_Li.png)
Visitor Number Prediction for Daegwallyeong Forest Trail Using Machine Learning


Abstract
1. Introduction
2. Literature Review
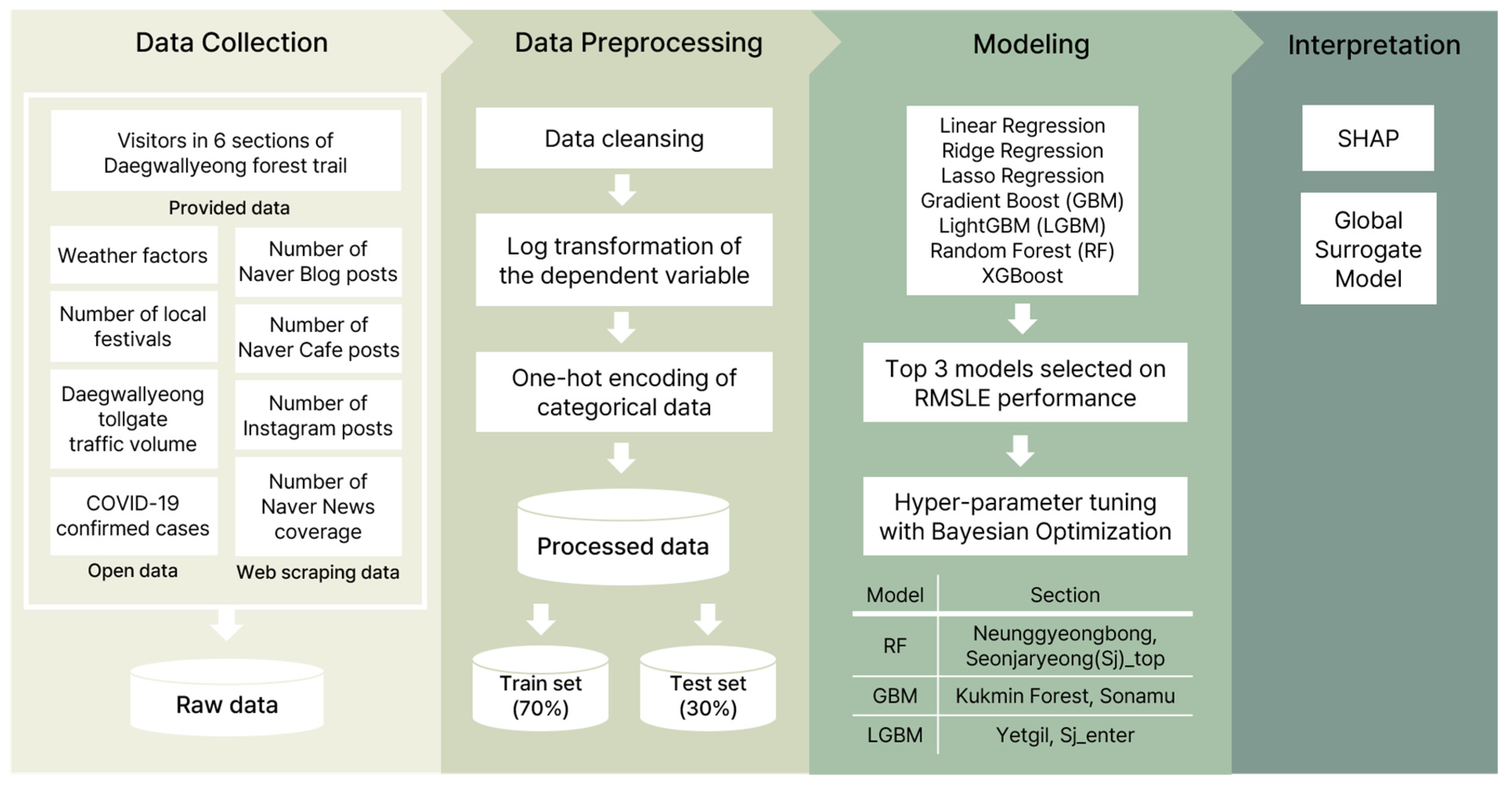
3. Materials and Methods
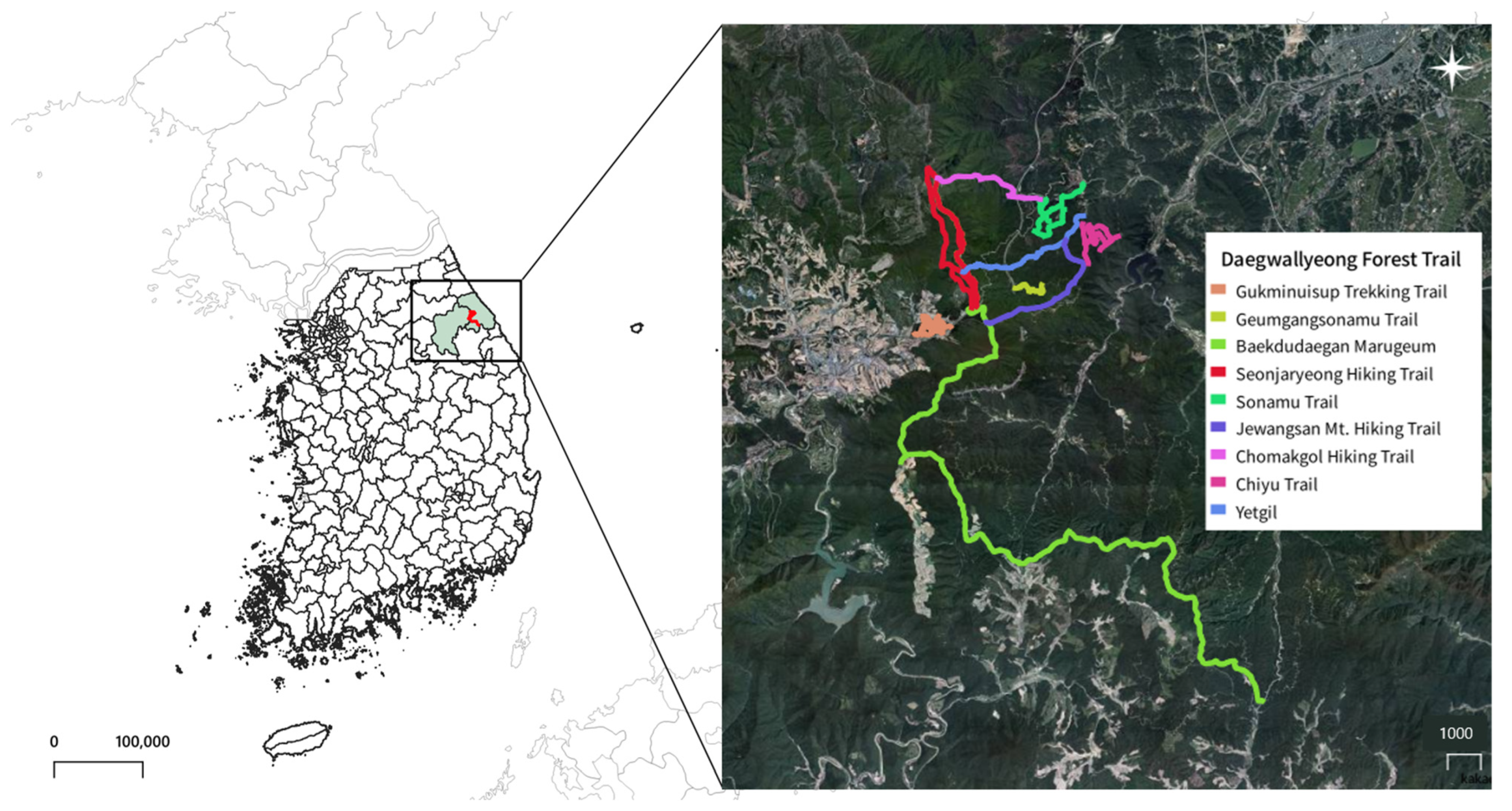
3.1. Study Area
3.2. Variable Selection
3.3. Data Collection
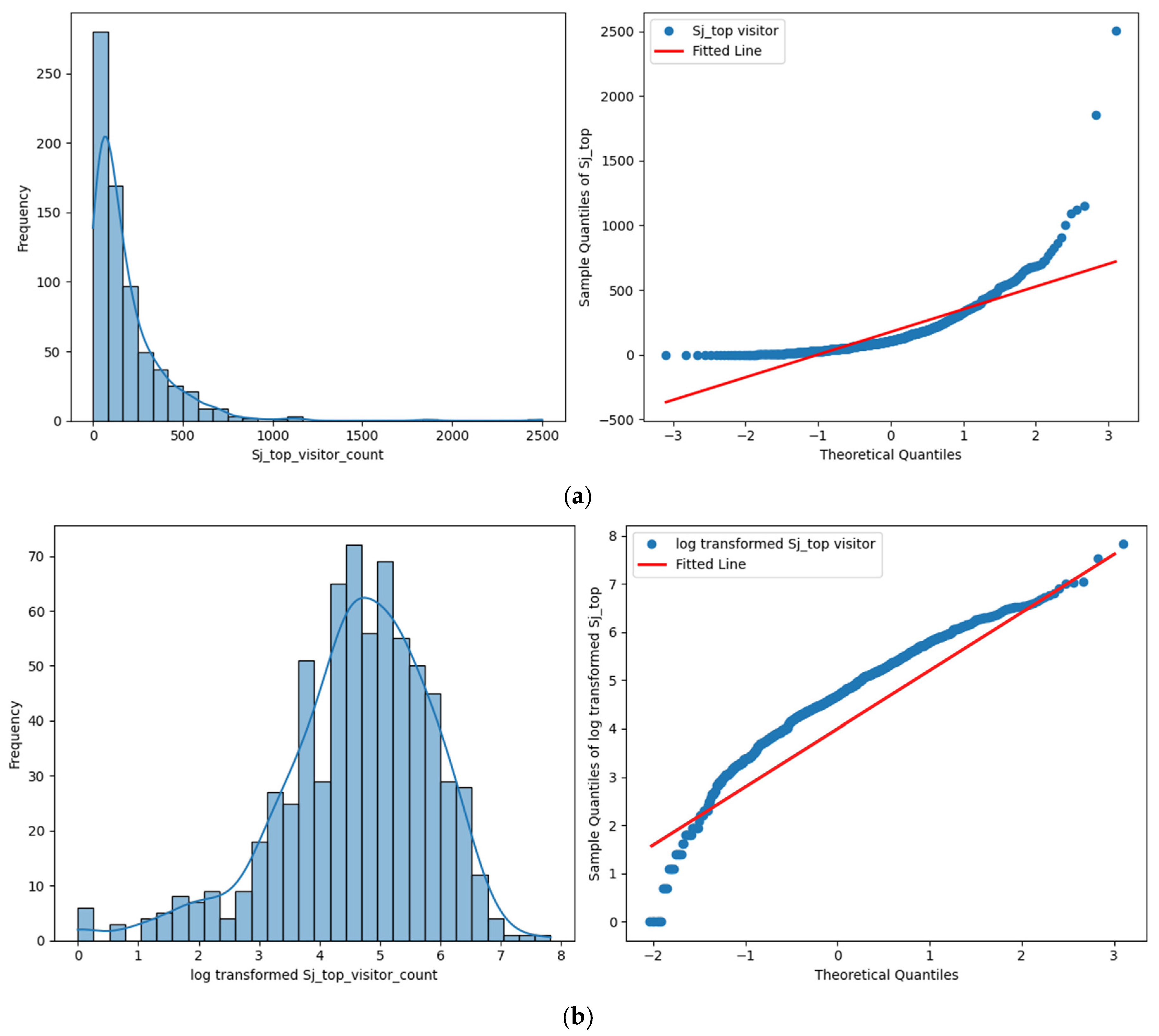
3.4. Data Preprocessing
3.5. Exploratory Data Analysis (EDA)
3.6. Machine Learning Model
3.6.1. Linear Regression
3.6.2. Ridge Regression
3.6.3. Lasso Regression
3.6.4. Random Forest
3.6.5. Gradient Boosting (GBM)
3.6.6. Extreme Gradient Boosting (XGBoost)
3.6.7. Light Gradient Boosting Machine (LGBM)
3.7. Performance Evaluation and Model Selection
3.8. Hyperparameter Tuning
3.9. Model Interpretation and Final Predictive Formula
4. Results
4.1. Numerical Variable Analysis
4.2. Categorical Variable Analysis
4.3. SHAP Analyses
4.3.1. Daegwallyeong Yetgil
4.3.2. Neunggyeongbong
4.3.3. Kukmin Forest
4.3.4. Sonamu Forest Trail
4.3.5. Seonjaryeong Entrance
4.3.6. Seonjaryeong Peak
4.4. Global Surrogate Model
5. Discussion
6. Conclusions
6.1. Summary of Key Findings
6.2. Research Contribution
6.3. Policy and Practical Implications
6.4. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- United Nations Human Settlements Programme (UN-Habitat). World Cities Report 2024: Cities and Climate Action. Available online: https://unhabitat.org/world-cities-report-2024-cities-and-climate-action (accessed on 18 April 2025).
- Korea Forest Service. Forest Terminology Dictionary. Available online: https://www.forest.go.kr/kfsweb/kfi/kfs/mwd/selectMtstWordDictionary.do?pageIndex=1&pageUnit=10&wrdSn=5391 (accessed on 18 April 2025).
- Sanesi, G.; Gallis, C.; Kasperidus, H.D. Urban Forests and Their Ecosystem Services in Relation to Human Health. For. Trees Hum. Health 2010, 1, 23–40. [Google Scholar] [CrossRef]
- Walton, A. Forests as Social Mirrors: What do Approaches to Forest Management Tell us About Human Social Relations? Bull. Ecol. Soc. Am. 2023, 105, e2110. [Google Scholar] [CrossRef]
- Mengist, W.; Soromessa, T. Assessment of forest ecosystem service research trends and methodological approaches at global level: A meta-analysis. Environ. Syst. Res. 2019, 8, 22. [Google Scholar] [CrossRef]
- Di Franco, C.P.; Lima, G.; Schimmenti, E.; Asciuto, A. Methodological Approaches to the Valuation of Forest Ecosystem Services: An Overview of Recent International Research Trends. J. For. Sci. 2021, 67, 307–317. [Google Scholar] [CrossRef]
- Food and Agriculture Organization of the United Nations (FAO). The State of the World’s Forests 2024. Available online: https://www.fao.org/documents/card/en/c/cd1211en/ (accessed on 18 April 2025).
- Stanford Institute for Human-Centered Artificial Intelligence (HAI). AI Index Report 2022. Available online: https://aiindex.stanford.edu/report/ (accessed on 18 April 2025).
- Samuel, A.L. Some Studies in Machine Learning Using the Game of Checkers. IBM J. Res. Dev. 2000, 44, 206–227. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Dhall, D.; Kaur, R.; Juneja, M. Machine Learning: A Review of the Algorithms and Its Applications. In Proceedings of the ICRIC 2019: Recent Innovations in Computing, Lecture Notes in Electrical Engineering; Springer; Cham, Switzerland, 2019; Volume 597, pp. 47–63. [Google Scholar] [CrossRef]
- Dahiya, N.; Gupta, S.; Singh, S. A Review Paper on Machine Learning Applications, Advantages, and Techniques. ECS Trans. 2022, 107, 6137. [Google Scholar] [CrossRef]
- Ray, S. A Quick Review of Machine Learning Algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 35–39. [Google Scholar] [CrossRef]
- Sakhypov, A.; Mektebayeva, A.; Rystyghulova, V.; Abildina, A.; Omarzhanova, G. Machine Learning Strategies and Algorithms for Enhancing Real-Time Data Processing in Dynamic and Big Data Systems. Vestn. KazATK 2024, 134, 278–291. [Google Scholar] [CrossRef]
- Wang, W.; Siau, K. Artificial Intelligence, Machine Learning, Automation, Robotics, Future of Work and Future of Humanity: A Review and Research Agenda. J. Database Manag. 2019, 30, 61–79. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Chen, X.; Avtar, R.; Umarhadi, D.A.; Louw, A.S.; Shrivastava, S.; Yunus, A.P.; Khedher, K.M.; Takemi, T.; Shibata, H. Post-Typhoon Forest Damage Estimation Using Multiple Vegetation Indices and Machine Learning Models. Weather Clim. Extrem. 2022, 38, 100494. [Google Scholar] [CrossRef]
- Staab, J.; Udas, E.; Mayer, M.; Taubenböck, H.; Job, H. Comparing Established Visitor Monitoring Approaches with Triggered Trail Camera Images and Machine Learning Based Computer Vision. J. Outdoor Recreat. Tour. 2021, 35, 100387. [Google Scholar] [CrossRef]
- Rahaman, M.; Morshed, M.M.; Bhadra, S. An Integrated Machine Learning and Remote Sensing Approach for Monitoring Forest Degradation Due to Rohingya Refugee Influx in Bangladesh. Remote Sens. Appl. Soc. Environ. 2022, 25, 100696. [Google Scholar] [CrossRef]
- Lee, S.; Lee, J.; Kim, S.; Seo, K.; Cho, J.; Seo, J. National Forest Trail Operation and Management Guidelines; Research Report 24-16; National Institute of Forest Science: Seoul, Republic of Korea, 2024; pp. 1–342. ISBN 979-11-6019-916-1.
- Kim, G.; Lee, J.; Lee, S. Activation Plan Through User Recognition Analysis of DMZ Punch Bowl Dulle-Gil: Focusing on Comparative Analysis of Survey and Text Mining. J. Tour. Leis. Res. 2022, 34, 47–66. [Google Scholar] [CrossRef]
- We, J.; Lee, S.; Lee, J.; Kim, S. The Impact of National Forest Trails on Quality of Life of Migrants from Urban to Mountain Villages: Focused on Jirisan Dullegil Trail. J. Korean Soc. For. Sci. 2023, 112, 230–247. [Google Scholar] [CrossRef]
- Lee, S.; Yang, J.D.; Lee, J. Estimating the Impact of DMZ Punchbowl Trail as a National Forest Trail on Local Economy Using the Regional Input-Output Model. J. Korean Soc. For. Sci. 2024, 113, 170–186. [Google Scholar] [CrossRef]
- Fuchs, M.; Zanker, M. Multi-Criteria Ratings for Recommender Systems: An Empirical Analysis in the Tourism Domain. Int. Conf. Electron. Commer. Web Technol. 2012, 7447, 100–111. [Google Scholar] [CrossRef]
- Jannach, D.; Zanker, M.; Fuchs, M. Leveraging Multi-Criteria Customer Feedback for Satisfaction Analysis and Improved Recommendations. Inf. Technol. Tour. 2014, 14, 119–149. [Google Scholar] [CrossRef]
- Gerakis, A.S. Effects of Exchange-Rate Devaluations and Revaluations on Receipts from Tourism. Staff Pap. Int. Monet. Fund 1965, 12, 365–384. [Google Scholar] [CrossRef]
- Gray, H.P. The Demand for International Travel by the United States and Canada. Int. Econ. Rev. 1966, 7, 83–92. [Google Scholar] [CrossRef]
- Bravo, J.; Alarcón, R.; Valdivia, C.; Serquén, O. Application of Machine Learning Techniques to Predict Visitors to the Tourist Attractions of the Moche Route in Peru. Sustainability 2023, 15, 8967. [Google Scholar] [CrossRef]
- Abang Abdurahman, A.Z.; Wan Yaacob, W.F.; Md Nasir, S.A.; Jaya, S.; Mokhtar, S. Using Machine Learning to Predict Visitors to Totally Protected Areas in Sarawak, Malaysia. Sustainability 2022, 14, 2735. [Google Scholar] [CrossRef]
- Yap, N.; Gong, M.; Naha, R.K.; Mahanti, A. Machine Learning-Based Modelling for Museum Visitations Prediction. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Bi, J.-W.; Li, C.; Xu, H.; Li, H. Forecasting Daily Tourism Demand for Tourist Attractions with Big Data: An Ensemble Deep Learning Method. J. Travel Res. 2021, 61, 1719–1737. [Google Scholar] [CrossRef]
- Li, W. Prediction of Tourism Demand in Liuzhou Region Based on Machine Learning. Mob. Inf. Syst. 2022, 2022, 9362562. [Google Scholar] [CrossRef]
- Jee, J.-B.; Zo, I.-S.; Bae, J.-H. Development of a Prediction Algorithm for the Number of Visitors with Municipality in Gangwon Province. J. Tour. Leis. Res. 2022, 34, 65–78. [Google Scholar] [CrossRef]
- Korea Forest Service. National Forest Trail—Daegwallyeong Homepage. Available online: http://www.daegwallyeongsupgil.kr/ (accessed on 18 April 2025).
- National Institute of Korean Language. Standard Korean Language Dictionary. Available online: https://stdict.korean.go.kr/main/main.do (accessed on 18 April 2025).
- Korea Meteorological Administration. Climate Statistics by Region. 2022. Available online: https://data.kma.go.kr/climate/RankState/selectRankStatisticsDivisionList.do?pgmNo=179 (accessed on 18 April 2025).
- Baclig, A.C.; Castres, D.R.M.; Florendo, M.A.C.; Malcino, L.J.; Padilla, J.M.P.; Covita, M.S. Social Media’s Influence on Tourists’ Choice of Destination. Int. J. Res. Innov. Soc. Sci. 2024, 8, 1507–1546. [Google Scholar] [CrossRef]
- Li, Y.; Lin, Z.; Xiao, S. Using social media big data for tourist demand forecasting: A new machine learning analytical approach. J. Digit. Econ. 2022, 1, 32–43. [Google Scholar] [CrossRef]
- WiseApp. The Most Frequently, Heavily, and Regularly Used Apps by Koreans. WiseApp Insight 2024. Available online: https://www.wiseapp.co.kr/insight/detail/613 (accessed on 10 June 2025).
- Lee, I.J.; Yoon, H.S. Development of a Model to Predict the Number of Visitors to Local Festivals Using Machine Learning. J. Inf. Syst. 2020, 29, 35–52. [Google Scholar] [CrossRef]
- Korea Meteorological Administration. Open Data Portal. Available online: https://data.kma.go.kr/cmmn/main.do (accessed on 4 June 2025).
- AirKorea. Air Quality Monitoring Platform. Available online: https://www.airkorea.or.kr/web/pmRelay?itemCode=10007&pMENU_NO=108 (accessed on 4 June 2025).
- Naver Blog. Available online: https://section.blog.naver.com/BlogHome.naver?directoryNo=0¤tPage=1&groupId=0 (accessed on 4 June 2025).
- Naver Café. Available online: https://cafe.naver.com (accessed on 4 June 2025).
- Naver News. Available online: http://news.naver.com (accessed on 4 June 2025).
- Instagram. Available online: https://instagram.com (accessed on 4 June 2025).
- Korea Expressway Corporation’s Public Data Portal. Available online: https://data.ex.co.kr (accessed on 4 June 2025).
- Korean Public Data Portal. Available online: https://www.data.go.kr (accessed on 4 June 2025).
- Osborne, J. Improving your data transformations: Applying the Box-Cox transformation. Pract. Assess. Res. Eval. 2010, 15, 12. [Google Scholar] [CrossRef]
- Massa, E.; Jonker, M.A.; Roes, K.; Coolen, A.C.C. Correction of Overfitting Bias in Regression Models. arXiv 2022, arXiv:2204.05827. [Google Scholar]
- Grizzle, J.E.; Starmer, C.F.; Koch, G.G. Analysis of categorical data by linear models. Biometrics 1969, 25, 489–504. [Google Scholar] [CrossRef] [PubMed]
- Tukey, J.W. Exploratory Data Analysis; Pearson: London, UK, 1977. [Google Scholar]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis, 6th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- XGBoost Developers. XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/stable/ (accessed on 10 June 2025).
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Microsoft. LightGBM Documentation. Available online: https://lightgbm.readthedocs.io/en/stable/index.html (accessed on 10 June 2025).
- Xie, W.; Chen, W.; Shen, L.; Duan, J.; Yang, M. Surrogate Network-Based Sparseness Hyper-Parameter Optimization for Deep Expression Recognition. Pattern Recognit. 2021, 111, 107701. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Kalita, K.; Čep, R.; Chakraborty, S. A Comparative Analysis on Prediction Performance of Regression Models during Machining of Composite Materials. Materials 2021, 14, 6689. [Google Scholar] [CrossRef]
- Mockus, J.; Tiesis, V.; Zilinskas, A. The Application of Bayesian Methods for Seeking the Extremum. In Towards Global Optimization; Dixon, L.C.W., Szegő, G.P., Eds.; Elsevier: Amsterdam, The Netherlands, 1978; Volume 2, pp. 117–129. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2951–2959. [Google Scholar]
- Scikit-learn. Forests of Randomized Trees. Available online: https://scikit-learn.org/stable/modules/ensemble.html#forests-of-randomized-trees (accessed on 18 April 2025).
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef]
- IT DAILY. AI Black Box, Ensuring Transparency through Explainable Artificial Intelligence (XAI). Available online: http://www.itdaily.kr/news/articleView.html?idxno=73632 (accessed on 18 April 2025).
- Das, A.; Rad, P. Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey. arXiv 2020. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4765–4774. [Google Scholar] [CrossRef]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward Safer Highways, Application of XGBoost and SHAP for Real-Time Accident Detection and Feature Analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef] [PubMed]
- Mokhtari, K.E.; Higdon, B.P.; Başar, A. Interpreting Financial Time Series with SHAP Values. In Proceedings of the 29th Annual International Conference on Computer Science and Software Engineering, Toronto, ON, Canada, 4–6 November 2019; pp. 166–172. Available online: https://dl.acm.org/doi/abs/10.5555/3370272.3370290 (accessed on 1 May 2025).
- Feng, D.C.; Wang, W.J.; Mangalathu, S.; Taciroglu, E. Interpretable XGBoost–SHAP Machine-Learning Model for Shear Strength Prediction of Squat RC Walls. J. Struct. Eng. 2021, 147, 04021173. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient Global Optimization of Expensive Black-Box Functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Cessford, G.; Muhar, A. Monitoring options for visitor numbers in national parks and natural areas. J. Nat. Conserv. 2003, 11, 240–250. [Google Scholar] [CrossRef]
- Ziesler, P.S.; Pettebone, D. Counting on Visitors: A Review of Methods and Applications for the National Park Service’s Visitor Use Statistics Program. J. Park Recreat. Adm. 2018, 36, 39–55. [Google Scholar] [CrossRef]
- Liu, C.; Susilo, Y.O.; Karlström, A. Investigating the Impacts of Weather Variability on Individual’s Daily Activity–Travel Patterns: A Comparison Between Commuters and Noncommuters in Sweden. Transp. Res. Part A Policy Pract. 2015, 82, 47–64. [Google Scholar] [CrossRef]
- Wu, J.; Liao, H. Weather, Travel Mode Choice, and Impacts on Subway Ridership in Beijing. Transp. Res. Part A Policy Pract. 2020, 135, 264–279. [Google Scholar] [CrossRef]
- Sohn, C.; Kim, G.H. Influences of Weather on the Inbound Traffic Volume of a Tourist Destination. Korea Spat. Plan. Rev. 2014, 83, 99–111. [Google Scholar] [CrossRef]
- Rutty, M.; Andrey, J. Weather Forecast Use for Winter Recreation. Weather Clim. Soc. 2014, 6, 293–306. [Google Scholar] [CrossRef]
- McCreary, A.; Seekamp, E.; Larson, L.R.; Smith, J.W.; Davenport, M.A. Predictors of Visitors’ Climate-Related Coping Behaviors in a Nature-Based Tourism Destination. J. Outdoor Recreat. Tour. 2019, 26, 23–33. [Google Scholar] [CrossRef]
- Ayeh, J.K. Travellers’ Acceptance of Consumer-Generated Media: An Integrated Model of Technology Acceptance and Source Credibility Theories. Comput. Hum. Behav. 2015, 48, 173–180. [Google Scholar] [CrossRef]
- Tamaki, S. Likes on Image Posts in Social Networking Services: Impact of Travel Episode. J. Destin. Mark. Manag. 2021, 20, 100615. [Google Scholar] [CrossRef]
- Ren, M.; Park, S.; Xu, Y.; Huang, X.; Zou, L.; Wong, M.S.; Koh, S.Y. Impact of the COVID-19 Pandemic on Travel Behavior: A Case Study of Domestic Inbound Travelers in Jeju, Korea. Tour. Manag. 2022, 92, 104533. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Method | Data | Key Variables | Main Contribution |
|---|---|---|---|---|
| Bravo et al. (2023) [28] | Linear regression (LR), k-NN, decision tree, random forest (RF) | Arrival of national and international tourists, tourism intelligence system, TripAdvisor, Google Trends | Hotels, area, access, domestic promotion, reviews (top 5 variables based on prediction model) | Prediction of visitors to tourist attractions on the Moche Route in northern Peru |
| Abang Abdurahman et al. (2022) [29] | k-NN, naïve Bayes, decision tree | Type of the park, size of the park, number of natural characteristics, number of recreational services, type of connectivity, distance from the nearest city | Domestic tourists: distance and park size International tourists: park type, natural attributes, and age | Prediction of visitors to protected areas in Sarawak |
| Yap et al. (2020) [30] | LR, XGBoost, RF, neural network | Weather, time, day of the week, school holidays | Primary key: temporal features Secondary: weather | Prediction of visitors to a museum |
| Bi et al. (2021) [31] | Comparison of 12 models, including ensemble LSTM with CPS | Search engine trends, weather, temperature, public holidays | Holiday | Prediction of visitors to Huangshan Mountain Area |
| Li (2022) [32] | RF, SVR, RNN, LSTM, CNN-LSTM, SPCA-LSTM, SPCA-CNNLSTM | Holiday, low temperature, PM2.5 concentration, historical passenger flow, average temperature, high temperature | - | Tourism demand forecast for Liuzhou |
| Jee et al. (2022) [33] | GBM | Temperature, cumulative precipitation, wind speed humidity, atmospheric pressure, sunshine duration, solar radiation, cloud cover, day of the week, week, year | Meteorological: temperature Non-meteorological: day of the week | Daily visitor forecasting for 18 municipalities in Gangwon Province |
| Trail Name | Distance | Difficulty level | Description |
|---|---|---|---|
| Daegwallyeong Yetgil (Yetgil) | 6.46 km | Moderate | Scenic streamside trail with views of natural landscape and historical pathways |
| Neunggyeongbong (Nk) | 1.95 km | Moderate | Short hiking distance to the highest peak in southern Daegwallyeong with panoramic landscape views |
| Kukmin Forest (Km) | 5.59 km | Very Easy | Well-maintained dirt path with wildflowers, diverse tree species, and coniferous forests rich in phytoncides |
| Daegwallyeong Sonamu Trail (Sonamu) | 8.60 km | Moderate | 400 ha area with dense Korean pine and spicebush stands, featuring exceptional pine tree scenery |
| Seonjaryeong (Sj_enter, Sj_top) | 8.36 km | Moderate | Route via Seonjaryeong Peak featuring grasslands, renowned backpacking destination, and popular winter trekking course |
| Variable | Description | ||
|---|---|---|---|
| Dependent | Weather | Tm_max | Daily maximum temperature (°C) |
| Ws | Average wind speed (m/s) | ||
| Rn | Daily precipitation (mm) | ||
| Dust_dgl | Daily average PM10 concentration in Daegwallyeong | ||
| Social media | Blog_dglf_cnt | Number of blog posts (count) | |
| Café_dglf_cnt | Number of café posts (count) | ||
| Insta_dglf_cnt | Number of Instagram posts (count) | ||
| News | News_dglf_cnt | Number of news posts (count) | |
| Others | Dgl_toll_cnt | Daegwallyeong tollgate traffic volume | |
| Corona_kr_lag | Confirmed COVID-19 cases in Korea (previous day) | ||
| Festival | Festival occurrence in Gangneung and Pyeongchang (yes/no) | ||
| Day_week | Day of the week and holidays (Mon–Sun, holidays) | ||
| Month | Month (January–December) | ||
| Independent | Visitor_sj_top | Daily visitors to the summit of Seonjaryeong Peak | |
| Visitor_sj_enter | Daily visitors to the summit of Seonjaryeong Entrance | ||
| Visitor_nk | Daily visitors to Neunggyeongbong | ||
| Visitor_sonamu | Daily visitors to Daegwallyeong Sonamu Trail | ||
| Visitor_yetgil | Daily visitors to Daegwallyeong Yetgil Trail | ||
| Visitor_km | Daily visitors to Kukmin Forest | ||
| Yetgil | Nk | Km | Sonamu | Sj_enter | Sj_top | Sum | |
|---|---|---|---|---|---|---|---|
| Random forest (RF) | 0.76 | 0.64 | 0.47 | 1.16 | 0.82 | 1.14 | 4.97 |
| LightGBM (LGBM) | 0.76 | 0.68 | 0.46 | 1.21 | 0.79 | 1.11 | 5.03 |
| Gradient boosting (GBM) | 0.80 | 0.69 | 0.45 | 1.21 | 0.74 | 1.21 | 5.11 |
| XGBoost | 0.85 | 0.71 | 0.42 | 1.21 | 0.84 | 1.37 | 5.41 |
| Lasso regression | 0.80 | 0.93 | 0.86 | 1.26 | 1.07 | 1.29 | 6.21 |
| Ridge regression | 0.83 | 0.79 | 0.40 | 2.14 | 0.9 | 1.17 | 6.22 |
| Linear regression | 0.88 | 0.82 | 0.44 | 2.17 | 0.91 | 1.19 | 6.40 |
| Model | Parameter | Range |
|---|---|---|
| RF | n_estimators | (100, 500) |
| max_depth | (6, 12) | |
| min_samples_leaf | (2, 10) | |
| min_samples_split | (4, 10) | |
| GBM | n_estimators | (100, 500) |
| max_depth | (6, 12) | |
| learning_rate | (0.001, 0.1) | |
| LGBM | num_leaves | (35, 60) |
| max_depth | (9, 20) | |
| min_child_weight | (20, 50) | |
| subsample | (0.1, 0.99) | |
| colsample_bytree | (0.1, 0.09) |
| RF | GBM | ||||
|---|---|---|---|---|---|
| Parameters | Nk | Sj_top | Parameter | Km | Sonamu |
| n_estimators | 196 | 112 | n_estimators | 221 | 351 |
| max_depth | 8 | 6 | max_depth | 9 | 7 |
| min_samples_leaf | 7 | 5 | learning_rate | 0.1 | 0.01 |
| min_samples_split | 9 | 5 | |||
| LGBM | Section | RMSLE | |||
| Parameter | Yetgil | Sj_enter | Yetgil | 0.555 | |
| num_leaves | 56 | 53 | Nk | 0.626 | |
| max_depth | 12 | 14 | Km | 0.443 | |
| min_child_weight | 27 | 48 | Sonamu | 1.116 | |
| subsample | 0.56 | 0.81 | Sj_enter | 1.077 | |
| colsample_bytree | 0.48 | 0.28 | Sj_top | 0.727 | |
| Variable Number | Variable Name | Coefficient | Variable Number | Variable Name | Coefficient |
|---|---|---|---|---|---|
| Month_OCT | 144.7 | Month_NOV | −31.33 | ||
| Dgl_toll_cnt | 88.05 | Day_week_Sun | 38.24 | ||
| Month_JAN | 26.4 | Day_week_Holiday | −30.54 | ||
| Month_FEB | 22.96 | Rn | −3.12 | ||
| Month_JUL | 2.74 | Day_week_Wed | −22.96 | ||
| Day_week_Fri | −39.21 | Day_week_Thu | −24.4 | ||
| Month_AUG | −25.93 | Month_APR | −34.94 | ||
| Month_MAR | −0.82 | Café_dglf_cnt | −0.32 | ||
| Month_SEP | −51.74 | Insta_dglf_cnt | 0.63 | ||
| Festival | −44.1 | WS | 0.18 | ||
| Month_JUN | −22.42 | News_dglf_cnt | −0.73 | ||
| Day_week_Mon | 2.3 | Blog_dglf_cnt | −0.6 | ||
| Day_week_Tue | −13.26 | Dust_dgl | 0.3 | ||
| Day_week_Sat | 89.83 | Tm_max | 5.96 | ||
| Month_MAY | −29.11 | Corona_kr_lag | 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, S.; Jung, S.-H.; Kim, G.-H.; Lee, S. Visitor Number Prediction for Daegwallyeong Forest Trail Using Machine Learning. Sustainability 2025, 17, 6061. https://doi.org/10.3390/su17136061
Ryu S, Jung S-H, Kim G-H, Lee S. Visitor Number Prediction for Daegwallyeong Forest Trail Using Machine Learning. Sustainability. 2025; 17(13):6061. https://doi.org/10.3390/su17136061
Chicago/Turabian StyleRyu, Sungmin, Seong-Hoon Jung, Geun-Hyeon Kim, and Sugwang Lee. 2025. "Visitor Number Prediction for Daegwallyeong Forest Trail Using Machine Learning" Sustainability 17, no. 13: 6061. https://doi.org/10.3390/su17136061
APA StyleRyu, S., Jung, S.-H., Kim, G.-H., & Lee, S. (2025). Visitor Number Prediction for Daegwallyeong Forest Trail Using Machine Learning. Sustainability, 17(13), 6061. https://doi.org/10.3390/su17136061