Model Fusion for Building Type Classification from Aerial and Street View Images




Abstract
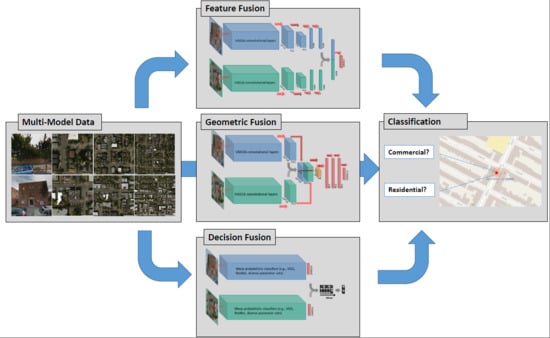
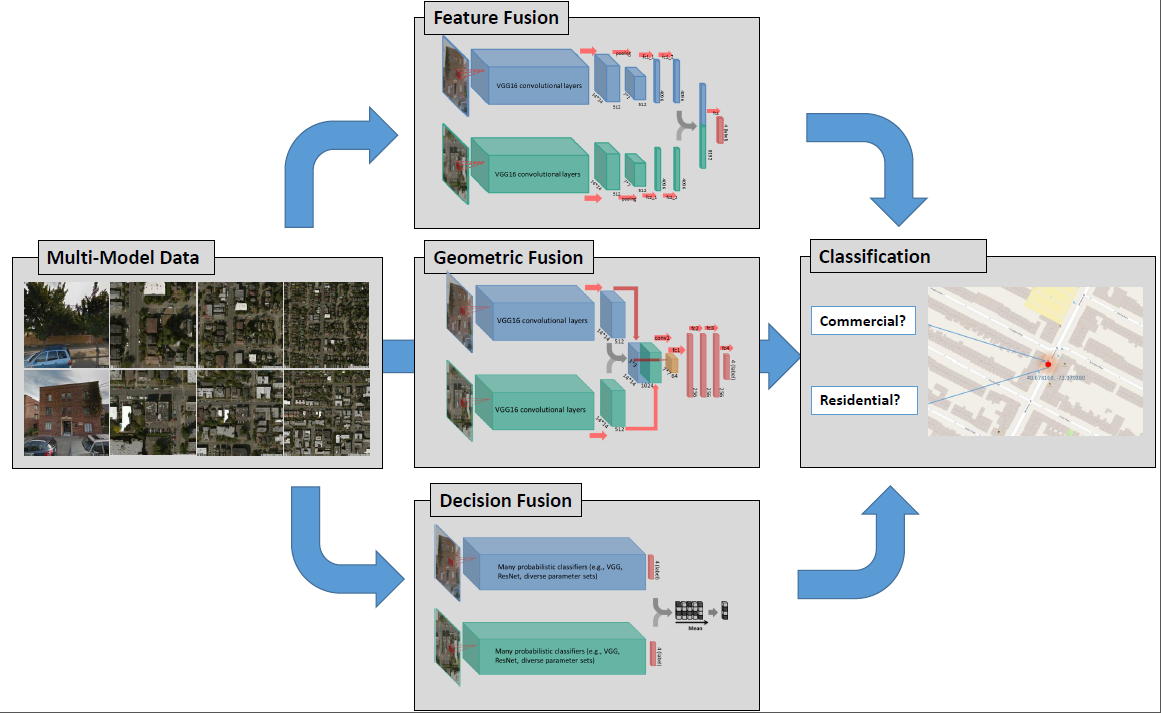
1. Introduction
Structure of This Article
2. Related Work
2.1. Land Use Classification Using Aerial View Images
2.2. Land Use Classification Using Ground View Images
2.3. Land Use Classification Combining Ground and Aerial View
2.4. Aspects of the Machine Learning Problem of Urban Land Use
2.5. Contribution of This Paper
- we compared two model fusion strategies: two-stream end-to-end fusion network (i.e., a geometric-level model fusion), and decision-level model fusion. Deep networks applied on individual data were also compared as baselines (i.e., no model fusion). A summary of the models and fusion strategies exploited in this article, as well as the corresponding literature, is shown in Table 2.
- we demonstrated that geometric combinations of the features of two types of images from distinct perspectives, especially combining the features in an early stage of the convolutional layers, will often lead to a destructive effect.
- without significantly altering the current network architecture, we propose to address this problem through decision-level fusion of a diverse ensemble of models pre-trained from convolutional neural networks. In this way, the significant differences in appearance of aerial and street view images are taken into account in contrast to many multi-stream end-to-end fusion approaches proposed in the literature.
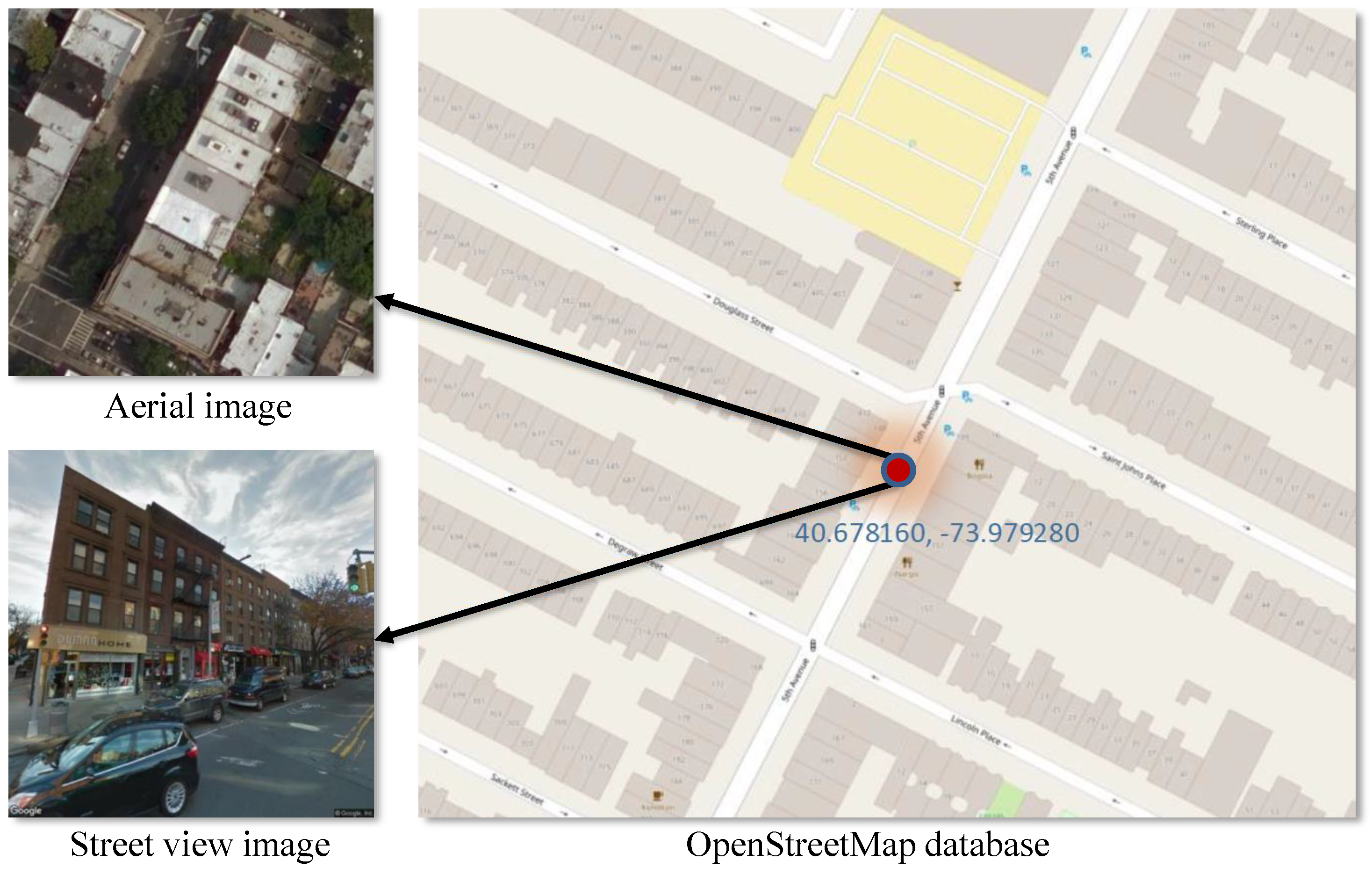
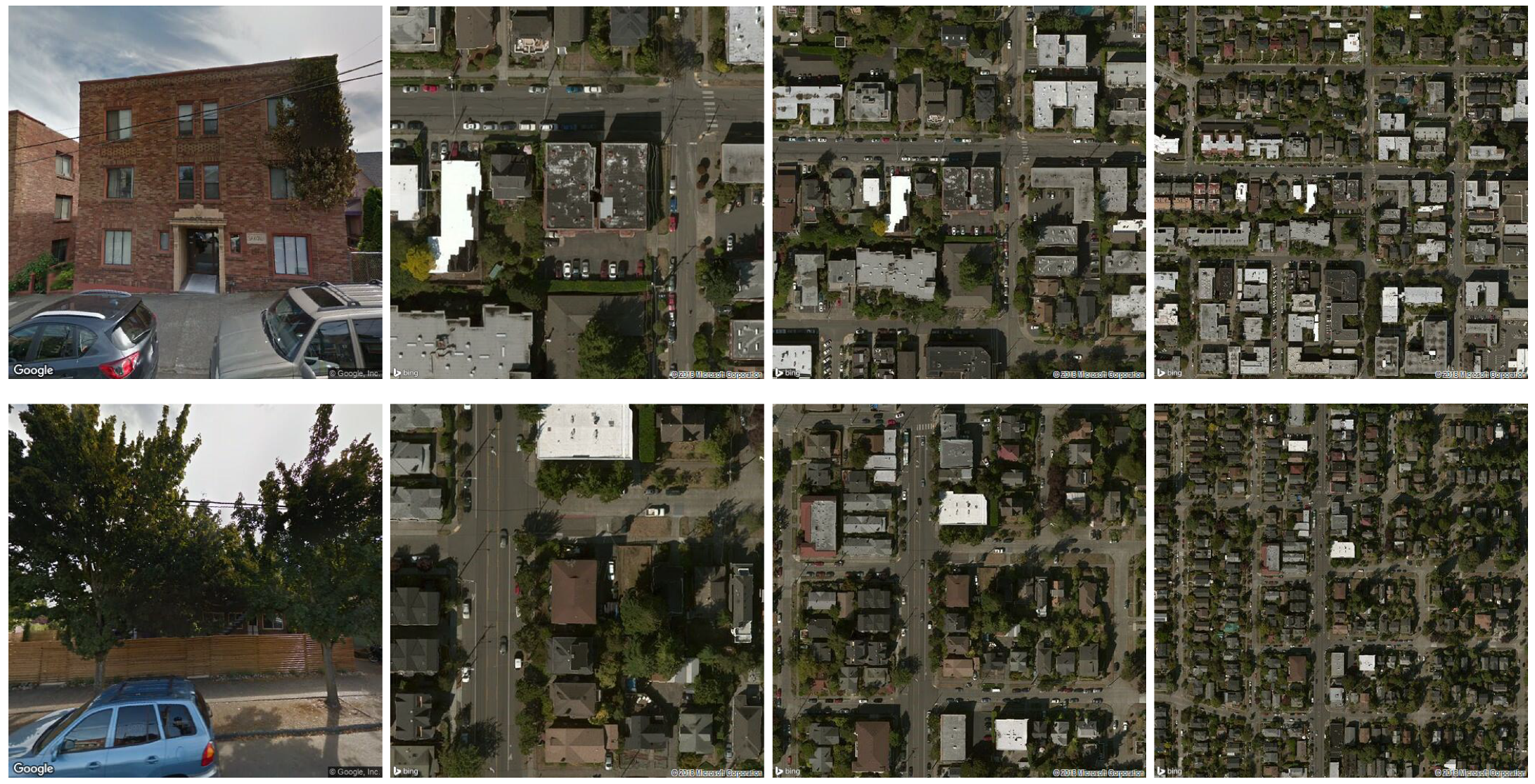
- we have collected a diverse set of building images from 49 US states plus Washington D.C. and Puerto Rico. Each building in this dataset consists of a set of four images—one Google Street View image, and three Google aerial/satellite images at an increasing zoom level.
3. Methodology
3.1. The Datasets
3.2. Fine-Tuning Exisiting CNNs for Individual Image Types
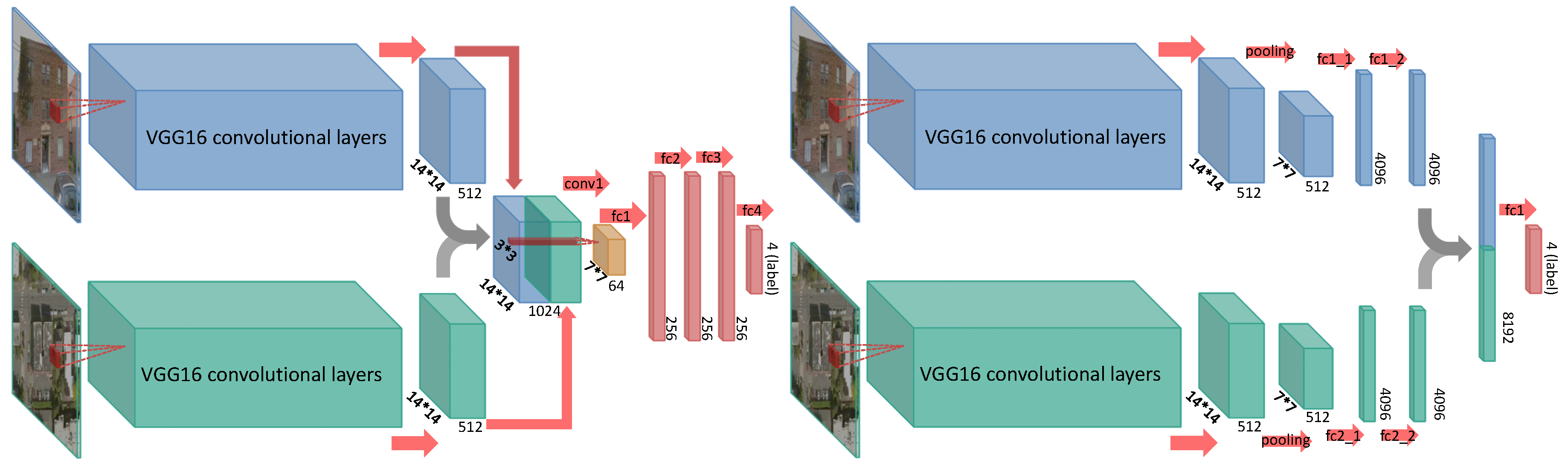
3.3. Fine-Tuning Two-Stream End-to-End Networks
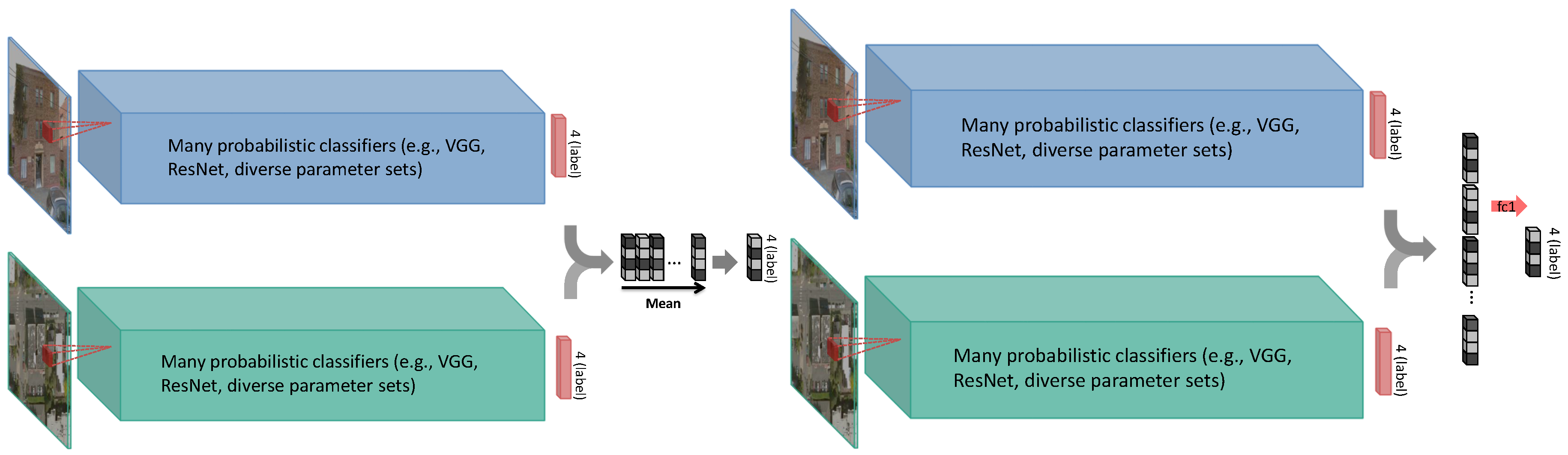
3.4. Decision-Level Model Fusion
3.4.1. Fusion through Model Blending
3.4.2. Fusion through Model Stacking
4. Experiments and Discussion
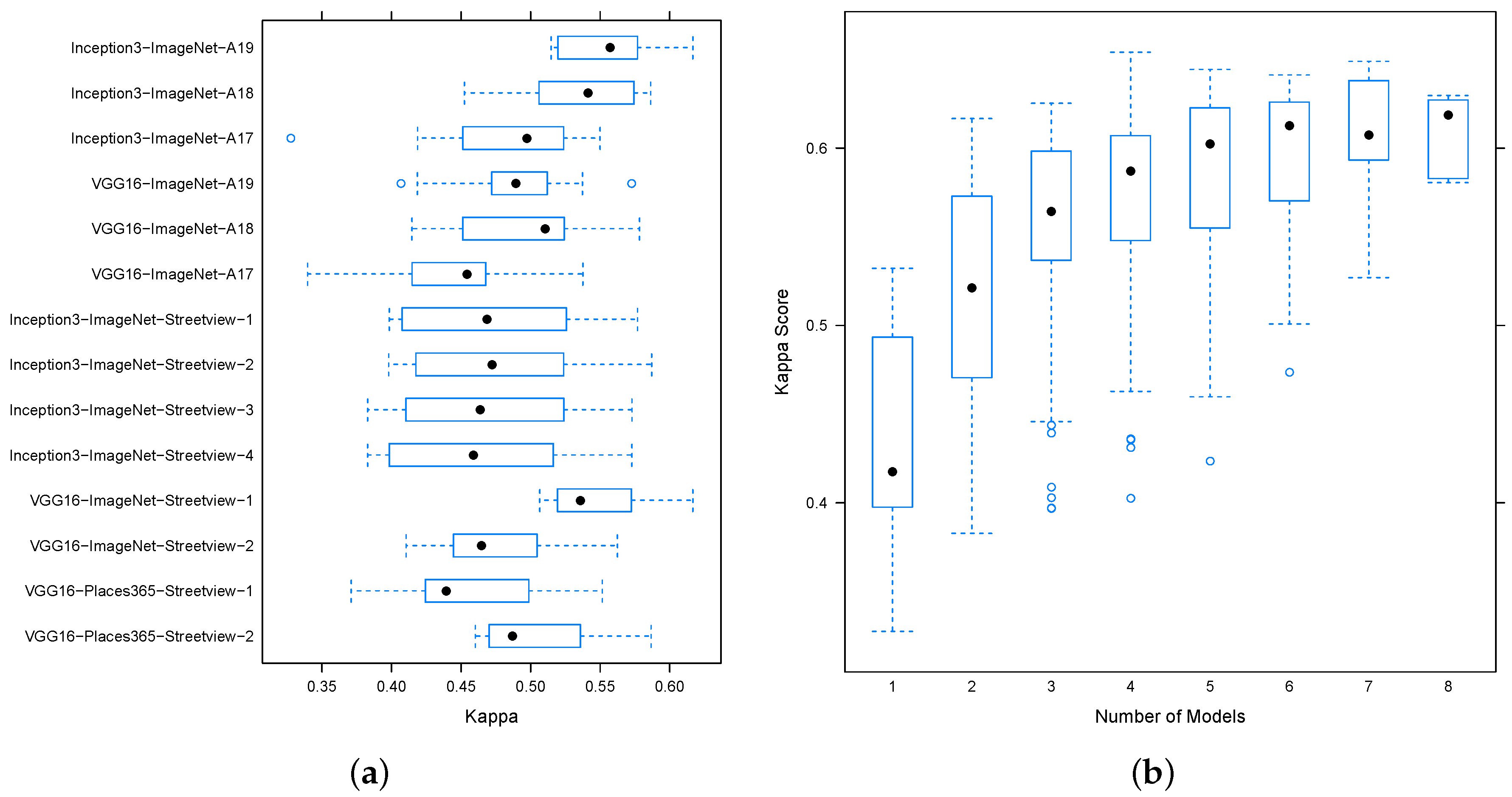
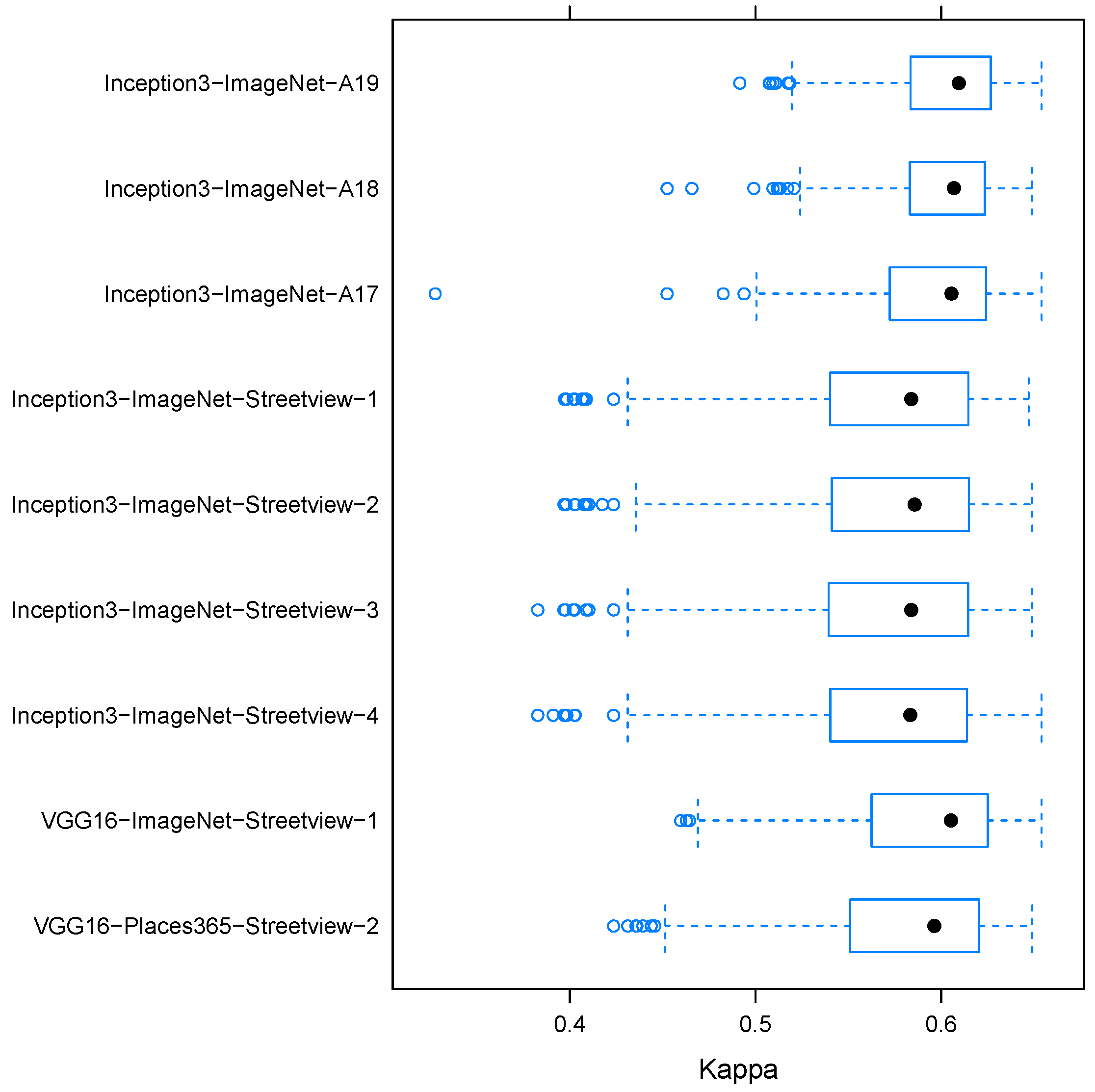
4.1. Performance of Existing CNNs on Individual Data
4.2. Performance of Two-Stream End-to-End Networks
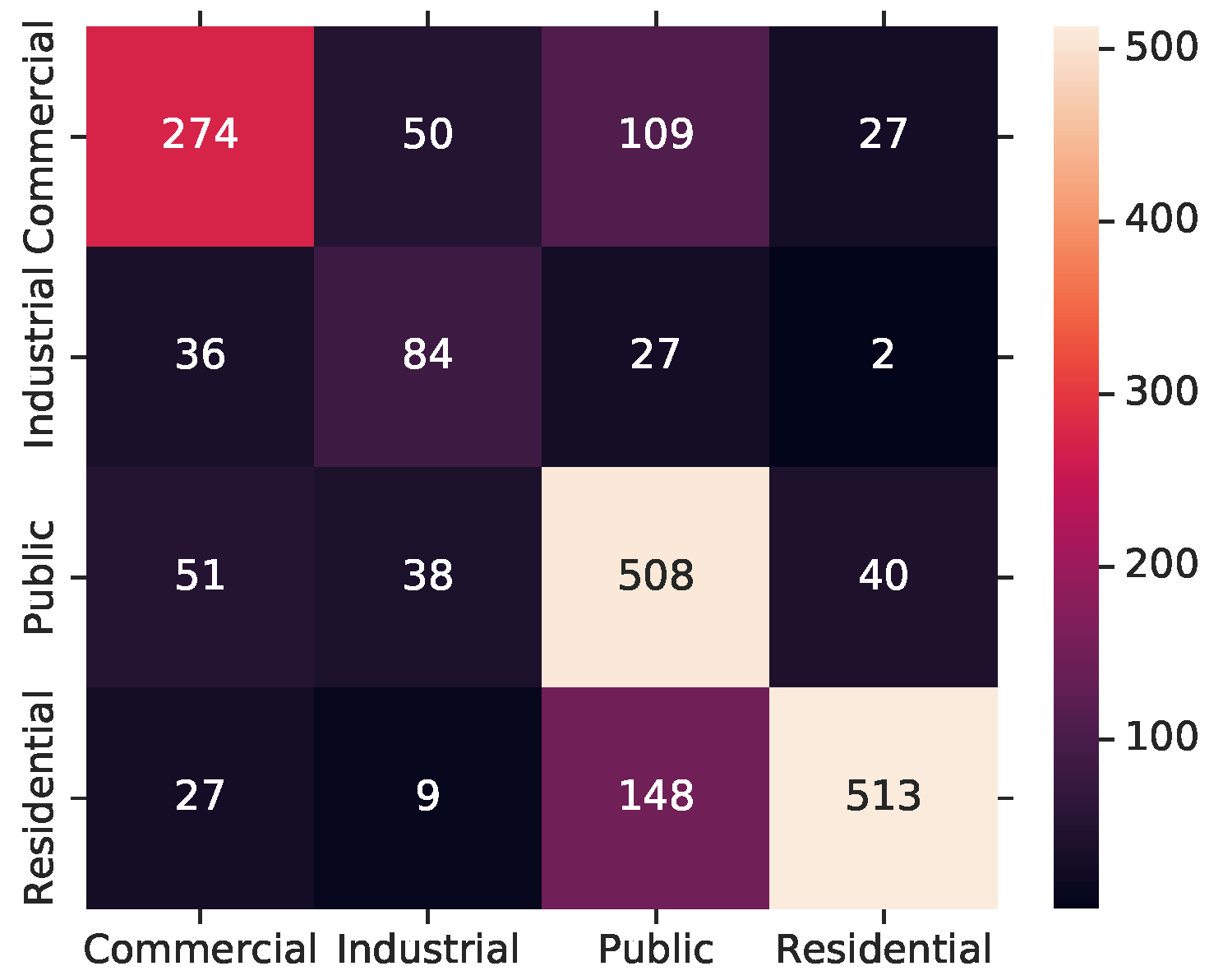
4.3. Performance of Decision-Level Fusion
4.3.1. Model Blending
4.3.2. Model Stacking
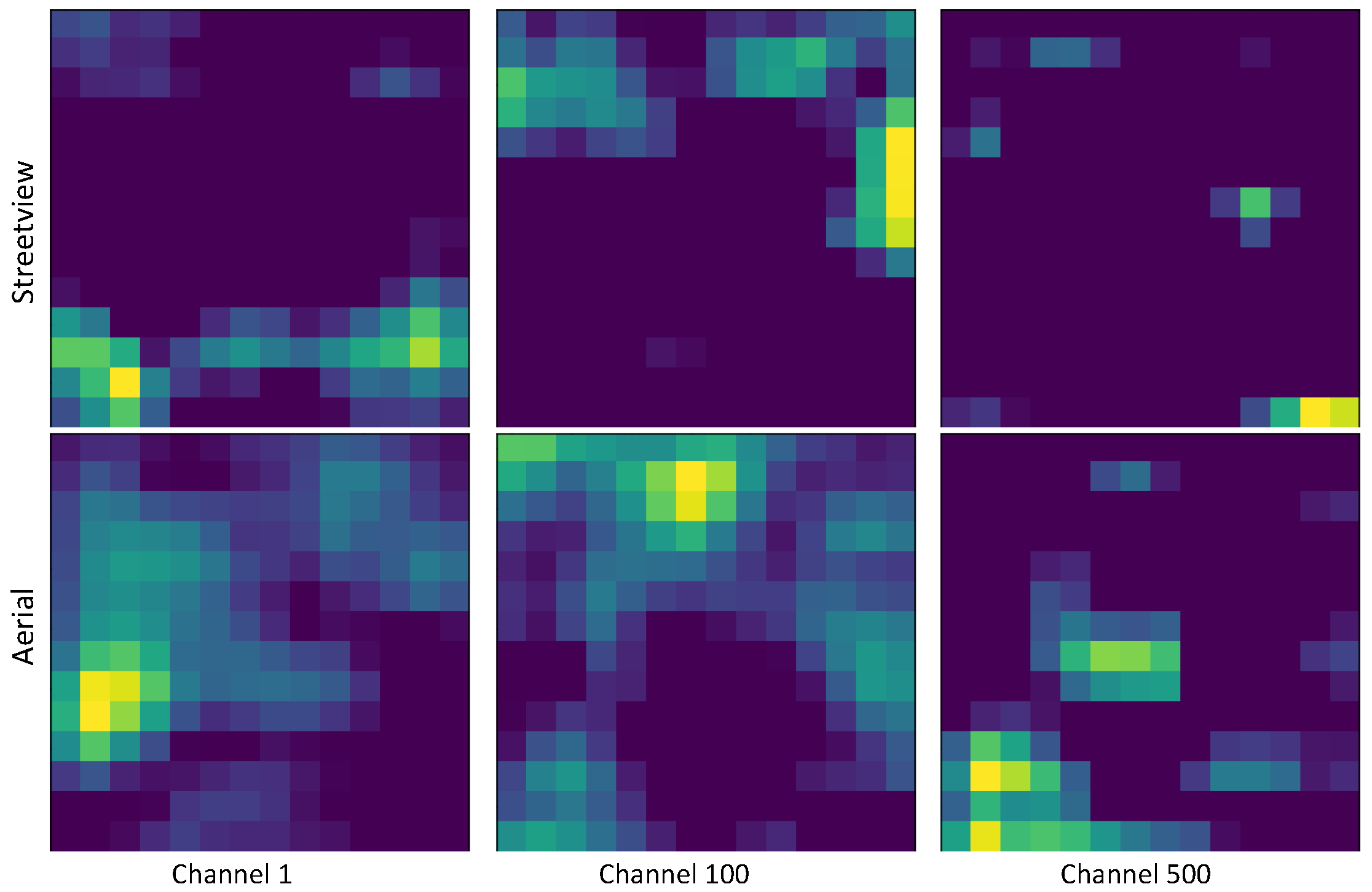
4.3.3. Influence of the Zoom Level on Classification Behavior
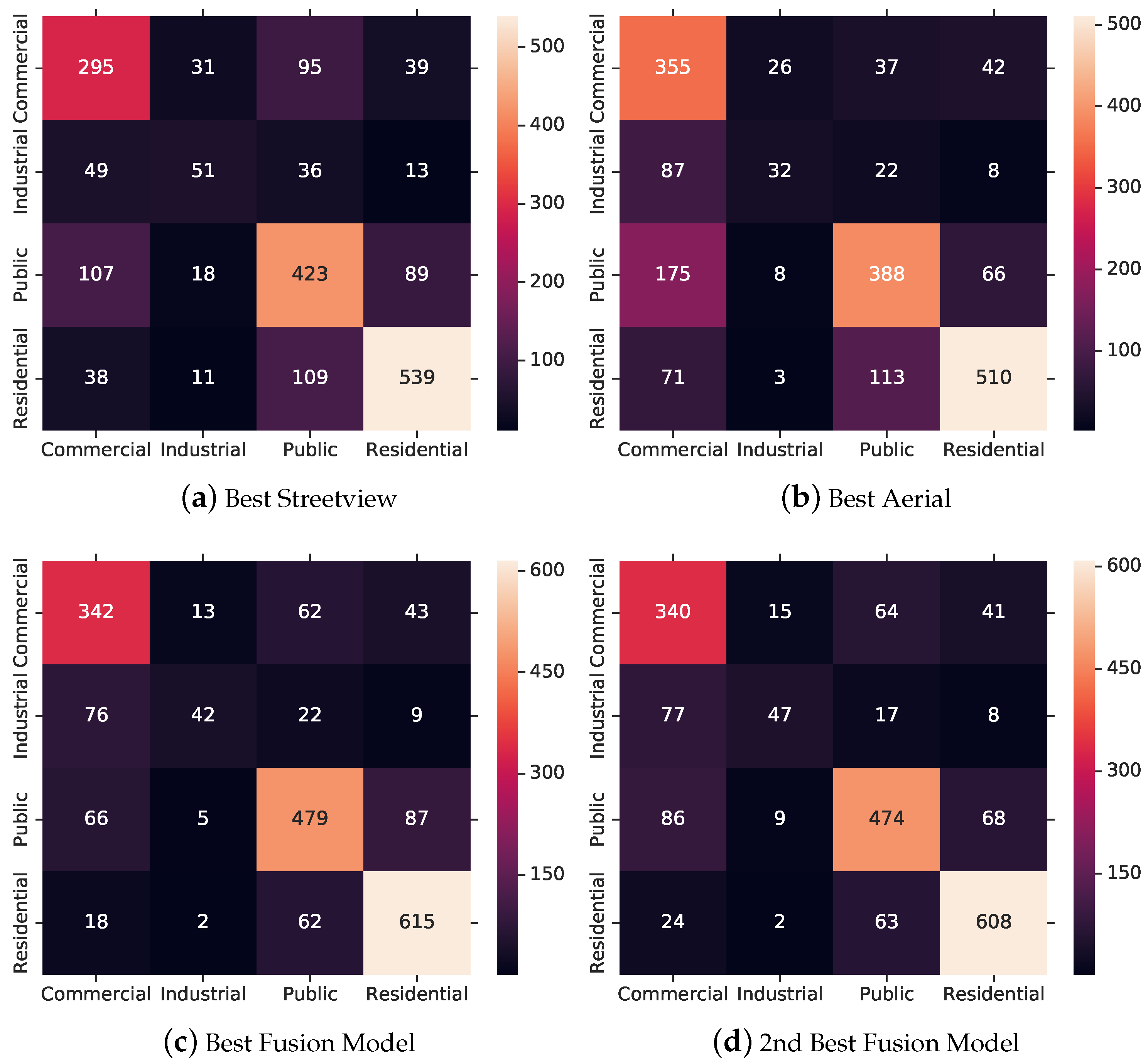
4.3.4. Best Model Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| API | Application programming interface |
| CNN | Convolutional Neural Network |
| OSM | OpenStreetMap |
| SVM | Support Vector Machine |
| CVUSA | Cross-View USA dataset [8] |
References
- Koch, T.; Körner, M.; Fraundorfer, F. Automatic Alignment of Indoor and Outdoor Building Models Using 3D Line Segments. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 689–697. [Google Scholar] [CrossRef]
- Rumpler, M.; Tscharf, A.; Mostegel, C.; Daftry, S.; Hoppe, C.; Prettenthaler, R.; Fraundorfer, F.; Mayer, G.; Bischof, H. Evaluations on multi-scale camera networks for precise and geo-accurate reconstructions from aerial and terrestrial images with user guidance. Comput. Vis. Image Underst. 2017, 157, 255–273. [Google Scholar] [CrossRef]
- Bansal, M.; Sawhney, H.S.; Cheng, H.; Daniilidis, K. Geo-localization of street views with aerial image databases. In Proceedings of the 19th ACM International Conference on Multimedia—MM’11, Scottsdale, AZ, USA, 28 November–1 December 2011; ACM Press: New York, NY, USA, 2011; p. 1125. [Google Scholar] [CrossRef]
- Majdik, A.L.; Albers-Schoenberg, Y.; Scaramuzza, D. MAV urban localization from Google street view data. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3979–3986. [Google Scholar] [CrossRef]
- Zhai, M.; Bessinger, Z.; Workman, S.; Jacobs, N. Predicting Ground-Level Scene Layout from Aerial Imagery. arXiv 2016, arXiv:1612.02709. [Google Scholar]
- Workman, S.; Zhai, M.; Crandall, D.J.; Jacobs, N. A Unified Model for Near and Remote Sensing. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, R.; Zhu, J.; Tu, W.; Li, Q.; Cao, J.; Liu, B.; Zhang, Q.; Qiu, G.; Cao, R.; Zhu, J.; et al. Integrating Aerial and Street View Images for Urban Land Use Classification. Remote Sens. 2018, 10, 1553. [Google Scholar] [CrossRef]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-Area Image Geolocalization with Aerial Reference Imagery. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Hu, S.; Wang, L. Automated urban land-use classification with remote sensing. Int. J. Remote Sens. 2013, 34, 790–803. [Google Scholar] [CrossRef]
- Ruiz Hernandez, I.E.; Shi, W. A Random Forests classification method for urban land-use mapping integrating spatial metrics and texture analysis. Int. J. Remote Sens. 2018, 39, 1175–1198. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems—GIS’10, San Jose, CA, USA, 2–5 November 2010; ACM Press: New York, NY, USA, 2010; p. 270. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep Learning Earth Observation Classification Using ImageNet Pretrained Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Albert, A.; Kaur, J.; Gonzalez, M.C. Using Convolutional Networks and Satellite Imagery to Identify Patterns in Urban Environments at a Large Scale. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD’17, Halifax, NS, Canada, 13–17 August 2017; ACM Press: New York, NY, USA, 2017; pp. 1357–1366. [Google Scholar] [CrossRef]
- Basu, S.; Ganguly, S.; Mukhopadhyay, S.; DiBiano, R.; Karki, M.; Nemani, R. DeepSat. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems—GIS’15, Seattle, WA, USA, 3–6 November 2015; ACM Press: New York, NY, USA, 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Leung, D.; Newsam, S. Exploring Geotagged images for land-use classification. In Proceedings of the ACM Multimedia 2012 Workshop on Geotagging and Its Applications in Multimedia—GeoMM’12, Nara, Japan, 29 October 2012; ACM Press: New York, NY, USA, 2012; p. 3. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition Using Places Database. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 1; MIT Press: Cambridge, MA, USA, 2014; pp. 487–495. [Google Scholar]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- Srivastava, S.; Vargas-Muñoz, J.E.; Swinkels, D.; Tuia, D. Multilabel Building Functions Classification from Ground Pictures using Convolutional Neural Networks. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Seattle, WA, USA, 6 November 2018; pp. 43–46. [Google Scholar] [CrossRef]
- Srivastava, S.; Vargas Muñoz, J.E.; Lobry, S.; Tuia, D. Fine-grained landuse characterization using ground-based pictures: A deep learning solution based on globally available data. Int. J. Geogr. Inf. Sci. 2018, 1–20. [Google Scholar] [CrossRef]
- Zhu, Y.; Deng, X.; Newsam, S. Fine-Grained Land Use Classification at the City Scale Using Ground-Level Images. IEEE Trans. Multimed. 2019. [Google Scholar] [CrossRef]
- Lin, T.Y.; Belongie, S.; Hays, J. Cross-View Image Geolocalization. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 891–898. [Google Scholar] [CrossRef]
- Lin, T.Y.; Yin, C.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5007–5015. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Anguelov, D.; Dulong, C.; Filip, D.; Frueh, C.; Lafon, S.; Lyon, R.; Ogale, A.; Vincent, L.; Weaver, J. Google Street View: Capturing the World at Street Level. Computer 2010, 43, 32–38. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Torralba, A.; Oliva, A. Places: An image database for deep scene understanding. arXiv 2016, arXiv:1610.02055. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the Conference on IEEE Computer Vision and Pattern Recognition, CVPR 2009, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 2951–2959. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aerial View | Ground View | Task | Dataset | Basic Architecture(s) | Method | Ref. |
|---|---|---|---|---|---|---|
| x | C | UC Merced Land Use | Overfeat | Fine-tuning from ImageNet | [15] | |
| x | C | Google Maps satellite imagery | VGG, ResNet | Fine-tuning from ImageNet and DeepSat | [18] | |
| x | S | High-res imagery from Manchester and Southampton | OCNN (based on AlexNet) | Markov process for joint learning two networks | [21] | |
| x | C | Flickr images from two university campuses | CaffeNet | Feature extraction from PlacesCNN and prediction with SVM | [22] | |
| x | C | Google Street View Imagery from 30 US cities | AlexNet, VGG, ResNet | Filtering with Places and then fine-tuning from ImageNet | [24] | |
| x | C | Google Street View imagery from Amsterdam | VGG | Finetuning from ImageNet and aggregating dense feature vectors using maximum or average | [25] | |
| x | C | Flickr and Google Street View imagery from San Francisco (augmented) | ResNet | Finetuning from ImageNet and Places to average probablity vectors | [27] | |
| x | x | S | Bing aerial images and Google Street View from New York boroughs Queens and Brooklyn | VGG, PixelNet | End-to-end learning by stacking features and performing kernel regression on features | [6] |
| x | x | S | Bing aerial images and Google Street View from New York boroughs Queens and Brooklyn | SegNet | End-to-end learning by using a two stream encoder with a single stream decoder | [7] |
| Basic Architecture(s) | Method | Section | Related Work |
|---|---|---|---|
| VGG, Inception | Fine-tuning from ImageNet | Section 3.2 | [15,24] |
| VGG | Fine-tuning two stream network from ImageNet by stacking convolution layer horizontally | Section 3.3 | [25,27] |
| VGG | Fine-tuning two stream network from ImageNet by stacking dense layer vertically | Section 3.3 | [25,27] |
| VGG, Inception | Fine-tuning single stream from ImageNet and Places365 then blend decision layers | Section 3.4.1 | [27] |
| VGG, Inception | Fine-tuning single stream from ImageNet and Places365 then stack decision layers with additional machine learning algorithm | Section 3.4.2 | - |
| Cluster Class | OpenStreetMap Tag | # of Buildings | |
|---|---|---|---|
| 1 | commercial | commercial | 5111 |
| 2 | commercial | office | 3306 |
| 3 | commercial | retail | 4906 |
| 4 | industrial | industrial | 3839 |
| 5 | industrial | warehouse | 2065 |
| 6 | public | church | 4153 |
| 7 | public | college | 1516 |
| 8 | public | hospital | 1758 |
| 9 | public | hotel | 2057 |
| 10 | public | public | 1966 |
| 11 | public | school | 4278 |
| 12 | public | university | 4020 |
| 13 | residential | apartments | 5039 |
| 14 | residential | dormitory | 2154 |
| 15 | residential | house | 5156 |
| 16 | residential | residential | 4935 |
| Model | Precision | Recall | F1-Score | Kappa |
|---|---|---|---|---|
| Inception3-ImageNet-A19 | 0.68 | 0.66 | 0.66 | 0.52 |
| Inception3-ImageNet-A18 | 0.68 | 0.63 | 0.60 | 0.47 |
| Inception3-ImageNet-A17 | 0.59 | 0.55 | 0.51 | 0.33 |
| VGG16-ImageNet-A19 | 0.65 | 0.60 | 0.59 | 0.42 |
| VGG16-ImageNet-A18 | 0.60 | 0.60 | 0.59 | 0.42 |
| VGG16-ImageNet-A17 | 0.59 | 0.55 | 0.54 | 0.34 |
| Inception3-ImageNet-Streetview-1 | 0.63 | 0.58 | 0.58 | 0.41 |
| Inception3-ImageNet-Streetview-2 | 0.63 | 0.59 | 0.59 | 0.42 |
| Inception3-ImageNet-Streetview-3 | 0.62 | 0.57 | 0.58 | 0.40 |
| Inception3-ImageNet-Streetview-4 | 0.62 | 0.57 | 0.57 | 0.39 |
| VGG16-ImageNet-Streetview-1 | 0.67 | 0.67 | 0.67 | 0.53 |
| VGG16-ImageNet-Streetview-2 | 0.61 | 0.59 | 0.59 | 0.41 |
| VGG16-Places365-Streetview-1 | 0.57 | 0.57 | 0.56 | 0.37 |
| VGG16-Places365-Streetview-2 | 0.67 | 0.65 | 0.65 | 0.49 |
| Model | Batch | Dropout | Decay | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Inception3-ImageNet-A19 | 32 | 0.2 | - | 10 | 10 | 10 | |||
| Inception3-ImageNet-A18 | 32 | 0.2 | - | 10 | 10 | 10 | |||
| Inception3-ImageNet-A17 | 32 | 0.2 | - | 10 | 10 | 10 | |||
| VGG16-ImageNet-A19 | 32 | 0.2 | 10 | 50 | - | - | |||
| VGG16-ImageNet-A18 | 32 | 0.2 | 10 | 50 | - | - | |||
| VGG16-ImageNet-A17 | 32 | 0.2 | 10 | 50 | - | - | |||
| Inception3-ImageNet-Streetview-1 | 64 | 0.2 | - | 10 | 10 | 10 | |||
| Inception3-ImageNet-Streetview-2 | 32 | 0.2 | - | 10 | 10 | 10 | |||
| Inception3-ImageNet-Streetview-3 | 64 | 0.3 | - | 10 | 10 | 50 | |||
| Inception3-ImageNet-Streetview-4 | 64 | 0.35 | - | 10 | 10 | 20 | |||
| VGG16-ImageNet-Streetview-1 | 64 | 0.2 | - | 10 | 10 | 20 | |||
| VGG16-ImageNet-Streetview-2 | 32 | 0.2 | 10 | 10 | 10 | ||||
| VGG16-Places365-Streetview-1 | 32 | 0.2 | 10 | 10 | 10 | ||||
| VGG16-Places365-Streetview-2 | 64 | 0.2 | 5 | 10 | 20 |
| Model | ||||||||
|---|---|---|---|---|---|---|---|---|
| VGG16-Model1-1 | 20 | 10 | 20 | 30 | ||||
| VGG16-Model1-2 | 20 | 10 | 20 | 30 | ||||
| VGG16-Model1-3 | 20 | 10 | 20 | 30 | ||||
| VGG16-Model2-1 | 30 | 5 | 20 | 30 | ||||
| VGG16-Model2-2 | 30 | 5 | 20 | 30 | ||||
| VGG16-Model2-3 | 30 | 5 | 20 | 30 |
| Model | Precision | Recall | F1-Score | Kappa |
|---|---|---|---|---|
| VGG16-Model1-1 | 0.63 | 0.62 | 0.62 | 0.50 |
| VGG16-Model1-2 | 0.61 | 0.62 | 0.60 | 0.48 |
| VGG16-Model1-3 | 0.66 | 0.61 | 0.61 | 0.47 |
| VGG16-Model2-1 | 0.68 | 0.67 | 0.67 | 0.57 |
| VGG16-Model2-2 | 0.66 | 0.67 | 0.66 | 0.55 |
| VGG16-Model2-3 | 0.65 | 0.65 | 0.64 | 0.53 |
| # of Models | Precision | Recall | F1-Score | Kappa | Models in Ensemble |
|---|---|---|---|---|---|
| 2 | 0.74 | 0.73 | 0.73 | 0.62 | Inception3-ImageNet-A19 VGG16-ImageNet-Streetview-1 |
| 3 | 0.74 | 0.74 | 0.73 | 0.63 | Inception3-ImageNet-A18 VGG16-ImageNet-Streetview-1 Inception3-ImageNet-Streetview-2 |
| 4 | 0.76 | 0.76 | 0.75 | 0.65 | Inception3-ImageNet-A19 Inception3-ImageNet-A17 VGG16-ImageNet-Streetview-1 Inception3-ImageNet-Streetview-4 |
| Model | Precision | Recall | F1 | Kappa |
|---|---|---|---|---|
| Streetview only | 0.67 | 0.67 | 0.67 | 0.53 |
| Streetview-Aerial 17 | 0.70 | 0.69 | 0.68 | 0.55 |
| Streetview-Aerial 18 | 0.73 | 0.71 | 0.70 | 0.57 |
| Streetview-Aerial 19 | 0.74 | 0.73 | 0.73 | 0.62 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoffmann, E.J.; Wang, Y.; Werner, M.; Kang, J.; Zhu, X.X. Model Fusion for Building Type Classification from Aerial and Street View Images. Remote Sens. 2019, 11, 1259. https://doi.org/10.3390/rs11111259
Hoffmann EJ, Wang Y, Werner M, Kang J, Zhu XX. Model Fusion for Building Type Classification from Aerial and Street View Images. Remote Sensing. 2019; 11(11):1259. https://doi.org/10.3390/rs11111259
Chicago/Turabian StyleHoffmann, Eike Jens, Yuanyuan Wang, Martin Werner, Jian Kang, and Xiao Xiang Zhu. 2019. "Model Fusion for Building Type Classification from Aerial and Street View Images" Remote Sensing 11, no. 11: 1259. https://doi.org/10.3390/rs11111259
APA StyleHoffmann, E. J., Wang, Y., Werner, M., Kang, J., & Zhu, X. X. (2019). Model Fusion for Building Type Classification from Aerial and Street View Images. Remote Sensing, 11(11), 1259. https://doi.org/10.3390/rs11111259