Heart ID: Human Identification Based on Radar Micro-Doppler Signatures of the Heart Using Deep Learning

Abstract
:1. Introduction
2. Experiment Setup and Data Analysis
2.1. Experiment Setup
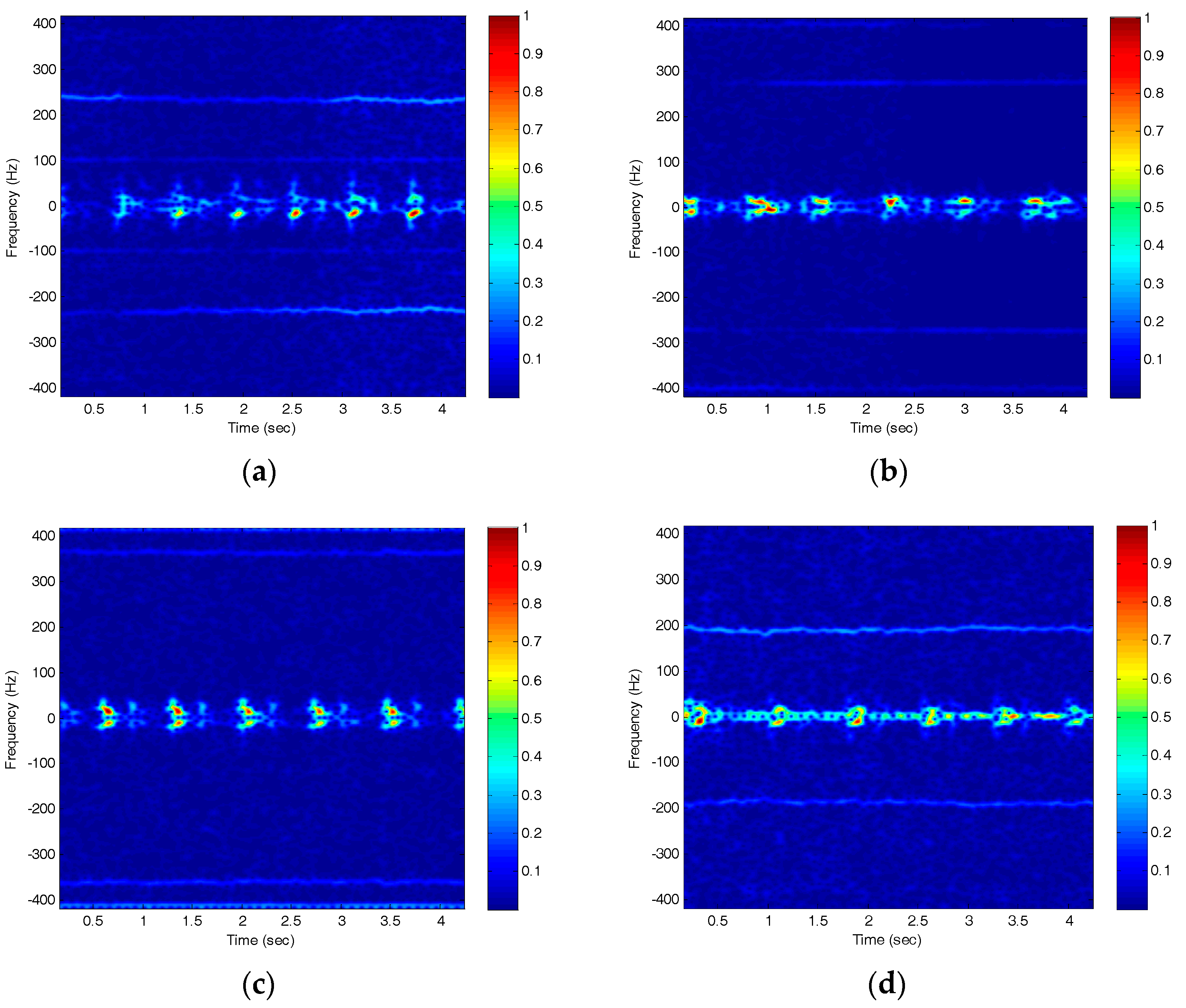
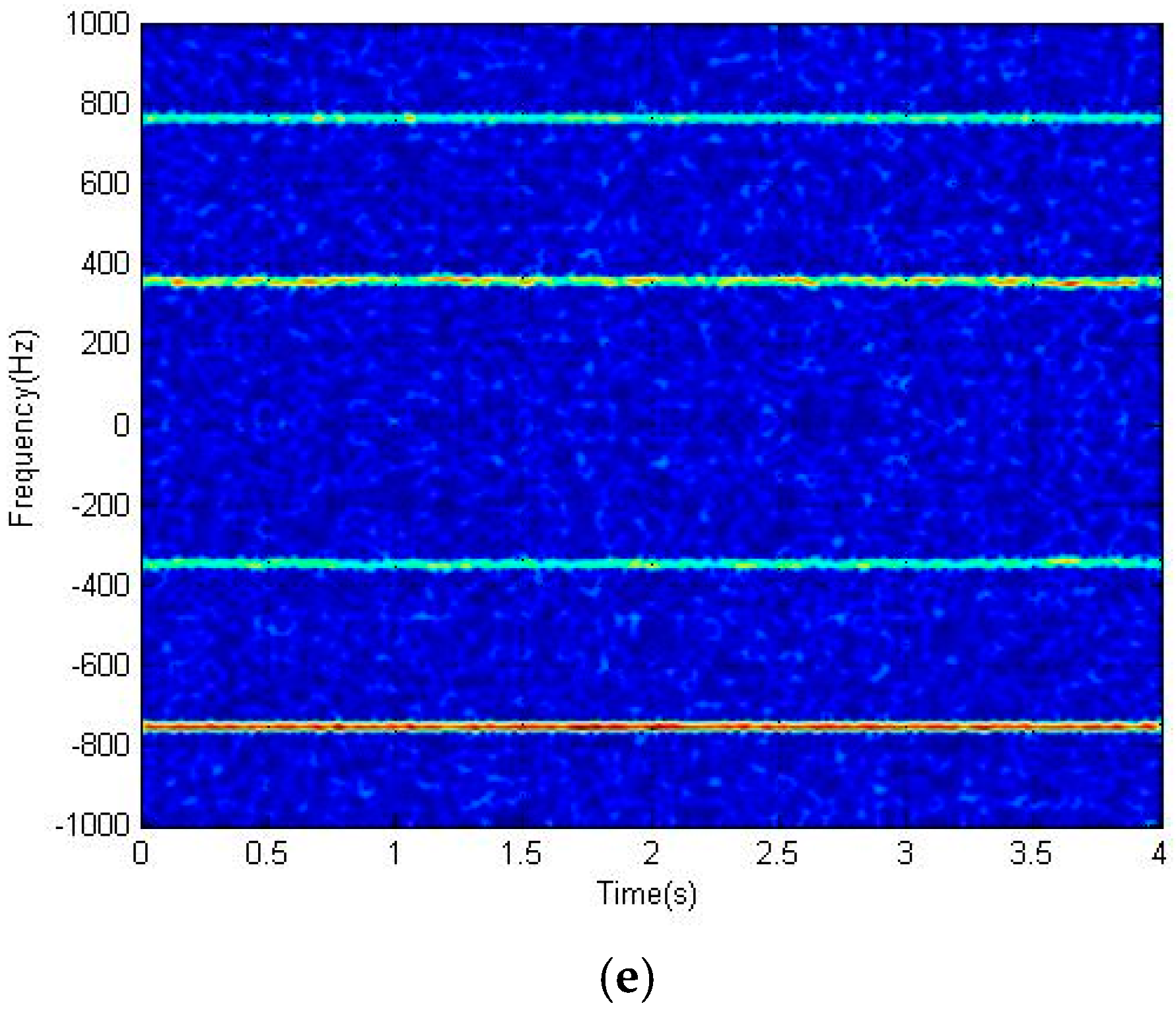
2.2. Micro-Doppler Signatures and Choice of Features
- (1)
- The period of the heartbeat;
- (2)
- The energy of the heartbeat;
- (3)
- The bandwidth of the Doppler signal.
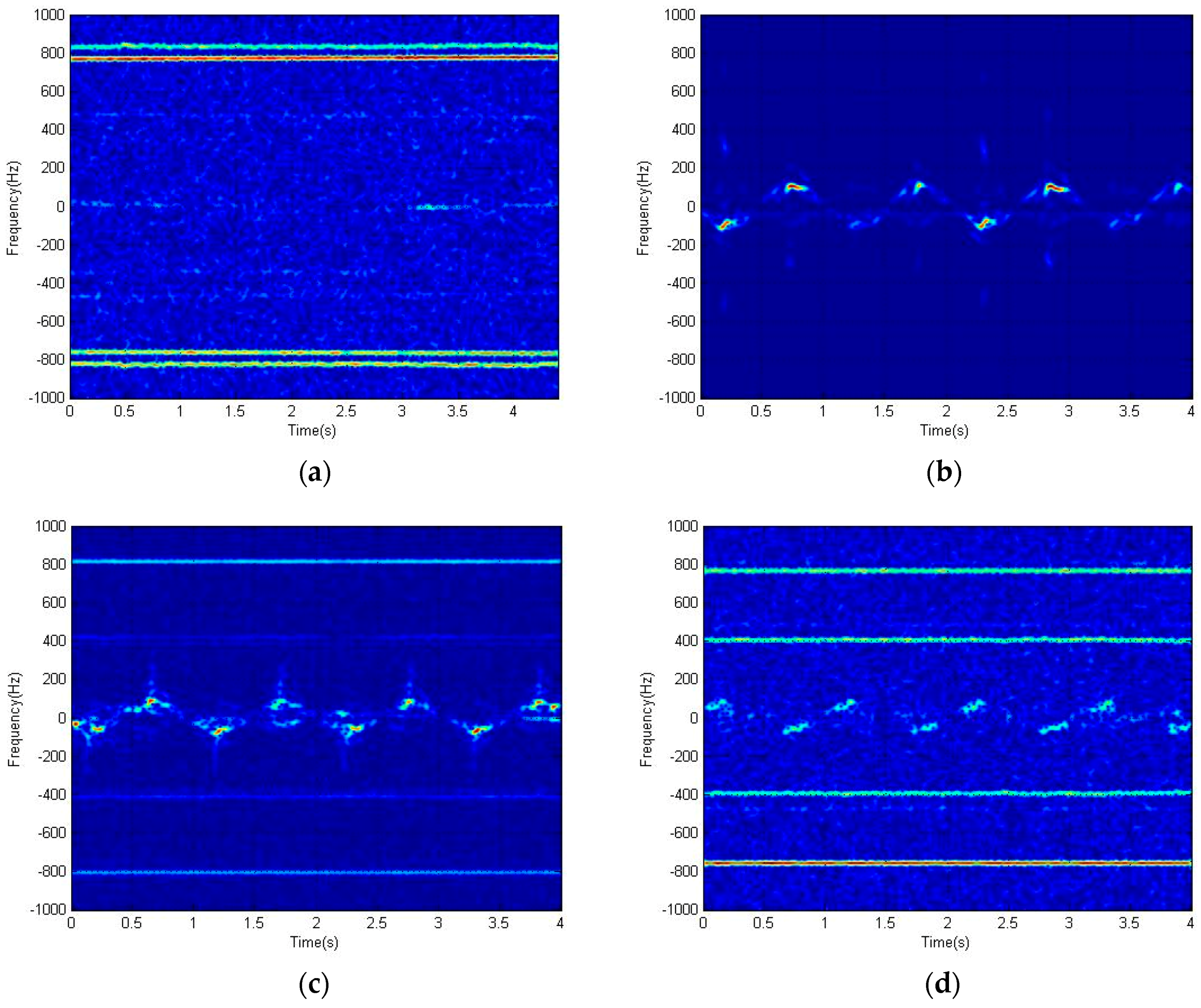
2.3. Experiment on the Penetrability of the Radar
3. Machine Learning
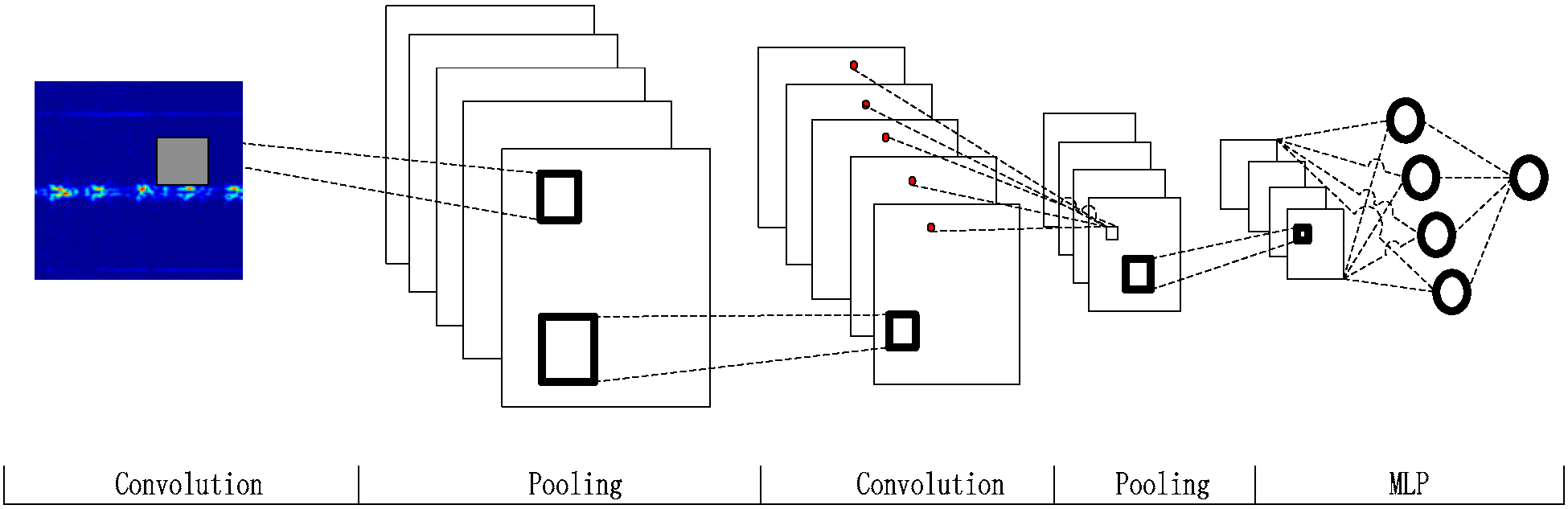
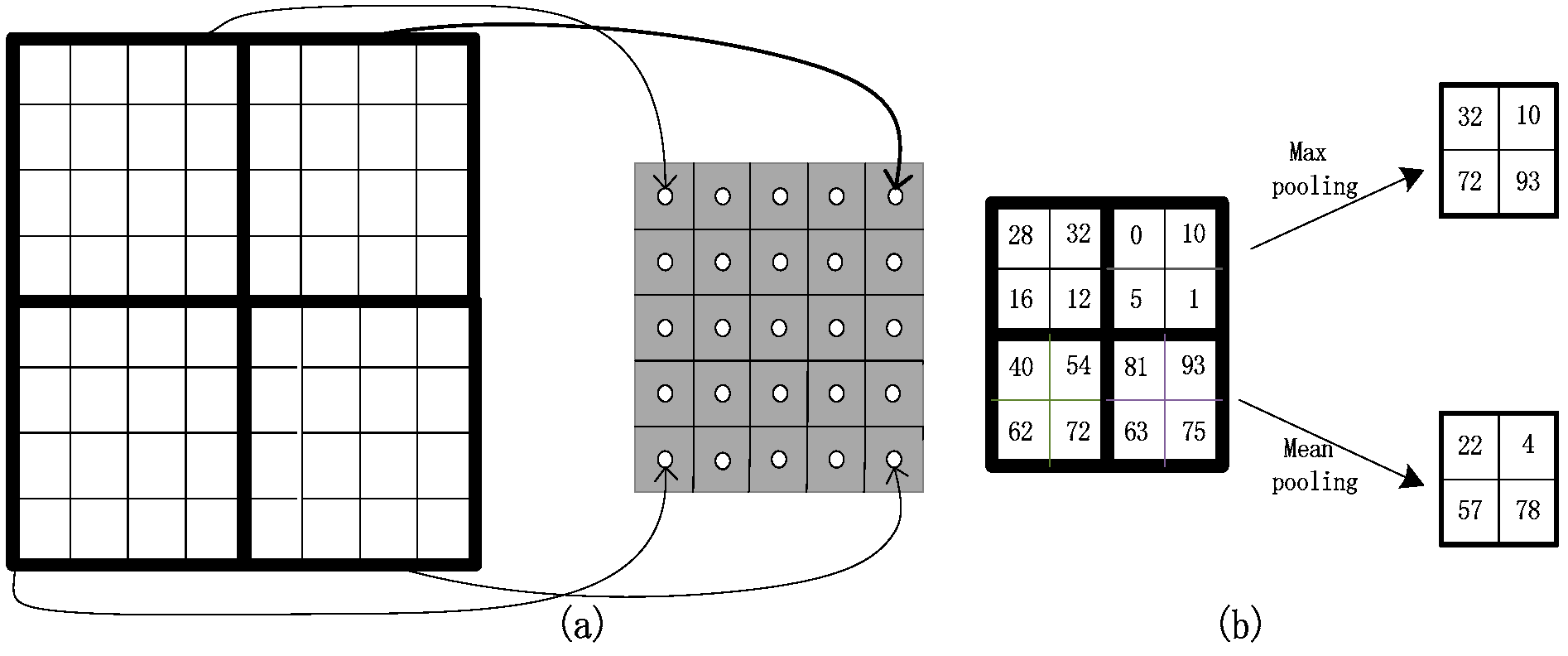
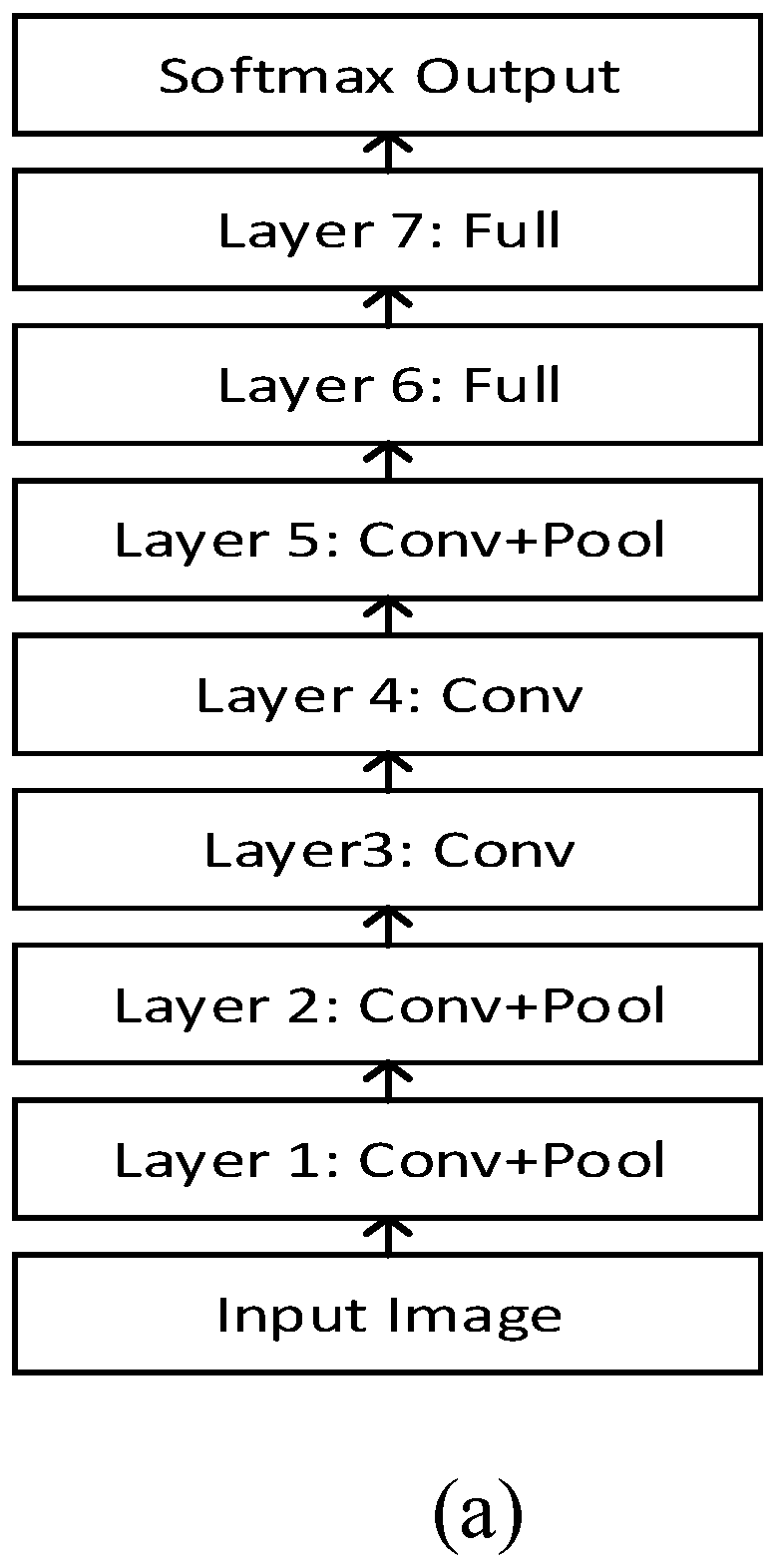
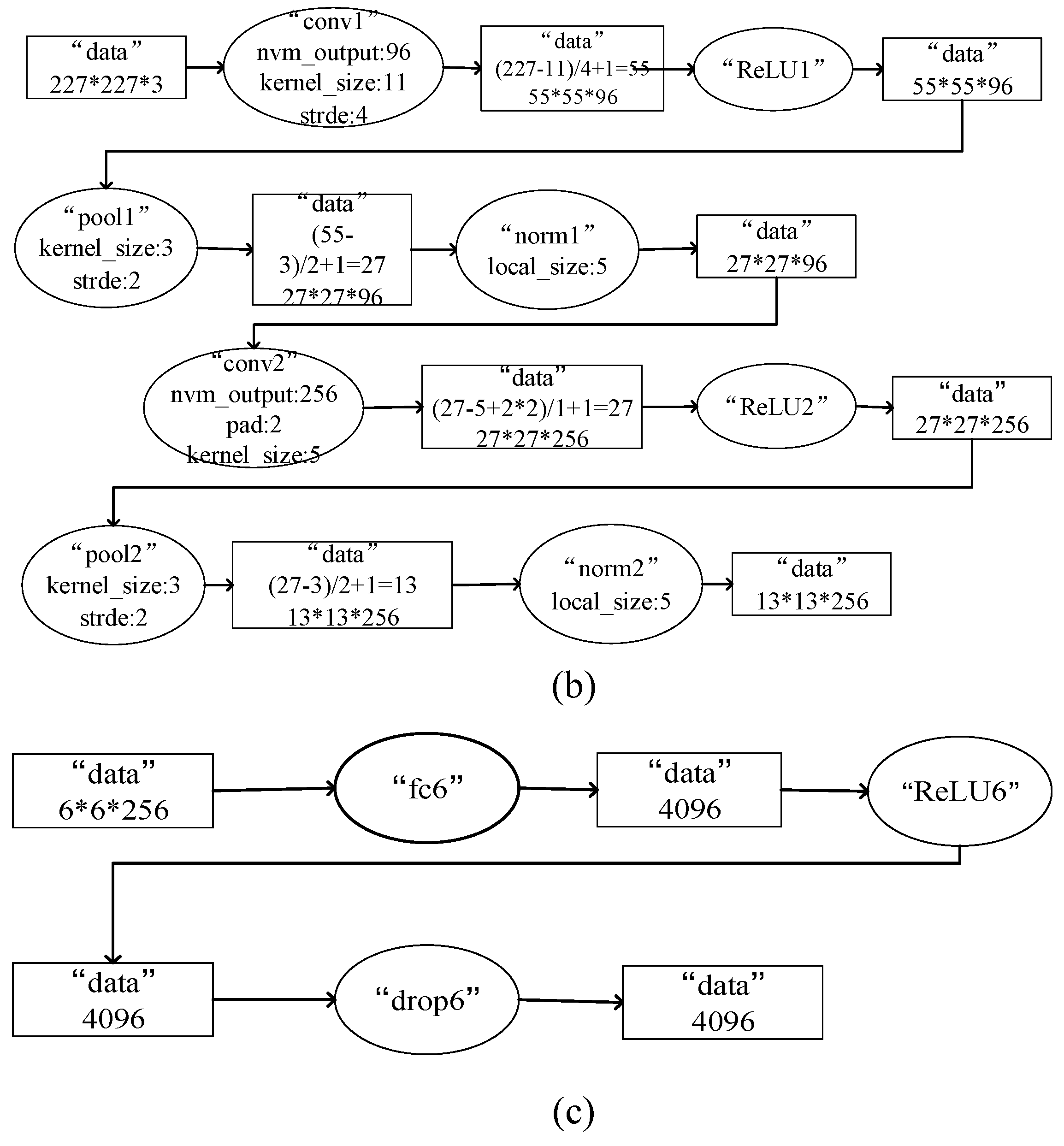
3.1. Deep Convolutional Neural Networks
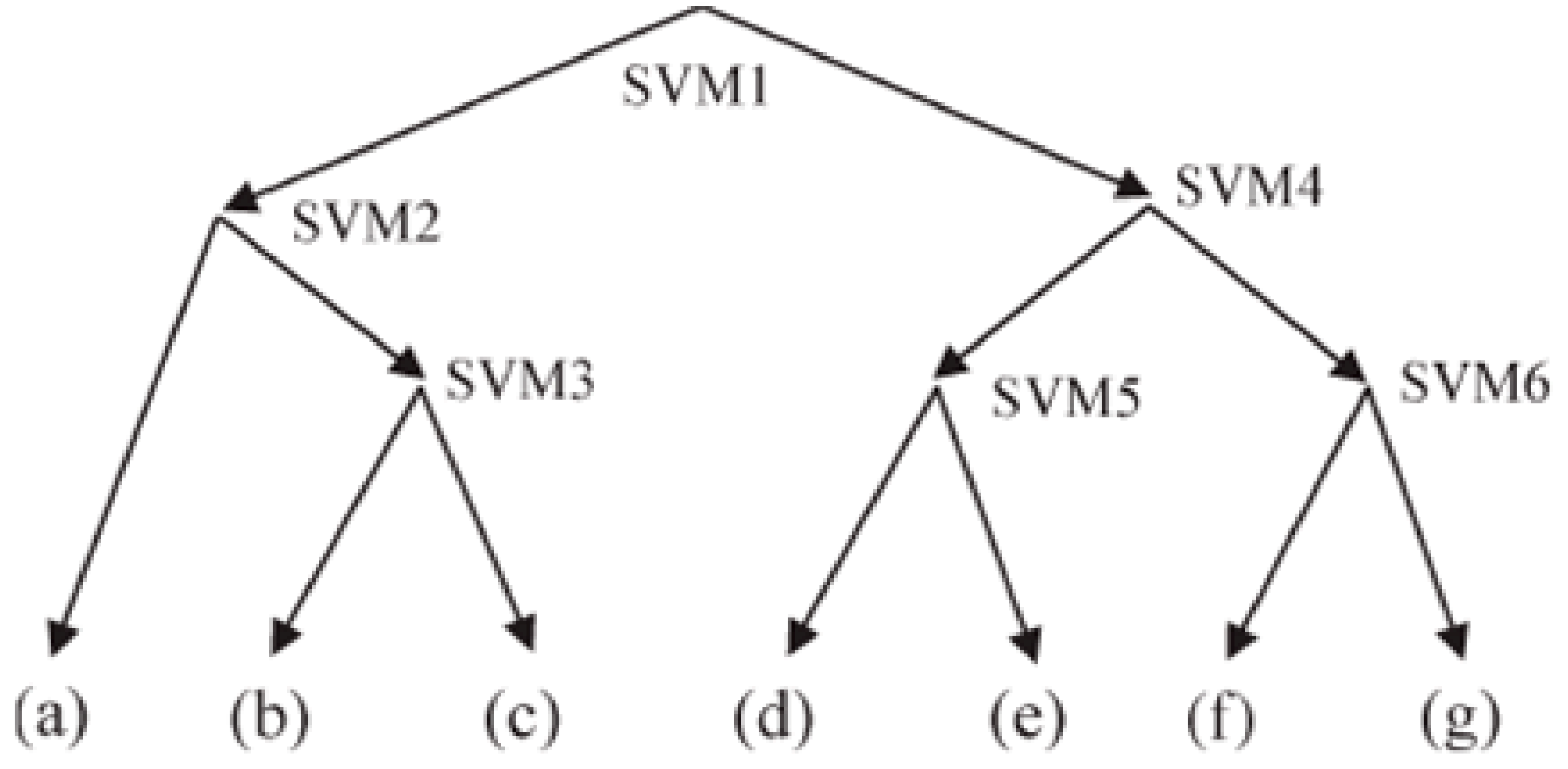
3.2. Support Vector Machine (SVM)
3.3. Naive Bayes (NB)
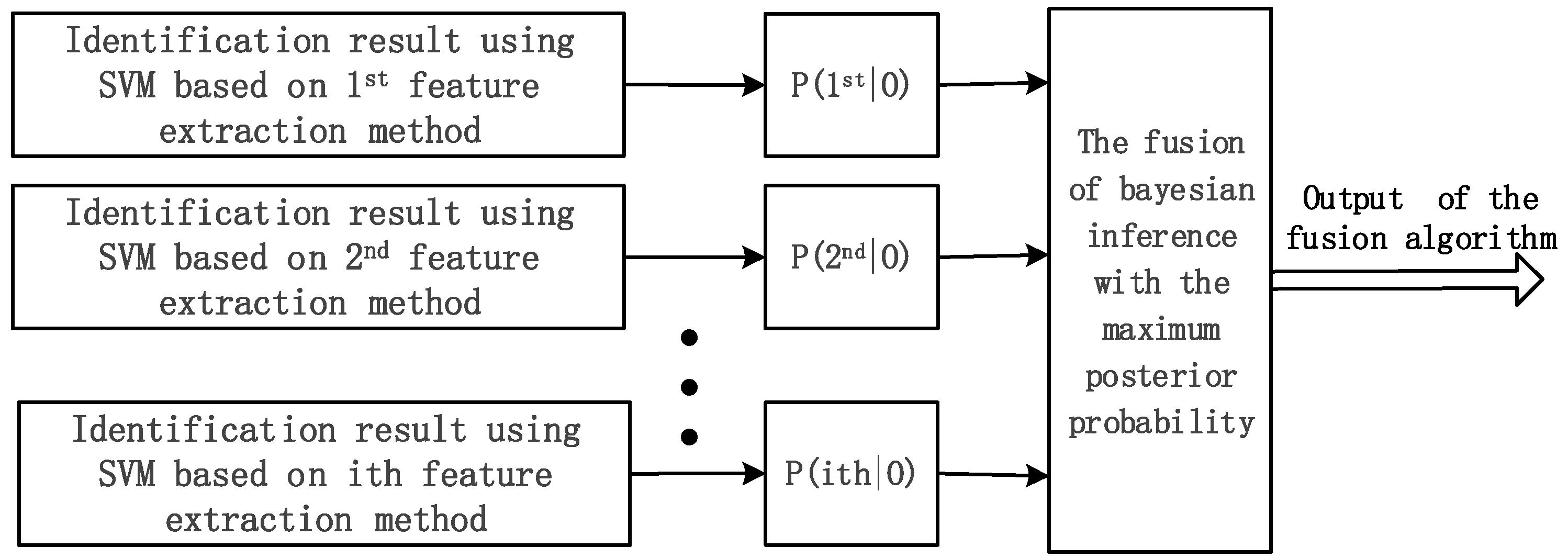
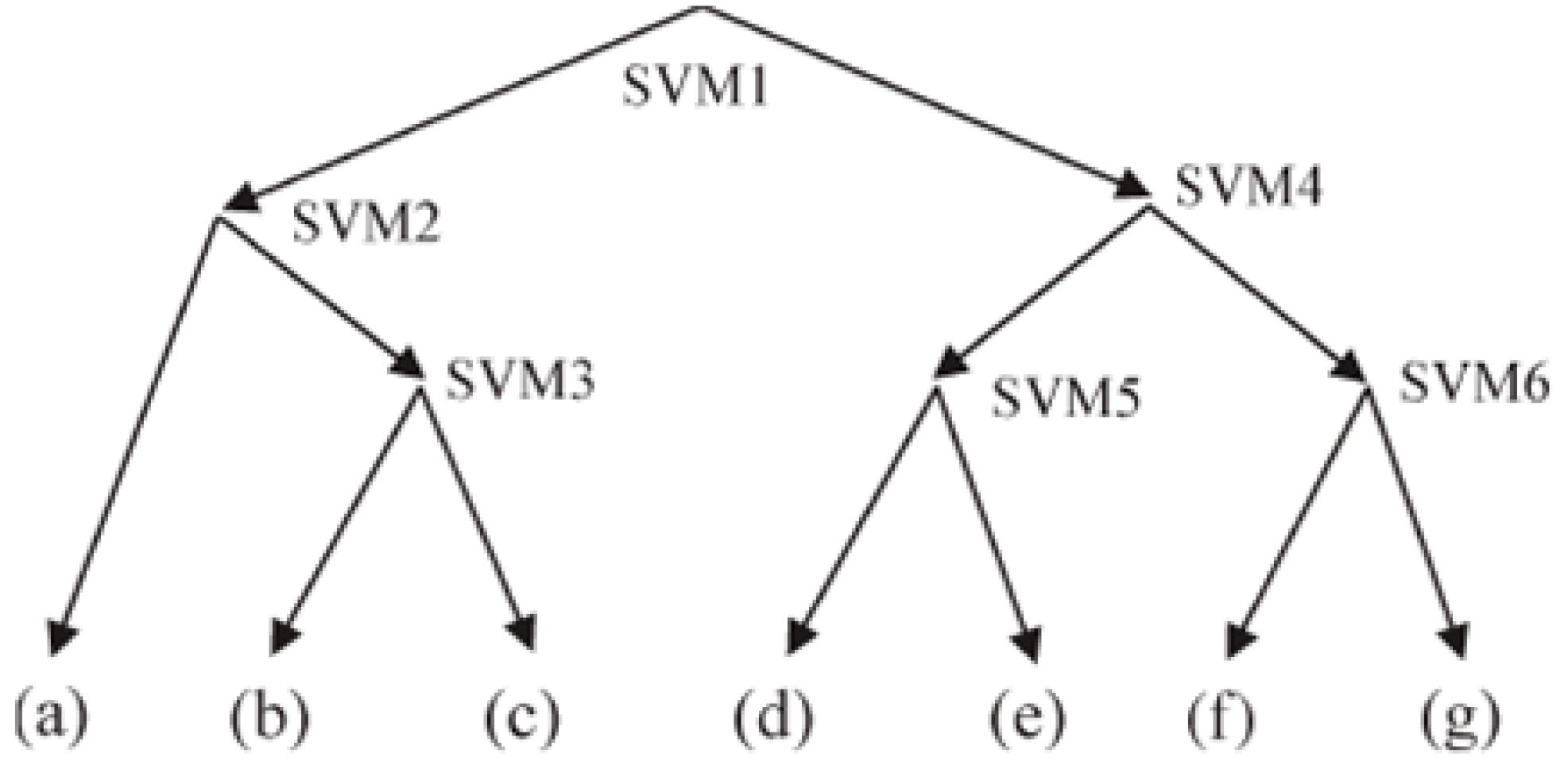
3.4. SVM–Bayes Fusion
4. Results and Discussion
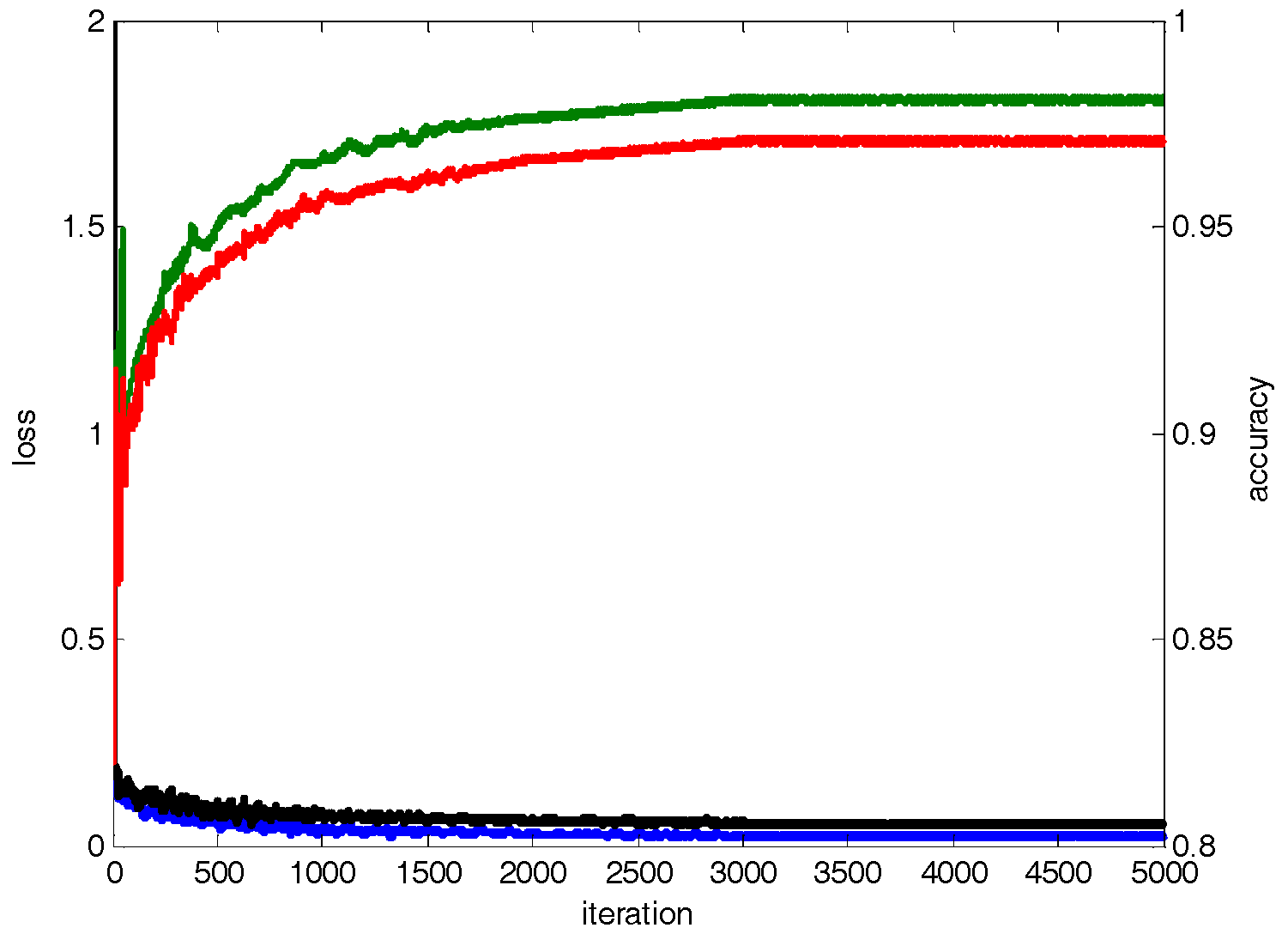
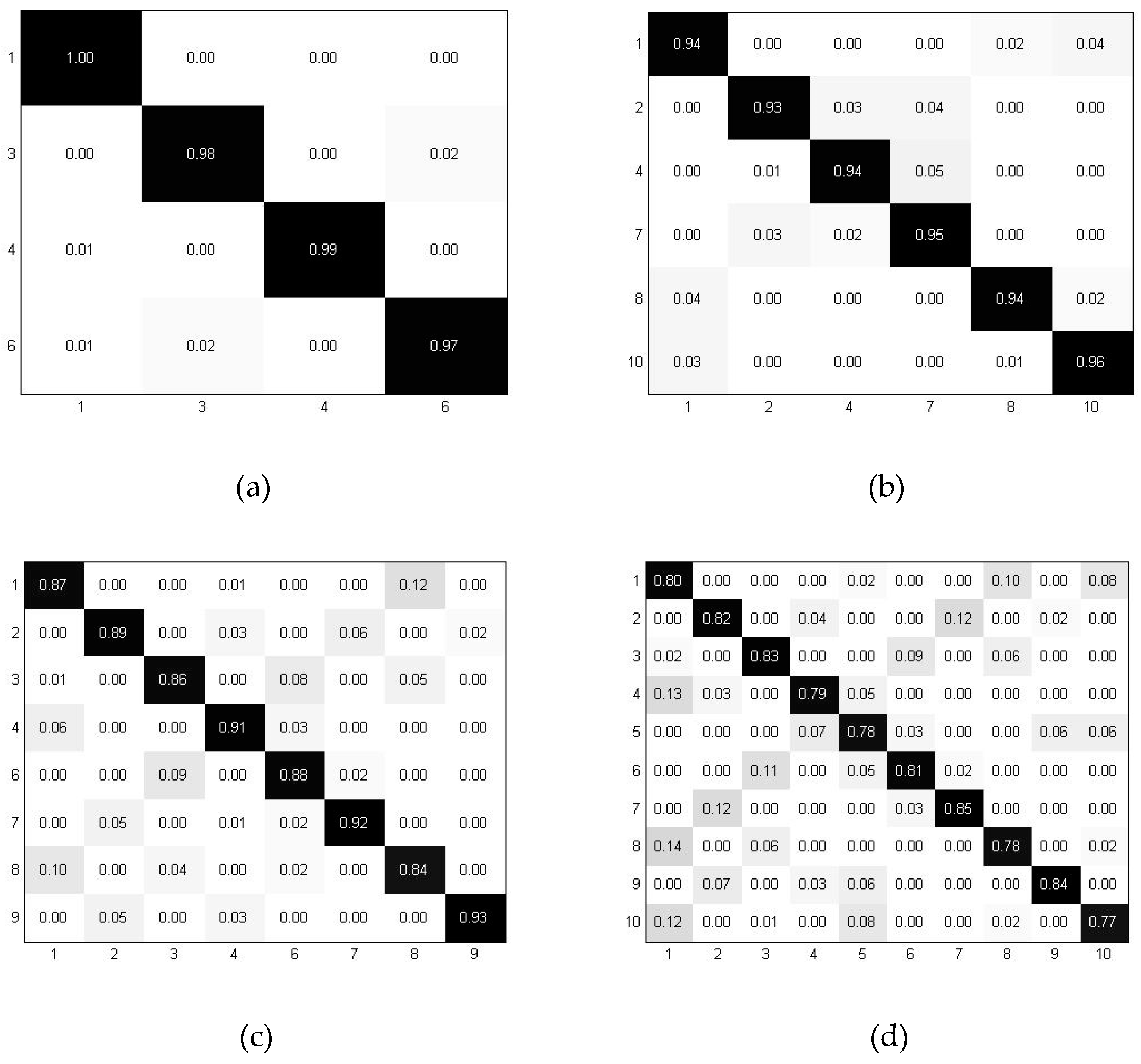
4.1. Based on Deep Learning
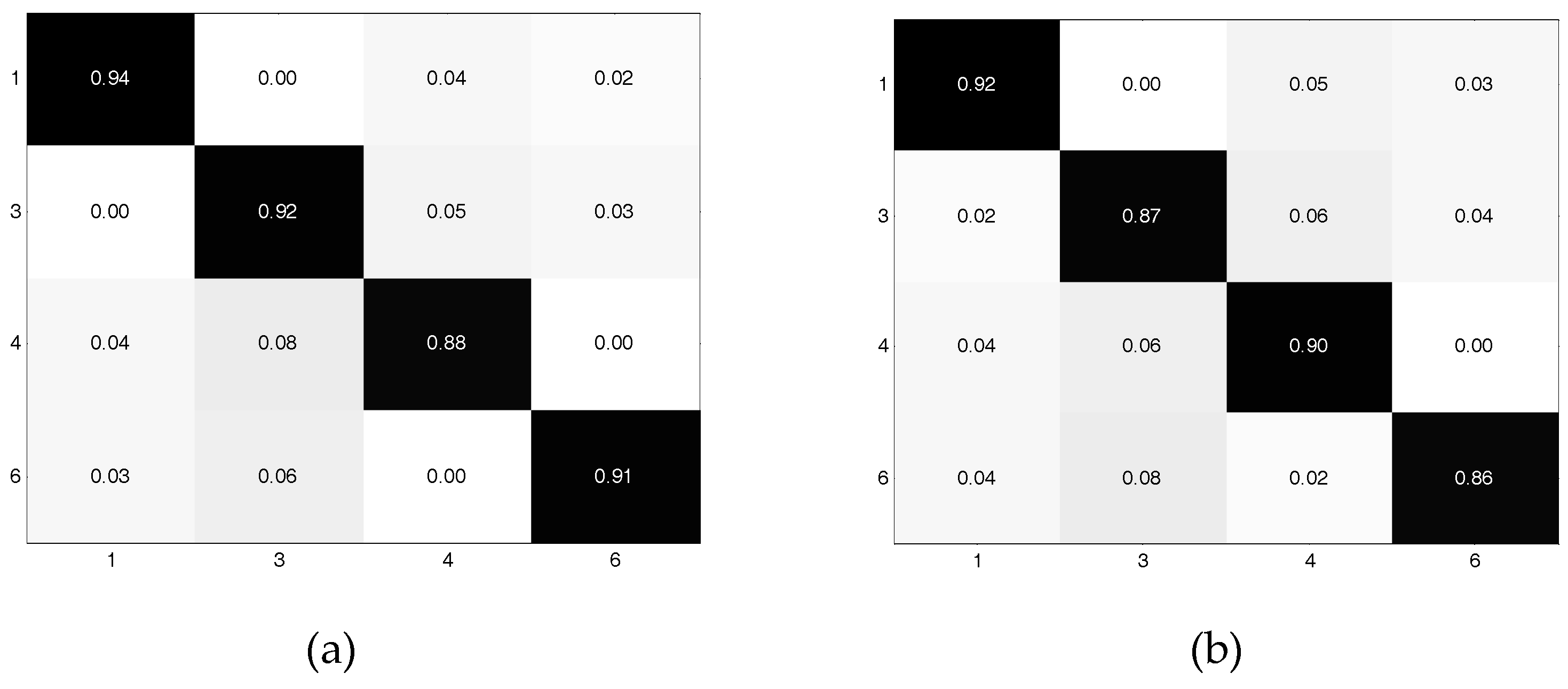
4.2. Based on Conventional Supervised Learning Algorithms
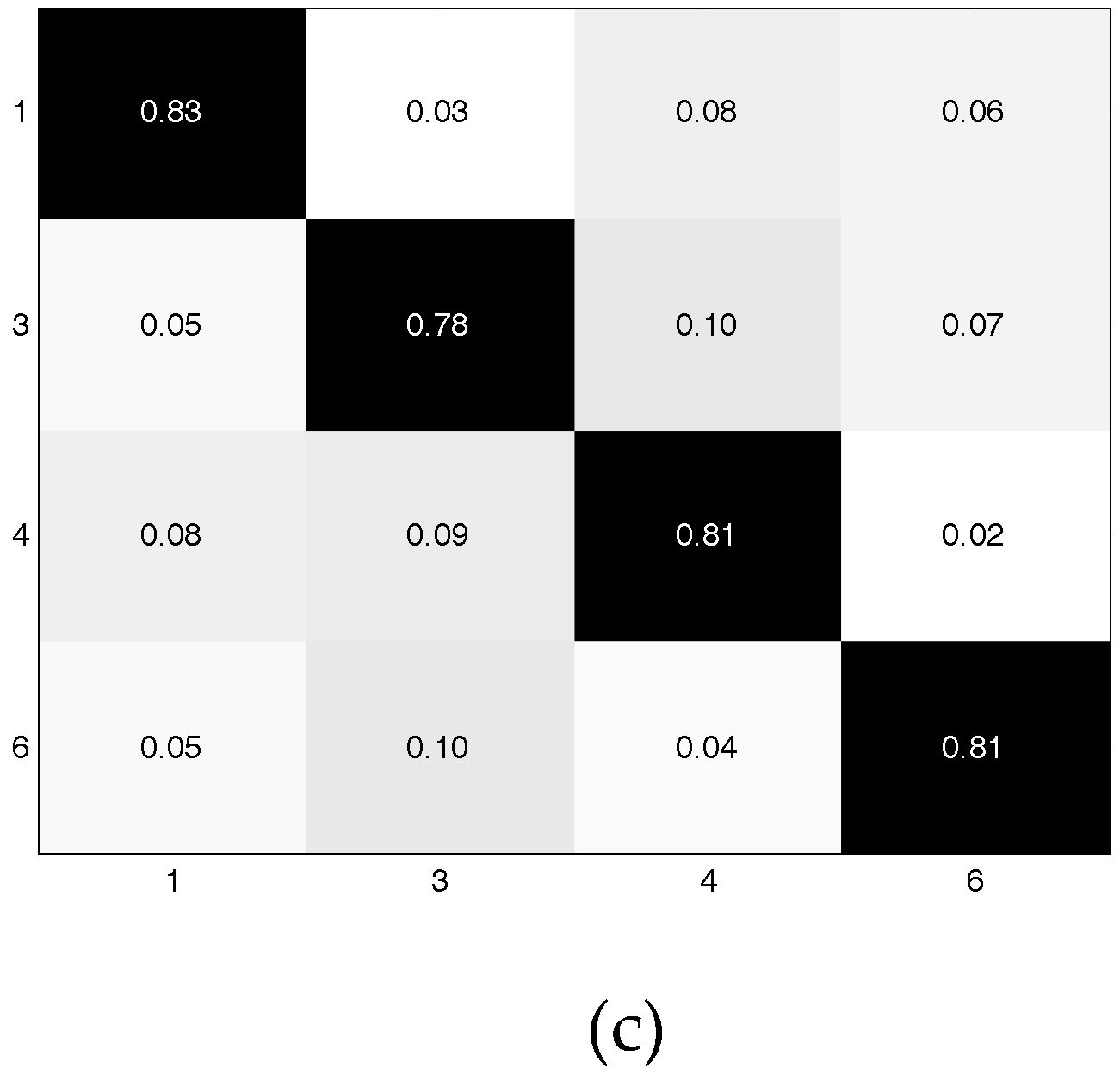
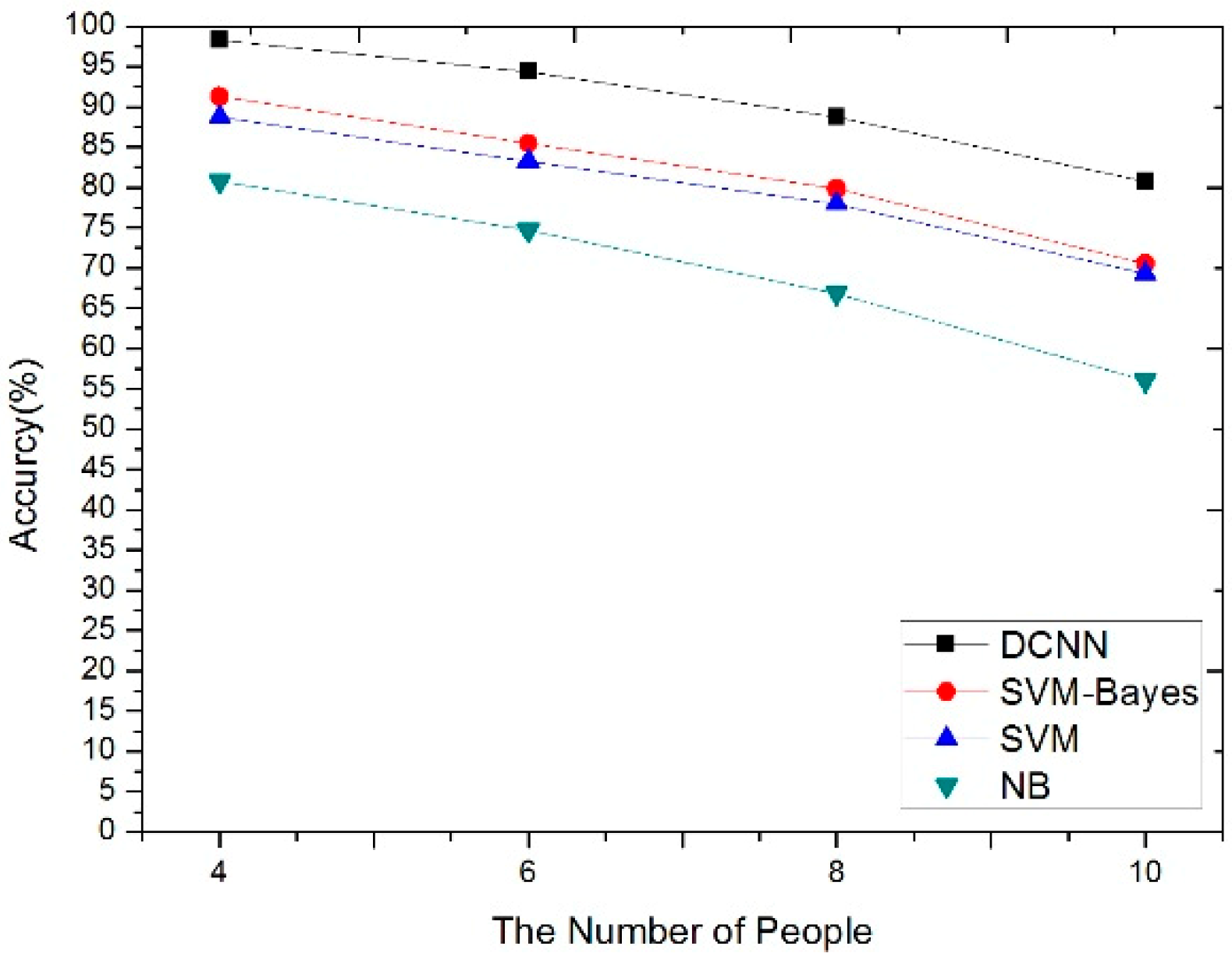
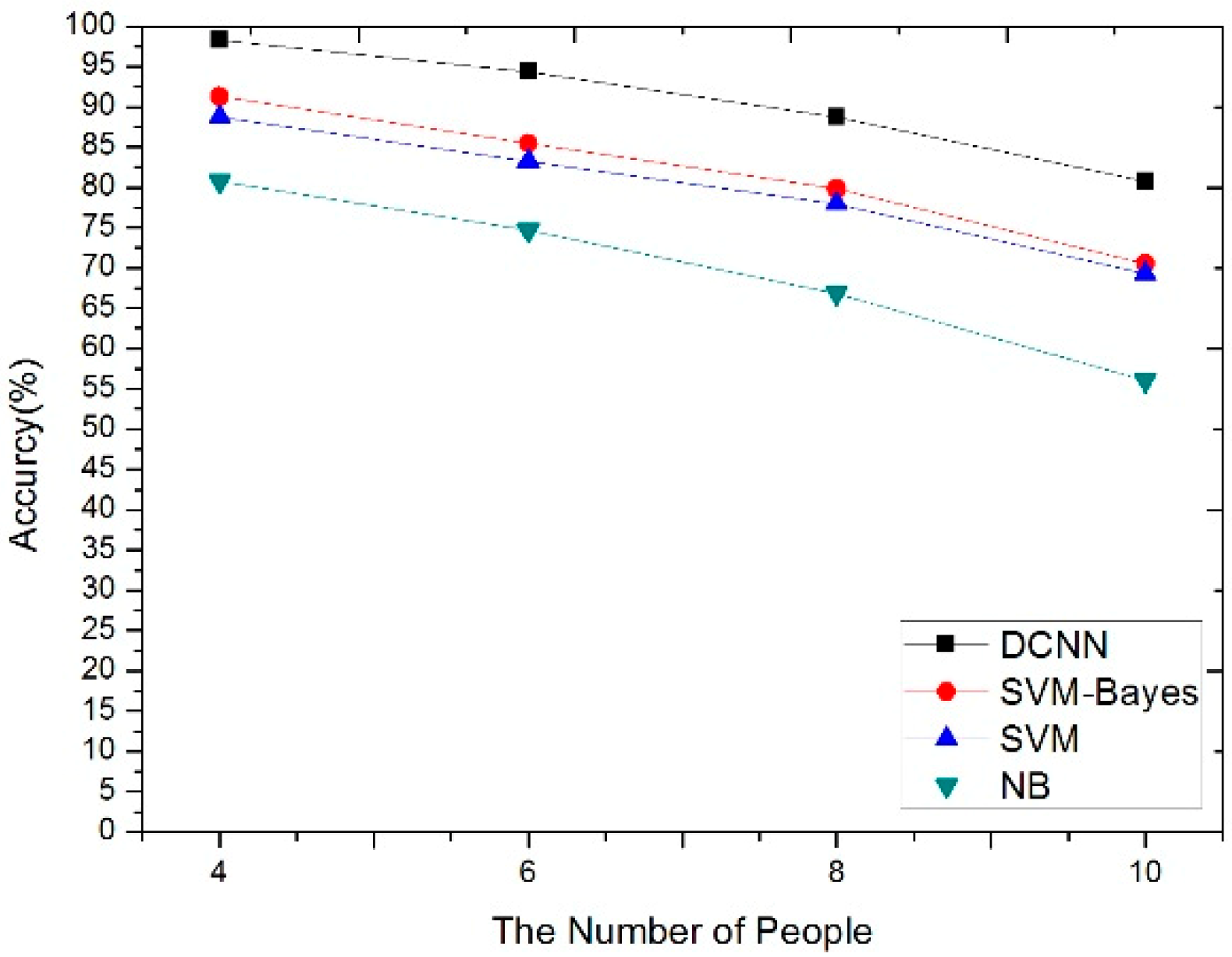
4.3. The Impact of Noise and Human Number for the Four Algorithms
4.4. Comparison with Other Techniques
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Molchanov, P.; Astola, J.; Egiazarian, K. Classification of ground moving radar targets by using joint time-frequency analysis. In Proceedings of the IEEE Radar Conference, Atlanta, GA, USA, 7–11 May 2012; pp. 366–371. [Google Scholar]
- Villeval, S.; Bilik, I.; Gürbüz, S.Z. Application of a 24 GHz FMCW automotive radar for urban target classification. In Proceedings of the IEEE Radar Conference, Cincinnati, OH, USA, 19–23 May 2014; pp. 1237–1240. [Google Scholar]
- Tahmoush, D.; Silvious, J.; Burke, E. A radar unattended ground sensor with micro-Doppler capabilities for false alarm reduction. In Proceedings of the Conference on Unmanned/Unattended Sensors and Sensor Networks VII, Toulouse, France, 20–23 September 2010; pp. 20–22. [Google Scholar]
- Robinette, C.D.; Silverman, C.; Jablon, S. Effects upon health of occupational exposure to microwave radiation (radar). Am. J. Epidemiol. 1980, 112, 39–53. [Google Scholar] [CrossRef]
- Chen, V.C. The Micro-Doppler Effect in Radar; Artech House: Norwood, MA, USA, 2011. [Google Scholar]
- Chen, V.C.; Tahmoush, D.; Miceli, W.J. Radar Micro-Doppler Signatures: Processing and Applications; Institution of Engineering and Technology: Stevenage, UK, 2014. [Google Scholar]
- Stankovic, L.; Stankovic, S.; Orovic, I. Time Frequency Analysis of Micro-Doppler Signals Based on Compressive Sensing. In Compressive Sensing for Urban Radar; CRC Press: Boca Raton, FL, USA, 2014; pp. 283–326. [Google Scholar]
- Zhao, M.; Adib, F.; Katabi, D. Emotion Recognition using Wireless Signals. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 95–108. [Google Scholar]
- Lin, F.; Song, C.; Zhuang, Y.; Xu, W.; Li, C.; Ren, K. Cardiac Scan: A Non-Contact and Continuous Heart-Based User Authentication System. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, Snowbird, UT, USA, 16–20 October 2017; pp. 315–328. [Google Scholar]
- Hinton, G.; Deng, L.; Dong, Y. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Huang, R.; Xie, X.; Feng, Z.; Lai, J. Face recognition by landmark pooling-based CNN with concentrate loss. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1582–1586. [Google Scholar]
- Javier, R.J.; Kim, Y. Application of linear predictive coding for human activity classification based on micro-Doppler signatures. IEEE Geosci. Remote Sens. Lett. 2013, 11, 781–785. [Google Scholar] [CrossRef]
- Chen, V.; Ling, H. Time-Frequency Transforms for Radar Imaging and Signal Analysis; Artech House: Norwood, MA, USA, 2002. [Google Scholar]
- Cherkassky, V.; Mulier, F. Statistical Learning Theory. In Learning from Data: Concepts, Theory, and Methods; Wiley-IEEE Press: Hoboken, NJ, USA, 2007; pp. 99–150. [Google Scholar]
- Furey, T.S.; Cristianini, N.; Duffy, N.; Bednarski, D.W.; Schummer, M.; Haussler, D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 2000, 16, 906–914. [Google Scholar] [CrossRef] [PubMed]
- Fumitake, T.; Shigeo, A. Decision-tree-based multi-class support vector machines. Proc. IEEE ICONIP 2002, 3, 1418–1422. [Google Scholar]
- Hsu, C.; Lin, C. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. Mar. 2002, 13, 415–425. [Google Scholar]
- Kim, C.J.; Hwang, K.B. Naive Bayes classifier learning with feature selection for spam detection in social bookmarking. In Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD); Springer Verlag: Antwerp, Belgium, 2008. [Google Scholar]
- Pop, I. An approach of the Naive Bayes classifier for the document classification. Gen. Math. 2006, 14, 135–138. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J. Caffe: Convolutional architecture for fast feature embed-ding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Ng, H.; Tong, H.L.; Tan, W.H.; Yap, T.T.; Chong, P.F.; Abdullah, J. Human identification based on extracted gait features. Int. J. New Comput. Archit. Their Appl. IJNCAA 2011, 1, 358–370. [Google Scholar]
- Zhang, J.; Bo, W. WiFi-ID: Human Identification using WiFi signal. In Proceedings of the IEEE International Conference on Distributed Computing in Sensor Systems, Washington, DC, USA, 26–28 May 2016; pp. 75–82. [Google Scholar]
- Pan, S.; Wang, N.; Qian, Y.; Velibeyoglu, I.; Noh, H.Y.; Zhang, P. Indoor Person Identification through Footstep Induced. In Proceedings of the International Workshop on Mobile Computing Systems & Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 81–86. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy | Training Time | Identification Time |
|---|---|---|---|
| DCNN | 98.5% | 12 min | 1.539 s |
| SVM–Bayes | 91.25% | 4.267 s | 0.771 s |
| SVM | 88.75% | 1.982 s | 0.643 s |
| NB | 80.75% | 1.674 s | 0.558 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, P.; Xia, W.; Li, Y. Heart ID: Human Identification Based on Radar Micro-Doppler Signatures of the Heart Using Deep Learning. Remote Sens. 2019, 11, 1220. https://doi.org/10.3390/rs11101220
Cao P, Xia W, Li Y. Heart ID: Human Identification Based on Radar Micro-Doppler Signatures of the Heart Using Deep Learning. Remote Sensing. 2019; 11(10):1220. https://doi.org/10.3390/rs11101220
Chicago/Turabian StyleCao, Peibei, Weijie Xia, and Yi Li. 2019. "Heart ID: Human Identification Based on Radar Micro-Doppler Signatures of the Heart Using Deep Learning" Remote Sensing 11, no. 10: 1220. https://doi.org/10.3390/rs11101220
APA StyleCao, P., Xia, W., & Li, Y. (2019). Heart ID: Human Identification Based on Radar Micro-Doppler Signatures of the Heart Using Deep Learning. Remote Sensing, 11(10), 1220. https://doi.org/10.3390/rs11101220