Adaptive Framework for the Delineation of Homogeneous Forest Areas Based on LiDAR Points




Abstract
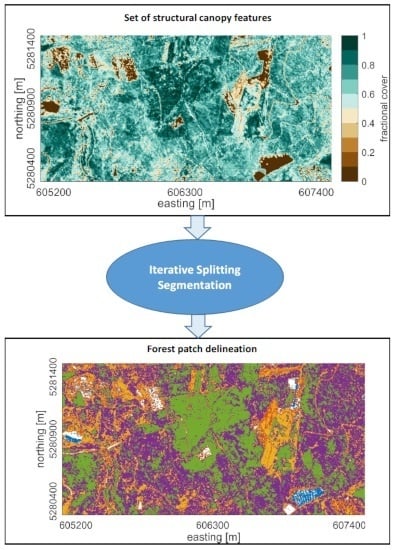
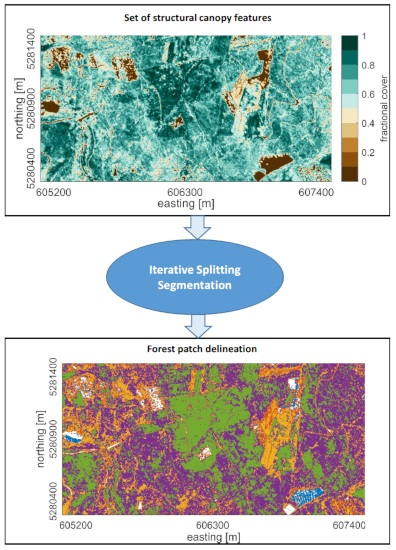
1. Introduction
- test the framework to capture the structures present in a forest scene accurately;
- evaluate the delineated forest patches for their specificity;
- discuss the process to parameterize the algorithm.
2. Study Data
2.1. Burgenland Scene
2.2. Ötscher Scene
3. Methods
3.1. Feature Computation
3.1.1. Forest Structure Characterization
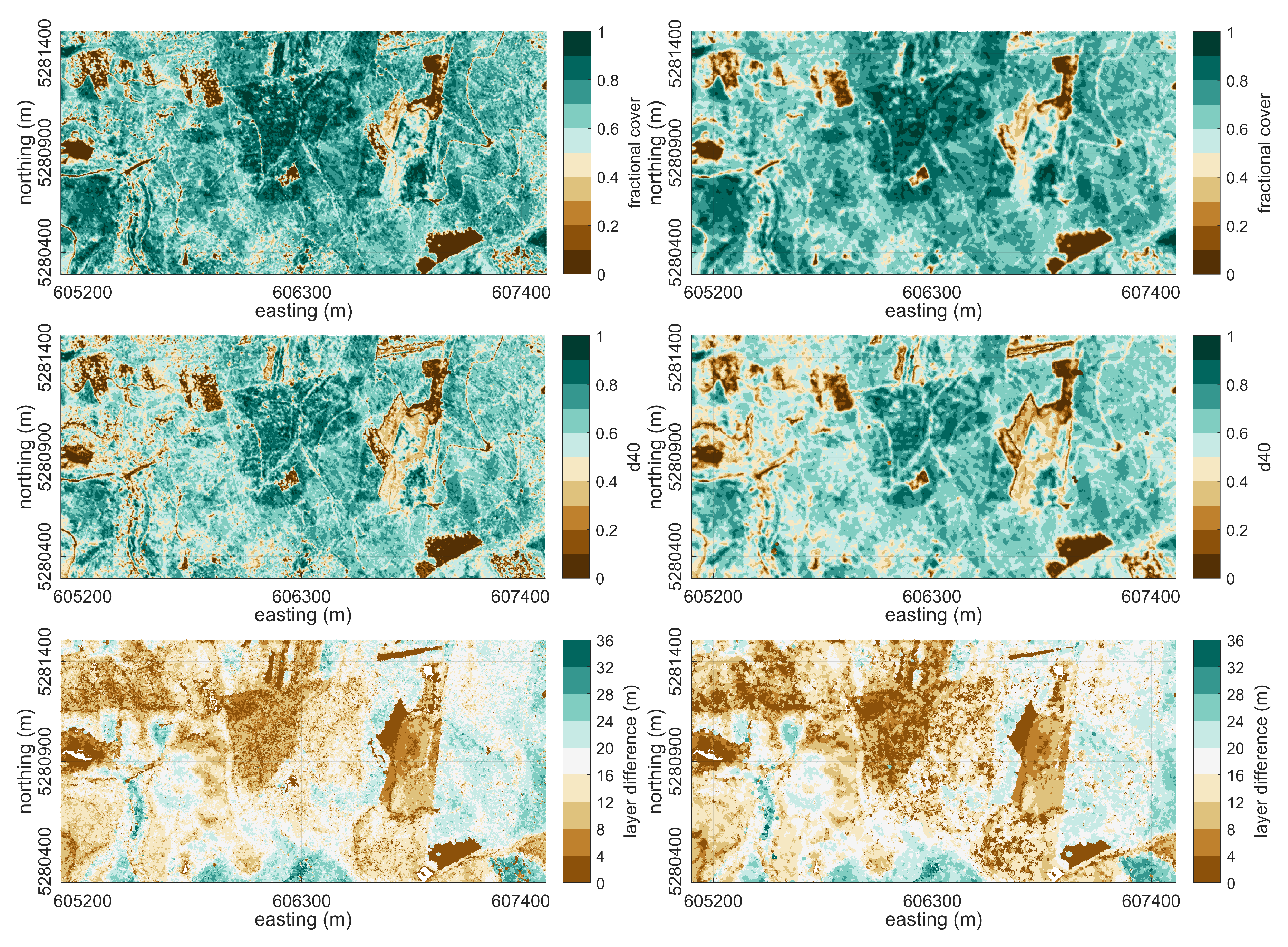
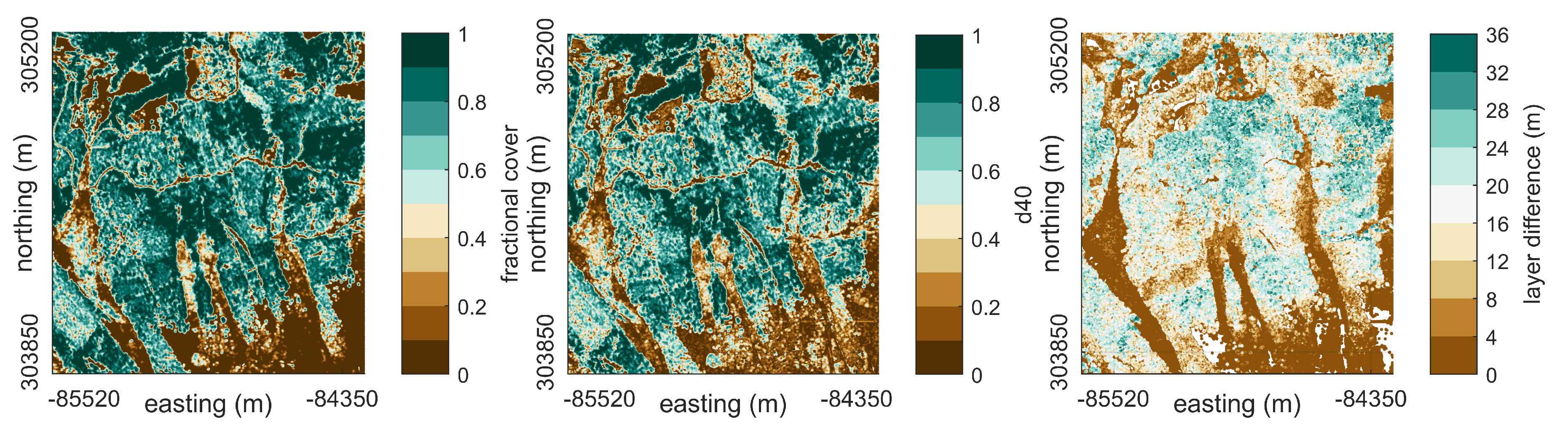
Fractional Cover
Canopy Density
95%-Height Quantile
Vegetation Profiles
3.1.2. Introduction of Scale
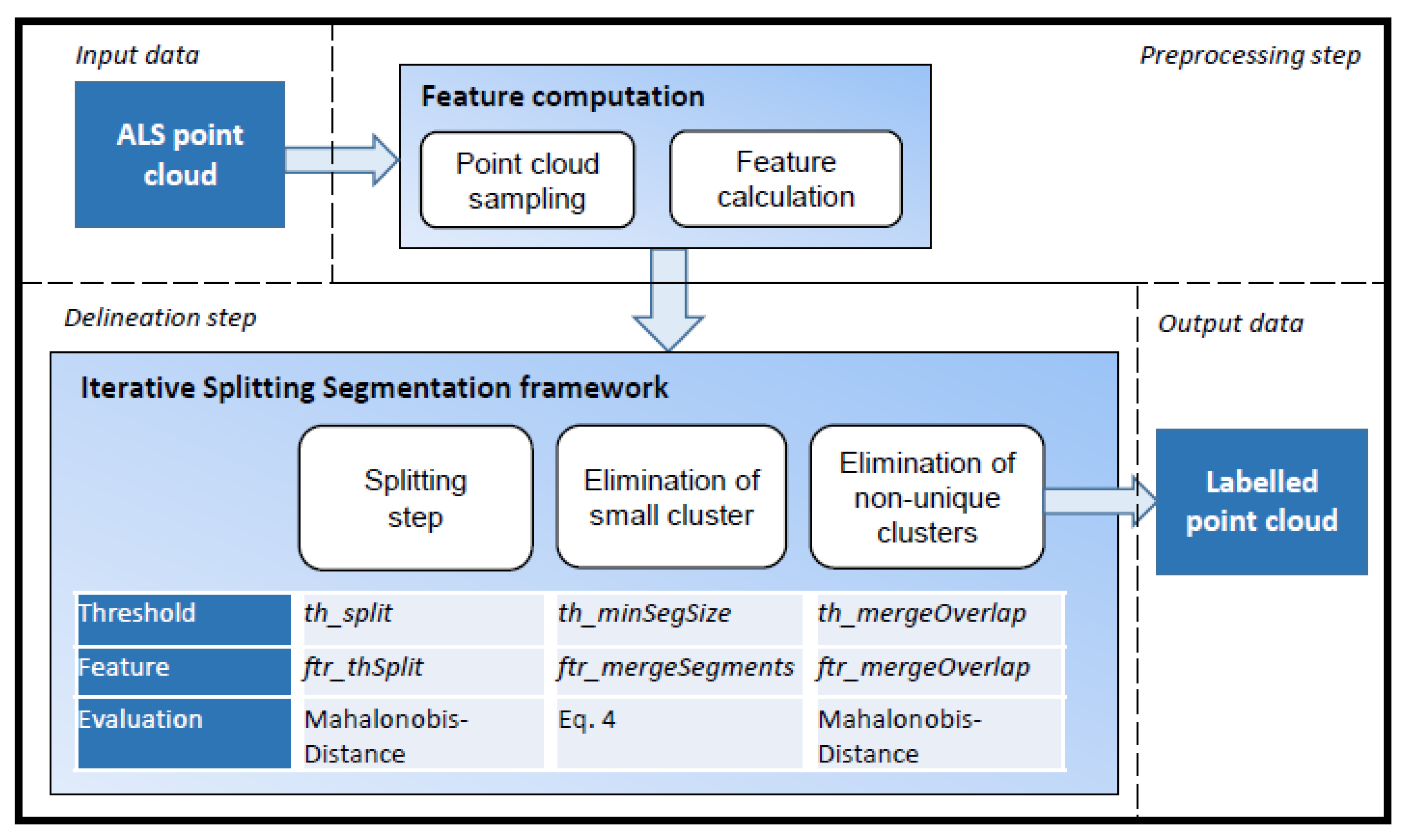
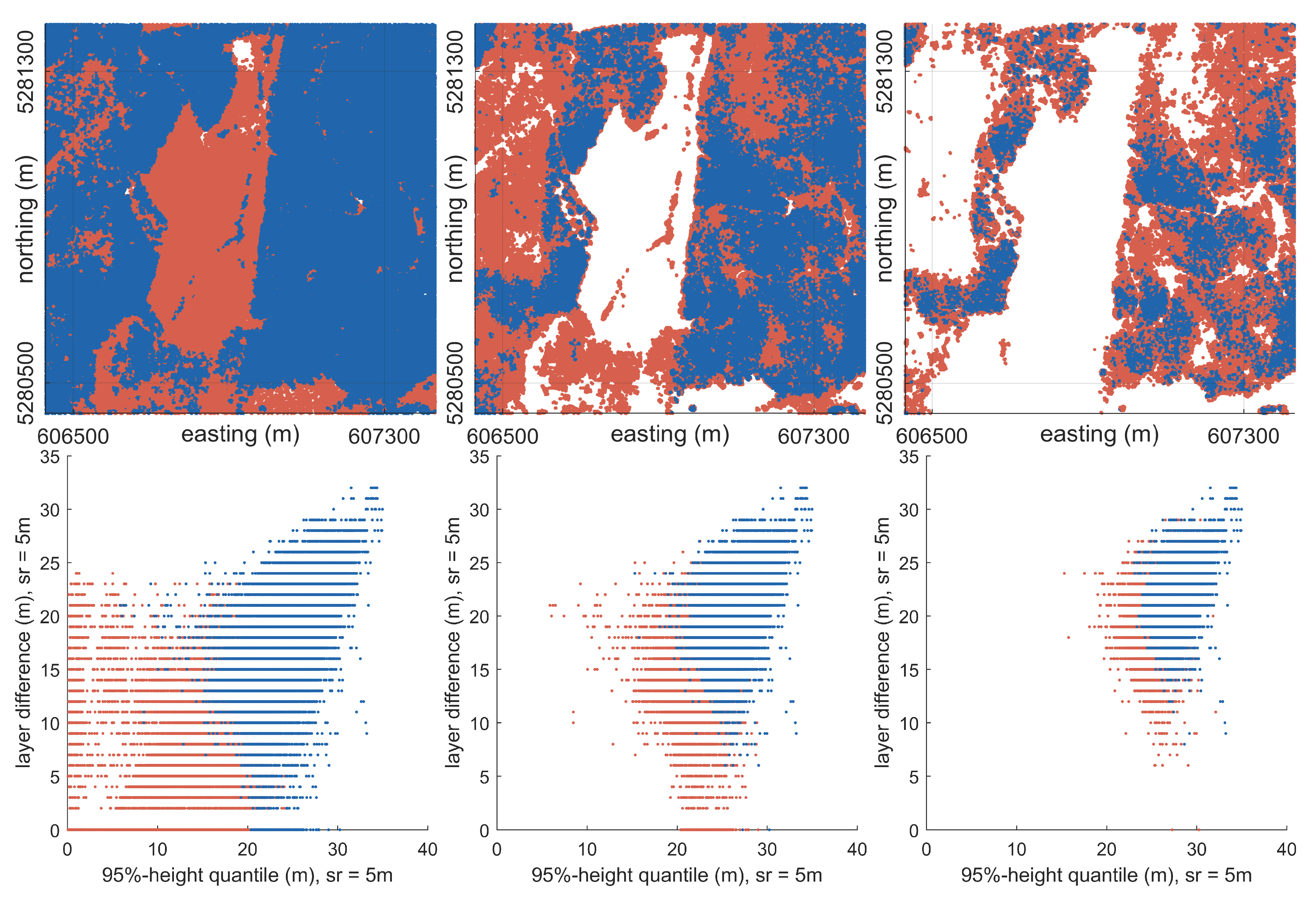
3.2. Iterative Splitting Segmentation
3.2.1. Splitting Step
3.2.2. Elimination of Small Clusters
3.2.3. Elimination of Non-Unique Clusters
3.3. Validation
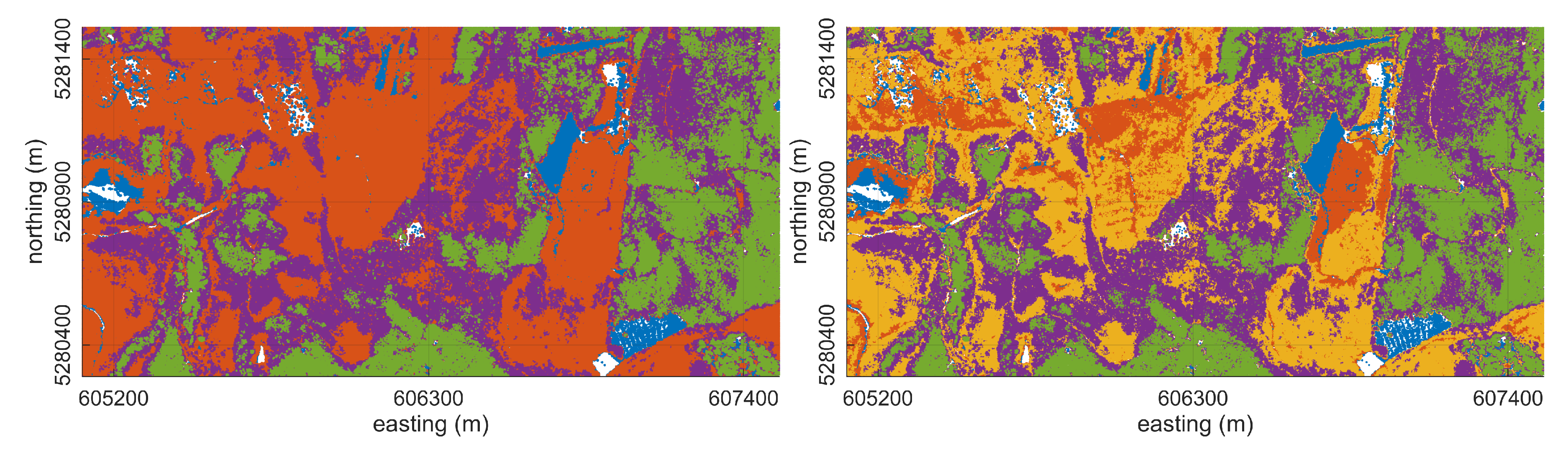
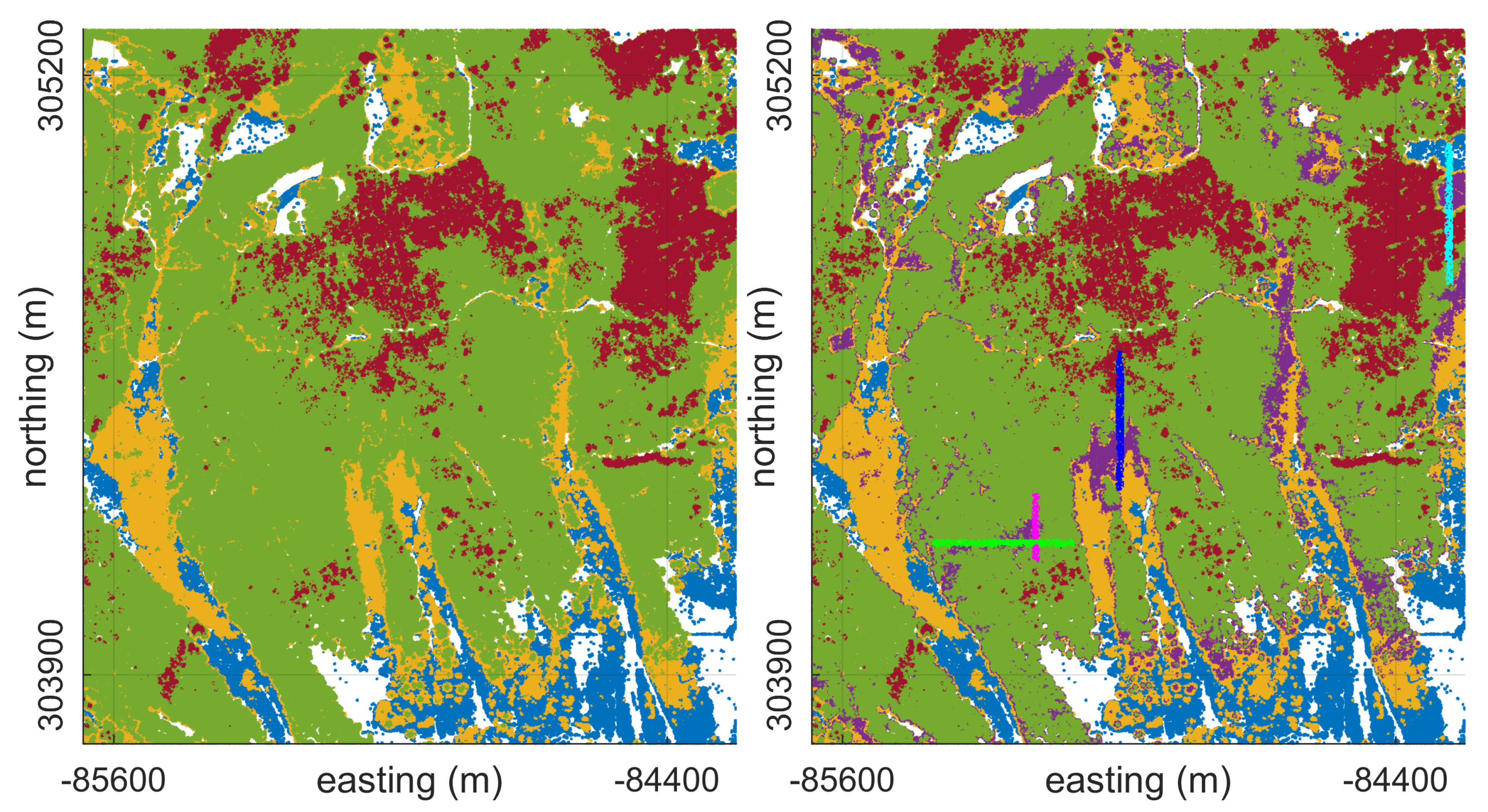
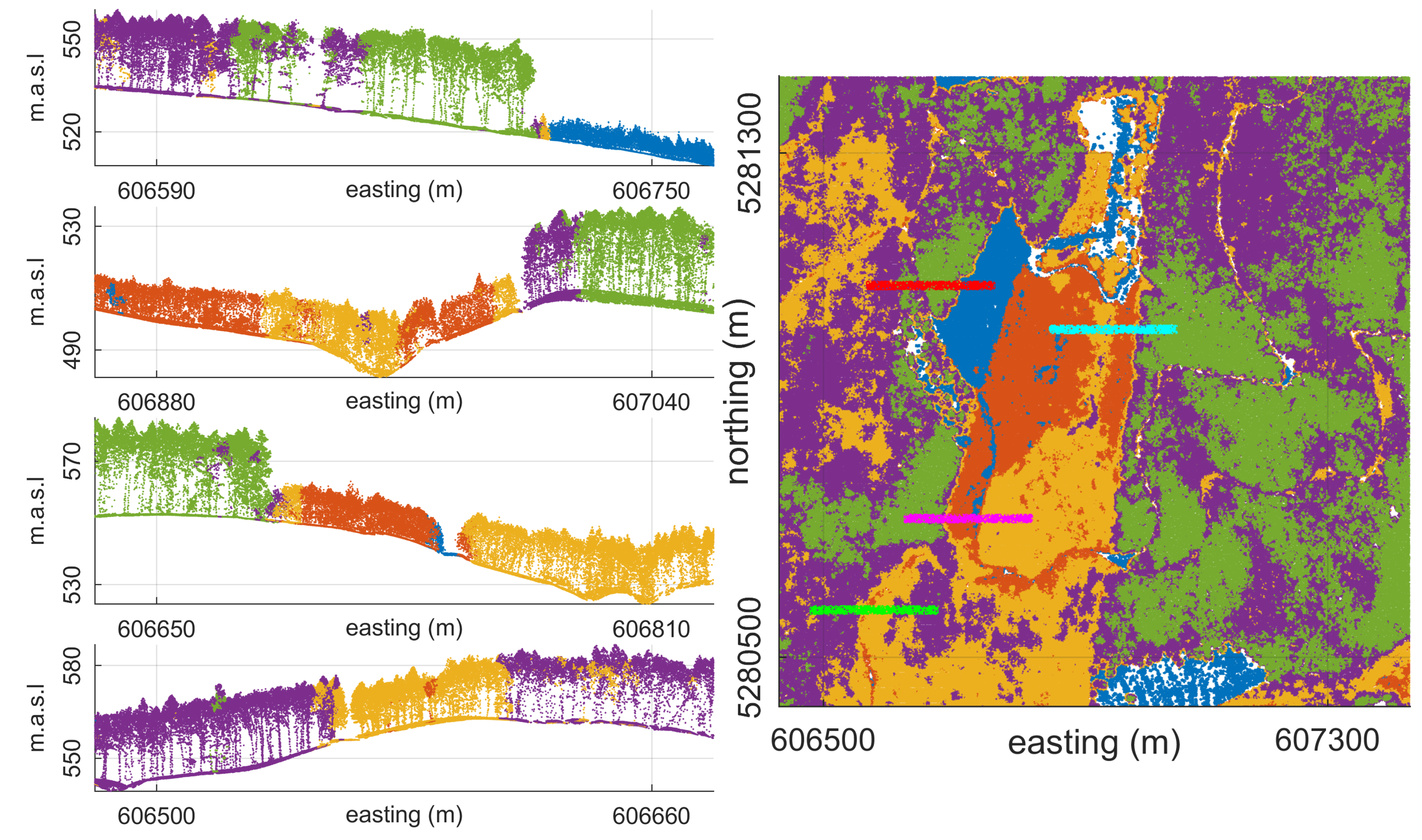
3.3.1. Forest Patch Delineation
Experiment 1: Forest Patch Segmentation with Similar Height Structure
Experiment 2: Forest Patch Segmentation for Water Cycle Studies
3.3.2. Definition of Number of Patch Classes
3.3.3. Sensitivity to Thresholds
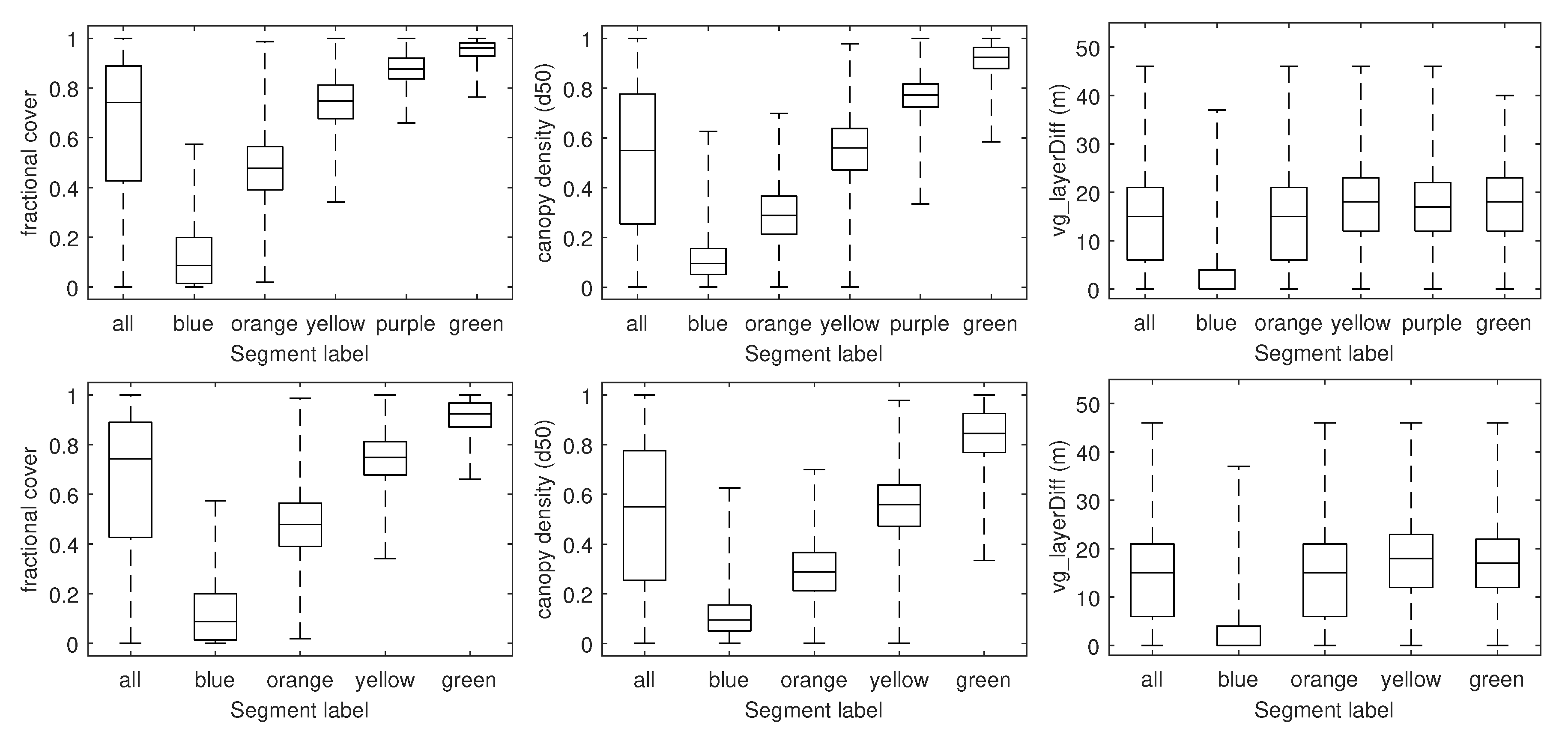
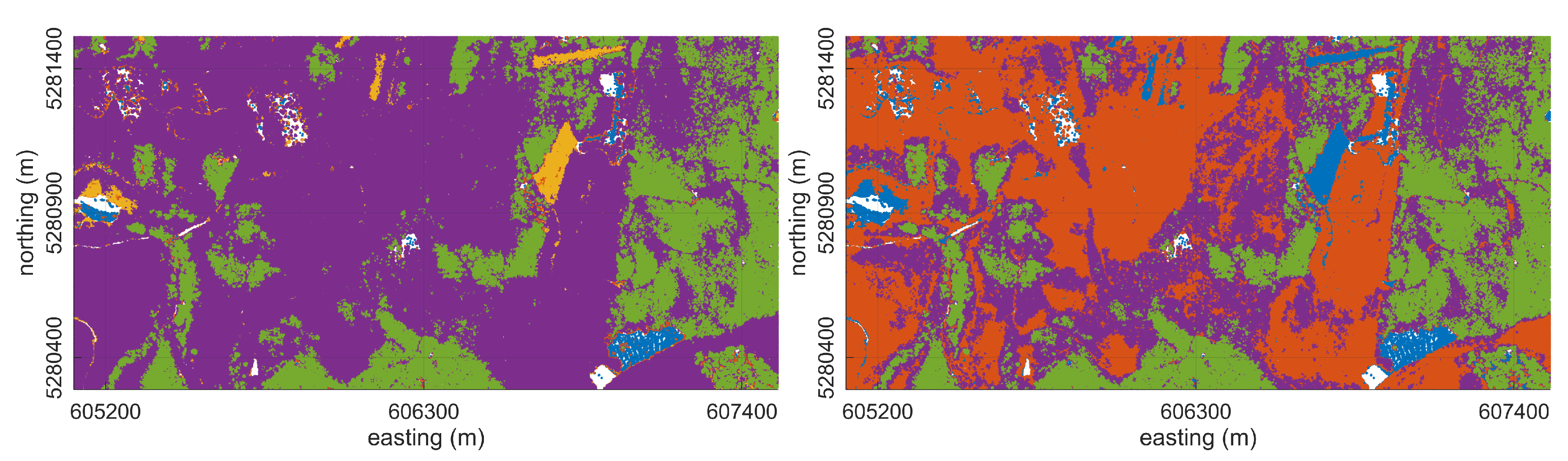
4. Results
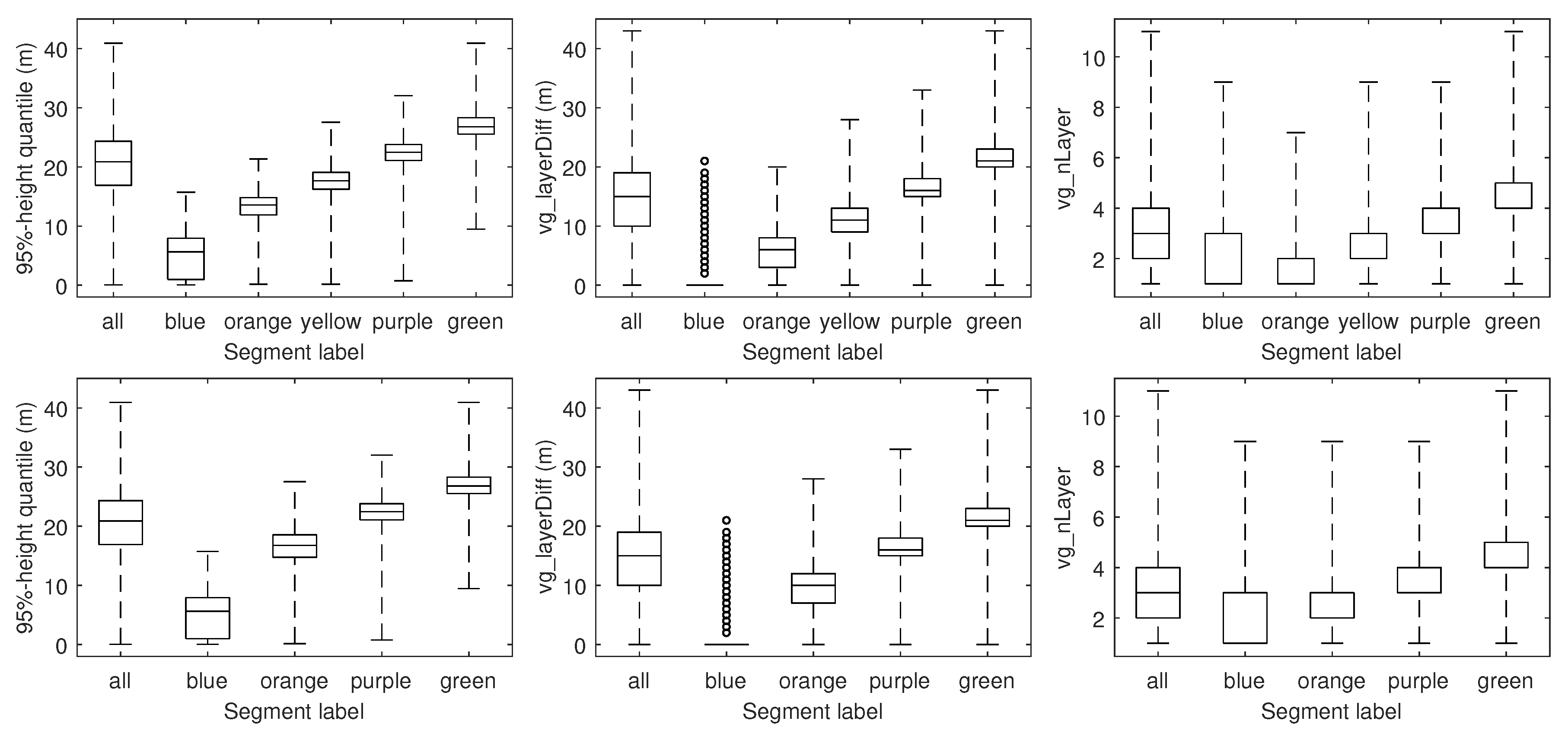
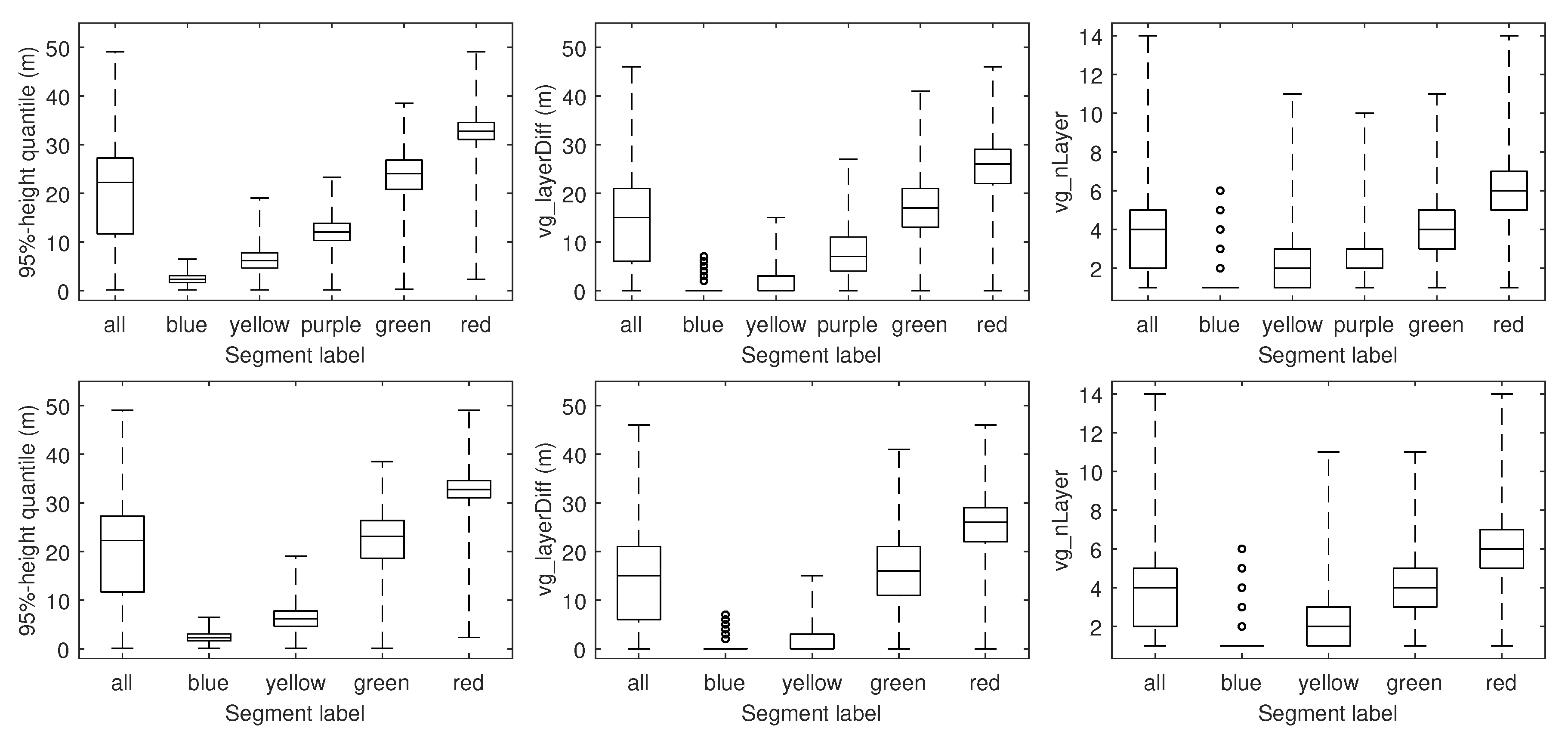
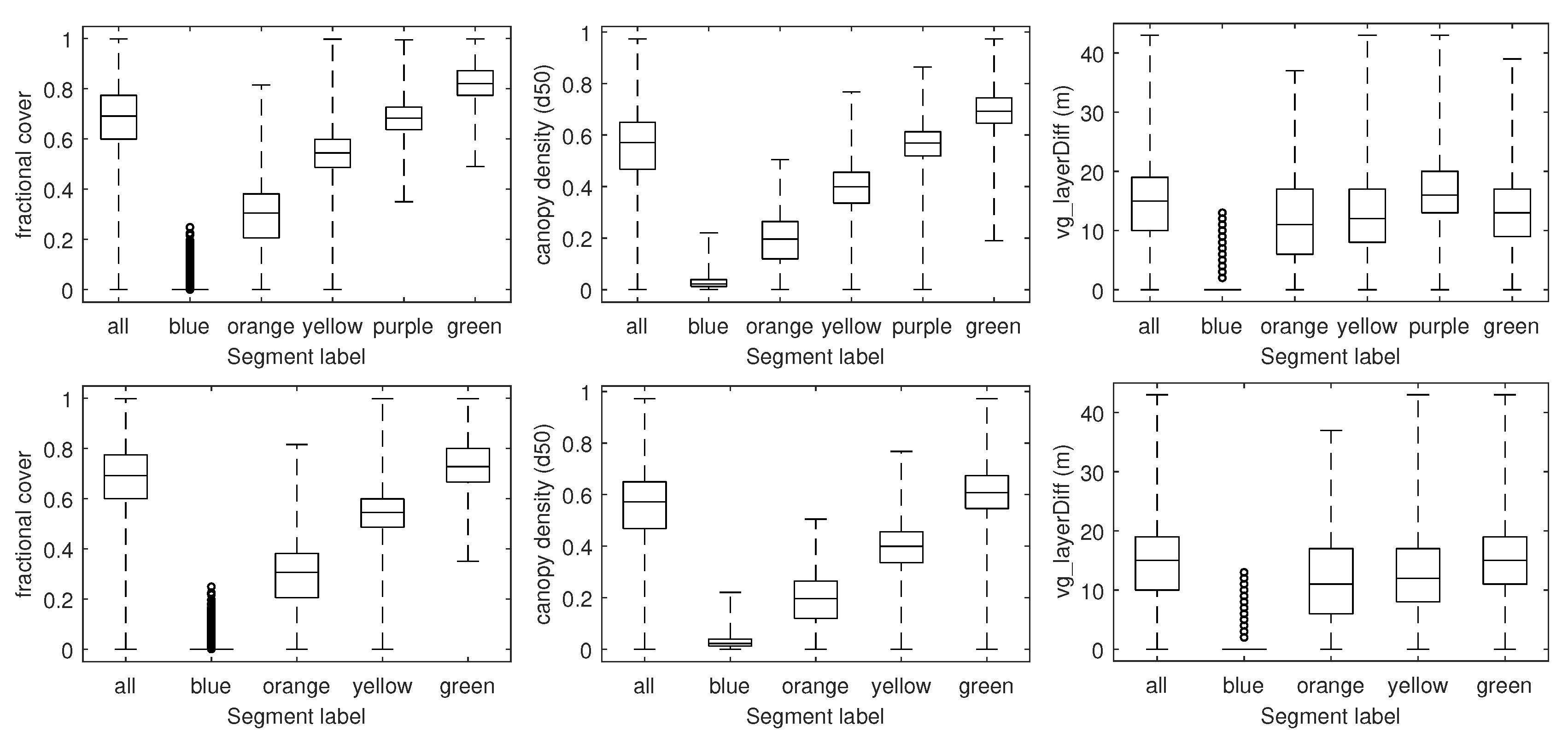
4.1. Feature Computation
4.2. Iterative Splitting Segmentation
4.3. Validation
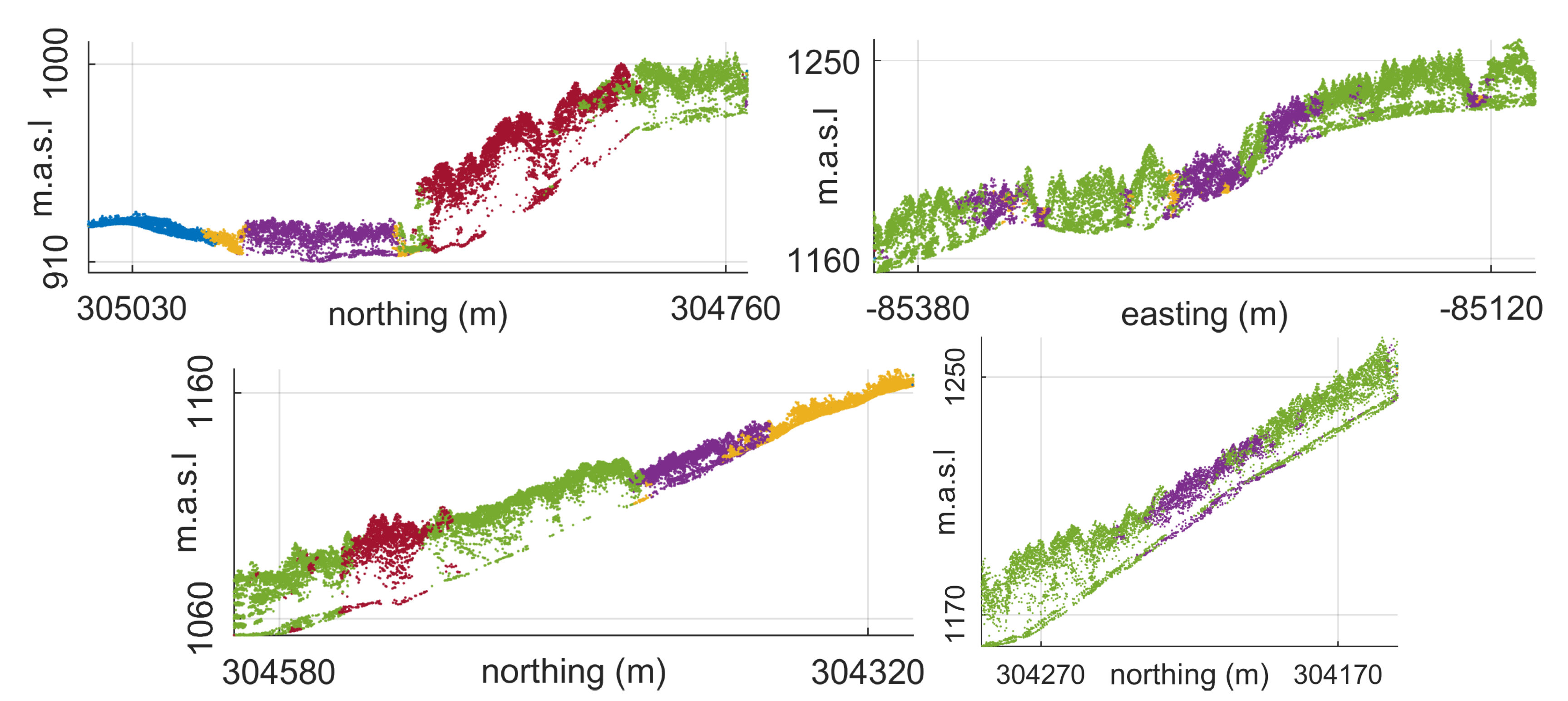
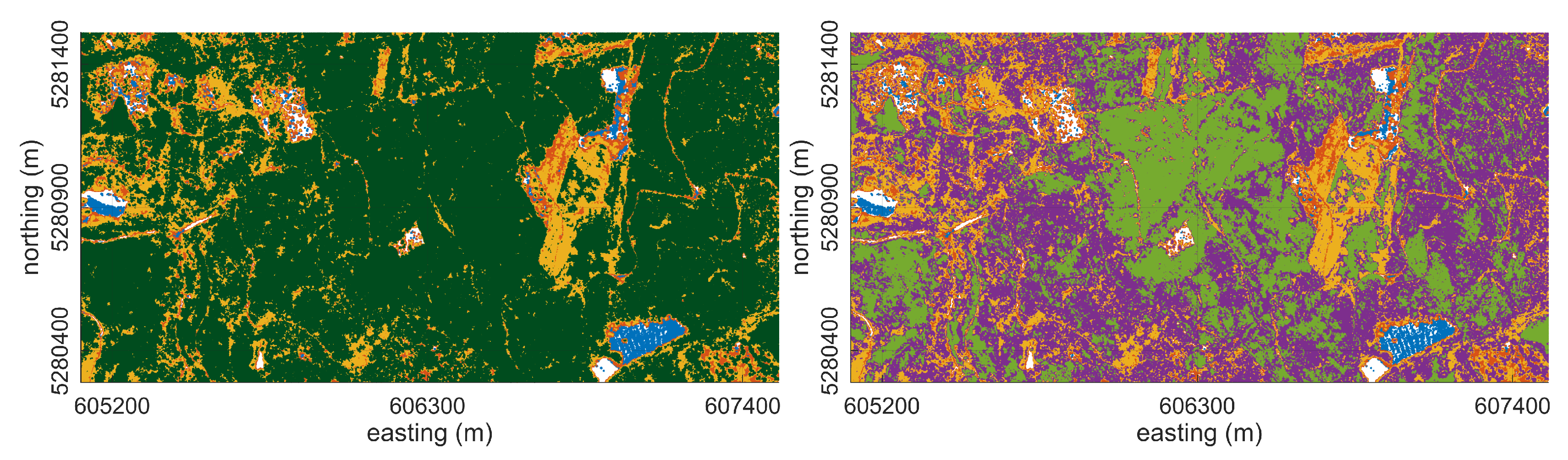
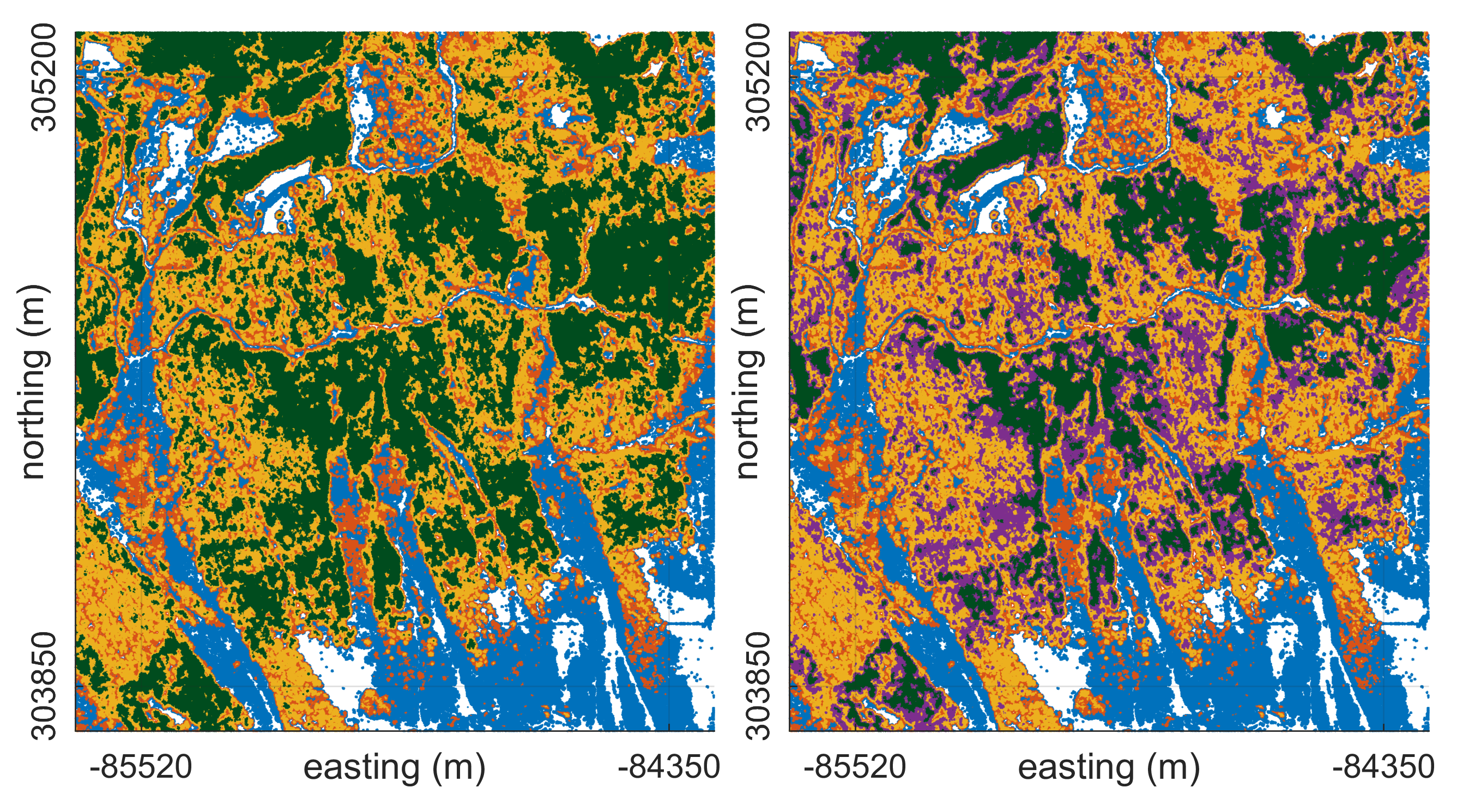
4.3.1. Forest Patch Delineation
Experiment 1
Experiment 2
4.3.2. Definition of Number of Patch Classes
4.3.3. Sensitivity to Thresholds
Sensitivity to
Sensitivity to
5. Discussion
5.1. Feature Computation
5.2. Iterative Splitting Segmentation
5.3. Validation
5.3.1. Forest Patch Delineation
Experiment 1
Experiment 2
5.3.2. Definition of Number of Patch Classes
5.3.3. Sensitivity to Thresholds
Sensitivity to
Sensitivity to
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- McKinley, D.C.; Ryan, M.G.; Birdsey, R.A.; Giardina, C.P.; Harmon, M.E.; Heath, L.S.; Houghton, R.A.; Jackson, R.B.; Morrison, J.F.; Murray, B.C.; et al. A synthesis of current knowledge on forests and carbon storage in the United States. Ecol. Appl. 2011, 21, 1902–1924. [Google Scholar] [CrossRef] [PubMed]
- Leiterer, R.; Furrer, R.; Schaepman, M.E.; Morsdorf, F. Forest canopy-structure characterization: A data-driven approach. For. Ecol. Manag. 2015, 358, 48–61. [Google Scholar] [CrossRef]
- Jackson, R.B.; Jobbágy, E.G.; Avissar, R.; Roy, S.B.; Barrett, D.J.; Cook, C.W.; Farley, K.A.; Le Maitre, D.C.; McCarl, B.A.; Murray, B.C. Trading water for carbon with biological carbon sequestration. Science 2005, 310, 1944–1947. [Google Scholar] [CrossRef]
- Bonan, G. Ecological Climatology: Concepts and Applications, 3rd ed.; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Noss, R.F. Indicators for monitoring biodiversity: A hierarchical approach. Conserv. Biol. 1990, 4, 355–364. [Google Scholar] [CrossRef]
- Franklin, J.F.; Spies, T.A.; Pelt, R.V.; Carey, A.B.; Thornburgh, D.A.; Berg, D.R.; Lindenmayer, D.B.; Harmon, M.E.; Keeton, W.S.; Shaw, D.C.; et al. Disturbances and structural development of natural forest ecosystems with silvicultural implications, using Douglas-fir forests as an example. For. Ecol. Manag. 2002, 155, 399–423. [Google Scholar] [CrossRef]
- Zellweger, F.; Morsdorf, F.; Purves, R.S.; Braunisch, V.; Bollmann, K. Improved methods for measuring forest landscape. Biodivers. Conserv. 2014, 23, 289–307. [Google Scholar] [CrossRef]
- Næsset, E. Estimating timber volume of forest stands using airborne laser scanner data. Remote Sens. Environ. 1997, 61, 246–253. [Google Scholar] [CrossRef]
- Lefsky, M.; Cohen, W.; Acker, S.; Parker, G.; Spies, T.; Harding, D. Lidar remote sensing of the canopy structure and biophysical properties of Douglas-fir western hemlock forests. Remote Sens. Environ. 1999, 70, 339–361. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Cohen, W.B.; Parker, G.G.; Harding, D.J. Lidar remote sensing for ecosystem studies. BioScience 2002, 52, 19–30. [Google Scholar] [CrossRef]
- Wehr, A.; Lohr, U. Airborne laser scanning—An introduction and overview. ISPRS J. Photogramm. Remote Sens. 1999, 54, 68–82. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Maltamo, M.; McRoberts, R.E.; Næsset, E. Introduction to Forestry Applications of Airborne Laser Scanning. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies. Managing Forest Ecosystems, 27; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 1–18. 464p. [Google Scholar]
- Parker, G.G.; Lefsky, M.A.; Harding, D.J. Light transmittance in forest canopies determined using airborne laser altimetry and in-canopy quantum measurements. Remote Sens. Environ. 2001, 76, 298–309. [Google Scholar] [CrossRef]
- Morsdorf, F.; Kötz, B.; Meier, E.; Itten, K.; Allgöwer, B. Estimation of LAI and fractional cover from small footprint airborne laser scanning data based on gap fraction. Remote Sens. Environ. 2006, 104, 50–61. [Google Scholar] [CrossRef]
- Solberg, S.; Brunner, A.; Hanssen, K.H.; Lange, H.; Næsset, E.; Rautiainen, M.; Stenberg, P. Mapping LAI in a Norway spruce forest using airborne laser scanning. Remote Sens. Environ. 2009, 113, 2317–2327. [Google Scholar] [CrossRef]
- Lovell, J.; Jupp, D.L.; Culvenor, D.; Coops, N. Using airborne and ground-based ranging lidar to measure canopy structure in Australian forests. Can. J. Remote Sens. 2003, 29, 607–622. [Google Scholar] [CrossRef]
- Coops, N.C.; Hilker, T.; Wulder, M.A.; St-Onge, B.; Newnham, G.; Siggins, A.; Trofymow, J.A. Estimating canopy structure of Douglas-fir forest stands from discrete-return LiDAR. Trees 2007, 21, 295–310. [Google Scholar] [CrossRef]
- Diedershagen, O.; Koch, B.; Weinacker, H. Automatic segmentation and characterisation of forest stand parameters using airborne lidar data, multispectral and fogis data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 36, 208–212. [Google Scholar]
- Koch, B.; Kattenborn, T.; Straub, C.; Vauhkonen, J. Segmentation of Forest to Tree Objects. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies. Managing Forest Ecosystems, 27; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 89–112. 464p. [Google Scholar]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Næsset, E. Area-Based Inventory in Norway—From Innovation to an Operational Reality. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies. Managing Forest Ecosystems, 27; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 215–240. 464p. [Google Scholar]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Koivuniemi, J.; Korhonen, K.T. Inventory by Compartments. In Forest Inventory - Methodology and Applications. Managing Forest Ecosystems, 10; Kangas, A., Maltamo, M., Eds.; Springer: Dordrecht, The Netherlands, 2006; pp. 271–278. 362p. [Google Scholar]
- Koch, B.; Straub, C.; Dees, M.; Wang, Y.; Weinacker, H. Airborne laser data for stand delineation and information extraction. Int. J. Remote Sens. 2009, 30, 935–963. [Google Scholar] [CrossRef]
- Hollaus, M.; Eysn, L.; Maier, B.; Pfeifer, N. Site index assessment based on multi-temporal ALS data. In Proceedings of the SilviLaser 2015, La Grande Motte, France, 28–30 September 2015; pp. 159–161. [Google Scholar]
- Almeida, A.C.; Sands, P.J. Improving the ability of 3-PG to model the water balance of forest plantations in contrasting environments. Ecohydrology 2016, 9, 610–630. [Google Scholar] [CrossRef]
- Dechesne, C.; Mallet, C.; Le Bris, A.; Gouet, V.; Hervieu, A. Forest stand segmentation using airborne lidar data and very high resolution multispectral imagery. In Proceedings of the ISPRS—International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Prague, Czech Republic, 12–19 July 2016; Volume XLI-B3, pp. 207–214. [Google Scholar] [CrossRef]
- Eysn, L.; Hollaus, M.; Schadauer, K.; Pfeifer, N. Forest delineation based on airborne LIDAR data. Remote Sens. 2012, 4, 762–783. [Google Scholar] [CrossRef]
- Wu, Z.; Heikkinen, V.; Hauta-Kasari, M.; Parkkinen, J.; Tokola, T. ALS data based forest stand delineation with a coarse-to-fine segmentation approach. In Proceedings of the IEEE 7th International Congress on Image and Signal Processing (CISP), Dalian, China, 14–16 October 2014; pp. 547–552. [Google Scholar] [CrossRef]
- Wang, Z.; Boesch, R.; Ginzler, C. Intergration of High Resolution Aerial Images and Airborne Lidar Data for Forest Delineation. In Proceedings of the ISPRS XXI Congress, Beijing, China, 3–11 July 2008; pp. 1203–1208. [Google Scholar]
- Wang, Z.; Boesch, R.; Ginzler, C. Forest delineation of aerial images with Gabor wavelets. Int. J. Remote Sens. 2012, 33, 2196–2213. [Google Scholar] [CrossRef]
- Straub, C.; Weinacker, H.; Koch, B. A fully automated procedure for delineation and classification of forest and non-forest vegetation based on full waveform laser scanner data. In Proceedings of the ISPRS XXI Congress, Beijing, China, 3–11 July 2008; pp. 1013–1019. [Google Scholar]
- Cheng, H.D.; Jiang, X.H.; Sun, Y.; Wang, J. Color image segmentation: Advances and prospects. Pattern Recognit. 2001, 34, 2259–2281. [Google Scholar] [CrossRef]
- Mustonen, J.; Packalen, P.; Kangas, A. Automatic segmentation of forest stands using a canopy height model and aerial photography. Scand. J. For. Res. 2008, 23, 534–545. [Google Scholar] [CrossRef]
- Sullivan, A.A.; McGaughey, R.J.; Andersen, H.E.; Schiess, P. Object-oriented classification of forest structure from light detection and ranging data for stand mapping. West. J. Appl. For. 2009, 24, 198–204. [Google Scholar]
- Fedrigo, M.; Newnham, G.J.; Coops, N.C.; Culvenor, D.S.; Bolton, D.K.; Nitschke, C.R. Predicting temperate forest stand types using only structural profiles from discrete return airborne lidar. ISPRS J. Photogramm. Remote Sens. 2018, 136, 106–119. [Google Scholar] [CrossRef]
- Walz, U. Monitoring of landscape change and functions in Saxony (Eastern Germany)—Methods and indicators. Ecol. Indic. 2008, 8, 807–817. [Google Scholar] [CrossRef]
- Müller, J.; Bae, S.; Röder, J.; Chao, A.; Didham, R.K. Airborne LiDAR reveals context dependence in the effects of canopy architecture on arthropod diversity. For. Ecol. Manag. 2014, 312, 129–137. [Google Scholar] [CrossRef]
- Valbuena, R.; Eerikäinen, K.; Packalen, P.; Maltamo, M. Gini coefficient predictions from airborne lidar remote sensing display the effect of management intensity on forest structure. Ecol. Indic. 2016, 60, 574–585. [Google Scholar] [CrossRef]
- Schindler, K. An overview and comparison of smooth labeling methods for land-cover classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4534–4545. [Google Scholar] [CrossRef]
- Hollaus, M.; Mücke, W.; Höfle, B.; Dorigo, W.; Pfeifer, N.; Wagner, W.; Bauerhansl, C.; Regner, B. Tree species classification based on full-waveform airborne laser scanning data. In Proceedings of the SilviLaser, College Station, TX, USA, 14–16 October 2009; pp. 54–62. [Google Scholar]
- Palace, M.W.; Sullivan, F.B.; Ducey, M.J.; Treuhaft, R.N.; Herrick, C.; Shimbo, J.Z.; Mota-E-Silva, J. Estimating forest structure in a tropical forest using field measurements, a synthetic model and discrete return lidar data. Remote Sens. Environ. 2015, 161, 1–11. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Mallet, C. Semantic 3D scene interpretation: A framework combining optimal neighborhood size selection with relevant features. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, II-3, 181–188. [Google Scholar] [CrossRef]
- Hilker, T.; van Leeuwen, M.; Coops, N.C.; Wulder, M.A.; Newnham, G.J.; Jupp, D.L.; Culvenor, D.S. Comparing canopy metrics derived from terrestrial and airborne laser scanning in a Douglas-fir dominated forest stand. Trees 2010, 24, 819–832. [Google Scholar] [CrossRef]
- Jones, E.; Oliphant, T.; Peterson, P. SciPy: Open Source Scientific Tools for Python. 2014. Available online: http://www.scipy.org/ (accessed on 17 January 2019).
- Glira, P. Point Cloud Tools for Matlab. 2017. Available online: http://www.geo.tuwien.ac.at/downloads/pg/pctools/pctools.html (accessed on 17 January 2019).
- Brassard, G.; Bratley, P. Fundamentals of Algorithmics; Prentice Hall: Upper Saddle River, NJ, USA, 1996; Volume 33. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MATLAB 9.3; The MathWorks Inc.: Natick, MA, USA, 2017.
- Mahalanobis, P. On the Generalised Distance in Statistics. In Proceedings of the National Institute of Sciences of India, Calcutta, India, 16 April 1936; Volume 2, pp. 49–55. [Google Scholar]
- Miralles, D.G.; Gash, J.H.; Holmes, T.R.; de Jeu, R.A.; Dolman, A. Global canopy interception from satellite observations. J. Geophys. Res. 2010, 115. [Google Scholar] [CrossRef]
- Mura, M.; McRoberts, R.E.; Chirici, G.; Marchetti, M. Estimating and mapping forest structural diversity using airborne laser scanning data. Remote Sens. Environ. 2015, 170, 133–142. [Google Scholar] [CrossRef]
- Zhang, Z.; Cao, L.; She, G. Estimating forest structural parameters using canopy metrics derived from airborne LiDAR data in subtropical forests. Remote Sens. 2017, 9, 940. [Google Scholar] [CrossRef]
- Wang, D.; Brunner, J.; Ma, Z.; Lu, H.; Hollaus, M.; Pang, Y.; Pfeifer, N. Separating Tree Photosynthetic and Non-Photosynthetic Components from Point Cloud Data Using Dynamic Segment Merging. Forests 2018, 9, 252. [Google Scholar] [CrossRef]
- Amiri, N.; Polewski, P.; Heurich, M.; Krzystek, P.; Skidmore, A.K. Adaptive stopping criterion for top-down segmentation of ALS point clouds in temperate coniferous forests. ISPRS J. Photogramm. Remote Sens. 2018, 141, 265–274. [Google Scholar] [CrossRef]
- Zhang, H.; Fritts, J.E.; Goldman, S.A. Image segmentation evaluation: A survey of unsupervised methods. Comput. Vision Image Underst. 2008, 110, 260–280. [Google Scholar] [CrossRef]
- Tokola, T.; Vauhkonen, J.; Leppänen, V.; Pusa, T.; Mehtätalo, L.; Pitkänen, J. Applied 3D texture features in ALS based tree species segmentation. In Proceedings of the International Archives of Photogrammetry, Remote Sensing and Spatial Information, GEOBIA 2008, Calgary, AB, Canada, 5–8 August 2008; Volume 38. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Usage in Segmentation Pipeline | Point Cloud Feature |
|---|---|
| Input to k-means | h95 for search radii = {2, 5, 10 m} |
| for search radii = {2, 5, 10 m} | |
| for search radii = {2, 5, 10 m} | |
| for search radius = {10 m} | |
| h95, search radius = 5 m | |
| h95, search radius = 5 m | |
| h95, search radius = 5 m |
| Canopy Parameters | ALS Metrics |
|---|---|
| Leaf area | fractional cover, |
| Foliage density | d40, |
| Tree functional type | d50 |
| Usage in Segmentation Pipeline | Point Cloud Feature |
|---|---|
| Input to k-means | fractional cover for search radii = {2, 5, 10 m} |
| d40 for search radii = {2, 5, 10 m} | |
| d50 for search radii = {2, 5, 10 m} | |
| for search radius = {2, 5, 10 m} | |
| for search radius = {10 m} | |
| fractional cover, search radius = 5 m | |
| d50, search radius = 5 m | |
| d50, search radius = 5 m |
| Threshold | Number of Segments k | ||
|---|---|---|---|
| k =4 | k =5 | k =8 | |
| 0.4 | |||
| 1000 | |||
| 20000 | |||
| 5.0 | 3.0 | 1.3 | |
| 0.79 | 0.84 | 0.85 | |
| 0.70 | 0.77 | 0.78 | |
| Threshold | Number of Segments k | ||
|---|---|---|---|
| k =4 | k = 5 | k = 7 | |
| 0.4 | |||
| 1000 | |||
| 20000 | |||
| 2.3 | 2.0 | 1.5 | |
| 0.75 | 0.86 | 0.86 | |
| 0.60 | 0.68 | 0.68 | |
| Threshold | Number of Segments k | ||
|---|---|---|---|
| k =4 | k = 5 | k =6 | |
| 0.22 | |||
| 1000 | |||
| 20,000 | |||
| 1.2 | 0.95 | 0.8 | |
| 0.67 | 0.80 | 0.82 | |
| 0.65 | 0.76 | 0.79 | |
| Threshold | Number of Segments k | ||
|---|---|---|---|
| k = 4 | k = 5 | k = 6 | |
| 0.4 | |||
| 1000 | |||
| 20,000 | |||
| 4.0 | 2.5 | 0.7 | |
| 0.90 | 0.91 | 0.91 | |
| 0.88 | 0.90 | 0.90 | |
| Class Label | Number of Classes k | ||
|---|---|---|---|
| k = 4 | k = 5 | k = 8 | |
| blue/S1 | 3.44 | 3.44 | 3.44 |
| orange/S2 | 41.12 | 10.55 | 7.14 |
| purple/S5 | 34.71 | 34.71 | 34.71 |
| green/S6 | 20.73 | 20.73 | 18.24 |
| yellow/S4 | 30.57 | 30.57 | |
| S3 | 3.42 | ||
| S7 | 0.70 | ||
| S8 | 1.79 | ||
| Class Label | Number of Classes k | ||
|---|---|---|---|
| k = 4 | k = 5 | k = 7 | |
| blue | 8.15 | 8.15 | 8.15 |
| yellow | 12.93 | 12.93 | 11.00 |
| green | 66.11 | 57.41 | 57.41 |
| red | 12.80 | 12.80 | 10.49 |
| purple | 8.70 | 8.70 | |
| orange | 1.93 | ||
| light blue | 2.31 | ||
| Number of Classes | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|
| 5.42 | 5.00 | 4.09 | 2.98 | 1.79 | 1.75 | 1.10 |
| Threshold | Parameter Value | ||
|---|---|---|---|
| 0.1 | 0.4 | 1.0 | |
| 1000 | |||
| 20,000 | |||
| 3.0 | |||
| Processing Step | Number of Classes | ||
| k-means | 217 | 12 | 7 |
| elimination | 33 | 10 | 7 |
| overlap merging | 5 | 5 | 7 |
| Threshold | Parameter Value | ||
|---|---|---|---|
| 0.1 | 0.4 | 1.0 | |
| 3.0 | 3.0 | 5.3 | |
| Attribute | Consistency | ||
| h95 | 0.60 | 0.84 | 0.80 |
| 0.47 | 0.77 | 0.72 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bruggisser, M.; Hollaus, M.; Wang, D.; Pfeifer, N. Adaptive Framework for the Delineation of Homogeneous Forest Areas Based on LiDAR Points. Remote Sens. 2019, 11, 189. https://doi.org/10.3390/rs11020189
Bruggisser M, Hollaus M, Wang D, Pfeifer N. Adaptive Framework for the Delineation of Homogeneous Forest Areas Based on LiDAR Points. Remote Sensing. 2019; 11(2):189. https://doi.org/10.3390/rs11020189
Chicago/Turabian StyleBruggisser, Moritz, Markus Hollaus, Di Wang, and Norbert Pfeifer. 2019. "Adaptive Framework for the Delineation of Homogeneous Forest Areas Based on LiDAR Points" Remote Sensing 11, no. 2: 189. https://doi.org/10.3390/rs11020189
APA StyleBruggisser, M., Hollaus, M., Wang, D., & Pfeifer, N. (2019). Adaptive Framework for the Delineation of Homogeneous Forest Areas Based on LiDAR Points. Remote Sensing, 11(2), 189. https://doi.org/10.3390/rs11020189