A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning

 , ,
, ,
Abstract
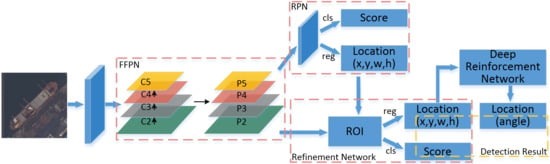
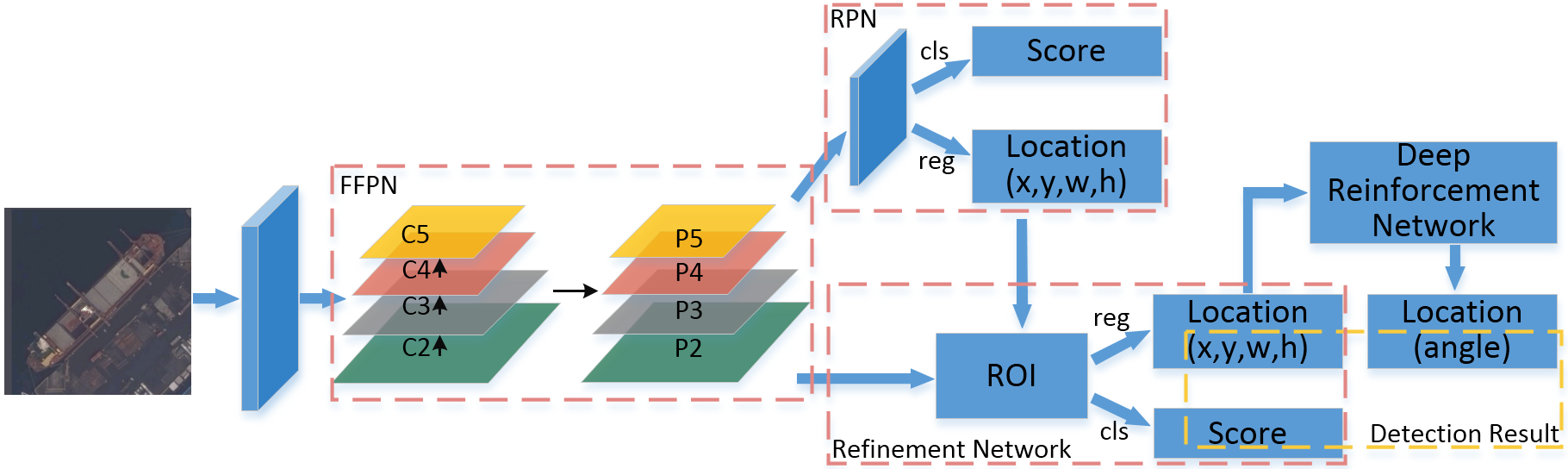
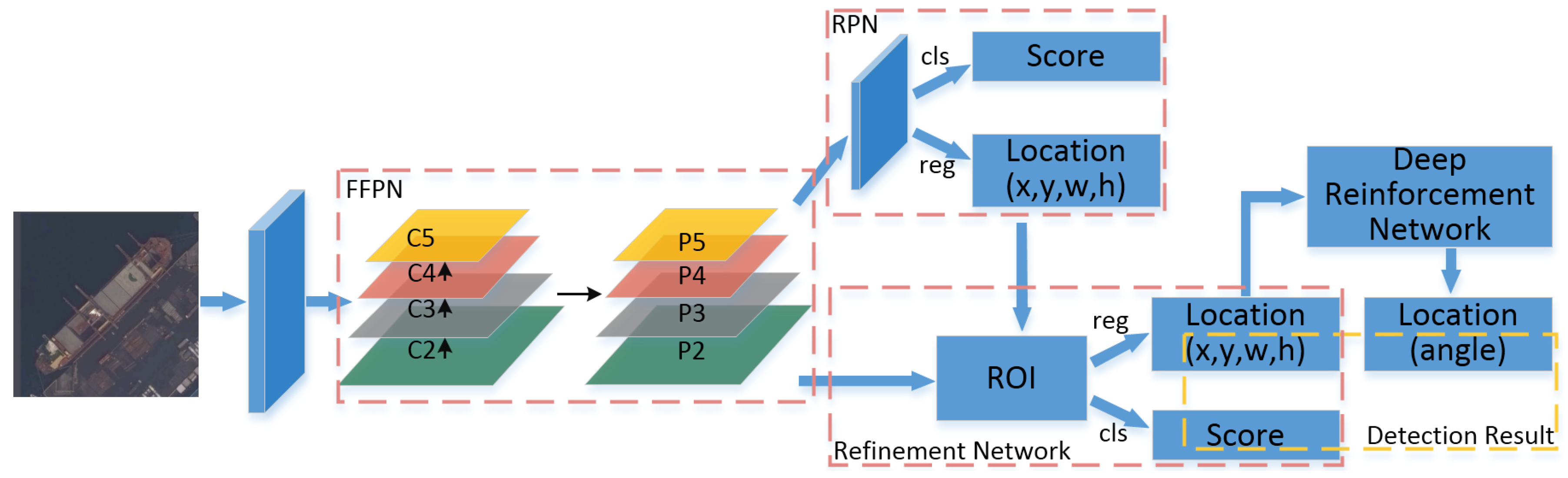
1. Introduction
- We construct an efficient ship detection model which unites Feature Fusion Pyramid Network and deep reinforcement learning. To the best of our knowledge, this is the first time that reinforcement learning is applied to the remote sensing ship detection task. The model achieves accurate detection results with angle information.
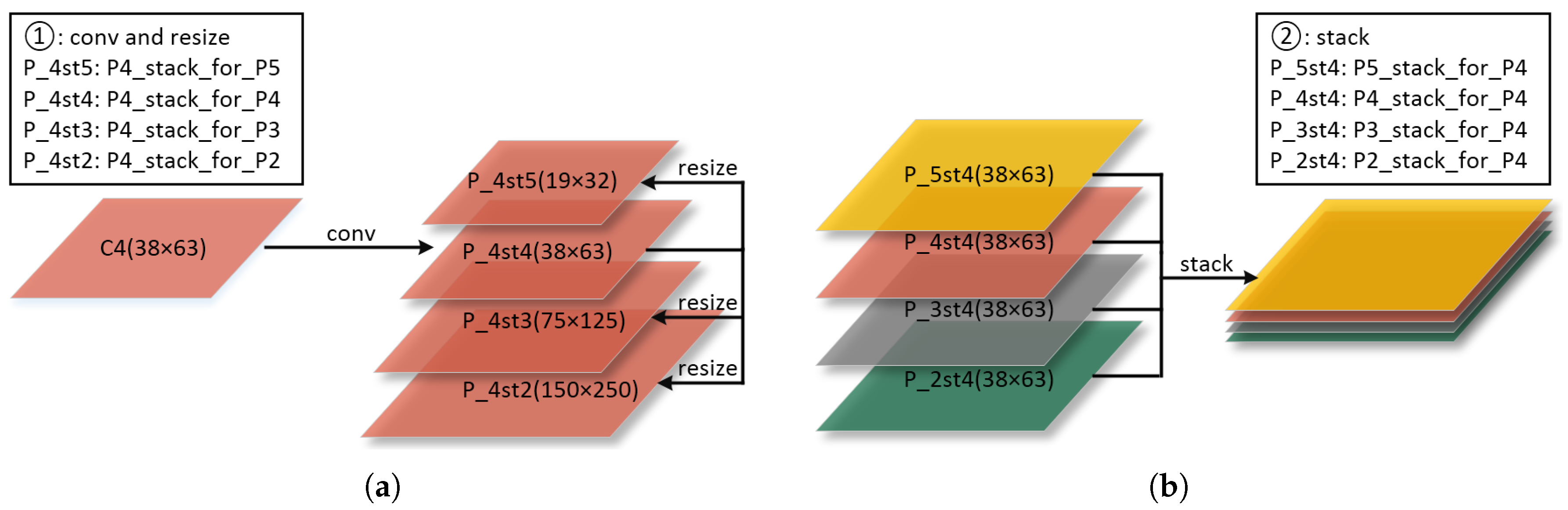
- We build the Feature Fusion Pyramid Network (FFPN) through the multi-scale feature reuse in feature pyramids. FFPN can fully utilize features of different scales, and sufficiently combines the location and semantic information. It is effective for ship detection of different scales. Semantic information is considered as discriminable features of ships. It is encoded by neural networks to represent the characteristics of ship category.
- We convert the ship angle prediction task to a Markov Decision Process. A prediction agent based on a dueling deep Q network is trained through policy guidance and a long-term training method proposed in this paper. By iteratively rotating the ship image, the agent can obtain the accurate orientation information of a ship.
- We adopt the soft rotation non-maximum suppression (SRNMS) algorithm to suppress redundant detection results. Combining the detection rectangle with an angle and the soft suppression strategy, SRNMS is able to avoid the absolute suppression, reduce the missed detection, and further improve the overall detection performance.
2. Proposed Ship Detection Method
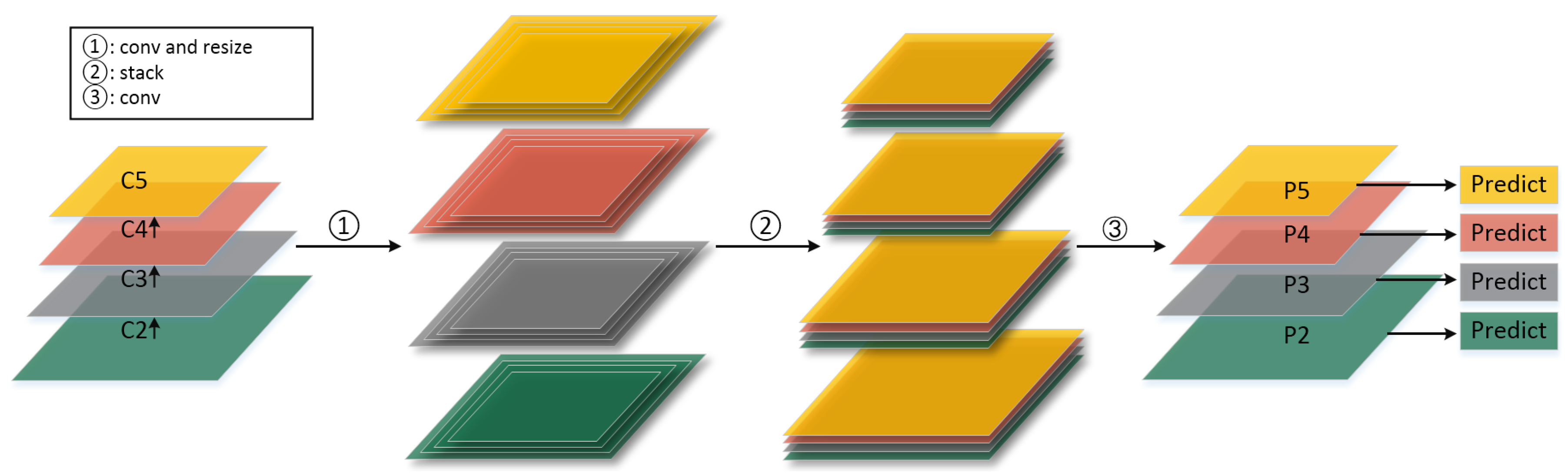
2.1. Feature Fusion Pyramid Network
2.2. Location and Classification Prediction in Ship Detection
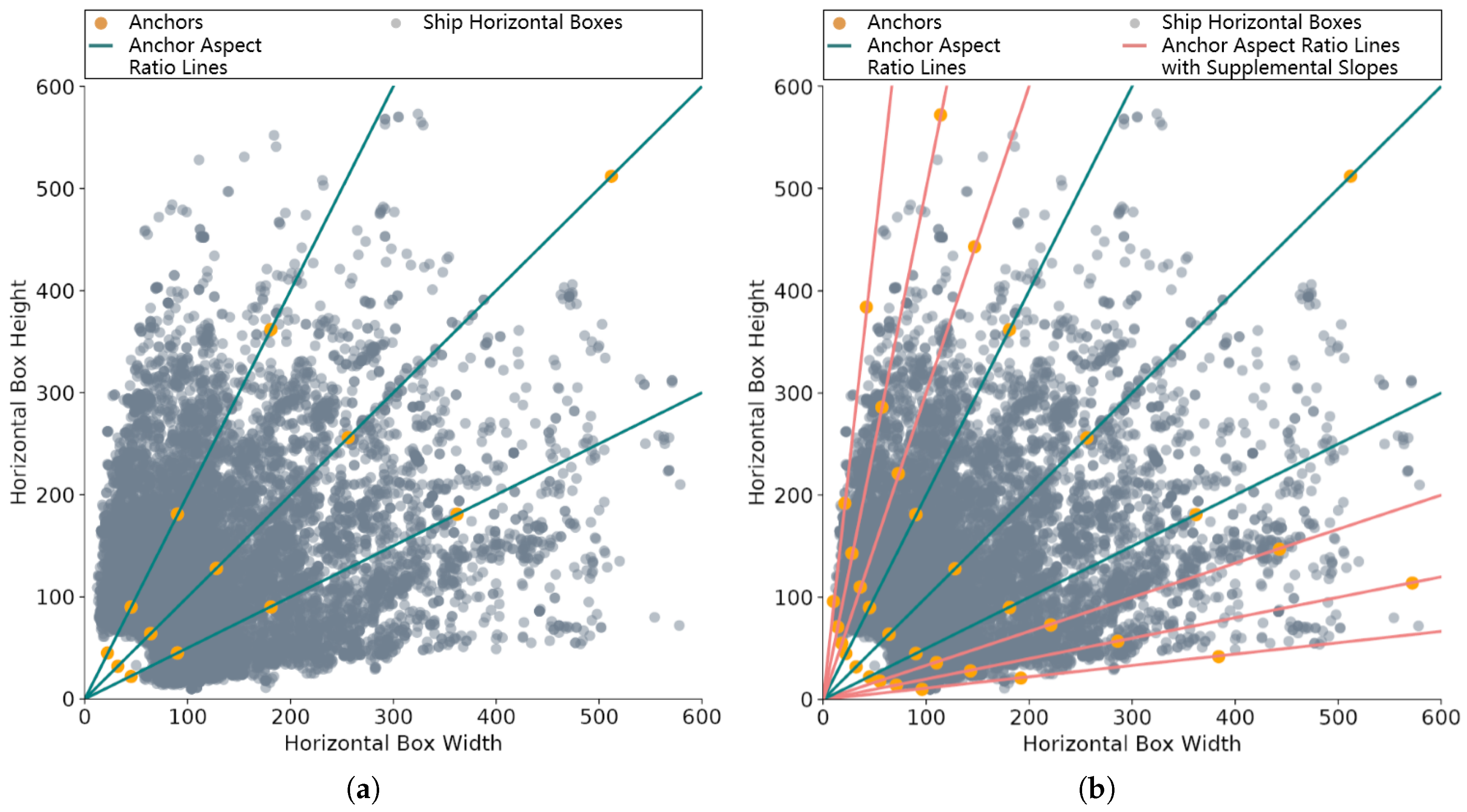
2.2.1. Ground Truth Definition
2.2.2. Location and Classification Prediction Networks
2.2.3. Multi-Task Loss Function
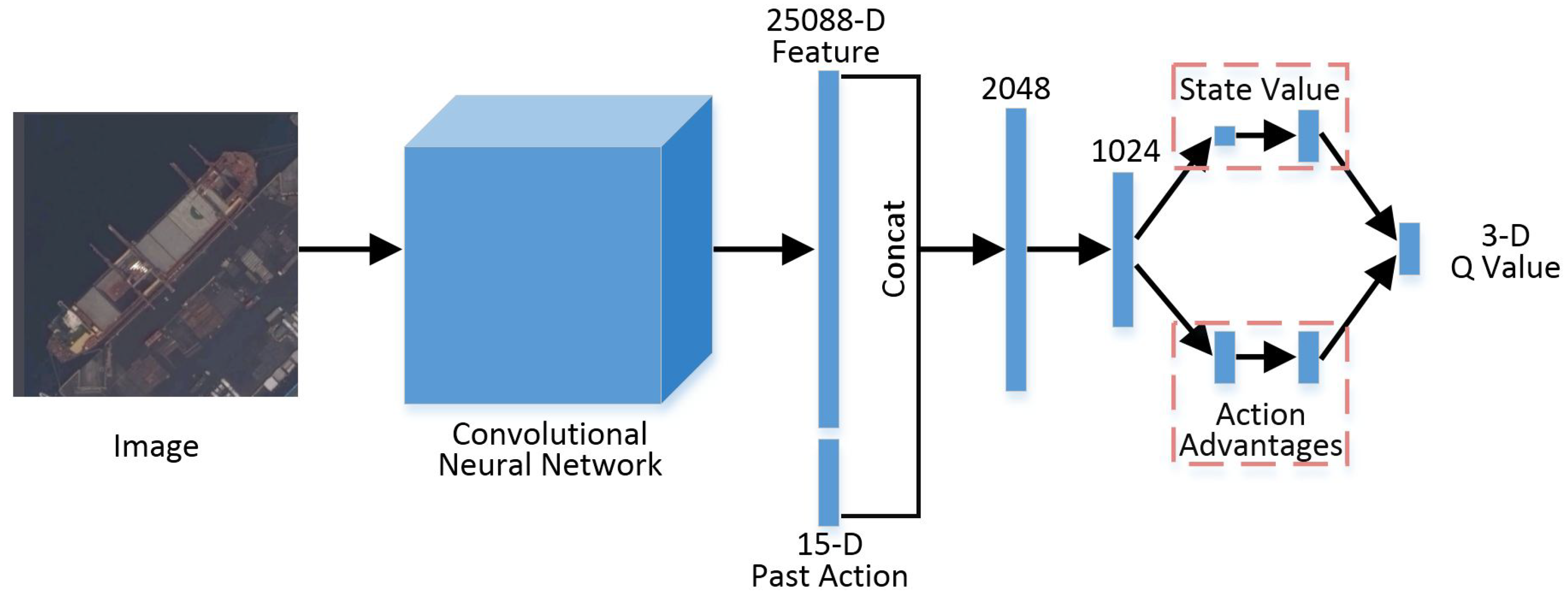
2.3. Angle Prediction Based on Deep Reinforcement Learning
2.3.1. Markov Decision Process of Ship Angle Prediction
2.3.2. Dueling Double Deep Q Learning
2.3.3. Training of Dueling Double Deep Q Network
| Algorithm 1 Optimized Dueling Double Deep Q Learning |
| Input: dueling deep Q network Q with weights w, target dueling deep Q network with weights which are duplicated from w, empty experience deque buffer B. Output: the weights of trained dueling deep Q network set with 100% in policy for loop counter = 1, I do update with for ship counter = 1, J do initialise state (inclined ship image + past action ) while True do duplicate with w each M action selection if random(0,1) > then select action corresponding to the maximum of the Q network output else compute angle difference and perform policy guidance to get action rotate the image clockwise by the angle corresponding to get new state (new inclined ship image + new past action ) and reward store in experience deque buffer B set current state with if then stop current cycle Sample random batch from experience deque buffer B if then set network label with else set network label with calculate loss and update the weights in Q with loss backpropagation |
2.4. Soft Rotation Non-Maximum Suppression
| Algorithm 2 Soft Rotation Non-Maximum Suppression |
| Input: inclined rectangle bounding Boxes: , bounding boxes length: L, bounding boxes Scores: , final threshold, Gaussian kernel function parameter: sigma. Output: Index of final result: Keep initialize empty index set: Keep, initialize all zero suppression flag set: Suppression for _i = 1, L do get the current score index in descending order: Order set current_index i with Order[_i] if Suppression[current_index] == 1 then stop current cycle add current_index i to Keep for _j = _i + 1, L do set the next score index j with Order[_j] if Suppression[current_index] == 1 then stop current cycle calculate rotated IoU of two inclined rectangles calculate suppression weight = update Scores[j] = weight × Score[j] if Scores[j]<final threshould then update suppression flag set element at index j to 1 |
3. Experiments and Analysis
3.1. Implementation Introduction
3.1.1. Ship Remote Sensing Image Dataset
3.1.2. Location and Classification Prediction Network
3.1.3. Angle Prediction Agent
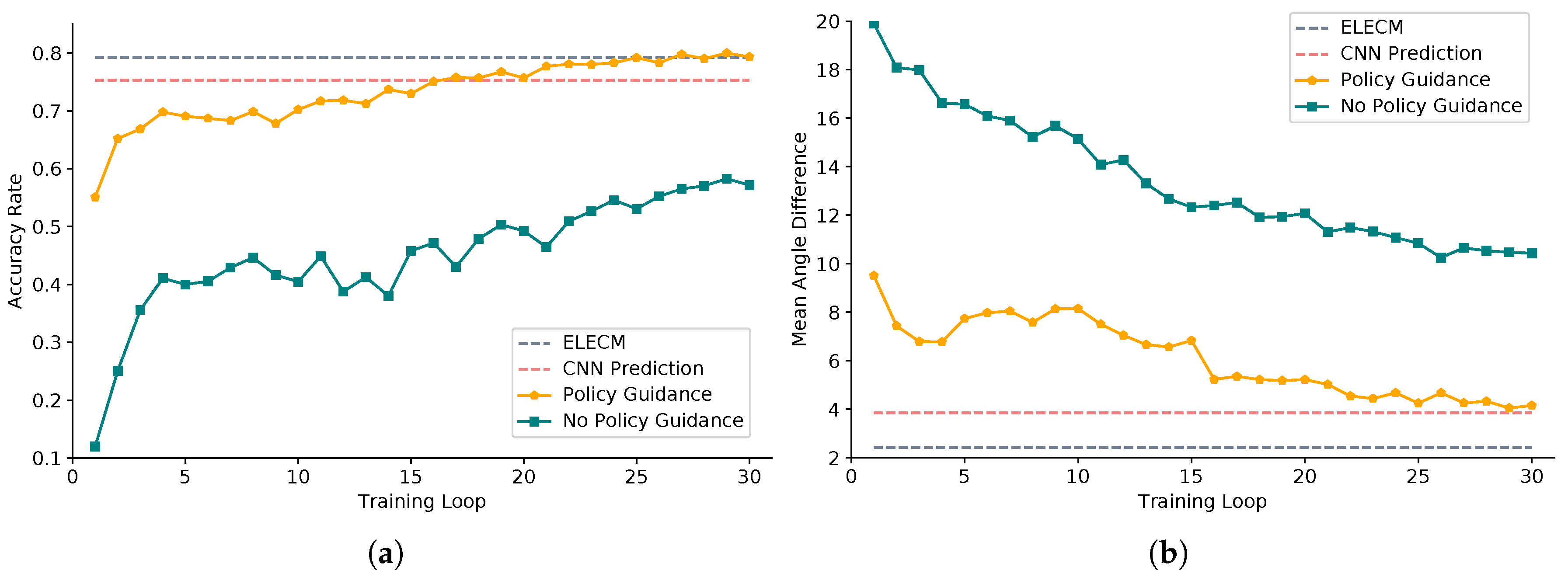
- In addition to action selection based on a deep Q network, the original training algorithm in dueling double deep Q network [31] randomly selects actions in action sets. However, our optimized algorithm adopts a priori policy guidance to help agents quickly accumulate the positive experience.
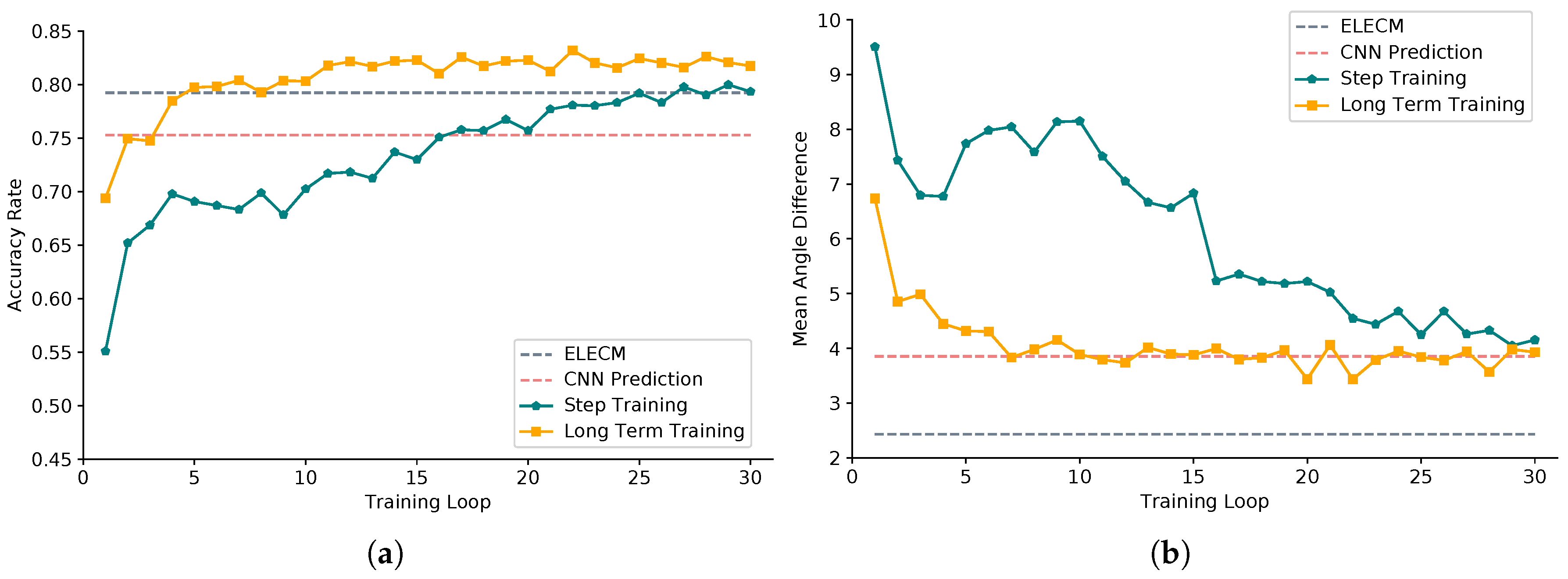
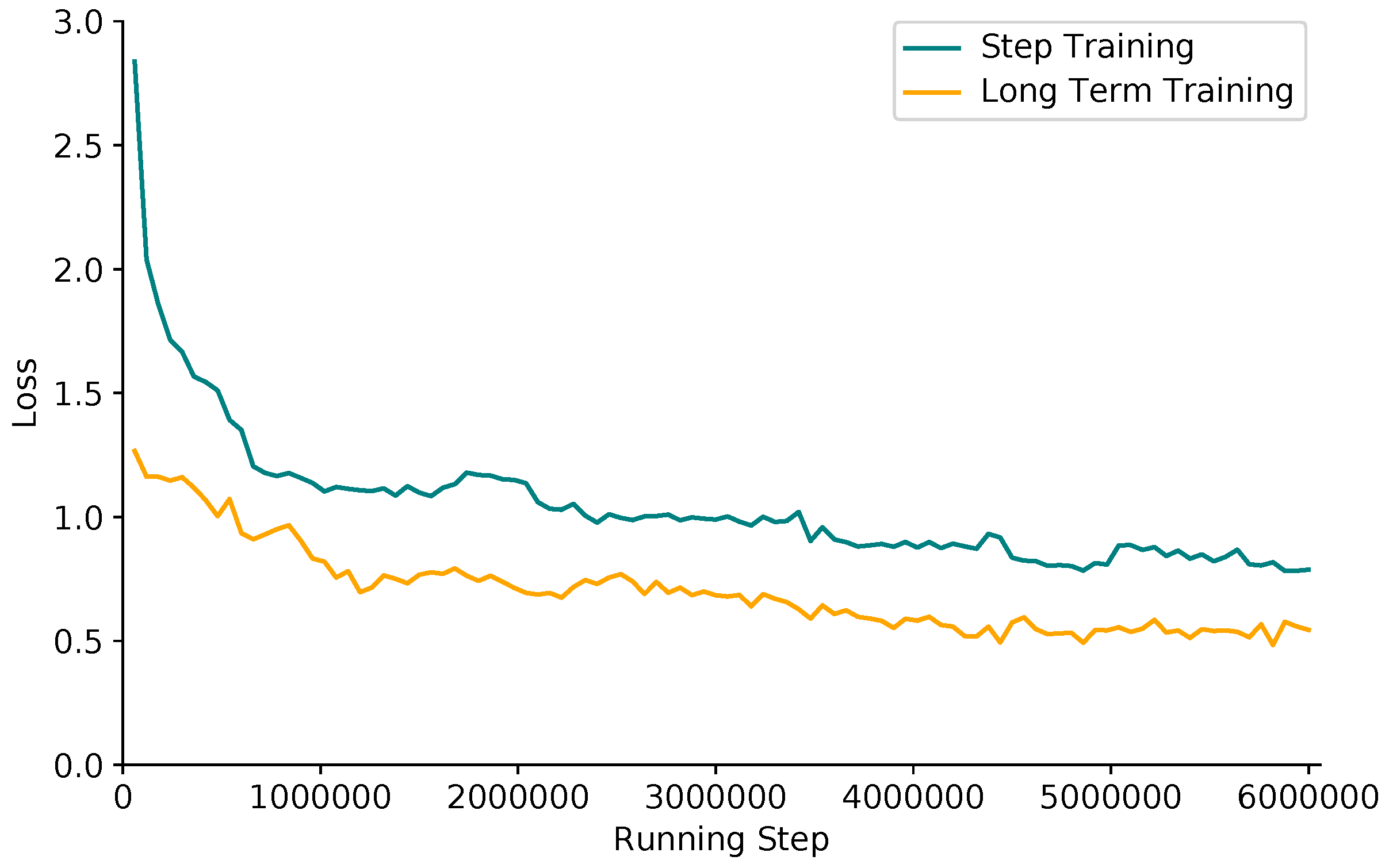
- We perform the long-term training method which trains the deep Q network after the rotation end action A3 is selected in Algorithm 1. The algorithm in [31] trains the network after the end of each action selection. The long-term training method can accelerate the convergence process of the network.
- Compared to the original simple video game scene, considering the complex background and difficult-to-distinguish objects in remote sensing images, we store the experiences to larger first-in-first-out experience deque buffer (length: 200,000) in Algorithm 1.
3.2. Evaluating the Angle Prediction Agent
3.3. Evaluating the Detection Model
3.3.1. The Influence of Feature Fusion Pyramid Network and Angle Prediction Agent
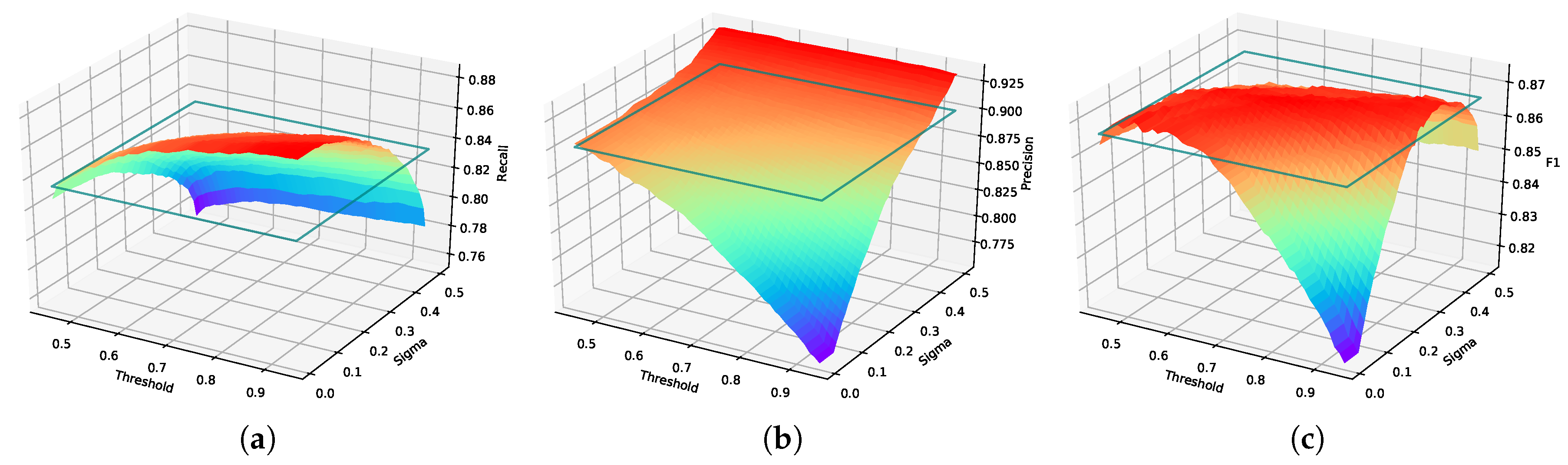
3.3.2. The Effect of Soft Rotation Non-Maximum Suppression
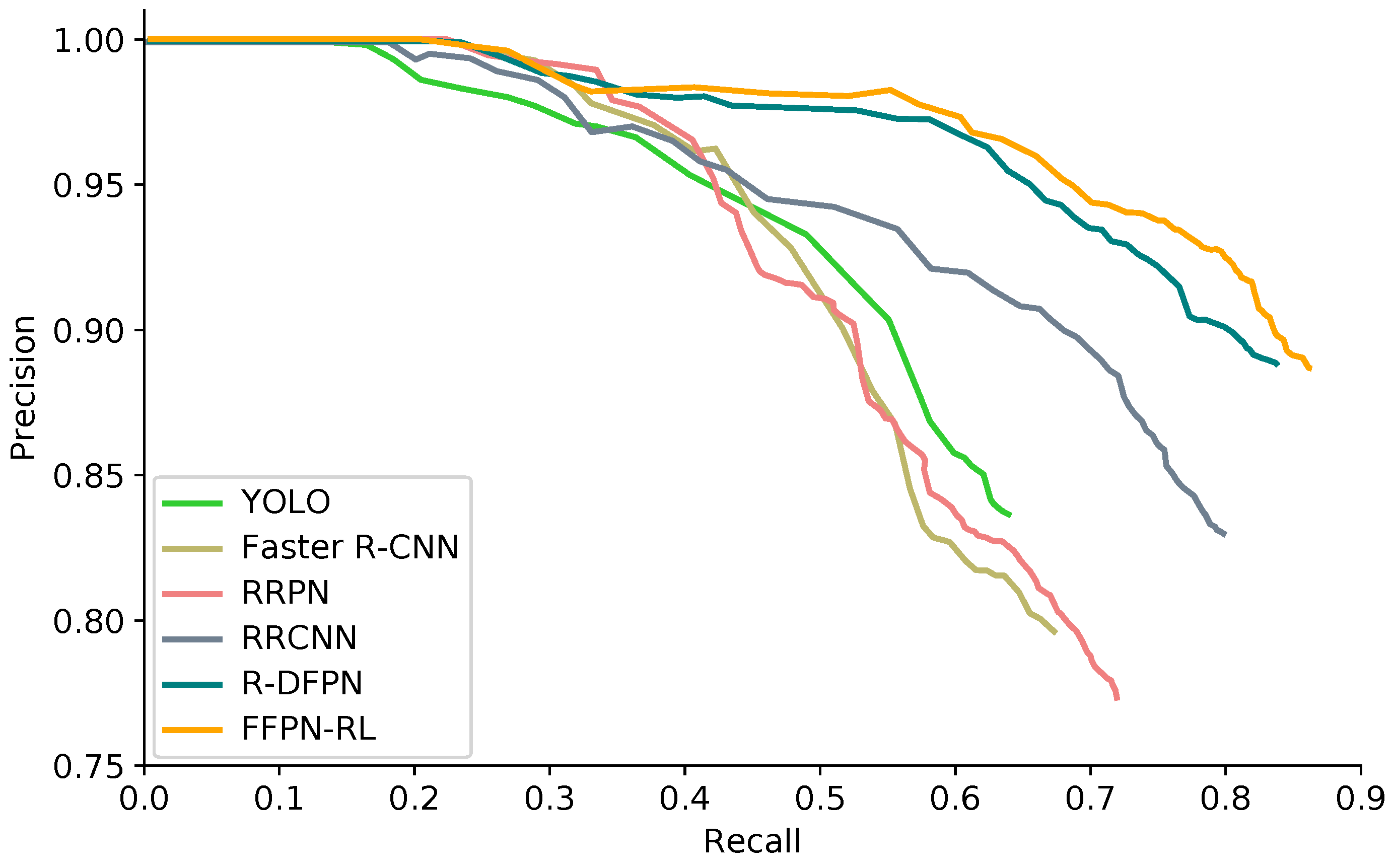
3.3.3. Comparison with Other Detection Models
4. Discussion
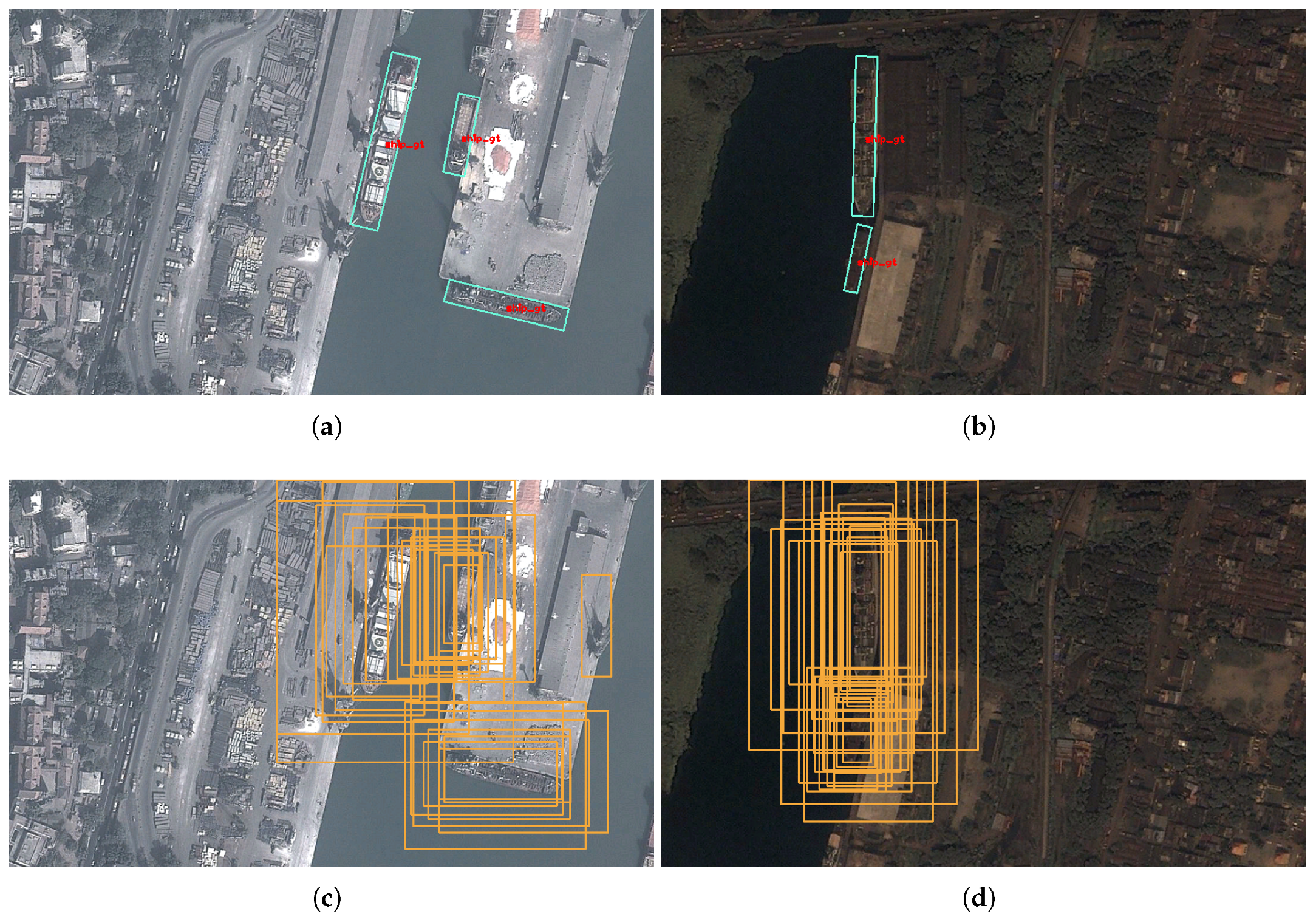
- We propose the Feature Fusion Pyramid Network (FFPN) to extract the ship features of different scales. Unlike the traditional two stage detectors, which only operate at the high feature maps, FFPN classifies and regresses on different scales feature maps. Figure 5 shows that, benefitting from FFPN, the Region Proposal Network can generate high-quality proposals for different scales’ ships. At the same time, the multi-scale reuse of features in FFPN also has a positive impact on the location and classification of the overall ship detection model. Table 2 shows that FFPN can achieve better performance compared with other feature connection methods.
- Angle is the vital information for the inclined ship detection. In addition, it affects the subsequent suppression processing and overall detection results. Therefore, accurate angle detection is very necessary. We propose using the deep reinforcement learning agent to iteratively predict the ship angle. We use a dueling network structure to approximate the Q value function, and we adopt the policy guidance and long-term training method to make the angle prediction agent learn effectively. Figure 11 and Figure 12 illustrate the validity of the optimized dueling double deep Q learning we proposed in Algorithm 1. Table 2 shows that, compared with the direct regression method, the agent prediction can continuously rotate the ship, and finally obtain the angle information more accurately, which is able to achieve higher Recall and Precision.
- Since the detection result is an inclined rectangle with angle information, we adopt a soft strategy in SRNMS to suppress redundant detection results. Different from the traditional NMS, the SRNMS can obtain some detection results that are suppressed in traditional NMS, and further reduce the missed detection, which is shown in Figure 16. This type of processing is advantageous for ship detection in dense parking situations.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Long, G.; Chen, X.Q. A Method for Automatic Detection of Ships in Harbor Area in High-Resolution Remote Sensing Image. Comput. Simul. 2007, 5, 53. [Google Scholar]
- Jiang, L.B.; Wang, Z.; Wei-Dong, H.U. An AIAC-based Inshore Ship Target Detection Approach. Remote Sens. Technol. Appl. 2007, 22, 88–94. [Google Scholar]
- Liu, G.; Zhang, Y.; Zheng, X.; Sun, X.; Fu, K.; Wang, H. A New Method on Inshore Ship Detection in High-Resolution Satellite Images Using Shape and Context Information. IEEE Geosci. Remote Sens. Lett. 2013, 11, 617–621. [Google Scholar] [CrossRef]
- Zhou, W.; Sun, Y.; Xu, C.; Guan, J. A Method for Discrimination of Ship Target and Azimuth Ambiguity in Multi-polarimetric SAR Imagery. J. Radars 2015, 4, 84. [Google Scholar] [CrossRef]
- Xu, C.; Zhou, W.; Cong, Y.; Guan, J. Ship Analysis and Detection in High-resolution Pol-SAR Imagery Based on Peak Zone. J. Radars 2015, 4, 367. [Google Scholar] [CrossRef]
- Li, W.; Fu, K.; Sun, H.; Sun, X.; Guo, Z.; Yan, M.; Zheng, X. Integrated Localization and Recognition for Inshore Ships in Large Scene Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 936–940. [Google Scholar] [CrossRef]
- Bi, F.; Zhu, B.; Gao, L.; Bian, M. A Visual Search Inspired Computational Model for Ship Detection in Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised Ship Detection Based on Saliency and S-HOG Descriptor From Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Dao, M.; Kwan, C.; Koperski, K.; Marchisio, G. A Joint Sparsity Approach to Tunnel Activity Monitoring Using High Resolution Satellite Images. In Proceedings of the 2018 9th IEEE Annual Ubiquitous Computing, Electronics and Mobile Communication Conference, New York, NY, USA, 8–10 November 2018. [Google Scholar]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral Image Classification Using Dictionary-Based Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Huang, X.; Wu, F.; Huang, P. Moving-object Detection Based on Sparse Representation and Dictionary Learning. Aasri Procedia 2012, 1, 492–497. [Google Scholar] [CrossRef]
- Xiao, Q.; Hu, X.; Gao, S.; Wang, H. Object Detection Based on Contour Learning and Template Matching. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation, Jinan, China, 7–9 July 2010; pp. 6361–6365. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv, 2014; arXiv:1409.4842. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. arXiv, 2016; arXiv:1603.05027. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv, 2016; arXiv:1608.06993. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Nguyen, P.; Arsalan, M.; Koo, J.; Naqvi, R.; Truong, N.; Kang, P. LightDenseYOLO: A Fast and Accurate Marker Tracker for Autonomous UAV Landing by Visible Light Camera Sensor on Drone. Sensors 2018, 18, 1315. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X.; Ma, J.; Shao, W.; Ye, H.; et al. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv, 2017; arXiv:1706.09579. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv, 2013; arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Kulkarni, T.D.; Narasimhan, K.; Saeedi, A.; Tenenbaum, J.B. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3675–3683. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D.P. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–3 May 2016. [Google Scholar]
- Yun, S.; Choi, J.; Yoo, Y.; Yun, K.; Choi, J.Y. Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1349–1358. [Google Scholar] [CrossRef]
- Lan, X.; Wang, H.; Gong, S.; Zhu, X. Identity Alignment by Noisy Pixel Removal. arXiv, 2017; arXiv:1707.02785. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.; Lam, V.; Bewley, A.; Shah, A. Learning to Drive in a Day. arXiv, 2018; arXiv:1807.00412. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Quek, A. Ship Orientation Estimation. 2015. Available online: https://alyssaq.github.io/2015/computing-the-axes-or-orientation-of-a-blob/ (accessed on 27 November 2018).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Model | ELECM | CNN | Agent |
|---|---|---|---|
| Time (s) | 0.005 | 0.065 | 0.122 |
| Method | Recall | Precision | F1 | |
|---|---|---|---|---|
| Original FPN | DR | 74.20% | 79.50% | 76.76% |
| AP | 76.94% | 82.41% | 79.58% | |
| DFPN | DR | 78.08% | 85.15% | 81.46% |
| AP | 79.85% | 88.08% | 83.76% | |
| FFPN | DR | 78.99% | 89.97% | 84.12% |
| AP | 83.42% | 90.05% | 86.61% | |
| Detection Model | Recall | Precision | F1 |
|---|---|---|---|
| YOLO | 63.53% | 83.04% | 71.98% |
| Faster R-CNN | 67.31% | 79.62% | 72.95% |
| RRPN | 71.95% | 77.34% | 74.55% |
| RRCNN | 79.83% | 82.99% | 81.38% |
| R-DFPN | 83.74% | 88.84% | 86.21% |
| FFPN-RL | 86.17% | 88.69% | 87.41% |
| Detection Model | YOLO | Faster R-CNN | RRPN | RRCNN | R-DFPN | FFPN-RL |
|---|---|---|---|---|---|---|
| Time (s) | 0.02 | 0.13 | 0.46 | 0.26 | 0.51 | 0.89 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, K.; Li, Y.; Sun, H.; Yang, X.; Xu, G.; Li, Y.; Sun, X. A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning. Remote Sens. 2018, 10, 1922. https://doi.org/10.3390/rs10121922
Fu K, Li Y, Sun H, Yang X, Xu G, Li Y, Sun X. A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning. Remote Sensing. 2018; 10(12):1922. https://doi.org/10.3390/rs10121922
Chicago/Turabian StyleFu, Kun, Yang Li, Hao Sun, Xue Yang, Guangluan Xu, Yuting Li, and Xian Sun. 2018. "A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning" Remote Sensing 10, no. 12: 1922. https://doi.org/10.3390/rs10121922
APA StyleFu, K., Li, Y., Sun, H., Yang, X., Xu, G., Li, Y., & Sun, X. (2018). A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning. Remote Sensing, 10(12), 1922. https://doi.org/10.3390/rs10121922