Multitemporal Classification of River Floodplain Vegetation Using Time Series of UAV Images


Abstract

1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Set and Processing
2.2.1. Reference Data
2.2.2. UAV Imagery Acquisition and Preprocessing
2.2.3. DSM and Orthophoto Processing
2.3. Methods
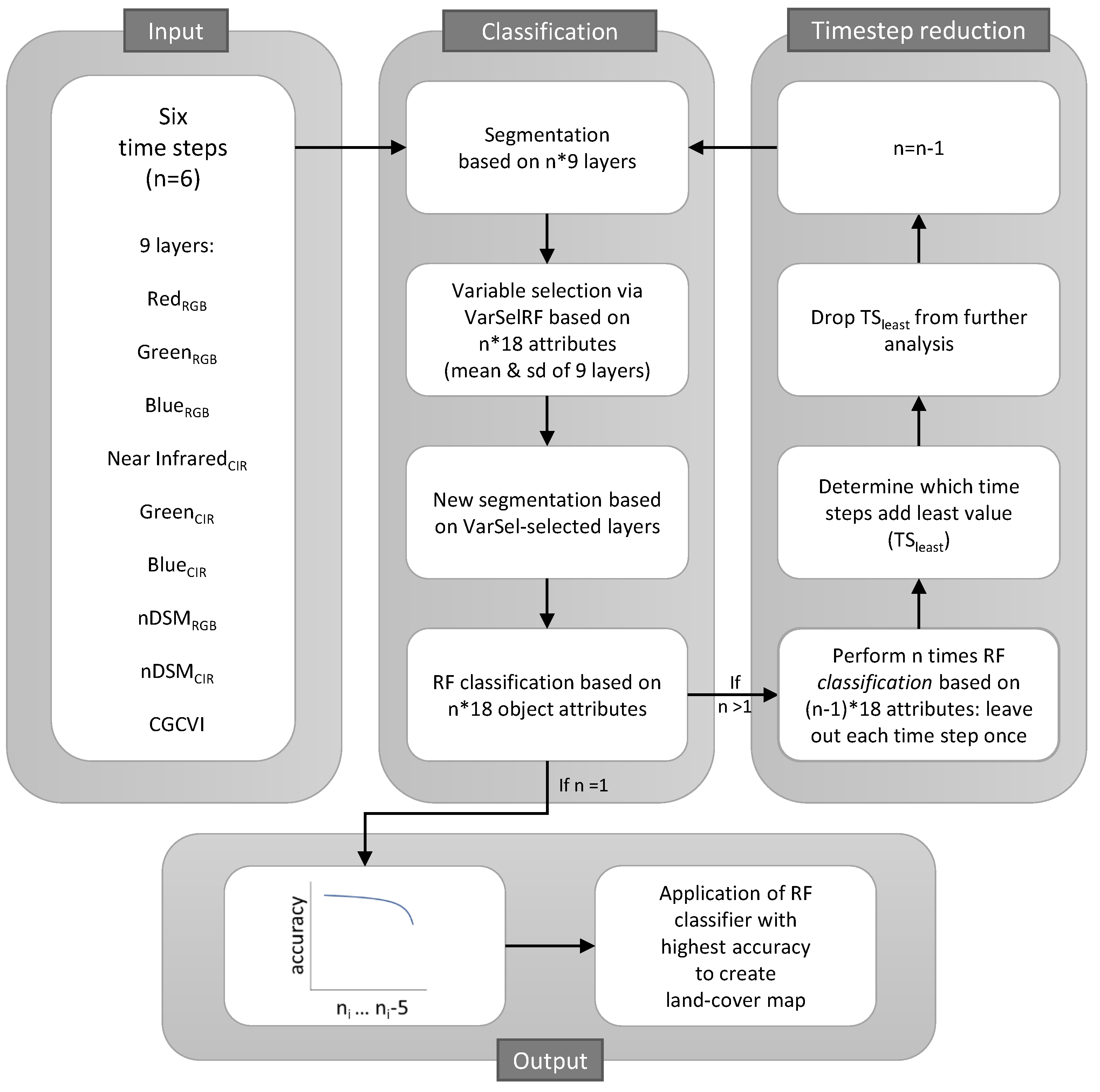
2.3.1. Object-Based Multitemporal Classification and Validation
Segmentation
Variable Selection and Second Segmentation
Classification
Validation
2.3.2. Classification Accuracy with Step-Wise Decrease in the Number of Time Steps
2.3.3. Varying Complexity of the Classification Model and the Data Set
3. Results
3.1. Object-Based Multitemporal Classification
3.2. Classification Accuracy with Step-Wise Decrease in the Number of Time Steps
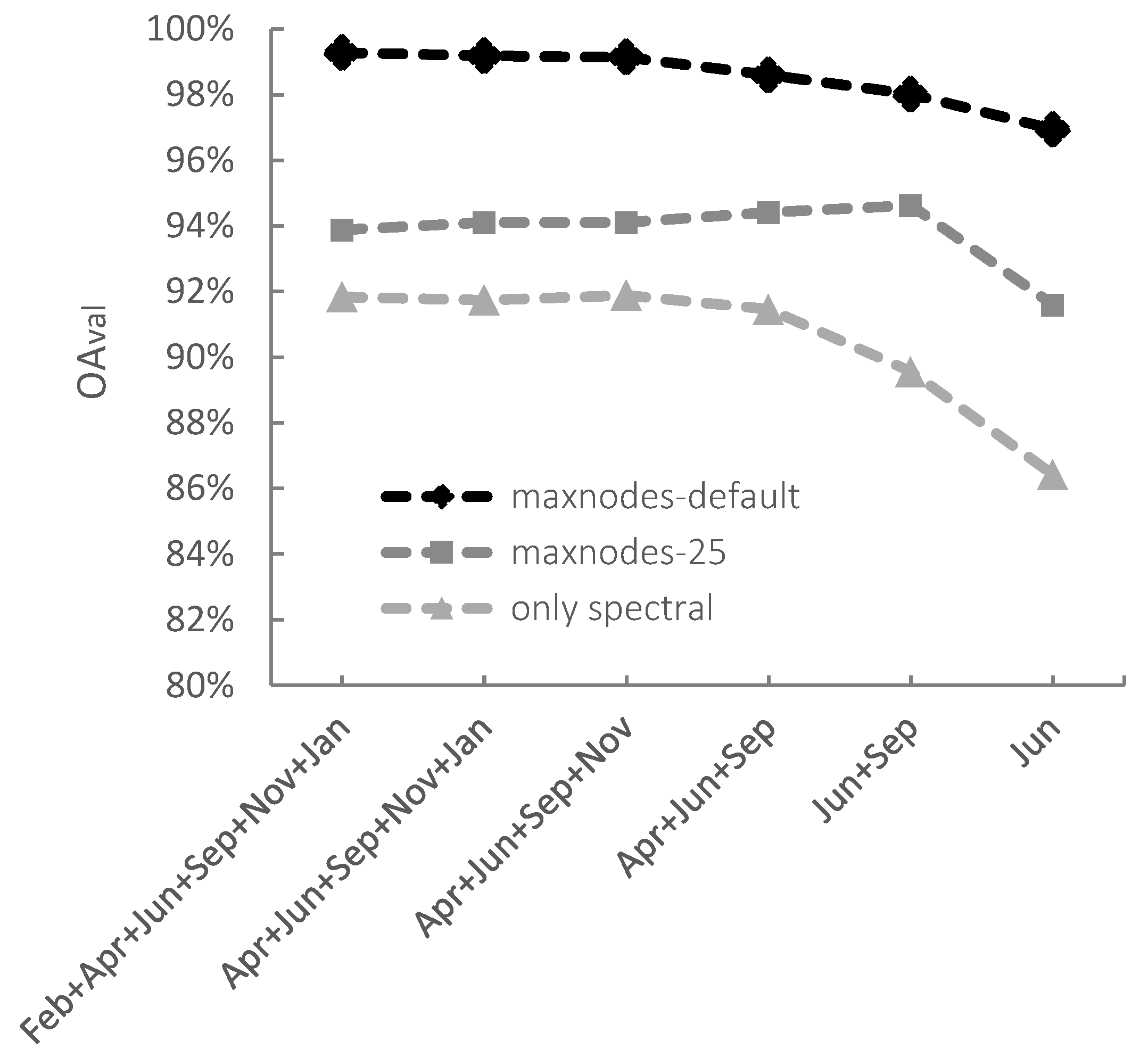
3.3. Varying Complexity of the Classification Model and Data Set
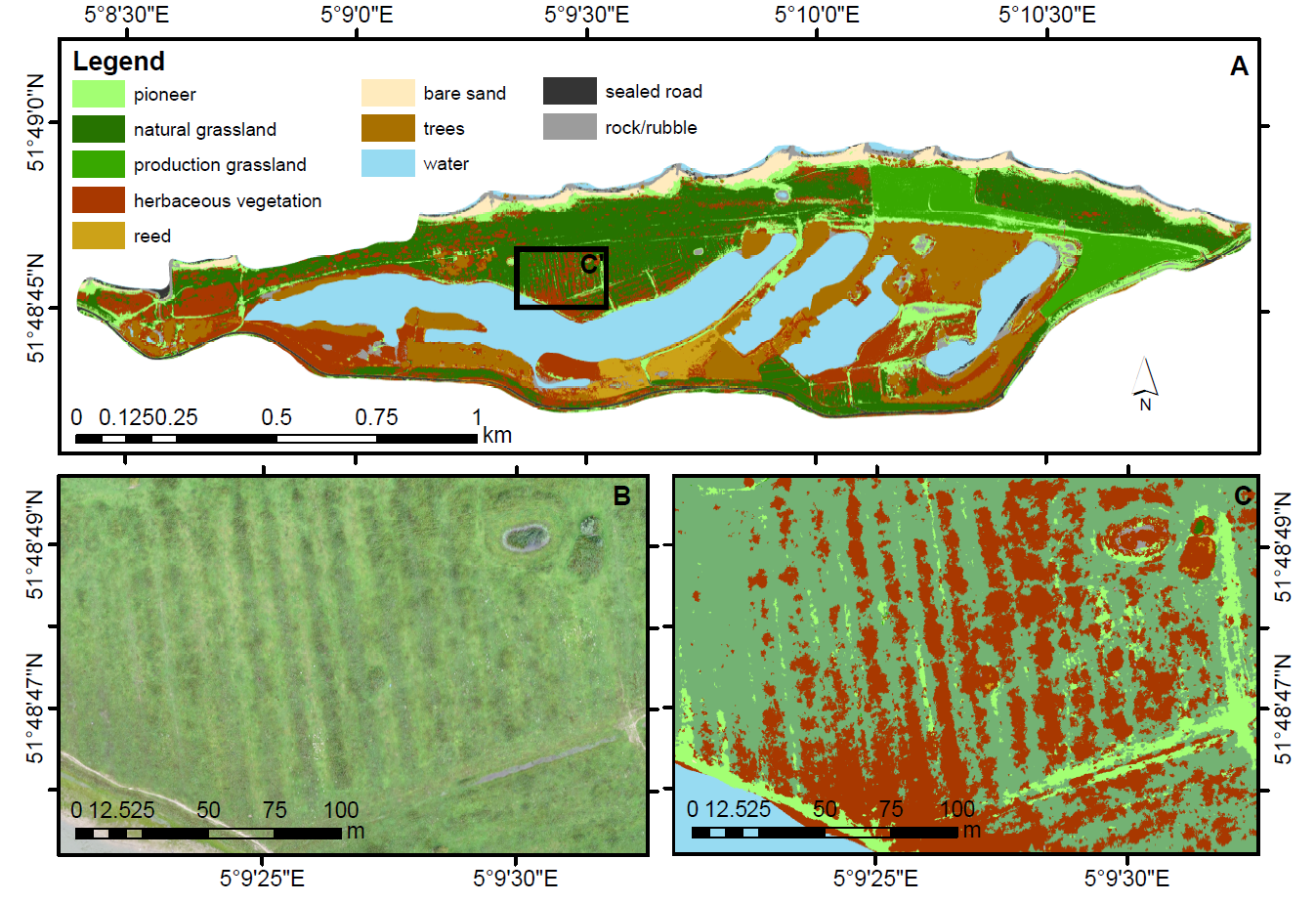
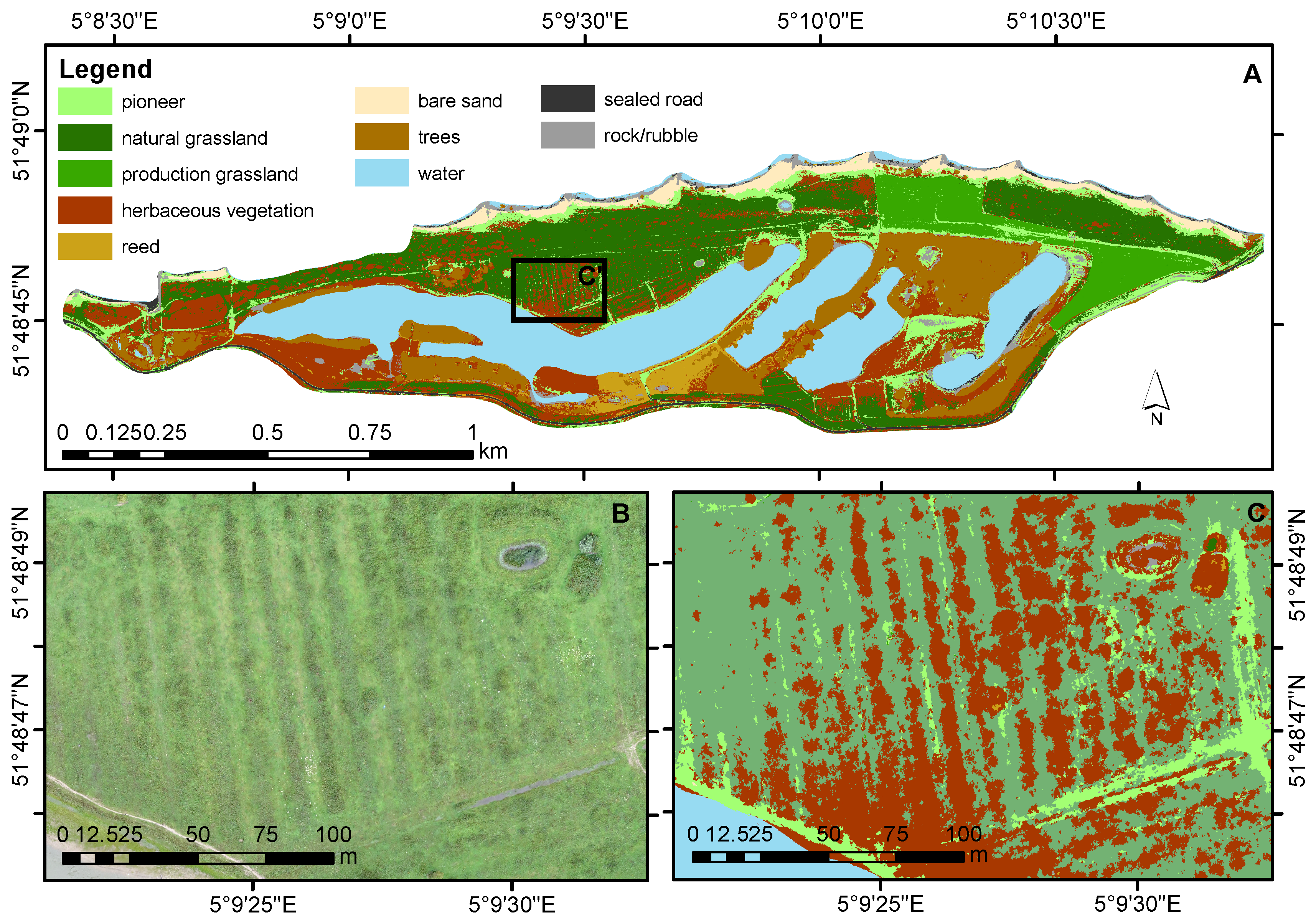
3.4. Classified Land-Cover Map
4. Discussion
4.1. Object-Based Multitemporal Classification
4.2. Required Number of Time Steps
4.3. Varying Complexity of the Classification Model and of the Data Set
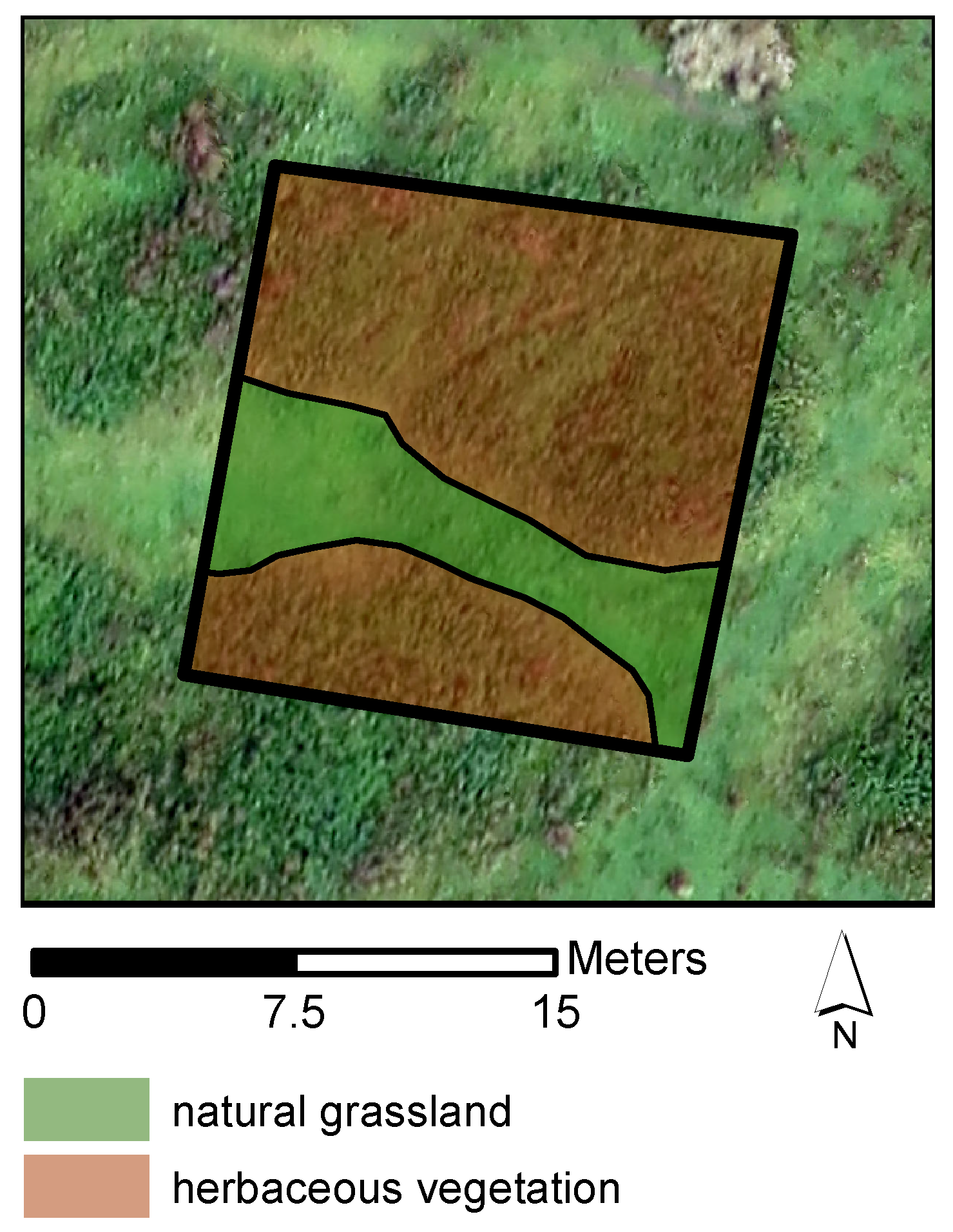
4.4. Training and Validation Sets
4.5. Floodplain Vegetation Map
4.6. Practical Considerations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tockner, K.; Pusch, M.; Borchardt, D.; Lorang, M.S. Multiple stressors in coupled river-floodplain ecosystems. Freshw. Biol. 2010, 55, 135–151. [Google Scholar] [CrossRef]
- Schindler, S.; Sebesvari, Z.; Damm, C.; Euller, K.; Mauerhofer, V.; Schneidergruber, A.; Biró, M.; Essl, F.; Kanka, R.; Lauwaars, S.G.; et al. Multifunctionality of floodplain landscapes: Relating management options to ecosystem services. Landsc. Ecol. 2014, 29, 229–244. [Google Scholar] [CrossRef]
- Van Iersel, W.K.; Straatsma, M.W.; Addink, E.A.; Middelkoop, H. ISPRS Journal of Photogrammetry and Remote Sensing Monitoring height and greenness of non-woody floodplain vegetation with UAV time series. ISPRS J. Photogramm. Remote Sens. 2018, 141, 112–123. [Google Scholar] [CrossRef]
- Dieck, J.; Ruhser, J.; Hoy, E.; Robinson, L. General Classification Handbook for Floodplain Vegetation in Large River Systems; Technical Report Book 2; U.S. Geological Survey Techniques and Methods: Reston, VA, USA, 2015.
- Eco Logical Australia. Vegetation of the Barwon-Darling and Condamine-Balonne Floodplain Systems of New South Wales Mapping and Survey of Plant Community Types; Technical Report; Eco Logical Australia: Sutherland, Australia, 2015. [Google Scholar]
- Houkes, G. Toelichting Ecotopenkartering Rijntakken-Oost 2005; Technical Report; Rijkswaterstaat, Data-ICT-Dienst: Delft, The Netherlands, 2008. [Google Scholar]
- Daphnia Ecologisch Advies. Ecotopenkartering Maas 2004; Biologische Monitoring Zoete Rijkswateren; Technical Report; Rijkswaterstaat: Brussels, Belgium, 2007. [Google Scholar]
- Van der Sande, C.J.; de Jong, S.M.; de Roo, A.P. A segmentation and classification approach of IKONOS-2 imagery for land cover mapping to assist flood risk and flood damage assessment. Int. J. Appl. Earth Obs. Geoinf. 2003, 4, 217–229. [Google Scholar] [CrossRef]
- Geerling, G.W.; Labrador-Garcia, M.; Clevers, J.G.P.W.; Ragas, A.M.J.; Smits, A.J.M. Classification of floodplain vegetation by data fusion of spectral (CASI) and LiDAR data. Int. J. Remote Sens. 2007, 28, 4263–4284. [Google Scholar] [CrossRef]
- Straatsma, M.W.; Baptist, M.J. Floodplain roughness parameterization using airborne laser scanning and spectral remote sensing. Remote Sens. Environ. 2008, 112, 1062–1080. [Google Scholar] [CrossRef]
- Knotters, M.; Brus, D.J. Purposive versus random sampling for map validation: A case study on ecotope maps of floodplains in the Netherlands. Ecohydrology 2013, 6, 425–434. [Google Scholar] [CrossRef]
- Straatsma, M.W.; Middelkoop, H. Extracting structural characteristics of herbaceous floodplain vegetation under leaf-off conditions using airborne laser scanner data. Int. J. Remote Sens. 2007, 28, 2447–2467. [Google Scholar] [CrossRef]
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: a review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- Wang, C.; Hunt, E.R.; Zhang, L.; Guo, H. Phenology-assisted classification of C3 and C4 grasses in the U.S. Great Plains and their climate dependency with MODIS time series. Remote Sens. Environ. 2013, 138, 90–101. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Duc, H.N.; Chang, L.Y. A phenology-based classification of time-series MODIS data for rice crop monitoring in Mekong Delta, Vietnam. Remote Sens. 2013, 6, 135–156. [Google Scholar] [CrossRef]
- Simonetti, D.; Simonetti, E.; Szantoi, Z.; Lupi, A.; Eva, H.D. First Results from the Phenology-Based Synthesis Classifier Using Landsat 8 Imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1496–1500. [Google Scholar] [CrossRef]
- Yan, E.; Wang, G.; Lin, H.; Xia, C.; Sun, H. Phenology-based classification of vegetation cover types in Northeast China using MODIS NDVI and EVI time series. Int. J. Remote Sens. 2015, 36, 489–512. [Google Scholar] [CrossRef]
- Senf, C.; Leitão, P.J.; Pflugmacher, D.; van der Linden, S.; Hostert, P. Mapping land cover in complex Mediterranean landscapes using Landsat: Improved classification accuracies from integrating multi-seasonal and synthetic imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Langley, S.K.; Cheshire, H.M.; Humes, K.S. A comparison of single date and multitemporal satellite image classifications in a semi-arid grassland. J. Arid Environ. 2001, 49, 401–411. [Google Scholar] [CrossRef]
- Nex, F.; Remondino, F. UAV for 3D mapping applications: A review. Appl. Geomatics 2014, 6, 1–15. [Google Scholar] [CrossRef]
- Michez, A.; Piégay, H.; Lisein, J.; Claessens, H.; Lejeune, P. Classification of riparian forest species and health condition using multi-temporal and hyperspatial imagery from unmanned aerial system. Environ. Monit. Assess. 2016, 188. [Google Scholar] [CrossRef] [PubMed]
- Tanteri, L.; Rossi, G.; Tofan, V.; Vannocci, P.; Moretti, S.; Casagli, N. Multitemporal UAV Survey for Mass Movement Detection and Monitoring; Work World Landslide Forum: Ljubljana, Slovenia, 2017; pp. 153–161. [Google Scholar]
- Esposito, G.; Mastrorocco, G.; Salvini, R.; Oliveti, M.; Starita, P. Application of UAV photogrammetry for the multi-temporal estimation of surface extent and volumetric excavation in the Sa Pigada Bianca open-pit mine, Sardinia, Italy. Environ. Earth Sci. 2017, 76, 1–16. [Google Scholar] [CrossRef]
- Cook, K.L. An evaluation of the effectiveness of low-cost UAVs and structure from motion for geomorphic change detection. Geomorphology 2017, 278, 195–208. [Google Scholar] [CrossRef]
- Lucieer, A.; de Jong, S.M.; Turner, D. Mapping landslide displacements using Structure from Motion (SfM) and image correlation of multi-temporal UAV photography. Prog. Phys. Geogr. 2014, 38, 97–116. [Google Scholar] [CrossRef]
- Bendig, J.; Bolten, A.; Bennertz, S.; Broscheit, J.; Eichfuss, S.; Bareth, G. Estimating biomass of barley using crop surface models (CSMs) derived from UAV-based RGB imaging. Remote Sens. 2014, 6, 10395–10412. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Peters, B.; Kurstjens, G.; van Diermen, J. Rijn in Beeld Natuurontwikkeling Langs de Grote Rivieren Deel 1 De Waal; Technical Report; Bureau Drift/Kurstjens Ecologisch Adviesbureau: Berg en Dal, The Netherlands, 2011. [Google Scholar]
- Sensefly. Extended User Manual Swinglet CAM; SenseFly Ltd.: Cheseaux-Lausanne, Switzerland, 2014. [Google Scholar]
- Agisoft. PhotoScan Professional 1.1 User Manual; Agisoft: St Petersburg, Russia, 2014. [Google Scholar]
- Van der Zon, N. Kwaliteitsdocument AHN2; Technical Report; Waterschapshuis: Amersfoort, The Netherlands, 2013. [Google Scholar]
- Trimble. eCognition Developer 7 Reference Book; Technical Report; Trimble Geospatial: München, Germany, 2007. [Google Scholar]
- Rasmussen, J.; Ntakos, G.; Nielsen, J.; Svensgaard, J.; Poulsen, R.N.; Christensen, S. Are vegetation indices derived from consumer-grade cameras mounted on UAVs sufficiently reliable for assessing experimental plots? Eur. J. Agron. 2016, 74, 75–92. [Google Scholar] [CrossRef]
- Addink, E.A.; Van Coillie, F.M.; De Jong, S.M. Introduction to the GEOBIA 2010 special issue: From pixels to geographic objects in remote sensing image analysis. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 1–6. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; Alvarez de Andrés, S. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Quartel, S.; Addink, E.A.; Ruessink, B.G. Object-oriented extraction of beach morphology from video images. Int. J. Appl. Earth Obs. Geoinf. 2006, 8, 256–269. [Google Scholar] [CrossRef]
- Weil, G.; Lensky, I.M.; Resheff, Y.S.; Levin, N. Optimizing the timing of unmanned aerial vehicle image acquisition for applied mapping ofwoody vegetation species using feature selection. Remote Sens. 2017, 9. [Google Scholar] [CrossRef]
- Makaske, B.; Maas, G.J.; Van Den Brink, C.; Wolfert, H.P. The influence of floodplain vegetation succession on hydraulic roughness: Is ecosystem rehabilitation in dutch embanked floodplains compatible with flood safety standards? Ambio 2011, 40, 370–376. [Google Scholar] [CrossRef] [PubMed]
- Suggitt, A.J.; Gillingham, P.K.; Hill, J.K.; Huntley, B.; Kunin, W.E.; Roy, D.B.; Thomas, C.D. Habitat microclimates drive fine-scale variation in extreme temperatures. Oikos 2011, 120, 1–8. [Google Scholar] [CrossRef]
- Blaschke, T.; Johansen, K.; Tiede, D. Object-Based Image Analysis for Vegetation Mapping and Monitoring. Adv. Environ. Remote Sens. 2011, 241–272. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Herold, M.; Roberts, D. Spectral characteristics of asphalt road aging and deterioration: Implications for remote-sensing applications. Appl. Opt. 2005, 44, 4327. [Google Scholar] [CrossRef] [PubMed]
- Straatsma, M.W.; van der Perk, M.; Schipper, A.M.; de Nooij, R.J.W.; Leuven, R.S.E.W.; Huthoff, F.; Middelkoop, H. Uncertainty in hydromorphological and ecological modelling of lowland river floodplains resulting from land cover classification errors. Environ. Model. Softw. 2013, 42, 17–29. [Google Scholar] [CrossRef]
- Wijnhoven, S.; Velde, G.; Leuven, R.S.E.W.; Smits, A.J.M. Flooding ecology of voles, mice and shrews: The importance of geomorphological and vegetational heterogeneity in river floodplains. Acta Theriol. (Warsz) 2005, 50, 453–472. [Google Scholar] [CrossRef]
- Blakey, R.V.; Kingsford, R.T.; Law, B.S.; Stoklosa, J. Floodplain habitat is disproportionately important for bats in a large river basin. Biol. Conserv. 2017, 215, 1–10. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Total Area (m) | |
|---|---|---|
| 1. | Pioneer vegetation | 676 |
| 2. | Natural grassland | 1986 |
| 3. | Production grassland | 758 |
| 4. | Herbaceous vegetation | 2975 |
| 5. | Reed | 621 |
| 6. | Bare sand | 1114 |
| 7. | Forest | 1662 |
| 8. | Water | 1211 |
| 9. | Sealed road | 198 |
| 10. | Rock/Rubble | 119 |
| Time Steps Included in Segmentation | Time Step Excluded from Classification | (%) | (%) | (%) | (%) | - | |
|---|---|---|---|---|---|---|---|
| n = 6 FEB APR JUN SEP NOV JAN | - | 93.9 | 92.6 | 94.5 | 93.3 | 0.60 | 0.78 |
| FEB * | 94.1 | 92.8 | 94.6 | 93.5 | 0.51 | 0.67 | |
| APR | 93.8 | 92.5 | 94.4 | 93.3 | 0.63 | 0.82 | |
| JUN | 93.2 | 91.7 | 94.1 | 92.9 | 0.92 | 1.16 | |
| SEP | 92.9 | 91.4 | 94.0 | 92.7 | 1.03 | 1.30 | |
| NOV | 93.8 | 92.5 | 93.2 | 94.4 | −0.58 | 1.91 | |
| JAN | 93.8 | 92.4 | 92.4 | 93.2 | −1.36 | 0.83 | |
| n = 5 APR JUN SEP NOV JAN | - | 94.1 | 92.7 | 94.1 | 92.8 | 0.01 | 0.04 |
| APR | 93.6 | 92.1 | 93.7 | 92.3 | 0.10 | 0.14 | |
| JUN | 93.0 | 91.4 | 93.2 | 91.6 | 0.15 | 0.20 | |
| SEP | 93.3 | 91.8 | 93.5 | 92.0 | 0.20 | 0.27 | |
| NOV | 93.8 | 92.4 | 93.8 | 92.4 | −0.04 | −0.03 | |
| JAN * | 94.1 | 92.7 | 94.1 | 92.7 | −0.05 | −0.05 | |
| n = 4 APR JUN SEP NOV | - | 94.1 | 92.7 | 95.0 | 93.9 | 0.93 | 1.24 |
| APR | 94.0 | 92.5 | 94.5 | 93.3 | 0.53 | 0.76 | |
| JUN | 92.7 | 91.0 | 93.7 | 92.3 | 0.98 | 1.33 | |
| SEP | 93.4 | 91.9 | 94.4 | 93.2 | 0.98 | 1.31 | |
| NOV * | 94.0 | 92.6 | 95.1 | 94.0 | 1.04 | 1.37 | |
| n = 3 APR JUN SEP | - | 94.4 | 93.2 | 94.4 | 93.2 | −0.02 | 0.04 |
| APR * | 94.5 | 93.3 | 94.5 | 93.3 | −0.06 | −0.02 | |
| JUN | 91.2 | 89.2 | 91.1 | 89.2 | −0.12 | −0.07 | |
| SEP | 92.8 | 91.2 | 92.9 | 91.4 | 0.18 | 0.28 | |
| n = 2 JUN SEP | - | 94.6 | 93.4 | 94.6 | 93.3 | 0.00 | −0.10 |
| JUN | 88.3 | 85.6 | 89.6 | 87.0 | 1.29 | 1.40 | |
| SEP * | 92.1 | 90.3 | 92.5 | 90.7 | 0.43 | 0.39 | |
| n = 1 JUN | - | 91.6 | 89.6 | 91.3 | 89.2 | −0.29 | −0.41 |
| Reference | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pioneer Vegetation | Sealed Road | Rock/Rubble | Natural Grassland | Prod. Grassland | Herb. Vegetation | Reed | Bare Sand | Forest | Water | User’s Accuracy | ||
| Pioneer Vegetation | 57,317 | 0 | 0 | 0 | 0 | 0 | 0 | 765 | 0 | 0 | 99% | |
| Sealed road | 0 | 38,362 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100% | |
| Rock/Rubble | 23 | 0 | 23,152 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100% | |
| Natural grassland | 0 | 0 | 0 | 72,422 | 0 | 2210 | 0 | 0 | 0 | 0 | 97% | |
| Prediction | Production grassland | 0 | 0 | 0 | 0 | 110,501 | 0 | 0 | 0 | 0 | 0 | 100% |
| Herbaceous vegetation | 60 | 0 | 0 | 1993 | 0 | 40,616 | 0 | 0 | 0 | 0 | 95% | |
| Reed | 0 | 0 | 0 | 0 | 0 | 0 | 24,759 | 0 | 0 | 0 | 100% | |
| Bare sand | 378 | 0 | 0 | 0 | 0 | 0 | 0 | 117,974 | 0 | 0 | 100% | |
| Forest | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 22,953 | 0 | 100% | |
| Water | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 245,643 | 100% | |
| Producer’s accuracy | 99% | 100% | 100% | 97% | 100% | 95% | 100% | 99% | 100% | 100% | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van Iersel, W.; Straatsma, M.; Middelkoop, H.; Addink, E. Multitemporal Classification of River Floodplain Vegetation Using Time Series of UAV Images. Remote Sens. 2018, 10, 1144. https://doi.org/10.3390/rs10071144
Van Iersel W, Straatsma M, Middelkoop H, Addink E. Multitemporal Classification of River Floodplain Vegetation Using Time Series of UAV Images. Remote Sensing. 2018; 10(7):1144. https://doi.org/10.3390/rs10071144
Chicago/Turabian StyleVan Iersel, Wimala, Menno Straatsma, Hans Middelkoop, and Elisabeth Addink. 2018. "Multitemporal Classification of River Floodplain Vegetation Using Time Series of UAV Images" Remote Sensing 10, no. 7: 1144. https://doi.org/10.3390/rs10071144
APA StyleVan Iersel, W., Straatsma, M., Middelkoop, H., & Addink, E. (2018). Multitemporal Classification of River Floodplain Vegetation Using Time Series of UAV Images. Remote Sensing, 10(7), 1144. https://doi.org/10.3390/rs10071144