Retrieval of Cloud Optical Thickness from Sky-View Camera Images using a Deep Convolutional Neural Network based on Three-Dimensional Radiative Transfer

 , ,
, ,
Abstract
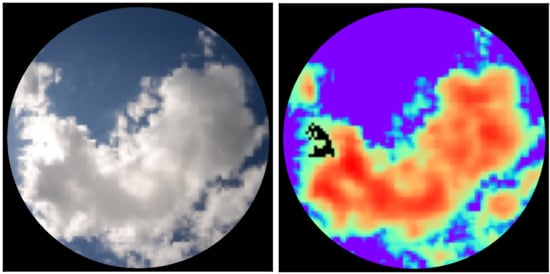
1. Introduction
2. Data and Methods
2.1. SCALE-LES Cloud-Field Data
2.2. Simulations of Spectral Radiance
3. Test of COT Retrieval from Zenith Transmittance
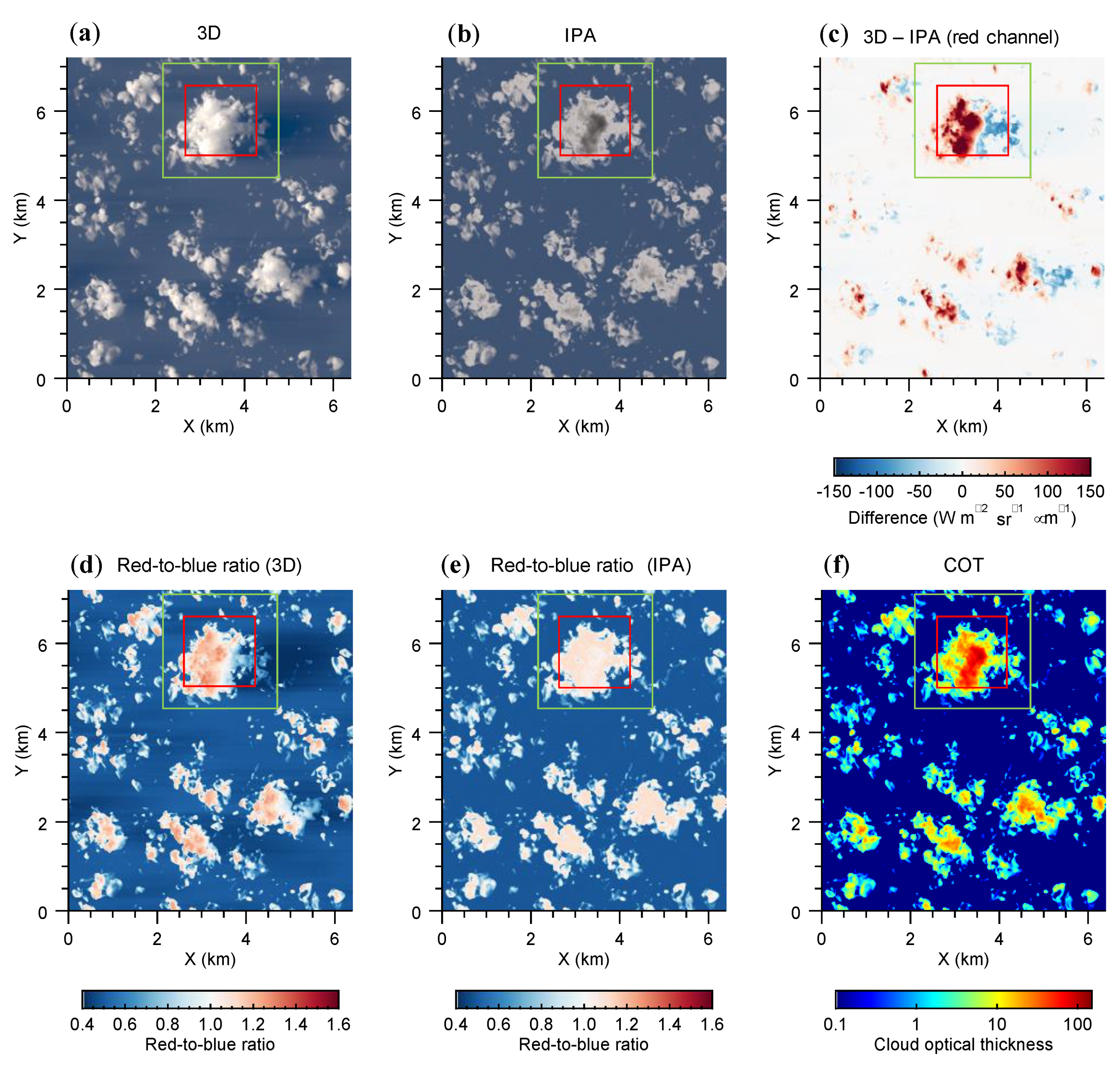
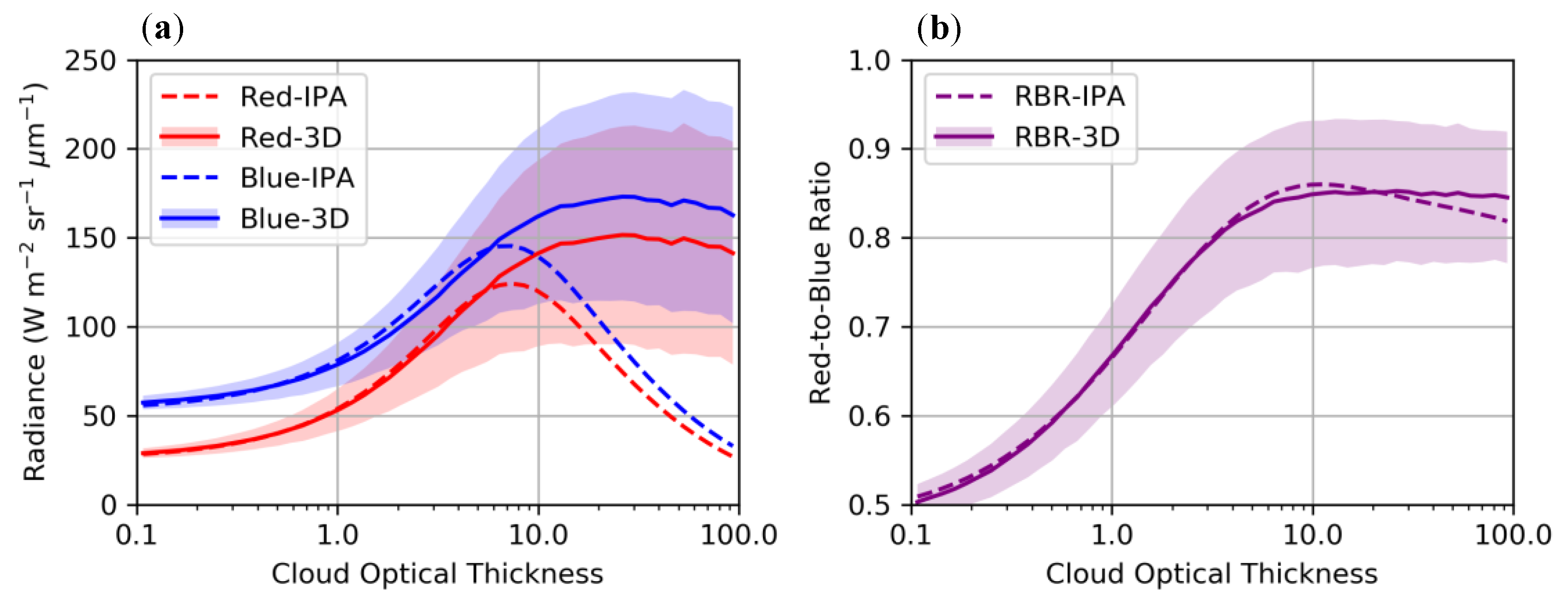
3.1. 3D Radiative Effects in Zenith Transmittance
3.2. Data Generation
3.3. Design and Configuration of NN and CNN Models
3.4. Comparison of Various NNs
4. COT Retrieval from Synthetic Sky-View Camera Images
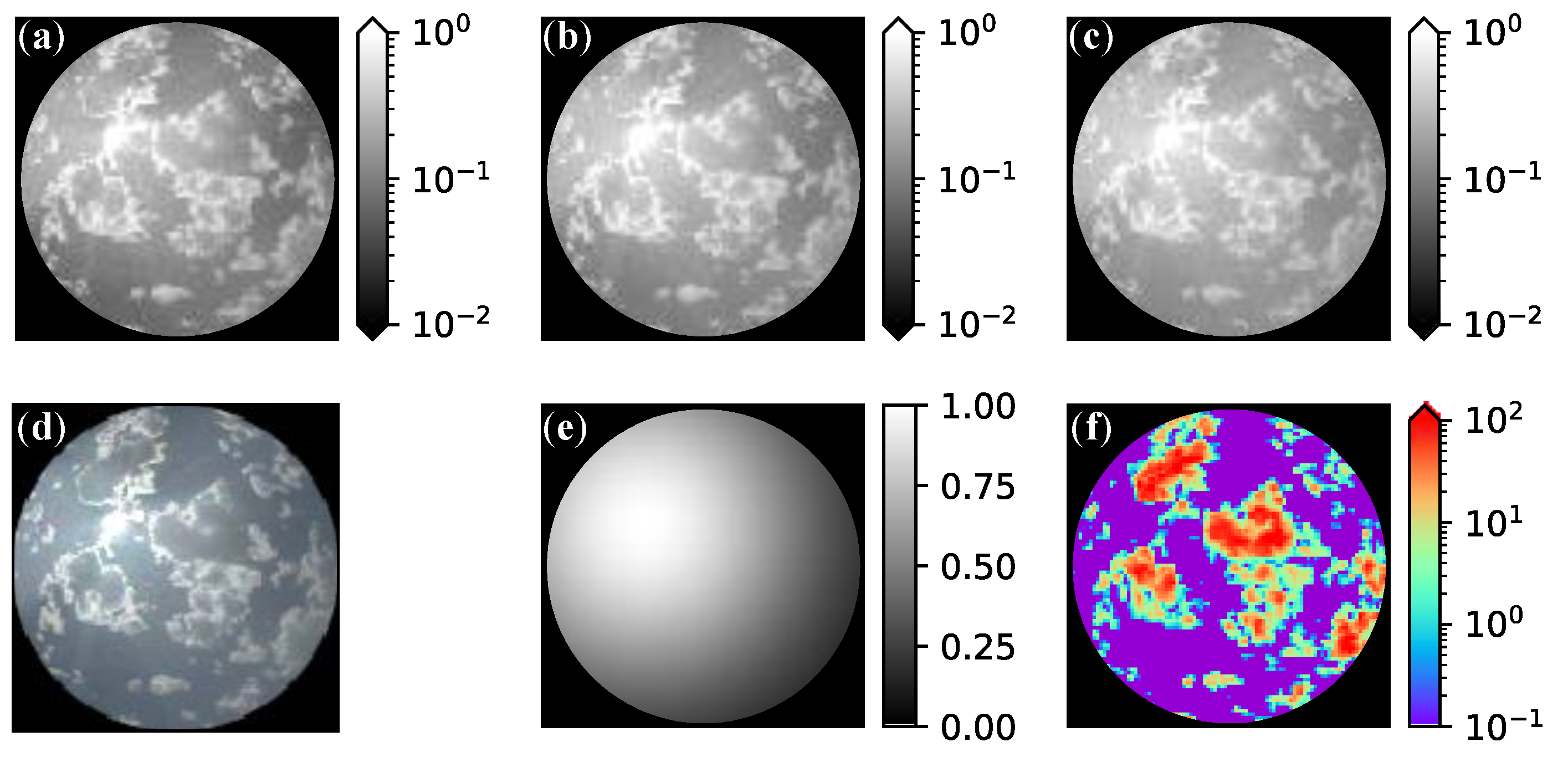
4.1. Data Generation
4.2. Design and Configuration of CNN Model
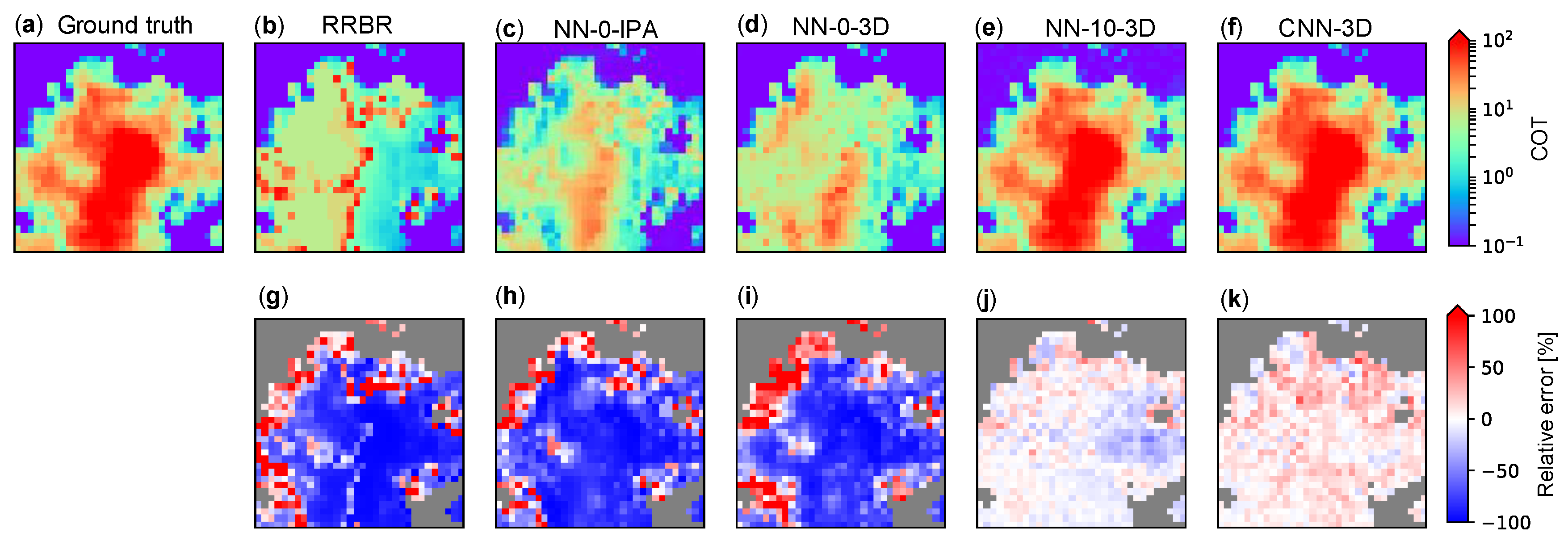
4.3. Examples of CNN Retrieval
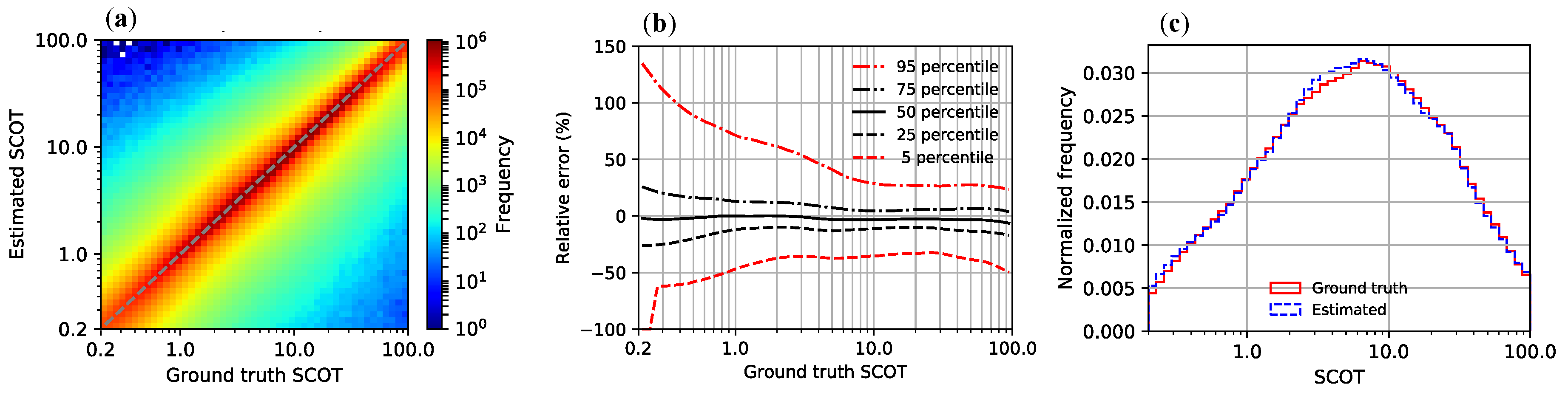
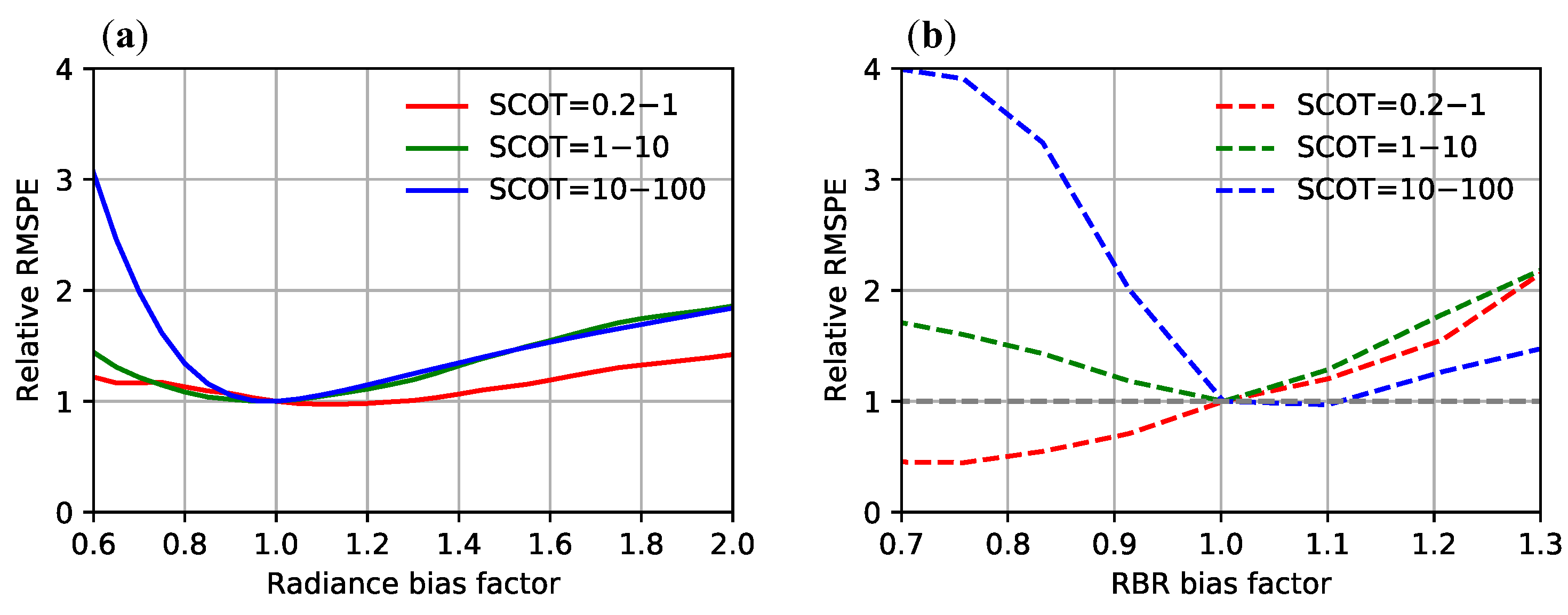
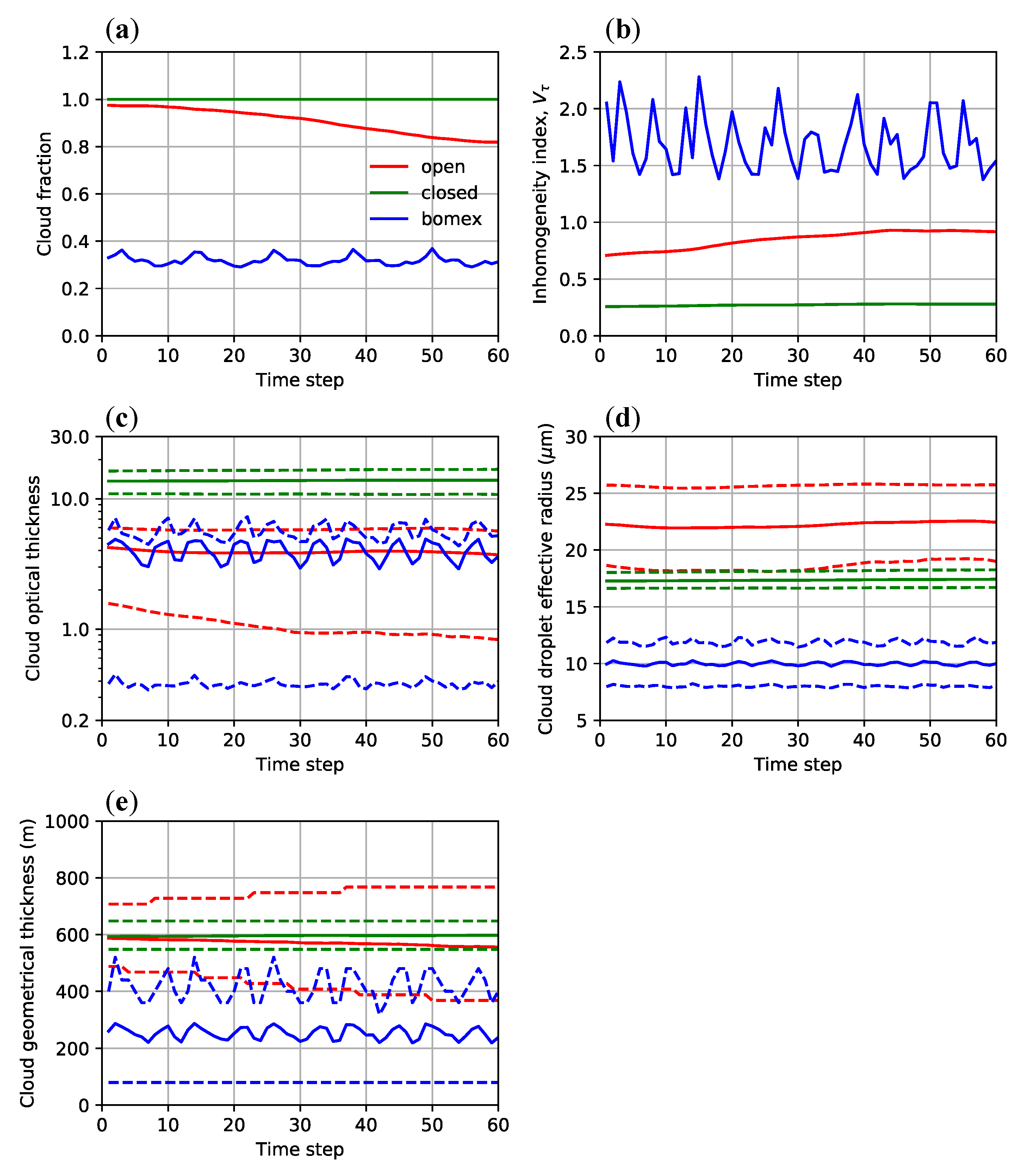
4.4. Evaluation of Retrieval Error
5. Applications to Sky-View Camera Observations
5.1. Overview of Observation
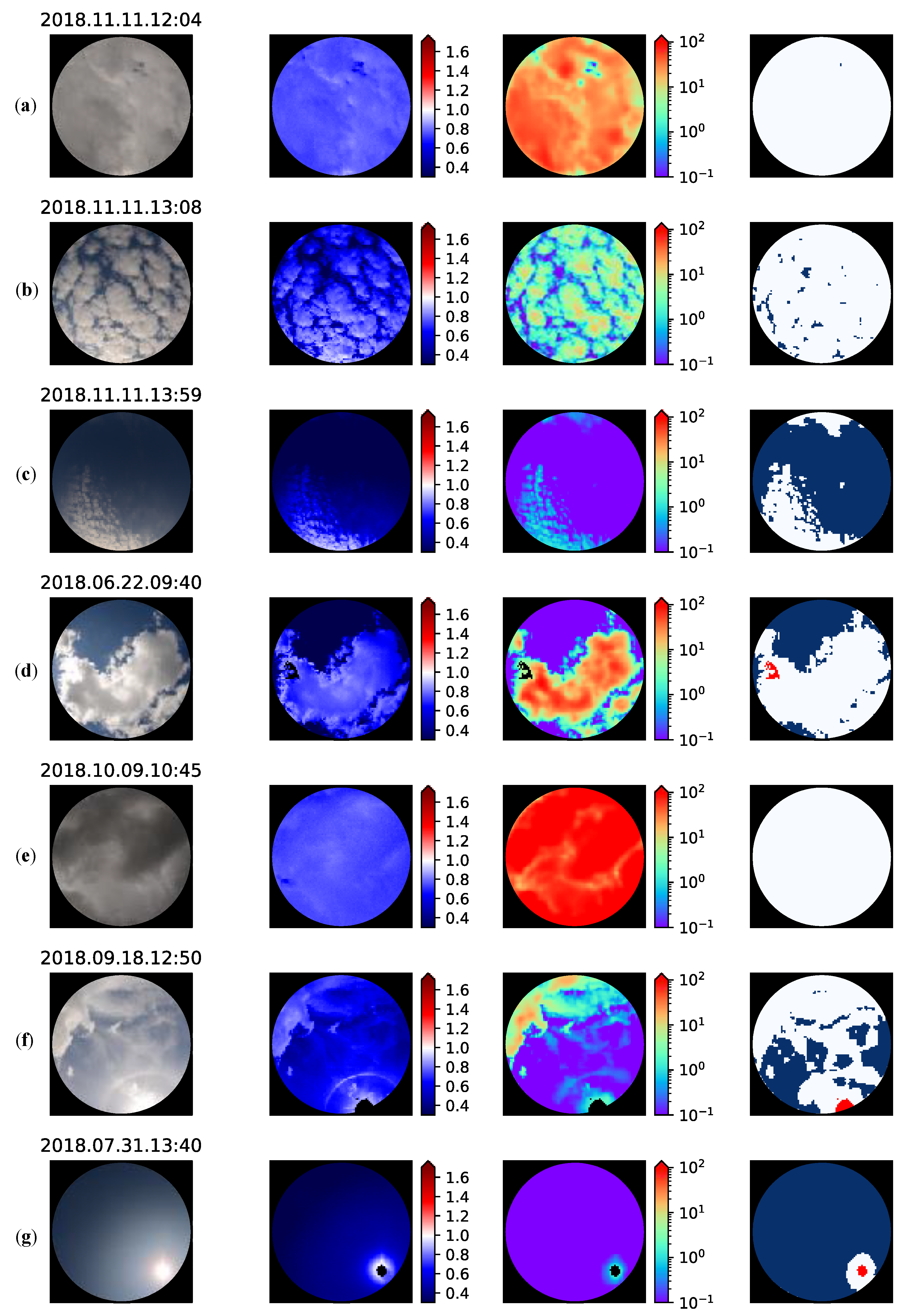
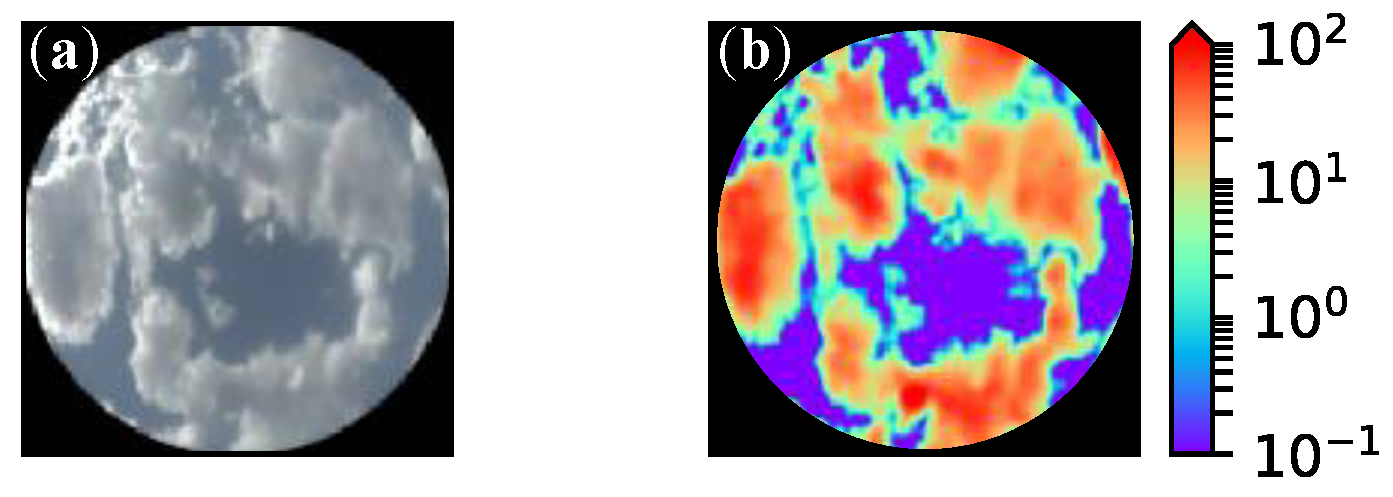
5.2. Example Results
5.3. Comparison with Pyranometer Measurements
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Clouds Simulated by SCALE-LES

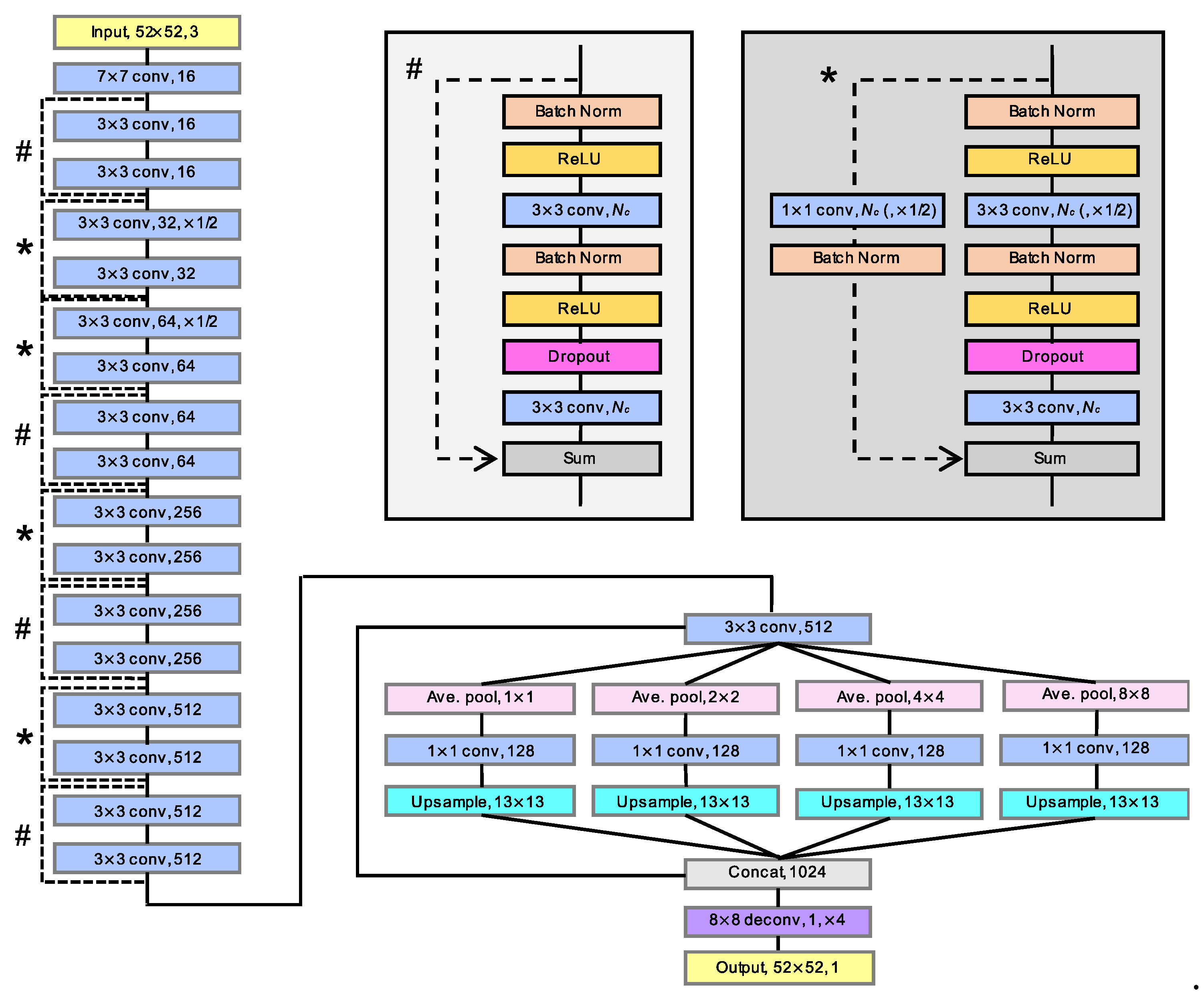
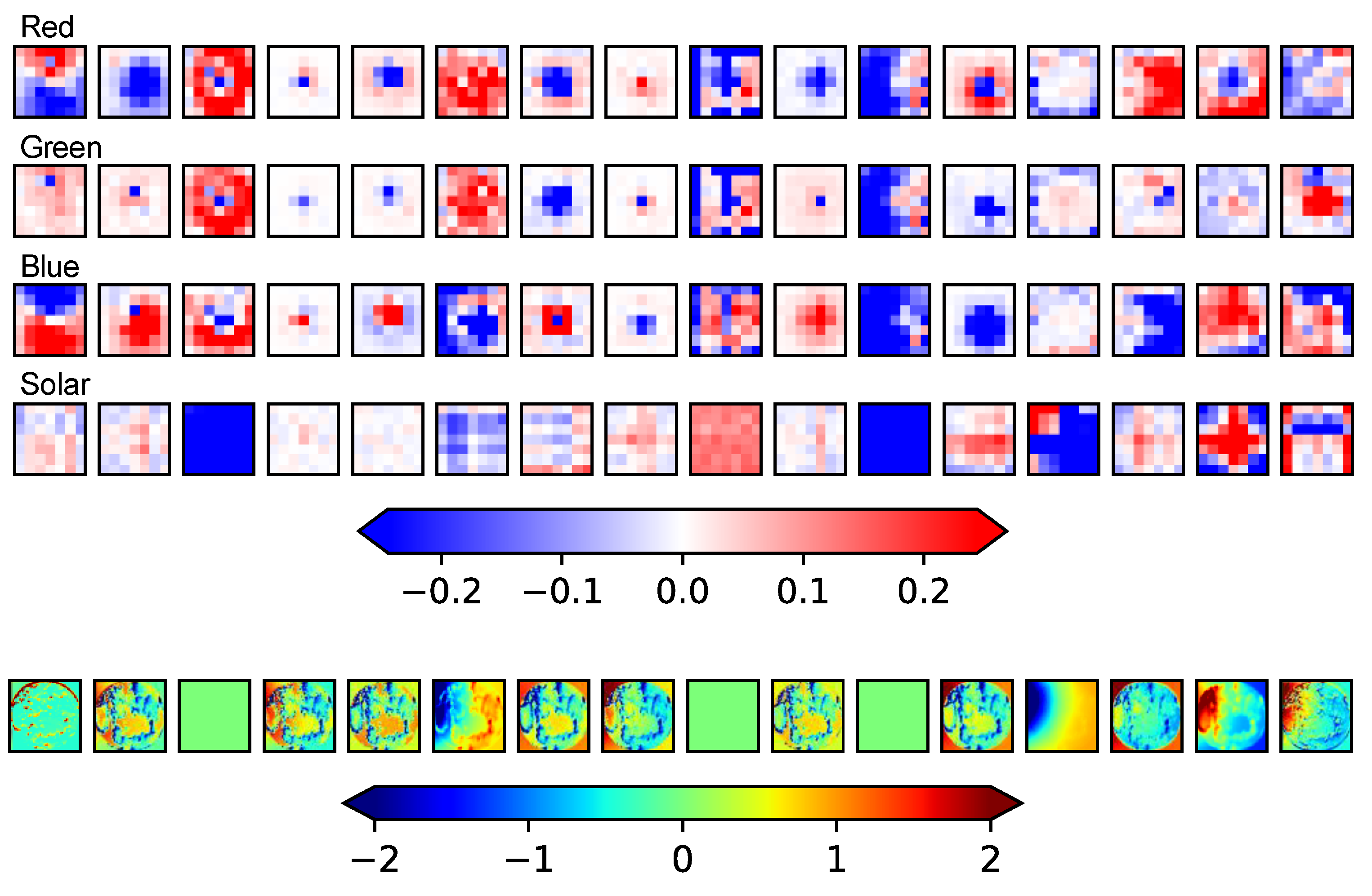
Appendix B. Anatomy of the CNN




References
- Chow, C.W.; Urquhart, B.; Lave, M.; Dominguez, A.; Kleissl, J.; Shields, J.; Washom, B. Intra-hour forecasting with a total sky imager at the UC San Diego solar energy testbed. Sol. Energy 2011, 85, 2881–2893. [Google Scholar] [CrossRef]
- Marshak, A.; Knyazikhin, Y.; Evans, K.D.; Wiscombe, W.J. The “RED versus NIR” plane to retrieve broken-cloud optical depth from ground-based measurements. J. Atmos. Sci. 2004, 61, 1911–1925. [Google Scholar] [CrossRef]
- Chiu, J.C.; Huang, C.-H.; Marshak, A.; Slutsker, I.; Giles, D.M.; Holben, B.N.; Knyazikhin, Y.; Wiscombe, W.J. Cloud optical depth retrievals from the Aerosol Robotic Network (AERONET) cloud mode observations. J. Geophys. Res. 2010, 115, 14202. [Google Scholar] [CrossRef]
- Kikuchi, N.; Nakajima, T.; Kumagai, H.; Kuroiwa, H.; Kamei, A.; Nakamura, R.; Nakajima, T.Y. Cloud optical thickness and effective particle radius derived from transmitted solar radiation measurements: Comparison with cloud radar observations. J. Geophys. Res.-Atmos. 2006, 111, 07205. [Google Scholar] [CrossRef]
- McBride, P.J.; Schmidt, K.S.; Pilewskie, P.; Kittelman, A.S.; Wolfe, D.E. A spectral method for retrieving cloud optical thickness and effective radius from surface-based transmittance measurements. Atmos. Chem. Phys. 2011, 11, 7235–7252. [Google Scholar] [CrossRef]
- Niple, E.R.; Scott, H.E.; Conant, J.A.; Jones, S.H.; Iannarilli, F.J.; Pereira, W.E. Application of oxygen A-band equivalent width to disambiguate downwelling radiances for cloud optical depth measurement. Atmos. Meas. Tech. 2016, 9, 4167–4179. [Google Scholar] [CrossRef]
- Mejia, F.A.; Kurtz, B.; Murray, K.; Hinkelman, L.M.; Sengupta, M.; Xie, Y.; Kleissl, J. Coupling sky images with radiative transfer models: A new method to estimate cloud optical depth. Atmos. Meas. Tech. 2016, 9, 4151–4165. [Google Scholar] [CrossRef]
- Cahalan, R.F.; Ridgway, W.; Wiscombe, W.J.; Bell, T.L.; Snider, J.B. The albedo of fractal stratocumulus clouds. J. Atmos. Sci. 1994, 51, 2434–2455. [Google Scholar] [CrossRef]
- Loeb, N.G.; Várnai, T.; Davies, R. Effect of cloud inhomogeneities on the solar zenith angle dependence of nadir reflectance. J. Geophys. Res. Atmos. 1997, 102, 9387–9395. [Google Scholar] [CrossRef]
- Várnai, T.; Davies, R. Effects of cloud heterogeneities on shortwave radiation: Comparison of cloud-top variability and internal heterogeneity. J. Atmos. Sci. 1999, 56, 4206–4224. [Google Scholar] [CrossRef]
- Várnai, T.; Marshak, A. Observations of three-dimensional radiative effects that influence MODIS cloud optical thickness retrievals. J. Atmos. Sci. 2002, 59, 1607–1618. [Google Scholar] [CrossRef]
- Kato, S.; Hinkelman, L.M.; Cheng, A. Estimate of satellite-derived cloud optical thickness and effective radius errors and their effect on computed domain-averaged irradiances. J. Geophys. Res. Atmos. 2006, 111, 17201. [Google Scholar] [CrossRef]
- Marshak, A.; Platnick, S.; Várnai, T.; Wen, G.; Cahalan, R.F. Impact of three-dimensional radiative effects on satellite retrievals of cloud droplet sizes. J. Geophys. Res. Atmos. 2006, 111, 09207. [Google Scholar] [CrossRef]
- Iwabuchi, H.; Hayasaka, T. A multi-spectral non-local method for retrieval of boundary layer cloud properties from optical remote sensing data. Remote Sens. Environ. 2003, 88, 294–308. [Google Scholar] [CrossRef]
- Faure, T.; Isaka, H.; Guillemet, B. Neural network retrieval of cloud parameters of inhomogeneous and fractional clouds: Feasibility study. Remote Sens. Environ. 2001, 77, 123–138. [Google Scholar] [CrossRef]
- Faure, T.; Isaka, H.; Guillemet, B. Neural network retrieval of cloud parameters from high-resolution multispectral radiometric data: A feasibility study. Remote Sens. Environ. 2002, 80, 285–296. [Google Scholar] [CrossRef]
- Cornet, C.; Isaka, H.; Guillemet, B.; Szczap, F. Neural network retrieval of cloud parameters of inhomogeneous clouds from multispectral and multiscale radiance data: Feasibility study. J. Geophys. Res. Atmos. 2004, 109, 12203. [Google Scholar] [CrossRef]
- Cornet, C.; Buriez, J.C.; Riédi, J.; Isaka, H.; Guillemet, B. Case study of inhomogeneous cloud parameter retrieval from MODIS data. Geophys. Res. Lett. 2005, 32, 13807. [Google Scholar] [CrossRef]
- Evans, K.F.; Marshak, A.; Várnai, T. The potential for improved boundary layer cloud optical depth retrievals from the multiple directions of MISR. J. Atmos. Sci. 2008, 65, 3179–3196. [Google Scholar] [CrossRef]
- Okamura, R.; Iwabuchi, H.; Schmidt, S. Feasibility study of multi-pixel retrieval of optical thickness and droplet effective radius of inhomogeneous clouds using deep learning. Atmos. Meas. Tech. 2017, 10, 4747–4759. [Google Scholar] [CrossRef]
- Marín, M.J.; Serrano, D.; Utrillas, M.P.; Núñez, M.; Martínez-Lozano, J.A. Effective cloud optical depth and enhancement effects for broken liquid water clouds in Valencia (Spain). Atmos. Res. 2017, 195, 1–8. [Google Scholar] [CrossRef]
- Fielding, M.D.; Chiu, J.C.; Hogan, R.J.; Feingold, G. A novel ensemble method for retrieving properties of warm cloud in 3-D using ground-based scanning radar and zenith radiances. J. Geophys. Res. Atmos. 2014, 119, 10912–10930. [Google Scholar] [CrossRef]
- Levis, A.; Schechner, Y.; Aides, A. Airborne Three-Dimensional Cloud Tomography. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3379–3387. [Google Scholar] [CrossRef]
- Levis, A.; Schechner, Y.Y.; Davis, A.B. Multiple-scattering Microphysics Tomography. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6740–6749. [Google Scholar]
- Holodovsky, V.; Schechner, Y.Y.; Levin, A.; Levis, A.; Aides, A. In-situ Multi-view Multi-scattering Stochastic Tomography. In Proceedings of the 2016 IEEE International Conference on Computational Photography (ICCP), Evanston, IL, USA, 13–15 May 2016; pp. 1–12. [Google Scholar] [CrossRef]
- Martin, W.G.K.; Hasekamp, O.P. A demonstration of adjoint methods for multi-dimensional remote sensing of the atmosphere and surface. J. Quant. Spectrosc. Radiat. Transf. 2018, 204, 215–231. [Google Scholar] [CrossRef]
- Mejia, F.A.; Kurtz, B.; Levis, A.; de la Parra, I.; Kleissl, J. Cloud tomography applied to sky images: A virtual testbed. Sol. Energy 2018, 176, 287–300. [Google Scholar] [CrossRef]
- Sato, Y.; Nishizawa, S.; Yashiro, H.; Miyamoto, Y.; Tomita, H. Potential of retrieving shallow-cloud life cycle from future generation satellite observations through cloud evolution diagrams: A suggestion from a large eddy simulation. Sci. Online Lett. Atmos. 2014, 10, 10–14. [Google Scholar] [CrossRef]
- Sato, Y.; Nishizawa, S.; Yashiro, H.; Miyamoto, Y.; Kajikawa, Y.; Tomita, H. Impacts of cloud microphysics on trade wind cumulus: Which cloud microphysics processes contribute to the diversity in a large eddy simulation? Prog. Earth Planet. Sci. 2015, 2, 23. [Google Scholar] [CrossRef]
- Nishizawa, S.; Yashiro, H.; Sato, Y.; Miyamoto, Y.; Tomita, H. Influence of grid aspect ratio on planetary boundary layer turbulence in large-eddy simulations. Geosci. Model Dev. 2015, 8, 3393–3419. [Google Scholar] [CrossRef]
- Iwabuchi, H. Efficient Monte Carlo methods for radiative transfer modeling. J. Atmos. Sci. 2006, 63, 2324–2339. [Google Scholar] [CrossRef]
- Iwabuchi, H.; Okamura, R. Multispectral Monte Carlo radiative transfer simulation by the maximum cross-section method. J. Quant. Spectrosc. Radiat. Transf. 2017, 193, 40–46. [Google Scholar] [CrossRef]
- Hänel, G. The properties of atmospheric aerosol particles as functions of the relative humidity at thermodynamic equilibrium with the surrounding moist air. Adv. Geophys. 1976, 19, 73–188. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; BMVA Press: Durham, UK, 2016; pp. 87.1–87.12. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; p. 37. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization CoRR, abs/1412.6980. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tokui, S.; Oono, K.; Hido, S.; Clayton, J. Chainer: A Next-generation Open Source Framework for Deep Learning. In Proceedings of the Workshop on Machine Learning Systems (LearningSys) in the Twenty-Ninth Annual Conference on Neural Information Processing Systems (NIPS), Montreal CANADA , 7–12 December 2015; Volume 5, pp. 1–6. [Google Scholar]
- Marshak, A.; Davis, A. 3D Radiative Transfer in Cloudy Atmospheres; Springer Science Business Media: Berlin, Heidelberg, Germany; New York, NY, USA, 2005. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale Context Aggregation by Dilated convolutions. In Proceedings of the International Conference Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing weight decay regularization in Adam, CoRR, abs/1711.05101. In Proceedings of the ICLR 2018 Conference Blind Submission, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zinner, T.; Hausmann, P.; Ewald, F.; Bugliaro, L.; Emde, C.; Mayer, B. Ground-based imaging remote sensing of ice clouds: Uncertainties caused by sensor, method and atmosphere. Atmos. Meas. Tech. 2016, 9, 4615–4632. [Google Scholar] [CrossRef]
- Saito, M.; Iwabuchi, H.; Murata, I. Estimation of spectral distribution of sky radiance using a commercial digital camera. Appl. Opt. 2016, 55, 415–424. [Google Scholar] [CrossRef]
- Damiani, A.; Irie, H.; Takamura, T.; Kudo, R.; Khatri, P.; Iwabuchi, H.; Masuda, R.; Nagao, T. An intensive campaign-based intercomparison of cloud optical depth from ground and satellite instruments under overcast conditions. Sci. Online Lett. Atmos. 2019, 15, 190–193. [Google Scholar] [CrossRef]
- Serrano, D.; Nunez, M.; Utrillas, M.P.; Marın, M.J.; Marcos, C.; Martınez-Lozano, J.A. Effective cloud optical depth for overcast conditions determined with a UV radiometers. Int. J. Climatol. 2014, 34, 3939–3952. [Google Scholar] [CrossRef]
- Damiani, A.; Irie, H.; Horio, T.; Takamura, T.; Khatri, P.; Takenaka, H.; Nagao, T.; Nakajima, T.Y.; Cordero, R. Evaluation of Himawari-8 surface downwelling solar radiation by ground-based measurements. Atmos. Meas. Tech. 2018, 11, 2501–2521. [Google Scholar] [CrossRef]
- Schwartz, S.E.; Huang, D.; Vladutescu, D.V. High-resolution photography of clouds from the surface: Retrieval of optical depth of thin clouds down to centimeter scales. J. Geophys. Res. Atmos. 2017, 122, 2898–2928. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Architecture (Nodes) | Input Image Size (Pixels) | Output Image Size (Pixels) | Number of Model Parameters (Millions) | Number of Epochs | Training Time (h) |
|---|---|---|---|---|---|---|
| NN-0 | NN (64) | 1 | 1 | 0.000321 | 500 | 3.0 |
| NN-1 | NN (288) | 3 × 3 | 1 | 0.00835 | 500 | 3.0 |
| NN-2 | NN (800) | 5 × 5 | 1 | 0.0616 | 500 | 3.0 |
| NN-3 | NN (1568) | 7 × 7 | 1 | 0.234 | 500 | 3.0 |
| NN-4 | NN (2592) | 9 × 9 | 1 | 0.635 | 500 | 3.0 |
| NN-5 | NN (3872) | 11 × 11 | 1 | 1.41 | 500 | 3.1 |
| NN-6 | NN (5408) | 13 × 13 | 1 | 2.75 | 500 | 3.1 |
| NN-7 | NN (7200) | 15 × 15 | 1 | 4.87 | 500 | 3.1 |
| NN-8 | NN (9248) | 17 × 17 | 1 | 8.04 | 500 | 3.1 |
| NN-9 | NN (11552) | 19 × 19 | 1 | 12.5 | 500 | 3.7 |
| NN-10 | NN (14112) | 21 × 21 | 1 | 18.7 | 500 | 5.1 |
| CNN | PSPNet | 52 × 52 | 52 × 52 | 10.8 | 2000 | 0.35 |
| Cloud Fraction | SCOT range | RMSPE 1 (%) | MAPE 1 (%) | MBPE 1 (%) |
|---|---|---|---|---|
| 0.7 | 1–100 | 23 | 13 | –0.2 |
| 0.2–100 | 30 | 14 | 0.3 | |
| 0.2–1 | 69 | 22 | 4.2 | |
| 1–10 | 26 | 14 | 1.1 | |
| 10–100 | 17 | 11 | –1.7 | |
| 0.7 | 1–100 | 118 | 49 | 7.0 |
| 0.2–100 | 189 | 52 | 12.6 | |
| 0.2–1 | 262 | 56 | 21.1 | |
| 1–10 | 128 | 48 | 12.9 | |
| 10–100 | 77 | 50 | –11.7 | |
| all | 1–100 | 48 | 18 | 0.8 |
| 0.2–100 | 87 | 21 | 2.6 | |
| 0.2–1 | 191 | 39 | 12.5 | |
| 1–10 | 59 | 20 | 3.2 | |
| 10–100 | 27 | 14 | –2.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Masuda, R.; Iwabuchi, H.; Schmidt, K.S.; Damiani, A.; Kudo, R. Retrieval of Cloud Optical Thickness from Sky-View Camera Images using a Deep Convolutional Neural Network based on Three-Dimensional Radiative Transfer. Remote Sens. 2019, 11, 1962. https://doi.org/10.3390/rs11171962
Masuda R, Iwabuchi H, Schmidt KS, Damiani A, Kudo R. Retrieval of Cloud Optical Thickness from Sky-View Camera Images using a Deep Convolutional Neural Network based on Three-Dimensional Radiative Transfer. Remote Sensing. 2019; 11(17):1962. https://doi.org/10.3390/rs11171962
Chicago/Turabian StyleMasuda, Ryosuke, Hironobu Iwabuchi, Konrad Sebastian Schmidt, Alessandro Damiani, and Rei Kudo. 2019. "Retrieval of Cloud Optical Thickness from Sky-View Camera Images using a Deep Convolutional Neural Network based on Three-Dimensional Radiative Transfer" Remote Sensing 11, no. 17: 1962. https://doi.org/10.3390/rs11171962
APA StyleMasuda, R., Iwabuchi, H., Schmidt, K. S., Damiani, A., & Kudo, R. (2019). Retrieval of Cloud Optical Thickness from Sky-View Camera Images using a Deep Convolutional Neural Network based on Three-Dimensional Radiative Transfer. Remote Sensing, 11(17), 1962. https://doi.org/10.3390/rs11171962