


Advanced Global CO2 Emissions Forecasting: Enhancing Accuracy and Stability Across Diverse Regions


Abstract
1. Introduction and Related Work
1.1. Background and Motivation
1.2. Related Work and Research Gap
2. Neural Networks for Time Series Forecasting
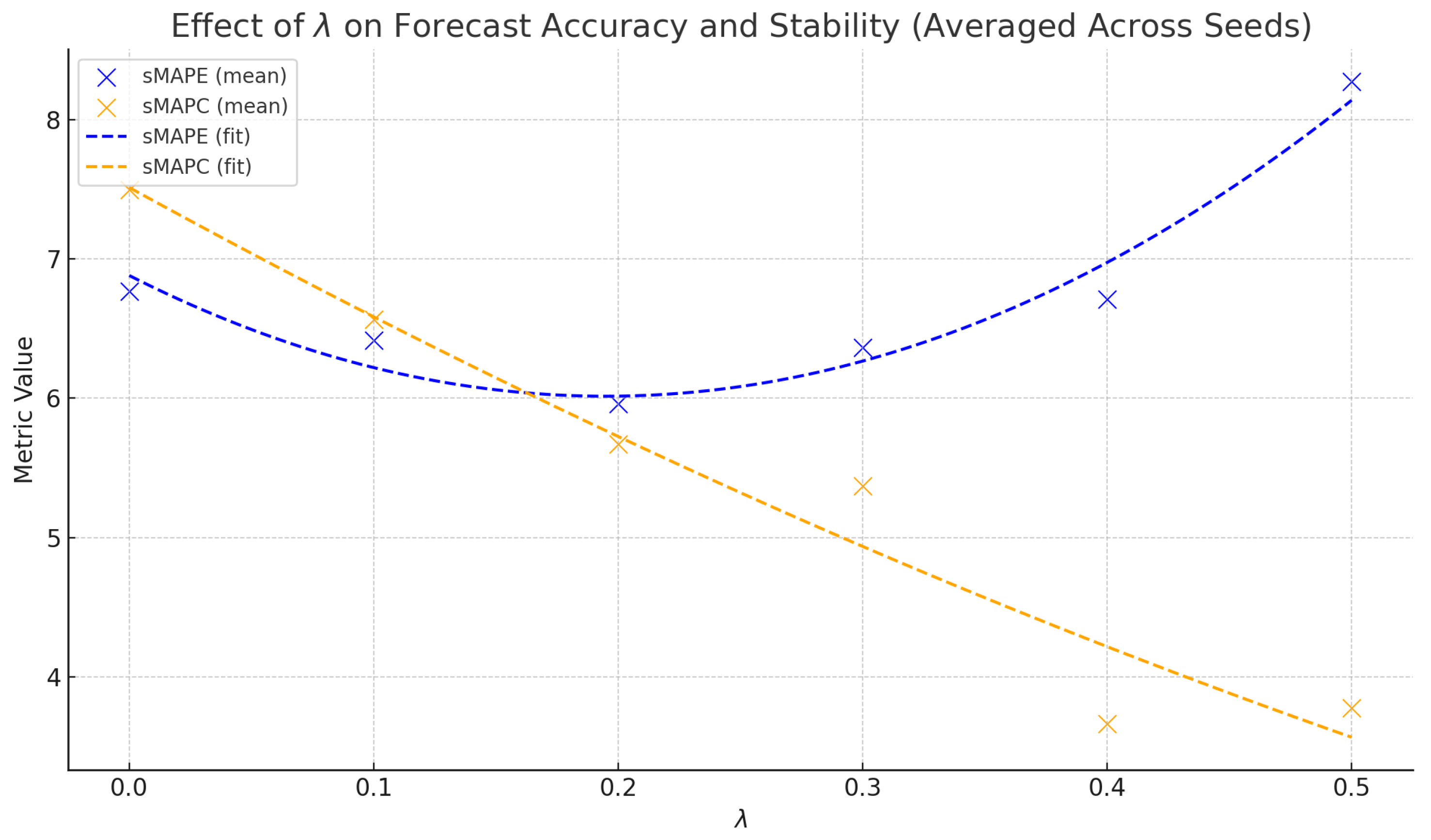
3. Improving the Stability of Multi-Step MLP Forecasts
4. Dataset Construction
4.1. Dataset Overview and Key Details
- Temporal Coverage: 1750–2023 (annual frequency).
- Geographical Coverage: Multiple countries and regions worldwide.
- Indicator: Annual total emissions of CO2 (excluding land-use change), measured in tonnes.
- Source: Global Carbon Budget (2024) with major processing by Our World in Data.
- Final Processing Date: 21 November 2024.
- Unit: Tonnes of CO2.
- Data Modifications:
- Conversion from tonnes of carbon to tonnes of CO2 using a factor of 3.664, as documented by Our World in Data.
- Removal of zero-emission entries from annual records.
- Standardization of country/region naming conventions and alignment of date ranges where applicable.
4.2. Summary Statistics
- No. of series: 244 (For example, each series corresponds to a distinct country/region that has non-zero emissions data over some portion of 1750–2023.)
- Min. length: 20 years (Reflecting countries with relatively few non-zero emission records, often due to late starts in industrial activity or incomplete historical data.)
- Max. length: 274 years (Indicating that some regions/countries have continuous non-zero records dating back to the mid-18th century.)
- Mean length: 114.8 years (The average count of non-zero annual entries per series.)
- Std. dev. length: 57.2 years (Highlighting moderate variability in the number of available non-zero data points across countries.)
4.3. Distribution of Time Series Lengths
4.4. Additional Context and Considerations
- Exclusions: The dataset excludes emissions from international aviation and shipping, and does not account for net imports or exports of embedded carbon in traded goods.
- Historical vs. Current Comparisons: Longer series provide valuable historical context, enabling trend analysis from the dawn of the Industrial Revolution to the present. Shorter series can still inform recent trajectories but may lack the breadth for extended historical comparisons.
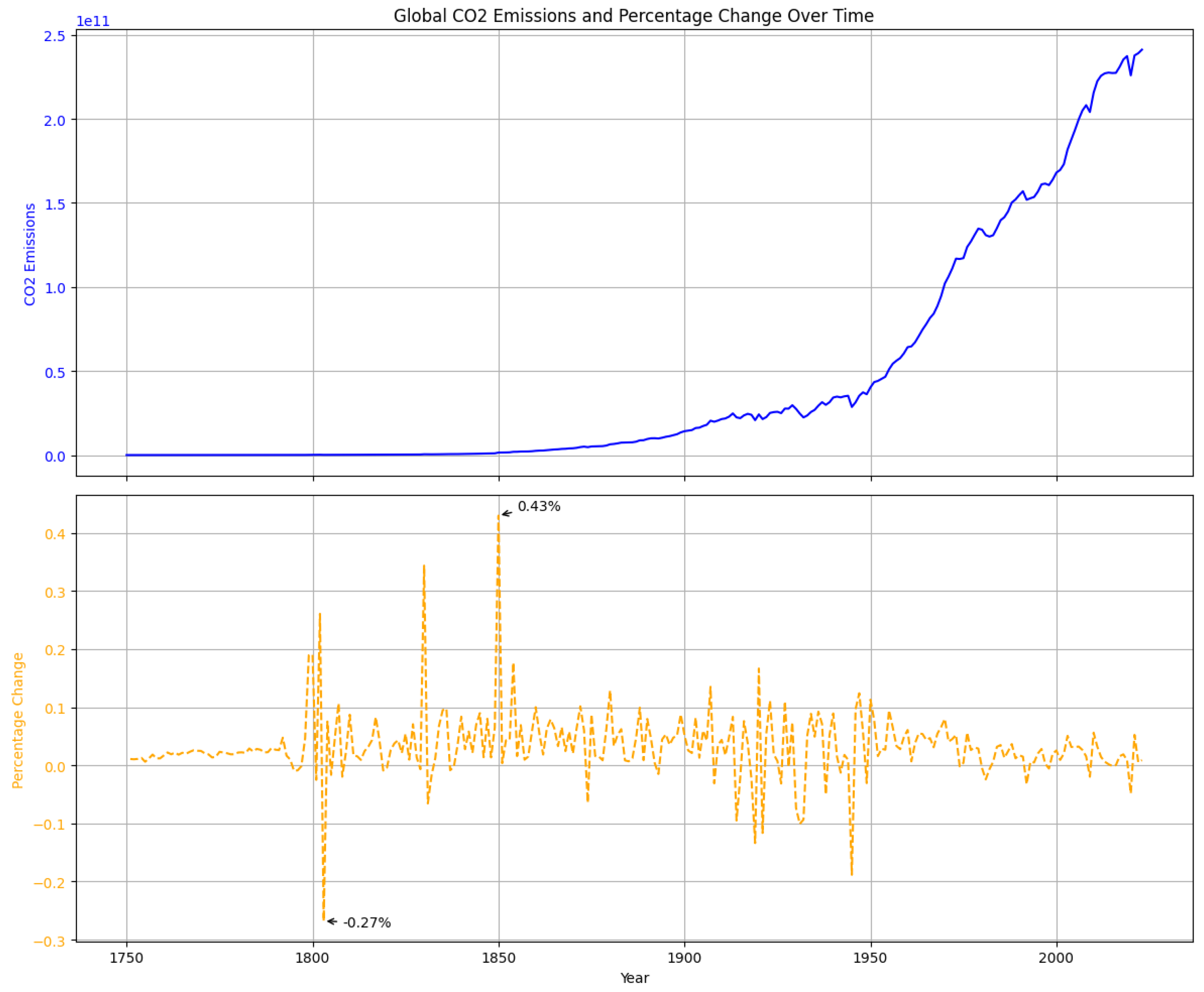
4.5. CO2 Emissions over Time: Absolute and Relative Change
4.6. Relevance to Modeling and Forecasting
5. Experimental Design and Methodology
5.1. Data Splitting Strategy
5.2. Hyperparameter Configuration
5.3. Implementation and Training Procedure
5.4. Evaluation Scheme
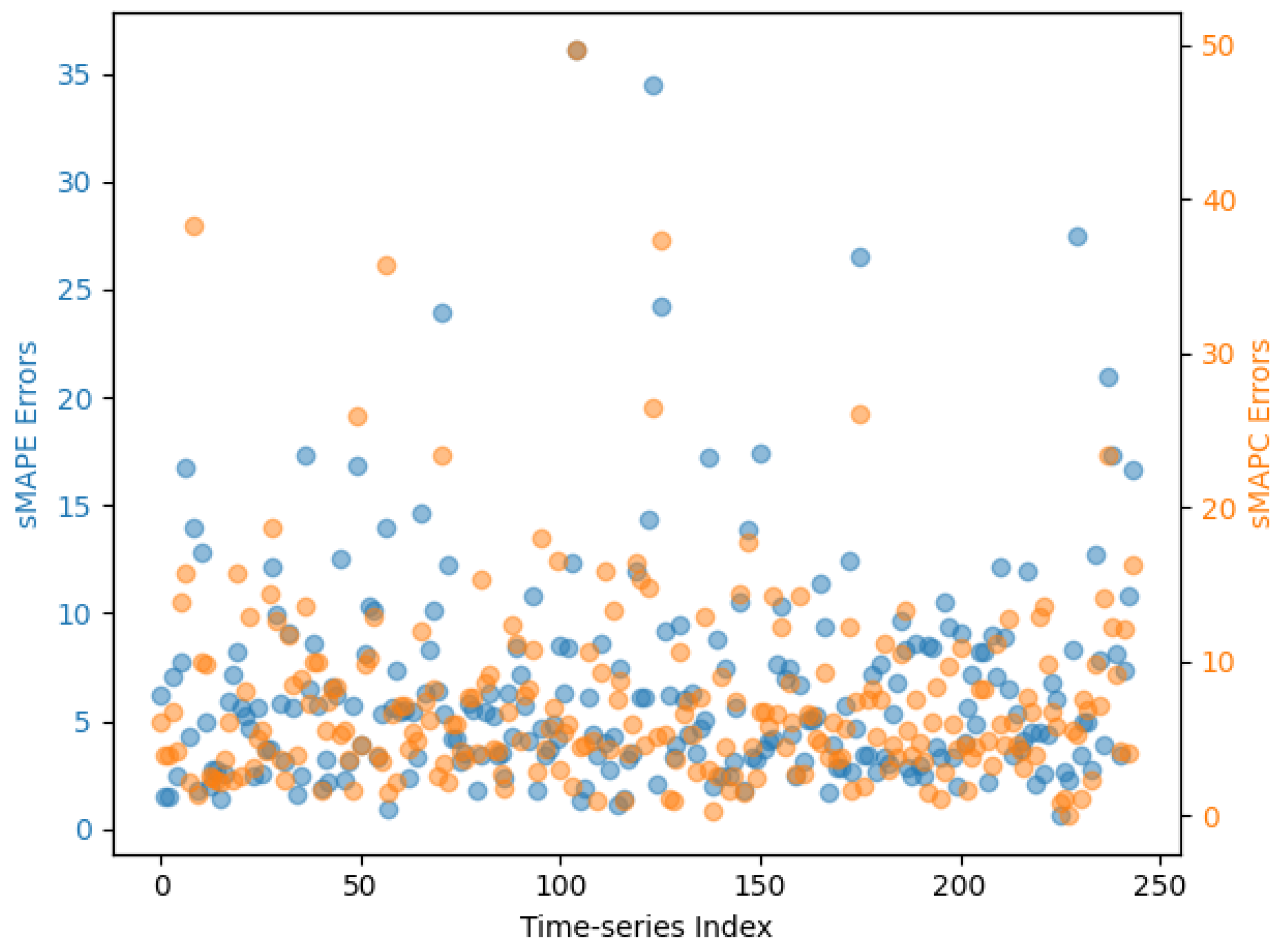
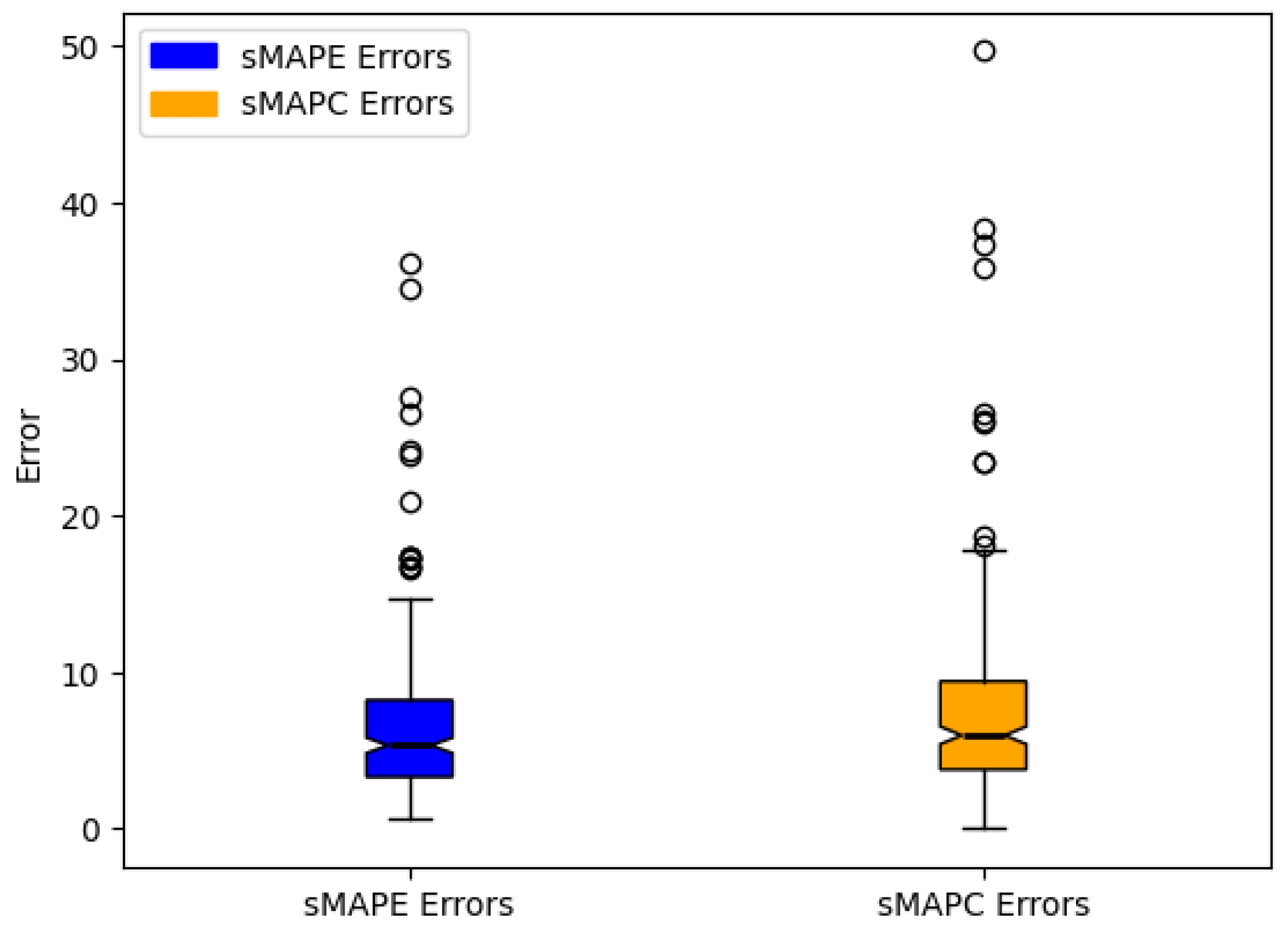
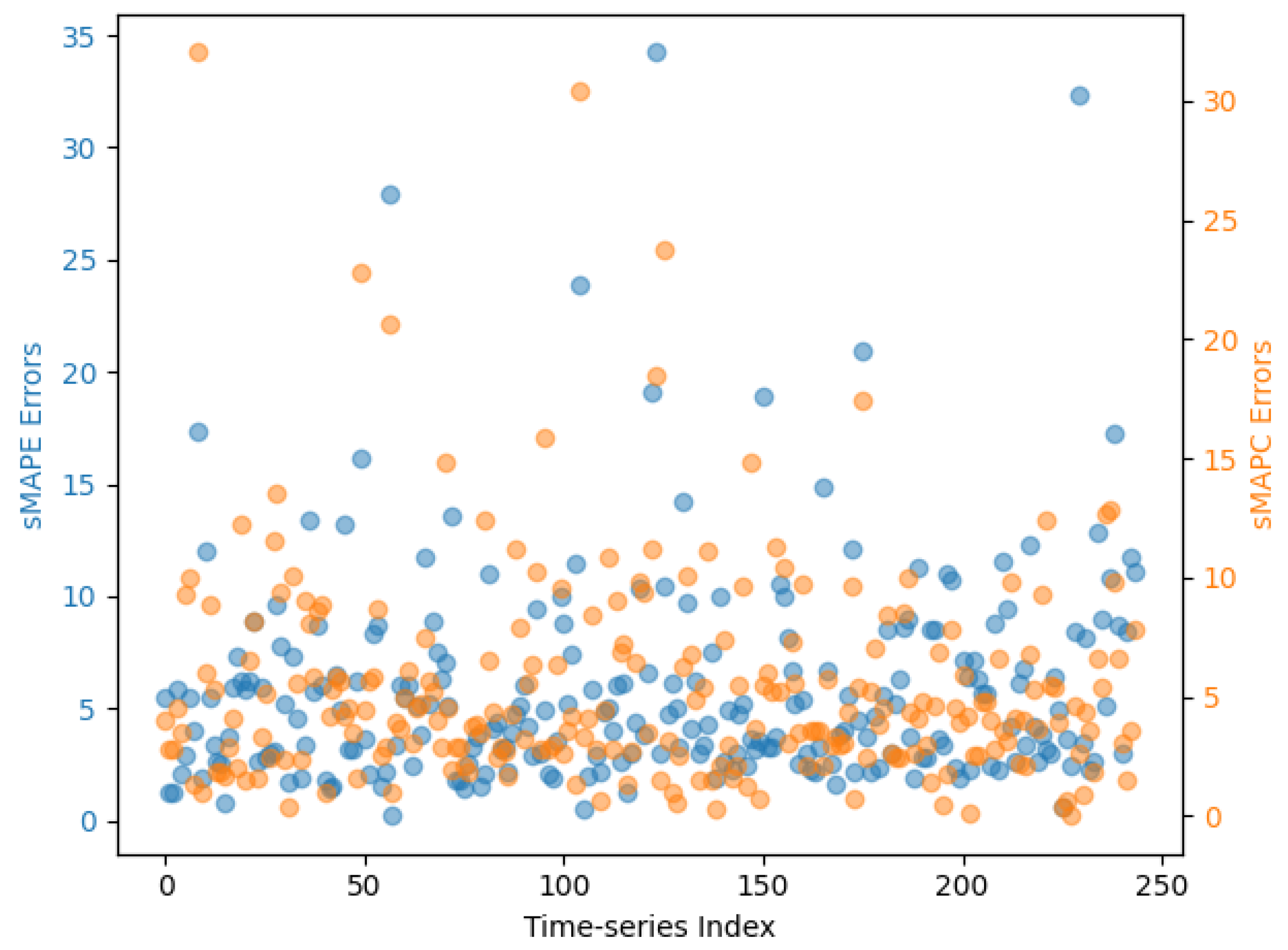
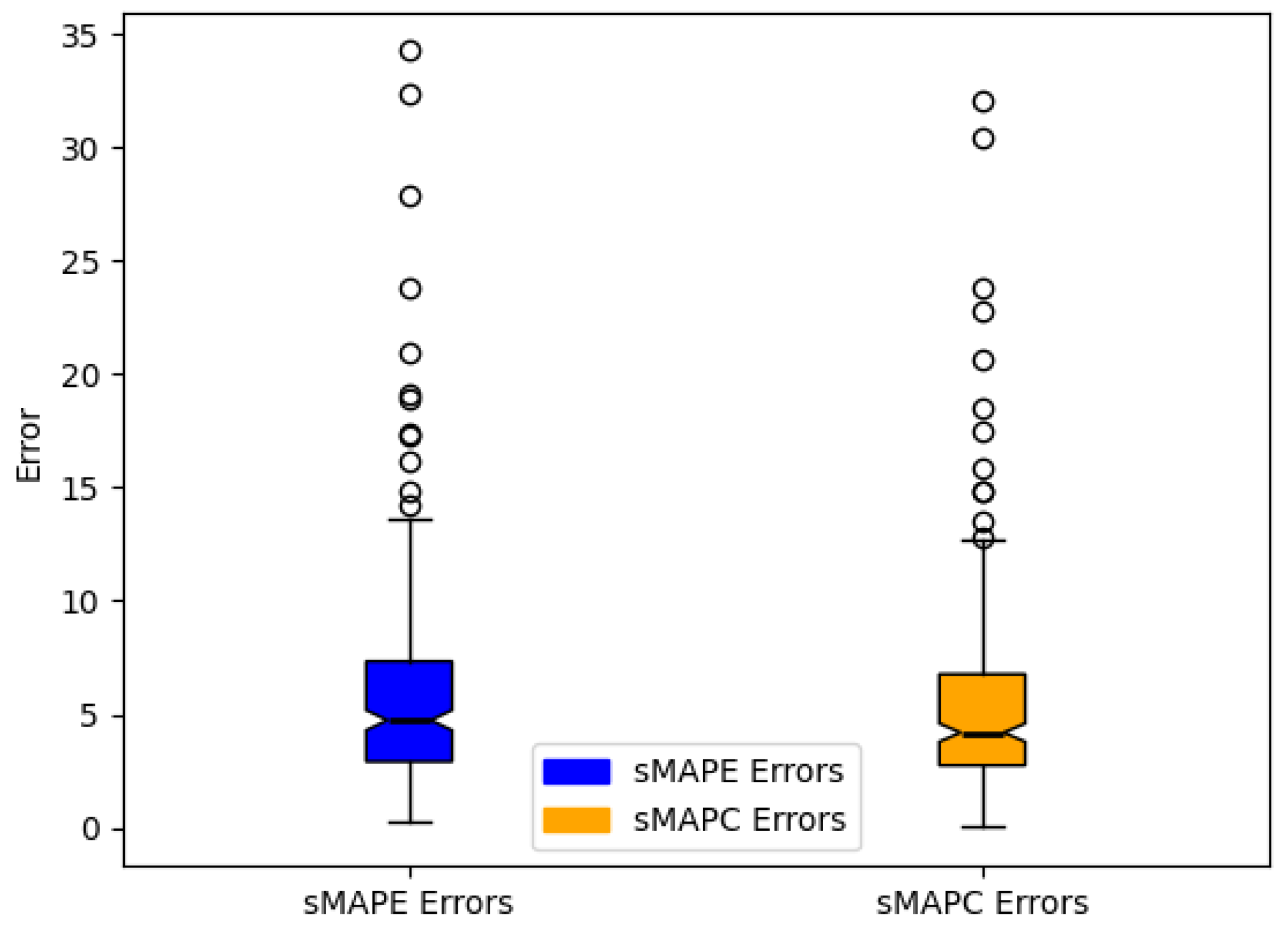
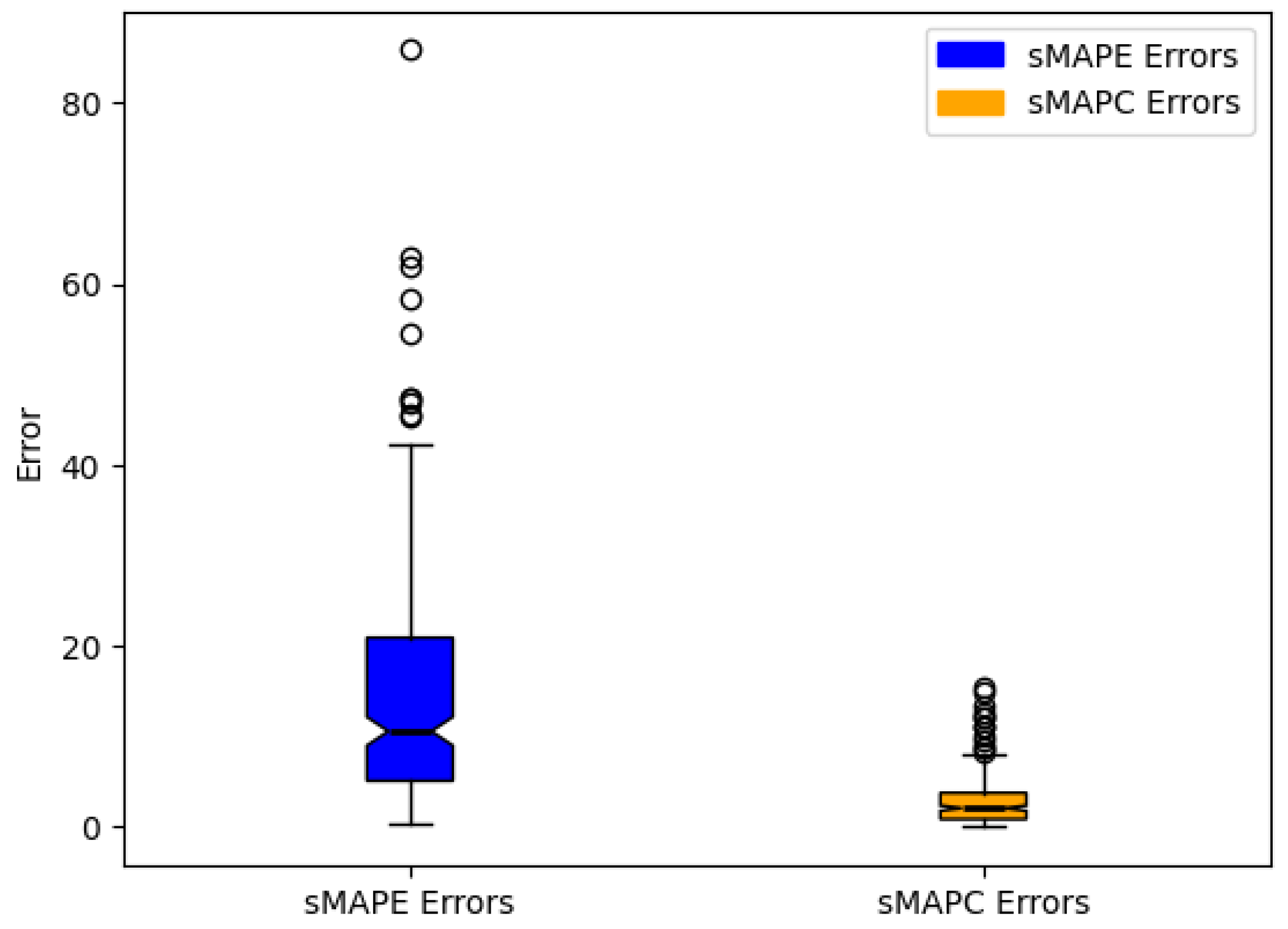
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eiglsperger, J.; Haselbeck, F.; Grimm, D.G. Foretis: A comprehensive time series forecasting framework in python. Mach. Learn. Appl. 2023, 12, 100467. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An experimental review on deep learning architectures for time series forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef]
- Steele, D.C. The nervous MRP system: How to do battle. Prod. Inventory Manag. 1975, 16, 83–89. [Google Scholar]
- Van Belle, J.; Crevits, R.; Verbeke, W. Improving forecast stability using deep learning. Int. J. Forecast. 2023, 39, 1333–1350. [Google Scholar] [CrossRef]
- Global Carbon Project. Global Carbon Budget (2024)—Annual CO2 Emissions. Processed by Our World in Data. 2024. Available online: https://www.globalcarbonproject.org/ (accessed on 1 May 2025).
- Alsharkawi, A. Improving Stability in Univariate Time Series Forecasting Using Multi-Layer Perceptron Neural Network. Master’s Thesis, KU Leuven, Faculty of Engineering Technology, Leuven, Belgium, 2023. [Google Scholar]
- Makridakis, S.; Hibon, M. The m3-competition: Results, conclusions and implications. Int. J. Forecast. 2000, 16, 451–476. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The m4 competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Dengerud, E.O. Global Models for Time Series Forecasting with Applications to Zero-Shot Forecasting. Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2021. [Google Scholar]
- Januschowski, T.; Kolassa, S. A classification of business forecasting problems. In Business Forecasting: The Emerging Role of Artificial Intelligence and Machine Learning; John Wiley & Sons: Hoboken, NJ, USA, 2021; p. 171. [Google Scholar]
- Akan, T. Forecasting the future of carbon emissions by business confidence. Appl. Energy 2025, 382, 125146. [Google Scholar] [CrossRef]
- Han, T.T.T.; Lin, C.Y. Exploring long-run CO2 emission patterns and the environmental kuznets curve with machine learning methods. Innov. Green Dev. 2025, 4, 100195. [Google Scholar] [CrossRef]
- Jha, R.; Jha, R.; Islam, M. Forecasting us data center CO2 emissions using ai models: Emissions reduction strategies and policy recommendations. Front. Sustain. 2025, 5, 1507030. [Google Scholar] [CrossRef]
- Zhong, W.; Zhai, D.; Xu, W.; Gong, W.; Yan, C.; Zhang, Y.; Qi, L. Accurate and efficient daily carbon emission forecasting based on improved arima. Appl. Energy 2024, 376, 124232. [Google Scholar] [CrossRef]
- Wu, B.; Zeng, H.; Wang, Z.; Wang, L. Interpretable short-term carbon dioxide emissions forecasting based on flexible two-stage decomposition and temporal fusion transformers. Appl. Soft Comput. 2024, 159, 111639. [Google Scholar] [CrossRef]
- Nguyen, V.G.; Duong, X.Q.; Nguyen, L.H.; Nguyen, P.Q.P.; Priya, J.C.; Truong, T.H.; Le, H.C.; Pham, N.D.K.; Nguyen, X.P. An extensive investigation on leveraging machine learning techniques for high-precision predictive modeling of CO2 emission. Energy Sources Part A Recover. Util. Environ. Eff. 2023, 45, 9149–9177. [Google Scholar]
- Hu, Y.; Wang, B.; Yang, Y.; Yang, L. An enhanced particle swarm optimization long short-term memory network hybrid model for predicting residential daily CO2 emissions. Sustainability 2024, 16, 8790. [Google Scholar] [CrossRef]
- Ding, S.; Zhang, H. Forecasting chinese provincial CO2 emissions: A universal and robust new-information-based grey model. Energy Econ. 2023, 121, 106685. [Google Scholar] [CrossRef]
- Ding, S.; Shen, X.; Zhang, H.; Cai, Z.; Wang, Y. An innovative data-feature-driven approach for CO2 emission predictive analytics: A perspective from seasonality and nonlinearity characteristics. Comput. Ind. Eng. 2024, 192, 110195. [Google Scholar] [CrossRef]
- An, Y.; Dang, Y.; Wang, J.; Zhou, H.; Mai, S.T. Mixed-frequency data sampling grey system model: Forecasting annual CO2 emissions in China with quarterly and monthly economic-energy indicators. Appl. Energy 2024, 370, 123531. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, B.; Yang, Y.; Yang, L. A novel approach for predicting CO2 emissions in the building industry using a hybrid multi-strategy improved particle swarm optimization–long short-term memory model. Energies 2024, 17, 4379. [Google Scholar] [CrossRef]
- Adegboye, O.R.; Ülker, E.D.; Feda, A.K.; Agyekum, E.B.; Mbasso, W.F.; Kamel, S. Enhanced multi-layer perceptron for CO2 emission prediction with worst moth disrupted moth fly optimization (wmfo). Heliyon 2024, 10, e31850. [Google Scholar] [CrossRef] [PubMed]
- Ajala, A.A.; Adeoye, O.L.; Salami, O.M.; Jimoh, A.Y. An examination of daily CO2 emissions prediction through a comparative analysis of machine learning, deep learning, and statistical models. Environ. Sci. Pollut. Res. 2025, 32, 2510–2535. [Google Scholar] [CrossRef]
- Zhou, Z.; Yu, L.; Wang, Y.; Tian, Y.; Li, X. Innovative approach to daily carbon dioxide emission forecast based on ensemble of quantile regression and attention bilstm. J. Clean. Prod. 2024, 460, 142605. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Z.; Liu, S. Enhance carbon emission prediction using bidirectional long short-term memory model based on text-based and data-driven multimodal information fusion. J. Clean. Prod. 2024, 471, 143301. [Google Scholar] [CrossRef]
- Filelis-Papadopoulos, C.K.; Kirshner, S.N.; O’Reilly, P. Sustainability with limited data: A novel predictive analytics approach for forecasting CO2 emissions. Inf. Syst. Front. 2024, 27, 1227–1251. [Google Scholar] [CrossRef]
- Mekouar, Y.; Saleh, I.; Karim, M. Greennav: Spatiotemporal prediction of CO2 emissions in paris road traffic using a hybrid cnn-lstm model. Network 2025, 5, 2. [Google Scholar] [CrossRef]
- Yuan, H.; Ma, X.; Ma, M.; Ma, J. Hybrid framework combining grey system model with gaussian process and stl for CO2 emissions forecasting in developed countries. Appl. Energy 2024, 360, 122824. [Google Scholar] [CrossRef]
- Sapnken, F.E.; Hong, K.R.; Noume, H.C.; Tamba, J.G. A grey prediction model optimized by meta-heuristic algorithms and its application in forecasting carbon emissions from road fuel combustion. Energy 2024, 302, 131922. [Google Scholar] [CrossRef]
- Zhu, P.; Zhang, H.; Shi, Y.; Xie, W.; Pang, M.; Shi, Y. A novel discrete conformable fractional grey system model for forecasting carbon dioxide emissions. Environ. Dev. Sustain. 2025, 27, 13581–13609. [Google Scholar] [CrossRef]
- Xie, Y.; Liu, L.; Han, Z.; Zhang, J. Mscl-attention: A multi-scale convolutional long short-term memory (lstm) attention network for predicting CO2 emissions from vehicles. Sustainability 2024, 16, 8547. [Google Scholar] [CrossRef]
- Wang, H.; Wei, Z.; Fang, T.; Xie, Q.; Li, R.; Fang, D. Carbon emissions prediction based on the giowa combination forecasting model: A case study of China. J. Clean. Prod. 2024, 445, 141340. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, X.; Zhu, W.; Yin, Y.; Bi, J.; Gui, R. Forecasting carbon dioxide emissions in chongming: A novel hybrid forecasting model coupling gray correlation analysis and deep learning method. Environ. Monit. Assess. 2024, 196, 941. [Google Scholar] [CrossRef] [PubMed]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts, 2018. [Google Scholar]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Chollet, F.; Others. Keras. 2015. Available online: https://keras.io (accessed on 1 May 2025).
- GitHub Repository. Available online: https://github.com/keras-team/keras (accessed on 1 May 2025).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Params |
|---|---|---|
| Input Layer (Input) | (None, 10) | 0 |
| Dense 1 (ReLU) | (None, 64) | 704 |
| Dense 2 (ReLU) | (None, 32) | 2080 |
| Dense 3 (ReLU) | (None, 16) | 528 |
| Output Layer (Linear) | (None, 2) | 34 |
| Statistic | Value | Description |
|---|---|---|
| No. of series | 244 | Distinct country/region time series |
| Min. length | 20 | Fewest non-zero annual records |
| Max. length | 274 | Most consecutive non-zero annual records |
| Mean length | 114.8 | Average series length |
| Std. dev. length | 57.2 | Variability in series lengths |
| sMAPE | sMAPC | |||||
|---|---|---|---|---|---|---|
| Mean | Std. dev. | Median | Mean | Std. dev. | Median | |
| GMS-MLP | 6.55 | 5.16 | 5.33 | 7.57 | 6.41 | 5.97 |
| EMS-MLP | 5.92 | 4.80 | 4.73 | 5.46 | 4.52 | 4.19 |
| AFS | 14.49 | 12.96 | 10.58 | 2.85 | 2.83 | 2.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsharkawi, A.; Al-Sherqawi, E.; Khandakji, K.; Al-Yaman, M. Advanced Global CO2 Emissions Forecasting: Enhancing Accuracy and Stability Across Diverse Regions. Sustainability 2025, 17, 6893. https://doi.org/10.3390/su17156893
Alsharkawi A, Al-Sherqawi E, Khandakji K, Al-Yaman M. Advanced Global CO2 Emissions Forecasting: Enhancing Accuracy and Stability Across Diverse Regions. Sustainability. 2025; 17(15):6893. https://doi.org/10.3390/su17156893
Chicago/Turabian StyleAlsharkawi, Adham, Emran Al-Sherqawi, Kamal Khandakji, and Musa Al-Yaman. 2025. "Advanced Global CO2 Emissions Forecasting: Enhancing Accuracy and Stability Across Diverse Regions" Sustainability 17, no. 15: 6893. https://doi.org/10.3390/su17156893
APA StyleAlsharkawi, A., Al-Sherqawi, E., Khandakji, K., & Al-Yaman, M. (2025). Advanced Global CO2 Emissions Forecasting: Enhancing Accuracy and Stability Across Diverse Regions. Sustainability, 17(15), 6893. https://doi.org/10.3390/su17156893