1. Introduction
The algorithms for compressing hyperspectral images, as any other state-of-the-art compression algorithm, take advantage of the redundancies in the image samples to reduce the data volume. Hyperspectral image compression algorithms may take into consideration the redundancies in the spatial and spectral domains for reducing the amount of data with or without losing information. Lossless compression algorithms have been traditionally preferred to preserve all the information present in the hyperspectral cube for scientific purposes despite their limited compression ratio. Nevertheless, the increment in the data-rate of the new-generation sensors is making more critical the necessity of obtaining higher compression ratios, making it necessary to use near-lossless and/or lossy compression techniques.
The general approach for compressing hyperspectral images consists of a spatial and/or spectral decorrelator, a quantization stage and an entropy coder, which tries to use shorter codewords for representing the symbols. The decorrelator can be transform-based or prediction-based. In the transform-based approaches, transforms like the
Discrete Wavelet Transform (DWT) [
1] or the
Karhunen–Loève Transform (KLT) [
2,
3] are applied to decorrelate the data, while, in the prediction-based approaches, the samples are predicted from neighbouring (in the spectral or spatial directions) samples, and the predictions errors are encoded. While lossless compression is more efficiently performed by prediction-based methods, transform-based approaches are generally preferred for lossy compression.
In this scenario, the transform-based lossy compression approaches, based on the KLT transform for decorrelating the spectral information, have been proven to yield the best results in terms of rate-distortion as well as in preserving the relevant information for the ulterior hyperspectral analysis [
4,
5,
6,
7]. In particular, the
Principal Component Analysis (PCA), which is equivalent to the KLT transform in this context, used for decorrelating and reducing the amount of spectral information, coupled with the JPEG2000 [
8] for decorrelating the spatial information and performing the quantization stage and the entropy coding, stands out due to its lossy compression results, which have been demonstrated to be comparatively better than the results provided by other state-of-the-art approaches [
5,
6,
7]. Indeed, the PCA algorithm has been widely used as a spectral decorrelator not only for compression, but also for other hyperspectral imaging applications such as classification or unmixing, increasing the accuracy of the obtained results [
9,
10].
Despite their optimal decorrelation features, the KLT approaches, including the PCA algorithm, have important disadvantages that prevent their use in several situations. These disadvantages include an extremely high computational cost, intensive memory requirements, high implementation costs and a non-scalable nature, which make these approaches not suitable for applications under latency/power/memory constrained environments, such as on-board compression. These limitations, as well as the promising compressions results achieved with the KLT approaches, have motivated the appearance of research works that aim to reduce the complexity of the transform by using divide-and-conquer strategies [
11]. Nevertheless, the compression performance of these approaches is lower than the performance of the general KLT approach, or, in particular, than the performance of the PCA transform, while their computational complexity is still very high.
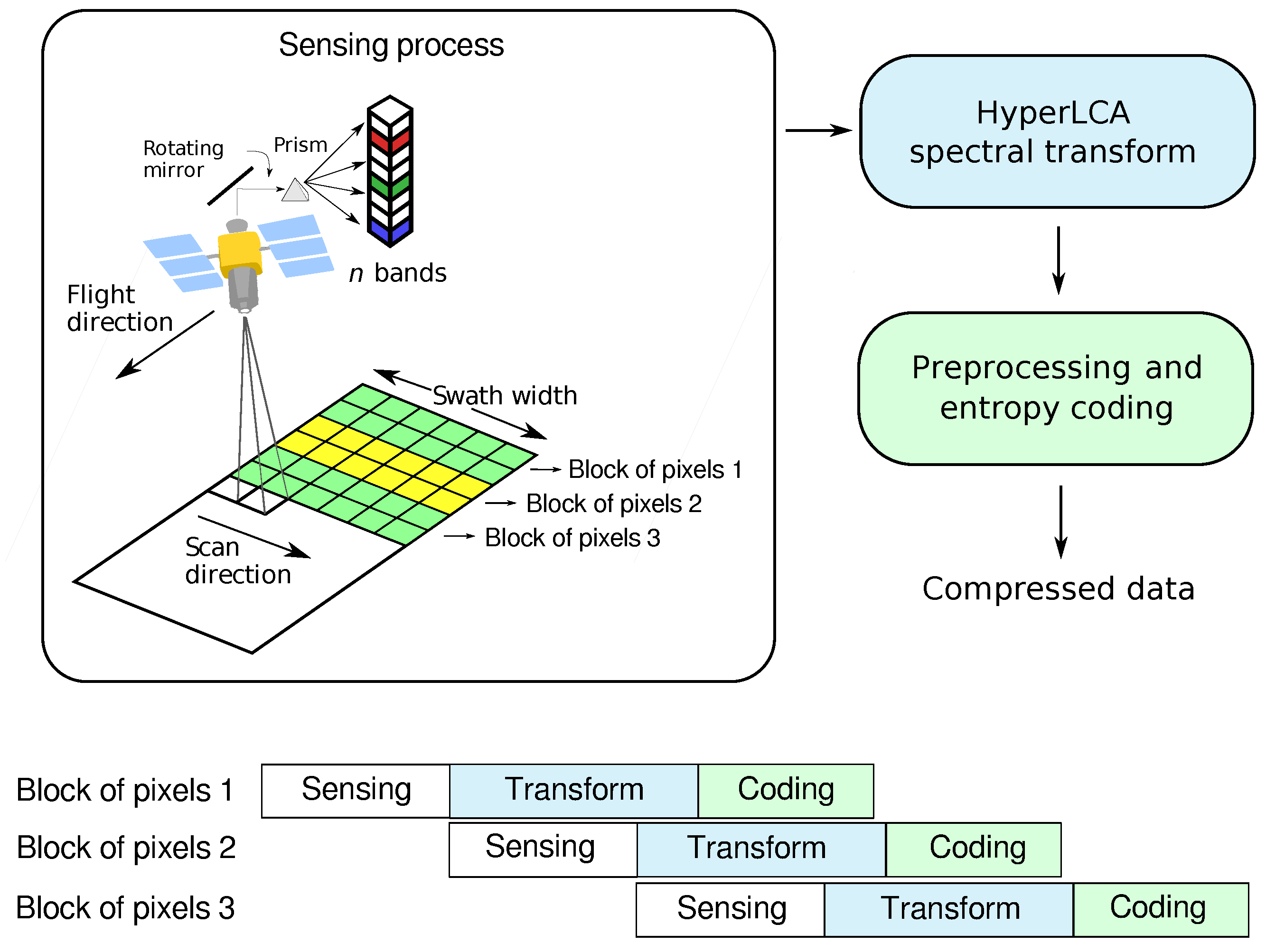
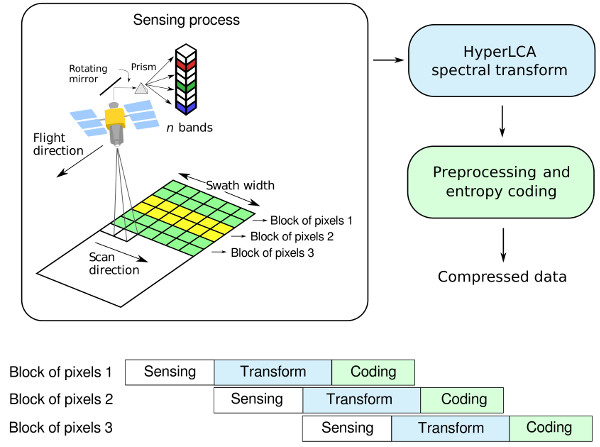
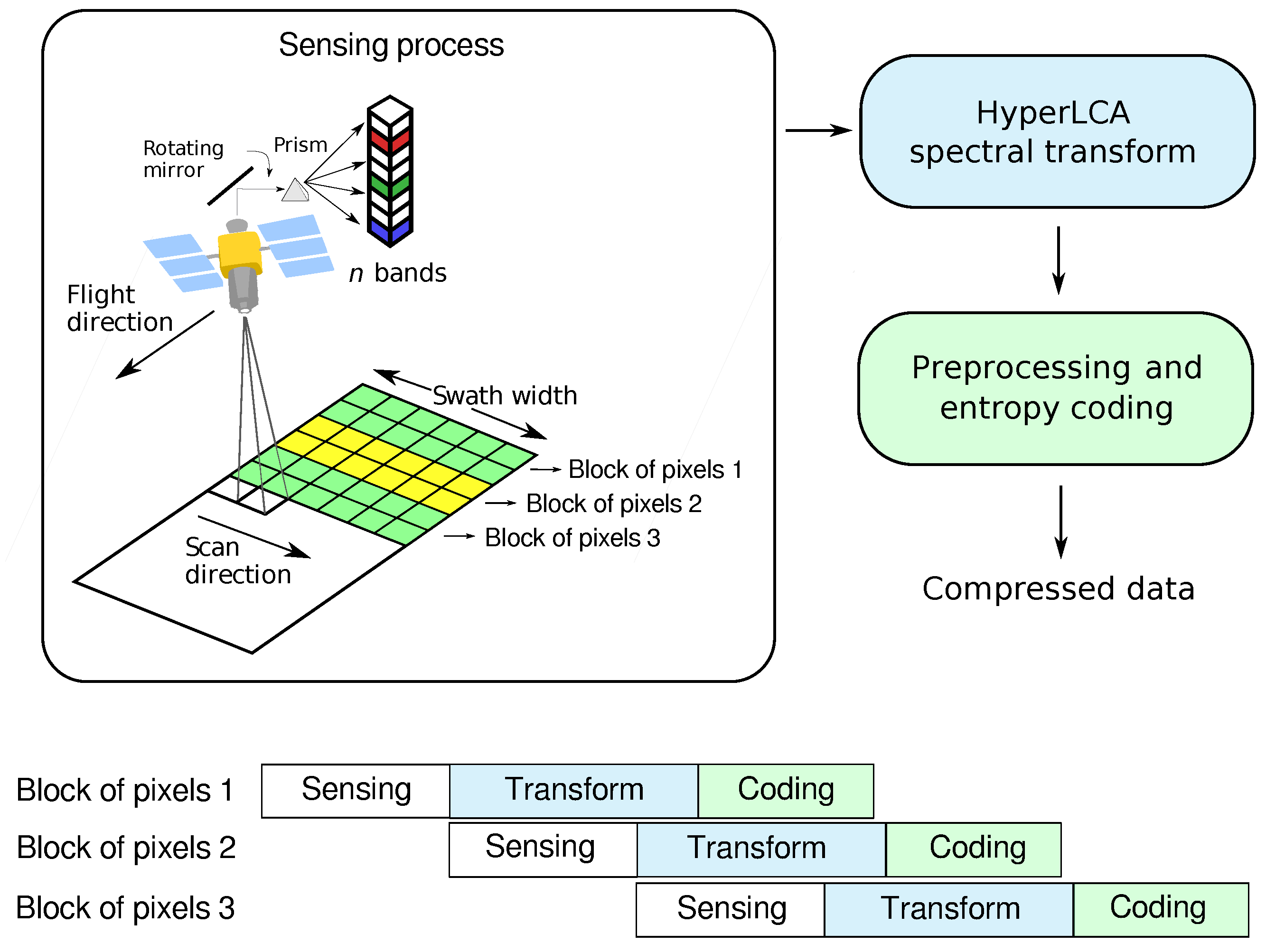
A new transform-based algorithm for performing lossy hyperspectral images compression, named Lossy Compression Algorithm for Hyperspectral image systems (HyperLCA), has been developed in this work with the purpose of providing a good compression performance at a reasonable computational burden. This compression process consists of three main compression stages, which are a spectral transform, a preprocessing stage and the entropy coding stage.
The compression process within the HyperLCA algorithm has been specifically designed for being able to independently compress blocks of pixels of the hyperspectral image without requiring any specific spatial alignment. The goal is to satisfy the requirements of the compression applications that must be executed under tight resources and latency constraints. The possibility of independently compressing blocks of pixels as they are captured avoids the necessity of storing big portions of the image until being able to compress them, reduces the amount of required resources for compressing the collected data, speeds up the process and provides parallelization and error-resilience. One example of application where this strategy may provide important advantages is the remote sensing on-board compression, especially when using pushbroom or whiskbroom sensors.
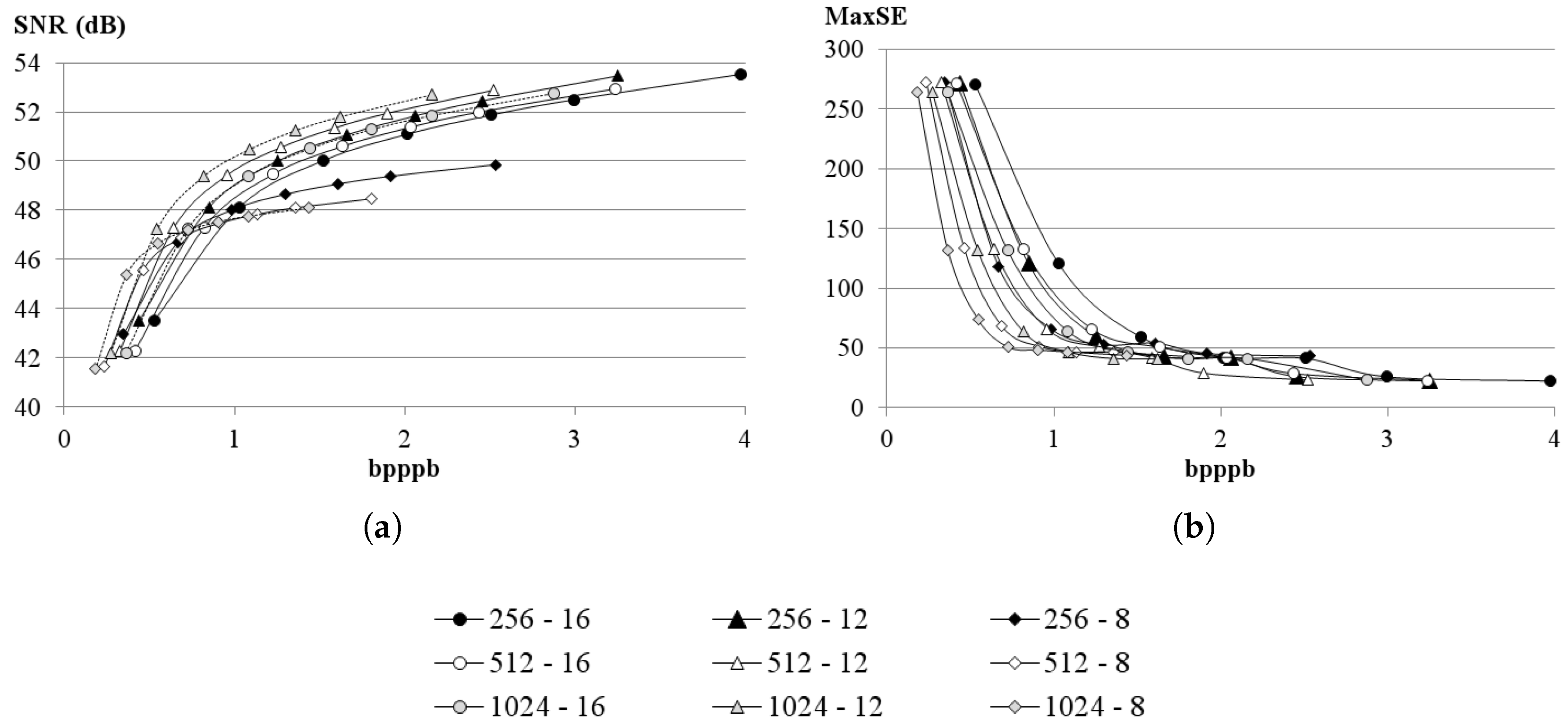
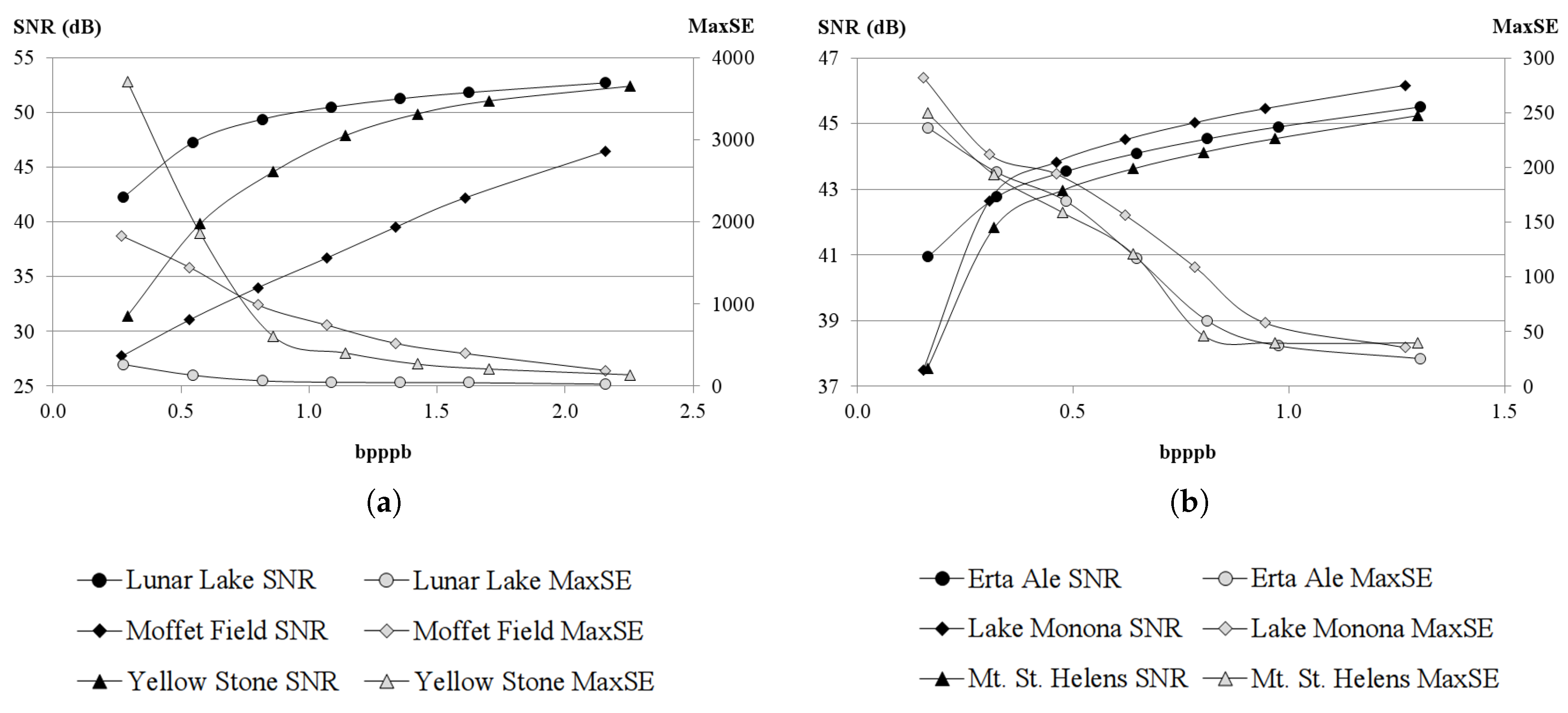
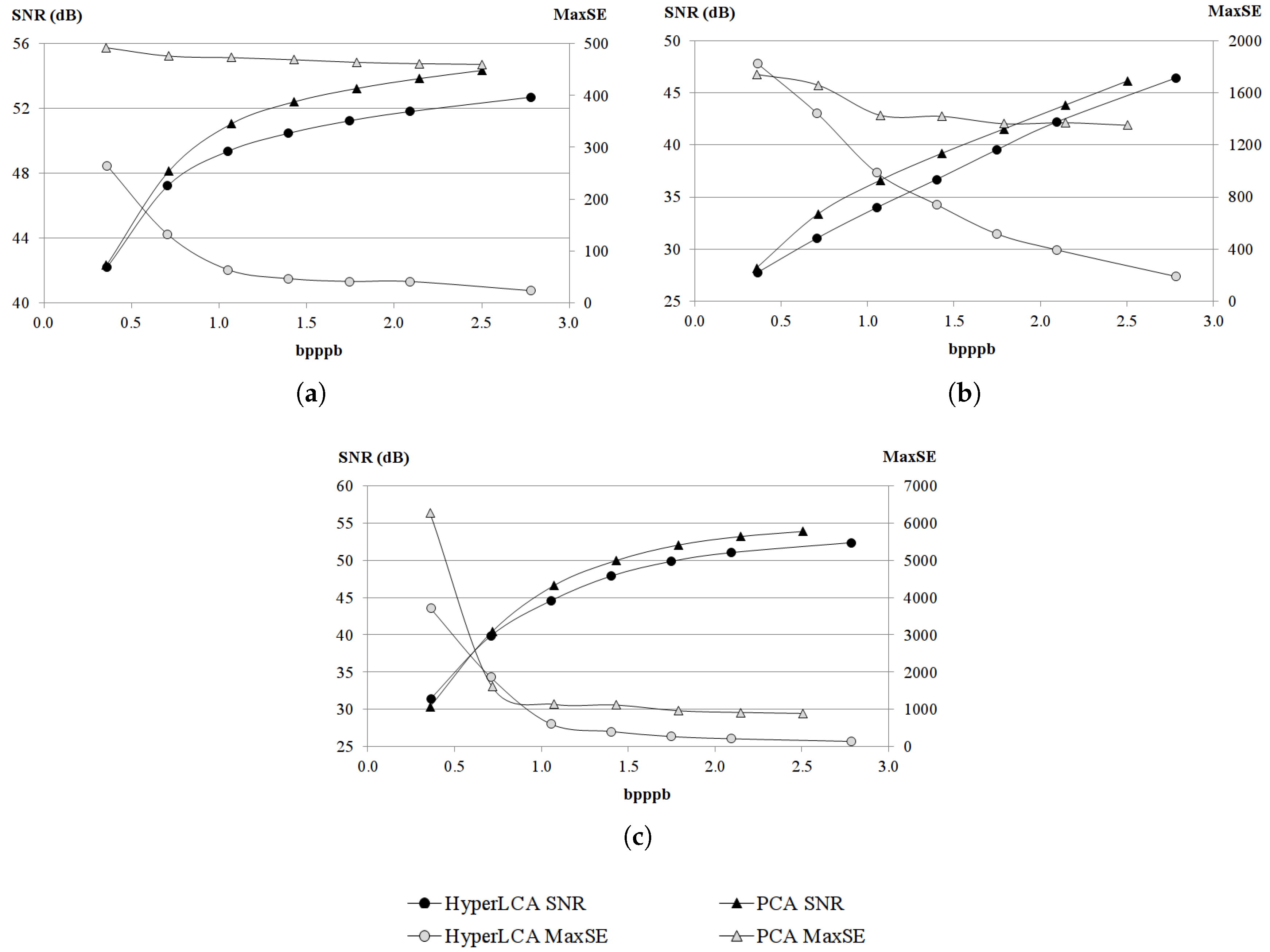
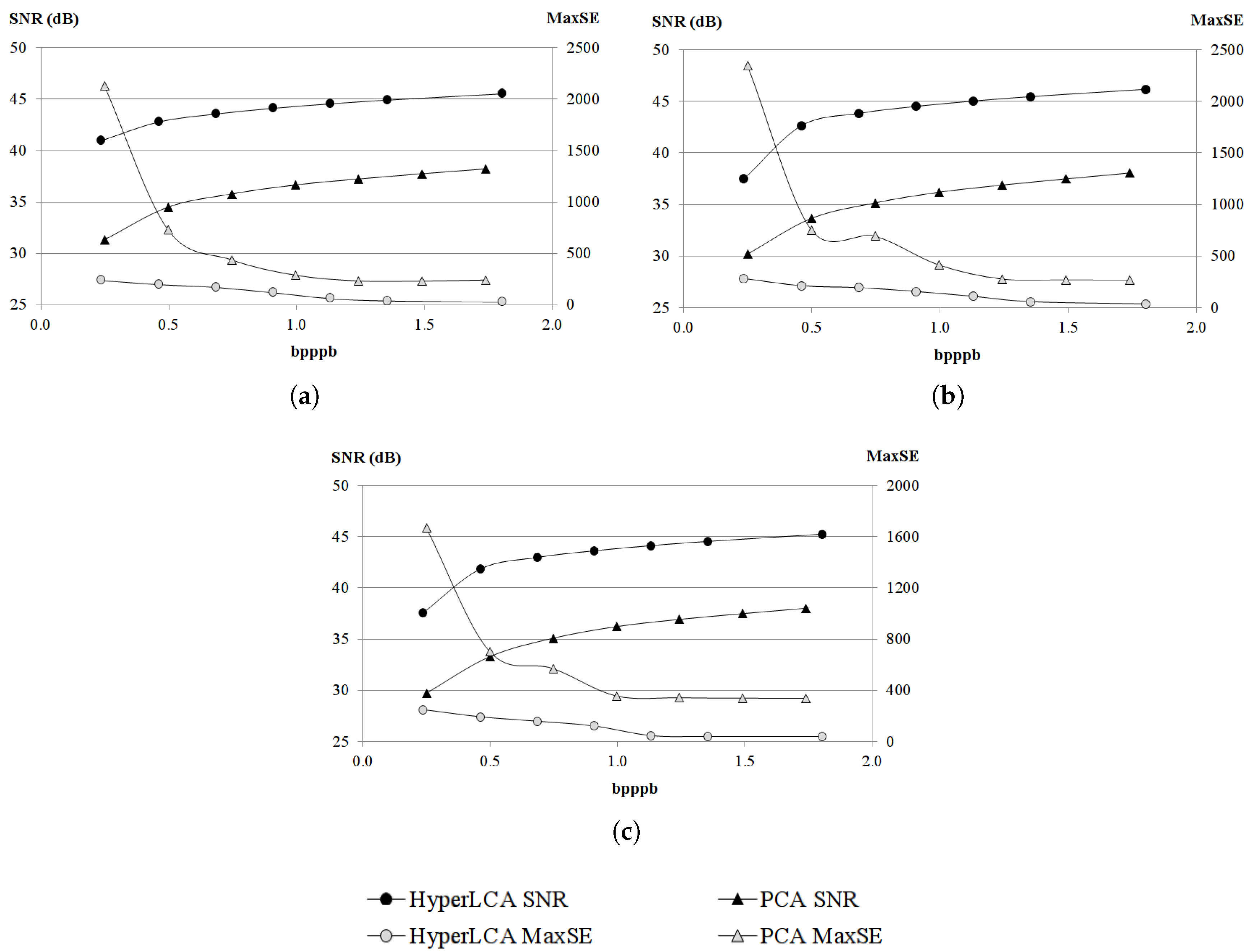
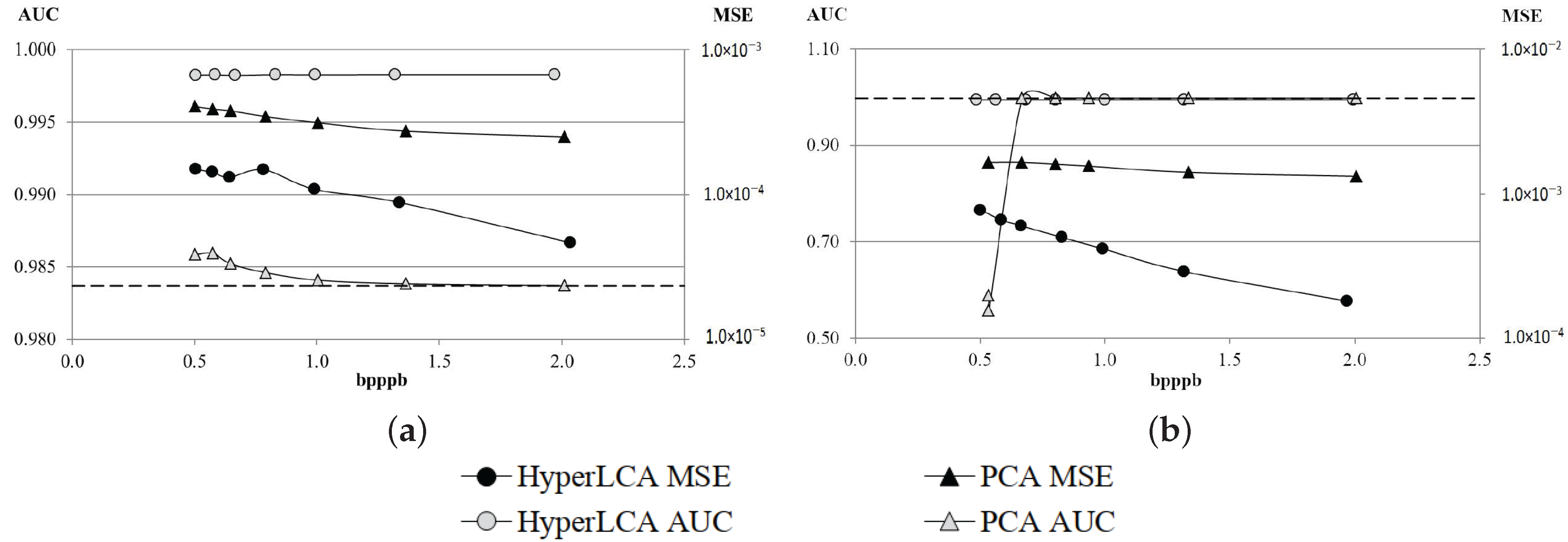
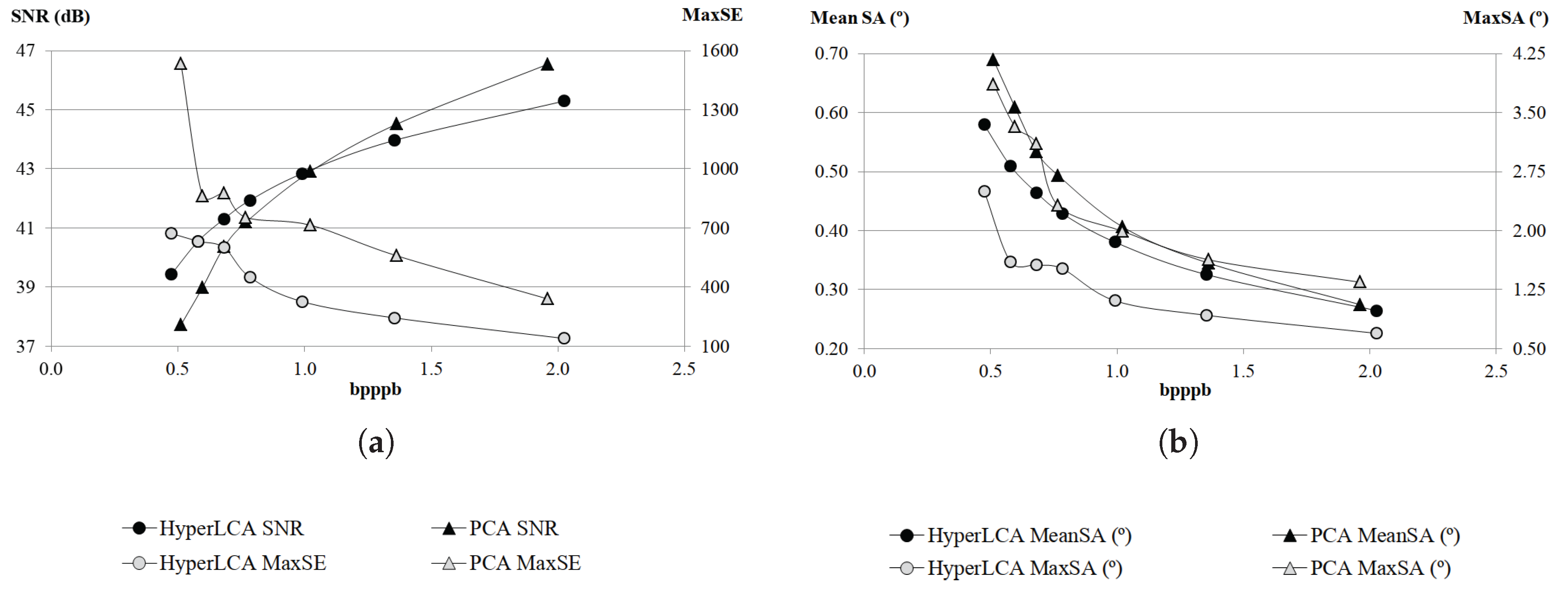
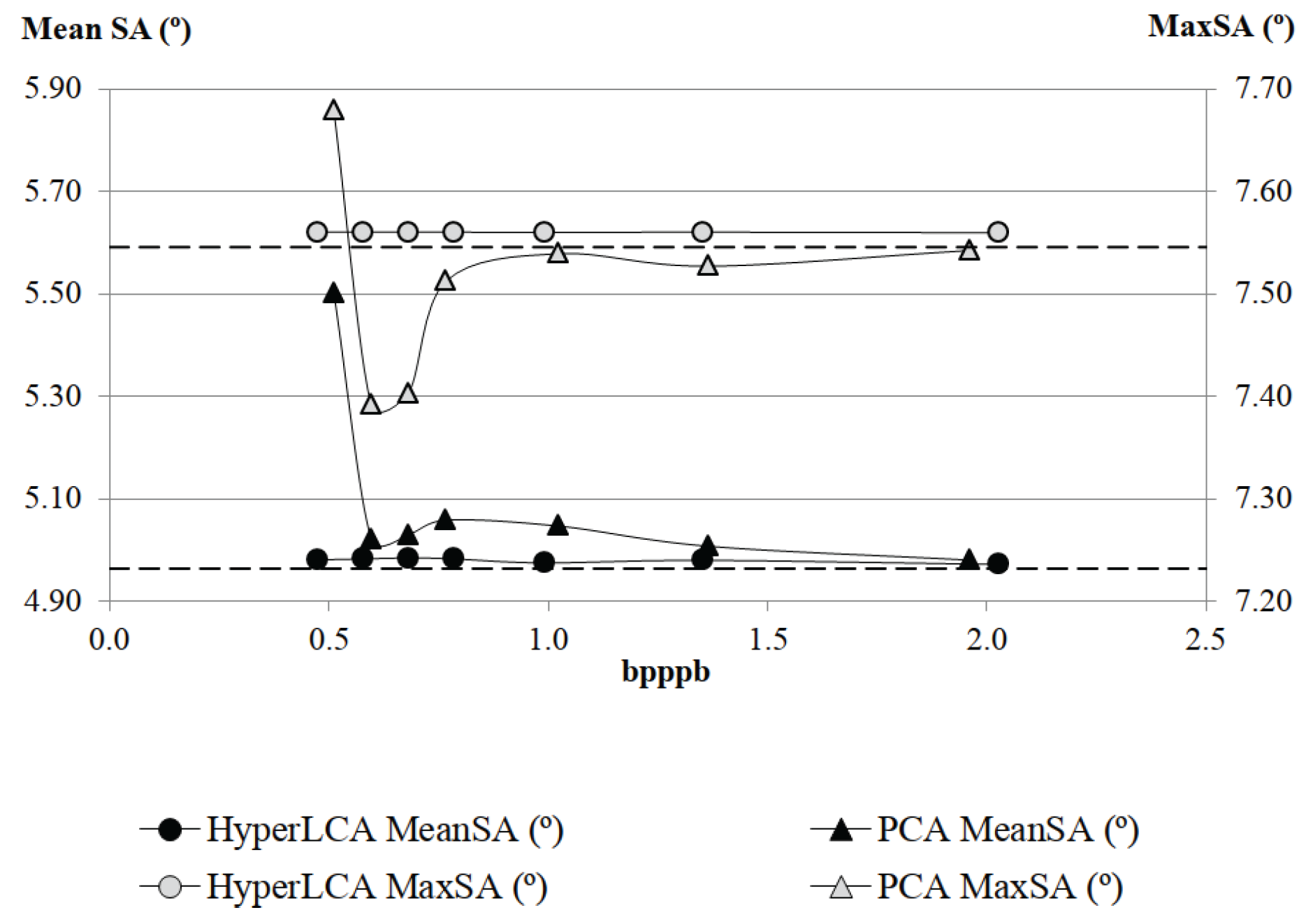
The most relevant contribution of this work consists in the HyperLCA spectral transform, which allows performing the spectral decorrelation and compression of the hyperspectral data. This transform is able to achieve high compression rate-distortion ratios with a low computational burden and high level of parallelism. The HyperLCA transform selects the most different pixels of the hyperspectral data to be compressed, and then compresses the image as a linear combination of these pixels. The number of selected pixels directly determines the compression ratio achieved in the compression process, and, hence, the compression ratio achieved by the HyperLCA transform can be perfectly fixed as an input parameter. The subsequent preprocessing and entropy coding proposed stages slightly increase the compression ratio achieved by the HyperLCA transform at a very low computational cost and without introducing additional losses of information. A further advantage of this methodology is that, after selecting each of the pixels used for compressing the image, the information that can be represented by the selected pixel is automatically subtracted from the image. Accordingly, the information remaining in the image corresponds with the information that would be lost in the compression–decompression process if no more pixels were selected. This fact enables the possibility of easily providing a stopping condition according to different quality measures such as the Signal-to-Noise Ratio (SNR) or the Maximum Single Error (MaxSE).
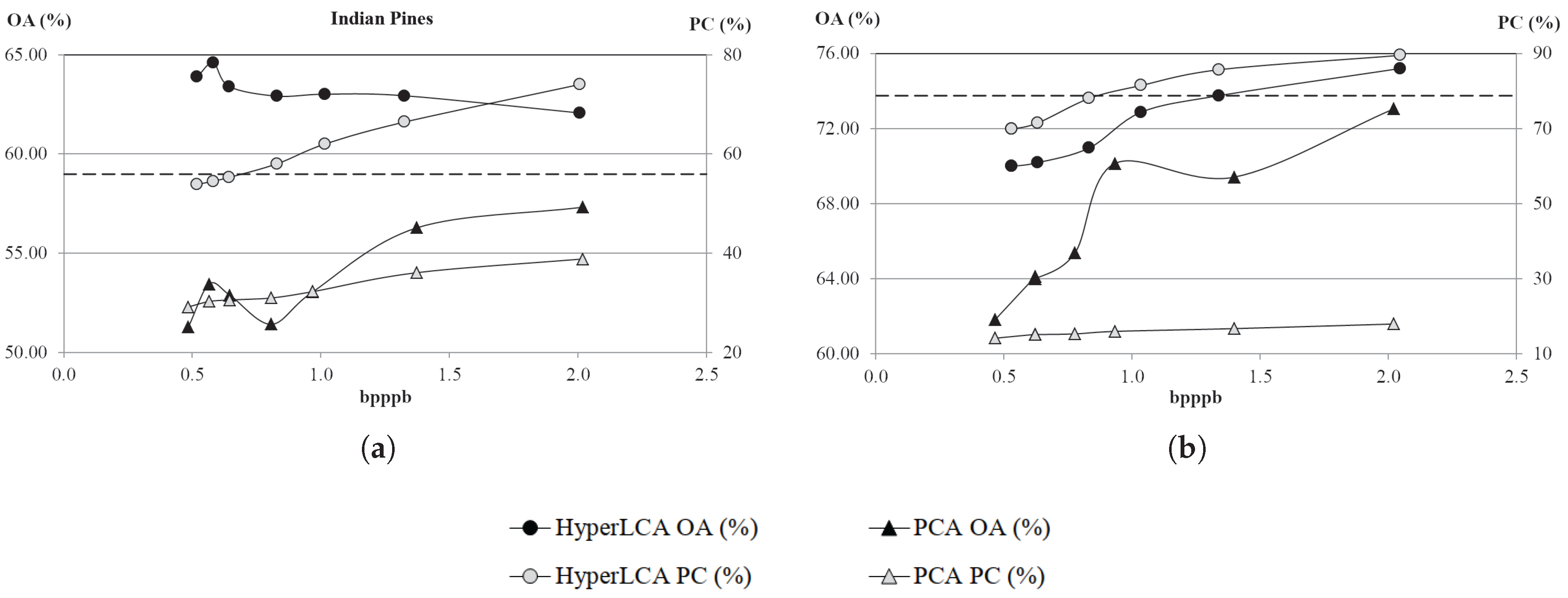
The HyperLCA algorithm has been developed also considering how the lossy compression–decompression process affects the ulterior hyperspectral imaging applications. Most of the lossy compression approaches typically behave as low pass filters, which may produce a reduction of the noise present in the image, positively affecting the results when processing the decompressed hyperspectral images in some applications [
12]; but, at the same time, the low pass filter can also remove the most atypical elements of the image, which are crucial for several applications, such as anomaly detection, classification, unmixing, or target detection [
13,
14,
15,
16,
17]. In this scenario, the HyperLCA algorithm provides important advantages with respect to the state-of-the-art solutions. Despite being a lossy compression approach, the HyperLCA algorithm is able to perfectly preserve the most different pixels in the data set through the compression–decompression process and also compresses the rest of the pixels introducing minimal spectral distortions, as it will be demonstrated in this paper.
This paper is organized as follows.
Section 2 describes the different compression stages of the HyperLCA algorithm.
Section 3 shows the followed methodology for evaluating the goodness of the proposed compressor while
Section 4 contains the results obtained in the different accomplished experiments. Finally,
Section 5 summarizes the conclusions that have been dragged from this work.
2. Hyperspectral Image Compression within the HyperLCA Algorithm
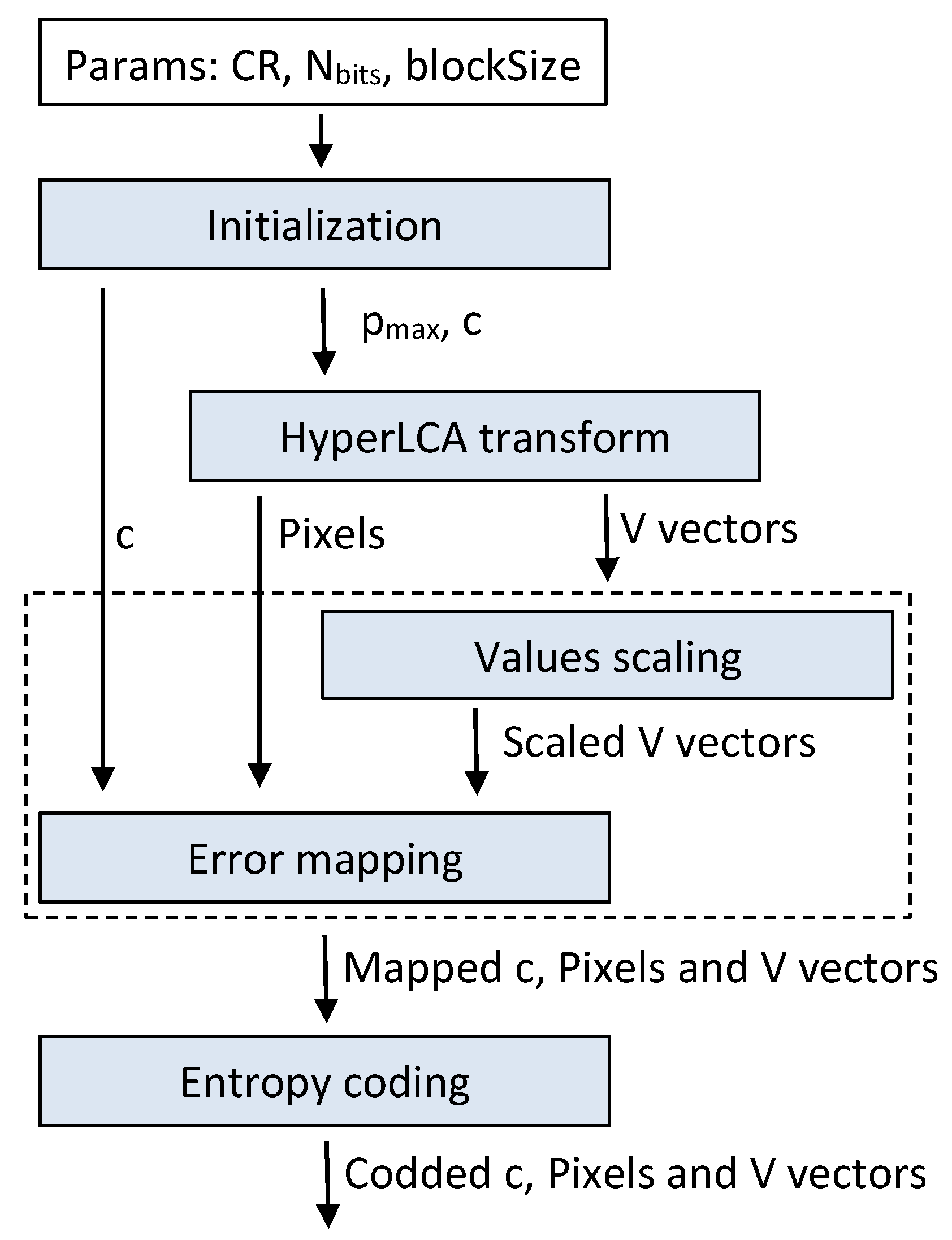
The HyperLCA algorithm is a lossy transform-based compressor specifically designed for providing a good compression performance at a reasonable computational burden for hyperspectral remote sensing applications. The compression process within the HyperLCA algorithm consists of three main compression stages, which are a spectral transform, a preprocessing stage and the entropy coding stage.
Figure 1 graphically shows these three compression stages.
The spectral transform stage, carried on by the HyperLCA spectral transform, performs the spectral decorrelation and compression of the hyperspectral data. The HyperLCA transform is able to achieve high compression rate-distortion ratios with a low computational burden and high level of parallelism. The result of the HyperLCA transform consists of three different sets of vectors, as shown in
Figure 1. First of all, a vector with
components that corresponds with the average pixel of the image or centroid pixel,
c, where
refers to the number of bands of the hyperspectral image. Secondly, the HyperLCA transform also provides a set of vectors of
components that contains real pixels of the hyperspectral image selected by the transform for being the most different pixels in the data set. This set of pixels vectors is referred to as
Pixels in the rest of the manuscript. Finally, the HyperLCA transform provides a set of vectors of
components, where
refers to the number of pixels of the image, which allows linearly combining the selected pixels,
Pixels, for recovering the real hyperspectral image. This set of vectors is referred as
V vectors in the rest of the manuscript.
After performing the HyperCLA transform, the HyperLCA algorithm executes a preprocessing stage followed by an entropy coding stage for slightly increasing the compression ratio achieved by the HyperLCA transform at a very low computational cost and without introducing further losses of information. These two compression stages independently process each of the different
Pixels and
V vectors as well as the centroid pixel,
c. The main goal of the preprocessing stage is to make a very simple prediction of the different vectors’ values, based on the previous value of the specific vector under analysis, and map the prediction error using positive values closer to zero in order to achieve a higher performance in the entropy coding stage. Before the prediction and error mapping, the
V vectors are also scaled to positive integer values that perfectly fit the dynamic range produced by the number of bits,
defined by the user, as shown in
Figure 1. Once that each individual vector is independently preprocessed, its values are entropy encoded using a Golomb–Rice coder [
18].
The HyperLCA algorithm has different characteristics that represent important advantages for remote sensing hyperspectral imaging applications. First of all, the compression process within the HyperLCA algorithm has been specifically designed for being able to independently compress blocks of pixels of the hyperspectral image without requiring any specific spatial alignment. The goal is to satisfy the remote sensing on-board compression requirements, especially when using pushbroom or whiskbroom sensors for collecting the images, allowing independently compressing the blocks of pixels as they are captured, as shown in
Figure 2. This strategy avoids the necessity of storing large amounts of data until being able to compress them, reduces the amount of required resources for compressing the collected data, speeds up the process and provides parallelization and error-resilience. Additionally, the process performed by the HyperLCA algorithm for compressing each single block of pixels is highly parallel and has a low computational complexity in relation to other state-of-the-art transform-based approaches.
Secondly, the HyperLCA transform selects the most different pixels from the data set. These pixels are preprocessed and coded without losing information and hence they are perfectly preserved through the compression–decompression process. This is one of the most important differences of the HyperLCA algorithm with respect to other state-of-the-art lossy compression approaches, in which the most different pixels are typically lost in the compression. This fact represents a very important advantage for hyperspectral applications such as anomalies detection, target detection, tracking or classification, where it is really important to preserve the anomalous pixels.
Finally, the losses in the compression–decompression process as well as most of the compression ratio obtained are achieved in the spectral transformed stage, carried on by the HyperLCA transform. This provides two more important advantages. On one side, after selecting each of the pixels used for compressing the image (extracting one Pixel vector and its corresponding V vector), the information that can be represented by the selected pixel is automatically subtracted from the image. Accordingly, the information remaining in the image corresponds with the information that would be lost in the compression–decompression process if no more pixels were selected. This fact enables the possibility of easily providing a stopping condition according to different quality measures such as the Signal-to-Noise Ratio (SNR) or the Maximum Single Error (MaxSE). By doing so, if the stopping condition is satisfied, the process finishes and no more Pixels or V vectors are extracted, else, one new Pixel vector is extracted, its corresponding V vector is calculated and the stopping condition is checked again. This procedure also enables a progressive decoding of the compressed bitstream. The image can be reconstructed using just the first Pixels and V vectors in the same order that they are received, and progressively add the information of the subsequent Pixels and V vectors contained in the bitstream if a higher quality is desired.
On the other side, the number of pixels selected by the HyperLCA transform directly determines the compression ratio achieved in the transform stage, and, hence, the minimum compression ratio to be achieved by the HyperLCA transform can be perfectly fixed as an input parameter, ensuring that the compression ratio achieved in the overall process will be always higher (higher means smaller compressed data sets). The compression ratio is defined as CR = (bits real image)/(bits compressed data) in this manuscript, and is used by the HyperLCA transform for determining the maximum number of V vectors and Pixels to be extracted, . Once Pixels and V vectors have been extracted, the HyperLCA transform finishes, even if the stopping condition based on a quality metric has not been satisfied.
2.1. HyperLCA Input Parameters
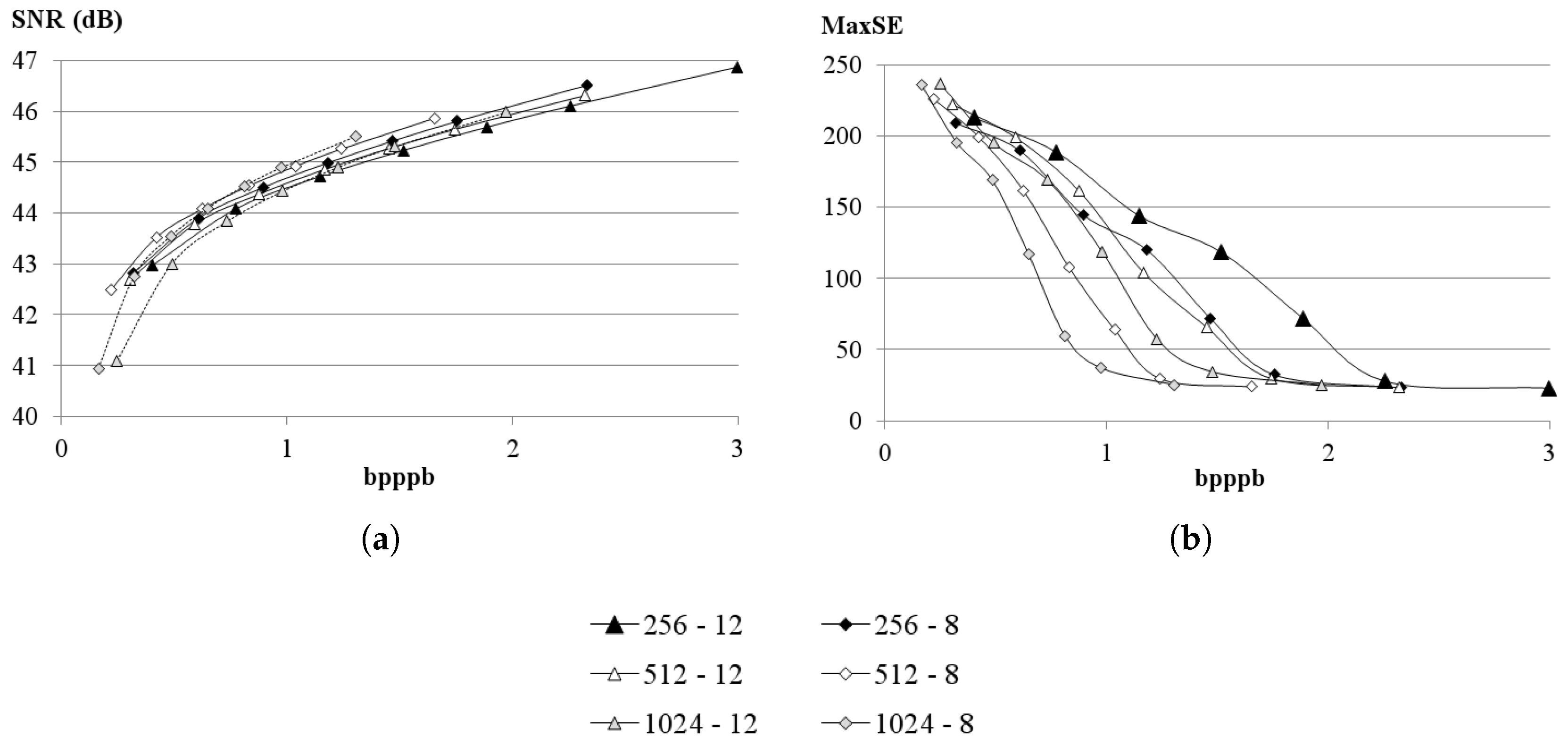
The HyperLCA algorithm has three main input parameters that need to be defined.
Compression ratio, CR, which indicates the maximum amount of data desired in the compressed image. The HyperLCA algorithm will provide a compressed image at least CR times smaller than the original one.
Number of pixels per block, blockSize. This is the number of pixels, with all their hyperspectral bands, to be independently compressed by the HyperLCA algorithm as a single block.
Bits for compressed image vectors,
. This is the number of bits used for scaling and coding the values of the
vectors, as described in
Section 2.5. The HyperLCA algorithm has been tested in this work using
,
and
.
2.2. HyperLCA Initialization
The HyperLCA algorithm needs to accomplish two main operations before performing the HyperLCA transform according to the characteristics of the image to be compressed and parameters introduced by the user.
2.2.1. Determining the Number of Pixels to be Extracted by the HyperLCA Transform
The compression ratio achieved by the HyperLCA transform is directly determined by the number of extracted vectors and the number of bits used for representing the compressed vectors
. Accordingly, the maximum number of vectors to be extracted by the HyperLCA transform for each block of pixels,
, is previously calculated according to the number of bands and the dynamic range of the image to be compressed, and the input parameters,
CR,
blockSize and
as shown in Equation (
1), where
is the number of pixels per block (
blockSize),
CR is the minimum compression ratio desired,
is the number of bits used for representing the compressed vectors
, and
DR and
refer to the dynamic range and number of bands of the hyperspectral image to be compressed, respectively:
The process can be simplified by using the same precision for representing the compressed vectors
,
, than for representing the image to be compressed,
, and the Equation (
1) would result in Equation (
2)
2.2.2. Calculating the Centroid Pixel for Each Block of Pixels
The HyperLCA transform requires the previous calculation of the average or centroid pixel,
c, for every block of pixels to be processed. With independence of the data precision used for calculating
c, it is rounded to the closest integer value before starting the HyperLCA transform stage. This has two main purposes. First of all, it eases the preprocessing and entropy coding stages, since these two stages need to work with integer values, as described in
Section 2.5. Additionally, rounding
c to integer values before performing the transformation stage ensures using the exact same vector
c in both the HyperLCA transform and inverse transform, which increases the overall accuracy of the compression–decompression process.
2.3. HyperLCA Transform
The HyperLCA transform sequentially selects the most different pixels of the hyperspectral data set. The set of selected pixels is then used for projecting the hyperspectral image, obtaining a spectral decorrelated and compressed version of the data. The compression achieved within this process directly depends on the number of selected pixels. Selecting more pixels provides better decompressed images but lower compression ratios, understanding the compression ratio as the relation between the size of the real image and the compressed one (the higher, the better). Since the pixels are sequentially selected, the sooner the algorithm stops, the higher the compression ratio will be. The proposed method takes advantage of this fact for allowing the user to determine a minimum desired compression ratio, which is used for calculating the maximum number of pixels to be extracted. By doing so, the proposed method ensures the achievement of a compression ratio that will always be higher than the compression ratio specified by the user.
Moreover, each time that a pixel is selected, the information of the image that can be represented using the selected pixel is subtracted from the image. Accordingly, the remaining information directly corresponds with the information that would be lost if no more pixels were selected. This can be used for stopping the sequential extraction of pixels once a specific accuracy level is achieved in the spectral transform step, according to any desired evaluation measurement, without reaching the maximum number of pixels to be extracted, as described in
Section 2.8. This way, the proposed method guarantees that if an accurate enough compression of the hyperspectral image is obtained before extracting all the required pixels according to the minimum compression ratio specified by the user, the algorithm will stop, providing a higher compression ratio at a lower computational burden.
Finally, both the extracted pixels as well as information of the image compressed as a linear combination of these pixels are set as the outputs of the HyperLCA transform. This is due to the fact that both are needed for recovering the original hyperspectral image.
The pseudocode that describes the HyperLCA transform for spectrally decorrelating and reducing the hyperspectral data set is presented in Algorithm 1, where matrix
M contains
real hyperspectral pixels
, placed in columns. Each of these pixels is a vector of
components,
being the number of bands of the hyperspectral image. The input parameter
, defined in
Section 2.1, determines the maximum number of pixels to be extracted. The input vector
c corresponds with the average pixel of the image, also called centroid, in integer values, as described in
Section 2.2. Additionally, the set of vectors
and
contain the vectors that are extracted by the HyperLCA transform as the compressed information. Specifically,
P will store the
real hyperspectral pixels selected by the HyperLCA transform as the most different pixels of the data set (
Pixels), and vectors contained in
V will store the information of the image that can be represented by the extracted pixels (
V vectors). Each of these vectors has
components, one per pixel. These vectors are used by the inverse transform for recovering the real image.
First of all, the hyperspectral data, M, is centered and stored in , in line 3. This is done by subtracting the centroid pixel to all the pixels of the image. The amount of information present in matrix decreases as more pixels are extracted. However, the real image matrix M is not modified.
Secondly, the pixels are sequentially extracted in lines 4–15. In this process, the brightness of each pixel within the image is first calculated in lines 5–7. The extracted pixels are selected as those pixels from M that correspond with the highest brightness in matrix , as shown in line 9. Then, the orthogonal projection vectors q and u are accordingly obtained as shown in lines 10 and 11.
After that, the information that can be spanned by the defined orthogonal vectors
u and
q is stored in the projected image vector
and subtracted from the
image in lines 12–13. The process finishes when the
pixels
have been selected and the information of the image that they can span has been stored in the
vectors, or if an additional stopping condition is previously accomplished, as described in
Section 2.8.
This methodology provides one important advantage for compressing and decompressing images for hyperspectral imaging applications. As described in lines 8 and 9 of Algorithm 1, the pixels to be transferred are selected as those with the largest amount of remaining information. By doing this, it is guaranteed that the most different pixels within the data set are perfectly preserved through the spectral decorrelation and compression steps of the compression–decompression process. This fact makes this compression approach especially suitable for applications in which some pixels may be very different from the rest of the pixels, such as anomaly detection, target detection, tracking or classification.
| Algorithm 1: HyperLCA transform. |
![Remotesensing 10 00428 i001]() |
2.4. HyperLCA Inverse Transform
The inverse HyperLCA transform linearly combines the centroid pixel, c, the extracted pixels and extracted vectors for reconstructing the hyperspectral image, obtaining the decompressed hyperspectral image, . The pseudocode that describes the inverse HyperLCA transform is presented in Algorithm 2. As shown in lines 2–4 of this pseudocode, all the pixels of are firstly initialized as the centroid pixel, c. After doing so, the centroid pixel, c, is subtracted to the pixels selected by the HyperLCA transform, as shown in lines 5–7. Finally, the decompressed image, , is obtained by sequentially adding the result of each of the vectors projected using the corresponding orthogonal vector q, as shown in lines 9–11. Lines 12–14 of the pseudocode show how the information that can be represented by the pixels that have been already used () is subtracted from the pixels that will be used in the next iterations ( to ) of the inverse HyperLCA transform.
2.5. HyperLCA Preprocessing
This compression stage of the HyperLCA algorithm is executed after the HyperLCA transform for adapting the output data for being entropy coded in a more efficient way. This compression stage is divided into two different parts.
2.5.1. Scaling the V Vectors
The HyperLCA transform provides two different sets of vectors as a result. These two different sets of vectors, which have different characteristics, are needed for reconstructing the image using the inverse HyperLCA transform, and, hence, both should be entropy coded and transferred. The entropy coder proposed in this manuscript works with integer values. Accordingly, these two sets of vectors must be represented as integers.
| Algorithm 2: Inverse HyperLCA transform. |
![Remotesensing 10 00428 i002]() |
The first set of vectors obtained contains the centroid pixel,
c, used for initializing the process, as well as the pixels selected by the HyperLCA transform,
. The pixels selected by the transform are already integers, since they are directly pixels of the image. The centroid pixel to be transferred has also been rounded to integers’ values before starting the HyperLCA transform, as described in
Section 2.2. Accordingly, adapting this set of vectors for the entropy coder is a straightforward step.
On the other hand, the second set of vectors obtained by the HyperLCA transform,
, contains the projection of the image pixels into the space spanned by the different orthogonal projection vector,
u, calculated in each iteration. The value obtained when projecting one pixel vector over one specific vector
u will be determined by the angle between both vectors and their magnitude, according to Equation (
3), which describes the scalar product between two vectors:
According to this equation, larger modules and smaller angles (more parallel vectors) will produce higher scalar product values. In the HyperLCA transform, we have selected the vector
u as
,
being the brightest pixel in the image (the pixel with the largest magnitude). Hence, if we perform the scalar product of all the image pixels and the
u vector as shown in Line 12 of Algorithm 1,
, the image pixel
will be the one producing the largest result, which will be exactly 1, as shown in Equations (
4)–(
8):
Since the rest of the image pixels
have smaller magnitudes than
and wider
angles with respect to the vector
u, the values
will be between −1 and 1. Accordingly, it can be said that all the values of the vectors
will be between −1 and 1, as shown in Equation (
9).
According to this particular property of the vectors
we can easily scale the
values for representing them in integer values using all the dynamic range in order to avoid loosing too much precision in the conversion. The
values are scaled in the HyperLCA algorithm according to the input number of bits ,
, defined by the user for this purpose, as shown in Equation (
10):
By doing this, it is guarantied that the maximum value obtained for each scaled vector is always , and its minimum value is always positive and very close to zero. After rescaling the values, they are rounded to the closer integer values so they can be entropy coded.
2.5.2. Represent the Data with Positive Values Closer to Zero
The entropy coding stage takes advantage of the redundancies within the data to be coded, assigning shorter word length to the most common values. In order to achieve higher compression ratios in this stage, the centroid pixel,
c, the selected pixels
, and the already scaled and converted to integer vectors
, are lossless preprocessed in the HyperLCA algorithm, making use of the prediction error mapper described in the CCSDS recommended standard for lossless multispectral and hyperspectral image compression [
19]. This compression stage independently processes each individual vector in order to represent its values using only positive integer values that are closer to zero than the original values of the vector, using the same dynamic range of the values.
Let us assume that we have a vector
whose components
are represented using
n-bits integers values. In the HyperLCA compressor, this vector
Y may be either the centroid pixel,
c, a pixel vector
or a
vector. Due to the spectral redundancies between contiguous bands, when the vector
Y corresponds with a pixel vector
or the centroid pixel
c, we can assume that the difference between the
and
components of the vectors is closer to zero than the
value itself. Similarly, we can make the same assumption when the vector
Y corresponds with a
vector, due to the spatial redundancies of the image. However, in order to prevent bit overflowing in this operation, the number of bits used for representing the prediction error,
, needs to be increased to
(n+1)-bits, and the values will be in the range
. In order to solve this issue, the prediction error,
, is mapped using the aforementioned prediction error mapper [
19].
The overall process works as follows. First of all, the possible minimum and maximum
values are calculated as
when the vector
Y contains negative integer values and
when it does not. Then,
is calculated as
. Finally, the prediction error
is mapped according to the
and
values as shown in Equation (
11):
By doing this, the values of the centroid pixel, c, the selected pixels , and the already scaled and converted to integer vectors , are represented using positive values closer to zero, and using the same amount of bits.
2.6. HyperLCA Entropy Coding
After the preprocessing stage of the HyperLCA compressor, the extracted vectors (centroid, Pixels and V vectors) are independently coded using a Golomb–Rice coding strategy. Each single vector is coded as follows:
First of all, the compression parameter, M, is calculated as the average value of the vector.
Secondly, the lowest power of 2 higher than M, , is calculated as .
Then, each value of the vector is divided by the calculated parameter, M, obtaining the division quotient, q, and the reminder, r.
Finally, each value of the vector is coded according to the q and r values obtained, as a code word composed by the quotient code followed by the reminder code.
- -
The quotient code is obtained by coding the q-value using unary code ( bits are required).
- -
The reminder code is obtained from the r-value. If M is a power of 2, the reminder code is obtained by coding r as plain binary using b bits. If M is not a power of 2, and , the reminder code is obtained by coding r in plain binary using bits. In any other situation, the reminder code is obtained by coding in plain binary using b bits.
The fact of independently coding each vector provides different advantages. On one side, it is possible to use the average value of each vector as the compression parameter,
M, which provides almost the best coding performance for the Golomb–Rice method [
20], without incrementing too much the complexity of the coder. Nevertheless, in those situations in which calculating the average value of the vector represents an important disadvantage due to its complexity, other solutions could be used, such as the median value, as it is done in other compression algorithms, without compromising its good performance.
On the other side, the fact of independently coding each vector allows coding them in the same order that they are obtained in the previous compression stages of the HyperLCA algorithm. This eases the parallelization of the process, making it possible to pipeline the inputs and outputs of the different compression stages for a single block of pixels, and also reducing the amount of memory required.
2.7. HyperLCA Bitstream Generation
Finally, the outputs of the previous compression stages are packed in the order that they are produced, generating the compressed bitstream. By doing so, the computational requirements for accomplishing this last step of the HyperLCA compressor are minimal. Additionally, this order also eases the decompression process, since the compressed data is used for reconstructing the image in the exact same order that it is produced by the compressor.
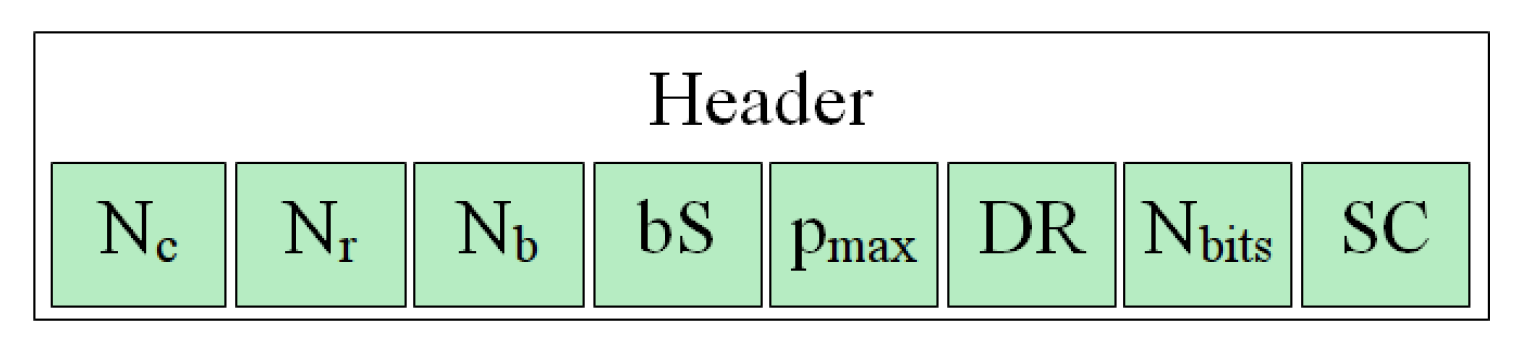
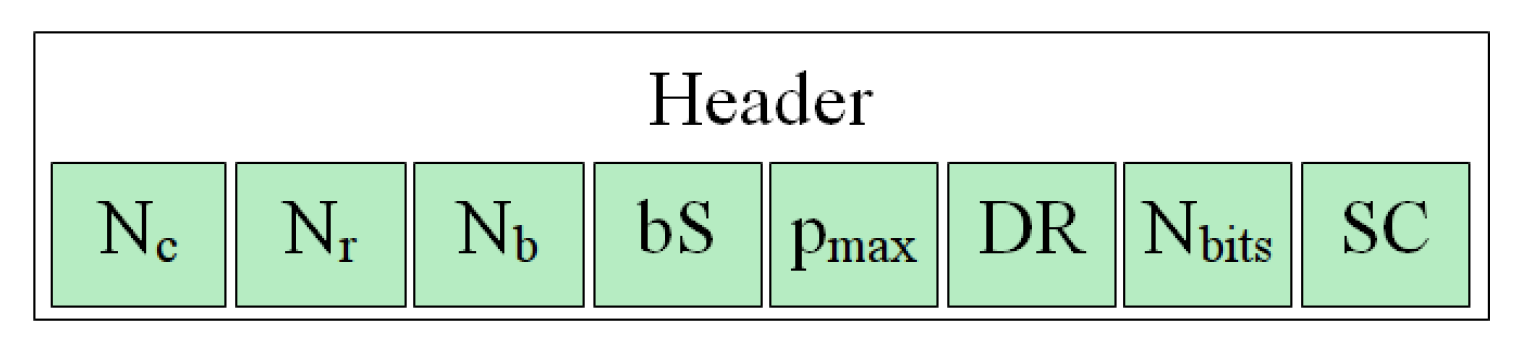
Figure 3 graphically shows the produced bitstream structure.
According to
Figure 3, the first part of the bitstream is a header that contains the global information about the hyperspectral image and the parameters used in the compression process within the HyperLCA algorithm, which are needed for decompressing the image. Then, the compressed information of each individual block of pixels is packed in the exact same way and sequentially added to the bitstream, as shown in
Figure 3.
The information contained in the header of the generated bitstream is:
Size of the hyperspectral image, , and , representing the number of columns, rows and bands, coded as plain binary using 16 bits each.
The number of pixels per block, blockSize, used for compressing the image within the HyperLCA algorithm, coded as plain binary using 16 bits.
The maximum number of V vectors and Pixels extracted for each block of pixels, , coded as plain binary using 8 bits.
The number of bits needed for covering the entire dynamic range of the hyperspectral image, DR, as well as the number of bits used for scaling the V vectors, , coded as plain binary using 8 bits each.
One extra bit, SC, which indicates if one additional stopping condition, based on a quality metric, has been used () or not ().
Figure 4 graphically describes the header structure. In this figure,
bS represents the number of pixels per block,
blockSize. According to the defined number of bits used for the different data contained in the header, 89 bits are required.
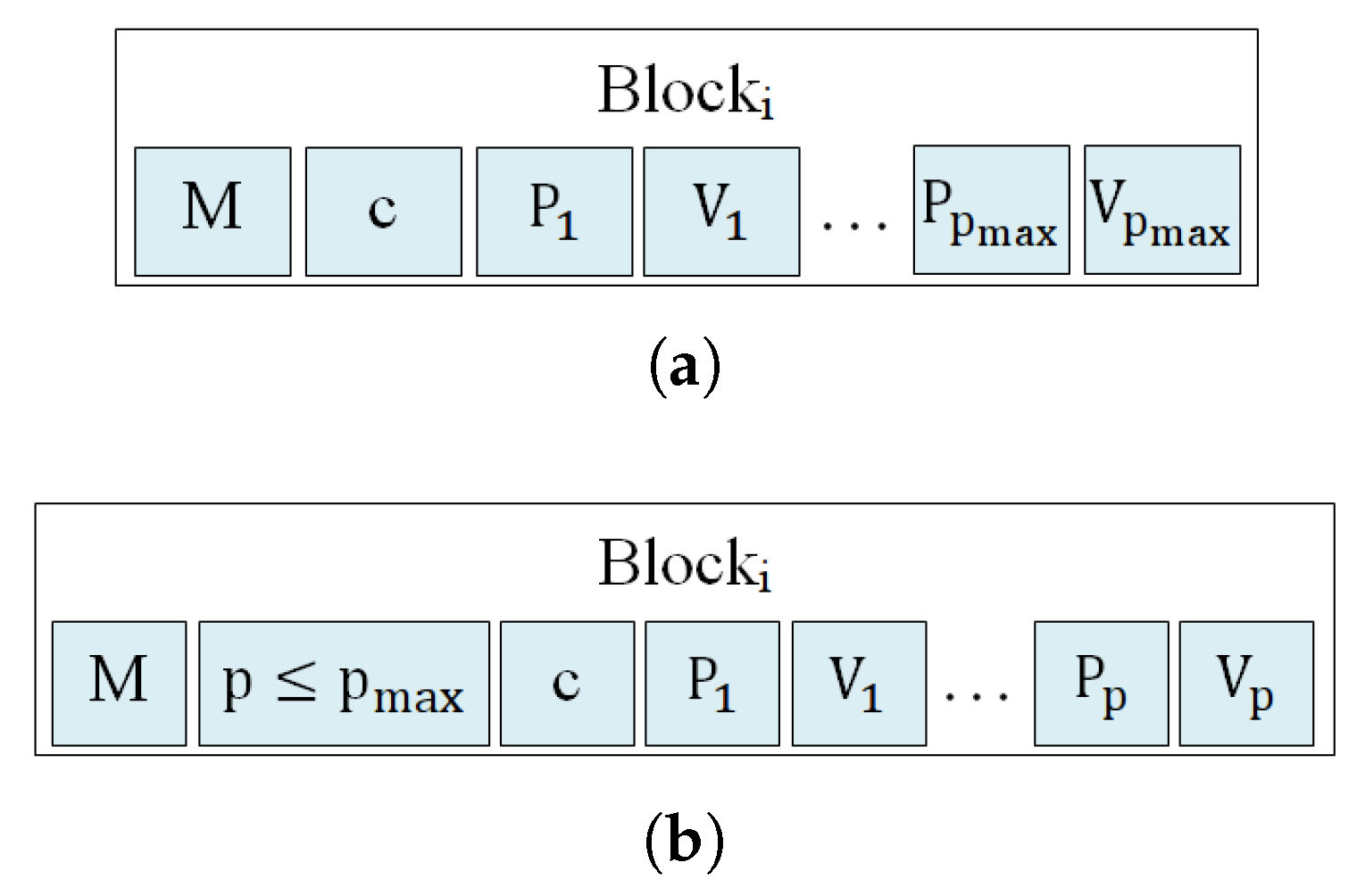
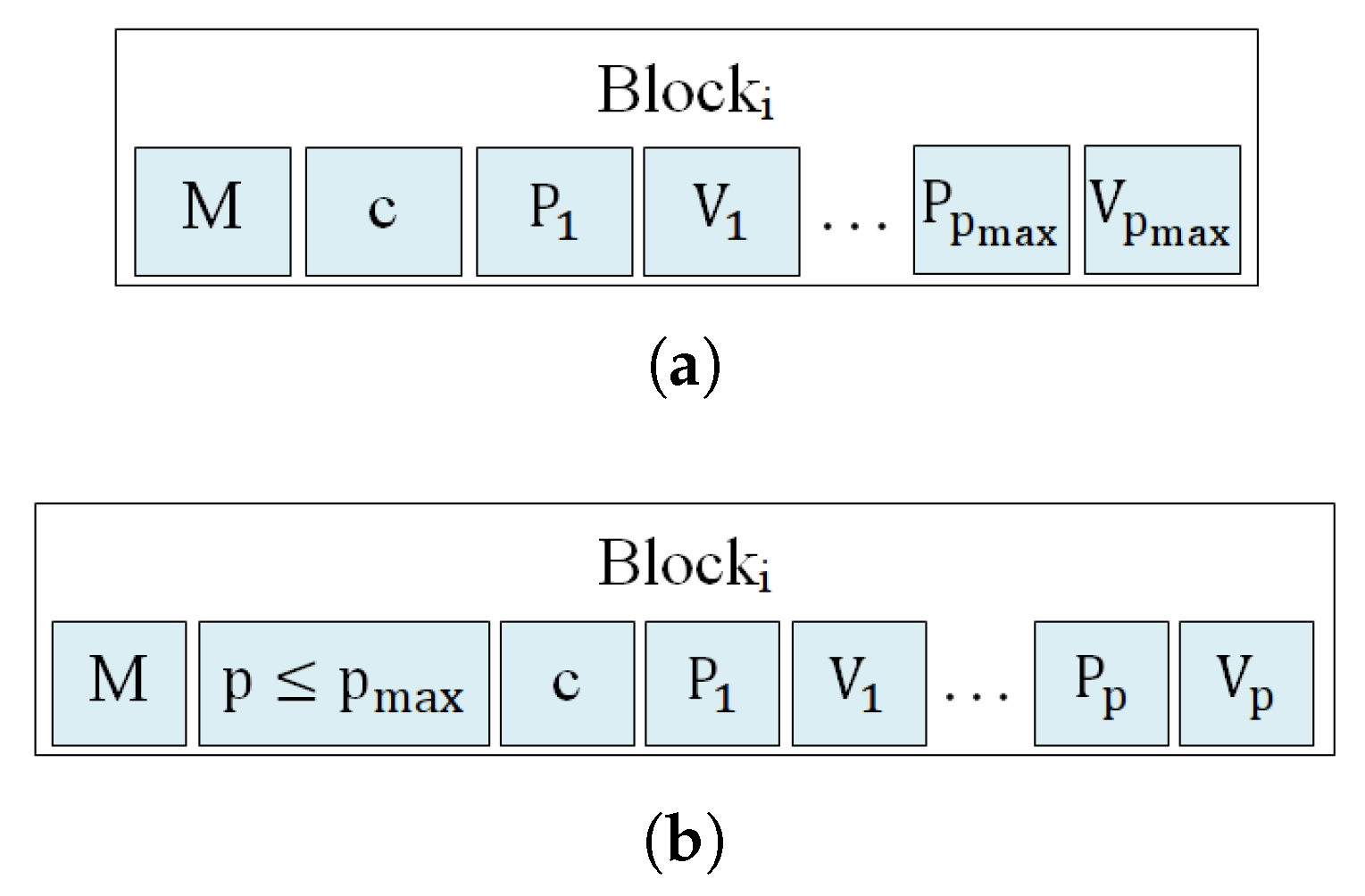
The information of each individual block of pixels may be packed in two ways that contain a minimal difference, as shown in
Figure 5. The first one, graphically described in
Figure 5a, is used when no additional stopping condition is used, and
Pixels and
V vectors are extracted for each individual block. In this situation, the amount of compressed elements in each block is perfectly determined by the
,
and
values that are already included in the bitstream header. On the contrary, when using an additional stopping condition for stopping the algorithm if the desired quality is achieved before extracting
Pixels and
V vectors, the number of
Pixels and
V vectors extracted for each block of pixels may be different and smaller than
, producing higher compression ratios. In this situation, the number of
Pixels and
V vectors used for compressing each block of pixels,
, needs to be included when coding each block of pixels, as shown in
Figure 5b. This
value is coded as plain binary using 8 bits.
2.8. Possible Stopping Conditions within the HyperLCA Algorithm
As previously described, all the losses of the compression–decompression process within the HyperLCA algorithm are produced in the spectral transformation and compression stage, carried on by the HyperLCA transform. As aforementioned, the HyperLCA transform sequentially selects the most different pixels of the image, and uses them for representing the hyperspectral data. Each time that a pixel is selected, the information that can be represented using that specific pixel is subtracted from the image, , as described in Line 13 of the Algorithm 1. Accordingly, matrix contains the information that would be lost if no more pixels were selected. This information can be used for setting an stopping condition in the sequential pixels selection process, based on the amount of losses desired within the compression–decompression process. For such purpose, two different approaches can be followed:
- ▪
Global error approaches measure the global or average error in the decompressed image with respect to the original one. Despite these approaches providing a good idea of the accuracy of the compression–decompression process, they do not necessarily yield an accurate reconstruction of the anomalous pixels.
- ▪
Single error approaches focus on measuring the largest single errors in the decompressed image. Despite these approaches not necessarily providing a very good idea of the overall compression–decompression performance, they are more suitable for verifying the accuracy of the reconstruction of the anomalous pixels.
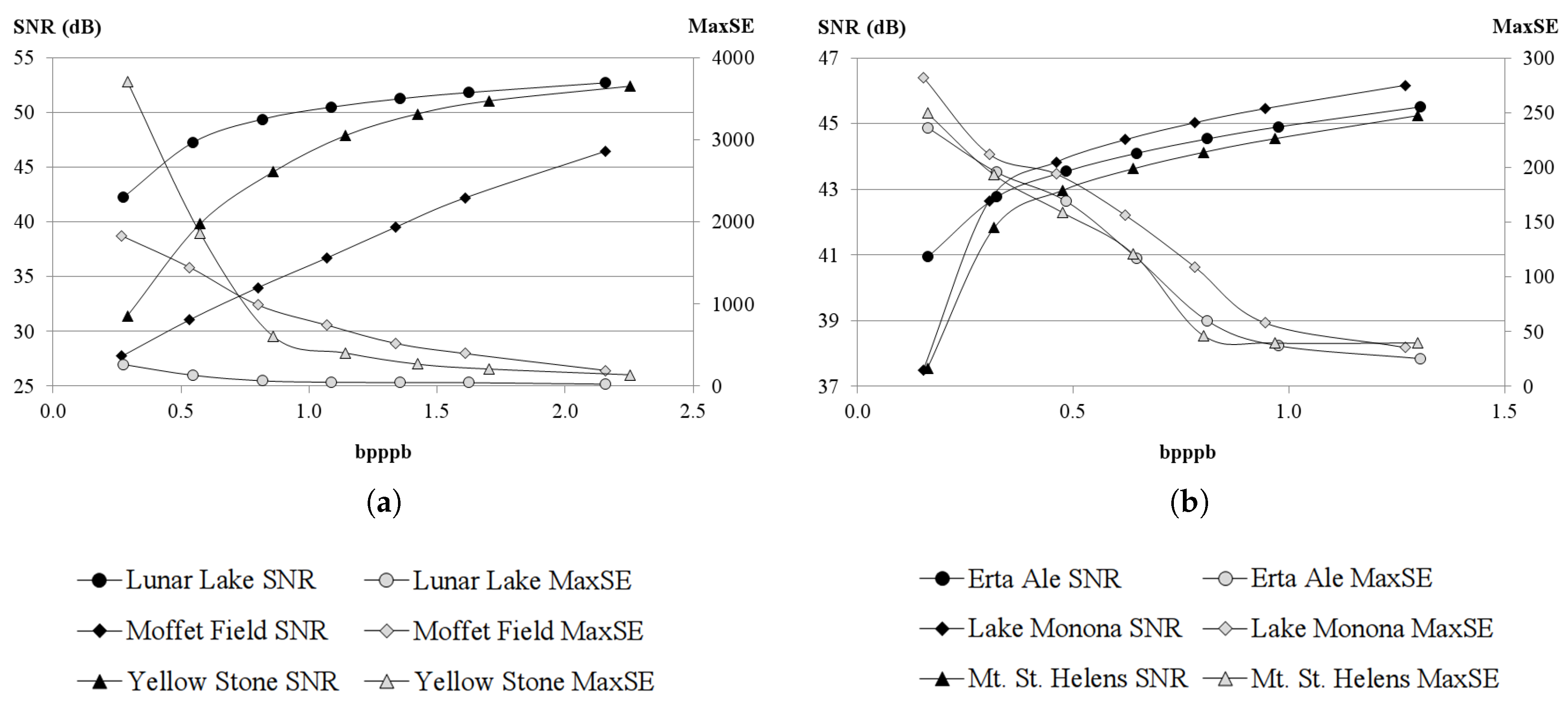
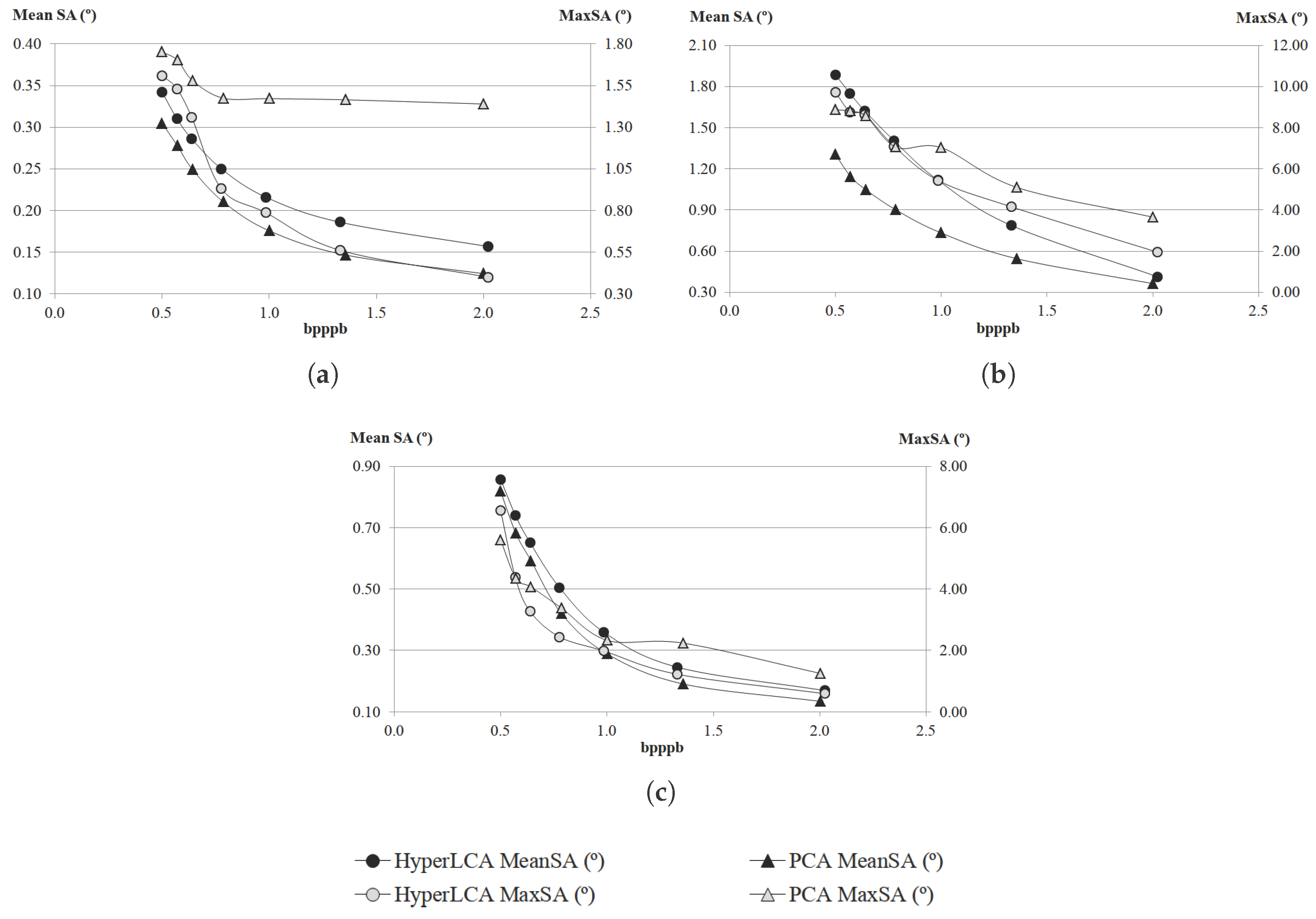
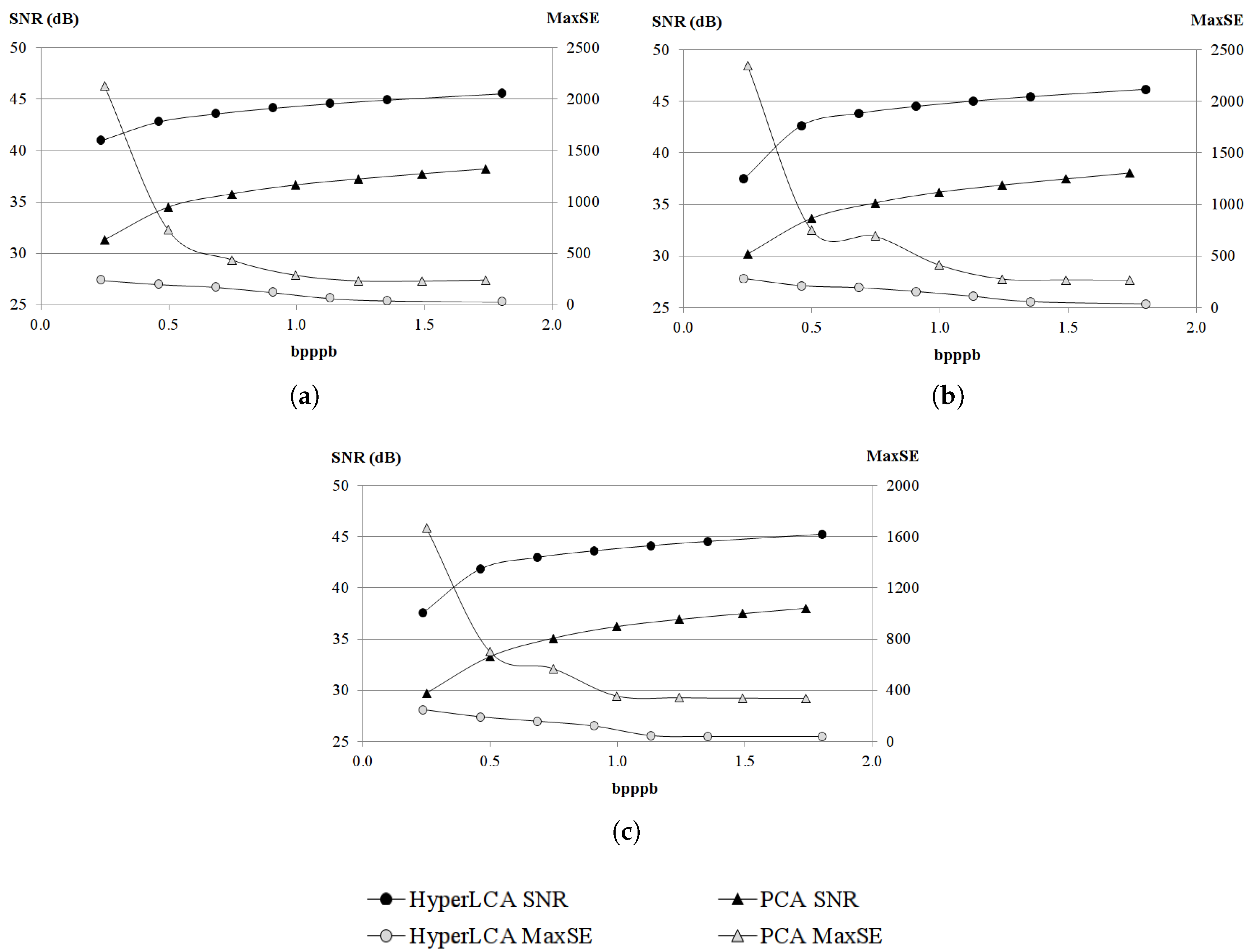
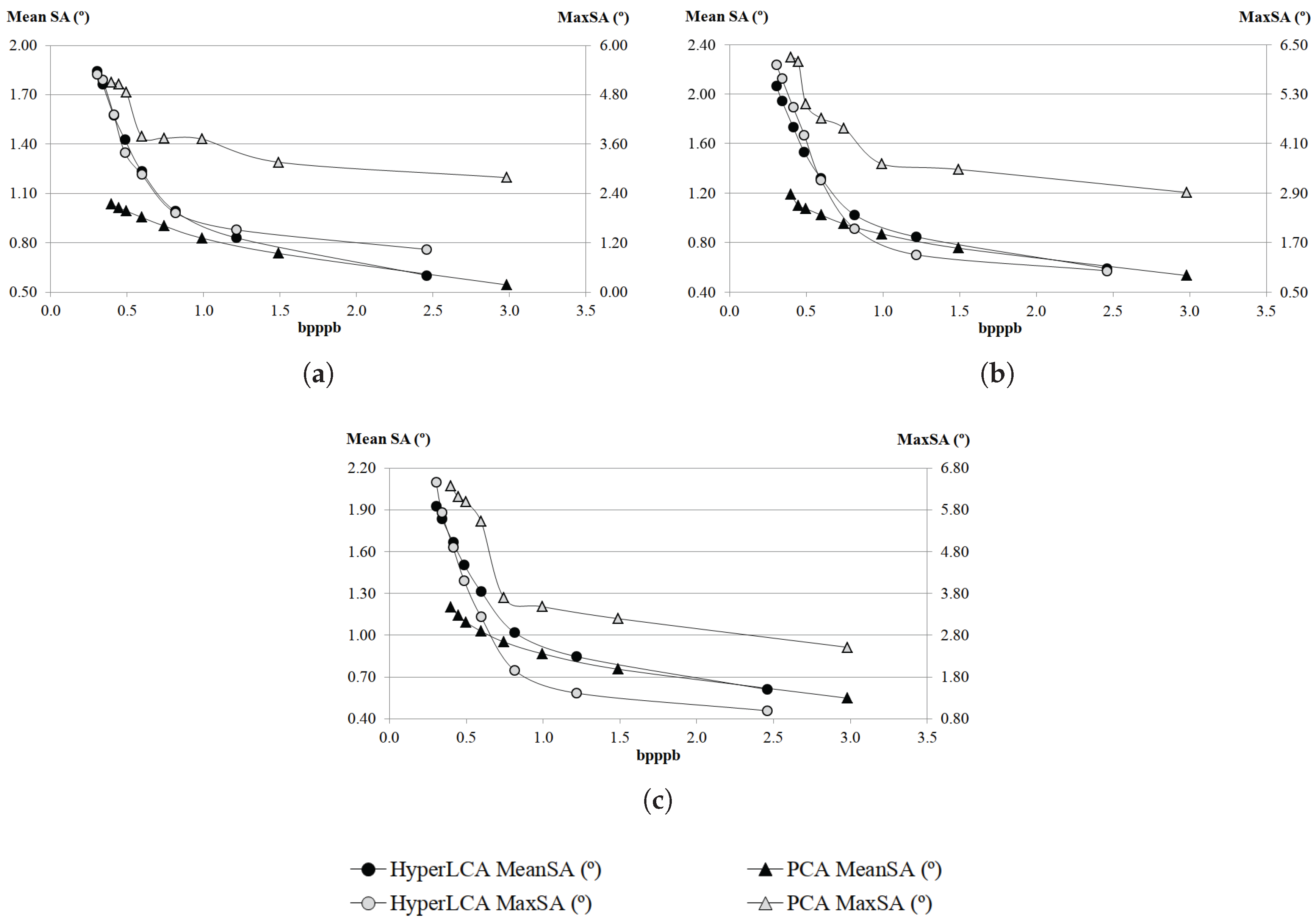
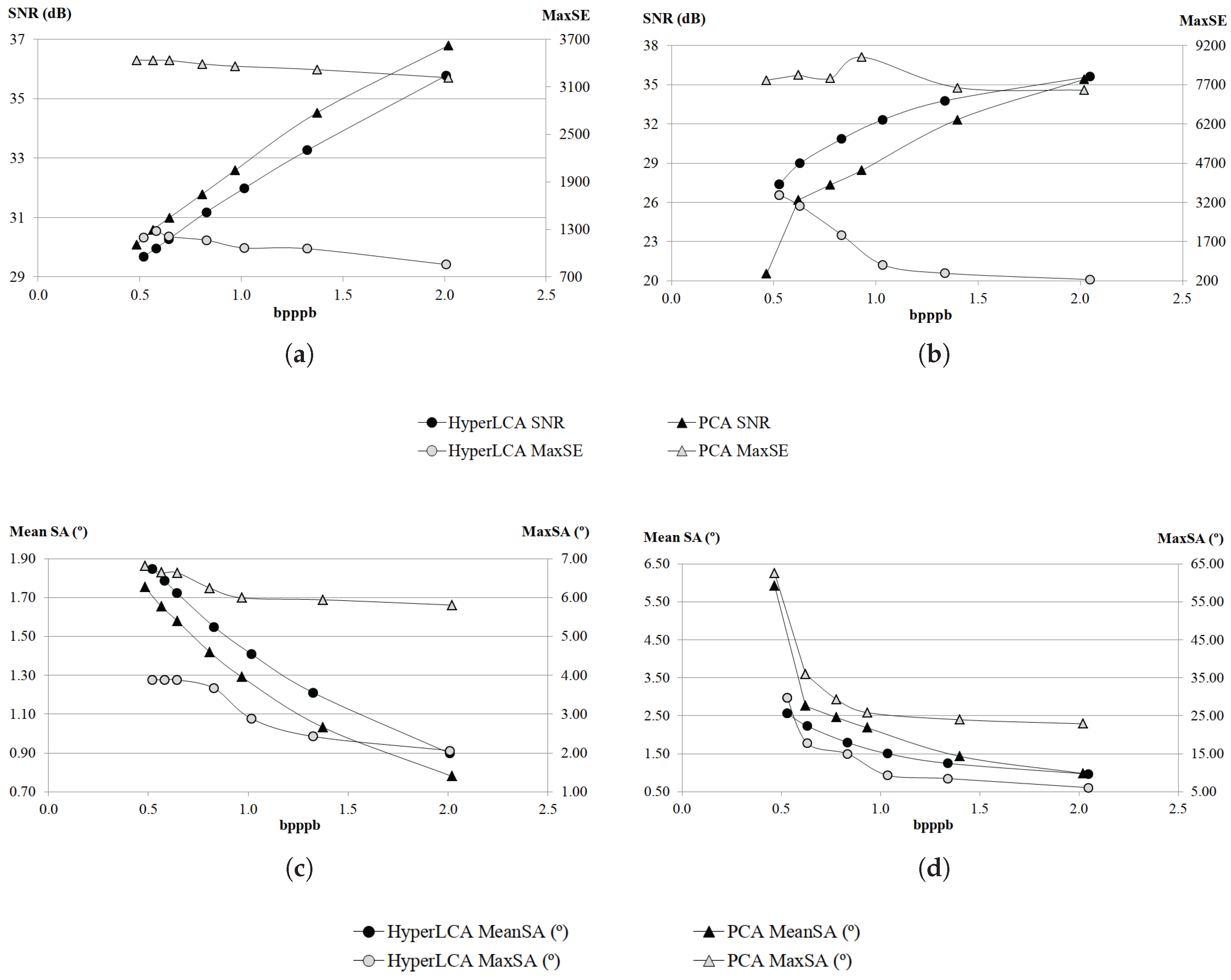
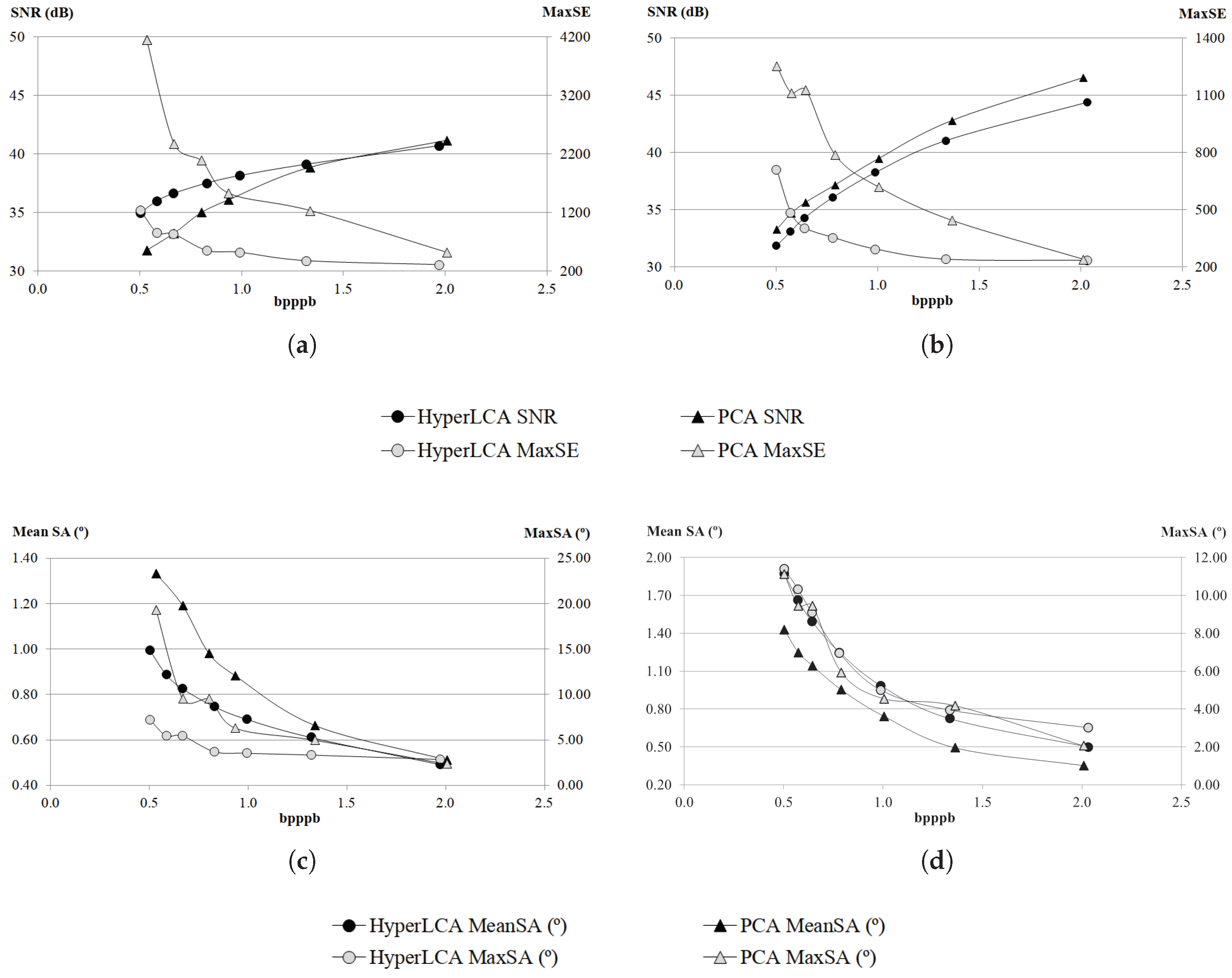
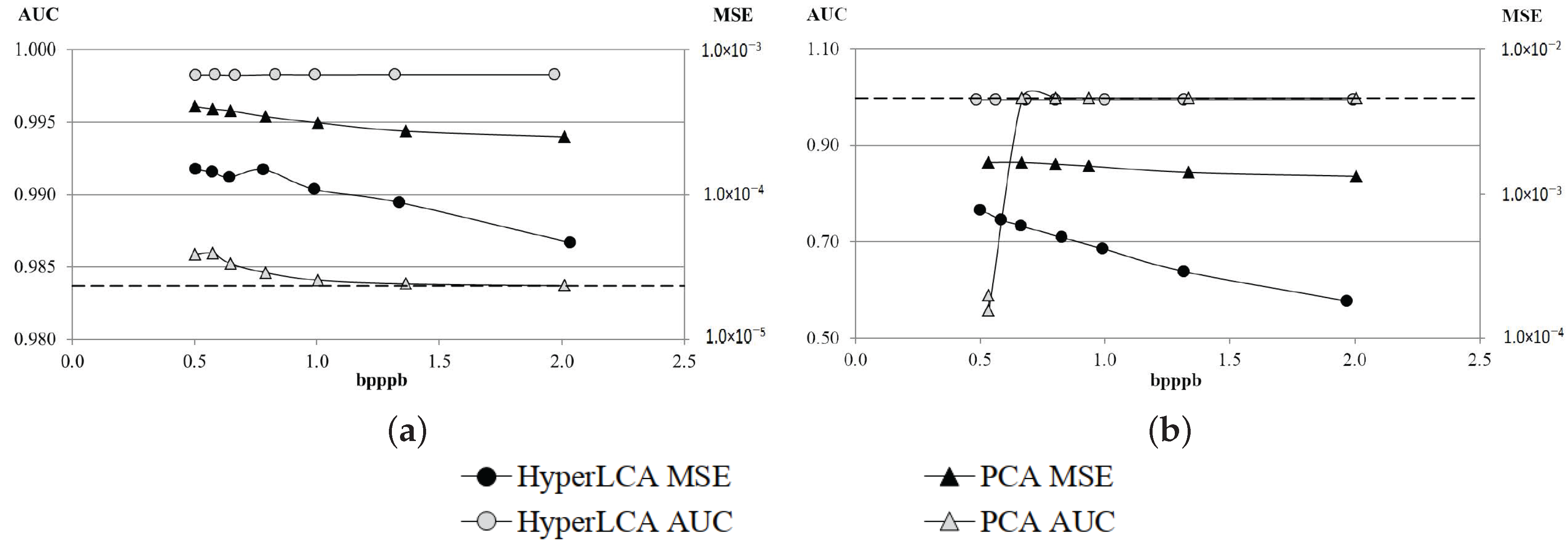
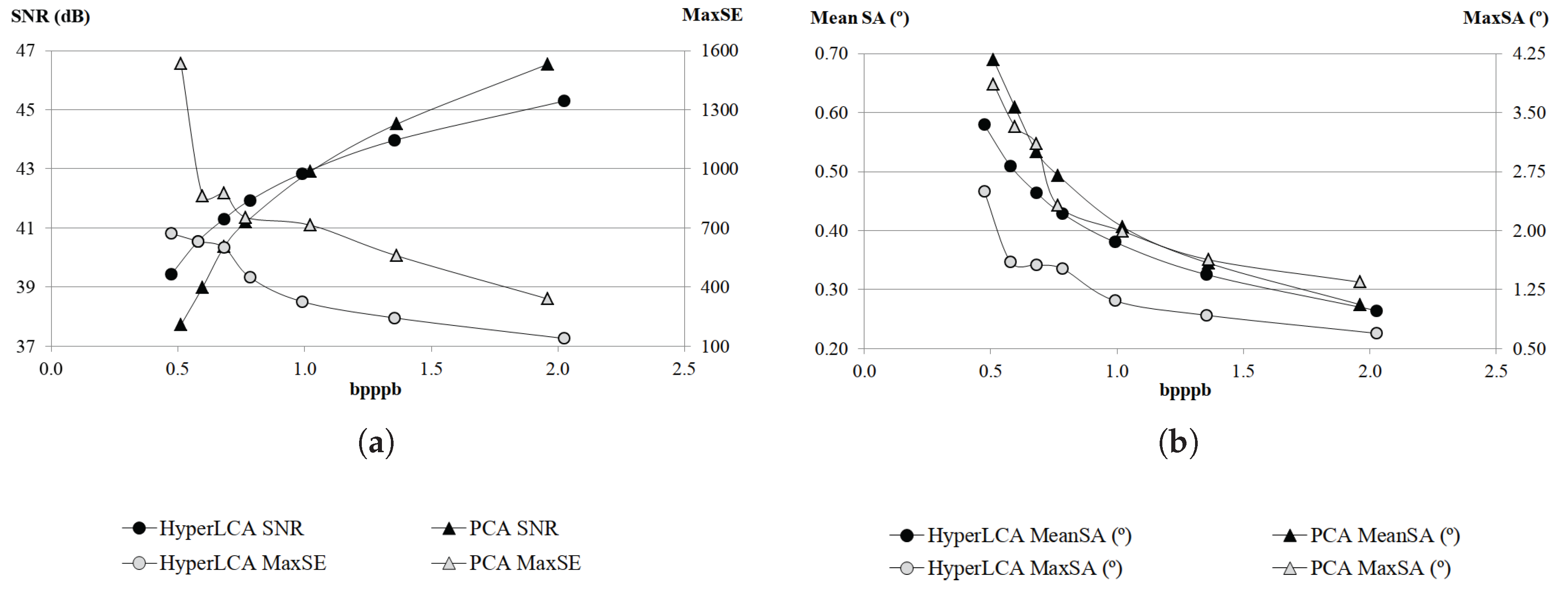
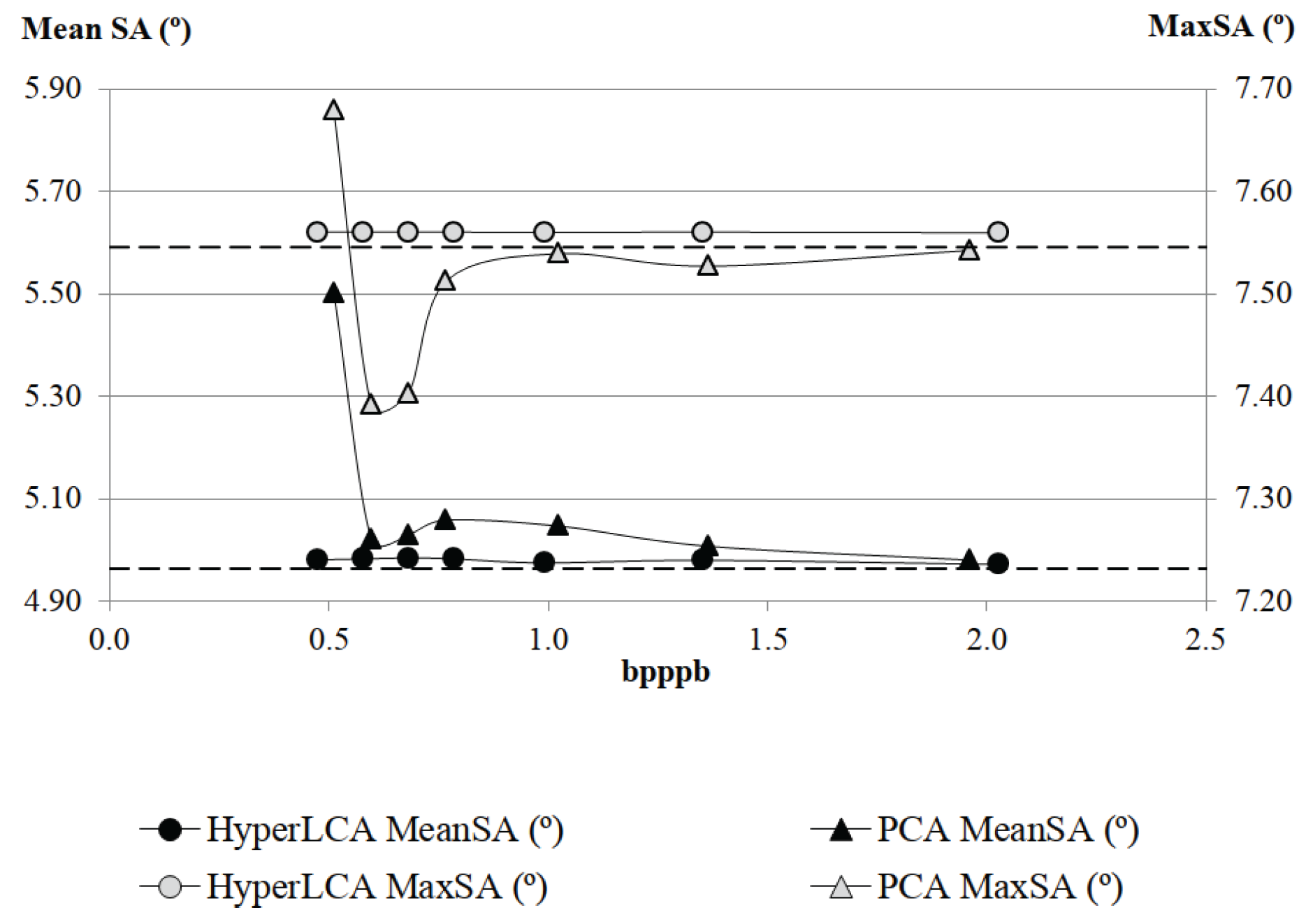
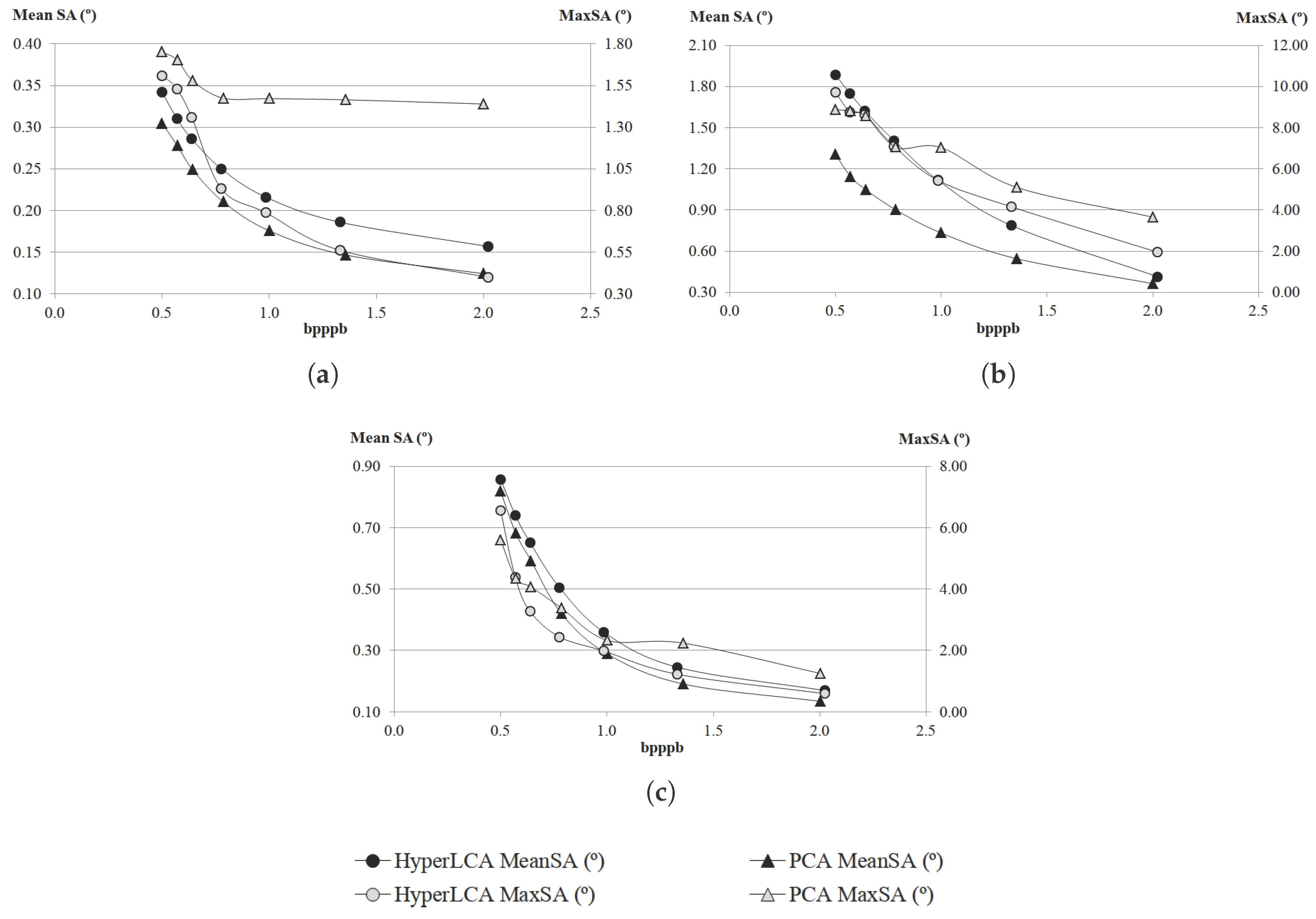
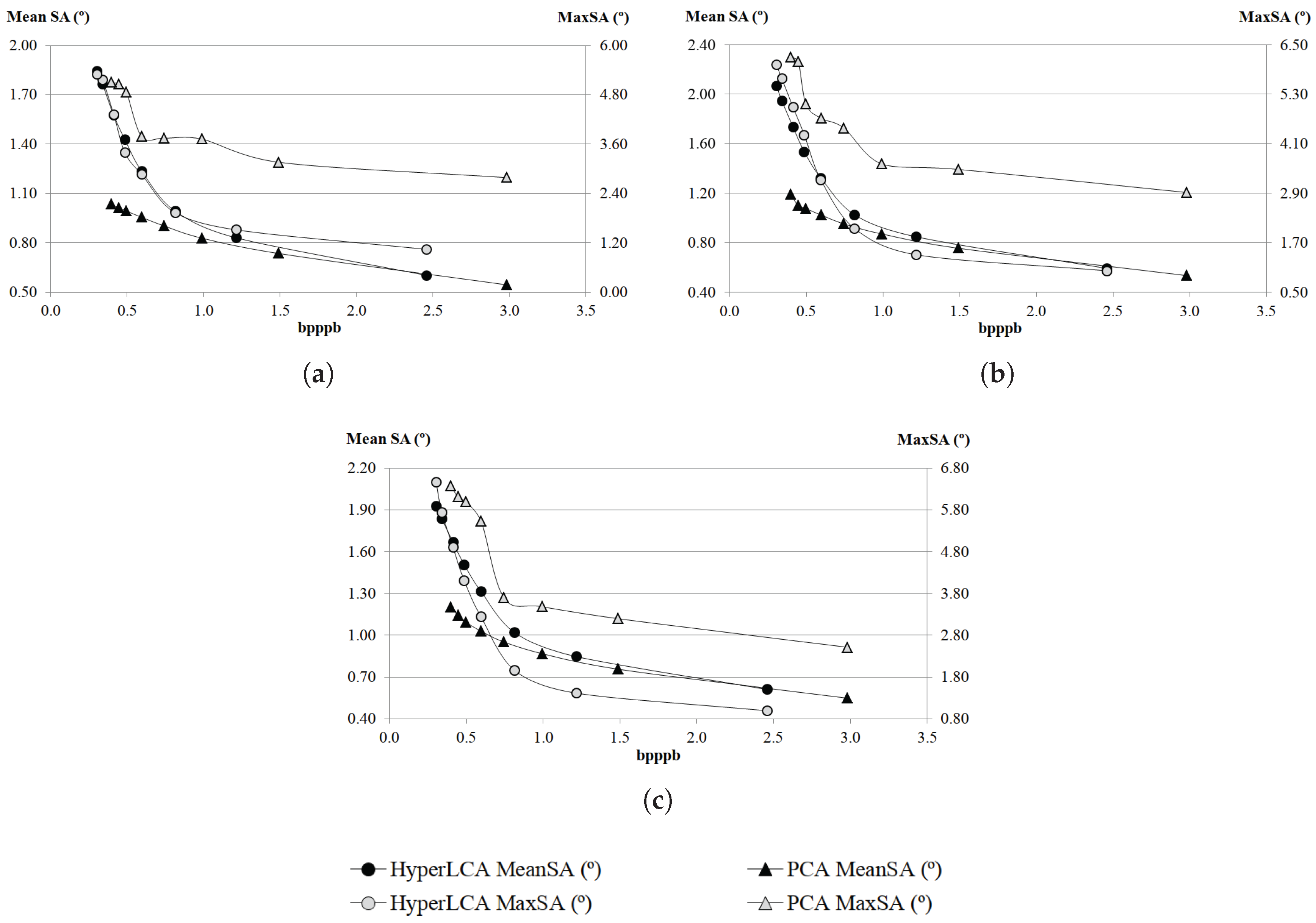
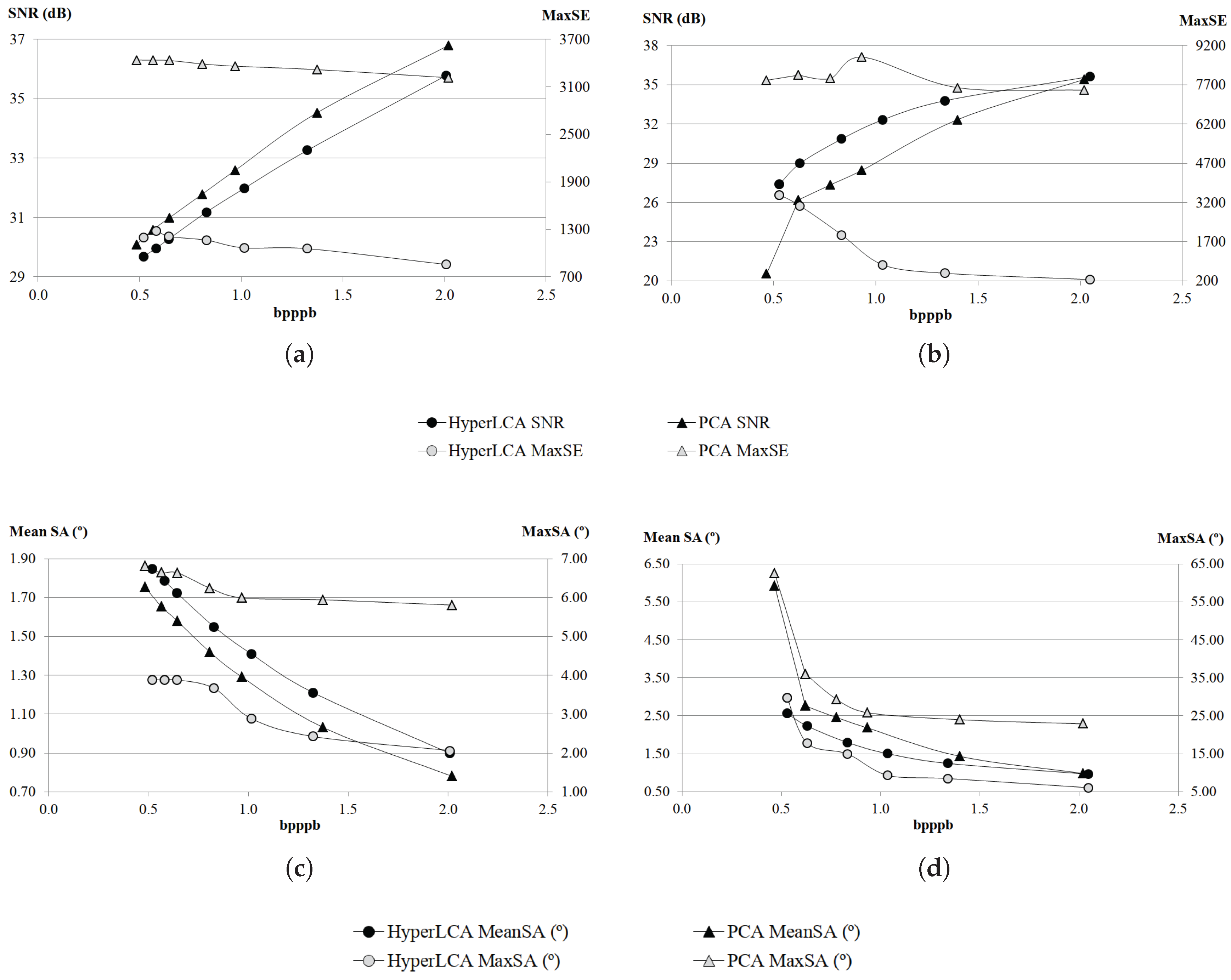
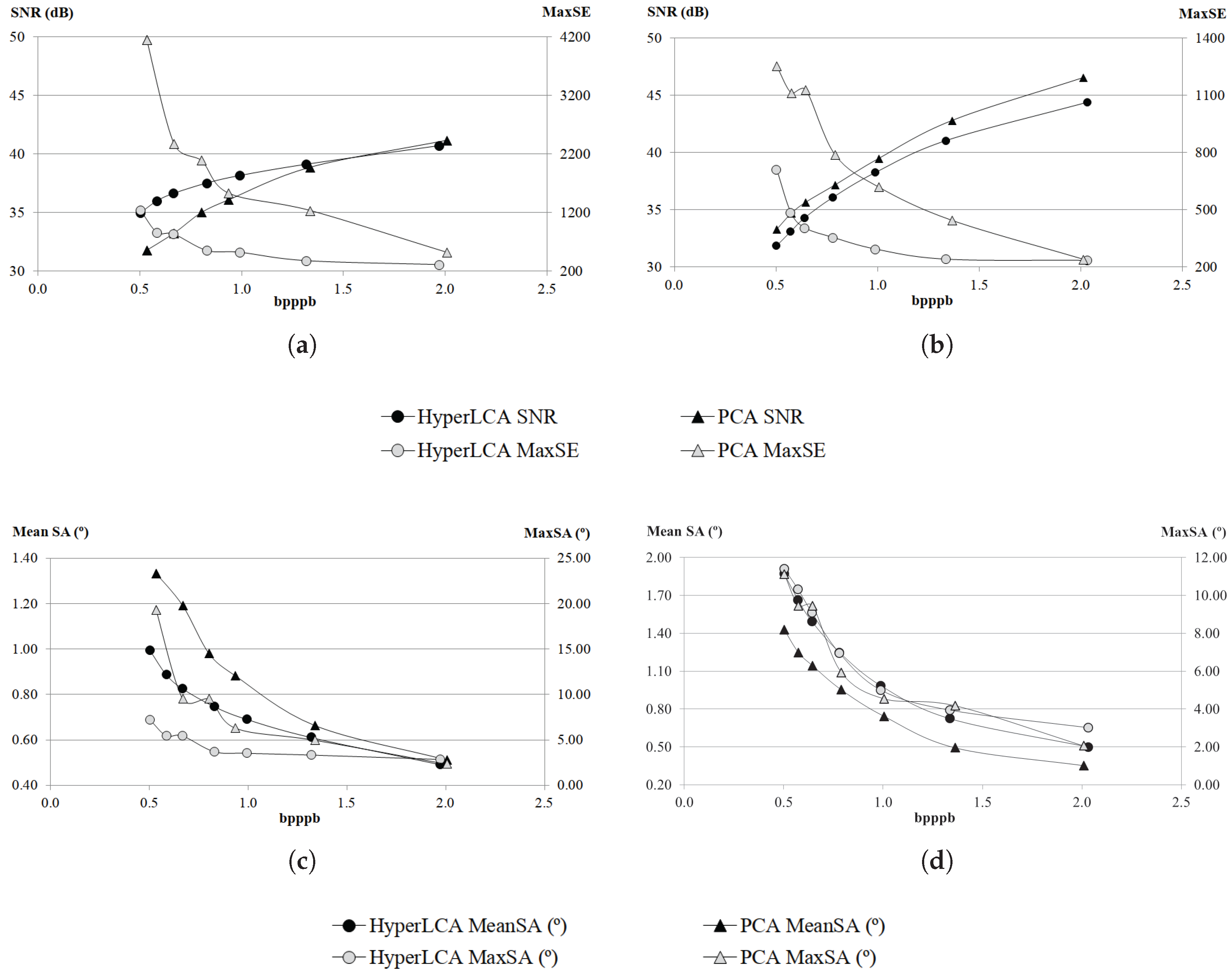
Although many different metrics can be efficiently applied to the proposed HyperLCA transform, we will focus on the RMSE, the SNR and the MaxSE metrics since these are widely used state-of-the-art metrics for evaluating the compression–decompression performance. While the RMSE and SNR are global evaluation metrics that are useful for verifying an average good compression–decompression performance, the MaxSE, despite its simplicity, is more suitable for ensuring that the anomalous pixels are preserved through the compression–decompression process. Any of the possible stopping conditions based on these metrics would be placed in line 14 of the Algorithm 1, and would prevent the extraction of more pixels if the losses achieved are small enough according to the quality metric used.
2.8.1. RMSE Based Stopping Condition
The
Root Mean Square Error (RMSE) is a frequently used metric for measuring the average differences between the real hyperspectral image and the decompressed one. A low RMSE represents low average compression–decompression errors. This metric is defined as:
where
M and
refer to the real hyperspectral image and to the decompressed one, and
and
refer to the number of pixels and the number of bands in the hyperspectral image, respectively. Since
contains the information that cannot be represented with the already selected pixels, it could be directly calculated within the HyperLCA algorithm as:
2.8.2. SNR Based Stopping Condition
The
Signal-to-Noise Ratio (SNR) generally compares the level of the desired signal to the level of background noise. It is defined as the ratio of signal power to the noise power, often expressed in decibels. In the compression scenario, the SNR metric measures the ratio between the real hyperspectral image power and the compression–decompression loses power, as shown in Equation (
14), where
M and
refer to the real hyperspectral image and to the decompressed one, and
and
refer to the number of pixels and the number of bands in the hyperspectral image, respectively:
As aforementioned,
directly corresponds with
. Hence, the SNR can be calculated within the proposed HyperLCA transform every time that a new pixel is extracted as:
As a further optimization, can be calculated just once at the beginning of the compression process, since it evaluates just the power of the real hyperspectral image, M.
Finally, it is important to remark that the HyperLCA transform is thought to be independently applied to blocks of pixels of the image, not to the entire image at once. Accordingly, these stopping conditions must be also independently applied to each block of pixels, and, hence, the number of pixels shown in this equations, , should be substituted by the number of pixels per block, defined as .
2.8.3. MaxSE Based Stopping Condition
The Maximum Single Error (MaxSE) evaluates the maximum absolute difference between the real hyperspectral image and the compressed-decompressed one. The MaxSE that would be obtained in the compression–decompression process within the HyperLCA algorithm if no more pixels were extracted can be directly calculated, in each iteration, as the maximum absolute value of .
2.9. Computational Complexity of the HyperLCA Compressor
The HyperLCA algorithm has been specifically designed for being able to independently compress blocks of pixels of the hyperspectral image without requiring any specific spatial alignment. This fact eases the image compression, especially when using pushbroom or whiskbroom sensors for collecting them, allowing for independently compressing the blocks of pixels as they are captured. This strategy avoids the necessity of storing big portions of the image until being able to compress them, reduces the amount of required resources for compressing the collected data, speeds up the process and provides parallelization and error-resilience. Besides the obvious gains that this fact brings in terms of lower computational complexity, the HyperLCA algorithm has the advantage that it uses simple mathematical operations that can be easily parallelized, avoiding complex matrix operations like, for instance, computing the eigenvalues and eigenvectors, operations that are present in many KLT based compression approaches.
The proposed HyperLCA compressor consists of different compression stages. The first and most computationally demanding one is the HyperLCA transform. This transform spectrally decorrelates each block of pixels of the image and reduces its number of spectral components, according to the specified compression ratio and/or quality measure stopping condition. The amount of data resulting from this transform is already much smaller than the original image. This, together with the simplicity of the subsequent compression stages, makes the computational complexity of these compression stages negligible in relation with the computational burden of the HyperLCA transform. Hence, this section focuses on analysing the computational complexity of the HyperLCA transform.
In order to simplify the analysis of the computational complexity of the HyperLCA transform, the description shown in Algorithm 1 has been followed, considering that no stopping condition based on quality metrics is used, and, hence, the maximum number of pixels to be extracted, , is always reached. In particular, the total number of operations done by the HyperLCA transform has been estimated. Despite the fact that the HyperLCA transform can be executed using integer or floating point values, the number of floating point operations (FLOPs) has been considered for simplicity. Additionally, since the HyperLCA transform is independently applied to each block of pixels, the estimation of the number of FLOPs has been done for a single block of pixels. The amount of FLOPs required for processing the entire image directly scales with the number of blocks.
As shown in Algorithm 1, there are three sets of operations that are applied to all the pixels in each of the iterations of the HyperLCA transform, and represents the majority of its required FLOPs. These are:
The calculation of the amount of remaining information in each pixel by calculating its brightness (lines 5–7 of Algorithm 1). The calculation of the brightness of one pixel corresponds with the inner product between two vectors of components, which results in FLOPs. This applied to all the pixels of the block produces a total of FLOPs.
The calculation of the information that can be spanned by the selected pixel, obtaining the corresponding V vector (line 12 of Algorithm 1). This also corresponds with one inner product between two vectors of components for each pixel of the image, resulting in FLOPs.
The subtraction of the information that can be spanned by the selected pixel (line 13 of Algorithm 1). This consists of first multiplying the vector, , with the vector, , obtaining a , and then subtracting this matrix to the image matrix, . Both steps require FLOPs, resulting in a total of .
The total number of FLOPs required by these three sets of operations is
. Since these operations are done once per each of the
iterations of the HyperLCA transform,
FLOPs are required for completely processing one block of
pixels of
. Additionally, the
value depends on the different HyperLCA input parameters, as it is described in
Section 2.2. Its exact value can be calculated as shown in Equation (
1). Accordingly, the amount of FLOPs to be done by the HyperLCA transform for a single block can be directly estimated from the input parameters as shown in Equation (
16):
Finally, since the HyperLCA transform is independently applied to each block of pixels, the amount of FLOPs required for processing the entire image can be estimated by multiplying the number of FLOPs required for processing one block by the number of blocks to be compressed. The resulting amount of FLOPs required for processing the entire image withing the HyperLCA transform is shown in Equation (
17)
Different conclusions can be dragged from these expressions. Firstly, it can be observed that higher CR leads to lower values, which results in less number of FLOPs required for compressing the image. Additionally, less data is produced by the HyperLCA transform as the CR increases, and, so, less data is to be compressed in the subsequent compression stages. These two facts make the HyperLCA compressor more efficient as the compression ratio increases. Secondly, for the same CR and values, smaller block sizes produce smaller values, decreasing the number of FLOPs required for compressing the entire image. This makes the HyperLCA compressor more efficient when smaller blocks are used. Additionally, the number of FLOPs required for processing each single block directly depends on the and the value, and, hence, the computational complexity (in terms of FLOPs) for independently processing one single block exponentially decreases by decreasing the number of pixels per block, . According to these facts, the HyperLCA compressor would be especially efficient (in terms of FLOPs) for processing hyperspectral images when it is desired to achieve high compression ratios and when using small blocks of pixels. All these facts present important advantages especially when using pushbroom or whiskbroom sensors for collecting the images. The strategy followed by the HyperLCA compressor, based on these facts, avoids the necessity of storing big portions of the image until being able to compress them, reduces the amount of required resources for compressing the collected data, speeds up the process and provides parallelization and error-resilience.
Finally, the operations done by the HyperLCA inverse transform, shown in Algorithm 2, are almost the same as the operations done by the HyperLCA transform, but are used for adding information to the image instead of subtracting it. In general, the operations required for decompressing the image using the HyperLCA algorithm are almost the same as the operations used for compressing it, but applied in reverse order. Due to this reason, the number of FLOPs required for decompressing each block of pixels of the image, as well as the entire image, can be also estimated as shown in Equations (
16) and (
17), respectively.
2.10. Advantages of the HyperLCA Compression Algorithm
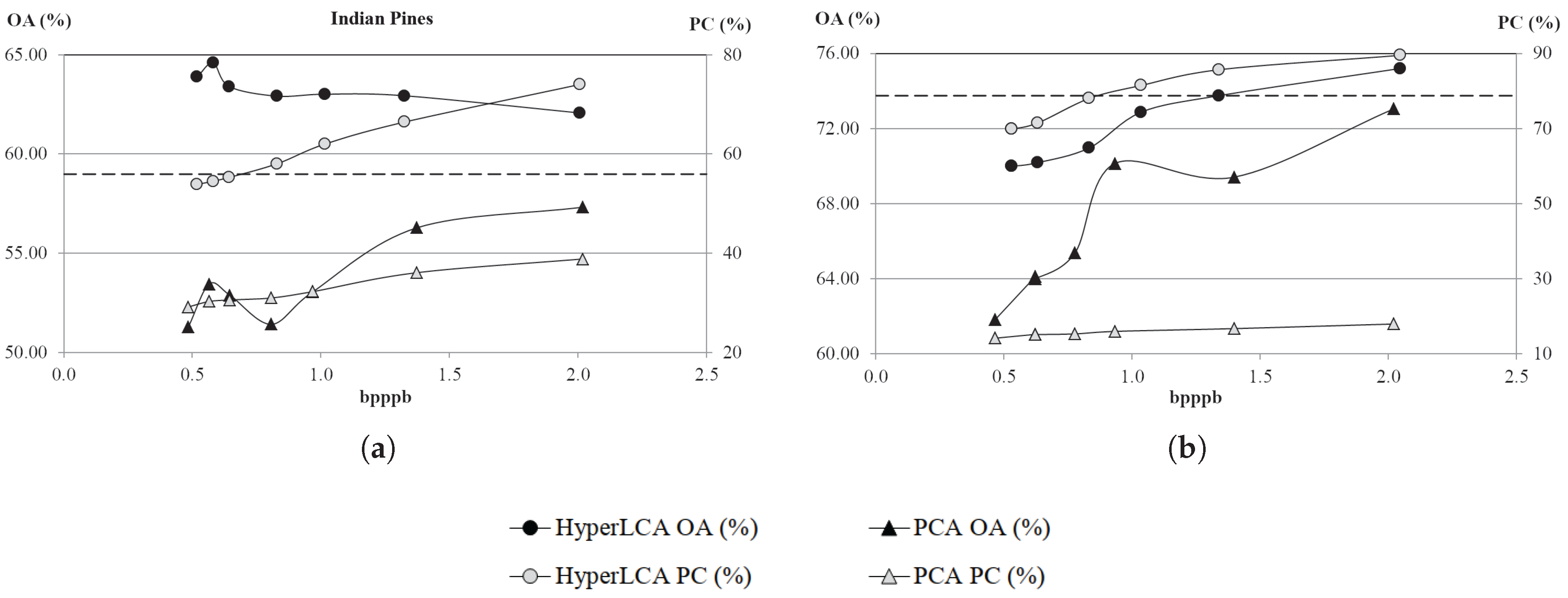
The HyperLCA algorithm has several advantages with respect to other state-of-the-art solutions for lossy compressing hyperspectral images, which will be demonstrated in
Section 4 of the current paper. The main advantages of the HyperLCA compressor are detailed next:
High compression ratios and decent rate–distortion compression performance.
Specially designed for preserving the most different pixels of the data set, which are important for several hyperspectral imaging applications such as anomalies detection, target detection, tracking or classification.
The minimal desired compression ratio can be perfectly fixed in advance.
Additional stopping conditions can be used for stopping the compression process if the desired quality is achieved at a higher compression ratio than the specified minimum compression ratio.
Allows a progressive decoding of the compressed bitstream according to different quality metrics.
Low computational complexity and high level of parallelism in relation with other transform-based compression approaches. This eases the hardware implementation of the HyperLCA algorithm for applications under tight latency constraints, also reducing the amount of required hardware resources.
Designed for independently compressing blocks of pixels of the image without requiring any spatial alignment between the pixels. This allows starting the compression process just after capturing a block of pixels. This is specially suitable when using pushbroom or whiskbroom hyperspectral sensors.
Error resilience. The HyperLCA algorithm independently compresses and codes each block of pixels, and, so, if there is an error in any block of pixels, that error will not affect any other block.
The range of values that can be produced by the HyperLCA transform can be perfectly known in advance, which makes it simple to use integer values for representing its results, or for accomplishing all its operations, introducing minimal compression–decompression losses. This eases the integration of the HyperLCA transform with the subsequent compression stages and makes it possible to achieve more efficient hardware implementations.
All these advantages make the HyperLCA algorithm a very suitable option for applications under tight latency constraints or with limited available resources, such as the compression of hyperspectral images on board satellites, where it is critical to consider the amount of power, time and computational resources used.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}