1. Introduction
Remote sensing images generally refer to the pictorial ground information acquired by satellite or aircraft sensor technologies. With sufficient spectral and spatial information, remote sensing images have played an important role in many applications, such as urban planning, agriculture management, climate monitoring, military affairs, etc. [
1,
2,
3], while for these applications, classification with a fine accuracy is essential [
4]. Different from common optical images, classifying remote sensing images is more difficult concerning their characteristics, such as having more spectral bands, rich spatial information, low spatial resolution, and so on [
5,
6]. Furthermore, remote sensing images usually have complex ground scenes and irregular objects, thus they are characteristic of irregular spatial dependency [
7], which further cause challenges for classification tasks.
There have been many methods designed for the classification of remote sensing images, which can be roughly grouped into three categories, i.e., supervised, semi-supervised and unsupervised methods [
8], according to the manner of the information exploration from labeled or unlabeled samples. On the one hand, unsupervised methods, generally using clustering strategies, such as fuzzy clustering [
9] and fuzzy C-Means algorithms [
10], which attempt to explore patterns from unlabeled samples [
11], have been proved to be efficient but incapable of bridging the gap between clusters and classes [
12]. On the other hand, supervised classifiers, such as support vector machine (SVM) [
13,
14], multinomial logistic regression [
15,
16] and artificial neural networks (ANN) [
17,
18], which learn from labeled samples to obtain prior knowledge, have demonstrated impressive performance. However, supervised classifiers heavily rely on the quantity and quality of labeled samples [
19,
20,
21]. In real scenarios, sample labeling is usually difficult, time-consuming, and expensive [
22]. Therefore, the labeled samples available are often insufficient, which leads to the occurrence of Hughes phenomenon [
23] and increases the possibility of overfitting [
24,
25].
Semi-supervised learning is usually used to relieve the conflict between training demand and limited labeled sample set. It aims to make use of both limited labeled samples and abundant unlabeled samples, binds together unsupervised and supervised learning [
26]. There exist many semi-supervised approaches in the literatures [
27]. For instance, generative semi-supervised learning methods use the conditional density to determine labels of unlabeled samples [
28,
29,
30]. However, those methods generally under the assumption that unlabeled samples follow a certain distribution which may limit the performance [
11]. Wrapper methods include self-training [
22,
31,
32] and co-training [
22,
33,
34,
35]. The former trains the classifier iteratively with new training samples labeled by the classifier itself, while the latter employ several classifiers to train with independent subsets of samples and the unlabeled samples with high reliability are then used to train another classifier. Self-training schemes may reinforce its poor predictions, while co-training algorithms demand that the samples can be divided into independent subsets [
11]. Low-density separation algorithms, such as the transductive SVMs [
36,
37,
38] which perform the classification by maximizing the margin for labeled and unlabeled samples, also suffer from the poor generalization ability. Graph-based approaches construct graphs to connect similar observations and spread labeled information in its neighbors by finding minimum energy function [
12,
39,
40,
41,
42], which also incur some problems such as being sensitive to the graph structure [
43,
44].
Recently, deep learning structures have attained great success owing to its outstanding generalization capacity compared with traditional shallow structures [
45]. Some of the recent developments are focused on semi-supervised learning, which exploits both labeled and unlabeled information to tackle the issue of overfitting, i.e., a limited number of labeled information and huge number of parameters involved [
46]. This new trend has been successfully applied for remote sensing image classifications. For instance, Ma et al. [
11] use a deep hierarchical structure to learn highly discriminative representation and pre-labels unlabeled samples, where multi-decision schemes are formed to update the labeled training data set and thus realize semi-supervised learning. However, this kind of purely discriminative and self-learning style semi-supervised way often rely on iterative training, thus are time-consuming and resource-consuming. He et al. [
8] apply popular GANs (Generative adversarial networks) to study the latent representation of the input data, whose model resorts to the regularization techniques to explore the information in unlabeled samples and hence assist the discriminative classification tasks. In that generative model, unsupervised embeddings or hidden representations are often used to help supervised objectives [
47]. Nevertheless, such latent variable models are still not suitable enough to match hidden representation with supervised tasks at hand. Rasmus et al. [
48] propose a Ladder Network by combining supervised learning with unsupervised learning in deep neural networks, which needs only a small number of labeled samples. However, the method lacks the mining to spatial information of unlabeled samples, which weakens its capacity and applications, especially for remote sensing images.
Remote sensing images have complex ground scenes and irregular objects; thus, they are naturally characteristic of irregular spatial dependency [
7], causing difficulties for classification. Deep supervised models such as CNNs are robust classifiers but require many training samples for fine tuning the network parameters, which conflicts with the reality that only a small number of labeled samples are available. To address these challenges, in this paper, we design a superpixel-guided layer-wise embedding CNN framework (SLE-CNN) for remote sensing image classification. It can automatically determine the neighborhood covering for a spatial dependency system and thus provide more
a priori information of high quality for labels, which can improve the training performance of the deep network in a semi-supervised manner. We use a superpixel-based random sampling strategy to select unlabeled samples since superpixels are adaptive to real scenes of remote sensing images [
7]. The involved layer-wise embedding CNN can fuse deep autoencoder (AE) and CNN in a layer-wise embedding fashion where unsupervised reconstruction cost and supervised cross entropy loss are optimized simultaneously, thus achieving an end-to-end structure. This structure can use information from both labeled and unlabeled samples and efficiently reduce the overfitting risks, therefore, well adapting to semi-supervised tasks. Moreover, instead of applying the unsupervised auxiliary tasks as only a part of pre-training procedure followed by normal supervised learning, the layer-wise embedding CNN shares the hidden representations between unsupervised generative representation and its discriminative counterpart, thus helps more informative unsupervised features to be learned for a discriminative purpose. All the above aspects contribute to the better classification performances for remote sensing images.
The main research objectives of this paper can be identified as follows:
Considering the fact that remote sensing images are characteristic of irregular spatial dependency, we introduce the superpixel sampling strategy to guide the use of unlabeled samples, which can achieve an automatic determination of the neighborhood covering for a spatial dependency system and thus adapting to real scenes of remote sensing images. With the aid of these highly representative and informative unlabeled samples, the training process will be boosted, leading to better classification results.
Deep CNNs are efficient classifiers, but it requires many labeled samples for training which conflicts with the reality that only limited labeled samples are available. To reduce the demand for labeled samples, we develop an SLE-CNN, which can take advantage of many unlabeled samples with the guide of superpixel-based random sampling. It regards CNN as the encoder part of the AE model and appends a reconstruction loss at each layer of the network that plays a role of extra supervision, thus combining the strong generalization capacity of deep CNN model with the detail preserving ability of AE.
To demonstrate the performance of our framework for classification tasks of different types of remote sensing data, we conducted experiments to provide the latest results on benchmark problems. In addition, we compared our framework with several typical semi-supervised and supervised methods, which also verifies the effectiveness of our proposed framework.
The remainder of the paper is organized as follows.
Section 2 presents our newly developed framework in detail. Experimental results with hyperspectral, multispectral and SAR image data are shown in
Section 3. Some discussions with extra experiments are placed in
Section 4. Finally,
Section 5 draws some conclusions.
2. Methodology
The block diagram of the proposed classification framework for remote sensing images is shown in
Figure 1. The core of the framework is SLE-CNN (shown in the purple block in
Figure 1), which is mainly composed of two sequential steps: heuristic sampling based on superpixel segmentation and the layer-wise embedding CNN. To exploit the full potential of remote sensing data, both limited labeled samples and sufficient unlabeled samples are used to construct a training dataset. Considering the irregular spatial dependency in remote sensing images, the random sampling strategy based on superpixels is employed to guide the selection of unlabeled samples. Superpixels are adaptive to real scenes of remote sensing images, which can improve the performance of the framework considering the variations of spatial characteristics of remote sensing images. Samples close to superpixel boundaries, viewed as samples likely to be class boundaries with difficulty to distinguish, are of high representativeness and entropy and can strengthen the generalization capacity of classifiers. Unlabeled samples along with a limited size of labeled samples are subsequently organized in the form of patches and both input to the layer-wise embedding CNN to fine tune the deep network and search for the best generalization of the input data. At last, classification maps can be obtained through the input of patches from remote sensing images to the fine-tuned layer-wise embedding CNN.
In this section, we will thoroughly present structure of SLE-CNN. In the first two parts, we will first introduce the basic background and knowledge of the proposed method, including the detailed description of the proposed superpixel-based random sampling strategy for unlabeled samples in
Section 2.1 and the structure of an autoencoder, one of the basic architectures used in our classifier, in
Section 2.2. At last, in
Section 2.3, we will illustrate the whole structure of the designed SLE-CNN in detail.
2.1. Superpixel-Based Random Sampling
To ensure both the representative ability and efficiency, we need to bring in a random sampling strategy to select just a portion of unlabeled dataset instead of using them all during the training process. However, absolute random strategy is not enough to exploit the potential of the unlabeled samples. To deal with this, we design a superpixel-based random sampling strategy.
Pixels close to the class boundaries usually have a higher error probability to be misclassified, which makes it informative for sample collection. After a beforehand segmentation, we can actually obtain a strong prior on both spectral and spatial domain. In addition, samples close to the boundaries are more likely to be those near the class boundaries. We can strengthen the generalization capacity of classifiers by taking into account these high entropy samples [
49].
Considering the irregular spatial dependency of remote sensing images, we use superpixels segmentation to produce the segmentation results in view of its adaptive ability to different scenes of remote sensing images.
Simple Linear Iterative Clustering (SLIC) [
50,
51] algorithm is used as the method to obtain superpixels mainly considering its efficient computational performance compared to other algorithms. SLIC, which is a simple and efficient segmentation method based on k-means clustering, generates superpixels by clustering pixels in both spectral and spatial domains with each pixel linked to a feature vector
:
where
is the spectral vector at position
.
is a coefficient to balance the spectral and spatial components of the vector,
.
S is the nominal size of superpixels, and
c is a variable to control the compactness of superpixels.
The algorithm starts by dividing image into
tiles (
, where
and
are the number of rows and columns in an image, respectively.
is the expected spatial size of superpixels.
represents ceiling function which maps a number to the least integer greater than or equal to the number) with initial cluster center (
) (
). To avoid placing centers at edges and selecting noisy pixels, the cluster centers are moved in a
window with the lowest gradient. The gradient is defined as:
where
is the
norm.
Then the superpixels are obtained by k-means clustering, where each pixel is assigned to the nearest initial cluster center, and a new center is recomputed as the average of the feature vectors of pixels belonging to the cluster. The process is iteratively repeated until convergence. After the k-means clustering, the SLIC algorithm assigns disjoint segments to the largest neighboring cluster to enforce connectivity.
Based on the SLIC algorithm, we can sample the most representative unlabeled data. With simple random sampling strategy, samples are selected randomly and may be biased, which cannot meet the need for semi-supervised learning [
52]. To select highly informative unlabeled samples automatically and reduce the demand of enlarging training samples, we introduce a superpixel segmentation-based random sampling strategy, which can also be regarded as a process to mine samples that are hard to distinguish:
Images are segmented to superpixels, and all pixels in images are recorded as set A;
Randomly choose a part of set A as set B;
Pixels located on the boundaries of superpixels are detected and recorded as set C;
For each pixel in set B, if its spatial distance to any pixel of the same superpixel in set C is less than or equal to k (pixel unit), put it in the candidate list.
This whole sampling procedure can be visualized as
Figure 2.
2.2. Autoencoder
An autoencoder (AE) is an artificial neural network used for unsupervised learning of efficient codings [
53,
54]. An AE aims to learn a representation (encoding) for a set of data.
Architecturally, the simplest form of an AE is a feedforward, non-recurrent neural network very similar to the multilayer perceptron (MLP)—having an input layer, an output layer and one or more hidden layers connecting them—but with the output layer having the same number of nodes as the input layer, and with the purpose of reconstructing its own inputs.
An AE always consists of two parts, the encoder and the decoder. In the simplest case, where there is one hidden layer, the encoder stage of an AE takes the input
x and maps it to
r
where the image
r is usually referred to as code, latent variables, or latent representation.
is an element-wise activation function such as a sigmoid function or a rectified linear unit (ReLU).
W is a weight matrix and
b is a bias vector.
After the encoder, the decoder stage of the AE maps
r to the reconstruction
of the same shape as
x
where
,
and
for the decoder may differ in general from the corresponding
,
W and
b for the encoder, depending on the design of the AE.
AEs are also trained to minimize reconstruction costs (such as square error):
where
x is usually averaged over some input training set.
Denoising AEs take a partially noisy input while training to recover the original clean input. This technique has been introduced with a specific approach to good representation [
55]. A good representation is one that can be obtained robustly from a noisy input and that will be useful for recovering the corresponding clean input.
2.3. Superpixel-Guided Layer-Wise Embedding CNN
Remote sensing images have complex ground scenes and irregular objects, thus irregular spatial dependency is one of the major characteristics of remote sensing images, which brings about challenges for classification tasks. Though prevailing deep supervised models usually have good feature generalization capacities with sufficient training samples, the situation will deteriorate rapidly when labeled data is limited [
56]. This dilemma originates from the conflict between huge parameter volume and insufficient training samples. To handle the irregular spatial dependency and relieve the training demand for labeled samples, we design a superpixel-guided layer-wise embedding CNN framework to assist the optimization process for remote sensing image classification introducing the use of unlabeled data.
Since the goal of using unlabeled data for unsupervised learning is actually a type of regularization for supervised learning, we expect our supervised tasks to perform better, which demand the hidden representations shared by both supervised and unsupervised parts to be more robust. To achieve this, we need on one hand to feed more informative training samples to learn the best representation, and on the other hand to design a more powerful network structure to capture the internal characteristics of the input data. For the latter, we establish a layer-wise embedding CNN structure to efficiently learn the best discriminate feature for final classification. For the former, we use the superpixel-based random sampling strategy (as introduced in
Section 2.1) to heuristically search useful and informative unlabeled samples without enlarging the labeled part of the training dataset. In particular, superpixels are usually spatially irregular subregions, but pixels inside them are homogenous, which means an automatic determination of the neighborhood covering for a spatial dependency system in a data-dependent manner [
7]. Thus, supepixels are adaptive to real scenes of remote sensing images considering the irregular spatial dependency in remote sensing images.
The proposed whole SLE-CNN structure is shown in
Figure 3, where all the inputs are organized as patches from pixels. Superpixel-guided patches, referring to unlabeled samples which are selected under the superpixel-based random sampling strategy shown in the left purple block of the figure, along with labeled patches are input to the layer-wise embedding CNN in the right part of the figure to fine tune the network. To get a classification map for a remote sensing image, each patch from each pixel need to be input to the fine-tuned layer-wise embedding CNN so that a class label at each pixel can be obtained, shown in the upper part of the figure with an orange-red color arrow.
From the denoising AE’s point of view, the layer-wise embedding CNN can be constructed by two parts in sequence, where two versions of encoder architectures, including one clean encoder (the green block in the top of
Figure 3) and one noisy encoder (the blue block at the bottom of
Figure 3), are followed by a mutual decoder architecture (the yellow block in the middle of
Figure 3). Here, noise is injected into hidden layers of the noisy encoder to obtain a better feature generalization, which is similar to the common regularization technique dropout [
57]. Specifically, we use a deep spectral-spatial CNN structure, which can make full use of spectral and spatial information of remote sensing images, as the architectures of the encoders to enhance the representative capacity and increase the supervised discriminative power. The parts of the structure are associated through skip connection and layer-wise embedding structures. The former technique strengthens the representative ability of the learned feature in the reconstruction stage by the superposition of the noisy encoder part upon the decoder part layer-wisely. The latter one serves as an extra supervision for the joint optimization process to achieve a strong regularization for raw remote sensing images and promote the discriminative ability.
Consider a dataset with labeled samples
and unlabeled samples
where
. The goal for the classifier is to learn a function that models
by using both the labeled samples and the unlabeled samples. Here, the objective function for the training of the layer-wise embedding CNN is casted as a sum of the supervised cross entropy (
in
Figure 3) related to labeled patches from the noisy encoder and the unsupervised reconstruction cost (
in
Figure 3) from superpixel-guided unlabeled patches at each layer of the decoder. Since all layers of the noisy encoder are corrupted by noise, another clean encoder path with shared parameters is responsible for providing the clean reconstruction targets. The whole structure is optimized by traditional backpropagation gradient descent.
At the end of the encoder path, we can obtain the one-hot encoded classification vector through a full connection layer combined with SoftMax operation. Please note that the ultimate class label for each input patch of remote sensing images at the test stage comes from the clean output from the clean encoder, while the noisy output from the noisy encoder is only for calculating the supervised cross entropy.
Each part of the layer-wise embedding CNN is explained in detail in the following.
2.3.1. General Steps for Constructing Layer-Wise Embedding CNN
Based on the structure of a denoising AE, we combine a noisy encoder and corresponding decoder layer via vertical skip connections, where two signals are fused by a denoising function to reconstruct the layer in the decoder. This technique helps the higher layer to focus on extracting more abstract and task-specific features, which can facilitate feature extraction from complex remote sensing images. Meanwhile, a clean encoder is trained in a feedforward fashion to evaluate the reconstruction effect [
58].
The layer-wise embedding CNN can be defined as (suppose we have a total of
L layers in both encoder and decoder parts):
where
,
and
represent the noisy encoder, the clean encoder, and the decoder, respectively.
x,
and
are the clean, noisy, and reconstructed input patches, respectively.
,
, and
are the clean hidden representation, its noisy version, and its reconstructed version at layer
l.
y and
, outputs after SoftMax operation, are the clean class label and the noisy class label, respectively. The noisy
is used to calculate supervised cross entropy during the training process as described in following Equation (
17), while the classification map is obtained from the clean
y at test stage.
2.3.2. CNN Based Encoder for Supervised Learning
To use both spectral and spatial information in remote sensing images and enhance the representative capacity, a spectral-spatial CNN structure is constructed into the encoder architecture in the forward path. Overall, the encoder consists of the convolution, max pooling, batch normalization, noise injecting (for the noisy encoder) and activation operations for each layer. At the end of the encoders, the output
y and
are obtained through SoftMax operation (see
Figure 3).
Firstly, 3-D convolution
and max pooling
transformations from layer
to layer
l are put on
, the post-activation at layer
, to obtain the pre-normalization
:
Batch normalization is then applied to
with the mini-batch mean
and standard deviation
. In addition, isotropic Gaussian noise
is added to compute pre-activation
:
Then, through a nonlinear activation function such as ReLU, defined as
, we can obtain
, the post-activation at layer
l, as the input for the next layer:
where
and
are trainable parameters responsible for shifting and scaling.
Please note that the above equations describe the noisy encoder, with noisy and . If we remove noise, we will obtain the clean version of the encoder with clean s and r.
2.3.3. Vertical Connection and Vanilla Combinator-Based Denoising Function for Unsupervised Learning
In the backward path, deconvolution, unpooling and batch normalization are performed at layers in the decoder. Besides, vanilla combinator-based denoising function is used for combining the signal from the noisy encoder and the signal in the decoder, which achieves the vertical connection. This technique strengthens the representative ability of the learned feature in the reconstruction stage.
For each layer of the decoder, deconvolution
and unpooling
operations from layer
to layer
l are employed to layer
:
Batch normalization is then implemented on
to get
:
After normalization correction, the signal from the layer
and the noisy
via vertical connection are combined into the reconstruction
through a denoising process:
where
is the vanilla combinator-based denoising function. It can combine the lateral
and the vertical
connections in an element-wise fashion.
Here, function
is to achieve the lowest reconstruction cost. Considering the conditional distribution
that we intend to model, the optimal functional form of
g will be linear with respect to
when
is Gaussian. The parametrization of the denoising function is therefore:
where we modeled both
and
with a multilayer architecture form nonlinear function:
and
.
to
are linear coefficients. For a given
u,
is linear related to the parametrization, and both
v and
depend nonlinearly on
u.
2.3.4. Overall Objective Function Formulation
Finally, the objective function for the layer-wise embedding is a balance of the supervised cross entropy from the noisy encoder and the unsupervised reconstruction cost at each layer of the decoder. Since all layers of the noisy encoder are corrupted by noise for the purpose of obtaining a better feature generalization, the clean encoder is providing the clean reconstruction targets as the reference of the decoder.
The objective function,
, is defined as the following shows:
where
is supervised cross entropy from the noisy encoder and
is unsupervised reconstruction costs from the decoder.
(with
N labeled patches) is calculated as the sum negative log probability of the noisy output
matching the target output
given the input
:
And
(with
M superpixel-guided unlabeled patches) represent the sum of reconstruction costs from all
L layers:
where
represents the layer-wise embedding unsupervised reconstruction cost which consists of cost from each decoder layer.
is a layer-wise coefficient. The denoising intensity of each layer can be tuned by changing each
.
in the above Equation (
18) is formalized as:
where
is performed batch normalization with mean and standard deviation of
in the noisy encoder part.
The feedforward pass of the layer-wise embedding CNN is listed in Algorithm 1, where means batch normalization, and is the nonlinear activation function, such as ReLU.
| Algorithm 1 Calculation of output class labels and objective function of the layer-wise embedding CNN |
Require: Noisy encoder for to L do end for Clean encoder for to L do end for Classification Decoder for to 0 do if then else end if end for Supervised cross entropy ifthen end if Unsupervised reconstruction costs Cost function for training
|
4. Discussion
We further make experiments to verify the effectiveness of the designed superpixel-based random sampling strategy compared with totally random sampling strategy based on the layer-wise embedding CNN. Accuracy results based on 5 labeled samples per class are shown in
Figure 11, which confirm the efficiency of the idea of superpixel-based random sampling. Overall, the above experimental results prove the superiority of our designed SLE-CNN framework for remote sensing image classification, considering both the sampling strategy and the deep network.
Also, we evaluate the performance of our designed SLE-CNN framework with the increase in the number of labeled samples and estimate its stability. We randomly choose 5, 10, 15, 20, 25 and 30 samples from each class as the labeled samples and the OA of above various methods is plotted in
Figure 12, which shows that the classification accuracy increases as the number of labeled samples goes up and our designed SLE-CNN framework is superior to other methods when the same number of labeled training samples is chosen. Although the performance of different methods changes as the number of training samples changes, the designed SLE-CNN framework provides higher classification accuracies than other methods.
It should be noted that under the condition of extremely limited training samples, our framework has the risk of becoming unstable and influenced by noises, which need to be improved in the algorithm. However, the superpixel-based random sampling strategy, used for the guide of the selection of unlabeled samples, has reduced such risks to some degree. It should also be mentioned that classification results produced by the designed framework may be over-smooth and some details may be lost. Therefore, it should be treated carefully.
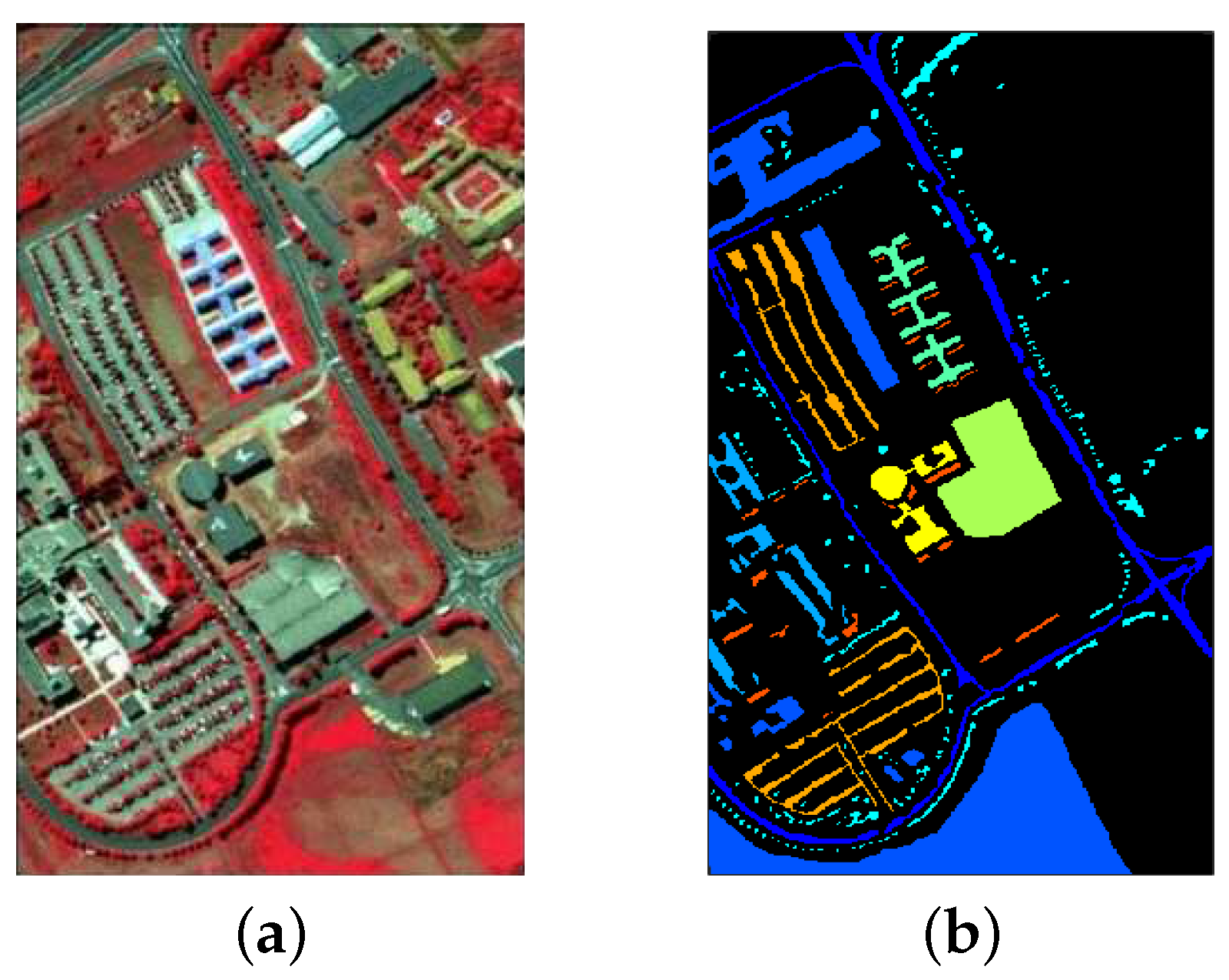
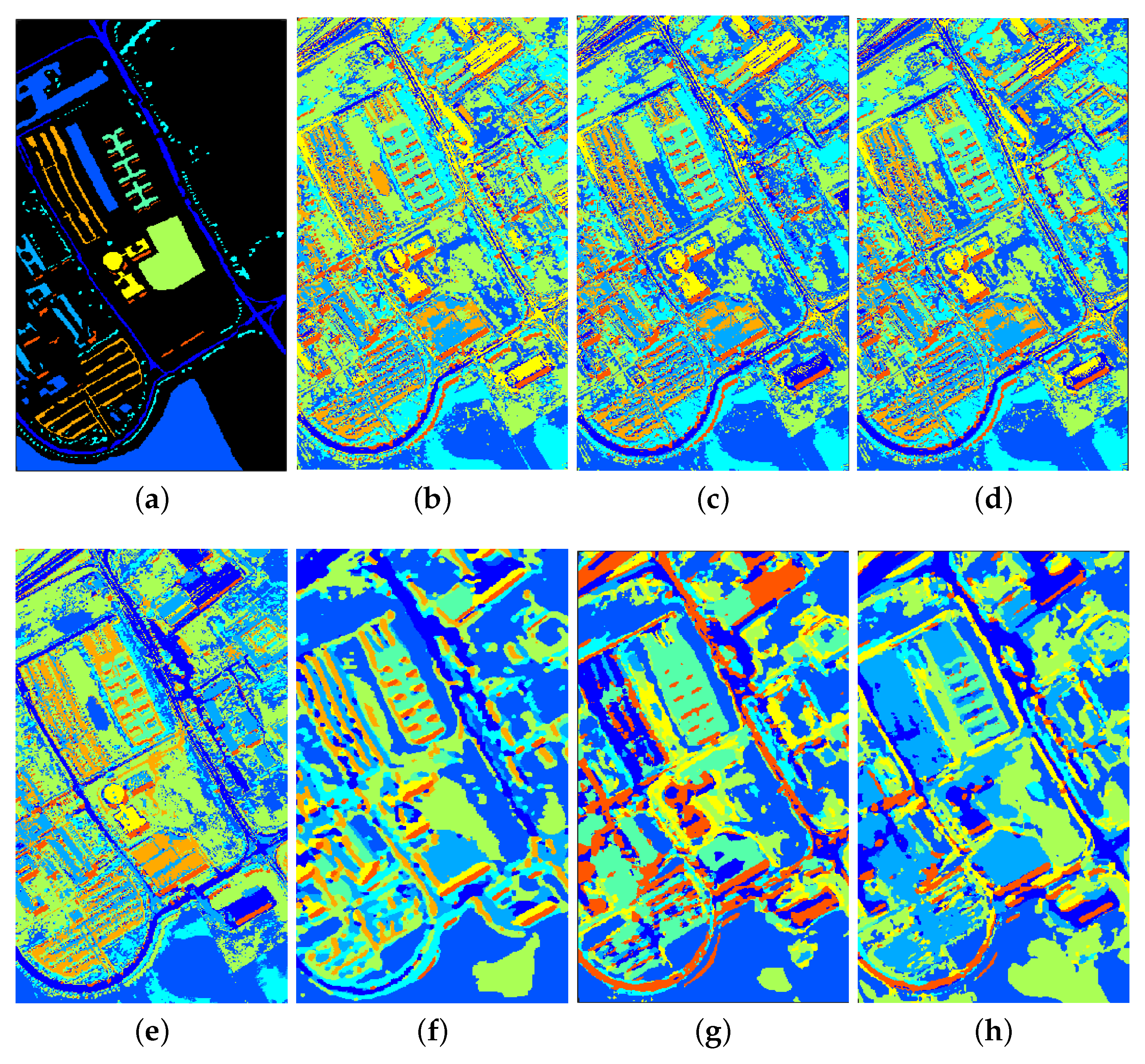
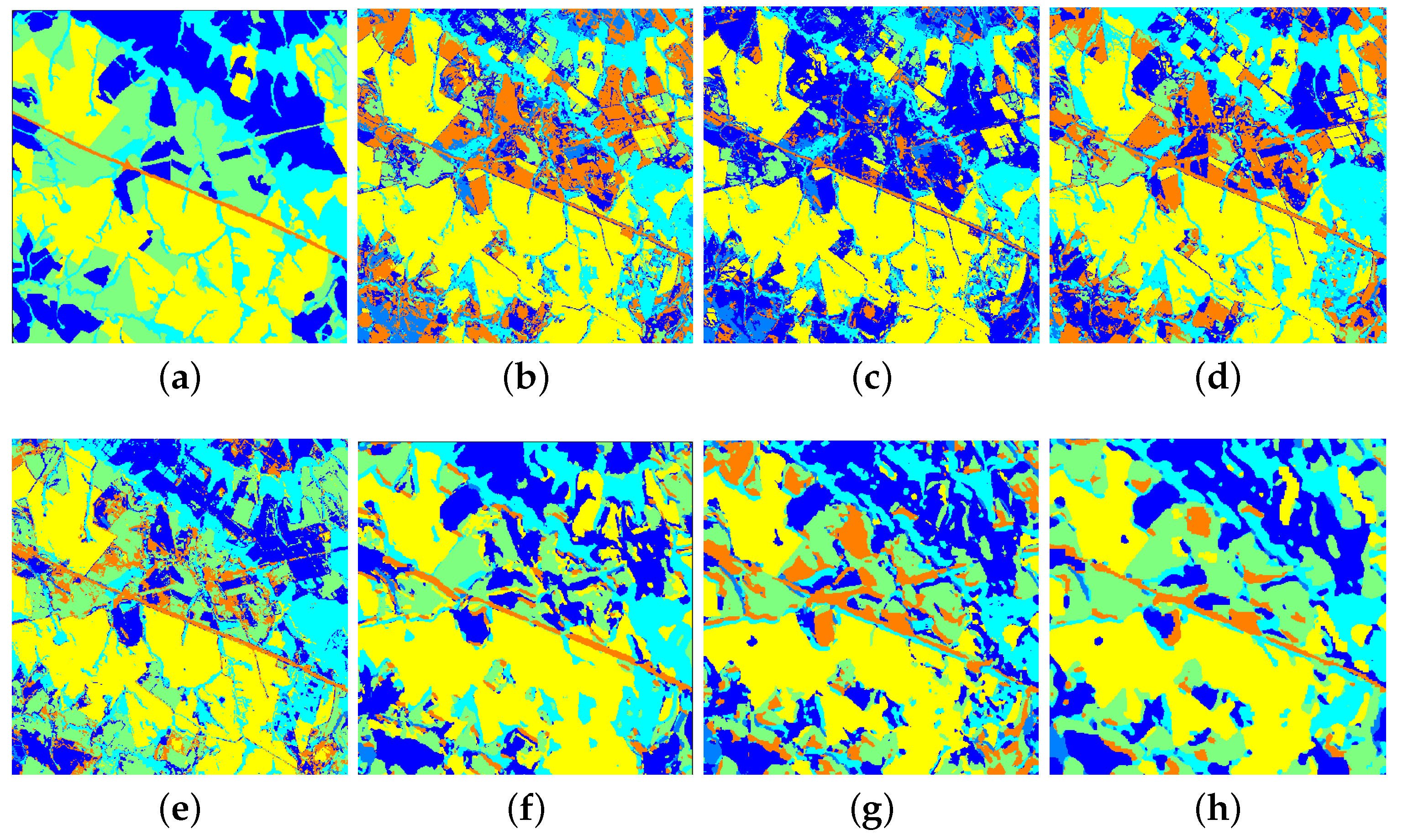
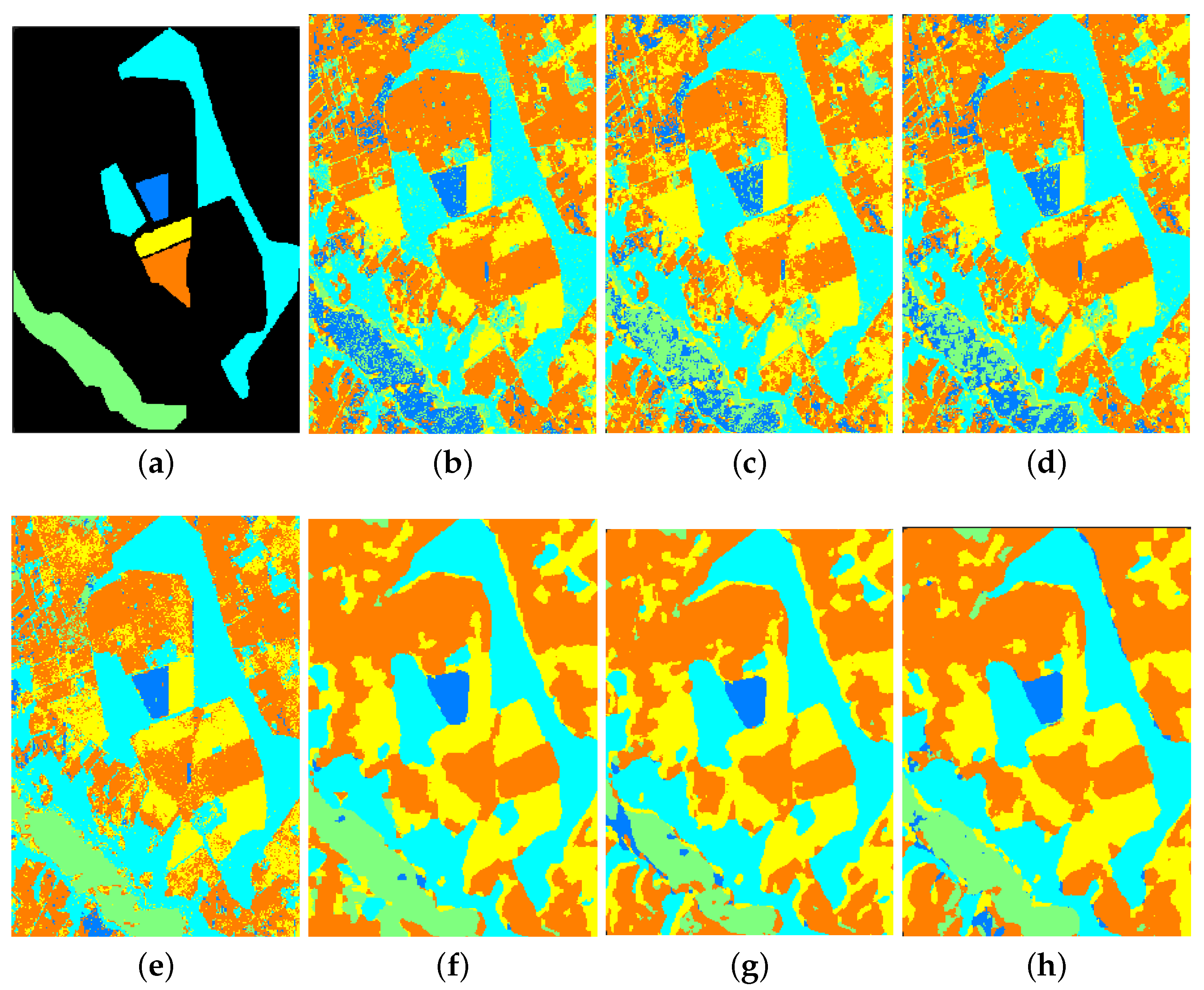
From the above
Table 5,
Table 6 and
Table 7, we can observe the phenomenon that the accuracies of some classes of other methods are higher than those of our proposed SLE-CNN. The accuracies shown in the tables are under the condition of only 5 labeled samples per class, where the phenomena can in some degree reflect that our proposed SLE-CNN has the risk of becoming unstable and influenced by noises with extremely limited training samples as stated above. However, with the increase in the number of samples, the situation turns good. In
Table 5, “bitumen” class of HSI data shows a relatively lower accuracy. However, the number of this class is small, so that the test results may be more likely to be interfered by randomness. As for “shadows” of HSI data in
Table 5 and “winter wheat”, “water” classes of SAR data in
Table 7, the accuracies of these classes, though not the highest among different methods, have already reached a high level. The relatively low accuracies of classes in MSI data in
Table 6 reflect that our proposed SLE-CNN performed not so well on MSI data compared to HSI and SAR data under the condition of 5 labeled samples per class. Though the OA and other global indexes are still better than other methods, the improvement on accuracy is relatively small. Considering this, we will make some adaptive adjustments to the MSI data in later research.
In the future, we plan to combine variational inference with the unsupervised autoencoder model to obtain a better regularization for supervised learning and improve the decision boundaries. It is also promising to directly fuse the superpixel-based hard mining criterion into the final optimization objective.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}