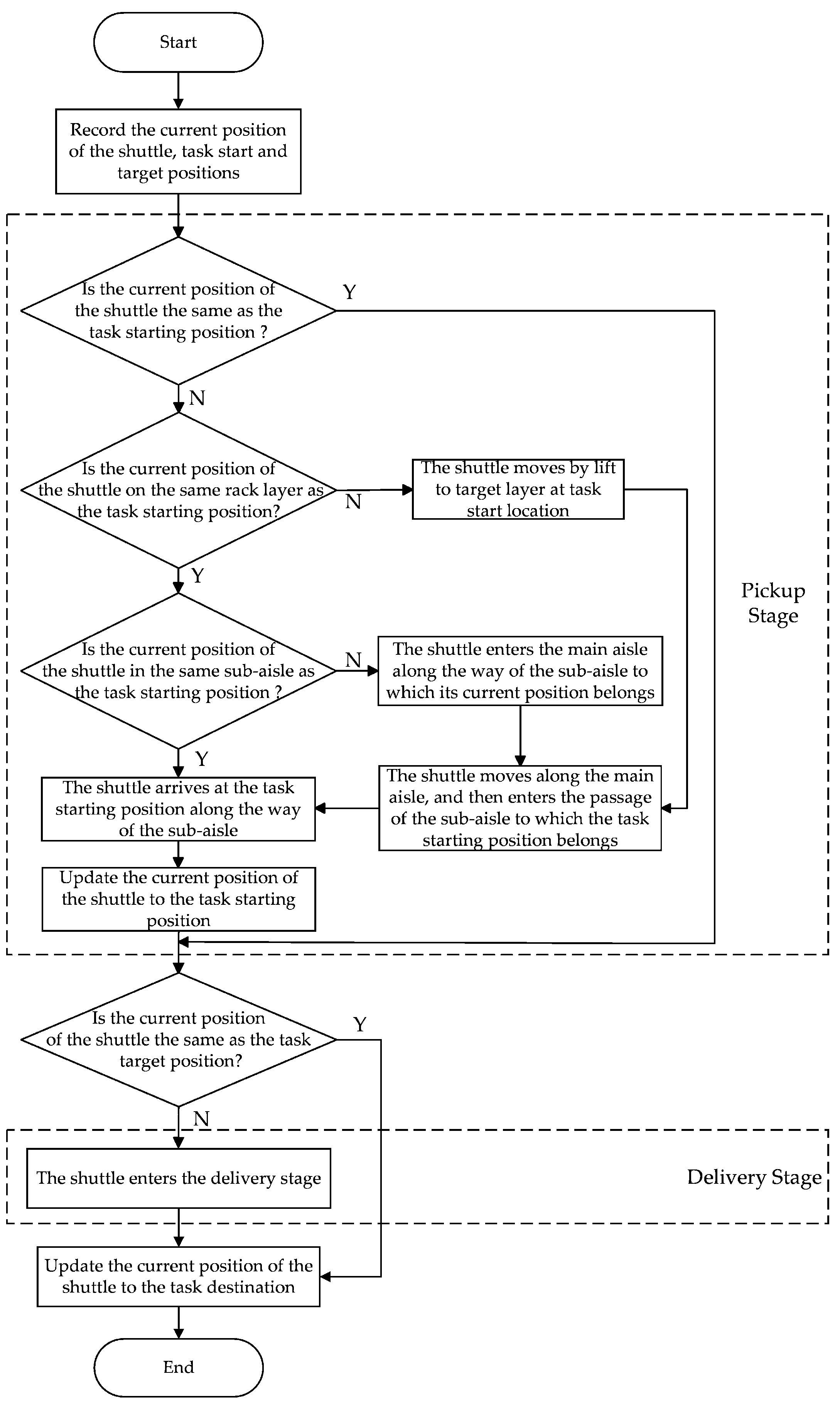
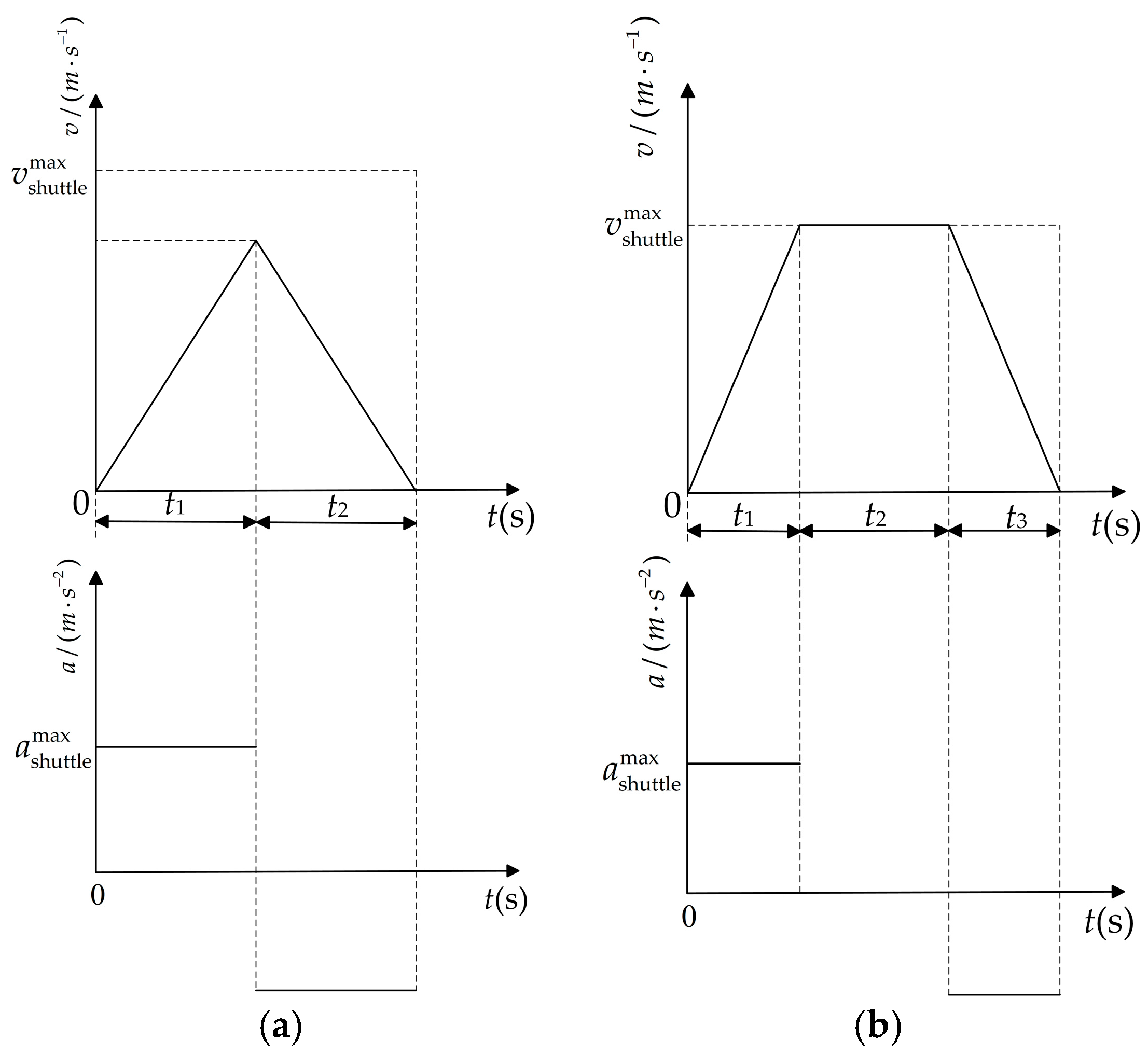
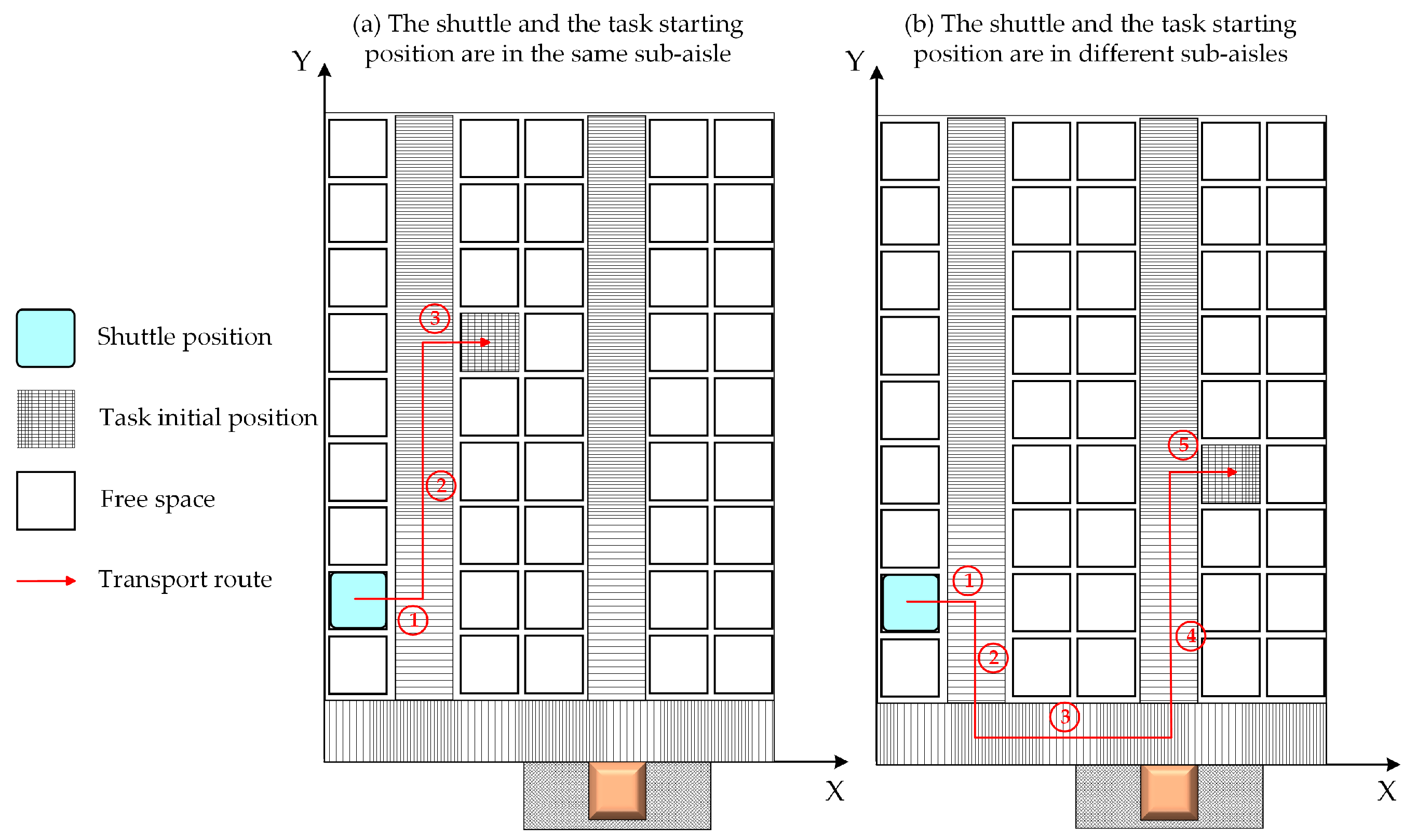
To verify the effectiveness of the proposed method, an experimental study is conducted. In the three-dimensional storage scenario from an enterprise, the IDQN applied in this study is compared with two representative task allocation methods in the existing research, i.e., the auction algorithm and the GA. Furthermore, the performance of these algorithms under different task volumes and transport resource configurations is analyzed to prove the advantages of the proposed method.
The proposed IDQN algorithm is implemented using the Python 3.8.5 language and Pytorch 2.1.0 framework on an HP PC configured with Intel(R) Core(TM) i9-9900K CPU@ 3.60 GHz, 32.0 GB RAM, and Windows 11 OS. The performance of the IDQN algorithm depends on its hyperparameters. The discount rate dictates the extent to which future returns affect current decisions. A higher discount rate, close to 1, places greater emphasis on long-term returns, whereas a lower discount rate, close to 0, prioritizes immediate rewards. From the nature of the scheduling problem, this study initially opts for a higher discount rate to facilitate the rational allocation of transportation resources over an extended period and thereby maximize overall benefits. The learning rate determines the step size of parameter updates. An excessively low learning rate results in slow algorithm convergence, while a learning rate that is too high leads to algorithm instability. Hence, it is crucial to set the learning rate appropriately to obtain high-quality solutions within the given computation time. Meanwhile, the
ε-greedy strategy is employed to balance exploration and exploitation. During training,
ε decays at a specific rate from its initial value, which enables more exploration in the early training stages to fully comprehend the environment, and gradually reduces exploration in the later stages, focusing more on utilizing the best strategies learned. The capacity of the experience replay pool affects the effectiveness of model training. A larger capacity increases computational cost, while a smaller capacity prevents the model from utilizing historical experiences for learning. Therefore, the capacity of the experience replay pool should be set to maintain the diversity of the training process while ensuring model convergence and stability. As for the update frequency of the target network, its setting is mainly based on stabilizing the learning process and improving training efficiency. According to the IDQN hyperparameter setting principles summarized in reference [
35] and our experience, the IDQN parameter settings are listed in
Table 3.
5.1. Experiment 1
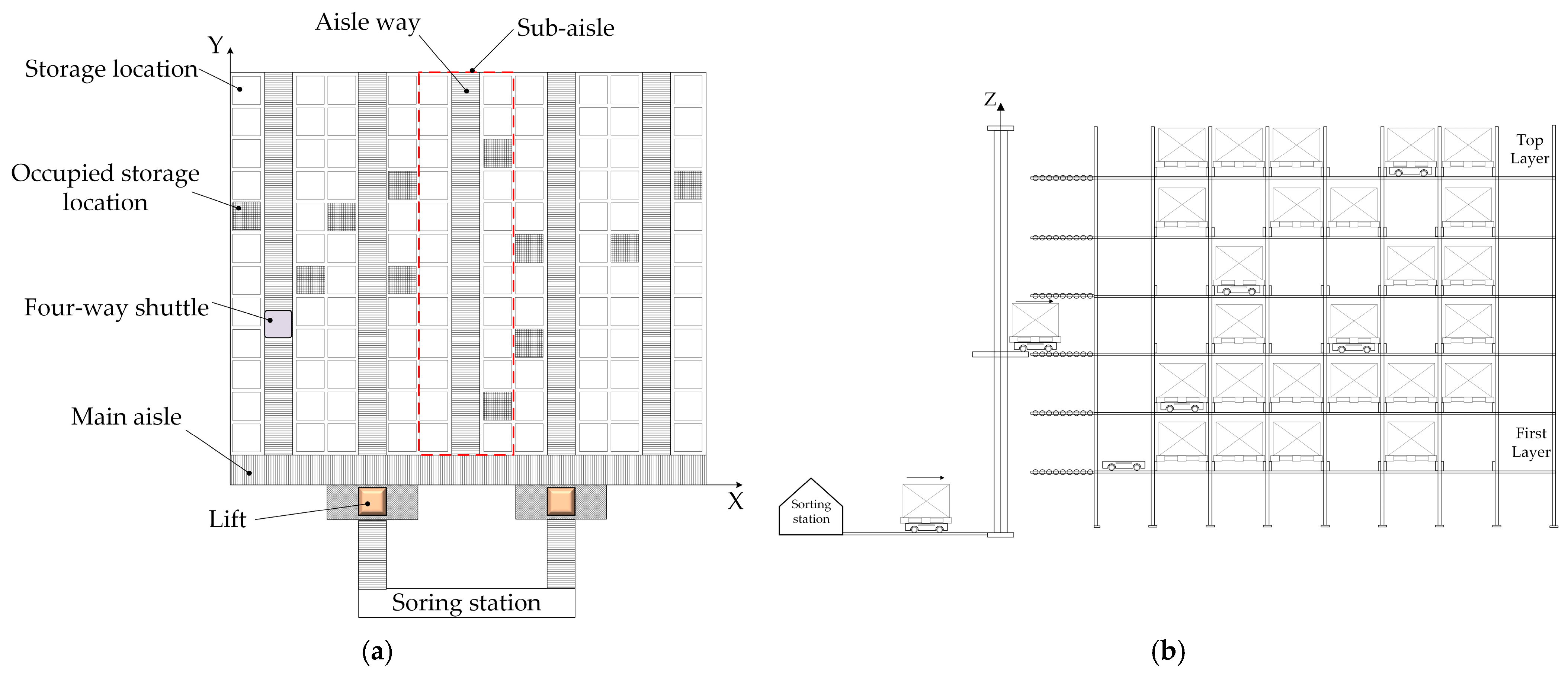
The scenario of Experiment 1 originates from an FWSS/RS of a packaging company, as depicted in
Figure 1. Combined with the symbols defined to describe the FWSS/RS task allocation problem, the information related to material handling resources and the warehouse environment is presented in
Table 4. Experiment 1 involves three four-way shuttles, two lifts, and 40 material handling tasks. Specifically, the number of inbound tasks is equal to that of the outbound tasks. To facilitate distinguishing tasks with different attributes, the indices of the inbound tasks are defined as 1–20, while those of the outbound tasks are defined as 21–40. The destinations of the inbound tasks and the starting locations of the outbound tasks are shown in
Table 5. Moreover, when the tasks were assigned simultaneously, all shuttles were located at the sorting station. Correspondingly, based on material handling resources and task information, the settings of estimation and target networks are shown in
Table 6.
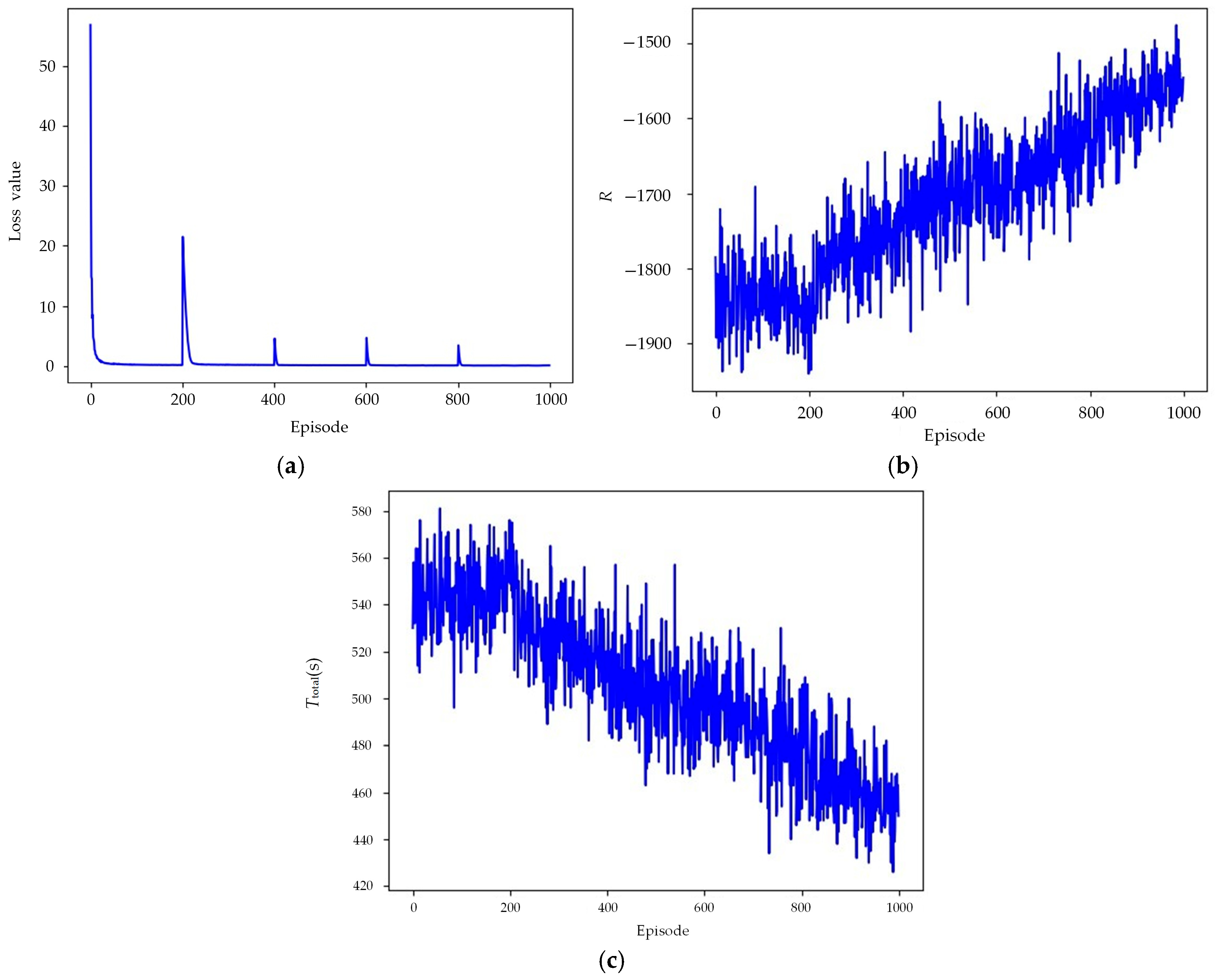
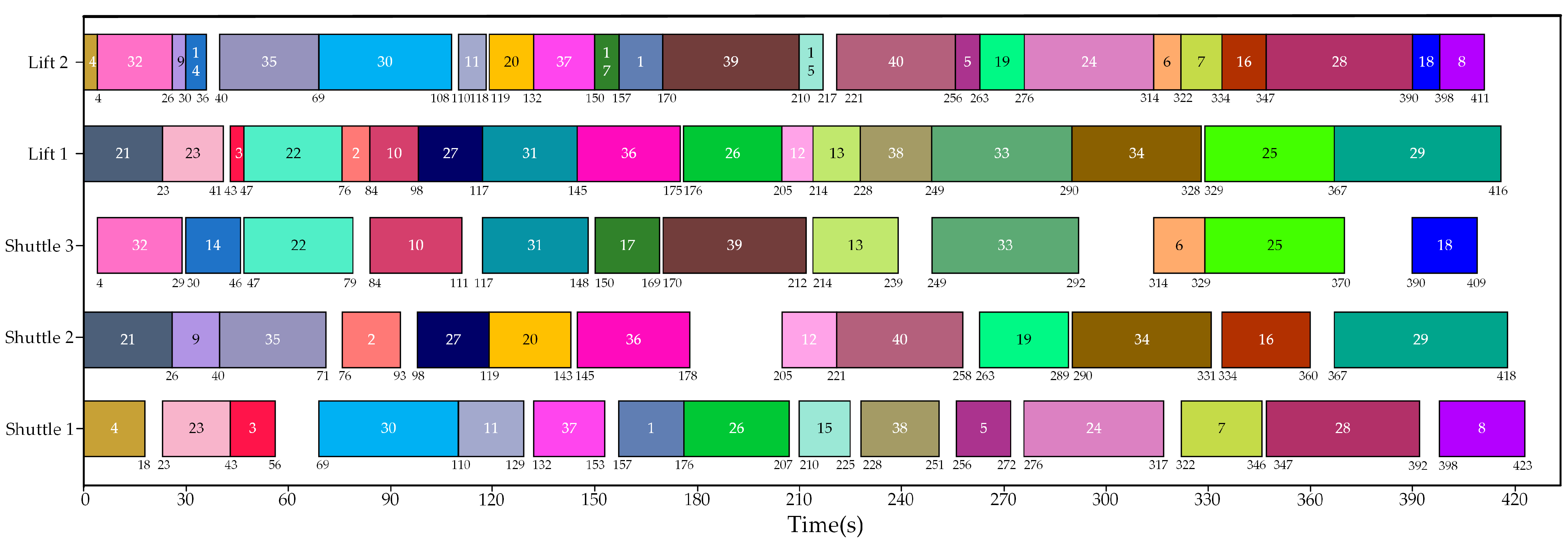
Figure 8 shows the changes in the loss function, reward, and optimization objective during the IDQN training process. It can be observed that as the training proceeds, the IDQN algorithm tends to converge. Correspondingly, the optimal result of task allocation can be presented in the form of a Gantt chart, as depicted in
Figure 9.
Moreover, to verify the effectiveness of the IDQN method utilized in this study, the optimal task allocation results obtained by the IDQN were compared with those obtained by two representative task allocation methods, the auction algorithm and the GA. The auction algorithm, which mimics market auction mechanisms for task allocation, offers notable problem-solving efficiency and scalability. It comprises four key components: participants, auction items, profit functions, and bidding strategies. Based on the classic auction algorithm [
36] and the characteristics of the task allocation problem in this study, the auction algorithm that integrates a two-stage auction mechanism was used to allocate tasks listed in
Table 5, and its workflow is illustrated in
Figure 10. The first round of bidding is to match a suitable shuttle for the task, and the second round of bidding is to determine the best lift that can collaborate with the selected shuttle to perform the task. Correspondingly,
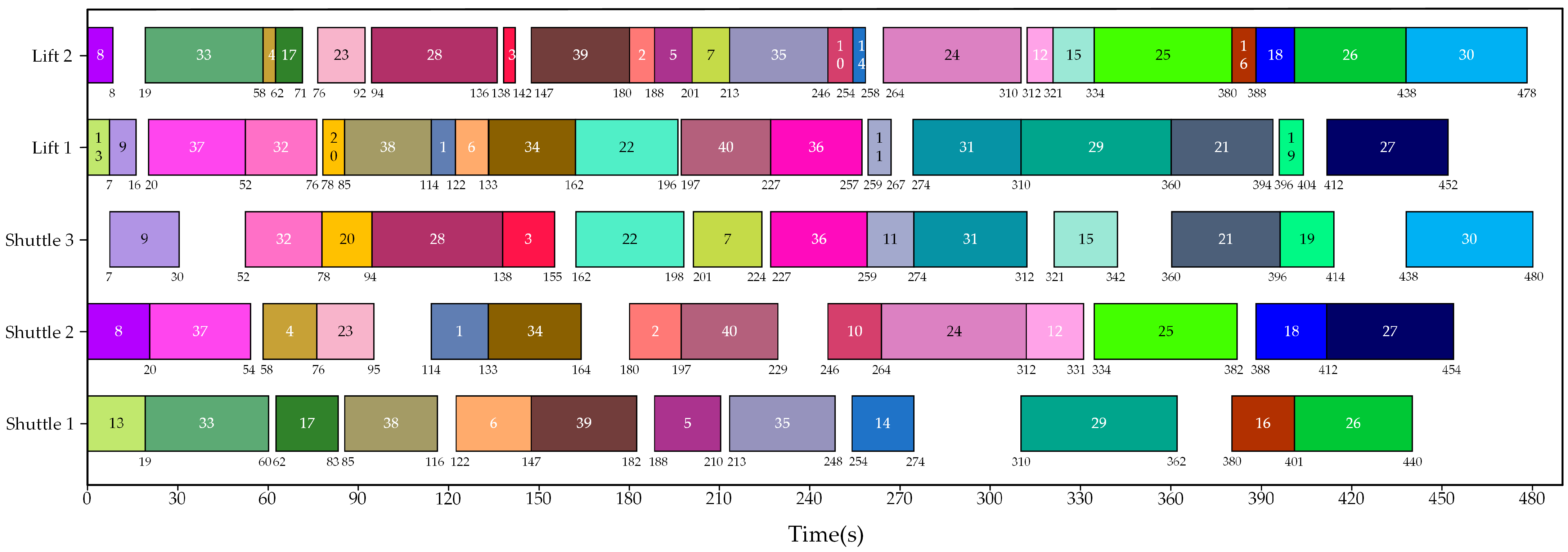
Figure 11 presents an optimal task allocation result obtained by running the auction algorithm five times.
In addition, the FWSS/RS task allocation problem was solved by the GA, and the key steps were designed as follows.
- (1)
Encoding scheme: According to the nature of the FWSS/RS task allocation problem, the chromosome of an individual representing a feasible problem solution is encoded in a hierarchical manner, and its length is equal to the total number of tasks to be executed. The first layer, named the task layer, records the task information; the second layer, named the shuttle layer, records the shuttle resources applied for executing tasks; the third layer, named the lift layer, records the lifts that cooperate with the shuttles to perform tasks. A single gene on the chromosome can be represented in the form of (i, j, l), which means that for task i, shuttle j is responsible for its horizontal transport, and lift l is responsible for its vertical transport.
- (2)
Decoding scheme: Decoding is to obtain the values of the decision variables in the model and calculate the values of the optimization objective, thereby evaluating the fitness of an individual. Here, the fitness function is defined as Formula (13). If all tasks are issued at time t and both the shuttle and lift resources are available at that moment, then the initial values of and are both set to t. The following are the specific steps for decoding an individual.
Step 1: Scan the chromosome genes from left to right to extract the shuttle and elevator selected to execute the task related to each gene and determine the tasks and sequence to be executed by each shuttle and each lift. Accordingly, based on the individual encoding scheme, the values of the decision variables Xij and Xil can be determined.
Step 2: Extract each gene from left to right and determine the starting time of each task () associated with each gene. Taking the gene (i, j, l) as an example, the execution of task i requires the invocation of shuttle j and lift l. If the tasks executed by shuttle j and lift l adjacent before task i are task i′ and task i″, respectively, then according to research assumption (8), , and . Consequently, can be determined, and .
Step 3: Based on the position information of the shuttle and the lift, as well as the starting and destination positions of task i, calculate the completion time of task i () using Formulas (10)–(12).
Step 4: After the completion of task i, shuttle j and lift l stay at the target position and the target floor of task i, respectively. Record and update the position information of shuttle j and lift l.
Step 5: Repeat steps (2) to (4) until all genes have been decoded. Then, Ttotal can be determined based on the decoded and Formula (13).
- (3)
Population initialization scheme: According to the individual encoding scheme, during the initialization of the population, the individual chromosome is initialized layer by layer. First, the real numbers representing tasks are randomly distributed across the gene loci on the first layer of the individual chromosome. Then, a shuttle and a lift are randomly selected for each task from left to right, and the indices of the selected shuttle and lift are assigned to the corresponding gene loci in the shuttle layer and lift layer, respectively.
- (4)
Selection operation: In addition to the roulette wheel selection strategy, the elitist retention strategy is also employed, i.e., the best individual in the current population is preserved for the next generation during the evolution process.
- (5)
Crossover operation: The commonly used two-point crossover operator [
37] is employed. According to the encoding scheme, illegal offspring will not be generated after crossover, but the values of the decision variables
Xij and
Xij will be changed accordingly.
- (6)
Mutation operation: Due to the layered coding of individual chromosomes, three mutation operators are designed: ① randomly select two gene loci and swap the genes on the task layer to alter the task execution order; ② randomly select a gene locus and change the gene on the shuttle layer to alter the shuttle resource for executing the task; and ③ randomly select a gene locus and change the gene on the lift layer to change the lift resource for executing the task. The values of the decision variables Xij and/or Xij will be changed according to the selected crossover operator.
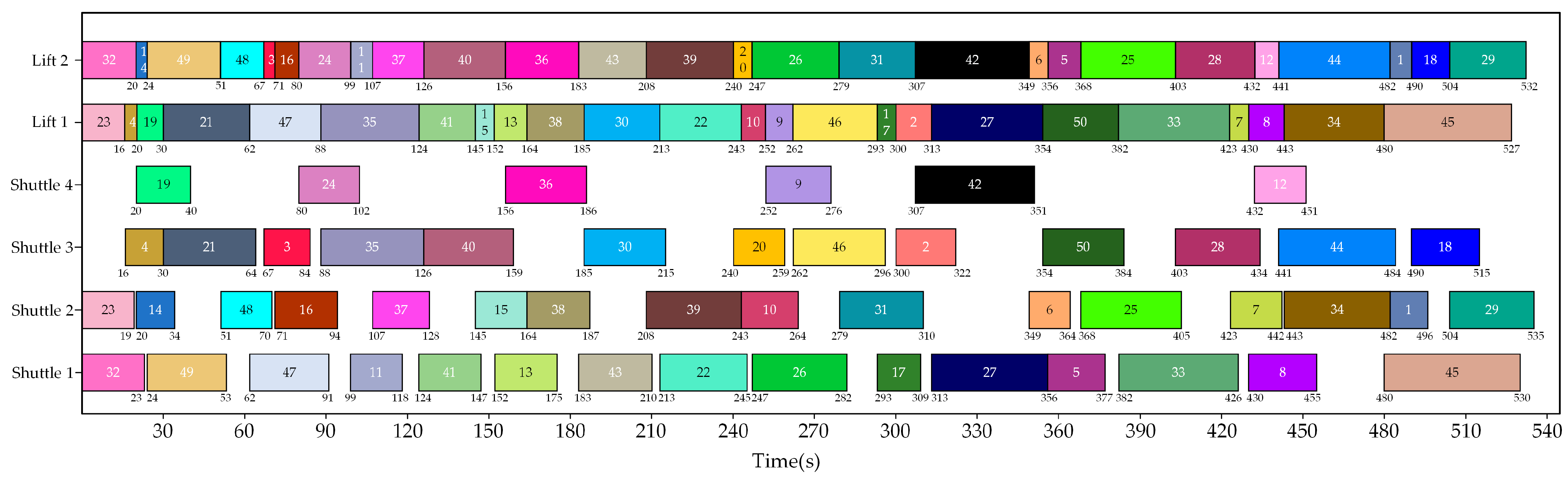
As for the basic GA parameters, the crossover probability, the mutation probability, the population size, and the maximum number of iterations were set to 0.8, 0.1, 50, and 500, respectively. After running the GA five times, an optimal task allocation scheme was obtained, as presented in
Figure 12.
5.2. Experiment 2
Experiment 1 verified the convergence and effectiveness of the MARL method adopted for solving the FWSS/RS task allocation problem. In Experiment 2, the scenario in Experiment 1 was extended, and the performance of different algorithms in handling tasks of various scales and transport resource configurations was compared. The experimental design parameters were selected as the number of shuttles, lifts, inbound tasks, and outbound tasks, with each parameter set at three levels. Accordingly, an L9(3
4) orthogonal experiment was performed, and the level values of each factor, sorted in ascending order, corresponded to level indices 1, 2, and 3, respectively. Note that, to evaluate the impact of task categories on algorithm performance and maintain consistency with the parameter level settings of the orthogonal experiment, a set of inbound tasks and a set of outbound tasks were added. Then, indices 21–30 were assigned to the newly added inbound tasks. The indices of the outbound tasks in
Table 5 were updated to 31–50, while indices 51–60 were allocated to the newly added outbound tasks. Furthermore, the inbound and outbound tasks were evenly divided into three groups according to the index order, respectively. In the orthogonal experiment, when the number of inbound tasks was 10, only tasks with indices 1–10 were involved. When the inbound tasks increased to 20, tasks with indices 1–20 were involved. Similarly, for the outbound job tasks, a quantity of 10 corresponded to tasks with indices 31–40, and when the quantity was 20, it involved tasks with indices 31–50. The information about the newly added inbound and outbound tasks is shown in
Table 7. Furthermore, all shuttles were initially located at the sorting station, and the newly added lifts were still located in the same sub-aisles as the original lifts in Experiment 1.
Furthermore, based on the orthogonal experiment designed, the optimal
Ttotal achieved by running different methods with the parameter settings in Experiment 1 five times, and the improvement rate of the IDQN solution compared to two comparison algorithms are presented in
Table 8. Specifically, the minimum
Ttotal was obtained in Example 4, while the maximum
Ttotal was obtained in Example 9. Correspondingly, the optimal task allocation schemes acquired by the IDQN in such two examples are presented in
Figure 13 and
Figure 14, respectively.
In addition, two comparative experiments were conducted under the transport resource configuration of three shuttles and two lifts, and they can be referred to as Examples 10 and 11 based on the orthogonal experimental scenarios in
Table 8. Example 10 involves 10 inbound tasks and 30 outbound tasks, while Example 11 involves 30 inbound tasks and 10 outbound tasks. Accordingly, the optimal
Ttotal acquired by the IDQN corresponding to such two examples was 485 s and 461 s, respectively.
5.3. Discussion
In Experiment 1, the convergence analysis of the loss function reveals that it rapidly decreases in the early stages of training and stabilizes within a relatively short number of training steps, as shown in
Figure 8a. This can be attributed to the following key factors:
- (1)
Efficient Q-value approximation: The IDQN adopts the PER mechanism, which reduces sample correlation and improves training stability. A target network is also introduced to mitigate Q-estimation fluctuations, enabling faster convergence to a reasonable Q-estimation and accelerating the decline of the loss function.
- (2)
Gradient optimization characteristics: In DRL, the loss function minimizes TDerror between predicted and target Q-values. In early training, the large TDerror leads to bigger gradients, enabling quick adjustment of neural network parameters and a rapid decline in the loss function. As training proceeds and the error gradually shrinks, gradient updates will slow down, stabilizing the loss function.
- (3)
Value function learning and policy optimization: Unlike policy gradient methods, Q-learning-based approaches first train the value function to converge to accurate Q-estimations, then improve the policy via a greedy strategy. Although the loss function converges early, the agent’s policy continues to optimize, causing the reward function to converge more slowly.
As shown in
Figure 8, after starting the training, the loss function, reward function, and the
Ttotal all improve with the increase in the number of training episodes. It can be observed that the algorithm’s performance metrics stabilize within a certain range after 900 episodes. This indicates that the IDQN algorithm is effective for solving the proposed model. Note that the loss function oscillates every 200 steps. The reason for this phenomenon is that under the IDQN algorithm framework, the estimation network needs to assign weights to the target network after a certain number of training steps. However, the amplitude of these oscillations will decrease with the increase in training steps.
According to
Figure 9,
Figure 11 and
Figure 12, the IDQN outperforms the auction algorithm and the GA in Experiment 1. Further analysis of the optimal task allocation scheme reveals that if a shuttle, after completing an inbound task, is subsequently assigned an outbound task, it is beneficial to shorten the pickup stage time of the outbound task, thereby reducing the total task completion time (
Ttotal). Meanwhile, due to the inevitable utilization of lifts in task execution, the utilization rate of lifts reflects the superiority or inferiority of the task allocation schemes to some extent.
Table 9 presents the comparison of the optimal task allocation schemes obtained by three algorithms in
Ttotal and indicators related to transport equipment utilization.
Regardless of which method is adopted for task allocation, lifts are generally much busier than shuttles. From the perspective of individual equipment utilization, when employing the IDQN for task allocation, lift 1 achieves the highest utilization rate at 99.04%. Meanwhile, although the utilization rate of shuttle 3 is not the highest, the total equipment utilization rate is the highest due to the efficient utilization of the vast majority of transport resources. Moreover, the IDQN outperforms the other two algorithms in terms of Ttotal, which indicates that the strategies learned by the IDQN not only focus on maximizing the utilization of each piece of equipment but also on the coordination and scheduling of transport resources at the system level.
In Experiment 2, an orthogonal experiment was designed and conducted to verify whether the IDQN still had advantages in different scenarios and investigate the impact of transport resource configuration and task attributes on task allocation. It can be observed from
Table 8 that the IDQN achieves superior results compared to the other two algorithms in all nine scenarios of the orthogonal experiment. Furthermore, combined with the optimal
Ttotal obtained by the IDQN, a range analysis was conducted to identify the degree of influence of various factors on the results.
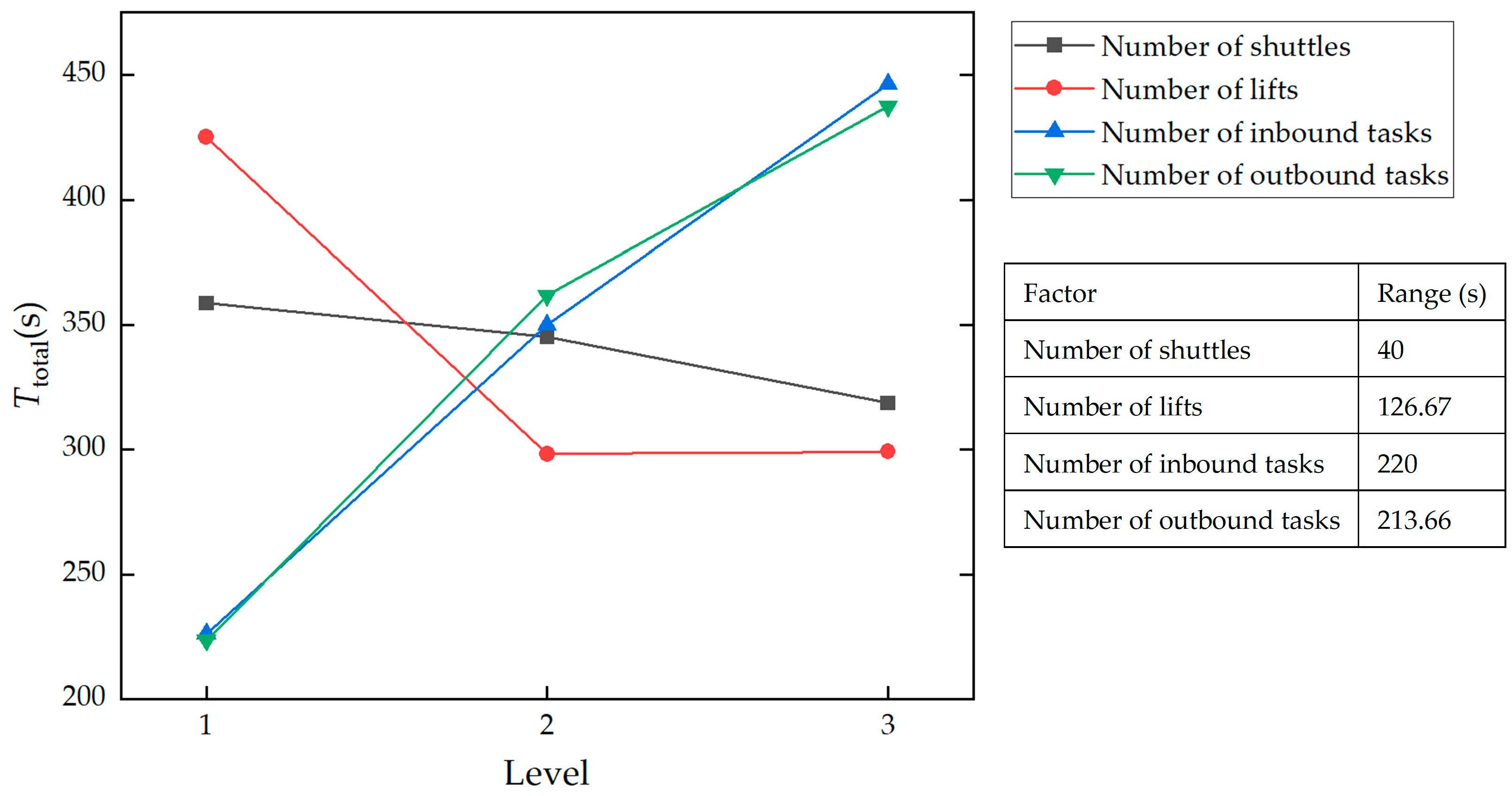
Figure 15 depicts the trend of factor levels in the orthogonal experiment.
From
Figure 15, the order of influence of various factors on the results can be derived, i.e., Number of inbound tasks > Number of outbound tasks > Number of lifts > Number of shuttles. Specifically, inbound and outbound task volumes are the core influencing factors. An increase in task volume will exacerbate the difficulty of equipment collaborative scheduling and prolong the completion time. Among transport resources, the number of lifts is more critical than that of shuttles, which is consistent with the characteristic of lifts as vertical material handling bottlenecks in warehousing systems. Both an excess and a shortage of lifts can easily induce waiting delays. The range of the number of shuttles is the smallest, and the average
Ttotal decreases with more shuttles, but the reduction is limited. This indicates that adding shuttles within the experimental scope can slightly shorten
Ttotal, but the number of shuttles is not a key control point of the warehouse system. In practical applications, shuttle deployment should be based on a cost-benefit analysis.
Furthermore, based on the orthogonal experiment data in
Table 8, an analysis of variance was conducted to identify whether different factors have a significant impact on the
Ttotal. However, in the orthogonal experiment, the initial degree of freedom of error was 0, preventing the
F-value calculation. Therefore, according to the results of the range analysis and the sum of squares of each factor, the insignificant factor, i.e., the number of shuttles, was merged to release the degrees of freedom. The variance analysis results are shown in
Table 10. If the significance level is set at 0.05, the null hypothesis can be rejected for factors related to inbound and outbound tasks. Their
p-values are both less than 0.05, thus indicating that both factors exert a statistically significant effect on the outcome. Meanwhile, for the factor related to lifts, the null hypothesis cannot be rejected as the corresponding
p-value is greater than 0.05. However, it is less than 0.1, which suggests that this factor is marginally significant at the significance level 0.1.
In addition, combining the experimental data from Experiment 1 and two comparative experiments in Experiment 2, it can be observed that the ratio of inbound tasks to outbound tasks also affects the task allocation results when transport resources and the total amount of tasks are determined. In the experimental study, all shuttles were assumed to be initially at the sorting station. When a batch of tasks with more outbound ones was issued, the pickup phase time related to outbound tasks was relatively long, resulting in a longer total task completion time. However, when the proportion of inbound and outbound tasks was balanced, after a shuttle completed an inbound task, it could immediately perform an outbound task since it had already entered the rack layer. This saved pickup time compared with the shuttle entering the rack layer from the sorting station. Similarly, when a shuttle was immediately assigned an inbound task after completing an outbound task, the execution of the inbound task directly entered the delivery stage, thus improving the efficiency of task execution. In practical applications, since hardware resources are not easily changed, it is essential to consider both task issuance volume and the proportion of different task types to fully and efficiently utilize transport equipment.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}