Approximating Empirical Surface Reflectance Data through Emulation: Opportunities for Synthetic Scene Generation

 ,
,  ,
,  ,
, 

Abstract

1. Introduction
2. Interpolation and Emulation
2.1. Interpolation
- Nearest-neighbor: This is the simplest method for interpolation, which is based on finding the closest node to a query point (e.g., by minimizing their Euclidean distance) and associating their output variables, i.e., . This fast method is valid for both gridded and scattered datasets. However, it produces discontinuities of the underlying model being interpolated.
- Piece-wise linear: This method is commonly used in remote sensing applications due to its balance between computation time and interpolation error. The implementation of linear interpolation is based on the Quickhull algorithm [21] for triangulations in multi-dimensional input spaces. For the scattered input data, the piece-wise linear interpolation method is reduced to finding the corresponding Delaunay simplex [22] (e.g., a triangle when ) that encloses a query D-dimensional point (see Equation (1)):where are barycentric coordinates of with respect to the D-dimensional simplex (with vertices) [23]. Since is a K-dimensional function, the result of the interpolation is also K-dimensional.However, linear interpolation causes discontinuities on the first derivative of the interpolated model. In addition, in scattered datasets, the underlying Delaunay triangulation is computationally expensive in high dimensional input spaces (typically 6) and is also limited by its intensive memory consumption [21,24]. In practice, it implies that it cannot do extrapolation. To predict the missing samples, here linear interpolation is used in combination with the following method:
- Inverse Distance Weighting (IDW) [8]: Also known as Shepard’s method, this method weights the n closest nodes to the query point (see Equation (2)) by the inverse of the distance metric (e.g., the Euclidean distance):where , and p (typically p = 2) is a tuneable parameter known as power parameter. When p is large, this method produces the same results as the nearest-neighbor interpolation. The method is computationally cheap but it is affected by nodes far from the query point. The modified Shepard’s method [25] aims to reduce the effect of distant grid points by modifying the weights with Equation (3):where R is the maximum Euclidean distance to the n closest nodes.
2.2. Emulation
3. Description of Used SPARC Dataset and Experimental Setup
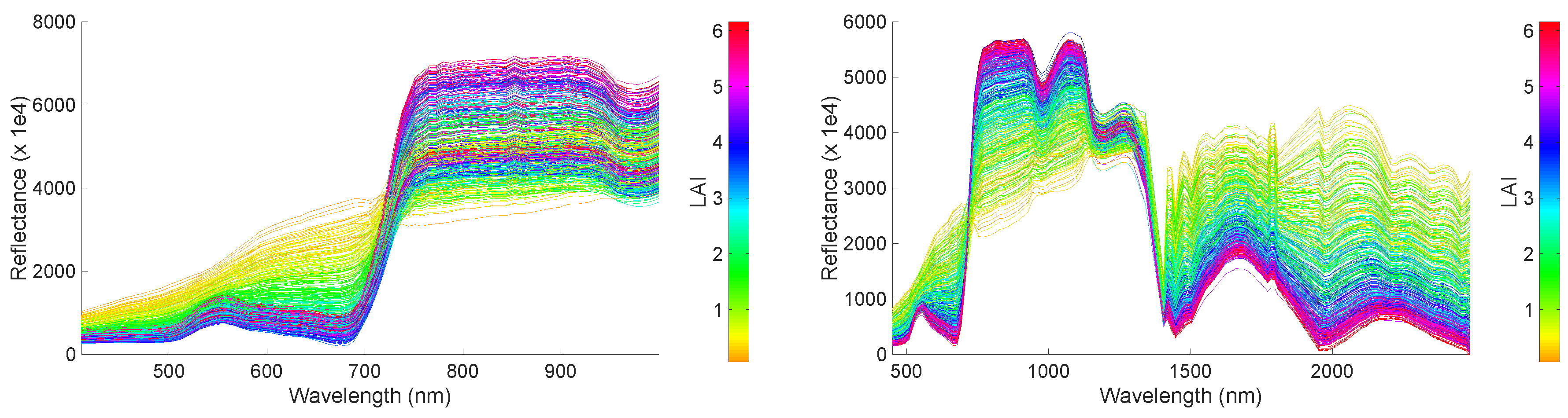
3.1. SPARC Dataset
3.2. Experimental Setup
4. Results
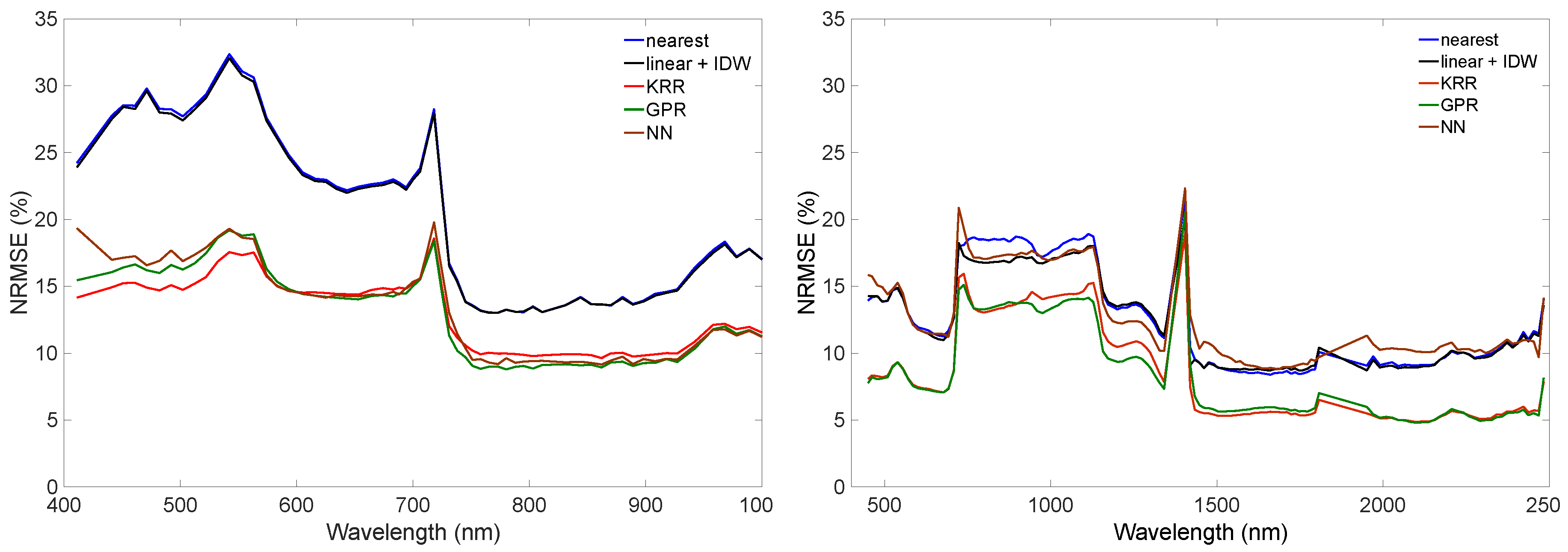
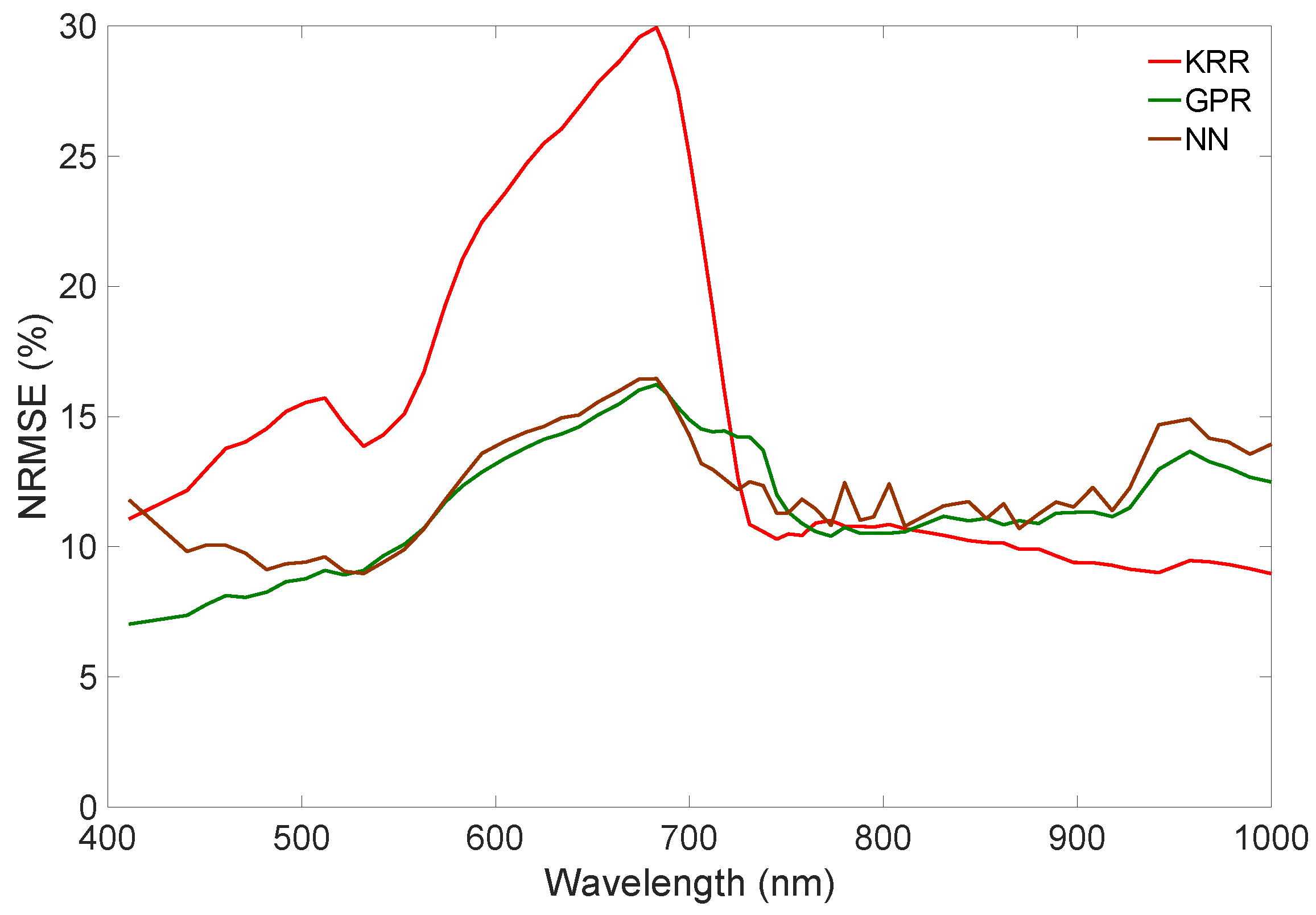
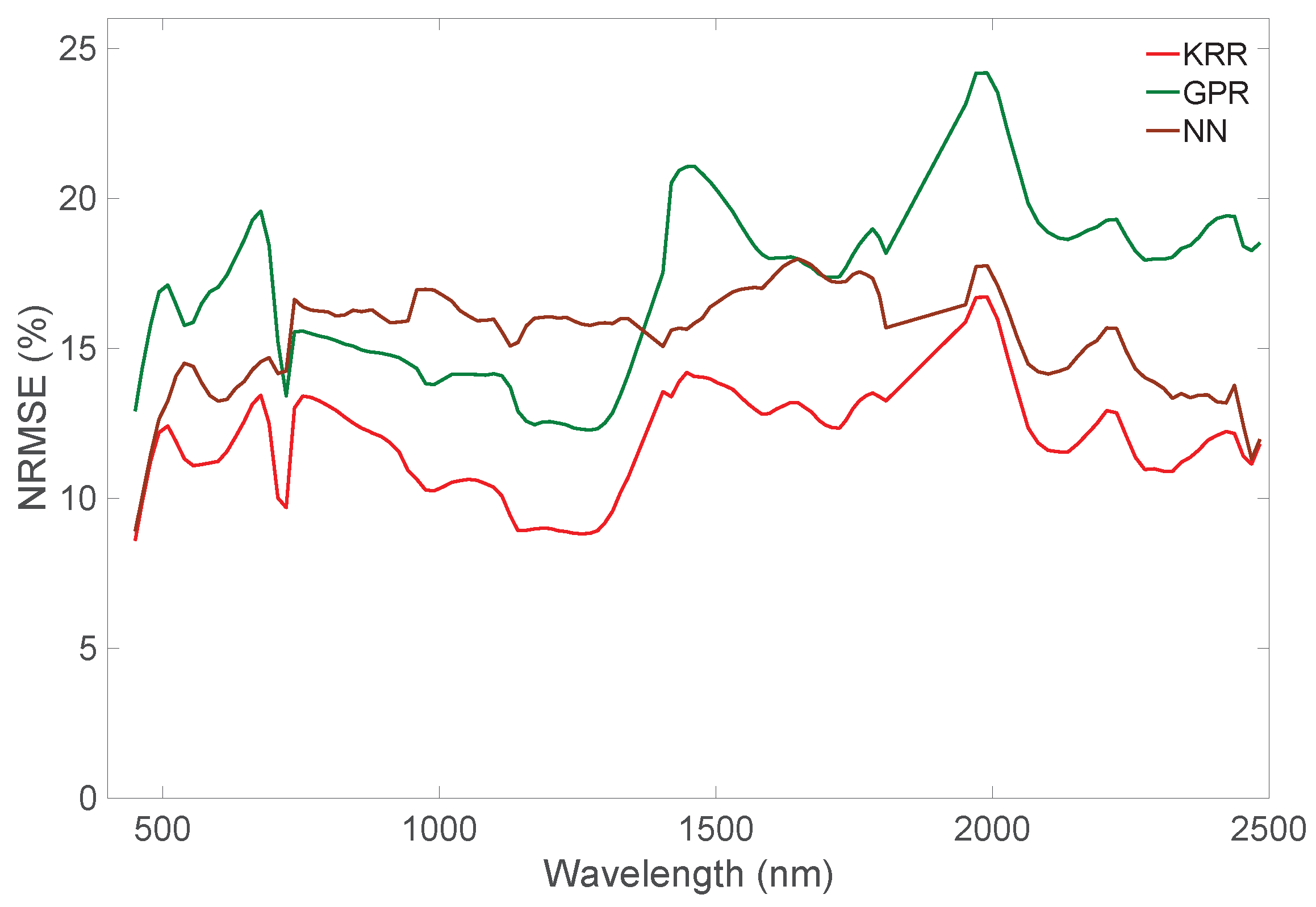
4.1. Interpolation vs. Emulation
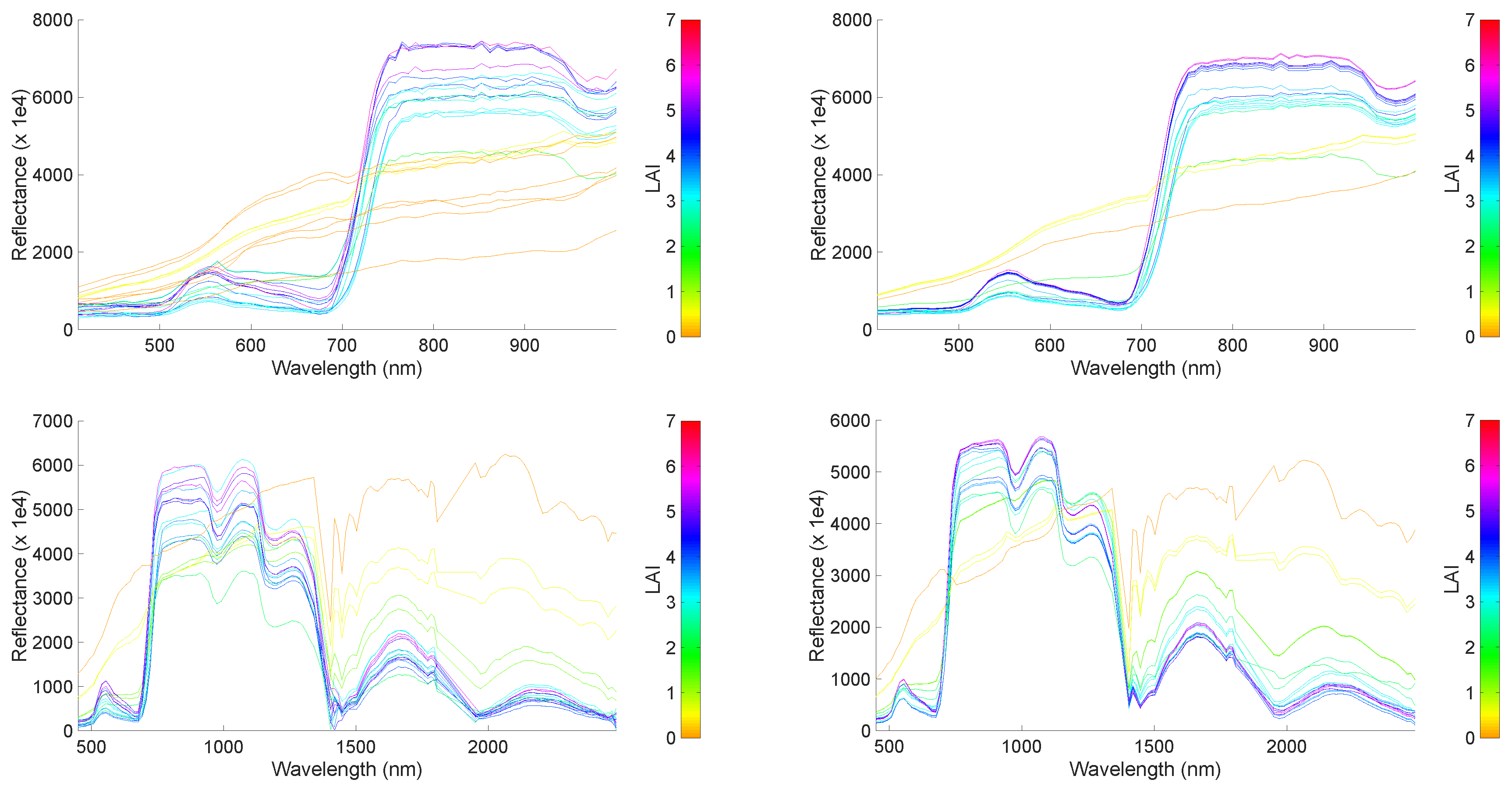
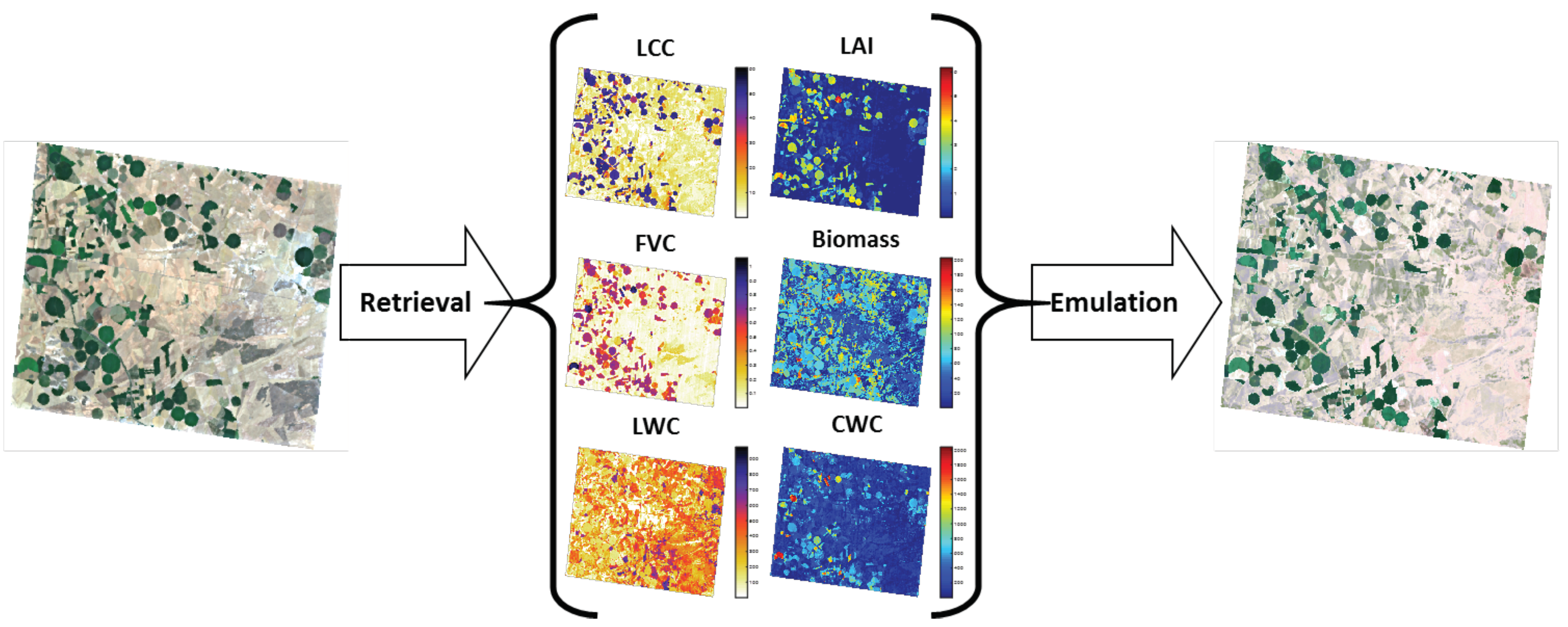
4.2. Emulation of Hyperspectral Imagery
4.2.1. CHRIS-Like Image
4.2.2. HyMap-Like Image
4.2.3. Sentinel-2-Like Hyperspectral Image
5. Discussion
6. Conclusions and Outlook
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Milton, E.; Schaepman, M.; Anderson, K.; Kneubühler, M.; Fox, N. Progress in field spectroscopy. Remote Sens. Environ. 2009, 113, S92–S109. [Google Scholar] [CrossRef]
- Goetz, A. Three decades of hyperspectral remote sensing of the Earth: A personal view. Remote Sens. Environ. 2009, 113, S5–S16. [Google Scholar] [CrossRef]
- Eismann, M. Hyperspectral Remote Sensing; SPIE: Bellingham, WA, USA, 2012; pp. 1–726. [Google Scholar]
- Kent, M. Vegetation Description and Data Analysis: A Practical Approach; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Abramowitz, M.; Stegun, I. Handbook of Mathematical Functions. In Applied Mathematics Series; National Bureau of Standards: Washington, DC, USA, 1964; Volume 55, Chapter 25.2. [Google Scholar]
- Lyapustin, A.; Martonchik, J.; Wang, Y.; Laszlo, I.; Korkin, S. Multiangle implementation of atmospheric correction (MAIAC): 1. Radiative transfer basis and look-up tables. J. Geophys. Res. Atmos. 2011, 116. [Google Scholar] [CrossRef]
- Scheck, L.; Frèrebeau, P.; Buras-Schnell, R.; Mayer, B. A fast radiative transfer method for the simulation of visible satellite imagery. J. Quant. Spectrosc. Radiat. Transf. 2016, 175, 54–67. [Google Scholar] [CrossRef]
- Shepard, D. Two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 23rd ACM National Conference, Las Vegas, NV, USA, 27–29 August 1968; pp. 517–524. [Google Scholar]
- O’Hagan, A. Bayesian analysis of computer code outputs: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 1290–1300. [Google Scholar] [CrossRef]
- Gómez-Dans, J.L.; Lewis, P.E.; Disney, M. Efficient Emulation of Radiative Transfer Codes Using Gaussian Processes and Application to Land Surface Parameter Inferences. Remote Sens. 2016, 8, 119. [Google Scholar] [CrossRef]
- Rivera, J.; Verrelst, J.; Gómez-Dans, J.; Muñoz Marí, J.; Moreno, J.; Camps-Valls, G. An Emulator Toolbox to Approximate Radiative Transfer Models with Statistical Learning. Remote Sens. 2015, 7, 9347. [Google Scholar] [CrossRef]
- Verrelst, J.; Sabater, N.; Rivera, J.; Muñoz Marí, J.; Vicent, J.; Camps-Valls, G.; Moreno, J. Emulation of Leaf, Canopy and Atmosphere Radiative Transfer Models for Fast Global Sensitivity Analysis. Remote Sens. 2016, 8, 673. [Google Scholar] [CrossRef]
- Verrelst, J.; Rivera Caicedo, J.; Muñoz Marí, J.; Camps-Valls, G.; Moreno, J. SCOPE-based emulators for fast generation of synthetic canopy reflectance and sun-induced fluorescence Spectra. Remote Sens. 2017, 9, 927. [Google Scholar] [CrossRef]
- Vicent, J.; Verrelst, J.; Rivera-Caicedo, J.; Sabater, N.; Muñoz-Marí, J.; Camps-Valls, G.; Moreno, J. Emulation as an Accurate Alternative to Interpolation in Sampling Radiative Transfer Codes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4918–4931. [Google Scholar] [CrossRef]
- Vicent, J.; Sabater, N.; Tenjo, C.; Acarreta, J.; Manzano, M.; Rivera, J.; Jurado, P.; Franco, R.; Alonso, L.; Verrelst, J.; et al. FLEX End-to-End Mission Performance Simulator. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4215–4223. [Google Scholar] [CrossRef]
- Tenjo, C.; Rivera-Caicedo, J.; Sabater, N.; Servera, J.; Alonso, L.; Verrelst, J.; Moreno, J. Design of a Generic 3-D Scene Generator for Passive Optical Missions and Its Implementation for the ESA’s FLEX/Sentinel-3 Tandem Mission. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1290–1307. [Google Scholar] [CrossRef]
- Han, S.; Kerekes, J. Overview of Passive Optical Multispectral and Hyperspectral Image Simulation Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4794–4804. [Google Scholar] [CrossRef]
- Moreno, J.; Participants of the SPARC Campaigns. SPARC Data Acquisition Report. Contract no: 18307/04/NL/FF; University Valencia: València, Spain, 2004. [Google Scholar]
- Guanter, L.; Richter, R.; Kaufmann, H. On the application of the MODTRAN4 atmospheric radiative transfer code to optical remote sensing. Int. J. Remote Sens. 2009, 30, 1407–1424. [Google Scholar] [CrossRef]
- Gastellu-Etchegorry, J.; Gascon, F.; Esteve, P. An interpolation procedure for generalizing a look-up table inversion method. Remote Sens. Environ. 2003, 87, 55–71. [Google Scholar] [CrossRef]
- Barber, C.; Dobkin, D.; Huhdanpaa, H. The Quickhull Algorithm for Convex Hulls. ACM Trans. Math. Softw. 1996, 22, 469–483. [Google Scholar] [CrossRef]
- Delaunay, B. Sur la sphère vide. A la mémoire de Georges Voronoï. Bulletin de l’Académie des Sciences de l’URSS. Classe des Sciences Mathématiques et na 1934, 793–800. Available online: http://www.mathnet.ru/php/archive.phtml?wshow=paper&jrnid=im&paperid=4937&option_lang=eng (accessed on 16 January 2019).
- Coxeter, H. Barycentric Coordinates. In Introduction to Geometry, 2nd ed.; John Willey & Sons, Inc.: New York, NY, USA, 1989; pp. 216–221, Chapter 13.7. [Google Scholar]
- The MathWorks, Inc. Interpolate N-D Scattered Data; The MathWorks, Inc.: Natick, MA, USA, 2017. [Google Scholar]
- Łukaszyk, S. A new concept of probability metric and its applications in approximation of scattered data sets. Comput. Mech. 2004, 33, 299–304. [Google Scholar] [CrossRef]
- Verrelst, J.; Malenovský, Z.; van der Tol, C.; Camps-Valls, G.; Gastellu-Etchegorry, J.P.; Lewis, P.; North, P.; Moreno, J. Quantifying Vegetation Biophysical Variables from Imaging Spectroscopy Data: A Review on Retrieval Methods. Surv. Geophys. 2018, 1–41. [Google Scholar] [CrossRef]
- Suykens, J.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: New York, NY, USA, 2006. [Google Scholar]
- Haykin, S. Neural Networks—A Comprehensive Foundation, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Verrelst, J.; Rivera, J.; Veroustraete, F.; Muñoz Marí, J.; Clevers, J.; Camps-Valls, G.; Moreno, J. Experimental Sentinel-2 LAI estimation using parametric, non-parametric and physical retrieval methods—A comparison. ISPRS J. Photogramm. Remote Sens. 2015, 108, 260–272. [Google Scholar] [CrossRef]
- Caicedo, J.; Verrelst, J.; Munoz-Mari, J.; Moreno, J.; Camps-Valls, G. Toward a semiautomatic machine learning retrieval of biophysical parameters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1249–1259. [Google Scholar] [CrossRef]
- Barnsley, M.J.; Settle, J.J.; Cutter, M.A.; Lobb, D.R.; Teston, F. The PROBA/CHRIS mission: A low-cost smallsat for hyperspectral multiangle observations of the earth surface and atmosphere. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1512–1520. [Google Scholar] [CrossRef]
- Guanter, L.; Alonso, L.; Moreno, J. A method for the surface reflectance retrieval from PROBA/CHRIS data over land: Application to ESA SPARC campaigns. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2908–2917. [Google Scholar] [CrossRef]
- Segl, K.; Guanter, L.; Rogass, C.; Kuester, T.; Roessner, S.; Kaufmann, H.; Sang, B.; Mogulsky, V.; Hofer, S. EeteSThe EnMAP end–to–end simulation tool. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 522–530. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, G. Estimation of soil moisture from optical and thermal remote sensing: A review. Sensors 2016, 16, 1308. [Google Scholar] [CrossRef]
- Ball, J.; Anderson, D.; Chan, C. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11. [Google Scholar] [CrossRef]
- Liu, L.; Ji, M.; Buchroithner, M. Transfer learning for soil spectroscopy based on convolutional neural networks and its application in soil clay content mapping using hyperspectral imagery. Sensors 2018, 18, 3169. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE | NRMSE (%) | CPU (s) |
|---|---|---|---|
| CHRIS | |||
| Interpolation: | |||
| - nearest | 653.3 | 20.7 | 0.1881 |
| - linear + IDW | 649.4 | 20.5 | 0.3040 |
| Emulation: | |||
| - KRR | 436.3 | 13.0 | 0.0007 |
| - GPR | 420.6 | 13.0 | 0.0096 |
| - NN | 432.5 | 13.4 | 0.0070 |
| HyMap | |||
| Interpolation: | |||
| - nearest | 405.4 | 12.5 | 0.1501 |
| - linear + IDW | 398.2 | 12.2 | 0.2428 |
| Emulation: | |||
| - KRR | 269.6 | 8.5 | 0.0006 |
| - GPR | 267.2 | 8.4 | 0.0086 |
| - NN | 412.0 | 12.6 | 0.0059 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verrelst, J.; Rivera Caicedo, J.P.; Vicent, J.; Morcillo Pallarés, P.; Moreno, J. Approximating Empirical Surface Reflectance Data through Emulation: Opportunities for Synthetic Scene Generation. Remote Sens. 2019, 11, 157. https://doi.org/10.3390/rs11020157
Verrelst J, Rivera Caicedo JP, Vicent J, Morcillo Pallarés P, Moreno J. Approximating Empirical Surface Reflectance Data through Emulation: Opportunities for Synthetic Scene Generation. Remote Sensing. 2019; 11(2):157. https://doi.org/10.3390/rs11020157
Chicago/Turabian StyleVerrelst, Jochem, Juan Pablo Rivera Caicedo, Jorge Vicent, Pablo Morcillo Pallarés, and José Moreno. 2019. "Approximating Empirical Surface Reflectance Data through Emulation: Opportunities for Synthetic Scene Generation" Remote Sensing 11, no. 2: 157. https://doi.org/10.3390/rs11020157
APA StyleVerrelst, J., Rivera Caicedo, J. P., Vicent, J., Morcillo Pallarés, P., & Moreno, J. (2019). Approximating Empirical Surface Reflectance Data through Emulation: Opportunities for Synthetic Scene Generation. Remote Sensing, 11(2), 157. https://doi.org/10.3390/rs11020157