Context-Aware Human Activity and Smartphone Position-Mining with Motion Sensors




Abstract

1. Introduction
- We proposed a joint recognition model to mine multiple contextual information from motion sensor signals of a smartphone. The feasibility and advantage of the proposed approach are demonstrated by its promising results achieved on an existing real-world datasets [6]. More than that, we extended the joint recognition model to an additional task, namely identifying smartphone users with biometric motion analysis [12,13].
- We developed a data preprocessing approach to deal with the problem caused by smartphone orientation variation. To evaluate this method, we collect a dataset that marks the sensor data with orientation labels in addition to human activity and smartphone position.
- To the best of our knowledge, this is the first study that systematically shows the feasibility and performance of mining multiple physical contextual information. We applied our framework on three machine learning models that have shown promising results in classical HAR tasks, including simple Multilayer Perceptron (MLP) with the statistical feature, and Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) with powerful and automatic data representation ability.
2. Related Work
2.1. Position Recognition and Position-Aware Human Activity Recognition
2.2. Deep Learning for Human Activity Recognition
2.3. Multi-Task Learning in Human Activity Recognition
3. Methods
3.1. Task Definition
3.2. Coordinate Transformation
3.3. Multi-Task Learning for Joint Recognition
3.4. Backbone Networks
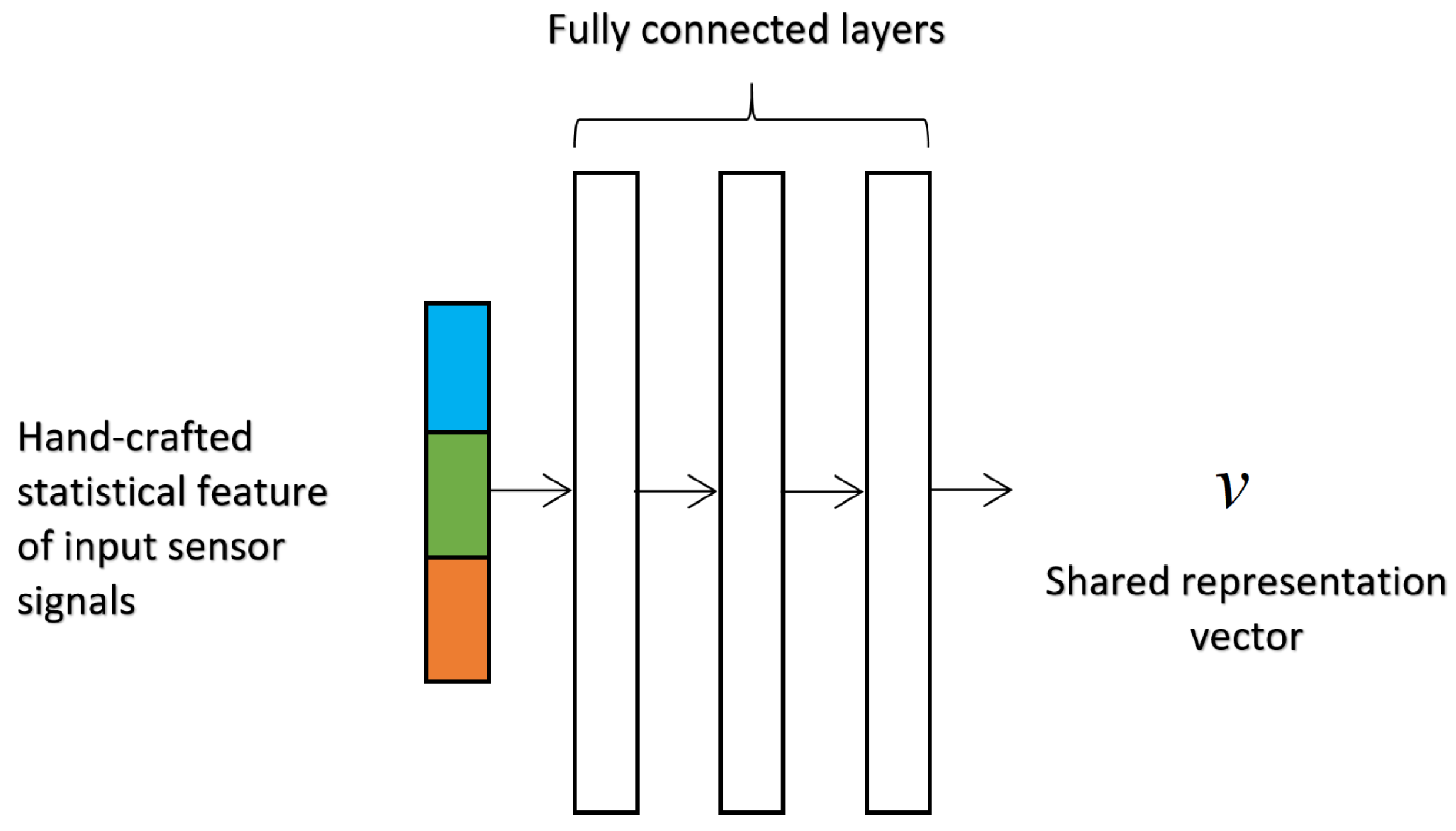
3.4.1. Multilayer Perceptron (MLP)
3.4.2. Convolutional Neural Network (CNN)
- is the number of feature maps in layer-;
- is a weight vector in filter that covers the f-th feature map in layer-, and k is filter size;
- is a bias value for the f-th feature map;
- denotes the f-th feature map in a subsequence in layer-; corresponds to the entire subsequence including all feature maps is defined as .
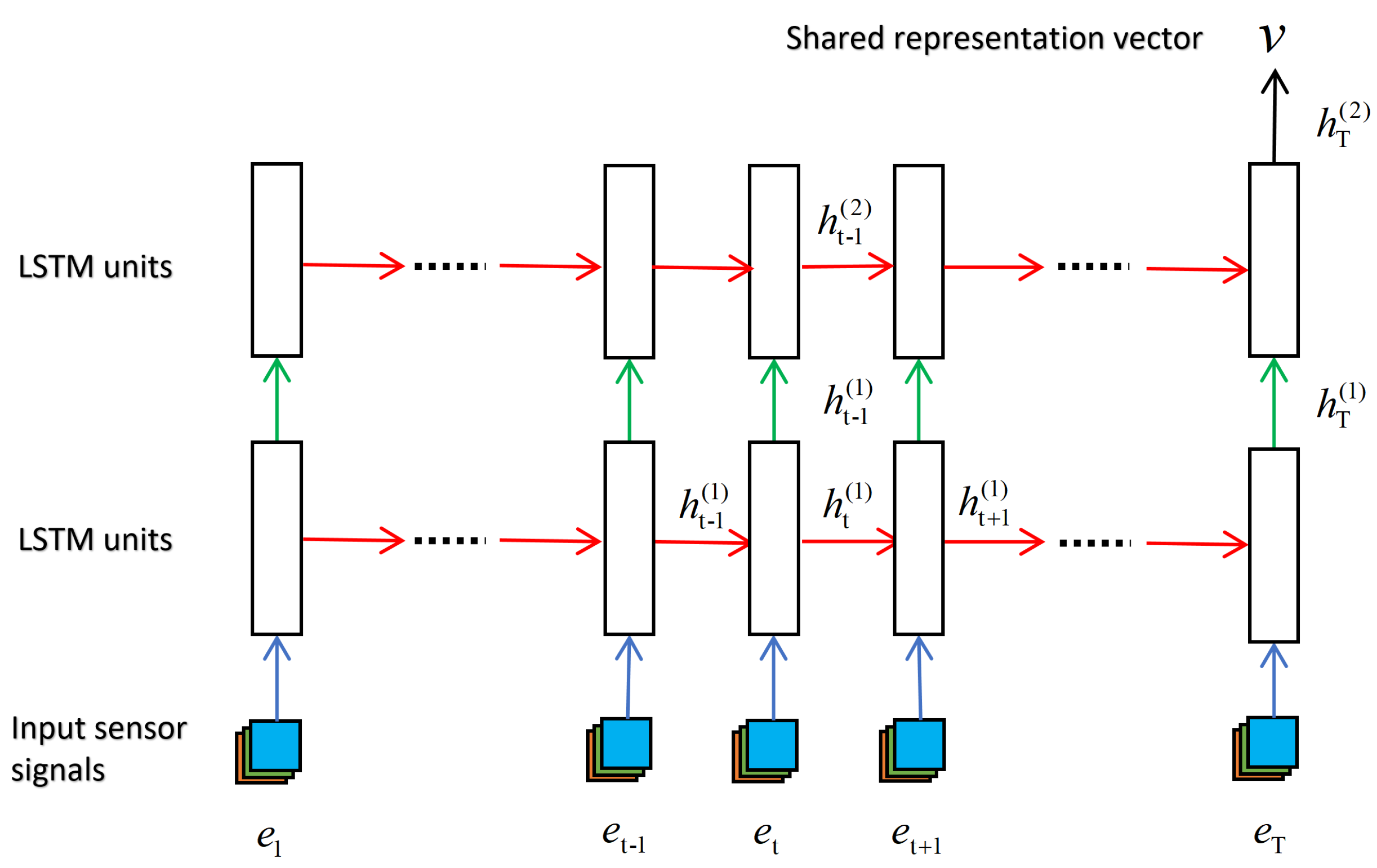
3.4.3. Long Short-Term Memory (LSTM)
4. Results and Analysis
4.1. Dataset
4.2. Experimental Setting
4.3. Optimization Hyper-Parameters
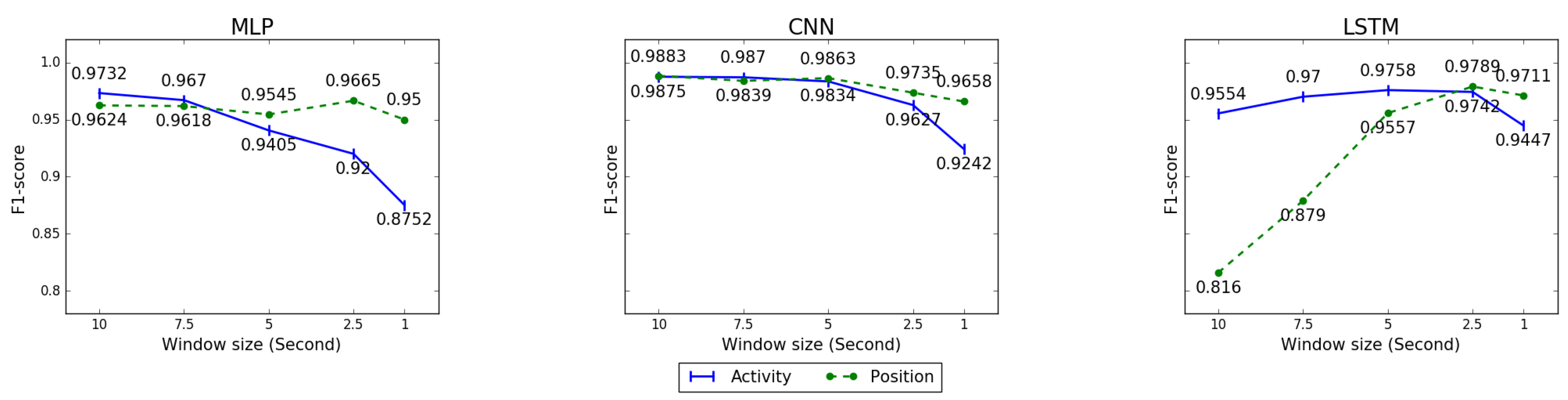
4.4. Coordinate Transformation
4.5. Multi-task Learning for Joint Recognition
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Coskun, D.; Incel, O.D.; Ozgovde, A. Phone position/placement detection using accelerometer: Impact on activity recognition. In Proceedings of the 2015 IEEE Tenth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Singapore, 7–9 April 2015; pp. 1–6. [Google Scholar]
- Alanezi, K. Impact of Smartphone Position on Sensor Values and Context Discovery; Technical Report; University of Colorado Boulder: Boulder, CO, USA, 2013. [Google Scholar]
- Fujinami, K. On-Body Smartphone Localization with an Accelerometer. Information 2016, 7, 21. [Google Scholar] [CrossRef]
- Miluzzo, E.; Papandrea, M.; Lane, N.D.; Lu, H.; Campbell, A. Pocket, Bag, Hand, etc.—Automatically Detecting Phone Context through Discovery. In Proceedings of the PhoneSense, Zurich, Switzerland, 2 November 2010. [Google Scholar]
- Martín, H.; Bernardos, A.M.; Iglesias, J.; Casar, J.R. Activity logging using lightweight classification techniques in mobile devices. Pers. Ubiquitous Comput. 2013, 17, 675–695. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H.; Petrich, W. Position-aware activity recognition with wearable devices. Pervasive Mob. Comput. 2017, 38, 281–295. [Google Scholar] [CrossRef]
- Yang, R.; Wang, B. PACP: A Position-Independent Activity Recognition Method Using Smartphone Sensors. Information 2016, 7, 72. [Google Scholar] [CrossRef]
- Yan, H.; Shan, Q.; Furukawa, Y. RIDI: Robust IMU double integration. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 621–636. [Google Scholar]
- Shin, B.; Kim, C.; Kim, J.; Lee, S.; Kee, C.; Kim, H.S.; Lee, T. Motion Recognition-Based 3D Pedestrian Navigation System Using Smartphone. IEEE Sens. J. 2016, 16, 6977–6989. [Google Scholar] [CrossRef]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. arXiv 2017, arXiv:1707.08114. [Google Scholar]
- Gadaleta, M.; Rossi, M. IDNet: Smartphone-based gait recognition with convolutional neural networks. Pattern Recognit. 2018, 74, 25–37. [Google Scholar] [CrossRef]
- Ren, Y.; Chen, Y.; Chuah, M.C.; Yang, J. Smartphone based user verification leveraging gait recognition for mobile healthcare systems. In Proceedings of the 2013 IEEE International Conference on Sensing, Communications and Networking (SECON), New Orleans, LA, USA, 24–27 June 2013; pp. 149–157. [Google Scholar] [CrossRef]
- Lu, H.; Yang, J.; Liu, Z.; Lane, N.D.; Choudhury, T.; Campbell, A.T. The Jigsaw Continuous Sensing Engine for Mobile Phone Applications. In Proceedings of the 8th ACM Conference on Embedded Networked Sensor Systems; ACM: New York, NY, USA, 2010; pp. 71–84. [Google Scholar]
- Antos, S.A.; Albert, M.V.; Kording, K.P. Hand, belt, pocket or bag: Practical activity tracking with mobile phones. J. Neurosci. Methods 2014, 231, 22–30. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bengio, Y. Deep learning of representations: Looking forward. In Proceedings of the International Conference on Statistical Language and Speech Processing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–37. [Google Scholar]
- Huang, K.; Hussain, A.; Wang, Q.F.; Zhang, R. Deep Learning: Fundamentals, Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2019; Volume 2. [Google Scholar]
- Vepakomma, P.; De, D.; Das, S.K.; Bhansali, S. A-Wristocracy: Deep learning on wrist-worn sensing for recognition of user complex activities. In Proceedings of the 2015 IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 9–12 June 2015; pp. 1–6. [Google Scholar]
- Walse, K.H.; Dharaskar, R.V.; Thakare, V.M. Pca based optimal ann classifiers for human activity recognition using mobile sensors data. In Proceedings of the First International Conference on Information and Communication Technology for Intelligent Systems: Volume 1; Springer: Berlin/Heidelberg, Germany, 2016; pp. 429–436. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2016; pp. 1533–1540. [Google Scholar]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Ha, S.; Yun, J.M.; Choi, S. Multi-modal convolutional neural networks for activity recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015; pp. 3017–3022. [Google Scholar]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2018, 119, 3–11. [Google Scholar] [CrossRef]
- Edel, M.; Köppe, E. Binarized-blstm-rnn based human activity recognition. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Madrid, Spain, 4–7 October 2016; pp. 1–7. [Google Scholar]
- Almaslukh, B.; AlMuhtadi, J.; Artoli, A. An effective deep autoencoder approach for online smartphone-based human activity recognition. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 160–165. [Google Scholar]
- Wang, A.; Chen, G.; Shang, C.; Zhang, M.; Liu, L. Human activity recognition in a smart home environment with stacked denoising autoencoders. In Proceedings of the International Conference on Web-Age Information Management, Nanchang, China, 3–5 June 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 29–40. [Google Scholar]
- Radu, V.; Lane, N.D.; Bhattacharya, S.; Mascolo, C.; Marina, M.K.; Kawsar, F. Towards multimodal deep learning for activity recognition on mobile devices. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 185–188. [Google Scholar]
- Pang, S.; Liu, F.; Kadobayashi, Y.; Ban, T.; Inoue, D. A learner-independent knowledge transfer approach to multi-task learning. Cogn. Comput. 2014, 6, 304–320. [Google Scholar] [CrossRef]
- Li, Y.; Wang, J.; Ye, J.; Reddy, C.K. A multi-task learning formulation for survival analysis. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1715–1724. [Google Scholar]
- He, D.; Kuhn, D.; Parida, L. Novel applications of multitask learning and multiple output regression to multiple genetic trait prediction. Bioinformatics 2016, 32, i37–i43. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.; Das, A.; Smola, A.J. Scalable hierarchical multitask learning algorithms for conversion optimization in display advertising. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 153–162. [Google Scholar]
- Dong, H.; Wang, W.; Huang, K.; Coenen, F. Joint Multi-Label Attention Networks for Social Text Annotation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1348–1354. [Google Scholar]
- Xiong, W.; Lv, Y.; Cui, Y.; Zhang, X.; Gu, X. A Discriminative Feature Learning Approach for Remote Sensing Image Retrieval. Remote Sens. 2019, 11, 281. [Google Scholar] [CrossRef]
- Qi, K.; Liu, W.; Yang, C.; Guan, Q.; Wu, H. Multi-task joint sparse and low-rank representation for the scene classification of high-resolution remote sensing image. Remote Sens. 2016, 9, 10. [Google Scholar] [CrossRef]
- Chang, T.; Rasmussen, B.P.; Dickson, B.G.; Zachmann, L.J. Chimera: A Multi-Task Recurrent Convolutional Neural Network for Forest Classification and Structural Estimation. Remote Sens. 2019, 11, 768. [Google Scholar] [CrossRef]
- Sun, X.; Kashima, H.; Tomioka, R.; Ueda, N.; Li, P. A new multi-task learning method for personalized activity recognition. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, Canada, 11–14 December 2011; pp. 1218–1223. [Google Scholar]
- Sun, X.; Kashima, H.; Ueda, N. Large-scale personalized human activity recognition using online multitask learning. IEEE Trans. Knowl. Data Eng. 2012, 25, 2551–2563. [Google Scholar] [CrossRef]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. AROMA: A Deep Multi-Task Learning Based Simple and Complex Human Activity Recognition Method Using Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 74. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, Z.; Chen, Y.; Wang, S.; Wang, H. A class incremental extreme learning machine for activity recognition. Cogn. Comput. 2014, 6, 423–431. [Google Scholar] [CrossRef]
- Ustev, Y.E.; Durmaz Incel, O.; Ersoy, C. User, device and orientation independent human activity recognition on mobile phones: Challenges and a proposal. In Proceedings of the 2013 ACM conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8–12 September 2013; pp. 1427–1436. [Google Scholar]
- Diebel, J. Representing attitude: Euler angles, unit quaternions, and rotation vectors. Matrix 2006, 58, 1–35. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Shen, S.; Gowda, M.; Roy Choudhury, R. Closing the Gaps in Inertial Motion Tracking. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking; ACM: New York, NY, USA, 2018; pp. 429–444. [Google Scholar] [CrossRef]
- Zhou, P.; Li, M.; Shen, G. Use it free: Instantly knowing your phone attitude. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 605–616. [Google Scholar]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. Model Compression and Acceleration for Deep Neural Networks: The Principles, Progress, and Challenges. IEEE Signal Process. Mag. 2018, 35, 126–136. [Google Scholar] [CrossRef]
- Yang, X.; Huang, K.; Zhang, R.; Hussain, A. Learning latent features with infinite nonnegative binary matrix trifactorization. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 450–463. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, K.; Zhang, R.; Hussain, A. Learning from few samples with memory network. Cogn. Comput. 2018, 10, 15–22. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Learning Type | Activity | Position | User | Average |
|---|---|---|---|---|---|
| MLP | ST-3L | 0.8837 | 0.9852 | 0.8364 | 0.9018 |
| MT-3L | 0.8910 | 0.9866 | 0.8484 | 0.9087 | |
| CNN | ST-3L | 0.8714 | 0.9862 | 0.8181 | 0.8919 |
| MT-3L | 0.8855 | 0.9848 | 0.8300 | 0.9001 | |
| LSTM | ST-3L | 0.8932 | 0.9810 | 0.8511 | 0.9084 |
| MT-3L | 0.8919 | 0.9802 | 0.8515 | 0.9079 | |
| Random Forest | S-A/P | 0.84 | 0.89 | – | 0.865 |
| Model Type | Learning Type | Activity | Position | User | Average |
|---|---|---|---|---|---|
| MLP | ST-3L | 0.8968 | 0.9859 | 0.8625 | 0.9151 |
| MT-0L | 0.8536 | 0.9742 | 0.8129 | 0.8802 | |
| MT-3L | 0.9002 | 0.9857 | 0.8680 | 0.9179 | |
| CNN | ST-3L | 0.9019 | 0.9893 | 0.8693 | 0.9202 |
| MT-0L | 0.8880 | 0.9831 | 0.8836 | 0.9183 | |
| MT-3L | 0.9067 | 0.9854 | 0.8774 | 0.9232 | |
| LSTM | ST-3L | 0.9265 | 0.9917 | 0.9115 | 0.9432 |
| MT-0L | 0.9080 | 0.9878 | 0.9043 | 0.9334 | |
| MT-3L | 0.9240 | 0.9906 | 0.9174 | 0.9440 |
| Model Type | ST-3L | MT-3L |
|---|---|---|
| MLP | 0.62 m × 3 | 0.76 m |
| CNN | 0.14 m × 3 | 0.29 m |
| LSTM | 0.19 m × 3 | 0.26 m |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Z.; Liu, D.; Huang, K.; Huang, Y. Context-Aware Human Activity and Smartphone Position-Mining with Motion Sensors. Remote Sens. 2019, 11, 2531. https://doi.org/10.3390/rs11212531
Gao Z, Liu D, Huang K, Huang Y. Context-Aware Human Activity and Smartphone Position-Mining with Motion Sensors. Remote Sensing. 2019; 11(21):2531. https://doi.org/10.3390/rs11212531
Chicago/Turabian StyleGao, Zhiqiang, Dawei Liu, Kaizhu Huang, and Yi Huang. 2019. "Context-Aware Human Activity and Smartphone Position-Mining with Motion Sensors" Remote Sensing 11, no. 21: 2531. https://doi.org/10.3390/rs11212531
APA StyleGao, Z., Liu, D., Huang, K., & Huang, Y. (2019). Context-Aware Human Activity and Smartphone Position-Mining with Motion Sensors. Remote Sensing, 11(21), 2531. https://doi.org/10.3390/rs11212531