1. Introduction
Hyperspectral cameras can acquire remotely sensed images for a large number of contiguous spectral bands. Thus, a hyperspectral image (HSI) contains detailed spectral information of a scene. Since many kinds of materials have unique spectral signatures, this type of image is useful for recognizing the types of materials in a captured scene [
1]. On the other hand, due to the Hughes effect [
2], which is also known as the curse of dimensionality, the high spectral dimensionality makes the analysis of HSIs a challenging task from both computational and statistical perspective. The limited availability of training samples is a common issue in this kind of analysis since their collection can be both time demanding and expensive [
3]. An increase in the number of spectral features, after a certain point, usually causes a decrease in classification accuracy when the number of training samples is limited. As a result, reducing the spectral dimensionality (or feature reduction) is of great interest in HSI analysis [
4]. In general, dimensionality reduction (DR) techniques can be divided into
feature selection (FS) and
feature extraction (FE). In this paper, we focus on FE.
FE is the process of finding a set of vectors that represent an observation while reducing the dimensionality. For data classification, it is desirable to extract informative features that are useful for differentiating between classes of interest. Although DR is important for HSI analysis, the error due to the reduction in dimension has to occur without sacrificing the discriminative power of the classifier [
5].
FE techniques can be broadly divided, based on the availability of training data, into two main groups: supervised FE (SFE) and unsupervised FE (USFE). The SFE methods require training samples while the USFE techniques are used to extract distinctive features in the absence of labeled training data.
SFE has been widely studied in the hyperspectral community [
1]. Discriminant analysis feature extraction (DAFE) [
6] is a classical SFE approach. It is a parametric method that extracts features that maximize the proportion of the between-class variance to within-class variance. The main shortcoming of DAFE is that this approach is not full rank and its rank at maximum is equal to the number of classes minus one. In addition, the class mean values can highly affect the performance of DAFE. Therefore, decision boundary feature extraction (DBFE) [
7] and nonparametric weighted feature extraction (NWFE) [
8] are suggested for HSI classification. In DBFE, the decision boundary is defined by applying the Bayes decision rules on the training samples and from that a decision boundary matrix transformation is calculated to extract the feature vectors. Hence, DBFE could fail in the case of having too few training samples since it directly works with the training samples to determine the location of the effective decision boundaries. NWFE is designed to improve the limitations of parametric feature extraction by putting different weights on samples to compute the local means and define a new nonparametric between-class and within-class scatter matrices to produce more features than DAFE. In addition, discriminant analysis based techniques such as the linear constraint distance-based discriminant analysis (LCDA) [
9], the modified Fisher’s linear discriminant analysis (MFLDA) [
10], and a tensor representation-based discriminant analysis [
11] were all proposed to improve the performance of the DAFE.
Recent SFE approaches take the advantage of the local neighborhood properties (spatial information) of data. Li et al. [
12] considered local Fisher’s discriminant analysis [
13] to perform DR while preserving the corresponding multi-modal structure. In [
14], local neighborhood information is taken into account in both spectral and spatial domains to obtain a discriminative projection for dimensionality reduction of hyperspectral data. Xue et al. [
15] introduced a nonlinear FE approach based on spatial and spectral regularized local discriminant embedding to address spatial variability and spectral multi-modality.
USFE techniques are usually based on optimizing an objective function to project the original features into a lower dimensional feature space. Principal component analysis (PCA) searches for a projection to maximize the signal variance [
16]. Maximum noise fraction (MNF) [
17] and noise adjusted principal components (NAPC) [
18] seek a projection that maximizes the signal-to-noise ratio (SNR). Such FE approaches are mostly used for data representation, usually as a preprocessing step, and address the large size of hyperspectral datasets. Independent component analysis (ICA) [
19,
20], non-negative matrix factorization (NMF) [
21,
22], and hyperspectral unmixing [
23,
24] are other examples of USFE techniques.
Some FE techniques are proposed based on preserving local (spatial) information [
25,
26]. Neighborhood preserving embedding (NPE) [
27], locality preserving projection (LPP) [
28] and linear local tangent space alignment (LLTSA) [
29] are proposed for hyperspectral FE [
30,
31]. The work in [
32] develops a tensor version of the LPP algorithm for hyperspectral DR and classification. The work in [
33] proposes a common minimization framework called graph-embedding (GE), which is based on estimating an undirected weighted graph to describe the desired intrinsic (statistical or geometrical) properties of the data. The method uses either scale normalization or penalty graph constraints that describe undesirable properties. In [
34], a sparse graph-based discriminant analysis (SGDA) technique that induces sparsity on the graph construction is proposed for hyperspectral DR and classification. SGDA may not obtain acceptable results when the input data have a nonlinear and complex nature. To address this issue, a kernel extension of SGDA is proposed in [
35]. Image fusion and recursive filtering [
36] are designed in [
37], which incorporate spatial information to extract informative features. In [
38], a DR approach is developed to estimate a sparse and low-rank projection matrix by fulfilling the restricted isometric property condition on all secants of hyperspectral data to preserve the nearest neighbor points of all pixels to improve the subsequent classification step further. Total variation (TV) regularization is suggested in [
39] for HSI feature extraction. Wavelet-based sparse reduced-rank regression [
40] and sparse and low-rank modeling [
41] are suggested for hyperspectral feature extraction. Recently, in [
42], orthogonal total variation component analysis (OTVCA) is proposed, where a non-convex cost function is optimized to find the best representation for HSI in a low dimensional feature space while controlling the spatial smoothness of the features by using a TV regularization. The TV penalty promotes piecewise smoothness (homogeneous spatial regions) on the extracted features, and thus substantially helps to extract spatial (local neighborhood) information that is very useful for classification.
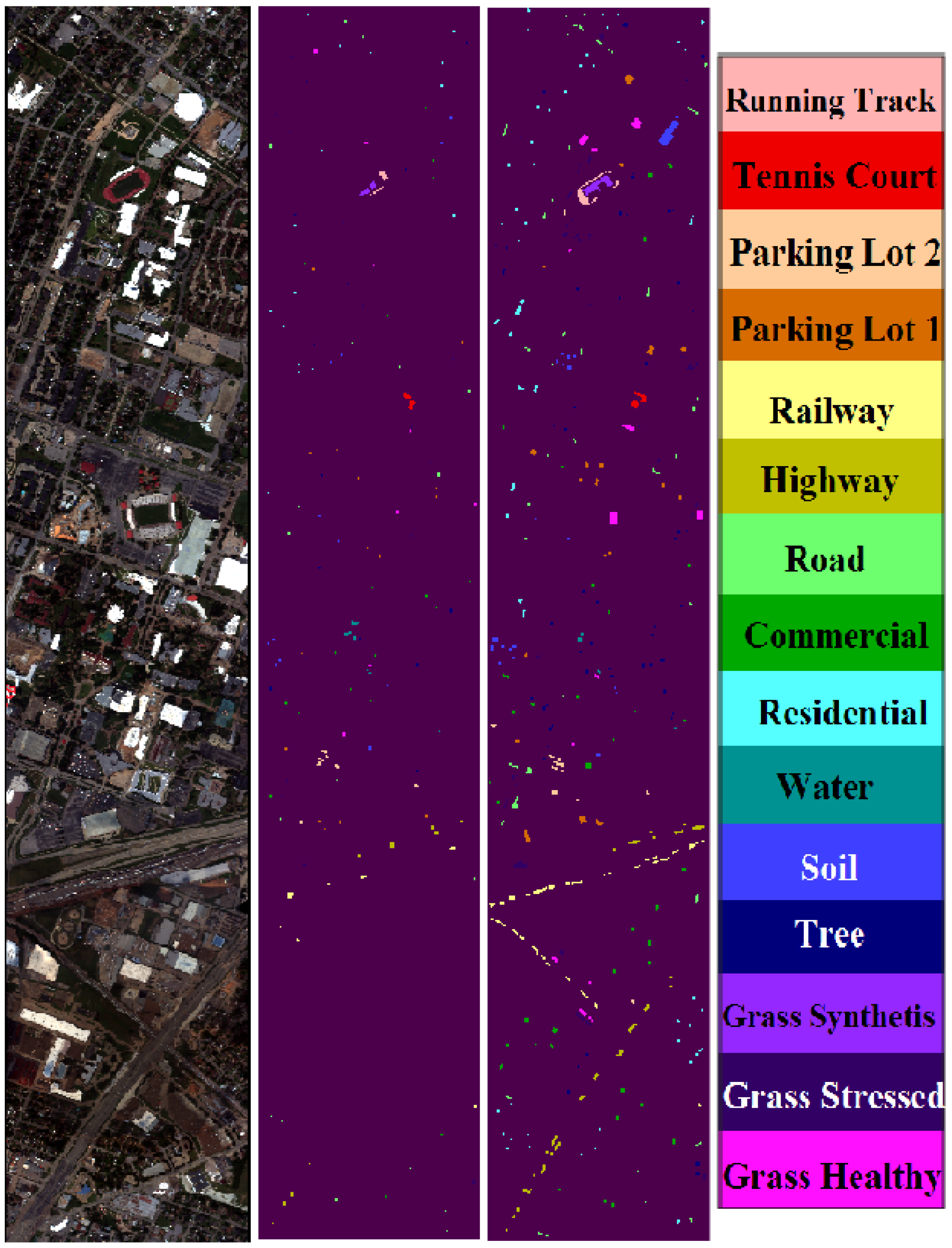
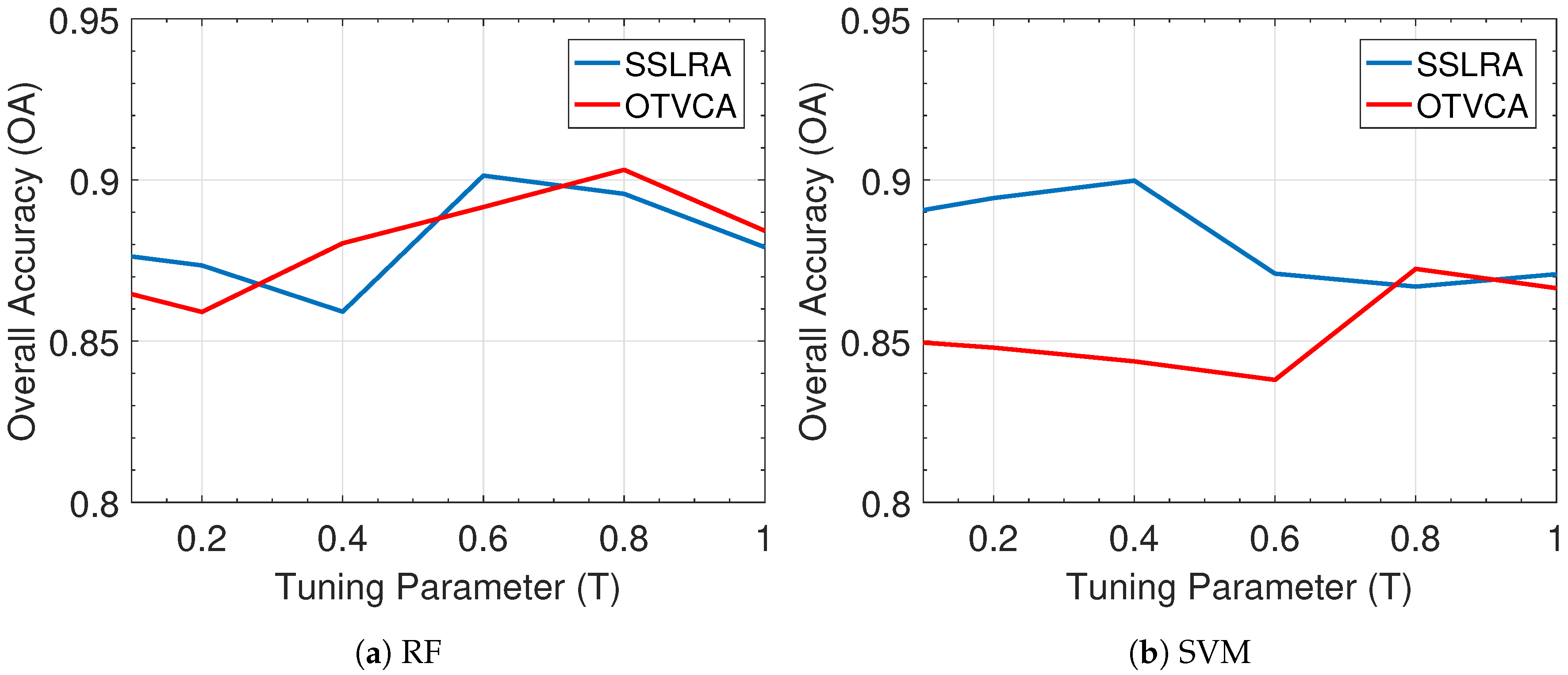
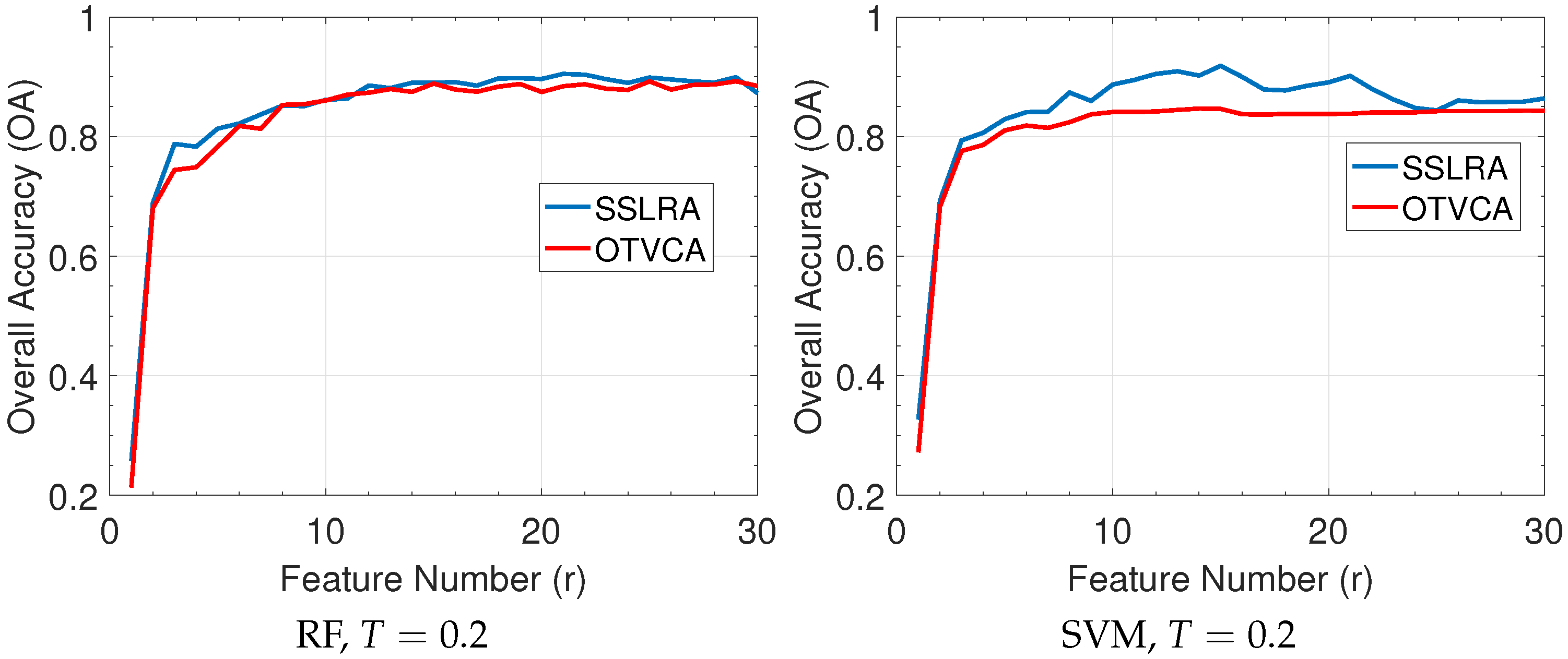
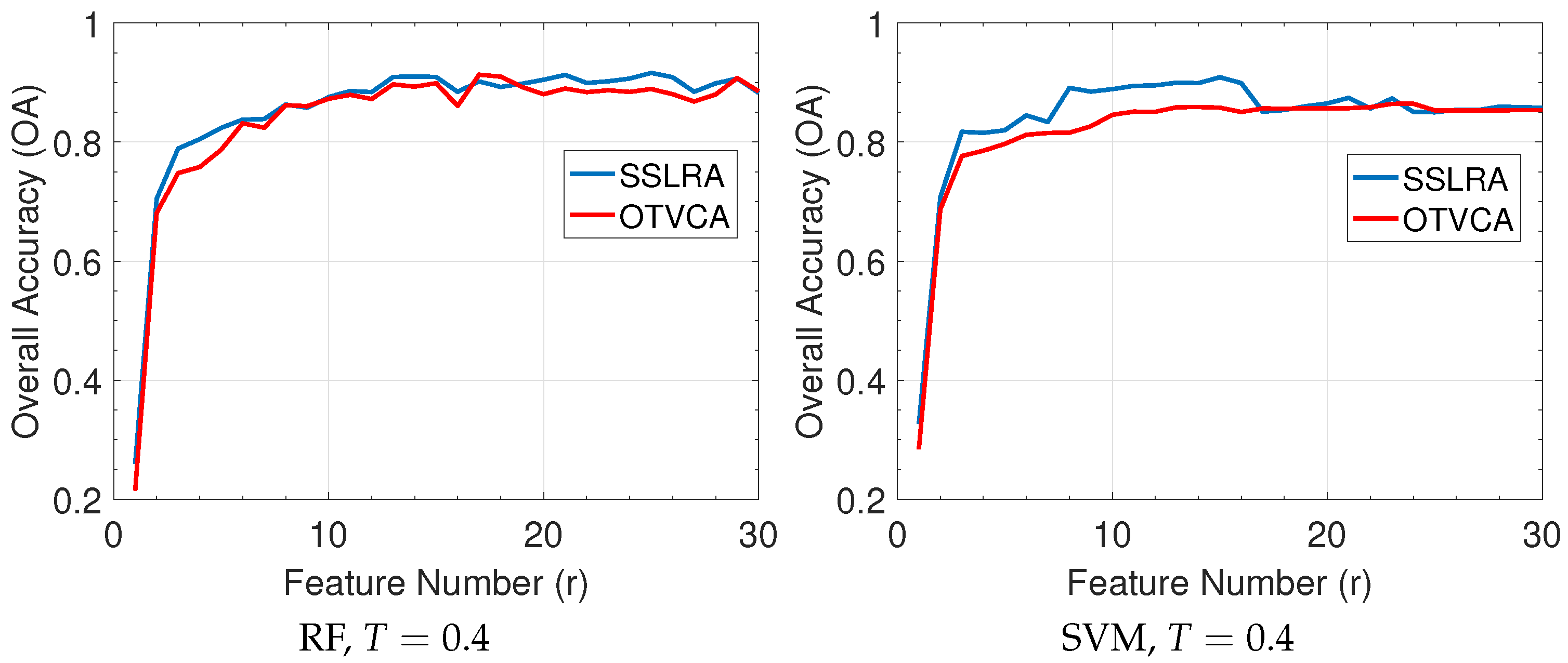
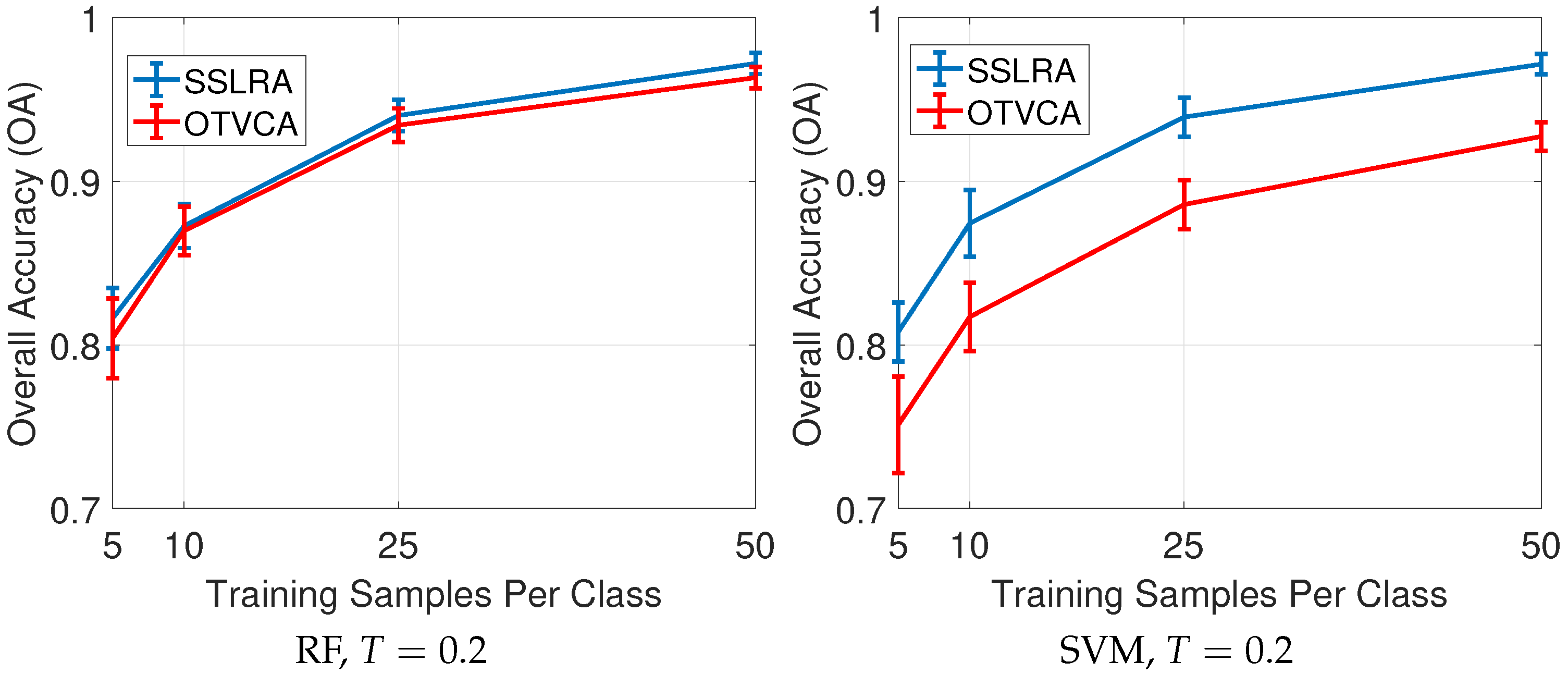
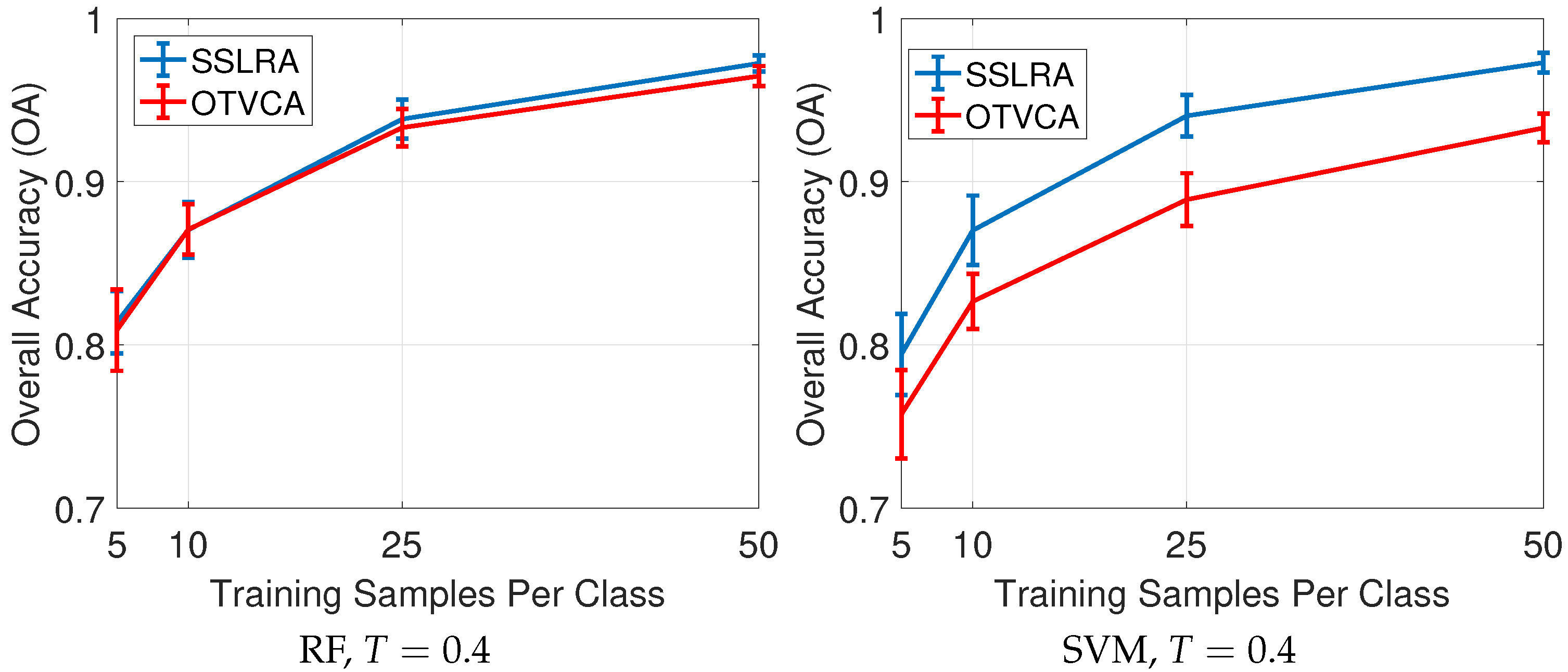
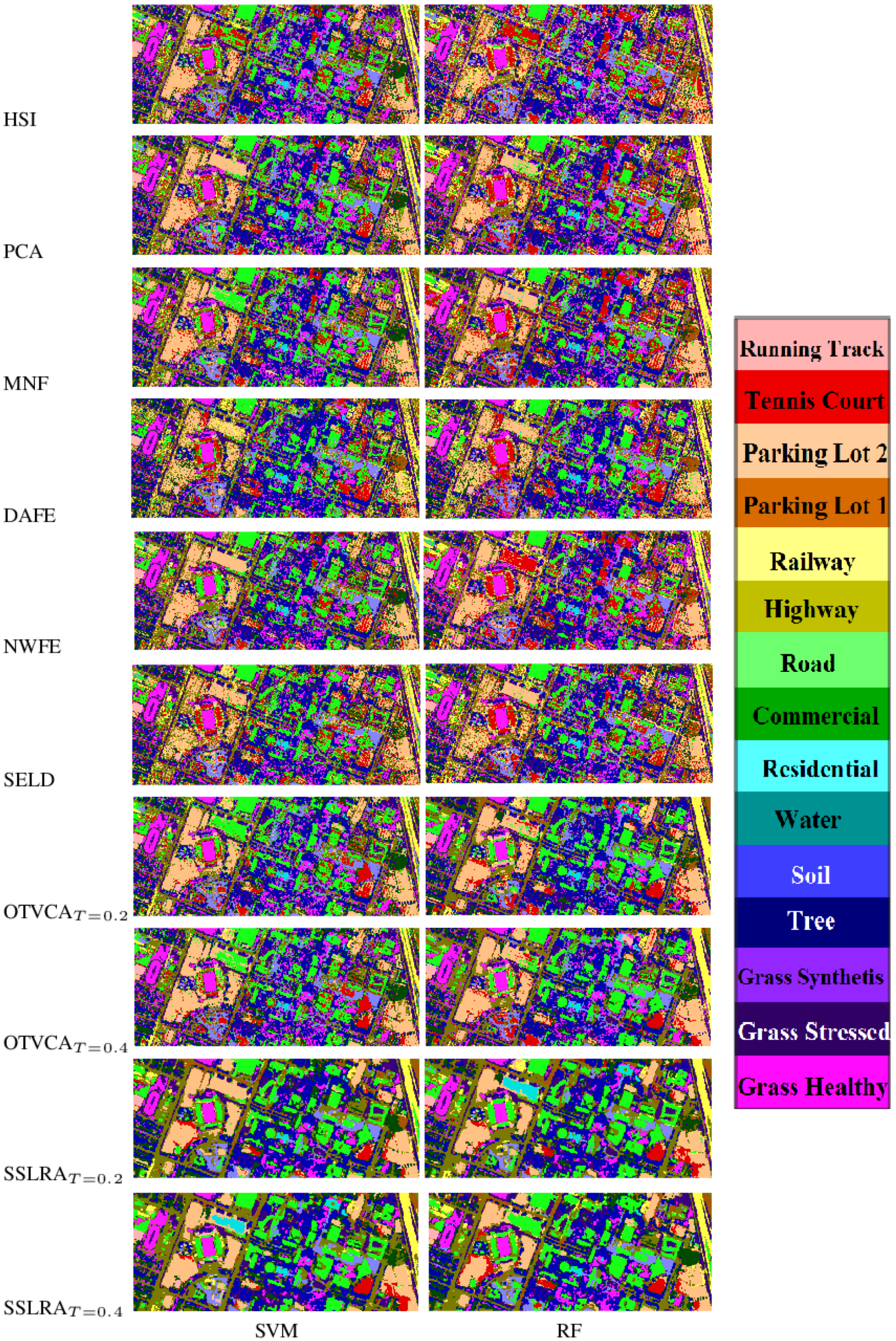
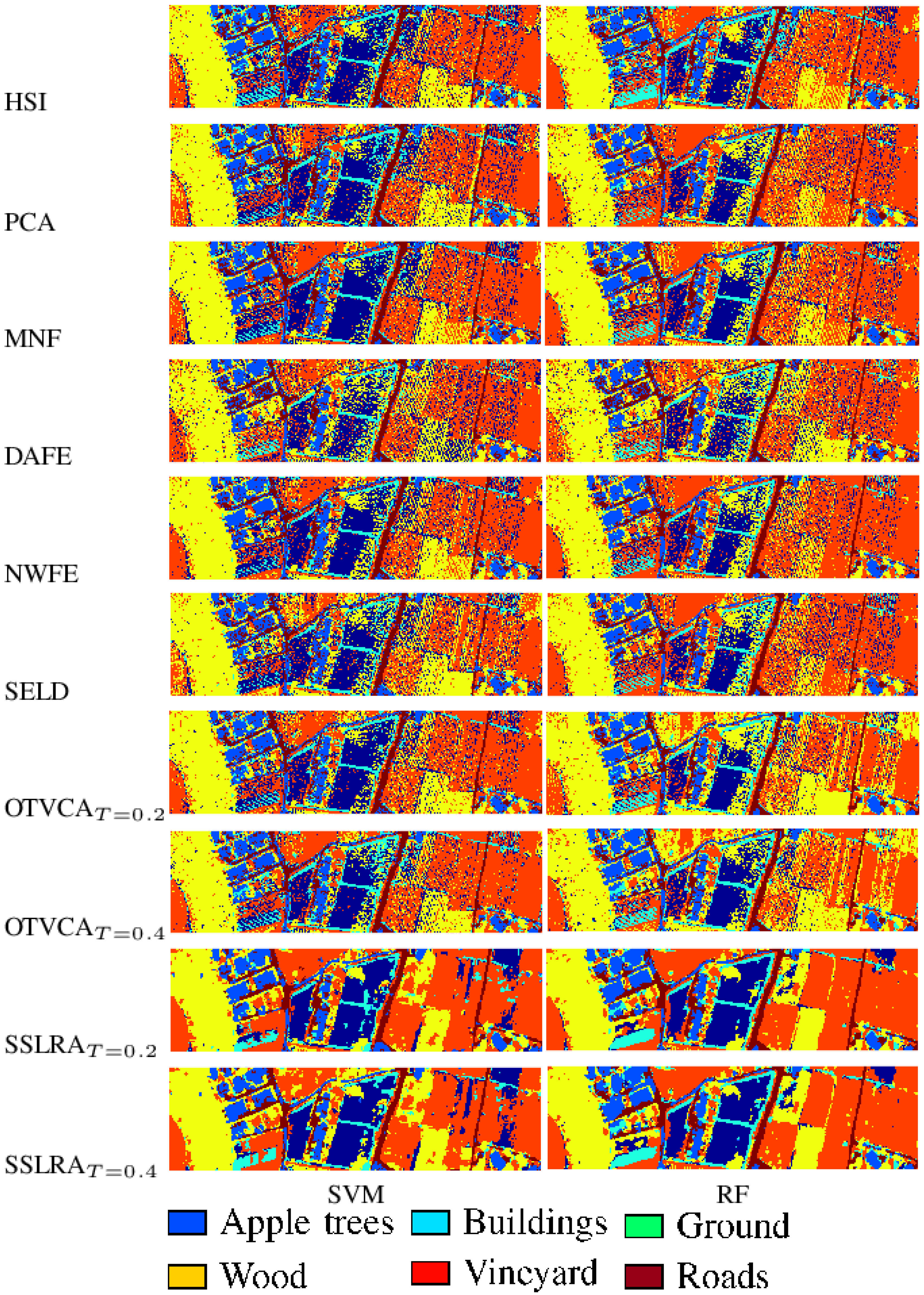
In this paper, we propose a USFE for the classification of HSI called sparse and smooth low-rank analysis (SSLRA). SSLRA decomposes the HSI into sparse and piecewise smooth components. To capture the spectral redundancy of HSI and perform DR, we assume that these components can be represented in a lower dimensional space. Therefore, we propose a low-rank model for HSI in which the HSI is modeled based on a combination of sparse and smooth components. The components are estimated simultaneously by optimizing a constrained penalized cost function (CPCF). The TV and penalties are exploited by the CPCF to promote the smoothness and the sparsity of the corresponding components, respectively. We assume that the unknown bases are orthogonal, and therefore we solve the CPCF by enforcing an orthogonality constraint. In the experiments, we used two HSIs: (1) an urban HSI of the University of the Houston campus; and (2) a rural HSI of the Italian city of Trento. The experiments confirmed that SSLRA outperforms both OTVCA and state-of-the-art FE techniques concerning classification accuracy.
The organization of the paper is as follows. The proposed hyperspectral feature extraction technique (SSLRA) and the corresponding algorithm are derived and explained in
Section 2.
Section 3 is devoted to the experimental results. Finally,
Section 4 concludes the paper.
Notation
The notations used in this paper are as follows. The number of spectral bands and pixels in each band are denoted by
p and
n, respectively.
r indicates the rank of the HSI. Matrices are represented by bold and capital letters, vectors by bold letters, the
th element of
by
, and the
ith column by
.
denotes identity matrix of size
.
stands for the estimate of
. The Frobenius norm and TV-normare denoted by
and
, respectively. The definitions of the symbols used in the paper are given in
Table 1.
2. Hyperspectral Modeling and Sparse and Smooth Low-Rank Analysis
HSIs are often represented by using low-rank models. Such models have, for example, been shown to be more appropriate for HSI in terms of mean squared error than full-rank models [
41]. However, the rank is unknown and has to be estimated [
43,
44]. We model the observed HSI as
where
is an
matrix containing the vectorized observed image at band
i in its
ith column,
is an
matrix representing the HSI, and
is an
matrix that represents the noise and model error. Here, we assume that
is a low-rank matrix, i.e., it has rank
. The low-rank property can be enforced by representing
as a product of two rank
r matrices
and
, which leads to the following low-rank model:
where
and
are matrices of size
containing the unknown smooth and sparse components, respectively, and
is an unknown
subspace matrix. The model in Equation (
2) separates the sparse features from the smooth features. The smooth features can be used to promote smooth regions of interests in the classification maps.
Assuming the model in Equation (
2), we propose a CPCF to simultaneously estimate
,
, and
by solving
where
In Equation (
4), the TV-norm (see
Appendix A) promotes piecewise smoothness on
, the
norm promotes sparsity on
, and the constraint
enforces the orthogonality condition on the subspace. Note that minimization of Equation (
3) is non-convex and therefore the solution might lead to a local minima.
To solve Equation (
3), we use a cyclic descent (CD) algorithm [
45,
46,
47] where the problem is solved with respect to one matrix at a time while the others are assumed to be fixed. As a result, the proposed CD approach consists of the four steps discussed below: initialization, the
step, the
step, and the
step.
2.1. Initialization
Decompose by using truncated (rank-r) singular value decomposition (SVD), i.e., . Then, initialize and .
2.2. F-Step
Given fixed
and
, get
by solving Equation (
3) which can be reduced to
where
. The problem in Equation (
4) can be thought of as
r-separable TV regularization problems [
48] that can be solved using the split Bregman iterations method given in [
49] (also known as the alternative direction method of multipliers (ADMM) [
50]) denoted by
2.3. S-Step
Given fixed
and
, get
by solving Equation (
3), i.e.,
It can be shown that Equation (
5) is separable and the solution is given by
which is called soft-thresholding and often is written as
Note that soft function in Equation (
7) is applied element-wise on matrix
.
2.4. V-Step
Given fixed
and
, get
by solving Equation (
3), which can be rewritten as
The solution is given by a low-rank Procrustes rotation [
51]
where the matrices
and
are given by the following truncated SVD of rank
r
where
is a diagonal matrix which contains the first
r singular values of
. The resulting algorithm is summarized in Algorithm 1.
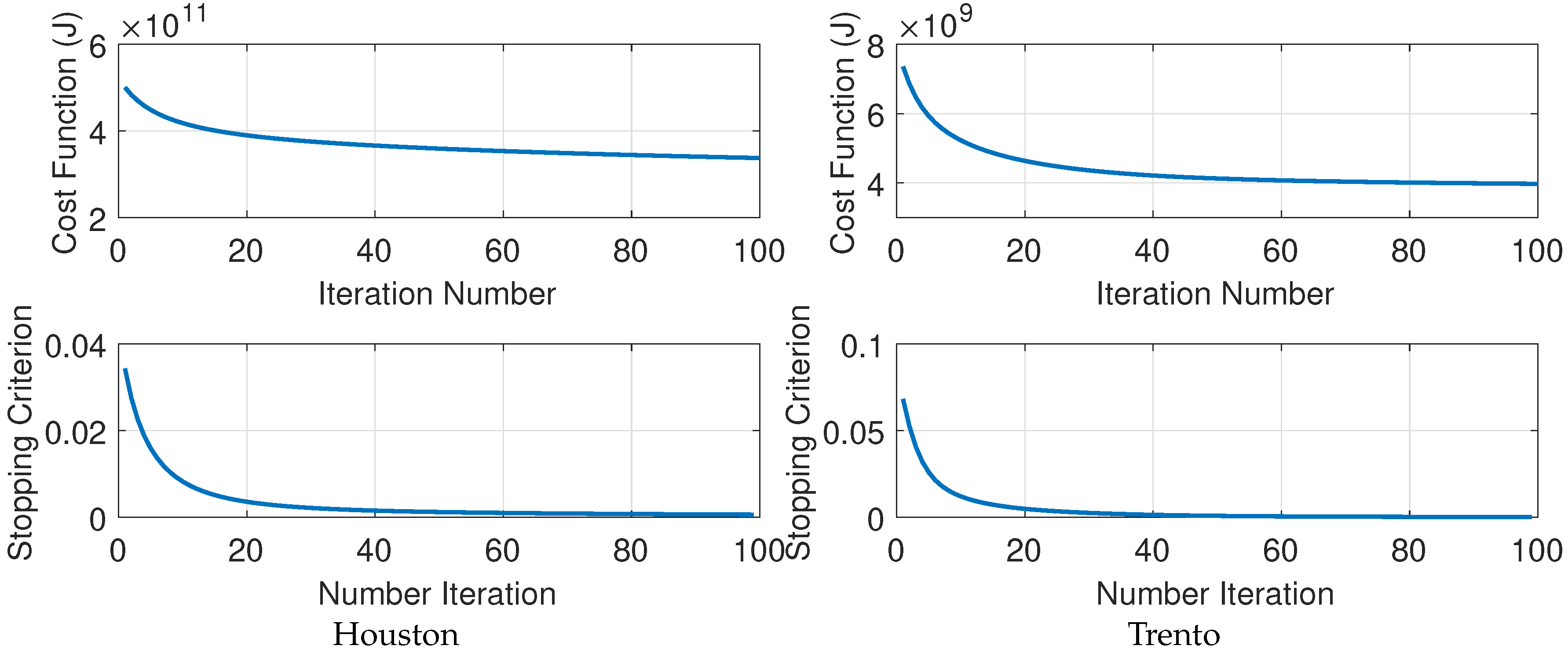
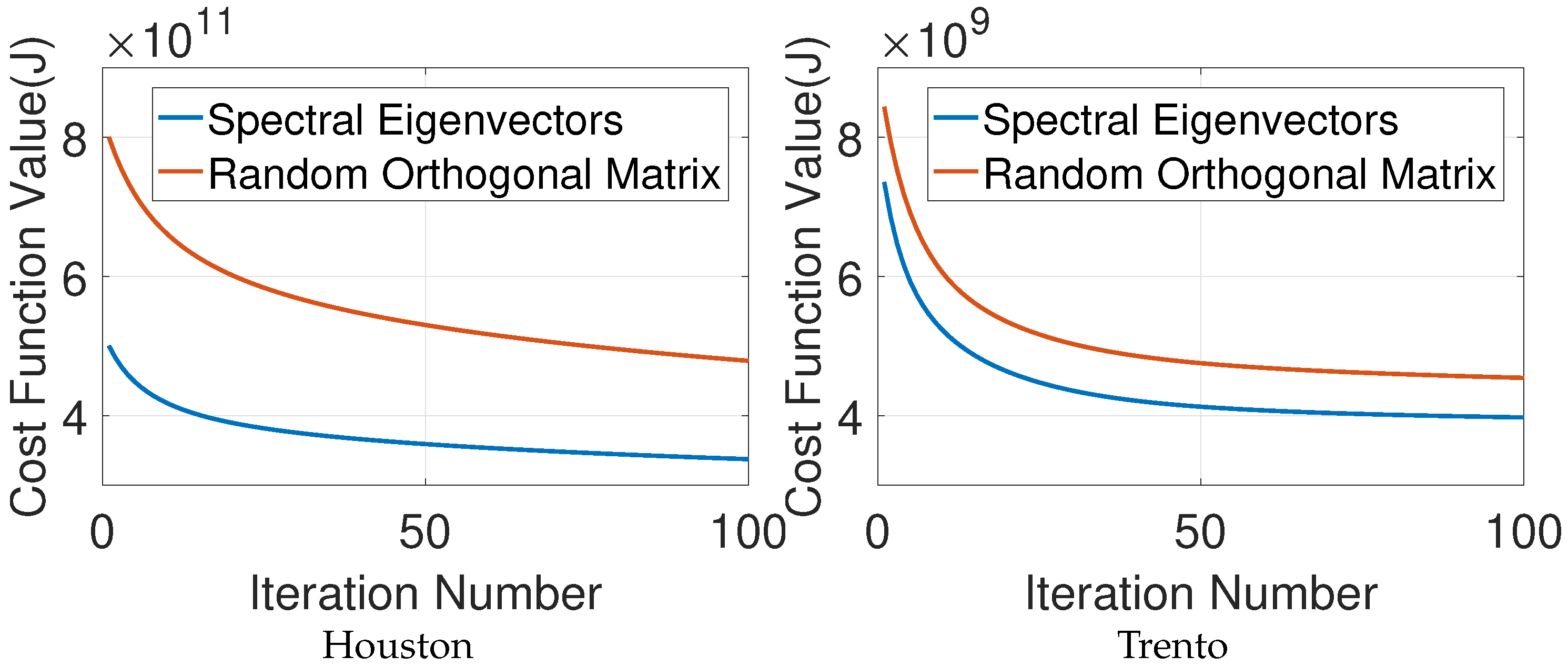
The monotonicity property of SSLRA can be observed easily since by construction the algorithm guarantees that the cost function is non-increasing with respect to the iteration index, i.e., . Therefore, the cost function is guaranteed to decrease or stay the same at each iteration of the algorithm. Since the cost function is both upper bounded (by the initial value) and lower bounded (since it is greater than or equal zero), the cost function iterations will converge to a finite value.
Note that the smooth features (
) extracted using SSLRA are used for classification purposes in this paper. This is discussed further in
Section 3.
| Algorithm 1: SSLRA. |
 |





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}