1. Introduction
The huge amount of digital text data produced each day makes it more and more difficult to quickly and accurately retrieve important information from texts [
1]. To obtain this data, an Automated Text Summarization (ATS) can be created. In order to solve this issue and enable Arabic Natural Language Processing (NLP) systems, specialized Arabic ATS techniques are required. Computerized textual content summarization means using a gadget or primarily computer-based equipment to supply a useful precis. Although primary computerized textual content summarization solutions were introduced in the 1950s [
2,
3], summarization has been lengthy and is one of the important challenges of natural language processing. Because machines have a very difficult time grasping a text’s substance based on its syntactic and semantic structure, computer-generated summaries frequently differ from those created by humans [
4]. Systems for summarizing information can be categorized according to the type of input, output, goal, language, and summary technique. Summarization systems are classified into two categories based on the variety of input documents: single-document and multi-document. A summarization system’s goals can vary depending on the type of input it receives, such as plain text, news articles, scientific articles, etc. These goals can include generating current information, running queries, or educating users about a particular topic. The method of summarizing is frequently heavily influenced by the goal for which it is being performed [
5]. The two types of summarization techniques are extractive and abstractive. The process of extractive summarization entails choosing a group of sentences or phrases from the text depending on the scores they receive in accordance with a specified criterion and pasting them verbatim into the summary. A concise interpretation of the original text is what is referred to as an abstractive summary. With this approach, the summary’s sentences may not always be written exactly as they were in the original text. The purpose for which summarization systems are designed can also be used to categorize them as either educational or informative.
Most present automated summarization structures are used with the extractive summarization approach. Extractive summarization can be accomplished with three strategies: statistical approach, linguistic method, and mixed method [
4]:
Statistical approach: This method of summary relies on the quantitative properties of the text and the statistical distribution of the features of interest. This method relies on information retrieval and classification methods without attempting to comprehend the entirety of the material. In this technique, an information retrieval algorithm examines the placement, length, and frequency of words and sentences in the document, and a classifier, using a collection of cases on which it has been trained, assesses which phrases could be included in the summary. With this approach, the original text’s sentences are taken out without considering the words’ semantics.
Linguistic approach: In this method, the computer must possess a thorough understanding of the language it is processing in order to analyze and comprehend sentences and select the phrases that should be included in the summary. This approach uses part-of-speech tagging, grammatical analysis, lexical analysis, and the extraction of significant phrases to determine links between words and phrases in the text. Sign words, characteristics, nouns, and verbs could all be used as the parameters for these processes. The linguistic technique frequently results in superior summaries because it takes into account the semantic relationships in the original text, even though the statistical approach is typically more computationally efficient.
Combination method: to produce more succinct and insightful summaries, this method combines both statistical and linguistic techniques. While statistical summarizing approaches are quite basic and adaptable because they use statistical features, they are also more prone to incoherence and inconsistently generated summaries.
The quality of output summaries can be greatly improved by combining several extractive summarization approaches. Based on the linguistic features extracted from the text structure analysis, modeling of the text structure and the relationships between its entities, and an improved single-document feature selection process, the combined approach to summarization is used in this study to produce unambiguous, succinct, consistent, and coherent summaries.
We suggested an extractive graph-based Arabic ATS technique in this research. It also describes how the choice of the phrase’s fundamental component—the stem, word, or n-gram, which serves as the foundation for the calculations of similarity and sentence ranking (summarization processes)—can affect the efficacy of the extracted summary.
The graph-based Arabic ATS method is based on the method developed by [
6]. Thakkar suggested a method for extracting the summary from a given English document by representing it as an undirected graph where sentences are represented by nodes, and the similarities (which refers to the word overlap) between every two sentences are represented by the edge weight. A summary is then generated by determining the shortest path between the first and remaining sentences of the original document. Moving from the first sentence to the last sentence broadens the summary and is more likely to include the most important parts of the original text.
2. Related Work
Luhn first proposed the idea of automatic text summarization in 1958, in the sense of figuring out how words are distributed inside sentences and identifying the document’s keywords [
7]. Since then, numerous summarizing techniques have been created using various methodologies and for various objectives. However, the majority of these approaches can be seen as advancements over earlier strategies. In this section, we concentrate on the studies using graph-based extraction techniques for a single document. We also explore research that introduced Arabic text summarizing tools.
Recently, several graph-based approaches for summarizing single and multiple English documents have been developed. Among these strategies are [
8,
9,
10,
11].
The researchers in ref. [
12] used a graph-based approach to extractive summarization. The later researchers suggested a brand-new summarizing technique based on a hybrid modeling graph. They suggested implementing a cutting-edge hybrid similarity function (H) that combines four different similarity measurements: cosine, Jaccard, word alignment, and window-based similarity. The method makes use of a trainable summarizer and takes into account a number of factors. It has been investigated how certain characteristics affect the work of summarization.
In ref. [
13], a graph reduction technique known as the Triangle Counting Method is developed to select essential phrases in the text. The initial stage is to visualize a text as a graph, where the phrases serve as the nodes, and the similarities between them serve as the edges. Following the representation of the bit vector, the creation of triangles comes next, and acquiring phrases based on the bit vector’s values comes last. This study demonstrated that it is possible to change one graph into another with a significantly smaller number of triangles. Adjacency Matrix Representation is simple to use and has sped up implementation times.
Two Arabic summarizing systems were created by El-Haj et al. [
14,
15]. The Arabic Question-Based Single Text Summarizer System (AQBTSS) works with an Arabic document and an Arabic query to provide a summary that is appropriate for the query of the document. The second system, called the Arabic Concept-Based Text Summarization System (ACBTSS), uses a set of words that reflect a certain concept as its input rather than a user’s query. The first two phases of the two systems are the same: selecting a document from the document collection that matches the user’s query and breaking the text up into sentences. Both systems use the Vector Space Model (VSM) in the summarization phase, where the weighting scheme is based on VSM and uses two measures, term frequency and inverse document frequency. In AQBTSS, each sentence is compared to the user query to find relevant sentences, whereas in ACBTSS, each sentence is matched against a set of keywords that represent a given concept. A panel of 1500 users evaluated the readability of the summaries of 251 articles produced by the two systems to evaluate them. The results revealed that AQBTSS performed better than ACBTSS.
A platform for summarizing Arabic texts was proposed by [
16] and includes the following modules: tokenization, morphological analyzer, parser, relevant sentence extraction, and extract revision. A variety of texts (short, average, and long) were used in the evaluation of this platform in terms of execution time, and it was discovered that the run time of the platform’s modules for a specific text was influenced by its size, i.e., the shorter the text, the weaker its run time.
The Sakhr Summarizer is an Arabic summarization tool that extracts the key phrases from the source text and summarizes them [
17]. The Summarization engine makes use of the Sakhr Corrector to automatically correct the input Arabic text for frequent grammatical errors and the Keywords Extractor to find a prioritized list of keywords to accurately identify the essential phrases.
Authors in ref. [
18] suggested a different summary system—the Arabic Intelligent Summarizer. The main machine-supervised learning technique is the foundation of this system. There are two phases to the system. The learning phase, which uses SVMs, is the first and instructs the algorithm on how to extract summary sentences. The users can summarize a new document during the use phase—the second stage.
P.M. Sabuna and D.B. Setyohadi [
19] describe the development of an abstractive automatic summarization system for online discussion papers using the vector space concept. The three modules that make up this system are point curation, point extraction, and summary creation. By dependency parsing and examining the grammatical structure, points are extracted. Shorter points are created by smaller indirect points after choosing the topic points and the points that might work for the summary.
An extractive summary technique for Arabic texts has been developed in [
20]. This approach combines rhetorical structure theory (RST), one of the most popular theories in natural language processing, with semantic data taken from the Arabic word net. The quality of Arabic text summarization is improved using this method, which combines linguistic selection methods with sentence feature selection methods. In order to determine how closely related sentences are to the main title and subheadings, the suggested RST-based method first constructs an initial summary and then uses the score of each sentence in that summary.
The automatic Indonesian text summarizing system described in [
21] generates summaries by combining sentence scores and decision trees. The C4.5 algorithm is employed in this system to pick the sentences that are of interest. After that, each sentence is scored using a sentence-scoring approach that takes into account eight variables, including TF-IDF, uppercase letters, proper nouns, cue phrases, numerical data, sentence length, sentence position, and title similarity. Following the creation of a decision tree model using the training data, the important sentences are identified, and the summary is prepared using the model’s rules. A combined statistical-linguistic approach-based extractive summary technique for Indian literature has been described in [
22]. Preprocessing, sentence feature extraction, and genetic algorithm (GA) for ranking sentences based on optimum feature weights are the three primary components of this summarization method. A sentence feature vector serves as a representation for each sentence. The statistical-linguistic properties of each sentence are analyzed, and a score is generated based on the importance of the features in that sentence. The sentences are then ranked based on the findings. Sentence characteristics accept values in the range of 0 to 1. After a predetermined number of generations in the GA, the fittest chromosome is chosen, and the Euclidean distance formula is used to calculate the distance between each sentence score and the fittest chromosome. The sentences are then arranged according to increasing distance. Finally, a summary is created by selecting a specific number of the document’s top-ranked sentences, depending on the level of summarization that is desired.
Authors in ref. [
23] suggested a multi-morphological analysis-based extractive graph-based approach for summarizing Arabic text. The original text was converted into a graph using this suggested strategy. The sentences were represented as vertices, and the linkages between the sentences were determined using the mutual nouns between the connected phrases and the cosine similarity between the sentences based on Term Frequency-Inverse Document Frequency (TF-IDF).
The extractive Arabic text summarizing approach proposed by [
24] employed the Firefly algorithm. The proposed approach comprised four basic steps: (1) text preprocessing techniques such as segmentation, tokenization, stop word elimination, and stemming; (2) using a phrase’s structural features, such as the title similarity, sentence length, sentence placement, and term TF-IDF weight, to calculate similarity scores; (3) creating a graph of potential answers, where the vertices are the original document’s sentences, and the edges are how close they are to one another; (4) choosing which sentences should be in the summary using the Firefly algorithm. The suggested method was assessed using the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics on the EASC corpus.
The QUESTS system, which was suggested in [
25,
26], is an integrated query system for producing extractive summaries from a collection of documents. In order to create many subgraphs from the main graph, this system first creates an integrated graph of the relationships between the sentences of all the input documents. Sentences that are more closely related to the topic at hand and to one another make up these subparagraphs. The highest-scoring subparagraph that is most pertinent to the query is chosen for inclusion in the summary after the algorithm ranks the subparagraphs using a scoring model.
3. The Roots of Arabic Words
The roots of words are one of the Arabic language’s strengths. Arabic words typically have a root, which means that the root can serve as the foundation for other words with similar meanings. By adding suffixes to the root, we can create a set of derivations. These derivatives cover the same ground. Finding an Arabic word’s root (also known as stemming) facilitates the mapping of grammatical differences to instances of the same term.
Multi-derivations of the wording structures in the Arabic language allow a semantic representation of the text that is closer to the semantic foundations. For instance, the root “درس” is used for many words relating to “reading”, including “ ‘.دارس” and “مدرسة”. It is worth noting that it is a difficult matter to determine the root of any Arabic word because of that.
Due to a variety of factors, the Arabic language has been regarded as difficult for automatic text summarization and information retrieval. Because Arabic words can take on a wide variety of forms and is a highly inflectional and derivational language, studying morphology can be exceedingly challenging. Additionally, the way a character is written depends on where the letter falls within a word, which might make it more difficult to analyze Arabic words. Therefore, for the Arabic language, obtaining the lemma, stem, or root is a challenging problem. Based on such Arabic language standards, natural language processing appears more complex and takes more time than what has been achieved in English and other European languages.
The quality and accuracy of the task of artificial text summarization may be positively impacted by a good representation of Arabic text. Additionally, as words with the same root are semantically connected, feature selection methods based on the root can enhance a method for determining how similar two passages of Arabic text are, which can be applied as the foundation for our Arabic text summarizing strategy.
4. Arabic Text Representation for Automatic Summarization Using Graphs
Different Natural Language Processing problems have recently been effective in using graph-based methods. There is a fairly solid mathematical foundation for term significance determination techniques. The approach of determining a textual unit’s relevance has become increasingly popular in graph-based ranking algorithms. It is possible to determine the relative relevance of a node within the graph using graph-based ranking algorithms. When determining the significance of a node, these algorithms consider the global information, or the entire graph, rather than just the local, vertex-specific information. Sentences or other text elements are connected by meaningful relations in a text that is represented as a graph. We will be better able to understand the relationship between the various components of the text by using the graph to depict the text’s organizational structure. The different sections of a text are ranked using graph-based methods, where each piece is treated as a node. The lexical or semantic relationships between two nodes will be represented by edges. It is possible to connect two graph vertices by drawing an edge between them, representing, for instance, lexical or semantic relationships. No matter the nature or qualities of the text we wish to graph, a graph-based ranking system must first perform the following basic steps:
Determine which text units—sentences, words, or other units—best describe the assignment and use them as nodes in a graph.
Identify the relationships that link these text units, then utilize those relationships to create edges between the graph’s vertices. Edges may be weighted or unweighted, directed or undirected.
Until convergence, use the graph ranking algorithm to determine a ranking over the graph’s nodes. Then, every node is arranged in order of ultimate score. Use the values associated with each vertex to determine ranking and selection.
As indicated in the third phase, nodes are ranked according to their final scores after specifying the final scores for each node. The best sentences are then chosen to participate in the final summary. Two of the most significant algorithms based on the graph are TexRank [
27] and LexRank [
28]. We then briefly looked at each of these algorithms.
The candidate sentences that might be included in the summary are all represented in a graph by the multi-document summarizing system called LexRank. If the similarity between two sentences exceeds a certain level, they are connected in this graph representation. A competitive advantage between two sentences is created if they have specific similarities. This similarity is computed using the function COSINUS. The system then conducts a random walk on the graph after constructing the network to identify the most crucial sentences.
All graphs that are derived from natural language texts are ranked using the graph-based model TextRank.
TextRank is a single document summarizing system that derives from the Google page ranking [
27,
29] paradigm. Keywords and sentences are extracted using TextRank. To extract sentences, a completely connected, undirected graph is used. An individual sentence is regarded as a vertex (or node) in a graph. A similarity connection that is calculated as a function of shared concepts is used to draw a line between two texts. Additionally, each edge has a weight that reflects how significant a relationship is. The best sentences are chosen after ranking each sentence according to its score.
Given a document , let be an undirected graph that represents the document with the set of nodes and the set of edges . This is for the text summarizing task. The nodes in this model stand in for the sentences in . Every edge has a weight that denotes how similar the nodes (sentences) and are to one another. If two sentences satisfy a similarity threshold and are similar to one another, then they are related. Based on the relationships with other connected nodes, each node in the graph is also given a salient score. This score, which was determined using a ranking system, shows how much information is contained in a sentence.
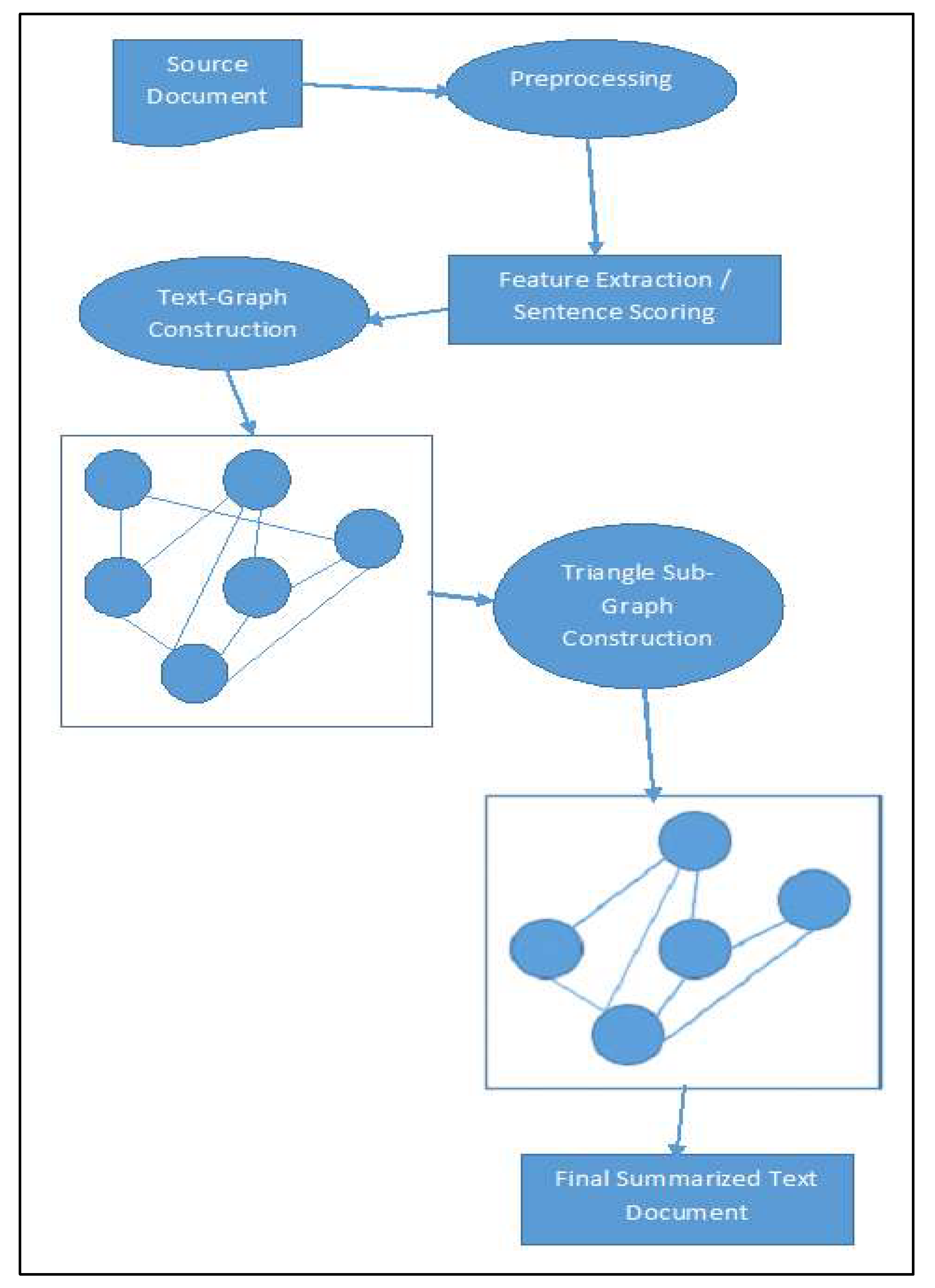
5. Proposed Arabic Summarization Method
In order to effectively summarize text, graph-based ranking algorithms have also been demonstrated to be useful. Each sentence in the text is added as a vertex, and the edges between the vertices are made up of connections made by other sentences. These relationships are established by the use of a similarity relation, where similarity is determined by the degree of content overlap. In this study, we demonstrate the outcomes of using graph theory for the summary of Arabic text.
Figure 1. bellow shows the overview of the proposed approach for triangle-graph based summarization system.
The five main steps of this approach are as follows:
5.1. Data Pre-Processing
It is challenging to test and evaluate an artificial text summarizing system since there is no perfect summary for almost any specific document or set of related texts. Additionally, as researchers typically gather their own information, the lack of Arabic standard datasets made the evaluation process more difficult and possibly subjective in some circumstances [
30]. As far as we are aware, there are four Arabic extractive single-document datasets that are available to the public. Summaries are produced automatically by translating an English corpus into Arabic using Google’s translation service. When compared to human translation, this method of dataset generation lowers the cost of creating an Arabic dataset. However, doing so could result in a document of poor quality or have an impact on semantics. To automatically produce extractive summaries that might be biased toward certain summarizers, authors in [
31] previously built Arabic summarizers. Finally, the dataset in [
15] was created using human-generated extractive summaries. In order to test and assess the suggested strategy, the Essex Arabic Summaries Corpus (EASC) [
15] has been used. A team of scholars at Essex University created the EASC corpus, an extraction summation that was published. It has 153 articles on various subjects that were compiled from Arabic newspapers and Wikipedia. There are five separate reference summaries produced by five different humans for each article in the EASC corpus. The one thing that sets this dataset apart from others is that it is the only Arabic dataset that has been created by humans. This makes the evaluation more realistic when compared to methods that rely on translated datasets or the output of summarizers that have already been produced.
The first stage in practically all summary methodologies is this one. Its major objective is to get the input text file ready for processing in subsequent phases. It primarily creates a uniform representation of the input document.
Due to the complexity of the Arabic language, developing the NLP system is not simple. The rich and intricate morphological and syntactic flexibility of Arabic is widely known [
32]. The preprocessing stage is essentially the same for all languages and often entails normalization, tokenization, POS tagging, stemming/lemmatization, and stop-word removal [
33,
34,
35]. Since most texts produced in Arabic and saved in electronic form do not have diacritical marks at first, the system deals with Arabic texts without them.
5.1.1. Tokenization
Tokenization, the first step in text preprocessing, divides input documents into units of varying levels to make it easier to access all of the input document’s content. These units can be tokens, sentences, paragraphs, numerals, or any other suitable unit [
36]. To give an example, the proposed tokenization is a morphological decomposition based on punctuation that begins by identifying the paragraphs the document is made up of. The newline character
serves as the paragraph divider in this scenario. Following that, paragraphs are divided into a collection of phrases using the full stop (.), question mark (?), and exclamation mark (!). Finally, delimiters such as white space, semicolons, commas, and quotations are used to separate these phrases into tokens. To handle the aforementioned series of actions, we used the AraNLP tool with minimal modification [
37].
5.1.2. Normalization
Some Arabic letters may take on several forms, while others may be used in place of others because of similarities in their shapes. Writers also employ diacritical marks in their writing. These result in a set of variations for the same term, which has an impact on how some attributes, such as term frequency (
), are computed. To avoid these variations, a normalization technique is needed to harmonize the many spellings of the same letter. The following activities are performed by the suggested normalization step using the AraNLP tool [
37]: (i) eliminating non-Arabic letters such as special symbols and punctuation; (ii) removing diacritics; (iii) replacing أ ، آ and إ with ا , ى with ي , and ة with ه [
38]; (iv) removing tattoos (stretching characters).
5.1.3. Stop Words Removal
Stop words are unimportant words that regularly appear in texts to build sentences, such as pronouns, prepositions, conjunctions, etc. [
39]. These words can be removed from sentences without changing their main ideas since they are not informative (do not add information). In fact, this phase is very important because several computations are based on the frequency of the words in the sentence or document. Therefore, by eliminating stop words, these calculations are made more pertinent and precise. Stop-words are eliminated from the text using a variety of stop-list techniques, including the general stop-list, corpus-based stop-list, and combined stop-list. The suggested strategy, which outperformed the other two ways, relies on a broad stop-list created with the AraNLP tool [
37,
40].
5.1.4. Stemming
Because Arabic is a highly inflectional and derivational language, words can take on a wide variety of forms while still having the same action-related abstract meaning. Evidently, this has an impact on a number of natural language processing techniques, including text similarity analysis and developing bag-of-word models. Stemming, then, is the process of deleting all or some affixes from a word, such as prefixes, infixes, postfixes, and suffixes. In other words, stemming reduces a word’s various forms and derivatives to a single, unified form (such as a root or stem) from which all other forms can be derived. There are two popular stemming techniques in Arabic: light stemming and morphological root-based stemming [
41]. When comparing these methods for text summarization, authors in ref. [
42] used three well-known Arabic stemmers, namely the Khoja root stemmer. Their research showed that root stemming outperforms light stemming for summarizing Arabic texts. We modified a Khoja root stemmer to handle the stemming operation as a preprocessing task for the proposed study based on those findings.
5.1.5. Feature Extraction
The set represents the textual document, with being a phrase from document . The textual contents are then subjected to feature extraction, and helpful primary sentence and word structures are identified. Each document includes a variety of structural elements, including title words, sentence lengths, sentence positions, numerical data, term weights, sentence similarity, thematic-word and proper-noun instances, and sentence lengths and positions.
Title words: Sentences containing title words that accurately reflect the meanings of the arguments are given higher ratings. The following method is used to determine this:
Sentence lengths: Lines including the date or author are eliminated from sentences that are too short. The normalized length of each sentence is calculated as:
Sentence positions: Sentences that appear earlier in their paragraphs are given higher grades. Each sentence in a paragraph with n sentences is scored as follows:
Numerical data: Each sentence containing numerical terms that duplicate significant statistical data points in the text is slated for summarization. The scores for each phrase are calculated as follows:
Thematic words: The number of thematic words, or domain-specific phrases exhibiting the highest level of relativeness, found in a sentence divided by the number of thematic words found in the sentences, is calculated as follows:
Sentences that are identical to one another: To determine commonalities between each sentence S and every other sentence, token-matching algorithms are used. The total number of sentences found is represented by the matrix
, and the diagonal components are set to zero because the sentences are not compared to one another. The evaluation of each sentence’s similarity score is as follows:
5.1.6. Similarity Measuring
One of the most widely used similarity measures for text documents is cosine similarity, which is used in many applications for information retrieval and clustering. Based on the
feature, the cosine similarity between two sentences,
and
, is as follows:
5.2. Text Graph Representation
A text is divided into sentences and words before being summarized. This stage involves formatting an Arabic text document as a graph. The collection of vertices and the set of edges that represent the document are created to form the undirected weighted graph . The sentences act as the graph’s nodes. When two sentences are similar to one another, they have an edge between them. The edges of the graph show this similarity, and the edge weight indicates how similar the phrases are. Many other approaches can be used to determine how similar two sentences are in Arabic text, including Cosine similarity, Jaccard, Word-Overlap, and dice. We employ the cosine similarity measure in this study. If the similarity between two sentences exceeds a predetermined threshold ( in the trials), the sentences are considered connected. This process produces a graph that is extremely linked. The link between the two sentences that each edge connects is represented by its edge. The edge weight represents how well the sentences in the paper are connected to one another. This undirected weighted graph serves as the input for the procedure used to determine each sentence’s salient points in the following section.
The sentences in a text will be ranked using random walk on
once the document graph has been constructed. Using the PageRank technique, we get the salience score for each node [
43]. PageRank was created as a mechanism for Web link analysis and is one of the most well-known link analysis algorithms. Using data from the graph’s structure, it assesses a node’s significance within the network. Although PageRank was designed to be used with directed graphs, it can also be effective with undirected graphs. By doing this, a vertex’s output-degree and input-degree are equal. In our case,
equals Out because the graph is undirected
. The score of a vertex
is given by Equation (8), where
is the set of nodes that point to
is the set of nodes that node
points to,
is the weight of the edge leading from node
to node
, and
is a damping factor that can be set between 0 and 1. This damping factor serves to incorporate into the model the probability of jumping from a given vertex to another random vertex. Typically, the value of
is 0.85 [
27].
To determine
, a starting score of 1 is given to each node, and Equation (8) is applied iteratively on the weighted graph
until the difference in scores between iterations for all nodes is less than a threshold of 0.001. The salient scores of the sentences determine the nodes’ weights. Nodes with higher scores correspond to sentences that are significant, relevant to the document, and have strong relationships with other sentences. Each vertex is given a score following the algorithm’s execution, and this score reflects the vertex’s “importance” or “power” inside the graph. After that, the sentences are arranged in order of their scores. Note that only the number of iterations necessary to reach convergence may be impacted by the initial value choice; the final values are unaffected.
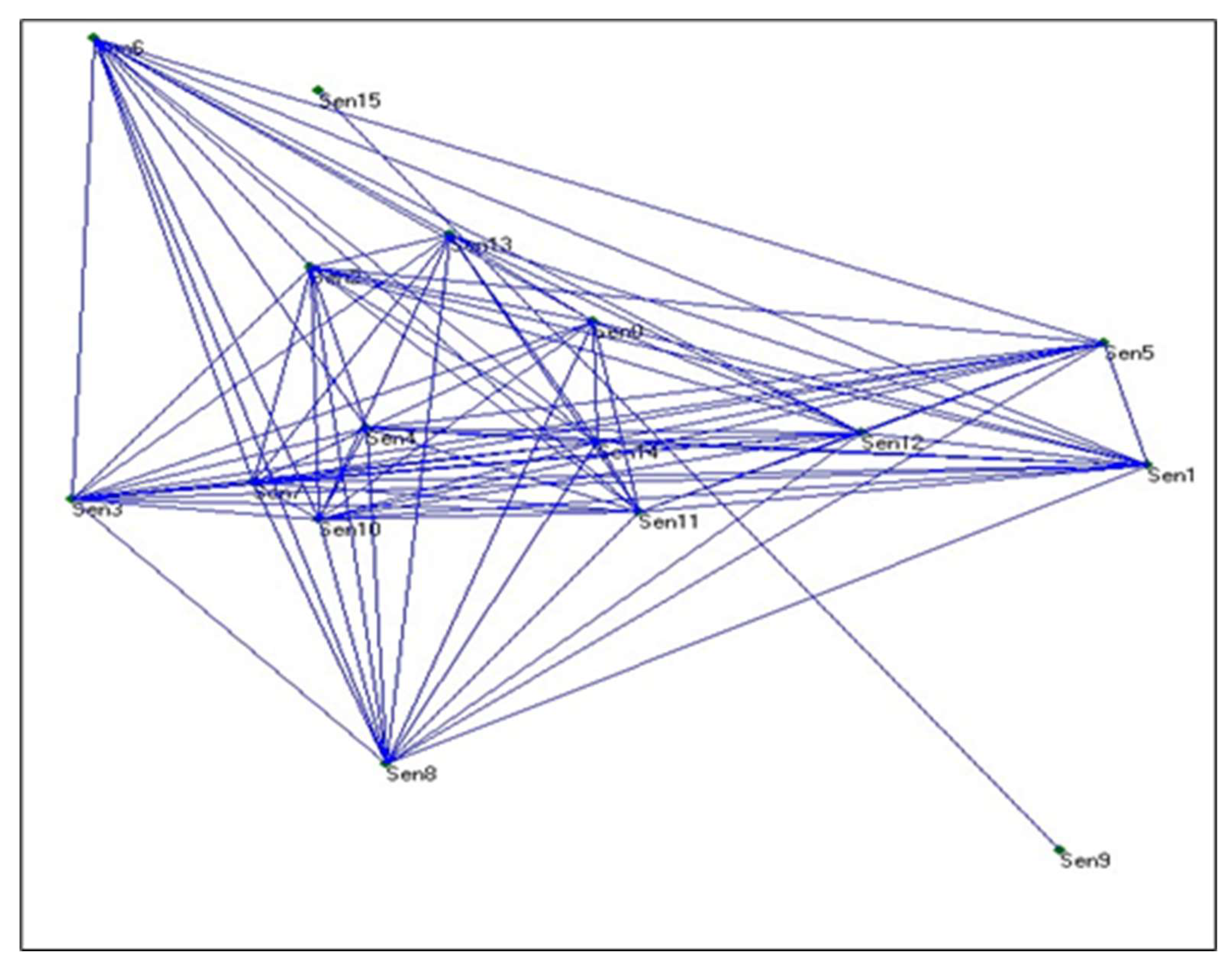
Figure 2. shows a graph representation built for a text sample, the blue lines are the edges between sentences of the text.
5.3. Sub-Graph Construction
The triangular sub-graph construction process comes next. Triangles use the axiom that people who know people who know people tend to be friends. We start by making an adjacency matrix. Algorithm 1. shows how the adjacency matrix works.
| Algorithm 1: Adjacency Matrix |
| Input: Graph Data Set with N nodes or no of sentences and E edges or relationships between sentences |
| Output: N*N Adjacency Matrix, showing the connections between nodes |
| Start |
| Determine the size of the matrix, which is N*N (N is the number of nodes in the graph) |
| Create the matrix A |
| For each node v ∈ N { |
| If there is any edge from vi to vj { |
| A (i,j) = 1 —if sim (Si, Sj) > 0 |
| Else |
| A (i,j) = 0 —if there is there is no words that are similar between sentences |
| } |
| Stop |
The next step is to create a list of triangles to represent the text. The procedure based on De- Morgan lows is used to locate the triangles in the graph. Algorithm 2. shows how this step was done.
| Algorithm 2: De-Morgan lows |
| Input: N*N adjacency matrix, (A(I,J)) |
| Output: Array of triangles |
| Start |
| Triangles_Array = [], |
| For each edge in the matrix A(I,J), namely XY, find all edges start with Y { |
| XY ˄ YZ ⟶ XZ |
| If XZ ∈ A(I,J) { |
| Add the triangle of edges (X,Y,Z) to Triangles_Array[]} |
| } |
| Stop |
After finding the nodes and edges representing the triangles in the main graph, we can construct the reduced graph.
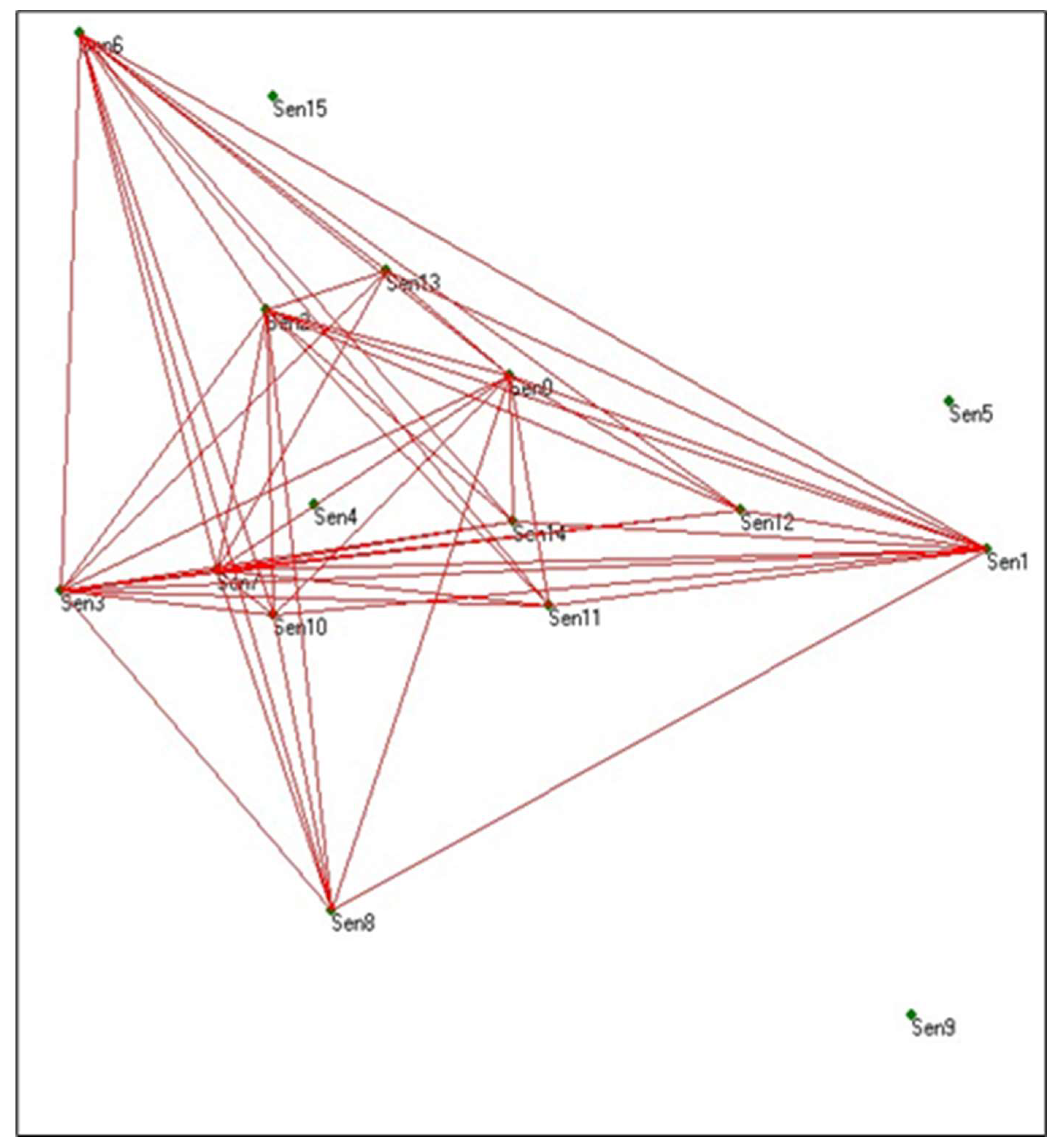
Figure 3 shows the Triangle graph for the sample text represented in
Figure 2. The blue lines are the edges between sentences of the text, while the red lines are the edges represent the reduced graph. That means only the red edges will be used to create the summary.
In
Figure 3, the red lines show the edges of the triangles from the main graph, while the blue ones were ignored.
5.4. Sentence Scoring
To find the most vital sentences, the Bit–vector exemplification was adopted in this work to symbolize the pruned graph from the preceding section. Each sentence has either one feature or multi-features. In our work, we used a combination of the six features discussed above. The combinations could be two, three, four, five, or six features. We had 63 probabilities for these combinations.
After scoring all six features explained above, a principle statistics method was used to construct a document summary. Text summarization based on general statistics methods was exploited to integrate the six feature scores combined with bit-vector values as the sentence weight.
After features were extracted by the system, the sentence scores were obtained. First, a weighted score function for a sentence
is exploited to integrate all six features, as calculated using Equation (9).
where
is the score of sentence
,
is the score of feature
and
is the number of features used to score the sentences.
5.5. Summary Generation
Each sentence in the manuscript was given a value based on the sentence scores acquired. Only sentences with sub-graph structures were chosen for analysis since they are connected to at least two additional sentences. According to its grade, each sentence was ranked in decreasing order. High-scoring candidates were removed for document summarizing, in accordance with the compression ratio. It has been shown that an extraction or compression rate of close to 20% of the core textual material is just as informative of the contents as the full text of the document [
44]. The summary sentences in the last step are arranged according to the order of the sentences in the original text.
6. Experimental Results
The proposed experiment aims to produce the following outcomes: (i) assess the proposed design of the chosen statistical and semantic features; (ii) assess the use of a statistical summarization method on the Arabic texts; and (iii) assess the comparison of our proposed method to other related works. As was already noted, the EASC dataset was used for testing and assessing the suggested method. In order to calculate the precision, recall, and F-score for each of the generated summaries for both summary methods, ROUGE-N (i.e., ROUGE-1, ROUGE-2) was employed.
In order to produce the output summaries in score-based summarization, an input threshold (summary ratio) needs to be modified. Finding the ideal ratio is challenging because the corpus includes 153 documents, each of which has five human reference summaries with a different ratio. To prevent this issue, the generated summaries are modified using an adaptive ratio dependent on the length of the reference summary we are comparing it to.
A majority summary, or so-called gold-standard summary, was created by a voting process among the five references to improve outcomes and avoid the problem of subjectivity. As a result, the statement was included in the gold-standard reference summary if it appears in three or more of the five references [
45].
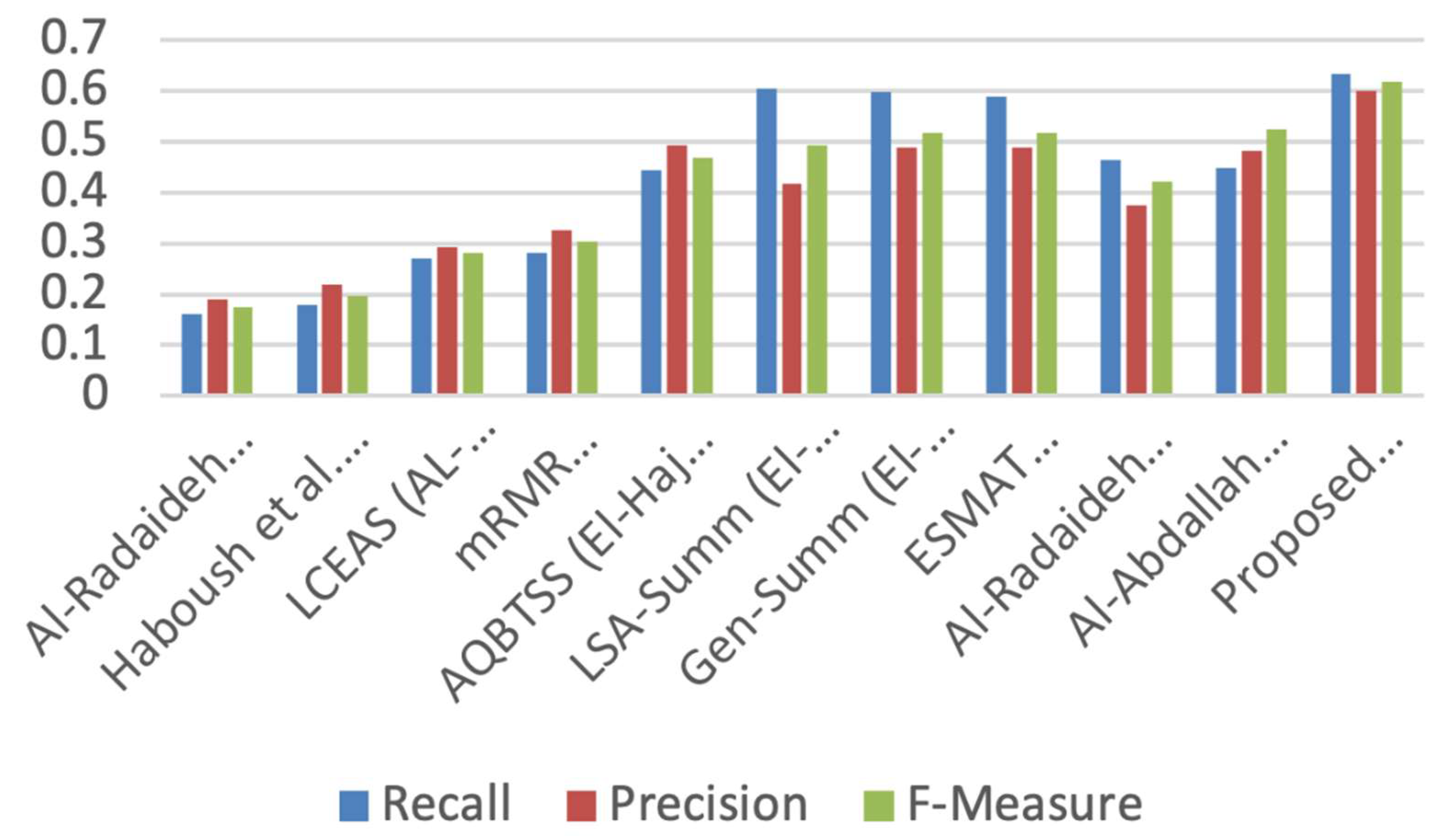
The results of the suggested approach are contrasted with those of other systems and methods for relevant Arabic summarization in this section. With a brief description of the summary type, summarization method, and features employed,
Table 1 presents ten similar summarization methods/systems. These systems were assessed using the Essex Arabic corpus and the “gold-standard” summary, which stipulates that no more than 50% of the original document’s words should be used in the summary.
Since ROUGE-N (N = 2) performs better for the evaluation of single document summarization, it was employed in the evaluation process as an automatic evaluation metric for recall, precision, and F-score. Based on their published results in terms of recall, precision, and F-Score,
Figure 4 compares the performance results of the proposed summarizing method to the performance results of the related summarization methods/systems. The suggested score-based strategy exceeds the competition in terms of recall, precision, and F-Score, with average improvements of 23%, 23%, and 24%, respectively (
Figure 4). This is due to the potency/strength of the chosen feature and the originality of their composition, in addition to the use of appropriate and modern Arabic NLP techniques.
7. Discussion
The experiment results of the proposed method based on the triangle sub-graph using cosine similarity measurement and specific selected features show that the resulting summaries could be better than other summaries. DUC 2002 was used as a data warehouse for news article collection as input in our experiment. Three pyramid evaluation metrics (mean coverage score (recall), average precision, and average F-measure) are employed for the comparative evaluation of the proposed approach and other summarization systems. In this approach, we used six different features for each sentence, and we used cosine similarity measurement to find the relations between the sentences (graph nodes) to represent the graph; then we pruned the graph by finding the triangles sub-graph and by using the sentences, formed this sub-graph to find the summary. The scoring process of the sentences was completed based on the values of the selected features. Based on the experimental results of the proposed method, we can say that if we can identify significant similarity measurements for representing relations between sentences and identify significant features for text summarization, it can produce a good summary.
8. Conclusions
Because of the Internet’s incredible rise in data, it is more important than ever to have an automated summarizing system that can reduce user time consumption and information overload. Key sentences from the document’s major concepts should be retained in a decent summary, and repetition should be minimized to create a summary that is information-rich. Despite current efforts to develop text summarization techniques and formulate representative characteristics, these formulations are still unable to adequately capture the relevance, coverage, and diversity of a phrase. The method for extracting single document summarization presented in this paper is general.
The score-based method makes use of a set of attributes that were selected and developed after a thorough examination of summarization techniques, Arabic text characteristics, and writing styles. These characteristics range from statistics to semantically-based ones. While keeping in mind that these sentences are varied and cover the entire notions of the document, the adopted formulations aid in determining the value of sentences, which is vital to the process of deciding whether to include them in the summary. We test the suggested strategy using the EASC dataset. The system achieved an F-score of 0.617 for the score-based method using ROUGE-2 as a performance metric.
The findings obtained demonstrate that our method outperforms the most cutting-edge score-based algorithms, particularly in terms of precision. This is a result of the proposed characteristics’ informative formulation, which aids in highlighting the significance of the statement.







{kind=link}
{kind=link}
{kind=link}
{kind=link}