Broad Area Target Search System for Ship Detection via Deep Convolutional Neural Network



Abstract
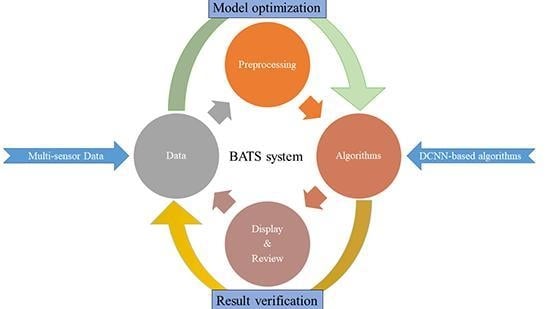
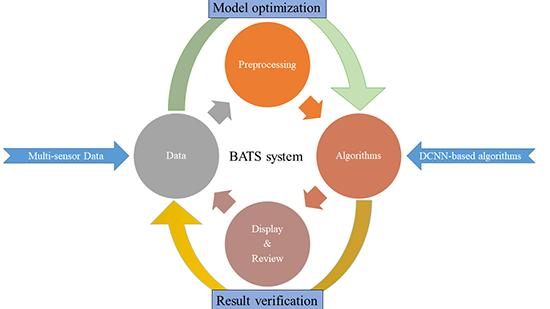
1. Introduction
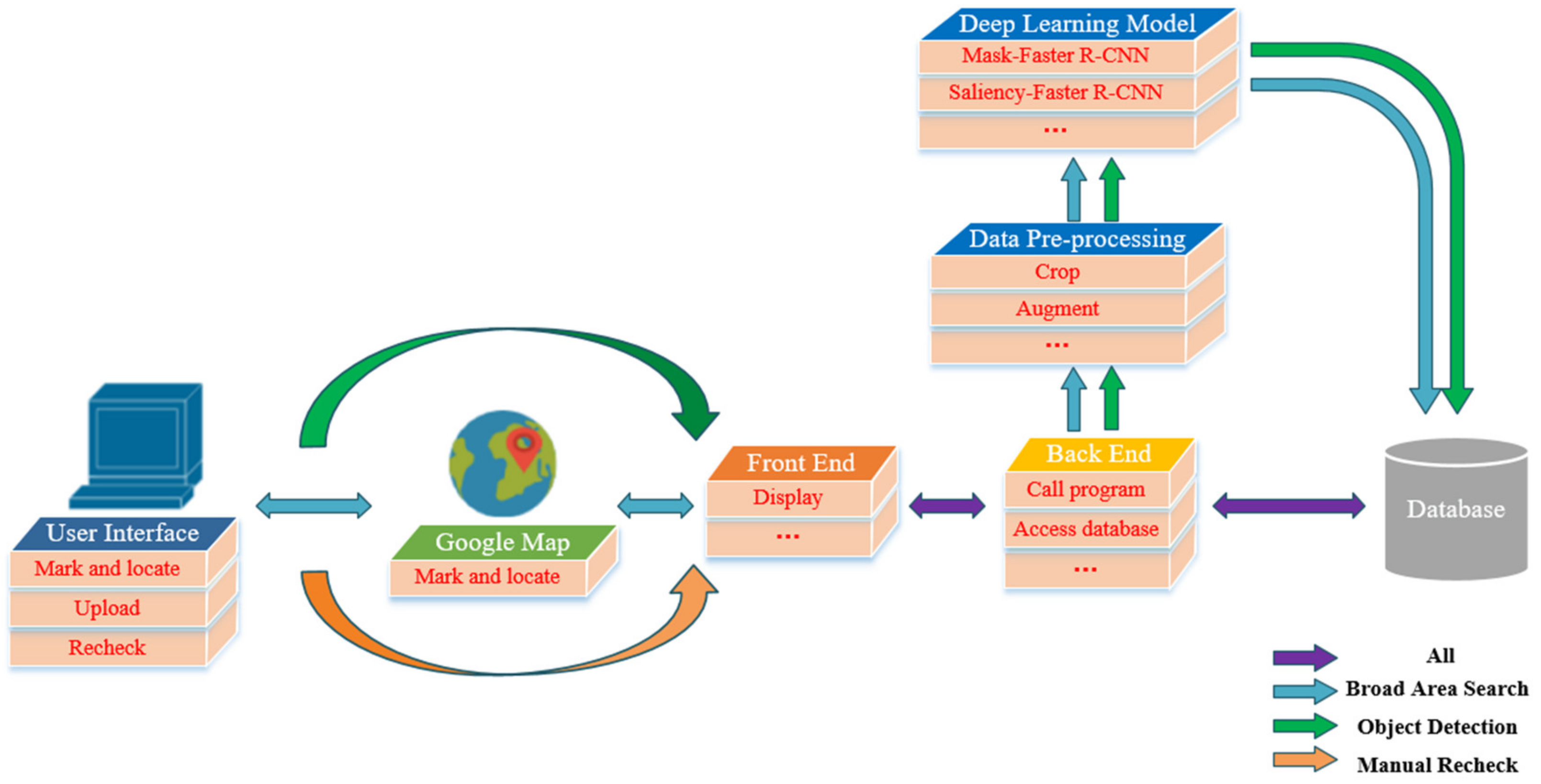
2. The Framework of Broad Area Target Search System
3. Ship Objects Detection Methods Based on DCNN
3.1. Object Detection Network from Faster R-CNN
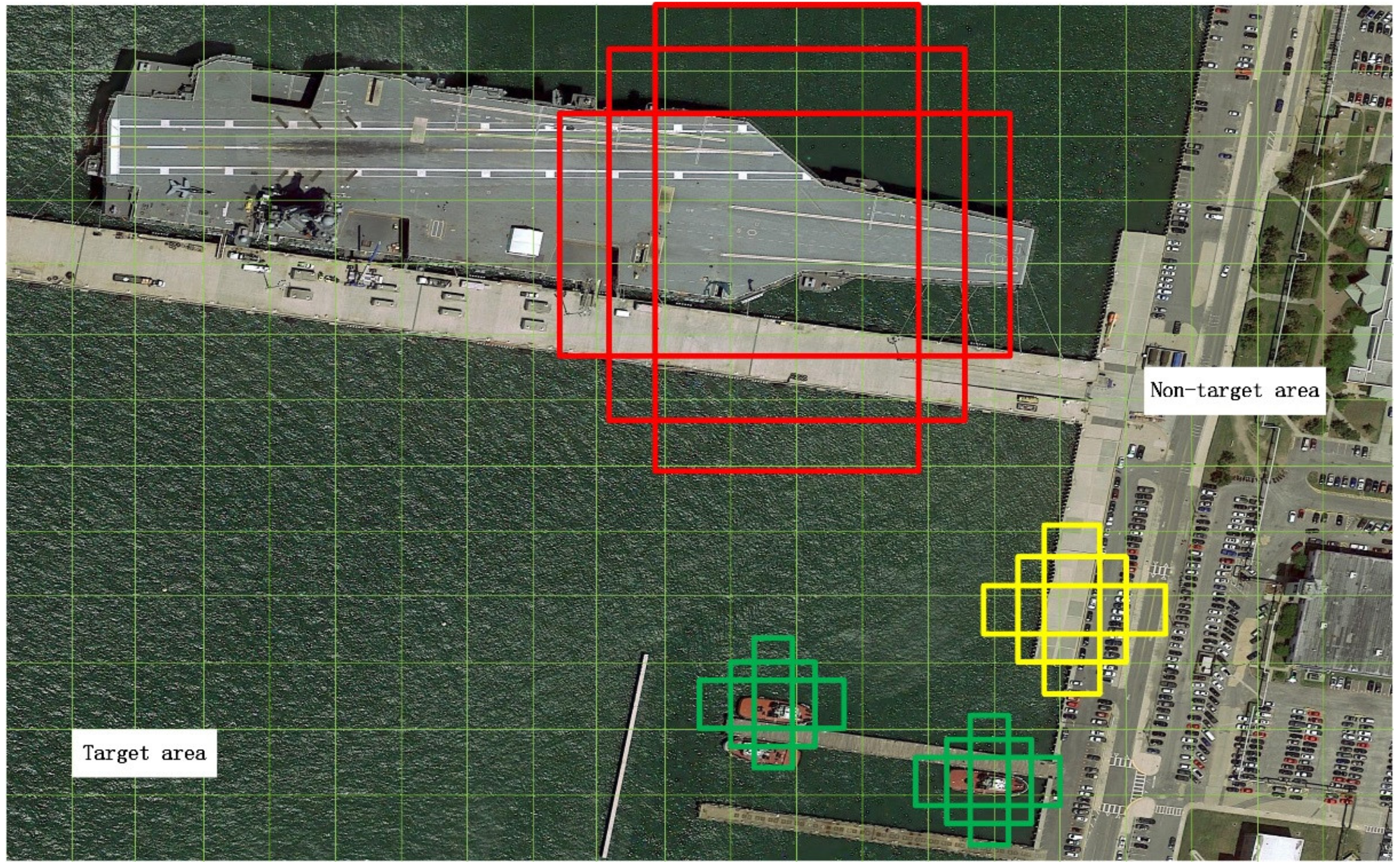
3.2. Mask-Faster R-CNN for Suppression of Onshore False Alarms
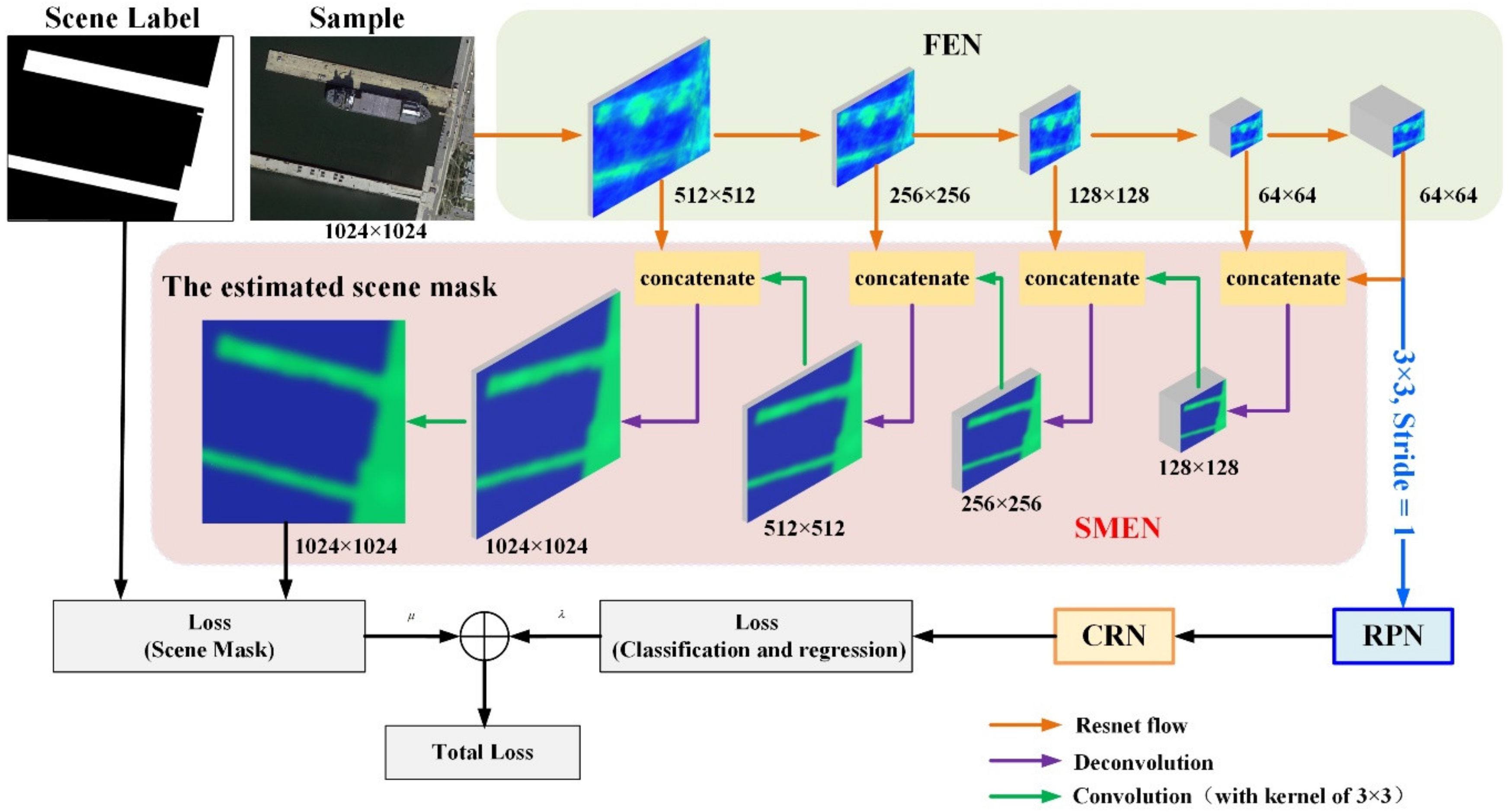
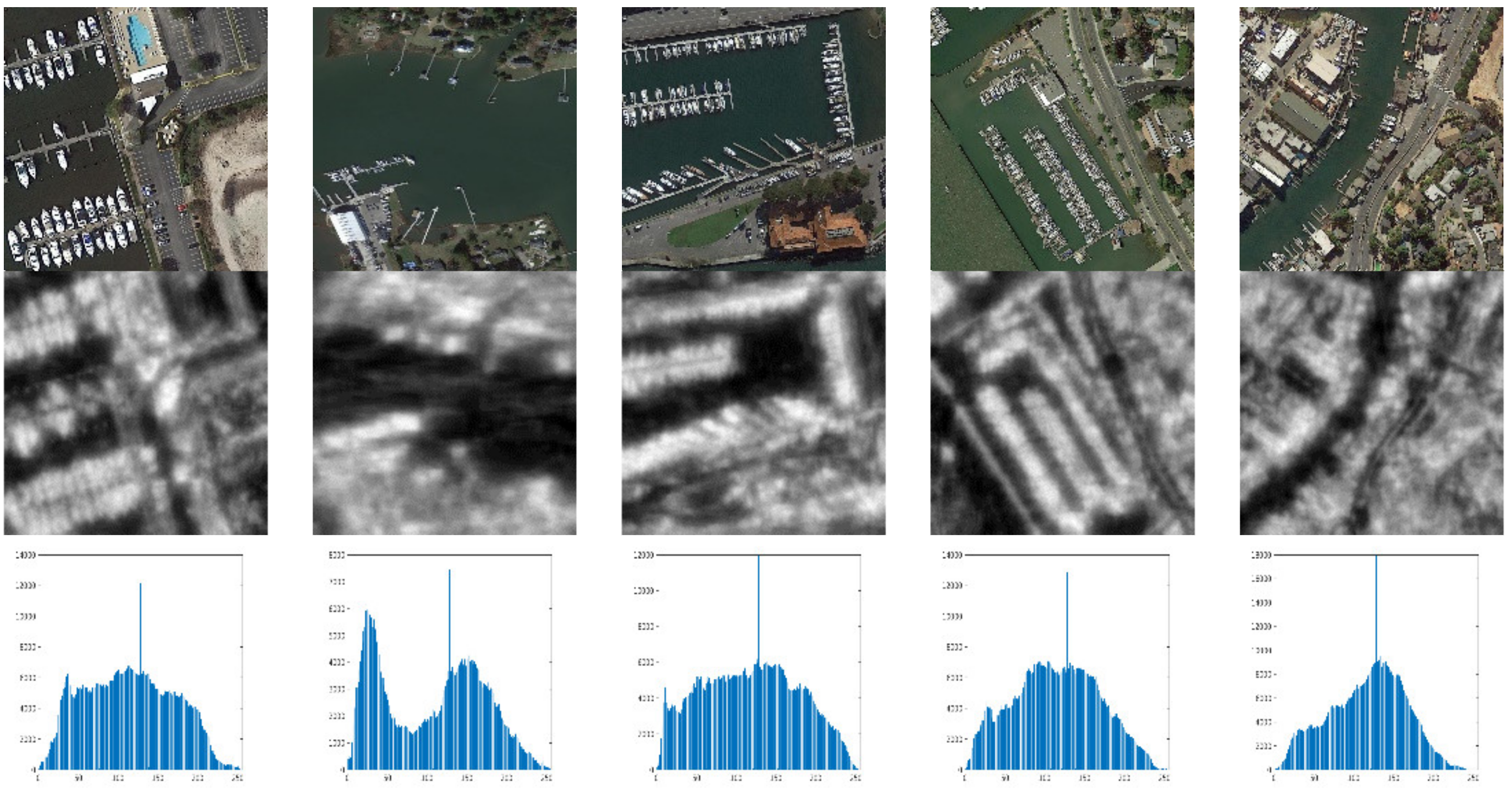
3.2.1. Scene Mask Extraction Network
3.2.2. Training Process
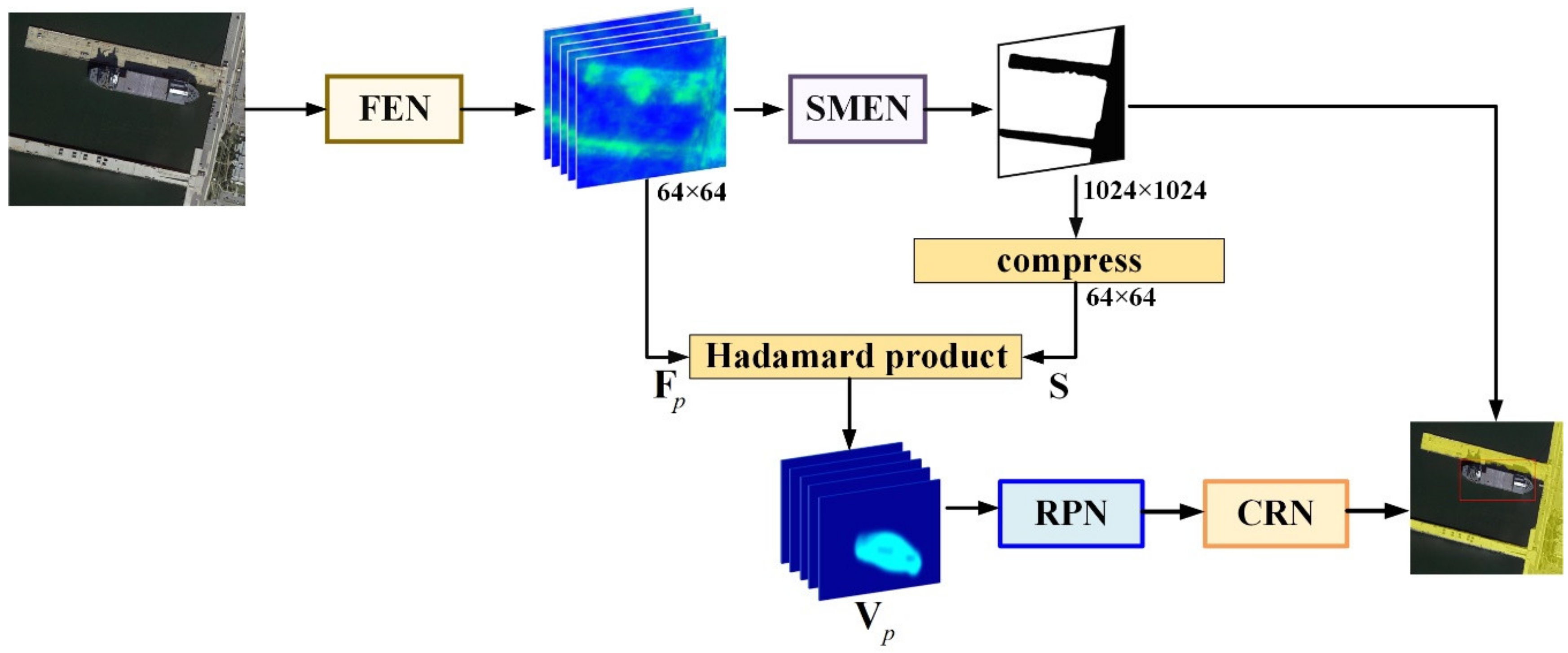
3.2.3. Inference Process
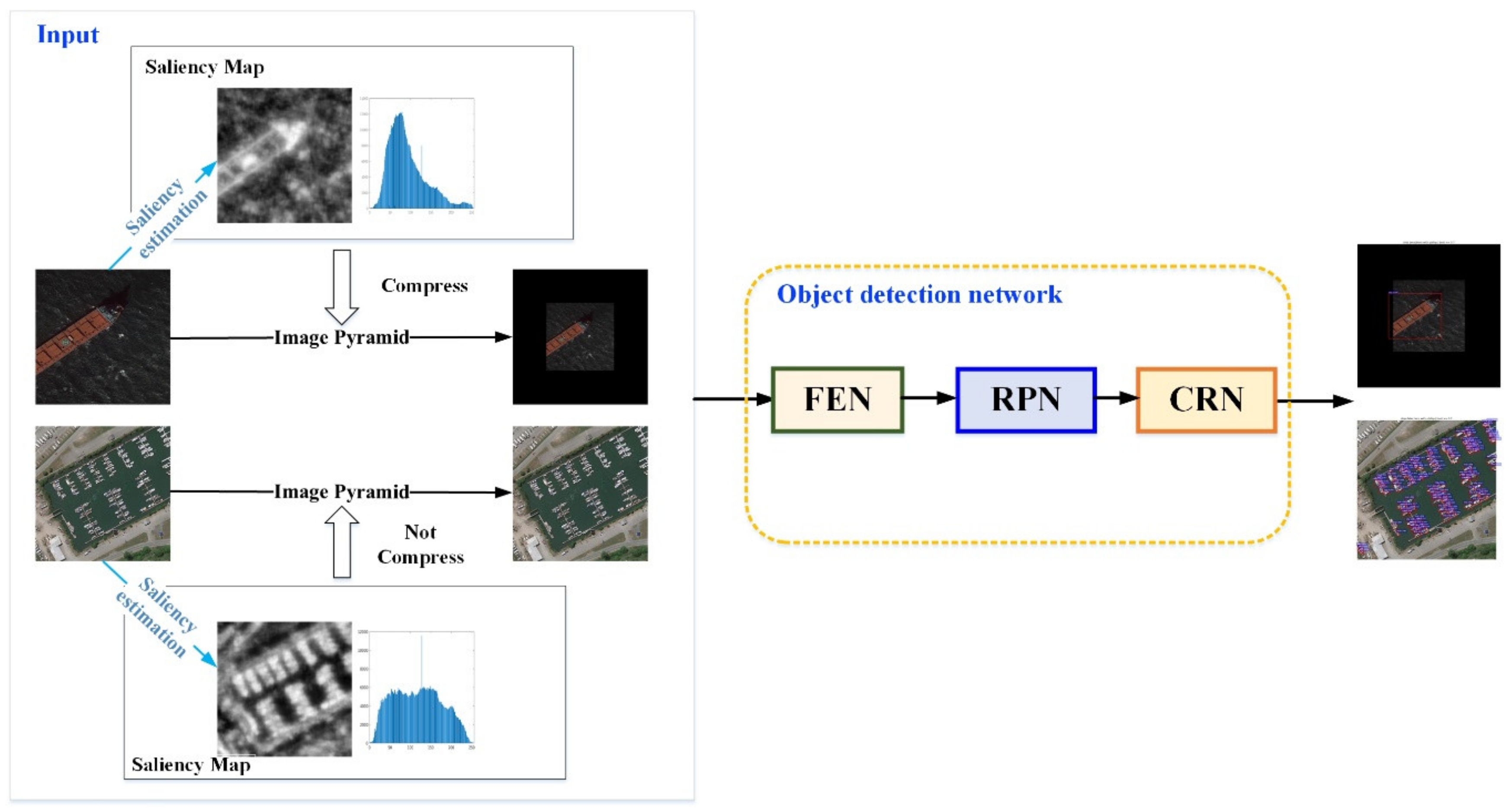
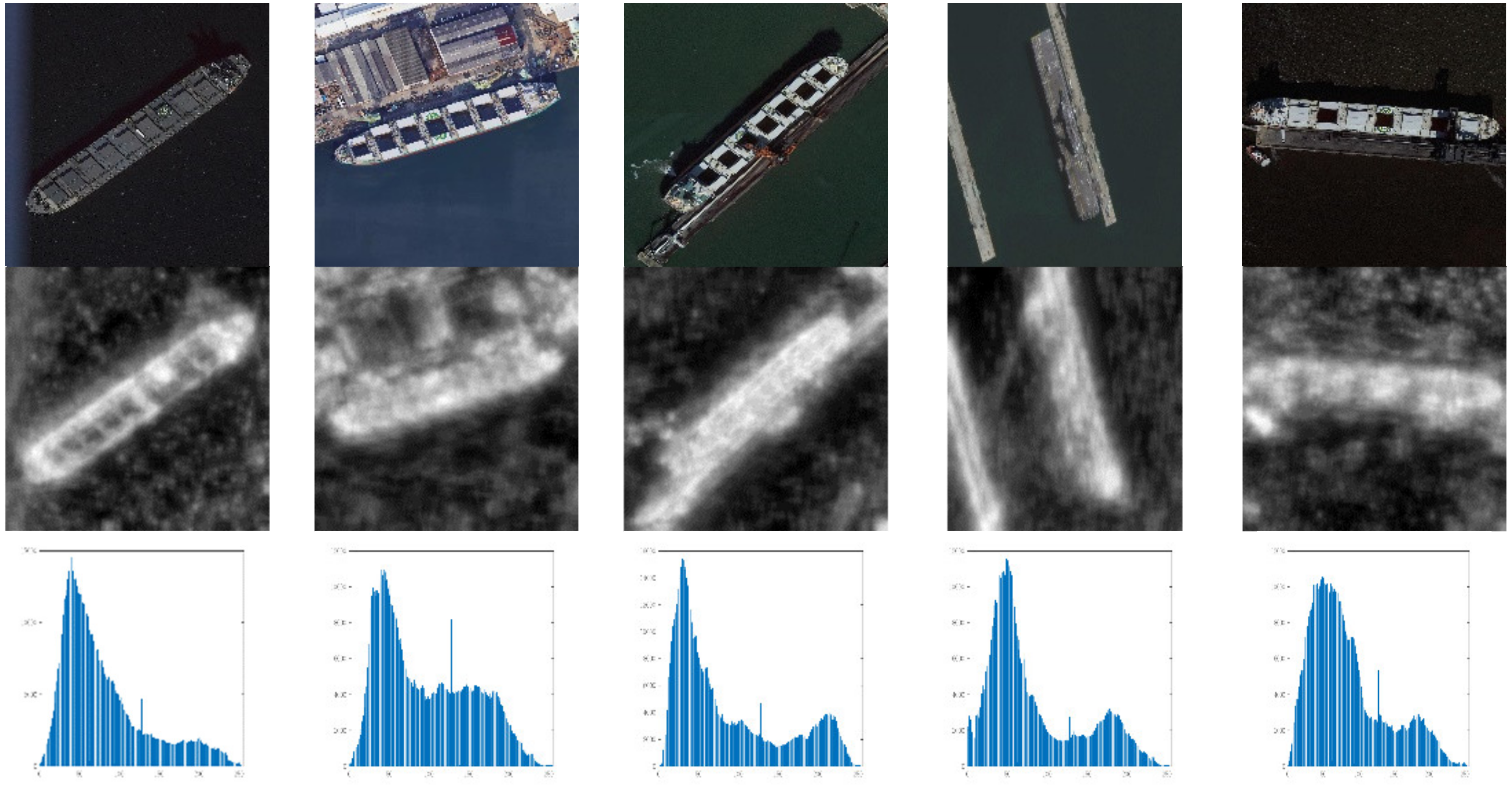
3.3. Saliency-Faster R-CNN for Multi-Scale Ship Detection
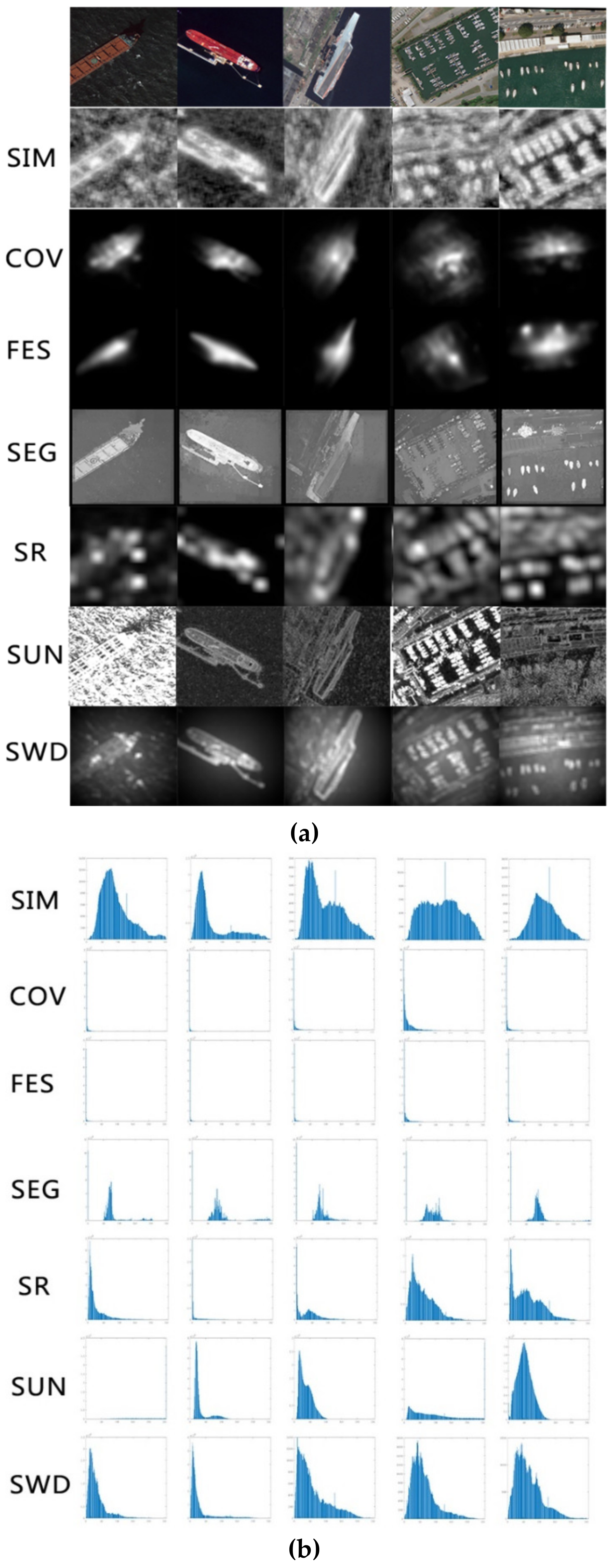
3.3.1. Saliency Estimation Network
3.3.2. Training and Inference
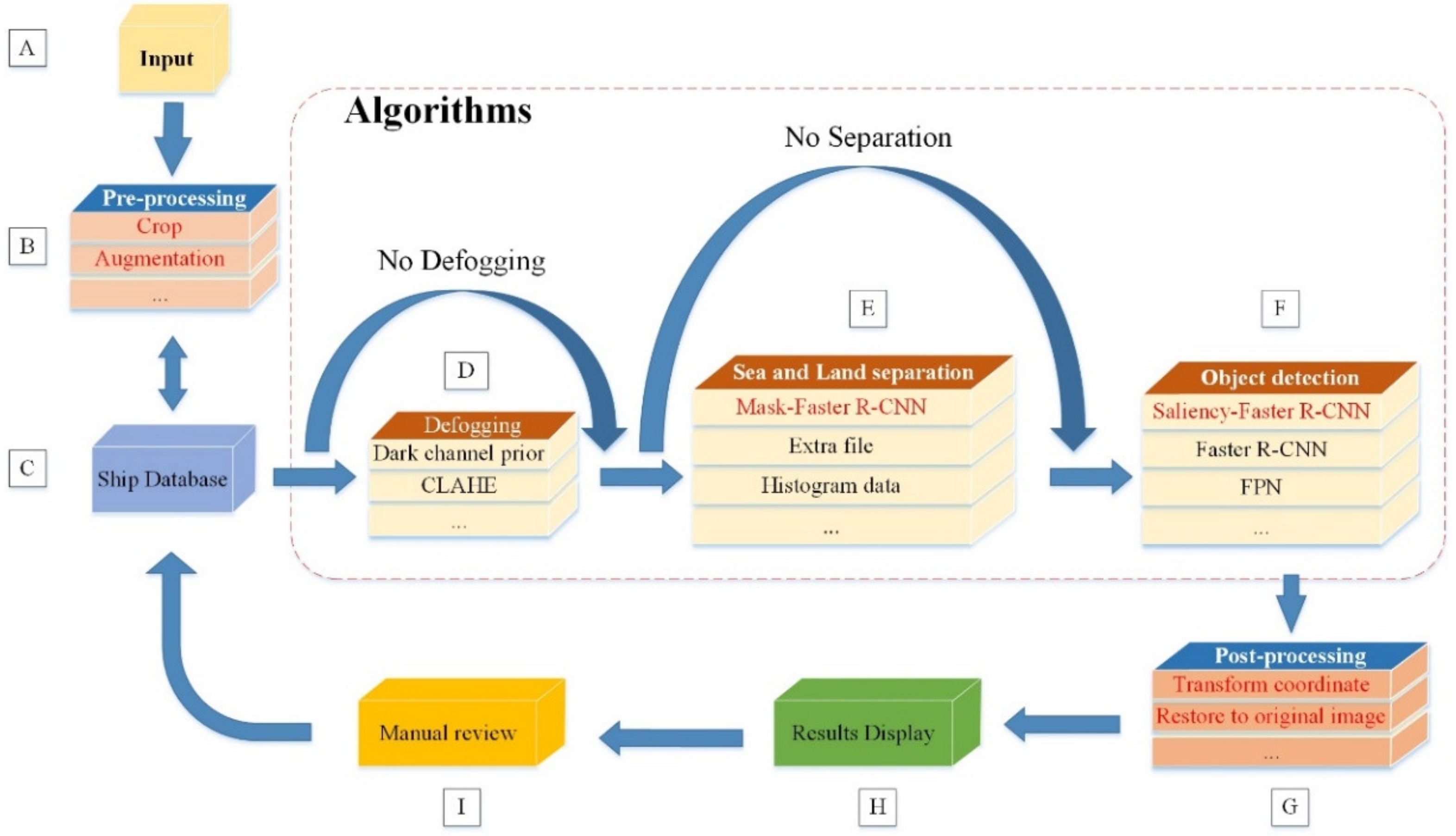
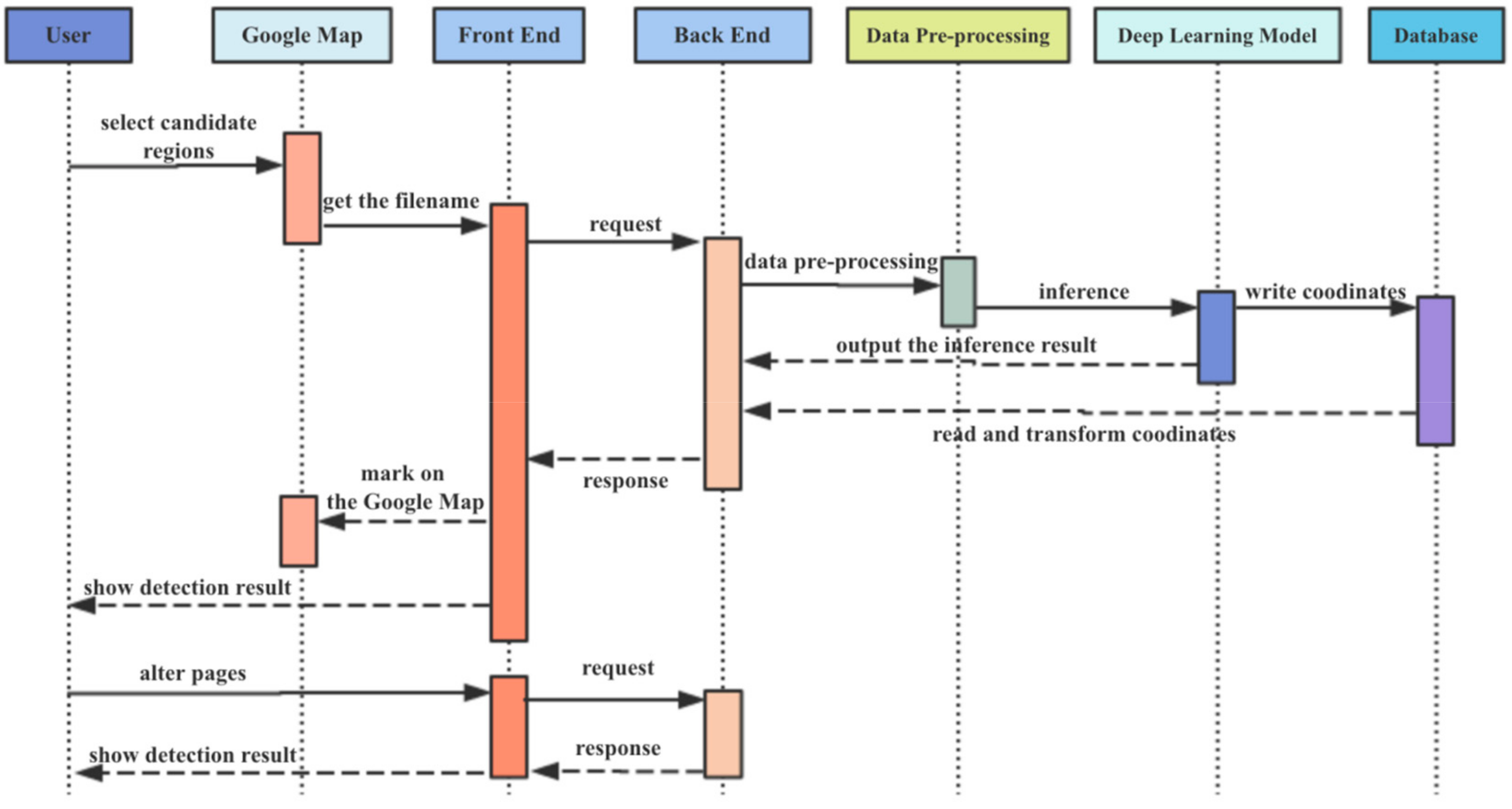
4. The Construction of the BATS System
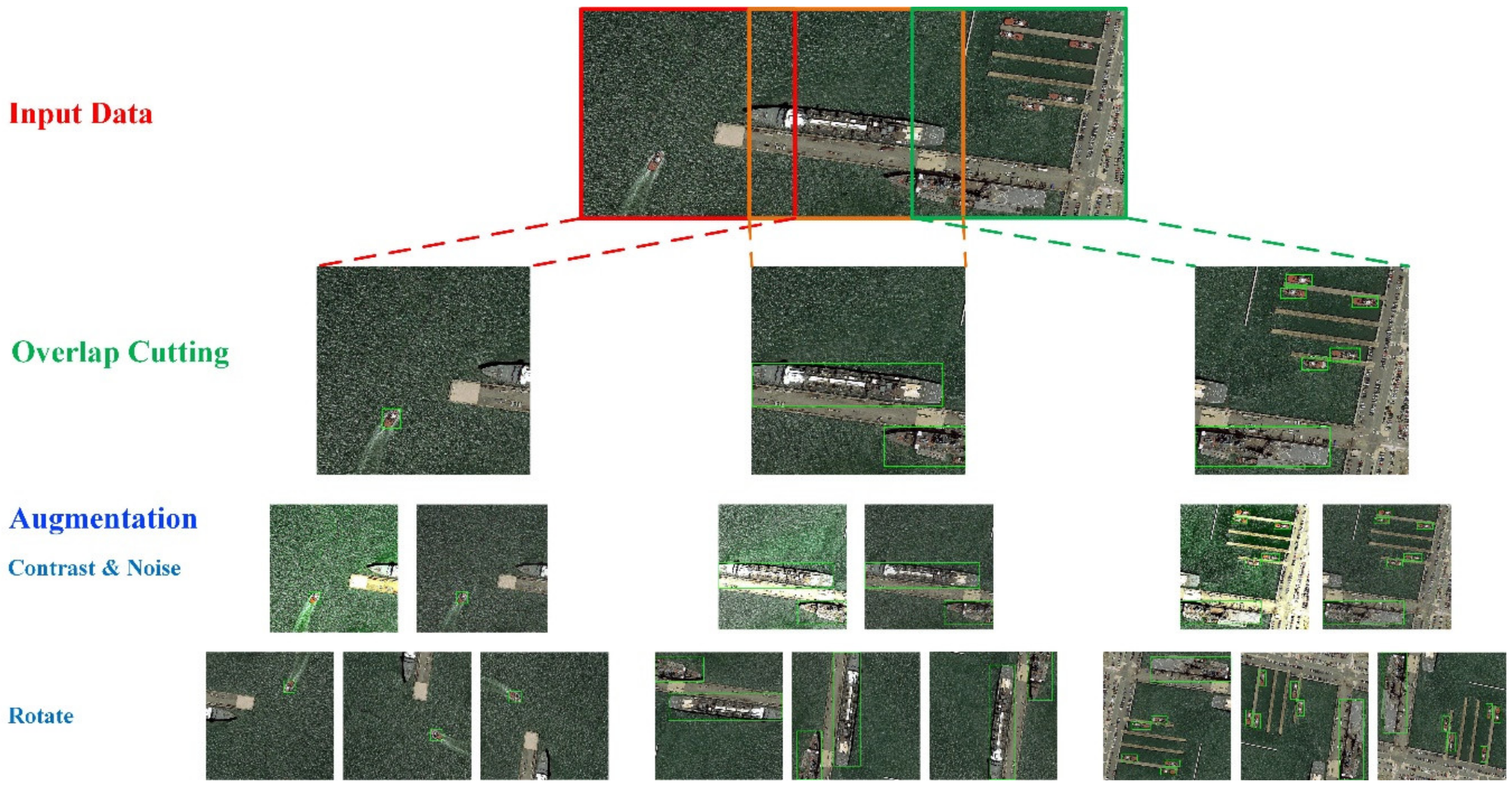
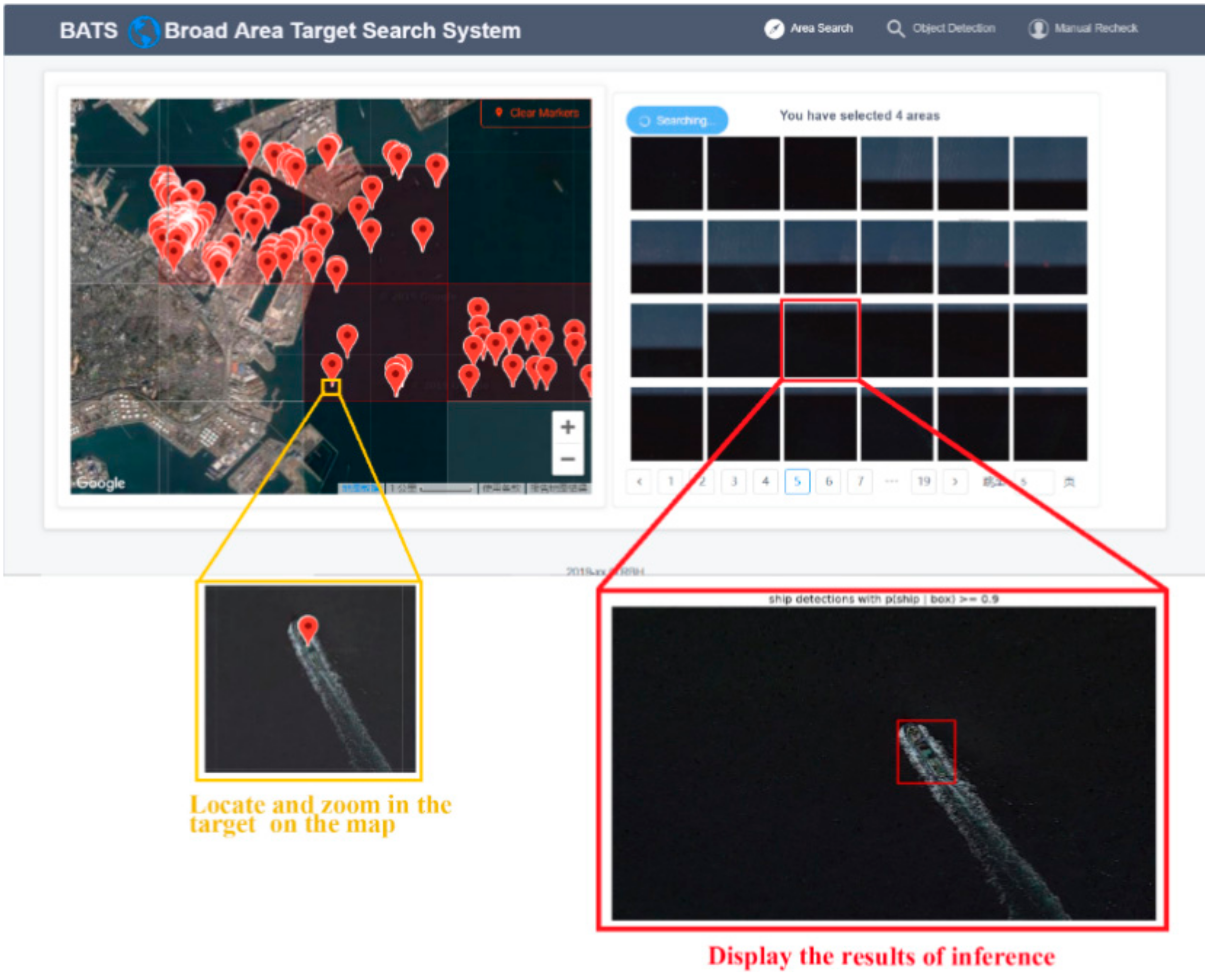
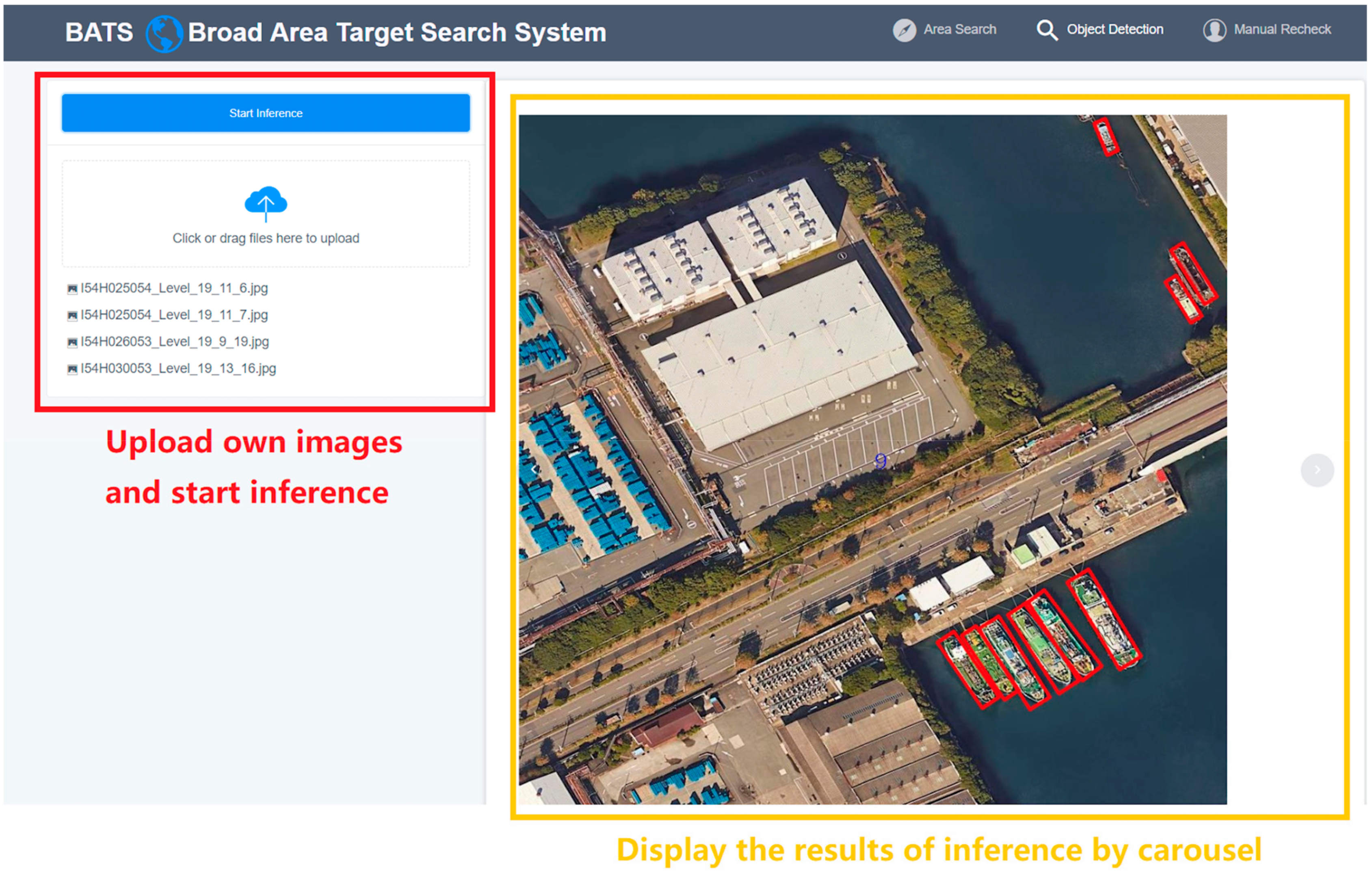
4.1. Broad Area Search Module
4.2. Target Detection Module
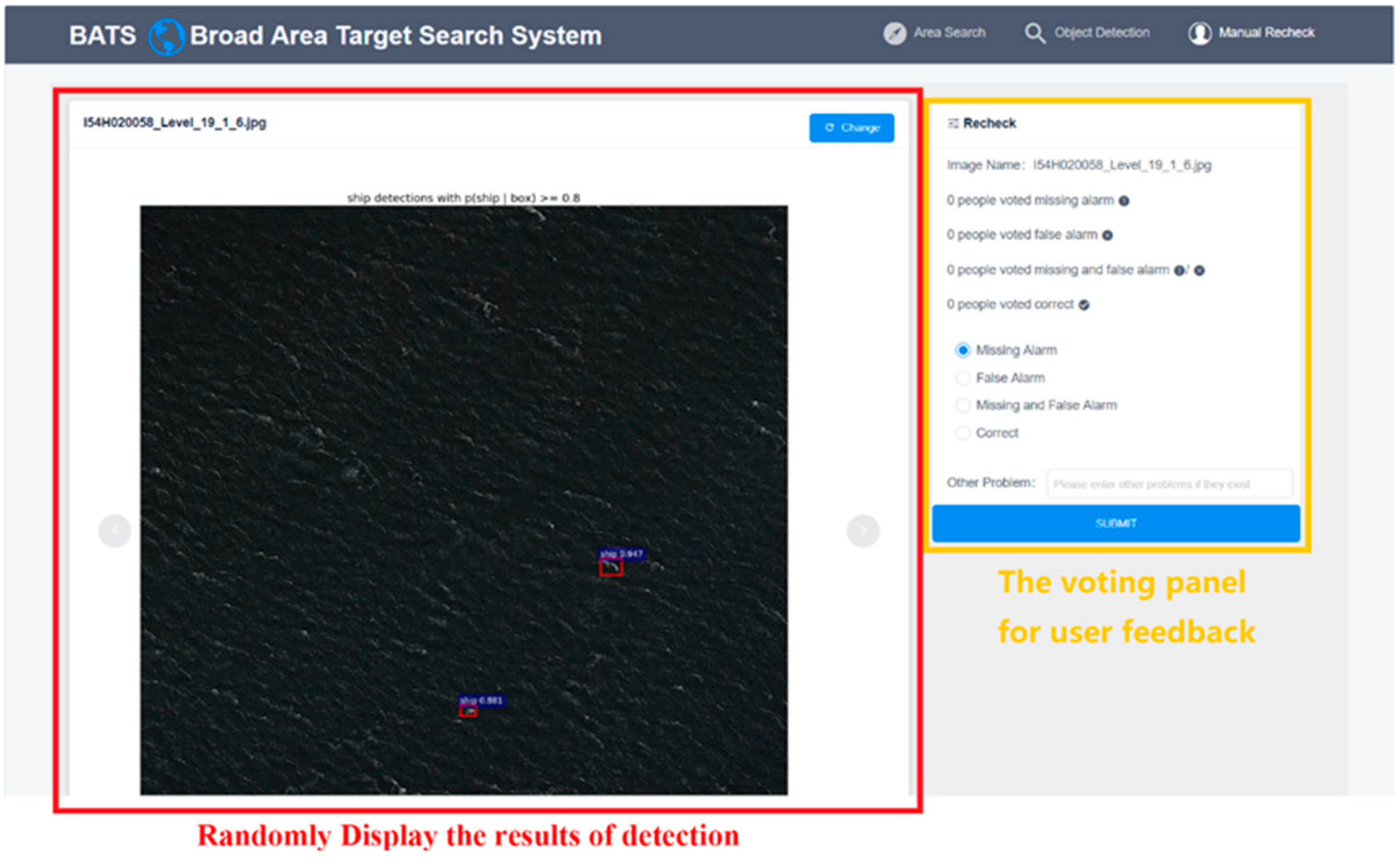
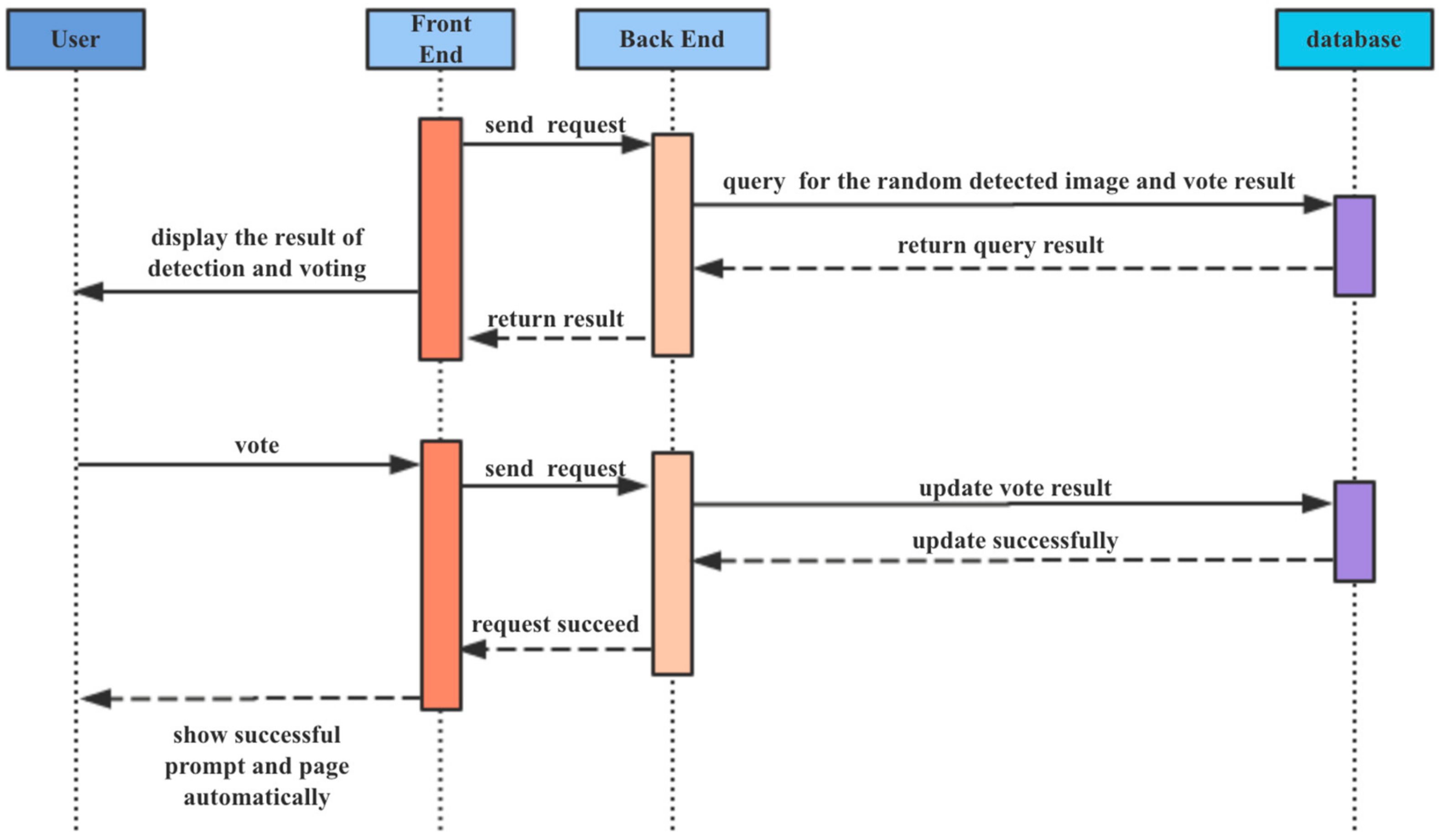
4.3. Manual Review Module
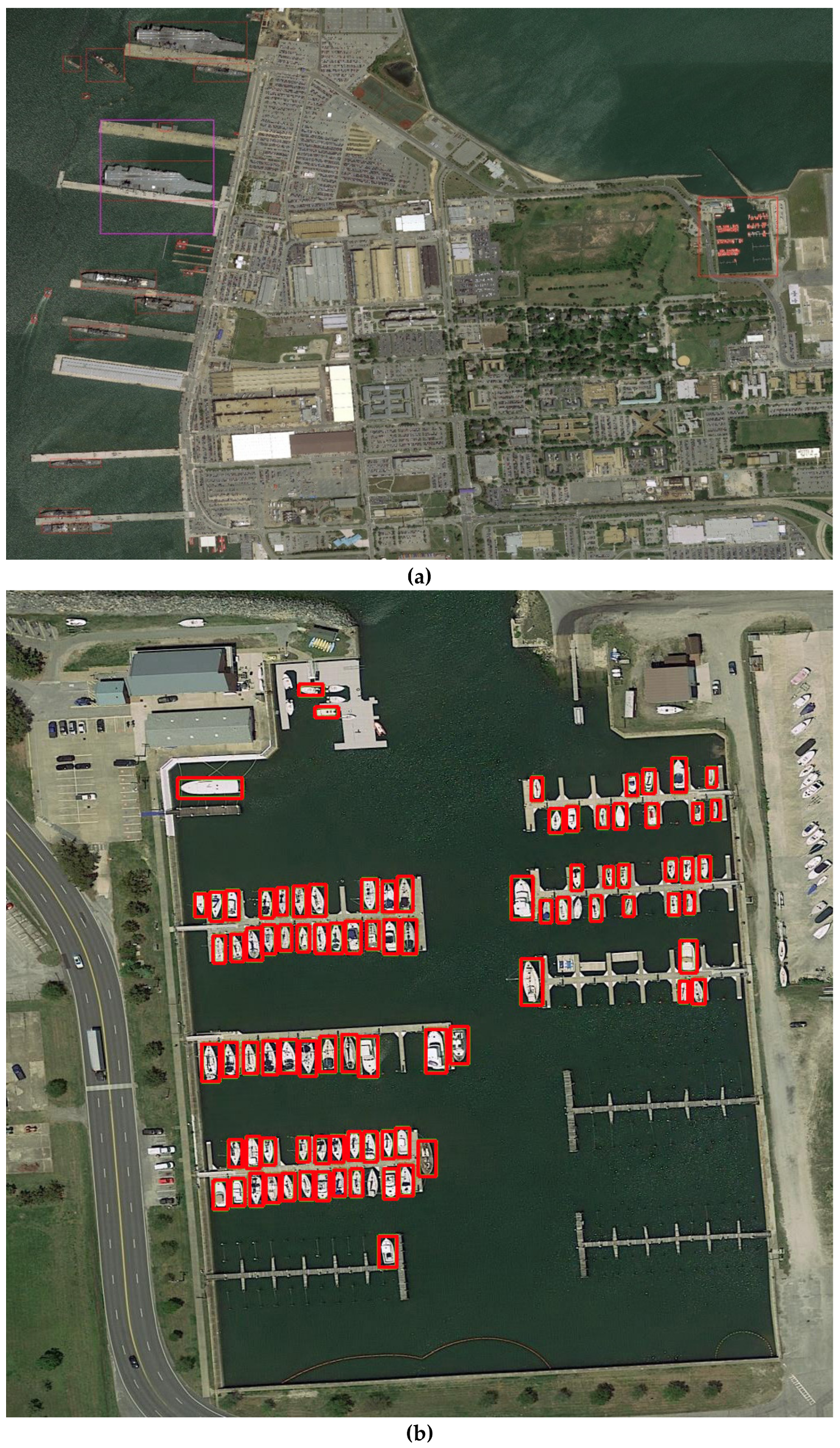
5. Results
5.1. Introduction of Dataset
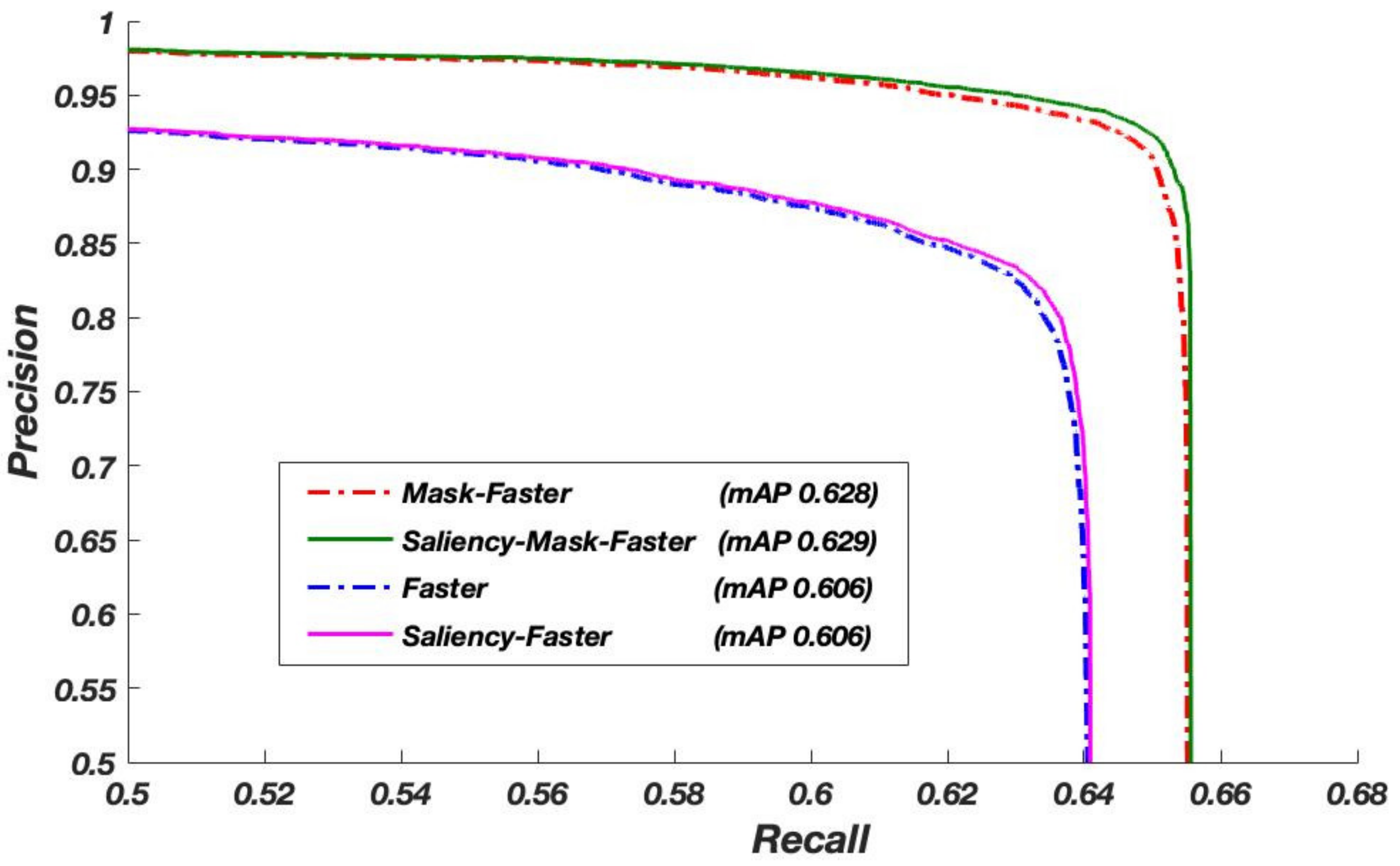
5.2. Results of Multi-Scale Ship Detection
5.3. Results of Onshore False Alarm Suppression
6. Discussions
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the 6th International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7–7 January 1998; pp. 555–562. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT press: Cambridge, MA, USA, 2016. [Google Scholar]
- Haykin, S. Neural networks: A Comprehensive Foundation; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1994. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Viola, P.; Jones, M. Others Rapid object detection using a boosted cascade of simple features. CVPR 2001, 1, 511–518. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–-12 June 2015; pp. 3431–3440. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 2015, 7–13 December; pp. 1440–1448.
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3578–3587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:180402767. [Google Scholar]
- Daniel, B.J.; Schaum, A.P.; Allman, E.C.; Leathers, R.A.; Downes, T.V. Automatic ship detection from commercial multispectral satellite imagery. In Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XIX; International Society for Optics and Photonics: Bellingham, WA, USA, 2013; Volume 8743, p. 874312. [Google Scholar]
- Kanjir, U.; Marsetič, A.; Pehani, P.; Oštir, K. An automatic procedure for small vessel detection from very-high resolution optical imagery. In Proceedings of the 5th GEOBIA, Thessaloniki, Greece, 21–24 May 2014; pp. 1–4. [Google Scholar]
- Buck, H.; Sharghi, E.; Bromley, K.; Guilas, C.; Chheng, T. Ship detection and classification from overhead imagery. In Applications of Digital Image Processing XXX; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6696, p. 66961C. [Google Scholar]
- Lavalle, C.; Rocha Gomes, C.; Baranzelli, C.; Batista e Silva, F. Coastal Zones Policy Alternatives Impacts on European Coastal Zones 2000–2050; JRC Technical Note; European Union: Brussels, Belgium, 2011; p. 64456. [Google Scholar]
- Jin, T.; Zhang, J. Ship detection from high-resolution imagery based on land masking and cloud filtering. In Seventh International Conference on Graphic and Image Processing (ICGIP 2015); International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9817, p. 981716. [Google Scholar]
- Li, N.; Zhang, Q.; Zhao, H.; Dong, C.; Meng, L. Ship detection in high spatial resolution remote sensing image based on improved sea-land segmentation. In Hyperspectral Remote Sensing Applications and Environmental Monitoring and Safety Testing Technology; International Society for Optics and Photonics: Bellingham, WA, USA, 2016; Volume 10156, p. 101560T. [Google Scholar]
- Xu, J.; Sun, X.; Zhang, D.; Fu, K. Automatic detection of inshore ships in high-resolution remote sensing images using robust invariant generalized Hough transform. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2070–2074. [Google Scholar]
- Beşbinar, B.; Alatan, A.A. Inshore ship detection in high-resolution satellite images: Approximation of harbors using sea-land segmentation. In Image and Signal Processing for Remote Sensing XXI; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9643, p. 96432D. [Google Scholar]
- Burgess, D.W. Automatic ship detection in satellite multispectral imagery. Photogramm. Eng. Remote Sens. 1993, 59, 229–237. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational Region Cnn for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:170609579. [Google Scholar]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position detection and direction prediction for arbitrary-oriented ships via multitask rotation region convolutional neural network. IEEE Access 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- Zhang, R.; Yao, J.; Zhang, K.; Feng, C.; Zhang, J. s-cnn-based ship detection from high-resolution remote sensing images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Yang, X.; Fu, K.; Sun, H.; Yang, J.; Guo, Z.; Yan, M.; Zhan, T.; Xian, S. R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy. arXiv 2018, arXiv:181107126. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA; 2018; pp. 3974–3983. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Québec city, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Borji, A.; Cheng, M.-M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed]
- Murray, N.; Vanrell, M.; Otazu, X.; Parraga, C.A. Saliency estimation using a non-parametric low-level vision model. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 433–440. [Google Scholar]
- Erdem, E.; Erdem, A. Visual saliency estimation by nonlinearly integrating features using region covariances. J. Vis. 2013, 13, 11. [Google Scholar] [CrossRef] [PubMed]
- Tavakoli, H.R.; Rahtu, E.; Heikkilä, J. Fast and Efficient Saliency Detection Using Sparse Sampling and Kernel Density Estimation. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2011; pp. 666–675. [Google Scholar]
- Rahtu, E.; Kannala, J.; Salo, M.; Heikkilä, J. Segmenting salient objects from images and videos. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 366–379. [Google Scholar]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Zhang, L.; Tong, M.H.; Marks, T.K.; Shan, H.; Cottrell, G.W. SUN: A Bayesian framework for saliency using natural statistics. J. Vis. 2008, 8, 32. [Google Scholar] [CrossRef] [PubMed]
- Duan, L.; Wu, C.; Miao, J.; Qing, L.; Fu, Y. Visual saliency detection by spatially weighted dissimilarity. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 473–480. [Google Scholar]
- You, E. Vue. js. Diakses Dari Httpsvuejs Org Pada Tanggal 2018. Available online: https://vuejs.org/pada tanggal (accessed on 17 September 2018).
- Svennerberg, G. Beginning Google Maps API 3; Apress: New York, NY, USA, 2010. [Google Scholar]
- Holovaty, A.; Kaplan-Moss, J. The Definitive Guide to Django: Web Development Done Right; Apress: New York, NY, USA, 2009. [Google Scholar]
- Owens, M. The Definitive Guide to SQLite; Apress: New York, NY, USA, 2006. [Google Scholar]
- Chen, P.-H.; Lin, C.-J.; Schölkopf, B. A Tutorial on ν-Support Vector Machines. Appl. Stoch. Models Bus. Ind. 2005, 21, 111–136. [Google Scholar] [CrossRef]
- Bengio, Y.; LeCun, Y. Scaling Learning Algorithms towards AI. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Output Size | Layers | Layer parameter |
|---|---|---|---|
| Part1 (FEN) | |||
| Conv1 | 512×512×64 | Convolution | 7×7, 64, stride = 2 |
| Pool1 | 256×256×64 | Max pooling | 3 × 3, stride = 2 |
| Block1 | 128×128×256 | Convolution group | ×3, stride = 2 |
| Block2 | 64×64×512 | Convolution group | ×4, stride = 2 |
| Block3 | 64×64×1024 | Convolution group | ×23, stride = 1 |
| Part2 (used after ROI Pooling) | |||
| Block 4 | 7×7×2048 | Convolution group | ×3, stride = 2 |
| Pool2 | 7×7×2048 | Average pooling | 2×2, stride = 1 |
| Layers | Layer parameter | Output size |
|---|---|---|
| Deconv 1 | 3 × 3, 512, stride = 2 | 128 × 128 × 512 |
| Conv 1 | 3 × 3, 512, stride = 1 | 128 × 128 × 512 |
| Deconv 2 | 3 × 3, 256, stride = 2 | 256 × 256 × 256 |
| Conv 2 | 3 × 3, 256, stride = 1 | 256 × 256 × 256 |
| Deconv 3 | 3 × 3, 128, stride = 2 | 512 × 512 × 128 |
| Conv 3 | 3 × 3, 128, stride = 1 | 512 × 512 × 128 |
| Deconv 4 | 3 × 3, 64, stride = 2 | 1024 × 1024 × 64 |
| Conv 4 | 3 × 3, 2, stride = 1 | 1024 × 1024 × 2 |
| Softmax | 1024 × 1024 × 2 |
| Method | AP | APL | NCR |
|---|---|---|---|
| Faster R-CNN | 0.606 | 0.664 | N/A |
| Saliency-Faster R-CNN | 0.606 | 0.727 | 0.105 (16/152) |
| Method | AP | False Rate | mIOU |
|---|---|---|---|
| Faster R-CNN | 0.606 | 0.686 | N/A 0.877 |
| Mask-Faster R-CNN | 0.628 | 0.397 |
| Baseline (Faster R-CNN) | Mask | Saliency | AP | Time (sec/image) |
|---|---|---|---|---|
| √ | 0.606 | 0.173 | ||
| √ | √ | 0.606 | 2.181 | |
| √ | √ | 0.628 | 0.231 | |
| √ | √ | √ | 0.629 | 2.233 |
| Size (MBytes) | Image pixels | Upload (sec/image) | Pre-processing (sec/image) | Post-processing (sec/image) | Num of Images |
|---|---|---|---|---|---|
| 1440.4 | 8576 × 5176 | 1.55 | 0.155 | 0.232 | 77 |
| 99.1 | 5896 × 5328 | 1.12 | 0.098 | 0.235 | 49 |
| 540.1 | 17152 × 10352 | 5.34 | 1.068 | 0.241 | 273 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, Y.; Li, Z.; Ran, B.; Cao, J.; Lv, S.; Liu, F. Broad Area Target Search System for Ship Detection via Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1965. https://doi.org/10.3390/rs11171965
You Y, Li Z, Ran B, Cao J, Lv S, Liu F. Broad Area Target Search System for Ship Detection via Deep Convolutional Neural Network. Remote Sensing. 2019; 11(17):1965. https://doi.org/10.3390/rs11171965
Chicago/Turabian StyleYou, Yanan, Zezhong Li, Bohao Ran, Jingyi Cao, Sudi Lv, and Fang Liu. 2019. "Broad Area Target Search System for Ship Detection via Deep Convolutional Neural Network" Remote Sensing 11, no. 17: 1965. https://doi.org/10.3390/rs11171965
APA StyleYou, Y., Li, Z., Ran, B., Cao, J., Lv, S., & Liu, F. (2019). Broad Area Target Search System for Ship Detection via Deep Convolutional Neural Network. Remote Sensing, 11(17), 1965. https://doi.org/10.3390/rs11171965