31 |  | 1110 | 23 | 26 | 74 | 75 |
| 32 |  | 5074 | 109 | 138 | 293 | 318 |
| 33 |  | 2726 | 45 | 61 | 159 | 166 |
| 34 |  | 11,802 | 249 | 266 | 677 | 707 |
| 35 |  | 10,387 | 247 | 253 | 660 | 608 |
| 36 |  | 2242 | 64 | 40 | 115 | 126 |
| 37 |  | 543 | 20 | 6 | 28 | 23 |
| 38 |  | 15,118 | 339 | 382 | 904 | 885 |
| 39 |  | 2667 | 49 | 63 | 166 | 159 |
| 40 |  | 1832 | 51 | 54 | 122 | 107 |
| 41 |  | 8098 | 188 | 186 | 460 | 484 |
| 42 |  | 4953 | 128 | 140 | 281 | 295 |
| 43 |  | 2157 | 41 | 55 | 133 | 137 |
| 44 |  | 2533 | 39 | 56 | 120 | 158 |
| 45 |  | 929 | 26 | 28 | 49 | 55 |
| 46 |  | 8731 | 221 | 215 | 535 | 498 |
| 47 |  | 583 | 11 | 16 | 36 | 30 |
| 48 |  | 3110 | 92 | 69 | 190 | 194 |
| 49 |  | 580 | 12 | 14 | 39 | 36 |
| 50 |  | 4979 | 118 | 118 | 281 | 293 |
| 51 |  | 63,562 | 1519 | 1486 | 3861 | 3715 |
| 52 |  | 144 | 3 | 3 | 16 | 9 |
| Total number | 333,951 | 8000 | 8000 | 20,000 | 20,000 | |
| Layers | Output Size | DenseNet |
|---|---|---|
| Convolution | 56 × 56 | 9 × 9 conv, stride = 1 |
| Dense Block (1) | 56 × 56 | |
| Transition Layer (1) | 56 × 56 | 1 × 1 conv |
| 28 × 28 | 2 × 2 average pool, stride = 2 | |
| Dense Block (2) | 28 × 28 | |
| Transition Layer (2) | 28 × 28 | 1 × 1 conv |
| 14 × 14 | 2 × 2 average pool, stride = 2 | |
| Dense Block (3) | 14 × 14 | |
| Transition Layer (3) | 14 × 14 | 1 × 1 conv |
| 7 × 7 | 2 × 2 average pool, stride = 2 | |
| Dense Block (4) | 7 × 7 | |
| Classification Layer | 1 × 1 | 7 × 7 global average pool |
| fully-connected, softmax |
| Number of Principal Components | 5 | 10 | 20 |
|---|---|---|---|
| OA (%) | 91.48 ± 0.42 | 92.35 ± 0.57 | 92.23 ± 0.53 |
| AA (%) | 86.54 ± 1.76 | 87.89 ± 2.07 | 87.44 ± 1.65 |
| K × 100 | 89.61 ± 0.54 | 91.30 ± 0.66 | 91.12 ± 0.79 |
| Model | Learning Rate | Number of Epochs | Batch Size |
|---|---|---|---|
| Auto-Encoder | 0.001 | 150 | 5000 |
| CNN | 0.001 | 150 | 200 |
| DenseNet | 0.001 | 150 | 200 |
| Semi-GAN | 0.0002 | 200 | 200 |
| No | Color | SVM | EMP-RF | EMAP-RF | CNN | CNN-CRF | PCA-DenseNet | Auto-Encoder-DenseNet | DenseNet-CRF |
|---|---|---|---|---|---|---|---|---|---|
| 1 | | 52.61 ± 4.35 | 69.71 ± 3.24 | 60.09 ± 3.24 | 77.77 ± 2.01 | 85.54 ± 1.17 | 84.45 ± 0.49 | 84.93 ± 2.74 | 90.92 ± 0.02 |
| 2 | | 32.68 ± 6.34 | 71.96 ± 5.69 | 66.84 ± 5.69 | 71.40 ± 4.56 | 85.08 ± 2.43 | 94.59 ± 0.82 | 89.44 ± 1.78 | 89.96 ± 0.26 |
| 3 | | 18.142 ± 6.12 | 28.43 ± 0.38 | 23.05 ± 0.16 | 72.72 ± 0.04 | 80.22 ± 0.50 | 87.22 ± 9.24 | 81.11 ± 2.54 | 86.67 ± 0.15 |
| 4 | | 17.00 ± 9.22 | 20.26 ± 5.12 | 49.05 ± 5.12 | 86.06 ± 5.35 | 72.05 ± 3.45 | 87.53 ± 3.54 | 76.86 ± 3.87 | 91.47 ± 0.19 |
| 5 | | 18.91 ± 5.32 | 60.81 ± 5.76 | 67.48 ± 6.34 | 88.39 ± 1.93 | 83.61 ± 0.12 | 90.37 ± 1.94 | 94.13 ± 4.33 | 91.41 ± 0.05 |
| 6 | | 28.30 ± 0.03 | 67.44 ± 4.35 | 78.24 ± 4.56 | 82.33 ± 0.45 | 84.90 ± 0.08 | 93.08 ± 0.21 | 90.26 ± 3.60 | 90.79 ± 0.07 |
| 7 | | 33.86 ± 2.15 | 75.58 ± 0.34 | 72.65 ± 0.08 | 77.46 ± 2.55 | 80.06 ± 1.45 | 93.07 ± 0.25 | 94.41 ± 3.05 | 92.67 ± 0.43 |
| 8 | | 34.25 ± 0.03 | 82.49 ± 1.04 | 85.05 ± 0.16 | 84.84 ± 1.45 | 84.87 ± 0.05 | 95.82 ± 0.35 | 94.68 ± 2.24 | 93.23 ± 0.21 |
| 9 | | 9.56 ± 2.54 | 66.34 ± 3.02 | 59.15 ± 2.24 | 87.36 ± 4.45 | 97.45 ± 0.46 | 100.00 ± 0.00 | 100.00 ± 0.00 | 96.97 ± 0.19 |
| 10 | | 16.10 ± 0.03 | 44.74 ± 8.43 | 68.45 ± 3.46 | 80.82 ± 5.34 | 90.90 ± 2.45 | 96.37 ± 1.48 | 96.18 ± 1.45 | 90.47 ± 0.03 |
| 11 | | 19.77 ± 0.13 | 42.31 ± 1.16 | 76.37 ± 2.08 | 72.11 ± 0.17 | 89.77 ± 2.56 | 87.78 ± 2.46 | 81.26 ± 3.65 | 87.02 ± 0.09 |
| 12 | | 27.30 ± 6.45 | 65.46 ± 5.02 | 76.15 ± 4.35 | 75.91 ± 3.45 | 89.94 ± 1.56 | 95.05 ± 0.71 | 92.90 ± 3.10 | 93.38 ± 0.16 |
| 13 | | 37.87 ± 5.63 | 74.57 ± 4.53 | 81.86 ± 0.03 | 86.37 ± 3.56 | 91.46 ± 4.32 | 93.58 ± 0.91 | 94.63 ± 2.70 | 90.93 ± 0.15 |
| 14 | | 36.31 ± 9.46 | 68.15 ± 3.46 | 81.58 ± 3.13 | 80.96 ± 0.08 | 86.49 ± 0.12 | 91.52 ± 0.24 | 88.32 ± 3.92 | 92.03 ± 0.23 |
| 15 | | 35.84 ± 1.98 | 58.33 ± 3.45 | 66.70 ± 0.21 | 77.63 ± 2.46 | 89.23 ± 1.56 | 90.91 ± 0.45 | 96.36 ± 2.53 | 96.42 ± 0.15 |
| 16 | | 57.14 ± 2.54 | 70.01 ± 0.42 | 85.65 ± 0.14 | 81.69 ± 0.43 | 83.57 ± 0.20 | 93.97 ± 0.96 | 96.97 ± 1.24 | 94.54 ± 0.06 |
| 17 | | 39.25 ± 12.53 | 55.56 ± 9.43 | 43.25 ± 0.15 | 73.33 ± 9.30 | 65.42 ± 0.14 | 3.82 ± 5.25 | 76.61 ± 2.14 | 91.37 ± 0.42 |
| 18 | | 23.19 ± 9.07 | 25.39 ± 7.45 | 34.78 ± 0.25 | 47.61 ± 0.15 | 78.72 ± 0.15 | 65.71 ± 5.81 | 69.27 ± 3.73 | 80.51 ± 0.32 |
| 19 | | 52.65 ± 7.53 | 66.62 ± 6.26 | 78.95 ± 2.43 | 85.81 ± 2.45 | 85.87 ± 3.56 | 87.67 ± 1.55 | 91.17 ± 2.96 | 91.28 ± 0.06 |
| 20 | | 48.63 ± 7.15 | 57.06 ± 4.56 | 55.58 ± 3.23 | 73.91 ± 3.45 | 90.47 ± 3.46 | 71.20 ± 3.96 | 92.23 ± 1.24 | 86.74 ± 0.04 |
| 21 | | 63.14 ± 0.06 | 69.24 ± 0.14 | 82.85 ± 0.02 | 62.48 ± 0.21 | 79.62 ± 2.35 | 90.01 ± 1.87 | 95.50 ± 2.37 | 92.83 ± 0.12 |
| 22 | | 68.35 ± 2.89 | 68.14 ± 1.35 | 83.25 ± 2.39 | 70.94 ± 0.98 | 79.36 ± 0.24 | 90.98 ± 1.55 | 91.07 ± 3.10 | 89.86 ± 0.14 |
| 23 | | 61.51 ± 0.24 | 83.33 ± 0.16 | 72.57 ± 0.03 | 92.85 ± 0.01 | 89.18 ± 0.46 | 79.36 ± 3.19 | 28.34 ± 2.45 | 100.00 ± 0.000 |
| 24 | | 39.94 ± 1.54 | 51.69 ± 0.68 | 71.34 ± 0.35 | 65.74 ± 0.15 | 89.20 ± 0.23 | 71.77 ± 3.64 | 79.79 ± 0.01 | 86.88 ± 0.16 |
| 25 | | 44.63 ± 7.54 | 58.35 ± 5.45 | 63.02 ± 5.01 | 76.54 ± 2.45 | 82.74 ± 0.34 | 77.45 ± 7.22 | 69.13 ± 2.56 | 75.67 ± 0.24 |
| 26 | | 33.24 ± 0.05 | 14.14 ± 0.04 | 37.35 ± 0.13 | 35.05 ± 0.25 | 72.35 ± 0.16 | 58.40 ± 9.37 | 54.13 ± 2.72 | 81.76 ± 0.32 |
| 27 | | 65.98 ± 4.33 | 76.01 ± 2.45 | 83.55 ± 3.09 | 90.36 ± 3.01 | 78.37 ± 0.26 | 91.13 ± 0.89 | 91.46 ± 1.50 | 91.92 ± 0.04 |
| 28 | | 28.33 ± 0.14 | 25.22 ± 4.64 | 23.79 ± 13.54 | 20.49 ± 10.24 | 26.25 ± 0.19 | 70.83 ± 1.31 | 70.79 ± 3.18 | 87.78 ± 0.42 |
| 29 | | 43.25 ± 3.46 | 69.28 ± 10.45 | 76.58 ± 0.19 | 73.01 ± 0.87 | 87.90 ± 1.56 | 89.48 ± 0.36 | 90.51 ± 1.07 | 90.73 ± 0.13 |
| 30 | | 16.56 ± 2.06 | 62.32 ± 0.11 | 69.36 ± 0.04 | 46.69 ± 2.56 | 86.06 ± 0.12 | 90.44 ± 0.97 | 92.20 ± 0.13 | 94.12 ± 0.04 |
| 31 | | 15.54 ± 6.74 | 70.62 ± 5.39 | 62.95 ± 6.43 | 89.41 ± 4.67 | 49.29 ± 1.45 | 84.97 ± 2.59 | 86.90 ± 1.08 | 91.91 ± 0.20 |
| 32 | | 29.97 ± 7.46 | 57.49 ± 6.34 | 66.75 ± 4.67 | 79.16 ± 0.36 | 90.12 ± 2.45 | 90.47 ± 0.14 | 92.92 ± 0.45 | 90.82 ± 0.05 |
| 33 | | 23.64 ± 6.42 | 68.59 ± 4.07 | 77.39 ± 1.56 | 91.51 ± 4.57 | 82.71 ± 0.25 | 90.52 ± 2.59 | 89.55 ± 2.85 | 88.65 ± 0.06 |
| 34 | | 35.00 ± 4.56 | 74.15 ± 8.31 | 76.85 ± 6.46 | 82.73 ± 5.67 | 86.54 ± 0.43 | 92.01 ± 0.14 | 91.24 ± 1.27 | 90.90 ± 0.23 |
| 35 | | 24.83 ± 5.03 | 68.78 ± 4.04 | 72.75 ± 6.23 | 87.37 ± 4.92 | 82.82 ± 0.51 | 95.29 ± 0.52 | 95.35 ± 0.15 | 91.35 ± 0.11 |
| 36 | | 47.15 ± 0.05 | 53.33 ± 0.06 | 74.55 ± 0.14 | 91.26 ± 0.45 | 86.71 ± 1.56 | 94.15 ± 1.80 | 85.65 ± 0.07 | 96.63 ± 0.39 |
| 37 | | 26.99 ± 5.43 | 54.77 ± 4.56 | 51.45 ± 6.43 | 81.42 ± 1.45 | 90.20 ± 0.32 | 92.47 ± 0.02 | 94.01 ± 0.04 | 98.96 ± 0.06 |
| 38 | | 40.86 ± 6.42 | 72.75 ± 3.64 | 69.75 ± 2.34 | 74.94 ± 2.45 | 89.96 ± 0.12 | 90.70 ± 0.49 | 92.95 ± 0.01 | 86.10 ± 0.24 |
| 39 | | 54.55 ± 4.56 | 68.54 ± 2.54 | 61.24 ± 2.45 | 88.53 ± 1.46 | 73.64 ± 1.57 | 90.18 ± 0.37 | 91.61 ± 2.64 | 89.91 ± 0.08 |
| 40 | | 50.53 ± 2.03 | 70.01 ± 0.74 | 62.99 ± 3.45 | 86.42 ± 1.90 | 82.37 ± 0.31 | 94.70 ± 1.63 | 97.26 ± 3.14 | 85.82 ± 0.25 |
| 41 | | 49.15 ± 6.64 | 71.46 ± 3.45 | 86.25 ± 0.13 | 89.72 ± 3.57 | 82.24 ± 0.34 | 96.32 ± 0.94 | 94.33 ± 0.13 | 90.99 ± 0.06 |
| 42 | | 31.88 ± 4.43 | 65.17 ± 2.15 | 78.95 ± 1.45 | 84.82 ± 0.03 | 84.94 ± 0,56 | 97.46 ± 0.37 | 95.84 ± 3.25 | 91.01 ± 0.05 |
| 43 | | 43.98 ± 9.46 | 65.55 ± 5.64 | 78.84 ± 0.09 | 85.49 ± 4.67 | 82.36 ± 0.45 | 86.02 ± 0.81 | 92.61 ± 2.14 | 94.90 ± 0.12 |
| 44 | | 41.55 ± 3.56 | 82.38 ± 0.04 | 60.65 ± 0.06 | 85.12 ± 2.54 | 91.44 ± 0.10 | 88.62 ± 1.83 | 96.16 ± 2.06 | 97.78 ± 0.10 |
| 45 | | 47.40 ± 3.64 | 59.18 ± 0.04 | 81.02 ± 3.42 | 72.66 ± 1.36 | 79.33 ± 0.42 | 69.66 ± 6.45 | 88.13 ± 1.02 | 78.03 ± 0.51 |
| 46 | | 61.53 ± 0.04 | 71.59 ± 0.56 | 87.55 ± 3.46 | 89.08 ± 0.67 | 82.66 ± 0.32 | 92.61 ± 0.26 | 91.35 ± 0.45 | 93.51 ± 0.05 |
| 47 | | 61.05 ± 1.97 | 40.18 ± 0.04 | 85.35 ± 0.32 | 86.04 ± 0.14 | 81.18 ± 0.24 | 94.75 ± 1.51 | 79.89 ± 4.88 | 91.30 ± 0.24 |
| 48 | | 69.26 ± 4.56 | 99.49 ± 3.53 | 81.97 ± 0.36 | 95.06 ± 2.56 | 88.41 ± 0.42 | 96.40 ± 1.19 | 98.26 ± 0.88 | 95.08 ± 0.04 |
| 49 | | 53.92 ± 0.14 | 79.82 ± 0.08 | 79.76 ± 0.57 | 78.37 ± 0.17 | 84.47 ± 3.46 | 79.32 ± 4.19 | 100.00 ± 0.00 | 95.99 ± 0.22 |
| 50 | | 78.48 ± 4.56 | 82.81 ± 4.34 | 65.86 ± 2.44 | 92.16 ± 2.45 | 83.47 ± 2.45 | 90.40 ± 2.49 | 93.02 ± 0.52 | 91.70 ± 0.34 |
| 51 | | 72.48 ± 4.64 | 96.95 ± 1.45 | 81.44 ± 0.97 | 96.26 ± 1.45 | 84.45 ± 0.46 | 97.96 ± 0.19 | 97.35 ± 0.21 | 96.58 ± 0.10 |
| 52 | | 83.28 ± 1.45 | 61.71 ± 3.45 | 43.25 ± 0.68 | 77.50 ± 0.14 | 85.01 ± 0.21 | 100.00 ± 0.00 | 79.58 ± 3.43 | 91.67 ± 0.12 |
| OA (%) | 52.24 ± 0.43 | 76.36 ± 0.24 | 77.95 ± 0.57 | 85.47 ± 0.28 | 86.08 ± 0.21 | 92.08 ± 0.87 | 92.35 ± 0.57 | 93.07 ± 0.18 | |
| AA (%) | 42.55 ± 0.16 | 64.79 ± 0.39 | 66.05 ± 0.12 | 78.29 ± 0.23 | 82.53 ± 0.86 | 87.01 ± 1.25 | 87.89 ± 2.07 | 91.45 ± 0.31 | |
| K × 100 | 47.15 ± 0.20 | 72.24 ± 0.35 | 73.72 ± 0.66 | 82.86 ± 0.13 | 85.64 ± 0.27 | 90.26 ± 0.94 | 91.30 ± 0.66 | 92.76 ± 0.19 | |
| NO. | Color | CNN | PCA-CNN | Auto-Encoder-CNN | DenseNet | PCA-DenseNet | DenseNet-1 × 1 Conv | Auto-Encoder-DenseNet |
|---|---|---|---|---|---|---|---|---|
| 1 | | 77.77 ± 2.01 | 77.69 ± 1.09 | 86.18 ± 0.45 | 83.32 ± 1.25 | 84.45 ± 0.49 | 82.45 ± 1.59 | 84.93 ± 2.74 |
| 2 | | 71.40 ± 4.56 | 84.91 ± 0.42 | 77.87 ± 0.78 | 93.16 ± 0.43 | 94.59 ± 0.82 | 93.28 ± 1.26 | 89.44 ± 1.78 |
| 3 | | 72.72 ± 0.04 | 72.40 ± 7.09 | 94.56 ± 0.23 | 68.58 ± 15.14 | 87.22 ± 9.24 | 66.59 ± 2.15 | 81.11 ± 2.54 |
| 4 | | 86.06 ± 5.35 | 90.87 ± 5.19 | 80.57 ± 2.53 | 67.79 ± 5.82 | 87.53 ± 3.54 | 75.86 ± 3.19 | 76.86 ± 3.87 |
| 5 | | 88.39 ± 1.93 | 94.02 ± 0.15 | 78.33 ± 0.66 | 88.62 ± 1.39 | 90.37 ± 1.94 | 81.19 ± 2.15 | 94.13 ± 4.33 |
| 6 | | 82.33 ± 0.45 | 85.16 ± 0.60 | 85.61 ± 0.60 | 91.65 ± 2.05 | 93.08 ± 0.21 | 92.45 ± 0.43 | 90.26 ± 3.60 |
| 7 | | 77.46 ± 2.55 | 89.57 ± 1.12 | 87.82 ± 0.16 | 93.63 ± 0.43 | 93.07 ± 0.25 | 93.79 ± 0.21 | 94.41 ± 3.05 |
| 8 | | 84.84 ± 1.45 | 93.75 ± 0.66 | 94.47 ± 0.66 | 95.61 ± 0.42 | 95.82 ± 0.35 | 95.69 ± 0.19 | 94.68 ± 2.24 |
| 9 | | 87.36 ± 4.45 | 100.00 ± 0.00 | 91.00 ± 0.12 | 96.98 ± 1.69 | 100.00 ± 0.00 | 96.46 ± 1.68 | 100.00 ± 0.00 |
| 10 | | 80.82 ± 5.34 | 95.11 ± 2.25 | 93.11 ± 0.79 | 95.79 ± 0.89 | 96.37 ± 1.48 | 90.36 ± 0.09 | 96.18 ± 1.45 |
| 11 | | 72.11 ± 0.17 | 75.95 ± 1.25 | 90.76 ± 1.25 | 94.58 ± 0.80 | 87.78 ± 2.46 | 88.04 ± 0.16 | 81.26 ± 3.65 |
| 12 | | 75.91 ± 3.45 | 85.67 ± 1.54 | 88.00 ± 0.76 | 93.59 ± 0.72 | 95.05 ± 0.71 | 93.18 ± 0.15 | 92.90 ± 3.10 |
| 13 | | 86.37 ± 3.56 | 94.41 ± 0.73 | 94.46 ± 0.11 | 97.06 ± 0.32 | 93.58 ± 0.91 | 92.43 ± 0.23 | 94.63 ± 2.70 |
| 14 | | 80.96 ± 0.08 | 88.89 ± 1.56 | 91.69 ± 0.02 | 88.36 ± 1.50 | 91.52 ± 0.24 | 94.73 ± 0.15 | 88.32 ± 3.92 |
| 15 | | 77.63 ± 2.46 | 95.19 ± 1.44 | 98.58 ± 0.02 | 85.33 ± 2.11 | 90.91 ± 0.45 | 96.47 ± 3.58 | 96.41 ± 2.53 |
| 16 | | 81.69 ± 0.43 | 98.49 ± 0.38 | 97.11 ± 0.69 | 96.71 ± 0.68 | 93.97 ± 0.96 | 95.96 ± 0.42 | 96.97 ± 1.24 |
| 17 | | 73.33 ± 9.30 | 60.02 ± 13.94 | 40.00 ± 13.34 | 32.75 ± 10.25 | 3.82 ± 5.25 | 98.67 ± 0.32 | 76.61 ± 2.14 |
| 18 | | 47.61 ± 0.15 | 63.06 ± 2.51 | 64.76 ± 2.54 | 71.55 ± 6.27 | 65.71 ± 5.81 | 75.26 ± 4.23 | 69.27 ± 3.73 |
| 19 | | 85.81 ± 2.45 | 93.22 ± 1.61 | 72.99 ± 2.03 | 83.52 ± 1.97 | 87.67 ± 1.55 | 94.18 ± 2.41 | 91.28 ± 2.96 |
| 20 | | 73.91 ± 3.45 | 52.05 ± 3.62 | 71.06 ± 0.11 | 73.99 ± 3.65 | 71.20 ± 3.96 | 79.58 ± 1.12 | 92.23 ± 1.24 |
| 21 | | 62.48 ± 0.21 | 93.11 ± 1.14 | 83.98 ± 0.22 | 71.94 ± 2.36 | 90.01 ± 1.87 | 90.14 ± 0.14 | 95.50 ± 2.37 |
| 22 | | 70.94 ± 0.98 | 86.22 ± 1.86 | 83.45 ± 0.45 | 93.12 ± 1.11 | 90.98 ± 1.55 | 83.54 ± 2.59 | 91.07 ± 3.10 |
| 23 | | 92.85 ± 0.01 | 77.19 ± 11.41 | 100.00 ± 0.00 | 96.29 ± 4.29 | 79.36 ± 3.19 | 90.91 ± 0.16 | 28.34 ± 2.45 |
| 24 | | 65.74 ± 0.15 | 78.47 ± 4.27 | 69.81 ± 2.27 | 70.66 ± 2.83 | 71.77 ± 3.64 | 67.53 ± 0.24 | 79.79 ± 0.01 |
| 25 | | 76.54 ± 2.45 | 75.59 ± 1.24 | 73.32 ± 1.89 | 70.16 ± 1.70 | 77.45 ± 7.22 | 71.69 ± 0.32 | 69.13 ± 2.56 |
| 26 | | 35.05 ± 0.25 | 54.55 ± 5.86 | 64.29 ± 4.77 | 42.20 ± 7.19 | 58.40 ± 9.37 | 66.25 ± 0.04 | 54.13 ± 2.72 |
| 27 | | 90.36 ± 3.01 | 93.01 ± 0.8 | 92.01 ± 0.17 | 93.55 ± 0.98 | 91.13 ± 0.89 | 93.59 ± 0.42 | 91.46 ± 1.50 |
| 28 | | 20.49 ± 10.24 | 20.42 ± 16.4 | 82.50 ± 1.67 | 58.45 ± 6.91 | 70.83 ± 1.31 | 13.25 ± 8.59 | 70.79 ± 3.18 |
| 29 | | 73.01 ± 0.87 | 83.14 ± 1.61 | 84.35 ± 0.87 | 83.44 ± 1.18 | 89.48 ± 0.36 | 83.25 ± 0.13 | 90.51 ± 1.07 |
| 30 | | 46.69 ± 2.56 | 75.73 ± 2.12 | 92.82 ± 1.67 | 86.65 ± 6.32 | 90.44 ± 0.97 | 71.25 ± 0.04 | 92.20 ± 0.13 |
| 31 | | 89.41 ± 4.67 | 94.56 ± 1.60 | 74.56 ± 1.76 | 81.53 ± 4.05 | 84.97 ± 2.59 | 75.24 ± 0.20 | 86.90 ± 1.08 |
| 32 | | 79.16 ± 0.36 | 87.03 ± 0.67 | 75.53 ± 0.67 | 95.10 ± 0.73 | 90.47 ± 0.14 | 83.02 ± 0.96 | 92.92 ± 0.45 |
| 33 | | 91.51 ± 4.57 | 86.67 ± 1.16 | 89.88 ± 1.28 | 85.94 ± 4.12 | 90.52 ± 2.59 | 80.15 ± 0.06 | 89.55 ± 2.85 |
| 34 | | 82.73 ± 5.67 | 85.51 ± 0.67 | 91.02 ± 0.67 | 85.60 ± 1.22 | 92.01 ± 0.14 | 87.25 ± 0.23 | 91.24 ± 1.27 |
| 35 | | 87.37 ± 4.92 | 85.16 ± 1.20 | 79.61 ± 0.30 | 93.39 ± 0.28 | 95.29 ± 0.52 | 76.59 ± 0.11 | 95.35 ± 0.15 |
| 36 | | 91.26 ± 0.45 | 87.39 ± 1.65 | 91.02 ± 1.45 | 91.42 ± 1.15 | 94.15 ± 1.80 | 91.03 ± 0.39 | 85.65 ± 0.07 |
| 37 | | 81.42 ± 1.45 | 94.80 ± 4.57 | 97.58 ± 1.62 | 95.22 ± 3.51 | 92.47 ± 0.02 | 95.13 ± 0.06 | 94.01 ± 0.04 |
| 38 | | 74.94 ± 2.45 | 86.04 ± 1.51 | 85.93 ± 0.30 | 88.88 ± 0.37 | 90.70 ± 0.49 | 85.69 ± 0.24 | 92.95 ± 0.01 |
| 39 | | 88.53 ± 1.46 | 88.68 ± 1.32 | 91.07 ± 1.32 | 92.27 ± 1.30 | 90.18 ± 0.37 | 83.06 ± 0.08 | 91.61 ± 2.64 |
| 40 | | 86.42 ± 1.90 | 84.69 ± 0.87 | 89.06 ± 0.34 | 92.10 ± 0.93 | 94.70 ± 1.63 | 72.28 ± 0.25 | 97.26 ± 3.14 |
| 41 | | 89.72 ± 3.57 | 91.47 ± 0.48 | 89.86 ± 1.06 | 91.44 ± 0.31 | 96.32 ± 0.94 | 93.27 ± 1.04 | 94.33 ± 0.13 |
| 42 | | 84.82 ± 0.03 | 90.37 ± 1.97 | 92.32 ± 0.09 | 95.59 ± 0.89 | 97.46 ± 0.37 | 95.27 ± 2.45 | 95.84 ± 3.25 |
| 43 | | 85.49 ± 4.67 | 89.61 ± 2.24 | 87.67 ± 2.21 | 85.54 ± 1.72 | 86.02 ± 0.81 | 94.39 ± 0.12 | 92.61 ± 2.14 |
| 44 | | 85.12 ± 2.54 | 97.45 ± 0.17 | 92.50 ± 0.46 | 97.99 ± 0.09 | 88.62 ± 1.83 | 95.52 ± 0.10 | 96.16 ± 2.06 |
| 45 | | 72.66 ± 1.36 | 89.25 ± 0.46 | 86.44 ± 0.88 | 79.09 ± 2.45 | 69.66 ± 6.45 | 92.59 ± 0.51 | 88.13 ± 1.02 |
| 46 | | 89.08 ± 0.67 | 91.75 ± 0.88 | 87.45 ± 0.49 | 92.50 ± 0.35 | 92.61 ± 0.26 | 92.10 ± 0.05 | 91.35 ± 0.45 |
| 47 | | 86.04 ± 0.14 | 91.07 ± 0.74 | 94.48 ± 4.03 | 96.34 ± 2.51 | 94.75 ± 1.51 | 83.32 ± 0.24 | 79.89 ± 4.88 |
| 48 | | 95.06 ± 2.56 | 98.08 ± 0.29 | 98.89 ± 0.05 | 98.91 ± 0.48 | 96.40 ± 1.19 | 94.09 ± 3.47 | 98.26 ± 0.88 |
| 49 | | 78.37 ± 0.17 | 90.01 ± 1.45 | 92.00 ± 0.13 | 96.09 ± 2.94 | 79.32 ± 4.19 | 97.26 ± 0.22 | 100.00 ± 0.00 |
| 50 | | 92.16 ± 2.45 | 89.11 ± 0.87 | 92.13 ± 0.10 | 87.92 ± 1.91 | 90.40 ± 2.49 | 92.14 ± 0.34 | 93.02 ± 0.52 |
| 51 | | 96.26 ± 1.45 | 98.22 ± 0.14 | 98.22 ± 0.14 | 98.62 ± 0.03 | 97.96 ± 0.19 | 96.58 ± 1.47 | 97.35 ± 0.21 |
| 52 | | 77.50 ± 0.14 | 75.68 ± 4.23 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 95.67 ± 1.89 | 79.58 ± 3.43 |
| OA (%) | 85.47 ± 0.28 | 87.95 ± 0.18 | 88.08 ± 0.29 | 90.84 ± 1.04 | 92.08 ± 0.87 | 91.17 ± 0.67 | 92.35 ± 0.57 | |
| AA (%) | 78.29 ± 0.23 | 84.43 ± 0.41 | 86.13 ± 0.59 | 85.98 ± 2.38 | 87.01 ± 1.25 | 86.21 ± 1.14 | 87.89 ± 2.07 | |
| K × 100 | 82.86 ± 0.13 | 86.44 ± 0.39 | 86.62 ± 0.11 | 90.27 ± 1.42 | 90.26 ± 0.94 | 90.54 ± 0.24 | 91.30 ± 0.66 | |
| Train Time (min.) | 457.25 | 40.12 | 143.20 | 785.64 | 188.16 | 544.63 | 284.71 | |
| Test Time (min.) | 23.55 | 0.51 | 0.58 | 28.64 | 2.05 | 7.13 | 2.15 | |
| DenseNet (1, 2, 3, 4) | DenseNet (2, 4, 6, 8) | DenseNet (3, 5, 7, 9) | |
|---|---|---|---|
| OA (%) | 90.97 ± 0.40 | 92.08 ± 0.87 | 91.12 ± 0.51 |
| AA (%) | 85.63 ± 1.09 | 87.01 ± 1.25 | 86.21 ± 0.90 |
| K × 100 | 89.75 ± 0.43 | 90.26 ± 0.94 | 89.13 ± 0.62 |
| Train Time (min.) | 117.74 | 188.16 | 224.86 |
| Test Time (min.) | 1.41 | 2.05 | 2.62 |
| No. | Name | TSVM | Label Propagation | Semi-GAN |
|---|---|---|---|---|
| 1 | Buildings | 54.48 ± 2.25 | 53.02 ± 2.32 | 82.15 ± 1.45 |
| 2 | Corn | 29.98 ± 0.43 | 39.96 ± 1.47 | 86.92 ± 2.29 |
| 3 | Corn? | 21.42 ± 8.56 | 22.02 ± 6.16 | 91.67 ± 0.59 |
| 4 | Corn-EW | 22.58 ± 6.82 | 44.67 ± 2.14 | 100.00 ± 0.00 |
| 5 | Corn-NS | 23.73 ± 2.39 | 33.33 ± 4.52 | 95.24 ± 0.45 |
| 6 | Corn-CleanTill | 25.58 ± 1.05 | 37.67 ± 2.59 | 96.40 ± 0.03 |
| 7 | Corn-CleanTill-EW | 44.21 ± 0.94 | 53.53 ± 3.62 | 96.38 ± 0.57 |
| 8 | Corn-CleanTill-NS | 66.54 ± 1.69 | 66.64 ± 0.02 | 91.15 ± 1.43 |
| 9 | Corn-CleanTill-NS-Irrigated | 6.12 ± 12.34 | 13.13 ± 9.54 | 83.44 ± 2.46 |
| 10 | Corn-CleanTill-NS? | 18.68 ± 1.34 | 26.24 ± 3.48 | 84.97 ± 2.16 |
| 11 | Corn-MinTill | 15.25 ± 0.13 | 32.36 ± 2.49 | 100.00 ± 0.00 |
| 12 | Corn-MinTill-EW | 27.65 ± 0.68 | 37.56 ± 3.49 | 81.23 ± 0.13 |
| 13 | Corn-MinTill-NS | 39.27 ± 0.72 | 49.34 ± 4.52 | 90.54 ± 0.01 |
| 14 | Corn-NoTill | 36.74 ± 1.97 | 48.21 ± 1.49 | 95.73 ± 0.45 |
| 15 | Corn-NoTill-EW | 37.36 ± 2.43 | 34.63 ± 3.21 | 91.26 ± 0.98 |
| 16 | Corn-NoTill-NS | 48.54 ± 0.68 | 63.52 ± 1.78 | 83.33 ± 4.07 |
| 17 | Fescue | 77.78 ± 5.62 | 79.00 ± 0.96 | 90.43 ± 1.45 |
| 18 | Grass | 20.69 ± 6.27 | 58.02 ± 4.78 | 100.00 ± 0.00 |
| 19 | Grass/Tress | 72.67 ± 1.97 | 74.67 ± 1.78 | 90.30 ± 2.45 |
| 20 | Hay | 46.38 ± 3.65 | 55.67 ± 0.79 | 66.67 ± 0.15 |
| 21 | Hay? | 69.23 ± 2.36 | 79.00 ± 6.23 | 90.91 ± 0.63 |
| 22 | Hay-Alfalfa | 77.27 ± 1.12 | 82.33 ± 0.25 | 85.71 ± 0.57 |
| 23 | Lake | 54.54 ± 3.29 | 63.14 ± 0.89 | 100.00 ± 0.00 |
| 24 | NotCropped | 38.18 ± 1.41 | 56.01 ± 0.21 | 66.91 ± 0.34 |
| 25 | Oats | 48.45 ± 4.29 | 43.94 ± 0.78 | 91.91 ± 4.57 |
| 26 | Oats? | 7.69 ± 2.83 | 4.34 ± 4.21 | 57.62 ± 0.45 |
| 27 | Pasture | 64.98 ± 1.07 | 75.00 ± 0.12 | 92.26 ± 2.35 |
| 28 | pond | 25.12 ± 7.21 | 40.14 ± 3.69 | 67.54 ± 0.25 |
| 29 | Soybeans | 40.25 ± 0.98 | 46.24 ± 0.36 | 98.81 ± 0.42 |
| 30 | Soybeans? | 20.23 ± 3.25 | 11.23 ± 4.56 | 80.79 ± 0.94 |
| 31 | Soybeans-NS | 19.64 ± 4.01 | 34.45 ± 7.52 | 89.48 ± 2.42 |
| 32 | Soybeans-CleanTill | 31.16 ± 2.73 | 37.54 ± 0.14 | 95.16 ± 0.35 |
| 33 | Soybeans-CleanTill? | 22.59 ± 1.22 | 32.45 ± 4.96 | 80.95 ± 1.47 |
| 34 | Soybeans-CleanTill-EW | 36.84 ± 0.85 | 44.33 ± 0.17 | 92.85 ± 0.45 |
| 35 | Soybeans-CleanTill-NS | 27.55 ± 1.15 | 27.24 ± 0.02 | 94.36 ± 0.56 |
| 36 | Soybeans-CleanTill-Drilled | 52.50 ± 3.50 | 46.00 ± 2.14 | 84.48 ± 0.35 |
| 37 | Soybeans-CleanTill-Weedy | 28.99 ± 0.98 | 23.67 ± 3.41 | 93.33 ± 1.27 |
| 38 | Soybeans- Drilled | 40.02 ± 1.30 | 52.32 ± 0.79 | 98.49 ± 1.45 |
| 39 | Soybeans-MinTill | 55.81 ± 0.93 | 65.00 ± 2.14 | 89.04 ± 0.92 |
| 40 | Soybeans-MinTill-EW | 53.84 ± 0.31 | 63.46 ± 3.78 | 99.01 ± 0.17 |
| 41 | Soybeans-MinTill-Drilled | 50.10 ± 0.89 | 50.36 ± 4.69 | 91.26 ± 2.45 |
| 42 | Soybeans-MinTill-NS | 31.10 ± 1.72 | 37.33 ± 0.05 | 100.00 ± 0.00 |
| 43 | Soybeans-NOTill | 49.62 ± 0.09 | 45.10 ± 0.03 | 86.45 ± 4.14 |
| 44 | Soybeans-NoTill-EW | 44.38 ± 2.45 | 47.33 ± 0.16 | 100.00 ± 0.00 |
| 45 | Soybeans-NoTill-NS | 16.20 ± 0.35 | 27.44 ± 0.79 | 98.16 ± 0.25 |
| 46 | Soybeans-NoTill-Drilled | 59.09 ± 2.51 | 70.00 ± 6.35 | 95.48 ± 0.03 |
| 47 | Swampy Area | 78.57 ± 0.47 | 94.38 ± 1.45 | 72.37 ± 0.11 |
| 48 | River | 98.94 ± 2.94 | 99.37 ± 1.79 | 88.12 ± 3.25 |
| 49 | Trees? | 48.57 ± 3.94 | 59.40 ± 0.17 | 94.78 ± 2.45 |
| 50 | Wheat | 78.87 ± 4.58 | 86.60 ± 4.23 | 100.00 ± 0.00 |
| 51 | Woods | 92.03 ± 1.94 | 90.23 ± 7.45 | 84.32 ± 0.01 |
| 52 | Woods? | 90.90 ± 1.59 | 91.96 ± 6.32 | 82.50 ± 3.45 |
| OA (%) | 55.49 ± 0.87 | 60.02 ± 0.21 | 94.02 ± 1.43 | |
| AA (%) | 43.02 ± 1.04 | 51.20 ± 0.43 | 90.11 ± 2.07 | |
| K × 100 | 50.38 ± 0.75 | 56.86 ± 0.24 | 92.76 ± 1.03 | |
| N | 4000 | 6000 | 8000 | |
|---|---|---|---|---|
| Methods | ||||
| Semi-GAN | OA (%) | 89.45 ± 3.02 | 92.53 ± 2.98 | 94.02 ± 2.43 |
| AA (%) | 83.41 ± 3.87 | 88.14 ± 3.07 | 90.11 ± 2.57 | |
| K × 100 | 87.76 ± 2.75 | 91.75 ± 2.09 | 92.76 ± 1.56 |
| Methods | Running Time (min.) | |
|---|---|---|
| SVM | Training | 2650.91 |
| Test | 32.92 | |
| CNN | Training | 457.25 |
| Test | 23.55 | |
| Semi-GAN | Training | 1053.42 |
| Test | 0.81 | |
| PCA-DenseNet | Training | 188.16 |
| Test | 2.05 | |
| Auto-Encoder-DenseNet | Training | 284.71 |
| Test | 2.15 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Huang, L.; Zhu, L.; Yokoya, N.; Jia, X. Fine-Grained Classification of Hyperspectral Imagery Based on Deep Learning. Remote Sens. 2019, 11, 2690. https://doi.org/10.3390/rs11222690
Chen Y, Huang L, Zhu L, Yokoya N, Jia X. Fine-Grained Classification of Hyperspectral Imagery Based on Deep Learning. Remote Sensing. 2019; 11(22):2690. https://doi.org/10.3390/rs11222690
Chicago/Turabian StyleChen, Yushi, Lingbo Huang, Lin Zhu, Naoto Yokoya, and Xiuping Jia. 2019. "Fine-Grained Classification of Hyperspectral Imagery Based on Deep Learning" Remote Sensing 11, no. 22: 2690. https://doi.org/10.3390/rs11222690
APA StyleChen, Y., Huang, L., Zhu, L., Yokoya, N., & Jia, X. (2019). Fine-Grained Classification of Hyperspectral Imagery Based on Deep Learning. Remote Sensing, 11(22), 2690. https://doi.org/10.3390/rs11222690