A Model-Dependent Method for Monitoring Subtle Changes in Vegetation Height in the Boreal–Alpine Ecotone Using Bi-Temporal, Three Dimensional Point Data from Airborne Laser Scanning


Abstract
1. Introduction
2. Materials and Methods
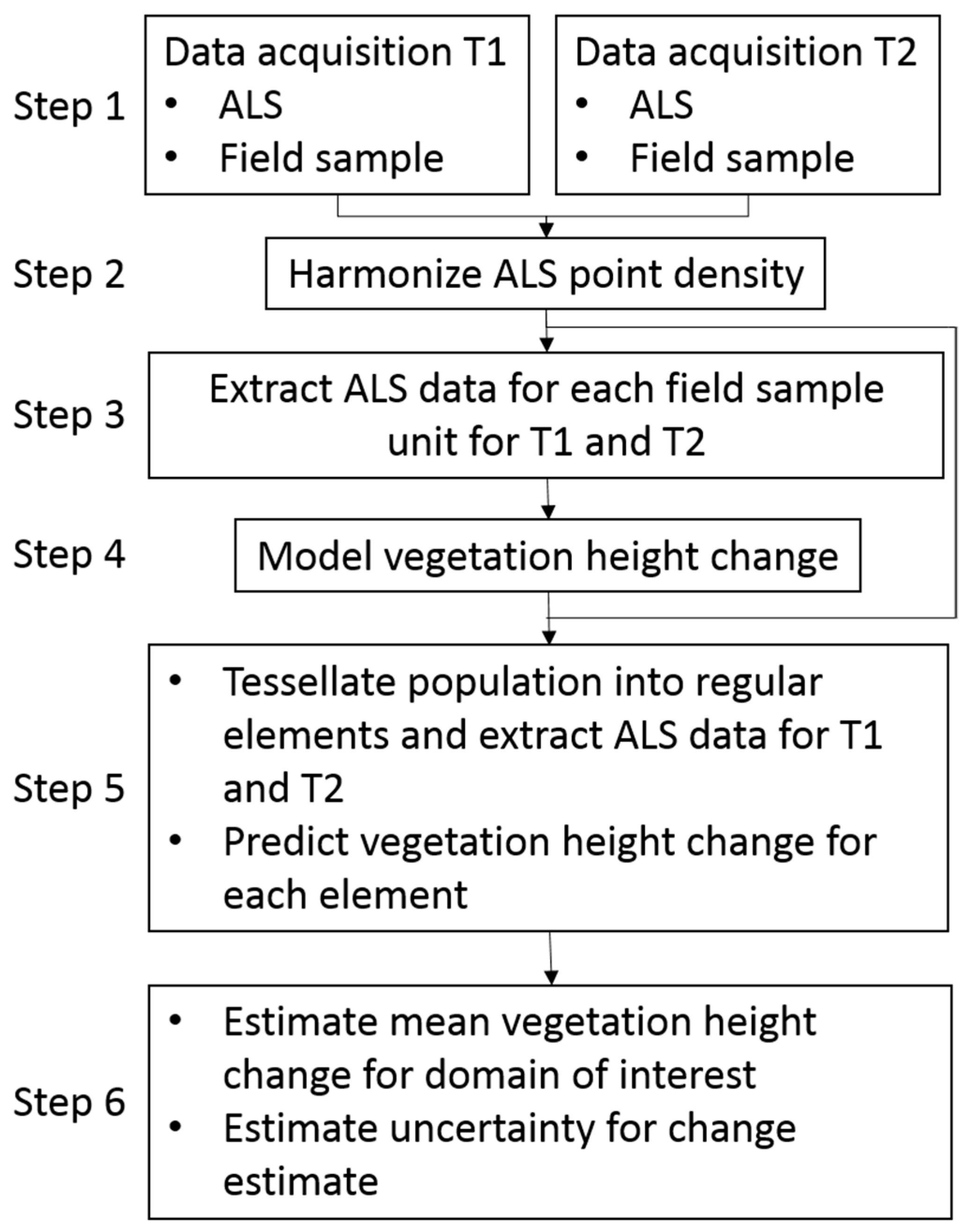
2.1. Overview of the Methodology
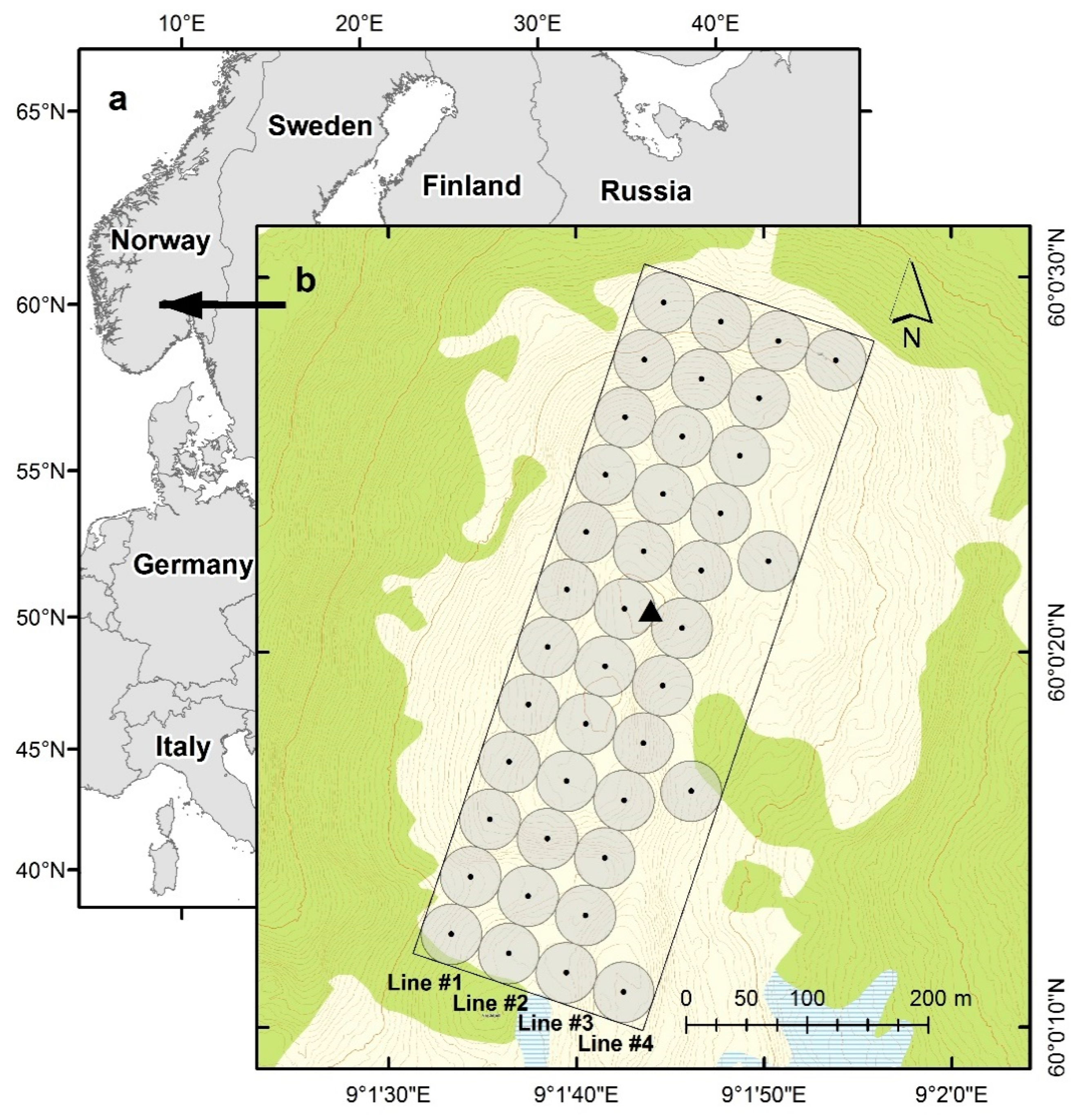
2.2. Study Area
2.3. Field Measurements
2.3.1. Field Work in 2006
2.3.2. Field Work in 2012
2.3.3. Combining 2006 and 2012 Field Data
2.4. Laser Scanner Data
2.4.1. Laser Data Acquisition in 2006
2.4.2. Laser Data Acquisition in 2012
2.4.3. Laser Data Processing
2.4.4. Laser Data Thinning
2.5. Laser Data Extraction for Sample Trees and Population Elements
2.6. Tree Height Change Model Construction
2.7. Modeling Probability of Tree
2.8. Model Parameter Independence
2.9. Model Prediction
2.10. Change Estimation
2.10.1. Point Estimators of Change
2.10.2. Estimators of Mean Square Error
Estimators Accounting for Model Parameter Uncertainty
Estimators Accounting for Residual Variance
Estimators Accounting for Residual Covariance
2.10.3. Assessment of Bias Properties of the Point Estimators
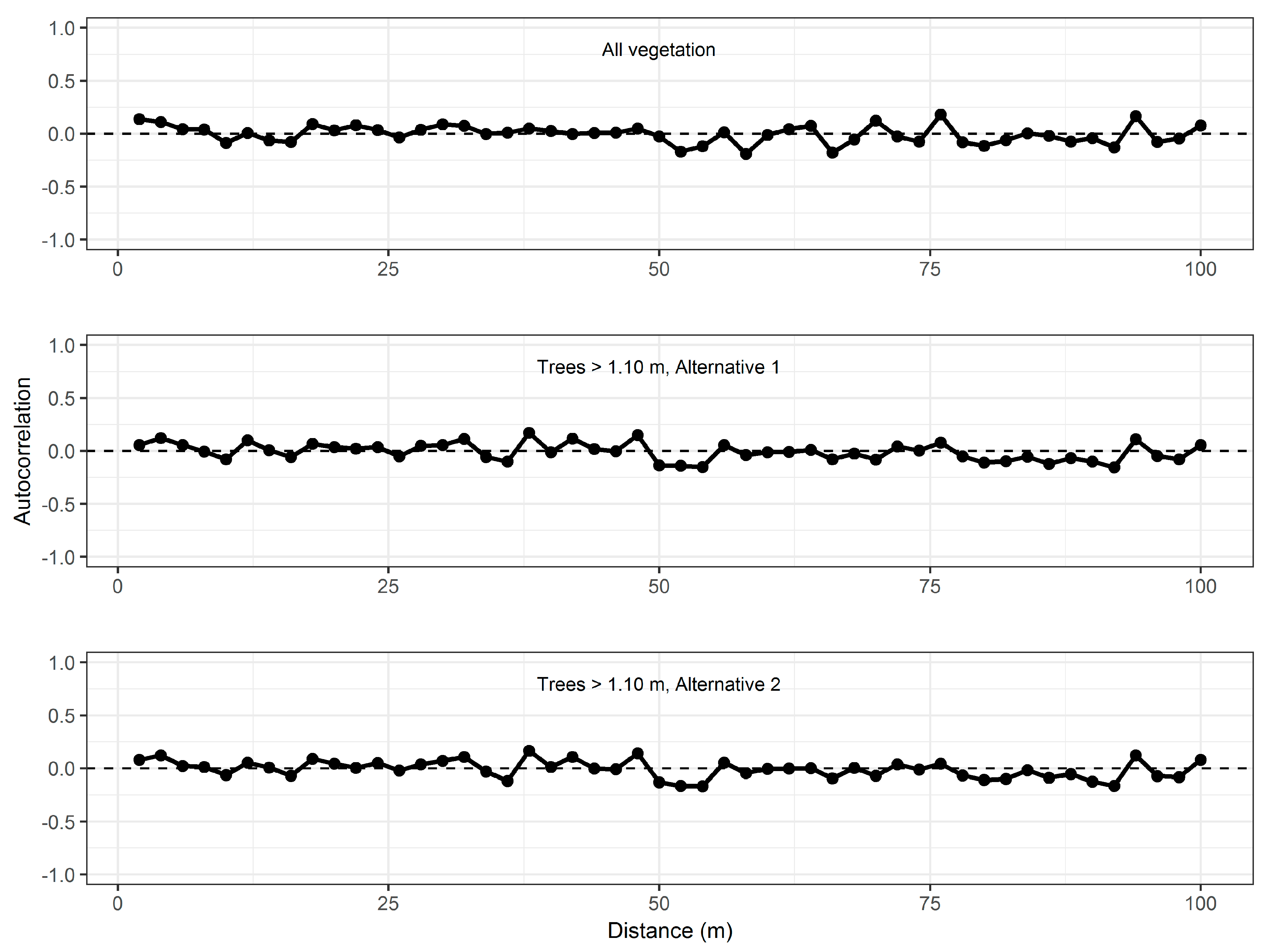
2.11. Analysis
3. Results and Discussion
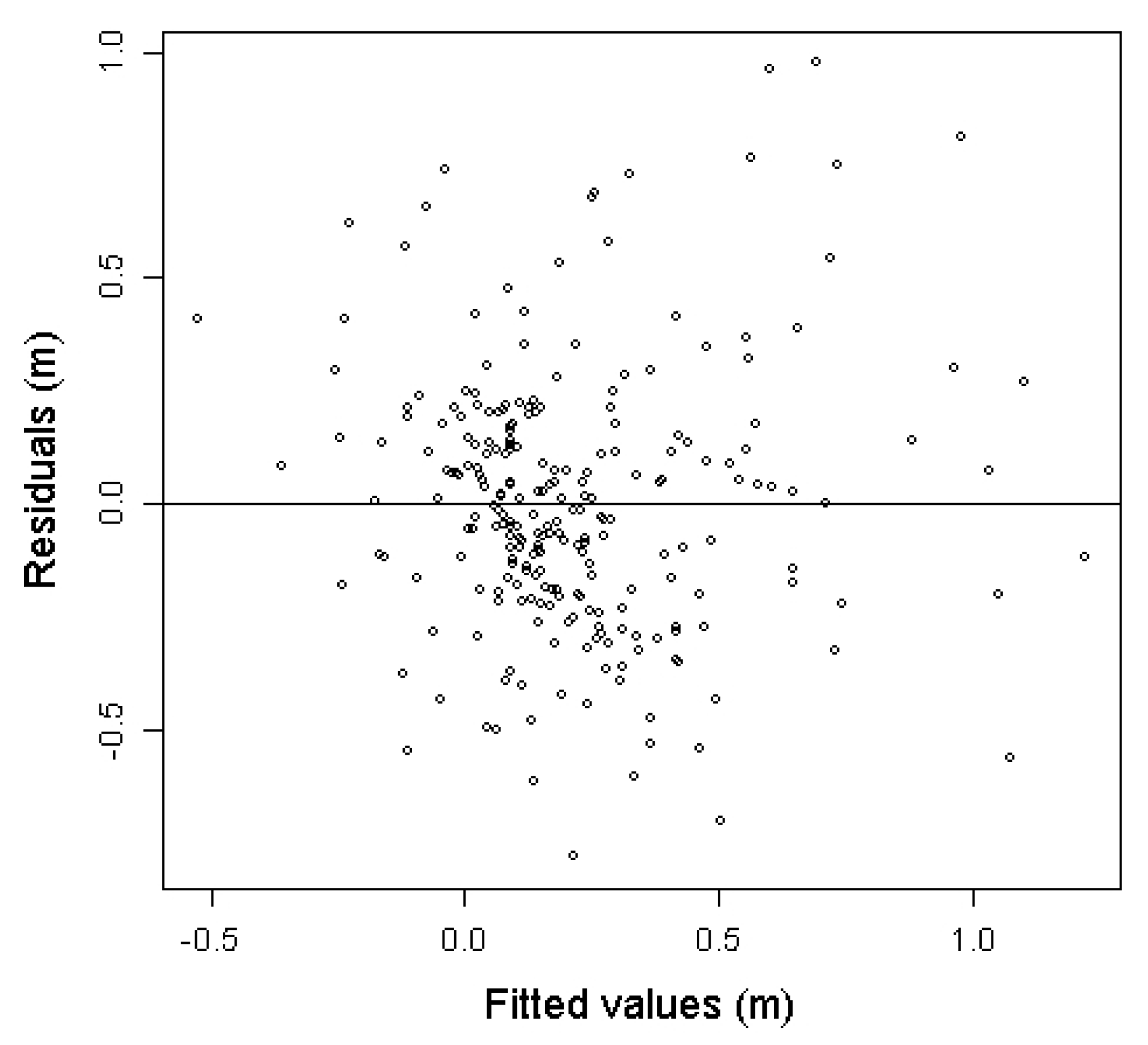
3.1. Model Construction
3.2. Overall Change Estimates
3.3. Change Estimates for Domains
3.4. Model-Dependent Inference for Domains
3.5. Bias Properties of the Point Estimators
3.6. Improvements of the Sampling Design
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zheng, D.; Freeman, M.; Bergh, J.; Røsberg, I.; Nilsen, P. Production of Picea abies in south-east Norway in response to climate change: A case study using process-based model simulation with field validation. Scand. J. For. Res. 2002, 17, 35–46. [Google Scholar] [CrossRef]
- Kullman, L. Recent tree-limit history of Piceaabies in the southern Swedish Scandes. Can. J. For. Res. 1986, 16, 761–771. [Google Scholar] [CrossRef]
- Kullman, L. Tree line population monitoring of Pinus sylvestris in the Swedish Scandes, 1973–2005: Implications for tree line theory and climate change ecology. J. Ecol. 2007, 95, 41–52. [Google Scholar] [CrossRef]
- Danby, R.K.; Hik, D.S. Variability, contingency and rapid change in recent subarctic alpine tree line dynamics. J. Ecol. 2007, 95, 352–363. [Google Scholar] [CrossRef]
- Kaplan, J.O.; New, M. Arctic climate change with a 2 °C global warming: Timing, climate patterns and vegetation change. Clim. Chang. 2006, 79, 213–241. [Google Scholar] [CrossRef]
- ACIA. Arctic Climate Impact Assessment; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Bryn, A.; Hemsing, L.Ø. Impacts of land use on the vegetation in three rural landscapes of Norway. Int. J. Biodivers. Sci. Ecosyst. Serv. Manag. 2012, 8, 360–371. [Google Scholar] [CrossRef]
- Gehrig-Fasel, J.; Guisan, A.; Zimmermann, N.E. Tree line shifts in the Swiss Alps: Climate change or land abandonment? J. Veg. Sci. 2007, 18, 571–582. [Google Scholar] [CrossRef]
- Tasser, E.; Walde, J.; Tappeiner, U.; Teutsch, A.; Noggler, W. Land-use changes and natural reforestation in the Eastern Central Alps. Agric. Ecosyst. Environ. 2007, 118, 115–129. [Google Scholar] [CrossRef]
- Callaghan, T.V.; Werkman, B.R.; Crawford, R.M.M. The tundra-taiga interface and its dynamics: Concepts and applications. Ambio 2002, 6–14. [Google Scholar] [CrossRef]
- Næsset, E.; Nelson, R. Using airborne laser scanning to monitor tree migration in the boreal-alpine transition zone. Remote Sens. Environ. 2007, 110, 357–369. [Google Scholar] [CrossRef]
- Stumberg, N.; Ørka, H.O.; Bollandsås, O.M.; Gobakken, T.; Næsset, E. Classifying tree and nontree echoes from airborne laser scanning in the forest–tundra ecotone. Can. J. Remote Sens. 2012, 38, 655–666. [Google Scholar] [CrossRef]
- Hauglin, M.; Bollandsås, O.M.; Gobakken, T.; Næsset, E. Monitoring small pioneer trees in the forest-tundra ecotone: Using multi-temporal airborne laser scanning data to model height growth. Environ. Monit. Assess. 2017, 190, 12. [Google Scholar] [CrossRef] [PubMed]
- Nyström, M.; Holmgren, J.; Olsson, H. Prediction of tree biomass in the forest–tundra ecotone using airborne laser scanning. Remote Sens. Environ. 2012, 123, 271–279. [Google Scholar] [CrossRef]
- Maltamo, M.; Bollandsås, O.M.; Gobakken, T.; Næsset, E. Large-scale prediction of aboveground biomass in heterogeneous mountain forests by means of airborne laser scanning. Can. J. For. Res. 2016, 46, 1138–1144. [Google Scholar] [CrossRef]
- Thieme, N.; Bollandsås, O.M.; Gobakken, T.; Næsset, E. Detection of small single trees in the forest-tundra ecotone using height values from airborne laser scanning. Can. J. Remote Sens. 2011, 37, 264–274. [Google Scholar] [CrossRef]
- Stumberg, N.; Bollandsås, O.; Gobakken, T.; Næsset, E. Automatic Detection of Small Single Trees in the Forest-Tundra Ecotone Using Airborne Laser Scanning. Remote Sens. 2014, 6, 10152–10170. [Google Scholar] [CrossRef]
- Hauglin, M.; Næsset, E. Detection and Segmentation of Small Trees in the Forest-Tundra Ecotone Using Airborne Laser Scanning. Remote Sens. 2016, 8, 407. [Google Scholar] [CrossRef]
- Rees, W.G. Characterisation of Arctic treelines by LiDAR and multispectral imagery. Polar Rec. 2007, 43, 345–352. [Google Scholar] [CrossRef]
- Næsset, E. Effects of different sensors, flying altitudes, and pulse repetition frequencies on forest canopy metrics and biophysical stand properties derived from small-footprint airborne laser data. Remote Sens. Environ. 2009, 113, 148–159. [Google Scholar] [CrossRef]
- Næsset, E. Discrimination between Ground Vegetation and Small Pioneer Trees in the Boreal-Alpine Ecotone Using Intensity Metrics Derived from Airborne Laser Scanner Data. Remote Sens. 2016, 8, 548. [Google Scholar] [CrossRef]
- Stumberg, N.; Hauglin, M.; Bollandsås, O.M.; Gobakken, T.; Erik, N. Improving Classification of Airborne Laser Scanning Echoes in the Forest-Tundra Ecotone Using Geostatistical and Statistical Measures. Remote Sens. 2014, 6, 4582–4599. [Google Scholar] [CrossRef]
- Nyström, M.; Holmgren, J.; Olsson, H. Change detection of mountain birch using multi-temporal ALS point clouds. Remote Sens. Lett. 2013, 4, 190–199. [Google Scholar] [CrossRef]
- Næsset, E. Vertical Height Errors in Digital Terrain Models Derived from Airborne Laser Scanner Data in a Boreal-Alpine Ecotone in Norway. Remote Sens. 2015, 7, 4702–4725. [Google Scholar] [CrossRef]
- Cottam, G.; Curtis, J.T. The Use of Distance Measures in Phytosociological Sampling. Ecology 1956, 37, 451–460. [Google Scholar] [CrossRef]
- Warde, W.; Petranka, J.W. A Correction Factor Table for Missing Point-Center Quarter Data. Ecology 1981, 62, 491–494. [Google Scholar] [CrossRef]
- Soininen, A. TerraScan User’s Guide. Available online: https://www.terrasolid.com/download/tscan.pdf (accessed on 21 March 2017).
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 111–118. [Google Scholar]
- Harter, H.L. Order Statistics and Their Use in Testing and Estimation; US Government Printing Office: Washington, DC, USA, 1970; Volume II.
- Magnusson, M.; Fransson, J.E.S.; Holmgren, J. Effects on estimation accuracy of forest variables using different pulse density of laser data. For. Sci. 2007, 53, 619–626. [Google Scholar]
- Gobakken, T.; Næsset, E. Assessing effects of laser point density, ground sampling intensity, and field sample plot size on biophysical stand properties derived from airborne laser scanner data. Can. J. For. Res. 2008, 38, 1095–1109. [Google Scholar] [CrossRef]
- Holmgren, J. Prediction of tree height, basal area and stem volume in forest stands using airborne laser scanning. Scand. J. For. Res. 2004, 19, 543–553. [Google Scholar] [CrossRef]
- Magnussen, S.; Næsset, E.; Gobakken, T. LiDAR-supported estimation of change in forest biomass with time-invariant regression models. Can. J. For. Res. 2015, 45, 1514–1523. [Google Scholar] [CrossRef]
- Bollandsås, O.M.; Gregoire, T.G.; Næsset, E.; Øyen, B.-H. Detection of biomass change in a Norwegian mountain forest area using small footprint airborne laser scanner data. Stat. Methods Appl. 2013, 22, 113–129. [Google Scholar] [CrossRef]
- Næsset, E.; Bollandsås, O.M.; Gobakken, T.; Gregoire, T.G.; Ståhl, G. Model-assisted estimation of change in forest biomass over an 11 year period in a sample survey supported by airborne LiDAR: A case study with post-stratification to provide “activity data”. Remote Sens. Environ. 2013, 128, 299–314. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T.; Bollandsås, O.M. Indirect and direct estimation of forest biomass change using forest inventory and airborne laser scanning data. Remote Sens. Environ. 2015, 164, 36–42. [Google Scholar] [CrossRef]
- Ene, L.T.; Næsset, E.; Gobakken, T.; Bollandsås, O.M.; Mauya, E.W.; Zahabu, E. Large-scale estimation of change in aboveground biomass in miombo woodlands using airborne laser scanning and national forest inventory data. Remote Sens. Environ. 2017, 188, 106–117. [Google Scholar] [CrossRef]
- Skowronski, N.S.; Clark, K.L.; Gallagher, M.; Birdsey, R.A.; Hom, J.L. Airborne laser scanner-assisted estimation of aboveground biomass change in a temperate oak–pine forest. Remote Sens. Environ. 2014, 151, 166–174. [Google Scholar] [CrossRef]
- Breusch, T.S.; Pagan, A.R. The Lagrange multiplier test and its applications to model specification in econometrics. Rev. Econ. Stud. 1980, 47, 239–253. [Google Scholar] [CrossRef]
- White, H. A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity. Econometrica 1980, 48, 817–838. [Google Scholar] [CrossRef]
- Team, R.C. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Long, J.S.; Ervin, L.H. Using Heteroscedasticity Consistent Standard Errors in the Linear Regression Model. Am. Stat. 2000, 54, 217–224. [Google Scholar] [CrossRef]
- MacKinnon, J.G.; White, H. Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties. J. Econom. 1985, 29, 305–325. [Google Scholar] [CrossRef]
- Zeileis, A. Econometric Computing with HC and HAC Covariance Matrix Estimators. J. Stat. Softw. 2004, 11, 1–17. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; John Wiley and Sons: New York, NY, USA, 2000. [Google Scholar]
- Lele, S.R.; Keim, J.L.; Solymos, P. ResourceSelection: Resource Selection (Probability) Functions for Use-Availability Data. R Package Version 0.3-2. Available online: https://CRAN.R-project.org/package=ResourceSelection (accessed on 10 May 2018).
- Zeileis, A. Object-oriented Computation of Sandwich Estimators. J. Stat. Softw. 2006, 16, 1–16. [Google Scholar] [CrossRef]
- Hansen, M.H.; Madow, W.G.; Tepping, B.J. An Evaluation of Model-Dependent and Probability-Sampling Inferences in Sample Surveys. J. Am. Stat. Assoc. 1983, 78, 776–793. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T. Inference for lidar-assisted estimation of forest growing stock volume. Remote Sens. Environ. 2013, 128, 268–275. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T.; Chirici, G.; Condés, S.; Hou, Z.; Saarela, S.; Chen, Q.; Ståhl, G.; Walters, B.F. Assessing components of the model-based mean square error estimator for remote sensing assisted forest applications. Can. J. For. Res. 2018, 48, 642–649. [Google Scholar] [CrossRef]
- Breidenbach, J.; McRoberts, R.E.; Astrup, R. Empirical coverage of model-based variance estimators for remote sensing assisted estimation of stand-level timber volume. Remote Sens. Environ. 2016, 173, 274–281. [Google Scholar] [CrossRef] [PubMed]
- Saarela, S.; Schnell, S.; Grafström, A.; Tuominen, S.; Nordkvist, K.; Hyyppä, J.; Kangas, A.; Ståhl, G. Effects of sample size and model form on the accuracy of model-based estimators of growing stock volume. Can. J. For. Res. 2015, 45, 1524–1534. [Google Scholar] [CrossRef]
- Ståhl, G.; Saarela, S.; Schnell, S.; Holm, S.; Breidenbach, J.; Healey, S.P.; Patterson, P.L.; Magnussen, S.; Næsset, E.; McRoberts, R.E.; et al. Use of models in large-area forest surveys: Comparing model-assisted, model-based and hybrid estimation. For. Ecosyst. 2016, 3, 5. [Google Scholar] [CrossRef]
- Mandallaz, D. A Unified Approach to Sampling Theory for Forest Inventory Based on in Finite Population and Superpopulation Models. Ph.D. Thesis, Swiss Federal Institute of Technology, Zürich, Switzerland, 1991. [Google Scholar]
- Ståhl, G.; Holm, S.; Gregoire, T.; Gobakken, T.; Næsset, E.; Nelson, R. Model-based inference for biomass estimation in a LiDAR sample survey in the county of Hedmark County, Norway. Can. J. For. Res. 2011, 41, 96–107. [Google Scholar] [CrossRef]
- Kangas, A. Small-area estimates using model-based methods. Can. J. For. Res. 1996, 26, 758–766. [Google Scholar] [CrossRef]
- Ene, L.T.; Næsset, E.; Gobakken, T.; Gregoire, T.G.; Ståhl, G.; Nelson, R. Assessing the accuracy of regional LiDAR-based biomass estimation using a simulation approach. Remote Sens. Environ. 2012, 123, 579–592. [Google Scholar] [CrossRef]
- McRoberts, R.E. A model-based approach to estimating forest area. Remote Sens. Environ. 2006, 103, 56–66. [Google Scholar] [CrossRef]
- Saarela, S.; Holm, S.; Grafström, A.; Schnell, S.; Næsset, E.; Gregoire, T.G.; Nelson, R.F.; Ståhl, G. Hierarchical model-based inference for forest inventory utilizing three sources of information. Ann. For. Sci. 2016, 73, 895–910. [Google Scholar] [CrossRef]
- Bollandsås, O.M.; Ene, L.T.; Gobakken, T.; Næsset, E. Estimation of biomass change in montane forests in Norway along a 1200 km latitudinal gradient using airborne laser scanning: A comparison of direct and indirect prediction of change under a model-based inferential approach. Scand. J. For. Res. 2018, 33, 155–165. [Google Scholar] [CrossRef]
- Ene, L.T.; Gobakken, T.; Andersen, H.-E.; Næsset, E.; Cook, B.D.; Morton, D.C.; Babcock, C.; Nelson, R. Large-area hybrid estimation of aboveground biomass in interior Alaska using airborne laser scanning data. Remote Sens. Environ. 2018, 204, 741–755. [Google Scholar] [CrossRef]
- Strîmbu, V.F.; Ene, L.T.; Gobakken, T.; Gregoire, T.G.; Astrup, R.; Næsset, E. Post-stratified change estimation for large-area forest biomass using repeated ALS strip sampling. Can. J. For. Res. 2017, 47, 839–847. [Google Scholar] [CrossRef]
- Kambo, D.; Danby, R.K. Factors influencing the establishment and growth of tree seedlings at Subarctic alpine treelines. Ecosphere 2018, 9, e02176. [Google Scholar] [CrossRef]
- Miller, R.G. Simultaneous Statistical Inference, 2nd ed.; Springer: New York, NY, USA, 1981; p. 299. [Google Scholar]
- Lohr, S.L. Sampling: Design and Analysis, 2nd ed.; Brooks/Cole, Cengage Learning: Boston, MA, USA, 2010; p. 596. [Google Scholar]
- Särndal, C.-E.; Thomsen, I.; Hoem, J.M.; Lindley, D.V.; Barndorff-Nielsen, O.; Dalenius, T. Design-based and model-based inference in survey sampling. Scand. J. Statist. 1978, 5, 27–52. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tree Species | Characteristic | n | 2006 | 2012 | ||
|---|---|---|---|---|---|---|
| Range | Mean | Range | Mean | |||
| Norway spruce | Tree height (m) | 122 | 0.25–5.20 | 1.83 | 0.29–6.30 | 2.21 |
| Crown area a (m2) | 122 | 0.034–14.522 | 2.314 | 0.061–23.562 | 3.070 | |
| Scots pine | Tree height (m) | 31 | 0.11–1.01 | 0.41 | 0.28–1.59 | 0.70 |
| Crown area a (m2) | 31 | 0.008–0.648 | 0.129 | 0.009–1.429 | 0.315 | |
| Mountain birch | Tree height (m) | 163 | 0.24–4.08 | 1.54 | 0.10–3.80 | 1.56 |
| Crown area a (m2) | 163 | 0.016–10.948 | 1.636 | 0.015–8.482 | 1.802 | |
| All trees | Tree height (m) | 316 | 0.11–5.20 | 1.54 | 0.10–6.30 | 1.73 |
| Crown area a (m2) | 316 | 0.008–14.522 | 1.75 | 0.009–23.562 | 2.151 | |
| Coefficient | Estimate | p-Value | |
|---|---|---|---|
| Intercept | 0.0911 | <0.001 | |
| hmax2006 | −0.3689 | <0.001 | |
| hmax2012 | 0.4391 | <0.001 | |
| RMSE (m) | 0.293 | ||
| R2 | 0.437 | ||
| Heteroscedasticity-consistent variance–covariance matrix of parameter estimates: | |||
| Intercept | Intercept | hmax2006 | hmax2012 |
| 0.000534 | −0.000197 | −0.000064 | |
| hmax2006 | −0.000197 | 0.002151 | −0.001880 |
| hmax2012 | −0.000064 | −0.001880 | 0.001927 |
| Coefficient | Estimate | Wald Chi-Square | p-Value |
|---|---|---|---|
| Intercept | −2.82 | 43.26 | <0.001 |
| hmax2006 | 4.61 | 24.17 | <0.001 |
| hmax2012 | 2.13 | 9.56 | 0.002 |
| Model fit a | 4.63 | 0.78 | |
| Overall accuracy b (%) | 87.5 | ||
| Commission error for TREE b (%) | 8.0 | ||
| Omission error for TREE b (%) | 11.1 | ||
| Heteroscedasticity-consistent variance–covariance matrix of parameter estimates: | |||
| Intercept | Intercept | hmax2006 | hmax2012 |
| 0.183 | −0.208 | −0.155 | |
| hmax2006 | −0.208 | 0.644 | −0.093 |
| hmax2012 | −0.155 | −0.093 | 0.522 |
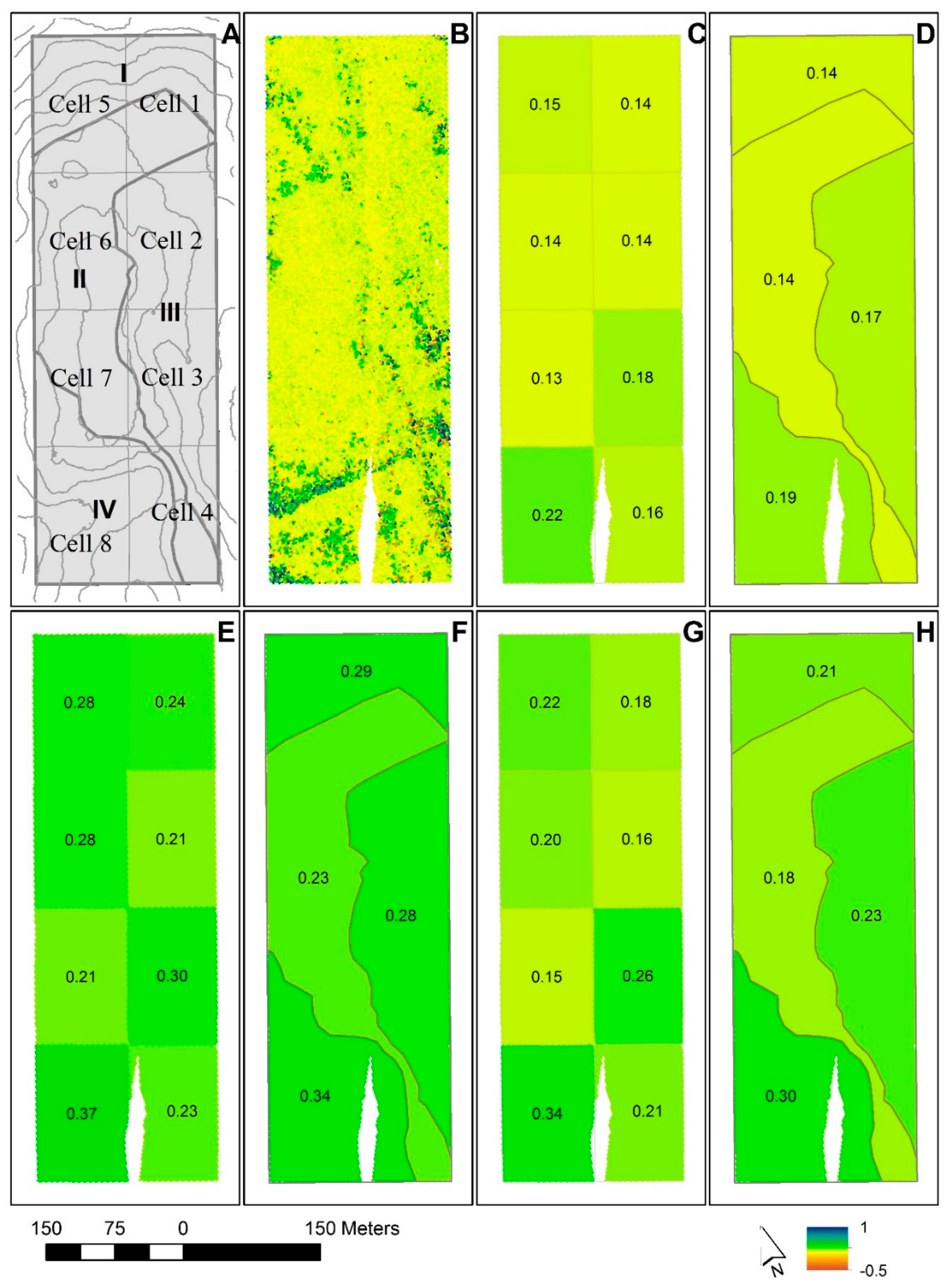
| Domain | All Vegetation (m) | Trees ≥1.10 m (m) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternative 1 b | Alternative 2 c | ||||||||||||||
| SE | CI | SE | CI | SE | CI | ||||||||||
| Study area | 0.16 | 0.020 | 0.12 | - | 0.20 | 0.29 | 0.027 | 0.24 | - | 0.34 | 0.24 | 0.024 | 0.19 | - | 0.28 |
| Case A: | |||||||||||||||
| Cell 1 | 0.14 | 0.022 | 0.10 | - | 0.18 | 0.24 | 0.023 | 0.19 | - | 0.28 | 0.18 | 0.021 | 0.14 | - | 0.22 |
| Cell 2 | 0.14 | 0.022 | 0.10 | - | 0.18 | 0.21 | 0.021 | 0.16 | - | 0.25 | 0.16 | 0.020 | 0.12 | - | 0.20 |
| Cell 3 | 0.18 | 0.019 | 0.14 | - | 0.22 | 0.30 | 0.030 | 0.24 | - | 0.36 | 0.26 | 0.026 | 0.21 | - | 0.31 |
| Cell 4 | 0.16 | 0.019 | 0.12 | - | 0.20 | 0.23 | 0.024 | 0.18 | - | 0.28 | 0.21 | 0.022 | 0.16 | - | 0.25 |
| Cell 5 | 0.15 | 0.021 | 0.11 | - | 0.19 | 0.28 | 0.024 | 0.23 | - | 0.32 | 0.22 | 0.023 | 0.18 | - | 0.27 |
| Cell 6 | 0.14 | 0.022 | 0.10 | - | 0.18 | 0.28 | 0.024 | 0.23 | - | 0.32 | 0.20 | 0.023 | 0.16 | - | 0.25 |
| Cell 7 | 0.13 | 0.023 | 0.09 | - | 0.17 | 0.21 | 0.020 | 0.17 | - | 0.25 | 0.15 | 0.021 | 0.11 | - | 0.19 |
| Cell 8 | 0.22 | 0.019 | 0.18 | - | 0.26 | 0.37 | 0.035 | 0.31 | - | 0.44 | 0.34 | 0.032 | 0.28 | - | 0.40 |
| Case B: | |||||||||||||||
| Sub-region I | 0.14 | 0.022 | 0.10 | - | 0.19 | 0.29 | 0.026 | 0.24 | - | 0.34 | 0.21 | 0.024 | 0.16 | - | 0.26 |
| Sub-region II | 0.14 | 0.022 | 0.10 | - | 0.18 | 0.23 | 0.022 | 0.18 | - | 0.27 | 0.18 | 0.020 | 0.14 | - | 0.22 |
| Sub-region III | 0.17 | 0.020 | 0.13 | - | 0.21 | 0.28 | 0.026 | 0.23 | - | 0.33 | 0.23 | 0.023 | 0.19 | - | 0.28 |
| Sub-region IV | 0.19 | 0.019 | 0.15 | - | 0.23 | 0.34 | 0.031 | 0.28 | - | 0.40 | 0.30 | 0.028 | 0.24 | - | 0.35 |
| Domain | n | All Vegetation | Trees ≥1.10 m | |||
|---|---|---|---|---|---|---|
| Alternative 1 a | Alternative 2 b | |||||
| ME (m) | ME (m) | |||||
| Study area | 247 | 0.4 | 0.028 | 0.2 | 0.021 | 0.2 |
| Case A: | ||||||
| Cell 1 | 25 | 1.6 | 0.104 | 0.5 | 0.052 | 0.5 |
| Cell 2 | 23 | 1.2 | 0.019 | 1.0 | 0.013 | 0.9 |
| Cell 3 | 26 | 2.9 | −0.047 | 1.1 | −0.046 | 1.5 |
| Cell 4 | 35 | 4.1 | 0.008 | 2.4 | 0.004 | 2.9 |
| Cell 5 | 43 | 2.4 | 0.061 | 1.8 | 0.056 | 1.8 |
| Cell 6 | 25 | 1.6 | 0.081 | 1.0 | 0.068 | 1.0 |
| Cell 7 | 21 | 2.1 | 0.108 | 1.5 | 0.084 | 1.2 |
| Cell 8 | 49 | 5.1 | −0.017 | 1.3 | −0.008 | 1.6 |
| Case B: | ||||||
| Sub-region I | 42 | 2.0 | 0.084 | 1.3 | 0.063 | 1.4 |
| Sub-region II | 66 | 0.6 | 0.088 | 0.3 | 0.073 | 0.4 |
| Sub-region III | 51 | 1.0 | −0.034 | 0.5 | −0.036 | 0.6 |
| Sub-region IV | 88 | 2.7 | 0.005 | 0.9 | 0.006 | 1.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Næsset, E.; Gobakken, T.; McRoberts, R.E. A Model-Dependent Method for Monitoring Subtle Changes in Vegetation Height in the Boreal–Alpine Ecotone Using Bi-Temporal, Three Dimensional Point Data from Airborne Laser Scanning. Remote Sens. 2019, 11, 1804. https://doi.org/10.3390/rs11151804
Næsset E, Gobakken T, McRoberts RE. A Model-Dependent Method for Monitoring Subtle Changes in Vegetation Height in the Boreal–Alpine Ecotone Using Bi-Temporal, Three Dimensional Point Data from Airborne Laser Scanning. Remote Sensing. 2019; 11(15):1804. https://doi.org/10.3390/rs11151804
Chicago/Turabian StyleNæsset, Erik, Terje Gobakken, and Ronald E. McRoberts. 2019. "A Model-Dependent Method for Monitoring Subtle Changes in Vegetation Height in the Boreal–Alpine Ecotone Using Bi-Temporal, Three Dimensional Point Data from Airborne Laser Scanning" Remote Sensing 11, no. 15: 1804. https://doi.org/10.3390/rs11151804
APA StyleNæsset, E., Gobakken, T., & McRoberts, R. E. (2019). A Model-Dependent Method for Monitoring Subtle Changes in Vegetation Height in the Boreal–Alpine Ecotone Using Bi-Temporal, Three Dimensional Point Data from Airborne Laser Scanning. Remote Sensing, 11(15), 1804. https://doi.org/10.3390/rs11151804