1. Introduction
Light Detection and Ranging (LiDAR) is a technology that is gradually being adopted as a mainstream surveying method. Time-of-flight LiDAR sensors measure the distance to the observed object by emitting a light pulse and by measuring the time the pulse takes to return back to the sensor, while phase-based LiDAR sensors measure this distance by using phase differences between the emitted and reflected pulse. These distances are then combined with a ground referencing system to produce a high-resolution 3-D record of the object in the form of a point cloud. In the past decades, the applications of LiDAR have been extensively studied. It can be employed to detect changes in the landscape, to estimate forest canopy fuel, or to create 3-D city models among many others. While applications vary, nearly all of them require one common step: The separation of ground from non-ground points, namely ground filtering, which is used in the process of creating Digital Elevation Models (DEMs). This is the flagship of LiDAR-derived products. Because of this, ground filtering remains one of the most discussed topics in the literature.
Several ground-filtering methods have been proposed based on different techniques, such as segmentation and cluster filters, morphological filters, directional scanning filters and contour-based filters, triangulated irregular network (TIN)-based filters, and interpolation-based filters [
1]. Although one particular method can hardly satisfy the requirements of every type of terrain, overall, satisfactory results have been achieved. State-of-the art methods achieve, approximately, an average kappa coefficient of 85% and a total error lower than 5% [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. However, using current methods in real-time scenarios may not be suitable. First, in some cases, the throughput will not be enough, as computational efficiency is generally not prioritised. Second, they process the point-cloud scene as a whole, while in a real-time scenario, data is acquired in a scan-line fashion. In airborne LiDAR, the most common scanning devices use an oscillating mirror or a rotating polygon, so that points are acquired in scan lines perpendicular to the flight path. These scan lines can be used as input to the algorithms in order to address real-time processing. Few studies have used scan lines in their methods. In Reference [
12] a 1-D bidirectional labelling along the scan-line profile followed by linear regression was presented. The detection of the ground level and the separation between clutter and man-made objects was addressed in Reference [
13]. In Reference [
14], a scan-line segmentation algorithm accelerated in GPU (Graphics Processing Unit) was proposed. Still, scan-line-based methods have limitations, particularly when dealing complex scenes, because only the information in one direction is used [
15]. Two-dimensional information should be considered to improve the results, but renouncing to scan-line-based processing would significantly reduce the computational efficiency.
Scan-line-based methods can also be valuable for offline processing. LiDAR data acquisition technologies are on an ongoing development, and the data volume is increasing consequently. This makes scan-line-based methods an appealing option given its high computational performance. Because of this, scan-line-based methods are also being studied for other applications such as building detection [
16] or plane extraction, where scan lines are used directly from the raw data [
17] or are even artificially created [
18].
In this paper, we propose a scan-line-based ground-filtering method suitable for both real-time scenarios and fast offline processing. The method takes the scan lines as input in the same way they are acquired. A scan line can be seen as a 1-D object, where a sequence of height values is given; therefore, the processing is performed in a 1-D space, making it highly efficient. This processing consists of an iterative spline interpolation, in which, after an initial interpolation, the spline is iteratively refined. Therefore, points above a certain residual to the spline are labelled as non-ground points. The use of a spline grants bending properties that are convenient when dealing with rough terrain. Nevertheless, it is challenging to identify ground accurately by processing scan lines individually, in other words, by using only the 1-D space. An alternative is to process adjacent scan lines (i.e., 2-D space). However, this requires the use of more elaborate data structures and neighbours queries, increasing the computational demand, which is not desirable for real-time applications. Because of this, a strategy of propagating the spline knots of a scan line to the next scan line is introduced in this work, thus taking advantage of some 2-D information while preserving 1-D scan-line-based processing. This improves the reliability in complex scenes while maintaining its high throughput.
The paper is organised as follows. The ground-filtering method is detailed in
Section 2. Both quantitative and qualitative results, along with throughput measurements, are presented in
Section 3. The implementation in an embedded system with field-programmable gate array (FPGA) modules is described in
Section 4. Discussion about survey requirements, comparison with other methods, and real-time processing is presented in
Section 5. Final conclusions are exposed in
Section 6.
2. Method
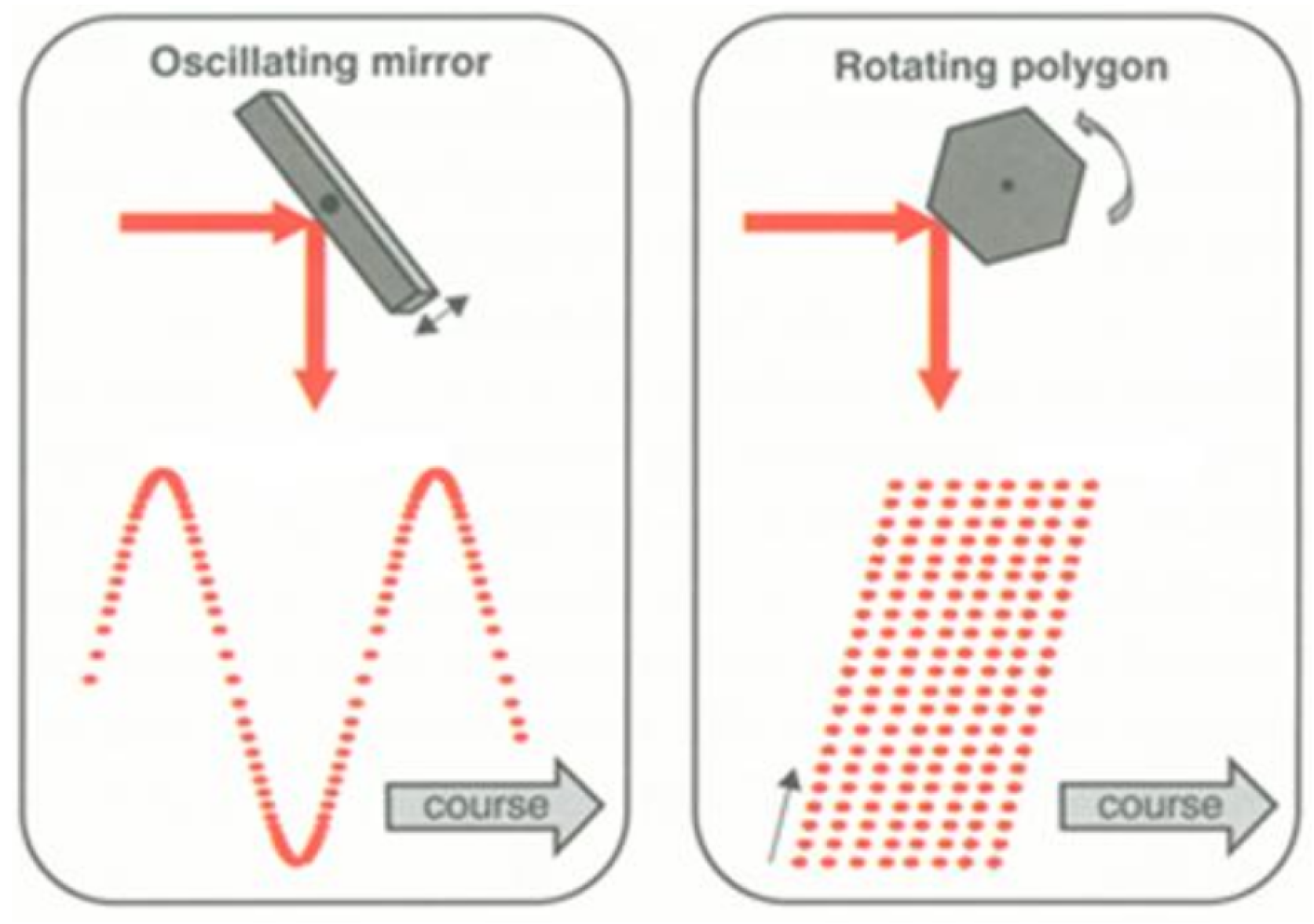
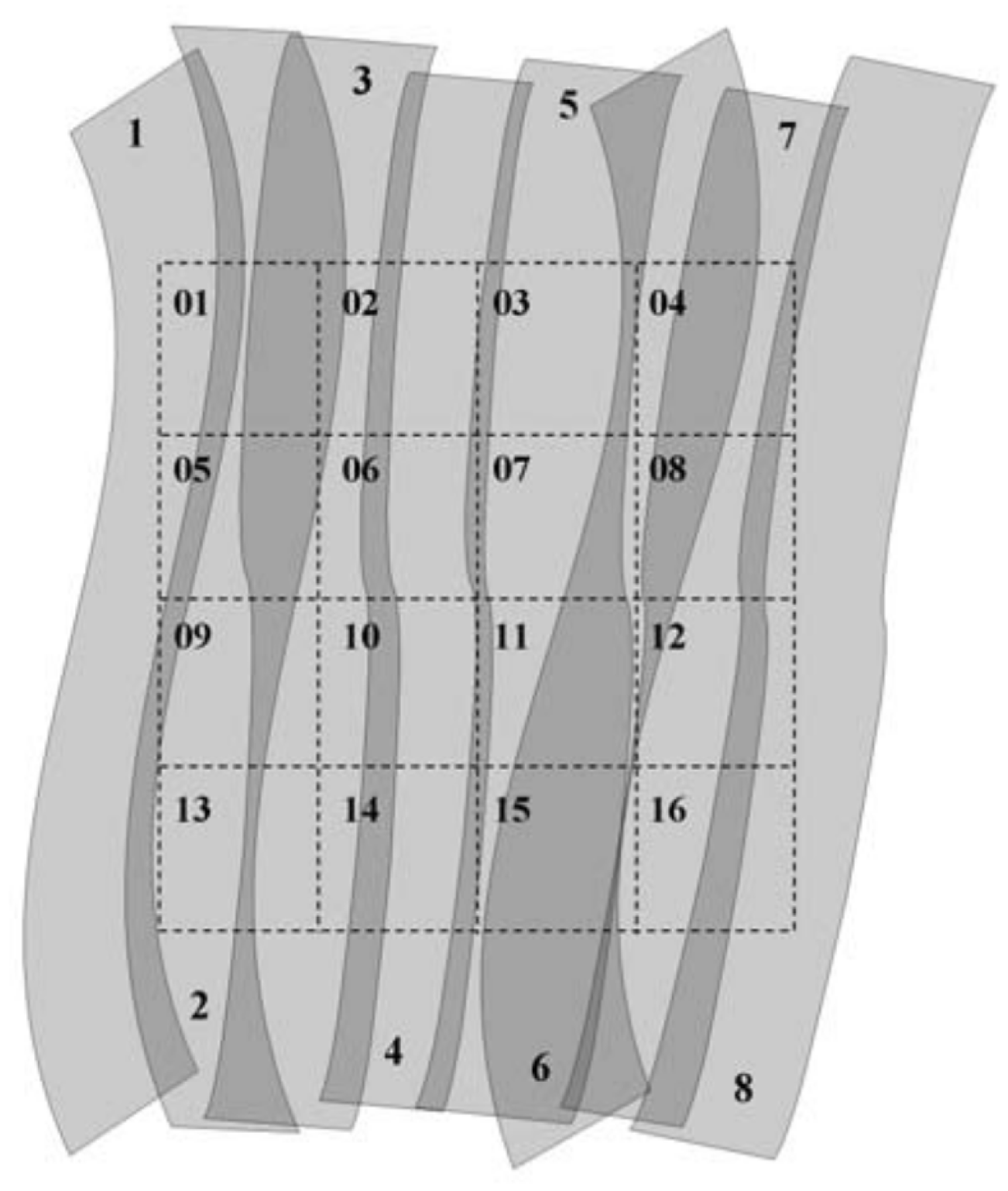
The input of this method is a set of scan lines, which can be a complete flight line or pieces of it. A scan line can be defined as the set of points recorded during the scanning mechanism rotation along the field of view. Scan lines are generally acquired in a zigzag or a parallel pattern, depending on the scanning mechanism (see
Figure 1). Consecutive scan lines during the same flight course form a flight line, which is stored in an LAS file [
19] (see
Figure 2). The stored LiDAR points follow the format established in the LAS specification, which defines the number, order, and data type of the data fields.
The LiDAR data must meet two requirements. First, points must be georeferenced. Georeferencing is the process of transforming scanner’s coordinates into a real-world spatial system. LiDAR scanners record data in its own coordinate system, which must be integrated with GPS (Global Positioning System) and IMU (Inertial Measurement Unit) data. Furthermore, these sensors typically use different sampling rates, so data must be interpolated. While this is generally granted for offline data, in the case of real-time processing, a scanner with this capability is needed. Second, individual scan lines must be identifiable. In the case of LAS data, this information is provided in the scan direction field and edge of flight line field. In fact, just one of these two fields is enough to identify scan lines. For simplicity in the processing, the points within each scan line must follow the same scanning direction. This is the case when data have been acquired with a rotating polygon mechanism. If an oscillating mirror mechanism is used instead, it is needed to invert the point ordering in the odd scan lines, as they are recorded in both directions of the scan.
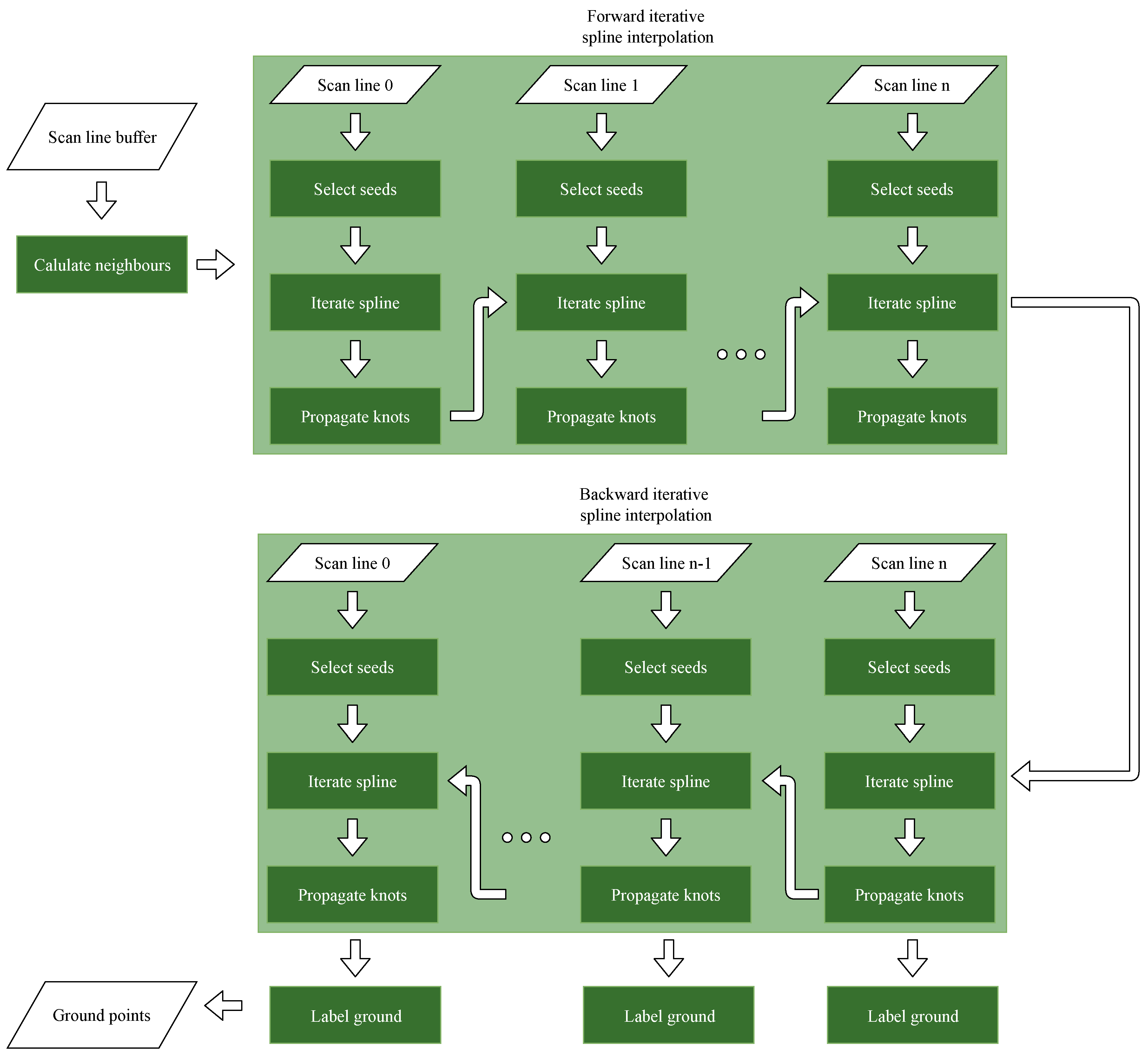
A flowchart of the whole method is depicted in
Figure 3. Note that only last-return points are taken into account, as possible previous returns are assumed to be non-ground points. The first step is to calculate the set of neighbours of each point. Then, an iterative spline interpolation is performed in each scan line sequentially. First, this is done from the first to the last scan line (forward), and then, it is done from the last to the first scan line (backwards). This iterative spline interpolation consists in three main stages: (1) the selection of the initial spline knots (seeds), (2) the iterative spline interpolation, and (3) the propagation of the final spline knots to the next scan line. Once the backward iterative spline interpolation of a scan line has been performed, the resultant spline is used to identify the ground points based on their residuals. Following, we describe each one of these steps.
2.1. Neighbour Calculation
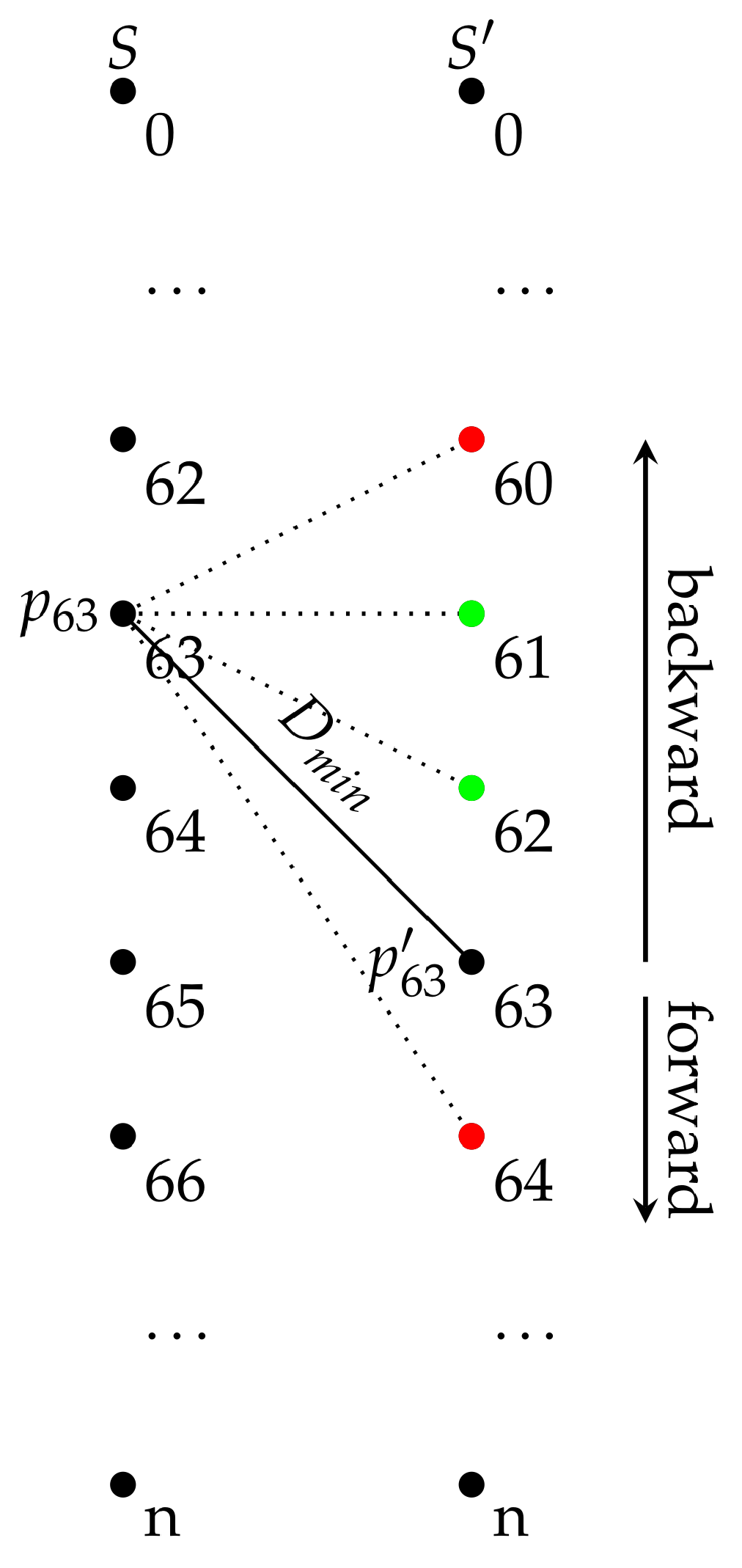
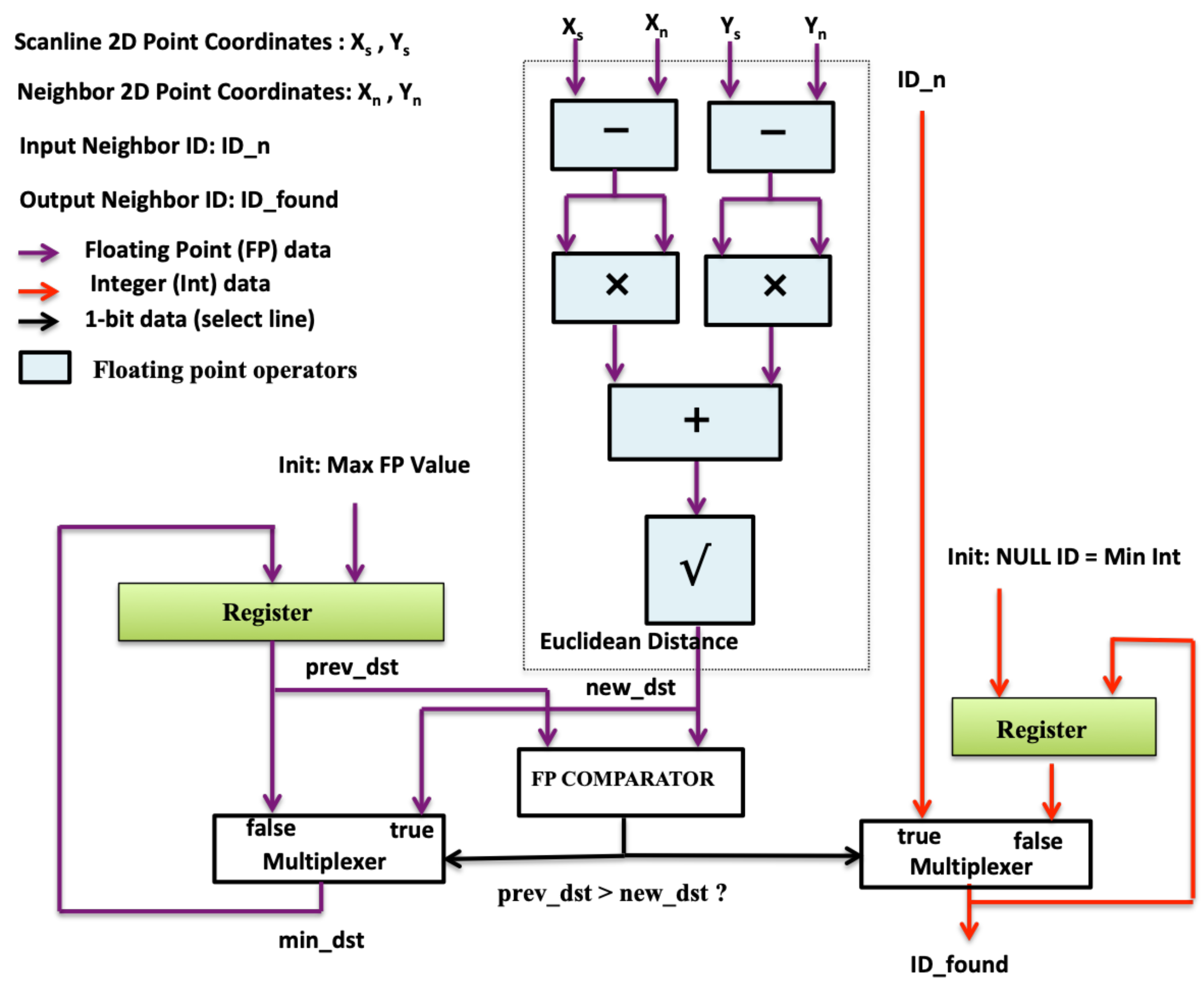
For each point, the closest point in the previous scan line and the closest point in the next scan line are calculated in this initial step. We further refer to these neighbours as the perpendicular neighbours. A perpendicular neighbour of a point can be calculated by brute force, computing all the distances from the point to all the points in the adjacent scan line and keeping the closest. Nevertheless, this is inefficient and severely increases the computing time. Moreover, it is reasonable to expect that a perpendicular neighbour will have a similar index within the scan line. This assumption can be exploited to speed up the neighbour search. The idea is to start the search at the adjacent point with the same index and to continue the search backwards and forward while the distance is being reduced. The process is depicted in
Figure 4. This calculation is faster the more similar the point spacing is in both scan lines, as it leads a point and its neighbour to yield a similar index. Therefore, its speed is influenced by the acquisition procedure to some extent (see
Section 4.1).
2.2. Seeds Selection
Before performing the interpolation, a set of initial knots, known as seeds, are selected. The number of seeds depends on the interpolation algorithm. The Akima interpolation algorithm [
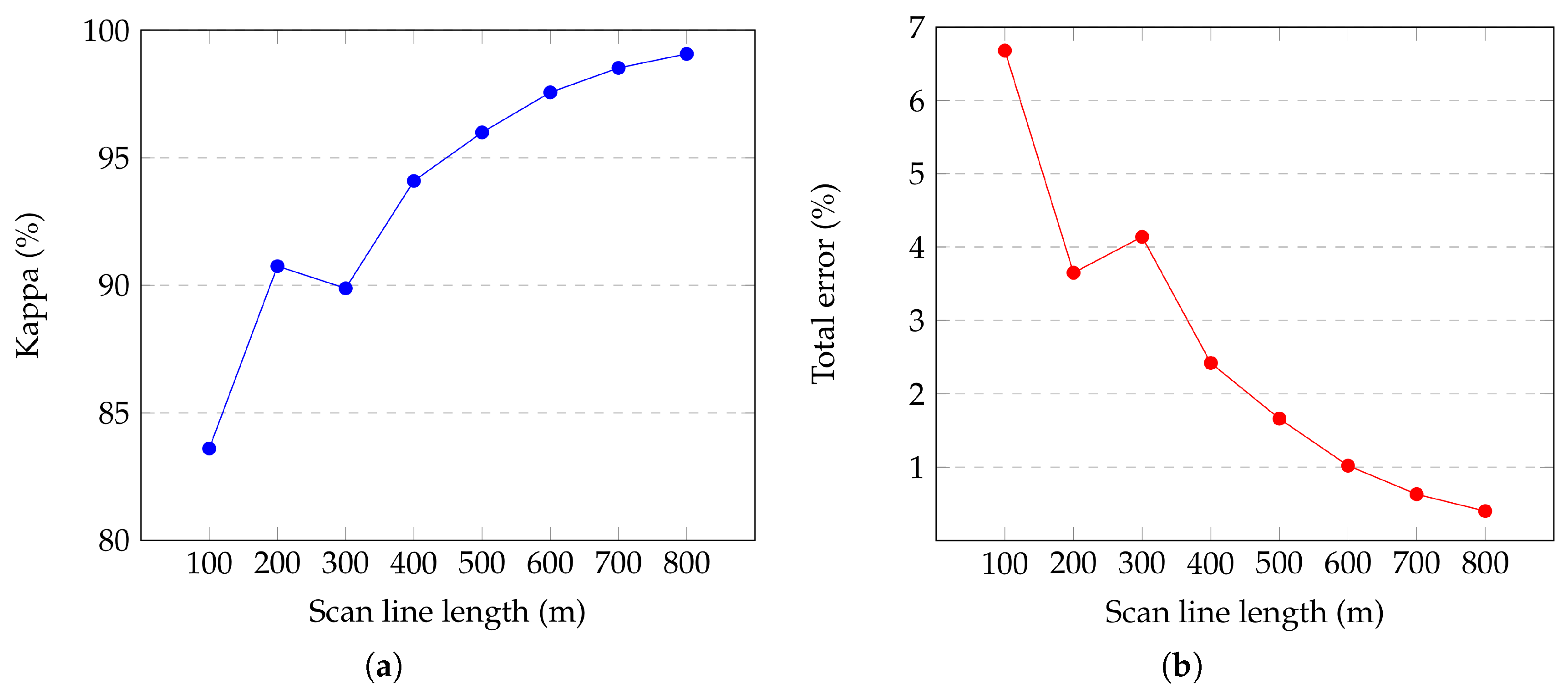
22] is used in this work, which requires a minimum number of 5 seeds. For its selection, the scan line is split into 5 segments of equal length and the lowest point in each segment is elected as a seed point. Seed points are assumed to be ground points. This assumption is acceptable when the length of the scan line is reasonably large. More specifically, this assumption is guaranteed when the length of each segment is larger than the largest non-ground object of the scene. Therefore, the length of the generated scan line must be taken into consideration when tuning the parameters of the LiDAR survey. The optimal scan line length can be calculated as follows:
where
is an user-defined constant (ideally 1),
n is the number of scan line segments (5 in our case), and
L is the largest non-ground object size. More details on this aspect are given in
Section 5.1.
2.3. Iterative Spline
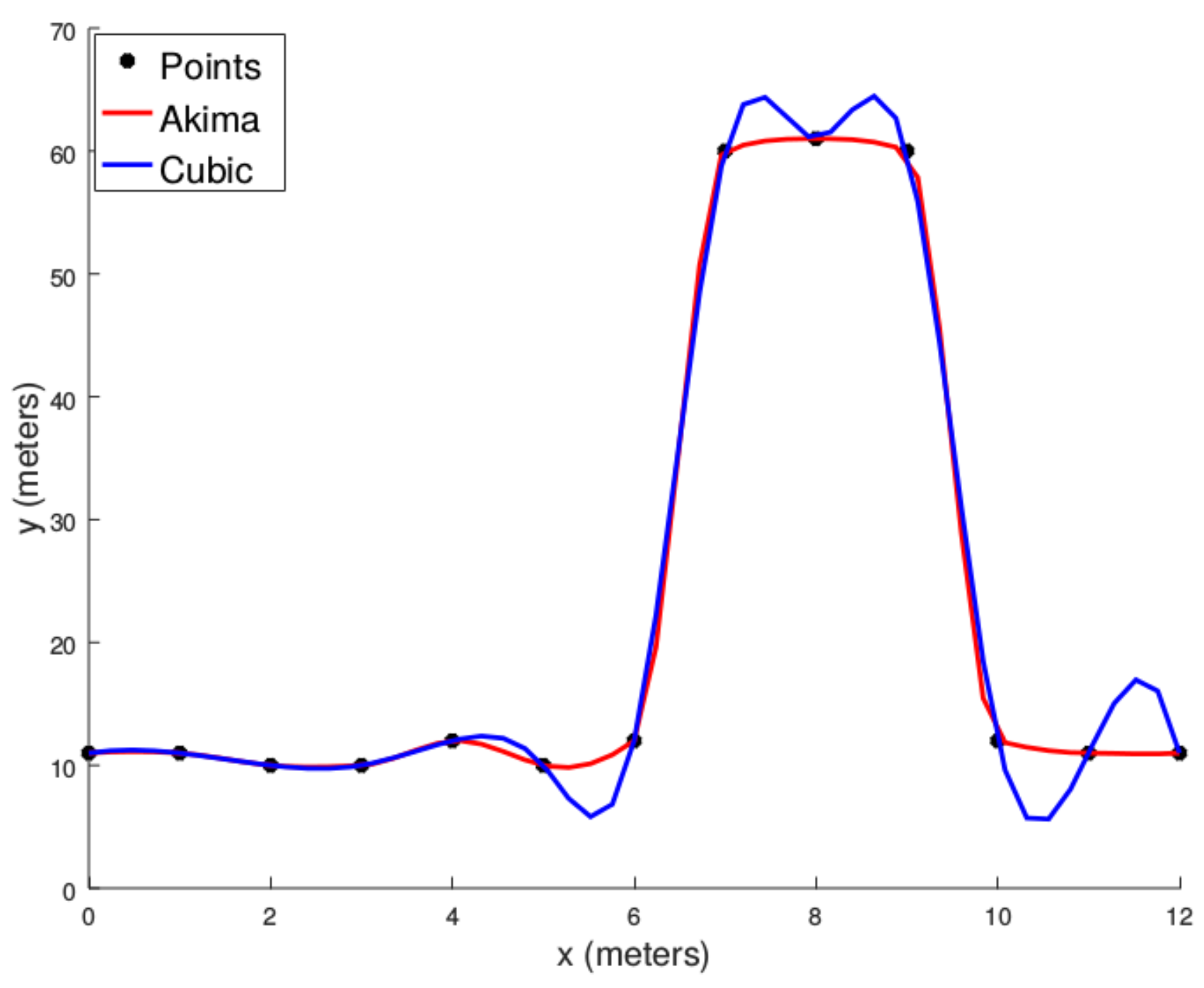
Based on the seeds, an initial interpolation of the scan line is performed. The Akima algorithm is a continuously differentiable sub-spline interpolation built from piecewise third-order polynomials. An important feature of this method is its locality: Function values on the interval
depend only on its neighbourhood
. The advantage of this fact is twofold: First, this method does not lead to unnatural wiggles in the resulting curve (see
Figure 5), and second, it is computationally efficient as there is no need to solve large systems of equations.
The LiDAR 3-D points are projected into 1-D as follows: Its original coordinates are converted into , where is the 2-D euclidean distance to the first point of the scan line and . Note that values must be monotonically increasing, so duplicated values are removed.
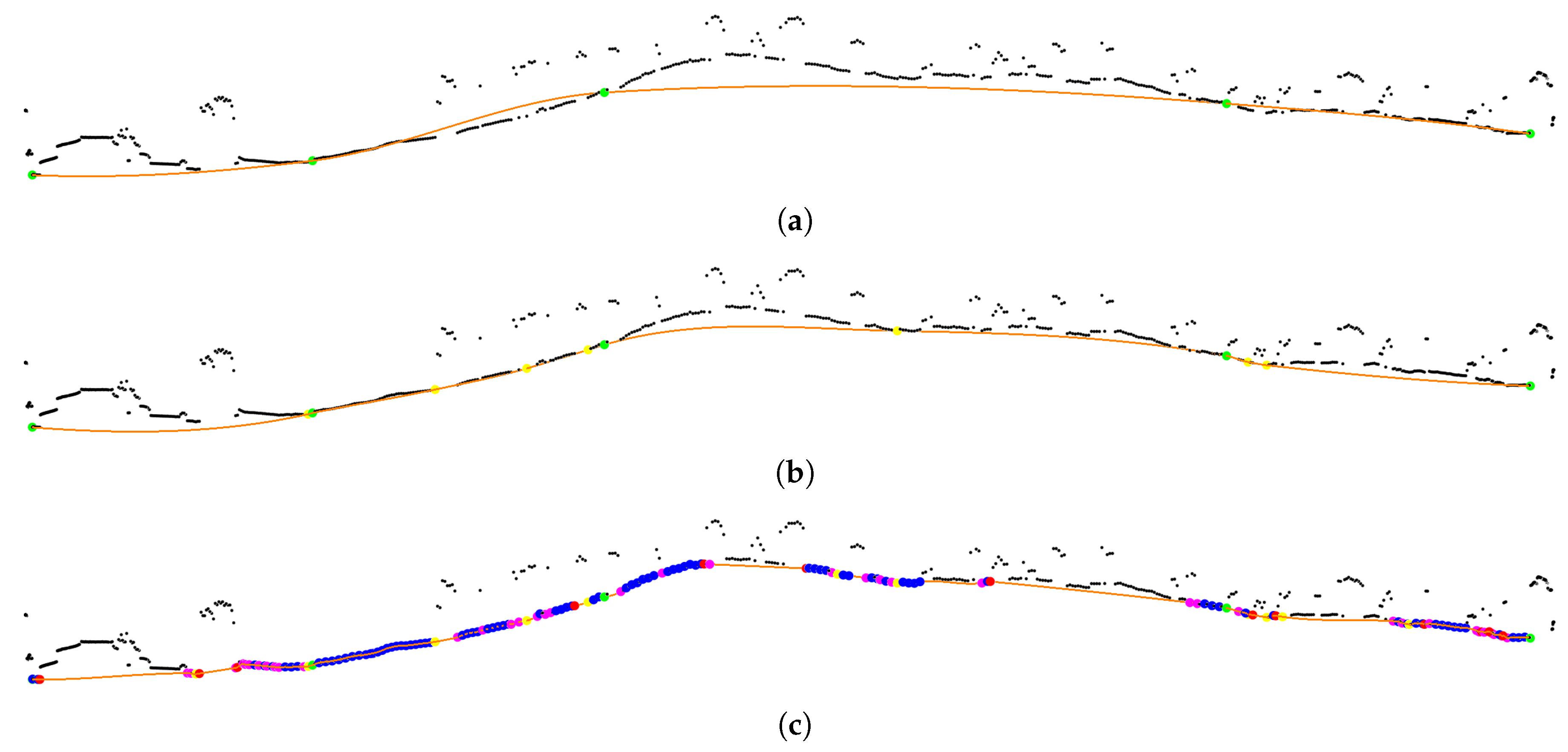
The proposed iterative interpolation consists in the execution of three stages: (1) interpolation, (2) push down, and (3) push up. The spline passes through a set of knots . The idea is to iteratively refine the spline by adding new knots into K. The steps are as follows:
The interpolation of the spline is performed. In the first iteration,
K consists of just the seed points, and the initial spline is a rough estimation of the ground level (see
Figure 6a).
In the push down stage, the spline descends into the ground level by adding ground points under the spline into
K (see
Figure 6b). For each knot pair
the point with the largest residual under the spline is added into
K if this residual is higher than a tolerance threshold
T, so that only significant residuals are considered. An adequate value for this threshold is between one and two times the vertical accuracy of the LiDAR data. In this work,
m is used. After processing all knot pairs, if
K has new points, we return to step 1; otherwise, this stage ends.
In the push up stage, the spline raises by adding ground points above the spline into
K (see
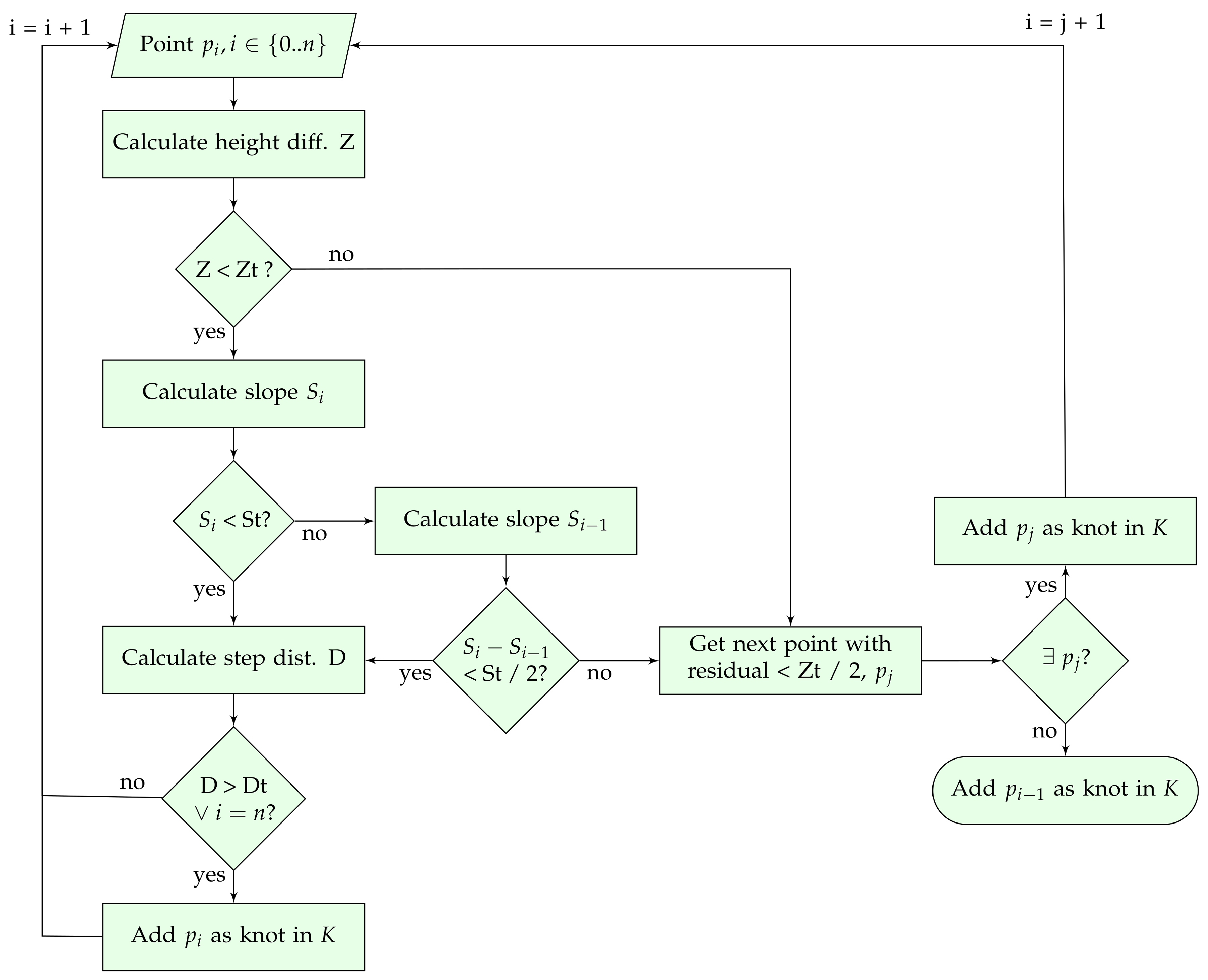
Figure 6c). The idea is to start at a known ground point and to consider the next point as ground as long as the transition is smooth. This is accomplished by a 1-D bidirectional labelling algorithm. For each knot, both forward and backward labelling are conducted. The labelling process is shown in
Figure 7. The process starts at the next point of the knot. This point has to fulfil three constraints based on height difference, slope, and step distance. The calculation of these constraints are given by Equations (
2)–(
4). First, the pairwise height difference must be lower than a given threshold
. Second, the pairwise slope must be lower than a given threshold
or the slope change (if available) must be lower than the half of
. Third, the 2-D distance to the previous knot must be higher than a given threshold
. This last constraint limits the number of points that will be labelled as knots, so that only meaningful knots are added, as processing all knots will increase the computational demand of the interpolation with little contribution to its accuracy. The height and slope thresholds can be tuned for a particular data to obtain better results. Common values can be widely found in the literature. Our suggestion is to use as default parameters
m and
or
for urban or rural sites, respectively. For the step distance threshold, we have found experimentally that
m provides the best trade-off between accuracy and throughput. If the point does not fulfill the height or slope constraints, the next point yielding a low residual is added into
K and the labelling continues in that point. The process ends if a knot is reached. Finally, if
K has new points, we return to step 1; otherwise, the iterative spline interpolation finishes.
2.4. Knot Propagation
The knot propagation is performed after the iterative spline interpolation. Its goal is to avoid errors when ground filtering is executed on each scan line individually without knowledge of the previous filtering. For example, in high-slope terrains, few ground points might not be identifiable for a given scan line, resulting in an inaccurate spline and causing several points to be mislabelled. However, this can be mitigated if the spline of the previously filtered scan line is considered.
The process is as follows: Let K be the set of knots of a scan line S after the iterative spline interpolation and be the set of knots of the next scan line to be processed, which is initially empty. The goal is to propagate the knots of K into . Propagating a knot means that its perpendicular neighbour will be added into . In order to be propagated, a knot has to fulfill the same but more restrictive height, slope, and step distance constraints than in the push up stage described previously. In particular, the height and slope thresholds used are reduced to half. Also, if a knot fulfils the height and slope constraints but the step distance is lower than , the knot is ignored. However, if a knot does not fulfill the constraints but the step distance is higher than , the last ignored knot is propagated. This way, the gap between propagated knots is reduced in the case of non-fulfilling knots.
Therefore, at the first iteration of the iterative spline interpolation, the initial knots of a scan line are formed by the selected seed points plus the knots propagated from the previous scan line.
2.5. Ground Labelling
Finally, the ground points of each scan line are identified using the resulting spline after forward and backward interpolation. For each point, the residual to the spline is calculated, and if this residual is lower than the tolerance threshold T, the point is labelled as a ground point.
4. Embedded System Implementation
In order to demonstrate the portability of the proposed method to embedded systems while maintaining its good performance, we implemented it in a ZedBoard platform [
33]. This is a low-cost, low-power consumption development board, and it is shipped with a Zynq-7000 System-on-Chip (SoC) from Xilinx, 512 MB of DDR3 RAM, and several I/O peripherals such as a 1-Gb ethernet module and an SD card reader. The Zynq SoC integrates a 32-bit dual-core ARM Cortex-A9 CPU and a low-range Z7020 FPGA [
34], which allows the implementation of simple custom hardware accelerators.
In this proof of concept, we deployed two different implementations in the Zedboard. The first implementation is just a porting of the original C source code, developed for the x86-64 architecture, to the ARM v7 architecture. The results and performance comparisons for different LiDAR data are described in
Section 4.1. The second implementation is a custom hardware accelerator on the FPGA for precomputing the perpendicular neighbours. The software–hardware system developed and the results of the evaluation test performed are described in
Section 4.2. Power and energy consumption is shown in
Section 4.3.
4.1. CPU Implementation
Since a bare-metal implementation (non-OS support) of the method in the Zynq SoC does not provide enough flexibility for future code development and enhancements, a 32-bit embedded Linux distribution (Xilinx Linux kernel 4.14.04 and an Ubuntu 16.04 root file system) was deployed in the ARM Cortex-A9. For porting the original C code to the ARM Cortex-A9, we tried to avoid any substantial code changes. The pre-compiled GNU GSL libraries [
35] with hardware floating-point support for the ARM Cortex-A9 were used, and the OpenMP [
36] directives presented in the original code were preserved. We show the trace results for the Alcoy, Trabada, and Vaihingen data samples in
Table 4. The timing figures are shown for the tests run in Zedboard (only in the dual-core ARM CPU run at 667 MHz).
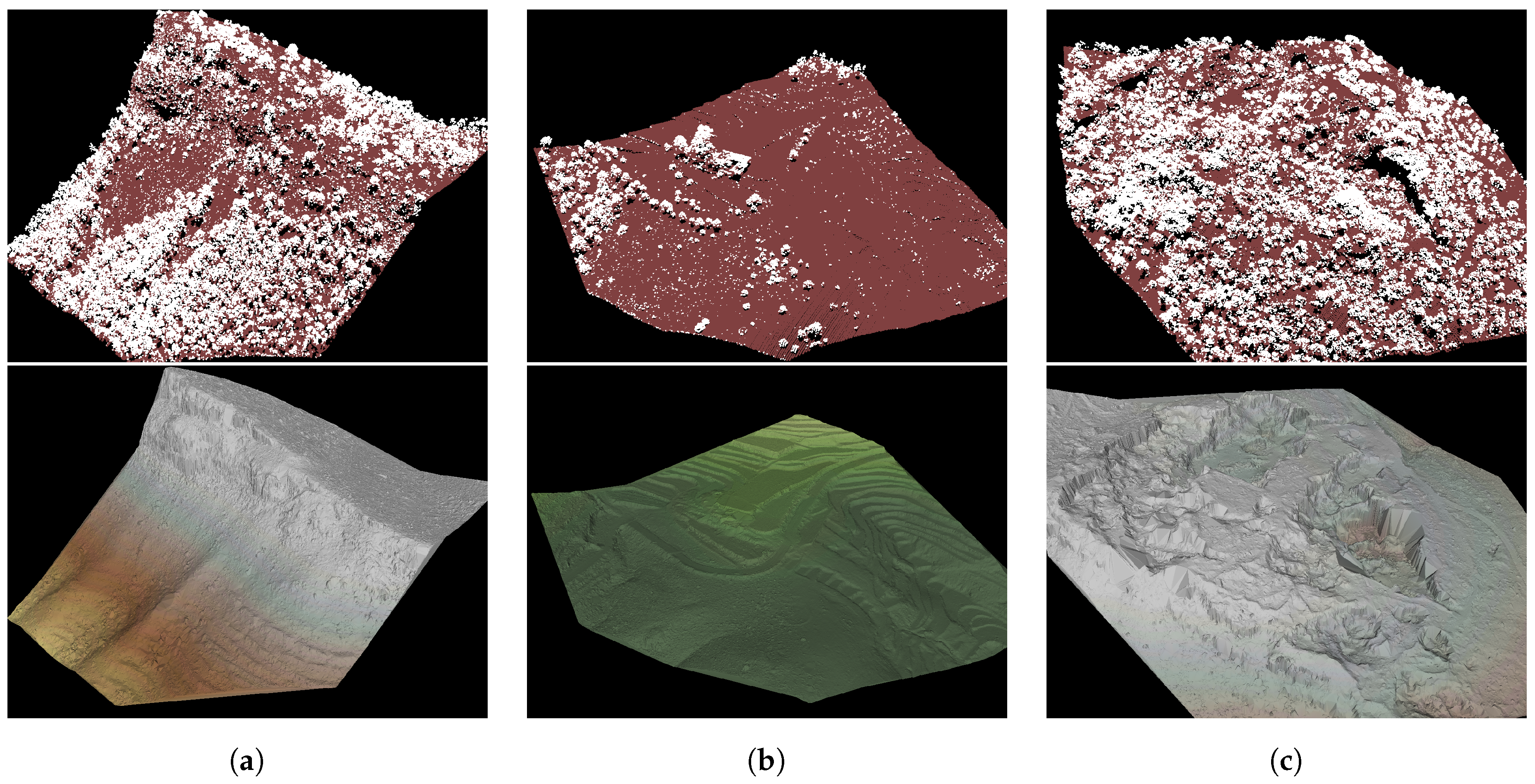
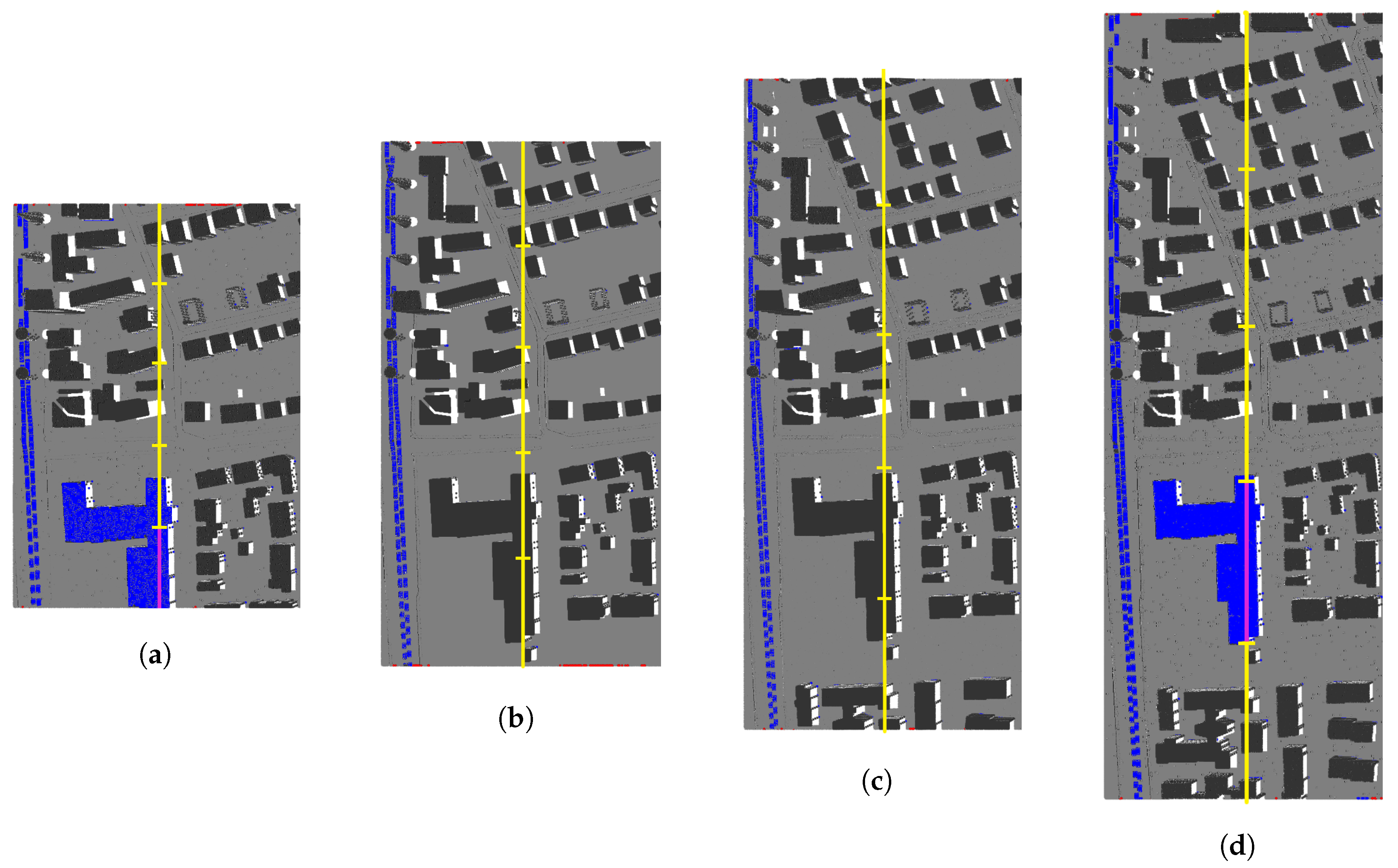
Note that the throughput in the Vaihingen sample is significantly lower than in the other samples. This is because the calculation of neighbours is quite costly in this particular sample. This is attributed to an accumulation of points at the sides of the point cloud. On the one hand, the deceleration of the sensor’s oscillating mirror when changing the scanning direction increases the number of points recorded at the edges of the point cloud (see
Figure 13a). On the other hand, the higher the scan angle, the higher the coverage of building facades, which also increases the number of points recorded (see
Figure 13b). These accumulations of points are detrimental for the computational performance of the neighbour search, which relies on the assumption that points of two adjacent scan lines present a similar point distribution. Furthermore, it is expected for point clouds generated in real-time to yield a more irregular scan-line point distribution than fully post-processed point clouds. In order to increase the throughput of the algorithm in such situations, a hardware accelerator was implemented on the PL (Programmable Logic) of the Zynq SoC.
4.2. Programmable Logic Acceleration
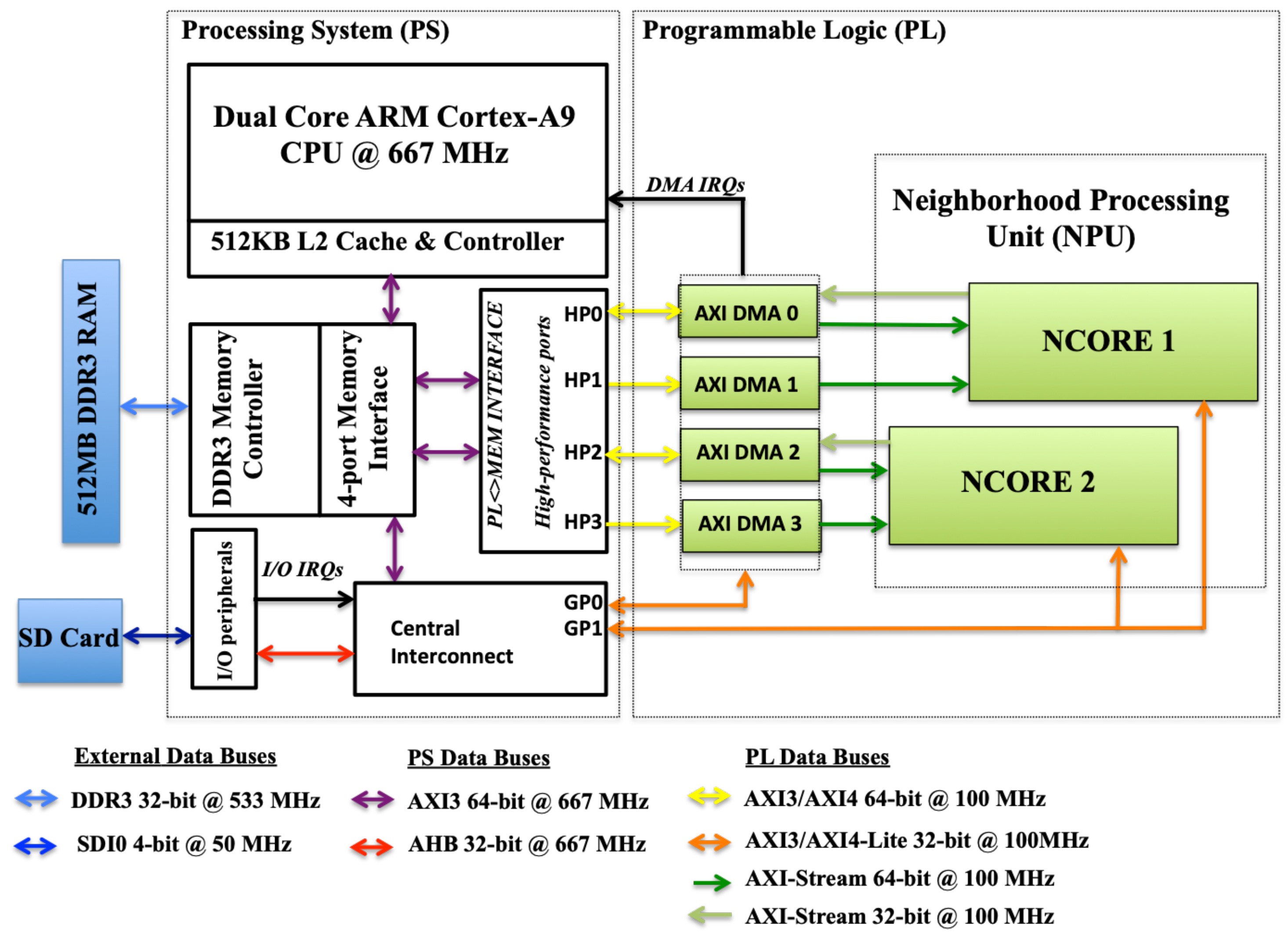
The hardware architecture of the system implemented is shown in
Figure 14. The hardware accelerator consists of two Neighbourhood Search Cores (NCOREs), each one computing the neighbours of different scan lines in parallel. Each NCORE communicates with the on-board DDR3 RAM and the CPU via DMA (Direct Memory Access) and high-performance (HP) ports. For optimal memory bandwidth use, two 64-bit DMA Controllers (AXI-DMA in
Figure 14) are needed for each NCORE implemented and run at the same clock speed as the NCORE. This bandwidth constraint is only required for reading data from RAM, since write operations to RAM are less frequent. Both the internal frequency of the PL and the input frequency run at 100 MHz, which is the maximum that allows processing one datum per cycle with the current design. The ARM cores in the PS (Processing System) of the Zynq SoC run at 667 MHz.
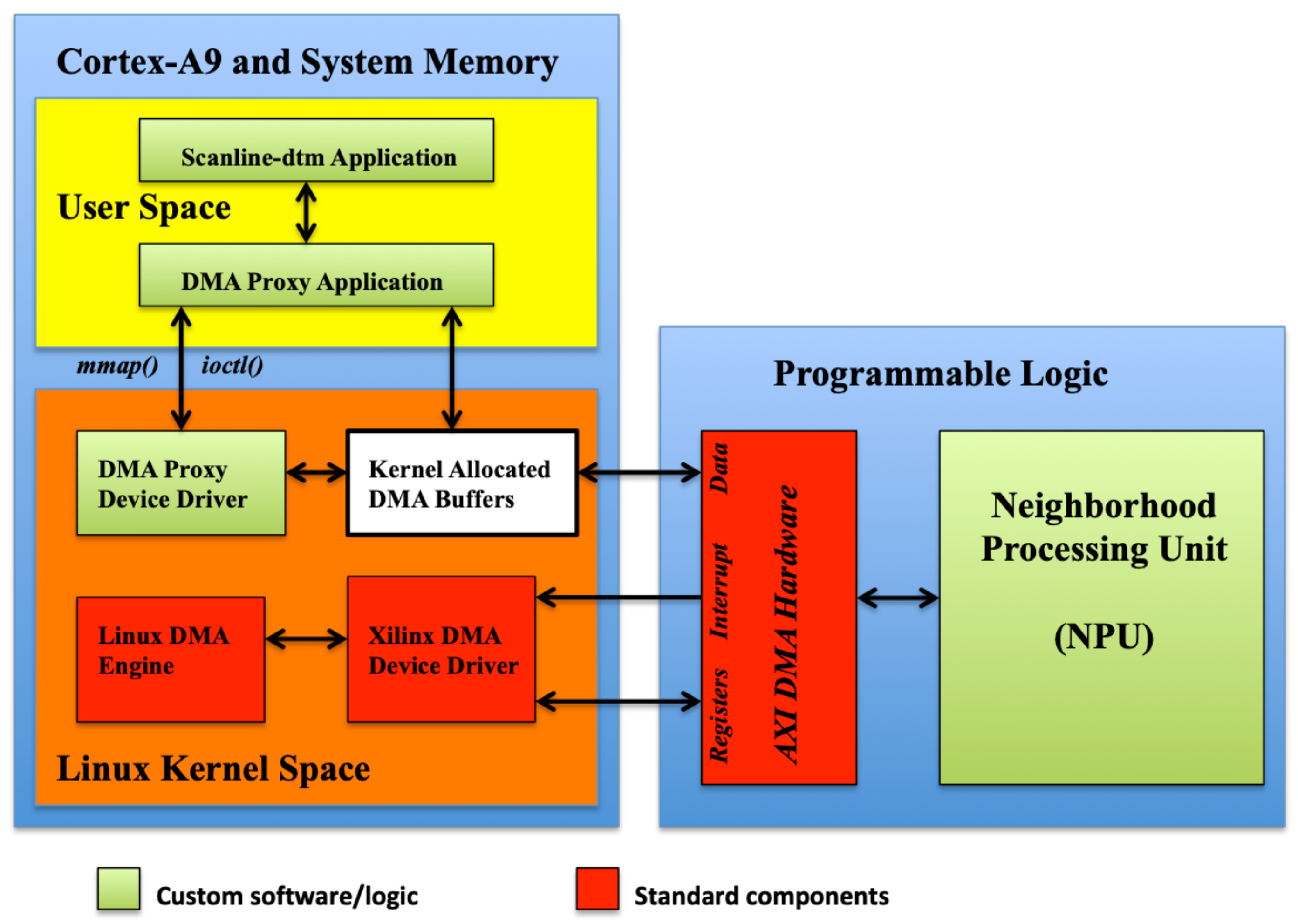
To interact with the hardware acceleration from the software application, which runs in the Linux environment in the ARM CPU, we rely on the DMA Engine framework and Xilinx DMA device drivers. A general view of the architecture of the software-hardware system deployed is shown in
Figure 15. In addition to the acceleration hardware, we developed a Linux kernel character driver and a DMA proxy user application. These software codes provide the control logic for the communication of the DMA controllers built in the FPGA with the CPU via RAM.
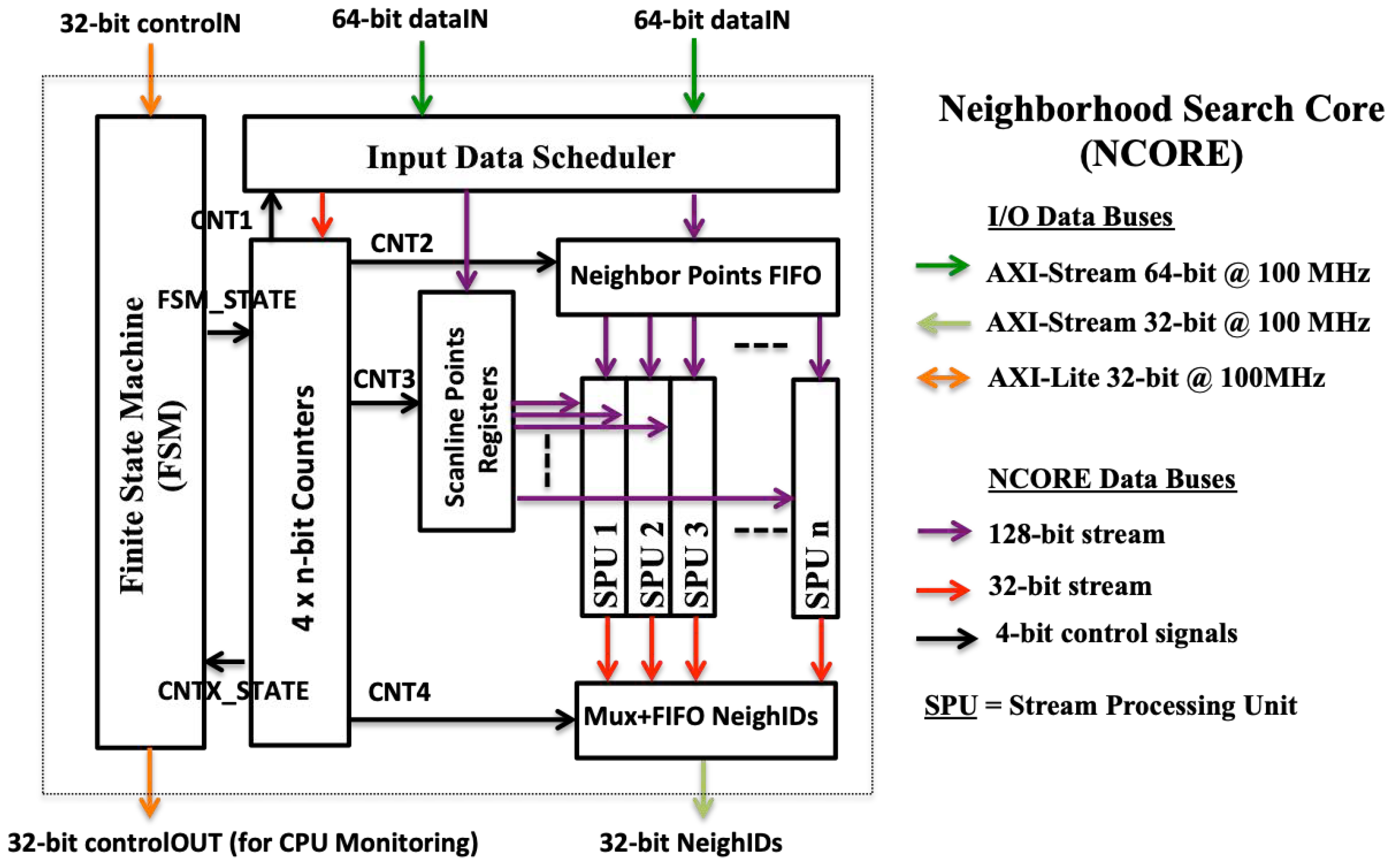
Finally, the architecture of the NCORE is shown in
Figure 16. In addition to the parallelism at the scan-line level (one scan line search per NCORE), each NCORE can search concurrently for the neighbours of several consecutive points of the same scan line, issuing one search for each SPU (Stream Processing Unit) implemented in the NCORE. The structure of the SPUs is shown is
Figure 17. Therefore, the total parallelism implemented in the hardware accelerator is given by the number of NCOREs multiplied by the number of SPUs of each NCORE. The optimal number of NCOREs is given by the ratio of the available DDR memory bandwidth with respect to the NCORE throughput (The NCORE throughput is proportional to the clock frequency and inverse to the maximum cycle interval between two consecutive data inputs.). For our Zynq FPGA this factor is close to two. On the other hand, we have implemented one core with 2 SPUs (NCORE 1) and the other (NCORE 2) with 3 SPUs. Therefore, the total number of SPUs (and the parallelisation factor) is 5.
The resources of the FPGA used and the total use percentage are summarised in
Table 5. The FF (Flip-Flop) resources are used for implementing registers and fast data storage. LUT (LookUp Table) are used for implementing combinational logic while the DSP48E are building blocks used in arithmetic (fixed and floating-point) operations. The performance is limited mainly by the available LUT resources, since embedding additional SPUs in a CORE does not modify the memory bandwidth usage.
To provide an estimation of the achievable acceleration of the execution time of the neighbour search of the scan-line points, we run the Vaihingen sample in the Zedboard with and without using the PL hardware acceleration. The results of these tests are shown in
Table 6. We show that the execution time of the neighbours search can be accelerated by a factor of 3.5 with a (non-optimised) custom hardware accelerator.
4.3. Power and Energy Consumption
Two different methods have been used in order to estimate power consumption. For early estimation of the Xilinx Zynq SoC power consumption during the cycle design, we have used the Xilinx Power Estimator (XPE). The XPE is a spreadsheet-based tool that provides detailed power and thermal information based on design information such as resource use and clock frequencies. For power consumption estimation of the Zedboard during execution, we use voltage measurements of the shunt-resistor mounted on the power supply of the ZedBoard. The shunt-resistor is a 10-m
resistor in series with the input supply line to the board; this resistor can be used to measure the current draw of the whole board. The current draw can be used to calculate the power consumption of the board using Ohm’s law and the supply voltage. As the power supply voltage is 12 V, the power consumption of the board can be obtained by measuring the voltage over the current sense resistor and by inserting the measured value into Equation (
5).
The power dissipation of the Zedboard during the tests performed with and without hardware acceleration was below 3 W. The results of these tests are summarised in
Table 7. Energy efficiency is increased by using hardware acceleration.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}