1. Introduction
The various ecological, social, and economic benefits of tree orchards in urban environments have been discussed extensively in previous studies [
1,
2,
3,
4,
5,
6,
7,
8]. However, despite the contributions of urban orchards to forming sustainable urban systems, these green spaces often encounter critical threats and stresses in the urban landscape. Among the most prevalent factors threating urban orchards are the cutting, removal, and killing of trees on private properties, which often occur in the process of urban expansion (e.g., to provide space for construction) [
6,
8]. This destructive process is more clear in less developed countries, where the rapid rates of urban expansion and/or the informal and unplanned processes of the urban development result in the disappearance of urban orchards from the landscape [
9]. Moreover, some other external factors such as water shortages, air pollution, and the presence of pests/plant diseases may critically threaten the existence or health of trees in urban orchards [
10,
11].
Compared to trees in public areas such as urban forests, public parks, streets, and highways in the urban environment, trees in urban orchards are mostly located on private properties. Therefore, local authorities usually have restricted access to these properties for the purposes of collecting information, periodically monitoring of the health and maintenance of trees, and recording the changes and damage occurring within the urban orchards. Furthermore, compared to public green spaces, the trees in urban orchards are often surrounded by physical barriers (e.g., walls or fences). This isolated and unexposed nature of urban orchards can limit the possibilities for authoritative and public ground-based observation supervision, and thus, the majority of the damage to (e.g., due to poor maintenance of the orchard) and (potentially illegal) destruction of the orchards may go undetected by the urban authorities and citizens. Consequently, in addition to the aforementioned risk factors that threaten the existence or health of trees in urban orchards, this lack or absence of supervision of urban orchards intensifies the risk of illegal damage and destruction of the trees on these properties.
Due to the significant functions of urban orchards and their high vulnerability in the urban environment, some governments have approved legal frameworks and measures at the national and local scales to manage, protect, and conserve the trees in urban orchards [
12]. In this sense, conducting a fine-scale (i.e., at single-tree level) and updated tree inventory for urban orchards is one of the most vital steps for studying the environmental, social, and economic services provided by urban orchard trees, for making informed decisions about them, and for conducting successful management and conservation programs to protect these urban green spaces.
Four major types of mapping techniques exist for inventory of trees at the individual tree level, namely, (1) field surveys; (2) terrestrial scanning and close-range photogrammetry; (3) aerial and satellite remote sensing; and (4) crowdsourcing [
12,
13,
14] (for more details, see
Section 2.1). Depending on the nature of the adopted technique and the characteristics of the deployed sensor for mapping of the tree crowns, each technique has some strong points and limitations for capturing the information about the tree crowns (for more details, see
Section 2.1). To overcome the limitations and to benefit from the advantages of each individual tree mapping technique, the hybrid approaches integrating different tree mapping techniques have been developed. Broadly categorized as a collective sensing (for more details see [
15]) approach, the hybrid approach combines a possibly large set of data stream that is acquired by different types of sensors to extract new information which cannot be obtained from any single data stream [
16], with the goal of providing more comprehensive and accurate characterization of the individual trees.
During recent years, the potential for integrating technical sensors [
17,
18] for means of individual tree detection have been explored in a number of previous studies (e.g., see [
19,
20,
21,
22]). The literature review indicates that the previous contributions on multi-technical-sensor fusion were mainly focused on the integration of airborne and spaceborne optical sensor data (mostly very high resolution (VHR) optical sensor data) with airborne LiDAR sensor data. The processing of both VHR optical and LiDAR data is often complex and computationally expensive when applied to large-scale problems [
23,
24]. Consequently, processing this combination of data can be very time consuming and may require access to very high computing power and data storage. Furthermore, despite the benefits of multi-technical-sensor fusion, adding an extra commercial data source to perform data fusion incurs extra costs on the project. Therefore, while a multi-technical-sensor data fusion approach appears to be effective in the GIScience research field [
25,
26], operationalizing the proposed hybrid approaches in practical large-scale individual tree mapping projects still remains a challenging issue.
Theoretically, the synergistic use of multi-sensor data for mapping individual trees can be extended beyond the hard infrastructure by the fusion of technical sensor data with human sensor [
17,
18,
27] data (for more details see
Section 2.1.3). However, the review of the literature revealed that despite the distinctive characteristics of Volunteered Geographic Information (VGI) [
28] (for more details see
Section 2.1.3) on individual trees collected through the crowdsourcing technique, until now, the possibility of collective sensing of trees at the single-tree level by integrating the technical sensor data with human sensor data has not been explored yet.
In this research project, we propose a collective sensing approach for mapping urban orchard trees at the single-tree level by incorporating VGI and VHR optical satellite data. Both of these types of data have their own strengths and weaknesses. While VGI is usually free and open to the public, it is widely known that the data often vary widely in terms of spatial data quality elements such as positional accuracy, thematic (attribute) accuracy, and completeness [
29,
30]. Therefore, the individual tree crown (ITC) detection solely based on a crowdsourcing approach, particularly in large-scale tree mapping projects that should be conducted during a limited period of time, may not achieve satisfactory results. On the other hand, the valuable spectral and contextual information that can be extracted from the optical data as well as the large-scale coverage of satellite remote sensing technique make this method a very useful data source for conducting ITC detection projects. However, previous studies indicate that ITC detection utilizing optical imagery and unsupervised classification approaches (e.g., see [
31,
32]) may not always reach to satisfactory results as classification performance can be severely affected by the complexity and heterogeneity of the scene, the existence of understory vegetation, and the overlapping of neighboring tree crowns (for more details see
Section 2.1.2) [
33,
34]. In this context, to overcome these negative effects, previous studies [
13,
21,
35] addressed the necessity of exploiting additional data sources in addition to optical data. To this end, several contributions [
36,
37] have studied the possibility of using supervised ITC detection approaches for processing optical imagery by employing authoritative training data. Nevertheless, the labor intensive, costly, and time-consuming nature of authoritative training data collection tasks by experts is considered the main weak point of this category of ITC detection approaches. On the other hand, some studies [
20,
22] mainly focused on utilizing the unsupervised approaches for processing of the accurate tree height information acquired through different technical remote sensors (e.g., LiDAR) alongside optical data for ITC detection. However, as high resolution elevation data are usually costly, computationally expensive, and not always available, the applicability of this category of ITC detection approaches for large-scale mapping projects is still a challenging issue (for more details, see
Section 2.1.2).
The proposed approach in this study employs VGI on the individual trees obtained through the remote mapping approach [
38,
39] (for more details, see
Section 2.1.3) for training a template matching (TM) algorithm [
40] (for more details see
Section 2.2) in order to extract the ITCs in VHR satellite optical imagery. The synergy of VGI and VHR optical remotely sensed data allow one to take the unique advantages of each of these data sources and eliminate the inherent limitations of each method. In this sense, the type and complementary nature of our multi-source data provides great opportunities for relatively low-cost, fine-scale, and accurate mapping of urban orchard trees, particularly the trees that are located on private isolated properties.
4. Methods
The following sections describe the methodology of the proposed ITC detection approach and data quality assessment in this study. In this sense, the backgrounds, components, and parameters of the proposed ITC detection approach based on crowdsourced training samples will be introduced and discussed in the
Section 4.1. To evaluate the impact of deploying the imperfect crowdsourced training samples compare to the error-free training samples, the proposed ITC detection approach was also trained with reference (i.e., authoritative) training samples that will be explained in
Section 4.2. To study the ITC detection performance of the proposed approach under the occurrence of a higher level of errors in the crowdsourced training samples, a preliminary study was conducted and is introduced and discussed in
Section 4.3.
Section 4.4 presents the details of the adopted reference data and measures for quality assessment of the crowdsourced tree data and evaluating the performance of the proposed approach when employing different types of training samples. The Cognition Developer 9.0 and ArcGIS 10.2 software were mainly used for processing the data and performing the analysis tasks in this study, and QGIS 2.18 software and R-3.4.2 were partially used for performing the pre- and post-processing tasks of this study.
4.1. The Workflow of the Proposed Approach for ITC Detection (Based on Collective Sensing)
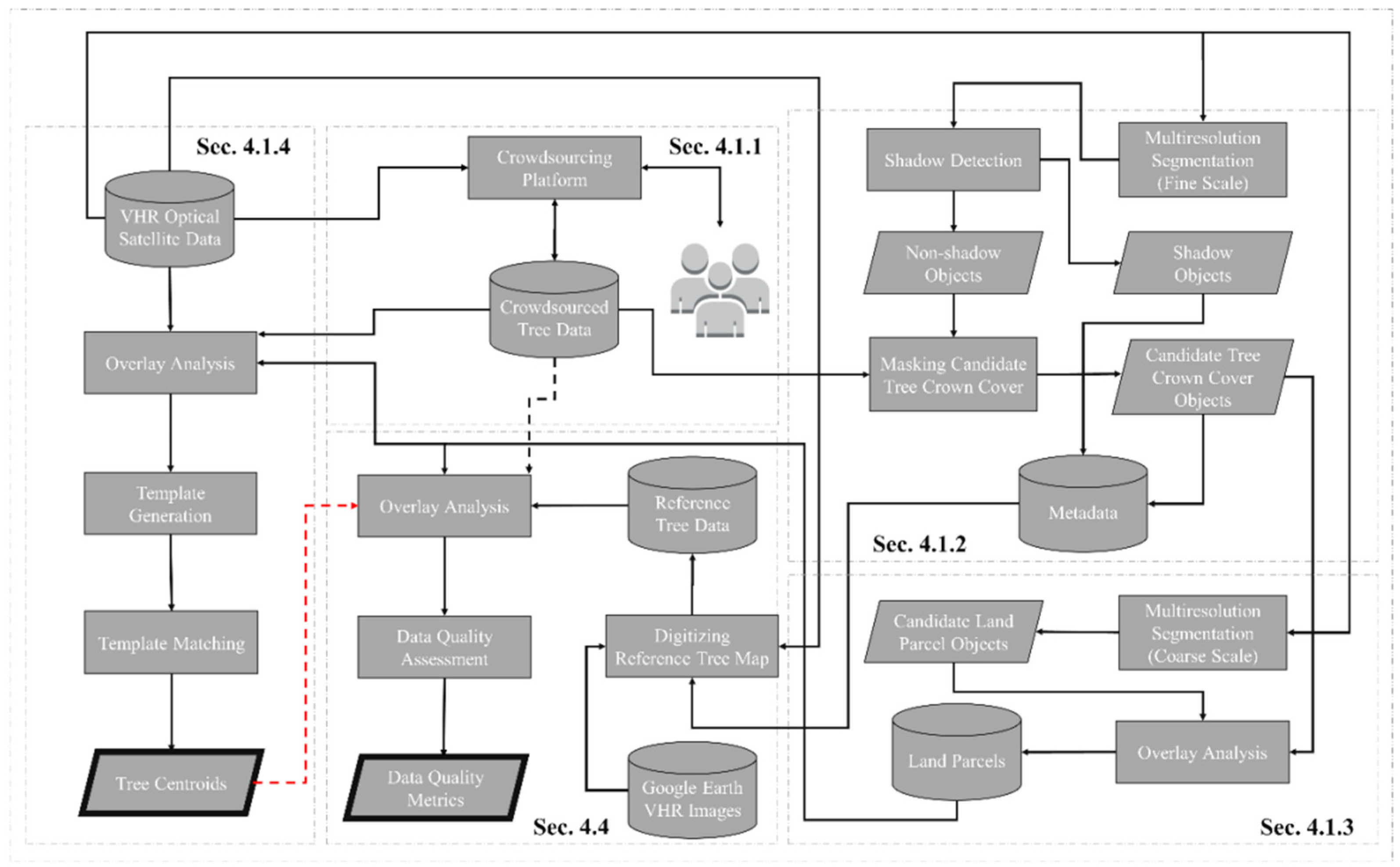
In this study, we deployed a collective sensing approach for ITC detection in urban private orchards. The proposed approach integrates the different spectral, spatial, and contextual information about the trees obtained by spaceborne technical remote sensor or human sensors for mapping the trees in the study area. The following subsections present the adopted workflow for conducting the proposed approach for ITC detection (based on collective sensing) (
Figure 2).
4.1.1. Collecting Data on Trees through Crowdsourcing
A crowdsourcing platform was employed to facilitate the participatory mapping and visualization of trees in the study area. The platform allowed for the real-time dissemination of the VGI generated by the volunteers and enabled them to update and modify the features in the crowdsourced tree database. To conduct the crowdsourcing phase of our pilot project, we asked a local group of undergraduate and graduate civil engineering students to participate in our project. A brief (15 min) introduction on the tree identification and measurement task and platform was provided for the participants. The volunteers were asked to map the centroid of each tree they preferred to digitize and measure and record the length of the longest spread (i.e., diameter) of that tree crown and the longest spread perpendicular to it in the scene. It is widely known that appropriate false color composite imagery can provide a great amount of information for the interpreter as it can considerably improve visual perception. A study by Svatonova [
124] showed that non-expert image interpreters can interpret false color satellite imagery very well. Specifically, Svatonova [
124] recommended providing false color imagery alongside true color imagery in web mapping services to enhance the image interpretation performance of the non-experts. Hence, to collect spatial data (i.e., tree locations) and attribute data (i.e., tree basic geometrical property) about ITCs through crowdsourcing approach (i.e., tree identification, ITC identification) in this study, true color R-G-B and false color NIR1-R-G composites of the aforementioned VW3 imagery were produced for the test plot and provided to the volunteers through the developed platform.
4.1.2. Masking Candidate Tree Crown Land Cover
The first step of the proposed image analysis framework was concentrated on masking out the candidate tree crown (CTC) class from a non-tree crown (NTC) class (including the understory vegetation, bare soil, and man-made features) and shadow class in the scene. The low spectral separability of the tree crown pixels and the understory vegetation and shrubs made this step very challenging. To overcome this problem, the spectral and texture properties of the imagery were used to separate the CTC and NTC and shadow class pixels. To utilize this spectral and contextual information, we adopted an Object-based Image Analysis (OBIA) approach [
125,
126,
127]) in
Section 4.1.2 and
Section 4.1.3.
Since the instances of each class occur at the different scales, hence in order to delineate image objects (i.e., image segments) in the scene for the aim of the CTC extraction, we adopted the multiresolution segmentation method. The multiresolution segmentation is a bottom-up region-merging segmentation technique that finds the image object of interest through an iterative object merging algorithm (for more details see [
128,
129]). For performing the image segmentation method, the parameters of the adopted segmentation method were set as scale parameter = 6, shape parameter = 0.2, and compactness parameter = 0.8 based on a trial and error approach involving visual interpretation of the generated boundaries of image objects vs. the actual condition for the target features at respective scale.
To classify the generated objects and finally extract the CTC class objects more accurately, several sub-steps have been considered. These sub-steps ensured that the CTC class was extracted from the scene with the minimum error in the inclusion of all CTC class objects and exclusion of the regions belonging to the NTC and shadow classes in the scene.
Shadow is considered as noise in some of the remote sensing existing literature [
130], and considerable studies have been conducted to develop methods for detection and reduction or removal of shadow in remotely sensed imagery (for more details [
131,
132,
133]). Nevertheless, one may employ shadows in the image as a valuable source of contextual information for enhancing the quality of tree identification tasks, as they provide a three-dimensional clue (i.e., proportional to width and height of the feature) on the existence of a tree feature adjacent to/in proximity to the shadow. The exploiting of contextual information from shadows for tree detection falls outside the scope of the current study. However, the shadow objects in the scene were extracted in this study for using as a metadata for promoting the performance of the visual tree identification task in the process of generating tree reference map in
Section 4.4. To this end, the objects belonging to shadow class were classified by using the thresholding of the mean intensity band (RE-NIR1), mean brightness band (R-G-B-NIR1), and simple ratio (NIR1-B) using a trial and error approach (
Table 1).
Next, the unclassified objects in the scene were assigned to non-shadow class (including CTC and NTC). In the absence of normalized digital surface model (nDSM) data, to mask CTC objects from NTC class objects, particularly the understory vegetation (i.e., grass and shrubs) objects, the following major steps were adopted in this study.
The roughness of the elevated vegetation layer (trees) is more than the understory vegetation layer in the image. Therefore, following [
134], for separation of the elevated vegetation (rough texture) surface from the understory vegetation surface (smooth texture), initially, edge extraction Lee Sigma filtering [
135,
136] was performed for detecting of both bright and dark edges in the red band (sigma value = 5) to produce bright and dark edge Lee Sigma bands. Then, a new band (LeeSigmaSum) was generated by adding the bright edge Lee Sigma band into the dark edge Lee Sigma band that were calculated in the previous step. To compute the Roughness band, the Gaussian smoothing filter [
137] with the kernel size of 25 × 25 pixels was applied to LeeSigmaSum band. The non-shadow objects were classified into CTC or NTC classes by thresholding of both R to Roughness ratio and normalized difference vegetation index (NDVI) (
Table 1). The thresholds for R to Roughness ratio and NDVI were automatically calculated through the following procedure. First, the image objects overlapped with the purported tree centroids (i.e., crowdsourced trees) to find the objects that belong to tree crowns. Then, the mean (
) and standard deviation (
) values of the respective index for the all overlapped objects were calculated, and the threshold for the corresponding index (i.e., the R to roughness ratio and NDVI) were computed as follows:
where
is a coefficient that was set for the respective index (
Table 1). The determination of the thresholds based on the mean and standard deviation values of the overlapped objects can address the within-crown spectral variances and reduce the negative effects of the existence of the errors (i.e., misidentified non-tree features as tree) within the crowdsourced dataset in the process of the automatic computation of the thresholds.
A cleaning process was applied to the extracted CTC objects to exclude some of the remaining misclassified NTC objects using the geometric and spatial relationship characteristics. Then, the processed CTC objects were used in the process of generating the land parcels in the test plot (
Section 4.1.3) as well as metadata for enhancing the performance of the visual tree identification task in
Section 4.4.
Figure 3 illustrates the distribution of the detected shadow and CTC regions over the study area.
4.1.3. Delineation of Land Parcels in the Test Plot
To improve the productivity and management of orchards, orchard plots are usually subdivided into several smaller land parcels, and the trees are cultivated regularly in each parcel according to a selected layout system (e.g., square, rectangular, quincunx, triangular patterns, etc.). The trees in each orchard land parcel are mostly homogeneous in the terms of species and crown size, and therefore, they have mostly similar geometric, contextual, and spectral characteristics. This basic assumption is consistent with the insight from the Tobler’s first law of geography (TFL) that implies that “everything is related to everything else, but near things are more related than distant things [
138]”.
In this study, the trees in the orchard are detected using the TM method. The TM algorithm employs a template that models the spectral and contextual properties of the target feature for detection of all instances of the target feature on the scene. To enhance the performance of the TM algorithm, for each homogenous group (i.e., class) of target objects (in terms of size, spectral, and contextual properties) in the population, a specific template using the obtained samples should be created. This process increases the correlation between the generated template and the samples [
139,
140] and enables the template to represent the different characteristics of the group more precisely. Furthermore, for improving the performance of the TM algorithm, the generated template has to be used only for detection of features in its corresponding group to increase the level of cross-correlation between the generated template and the image (for more details see
Section 4.1.4 and
Section 6.2.1.2).
In the absence of ground truth information about the characteristics (e.g., species, etc.) of the trees in the orchard, by using insights from TFL, one may assume that the trees in a homogeneous region in the image have more uniformity and similarity in terms of their characteristics. Therefore, to cover both of the aforementioned considerations for improving the TM algorithm performance, we subdivided the test plot into more homogeneous regions (i.e., land parcels) in terms of tree characteristics and limited the tasks of collecting the image samples and applying the TM algorithm for each group to the extent of the respective regions.
Therefore, to detect and delineate the land parcels within the test plot, the following main steps were followed. First, a multiresolution segmentation method was performed at the coarse scale (scale parameter = 300) on the image, as the trees are planted in the relatively large parcels in the orchards. The shape parameter and compactness parameters were determined as 0.2 and 0.5, respectively, by using the trial and error method. The segmented objects were then overlayed with the CTC objects that were extracted in the previous section to exclude the non-planted segments. Finally, the remaining segments (totally 6 segments) were assigned to the parcel class that subdivided the existing trees in the test plot into six subregions (i.e., 6 parcels) (
Figure 4). The generated parcels are employed for partitioning the image, tree samples, and reference data into more homogeneous regions in the next sections for conducting the overlay analysis.
4.1.4. Tree Detection Using TM Algorithm Based on Crowdsourced Training Samples (TM-CS)
In this study, we adopted a TM algorithm for tree detection (ITC detection) in the urban orchard. To this end, first, a template image was generated for each parcel by sampling from the image at the locations of all the points tagged as “tree” in the parcel by the volunteers. The image samples were obtained from the NIR1 band because previous studies [
105] have proven that the NIR band is the most appropriate band for obtaining the image samples about trees for training the TM algorithm. Then, the mean of all collected sample images for each parcel was calculated (the negative impacts of the noise can be reduced by averaging over a large number of samples). The sample width and height for each parcel was selected proportional to the mean tree crown diameter of parcel. To calculate the mean crown diameter of the parcel, first, we computed the diameter of tree crowns for each crowdsourced tree feature in a parcel. Let
and
represent the length of the longest spread of each purported tree crown and the longest spread perpendicular to it in the scene, respectively. The purported tree crown diameter (for an individual crowdsourced observation) (
(i.e., the average crown spread for an ITC for the crowdsourced observations) can be measured as follows:
The mean tree crown diameter of parcel (for the crowdsourced observations) (
) was computed as follows:
where
is the total number of purported tree crowns in the crowdsourced dataset by the volunteers in a parcel (i.e., the number of image samples collected based on the locations of all crowdsourced observations).
The size (i.e., dimensions) of all image samples in a parcel is equal to a square kernel with dimension ( ), where is equivalent to the length of in pixels.
In total, six templates were created in this study, and each template was used only for the detection of the trees in its own respective parcel.
Table 2 shows the total number of selected samples for generating the template in each parcel as well as the parcel mean tree crown diameter value of each parcel and the dimensional and quality specifications of the generated templates.
To detect tree crowns in the image by TM algorithm, the template kernel sliding on the image (in this study, the NIR1 band) and the similarity measure between the template and the image is calculated for each pixel, and the similarity image is generated. Among the different suggested similarity measures, such as normalized cross-correlation (NCC), the sum of squared differences, and Euclidean distance (for more details see [
141]), we adopted the NCC measure as it showed a promising performance in previous remote sensing studies [
142]. The NCC value (
) is computed as follows:
where
is the intensity of the pixel,
is the mean intensity for the pixels under the template,
is the intensity for the corresponding pixel in the template, and
is the mean intensity for the template. The NCC value ranges from −1 to 1, where the higher values indicate a better match between the image and the template at that particular position.
The position of the occurrence of the best matches on the similarity image indicate the position of the pixels with the highest probability of being a tree crown centroid. Thus, to find the tree crown centroids in the adopted TM algorithm, the NCC values were thresholded (for more details see [
52,
102,
143]). The template match threshold value should be selected with care to meet the requirements of the map users, as setting the threshold value too high leads to a large number of false negative (FN) errors (i.e., undetected tree crowns), while setting the threshold value too low leads to a high number of false positive (FP) errors (i.e., misdetection of non-tree features as tree crowns). In this study, it is desirable to increase the number of TP detections and decrease the number of FN and FP errors and the occurrence of FN errors is considered more unwanted than the occurrence of FP errors. Since we aimed to compare the performance of the tree detection task only in respect to the quality of the deployed templates created based on the crowdsourced samples, to consider all other conditions similar, the template match threshold was consistently selected as 0.65 for all the TM attempts in this study.
Finally, the detected tree crown centroid pixels were converted into the vector data format (i.e., point objects) to prepare the data for further data quality investigation in the next step.
4.2. Tree Detection Using TM Algorithm Based on Reference Training Samples (TM-REF)
To assess the impact of using imperfect crowdsourced sample data instead of error-free sample data for training the proposed approach, the TM algorithm was trained with the reference training samples (TM-REF), and the TM-CS performance was compared with it. To provide similar image sampling conditions in this comparison, corresponding reference tree centroids that were overlapped on the correctly identified crowdsourced trees in each parcel were selected for collecting the image samples for that parcel (i.e., we collected the sample at the tree centroid location on the image only if the tree crown was also marked in the crowdsourced data). The size of the image samples and the generated template in a parcel was selected as a square kernel with a dimension of
(which is equal to the dimension of the kernel that was created based on the crowdsourced samples in a parcel) (for more details, see
Table 2) rather than selecting the size according to the mean tree crown diameter of the parcel for the reference observation (
) (for more details see
Section 4.4.1) and its corresponding equivalent length in pixels (
) (
Table 3). This assumption was made because we mainly aimed to study the impacts of the positional and thematic mapping accuracy of crowdsourced data on the performance of the TM algorithm. Therefore, we selected the same TM parameters for both the crowdsourced and reference samples.
The template for each parcel was generated according to the instruction that was described in
Section 4.1.4. Then, similar to the procedure that we followed in
Section 4.1.4, the TM algorithm was applied on the image in each parcel to detect the tree crown centroids.
4.3. A Preliminary Experiment on the ITC Detection Performance of the Proposed Approach under a Higher Level of Uncertainty in the Crowdsourced Training Samples
Visual interpretation is a subjective process that is context-dependent and impacted by the different factors [
144,
145], and hence, one may expect that the occurrence rates of unintentional and intentional (i.e., vandalism) [
146] errors in the remote mapping tasks are variable. Therefore, it is worth investigating the performance of the proposed approach for ITC detection (i.e., the quality of the TM-CS output) under the occurrence of higher level of errors in the crowdsourced training samples.
Depending on the source of the thematic or positional errors in the crowdsourced training samples, they could exhibit either random or spatially biased patterns. The modeling of the different patterns and scenarios of error occurrence in the crowdsourced tree data, as well as systematic assessment of the impact of these patterns and scenarios on the performance of the proposed TM-based approach, are beyond the scope of this paper. However, in the absence of an independent study in this area and to open a discussion for future works, we conducted a limited preliminary study on ITC detection performance of the proposed approach under the occurrence of the higher levels of misidentification errors in the crowdsourced training samples by modeling of errors using a simple random pattern.
To perform this preliminary study, we selected parcels 3, 6, and 5. The first two parcels were selected because they had the highest and lowest number of the contributions, respectively. Parcel 5 was selected because it was covered with very thick understory vegetation, leading to a very low spectral separability between tree crowns and their surrounding vegetation. To provide the required training datasets for evaluating the performance of the proposed approach for ITC detection under a higher level of uncertainty in the crowdsourced training samples, we gradually corrupted the initial quality of the original crowdsourced dataset in each parcel. In this sense, we generated the test training dataset (i.e., the synthetic crowdsourced training samples) at the following thresholds of the false positive to true positive (FP:TP) ratio: 0.25, 0.50, 0.75, 1.00, 1.25, 1.50, 1.75, 2.00, 5.00, 8.00, and
for each selected parcel. In the following, we will briefly explain the adopted methodology for generating the test training dataset in this preliminary experiment. We considered the size of the test training dataset at each threshold of FP:TP ratio constant that is equal to the size of the original crowdsourced data (
) at the corresponding parcel (=215, 70, and 3 respectively for parcels 3, 5, and 6). The portion of the FP errors (and consequently, the portion of TP observations) for the test training dataset at each threshold of FP:TP ratio in each selected parcel was determined by solving of the following linear system under the following constraints:
To compute the values of the FP and TP observations, the values were rounded to the closest integer values. Then, the following error injection procedure was adopted to generate the test training dataset. In this context, to reduce the initial quality of the original crowdsourced data and generate a test training dataset with FP:TP ratio of 0.25, first a certain number of TP observations (according to the results of solving Equation (5)) were randomly selected by an automated approach and removed from the original crowdsourced data. Then, a certain number of FP errors (according to the results of solving Equation (5)) were created and randomly distributed in the areas that were classified as NTC and shadow land cover in the corresponding parcel through an automatic process. Next, the synthetically created FP records (i.e., FP errors) were added to the remaining TP observations to create a test training dataset with records. This test training dataset was used as the test training dataset for evaluating the approach’s performance for the FP:TP ratio of 0.25.
To create the corresponding test training dataset (with records) for the next FP:TP ratio (=0.50), the test training dataset that was created in the previous step (FP:TP ratio = 0.25) was corrupted by randomly removing a certain number of remaining TPs from the previous test training dataset and adding (and randomly distributing) a certain number of synthetic FPs (based on the results of solving Equation (5)) by adopting the similar method as the previous step. This procedure was repeated continuously to create the respective test training datasets for the thresholds in each parcel and ended after generating the respective test training dataset for FP:TP ratio equal to . It is clear that as the initial number of the original crowdsourced data in parcel 6 is very low ( = 3), it is not possible to create a test training dataset for all the thresholds in this parcel.
The generated test training dataset at each threshold were used for creating the templates. To this end, we adopted the same methodology and parameters as were adopted in
Section 4.1.4. Finally, the TM-CS was conducted for each FP:TP ratio threshold at each selected parcel according to the procedure that was explained in
Section 4.1.4. Then, the quality of TM-CS outputs for each selected parcel were evaluated using the introduced quality measures in
Section 4.4.2 to investigate the changes in the performance of the proposed ITC detection approach (based on collective sensing) in the gradual increasing of the amount of error in the training samples.
4.4. Data Quality Assessment
4.4.1. Reference Data
In the absence of the ground truth data, and due to the inability to conduct a field survey in the test plot (as it is located on private property), we asked an independent remote sensing expert to visually interpret the WV3 imagery of the test plot and mark the centroid positions of all tree crowns in the image (
Figure 5). In the process of image interpretation, the expert used Google Earth image time series and the metadata that were produced in
Section 4.1.2 as supplemental sources of information to ensure a high accuracy in the visual interpretation task. A total of 2640 trees were identified in the test plot by the expert.
Furthermore, the crowdsourced tree data were provided to the independent expert, and he was asked to digitize (as polygon features) the tree crowns in the image that overlapped with the crowdsourced observation in the study area.
To measure the reference value for the tree crown diameter (
) for the tree crowns in the image that overlapped with the crowdsourced tree, we adopted the Spoke method [
147], as it is indicated as the most accurate method for the computation of the average crown spread for an individual crown [
147]. To this end,
was computed using the following equation by measuring the distance of the crown centroid to the vertices of the crown polygon (
).
where
is the number of vertices of the polygon.
The mean tree crown diameter of the parcels (for the reference observation) (
) was computed as follows:
where
is the total number of tree crowns in the corresponding reference dataset in the parcel.
Table 3, shows the
and the measured
values for each parcel.
As the ground truth data were not available for the test plot, the data that were generated by the independent expert were assumed as the high-quality data and adopted as the reference data in this study.
4.4.2. Data Quality Measures
To assess the quality of the collected crowdsourced data (
Section 3.3.2), the three spatial data quality elements of completeness, thematic accuracy (thematic mapping accuracy and quantitative attribute accuracy), and positional accuracy were measured by comparing the outputs against the reference dataset (
Figure 2). To evaluate the quality of the crowdsourced data (
Section 3.3.2), we assessed the data using the measures of completeness (C), positive predictive value (PPV), false discovery rate (FDR), diameter error for a correctly identified ITC (
, root mean square error (RMSE) for the tree crown diameter measurement for crowdsourced observation (
), positional error (distance error) of the crown centroid for a correctly identified ITC (
), and the RMSE for the tree crown centroid position measurement (
).
To evaluate the quality of the generated test training datasets in
Section 4.3, the two spatial data quality elements of thematic accuracy (thematic mapping accuracy) and positional accuracy were measured by comparing the outputs against the reference dataset. To assess the thematic mapping accuracy of the generated test training datasets (
Section 4.3), the spatial data quality measure of FDR was employed. To quantify the TP and FP observations positional accuracies at each test training dataset in
Section 4.3, we used
,
,
, and
indicators. The
,
,
, and
values indicate the mean of the positional errors (
) for the TP observations, the mean of the positional errors (
) for FP observations (i.e., the mean of Euclidian distances between FP observations and their nearest tree crown centroids in the reference dataset), the standard deviation of positional errors for TP observations, and the standard deviation of positional errors for FP observations, respectively.
To evaluate the quality of TM-CS output (
Figure 2) and TM-REF output in
Section 4.1.4 and
Section 4.2, three spatial data quality elements of completeness, thematic accuracy (thematic mapping accuracy), and positional accuracy were measured by comparing the outputs against the reference dataset. The quality of the TM-CS output (i.e., the performance of the proposed approach for ITC detection (based on collective sensing)) (
Section 4.1.4), and the TM-REF output (
Section 4.2) were assessed using the spatial data quality measures of C, FDR, false negative rate (FNR),
score (
), and
.
To assess the ITC detection performance of the proposed approach under higher levels of uncertainty in the crowdsourced training samples (
Section 4.3), two spatial data quality elements of completeness and thematic accuracy (thematic mapping accuracy) were measured by comparing the outputs against the reference dataset. In this sense, the quality of the TM-CS output under the higher levels of uncertainty in the crowdsourced training samples (
Section 4.3) was evaluated using the spatial data quality measures of C, FDR, FNR, and
. The aforementioned data quality measures were calculated according the equations in
Table 4.
5. Results
5.1. Quality of the Identified Trees Using Crowdsourcing Approach
The total number of purported trees in the crowdsourced dataset, the total number of counted trees in the reference dataset, and the quality elements of the crowdsourced dataset were measured for both parcels and the test plot in this study (
Table 5). A total of 612 purported tree features were recorded by the volunteers for our test plot, which contained a total of 2640 trees. Cross-checking the crowdsourced data against the reference data showed that 594 out of the volunteers’ 612 purported trees were identified correctly (i.e., TP observations), with the remaining 18 purported tree features being false observations (i.e., FP error). The degree of completeness of the crowdsourced dataset for the test plot was relatively low, with only 22.5% of the trees in the test plot being mapped by the volunteers. The degree of completeness of the data varied in the different parcels, ranging from 14% in parcel 5 to 34.1% in parcel 1. The variability in the degree of completeness among the plots and the sparse contribution pattern of the VGI (
Figure 4) mostly originated from the opportunistic nature (for more details, see [
148,
149]) of the voluntary contributions and affected by the different VGI completeness impacting factors (for more details, see
Section 6.1.1). For instance, a visual interpretation of
Figure 1 and
Figure 4 demonstrated that generally, there were fewer contributions in areas where trees were surrounded by dense understory vegetation that had a high spectral similarity to tree crowns (i.e., low-contrast areas). Thus, the low degrees of completeness in parcel 5 could mainly have originated from the high level of the complexity because of the low contrast in this parcel.
The high PPV of crowdsourced data for the test plot (PPV = 0.971) indicated that the crowdsourced data in general had a very high thematic accuracy in terms of tree feature identification (i.e., thematic mapping accuracy). The PPV ranged from 0.926 (in parcel 4) to 1.000 (in parcels 2 and 6). The FDR, as a complement of the PPV, indicates the level of noise (originating from tree identification errors, the thematic mapping errors) in the crowdsourced data that were obtained without any correction for training of TM algorithm. The noise level of the crowdsourced training samples at the test plot level was very low (2.9%), and varied between 0% (for parcels 2 and 6) to 7.4% (for parcel 4).
Figure 6 depicts the examples of the different types of occurred thematic mapping errors in the gathered VGI. In addition to the evident gross thematic mapping errors (referred to as type “A” errors) that occurred because of observers’ immense carelessness in the crowdsourcing task, some misidentification errors occurred because of the low contrast, limited spatial resolution, and existing complexities in the scene (particularly when the observer performed the visual interpretation task solely based on the true color image). In this context, the misidentification errors most frequently occurred in low-contrast areas (referred to as type “B” errors), in areas where the remains of removed trees were present (referred to as type “C” errors), and in areas with tree crown shadows (referred to as type “D” errors) (
Figure 6).
Figure 7a shows the distribution of
for the crowdsourced ITC observations using box plots. The average
values for the crowdsourced tree observations of parcels 1 to 6 were 0.81 m, 0.73 m, 0.58 m, 0.77 m, 0.86 m, and 0.27 m respectively (the average of
values for the test plot was 0.71 m i.e., 2.29 pixels). The medians and the average of the absolute
values are approximately the same in all parcels (but with more fluctuations compare to diameter errors), except in parcel 6 where there were fewer crowdsourced contributions. In parcel 5, substantially more variation is observed in the box plot, possibly due to the higher level of the scene complexity (because of the low contrast) in this parcel that affected the quality of the tree centroid location task. While the
was computed only for the correctly identified tree crowns, the visual screening of the outlier observations in the box plots (in
Figure 7a) showed that the majority of the gross positional errors occurred in low-contrast areas, in areas where the tree crowns are overlapping, and in areas where the tree crowns were located near relatively larger shaded areas. The
value was 0.83 m (i.e., 2.67 pixels) for the crowdsourced tree crowns in the test plot and ranged from 0.28 m (for parcel 6) to 1.01 m (for parcel 5). The
values and
value for the observations in the test plot indicated that the overall positional accuracy of the mapped crowdsourced tree crowns was not very high but was fair. According to the proposed mapping protocol for the volunteers in this study, we expected that the tagged points represented the centroids of tree crowns. Moreover, to create the templates, the image was sampled on the purported tagged tree points. Therefore, ideally, it is expected that the centroid of the tree crowns matches the centroid of the respective crowdsourced training samples and the respective template kernel. However, as crowdsourced observations were subjected to some positional errors, this assumption is violated. In this sense, the positional errors in the crowdsourced tree crowns centroids introduce some noise into TM algorithm.
The distributions of
for the crowdsourced ITC observations are displayed in
Figure 7b as box plots. The average of the absolute
values for the crowdsourced ITC observations for the parcels 1 to 6 were 0.55 m, 0.50 m, 0.48 m, 0.55 m, 0.56 m, and 0.88 m, respectively (average of the absolute
values for the test plot as a whole was 0.52 m, i.e., 1.67 pixels). The medians and the averages of the absolute
values were approximately the same in all parcels (except in parcel 6, where fewer trees were observed by the volunteers). The box plots for parcels 1 to 5 are approximately balanced around the median value of 0 (with the similar variations) indicating that the chance of underestimation and overestimation of the diameter value was approximately the same over a large number of observations. While the
was computed only for the correctly identified tree crowns, a visual screening of the outlier observations in the box plots shows, similarly to the
errors, the majority of the gross diameter errors occurred in the low-contrast areas, areas with overlapping tree crowns, and areas where trees were adjacent to the large shaded areas. Furthermore, some gross errors seemed to have occurred because of the incorrect identification and measurement of the longest spread and the longest spread perpendicular to it. The
was 0.76 m (i.e., 2.45 pixels) for the crowdsourced ITC observations in the entire test plot and ranged from 0.67 m (in parcel 2) to 0.93 m (in parcel 6). The
values and
value for the crowdsourced observations in the test plot indicated that the overall thematic accuracy of the measured diameters (i.e., the quantitative attribute accuracy) was fair.
5.2. ITC Detection Performance of the TM-CS
The quality of the tree crowns detected by TM-CS was evaluated.
Table 6 presents the results. Quality measures were calculated for each individual parcel and at total parcel level (i.e., for all parcels combined). To assess the quality measures for all the parcels combined, we combined the trees detected by the TM algorithm in each parcel together into a single dataset.
The numbers of features detected by TM-CS as tree features (i.e., the number of TP and FP tree features) in each parcel (
) are reported in the
Table 6. Using the six different TM templates, a total of 2690 tree features were detected over the six parcels (=
). A cross-checking of the TM outputs against the reference data showed that TM-CS was able to correctly detect (i.e., hit) 2448 trees over six parcels correctly (=number of TP tree features).
Table 6 shows the degree of completeness of the detected trees by TM-CS. The degree of completeness ranged from 69.2% (in parcel 6) to 96.6% (in parcel 3). Overall, the TM-generated data achieved a relatively high degree of completeness (92.7%). Compared to the initial degrees of completeness of the crowdsourced data at the individual parcel and the total parcels level, the completeness of TM-CS was much higher in all parcels (from 45.3% in parcel 6 to 76.4% in parcel 5) and over the all parcels (70.2%). These results demonstrate the significant power and efficiency of the proposed approach for improving the degree of completeness of the gathered VGI in a crowdsourcing project for the remote mapping of urban orchard trees.
The cross-checking of the TM outputs against the reference data showed that a total of 192 existing trees over the all parcels remained undetected (i.e., missed) by TM-CS (= number of FN errors). A total of 242 features were incorrectly recognized as trees (= number of FP errors); 16 of which were overdetected trees (i.e., multiple hits within a single tree crown) and the rest (226 errors) were falsely detected trees (i.e., non-tree features incorrectly detected as tree features).
Figure 8 illustrates some examples of the tree detection performance of the TM-CS. A visual interpretation of the error occurrences indicated that most of the FN errors occurred in locations with apparently unhealthy (e.g., trees with a low canopy density) or smaller (than the parcel’s average) trees. Overdetection FP errors occurred for trees with larger crown sizes (than the parcel’s average) or apparently multi-branches trees. Furthermore, our observations showed that the falsely detected FP errors frequently occurred at locations with dead (or almost dead) trees, locations with thick understory vegetation (e.g., shrubs), and locations on or close to the borders of a tree crown. Nevertheless, some of the falsely detected FP errors occurred far from non-vegetated areas. These types of FP errors mainly occurred in areas with sharp edges (particularly on the edges of passages exiting the test plot), where sharp variations in the intensity of the NIR1 band occurred, making the spectral and contextual pattern of the falsely detected feature resemble the spectral and contextual pattern of trees in the scene (where the bright pixels of the tree crown intersected with the dark pixels of the tree shadow in the NIR1 band).
Figure 9a illustrates the spatial distribution of the detected, undetected, overdetected, and falsely detected trees by TM-CS.
The FDR, FNR, and
values in
Table 6 reflected the thematic mapping accuracy of the detected trees by TM-CS. The results of the accuracy evaluation show that the highest rate of FP errors (i.e., FDR) and FN errors (i.e., FNR) occurred in parcel 6 (0.550 and 0.308, respectively). In the other remaining parcels, the FDR and FNR values ranged from 0.037 in parcel 3 to 0.136 in parcel 2 and 0.033 in parcel 3 to 0.139 in parcel 1, respectively. The overall FDR (0.090) and FNR (0.073) values at the total parcels level indicated that the number of FP and FN errors were quite low (i.e., a low number of over- and under-detection errors occurred) compared to the number of successful ITC detections (TP detections).
Table 6 shows that with the exception of parcel 6, which had a relatively low
score (0.545), the
scores in other parcels varied were quite high, ranging from 0.879 (in parcel 2) to 0.964 (in parcel 3). The TM-CS approach does not show a satisfactory ITC detection performance in parcel 6 because of the following reasons. The majority of the parcel 6 is covered by NTC land cover, and the existence of understory vegetation and sharp edges (the passage) caused the occurrence of FP errors (falsely detected trees). Furthermore, the previous studies showed that the TM algorithm-based NCC similarity measure could not perform well in the presence of the significant scale changes between the generated template and target feature [
139]. In this sense, if the target tree crown is significantly larger than the modeled tree crown in the template, the TM algorithm produces FP error (overdetection error) or FP error (falsely detected trees) around the tree. On the other hand, if the target tree crown is significantly smaller than the template, the TM algorithm produces the FN error (under-detection error). The considerable variation in the sizes of the trees in parcel 6 resulted in the scale change problem that triggered the production of more FN and FP errors by the TM algorithm in this parcel. On the other hand, a limited number of trees in this parcel fit with the scale of the template that caused the production of few TP detections by TM algorithm. Therefore, the TM algorithm performance achieved a low signal-to-noise ratio.
At the total parcels level, TM-CS achieved a score of 0.918, which is also quite high. Based on these results, we generally concluded that the proposed ITC detection approach (based on collective sensing) in the urban orchards produced very satisfactory thematic mapping accuracy (i.e., achieved a high signal-to-noise ratio).
Ideally, a point feature generated by the TM algorithm should represent the centroid of the detected tree. However, different sources of error may lead to differences in the locations of the TM-detected tree centroids and the actual tree centroids (i.e., positional errors). Contrary to the thematic mapping accuracy of the detected trees, the positional accuracy of the correctly detected trees usually is not considered an important factor in most of the conventional tree inventory projects. However, as the imperfections in the VGI used in the proposed TM-CS approach could theoretically affect not only the thematic mapping accuracy but also the positional accuracy of the TM outputs, the positional accuracy of the correctly detected trees was evaluated in this study (using
) and is reported in
Table 6. The
values for the outputs of TM-CS ranged from 0.91 m (in parcel 3) to 1.27 m (in parcel 1). At all the parcels level, the proposed approach achieved an
value of 1.02 m (i.e., 3.2 pixels), indicating that the tree crown centroids generated by TM-CS had a moderate positional accuracy overall.
5.3. The Impact of Using the Crowdsourced Training Samples Instead of the Reference Training Samples on the ITC Detection Performance of the Proposed Approach
The thematic and positional accuracies of ITCs detected by TM-CS are likely affected in part by thematic/positional inaccuracies of the crowdsourced training samples. To evaluate the potential impacts of these inaccuracies in the crowdsourced training samples, in this section, we calculated the quality measures for tree ITCs detected by TM-REF. Differences in the thematic/positional accuracies of TM-CS and TM-REF are likely due to differences in the accuracies of the crowdsourced and reference training datasets. As shown in
Table 7, a total of 2691 features were detected as tree features over the 6 parcels by TM-REF (based on the reference training samples). Among these features, 2469 were correctly detected trees (= number of TP tree features), 172 were undetected trees (= number of FN tree features), and the remaining (i.e., 222 features) were incorrectly recognized as trees (= number of FP tree features).
The quality measures values (i.e., values of C (%), FDR and FNR,
, and
) for the outputs of TM-CS (
Table 6) and TM-REF (
Table 7) were compared parcel by parcel and for all the parcels as a whole. As was expected, generally, the degree of completeness, thematic mapping accuracy, and positional accuracy of the detected trees were higher using the reference training samples. The main exceptions were the values of FDR in parcel 3 and 6 and the
in parcel 6, which indicated slightly lower accuracies for TM-REF (because of the impact of the higher rate of FP errors generation in return for the generation of TP detections and the higher number of the generated TPs respectively). The cross-checking of the quality measures in the
Table 6 and
Table 7 at the total parcel level indicated that adopting the reference training samples for training the TM algorithm slightly increased the degree of completeness (by approximately 0.8%), and the thematic mapping accuracy in terms of reduced FDR and FNR (both by approximately −0.008) and increased
(by approximately 0.008), and the positional accuracy of the output (by approximately 0.09 m).
Figure 9b illustrates the spatial distribution of the detected, undetected, overdetected, and falsely detected trees by the TM-REF approach. The comparison of
Figure 9a with
Figure 9b revealed that the spatial distribution patterns of the detected, undetected, overdetected, and falsely detected trees by TM-CS and TM-REF were almost the same.
Errors in the outputs of the TM algorithm arise not only from the imprecision of the training samples but also the algorithm and the tuning of its parameters. As we used the same algorithm and the parameter settings for the both TM-CS and TM-REF, it seems that the small differences between the quality measure values in
Table 6 and
Table 7 at the total parcel level mainly originated from the existence of the thematic and positional errors in the crowdsourced training samples. At the test plot level, the prevalence of thematic mapping errors in the adopted crowdsourced training sample was 2.9%, the average positional error for these samples was 0.71 m, and the
value for the samples is 0.83 m (for more details see
Section 5.1). However, these levels of imperfections in the VGI resulted in a small difference in the performance of the proposed approach, TM-CS, compared to the performance of the TM-REF. Therefore, it can be generally concluded that the incorporation of VGI with VHR optical imagery through the proposed workflow results in promising performance in this pilot project and can pave the road for conducting further studies in this area.
While the TM-CS approach generally showed a promising performance in this pilot project, exploiting the solutions for enhancing the quality of TM-CS output allow us to remove/modify most of the existing inaccuracies in the TM-CS output. For example, a considerable number of the generated FP errors (falsely detected trees) in this study (e.g., the FP errors parcel 6) could be detected and filtered if the TM output is simply overlayed with the NTC and shadow layers (for more details, see
Section 6.2).
5.4. The Results of the Preliminary Experiment on the ITC Detection Performance of the Proposed Approach under a Higher Level of Uncertainty in the Crowdsourced Training Samples
Table 8 presents the specifications and quality measures for the generated test training datasets and the created templates at the different FP:TP ratio thresholds in parcels 3, 5, and 6. It is logical that by increasing the level of noise in the test training datasets and reducing the TPs, the FDR should increase steadily. The values of
,
,
, and
fluctuated at the different thresholds as the TP records were randomly removed and TF records were randomly distributed in this experiment.
Table 9 demonstrates the result of the data quality measures for the output of the TM-CS under the different FP: TP ratio thresholds in parcels 3, 5, and 6. The results indicate that by increasing the FP: TP ratio value, the completeness and thematic mapping accuracy of the detected trees over the selected parcels generally decreased. Nevertheless, the random removal of the TP records and random generation and distribution of TF records at each step caused the occurrence of minor fluctuations in the values of some quality measures for some thresholds.
The adopted ITC detection approach generally showed a very good performance in terms of completeness and thematic mapping accuracy in the FP:TP ratio range of 0.25 to 2.00 in parcel 3. The quality assessment of TM-CS output at the FP: TP ratio value of 0.25 shows that the output has a very high degree of completeness (C = 96.5%) and thematic mapping accuracy (FDR = 0.040, FNR = 0.034, and
= 0.962). The TM-CS output at the FP: TP ratio value of 2.00 achieved a high degree of completeness (C = 90.2%) and thematic mapping accuracy (FDR = 0.058, FNR = 0.097, and
= 0.921).
Table 9 shows that the quality of the detected trees deteriorated significantly at the FP:TP ratio value of 5.00 and above.
The proposed approach demonstrates a promising performance under the occurrence of the higher levels of errors in the training samples in parcel 5. The trees detected by TM-CS in parcel 5 had a high quality (C = 90.4%, FDR = 0.062, FNR = 0.096, and = 0.920), but the quality was lower than that of the trees detected by TM-CS in parcel 3 (C = 96.7%, FDR = 0.037, FNR = 0.033, and = 0.964). In this parcel, at the FP: TP ratio value of 0.25, the trees detected by the proposed approach achieved relatively high completeness and thematic mapping accuracy (C = 89.9%, FDR = 0.064, FNR = 0.100, and = 0.917). The TM-CS output at the FP: TP ratio value of 2.00 achieved an above average degree of completeness (C = 76.1%) and thematic mapping accuracy (FDR = 0.195, FNR = 0.238, and = 0.782).
Initially, the TM-CS output in parcel 6 has a relatively low quality (C = 69.2, FDR = 0.550, FNR = 0.308, and = 0.545). Consequently, the TM algorithm using the corrupted training samples did not achieve an acceptable quality level in this parcel.
The results of our preliminary experiment showed that the TM algorithm performance under the presence of synthetic errors in the training samples is not the same at the same FP:TP ratio values in the different parcels. In this context, it seems that several issues—e.g., the degree of homogeneity of TP image samples, the degree of heterogeneity of FP image samples, and the degree of homogeneity of the tree population in terms of geometric, contextual, and spectral characteristics in the parcel—affect the magnitude of the quality deterioration at each threshold FP:TP ratio in our study.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}