_Li.png)
Woodot: An AI-Driven Mobile Robotic System for Sustainable Defect Repair in Custom Glulam Beams




Abstract
1. Introduction
2. Materials
2.1. System Overview
2.2. Hardware Infrastructure
2.3. Software Infrastructure
3. Methods
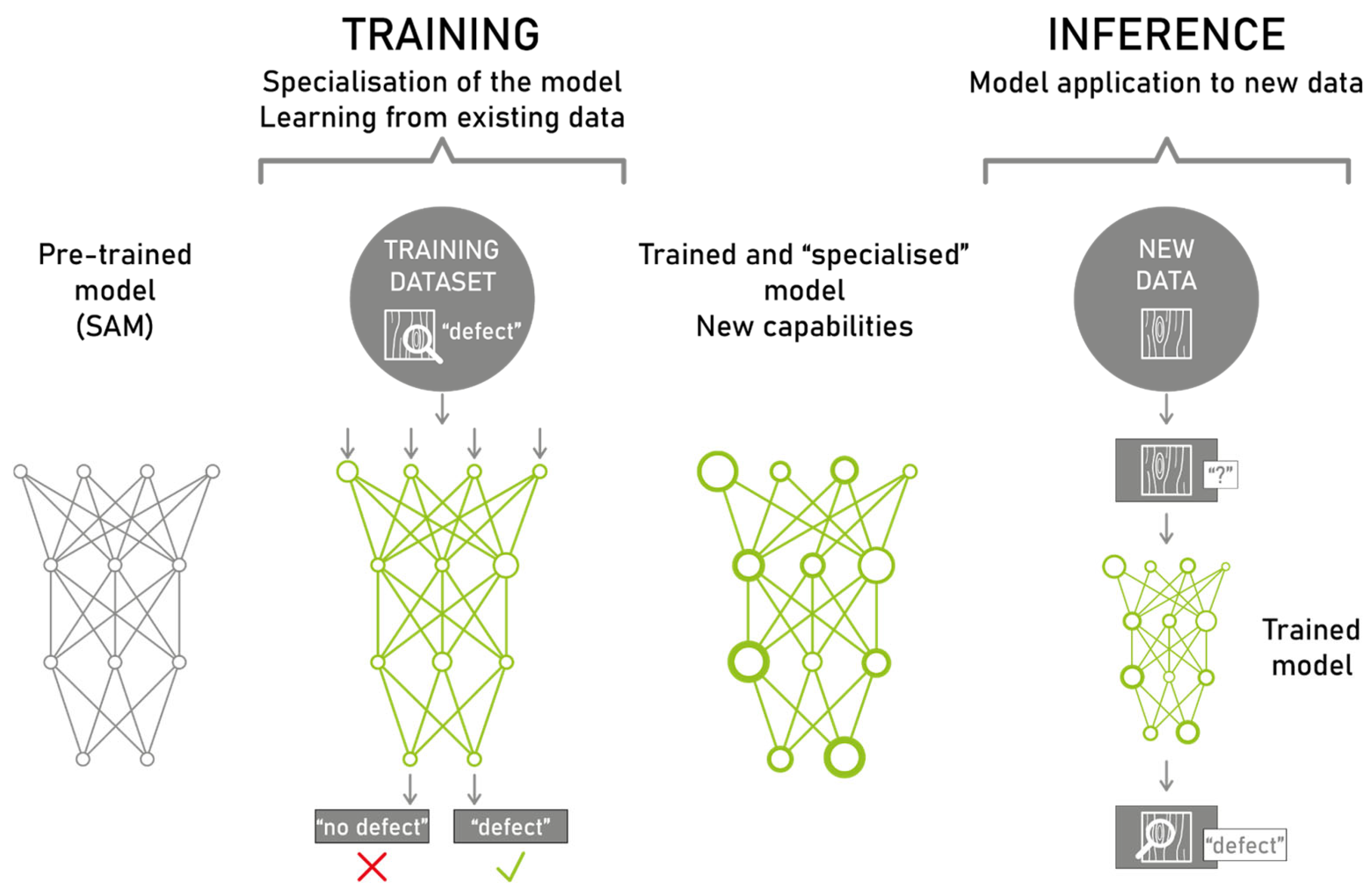
3.1. Fine-Tuning a Segmentation Model to Perform Defect Recognition
3.1.1. Introduction to SAM Fine-Tuning
3.1.2. Dataset Preparation for Fine-Tuning
3.1.3. Fine-Tuning Process
3.1.4. Dataset Preparation for Inference
3.1.5. Inference Pipeline Configuration
3.2. The Five Woodot Subsystems
3.2.1. Rover Handling
3.2.2. Image Acquisition
3.2.3. Image Elaboration for Defect Identification
3.2.4. Defect Removal
3.2.5. Insertion of Restoration Material
4. Results
4.1. Navigation and Positioning Performance
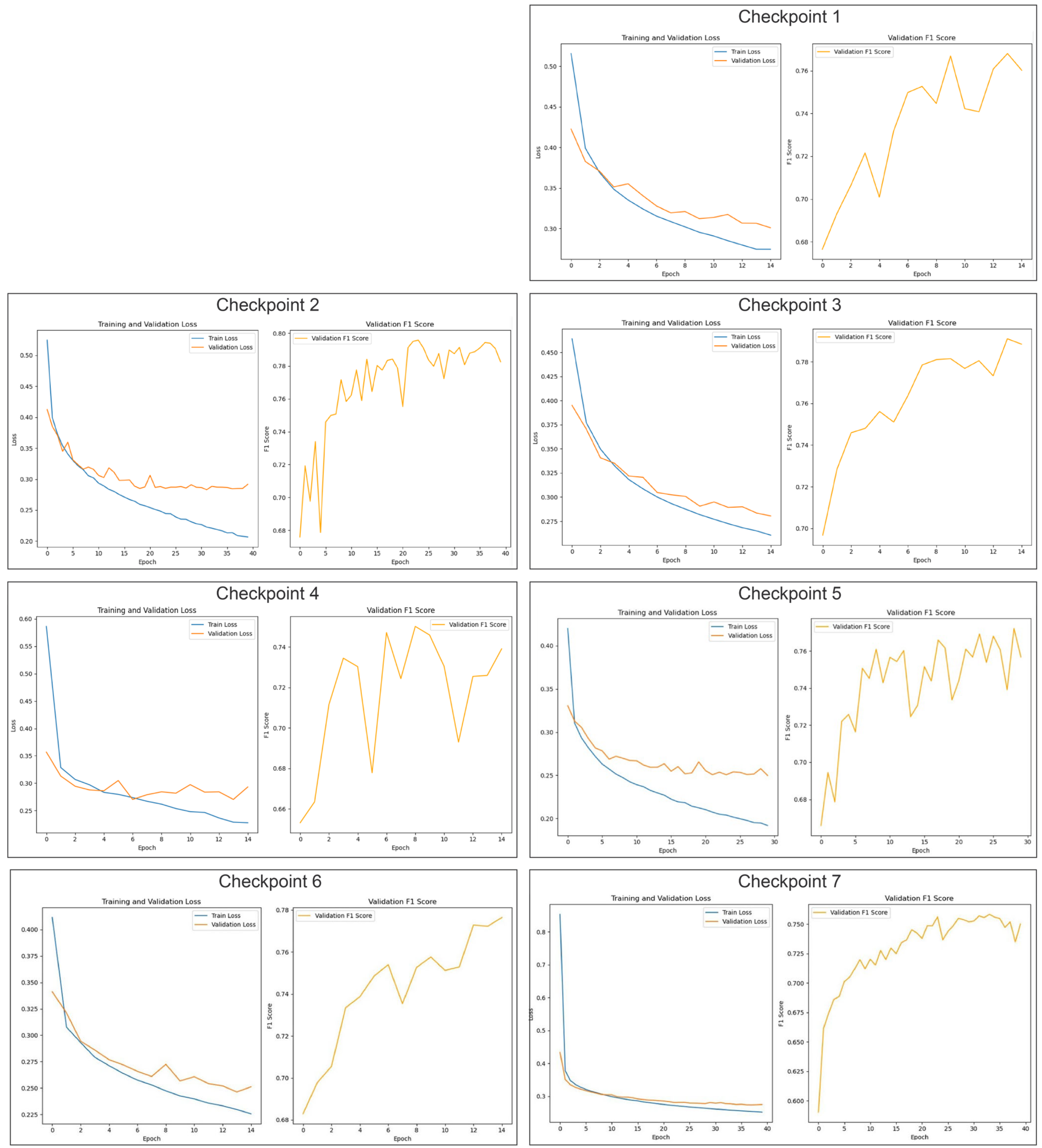
4.2. Defect Identification Accuracy
4.3. Restoration Workflow Effectiveness
4.4. Operational Cycle Time
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Amiri, A.; Ottelin, J.; Sorvari, J.; Junnila, S. Cities as Carbon Sinks—Classification of Wooden Buildings. Environ. Res. Lett. 2020, 15, 094076. [Google Scholar] [CrossRef]
- Dzhurko, D.; Haacke, B.; Haberbosch, A.; Köhne, L.; König, N.; Lode, F.; Marx, A.; Mühlnickel, L.; Neunzig, N.; Niemann, A.; et al. Future Buildings as Carbon Sinks: Comparative Analysis of Timber-Based Building Typologies Regarding Their Carbon Emissions and Storage. Front. Built Environ. 2024, 10, 1330105. [Google Scholar] [CrossRef]
- APA—The Engineered Wood Association. Technical Note: Glulam Appearance Classifications for Construction Applications; APA: Tacoma, WA, USA, 2010; Available online: https://www.apawood.org/publication-search?q=y+110&tid=1 (accessed on 28 May 2025).
- APA—The Engineered Wood Association. ANSI 117-2020: Standard Specification for Structural Glued Laminated Timber of Softwood Species; APA: Tacoma, WA, USA, 2020; Available online: https://www.apawood.org/publication-search?q=ansi+117&tid=1 (accessed on 28 May 2025).
- Rothoblaas Srl. TAPS—Timber Caps. Available online: https://www.rothoblaas.com/products/tools-and-machines/wood-repair-items/taps (accessed on 28 May 2025).
- Hirsch, R.; Hahn, C.; Jäger, W. Nachweis Der Feuerwiderstandsklasse von Mauerwerk—Aktuelle Aussagen Im Rahmen Der Überarbeitung von DIN 4102:1994-03 Und DIN 4102-4/A1:2004-11 Sowie DIN 4102-22:2004-11. Mauerwerk 2009, 13, 203–206. [Google Scholar] [CrossRef]
- Hashim, U.R.; Hashim, S.Z.M.; Muda, A. Automated vision inspection of timber surface defect: A review. J. Teknol. 2015, 77, 1–10. [Google Scholar] [CrossRef]
- Biederman, M. Robotic Machining Fundamentals for Casting Defect Removal. Master’s Thesis, Oregon State University, Corvallis, OR, USA, 2016. [Google Scholar]
- Li, R.; Zhong, S.; Yang, X. Wood Panel Defect Detection Based on Improved YOLOv8n. BioResources 2025, 20, 2556–2573. [Google Scholar] [CrossRef]
- Andersson, P. Automated Surface Inspection of Cross Laminated Timber. Master’s Thesis, University West, Trollhättan, Sweden, 2020. [Google Scholar]
- Nagata, F.; Kusumoto, Y.; Fujimoto, Y.; Watanabe, K. Robotic sanding system for new designed furniture with free-formed surface. Robotics Comput. Integr. Manuf. 2007, 23, 371–379. [Google Scholar] [CrossRef]
- Timber Products Company. Robots Introduced to Grants Pass—Automated Panel Repair Line. Available online: https://timberproducts.com/robots-introduced-to-grants-pass/ (accessed on 19 April 2025).
- Toman, R.; Rogala, T.; Synaszko, P.; Katunin, A. Robotized Mobile Platform for Non-Destructive Inspection of Aircraft Structures. Appl. Sci. 2024, 14, 10148. [Google Scholar] [CrossRef]
- Giftthaler, M.; Sandy, T.; Dörfler, K.; Brooks, I.; Buckingham, M.; Rey, G.; Kohler, M.; Gramazio, F.; Buchli, J. Mobile Robotic Fabrication at 1:1 Scale: The In Situ Fabricator. Constr. Robot. 2017, 1, 3–14. [Google Scholar] [CrossRef]
- Huo, Y.; Chen, D.; Li, X.; Li, P.; Liu, Y.-H. Development of an Autonomous Sanding Robot with Structured-Light Technology. arXiv 2019, arXiv:1903.03318. [Google Scholar] [CrossRef]
- Rossini, L.; Romiti, E.; Laurenzi, A.; Ruscelli, F.; Ruzzon, M.; Covizzi, L.; Baccelliere, L.; Carrozzo, S.; Terzer, M.; Magri, M.; et al. CONCERT: A Modular Reconfigurable Robot for Construction. arXiv 2025, arXiv:2504.04998. [Google Scholar] [CrossRef]
- Sigma Ingegneria. Il Sistema Woodot per l’edilizia del futuro: Un rover con Braccio Robotico per le Travi Lamellari. Blog Sigma—SAIE 2024 Preview, 26 September 2024. [Google Scholar]
- Ruttico, P.; Pacini, M.; Beltracchi, C. BRIX: An autonomous system for brick wall construction. Constr. Robot. 2024, 8, 10. [Google Scholar] [CrossRef]
- FBR Ltd. Hadrian X®|Outdoor Construction & Bricklaying Robot from FBR. Available online: https://www.fbr.com.au/view/hadrian-x (accessed on 29 May 2025).
- Helm, V.; Ercan, S.; Gramazio, F.; Kohler, M.; Willmann, J.; Dörfler, K.; Giftthaler, M.; Buchli, J.; Sandy, T.; Rey, G.; et al. Mobile Robotic Fabrication on Construction Sites: DimRob. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2684–2689. [Google Scholar] [CrossRef]
- Helm, V.; Willmann, J.; Gramazio, F.; Kohler, M. In-Situ Robotic Fabrication: Advanced Digital Manufacturing Beyond the Laboratory. In Gearing up and Accelerating Cross-Fertilization Between Academic and Industrial Robotics Research in Europe: Technology Transfer Experiments from the ECHORD Project; Röhrbein, F., Veiga, G., Natale, C., Eds.; Springer Tracts in Advanced Robotics; Springer: Cham, Switzerland, 2014; Volume 94, pp. 63–83. [Google Scholar] [CrossRef]
- Patil, S.; Vasu, V.; Srinadh, K.V.S. Advances and perspectives in collaborative robotics: A review of key technologies and emerging trends. Discov. Mech. Eng. 2023, 2, 13. [Google Scholar] [CrossRef]
- Faccio, M.; Granata, I.; Menini, A.; Milanese, M.; Rossato, C.; Bottin, M.; Minto, R.; Pluchino, P.; Gamberini, L.; Boschetti, G.; et al. Human factors in cobot era: A review of modern production systems features. J. Intell. Manuf. 2023, 34, 85–106. [Google Scholar] [CrossRef]
- Fang, X.; Luo, Q.; Zhou, B.; Li, C.; Tian, L. Research Progress of Automated Visual Surface Defect Detection for Industrial Metal Planar Materials. Sensors 2020, 20, 5136. [Google Scholar] [CrossRef]
- Reu, P.; Sweatt, W.; Miller, T.; Fleming, D. Camera System Resolution and Its Influence on Digital Image Correlation. Exp. Mech. 2014, 55, 9–25. [Google Scholar] [CrossRef]
- Arza-García, M.; Núñez-Temes, C.; Lorenzana, J.A.; Gutiérrez, J.J. Evaluation of a Low-Cost Approach to 2-D Digital Image Correlation vs. a Commercial Stereo-DIC System in Brazilian Testing of Soil Specimens. Arch. Civ. Mech. Eng. 2022, 22, 4. [Google Scholar] [CrossRef]
- Available online: https://www.dewalt.co.uk/product/d26200-gb/8mm-14-fixed-base-router (accessed on 20 August 2024).
- KEYENCE. IV4-500CA Vision Sensor. KEYENCE America. Available online: https://www.keyence.com/products/vision/vision-sensor/iv4/models/iv4-500ca/ (accessed on 28 May 2025).
- Robert McNeel & Associates. Grasshopper3D. Available online: https://www.grasshopper3d.com/ (accessed on 20 August 2024).
- He, T.; Liu, Y.; Xu, C.; Zhou, X.; Hu, Z.; Fan, J. A Fully Convolutional Neural Network for Wood Defect Location and Identification. IEEE Access 2019, 7, 123453–123462. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, H.; Jiang, D.; Hu, Z. Surface Detection of Solid Wood Defects Based on SSD Improved with ResNet. Forests 2021, 12, 1419. [Google Scholar] [CrossRef]
- Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Wang, J.; Wang, L.; Gao, J.; Lee, Y.J. Segment Everything Everywhere All at Once. arXiv 2023, arXiv:2304.06718. Available online: https://arxiv.org/abs/2304.06718 (accessed on 29 May 2025).
- Meta AI. Segment Anything GitHub Repository. Available online: https://github.com/facebookresearch/segment-anything (accessed on 20 August 2024).
- Ji, W.; Li, J.; Bi, Q.; Liu, T.; Li, W.; Cheng, L. Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications. Mach. Intell. Res. 2024, 21, 617–630. [Google Scholar] [CrossRef]
- Meta AI. Introducing Segment Anything: Working Toward the First Foundation Model for Image Segmentation. Meta AI Blog, 2023. Available online: https://ai.meta.com/blog/segment-anything-foundation-model-image-segmentation/ (accessed on 29 May 2025).
- Kodytek, P.; Bodzas, A.; Bilik, P. A large-scale image dataset of wood surface defects for automated vision-based quality control processes. F1000Research 2022, 10, 581. [Google Scholar] [CrossRef] [PubMed]
- TorchVision Contributors. TorchVision: Image Transformations for PyTorch. 2023. Available online: https://pytorch.org/vision/stable/index.html (accessed on 29 May 2025).
- Kumar, T.; Mileo, A.; Brennan, R.; Bendechache, M. Image Data Augmentation Approaches: A Comprehensive Survey and Future Directions. arXiv 2023, arXiv:2301.02830. Available online: https://arxiv.org/abs/2301.02830 (accessed on 26 May 2025). [CrossRef]
- PyTorch Contributors. torch.optim.Adam—PyTorch Documentation. Available online: https://docs.pytorch.org/docs/stable/optim.html#torch.optim.Adam (accessed on 27 May 2025).
- MONAI Consortium. monai.losses.DiceCELoss—MONAI Documentation. Available online: https://docs.monai.io/en/stable/losses.html#monai.losses.DiceCELoss (accessed on 27 May 2025).
- Scikit-Learn Developers. sklearn.metrics.f1_score—scikit-learn Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html (accessed on 27 May 2025).
- Deval, M.; Bianchi, F.; Moroni, C. Wood knots defects dataset [Data set]. Zenodo 2025. [Google Scholar] [CrossRef]
- Adobe Inc. Adobe Illustrator (Version 2024) [Software]. Available online: https://www.adobe.com/products/illustrator.html (accessed on 27 May 2025).
- gphoto.org. gPhoto Website. Available online: http://gphoto.org/ (accessed on 20 August 2024).
- Weimer, D.; Scholz, P.; Klein, L.; Merhof, D. Segmentation-Based Deep-Learning Approach for Surface-Defect Detection. arXiv 2019, arXiv:1903.08536. Available online: https://arxiv.org/abs/1903.08536 (accessed on 29 May 2025).
- Ye, Y.; Huang, Q.; Liu, Y.; Fan, X.; Lu, S. Reference-Based Defect Detection Network. arXiv 2021, arXiv:2108.04456. Available online: https://arxiv.org/abs/2108.04456 (accessed on 29 May 2025).
- Nair, A.; Asari, V.K. Detection and Segmentation of Manufacturing Defects Using Deep Convolutional Neural Networks and Transfer Learning. Sensors 2019, 19, 4262. [Google Scholar] [CrossRef]
- Ibarra-Castanedo, C.; Gonzalez, D.; Maldague, X. Automatic Defects Segmentation and Identification by Deep Learning Algorithm with Pulsed Thermography. J. Imaging 2019, 5, 9. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, T.; Yeh, C.; Lin, B. YOLOSeg with Applications to Wafer Die Particle Defect Segmentation. Micromachines 2024, 15, 378. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, Y.; Wang, L.; Liu, S.; Zhang, S. The Amalgamation of Object Detection and Semantic Segmentation for Steel Surface Defect Detection. Appl. Sci. 2022, 12, 6004. [Google Scholar] [CrossRef]
- Visose. Robots GitHub Repository. Available online: https://github.com/visose/Robots (accessed on 20 August 2024).
- IndexLab. Woodot. Available online: https://www.indexlab.it/woodot (accessed on 20 August 2024).
- Robert McNeel & Associates. Rhino3D Compute Developer Guide. Available online: https://developer.rhino3d.com/guides/compute/ (accessed on 20 August 2024).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Checkpoint | Dataset | Patches | Epochs | WeightDecay | LearningRate |
|---|---|---|---|---|---|
| Ch1 | Dataset 1 | 6.760 | 15 | 0 | 1 × 10−5 |
| Ch2 | Dataset 1 | 6.760 | 40 | 0 | 1 × 10−5 |
| Ch3 | Dataset 3 | 53.117 | 15 | 0 | 1 × 10−5 |
| Ch4 | Dataset 2 | 642 | 15 | 0 | 1 × 10−5 |
| Ch5 | Dataset 4 | 5.099 | 30 | 0 | 1 × 10−5 |
| Ch6 | Dataset 4 | 5.099 | 15 | 1 × 10−4 | 1 × 10−5 |
| Ch7 | Dataset 4 | 5.099 | 40 | 1 × 10−4 | 1 × 10−6 |
 | |||||
| Checkpoint | Inference_Dataset | adp_Threshold | min_Size | Patch_Size | Mean F1 Score | std_dev | std_Error | CI_95_Low | CI_95_High |
|---|---|---|---|---|---|---|---|---|---|
| Ch1 | Far-100 | 0.8 | 30 | 256 | 0.353 | 0.167 | 0.021 | 0.312 | 0.394 |
| Ch1 | Near-70 | 0.12 | 30 | 512 | 0.315 | 0.223 | 0.028 | 0.259 | 0.370 |
| Ch2 | Far-100 | 0.8 | 30 | 256 | 0.274 | 0.173 | 0.021 | 0.231 | 0.317 |
| Ch2 | Near-70 | 0.5 | 30 | 512 | 0.269 | 0.247 | 0.031 | 0.208 | 0.330 |
| Ch3 | Far-100 | 0.8 | 30 | 256 | 0.178 | 0.154 | 0.019 | 0.140 | 0.217 |
| Ch3 | Near-70 | 0.5 | 30 | 512 | 0.225 | 0.215 | 0.027 | 0.171 | 0.278 |
| Ch4 | Far-100 | 0.12 | 10 | 256 | 0.659 | 0.110 | 0.014 | 0.631 | 0.686 |
| Ch4 | Near-70 | 0.12 | 10 | 512 | 0.657 | 0.175 | 0.022 | 0.613 | 0.700 |
| Ch5 | Far-100 | 0.4 | 10 | 256 | 0.600 | 0.141 | 0.017 | 0.566 | 0.635 |
| Ch5 | Near-70 | 0.12 | 10 | 512 | 0.681 | 0.167 | 0.021 | 0.639 | 0.722 |
| Ch6 | Far-100 | 0.8 | 0 | 256 | 0.563 | 0.157 | 0.020 | 0.524 | 0.602 |
| Ch6 | Near-70 | 0.12 | 10 | 512 | 0.628 | 0.200 | 0.025 | 0.579 | 0.678 |
| Ch7 | Far-100 | 0.4 | 10 | 256 | 0.608 | 0.150 | 0.019 | 0.571 | 0.645 |
| Ch7 | Near-70 | 0.12 | 10 | 512 | 0.686 | 0.150 | 0.019 | 0.649 | 0.723 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruttico, P.; Bordoni, F.; Deval, M. Woodot: An AI-Driven Mobile Robotic System for Sustainable Defect Repair in Custom Glulam Beams. Sustainability 2025, 17, 5574. https://doi.org/10.3390/su17125574
Ruttico P, Bordoni F, Deval M. Woodot: An AI-Driven Mobile Robotic System for Sustainable Defect Repair in Custom Glulam Beams. Sustainability. 2025; 17(12):5574. https://doi.org/10.3390/su17125574
Chicago/Turabian StyleRuttico, Pierpaolo, Federico Bordoni, and Matteo Deval. 2025. "Woodot: An AI-Driven Mobile Robotic System for Sustainable Defect Repair in Custom Glulam Beams" Sustainability 17, no. 12: 5574. https://doi.org/10.3390/su17125574
APA StyleRuttico, P., Bordoni, F., & Deval, M. (2025). Woodot: An AI-Driven Mobile Robotic System for Sustainable Defect Repair in Custom Glulam Beams. Sustainability, 17(12), 5574. https://doi.org/10.3390/su17125574