Context Aggregation Network for Semantic Labeling in Aerial Images



Abstract
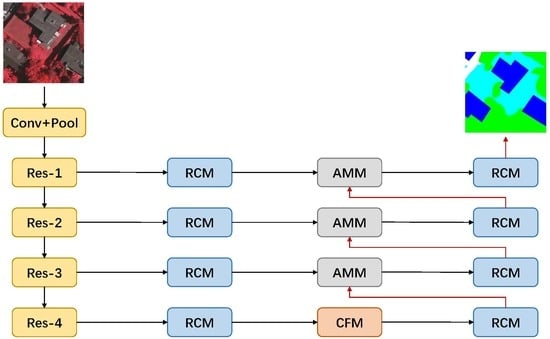
1. Introduction
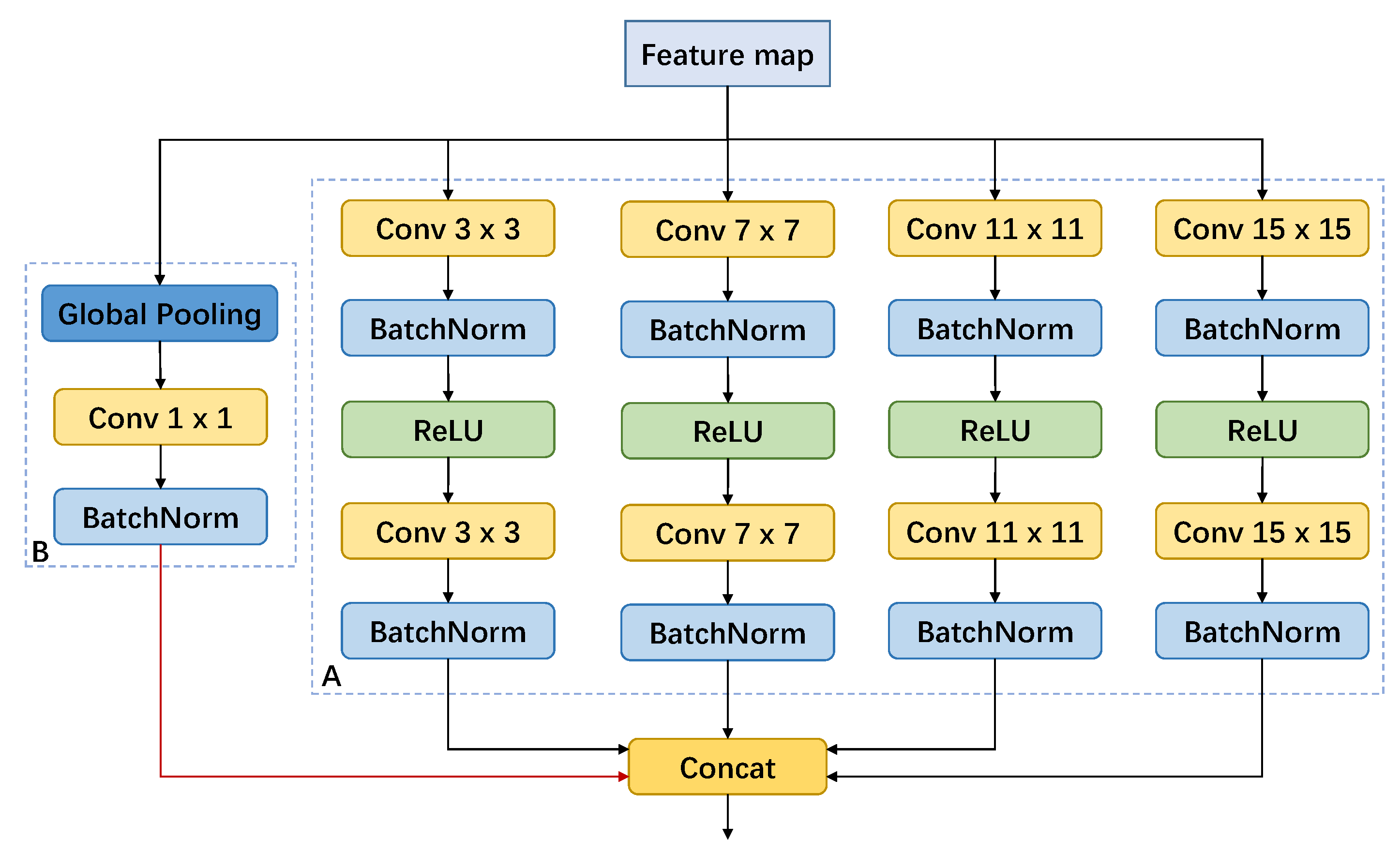
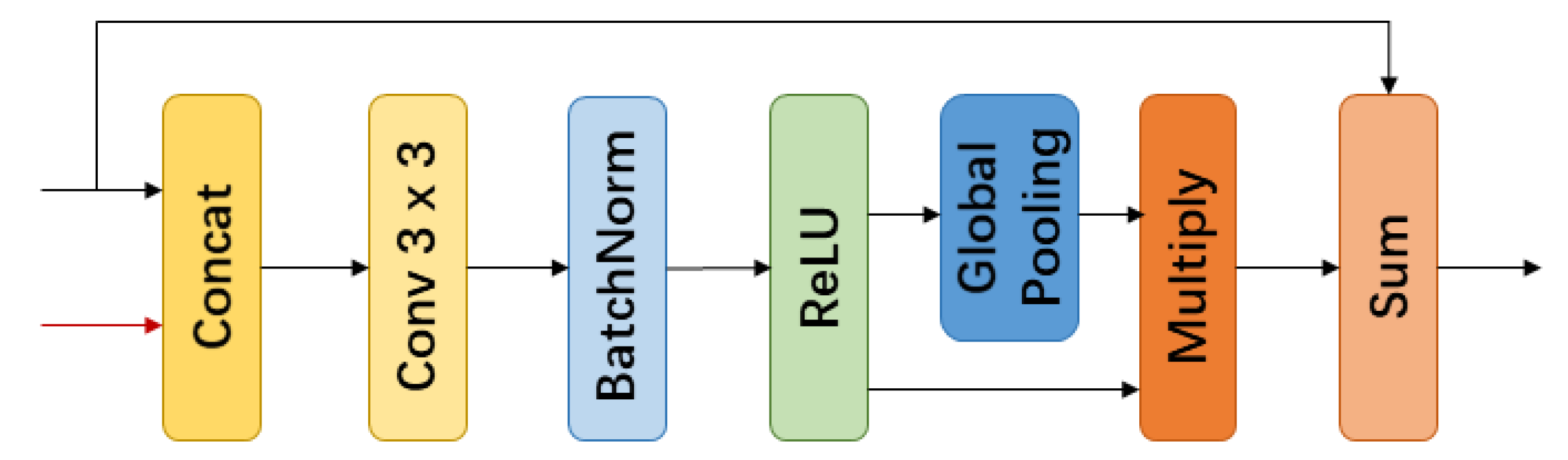
- We design a Context Fuse Module to exploit context information extensively. It is composed of parallel convolutional layers with different size kernels to aggregate context information with multiple receptive fields, and a global pooling branch to introduce global information.
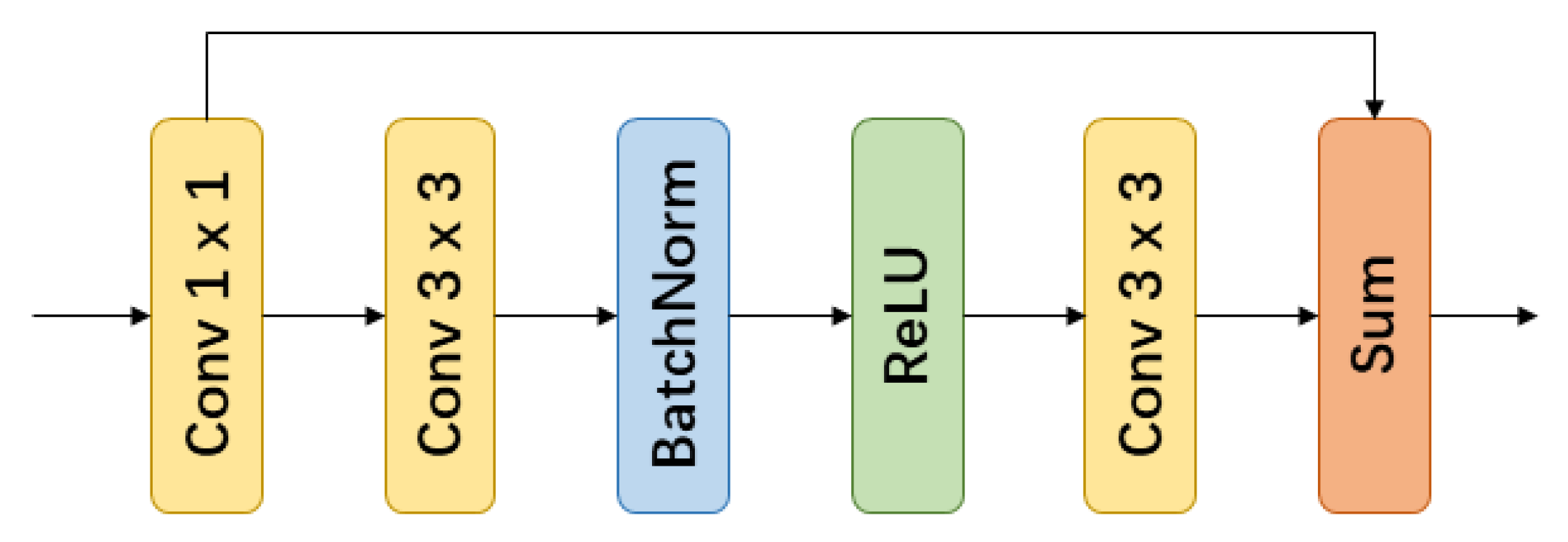
- We propose an Attention Mix Module, which utilizes channel-wise attention mechanism to combine multi-level features and selectively emphasizes more discriminative features for recognition. We further employ a Residual Convolutional Module to refine features in all feature levels.
- Based on these models, we construct a new end-to-end network for semantic labeling in aerial images. We evaluate the proposed network on ISPRS Vaihingen and Potsdam datasets. Experimental results demonstrate that our network outperforms other state-of-the-art CNN-based models and top methods on the benchmark with only raw image data, without using digital surface model information.
- We make our PyTorch-based implementation of the proposed model publicly available at https://github.com/Spritea/Context-Aggregation-Network.
2. Methods
2.1. Context Fuse Module
2.2. Attention Mix Module
2.3. Residual Convolutional Module
2.4. Context Aggregation Network
3. Results and Analysis
3.1. Experimental Settings
3.1.1. Dataset Description
3.1.2. Dataset Preprocess
3.1.3. Training Details
3.1.4. Metrics
3.2. Local Evaluation
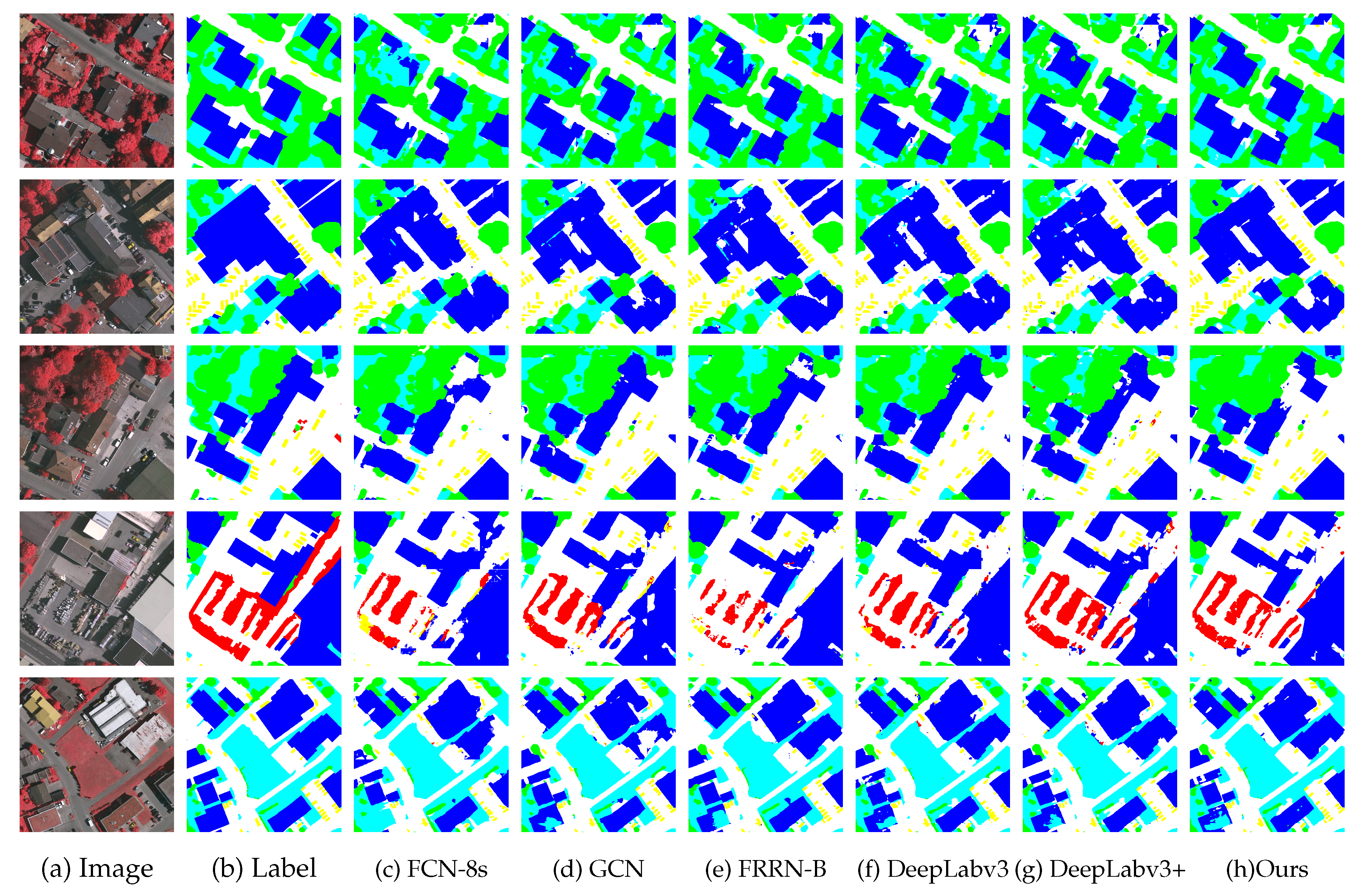
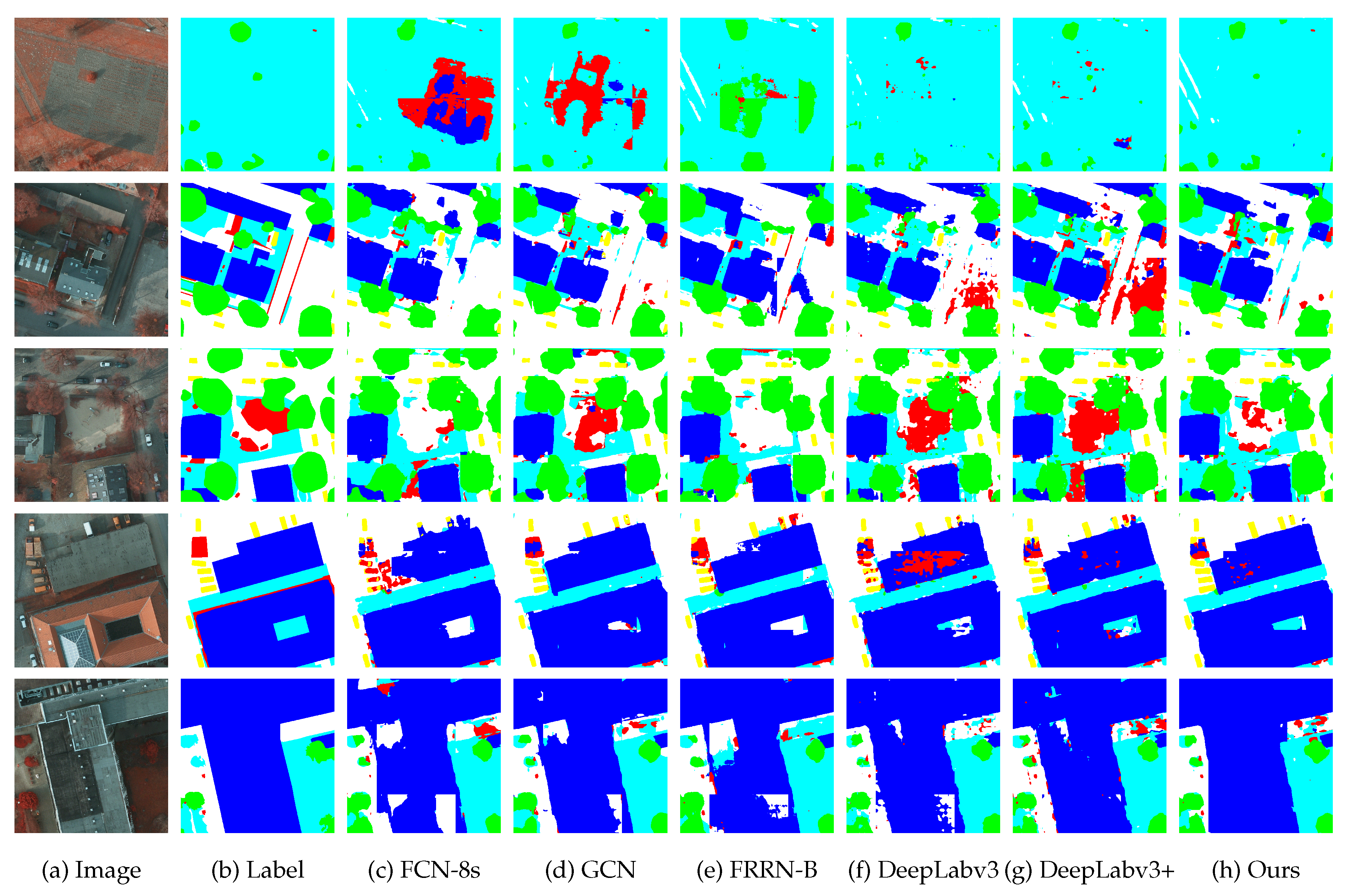
3.2.1. Vaihingen Local Evaluation
3.2.2. Potsdam Local Evaluation
3.3. Benchmark Evaluation
3.3.1. Vaihingen Benchmark Evaluation
3.3.2. Potsdam Benchmark Evaluation
4. Discussion
4.1. Ablation Study
4.2. Model Performance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNNs | Convolutional Neural Networks |
| SIFT | Scale Invariant Feature Transform |
| HOG | Histogram of Oriented Gradients |
| FAST | Accelerated Segment Test |
| FCN | Fully Convolutional Networks |
| CFM | Context Fuse Module |
| AMM | Attention Mix Module |
| RCM | Residual Convolutional Module |
| CAN | Context Aggregation Network |
| IRRG | Infrared, Red and Green |
| DSM | Digital Surface Model |
| NDSM | Normalized Digital Surface Model |
| GSD | Ground Surface Distance |
| IRRGB | Infrared, Red, Green, Blue |
| SGD | Stochastic gradient descent |
| F1 | F1 score |
| OA | Overall Accuracy |
| IoU | Intersection over Union |
| PR | Precision-recall |
| CRF | Conditional Random Field |
References
- Li, J.; Huang, X.; Gamba, P.; Bioucas-Dias, J.M.; Zhang, L.; Benediktsson, J.A.; Plaza, A. Multiple feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1592–1606. [Google Scholar] [CrossRef]
- Xue, Z.; Li, J.; Cheng, L.; Du, P. Spectralspatial classification of hyperspectral data via morphological component analysis-based image separation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 70–84. [Google Scholar]
- Xu, X.; Li, J.; Huang, X.; Mura, M.D.; Plaza, A. Multiple morphological component analysis based decomposition for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3083–3102. [Google Scholar] [CrossRef]
- Moser, G.; Serpico, S.B.; Benediktsson, J.A. Land-cover mapping by Markov modeling of spatial-contextual information in very-high-resolution remote sensing images. Proc. IEEE 2013, 101, 631–651. [Google Scholar] [CrossRef]
- Lu, X.; Yuan, Y.; Zheng, X. Joint dictionary learning for multispectral change detection. IEEE Trans. Cybern. 2017, 47, 884–897. [Google Scholar] [CrossRef]
- Matikainen, L.; Karila, K. Segment-based land cover mapping of a suburban area-comparison of high-resolution remotely sensed datasets using classification trees and test field points. Remote Sens. 2011, 3, 1777–1804. [Google Scholar] [CrossRef]
- Zhang, Q.; Seto, K.C. Mapping urbanization dynamics at regional and global scales using multi-temporal dmsp/ols nighttime light data. Remote Sens. Environ. 2011, 115, 2320–2329. [Google Scholar] [CrossRef]
- Xin, P.; Jian, Z. High-resolution remote sensing image classification method based on convolutional neural network and restricted conditional random field. Remote Sens. 2018, 10, 920. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 90–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Turgay, C. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 3, 772–776. [Google Scholar] [CrossRef]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sending images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Mariana, B.; Lucian, D. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; van den Hengel, A. Semantic labeling of aerial and satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. 2016, 9, 2868–2881. [Google Scholar] [CrossRef]
- Nogueira, K.; Mura, M.D.; Chanussot, J.; Schwartz, W.R.; Santos, J.A.D. Learning to semantically segment highresolution remote sensing images. Proceedings of IEEE International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3566–3571. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Mostajabi, M.; Yadollahpour, P.; Shakhnarovich, G. Feedforward semantic segmentation with zoom-out features. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3376–3385. [Google Scholar]
- Zhao, W.; Jiao, L.; Ma, W.; Zhao, J.; Zhao, J.; Liu, H.; Cao, X.; Yang, S. Superpixel-based multiple local cnn for panchromatic and multispectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4141–4156. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention(MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-resolution residual networks for semantic segmentation in street scenes. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4151–4160. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 5168–5177. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv, 2017; arXiv:1706.05587. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters–Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision(WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Proceedings of International Conference on Machine Learning(ICML), San Diego, CA, USA, 7–9 May 2015; pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. In Proceedings of the International Conference on Learning Representations (ICLR), Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1857–1866. [Google Scholar]
- ISPRS. International Society For Photogrammetry And Remote Sensing. 2D Semantic Labeling Challenge. 2016. Available online: http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html (accessed on 13 May 2019).
- Piramanayagam, S.; Saber, E.; Schwartzkopf, W.; Koehler, F. Supervised Classification of Multisensor Remotely Sensed Images Using a Deep Learning Framework. Remote Sens. 2018, 10, 1429. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Context-aware cascade network for semantic labeling in VHR image. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 575–579. [Google Scholar]
- Gerke, M. Use of the Stair Vision Library within the ISPRS 2d Semantic Labeling Benchmark (Vaihingen); Technical Report; University of Twente: Enschede, The Netherlands, 2015. [Google Scholar]
- Gould, S.; Russakovsky, O.; Goodfellow, I.; Baumstarck, P. The Stair Vision Library (v2.5); Stanford University: Stanford, CA, USA, 2011. [Google Scholar]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv, 2016; arXiv:1606.02585. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Imp surf | Building | Low veg | Tree | Car | Avg. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mF1 | Acc. | |
| FCN-8s [27] | 80.3 | 89.1 | 83.0 | 90.7 | 67.4 | 80.6 | 73.4 | 84.7 | 58.3 | 73.7 | 72.5 | 83.7 | 85.9 |
| GCN [36] | 81.6 | 89.8 | 86.2 | 92.6 | 68.5 | 81.3 | 74.2 | 85.2 | 61.4 | 76.1 | 74.4 | 85.0 | 86.9 |
| FRRN-B [31] | 81.5 | 89.8 | 86.8 | 92.9 | 68.5 | 81.3 | 73.6 | 84.8 | 63.6 | 77.7 | 74.8 | 85.3 | 86.9 |
| DeepLabv3 [35] | 81.8 | 90.0 | 87.4 | 93.3 | 70.0 | 82.3 | 74.5 | 85.4 | 61.2 | 75.9 | 75.0 | 85.4 | 87.4 |
| DeepLabv3+ [43] | 81.2 | 89.6 | 86.7 | 92.9 | 68.6 | 81.4 | 74.9 | 85.6 | 64.3 | 78.3 | 75.1 | 85.5 | 87.2 |
| Ours | 82.6 | 90.5 | 87.2 | 93.1 | 70.3 | 82.5 | 75.2 | 85.9 | 68.7 | 81.4 | 76.8 | 86.7 | 87.8 |
| Model | Imp surf | Building | Low veg | Tree | Car | Avg. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mF1 | Acc. | |
| FRRN-B [31] | 78.6 | 88.0 | 86.2 | 92.6 | 68.9 | 81.6 | 70.1 | 82.4 | 78.1 | 87.7 | 76.4 | 86.5 | 85.5 |
| FCN-8s [27] | 79.6 | 88.6 | 86.0 | 92.4 | 70.1 | 82.4 | 70.8 | 82.9 | 78.3 | 87.8 | 77.0 | 86.8 | 86.1 |
| GCN [36] | 80.1 | 88.9 | 87.5 | 93.3 | 70.1 | 82.4 | 70.7 | 82.8 | 78.1 | 87.7 | 77.3 | 87.0 | 86.4 |
| DeepLabv3 [35] | 80.7 | 89.3 | 88.5 | 93.9 | 69.9 | 82.3 | 70.4 | 82.6 | 78.7 | 88.1 | 77.7 | 87.2 | 86.7 |
| DeepLabv3+ [43] | 80.6 | 89.2 | 88.5 | 93.9 | 70.3 | 82.6 | 71.2 | 83.2 | 80.1 | 88.9 | 78.1 | 87.6 | 86.5 |
| Ours | 80.7 | 89.3 | 86.8 | 92.9 | 71.0 | 83.0 | 72.7 | 84.2 | 79.6 | 88.6 | 78.2 | 87.6 | 86.9 |
| Methods | Imp surf | Building | Low veg | Tree | Car | Overall Acc.(%) |
|---|---|---|---|---|---|---|
| SVL_6 [49] | 86.0 | 90.2 | 75.6 | 82.1 | 45.4 | 83.2 |
| UZ_1 [51] | 89.2 | 92.5 | 81.6 | 86.9 | 57.3 | 87.3 |
| ADL_3 [20] | 89.5 | 93.2 | 82.3 | 88.2 | 63.3 | 88.0 |
| DST_2 [52] | 90.5 | 93.7 | 83.4 | 89.2 | 72.6 | 89.1 |
| DLR_8 [53] | 90.4 | 93.6 | 83.9 | 89.7 | 76.9 | 89.2 |
| CASIA [48] | 92.7 | 95.3 | 84.3 | 89.6 | 80.8 | 90.6 |
| Ours | 93.0 | 95.8 | 85.0 | 90.2 | 89.7 | 91.2 |
| Methods | Imp surf | Building | Low veg | Tree | Car | Overall Acc.(%) |
|---|---|---|---|---|---|---|
| SVL_3 [49] | 84.0 | 89.8 | 72.0 | 59.0 | 69.8 | 77.2 |
| UZ_1 [51] | 89.3 | 95.4 | 81.8 | 80.5 | 86.5 | 85.8 |
| KLab_2 [54] | 89.7 | 92.7 | 83.7 | 84.0 | 92.1 | 86.7 |
| RIT_2 [47] | 92.0 | 96.3 | 85.5 | 86.5 | 94.5 | 89.4 |
| DST_2 [52] | 91.8 | 95.9 | 86.3 | 87.7 | 89.2 | 89.7 |
| Ours | 93.1 | 96.4 | 87.7 | 88.8 | 95.9 | 90.9 |
| Model | Imp surf | Building | Low veg | Tree | Car | Mean IoU(%) |
|---|---|---|---|---|---|---|
| Res-50 | 78.2 | 85.4 | 66.9 | 72.8 | 43.5 | 69.3 |
| Res-50+RCM | 81.9 | 87.1 | 69.8 | 75.2 | 65.6 | 75.9 |
| Res-50+RCM+CFM | 82.2 | 87.3 | 70.1 | 75.6 | 67.1 | 76.5 |
| Res-50+RCM+CFM+AMM | 82.6 | 87.2 | 70.3 | 75.2 | 68.7 | 76.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, W.; Yang, W.; Wang, M.; Wang, G.; Chen, J. Context Aggregation Network for Semantic Labeling in Aerial Images. Remote Sens. 2019, 11, 1158. https://doi.org/10.3390/rs11101158
Cheng W, Yang W, Wang M, Wang G, Chen J. Context Aggregation Network for Semantic Labeling in Aerial Images. Remote Sensing. 2019; 11(10):1158. https://doi.org/10.3390/rs11101158
Chicago/Turabian StyleCheng, Wensheng, Wen Yang, Min Wang, Gang Wang, and Jinyong Chen. 2019. "Context Aggregation Network for Semantic Labeling in Aerial Images" Remote Sensing 11, no. 10: 1158. https://doi.org/10.3390/rs11101158
APA StyleCheng, W., Yang, W., Wang, M., Wang, G., & Chen, J. (2019). Context Aggregation Network for Semantic Labeling in Aerial Images. Remote Sensing, 11(10), 1158. https://doi.org/10.3390/rs11101158