Mapping Plastic Mulched Farmland for High Resolution Images of Unmanned Aerial Vehicle Using Deep Semantic Segmentation

 and
and
Abstract
1. Introduction
2. Study Area and Data Set
2.1. Study Area
2.2. Data Set
2.2.1. Data Sets Acquisition
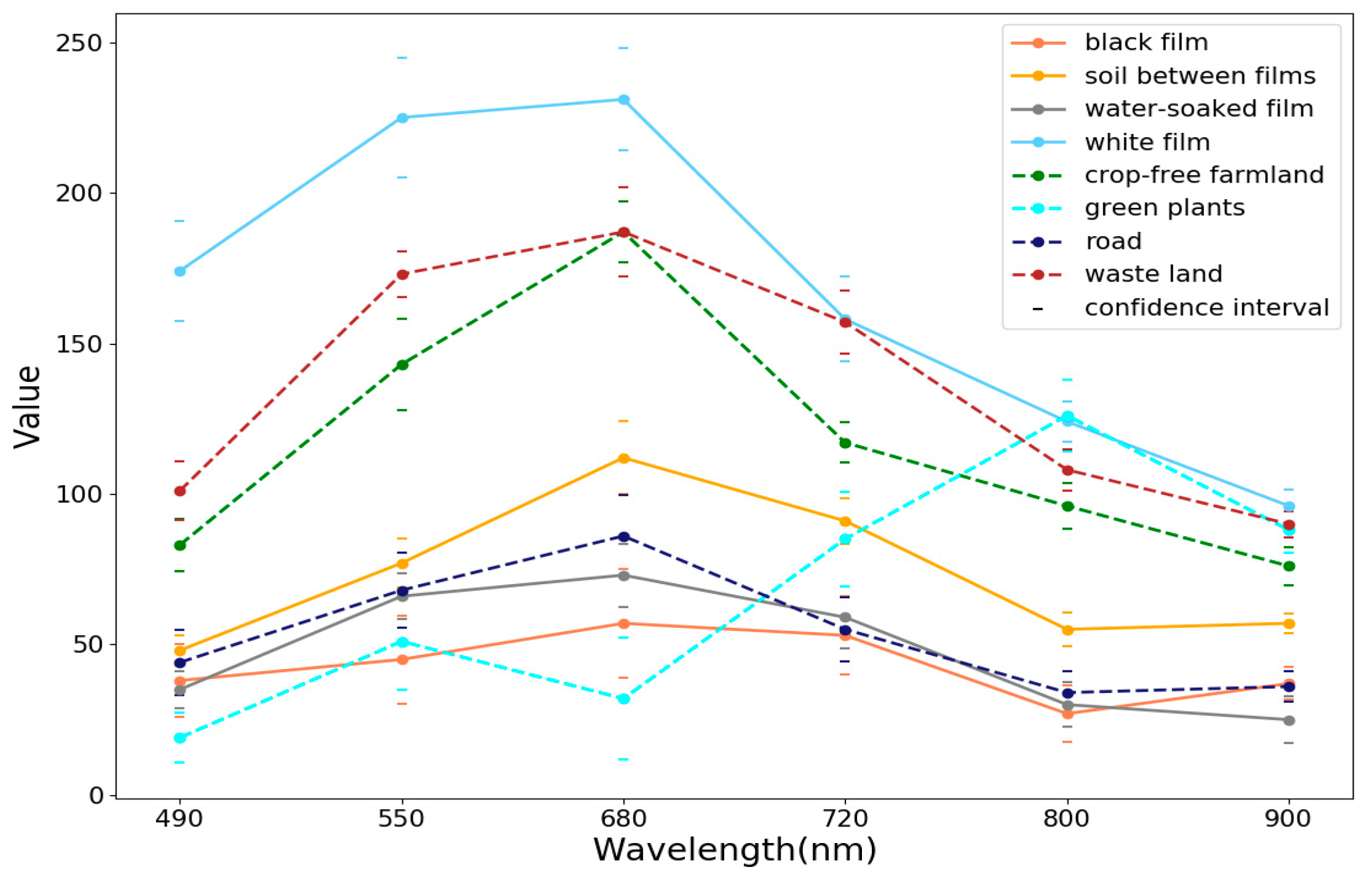
2.2.2. Image Labeling and Analysis
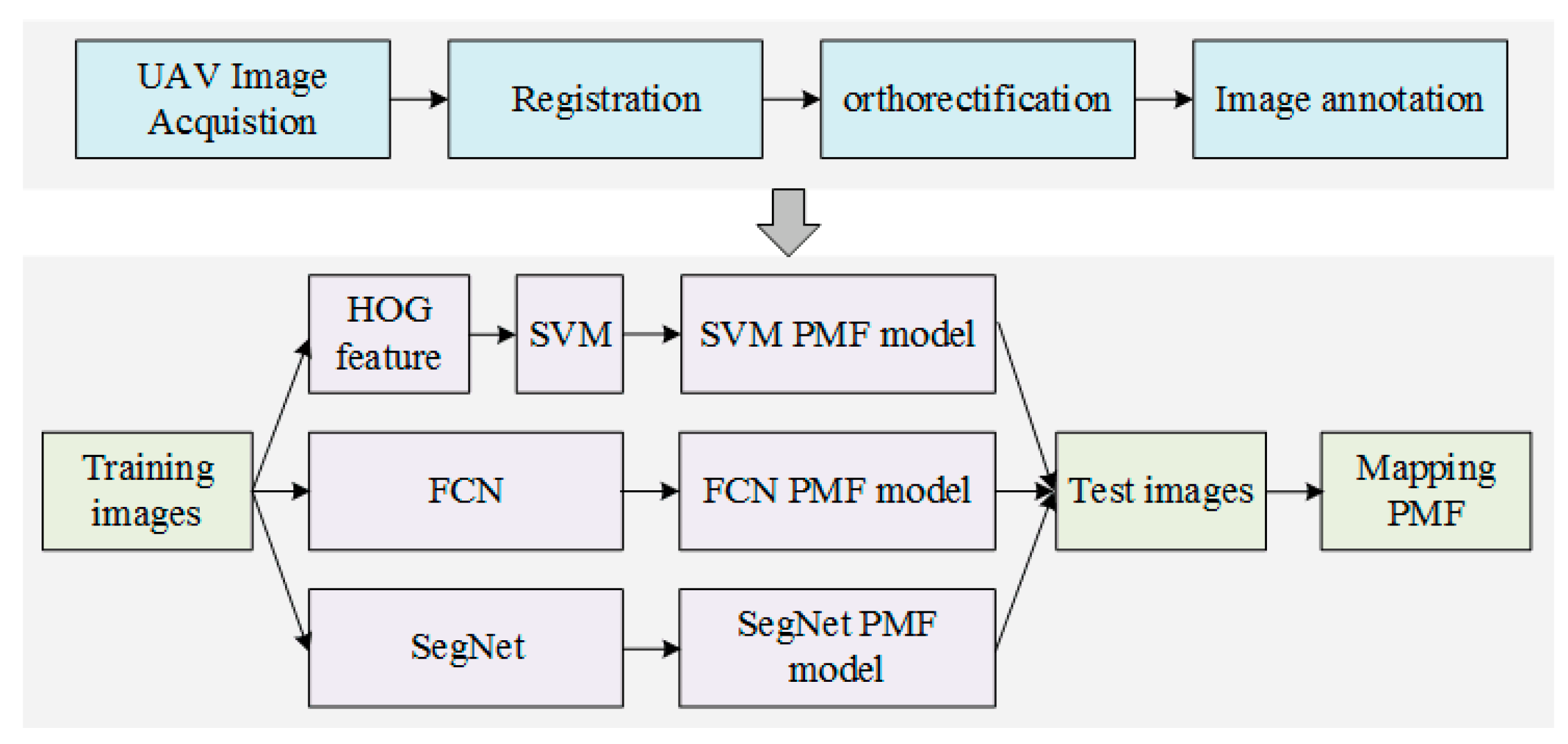
3. Methods
3.1. Traditional SVM Method
3.1.1. Feature Extraction
3.1.2. SVM Classification Method
3.2. Deep Semantic Segmentation Methods
3.2.1. Fully Convolutional Network
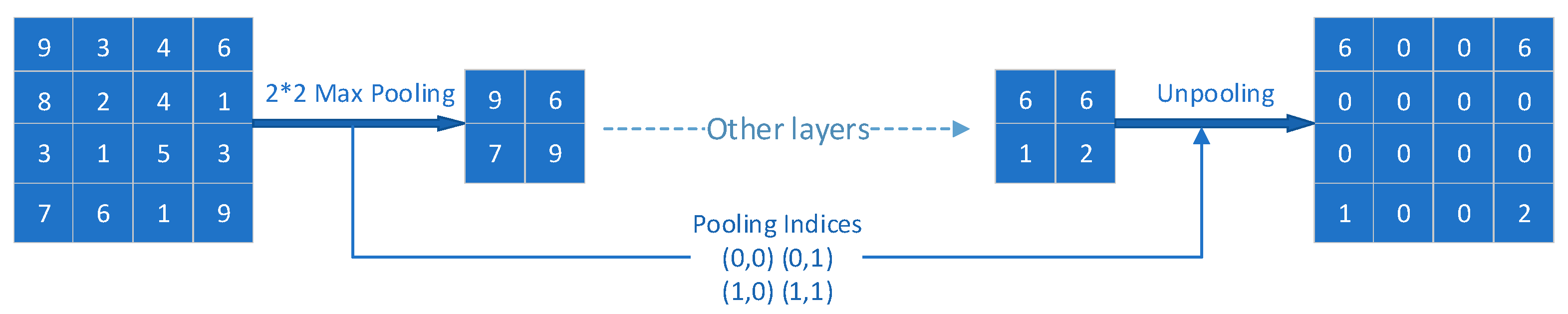
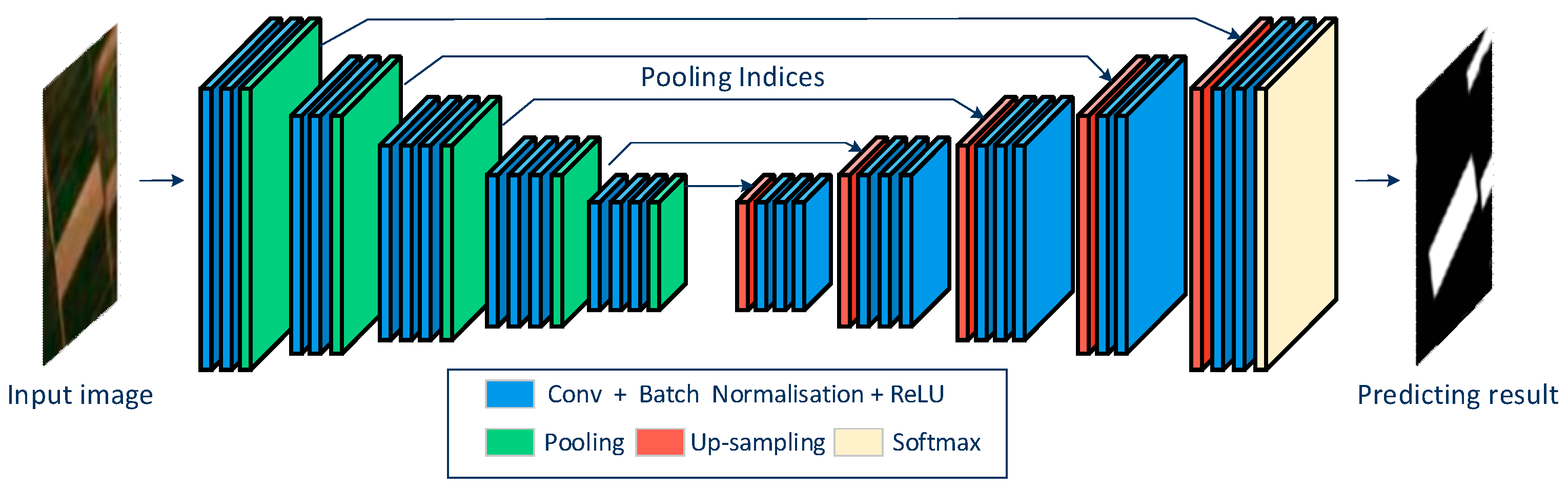
3.2.2. SegNet
3.2.3. Network Training
3.2.4. Model Test and Accuracy Assessment
4. Results
4.1. PMF Identification Only with Texture Feature
4.2. PMF Identification Using Multiple-Band Images
5. Discussion
5.1. Contribution of Texture Feature
5.2. Combination of Spectral and Texture Feature
5.3. Advantage of Deep Learning over Traditional SVM
5.4. Differences from Existing Works
5.5. Limitations and Future Work
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Espí, E.; Salmerón, A.; Fontecha, A.; García, Y.; Real, A.I. Plastic Films for Agricultural Applications. J. Plast. Film Sheet. 2016, 22, 85–102. [Google Scholar] [CrossRef]
- Mormile, P.; Stahl, N.; Malinconico, M. The World of Plasticulture. In Soil Degradable Bioplastics for a Sustainable Modern Agriculture, 1st ed.; Malinconico, M., Ed.; Springer: Heidelberger, Germany, 2017; Volume 1, pp. 1–21. [Google Scholar]
- Liu, E.K.; He, W.Q.; Yan, C.R. ‘White Revolution’ to ‘White Pollution’—Agricultural Plastic Film Mulch in China. Environ. Res. Lett. 2014, 9, 91001. [Google Scholar] [CrossRef]
- Yan, C.R.; Liu, E.K.; Shu, F.; Liu, Q.; Liu, S.; He, W.Q. Review of Agricultural Plastic Mulching and Its Residual Pollution and Prevention Measures in China. J. Agric. Resour. Environ. 2014, 31, 95–102. [Google Scholar]
- Hasituya; Chen, Z.; Wang, L.; Wu, W.; Jiang, Z.; Li, H. Monitoring Plastic-Mulched Farmland by Landsat-8 Oli Imagery Using Spectral and Textural Features. Remote Sens. 2016, 8, 353. [Google Scholar] [CrossRef]
- Hasituya; Chen, Z.X.; Li, F.; Hong, M. Mapping Plastic-Mulched Farmland with C-Band Full Polarization Sar Remote Sensing Data. Remote Sens. 2017, 9, 1264. [Google Scholar] [CrossRef]
- Lu, L.; Di, L.; Ye, Y. A Decision-Tree Classifier for Extracting Transparent Plastic-Mulched Landcover from Landsat-5 Tm Images. IEEE J. Stars 2014, 7, 4548–4558. [Google Scholar] [CrossRef]
- Lu, L.; Hang, D.; Di, L. Threshold Model for Detecting Transparent Plastic-Mulched Landcover Using Moderate-Resolution Imaging Spectroradiometer Time Series Data: A Case Study in Southern Xinjiang, China. J. Appl. Remote Sens. 2015, 9, 97094. [Google Scholar] [CrossRef]
- Hasituya; Chen, Z.X.; Wang, L.M.; Liu, J. Selecting Appropriate Spatial Scale for Mapping Plastic-Mulched Farmland with Satellite Remote Sensing Imagery. Remote Sens. 2017, 9, 265. [Google Scholar] [CrossRef]
- Hasituya; Chen, Z.X. Mapping Plastic-Mulched Farmland with Multi-Temporal Landsat-8 Data. Remote Sens. 2017, 9, 557. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A. An Object-Based Image Analysis Method for Enhancing Classification of Land Covers Using Fully Convolutional Networks and Multi-View Images of Small Unmanned Aerial System. Remote Sens. 2018, 10, 457. [Google Scholar] [CrossRef]
- Liang, H.; Li, Q. Hyperspectral Imagery Classification Using Sparse Representations of Convolutional Neural Network Features. Remote Sens. 2016, 8, 99. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.W.; Zhang, L.P. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, R.R.; Liu, W.J.; Yang, L. Deepunet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Stars 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.J.; Zhou, R.; Sun, T.; Zhang, Q.J. Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Chen, R.M.; Sun, S.L. Automatic Extraction of Infrared Remote Sensing Information Based on Deep Learning. Infrared 2017, 38, 37–43. [Google Scholar]
- Sherrah, J. Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Cortes, C.; Vapnick, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Ding, Y.; Sarula; Liu, P.T.; Li, X.L.; Wu, X.H.; Hou, X.Y. Spatial Changes of Temperature and Precipitation in Inner Mongolia in the Past 40 Years. J. Agric. Resour. Environ. 2014, 28, 97–102. [Google Scholar]
- Image Polygonal Annotation with Python (Polygon, Rectangle, Circle, Line, Point and Image-Level Flag Annotation). Available online: https://github.com/wkentaro/labelme (accessed on 9 May 2018).
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Duguay, Y.; Bernier, M.; Lévesque, E.; Domine, F. Land Cover Classification in Subarctic Regions Using Fully Polarimetric Radarsat-2 Data. Remote Sens. 2016, 8, 697. [Google Scholar] [CrossRef]
- Heumann, B.W. An Object-Based Classification of Mangroves Using a Hybrid Decision Tree—Support Vector Machine Approach. Remote Sens. 2011, 3, 2440–2460. [Google Scholar] [CrossRef]
- Crammer, K.; Singer, Y. On the Algorithmic Implementation of Multiclass Kernel-Based Vector Machines. JMLR 2001, 2, 265–292. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Stateline, NV, USA, 3–6 December 2012. [Google Scholar]
- Hu, W.; Huang, Y.Y.; Wei, L.; Zhang, F.; Li, H.C. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 1–12. [Google Scholar] [CrossRef]
- Guo, Y.D.; Zou, B.J.; Chen, Z.L.; He, Q.; Liu, Q.; Zhao, R.C. Optic Cup Segmentation Using Large Pixel Patch Based Cnns. In Proceedings of the Ophthalmic Medical Image Analysis Third International Workshop, Anthens, Greece, 21 October 2016. [Google Scholar]
- Song, H.S.; Kim, Y.H.; Kim, Y.I. A Patch-Based Light Convolutional Neural Network for Land-Cover Mapping Using Landsat-8 Images. Remote Sens. 2019, 11, 114. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.H.; Han, B.Y. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- De Boer, P.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Siam, M.; Gamal, M.; Abdel-Razek, M.; Yogamani, S.; Jagersand, M. Rtseg: Real-Time Semantic Segmentation Comparative Study. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Best 2 Bands (nm) | Accuracy (mIoU, %) | Time (/Field) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Field1 | Field2 | Field3 | Field4 | Field5 | Field6 | Average | |||
| SVM | 720 | 75.35 | 60.43 | 57.44 | 78.38 | 93.76 | 70.35 | 72.62 | 2 h 17 m |
| 800 | 59.50 | 66.31 | 65.15 | 76.88 | 95.42 | 69.66 | 72.15 | 2 h 15 m | |
| FCN_8s | 800 | 93.51 | 81.07 | 78.80 | 86.89 | 96.84 | 86.46 | 87.30 | 10.09 s |
| 900 | 85.31 | 83.32 | 82.94 | 88.51 | 92.12 | 87.21 | 86.57 | 10.13 s | |
| SegNet | 800 | 96.38 | 83.38 | 82.00 | 93.39 | 93.66 | 83.15 | 88.66 | 16.50 s |
| 900 | 95.39 | 83.26 | 84.12 | 93.05 | 91.37 | 84.90 | 88.68 | 16.44 s | |
| Methods | Number of Bands | Accuracy (mIoU, %) | Time (/Field) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Field1 | Field2 | Field3 | Field4 | Field5 | Field6 | Average | |||
| SVM | 3 | 90.45 | 66.27 | 64.43 | 72.65 | 96.6 | 72.03 | 77.07 | 5 h 3 m |
| 6 | 92.34 | 67.66 | 76.14 | 81.45 | 96.3 | 74.27 | 81.36 | 8 h 31 m | |
| FCN_8s | 3 | 92.42 | 76.44 | 70.69 | 78.16 | 97.77 | 70.97 | 81.08 | 10.83 s |
| 6 | 96.51 | 85.29 | 81.97 | 91.2 | 99.65 | 83.54 | 89.69 | 11.15 s | |
| SegNet | 3 | 96.99 | 84.51 | 80.77 | 93.37 | 99.94 | 81.85 | 89.62 | 17.37 s |
| 6 | 97.35 | 85.53 | 82.41 | 96.65 | 99.70 | 81.94 | 90.60 | 17.92 s | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Liu, M.; Zhang, Z.; Yang, S.; Ning, J.; Han, W. Mapping Plastic Mulched Farmland for High Resolution Images of Unmanned Aerial Vehicle Using Deep Semantic Segmentation. Remote Sens. 2019, 11, 2008. https://doi.org/10.3390/rs11172008
Yang Q, Liu M, Zhang Z, Yang S, Ning J, Han W. Mapping Plastic Mulched Farmland for High Resolution Images of Unmanned Aerial Vehicle Using Deep Semantic Segmentation. Remote Sensing. 2019; 11(17):2008. https://doi.org/10.3390/rs11172008
Chicago/Turabian StyleYang, Qinchen, Man Liu, Zhitao Zhang, Shuqin Yang, Jifeng Ning, and Wenting Han. 2019. "Mapping Plastic Mulched Farmland for High Resolution Images of Unmanned Aerial Vehicle Using Deep Semantic Segmentation" Remote Sensing 11, no. 17: 2008. https://doi.org/10.3390/rs11172008
APA StyleYang, Q., Liu, M., Zhang, Z., Yang, S., Ning, J., & Han, W. (2019). Mapping Plastic Mulched Farmland for High Resolution Images of Unmanned Aerial Vehicle Using Deep Semantic Segmentation. Remote Sensing, 11(17), 2008. https://doi.org/10.3390/rs11172008