1. Introduction
Pollution control remains a critical issue for global sustainable development [
1]. With the acceleration of urbanization, the annual generation of municipal solid waste (MSW) worldwide continues to grow steadily at a rate of 8–10% [
2]. In developing countries where waste classification systems are not yet well-established, the problem of “waste surrounding cities” has become increasingly severe [
3]. Therefore, effective measures must be taken to address the growing volume of waste in order to prevent further environmental deterioration. Compared to traditional waste management methods, municipal solid waste incineration (MSWI) offers significant advantages and can effectively reduce pollution. Traditional methods such as landfilling and open burning often lead to land and air pollution, whereas MSWI converts waste into energy through advanced combustion technologies. This not only alleviates environmental pressure but also recovers thermal energy, promoting sustainable urban development. However, during the incineration process, the stable control of the main steam flow rate (MSFR) is one of the key factors for the stable operation of the MSWI system. Stable control of MSFR can improve energy efficiency, reduce emissions, and promote resource recycling [
4,
5]. Therefore, stable control of the MSFR is crucial for both the MSWI operation and the sustainable development of cities.
In developed countries, waste separation systems are well implemented. This results in relatively uniform MSW composition and stable calorific values. Such conditions provide a solid foundation for applying automated combustion control strategies [
6]. However, in developing countries, where waste classification is still under development, MSW composition and calorific value fluctuate widely. These fluctuations cause frequent disturbances in incineration, making it difficult to directly apply control strategies developed abroad [
7]. Therefore, the effective MSFR control technologies tailored to developing countries’ complex conditions are essential for improving incineration stability and pollution control efficiency.
Thanks to rigorous classification and standardized pretreatment, developed countries have created stable incineration environments. Highly automated control systems further ensure these environments are well controlled. This provides ideal conditions for advanced mechanistic model-based control strategies [
8,
9]. For example, a pioneering two-stage closed-loop identification method was proposed [
10], which introduces an input sensitivity function to reduce the impact of disturbances on modeling accuracy. This approach produced a multiple-input multiple-output (MIMO) model that maintained MSFR prediction errors below 4% at the HVC incineration plant in the Netherlands. Building on this, a nonlinear model predictive control (MPC) system based on a three-zone combustion model was developed [
11]. By optimizing grate speed and secondary air distribution, the system decoupled MSFR and carbon monoxide emissions and reduced steam flow response delay to 80 s, greatly improving dynamic performance. Another study applied MPC to MSFR control by constructing a precise predictive model [
12] that accounted for variations in waste composition and equipment status. This method significantly enhanced MSFR control stability and accuracy.
The above mechanistic modeling and advanced control methods, grounded in stable operation conditions, provide valuable theoretical and practical foundations for global MSWI control technologies. However, in developing countries, kitchen waste accounts for more than 50% of MSW, leading to high moisture content and low calorific value. These factors severely reduce combustion stability and cause MSFR to be highly sensitive to fuel disturbances [
13]. There is a strong coupling among furnace temperature, flue gas oxygen concentration, and MSFR during incineration [
14]. Empirical data show that every 5% increase in moisture content expands the MSFR fluctuation range by ±1.2% [
15]. This makes it difficult to directly transfer control strategies from developed countries to practical applications in developing countries.
To address these challenges of varying operating conditions in developing countries, researchers have carried out systematic technological innovations based on data-driven approaches and intelligent algorithms. Traditional PI parameter tuning methods are unsuitable due to changes in process characteristics [
16,
17], an event-triggered RBF–PID controller is developed in [
18]. It can adaptively adjust PID parameters based on dynamic furnace temperature changes. It reduces MSFR recovery time under load disturbances to 120 s while keeping fluctuations within ±2%. To better serve control objectives, a fuzzy-width forest regression soft sensing method is proposed in [
19], maintaining MSFR prediction errors within ±3.5% even under calorific value fluctuations of ±15%. A Takagi–Sugeno (TS) fuzzy neural network is employed to achieve nonlinear decoupling among multiple variables in [
20], keeping MSFR prediction errors below 5%, further improving control accuracy. Additionally, advances in swarm intelligence have opened new perspectives for MSFR control [
21,
22]. For instance, the beetle antennae search–support vector machine (BAS–SVM) algorithm, inspired by swarm behavior, achieves global optimization of control variables. It balances multiple objectives, including steam flow stability, energy efficiency, and pollutant emissions [
23]. This method enhances system adaptability, robustness, and optimization, greatly improving steam flow control effectiveness.
Although the previous studies have significantly improved system control performance, several key technical challenges remain. For example, in multivariable decoupling, relative gain array (RGA)-based methods reduce coupling to some extent [
24], but MSWI involves complex pyrolysis, gasification, and combustion reactions. The strong nonlinearity and uncertainty often cause model mismatch, limiting these methods’ broad application. More importantly, existing control strategies mainly focus on precise tracking of target variables but lack the ability to dynamically optimize control setpoints [
25]. However, in dynamic operating conditions, the predefined setpoints often deviate from their optimal values. In such cases, experienced operators must manually adjust parameters such as airflow based on empirical judgment. Yet, when the composition of waste varies significantly or combustion conditions fluctuate rapidly, expert intervention may be delayed or inconsistent due to differences in individual expertise, experience, and skill levels. This subjectivity can hinder effective steam flow regulation and compromise overall system performance. Reference [
26] addresses the issue of varying operating conditions by proposing a two-layer control architecture for operational management and hydroelectricity production maximization in inland waterways. It eliminates the subjective errors introduced by manual settings.
Developing countries face challenges due to immature waste sorting systems, large fluctuations in waste composition and calorific value, and frequent changes in combustion conditions. This makes it difficult to achieve automated combustion control like in developed nations. To address this, we propose a two-layer intelligent control system for the MSFR. The system proposed in the paper accounts for computational and infrastructure limitations while handling changing conditions. Regarding hardware limitations, we use a two-layer structure in the system design. The optimization setting and loop control layers operate on separate devices. This reduces reliance on a single device and ensures better task distribution. The system can adjust control parameters in real-time, based on current conditions. A PI controller tracks the new set points, ensuring stable and efficient operation. On the other hand, the antlion optimization (ALO) and reinforcement learning algorithms are innovative but have existing applications. Local technicians in developing countries can perform routine maintenance after proper training, reducing reliance on external experts and lowering costs. Furthermore, the system uses buffering and data interpolation. This ensures stable operation even when data acquisition devices are incomplete or delayed. Therefore, the main contributions of this study are as follows:
- (1)
An RBF neural network prediction model was established at the optimization setting level to accurately predict the MSFR. By introducing the OPTICS algorithm, the centers and widths of the RBF hidden layer were objectively determined, and the gradient descent algorithm was used to adaptively adjust the neural network parameters. The model’s accuracy and good convergence were validated through experiments involving five different models (BP neural network, RBF neural network, RBF neural network with maximum matrix element algorithm, and RBF neural network with K-means clustering).
- (2)
Additionally, optimization setting of the manipulated variables based on IALO is proposed. The manipulated variables’ setting values can be dynamically adjusted in response to changes in operating conditions.
- (3)
In the control layer, reinforcement learning was introduced to the PI control system, which can quickly track the set values, especially when operating conditions change, with the PI parameters automatically tuned. Compared to the QDRNN-PID control system and the standard PID control system, the proposed intelligent optimization control method for MSFR demonstrated strong robustness and dynamic response capabilities.
The remainder of this article is organized as follows.
Section 2 analyzes the MSWI process and control problems.
Section 3 introduces the methodology of the MSFR control.
Section 4 discusses experimental results. Finally,
Section 5 concludes this article.
3. Methodology
The objective of the MSFR control is shown in Equations (4) and (5). It is to maintain the steam flow within the target range required by the process and to bring it as close as possible to the target MSFR value.
where
represents the measured MSFR, and
represents the target MSFR. The absolute deviation between the target and the measured MSFR must satisfy the condition of not exceeding epsilon
.
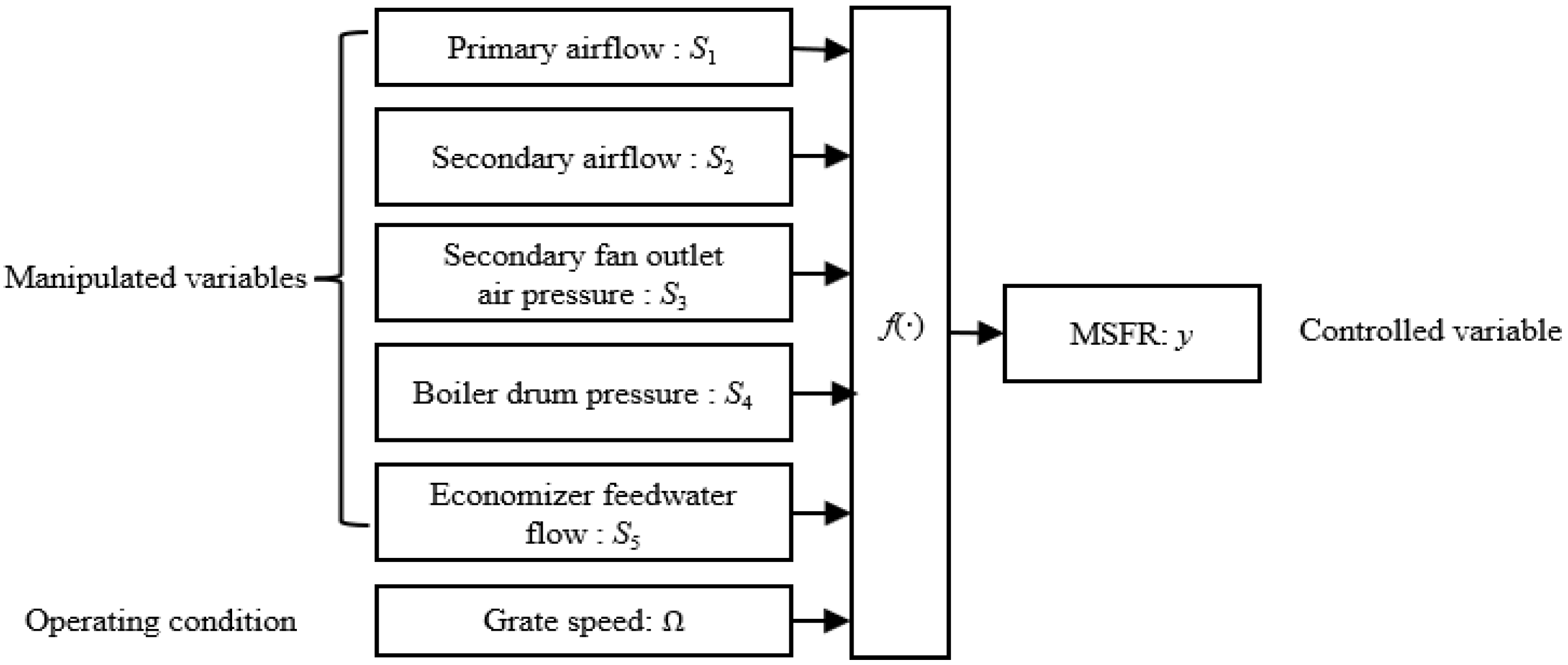
The achievement of this objective relies on the coordinated regulation of several key parameters, including primary airflow
, secondary airflow
, secondary air fan outlet pressure
, boiler drum pressure
, and economizer feedwater flow
. The grate speed serves as an indicator of changes in operating conditions. Since fluctuations in solid waste composition and changes in environmental temperature can lead to dynamic changes in operating conditions, the control system must not only focus on the loop’s tracking performance of setpoints but also investigate how to optimize the setpoints of key manipulated variables in real-time according to the changing operating conditions. To tackle this, this article proposes a two-layer intelligent control method that includes an optimization setting layer and a loop control layer, aiming to maintain the MSFR within the target range while ensuring the combustion process operates in an optimized state. Essentially, this problem is a multivariable nonlinear optimization issue in a dynamic environment [
35].
Inspired by the application of the antlion optimizer to solve the nonlinear optimization problem of multivariable manipulated variables in voltage source converters [
36]. The antlion optimizer is applied in the setpoint optimization layer [
37]. On the other hand, the RBF technique is used to solve the nonlinear modeling problem of the alkali borosilicate glass transition temperature [
38]. Given the nonlinear fitting capability of RBF neural networks to asymptotically approximate real values, which has been widely applied in modeling complex nonlinear industrial processes [
39], the RBF technique is used to model the nonlinear relationship between the MSFR and its influencing factors. In the loop control system, the incorporation of reinforcement learning techniques is considered. Reinforcement learning, as a function approximation-based approach, has achieved significant success in solving complex tasks with high-dimensional state spaces and nonlinear control problems, such as robot control [
40]. We explored integrating reinforcement learning into the design of the loop control system. A variable PI controller is developed to enhance the system’s adaptability, aiming at the complex operating conditions [
41,
42].
3.1. Intelligent Control Strategy
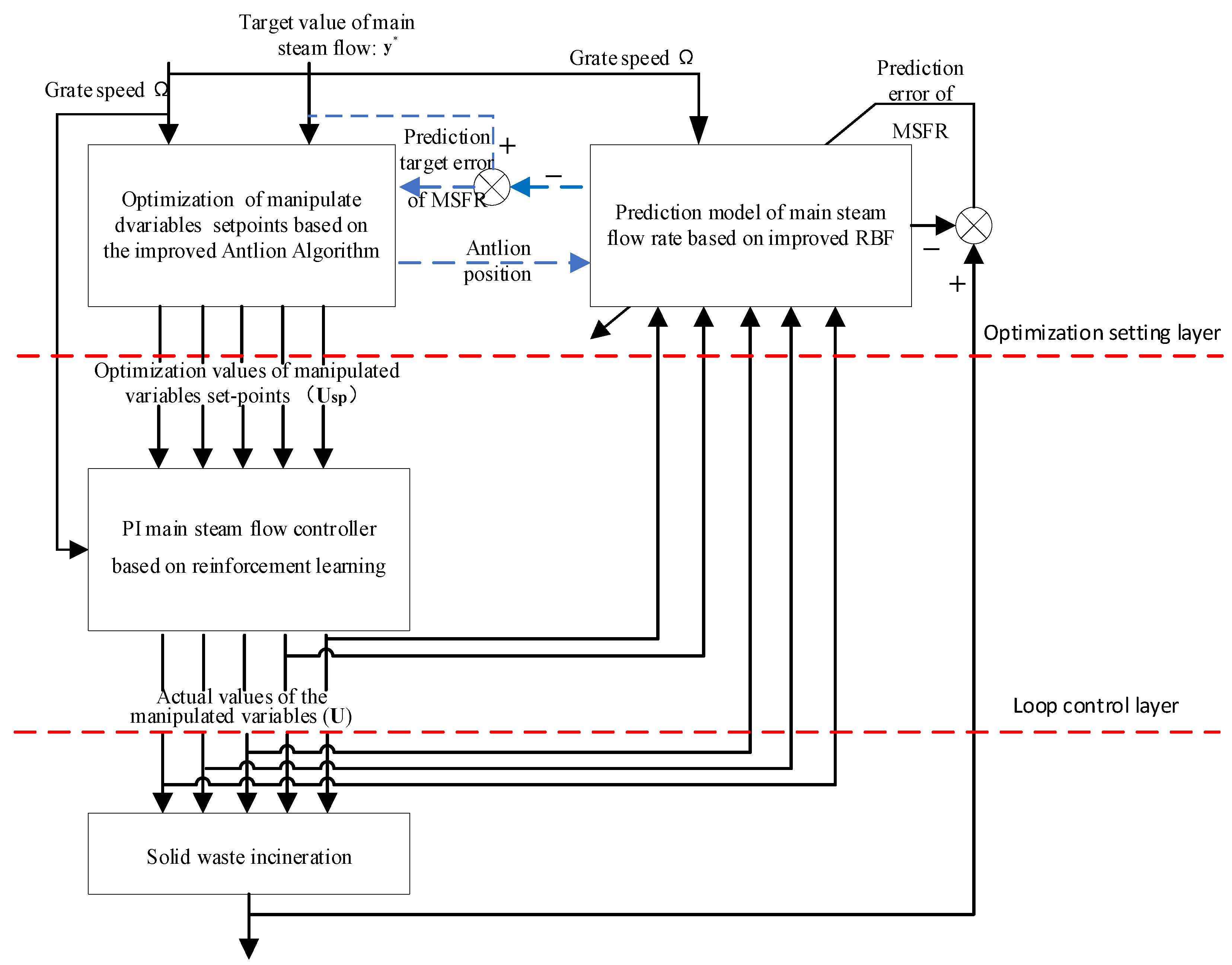
In consideration of the multivariable, nonlinear, and dynamic characteristics of the MSFR control problem within the MSWI system, this article presents a two-layer intelligent control method, as depicted in
Figure 3. The method comprises a manipulated variables optimization setpoint layer and a loop control layer. There are three key modules: the MSFR prediction module based on the improved RBF, the manipulated variables optimization setpoints module based on the improved antlion algorithm, and the PI loop control system module based on reinforcement learning. Within the MSFR prediction module relying on the improved RBF, the inputs incorporate key manipulated variables (
) and the grate speed, which characterizes the operating conditions. This module utilizes RBF techniques for modeling and employs gradient descent algorithms to conduct self-learning of the model’s key parameters, ultimately yielding the predicted MSFR for the MSWI. The manipulated variables optimization setpoint module, relying on the improved antlion algorithm, uses the target MSFR as an input and optimizes the key manipulated variables (
) via the improved antlion algorithm. The PI MSFR control system module, which relies on reinforcement learning, constitutes a PI control system. It utilizes the grate speed, which represents operating conditions, and the optimized key manipulated variables (
) as inputs. This module applies reinforcement learning techniques. The module is designed to enable the adaptive adjustment of PI parameters by changing operating conditions, thus achieving more precise and efficient MSFR control.
3.2. Intelligent Control Algorithm
3.2.1. MSFR Prediction Module Based on the Improved RBF
- (1)
Model Structure
The MSFR prediction module utilizes a three-layer RBF neural network composed of an input layer, a hidden layer, and an output layer. The input layer comprises six nodes, which correspond to the key manipulated variables (
) and the grate speed (
), the latter of which characterizes the operating conditions. The output layer is composed of a single neuron that represents the predicted value of the MSFR (
). The quantity of nodes in the hidden layer is determined by means of the OPTICS clustering algorithm. The nodes within the hidden layer employ a Gaussian radial basis function,
where
,
, represents the inputs;
m is the number of hidden layer nodes; and
is the center of the
g-th radial basis function. The values of
m and
are determined using the OPTICS clustering algorithm;
is the width parameter of the neuron; and
is the connection weight between the
g-th hidden layer node and the output layer node, which are determined using the gradient descent algorithm. The network output is the predicted MSFR value
.
- (2)
Determination of RBF hidden layer node number m and parameter based on the OPTICS clustering algorithm
The OPTICS clustering algorithm was chosen over DBSCAN and K-means++ because it can better handle data with varying densities, noise, and uncertain cluster numbers, and it does not require the number of clusters to be set in advance, offering greater flexibility and accuracy.
The Euclidean distance formula is used to calculate the distance metric between sample data points.
where
represent the inputs vectors of two sample data in a six-dimensional space; and
are the values of the
s-th dimension.
The core distance is defined as follows:
where
represents the neighborhood range radius of the MSFR; and
is the number of MSFR samples which are within the range
. The reachable distance is defined as follows:
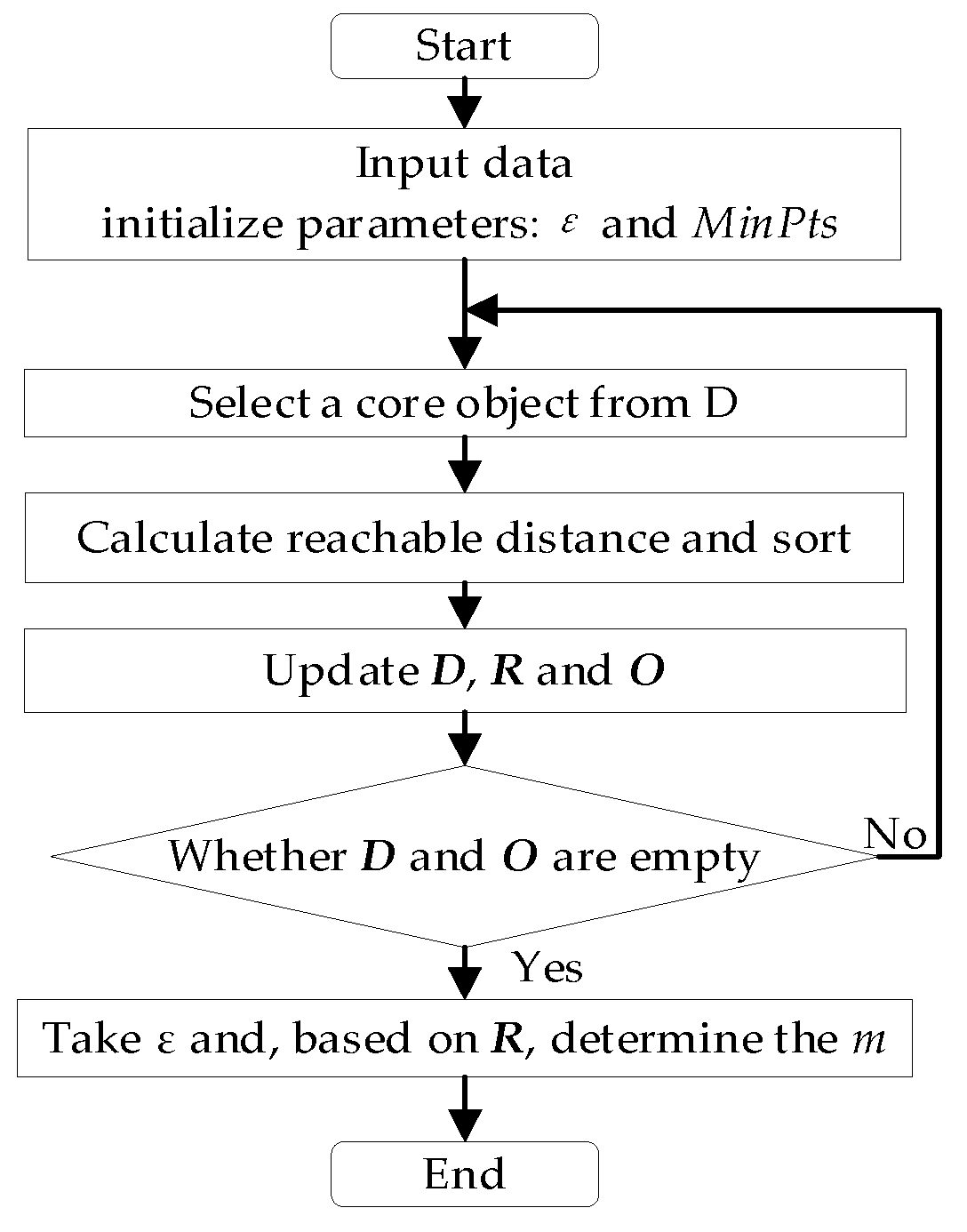
The specific clustering process is shown in
Figure 4 and is described as follows:
Step 1: Input the sample data of manipulated variables and operating conditions, initialize the reachable distances, and create an ordered queue O and a result queue R.
Step 2: Use Equation (8) to calculate the dataset D, and compute all the core distances using Equation (9).
Step 3: Select an object from D as the core object P, place it into R, and remove it from D. Use Equation (11) to calculate the reachable distance of other data points to the core object P, sort them by reachable distance, and add them to O.
Step 4: Select the data point with the smallest reachable distance from O as the new core object P, place it into R, and remove it from both O and D. Calculate the reachable distance of the remaining data points to the new core object, and update O.
Step 5: Check if O and D are empty. If not, repeat Step 4.
Step 6: Take and, based on R, determine the number of clusters m.
After determining the number of clusters
m, and the center points of the RBF, hidden layer neurons are determined using Equation (12).
where
N represents the total number of data points in the
g-th cluster of MSFR, and
denotes the sample belonging to this cluster.
- (3)
Correction of RBF neural network parameters and based on the gradient descent algorithm.
The gradient descent algorithm is used to update the width parameter
of the neurons and the output layer weights
. The loss function is defined as follows:
where
and
represent the measured and predicted values of the MSFR for the
i-th sample, respectively. The updated formulas for the neuron width parameter
and the output layer weights
are as follows:
where
denotes the learning rate. The update formulas are derived through the calculation of the partial derivatives of the loss function with respect to the neuron width parameter
and the output layer weights
. This enables the correction of the error function along the direction of the negative gradient, facilitating the iterative optimization of the parameters.
3.2.2. Optimization of Manipulated Variables Setpoint Based on the IALO
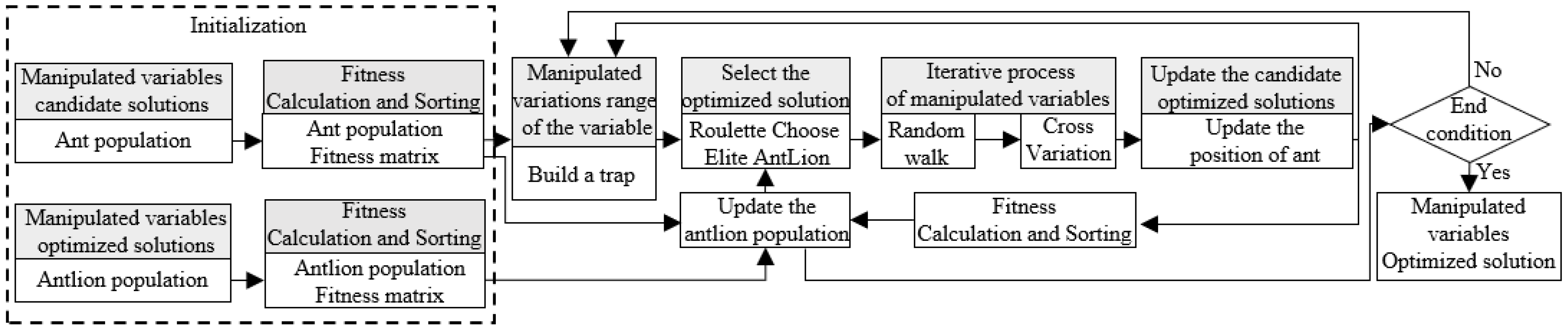
The optimization of the manipulated variables setpoint based on the IALO for the MSFR is designed to optimize the manipulated variables based on the input target value of the MSFR. The optimization is performed using the IALO algorithm, with the strategy diagram shown in
Figure 5. The module randomly generates candidate solutions for the manipulated variables and their optimized counterparts. The MSFR prediction model is then used to predict the MSFR for each solution, from which the fitness is calculated. The antlion algorithm attracts ants toward the optimal manipulated variables solutions by constructing traps. The ants adjust their positions through random walks, while the elite antlions guide the search process. The solutions for both ants and antlions are merged and sorted, and continuously updated until the termination conditions are met. The optimized manipulated variables are ultimately output to ensure the MSFR reaches the target value. In the event of a change in the operating conditions, such as furnace grate speed, the manipulated variables will be re-optimized.
The objective function
and fitness function
for the optimization of the MSFR are presented by the equations as follows:
where
and
represent, respectively, the measured and predicted values of the MSFR for the
i-th sample. The value of
is determined via the MSFR prediction model.
Table 1 shows the relationship between the improved antlion optimizer and the MSFR parameter optimization problem. The ants represent candidate solutions for the manipulated variables, the antlion represents the optimized solution for the manipulated variables, and the elite antlion represents the global optimized solution for the manipulated variables.
The antlion optimization algorithm draws inspiration from the predatory behavior of antlions in the natural realm and their interactions with ants. The algorithm involves a series of steps to find the optimal solution, including the random walk of ants, the construction of traps by the antlions, ants being trapped, the antlions capturing their prey, and the reconstruction of traps. The process is described as follows:
- (1)
The random walk of ants and the normalization process.
In the given equation, the cumulative
is calculated, and
rand represents a random number uniformly distributed within the interval [0, 1].
where
and
represent, respectively, the minimum and maximum values of the random walk for the
s-th dimension of the manipulated variables;
and
denote the minimum and maximum values of the manipulated variables in the
l-th iteration for the
s-th dimension; and
E is the error between the predicted and target values of the MSFR. The five-dimensional manipulated variables (
) are primary airflow, secondary airflow, secondary fan outlet air pressure, boiler steam drum pressure, and economizer feedwater flow.
Two improvements are proposed based on the antlion optimization algorithm to tackle the problems of premature convergence and getting trapped in local optima during the optimization of the MSFR manipulated variables. Firstly, an adaptive step-size factor is introduced during the random movement of the ants, which dynamically adjusts the search step size to enhance search efficiency and avoid premature convergence. Secondly, during the update of the ants’ positions, crossover and mutation operations from genetic algorithms are integrated to increase the diversity of the population. It can prevent the algorithm from converging to local optima and enhance its global search capability.
Improvement 1: The position update strategy is given by the following equation:
where
L denotes the maximum number of iterations, and
l represents the current iteration number.
In the given equation, and represent the lower and upper bounds of the search space for the s-th dimension of the MSFR.
- (2)
The antlion constructs traps that affect the random movement of ants within the search domain. This effect can be represented as follows:
where
and
represent, respectively, the minimum and maximum values of the manipulated variables in the
s-th dimension during the
l-th iteration; and
represents the position of the antlion in the
s-th dimension during the
l-th iteration.
- (3)
To simulate the process of ants approaching the antlions, the boundaries of the random movement should be gradually narrowed.
In the given equation,
,
l represents the current iteration index, and
L represents the maximum number of iterations, while
V must adhere to the following condition:
- (4)
During the process of the antlion capturing prey, if the value of the objective function of an ant is superior to that of the selected antlion, the position of the antlion will be replaced by the most recent position of the captured ant, thereby enhancing the probability of capturing ants. The equation is presented as follows:
During the iteration process, the antlion with the highest fitness value in each generation is selected as the elite antlion. Additionally, another antlion is selected via the roulette wheel selection method. The random movements of all other ants are attracted to these two antlions. The equation is presented as follows:
where
and
denote the positions of the ant after conducting a random movement, when the ant has to choose between the normal and elite antlion via the roulette wheel selection method during the
l-th iteration.
3.2.3. PI Control System for MSFR Based on Reinforcement Learning
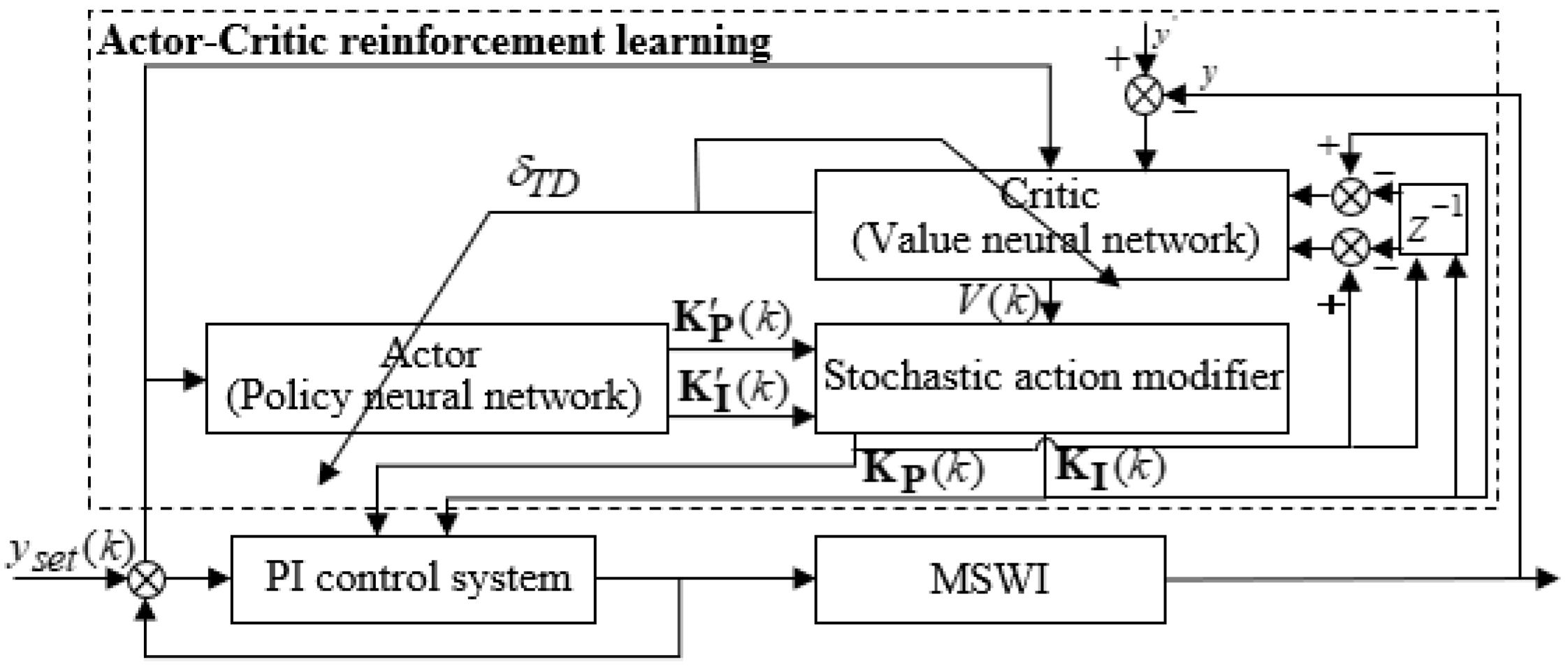
Traditional PI control systems perform suboptimally when confronted with strong nonlinearities and time-varying systems. In such cases, operators need sufficient experience to adjust the parameters manually. However, manual adjustments are time-consuming and often fail to achieve the desired results, especially in complex environments. To address this issue, this study adopts a reinforcement learning framework based on the actor–critic architecture and proposes a PI tuning method, as illustrated in
Figure 6. The control system consists of three components: the actor (policy neural network), the critic (value neural network), and the Stochastic Action Modifier. Firstly, the actor (policy neural network) generates reference PI manipulated variables based on the setpoints of the manipulated variables and the grate speed provided by the optimization layer. Next, the critic (value neural network) computes the value function estimate based on the setpoints of the manipulated variables and the grate speed provided by the optimization layer. Finally, the Stochastic Action Modifier combines the reference PI values generated by the actor with the value function estimate produced by the critic to obtain the actual PI parameters for optimized system control. When the grate speed operating condition changes, the optimization layer adjusts the corresponding setpoints of the manipulated variables, and the reinforcement learning system updates the PI parameters according to variations in the grate speed and manipulated variable setpoints.
An incremental PI controller is designed as defined in Equation (32),
where
and
, where
is the setpoint of the manipulated variables, and is the actual value of the manipulated variables.
The RBF network is used to approximate both the policy function of the Actor and the value function of the Critic [
43]. The policy and value neural networks share the input and hidden layers of the RBF network, which not only reduces memory requirements but also enhances learning efficiency. The AC learning structure based on RBF is illustrated in
Figure 7.
- (1)
Determination of PI values based on the RBF neural network
The three inputs of the RBF are
,
and
, as shown in Equation (33).
The radial basis function of the hidden layer adopts the Gaussian kernel function as follows:
The output layer has 3 nodes, and the outputs are
,
, and the value function of the value neural network. The mathematical expression is as follows:
where
represents the weight between the
h-th hidden unit and the critic output layer, and
represents the weight between the
h-th hidden unit and the output layer of the actor.
To resolve the exploration–exploitation dilemma, the outputs from the Actor are not directly passed to the PI controller. Instead, a Gaussian noise term
is added to the recommended PI parameters
coming from the Actor. Thus, the actual PI parameters are modified as shown in Equation (37). The magnitude of the Gaussian noise depends on
. When
is large, the noise term is small, and vice versa.
where
.
- (2)
Parameter update method for , , , and based on the gradient descent algorithm
The calculation of the error is as follows, using the temporal difference algorithm:
where
represents the value function, and
is the reward at
k-th time;
denotes the discount factor. The reward
R(
k) is defined as follows:
where
and
are the change proportional and integral gain of each manipulated variable at the current moment
k;
is the error value of each manipulated variable; and
and
are, respectively, the target value and measured value of the MSFR. The weights are updated using Equations (40) and (41),
where
and
are the learning rates of the policy neural network and the value neural network, respectively. The center
and center width
of the neurons are updated using Equations (42) and (43),
3.3. Realization Steps of the Intelligent Control Method for MSFR
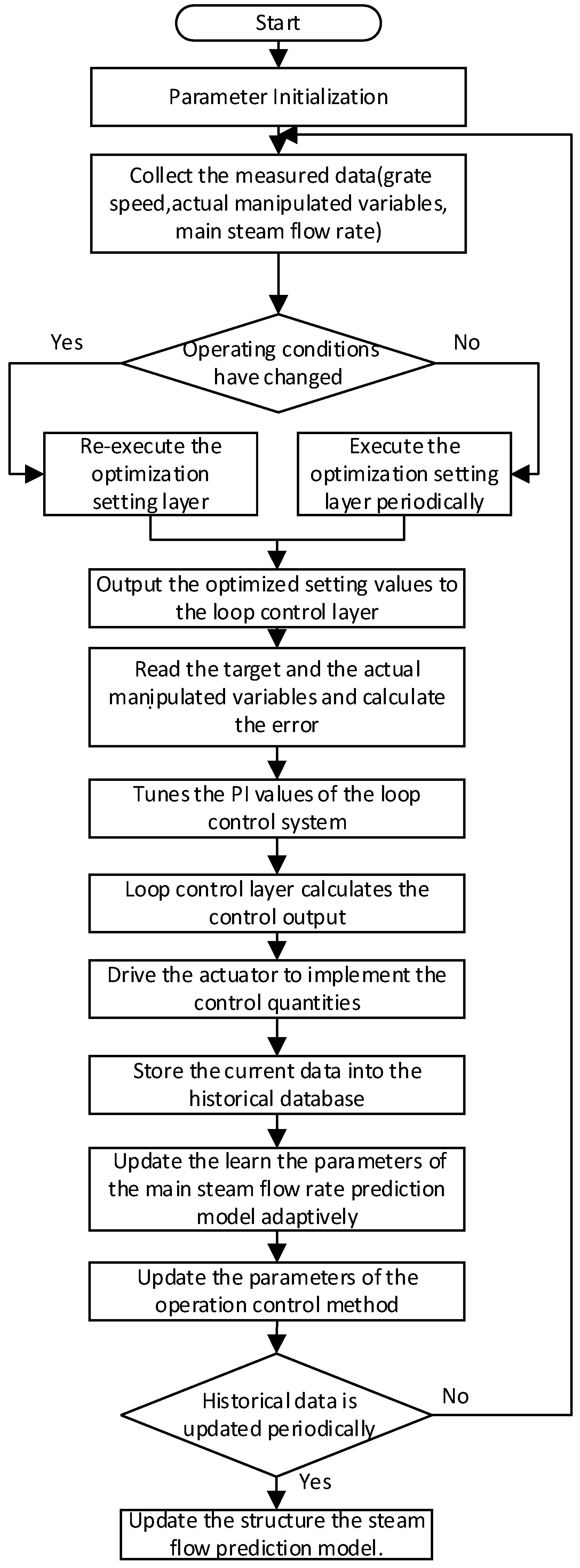
As shown in
Figure 8, the steps for implementing the two-layer intelligent control method for the MSFR are as follows:
Step 1: Parameter Initialization: The ant population, antlion population, maximum number of iterations, and search range are initialized, and an initial solution is randomly generated within the search range.
Step 2: Collect the measured data, including the grate speed, the actual control values, parameters, and the measured MSFR.
Step 3: Identify whether the working operating conditions have changed. If the grate speed changes, re-execute the optimization setting layer at once. Otherwise, execute the optimization setting layer periodically.
Step 4: Output the optimized setting values of the manipulated variables and send them to the loop control layer to execute.
Step 5: Compute the error between the target and the actual manipulated variables.
Step 6: The loop control layer tunes the PI values of the loop control system according to Equations (35)–(37) and implements the optimized setting values of the manipulated variables based on Equation (32).
Step 7: Drive the actuator to implement the control quantities.
Step 8: Store the current data into the historical database, and update the learn parameters of the MSFR prediction model adaptively.
Step 9: Update the parameters of the intelligent control method.
Step 10: Is the historical data updated periodically? If yes, update the structure of the steam flow prediction model. If no, back to step 2.
Figure 8.
The steps for implementing the two-layer intelligent control method.
Figure 8.
The steps for implementing the two-layer intelligent control method.
4. Experiments and Analysis
In this section, we designed three experiments to validate the efficacy of the intelligent control approach for the MSFR presented in this article. All the experiments were conducted using on-site data collected from the DCS system of a forward-moving grate furnace in a waste incineration plant.
4.1. Verification of the MSFR Prediction Model Based on RBF
In this study, a total of 5000 sets of experimental data were used. The range of sample variations in the manipulated variables (primary and secondary airflow, secondary fan outlet air pressure, boiler drum pressure, and economizer feedwater flow) is as follows: , , , and , and grate speed variations range is . We took 3500 sets (70%) of the data as the training set for the MSFR prediction model, and 750 sets (15%) were used as the validation set. Another 750 sets (15%) were taken as the test set for the MSFR prediction model.
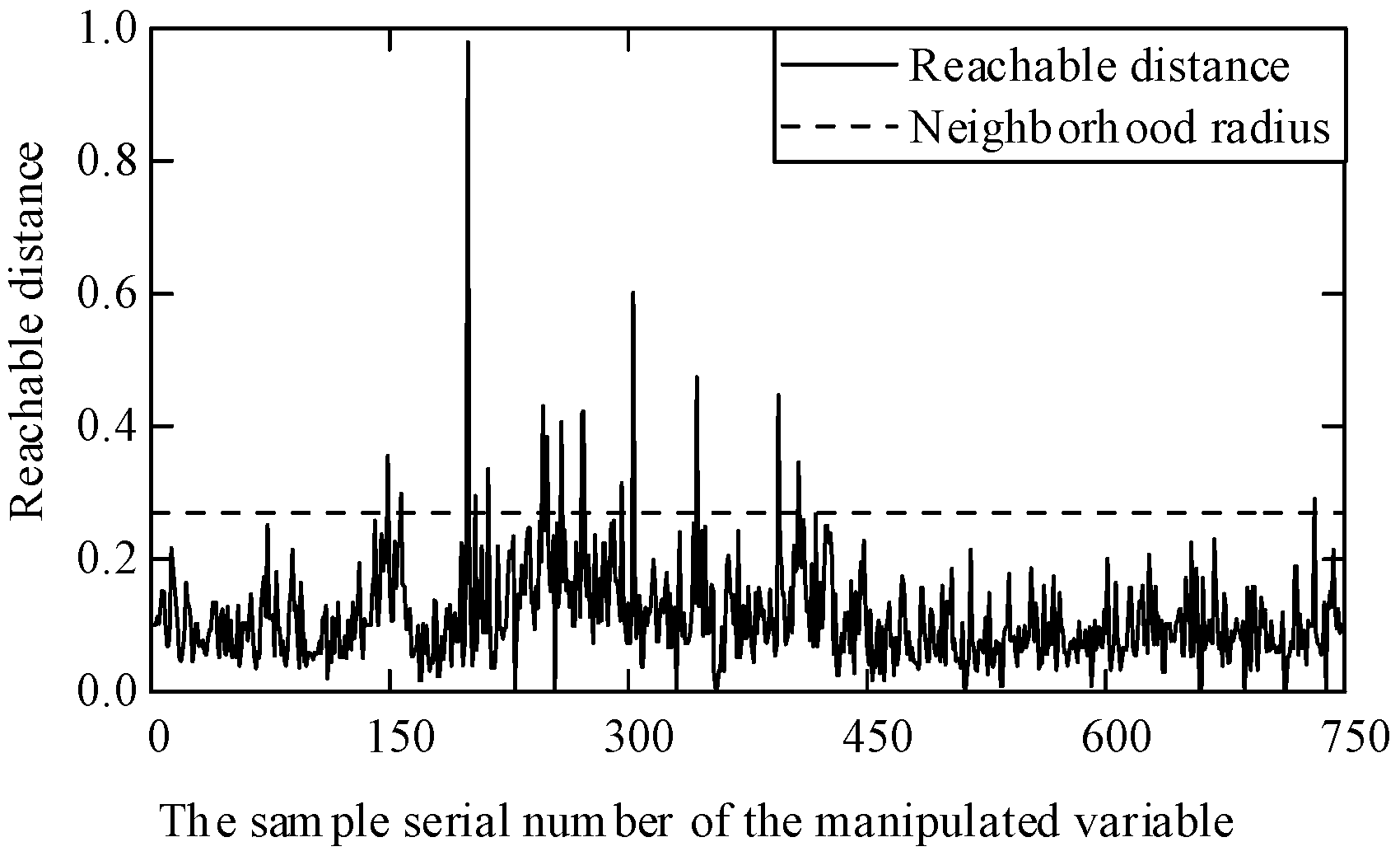
The OPTICS clustering algorithm uses six input variables of the MSWI system (primary airflow, secondary airflow, economizer feedwater flow, boiler drum pressure, secondary fan outlet air pressure, and grate speed under operating conditions) for clustering. The optimal combination of minimum sample size and neighborhood radius is determined through orthogonal experiments, with each parameter set at 5 levels. The minimum sample size is set at five levels: 4, 8, 12, 16, and 20. The initial neighborhood radius is set to infinity, and based on the reachable distance results obtained from the experiments, the neighborhood radius is divided into five levels: 0.11, 0.19, 0.27, 0.35, and 0.43.
Table 2 shows the number of clusters for each parameter combination.
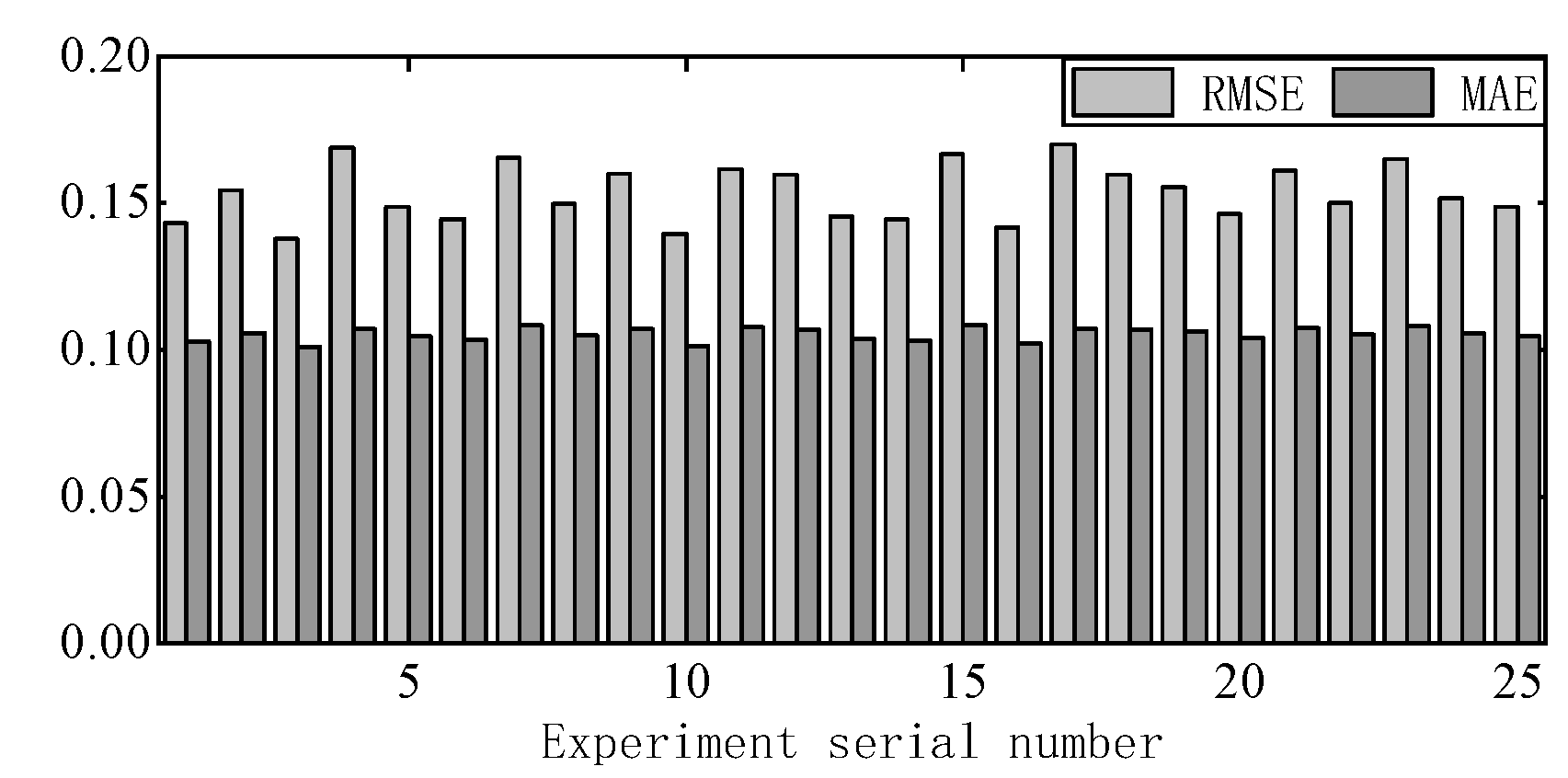
The neuron centers for each group of experiments are calculated using Equation (12). The model is trained using the training set data, with RMSE and MAE as performance evaluation metrics to determine the optimal parameter combination.
Figure 9 shows the RMSE and MAE for each experimental combination. As can be seen from the figure, the model performs best when
. Under this condition,
Figure 10 shows the reachable distance sorting chart, while the corresponding neuron centers are listed in
Table 3.
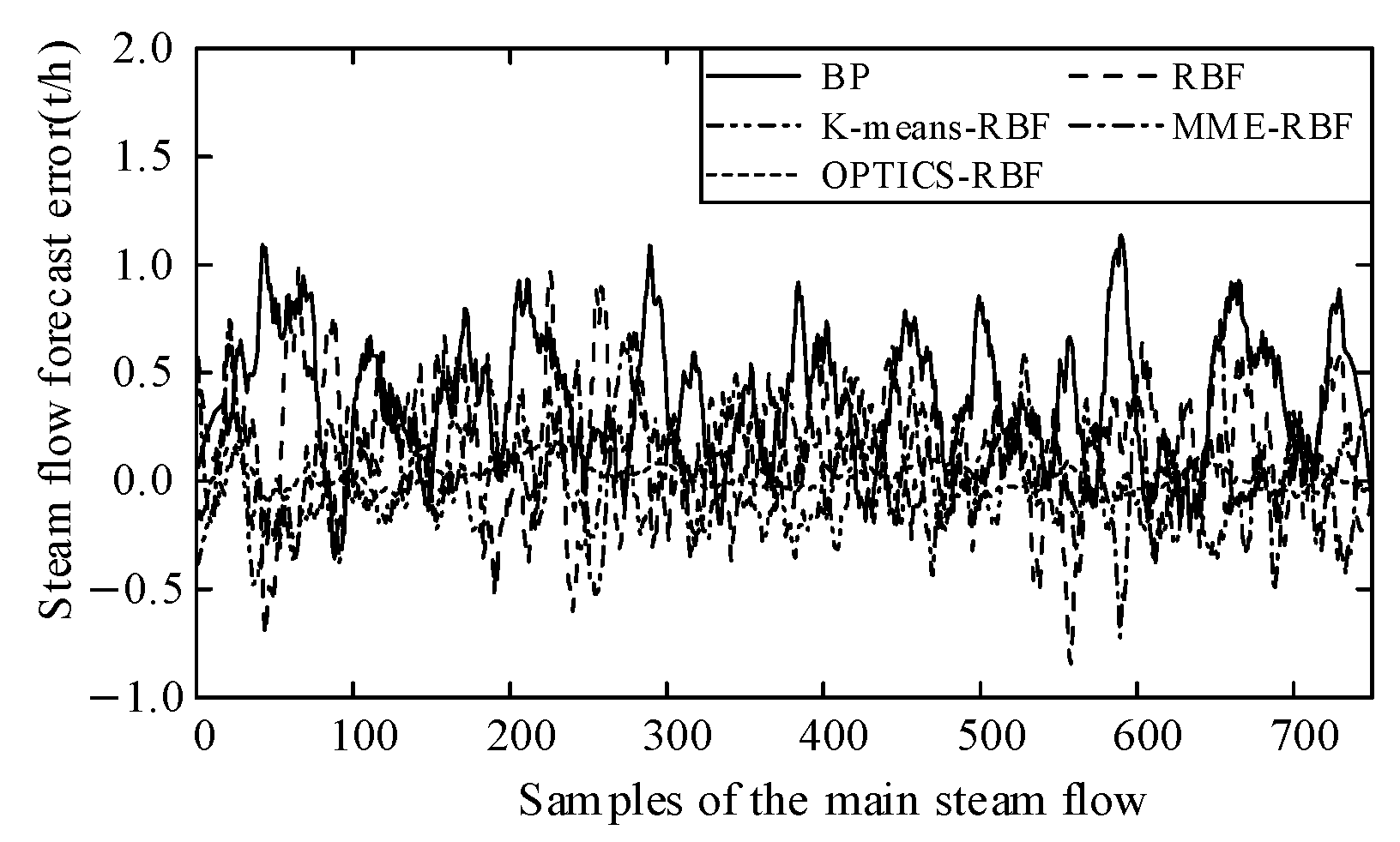
To verify the effectiveness of the forecasting model, it is compared with the widely used BP neural network, RBF neural network, maximum matrix element (MME) RBF neural network, and K-means clustering-based RBF neural network models. The root mean square error is selected as the evaluation metric for the models. The training RMSE of each model is shown in
Figure 11 and
Table 4. As can be seen, the proposed OPTICS-RBF neural network outperforms the other four neural networks in terms of faster convergence and higher accuracy.
Experiments were conducted on the test set.
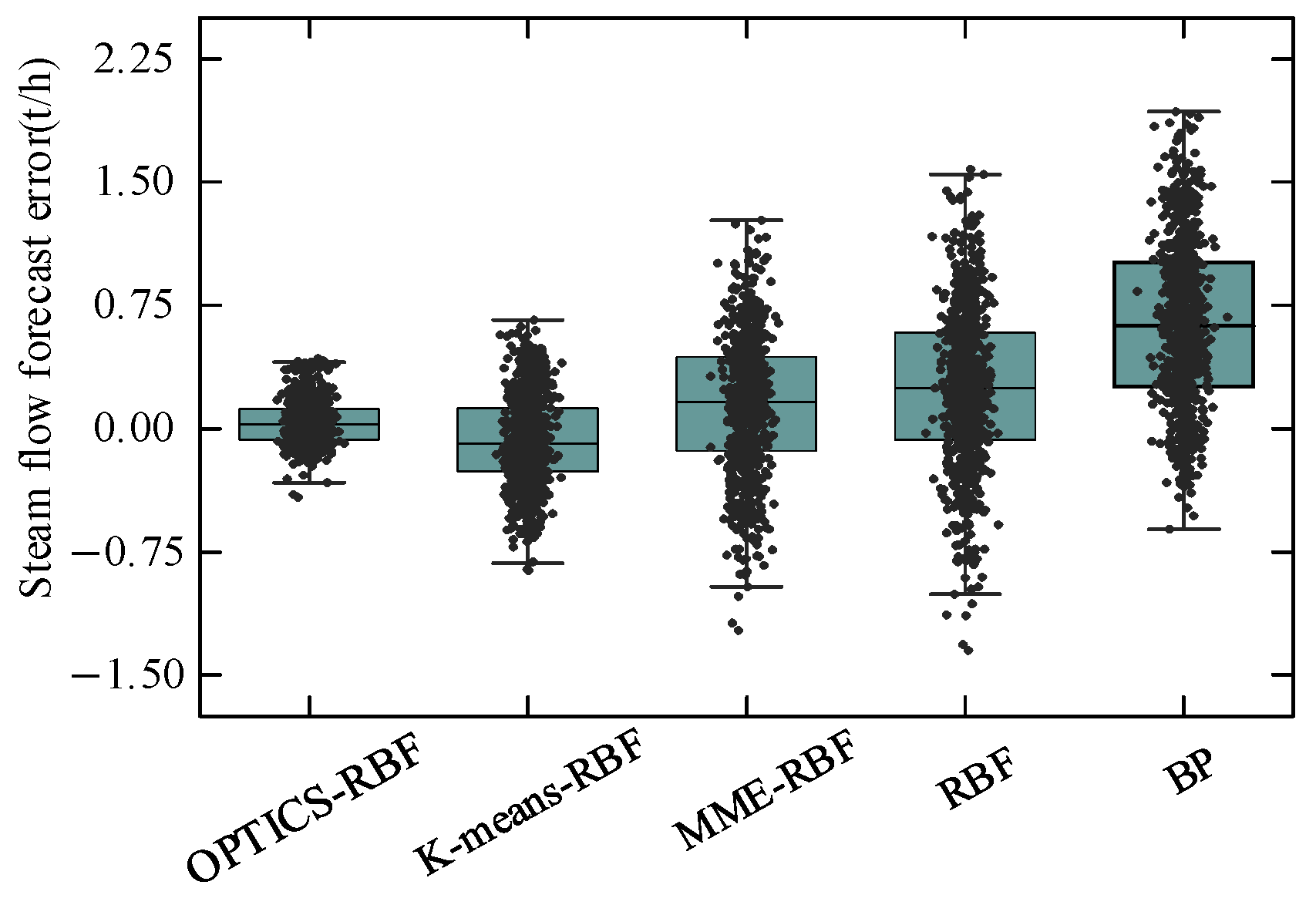
Figure 12 and
Table 5 present the errors between the predicted and actual values of the MSFR for five forecasting models on the test set.
Figure 13 further visualizes the error distribution using a box plot. The results show that the OPTICS-RBF neural network has the smallest error range, which falls between [−0.420, 0.429].
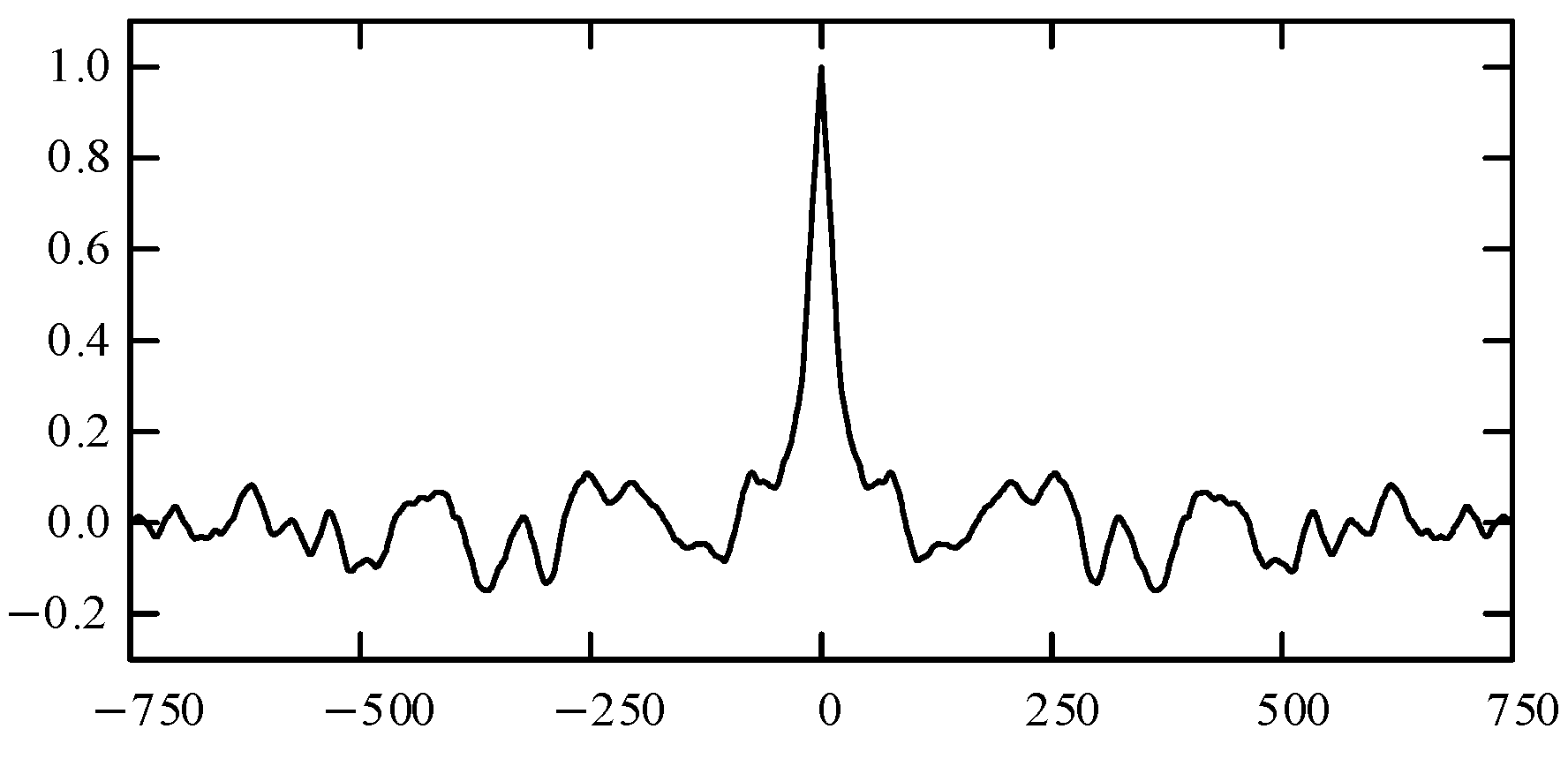
To further validate the effectiveness of the proposed MSFR forecasting model,
Figure 14 shows the autocorrelation function of the normalized deviation between the predicted MSFR and the actual MSFR. From the figure, it can be observed that the autocorrelation coefficients of the deviation sequence mostly fall within the 95% confidence interval, indicating that the residual sequence can be considered as white noise.
4.2. Validation of the Intelligent Control Method
To verify the effectiveness of the IALO, it is compared with the widely used Particle Swarm Optimization (PSO) algorithm and Artificial Bee Colony (ABC) optimization algorithm. First, comparative tests are performed on the standard test functions shown in
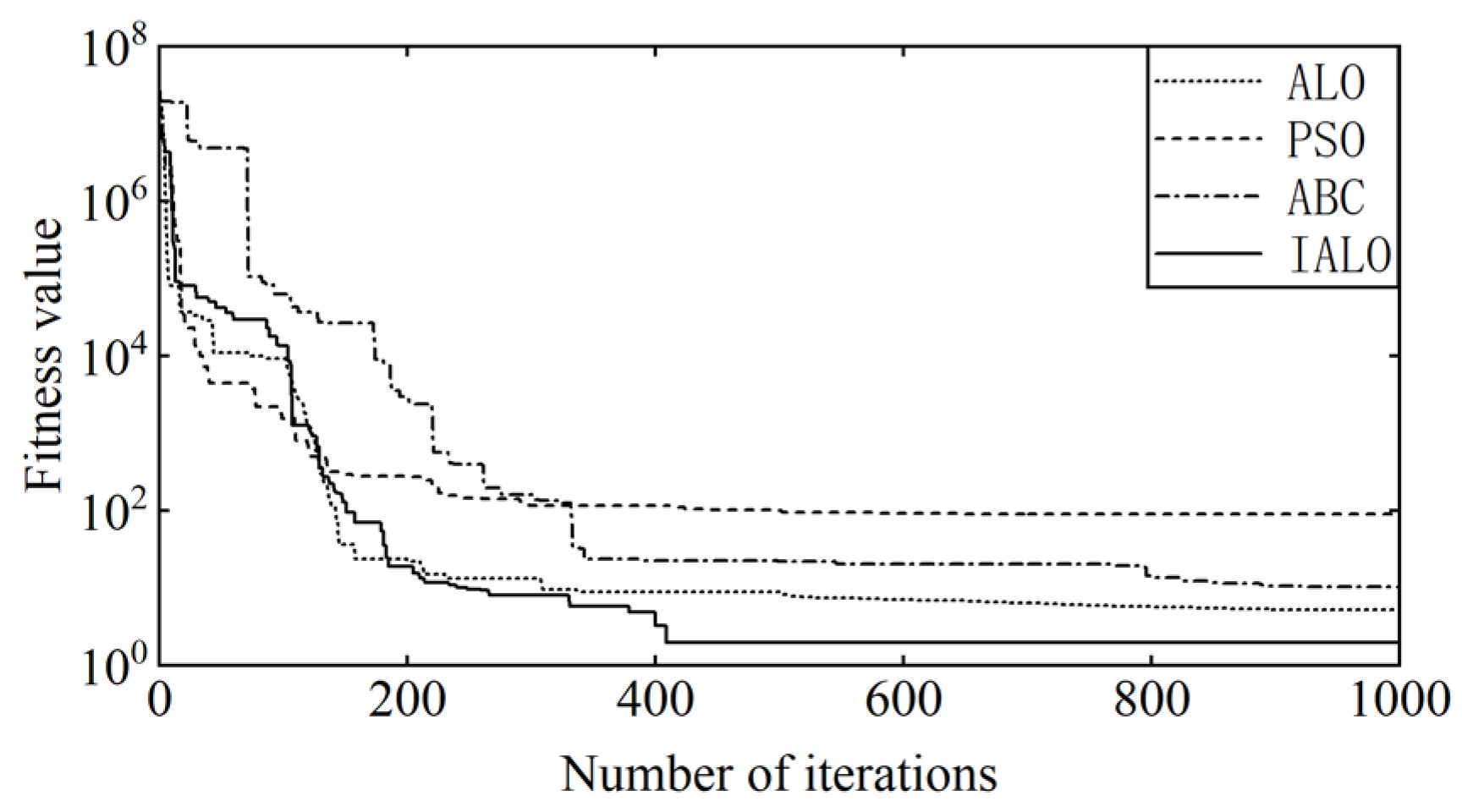
Table 6, where F5 is a unimodal benchmark function and F12 is a multimodal benchmark function. A total of 50 candidate solutions are set, and the number of iterations is 1000. For the unimodal benchmark function F5, the fitness change curve in
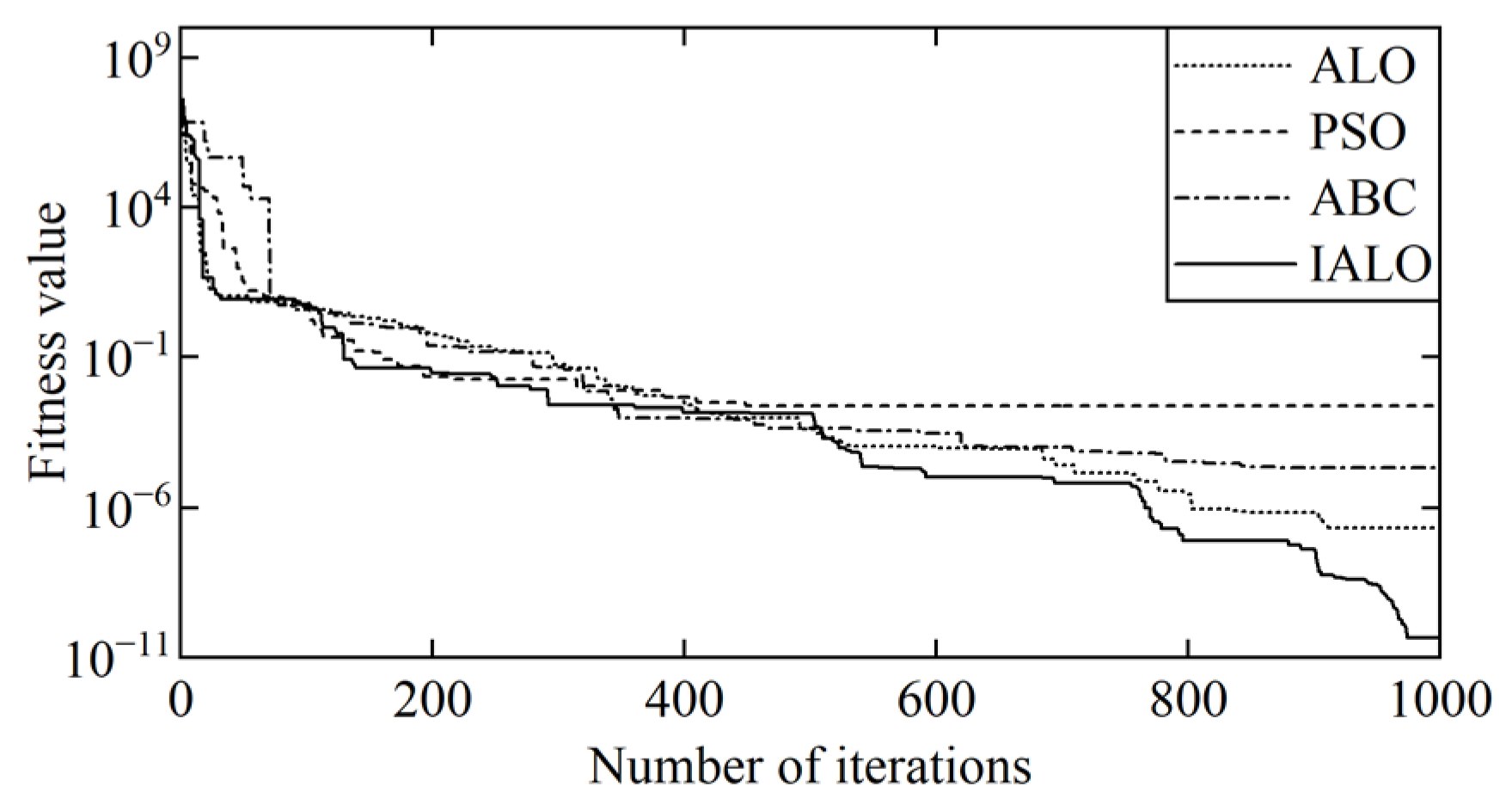
Figure 15 shows that the ALO achieves a fitness value of 5.2827 at 957 iterations, PSO reaches a fitness value of 90.5459 at 988 iterations, ABC achieves a fitness value of 10.4729 at 922 iterations, and IAO achieves a fitness value of 1.9508 at 410 iterations. For the multimodal benchmark function F12, the fitness change curve in
Figure 16 shows that ALO achieves a fitness value of 2.19 × 10
−7 at 912 iterations, PSO reaches a fitness value of 0.0024 at 449 iterations, ABC achieves a fitness value of 2.12 × 10
−5 at 872 iterations, and IALO achieves a fitness value of 4.69 × 10
−11 at 974 iterations. From the test results in
Table 7, it can be concluded that the IALO proposed in this article exhibits better convergence and higher accuracy compared to ALO, PSO, and ABC.
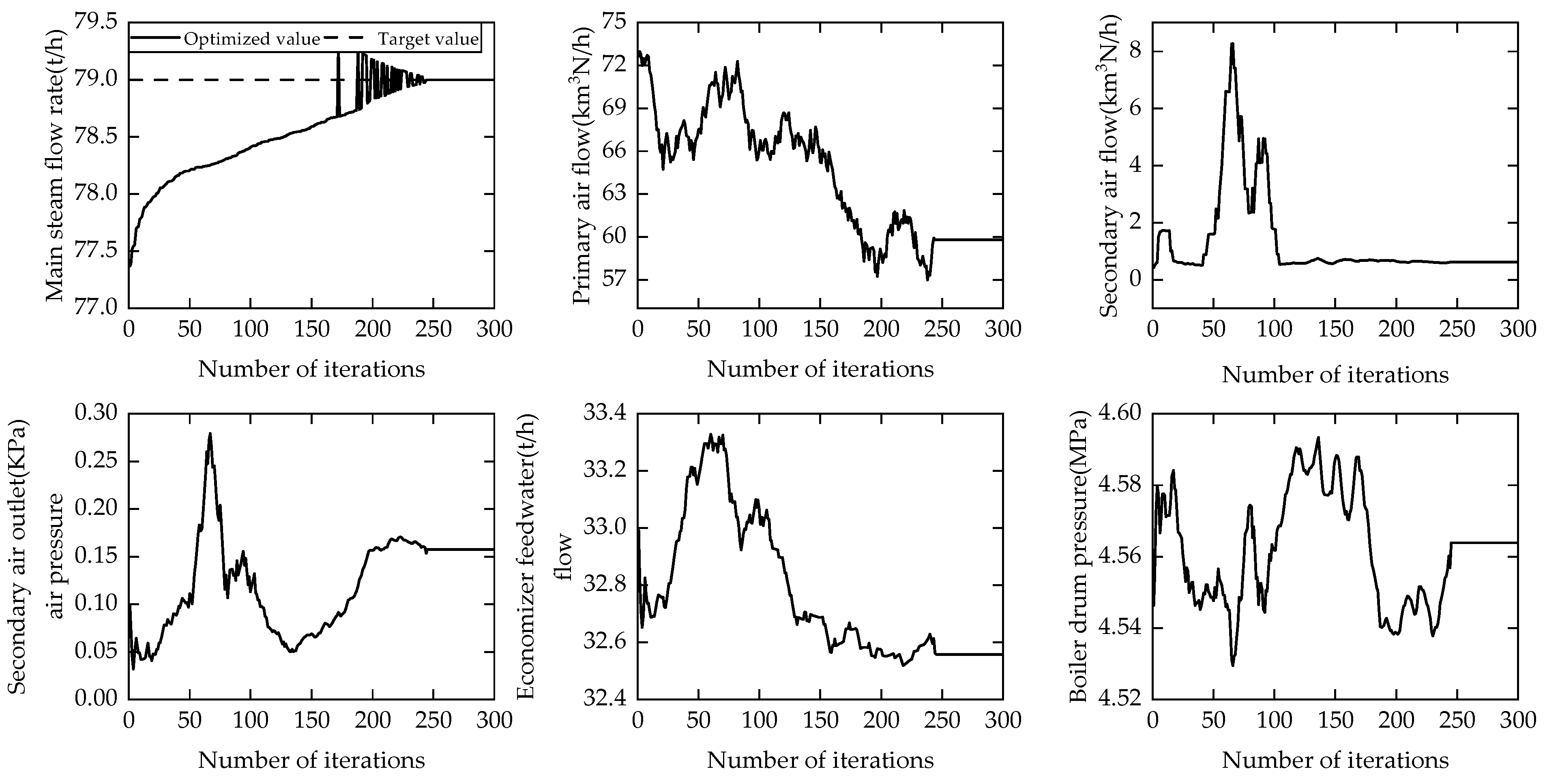
When validating the optimization setting of the manipulated variables based on IALO, the maximum number of iterations is set to 300, and the ant population is set to 40. Also, the antlion population is set to 40. The target MSFR value is 79. The search ranges of the primary airflow, secondary airflow, secondary fan outlet air pressure, boiler drum pressure, and economizer feedwater flow are
,
,
,
and
. The optimization process is shown in
Figure 17. After 243 iterations, the target values are found, where the corresponding parameters are primary airflow of 59.8, secondary airflow of 0.622, secondary fan outlet air pressure of 0.158, boiler steam drum pressure of 4.564, and economizer feedwater flow of 32.558.
4.3. Validation of the Effectiveness of the Intelligent Control Method Under Varying Operating Conditions
The purpose of this experiment is to verify whether the intelligent control method can effectively control the MSFR when operating conditions change.
First, the optimal hyperparameter combination for each loop of the reinforcement learning control system is determined through orthogonal experiments. Based on experience, the learning rate is set at three levels: 0.001, 0.01, and 0.02; the discount factor is set at three levels: 0.90, 0.95, and 0.99. The number of hidden layer center nodes and their positions in the RBF network are determined using the OPTICS algorithm. This algorithm performs clustering analysis on the input data, effectively identifying the appropriate center points and the number of nodes. Based on the optimization results from the OPTICS algorithm, the network’s topology is determined to be 3-8-4. The experimental design is shown in
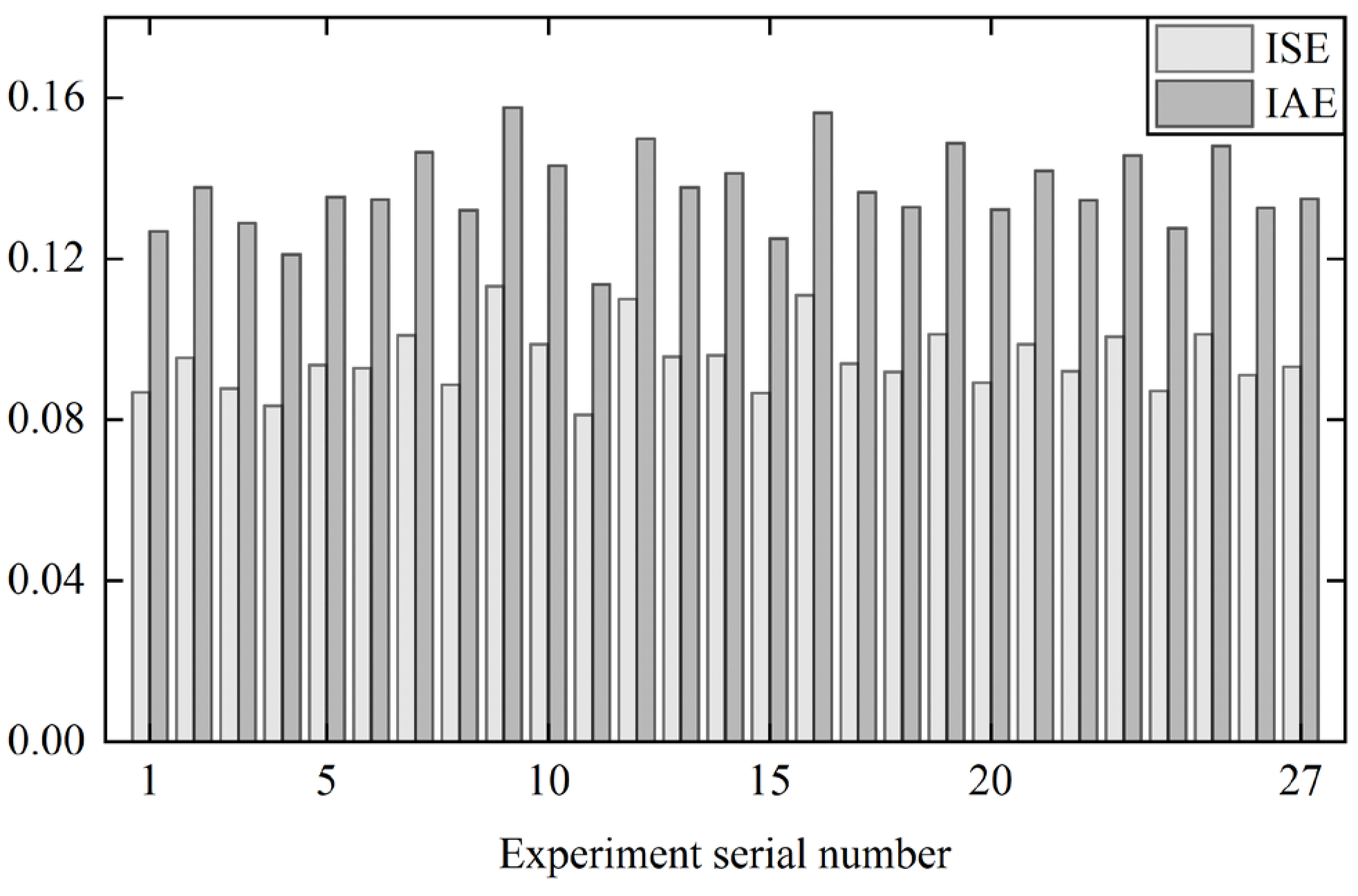
Table 8, using the standard L₍
27₎(3
13) orthogonal table for combination design. A total of 100 groups are randomly selected from the dataset for the experiment, and the ISE and IAE are used as evaluation metrics.
Figure 18 shows the experimental results of various hyperparameter combinations for the primary airflow PI control system. It can be observed that Experiment Group 11 performs the best.
Table 9 presents the optimal hyperparameter combinations for all sub-loop PI control systems obtained through the orthogonal experiment.
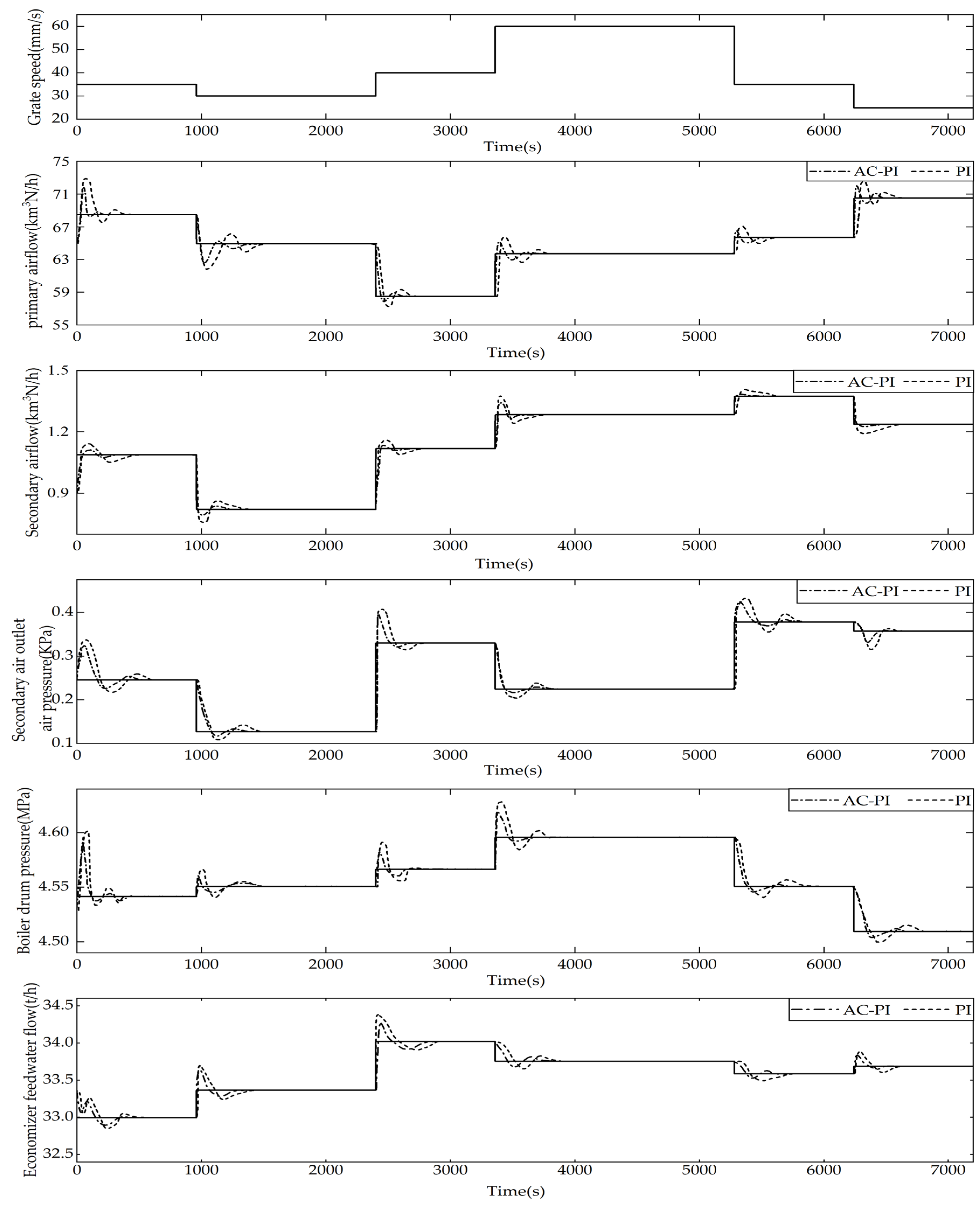
Figure 19 shows that when the grate speed changes, the optimization setting module of manipulated variables based on IALO can recognize the change in operating conditions and automatically updates the setting values of the manipulated variables (
) to better fit the changed conditions. The updated setting values are then sent to the reinforcement learning-based PI MSFR control system to execute the new setting values.
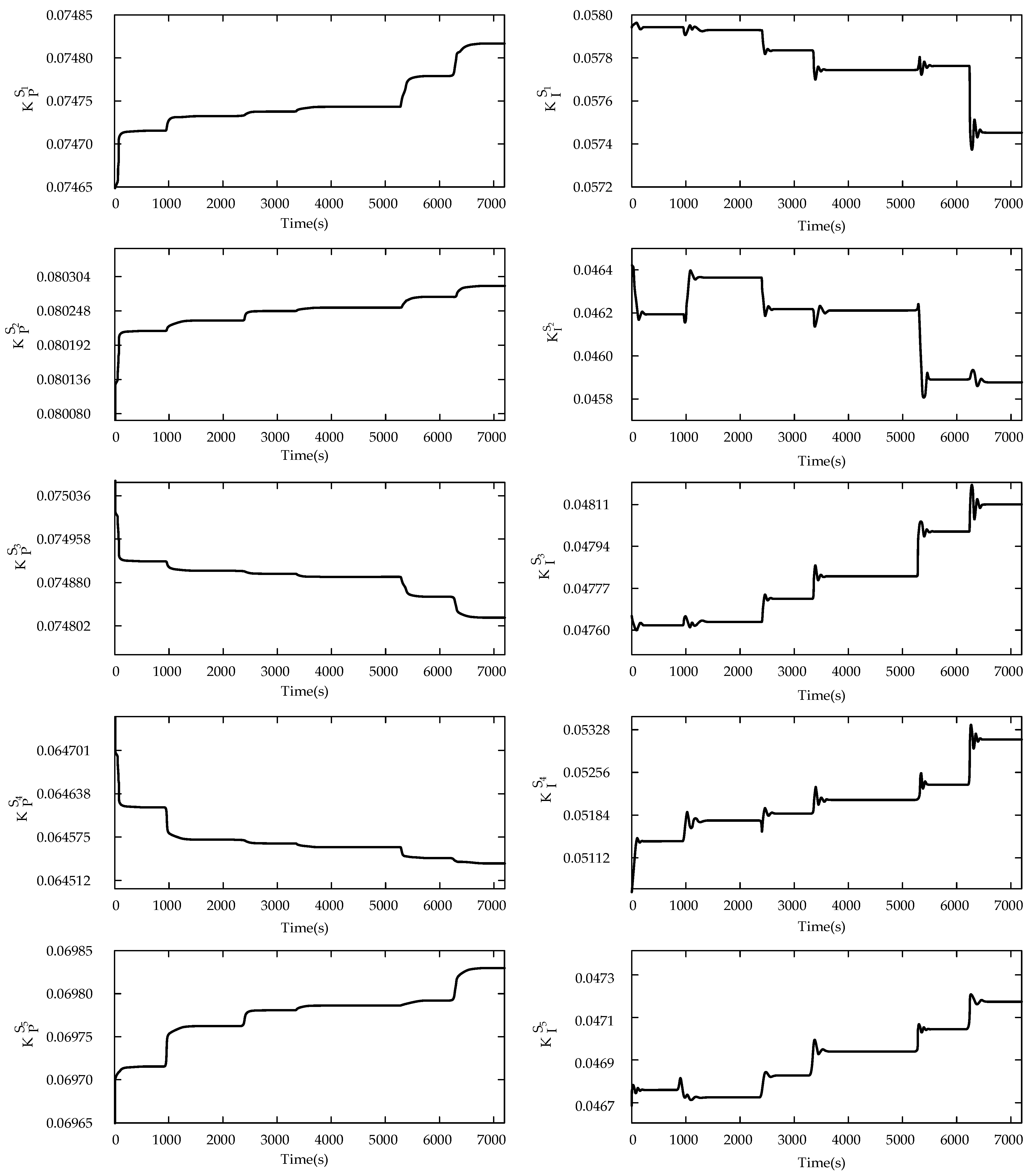
The loop control system automatically tunes the PI parameters according to the changed operating conditions, enabling rapid tracking of the updated manipulated variables settings.
Figure 20 shows the process of adaptive adjustment of PI parameters in the AC-PI control system, and
Table 10 lists the PI setpoints of the PI control system. The actual manipulated variables of the control system are then sent to the object model of the MSFR in the MSWI process [
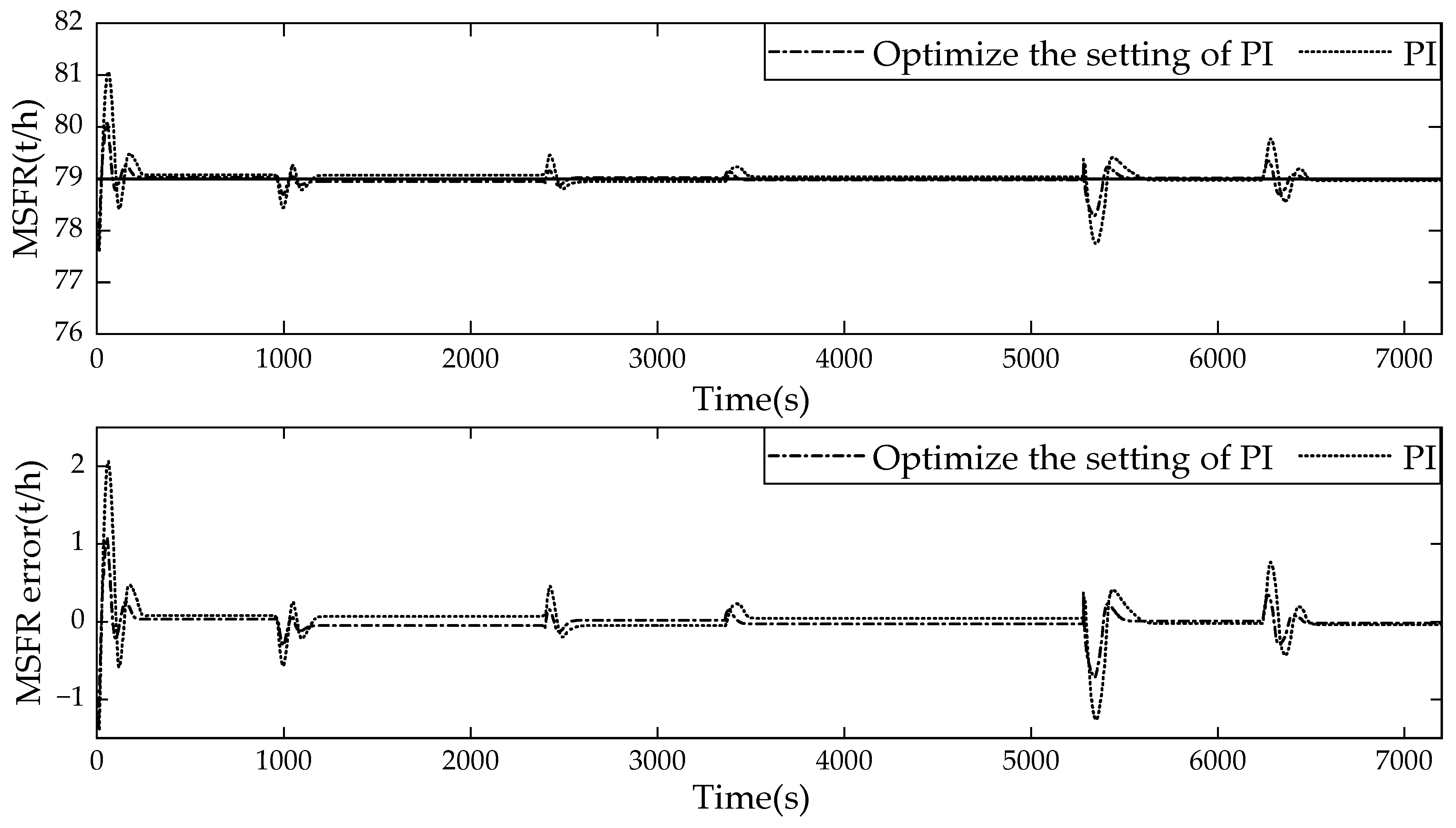
44], and the controlled MSFR results are shown in
Figure 21. It can be seen that, compared to traditional PI methods, the intelligent control method proposed in this article can control the MSFR within the target range.
Table 11 shows the compared results with traditional PID methods, such as QDRNN-PID from the literature [
44]. The comparison is evaluated based on integral square error (ISE), absolute error integral (AIE), maximum deviation, average quantization overshoot, average rise time, and average response time. It can be seen that the proposed method demonstrates good transient response, stability, and anti-interference ability, showing superior performance.
4.4. Comprehensive Analysis
The experimental results show that when the grate speed changes, indicating a shift in the operating conditions of the solid waste incineration process, the proposed method effectively detects these changes and re-optimizes the key control variables (such as primary airflow, secondary airflow, secondary fan outlet air pressure, boiler drum pressure, and economizer feedwater flow). By employing the IALO method, the system can rapidly optimize the setpoints of the control variables based on the target MSFR, ensuring alignment with the current operating conditions. The loop control layer then implements the new optimized setpoints. In the loop control layer, the PI controller parameters can be dynamically adjusted in response to changing operating conditions. Experimental results demonstrate that when the working operating conditions change, the optimized setpoints are recalibrated accordingly, and the control loop can quickly track the new setpoints, thereby maintaining the MSFR within the target range.
5. Conclusions
The MSFR in the MSWI process is one of the key factors for the stable operation of the incineration system. Due to its strong coupling, nonlinearity, and multivariable nature, effectively controlling the MSFR presents significant challenges. To address the control needs of the MSWI process’s MSFR, a two-layer intelligent control method is proposed, consisting of an optimization setting layer and a loop control layer. This method can adaptively adjust the setpoints of key manipulated variables under varying operating conditions. The loop control system then implements these setpoints, ultimately ensuring that the MSFR is controlled within the target range. Simulations based on industrial sample data collected from the field were conducted to verify the effectiveness of the proposed method.
Although this study has made progress in the control strategy for MSFR, several issues require further attention. For example, the two-layer structure control method used in this paper helps alleviate the computational burden by distributing algorithms across different devices. However, it inevitably increases computational costs. The system is also highly sensitive to sensor noise, which can interfere with data collection and affect control decisions. This issue is particularly significant in developing countries, where computational resources are limited and may become more pronounced.
Additionally, there is a lack of systematic research on the trade-offs between energy recovery and toxic emissions (e.g., dioxins). This gap arises mainly from the asymmetry of monitoring data—high-frequency energy recovery data and low-frequency dioxin sampling data are difficult to correlate effectively.
Future research will involve empirical experiments in collaboration with industry partners. The goal is to develop a multi-objective optimization model that provides innovative solutions for achieving energy-environmental synergy. Moreover, another important aspect is balancing MSFR stability with emission control. Future studies could focus on developing a multi-objective function that integrates both MSFR stability and emission control. This approach would optimize both the control accuracy of the MSFR and emission control, offering a more comprehensive and effective solution.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}