Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network

 , , ,
, , ,  , and
, and
Abstract
1. Introduction
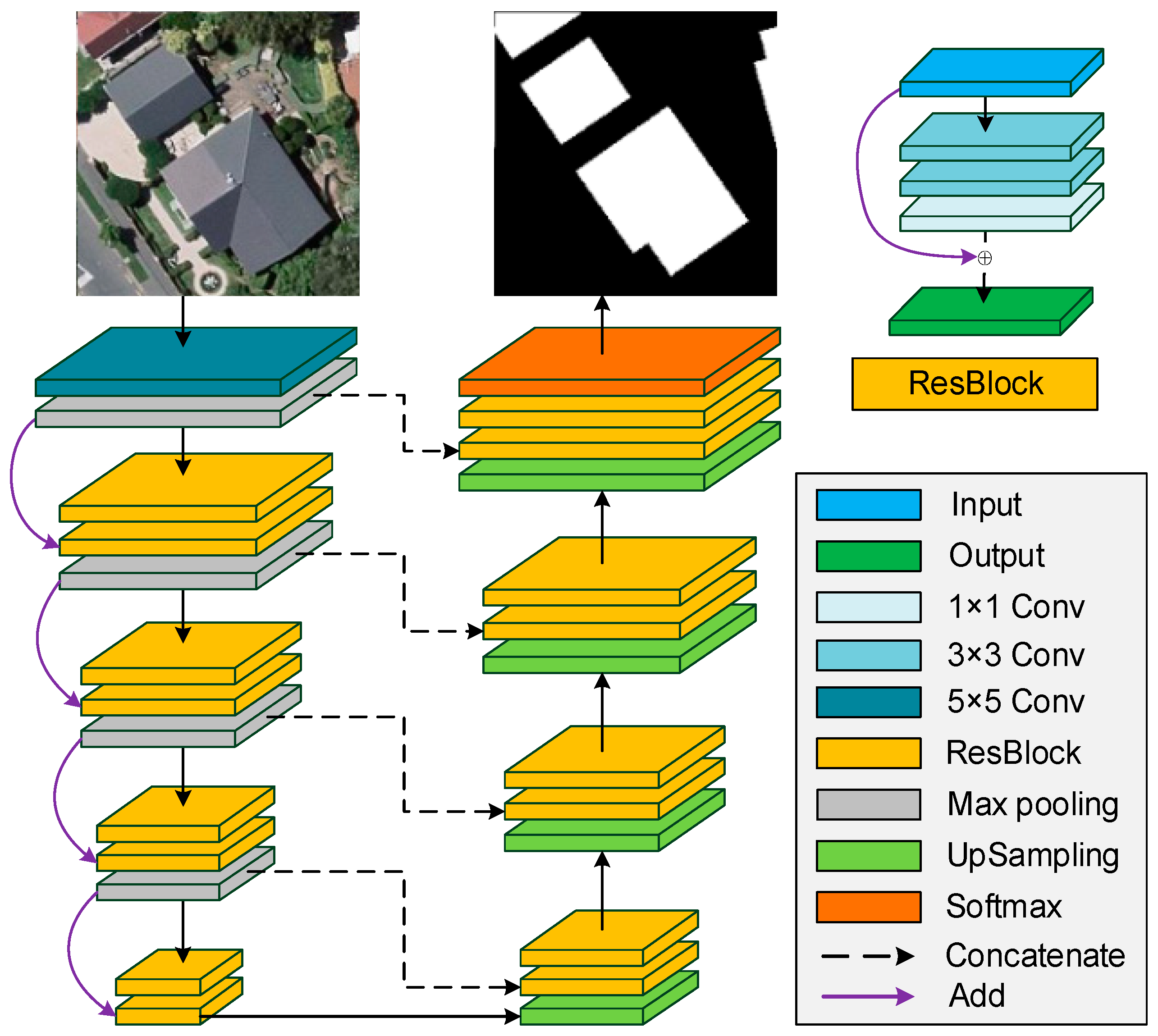
2. Methodology
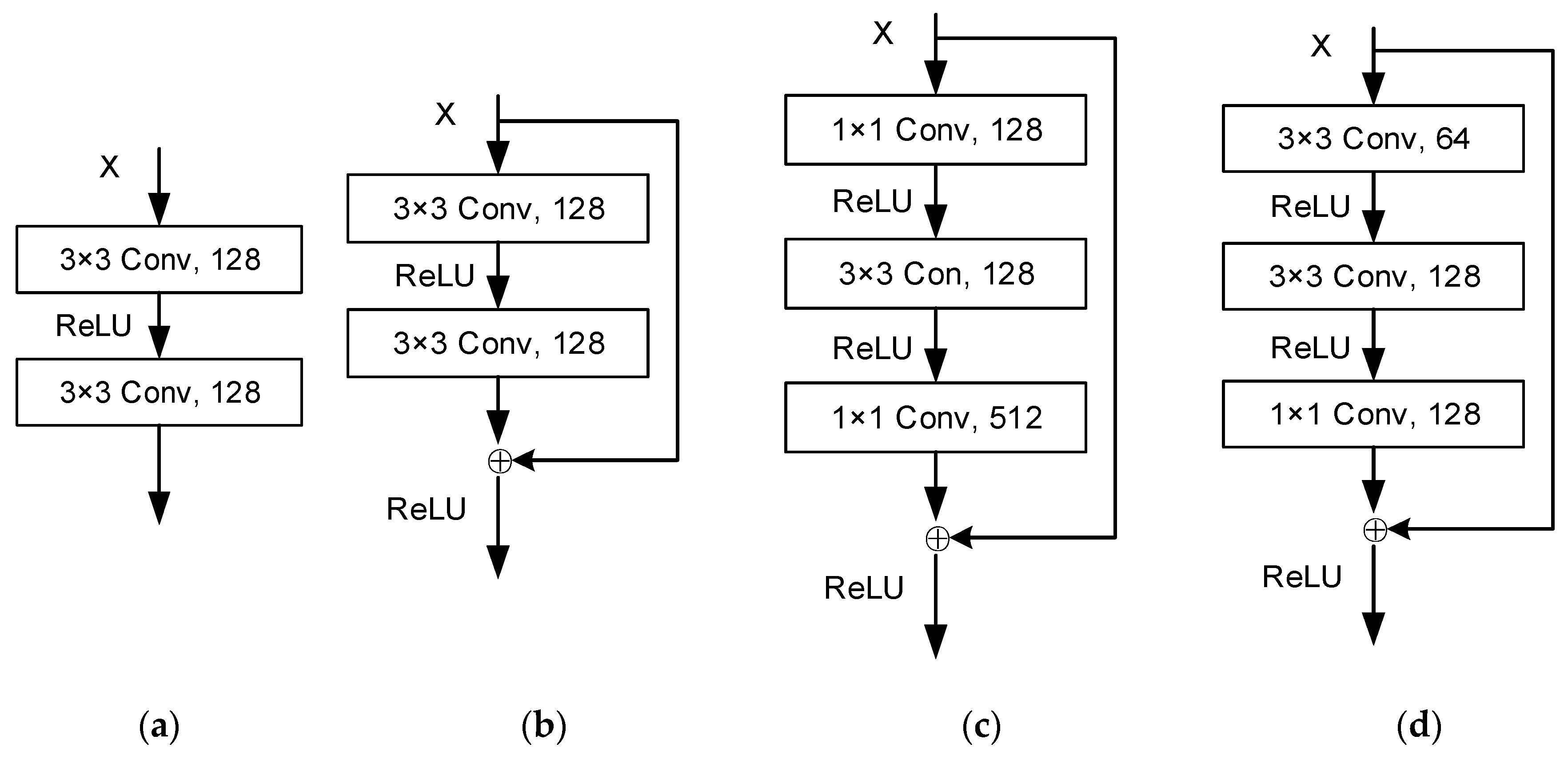
2.1. ResBlock
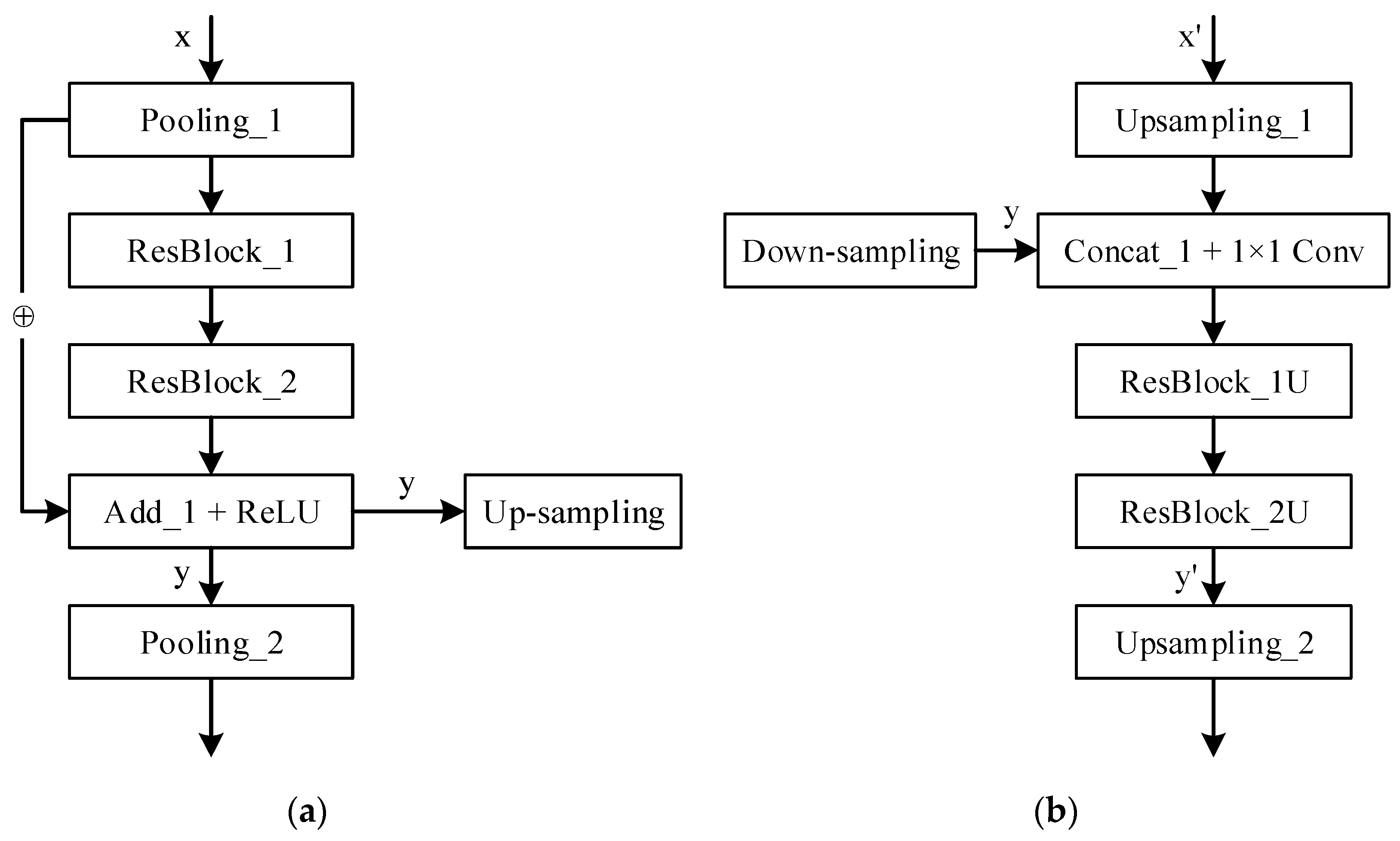
2.2. Down-Sampling Network
2.3. Up-sampling Network
3. Experiments and Results
3.1. Dataset
3.2. Experimental Setup
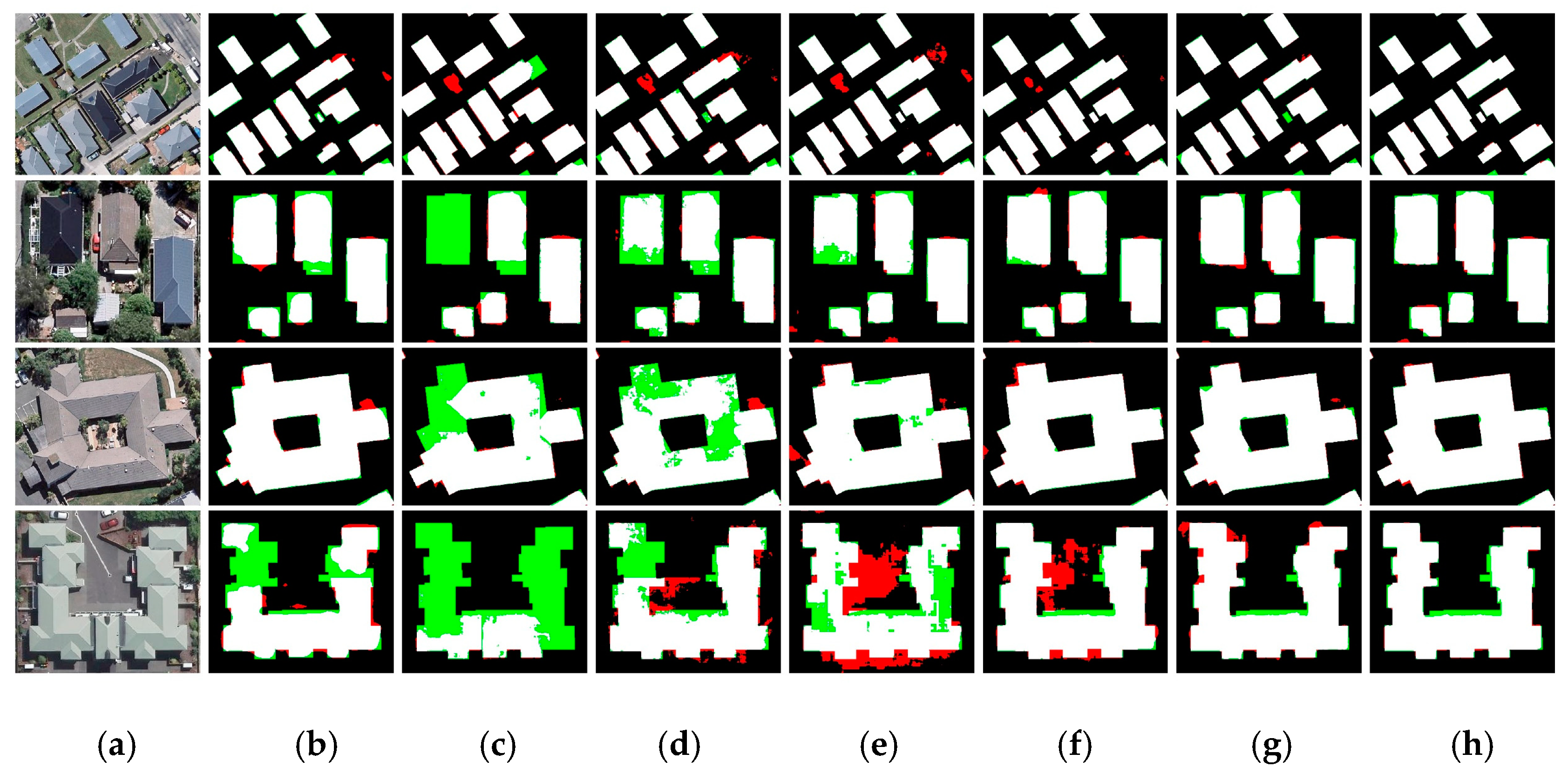
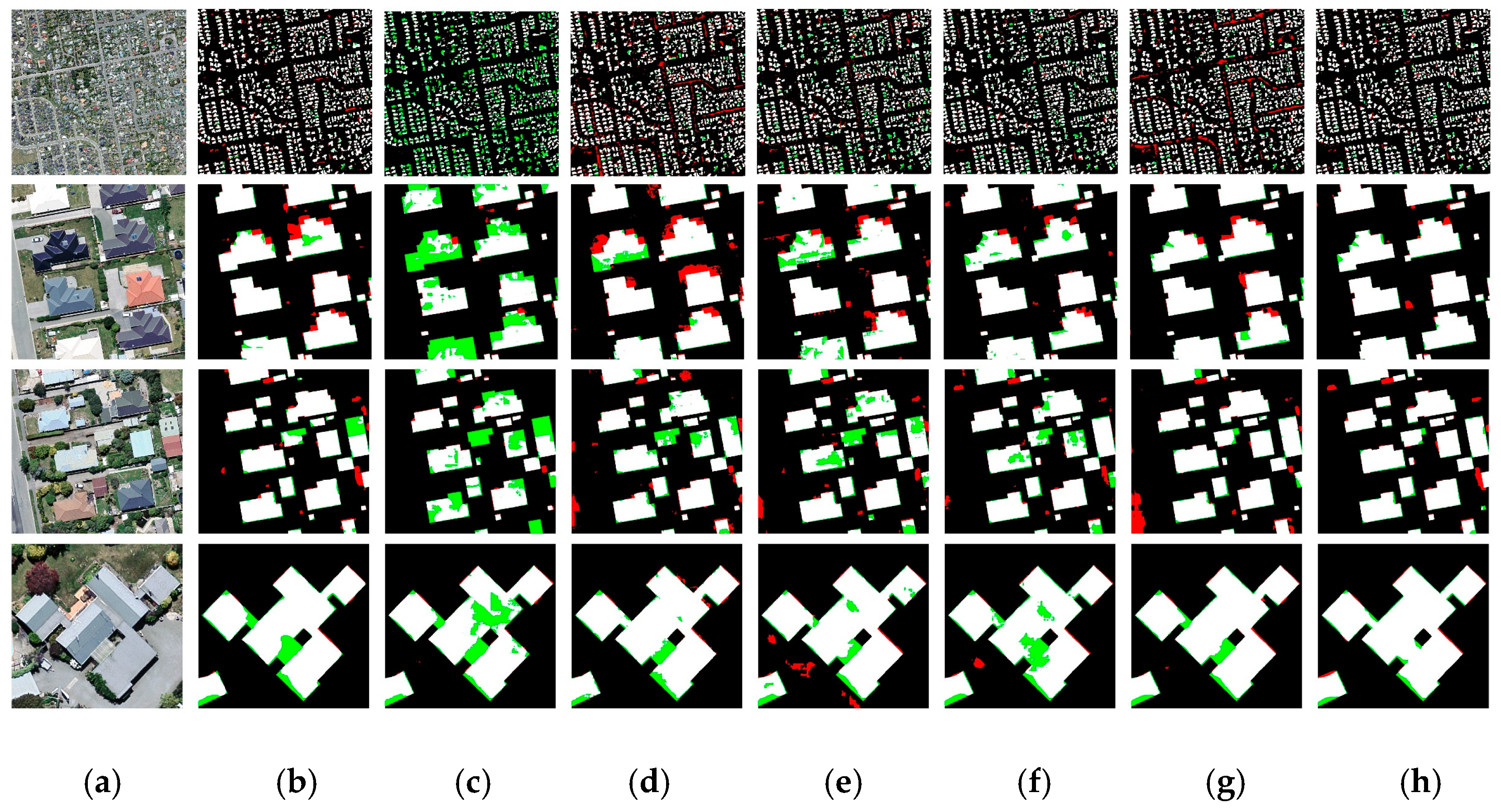
3.3. Results
4. Discussion
4.1. About the DeepResUnet
4.2. Effects of Resblock
4.3. Complexity Comparison of Deep Learning Models
4.4. Applicability Analysis of DeepResUnet
4.5. Limitations of Deep Learning Models in This Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Montoya-Zegarra, J.A.; Wegner, J.D.; Ladicky, L.; Schindler, K. Semantic segmentation of aerial images in urban areas with class-specific higher-order cliques. In Proceedings of the Joint ISPRS workshops on Photogrammetric Image Analysis (PIA) and High Resolution Earth Imaging for Geospatial Information (HRIGI), Munich, Germany, 25–27 March 2015; pp. 127–133. [Google Scholar]
- Erener, A. Classification method, spectral diversity, band combination and accuracy assessment evaluation for urban feature detection. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 397–408. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Li, J.; Ding, W.; Li, H.; Liu, C. Semantic segmentation for high-resolution aerial imagery using multi-skip network and Markov random fields. In Proceedings of the IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 12–17. [Google Scholar]
- Zhou, H.; Kong, H.; Wei, L.; Creighton, D.; Nahavandi, S. On Detecting Road Regions in a Single UAV Image. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1713–1722. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W. Building Segmentation of Aerial Images in Urban Areas with Deep Convolutional Neural Networks. In Proceedings of the Advances in Remote Sensing and Geo Informatics Applications, Tunisia, 12–15 November 2018; pp. 61–64. [Google Scholar]
- Shu, Z.; Hu, X.; Sun, J. Center-Point-Guided Proposal Generation for Detection of Small and Dense Buildings in Aerial Imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1100–1104. [Google Scholar] [CrossRef]
- Moser, G.; Serpico, S.B.; Benediktsson, J.A. Land-Cover Mapping by Markov Modeling of Spatial-Contextual Information in Very-High-Resolution Remote Sensing Images. Proc. IEEE 2013, 101, 631–651. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Matikainen, L.; Karila, K. Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points. Remote Sens. 2011, 3, 1777–1804. [Google Scholar] [CrossRef]
- Zhang, W.; Li, W.; Zhang, C.; Hanink, D.M.; Li, X.; Wang, W. Parcel-based urban land use classification in megacity using airborne LiDAR, high resolution orthoimagery, and Google Street View. Comput. Environ. Urban Syst. 2017, 64, 215–228. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Solórzano, J.V.; Meave, J.A.; Gallardo-Cruz, J.A.; González, E.J.; Hernández-Stefanoni, J.L. Predicting old-growth tropical forest attributes from very high resolution (VHR)-derived surface metrics. Int. J. Remote Sens. 2017, 38, 492–513. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 54. [Google Scholar] [CrossRef]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Yousefi, B.; Mirhassani, S.M.; AhmadiFard, A.; Hosseini, M. Hierarchical segmentation of urban satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2014, 30, 158–166. [Google Scholar] [CrossRef]
- Gilani, A.S.; Awrangjeb, M.; Lu, G. An Automatic Building Extraction and Regularisation Technique Using LiDAR Point Cloud Data and Orthoimage. Remote Sens. 2016, 8, 258. [Google Scholar] [CrossRef]
- Song, M.J.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef]
- Tian, S.H.; Zhang, X.F.; Tian, J.; Sun, Q. Random Forest Classification of Wetland Landcovers from Multi-Sensor Data in the Arid Region of Xinjiang, China. Remote Sens. 2016, 8, 954. [Google Scholar] [CrossRef]
- Wang, Y.; Song, H.W.; Zhang, Y. Spectral-Spatial Classification of Hyperspectral Images Using Joint Bilateral Filter and Graph Cut Based Model. Remote Sens. 2016, 8, 748. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep Neural Networks for object detection. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2013; pp. 2553–2561. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 15th IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Scarpa, G.; Gargiulo, M.; Mazza, A.; Gaetano, R. A CNN-Based Fusion Method for Feature Extraction from Sentinel Data. Remote Sens. 2018, 10, 236. [Google Scholar] [CrossRef]
- Schilling, H.; Bulatov, D.; Niessner, R.; Middelmann, W.; Soergel, U. Detection of Vehicles in Multisensor Data via Multibranch Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4299–4316. [Google Scholar] [CrossRef]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle Detection in Satellite Images by Hybrid Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Zhong, Z.; Fan, B.; Ding, K.; Li, H.; Xiang, S.; Pan, C. Efficient Multiple Feature Fusion With Hashing for Hyperspectral Imagery Classification: A Comparative Study. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4461–4478. [Google Scholar] [CrossRef]
- Ma, X.R.; Fu, A.Y.; Wang, J.; Wang, H.Y.; Yin, B.C. Hyperspectral Image Classification Based on Deep Deconvolution Network With Skip Architecture. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4781–4791. [Google Scholar] [CrossRef]
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms. Remote Sens. 2019, 11, 917. [Google Scholar] [CrossRef]
- Yuan, J. Learning Building Extraction in Aerial Scenes with Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2793–2798. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple Object Extraction from Aerial Imagery with Convolutional Neural Networks. J. Imaging Sci. Technol. 2016, 60, 104021–104029. [Google Scholar] [CrossRef]
- Bittner, K.; Adam, F.; Cui, S.; Körner, M.; Reinartz, P. Building Footprint Extraction From VHR Remote Sensing Images Combined With Normalized DSMs Using Fused Fully Convolutional Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2615–2629. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated Convolutional Neural Network for Semantic Segmentation in High-Resolution Images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Xiang, S.; Pan, C. FusionNet: Edge Aware Deep Convolutional Networks for Semantic Segmentation of Remote Sensing Harbor Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5769–5783. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2017, 145, 78–95. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; p. 13. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images With Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic Building Segmentation of Aerial Imagery Using Multi-Constraint Fully Convolutional Networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Sun, W.; Wang, R. Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined With DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Wang, H.; Mayer, H. Effective Fusion of Multi-Modal Remote Sensing Data in a Fully Convolutional Network for Semantic Labeling. Remote Sens. 2018, 10, 52. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Kernel Size | Stride | Pad | Output Size |
|---|---|---|---|---|
| Down-sampling network | ||||
| Input | -- | -- | -- | 256 × 256 × 3 |
| Conv_1 | 5 × 5 | 1 | 2 | 256 × 256 × 128 |
| Pooling_1 | 2 × 2 | 2 | 0 | 128 × 128 × 128 |
| ResBlock_1 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 128 × 128 × 128 |
| ResBlock_2 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 128 × 128 × 128 |
| Add_1 | -- | -- | -- | 128 × 128 × 128 |
| Pooling_2 | 2 × 2 | 2 | 0 | 64 × 64 × 128 |
| ResBlock_3 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 64 × 64 × 128 |
| ResBlock_4 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 64 × 64 × 128 |
| Add_2 | -- | -- | -- | 64 × 64 × 128 |
| Pooling_3 | 2 × 2 | 2 | 0 | 32 × 32 × 128 |
| ResBlock_5 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 32 × 32 × 128 |
| ResBlock_6 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 32 × 32 × 128 |
| Add_3 | -- | -- | -- | 32 × 32 × 128 |
| Pooling_4 | 2 × 2 | 2 | 0 | 16 × 16 × 128 |
| ResBlock_7 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 16 × 16 × 128 |
| ResBlock_8 | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 16 × 16 × 128 |
| Add_4 | -- | -- | -- | 16 × 16 × 128 |
| Up-sampling network | ||||
| UpSampling_1 | 2 × 2 | 2 | 0 | 32 × 32 × 128 |
| Concat_1 | -- | -- | -- | 32 × 32 × 256 |
| Conv_1U | 1 × 1 | 1 | 0 | 32 × 32 × 128 |
| ResBlock_1U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 32 × 32 × 128 |
| ResBlock_2U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 32 × 32 × 128 |
| UpSampling_2 | 2 × 2 | 2 | 0 | 64 × 64 × 128 |
| Concat_2 | -- | -- | -- | 64 × 64 × 256 |
| Conv_2U | 1 × 1 | 1 | 0 | 64 × 64 × 128 |
| ResBlock_3U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 64 × 64 × 128 |
| ResBlock_4U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 64 × 64 × 128 |
| UpSampling_3 | 2 × 2 | 2 | 0 | 128 × 128 × 128 |
| Concat_3 | -- | -- | -- | 128 × 128 × 256 |
| Conv_3U | 1 × 1 | 1 | 0 | 128 × 128 × 128 |
| ResBlock_5U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 128 × 128 × 128 |
| ResBlock_6U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 128 × 128 × 128 |
| UpSampling_4 | 2 × 2 | 2 | 0 | 256 × 256 × 128 |
| Concat_4 | -- | -- | -- | 256 × 256 × 256 |
| Conv_4U | 1 × 1 | 1 | 0 | 256 × 256 × 128 |
| ResBlock_7U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 256 × 256 × 128 |
| ResBlock_8U | 3 × 3/3 × 3/1 × 1 | 1 | 1 | 256 × 256 × 128 |
| Conv_5U | 1 × 1 | 1 | 0 | 256 × 256 × 2 |
| Output | -- | -- | -- | 256 × 256 × 2 |
| Models | Precision | Recall | F1 | Kappa | OA |
|---|---|---|---|---|---|
| FCN-8s [28] | 0.9163 | 0.9102 | 0.9132 | 0.8875 | 0.9602 |
| SegNet [29] | 0.9338 | 0.8098 | 0.8674 | 0.8314 | 0.9431 |
| DeconvNet [31] | 0.8529 | 0.9001 | 0.8758 | 0.8375 | 0.9413 |
| U-Net [30] | 0.8840 | 0.9190 | 0.9012 | 0.8709 | 0.9537 |
| ResUNet [51] | 0.9074 | 0.9315 | 0.9193 | 0.8948 | 0.9624 |
| DeepUNet [57] | 0.9269 | 0.9245 | 0.9257 | 0.9035 | 0.9659 |
| DeepResUnet | 0.9401 | 0.9328 | 0.9364 | 0.9176 | 0.9709 |
| Metrics | Baseline + Plain Neural Unit | Baseline + Basic Residual Unit | Baseline + Bottleneck | Baseline + Resblock (DeepResUnet) |
|---|---|---|---|---|
| Precision | 0.9234 | 0.9329 | 0.9277 | 0.9401 |
| Recall | 0.9334 | 0.9330 | 0.9321 | 0.9328 |
| F1 | 0.9283 | 0.9329 | 0.9299 | 0.9364 |
| Kappa | 0.9068 | 0.9129 | 0.9089 | 0.9176 |
| OA | 0.9669 | 0.9691 | 0.9677 | 0.9709 |
| Parameters (m) | 4.89 | 4.89 | 3.06 | 2.79 |
| Training time (second/epoch) | 1485 | 1487 | 1615 | 1516 |
| Inference time (ms/image) | 63.5 | 63.8 | 72.5 | 69.3 |
| Model | Parameters (m) | Training Time (Second/Epoch) | Inference Time (ms/image) |
|---|---|---|---|
| FCN-8s [28] | 134.27 | 979 | 86.1 |
| SegNet [29] | 29.46 | 1192 | 60.7 |
| DeconvNet [31] | 251.84 | 2497 | 214.3 |
| U-Net [30] | 31.03 | 718 | 47.2 |
| ResUNet [51] | 8.10 | 1229 | 55.8 |
| DeepUNet [57] | 0.62 | 505 | 41.5 |
| DeepResUnet | 2.79 | 1516 | 69.3 |
| Models | Precision | Recall | F1 | Kappa | OA |
|---|---|---|---|---|---|
| FCN-8s [28] | 0.8831 | 0.9339 | 0.9078 | 0.8807 | 0.9581 |
| SegNet [29] | 0.9475 | 0.6174 | 0.7477 | 0.6944 | 0.9079 |
| DeconvNet [31] | 0.8004 | 0.9135 | 0.8532 | 0.8080 | 0.9306 |
| U-Net [30] | 0.8671 | 0.8621 | 0.8646 | 0.8263 | 0.9403 |
| ResUNet [51] | 0.9049 | 0.8895 | 0.8972 | 0.8683 | 0.9549 |
| DeepUNet [57] | 0.8305 | 0.9219 | 0.8738 | 0.8356 | 0.9412 |
| DeepResUnet | 0.9101 | 0.9280 | 0.9190 | 0.8957 | 0.9638 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. https://doi.org/10.3390/rs11151774
Yi Y, Zhang Z, Zhang W, Zhang C, Li W, Zhao T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sensing. 2019; 11(15):1774. https://doi.org/10.3390/rs11151774
Chicago/Turabian StyleYi, Yaning, Zhijie Zhang, Wanchang Zhang, Chuanrong Zhang, Weidong Li, and Tian Zhao. 2019. "Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network" Remote Sensing 11, no. 15: 1774. https://doi.org/10.3390/rs11151774
APA StyleYi, Y., Zhang, Z., Zhang, W., Zhang, C., Li, W., & Zhao, T. (2019). Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sensing, 11(15), 1774. https://doi.org/10.3390/rs11151774