2.1. Multi-Cue Foreground Segmentation
The main problem when trying to detect small moving objects from aerial video is to separate the changes in the image caused by objects from those caused by the dynamic background. Therefore, at the beginning, we present a multi-cue foreground segmentation method to extract the potential target region that needs visual detail augmented mapping. As
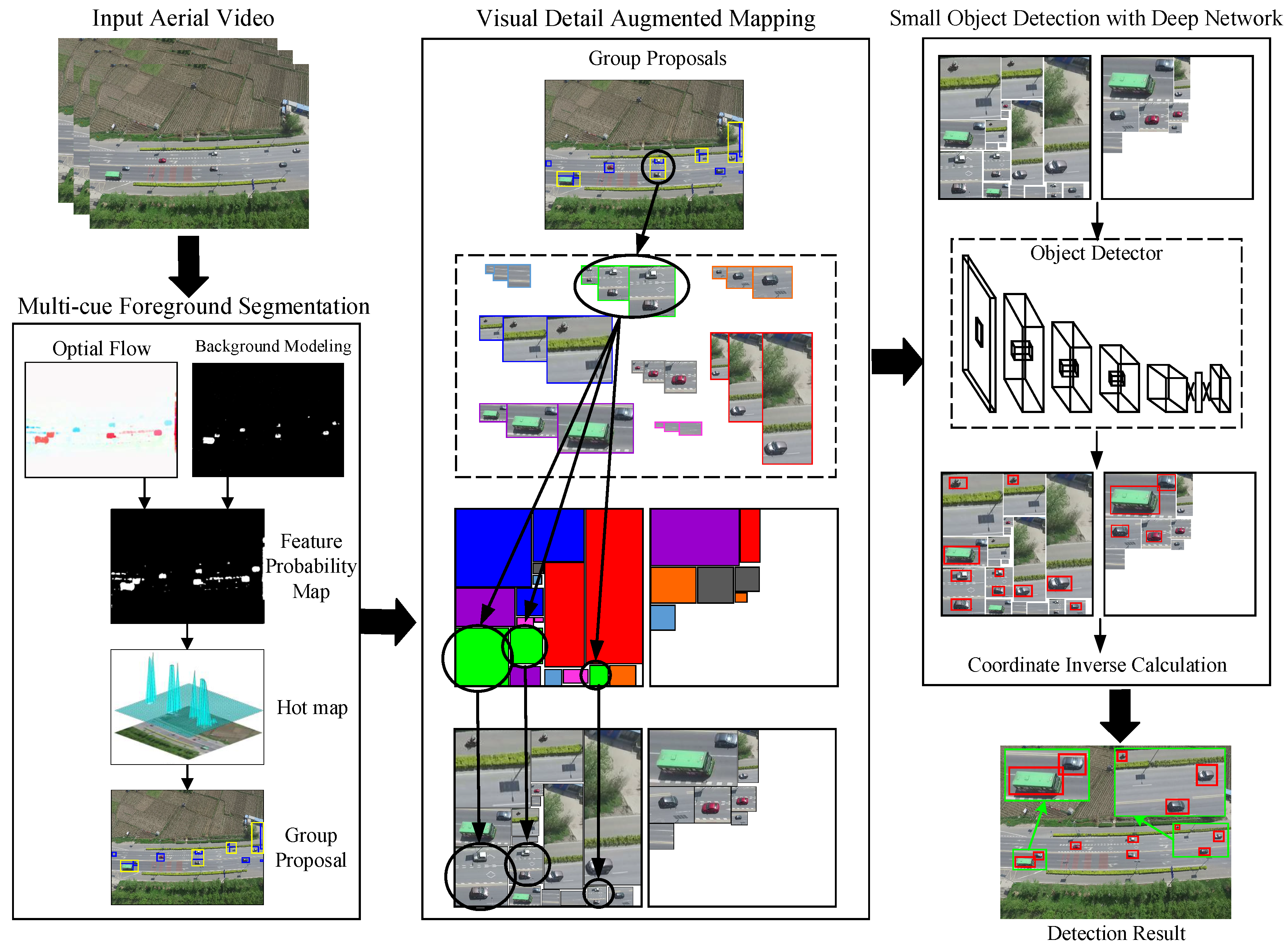
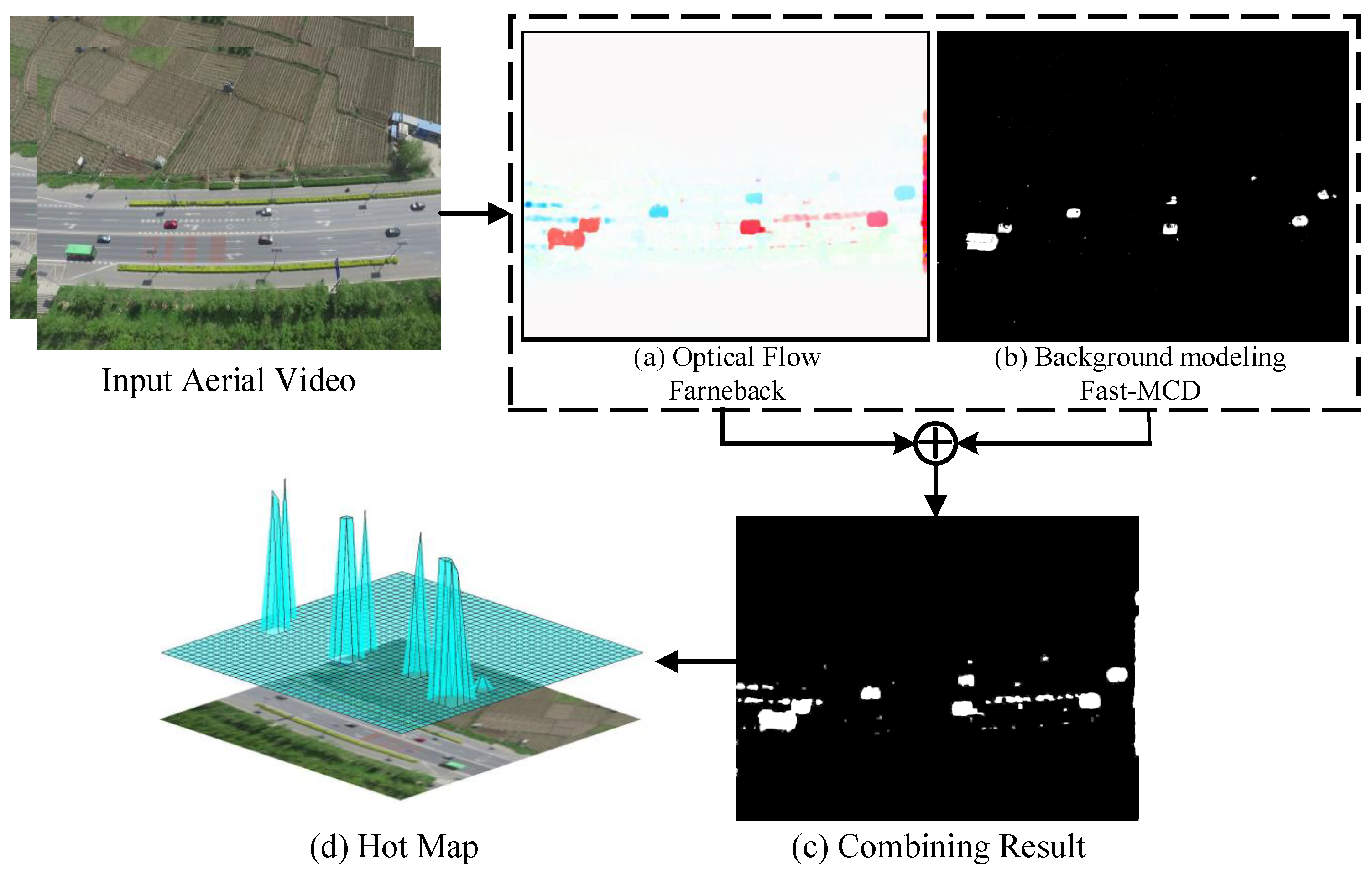
Figure 3 shows, the proposed method comprehensively analyzes the optical flow and background changes that might be caused by moving objects. Through the process above, its feature probability map is obtained by combining these two pieces of information. Then, in order to reduce the noise effect, the probability map is smoothed and its corresponding hot map is generated. The hot map symbolically depicts the possible position of the target. Then, single potential targets are clustered into group proposals and follow-up detection algorithm is processed in group.
As for multi-cue object information, optical flow and background modeling are adopted to jointly obtain the target probability map. The choice of these two algorithms is mainly based on two points: (1) Optical flow is an important technology for motion estimation, as it represents the relative motion information for each pixel. Optical flow can help us to pinpoint small targets more accurately. (2) The background modeling method describes grayscale changes between the current image and background by modeling the image background. This method is sensitive to small and weak changes and therefore is suitable for small target detection. However, both approaches have their merits and shortcomings. Optical flow is not robust on small targets and might result in missed detections. Background modeling can be easily disturbed by noise which may be mistaken for small targets, leading to a high false alarm rate. Though the two methods have their own limitations, there is a complementary role between them. The background modeling method will produce a miscarriage of justice when there is only a little gray contrast between the target and background, while optical flow can maintain good performance because its similar background also has a certain degree of motion. However, the optical flow method is insensitive to weak motion, which is advantageous for the background modeling method. In other words, optical flow and background modeling are different ways to describe the moving object. This means that the optical flow method combined with background modeling will have dual advantages and gain better effects for small target detection from aerial video. Based on the above analysis, the proposed method utilizes the advantages of the two methods to get the potential object region.
In the process of implementation, Farneback [
22] is first employed to calculate the optical flow information on the basis of considering detection speed and accuracy. The Farneback algorithm was proposed by Gunnar Farneback in 2003. It is a global dense optical flow algorithm based on two-frame motion estimation. Suppose that the two adjacent frames to be detected are denoted as
and
, respectively. Firstly, the coefficient vector of each pixel is calculated by the polynomial expansion transform. Taking pixel point
on
as an example, the approximate position
of this pixel on the next frame image
is
If the parameter of
is
and
is
, the intermediate variable
can be formulated as
Thus, we can get the coefficient vectors
and
by further calculations. Suppose that
is the scale matrix. The optical flow
is directly solved by
The Farneback method obtains the object’s moving information by analyzing its optical flow transformation, as shown in
Figure 4a. Its high detection accuracy and rapid data processing speed fit the requirements of a real-time aerial object detection system.
As for the background modeling method, the Fast-MCD algorithm [
23], which was proposed by Kwang et al. in 2013, was used. It segments the moving foreground by modeling the image background through the dual-mode Single Gaussian Model (SGM) with age. This method was chosen for two reasons: its robustness for testing moving backgrounds which frequently appear in aerial videos and its attention to small changes which tends to result in a lower missed detection rate on small targets.
Specifically, the procedure consists of the following steps. First of all, in order to remove background movement, Fast-MCD calculates a homograph matrix for the perspective transform from
to
. Then, the SGM model of the candidate background and the apparent background can be obtained. Assume that the input aerial image
is divided into several grids of the same size, the
ith grid is denoted as
in this paper. Through analysing the mean, variance, age of the candidate model, and the apparent model, the background model is selectively updated. Finally, after obtaining the background model, the image foreground is detected. On the basis of the updated apparent model with the mean
, variance
, and threshold
, the pixel
p with gray scale
which satisfies Formula (4) is the foreground. Thus, the moving foreground which contains small targets is segmented from the complex background:
Figure 4a,b show the moving foreground segmentation results of the Farneback and Fast-MCD, respectively. These figures show that the two methods have their own advantages as well as drawbacks. On the one hand, the overall outline of Farneback is more complete, but it lacks the small target on the upper right corner, while Fast-MCD can accurately obtain each small gray scale change, which is the disadvantage of Farneback approach. On the other hand, there are some holes in the detection results of Fast-MCD. The production of imcomplete objects can be avoided by Farneback. Overall, the results show that the two algorithms can exert a complementary action in small object detection. From another perspective, the purpose of foreground segmentation is to enhance the target saliency relative to the background. Background modeling and optical flow start from two different views to describe an object’s characteristics. The combination of the two methods actually improves object saliency and that helps us to segment a potential object region from the complex background. Thereafter, Farneback and Fast-MCD are combined to calculate the probability map. For the combined method, this paper takes the union of the two segmentation results to retain every possible position of the target, as shown in
Figure 4c shown. The combination of the two methods can be regarded as its feature probability map. It not only combines the advantages of optical flow and Fast-MCD, but also overcomes the shortcomings of both to a certain extent.
With probability map, the following is the potential area identified. In this step, considering that noise will damage the detection performance, the proposed method first smooths it. Mean filtering is used as the image smoothing algorithm. The mean filter is one of the most commonly used linear filters whose output is a simple average of all neighborhood pixels. This algorithm reduces sharp changes in the probability map and some noise can be filtered out from the probability map. As for the fuzzy problem caused by the mean filter, this paper employs it to locate potential objects in the probability map rather than in the aerial image. Therefore, it will not cause the blurring of the image in follow-up links. The detailed calculation process of the hot map is as follows. Take the pixel with coordinates in the probability map
g of (
) as an example, the filter window size is
. The pixel value
of this point in the hot map is
In this way, the hot map can be calculated from probability map with less noise impact.
Figure 4d show the visualization results of the hot map. The larger the hot value is, the greater the probability that a moving object exists. On this basis, the foreground area is selected from the detected hot map with the minimal bounding box and a set of candidate bounding boxes is obtained. These positions are where small targets might appear.
However, overlaps exist between these bounding boxes. As for the small targets placed in the far source, they occupy too few pixels and these overlaps may split a target. Incomplete objects have a great impact on the detection performance. This problem lets us think of a human visual system. Imagine a scenario with trees and mountains, with a user admiring the view. To detect tree regions from this scene, the human visual system only needs to group the forest area roughly. Similarly, we just need to segment the potential small targets into a group for the aerial video to obtain the region of interest. Inspired by this idea, in this paper, we apply it to the moving foreground segmentation.
To be more specific, the initial bounding boxes are clustered based on the distances between them to get group proposals. This reduces the target fragmentation caused by overlap which brings in a few parts of the background. In the processs of implementation, there are two cases that need to be clustered. First, the proposed method merges these overlapped boxes into one bounding box. This reduces the situation where overlapped boxes split the real object and provides more precise information for the following detection. Second, bounding boxes that are close together are clustered. Rather than using single objects, the division into groups is more suitable for small target detection due to the small sizes of the objects. In addition, it is enough to confirm the approximate locations of small targets at the preprocessing stage, and then have accurate detection followed up by the algorithm. In this way, the bounding boxes are synthesized into a group. These areas are the regions of interest in the aerial video. This has the benefit of improving the detection accuracy by avoiding the situation of small bounding boxes splitting the real target and reduces the complexity of subsequent computing with fewer areas of interest. Through the above processes, the group proposals that contain the small targets of interest are all segmented.
2.2. Visual Detail Augmented Mapping
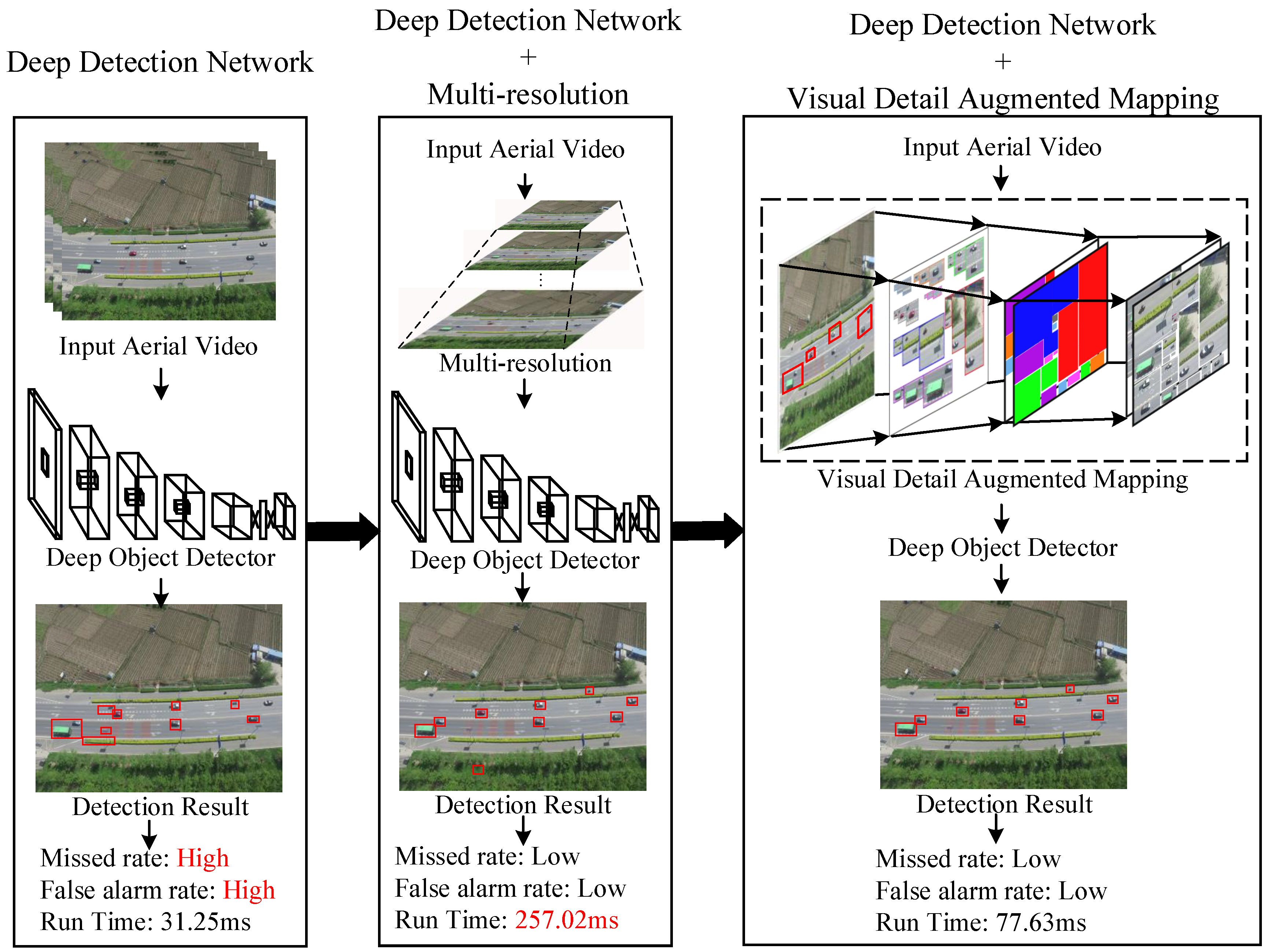
So far, these regions of interest that might contain real small targets have been segmented from the input aerial video. The next step is to accurately detect whether these regions have moving objects or not. However, due to the small size of the aerial targets, direct detection will lead to a high false alarm rate and missed rate. To solve this problem, this section describes the corresponding analysis research and proposes a novel approach to solve this problem.
First of all, we explore the root cause of the small target detection failure. From the results obtained in the previous step, we make the following conclusion. Although the group proposal can basically frame all potential moving targets, it still contains some problems. The targets in an aerial image are so small that we cannot obtain enough information from them. The limited visual data makes it difficult for us to represent object well. This is the fundamental reason why the accuracy of small targets is low. To tackle this problem, the simplest solution is to enlarge the aerial image and get more detailed characteristics about the object representation. However, as the experimental results in
Figure 2 show, the larger the image is, the more pixel level information it contains. This means that a number of calculations are required in many image processing links. In aerial video, unrelated background areas usually occupy a large proportion of the total area, and there is only a tiny area with the target of interest. That is to say, enhancement of only a few pixels is enough to achieve accurate target detection. According to this principle, in this paper, we present a visual detail augmented mapping algorithm approach which gives attention to both the detection speed and precision.
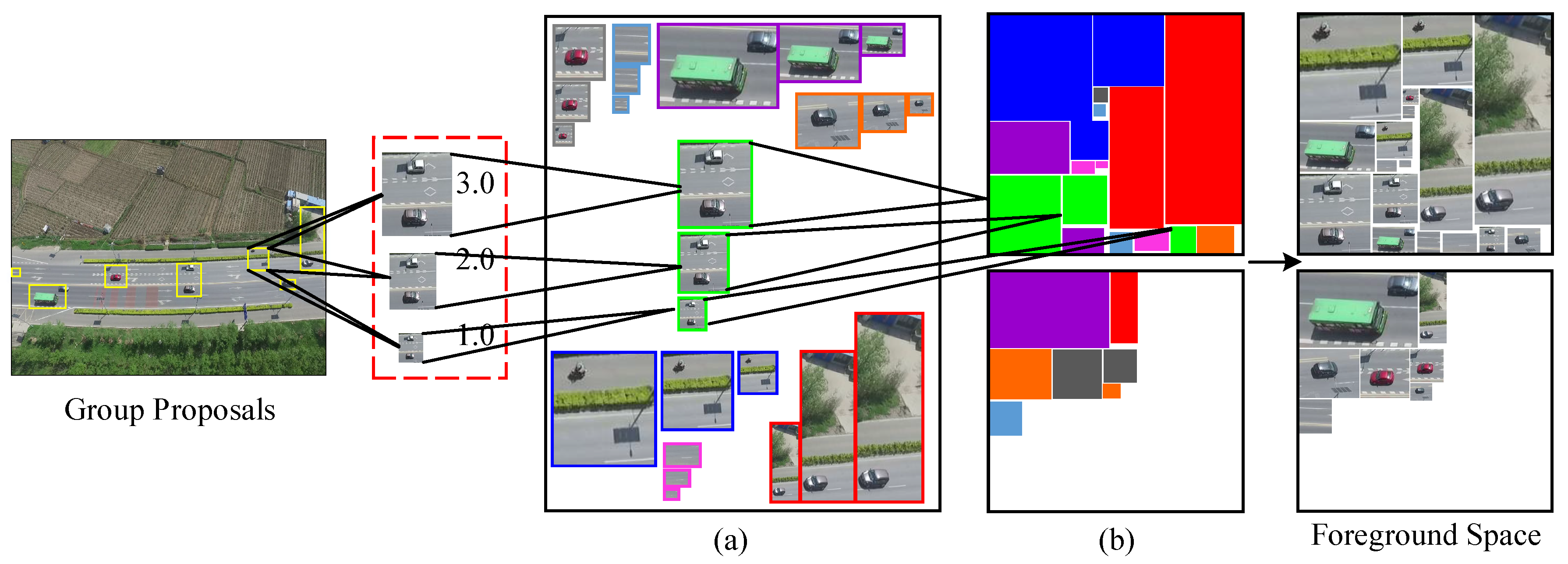
This mapping mainly includes two modules: one is multi-resolution mapping which selectively enlarges the potential region to different sizes to give detailed object information; the other is foreground augmented mapping which maps the original target to a more compact foreground space for visual augmentation. The framework is given in
Figure 5.
In the first part, the proposed approach performs multi-resolution mapping on the group proposals obtained in the previous section. Let the input
contain
N group proposals; its group proposal set is denoted as
.
is the
group proposal with coordinates
, where
are the coordinates of the upper left corner and
is the corresponding bounding box size. For one group proposal, the proposed method enlarges it into different scales. That can transform the small target in an aerial video into its normal size. For example,
covers an area of
. We magnify it into three sizes, and the scale factors are 1.0, 2.0, 3.0. Thus, the size of
is increased to
, respectively. For the amplification interpolation method, we utilize linear interpolation, which is a commonly used method. By enlarging all group proposals with linear interpolation to the three scales above, we obtain the amplified results of each region, as shown in
Figure 5a. We can see from the figure that small targets in the input aerial image are converted into normal size through mapping at the three scales. More detailed target information is mapped out.
Through the multi-resolution mapping processing, the specific characteristics of small targets are mined out which is advantageous to object representation and, in turn, strengthens the detection performance. For efficiency, we only map a small portion of the input image which takes little additional computation cost. In other words, our method improves the detection accuracy of small aerial targets and also gives attention to the detection speed.
After that, how do we integrate this detailed target information? The most simple and direct way is to send these enlarged regions to be detected one by one. This method requires as many detection times as the number of enlarged regions. This leads to a low detection efficiency. Another solution is to put all of them directly into a large enough foreground image, and then the large foreground image is sent once into the deep detection network. Though the efficiency of this method is high, its foreground images will be resized to a small scale and that will destroy the object’s detailed information. Therefore, in this part, we present a novel foreground augmented mapping method which rearranges these regions into a efficient and compact space. Compared with the other two methods, foreground mapping provides a method to minimize the loss of efficiency while retaining the augmented visual effect. As
Figure 5b shows, the proposed method maps the potential area with multi-resolution into a set of foreground augmented maps and ditches the irrelevant background part. Thus, it not only can reduce the influence of the background and avoid computing resources waste, but also further visually enhance the valuable detailed target information. To be specific, the proposed method first creates a set of empty images in the new foreground space. The size of foreground augmented map is designed to be dependent on the follow-up deep detection network. This ensures that the target regions are not reduced by the detector’s internal steps, and there is no target information loss in this step. The number of these images is determined by potential region’s size. Then, in order to make full use of each augmented map in the foreground space and to save the computation source, we pack as much of the region as possible into the limited image space. This issue can be regarded as the rectangular packing problem which is a combinatorial optimization problem. In this paper, we employ the rectangular packing algorithm to find the optimal solution for potential target region location. The packing result is shown in
Figure 5b. As we can see, all regions of this instance are packed into two foreground augmented maps with maximum space utilization. The two foreground augmented maps are what we will send to the deep detection network. Through visual detail augmented mapping, the input aerial video is visually augmented in two ways: (1) Potential target regions are mapped into multiple resolution which enhances the detailed target features and provides a subsequent detection network with more abundant visual information. (2) The new foreground space filters out most of the irrelevant background and only rearranges the potential target regions. In some sense, the foreground augmented maps are the visual augmentation of the original aerial data.
Now, after visual detail augmented mapping, the preprocessing work before detection is finished. The result of the procedure above is a set of foreground augmented maps which are mapped from the original aerial image and they only contain some valuable potential target regions which need further precise detection.
2.3. Small Object Detection with the Deep Network
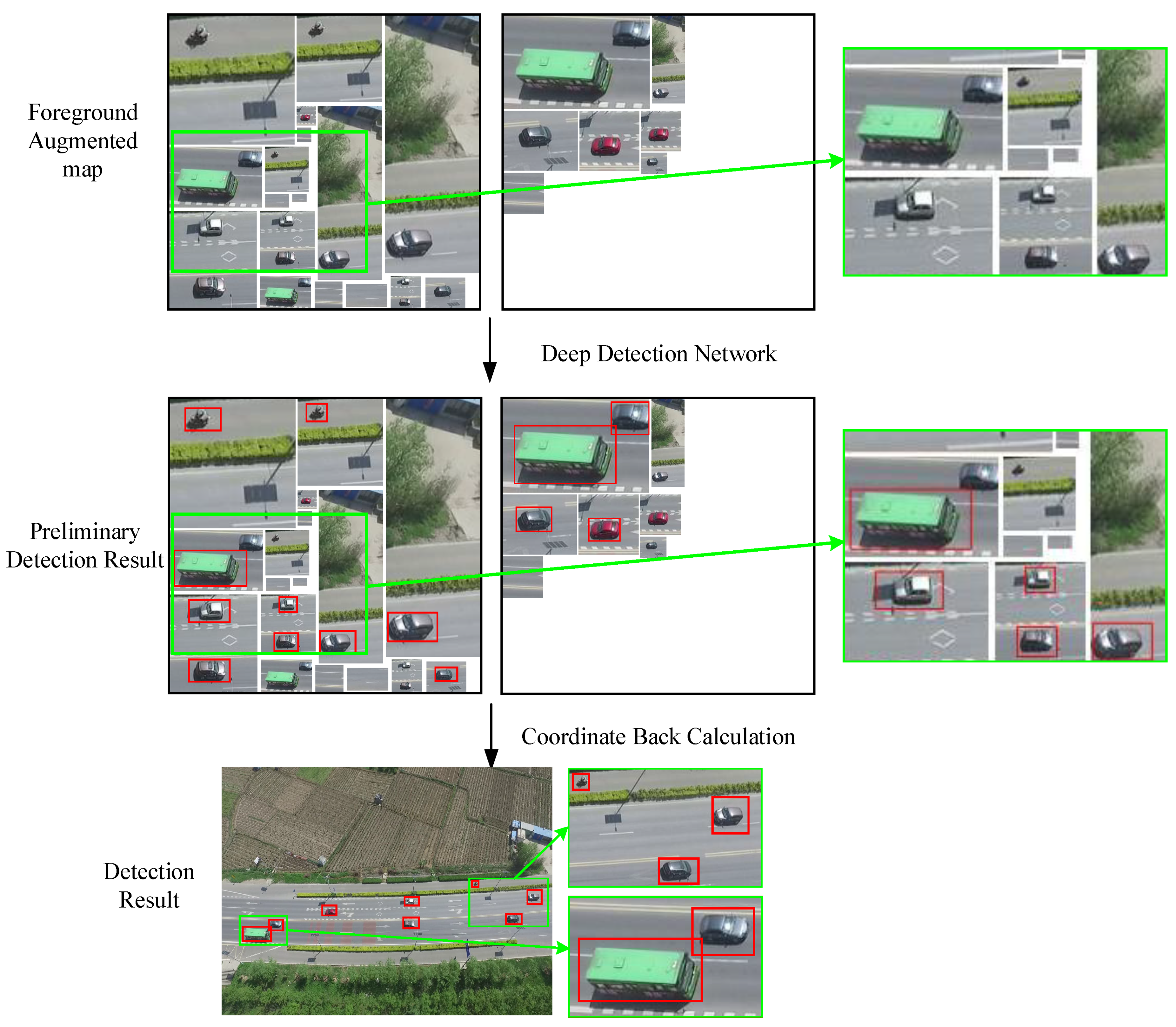
Through the methods described the previous sections, a set of foreground augmented maps constructed by visual detail augmented mapping is obtained. All potential regions on different scales are well arranged in these foreground augmented maps. As
Figure 6 shows, a large proportion of the foreground augmented map is the valuable object area and the unrelated background only occupies a small part. The reverse situation appears in the input aerial video. Based on this prospective image which is beneficial to detection, this section sends them to the deep detection network and outputs the final detection result. Concretely, this part is composed of two modules: preliminary small detection and coordinate back calculations.
For the first detection part, we employ You Only Look Once Version 2 (YOLO v2) [
24] as the deep detection model. YOLO v2 is proposed by Joseph and Ali in 2017. It is a real-time object detection network which has achieved widespread success in most normal object detection tasks. YOLO v2 can detect over 9000 object categories, and it is robust to different tasks with fast processing speed and high detection accuracy. However, the main disadvantages of YOLO v2 is that its performance degrades badly when object size is small. Therefore, we apply visual detail augmentation mapping to overcome the limitations of a YOLO v2 deep detection network. The basic detection process of YOLO v2 is as follows: (1) The well rearranged foreground images are in turn sent to the pre-trained detection neural network. In general, the YOLO v2 detector is generated by training a large amount of data and the detector performance is heavily influenced by training data. However, with previous visual detail augmented mapping, our method does not need to change the detection network for a small target and it utilizes the pre-trained detector which is generated for normal size target detection. After multiple layers operation, the feature maps of each foreground augmented map with size
can be obtained. (2) On the basis of feature map, YOLO v2 predicts the bounding box and calculates their confidence in each category. (3) With the loss function, the trained network detection further screens these bounding boxes and the targets with high confidence can be considered as the real object. Thus, the object detection procedure is finished. The detection result which contains each object’s location is shown in
Figure 6. Though there is still a small proportion of background, almost all objects can be detected accurately in foreground augmented map at least one scale. It has proved the performance of the proposed method once again. In addition, the limitation of aerial data and long training time make it difficult to retrain an appropriative deep network for small object detection. In addition, our method with a pre-trained network for normal size object detection shows its great advantages in small target detection.
However, the positions of these detection results are coordinates in the mapped foreground space. Therefore, in the final step, we inverse calculate these coordinates. Specifically, the proposed method filters the bounding boxes which are the same objects on different scales at first. Only the bounding box with the highest overlapping rate is retained. Then, based on the mapping relation, we back calculate their coordinates on the initial aerial image and do the corresponding scaling. In this way, we finish all of the small target detection steps. The detection results are labeled on the input image as shown in
Figure 6.
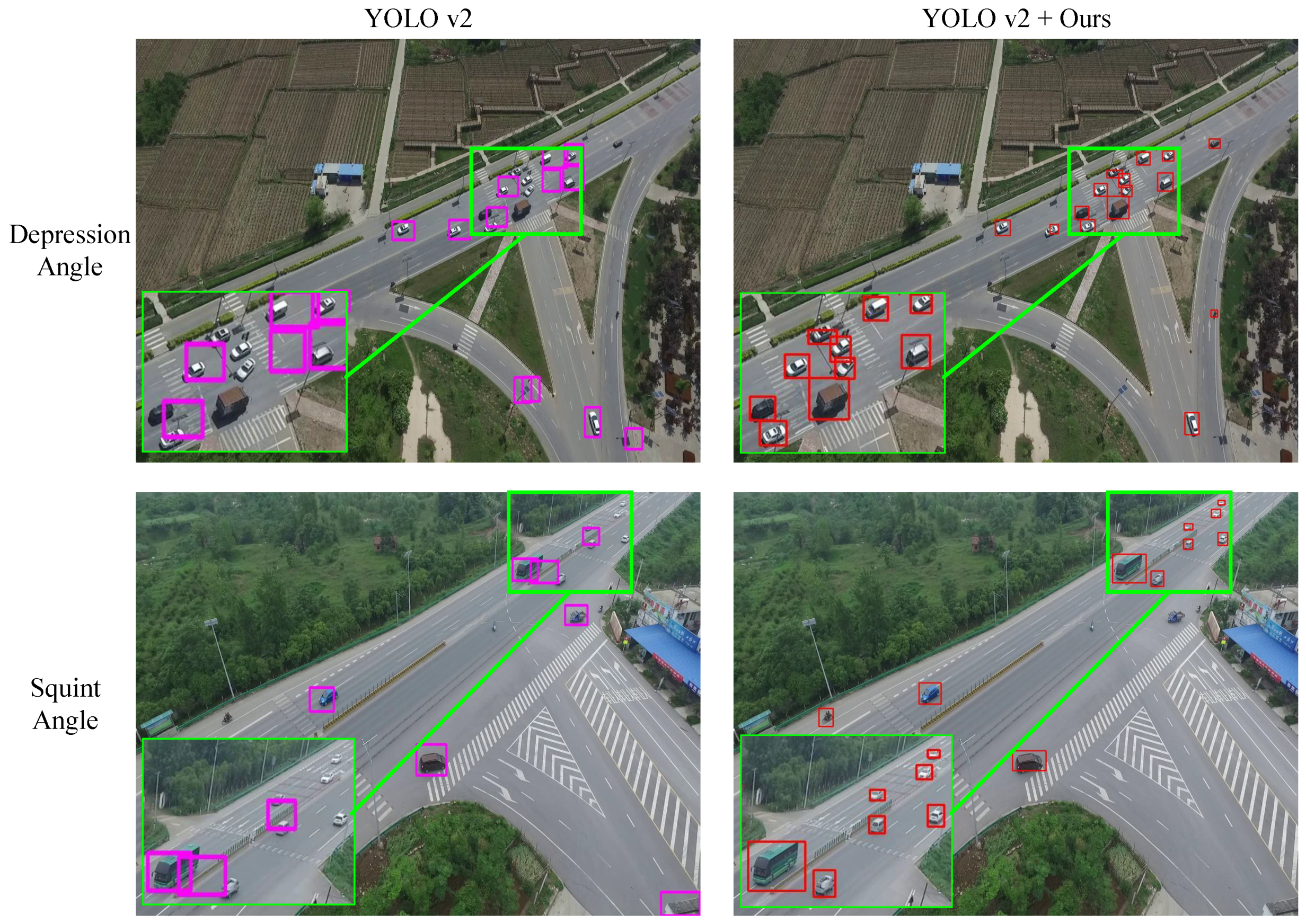
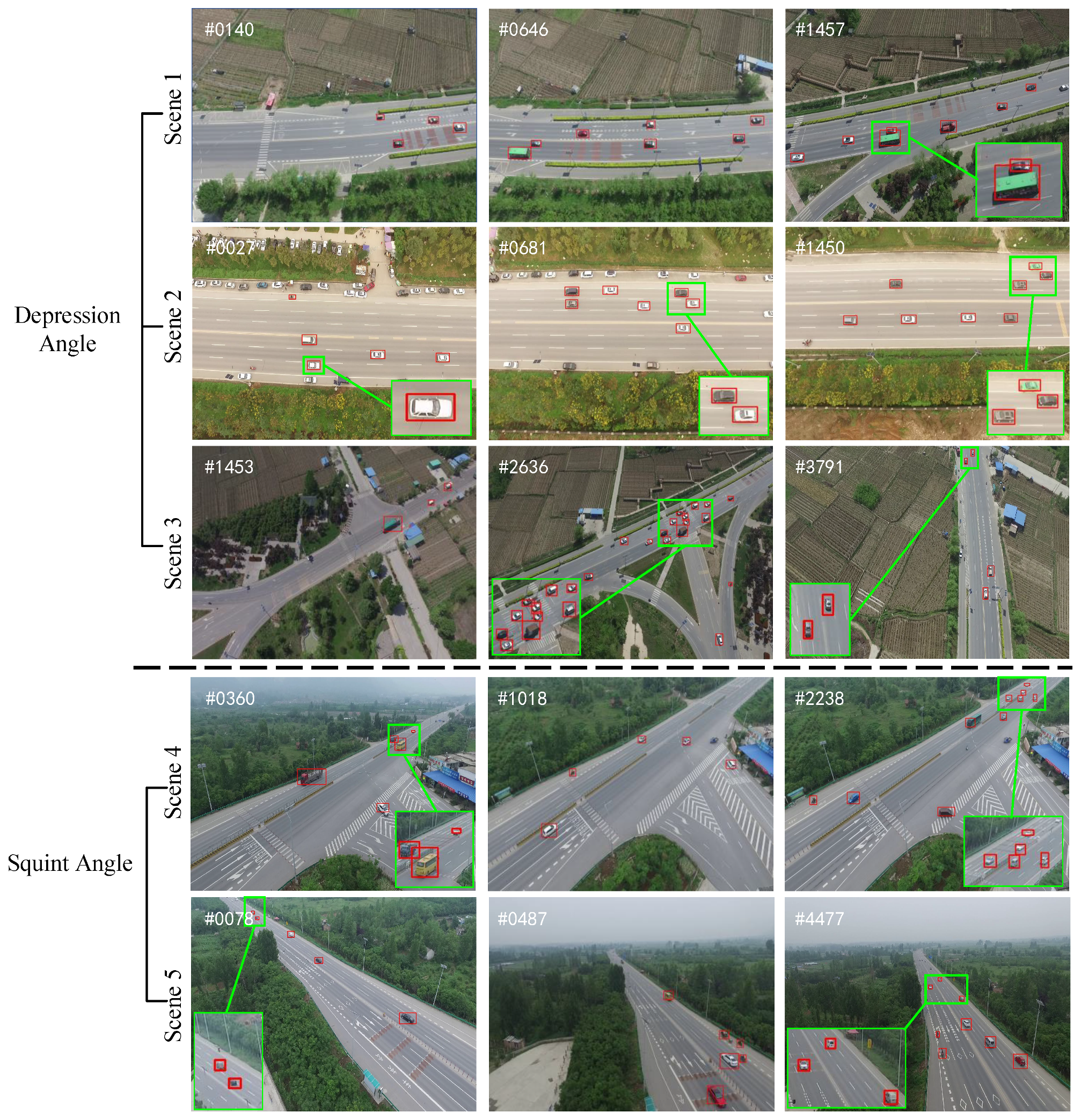
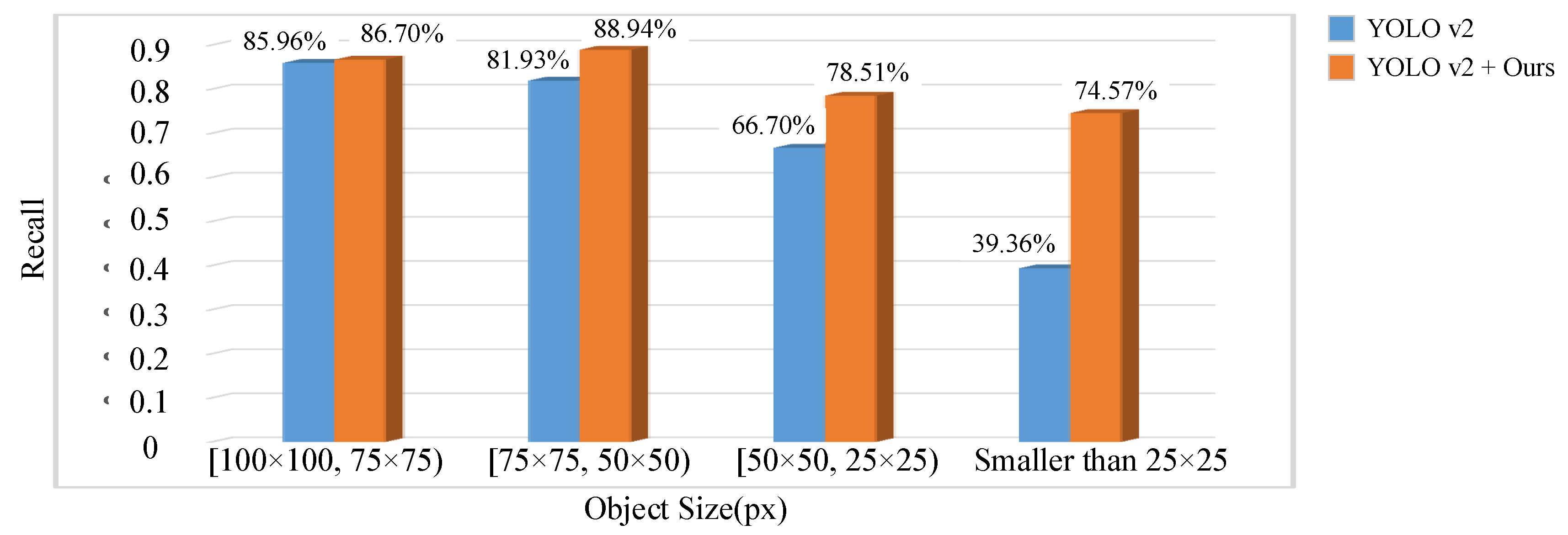
To summarize, based on the multi-cue foreground segmentation method and the visual detail augmented mapping algorithm, the follow-up deep detection network obtains more detailed and specific target information in the new mapped foreground space. With no need to change the framework of the detection network and with a small increase in computation, the proposed approach implements a small moving object detection system for the aerial video quickly and accurately. Compared with direct deep network detection, the detection performance of small targets is greatly improved.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}