1. Introduction
With the rapid advancement of logistics automation and smart transportation, unattended truck scale systems have been widely deployed in logistics, manufacturing, and related industries, significantly enhancing weighing efficiency and intelligent management [
1]. However, the lack of effective supervision mechanisms has led to frequent incidents of weighing fraud, undermining system reliability. Traditional video playback-based detection methods suffer from time lags and omission risks, limiting their effectiveness in real-time fraud prevention. Therefore, there is an urgent need for intelligent recognition technologies to enable timely and accurate anti-fraud monitoring. Human pose estimation, a key technique for identifying human intervention, offers a promising solution by leveraging advances in artificial intelligence and machine learning to enhance the intelligent supervision capabilities of unattended truck scale systems.
Conventional anti-cheating measures primarily involve additional hardware installations and enhanced manual monitoring, such as infrared detectors, sensor-encrypted communications, and RFID technologies to counteract common fraudulent behaviors [
2,
3,
4]. With the evolution of deep learning, data-driven intelligent prevention and control systems based on image recognition have emerged as a promising research direction, substantially improving the monitoring of abnormal human activities or intrusions into truck scale areas [
5,
6,
7]. To further enhance detection precision, advanced methods based on human contour variations, 3D skeleton modeling, biomechanical features, and graph-structured behavior analysis have been proposed [
8,
9,
10,
11,
12,
13]. Meanwhile, background segmentation and foreground comparison techniques, through methods like background subtraction, edge detection, and connected component analysis, have effectively improved the accuracy of non-vehicle object detection [
14,
15,
16,
17].
Human pose estimation, a pivotal research area in computer vision, has been extensively applied in human–computer interaction, sports analytics, virtual reality, and rehabilitation [
18,
19,
20]. While traditional visual sensor-based approaches have achieved initial success, challenges such as illumination changes, occlusions, and complex motion recognition persist [
21]. Advances in deep learning and sensing technologies have introduced depth image-based joint detection methods, significantly improving accuracy by integrating implicit and explicit localization strategies [
22]. In dynamic environments, pose estimation frameworks that incorporate body part detection and multi-dimensional feature extraction have improved the robustness of action recognition [
19,
20]. Additionally, non-invasive posture detection based on fiber Bragg grating (FBG) sensors has shown promising applications in rehabilitation and virtual interaction [
23], and open-source systems like OpenPose have demonstrated strong resilience under occlusions and non-frontal viewing conditions [
21]. Moreover, gait recognition methods utilizing spatiotemporal feature modulation have achieved high accuracy on large-scale datasets [
24] while skeleton extraction and dynamic modeling have supported specific applications such as basketball training monitoring [
25]. Nevertheless, achieving high-precision and efficient flexible joint detection in complex multi-person scenes remains a significant challenge, driving research toward attention mechanisms, hard example mining, lightweight architectures, and hybrid inference strategies [
26,
27,
28,
29,
30,
31,
32].
In summary, despite substantial progress in human pose estimation, challenges remain in achieving accurate detection under complex environments, especially when dealing with small-scale targets and the need for lightweight, real-time deployment in practical applications. These limitations hinder the development of intelligent systems that support automation and energy-efficient operation in industrial contexts. Motivated by the demand for sustainable and intelligent monitoring solutions, especially in unattended truck weighing systems, this study proposes a human joint point detection framework designed to enhance operational efficiency and reduce manual intervention. The main contributions of this work are as follows:
A channel hourglass convolution module is proposed to symmetrically compress and recover channel dimensions, improving feature extraction while reducing model complexity, striking a balance between accuracy and efficiency for edge deployment.
A hybrid attention mechanism integrating spatial and channel attention with depthwise separable convolution is designed, significantly enhancing robustness and representational capacity in complex environments.
A multi-target pose estimation system for truck scales anti-cheating scenarios is constructed, combining cascade detection and lightweight strategies to achieve real-time performance and strong generalization, demonstrating broad potential for applications in intelligent transportation and industrial supervision.
2. Background
BlazePose is a lightweight convolutional neural network architecture developed by Google, specifically designed for real-time pose estimation on mobile terminals. It primarily targets single-person pose estimation tasks and can achieve a stable inference speed exceeding 30 frames per second on mobile devices such as smartphones. The model efficiently detects 33 keypoint coordinates of the human body and demonstrates a certain degree of robustness against occlusion. In terms of performance, the BlazePose Heavy model achieves a PCK@0.2 of 84.1% on the AR dataset and 77.6% on the Yoga dataset, where PCK@0.2 refers to the Percentage of Correct Keypoints within 20% of the torso length. These results reflect its strong capability in human pose estimation under various conditions.
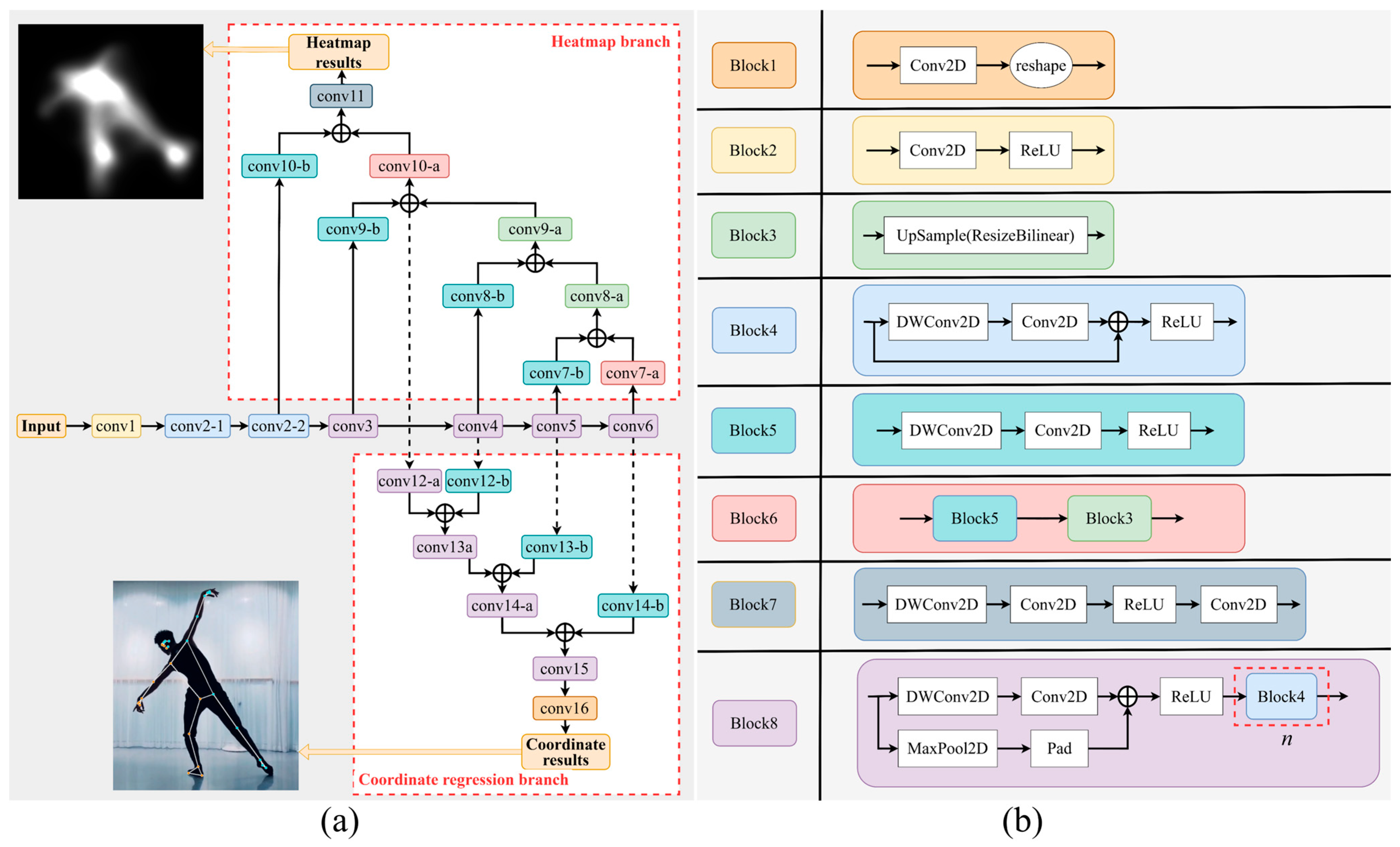
The BlazePose network comprises 24 convolutional modules that incorporate a combination of deep separable convolutions, standard convolutions, max pooling, and upsampling operations. Residual connections are employed to enhance feature propagation and network representational capacity. The network takes RGB images as input and produces two output branches: the heatmap branch, which generates probability heatmaps for human joints, and the coordinate regression branch, which directly regresses the precise coordinates of the joints. The overall architecture is illustrated in
Figure 1a, where different convolutional modules are distinguished by different colors, and the internal structure of each module is detailed in
Figure 1b.
Early approaches to human keypoint detection often relied on direct coordinate regression, which typically adds a fully connected layer before the output layer to directly predict joint coordinates in an end-to-end fashion. This method offers fast training and inference speeds; however, it tends to overfit to specific datasets and lacks strong spatial generalization capabilities. The heatmap regression approach was subsequently introduced. In this method, the location of each joint in the training image is represented by a 2D Gaussian probability distribution centered at the joint position, which can be formally expressed as follows:
where
denotes the pixel coordinates of the feature map,
represents the pixel coordinates of the annotated joint location, and
is a hyperparameter that controls the width of the Gaussian distribution and indicates the degree of decrease in the confidence of the joint point.
Compared with direct coordinate regression, heatmap regression provides more spatially guided supervision, enabling the network to converge toward target joint positions more effectively. It helps to better optimize the network weights, thereby improving the inference accuracy. Moreover, heatmap regression is compatible with fully convolutional network designs, which significantly reduces the number of training parameters and improves training efficiency.
From an architectural perspective, the BlazePose network integrates both heatmap regression and coordinate regression approaches. During training, the convolutional modules associated with the coordinate regression branch are initially frozen. The coordinates of the joint points marked from the dataset are used to generate Gaussian heatmaps which serve as the target outputs. The loss between the predicted heatmap and the real heatmap is then computed, and the network parameters are updated through backpropagation. Once the gradient descent of the heatmap branch stabilizes, that is, the loss gradient approaches zero, the training of this branch is considered complete.
Next, the network freezes the parameters of the heatmap branch, keeps the weights of the backbone network unchanged, and begins training the coordinate regression branch. As illustrated in
Figure 1a, the four dotted lines indicate that gradients from the coordinate regression branch do not propagate back to the backbone network. This gradient-blocking mechanism allows each branch to focus on its respective subtask during training. Such a separation not only helps to improve the quality of heatmap predictions but also enhances the accuracy of the final coordinate regression. The final output of the coordinate regression branch is a 51 × 1 feature vector, representing the x and y pixel coordinates of 17 key points along with their corresponding confidence scores p.
During the network training process, the loss function comprises two components, each corresponding to the optimization of the heatmap branch and the coordinate regression branch, respectively. For the heatmap branch, the binary cross-entropy (BCE) loss function is employed to quantify the discrepancy between the predicted heatmap and the true heatmap, and its expression is as follows:
where
represents the true value of the Gaussian heatmap generated according to the annotation,
represents the predicted value during the training process, and N represents the number of feature pixels.
For the coordinate regression branch, the Huber loss function is adopted to measure the prediction error of joint coordinates, and is defined as follows:
where
y represents the true coordinate value of the annotation,
represents the predicted coordinate value during training, and
is a hyperparameter representing the error threshold.
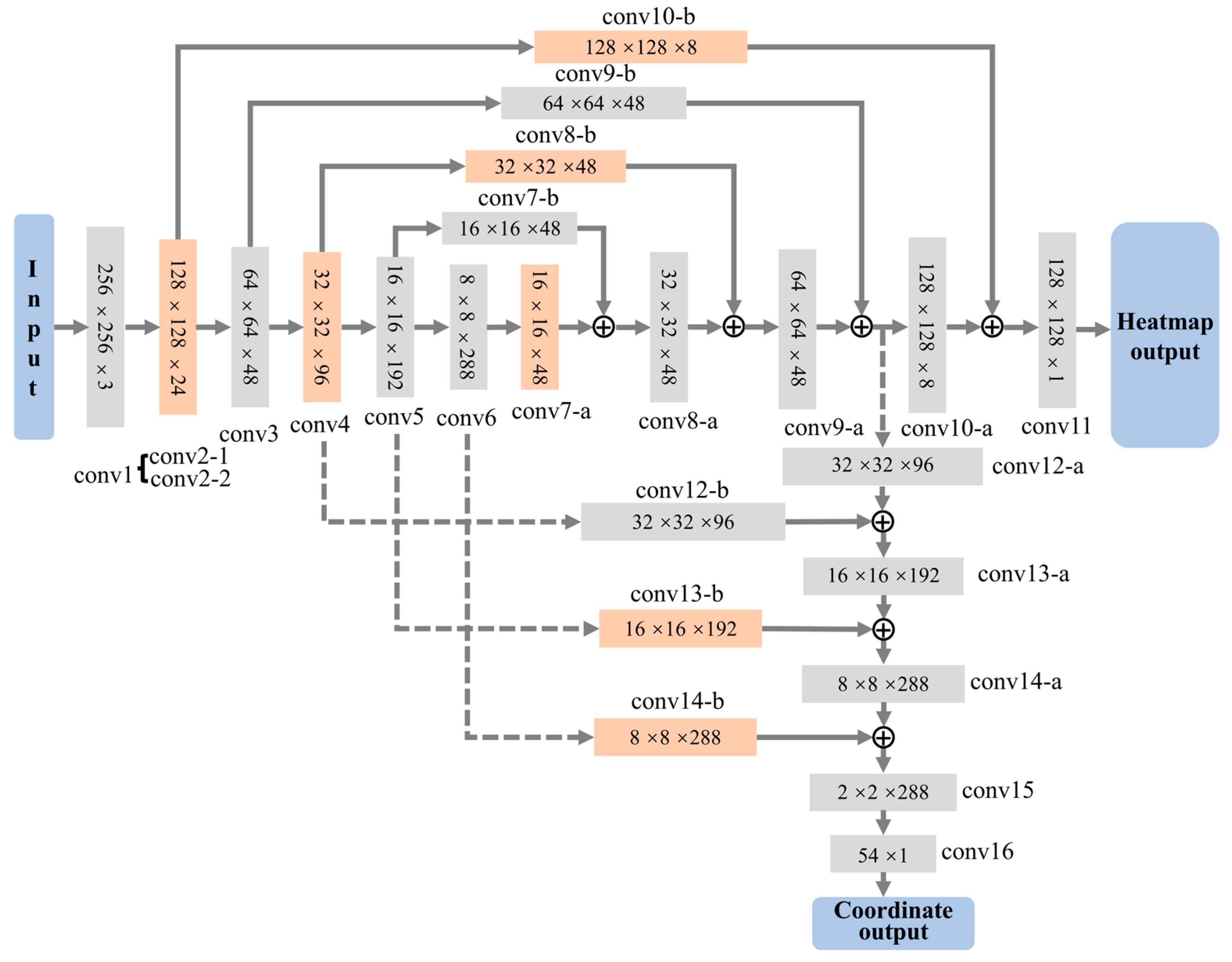
The variation in feature map dimensions during forward propagation in the BlazePose network is illustrated in
Figure 2. The heatmap branch adopts a stacked hourglass convolutional architecture, which progressively refines low-level visual cues into high-level semantic features as the network deepens. Notably, salient joint-related features may emerge in intermediate layers rather than solely in the final output layer. Therefore, relying solely on the final layer risks omitting critical information necessary for accurate keypoint detection.
To address this issue, the stacked hourglass structure enhances the feature extraction process for human keypoint detection. Specifically, it performs downsampling via convolutional layers and upsampling through nearest-neighbor interpolation to achieve forward propagation. During upsampling, features from corresponding resolution levels in the downsampling path are fused, enabling effective multi-scale feature integration. Compared with the traditional serial network, the advantage of the hourglass structure is that it improves the recognition accuracy of a single joint point by reusing the whole-body joint information. This strategy enables the network to more comprehensively extract the features of joint points at different levels, thereby significantly improving the accuracy of detection.
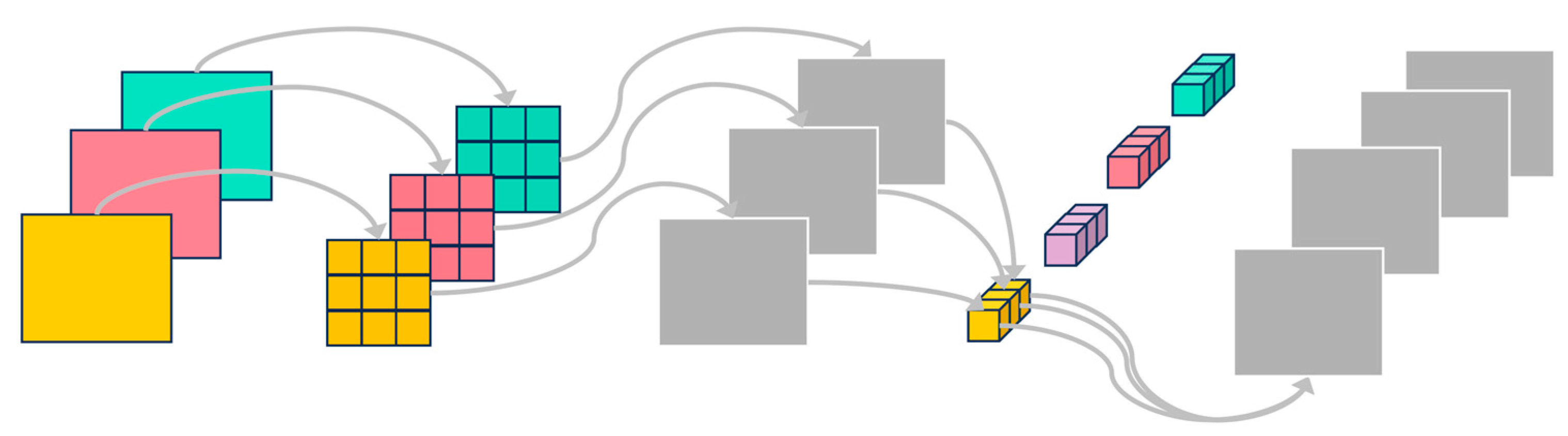
From a structural perspective, the keypoint inference network adopts a lightweight design inspired by MobileNetV1, extensively employing depthwise separable convolutions to replace conventional standard convolutions. This operation decomposes standard convolution into two sequential steps: (1) depthwise convolution, which applies a spatial filter independently to each input channel, preserving the channel count; (2) pointwise convolution, which uses a 1 × 1 kernel to linearly combine features across channels for inter-channel information fusion, as illustrated in
Figure 3.
This strategy markedly enhances computational efficiency while preserving model performance. For instance, in the conv2-1 module of
Figure 1b, depthwise separable convolution reduces the parameter count by approximately 84.72% and the computational cost by 85.12%, compared to standard convolution under the same input–output feature dimensions.
In addition, BlazePose extensively incorporates residual structures, such as the Block4 and Block8 modules shown in
Figure 1b. By introducing a residual learning mechanism, these structures effectively mitigate the degradation issues commonly encountered in deep neural networks. A typical residual block consists of multiple convolutional layers, batch normalization, and activation functions, allowing the input to bypass intermediate layers via shortcut connections. This design helps alleviate gradient vanishing or exploding, thereby enhancing training stability in deep architectures.
The traditional BlazePose algorithm is evaluated in terms of both detection speed and pose estimation accuracy. On the server platform used in this study, the average single-person video detection frame rate reaches 20.60 fps. For accuracy evaluation, common metrics include the PCK and the MAE.
The PCK indicator mainly measures the accuracy of the model in predicting joint points within different tolerance ranges. The higher the value, the more accurate the joint point positioning and the better the overall performance. Its definition is as follows:
where
represents the predicted pixel coordinates,
denotes the marked pixel coordinates, N is the number of recognized joint points, and
is a small constant (
) to prevent division by zero.
is the pixel coordinate error threshold, defined as 0.1 times the distance between the left and right shoulder pixels. The function
equals 1 if the left parameter is less than
, and 0 otherwise.
Another commonly used evaluation metric is the MAE, which quantifies the average absolute difference between the predicted and ground-truth joint coordinates. A lower MAE indicates that the predicted values are closer to the actual positions, reflecting higher localization accuracy and reduced prediction variance.
3. Method
3.1. Improvement of Top-Down Multi-Person Joint Detection Method
Human joint detection was initially developed for single-person scenarios, with models such as BlazePose specifically designed for such tasks. However, real-world applications often involve complex scenes containing multiple human subjects simultaneously. Experimental results show that when multiple individuals appear in the frame, BlazePose tends to erroneously assign keypoints across different persons, leading to a substantial increase in detection errors, as illustrated in
Figure 4.
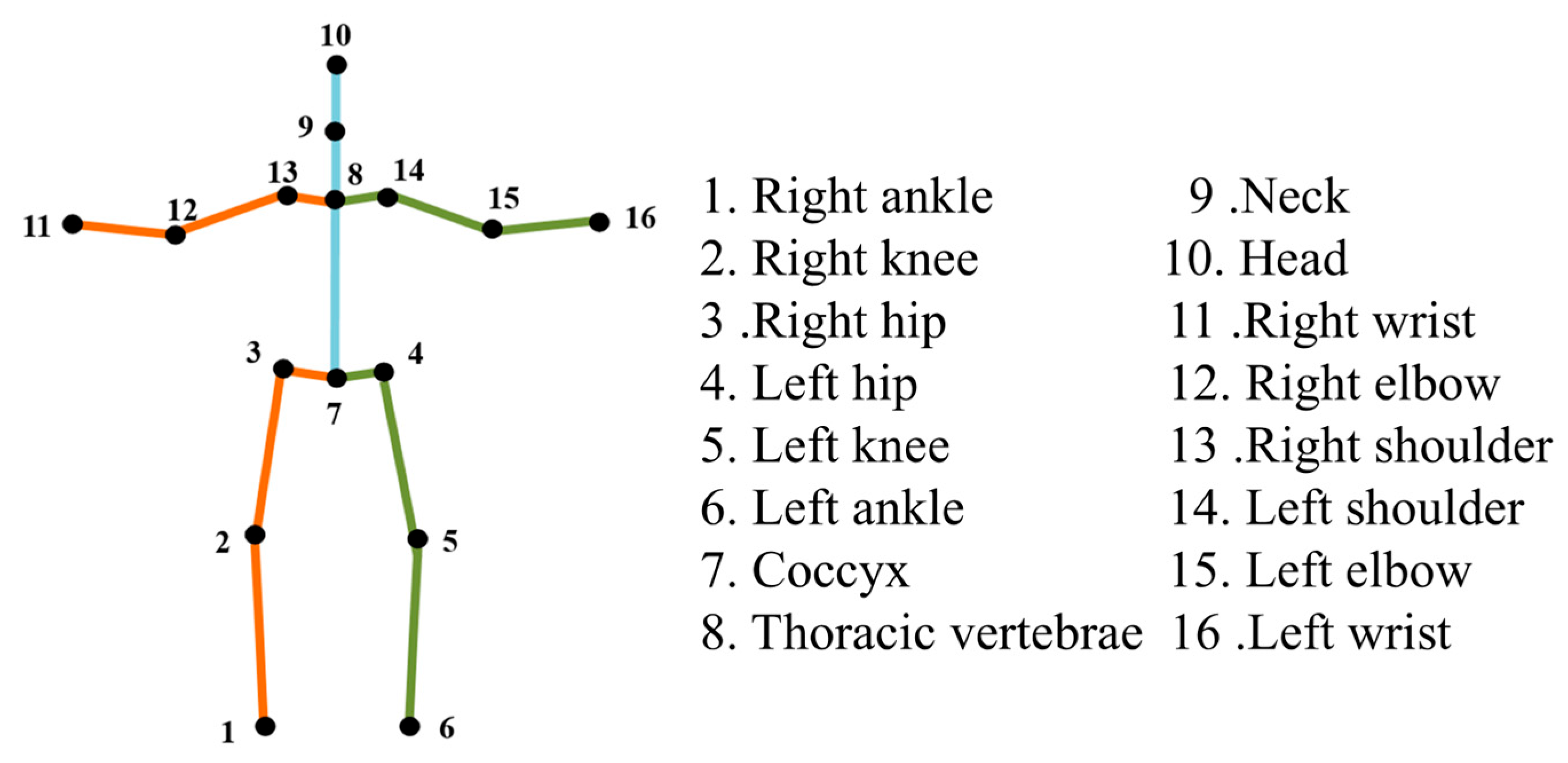
This degradation in performance is primarily attributed to the limited adaptability of traditional single-person detection algorithms in multi-person environments. Occlusions, interactions, and diverse human poses significantly increase the complexity of both joint detection and model design. As a result, the original single-person detection strategy suffers from poor generalization, often leading to false positives and missed detections. In contrast, single-person detection benefits from clearer task boundaries and a more stable target structure. When only one human subject is present, the number and types of keypoints are fixed, and their spatial relationships are predictable, enabling high-precision detection with relatively simple network architectures. In this study, the joint detection algorithm is designed to recognize 16 types of human keypoints, as shown in
Figure 5.
To facilitate accurate joint detection in multi-person settings, a top-down pose estimation strategy is adopted. This approach first employs object detection algorithms to locate all human targets in an image, followed by the application of a single-person joint detection model to each cropped region individually.
This method effectively isolates and processes the pose features of each person, thereby enhancing both detection accuracy and robustness, particularly in dense or occluded scenes. Specifically, YOLOv5 serves as the underlying object detection framework, extracting bounding boxes of human regions. Each local image region is then input into the BlazePose network for individual pose estimation, ultimately achieving accurate multi-person joint detection, as depicted in
Figure 6.
The deployment of the proposed multi-person joint detection algorithm on a server revealed that when five individuals were present in a scene, the system achieved an average processing speed of 16.7 fps when only object detection was performed. However, the inclusion of the joint detection module reduced the frame rate significantly to 3.5 fps. This indicates that joint detection becomes the primary performance bottleneck as the number of detected individuals increases.
To mitigate this issue and improve computational efficiency, a discriminative detection strategy was designed based on the behavioral patterns relevant to cheating behavior in truck scale monitoring. In this strategy, joint detection is selectively applied only to individuals whose bounding boxes intersect with predefined high-risk zones. This approach effectively eliminates redundant pose analysis for individuals far from the truck scale or unrelated to cheating behavior, thereby reducing computational overhead. As a result, system speed is significantly improved while maintaining real-time detection capability.
Further analysis revealed that in the five-person scenario, the computation time for joint detection was approximately 3.77 times greater than that for target detection, occupying the majority of computing resources and contributing significantly to system delays. Therefore, optimizing the joint detection process through lightweight model design becomes a critical strategy for enhancing overall system responsiveness.
3.2. Improvements in Lightweighting Methods
The objective of lightweight network design is to reduce model parameters and computational complexity while maintaining detection accuracy. Common metrics for evaluating lightweight models include floating-point operations (FLOPs) and parameter count (Params), both of which reflect the computational resources required during inference.
In the original BlazePose network, the heatmap inference component involves 885,559 parameters and 1,754,264 FLOPs. In contrast, during the pixel coordinate regression process, the model involves 3,286,992 parameters and 6,460,266 FLOPs, resulting in significantly higher computational demands. Layer-wise analysis reveals that the convolution modules conv15, conv6, and conv14a are the major contributors to this complexity, as shown in
Table 1. Therefore, the lightweight redesign in this study focuses on compressing and optimizing these modules while preserving critical feature extraction capabilities.
To address the structural redundancy identified in the three convolution modules discussed above, this paper proposes three lightweight optimization strategies. These strategies aim to effectively reduce network complexity and computational overhead while preserving model accuracy.
- 1.
Reducing the number of residual block cascades n in the Block8 module.
The Block8 module is composed of two parts: the first compresses the spatial dimensions of the feature maps through a combination of depthwise separable convolution and max-pooling, while the second enhances feature representation by stacking multiple depthwise separable residual units. Taking the conv15 module as an example, it contains n = 8 residual units, which contribute approximately 87.5% of the module’s overall parameters and computational cost. Therefore, reducing n moderately can significantly alleviate computational burden without sacrificing performance.
- 2.
Improving pointwise convolutions in the Block8 module to grouped convolutions.
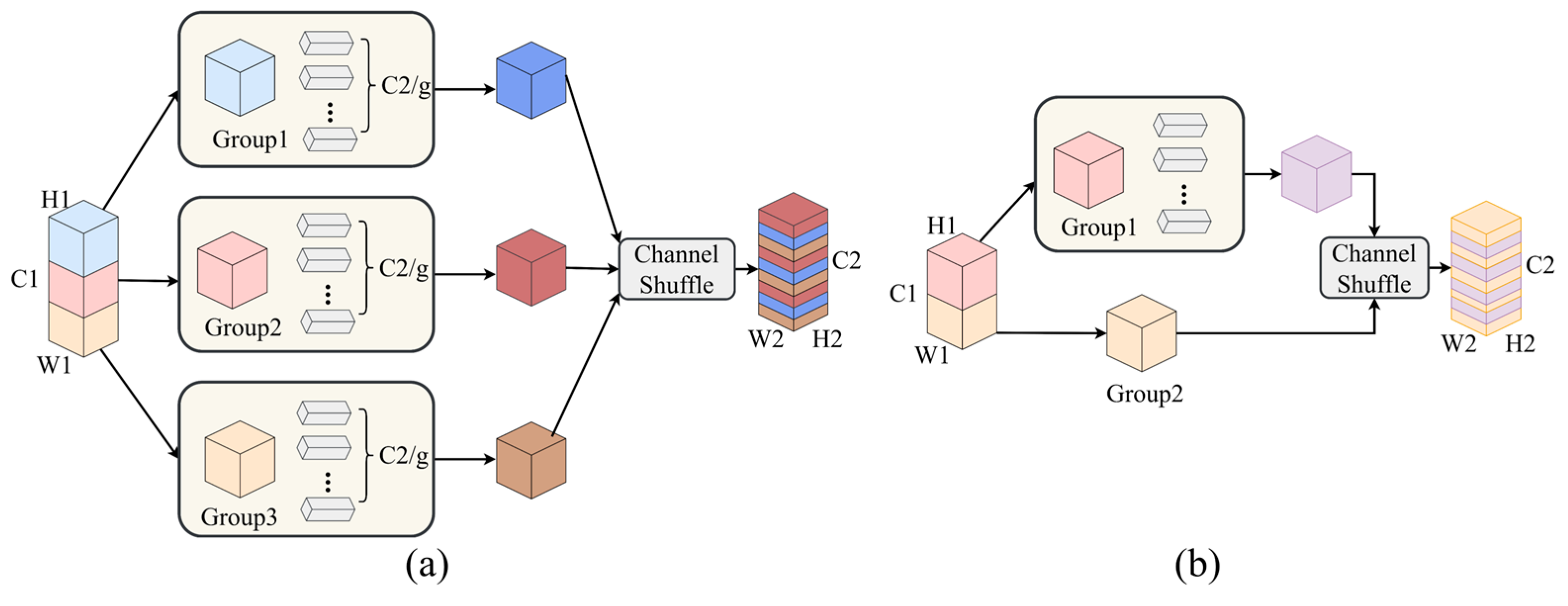
Although depthwise separable convolution significantly reduces computation, its 1 × 1 pointwise convolution component still introduces substantial parameter overhead, especially when the number of channels is large. To address this, two grouped convolution strategies are proposed:
Grouped Full Convolution: The input feature channels are divided into g groups, each of which is convolved independently. A subsequent channel shuffle operation restores inter-group information exchange. This structure, illustrated in
Figure 7a, reduces the number of pointwise convolution parameters by approximately a factor of g.
Grouped Half Convolution: Inspired by ShuffleNet V2, this method splits the input channels into two parts. One part undergoes depthwise separable convolution, while the other bypasses computation and is concatenated with the first along the channel dimension. A final channel shuffle step improves inter-channel feature interaction. This design, shown in
Figure 7b, further reduces parameter count while retaining expressive capability.
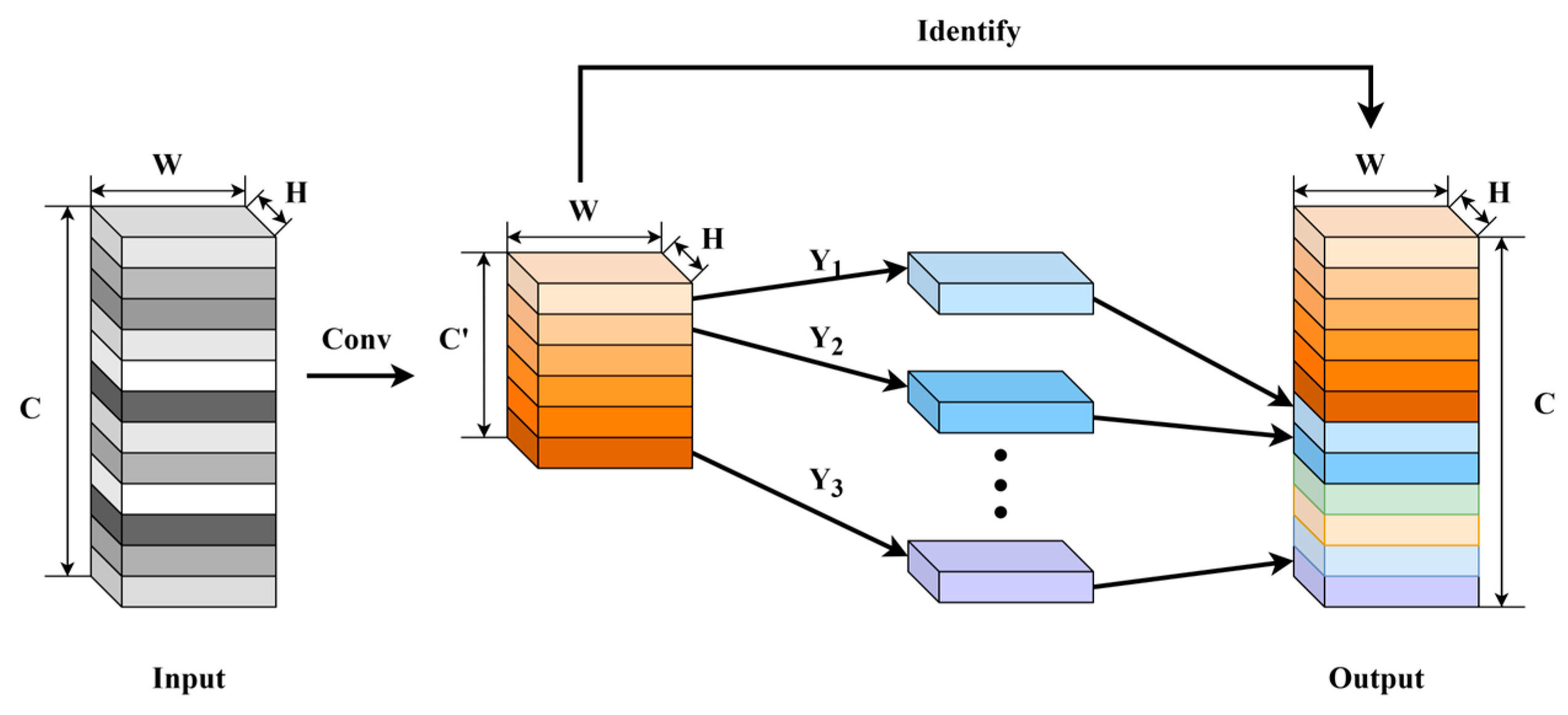
- 3.
Improvement of the GhostNet-Based residual connection structure in the Block8 module.
To reduce the computational overhead of pointwise convolution on small spatial but high-channel features in residual connections, GhostNet decomposes the convolution into two parts: one uses standard convolutional kernels to generate primary feature maps, while the other employs simple linear operations (e.g., depthwise convolutions) to produce additional “ghost” feature maps [
33]. These two outputs are then combined to form a feature map matching the input dimensions. The structure of Ghost convolution is illustrated in
Figure 8.
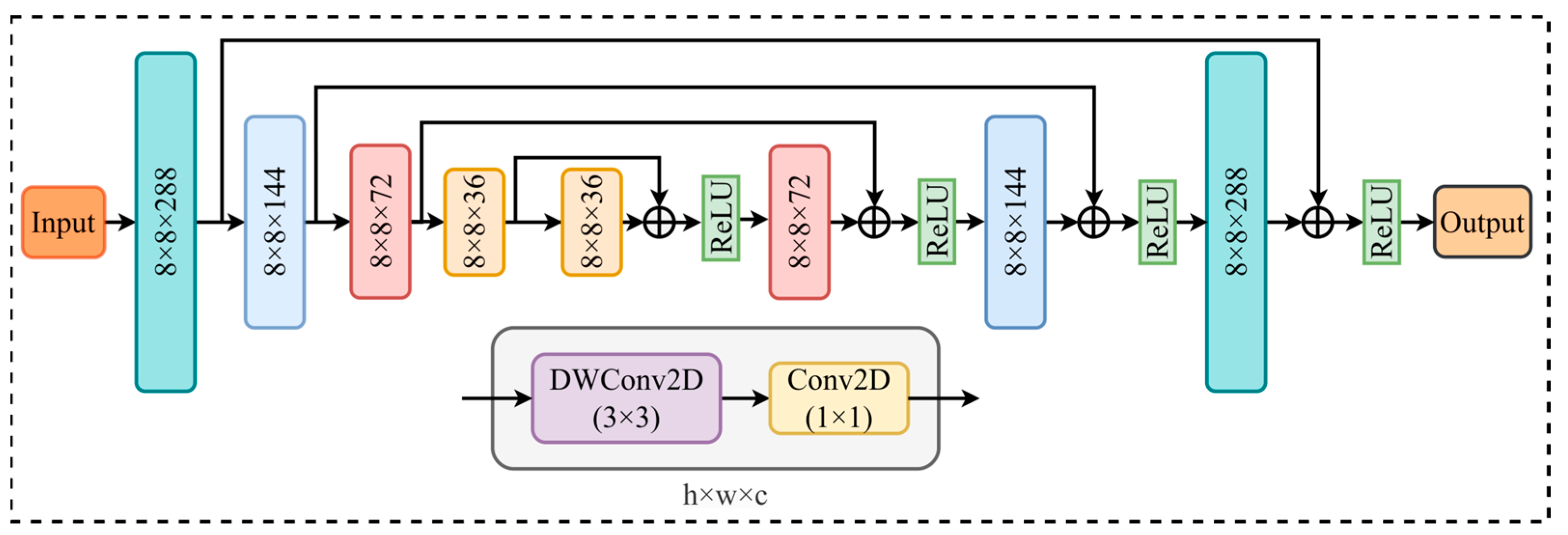
- 4.
Improvement of the channel hourglass residual connection structure in the Block8 module.
Drawing inspiration from the hourglass network architecture, this paper proposes a channel-wise hourglass-shaped convolutional structure that performs a symmetrical transformation along the channel dimension. Specifically, the number of channels in the input feature map is first gradually reduced through 1 × 1 pointwise convolutions within the depthwise separable convolution. Subsequently, a mirrored 1 × 1 convolution is employed to restore the number of channels to its original size, forming a compression-recover hourglass pattern. To enhance the network’s representational capacity and mitigate gradient vanishing during training, the residual connection is preserved throughout this process. The connection is applied symmetrically between the input and output feature maps with matching channel dimensions, ensuring effective feature fusion. The detailed structural design is illustrated in
Figure 9.
3.3. Improved Recognition Accuracy in Complex Environments
Following the lightweight optimization of BlazePose, the enhanced model was deployed in truck scale monitoring scenarios for validation. Experimental testing revealed that under complex environmental conditions such as low lighting or when individuals occupy only a small pixel area, the person detection module was still able to accurately localize human targets. However, the joint point detection module frequently failed to correctly output keypoints under these circumstances, as shown in
Figure 10.
To address this issue, this study integrates attention mechanisms into lightweight architecture. These mechanisms selectively focus on informative regions or channels, enhancing the model’s ability to capture key features under challenging conditions. For the task of human joint point detection, incorporating attention modules mitigates the degradation or loss of critical features, enhancing both detection accuracy and reliability in real-world applications.
In this work, both channel and spatial attention mechanisms are designed and integrated into the lightweight improved network. The channel attention mechanism strengthens the representation of important feature channels, while spatial attention enhances the extraction of discriminative local features. The combined effect of these mechanisms is expected to significantly improve joint point detection performance without incurring substantial computational overhead.
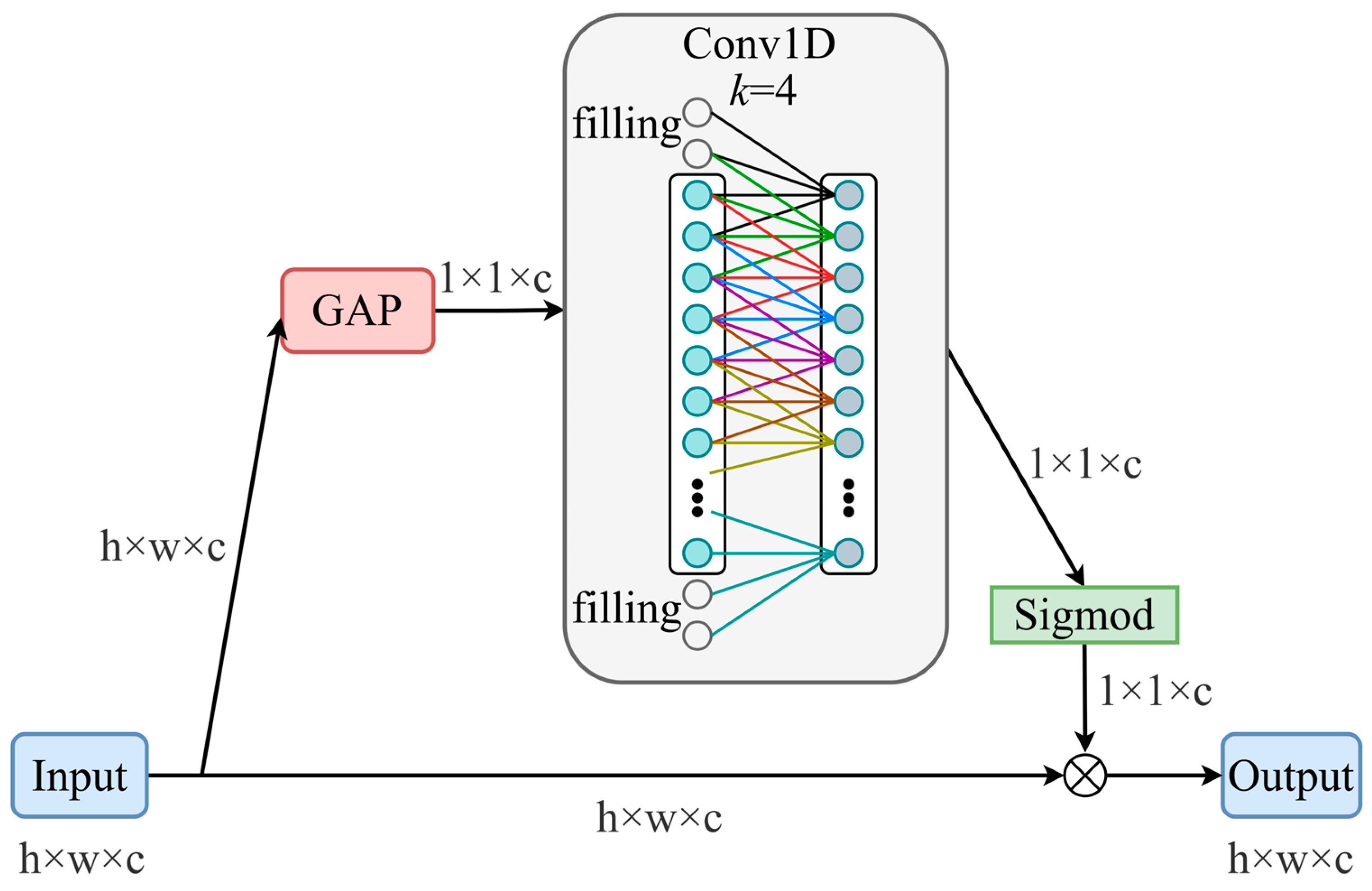
For channel attention, ECANet is employed in place of traditional SENet. While SENet uses global average pooling and fully connected layers to generate channel weights, its dimensionality reduction can lead to information loss. ECANet overcomes this by applying a dynamically sized 1D convolution to capture local cross-channel interactions, thereby avoiding the need for fully connected layers. The structure is shown in
Figure 11, and the kernel size k is determined by Equation (5).
where
= 2,
b = 1, and
C is the number of channels.
The ECANet utilizes a one-dimensional convolutional kernel that traverses the channel dimension to capture local inter-channel dependencies, with dynamic weights generated via a Sigmoid activation. Unlike the SENet, the ECANet removes fully connected layers, significantly reducing model parameters. This lightweight design enhances both computational efficiency and generalization.
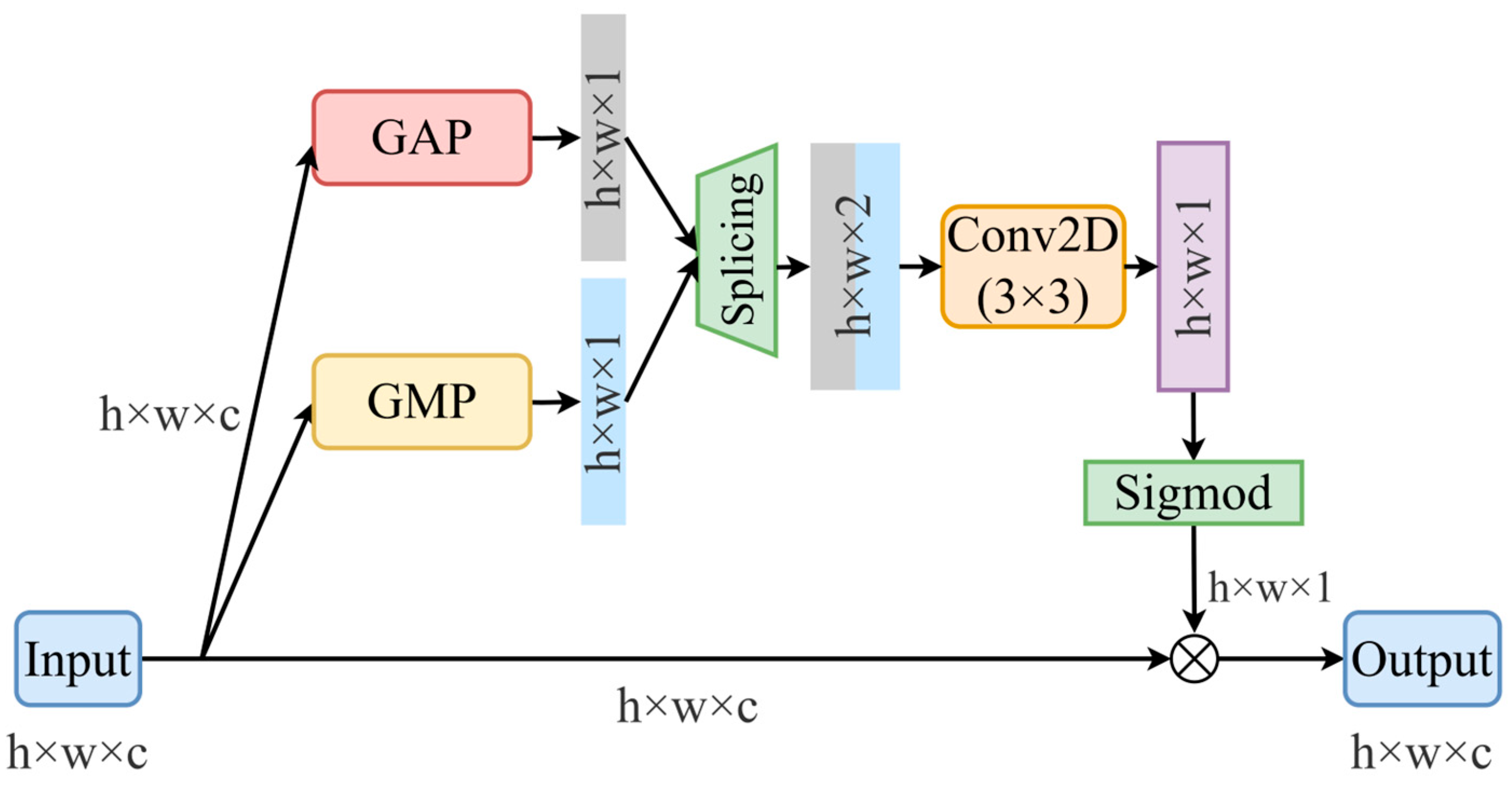
Beyond channel-wise attention, spatial features are refined using a spatial attention mechanism inspired by the CBAM architecture, as illustrated in
Figure 12. The module applies GAP and global max pooling (GMP) along the channel axis to extract spatial context. The fused outputs generate a position-sensitive attention map that assigns adaptive weights to spatial locations, enhancing focus on key regions while suppressing background noise. This improves feature quality and model efficiency.
To leverage the depthwise separable convolutions in the BlazePose network, a spatial attention module is introduced immediately after the depthwise convolution layer to enhance salient spatial features and suppress irrelevant information. Following the pointwise convolution, which fuses channel information, a channel attention module is applied to strengthen key channel representations. This combined strategy enables simultaneous enhancement of spatial and channel features. The architecture of this fused attention mechanism is shown in
Figure 13.
Although attention mechanisms have shown strong performance in image recognition tasks, prior studies often integrate them extensively into classical architectures such as the ResNet and VGG to boost overall accuracy. However, indiscriminate insertion of attention modules throughout deep convolutional networks can substantially increase model complexity and computational overhead. It may also amplify noise in the data, adversely affecting accuracy and training stability. Furthermore, the effectiveness of attention mechanisms is highly architecture-dependent, and no standardized integration strategy currently exists.
To address these issues, this study proposes a targeted attention integration strategy tailored to the multi-branch architecture used in human joint point detection. The backbone network extracts semantic features, while the heatmap and coordinate regression branches capture and refine global and local cues through multi-level feature fusion. Each branch plays a distinct role, contributing jointly to the enhancement of detection accuracy. To determine optimal insertion points for attention modules, a series of ablation studies are conducted to systematically evaluate the effects of different integration strategies on model performance.
4. Results and Discussion
4.1. The Experimental Results of Lightweight Improvement
In this study, the MPII dataset was employed for training and validation. To enable a preliminary comparison of various network structures, approximately 1/10 of the dataset (consisting of 2521 images and their corresponding JSON annotation files) was randomly selected and subsequently divided into training and validation sets in a 4:1 ratio. During the training process, a batch size of 16 was used, and the Adam optimizer was adopted. Both the heatmap and coordinate regression branches were initialized with a learning rate of 0.001, incorporating a dynamic adjustment strategy: if no reduction in the training and validation losses was observed over five consecutive epochs, the learning rate was reduced to 10% of its previous value. An early stopping mechanism was also applied, terminating training if validation loss variation remained below 0.0001 for 30 consecutive epochs to prevent overfitting.
Upon completion of heatmap branch training, the learned weights were employed to initialize the coordinate regression branch, which was subsequently trained under identical configurations. Since the goal of this experiment is to verify the effectiveness of network structure improvements rather than to achieve state-of-the-art performance, a reduced version of the training data was used, resulting in relatively higher MAE and slightly lower PCK values. Experimental results are presented in
Table 2. The first row reports the baseline performance of the original BlazePose network, followed by rows showing the results of different improvement strategies. Values in parentheses indicate the percentage change relative to the baseline. Frame rate (FPS) metrics were measured in a single-person test scenario, with bold font indicating the best performance for each metric.
To reduce model parameters and computational complexity, a straightforward method is to decrease the number of residual blocks. However, this inevitably reduces the number of convolutional layers, thereby weakening feature extraction and leading to a marked decline in accuracy metrics.
To improve efficiency without sacrificing performance, this study introduces grouped convolution to optimize the pointwise convolution module within the depthwise separable convolution framework. While conventional pointwise convolution primarily facilitates information fusion across channels, grouped convolution partitions channels into separate groups for independent processing. Although this significantly improves computational efficiency, it limits inter-channel information exchange. Among the two improvement strategies evaluated, the grouped full convolution approach enhances high-level semantic feature extraction but compromises shallow feature retention, resulting in diminished joint point regression accuracy. In contrast, the grouped half convolution strategy preserves half of the original channels during the pointwise convolution process, thereby maintaining critical shallow features such as edges and textures. This approach reduces outliers in joint regression and yields better MAE performance with higher inference speed. Comparative analysis shows that grouped half convolution offers a more favorable balance between accuracy and efficiency.
Although the GhostNet-based modification achieves notable improvements in inference speed, its performance on accuracy metrics is relatively limited. This may be attributed to the fact that GhostNet reduces the number of parameters by compressing channel dimensions through pointwise convolutions, which can, in certain cases, compromise the extraction of fine-grained features critical for keypoint detection. Small-scale, high-channel feature maps typically contain rich local information, and the redundant feature generation mechanism of GhostNet may fail to adequately preserve these essential details.
Beyond simple lightweighting strategies such as reducing residual blocks or introducing grouped convolutions, this paper proposes a novel channel hourglass convolution structure to further reduce computational cost while maintaining model expressiveness. By dynamically adjusting channel configuration in the pointwise convolution module, this structure compresses and restores feature channels without changing network depth. It significantly lowers parameter count and computation while improving both training efficiency and inference speed.
In addition, the proposed channel hourglass structure enhances multi-scale feature extraction and fusion, thereby improving the accuracy of feature representation. The integration of scalable skip connections facilitates effective transmission and fusion of cross-layer features, which helps mitigate issues such as gradient vanishing. Moreover, this design addresses the limitations of GhostNet in preserving fine-grained information, leading to improved model accuracy, training stability, and generalization performance. Experimental results demonstrate that the channel hourglass structure achieves an optimal balance between accuracy and efficiency among the evaluated lightweight strategies, making it a central innovation of this work.
In the BlazePose architecture, Block8-type modules are widely distributed across both the backbone network and the coordinate regression branch. In this work, we selectively applied lightweight modifications to the three Block8 modules with the highest parameter counts. Comparative experiments demonstrate that the proposed channel-sandglass structure leads to consistent improvements in both accuracy and computational efficiency. To further investigate where this structure yields the most benefit and whether it should be universally applied to all Block8 modules, we conducted additional ablation studies. The results, presented in
Table 3, reveal that integrating the channel-sandglass structure into conv6, conv14-a, and conv15 independently improves both inference accuracy and speed, with the combined configuration outperforming any single deployment.
Notably, these three modules are located at the output stages of either the backbone or the coordinate regression branch, and their feature map dimensions are all identical: (None, 8, 8, 288). This observation suggests that the channel bottleneck design is particularly effective when operating on high-dimensional feature maps. By performing channel-wise compression and recovery, the structure significantly reduces parameter count and FLOPs while enhancing feature selection and fusion. This design facilitates the extraction of more abstract and discriminative representations, supports better generalization by mitigating overfitting risks, and improves gradient flow through a form of architectural regularization. As such, the channel bottleneck strategy serves as an effective means to enhance both the representational power and deployment efficiency of deep networks.
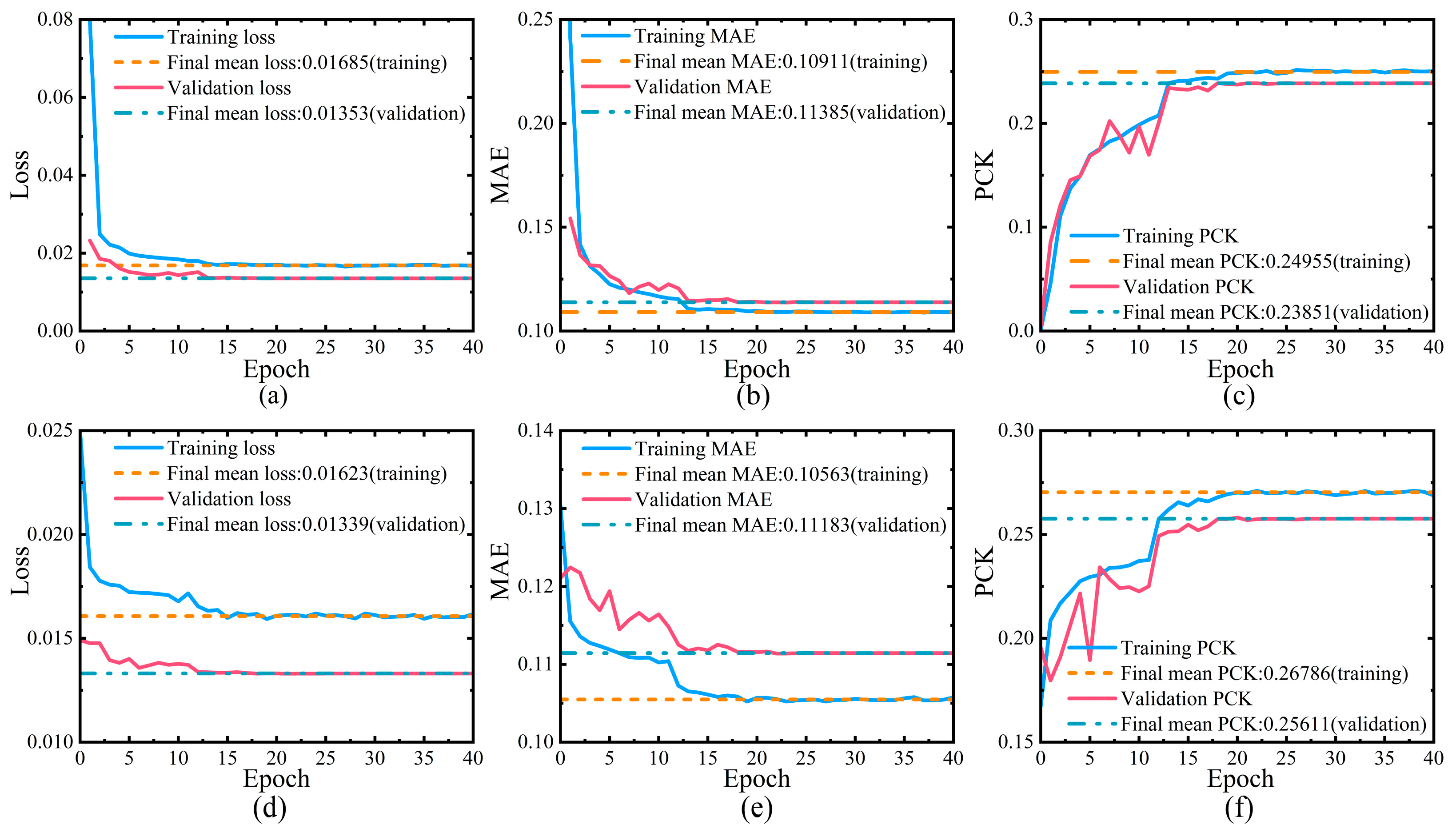
The improved network was trained on the complete MPII dataset, and the comparative performance results are presented in
Figure 14. Experimental findings demonstrate that, relative to the original BlazePose network, the proposed channel hourglass convolution structure achieves an improvement of 1.77% in MAE and 7.38% in PCK. In actual deployment scenarios, when five individuals are present within the video frame, the enhanced model maintains a real-time detection frame rate of 4.0 fps. Furthermore, experimental observations indicate that to sustain an average system frame rate of 5 fps, the number of detected individuals within the scene should be limited to four or fewer.
Building upon these results, this study adopts the channel hourglass convolution structure as the final lightweight optimization solution. By dynamically adjusting the number of pointwise convolution kernels, this design achieves an initial reduction followed by an expansion of feature channels, thereby substantially decreasing model parameters and computational complexity without altering the depth of the convolutional layers. This compression–expansion scheme enhances hierarchical feature extraction and multi-scale fusion. When combined with symmetric skip connections, it further strengthens feature representation and improves joint detection accuracy. Owing to its architectural simplicity and flexibility, the proposed structure also exhibits strong generalizability across different network architectures, underscoring its potential as a robust and scalable solution for lightweight model design.
4.2. The Experimental Results of Improved Attention Mechanism
To validate the superiority of the proposed deep separable convolution fusion hybrid attention mechanism (integrating spatial and channel attention), a series of controlled experiments were conducted. Specifically, comparative groups were designed by reversing the fusion order of the deep separable convolution and attention modules, including configurations where deep convolution was followed by a cascaded channel attention mechanism and where pointwise convolution was followed by a cascaded spatial attention mechanism. Additionally, we conducted ablation experiments to individually evaluate the hybrid attention mechanism, the channel attention mechanism, and the spatial attention mechanism.
Table 4 summarizes their performance across different feature scales, with the best results highlighted in bold.
As shown in
Table 4, the fusion of deep separable convolution with the hybrid attention mechanism consistently outperforms alternative strategies across various feature scales. To further evaluate the effect of various integration strategies, ablation experiments were conducted, and the results are summarized in
Table 5, where bolded values indicate performance gains attributed to embedding the hybrid attention mechanism at specific network layers.
The results in
Table 5 demonstrate that the incorporation of the proposed hybrid attention mechanism introduces only a marginal and acceptable increase in model parameters and computational overhead. Meanwhile, embedding the hybrid attention mechanism into seven targeted modules of the network yields a notable improvement in overall recognition accuracy. The distribution of these seven modules within the network architecture is illustrated by the orange regions in
Figure 2, primarily located at the initial stages of the channel hourglass convolution structure, within the downsampling pathways, and across corresponding bypass convolution layers. Notably, integrating the hybrid attention mechanism during the early downsampling stages of the heatmap branch (particularly at 128 × 128 and 32 × 32 feature scales) further enhances model performance. This finding suggests that early-stage attention helps the network better focus on salient features under complex backgrounds or noisy environments, thereby improving its ability to extract critical information.
However, as features propagate into deeper stages of the network, the fusion and refinement of information become increasingly sufficient. Consequently, introducing additional attention mechanisms at these stages does not yield further performance gains and may, in fact, disrupt the balanced feature representations by either attenuating or excessively amplifying specific features.
Moreover, since the training of the coordinate regression branch is based on the pretrained weights of the heatmap network, gradient backpropagation to the backbone network is disabled during its training. As a result, the backbone structure cannot be further optimized through the coordinate regression branch. Under these constraints, enhancing the feature extraction capabilities of the bypass convolution layers within the hourglass structure (specifically, conv-13b and conv-14b) in the coordinate regression branch proves effective for improving the final positioning performance of the model.
Experimental results further reveal that although integrating the hybrid attention mechanism across multiple modules generally leads to performance improvement, excessive deployment of attention mechanisms can occasionally cause performance degradation. As shown in
Table 6, the addition of attention mechanisms to certain modules failed to produce performance gains and, in some cases, even resulted in slight declines. Based on these controlled experiments, the final model adopts a selective attention integration strategy, embedding the hybrid attention mechanism only into the conv8-b module. This targeted deployment achieves a more efficient and effective enhancement of recognition accuracy.
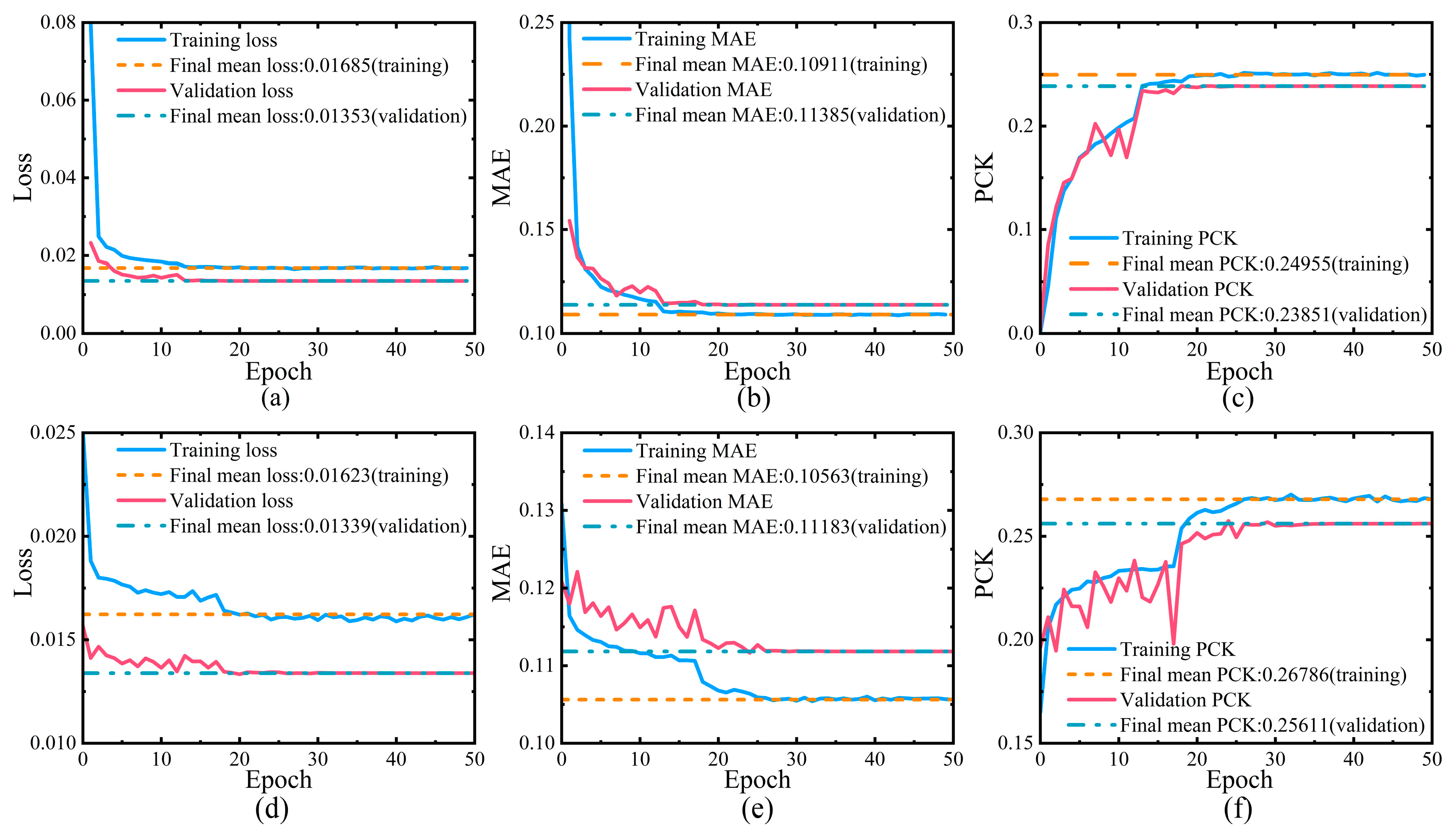
Building upon the lightweight model proposed in this study, a hybrid attention mechanism was further integrated into the conv8-b convolution module, and the model was trained on the complete MPII dataset until convergence. The comparative performance results, as shown in
Figure 15, indicate that the improved model achieves notable gains over the original network, with MAE reduced by 2.12% and PCK increased by 8.00%.
Since the MPII dataset predominantly consists of uniform scenes, it does not adequately reflect the advantages of our proposed algorithm under challenging conditions such as low-light environments or small-scale targets. To address this limitation, we conducted supplementary experiments using a self-collected dataset specifically designed for real-world truck scale scenarios. The evaluation set includes a total of 510 images encompassing various complex conditions, including shadowed environments, nighttime low-light settings, multi-person scenes, and small-target instances.
The goal of the test is to detect all human keypoints present in the scenes. We compared the performance of the proposed improved algorithm with BlazePose, Lite-HRNet-18, and MobileNetV2 (all trained on the MPII dataset using their respective pretrained models). The comparison results are summarized in
Table 7. Specifically, the following metrics are reported:
Miss Detection: Failure to detect a person present in the scene.
Misalignment Detection: Person is detected, but keypoints are noticeably misplaced.
Accurate Detection: All keypoints of all persons are correctly detected.
Average Precision (AP): Overall accuracy of keypoint recognition.
This real-world test demonstrates the robustness and practical applicability of our method in deployment scenarios beyond the controlled MPII dataset.
To further evaluate the practical effectiveness of the proposed improvements, both the lightweight-enhanced model and the model incorporating the hybrid attention mechanism were applied to inference scenarios, particularly under challenging conditions such as poor lighting and small target pixel areas. The comparative results are illustrated in
Figure 16. Compared to the original model, the recognition performance is significantly enhanced, thereby verifying the robustness and practical applicability of the proposed approach.
4.3. The Comparison of Lightweight and Accurate Models
To better align with the experimental setups of existing methods, we relaxed the evaluation metric from the stricter PCK@0.1 to a more widely used PCK@0.5. We further conducted a per-joint accuracy analysis across seven key joint types and calculated the overall mean accuracy (mean). In addition to accuracy, we measured the real-time performance in terms of FPS using our system on a real-world single-person truck scale monitoring video.
Among the compared methods, the first six are categorized as large networks, which focus primarily on detection accuracy but involve a large number of parameters and suffer from lower inference speed in deployment scenarios. The latter four are small networks, designed with lightweight architectures to achieve higher inference speed at the cost of slightly reduced keypoint accuracy. These include recent state-of-the-art models such as MobileNetV2-based pose estimation networks and HRNet-Lite, which are widely used in mobile and embedded applications.
To comprehensively evaluate both accuracy and efficiency, we adopted a normalized composite scoring method. Specifically, the accuracy score was normalized using a 100% detection accuracy baseline, and the speed score was normalized using a baseline of 30 FPS (the frame rate of the original video). A weighting factor of α = 0.5 was used to balance the importance of accuracy and speed in the final score. The composite score for each model is listed in
Table 8.
As shown in the results, our proposed method achieves a competitive balance between accuracy and efficiency, ranking among the top methods in terms of overall composite score. This highlights the practical value and deployment potential of the proposed approach in real-time intelligent truck scale supervision scenarios.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}