Detecting Power Lines in UAV Images with Convolutional Features and Structured Constraints





Abstract
:1. Introduction
1.1. Motivation and Objective
1.2. Related Works
1.3. Contribution of The Work
- A power line detection method is proposed by using convolutional features and structured constraints. We fully exploit the coarse-to-fine feature maps generated by the convolutional layers, which are integrated to produce a fusion output. The structured features are extracted from the coarsest feature map and then combined with fusion output to sweep out noisy segments.
- Two public datasets with pixel-level annotations are released for power line detection. We collect aerial power line images using UAVs in two different scenes and annotate the images with pixel-level precision. The datasets will be useful for developing learning-based methods in power line detection.
2. Power Line Detection
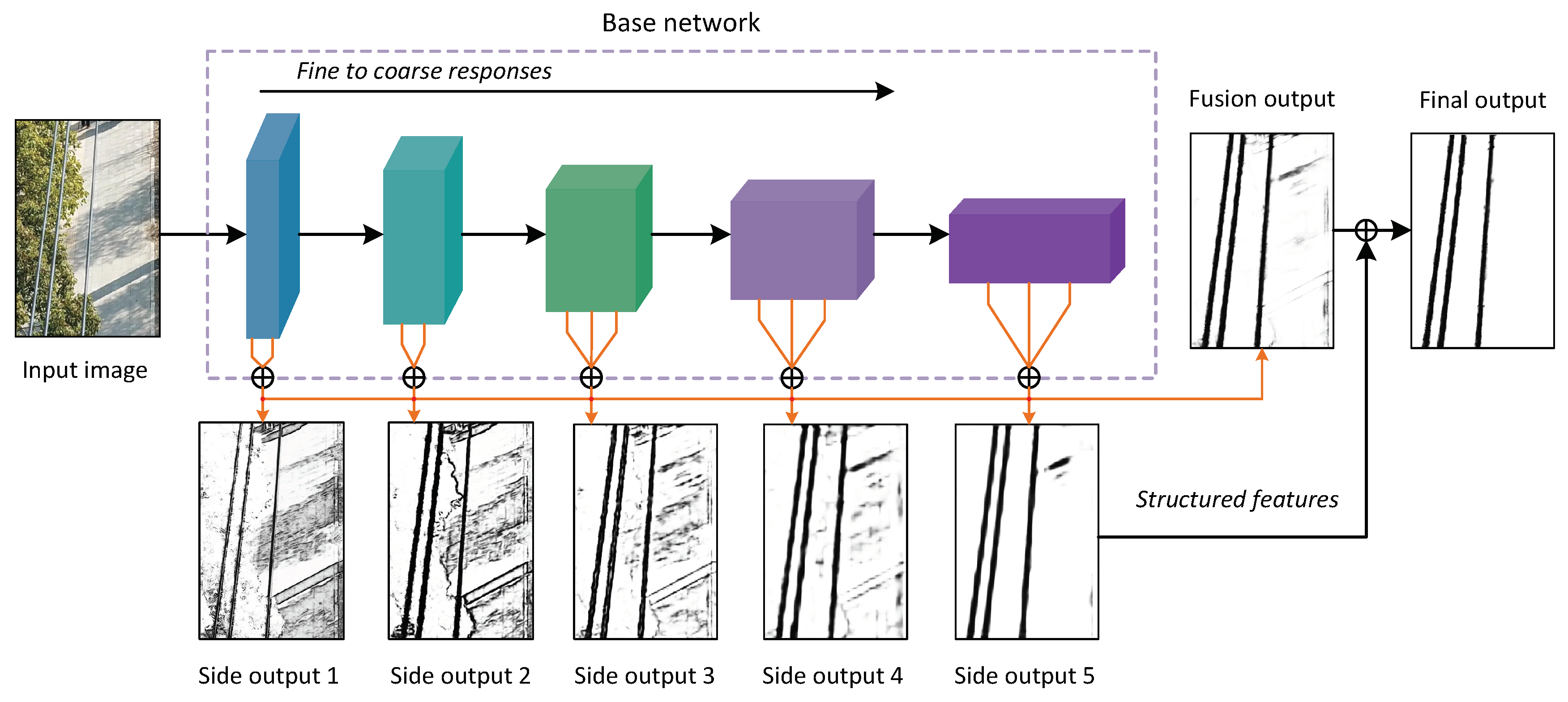
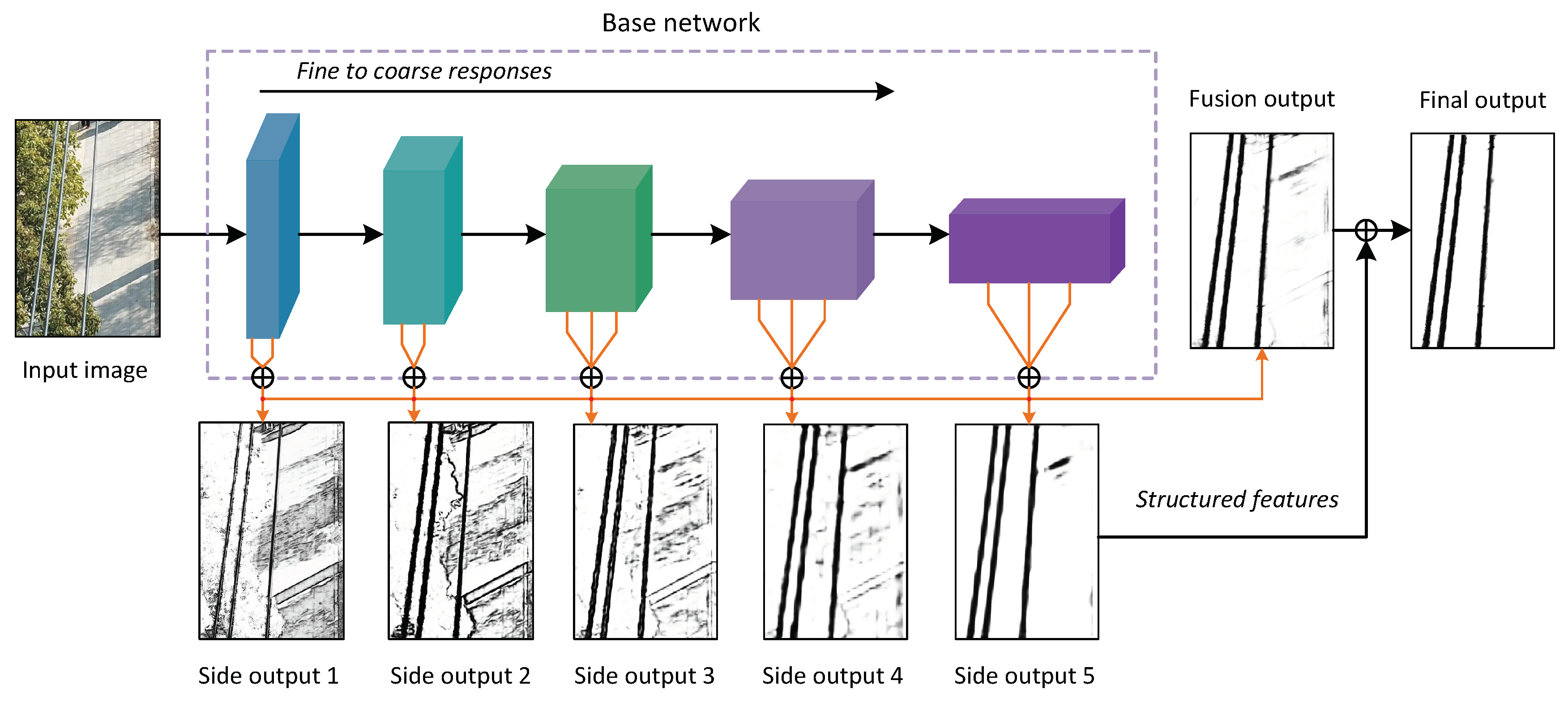
2.1. Network Architecture
2.2. Class-Balanced Loss Function
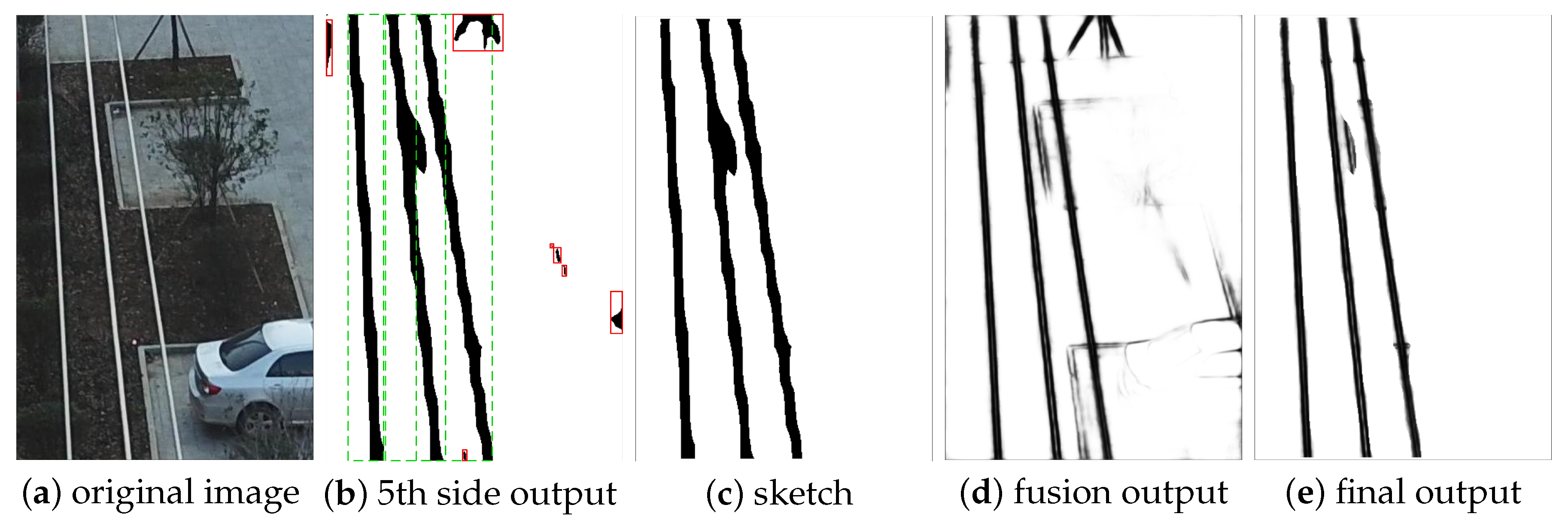
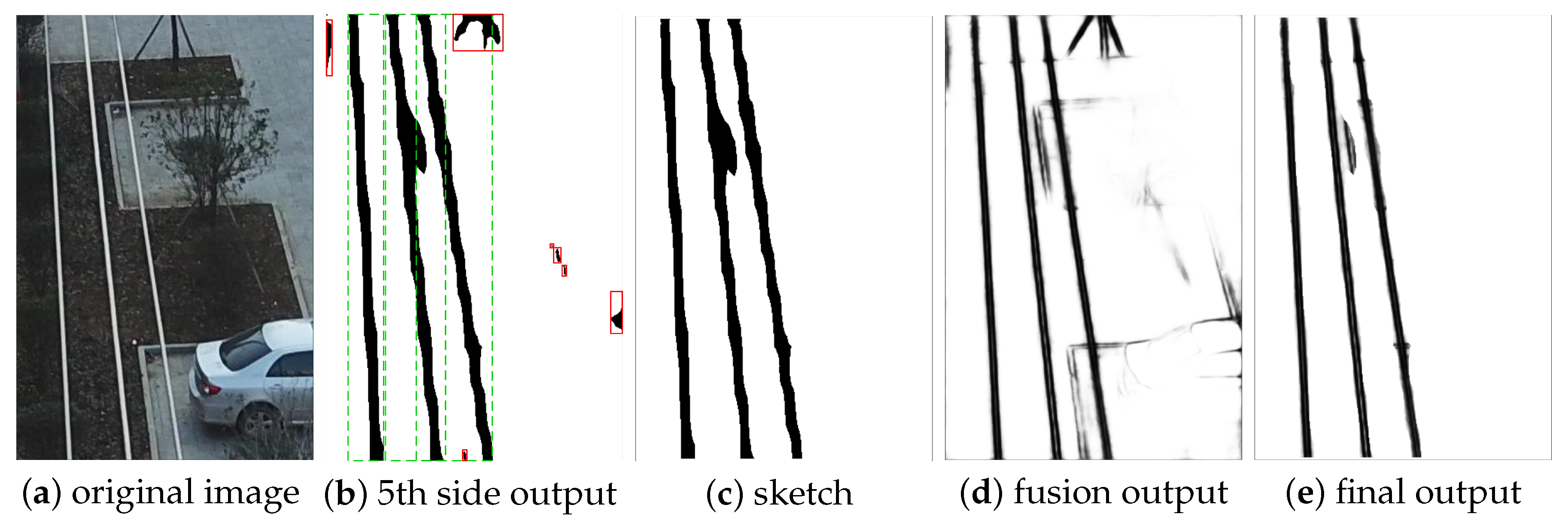
2.3. Structured Features
3. Power Line Datasets
4. Experimental Results
4.1. Implementation
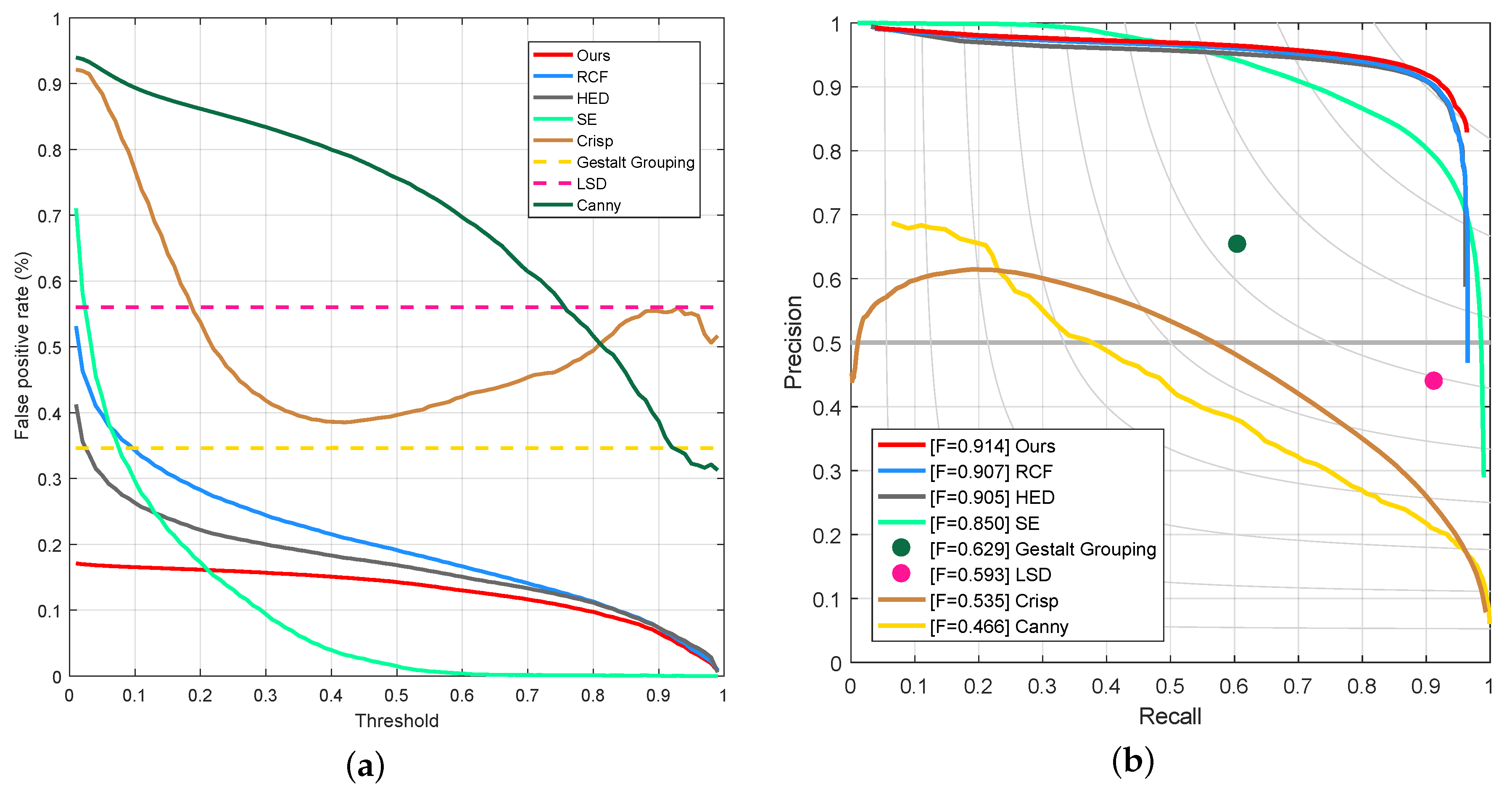
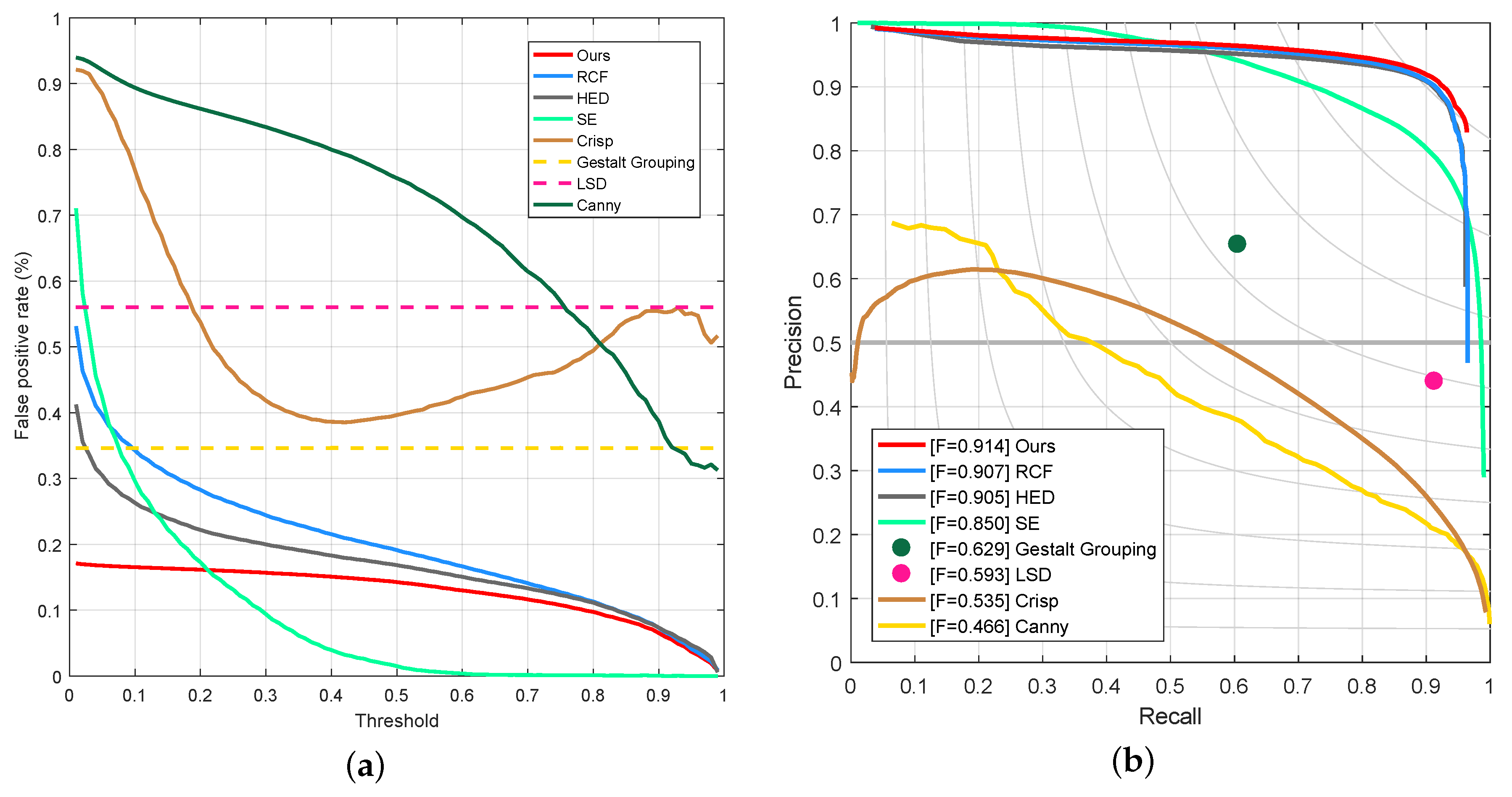
4.2. Experiments on PLDU Dataset
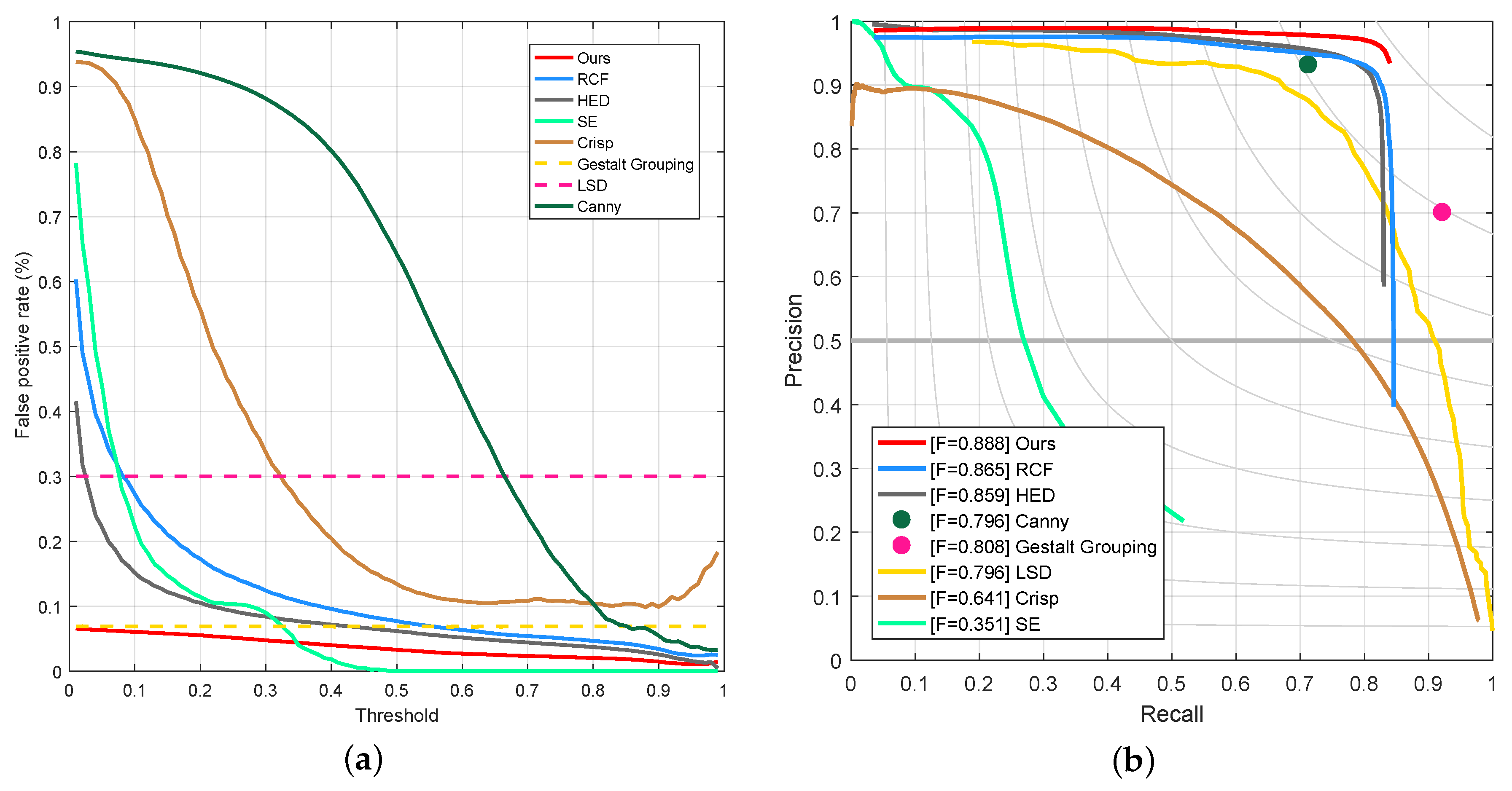
4.3. Experiments on PLDM Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Matikainen, L.; Lehtomäki, M.; Ahokas, E. Remote sensing methods for power line corridor surveys. ISPRS J. Photogramm. Remote Sens. 2016, 119, 10–31. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Hyyppä, J. Fully-automated power line extraction from airborne laser scanning point clouds in forest areas. Remote Sens. 2014, 6, 11267–11282. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Liu, L.; Zheng, D. Supervised classification of power lines from airborne LiDAR data in urban areas. Remote Sens. 2017, 9, 771. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Li, J.; Ji, Z.; Zhang, Q. Extraction of power-transmission lines from vehicle-borne lidar data. Int. J. Remote Sens. 2016, 37, 229–247. [Google Scholar] [CrossRef]
- Yan, G.; Li, C.; Zhou, G.; Zhang, W.; Li, X. Automatic extraction of power lines from aerial images. IEEE Geosci. Remote Sens. Lett. 2007, 4, 387–391. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Zhang, H. Automatic power line extraction from High resolution remote sensing imagery based on an improved radon transform. Pattern Recognit. 2016, 49, 174–186. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Y.; Walker, R.; Hayward, R.; Zhang, J. Towards automatic power line detection for a UAV surveillance system using pulse coupled neural filter and an improved Hough transform. Mach. Vis. Appl. 2010, 21, 677–686. [Google Scholar] [CrossRef]
- Candamo, J.; Kasturi, R.; Goldgof, D.; Sarkar, S. Detection of thin lines using low-quality video from low-altitude aircraft in urban settings. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 937–949. [Google Scholar] [CrossRef]
- Song, B.; Li, X. Power line detection from optical images. Neurocomputing 2014, 129, 350–361. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, J.; Cao, X. Object-aware power line detection using color and near-infrared images. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 1374–1389. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, X.; Li, W.; Chen, S. Automatic power line inspection using UAV images. Remote Sens. 2017, 9, 824. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, X.; Fang, Y.; Chen, S. UAV low altitude photogrammetry for power line inspection. ISPRS Int. J. Geo-Inf. 2017, 6, 14. [Google Scholar] [CrossRef]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. From contours to regions: An empirical evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2294–2301. [Google Scholar]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef]
- Shen, W.; Wang, X.; Wang, Y.; Xiang, B. DeepContour: A deep convolutional feature learned by positive- sharing loss for contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3982–3991. [Google Scholar]
- Bertasius, G.; Shi, J.; Torresani, L. DeepEdge: A multi-scale bifurcated deep network for top-down contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4380–4389. [Google Scholar]
- Yang, J.; Price, B.; Cohen, S. Object Contour Detection with a Fully Convolutional Encoder-Decoder Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 193–202. [Google Scholar]
- Maninis, K.K.; Pont-Tuset, J.; Arbeláez, P. Convolutional oriented boundaries: From image segmentation to high-level tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 819–833. [Google Scholar] [CrossRef]
- Madaan, R.; Maturana, D.; Scherer, S. Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3487–3494. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, Y.; Cheng, M.-M.; Hu, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5872–5881. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. Int. J. Comput. Vis. 2017, 125, 3–18. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 8–12 July 2001; pp. 416–423. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef]
- Qin, X.; He, S.; Zhang, Z.; Dehghan, M. ByLabel: A Boundary Based Semi-Automatic Image Annotation Tool. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1804–1813. [Google Scholar]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, W.; Zou, Y. Simultaneous Edge Alignment and Learning. arXiv 2018, arXiv:1808.01992. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef]
- Rajaei, B.; von Gioi, R.G. Gestaltic Grouping of Line Segments. Image Process. Line 2018, 37–50. [Google Scholar] [CrossRef]
- Isola, P.; Zoran, D.; Krishnan, D. Crisp boundary detection using pointwise mutual information. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 799–814. [Google Scholar]
- Dollár, P.; Zitnick, C.L. Fast edge detection using structured forests. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1558–1570. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| layer | conv1_1 | conv1_2 | pooling1 | conv2_1 | conv2_2 | pooling2 |
|---|---|---|---|---|---|---|
| rf size | 3 | 5 | 6 | 10 | 14 | 16 |
| stride | 1 | 1 | 2 | 2 | 2 | 4 |
| layer | conv3_1 | conv3_2 | conv3_3 | pooling3 | conv4_1 | conv4_2 |
| rf size | 24 | 32 | 40 | 44 | 60 | 76 |
| stride | 4 | 4 | 4 | 8 | 8 | 8 |
| layer | conv4_3 | pooling4 | conv5_1 | conv5_2 | conv5_3 | pooling5 |
| rf size | 92 | 100 | 132 | 164 | 196 | 212 |
| stride | 8 | 16 | 16 | 16 | 16 | 32 |
| Dataset | Train | Test | maxDist |
|---|---|---|---|
| PLDU | 453 | 120 | 0.0075 |
| PLDM | 237 | 50 | 0.0075 |
| Method | ODS | OIS | FPS |
|---|---|---|---|
| Ours | 0.914 | 0.938 | 15.6 |
| RCF | 0.907 | 0.931 | 18.2 |
| HED | 0.905 | 0.927 | 18.2 |
| SE | 0.850 | 0.898 | 1.7 |
| Gestalt Grouping | 0.629 | 0.629 | 2.0 |
| LSD | 0.593 | 0.593 | 26.7 |
| Crisp | 0.535 | 0.622 | 0.3 |
| Canny | 0.466 | 0.643 | 22.4 |
| Method | ODS | OIS | FPS |
|---|---|---|---|
| Ours | 0.888 | 0.902 | 15.6 |
| RCF | 0.865 | 0.893 | 18.2 |
| HED | 0.859 | 0.883 | 18.2 |
| SE | 0.351 | 0.340 | 2.5 |
| Gestalt Grouping | 0.808 | 0.808 | 5.6 |
| LSD | 0.796 | 0.796 | 24.7 |
| Crisp | 0.641 | 0.752 | 0.3 |
| Canny | 0.796 | 0.866 | 20.6 |
| Method | PLDU | PLDM | ||
|---|---|---|---|---|
| ODS | OIS | ODS | OIS | |
| fusion+side5 | 0.909 | 0.933 | 0.871 | 0.895 |
| side5+SF | 0.725 | 0.736 | 0.689 | 0.693 |
| fusion+SF | 0.909 | 0.934 | 0.880 | 0.899 |
| full | 0.914 | 0.938 | 0.888 | 0.902 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Yang, W.; Yu, H.; Zhang, H.; Xia, G.-S. Detecting Power Lines in UAV Images with Convolutional Features and Structured Constraints. Remote Sens. 2019, 11, 1342. https://doi.org/10.3390/rs11111342
Zhang H, Yang W, Yu H, Zhang H, Xia G-S. Detecting Power Lines in UAV Images with Convolutional Features and Structured Constraints. Remote Sensing. 2019; 11(11):1342. https://doi.org/10.3390/rs11111342
Chicago/Turabian StyleZhang, Heng, Wen Yang, Huai Yu, Haijian Zhang, and Gui-Song Xia. 2019. "Detecting Power Lines in UAV Images with Convolutional Features and Structured Constraints" Remote Sensing 11, no. 11: 1342. https://doi.org/10.3390/rs11111342
APA StyleZhang, H., Yang, W., Yu, H., Zhang, H., & Xia, G.-S. (2019). Detecting Power Lines in UAV Images with Convolutional Features and Structured Constraints. Remote Sensing, 11(11), 1342. https://doi.org/10.3390/rs11111342