1. Introduction
A dynamic scene contains various moveable objects, such as pedestrians. It is important for intelligent systems and location-based services [
1] to recognize in real time such dynamic objects and construct scene maps with semantic information of dynamic objects. For example, a robot needs to understand what objects are in the scene and where such objects are located so that the robot can perform more intelligently. This task can be accomplished by combining a semantic segmentation network and mobile mapping. However, dynamic objects in the scene will challenge the localization and mobile mapping, which is largely accomplished by simultaneous localization and mapping (SLAM) [
2] algorithms. Dynamic objects in a scene will degrade the localization accuracy of SLAM processing, and moving objects will degrade the quality of the generated maps. Since the real world contains dynamic objects, current approaches are prone to failure, the pose estimation might drift or even be lost as there are false correspondences or not sufficiently many features to be matched [
3]. A pedestrian may appear in several continuous images, and the resulting generated map is negatively impacted with a blurry pedestrian. In addition, if the dynamic object in the scene is a non-rigid object, the result will be worse because we need to handle deformable objects in a SLAM context [
4,
5]. Meanwhile, a mobile platform such as a robot has limited computational capability, and it is difficult to synchronously implement a semantic segmentation network and mobile mapping in real time [
6,
7]. A computationally efficient solution for synchronously extracting object semantic information and mobile mapping will enable a variety of novel intelligent systems and applications.
Vision-based SLAM has been developed for a long time and mainly solves two problems: the first is estimating the camera trajectory, and the second is reconstructing the geometry of the environment at the same time. In recent years, keyframe-based SLAM has almost become the dominant technique. According to Strasdat et al. [
8], keyframe-based techniques are more accurate than filtering-based approaches. Keyframe-based parallel tracking and mapping (PTAM) [
9] was once regarded by many scholars as the gold standard in monocular SLAM [
10]. Currently, the most representative keyframe-based systems are probably ORB-SLAM2 [
10] and DSO [
11], both of which achieve unprecedented performance with respect to other state-of-the-art visual SLAM approaches in terms of localization accuracy. However, their shortcomings are also clear. These approaches are not good at building maps, and the generated sparse point cloud map is not sufficient for the intelligent autonomous navigation of robots.
Semantic SLAM incorporates artificial intelligence methods, such as deep learning, with SLAM processing, and it can achieve the calculation of scene geometry mapping and semantic object extraction simultaneously, which is of great importance for autonomous robots and intelligent systems. Nüchter [
12] first proposed the concept of constructing semantic maps for mobile robots in 2008. In 2011, Bao [
13] proposed the reconstruction of semantic scenes using semantic information and SFM. Salas-Moreno [
14] proposed an “object-oriented” SLAM system (SLAM++) in 2013. SLAM++ first constructed the point cloud map of a scene with an RGB-D camera, and then it recognized 3D objects in the scene using the point cloud map. Finally, fine 3D models prepared beforehand are added to the point cloud map. Considering that there are many features of non-object structures in the scene, Salas-Moreno [
15] proposed a dense plane SLAM algorithm in 2014 to improve semantic SLAM by detecting the plane in the scene. Vineet [
16] proposed a real-time, binocular, large-scene semantic reconstruction algorithm in 2015. This algorithm first segmented the image through a random forest, then reconstructed the three-dimensional scene with KinectFusion, and finally corrected it with a conditional random field. Leutenegger and McCormac [
17] proposed SemanticFusion in 2016, which combines ElasticFusion with a convolutional neural network (CNN). SemanticFusion is semantically segmented by the CNN and then constructs semantic maps with ElasticFusion.
Although the established semantic SLAM methods have achieved good performance, there are still several aspects to be improved. (1) The computational efficiency of mapping needs to be enhanced such that it can be applied on a mobile platform, such as a robot, in real time. The current methods build a map with much more information than needed, which will largely reduce the efficiency of SLAM. (2) The adaptability to the dynamic environment needs to be enhanced. In a dynamic environment, moving objects appear in the map when using the current methods, which will bring difficulties to map applications, such as using maps for path planning. (3) The semantic segmentation accuracy of objects needs to be improved. The semantic segmentation result of the current method is not accurate enough for the robot to understand the scene correctly.
Figure 1 shows several keyframe images selected by the traditional visual SLAM system (ORB-SLAM2). Comparing several images shows that the similarity between adjacent keyframes is 90% or even 95%, which will bring substantial redundant information to the SLAM algorithm when constructing a dense point cloud map, and the redundant information will significantly increase the computational complexity but without any benefit for the quality of mapping. When there are moving targets in the scene, the residual image of the moving object will appear in the dense point cloud map constructed by keyframe-based SLAM, as shown in
Figure 2.
Traditional visual SLAM methods construct only a geometric map of a scene and are not able to address semantic information of the scene. Semantic SLAM methods combine visual SLAM with semantic segmentation networks, and they have high computational complexity, which is challenging for real-time systems.
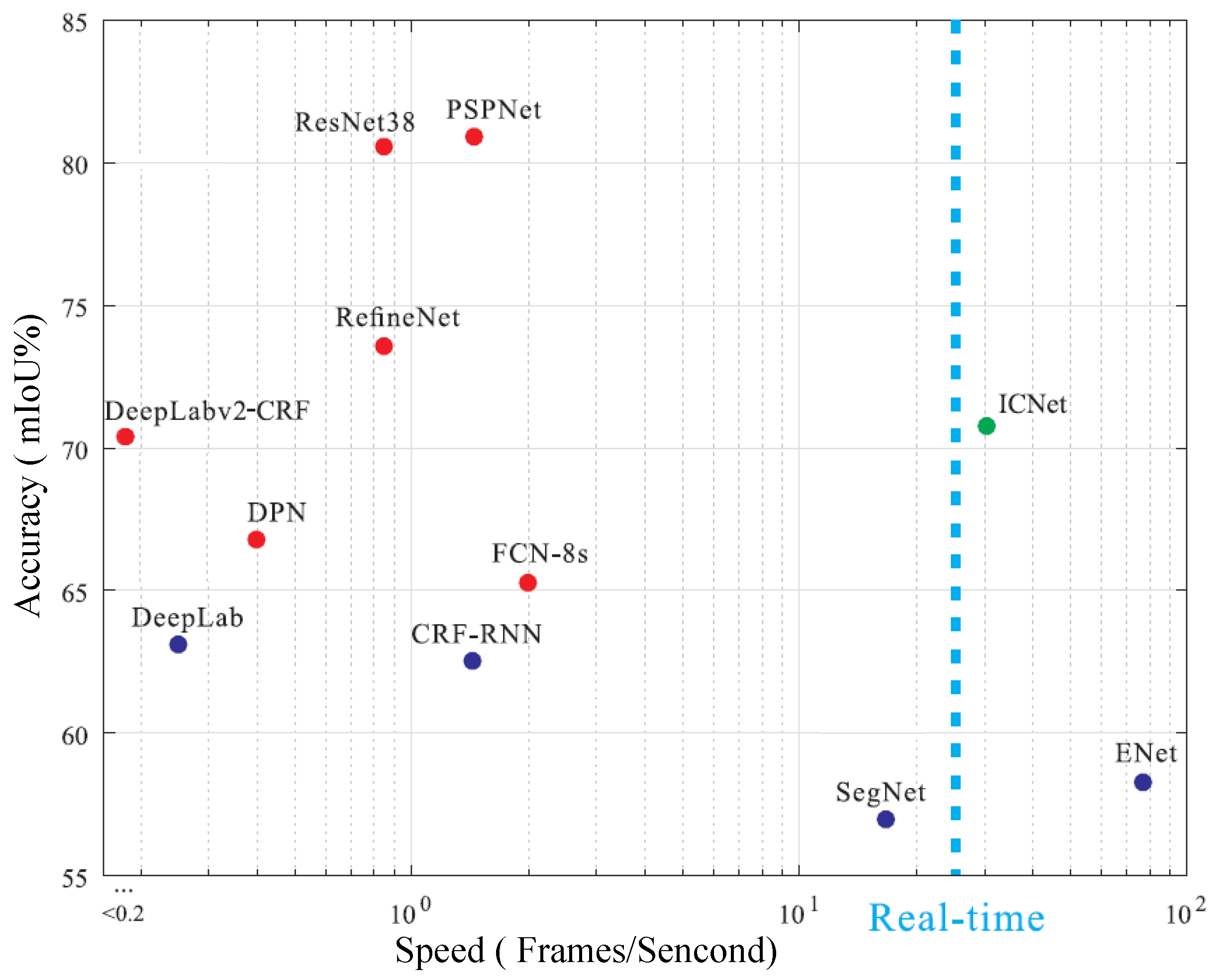
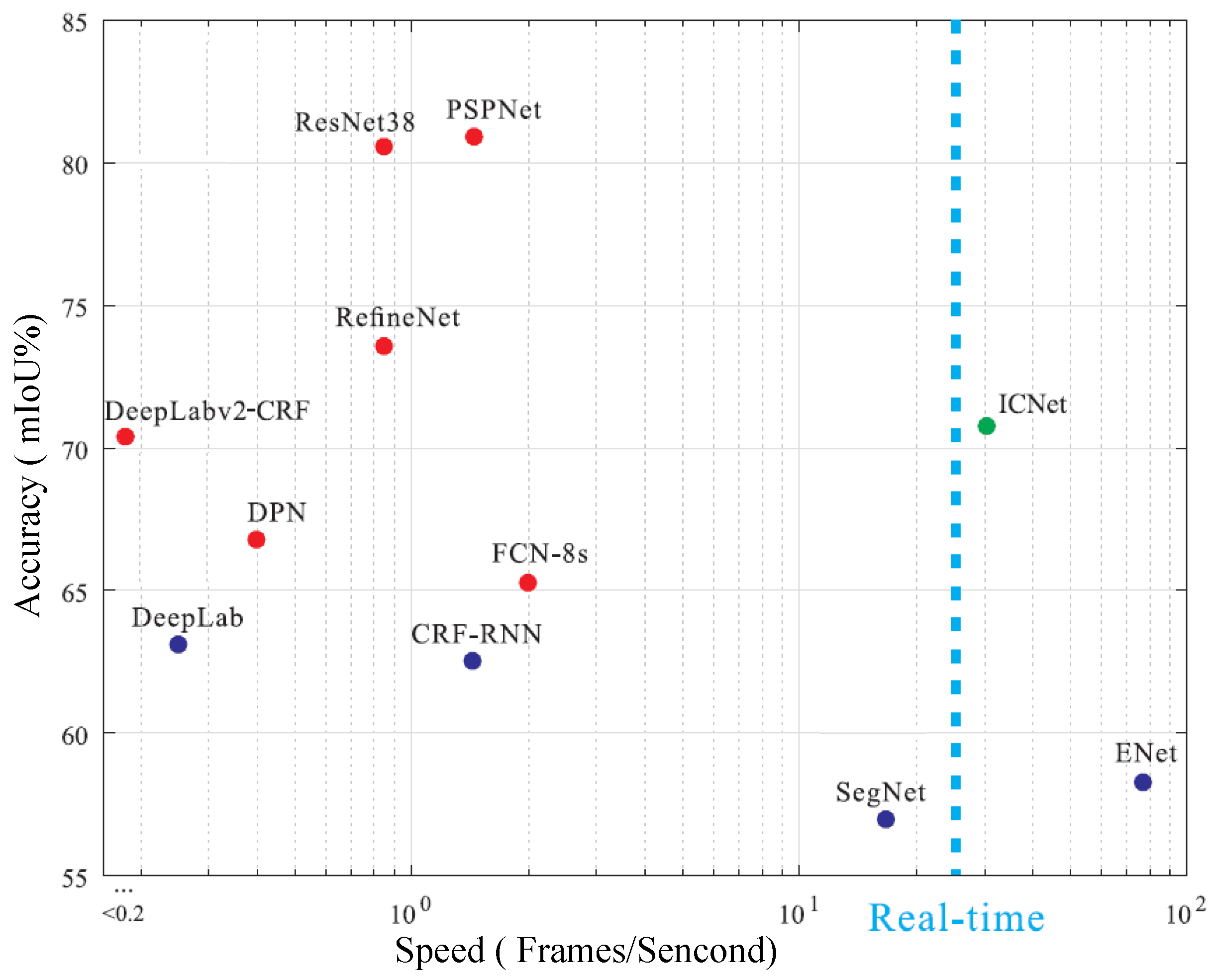
Figure 3 shows the inference speed and accuracy of the current semantic segmentation network, and we find that it is difficult to balance the accuracy and speed of segmentation. The semantic segmentation network with the highest accuracy in
Figure 3 is PSPNet [
18]. Its segmentation accuracy is approximately 81%, while its segmentation speed is only approximately 1.5 frames per second. The fastest semantic segmentation network is ENet [
19], with a segmentation speed of approximately 75 frames per second and a segmentation accuracy of only approximately 58%. The compromise is ICNet [
20], which can also achieve real-time performance, but its segmentation accuracy is not satisfactory.
In this paper, a semantic SLAM solution is proposed, and it achieves high-precision single-object semantic segmentation and generates semantic maps of a dynamic scene in real time. Our contributions are as follows:
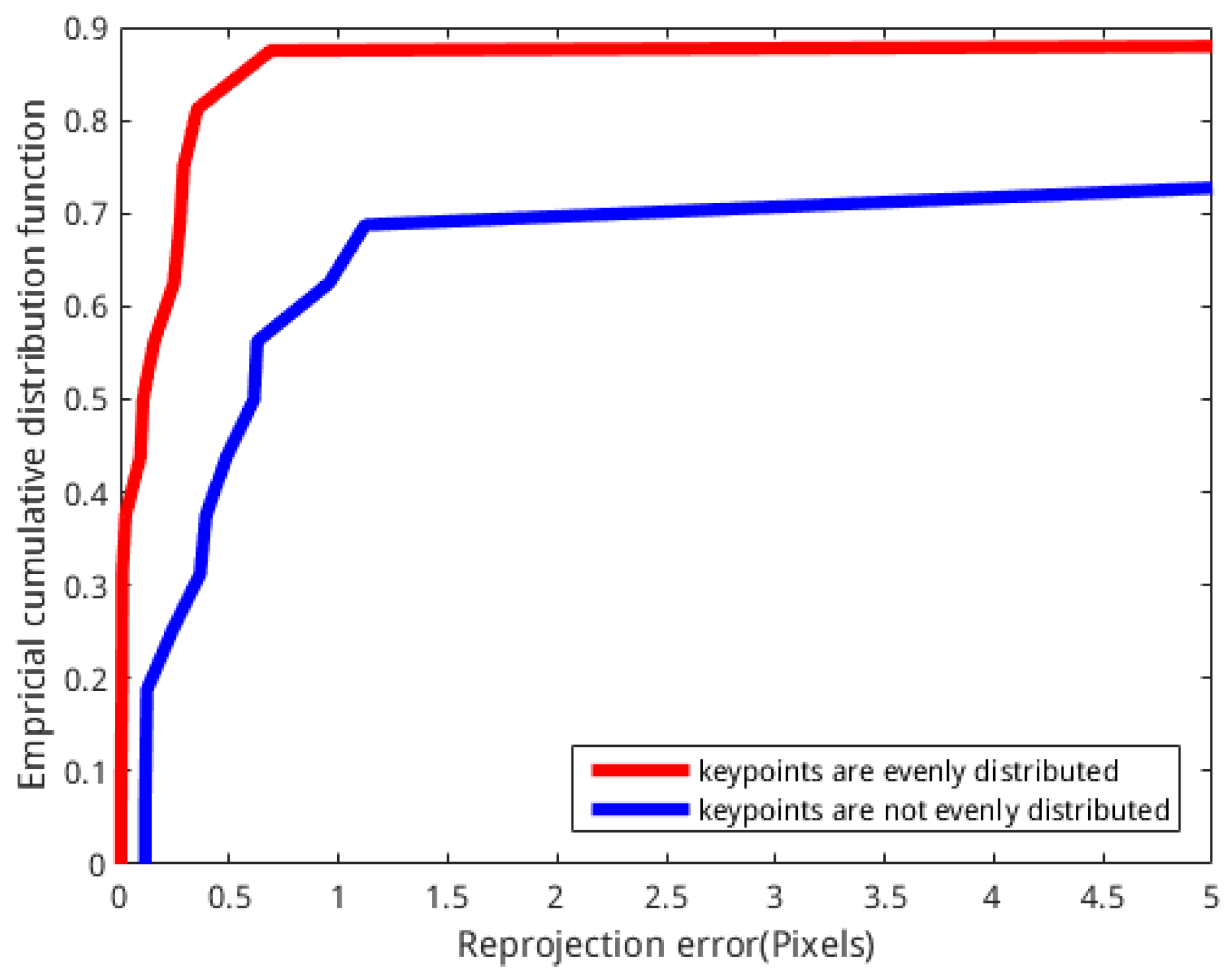
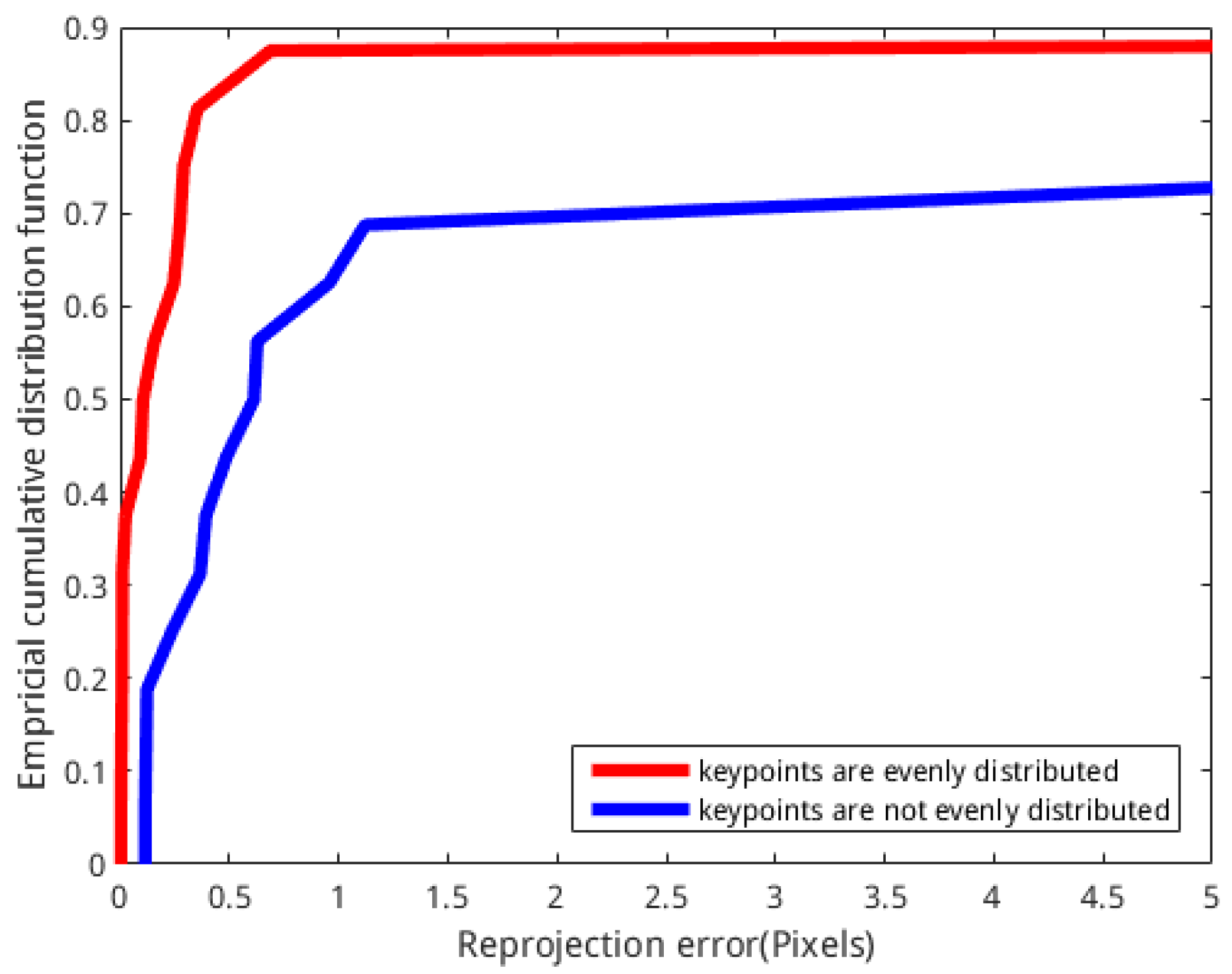
A lookup table (LUT) method is proposed for the first time to our knowledge. This method is applied in SLAM to improve the relative positioning accuracy of SLAM by increasing the number of feature points and distributing the feature points evenly, and it improves the efficiency of map reconstruction because it reduces redundant information that is not useful for building maps in the data.
This study addresses the impact of dynamic objects on SLAM, and it detects and removes moving objects from the scene and generates the static map of a dynamic scene without moving objects.
In contrast to traditional object semantic segmentation methods, the proposed solution adopts a step-wise approach that consists of object detection and contour extraction. The step-wise approach significantly reduces the computational complexity and makes the semantic segmentation process capable of operating in real time.
The proposed solution incorporates the semantic information of objects with the SLAM process, and it eventually generates semantic maps of a dynamic scene, which is significant for semantic-information-based intelligent applications.
The remainder of this paper is organized as follows. A brief introduction to the framework is presented in
Section 2. Details of the key techniques are described in
Section 3 and
Section 4. The experimental results are shown in
Section 5. Finally,
Section 6 provides the conclusion.
3. Semantic Segmentation of Objects
In this study, we applied the state-of-the-art object detection network YOLOv3 for the detection of specific moving objects, and then we used the depth map-based flood filling algorithm for extracting the contour of specific objects. It can acquire highly precise semantic segmentation results of specific objects with a reduced computational complexity.
3.1. Object Detection with Deep Learning
Deep learning networks for object detection have developed very rapidly in recent years. The most highlighted methods include R-CNN [
29], Fast R-CNN [
30], Faster R-CNN [
31], MasK R-CNN [
32], SSD [
33] and YOLO [
34,
35,
36]. YOLOv3 [
36] is currently the preferred method due to its comprehensive excellent performance, and its network structure is shown in
Table 1. The speed and accuracy can be adjusted by changing the size of the model structure.
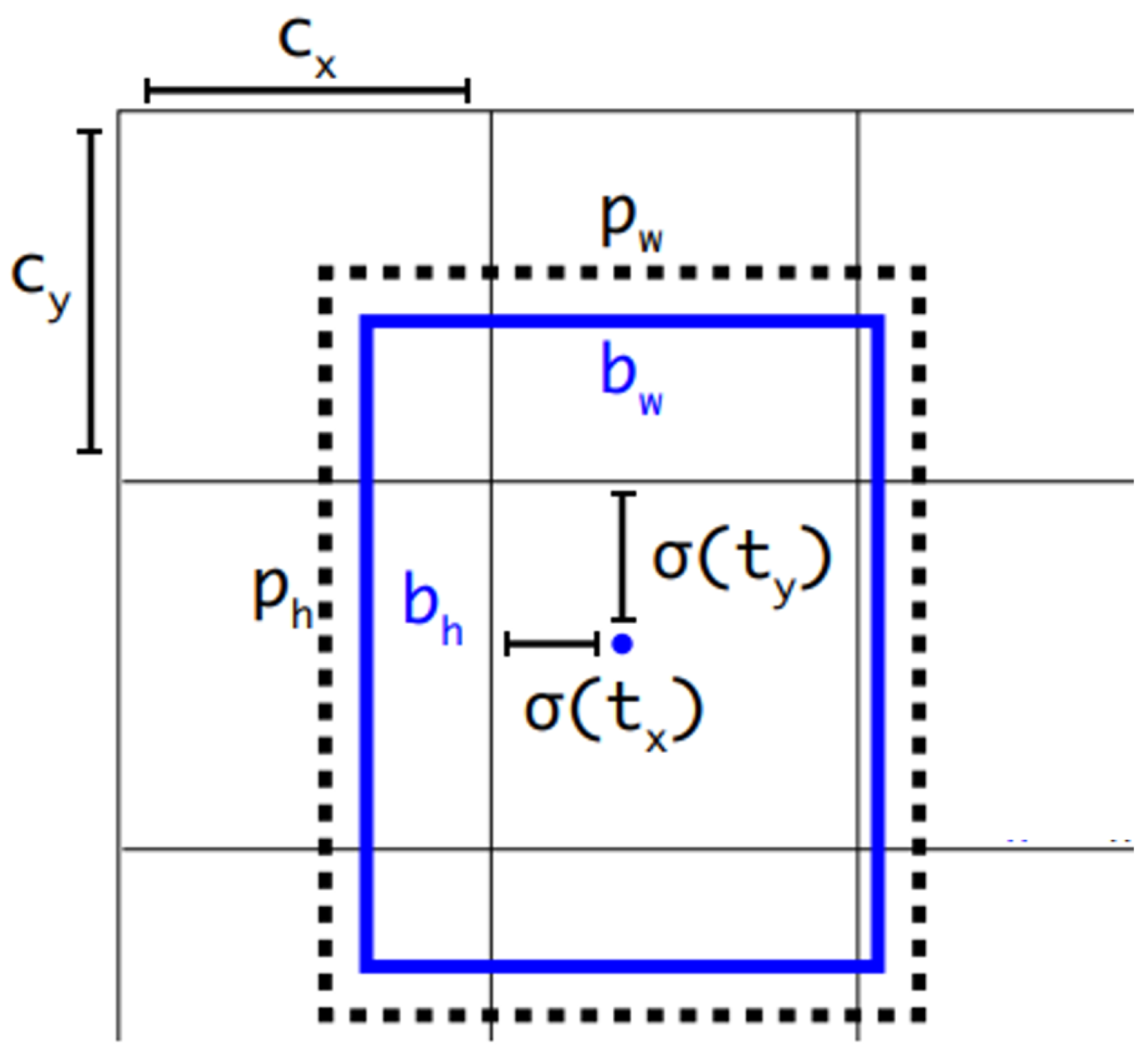
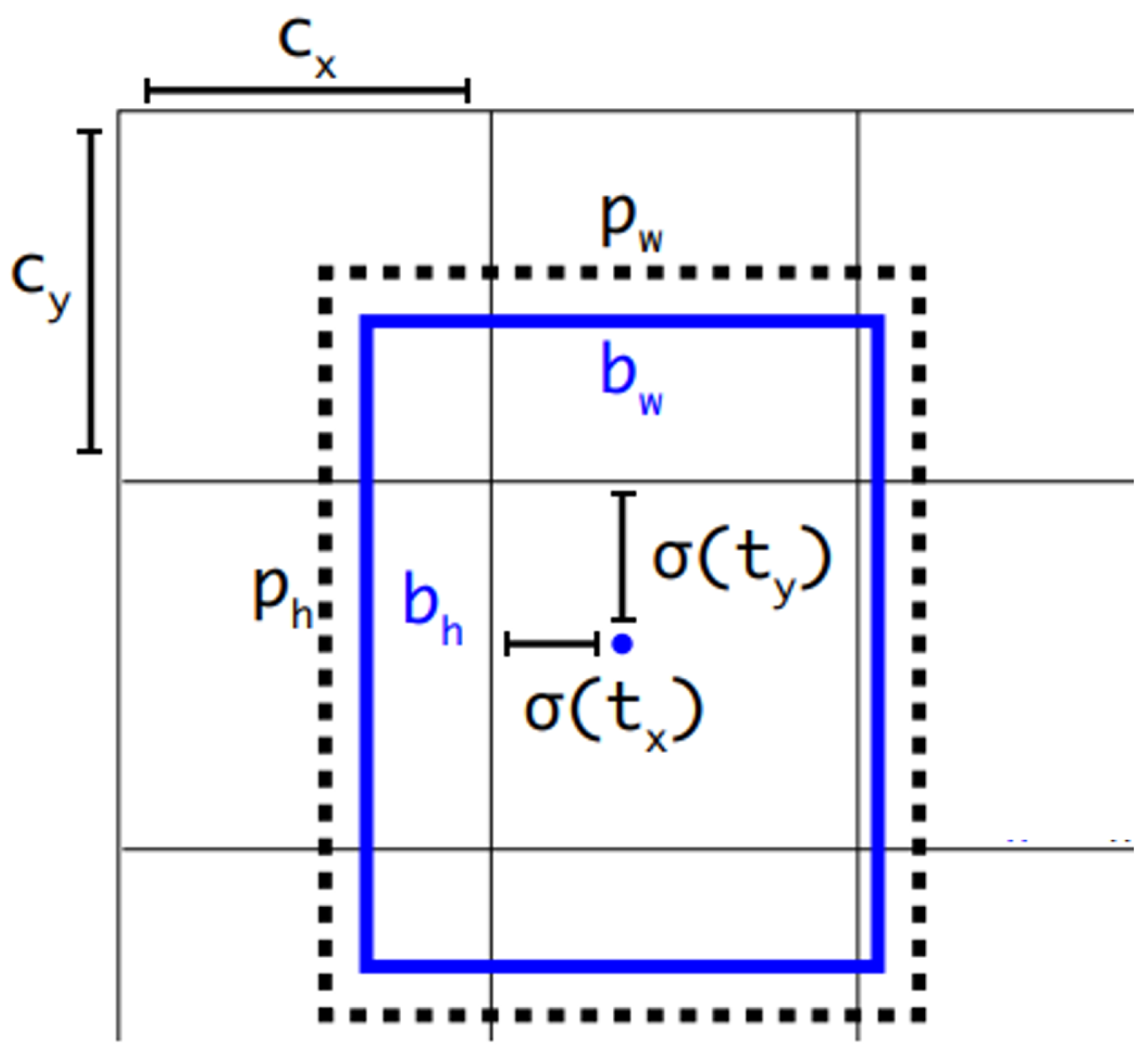
As shown in
Figure 5, YOLOv3 predicts bounding boxes using dimension clusters as anchor boxes. The network predicts 4 coordinates
for each bounding box by using the sum of squared error loss, where
and
represent the horizontal and vertical coordinates of the bounding box centre point and the length and width of the bounding box, respectively.
If the cell is offset from the top left corner of the image by
and the bounding box prior has width and height
, then the predictions correspond to:
YOLOv3 predicts an object score for each bounding box using logistic regression. This score should be 1 if the bounding box prior overlaps a ground-truth object by more than any other bounding box prior. If the overlap is not more than some threshold (YOLOv3 is set to 0.5), then the prediction is ignored. In addition, YOLOv3 uses independent logistic classifiers for the class predictions. The loss function is binary cross-entropy loss.
3.2. Contour Extraction of Moving Objects
This study applied the depth map-based flood filling algorithm for extracting the contour of a moving object. The depth map-based flood filling algorithm determines whether the pixel belongs to the connected region of the seed point by evaluating whether the depth value of the pixel is the close to the depth value of the seed point, and it then fills the connected region with the specified colour to achieve the block segmentation effect of the image. Namely the flood filling algorithm uses the specified colour to fill the connected region. The key of the flood filling algorithm is actually to determine the connected region of the image. The implementation of the flood filling algorithm mainly includes two methods: seed filling method and scan line filling method.
The seed filling method is to recursively scan the four-neighbourhood or eight-neighbourhood pixels of the seed point until all pixels have been traversed or the contour boundary line of the target is found, i.e., the connected region is closed. The seed filling method is simple and intuitive, and it is easy to program. However, since the correlation between adjacent pixels is not considered, each pixel may be traversed multiple times; thus, its running efficiency is low, particularly when the connected area is larger, and the time consumption will substantially increase.
The scan line filling method does not detect the connected region by sequentially scanning the four-neighbourhood or the eight-neighbourhood pixels of the seed point but rather by detecting the area connected to the seed point in the current line to the left and right two directions from the seed point and then evaluating the pixels connected to the connected region in the upper and lower two lines of the current row. In this way, the upper and lower two rows of pixels of the connected region are scanned in turn until all the pixels are traversed or the contour boundary of the target is found. The scan line filling method considers the correlation between the four-neighbourhood or the eight-neighbourhood pixels of the seed point, and it avoids the repeated detection of the pixel points by progressive scanning, thereby greatly improving the efficiency of the operation.
In this paper, the eight-neighbourhood seed filling method is used to segment the target area of the object detection network output, and the semantic information for the segmentation target is provided by the target detection network. The specific algorithm steps are shown in Algorithm 1.
| Algorithm 1 Depth Map-Based Flood Filling Algorithm. |
- 1:
Select the target area centre of the object detection network output as the initial seed point. - 2:
A new seed point is determined by evaluating whether the depth value difference between the pixel depth value of the eight-neighbourhood of the seed point and the pixel depth value of the seed point is within a certain threshold, i.e., the pixel depth value of the new seed point is in a certain threshold value, and is expressed as a formula.
where DEPTH is depth value of eight-neighbourhood pixels, and depth is depth value of the seed point. - 3:
When the new seed point is detected, the colour is replaced by the specified RGB. - 4:
The circumscribed rectangle is represented by the coordinates of the upper left corner and the coordinates of the lower right corner, and then all the non-seed points in the circumscribed rectangular area are traversed by repeating steps 2 and 3, and the update of the connected region is finally completed. The termination condition is that until all the pixels are traversed or the contour boundary line of the target is found, i.e., the closed connection area.
|
6. Conclusions
In this paper, we present a computationally efficient solution of semantic SLAM, which is applicable for dynamic scenes containing moving objects. On the one hand, the proposed solution incorporates a deep learning method with LUT-based SLAM, and it detects and recognizes specific moving objects using the deep learning method YOLOv3; correspondingly, these moving objects are removed from the point cloud maps of scenes in the process of SLAM. Consequently, the localization accuracy and the quality of the generated maps are improved compared to established SLAM methods. On the other hand, in contrast to traditional semantic SLAM methods, which obtain semantic information by using semantic segmentation networks that are computationally intensive and where the segmentation results are not very accurate, the proposed solution replaces semantic segmentation networks with object detection networks and depth map-based flood filling algorithms. As a result, it can obtain high-precision semantic information of specific objects in real time. Finally, the proposed solution is able to generate static geometric map of a scene, as well as a semantic map including semantic information of moving objects.
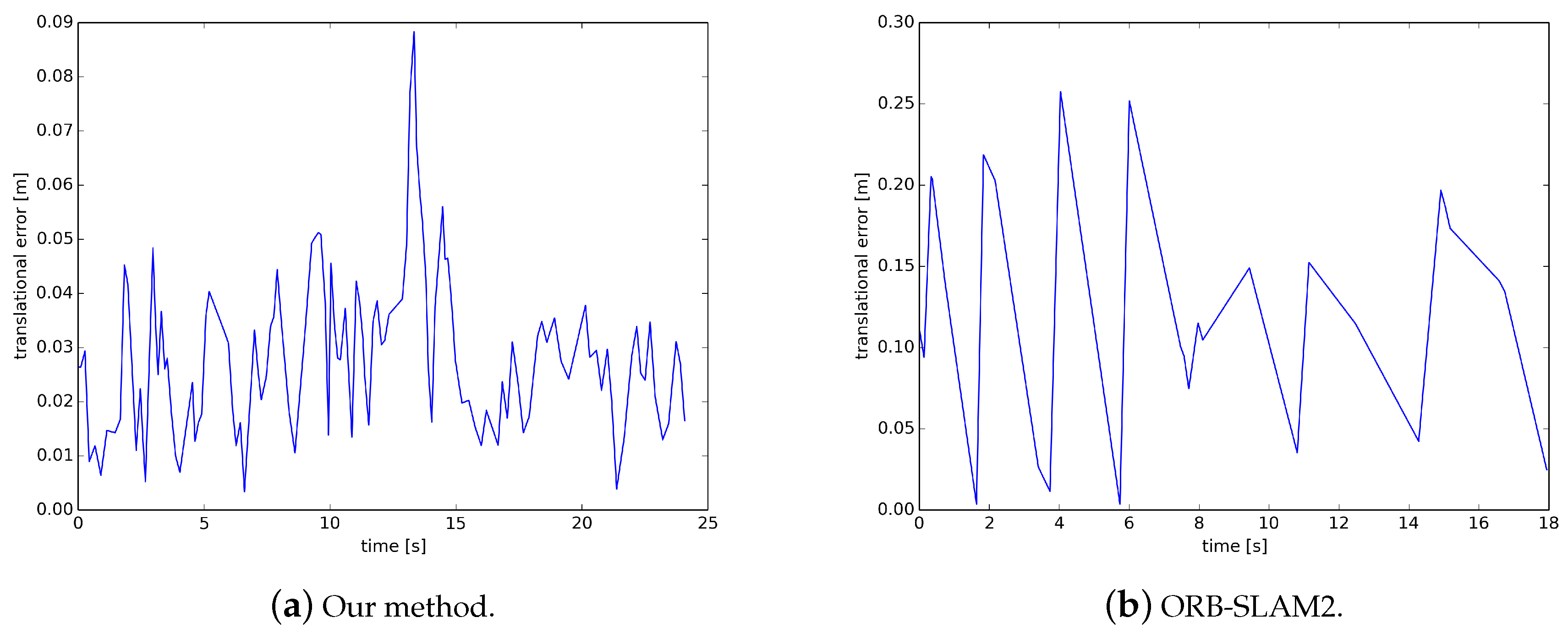
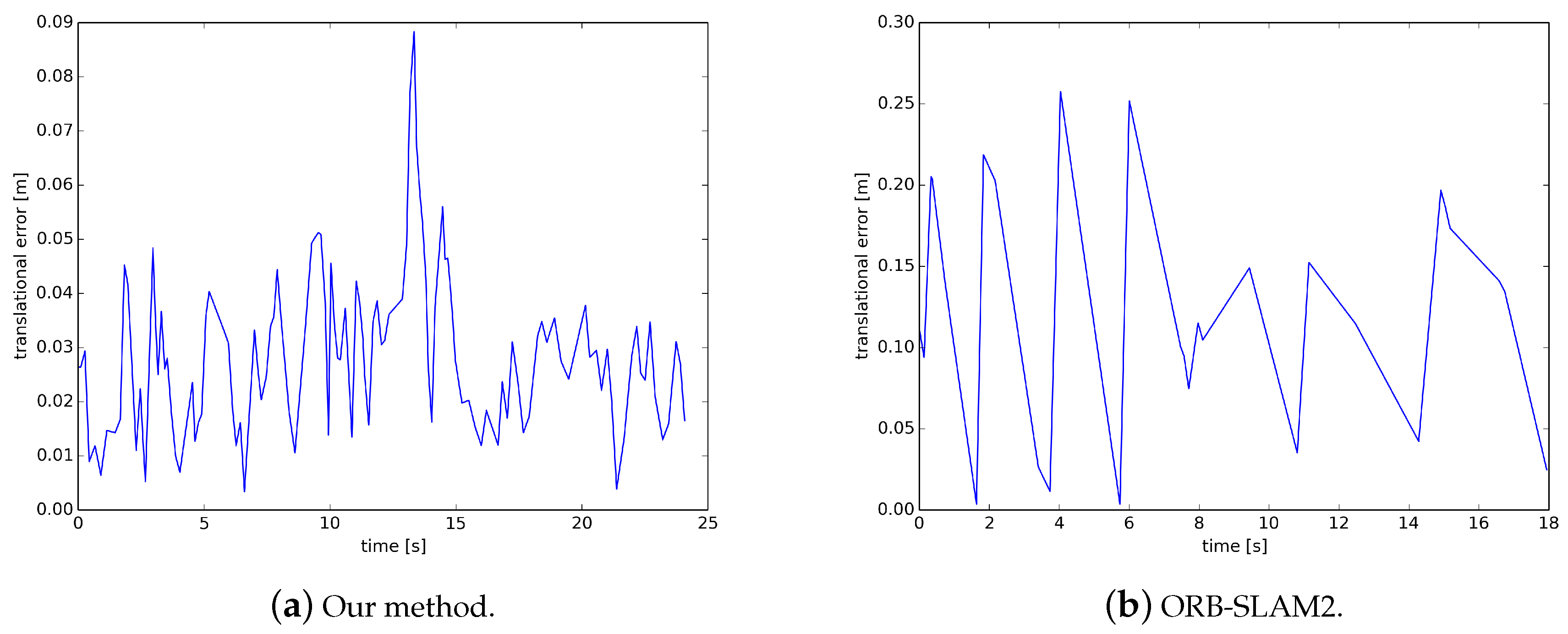
The experiments show that the proposed solution is very efficient in building maps; it can construct a better quality map in one-third of the time of the traditional method. Its relative pose accuracy is an order of magnitude higher than that of ORB-SLAM2. The relative translation error of ORBSLAM2 on the TUM dataset is 0.123 m, while ours is only 0.028 m. In addition, its semantic segmentation is highly accurate and fast. The traditional semantic segmentation method has the highest accuracy of only 81%, and the processing speed is 1.5 FPS. However, the segmentation accuracy of our method can reach more than 95%, and the running speed can reach 35 FPS. Moreover, it is not interfered by moving objects, can run in a dynamic scene, generate static maps of dynamic scenes and semantic maps with high-precision semantic information of specific objects in real time.
Our solution is applicable for real-time intelligent systems such as mobile robots. In the future, we will explore the use of semantic information to constrain the tracking process, further improving the accuracy and robustness of localization. In addition, the moving objects do have a significant impact on loop closure, whether the strategy of loop detection is matching feature points or Bag of Words(DBOW2) [
10]. In theory, this problem can be solved by removing the moving objects in the original data before the loop detection, or using a semantic-based loop detection strategy, and we plan to conduct a further study in the future.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}